The global join method refers to the implementation of the join operation across all processors. The above algorithm will perform poorly if the data is skewed due to the following two reasons. In the join phase, each processor builds a local hash table for its local fragment of one of the relations, i.e.
Like the ranking-based algorithm, the hash-based method is very sensitive to data skew that is expected to perform poorly in the presence of data skew. As noted in the literature, its performance deteriorates significantly with the presence of data skew (a single or double skew) [13,1]. In the rest of this paper, we assume that both relations are approximately disjoint among processors p.
The sizes of the buckets for one or both relations are used in the allocation process. Several parallel join algorithms have been proposed to alleviate the presence of the data bias, e.g. [15 - 25]. Both of these algorithms use a preprocessing phase (before the redistribution phase) to collect perfect information about the join attribute distribution.
In the partition phase of the join algorithm, p partitions with approximately equal weights are generated.

The sort-based algorithm
Potentially, more complex functions can be defined that include the (exact or estimated) cost of subsequent phases of the clustering algorithm, i.e., the cost of interprocessor communication and the cost of string processing during the local clustering method. One advantage of the above weight functions is that the set of weights can be computed locally. During the previous step, each processor keeps track of its local sum of its weights wi. The total sum of the weights w is calculated by performing a global aggregation of the sum of unit sizes on wi.
In the first step, the ranking of the first weight of each processor (Rank0) is calculated by performing global exclusive-prefix sum of unit size on wis. There are two approaches that have been used to allocate tuples to processors: full fragmentation and fragmentation-replication. In the full-fragmentation approach, both relations are split into disjoint fragments; these fragments are then allocated between the processors.
A fragmentation and replication approach can split one or both relations into unrelated fragments, ie. replicates some data between more than one fragments. Ideally, you would want to use the full fragmentation approach because it incurs less overhead than the fragmentation and replication approach. These partitions are chosen so that the sum of the weights of each partition c is w/p+ê and all values of the join attribute in partition i are less than the value in partition i+1.
For tuples that have join attribute values equal to the value of splitter i, we do the following. Assigns those tuples belonging to the duplicate relation to all processors with addresses equal to d1i, …, d1i +ni-1. For those tuples belonging to the fragmented relation, it calculates the number of duplicates of that value, ndup, and assigns the tuple ndup × wdistij to the processor with an address equal to d1i+j.
The communication required between the processors and the aggregation phase are exactly the same as in the full fragmentation approach. The total time requirement of the new sorting-based algorithm is the sum of the time required by all phases. It can be simplified to the time taken by the sorting phase, the transport primitive, the merging of R tuples, the merging of S tuples, and the final merging.

The hash-based algorithm
Calculating the ranking Rank, total sum of the weights set and finding the split phase is exactly similar to the sorting based algorithm. However, the redistribution phase is quite different because the local fragments of the ratios R and S are not sorted. The overall time requirement of the new hash-based is the sum of the time required by all the phases.
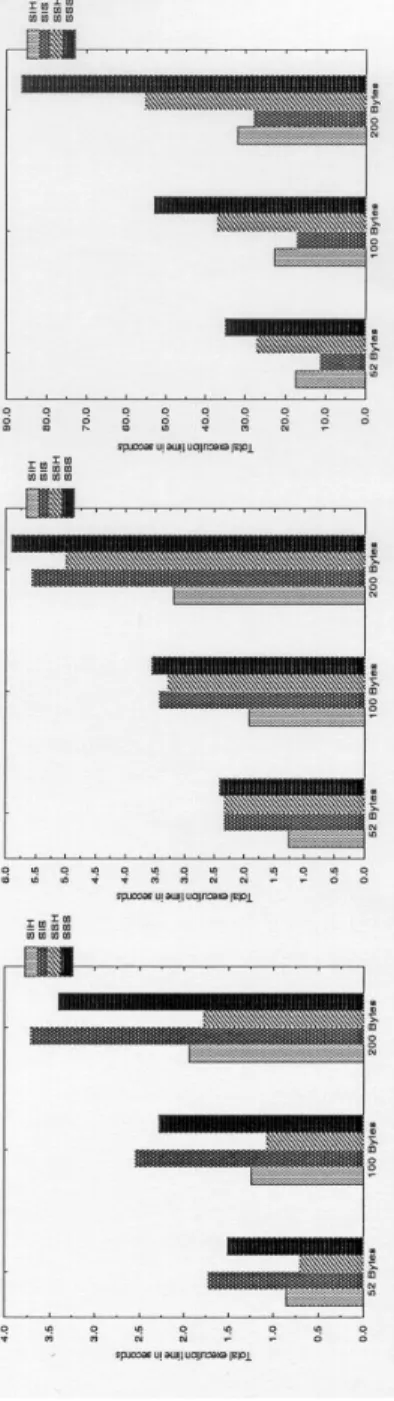
In real database applications, the sizes of the tuples tR and tS are typically several hundred bytes. In the two new algorithms, the total cost of the pre-processing step is proportional to the cardinality of the relationships times the size of the join attribute. While all the costs of both algorithms are proportional to the cardinality of the relations times the size of the tuples.
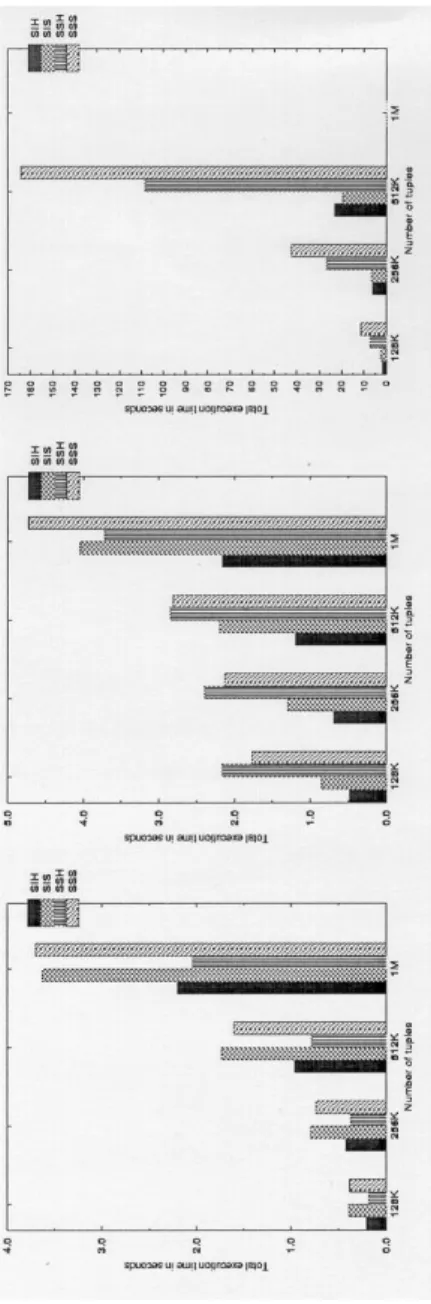
The size of the join property is generally smaller than the size of the tuples by one to two orders of magnitude. Therefore, we expect that the cost of the preprocessing step is relatively small in the case of uniform distribution. Our experiments were directed to study the effect of the weight functions, the load factor, the tuple size and the size of the relations.
Zipf distribution: The Zipf distribution has two parameters that determine the degree of skewness of the data [27]. The default values of both relationship sizes and tuple size are 256K and 100 bytes respectively. This is done to reduce the effect of the randomization of the communication from the underlying network.
We also ran the new algorithms using different load factors (1, 1.25 and 1.5), the overall performance is almost independent of the load factor for the three datasets. For uniform distribution, the absolute cost of the preprocessing phase is independent of the tuple size. When the amount of work required is not high, our algorithms do not achieve any speedup.
3 The speed of the hash-based (sort-based) algorithms is measured against the sequential hash-hashed (sort-based) algorithm. However, our algorithms achieved almost the same speed as the conventional algorithms for these cases. Both of these algorithms use a preprocessing phase (before the reallocation phase) to divide the work equally among the processors using perfect information about the join attribute distribution.
Then one can apply the state-of-the-art sequential join algorithm for the local disk-resident fragments in the join/merge phase.
ﻲﻘﺋﻼﻌﻟا ﻂﺑﺮﻠﻟ ﺔﻓﺮﺤﻨﻣ ﺮﻴﻏ ﺔﻳزاﻮﺘﻣ تﺎﻴﻣزراﻮﺧ
ﺎﻜﻧار يﺎﺠﻧﺎﺳ و *ﻲﺘﺒﺴﻟا ﷲاﺪﺒﻋ ﺪﻟﺎﺧ
ﺚﺤﺒﻟا ﺺﺨﻠﻣ ﻂﺑﺮﻟا نأ ﺎﻤﻛ ،ﺔﻔﻠﻜﺗ ﺎﻫﺮﺜﻛأ ﻦﻣو ﺔﻴﻘﺋﻼﻌﻟا تﺎﻧﺎﻴﺒﻟا ﺪﻋاﻮﻗ ﰲ ﺔﻴﻠﻤﻋ ﻢﻫأ ﻂﺑﺮﻟا ﱪﺘﻌﻳ
ﲔﺗﺪــﻳﺪﺟ ﲔﺘﻳزاﻮــﺘﻣ ﲔﺘﻴﻣزراﻮــﺧ مﺪــﻘﻧ ﺔــﻗرﻮﻟا ﻩﺬــﻫ ﰲو .ﺔــﻴﻧﺎﻴﺑ تﺎــﻓاﺮﳓا دﻮــﺟﻮﻟ ﺔــﺳﺎﺴﺣ ﺔــﻴﻠﻤﻋ يزاﻮــﺘﳌا ــﻠﻋ ﻂﺑﺮــﻟا ﺔـﻴﻠﻤﻌﻟ
ةﺰــﻬﺟﻷا تﺎــﻧﺎﻴﺑ دﻮــﺟو ﺔــﻟﺎﺣ ﰲ ﱄﺎــﺜﻣ ﻞﻜــﺸﺑ نﻼــﻤﻌﺗ نﺎــﺘﻴﻣزراﻮﳋا نﺎــﺗﺎﻬﻓ ،ﺔــﻳزاﻮﺘﳌا
ﺚــﻴﺣ .ﺔــﻓﺮﺤﻨﻣإ
ﻰــﻠﻋ ةﺰــﻜﺗﺮﻣ ﺔــﻴﻧﺎﺜﻟا ﺔــﻴﻣزراﻮﳋا نأ ﲔــﺣ ﰲ ،ﺐــﻴﺗﱰﻟا ﻰــﻠﻋ ةﺰــﻜﺗﺮﻣ ﱃوﻷا ﺔــﻴﻣزراﻮﳋا ن
ﻮـﺟ ﺢـﺿﻮﻧو .ﺔـﻳﺪﻴﻬﻤﺘﻟا ﺔـﻠﺣﺮﳌا ﰲ تﺎـﳉﺎﻌﳌا ﻰﻠﻋ ﻞﻤﻌﻟا نﺎﻤﺴﻘﺗ نﺎﺘﻴﻣزراﻮﳋا ﺎﺘﻠﻛو .ﺖﺘﺸﺘﻟا ﲔﺗﺎـﻫ ةد
ﺎﻴﻠﻤﻋو ًﺎﻳﺮﻈﻧ ﲔﺘﻴﻣزراﻮﳋا