This project/internship titled Sentiment Analysis of Customer, Based on Customer Reviews in Bangla Language Using Machine Learning, submitted by Shantonu Saha, ID no. to the Department of Computer Science and Engineering, Daffodil International University has been accepted as satisfactory for the partial fulfillment of the requirements for the degree of B.Sc. Department of Computer Science and Engineering Faculty of Natural Sciences and Information Technology Påskelilje International University. We hereby declare that this thesis has been carried out by us under the guidance of Md.
We also declare that neither this dissertation nor any part of this dissertation has been submitted elsewhere for the award of a degree or degree. In-depth knowledge and great interest of our tutor in the field of "Natural Language Processing and Machine Learning" to carry out this assignment. We are also very grateful to other faculty members and staff of CSE department of Daffodil International University.
We would like to thank our entire coursemate in Daffodil International University who participated in this discussion while completing the coursework. Taking their customer feedback as an example, sentiment analysis (a form of text analysis) measures the attitude of the customer towards the aspects of a service or product that they describe in the text [1]. So, in this sentiment analysis work, we collected many customer reviews from different platforms for training data sets.
After a huge observation, I saw that a lot of research has been done on this site for customer reviews that are in English.
Rationale of The Study
I also saw that a limited amount of data is largely responsible for that limited research work. And another thought of this paper was to observationally evaluate the elements that influence customers' decisions when purchasing food from a food delivery website or app. The objective was to investigate customer behavior in the established online food delivery business in a developing economy, Bangladesh.
Research Questions
Expected output
Project Management and Finance I have financed in my own research work
Report Layout
BACKGROUND
Measure
- Related Works
- Comparative Analysis and Summery
- Scope of the Problem
- Challenges
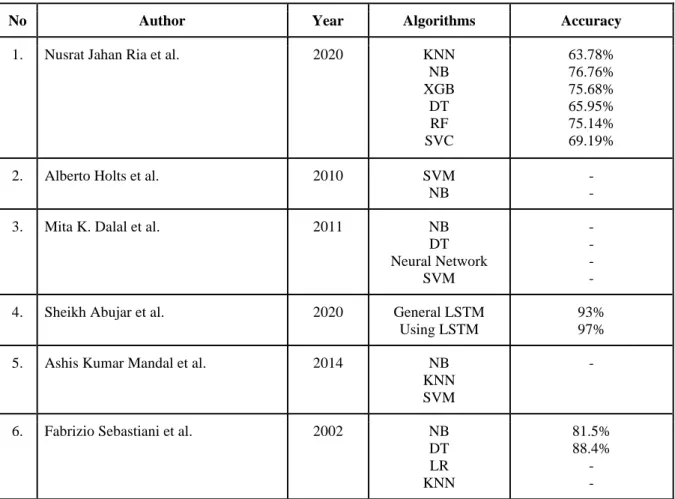
Automatic text classification has always been an important application and research topic since the beginning of digital documents. Among the various machine learning approaches to document categorization, the most popular is supervised learning where the basic input-output relationship is learned from a small amount of training data and then output values are predicted for unseen input points. Some of the important works done in Bangla language focusing on text classification are analyzed in the following paragraphs along with their limitations and strengths.
After applying preprocessing to their data set, their data were labeled and sorted into input sequence and N-gram. They used supervised machine learning methods such as Naive Bayes, K-Nearest Neighbor, Decision Tree and Support Vector Machines on their data [5]. In their work they used the DNF formula which helps to get good effective results.
They used supervised machine learning algorithms such as K-Nearest Neighbor (KNN), Naive Bayes (NB) and Support Vector Machine (SVM) as their classification algorithm while conducting the search. Bengali text summarization using word2vector approach was presented by Sheikh Abujar et al. In their work they summarized Bengali text using word2vector approach where word2vector takes data as a text corpus and returns the result as a vector.
They built their dataset by collecting data from various web portals, news portals and social media sites. They used the Skip Gram model to identify the words that were based on other words in a similar sentence. To get all the words in the same position, they applied this model to their dataset.
In their work they define a single category for each document which they defined as a hard categorization [13]. Basically, we will check which machine learning algorithms work very well with Bangla text data. From the above table we saw that most of the work is related to Bangla NLP and Bangla Text classification.
RESEARCH METHODOLOGY
- Research Subject and Instrumentation
- Data Collection Procedure
- Statistical Analysis
- Proposed Methodology
- Data Preprocessing
- Feature extraction
- Model Selection
- Implementation Requirements
This algorithm is used for both classification and regression analysis and is a supervised machine learning algorithm. This algorithm is a tree-based ensemble machine learning algorithm that is famous for its scalability. A large amount of data for this research work was collected from different types of online food delivery platforms.
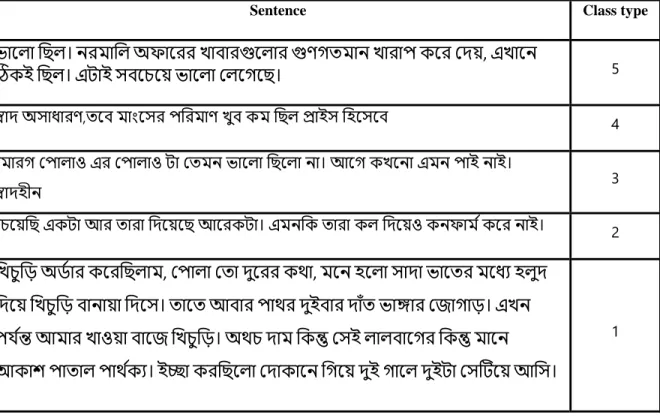
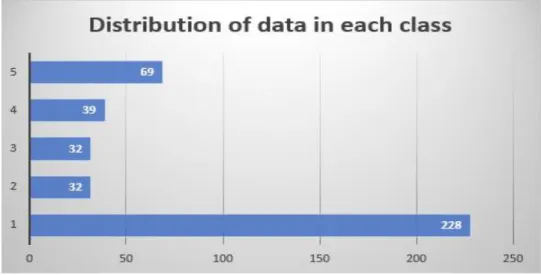
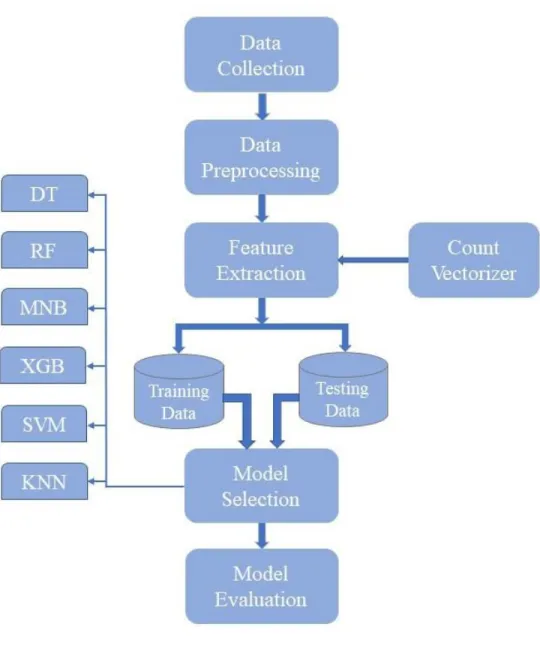
For this research work, I have collected data from online food delivery platforms foodpanda and HungryNaki. In our work, we use six supervised machine learning classifiers MNB, DT, RF, KNN, SVM and XGB to classify food reviews from Bengali sentences. Because sometimes the raw text data has some characters or symbols that are not essential and suitable for our classifier model.
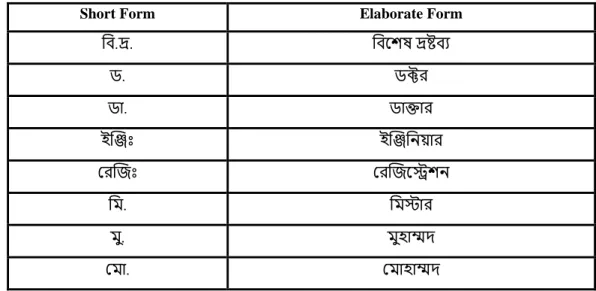
So, before we input our model, we need to apply some preprocessing techniques to the raw text data. To do this, we create a python dictionary with a short form and a constructed form, then split our text data and compare the data to the dictionary. In the part of NLP, in every language there are some words that are commonly used and these words are irrelevant to the machine learning model, this data set is called stop words.
We need to use Bangla stopword corpus to remove stopwords from our dataset. We remove stopwords from our dataset using our own custom Bangla stopword corpus. After preprocessing our data, we have clean text, but we can't feed our machine learning model with this text.
But we need to extract the features in the right way because extracting the right features from the text has an impact on the performance of the machine learning model. For this we need to apply some techniques which convert our text data into vector, that is, into numerical value. Basically, the Count vectorizer creates a vector from the text data based on the word frequency (count) of each word that occurs in the sentences.
Count vectorizer creates a vector or matrix where unique words are represented as matrix columns and each row of text data from dataset is represented as matrix row. In our work, we have input and output data to train a model, so we have to use Supervised Learning algorithms.
EX PERIMENTAL RESULTS AND DISCUSSION
Experimental Setup
Experimental Results and Analysis
Discussion
IMPACT ON SOCIETY, ENVIRONMENT AND SUSTAINABILITY
- Impact on Society
- Impact on Environment
- Ethical Aspects
- Sustainability Plan
But the quality of a restaurant's food or service can spoil the fun and put extra pressure on someone.
SUMMARY, CONCLUSION, RECOMMENDATION AND IMPLICATION FOR FUTURE RESEARCH
- Summary of the study
- Conclusion
- Recommendation
- Implication for Further Research
After performing all the steps, finally we are able to make our model which can detect class level of Bangla customer review. In our work, we proposed to build a model on six different algorithms such as DT, RF, MNB, XGB, KNN and SVM using our Bangla Dosh dataset. All classification algorithms perform very well, but KNN came out with the highest performance accuracy with our dataset.
Without increasing the data volume, we cannot get the better accuracy of the deep learning model. We also use Word embedding techniques to vectorize the text data into numeric value. 2] Nusrat Jahan Ria, Sharun Akter Khushbu, Mohammad Abu Yousuf, Abu Kaisar Mohammad Masum, Sheikh Abujar, “Syed Akhter Hossain, Toward an Enhanced Bengali Text Classification Using Saint and Common Form”, 11th ICCCNT, 2020.
3] Alberto Holts, Claudio Riquelme, Rodrigo Alfaro, “Automated Text Binary Classification using Machine Learning approach”, XXIX International Conference of the Chilean Computer Society, 2010. Sanzidul Islam, Fahad Faisal and Syed Akhter Hossain “A Bengali Text Generation Approach in the Context of Summarizing Abstract text using RNN”, 7th ICICSE, 2020. 6] Ashis Kumar Mandal, Rikta Sen, “SUPERVISED LEARNING METHODS FOR CATEGORIZATION OF BANGLA WEB DOCUMENTS”, International Journal of Artificial Intelligence & Applications (IJAIA), 2014.
7] Fabrizio Sebastiani, Consiglio Nazionale delle Ricerche, “Machine Learning in Automated Text Categorization”, ACM Computing Surveys, 2002. 8] Fang Miao, Pu Zhang, Libiao Jin, Hongda Wu, “Chinese News Text Classification Based on”, Conference on 10th International on Intelligent Human-Machine Systems and Cybernetics, 2018 [9] Sheikh Abujar, Abu Kaisar Mohammad Masum, Ohidujjaman, Syed Akhter Hossain, “An Approach to Bengal. Text summarization using Word2Vector”, 10th ICCCNT (International Conference on Computing, Communication and Network Technologies), 2019.
10] Abu kaiser Mohammad Masum, Sheikh Abujar, Md Ashraful Islam Talukder, AKM Shahriar Azad Rabbi, Syed Akhter Hossain, "Abstrakt metode til tekstopsummering med sekvens-til-sekvens RNN'er", 10. ICCCNT, 2019. 11] Sharun, Akter Khushbu, Akter Mohammad Abu Yousuf, Abu Kaisar Mohammad Masum, Sheikh Abujar, Syed Akhter Hossain, "Neural Network Based Bengali News Headline Multi Classification System: Selection of Features Describes Comparative Performance", 11. ICCCNT, 2020. 13] Jingjing Cai, Li Jianping Li, Ji Wang, "Deep Learning Model Used in Text Classification", ICCWAMTIP, 2018.
Plagiarism Report