This thesis titled “Automated Dhaka city vehicle detection for traffic flow analysis using deep learning.” submitted by MD. Tanvir Islam, ID in the Department of Software Engineering, Daffodil International University, has been accepted as satisfactory in partial fulfillment of the requirements for the degree of B.Sc. The width and height of the bounding box preceding an anchor labeled Pw and Ph.
If an object is displayed at the top of the left corner grid cell of the given image (Cx, Cy) and the following coordinates (tx, ty, tw and th) for each grid cell. The width and height of the predictive bounding boxes (bw, bh) can be obtained using an exponential function, e.g. The YOLOv5s architecture builds on the Darknet53 backbone. There are many ways to prevent traffic jams from spreading, and one of the most effective is to detect the vehicle.
To solve this problem, our research incorporates a deep learning methodology for the autonomous detection and localization of vehicles from optical scans. Vehicle detection challenges on urban roads arise from camera position, context variations, obstacles, multiple objects in the current frame, and vehicle position. The current study provides a summary of the state-of-the-art vehicle detection techniques, both categorized by motion and aesthetics techniques, starting with frame discrimination and background subtraction and progressing to feature extraction, a more complex model in benchmarking.
The pre-processed data, as well as the fine-tuning hyperparameter, are then fed into the pioneering YOLOv5's deep learning model for autonomous vehicle detection and recognition.
INTRODUCTION 1.1 Background
Research Questions
How can I achieve good accuracy for vehicle image detection tasks if the dataset is highly labeled. How can we achieve high accuracy for vehicle image segmentation tasks when we have limited computing resources.
Research Objectives
Thesis Organization
LITERATURE REVIEW
Data Set & Data Processing
According to the dataset images are divided into three groups namely i) Train, ii) Test and iii) Validation. In the PoribohonBD dataset, 70% of the image data is used for training purposes, 20% of the images are used in testing, and 10% of the images are used in validation above 9058 images.
METHODOLOGY
The Detection Principle of Yolov5s
If any object is located in the upper left corner grid cell for the given image (𝑐𝑥 , 𝑐𝑦) and the height and width of the bounding box is (𝑝ℎ , 𝑝𝑤), then the corresponding prediction is fig.5. Bounding box dimension progressions and position prediction before it was used as an anchor, the bounding box width and height were denoted as 𝑝𝑤 and 𝑝ℎ. If any object is visible in the top left corner grid cell of the given image (𝑐𝑥 , 𝑐𝑦) and the following coordinates 𝑡𝑥 , 𝑡𝑦 , 𝑡𝑤 𝑎𝑛𝑑 𝑡⎄ and each grid cell.
The exponential function 𝑒𝑥 can be used to obtain the width and height of the predictive bounding boxes ( 𝑏ℎ , 𝑏𝑤). If any prior bounding box overlaps the ground truth more than other bounding boxes, this confidence score should be 1. The bounding boxes overlapped the ground truth at this stage, but did not get the best bounding box prior.
After predicting bounding boxes, each box can predict classes using multilevel classification. And using non-maximum suppression (NMS) to reduce unnecessary prediction of the best match in the final detection.
Network Architecture of YOLOv5s
- Backbone
- Neck
- Head
In the neck structure of YOLOv5s, the CSP2 structure designed by CSPnet is used to strengthen the capability of network function integration [35]. Head takes neck features according to input image size, squares and predicts the class or object size (large, medium, small). YOLOv5s detects large or medium or small size objects while other versions of YOLO could not detect different size objects.
To detect small objects, the rectangular target area is less than 32 pixels * 32 pixels. And finally, to detect large-sized objects, the target area needs more than 96 pixels * 96 pixels [36]. In the Neck structure of YOLOv5s, the CSP2 structure created by CSPnet is used to strengthen the network feature integration capability.
In YOLOv5's network architecture, regression loss of bounding box and intersection over union (IOU) function. In this study 𝐵𝐵𝑔𝑡 is shown the intersection of 𝐵 and 𝐵𝑔𝑡 and 𝐵𝐵𝑔𝑡 is shown the union of Band 𝐵𝑔𝑡 is clearly seen. In non-overlapping cases, the predicted bounding box will be moved forward to the target box due to the penalty term.
In 𝐺𝐼𝑜𝑈, there are several constraints despite vanishing gradient problems for non-overlapping cases [37]. 𝐵𝑔𝑡 is the ground truth and 𝐵 is the predicted bounding box. (b) 𝐵 intercept 𝐵𝑔𝑡. d) The smallest box of 𝐵 and 𝐵𝑔𝑡 is 𝐶. During the training period, the training image data is input into the YOLOv5s model by data increment and resizing.
Then the bounding box provided in the YOLOv5s model, that information can be obtained based on the anchor boxes. After that, to perform the training epoch, calculate the loss between the predicted bounding boxes and the ground truth. At this stage, the detection process obtained by the YOLOv5s model can be the first expected bounding box to be reliable, and then the final detection results can be obtained by non-maximum suppression (NMS) or its alternative, which is used to reduce irrelevant detection and find the best match.
MODEL TRAINING
Training Setting
RESULT AND DISCUSSION
Model Evaluation Metrics
- Precision and Recall Rates
- Mean Average Precision and F1 Score
- Frames per Second and Inference Time
Mean Average Accuracy (mAP) is used to find the average accuracy of object detection models such as YOLO. FPS is a standard measure of frame rate, which is the number of consecutive full-screen images displayed per second.
Training Results and Analysis
The mAP provides the score by corresponding the ground-truth bounding box with the detected box. From the results, the model discovered that the performance of all approaches is very high due to the use of smaller data sets. Meanwhile, there is no doubt that the YOLO model technique used contributed to the model's excellent performance.
In Fig.12, the YOLOv5s model can be trained and the different backgrounds are considered as a variable in this study. The PR curve of the model can reach all the class accuracy is 0.794% for the detection of vehicles. Loss functions the incorrect prediction of the cubes and objects constancy to specify the correct one.
The box_loss of the training model finds the best accuracy of bounding box regression that accurately locates the vehicle.
Detecting Result and Discussion
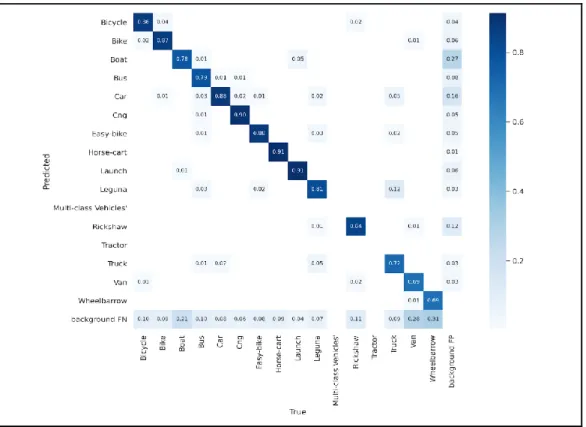
X axis shows the true value of 16 class and Y axis shows the predicted value of vehicle class. Judging by the results determined in the test set image detection, YOLOv5's large objects get better performance. It is clear that in the object detection model of YOLOV5s, there are several differences in detection confidence.
The confidence of the result in the range of YOLOv5s is 0.4-0.9, and the test result is satisfied. As a result, better performance is achieved using YOLOv5s, inference speed, time and FPS can be detected very quickly.
CONCLUSION
Missing data reconstruction in a remote sensing image with a uniform spatio-temporal-spectral deep convolutional neural network. Palubinskas, "Model-Based Traffic Congestion Detection in Optical Remote Sensing Imagery," European Transport Research Review, no. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (pp.
