Comedy
dengan Menggunakan
Support Vector Machine
dan
Naïve
Bayes Classifier
SKRIPSI
Diajukan Untuk Menempuh Ujian Akhir Sarjana
RINA PRIYANI
10109027
Program Studi Teknik Informatika
Fakultas Teknik Dan Ilmu Komputer
Universitas Komputer Indonesia
iii
KATA PENGANTAR
AlhamdulillahiRabbil ‘Alamiin,
segala puji dan syukur penulis panjatkan
kehadirat Allah SWT yang telah memberikan rahmat dan karunia-Nya, shalawat
serta salam semoga tercurah kepada Rasulullah SAW, sehingga penulis dapat
menyelesaikan
skripsi yang berjudul “
ANALISIS SENTIMEN PENGGUNA
TWITTER TERHADAP ACARA STANDUP KOMEDI DENGAN
MENGGUNAKAN SUPPORT VECTOR MACHINE DAN NAÏVE BAYES
CLASSIFIER
”
untuk memenuhi salah satu syarat dalam menyelesaikan studi
jenjang strata satu (S1) di Program Studi Teknik Informatika Universitas
Komputer Indonesia.
Dengan keterbatasan ilmu dan pengetahuan serta pengalaman penulis,
maka penulis mendapat banyak bantuan serta dukungan dari berbagai pihak. Oleh
karena itu, penulis mengucapkan terimakasih yang sebesar
–
besarnya kepada:
1.
Yang tercinta Ibunda (Neni Setiani) dan Ayah (Ade Nanang Sujana) yang
telah memberikan kasih sayang, cinta, doa, dan dukungan baik moril maupun
materi agar penulis dapat menyelesaikan skripsi ini tepat pada waktunya.
2.
Ibu Tati H.M., S.T., M.T., selaku wali kelas IF-1/2009 yang selalu
memberikan beberapa pengarahan kepada penulis.
3.
Ibu Ednawati Rainarli, S.Si.,M.Si., selaku dosen pembimbing. Terimakasih
karena telah banyak meluangkan waktu untuk memberikan bimbingan, saran
dan nasehatnya selama proses penyusunan skripsi ini.
4.
Bapak Erick Wijaya, S.Kom., selaku reviewer yang telah meluangkan waktu
dan memberikan saran beserta ilmunya selama proses penyusunan skripsi ini.
5.
Bapak Alif Finandhita, S.Kom., M.T., selaku penguji tiga memberikan saran
beserta ilmunya selama proses penyusunan skripsi ini.
6.
Bapak dan Ibu dosen serta seluruh staf pegawai Program Studi Teknik
Informatika Universitas Komputer Indonesia yang telah banyak membantu
penulis.
7.
Adik tersayang, Farhan Ramadhan yang telah memberikan semangat dan doa
iv
8.
Orang terkasih, Robin Nasir yang selalu memberikan semangat, dukungan,
doa dan kasih sayang yang tiada hentinya kepada penulis.
9.
Seluruh teman-teman IF1/2009 yang selalu memberikan dukungan, bantuan,
dan semangat selama penyelesaian skripsi ini.
10.
Seluruh keluarga dan sahabat yang tidak dapat penulis sebutkan satu persatu,
terimakasih telah memberikan segala bentuk bantuan untuk menyelesaikan
skripsi ini.
Penulis menyadari bahwa penulisan skripsi ini masih jauh dari sempurna.
Untuk perbaikan dan pengembangan, penulis mengharapkan saran dan kritik yang
bersifat membangun. Akhir kata, semoga penulisan skripsi ini dapat bermanfaat
bagi penulis khususnya, dan semua yang membaca.
Bandung, 19 Agustus 2015
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... xi
DAFTAR SIMBOL ... xiii
DAFTAR LAMPIRAN ... xv
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 2
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah ... 3
1.5 Metodologi Penelitian ... 3
1.6 Sistematika Penulisan ... 5
BAB 2 LANDASAN TEORI ... 7
2.1 Media Sosial ... 7
2.1.1 Twitter ... 7
2.2 Text Mining ... 9
2.3 Analisis Sentimen ... 10
2.4 Text Preprocessing ... 10
2.4.1 Case Folding ... 11
2.4.2 Cleansing ... 11
2.4.3 Stopword Removal ... 12
2.4.4 Convert Emoticon ... 13
vi
2.5 Ekspresi Reguler ... 14
2.6 Pembelajaran Mesin ... 17
2.7 Term Weighting ... 19
2.8 Informasi Retrieval ... 19
2.9 Support vector Machine ... 20
2.10 Naïve Bayes Classifier ... 23
2.11 Evaluasi Kinerja Classifier ... 25
2.11.1 K-fold Cross Validation ... 25
2.12 Object Oriented Analysis and Design ... 27
2.13 Unified Modeling Language ... 29
2.14 Bahasa Pemrograman PHP ... 30
2.15 JavaScript ... 30
2.16 Cascading Style Sheet (CSS) ... 31
2.17 XAMPP ... 33
BAB 3 ANALISIS MASALAHN DAN PERANCANGAN ... 34
3.1 Analisis Masalah ... 34
3.2 Analisis Sistem ... 34
3.3 Analisis Data Masukan ... 37
3.4 Analisis Metode / Algoritma ... 38
3.5 Spesifikasi Kebutuhan Perangkat Lunak ... 57
3.6 Analisis Kebutuhan Non Fungsional ... 58
3.6.1 Analisis Kebutuhan Perangkat Keras (Hardware) ... 58
3.6.2 Analisis Kebutuhan Perangkat Lunak (Software) ... 59
3.6.3 Analisis Kebutuhan Perangkat Pikir (Brainware) ... 59
3.7 Analisis Kebutuhan Fungsional ... 60
3.8 Perancangan Sistem ... 85
vii
3.8.2 Perancangan Arsitektur ... 87
3.8.3 Perancangan Antarmuka Perangkat Lunak ... 88
3.8.3.1 Perancangan Tampilan Halaman Crawling ... 88
3.8.3.2 Perancangan Tampilan Halaman Preprocessing ... 89
3.8.3.3 Perancangan Tampilan Halaman Support Vector Machine ... 89
3.8.3.4 Perancangan Tampilan Halaman Naïve Baye ... 90
3.8.4 Perancangan Pesan ... 90
3.8.5 Jaringan Semantik ... 91
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 92
4.1 Implementasi Sistem ... 92
4.1.1 Lingkungan Implementasi ... 92
4.1.2 Implementasi Data ... 93
4.1.3 Implementasi Antarmuka ... 95
4.2 Pengujian Sistem ... 95
4.2.1 Rencana Pengujian ... 95
4.2.2 Skenario Pengujian... 96
4.2.3 Hasil Pengujian ... 99
4.2.4 Evaluasi Pengujian ... 105
BAB 5 KESIMPULAN DAN SARAN ... 106
5.1 Kesimpulan ... 106
5.2 Saran ... 106
107
[1]
[Online]. Available :
http://suc.metrotvnews.com/article/ensiklopedia/13
.
[Accessed 12 Februari 2014].
[2]
Ni Wayan Sumartini Saraswati
, “pps.unud.ac.id,” [Online]. Available:
www.pps.unud.ac.id/thesis/pdf_thesis/unud-209-236721286-tesis.pdf
.
[Accessed 10 Februari 2014]
[3]
I Sommerville, Softwere Engeneering, United States Of America: Addison
Wesley 2011.
[4]
[Online]. Available:
http://romeiteamedia.com/2014/04/media-sosial-pengertian-karakteristik.html
.
[Accessed 20 Maret 2014]
[5]
I. H. Wltten, "Text Mining," in
Computer Science, University of Waikato
,
Hamilton, New Zealand, 2003.
[6]
I. Sunni and D. H. Widyantoro, "Analisis Sentimen dan Ekstraksi Topik
Penentu Sentimen pada Opini Terhdap Tokoh Publik,"
Jurnal Sarjana
Institut Teknologi Bandung Bidang Elektro dan Informatika,
vol. 1, pp. 200
- 206, 2012.
[7]
[Online]. Available:
http://tutorial.dumbstrack.org/mengenal-reguler-expression-regex/
.
[Accessed 21 April 2015]
[8] Online].Available:
http://lantip.net/tentang-machine-learning/
.
[Accessed 20 Maret 2014]
[9]
Nugroho A.S., Arief Budi, and Dwi Handoko. 2003. Support Vector
Machine Teori dan Aplikasinya dalam Bioinformatika, kuliah umum
IlmuKomputer.Com.
[10] R. Kohavi, "A study of Cross-Validation and Bootstrap for Accuracy
Estimation
and
ModelSelection,"1995.
[Online].
Available:
108
[11]
Wahono, Romi Satria. 2003. Object-Oriented Analysis and Design
Methodology, kuliah umum IlmuKomputer.Com.
[12] [Online].Available:
http://academia.edu/48887559/fungsi_dan_pengertian_UML
.
[Accessed 25 Juni 2015]
[13]
Solichin Achmad S.Kom.,
“Pemrograman Web dengan PHP dan
MYSQL”,
[Online]. Available:
http://achmatim.net
.
[Accessed 25 Juni 2015]
[14]
Sunyoto, Andi. 2007. Ajax Membangun Web dengan Teknologi
Asynchronouse Javascript & XML. Yogyakarta: Penerbit Andi Offset.
[15]
Hadisaputra Adi, “HTML dan CSS Fundamental dari Akar ke Daun”,
[Online]. Available:
http://ilmuwebsite.com
.
[Accessed 28 Juni 2015]
[16]
[Online]. Available:
http://www.pusatdesainweb.com/2014/06/29/pengetian-dan-kegunaan-xampp/
1
PENDAHULUAN
1.1
Latar Belakang Masalah
Dewasa ini perkembangan pertelevisian Indonesia sangatlah pesat, sehingga
banyak bermunculan acara-acara baru yang bervariasi. Mulai dari acara
news
,
talk
show
,
variety show
hingga acara lawak atau komedi. Salah satu acara komedi
adalah
standup comedy
, yaitu salah satu genre profesi melawak yang pelawaknya
membawakan lawakannya di atas panggung seorang diri, dengan cara bermonolog
mengenai suatu topik. Orang yang melakukan kegiatan ini disebut pelawak
tunggal atau komik
[1].
Salah satu televisi yang mempunyai acara
standup comedy
yaitu kompastv.
Tak sekedar memberi hiburan komedi dengan komik yang sudah ada, kompastv
pun beberapa kali menggelar acara pencarian bakat
standup comedy
, yang
audisinya tersebar di seluruh Indonesia. Oleh karena antusias masyarakat yang
cukup besar terhadap
standup comedy
ini, maka kompastv pun memiliki media
sosial sebagai sarana promosi acara
standup comedy
, salah satunya yaitu twitter.
Twitter digunakan kompastv untuk menampilkan jadwal acara standup comedy
yang akan ditayangkan sehingga masyarakat dapat menonton acara tersebut.
Adanya akun resmi
standup comedy
kompastv di twitter, memungkinkan
masyarakat yang menjadi followers akun tersebut melakukan
feedback
dengan
menanggapi setiap postingan
tweet
dari akun tersebut. Karena ketersediaan
sentimen untuk acara
standup comedy
kompastv sangat melimpah, sehingga
feedback
yang disampaikan oleh
followers
dapat digunakan untuk mengukur
analisis sentimen
followers
terhadap acara
standup comedy
di kompastv.
Permasalahan analisis sentimen adalah bagaimana melakukan klasifikasi
sentimen pada data twitter yang hasilnya dapat dimanfaatkan untuk evaluasi
mengenai kualitas suatu acara televisi. Banyaknya
tweet
yang masuk ke akun
standup comedy
kompastv dapat digunakan untuk mengetahui sentimen
2
maka dari itu sebelum sentimen diklasifikasikan ke dalam kategori positif dan
negatif, sebuah data twitter harus dipisahkan ke dalam kategori relevan dan tidak
relevan dengan menggunakan metode
Support Vector Machine
. Setelah data
twitter masuk ke dalam kategori relevan, selanjutnya data twitter tersebut
diklasifikasikan ke dalam kategori positif dan negatif dengan menggunakan
metode
Naïve Bayes Classifier
.
Penggunaan
Support Vector Machine
dan
Naïve
Bayes Classifier
tersebut dikarenakan performasinya lebih baik untuk klasifikasi
teks berbahasa Indonesia, sehingga analisis sentimen dapat diterapkan pada
tweet
bahasa Indonesia yang memiliki nilai subyektif
[2].
Dari pemaparan di atas, studi kasus pada skripsi ini adalah analisis sentimen
terhadap akun
standup comedy
kompastv. Data masukan analisis sentimen berasal
dari postingan
tweet
akun
standup comedy
kompastv.
1.2
Rumusan Masalah
Berdasarkan uraian yang terdapat pada latar belakang masalah, maka rumusan
masalah yang ada yaitu bagaimana melakukan analisis sentimen pengguna twitter
terhadap acara
standup comedy
kompastv dengan menggunakan
Support Vector
Machine
dan
Naïve Bayes Classifier
.
1.3
Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dari penulisan tugas
akhir ini adalah melakukan analisis sentimen pengguna twitter terhadap acara
standup comedy
kompastv dengan menggunakan metode
Support Vector Machine
dan
Naïve Bayes Classifier.
Adapun tujuan yang akan dicapai dalam tugas akhir ini adalah:
1.
Untuk mengetahui sentimen pengguna twitter terhadap acara
standup comedy
kompastv dengan menggunakan metode
Support Vector Machine
dan
Naïve
Bayes Classifier.
2.
Untuk mengetahui besarnya akurasi dari penggunaan metode
Support Vector
Machine
dan
Naïve Bayes Classifier
dalam melakukan analisis sentimen
1.4
Batasan Masalah
Batasan masalah dalam pembangunan aplikasi ini adalah sebagai berikut :
1.
yang
dianalisis
yaitu
standup
comedy
kompastv
“@StandUpKompasTV”
.
2.
Tweet yang digunakan adalah teks
tweet
berbahasa Indonesia.
3.
Praproses yang dilakukan adalah
Case Folding, Cleansing, Stopword
Removal, Convert Emoticon, Convert
Negasi, dan
Tokenizer
.
4.
Klasifikasi opini dalam bentuk relevan, tidak relevan, positif dan negatif.
5.
Klasifikasi relevan dan tidak relevan menggunakan
Support Vector Machine
.
6.
Klasifikasi positif dan negatif menggunakan Naïve Bayes
Classifier
.
7.
Pengujian akurasi menggunakan
K-Cross Validation
.
8.
Bahasa pemrograman dalam sistem ini menggunakan bahasa pemrograman
PHP.
9.
Sistem yang dibangun adalah website dengan menggunakan pendekatan
OOAD (Object Oriented Analysis and Design)
.
10.
Diagram UML yang digunakan yaitu
usecase diagram, activity diagram,
sequence diagram, dan class diagram
.
1.5
Metodologi Penelitian
Dalam penelitian tugas akhir ini, dilakukan beberapa metode untuk
memperoleh data atau informasi dalam menyelesaikan permasalahan. Metodologi
penelitian yang digunakan dalam penulisan tugas akhir ini adalah sebagai berikut:
1.
Studi Literatur
Dalam pengumpulan data untuk menyusun skripsi ini menggunakan studi
literatur, yaitu sebuah penelitian ilmiah mengenai kesusastraan. Penulis
melakukan studi pustaka dengan cara mempelajari literatur berupa
textbook
,
jurnal elektronik, artikel ilmiah dan dokumen web yang relevan dengan topik
4
2.
Pengumpulan Data Twitter
Pengumpulan data menggunakan sumber data primer yang diambil secara
langsung dari akun
standup comedy
kompastv dengan memanfaatkan
streamAPI (Application Programming Interface)
yang disediakan oleh twitter.
3.
Metode Pembangunan Perangkat Lunak
Dalam tahap ini, teknik analisis data menggunakan metode pengembangan
perangkat lunak secara waterfall yang meliputi:
a.
Requirements analysis and definition
Tahap ini merupakan tahap mengumpulkan kebutuhan secara lengkap
kemudian dianalisis dan diidentifikasi kebutuhan yang harus dipenuhi oleh
program yang akan dibangun.
b.
System and software design
Tahap ini merupakan tahap desain yang dikerjakan setelah kebutuhan
selesai dikumpulkan secara lengkap.
c.
Implementation and unit testing
Tahap ini merupakan tahap menerjemahkan desain program ke dalam
kode-kode dengan menggunakan bahasa pemrograman yang sudah ditentukan.
Program yang dibangun langsung diuji baik secara unit.
d.
Integration and system testing
Tahap ini merupakan penyatuan unit-unit program kemudian diuji secara
keseluruhan (
system testing
).
e.
Operation and maintenance
Tahap ini merupakan tahap mengoperasikan program dilingkungannya dan
melakukan pemeliharaan, seperti penyesuaian atau perubahan karena
adaptasi dengan situasi sebenarnya. Untuk lebih jelasnya tahapan-tahapan
Gambar 1. 1 Model Proses
Waterfall
[3]4.
Evaluasi Hasil
Evaluasi performansi dilakukan dengan melihat nilai dari perhitungan
accuracy
yang didapat dengan menggunakan metode
k-fold cross validation
.
1.6
Sistematika Penulisan
Sistematika penulisan tugas akhir ini disusun untuk memberikan gambaran
umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini
adalah:
BAB I PENDAHULUAN
Bab ini menguraikan tentang latar belakang masalah, rumusan masalah,
maksud dan tujuan, batasan masalah, metodologi penelitian dan sistematika
penulisan.
BAB II LANDASAN TEORI
Pada bab ini membahas berbagai konsep dasar dan teori-teori yang
berkaitan dengan topik penelitian yang dilakukan. Landasan teori yang digunakan
antara lain tentang twitter, analisis sentimen, teknik analisis sentimen
6
BAB III ANALISIS MASALAH DAN PERANCANGAN
Bab ini membahas mengenai penentuan atribut analisis sentimen, cara
pengambilan data mentah dari twitter, serta implementasi
Support Vector Machine
dan
Naïve Bayes Classifier
dalam pengklasifikasian data.
BAB IV IMPLEMENTASI DAN PENGUJIAN
Bab ini membahas mengenai implementasi metode
Support Vector
Machine
dan
Naïve Bayes Classifier
pada sistem yang dibuat, serta pengujian
sistem beserta hasil pengujian dari analisis sistem yang ada pada Bab III
kemudian melakukan analisis terhadap informasi dari hasil uji coba.
BAB V KESIMPULAN DAN SARAN
Bab ini berisi tentang kesimpulan-kesimpulan dari skripsi, dan terdapat
pula saran yang sudah diperoleh dari hasil penulisan tugas akhir agar dapat
digunakan di masa mendatang untuk pengembangan lebih lanjut analisis sentimen
A.
Data Pribadi
Nama Lengkap
: Rina Priyani
Nama Panggilan
: Rina
Tempat, Tgl Lahir
: Cirebon, 23 Maret 1992
Jenis Kelamin
: Perempuan
Agama
: Islam
Kewarganegaraan
: Indonesia
Alamat : Jln. Veteran Gang Palem rt/rw 03/01 Ciseureuh
Purwakarta 41118
No. HP/Tlp
: 085659261764
:
B.
Pendidikan Formal
1997-2003
: SD Negeri 1 Ciseureuh, Purwakarta
2003-2006
: SMP Negeri 7 Purwakarta
2006-2009
: SMA Negeri 1 Jatiluhur, Purwakarta
ANALISIS SENTIMEN
PENGGUNA TWITTER TERHADAP ACARA STANDUP COMEDY
DENGAN MENGGUNAKAN SUPPORT VECTOR MACHINE DAN
NAÏVE BAYES CLASSIFIER
Rina Priyani
Teknik Informatika - Universitas Komputer Indonesia
Jl. Dipatiukur 112-114 Bandung
E-mail : [email protected]
ABSTRAK
Salah satu acara standup comedy adalah standup comedy kompastv. Adanya akun resmi standup comedy kompastv di twitter, memungkinkan masyarakat yang menjadi followers akun tersebut melakukan feedback dengan menanggapi setiap postingan tweet dari akun tersebut. Karena ketersediaan sentimen untuk acara standup comedy kompastv sangat melimpah, sehingga feedback yang disampaikan oleh followers dapat digunakan untuk mengukur analisis sentimen followers terhadap acara standup comedy di kompastv. Banyaknya tweet yang masuk ke akun twitter standup comedy kompastv dapat digunakan untuk mengetahui sentimen followers terhadap acara standup comedy kompastv, akan tetapi dalam penyampaian sentimen tersebut terdapat sentimen yang bukan merupakan opini, maka dari itu sebelum sentimen diklasifikasikan ke dalam kategori positif dan negatif, sebuah data twitter harus dipisahkan ke dalam kategori relevan dan tidak relevan dengan menggunakan metode Support Vector Machine. Setelah data twitter masuk ke dalam kategori relevan, selanjutnya data twitter tersebut diklasifikasikan ke dalam kategori positif dan negatif dengan menggunakan metode Naïve Bayes Classifier.
Permasalahan analisis sentimen adalah bagaimana mengklasifikasikan sentimen kedalam kelas-kelas yang sudah ditentukan. Selanjutnya, untuk mengatasi permasalahan tersebut dilakukan pembelajaran mesin dengan menggunakan Support Vector Machine untuk pemisahan data relevan dan tidak relevan, dan Naïve Bayes Classifier untuk klasifikasi data positif dan negative. Penggunaan Support Vector Machine dan Naïve Bayes Classifier dikarenakan performasinya lebih baik untuk teks berbahasa Indonesia, sehingga analisis sentiment dapat diterapkan pada tweet yang memiliki nilai subyektif.
Dari hasil pengujian dengan metode 10-fold cross validation menunjukkan bahwa kedua metode yang digunakan memiliki tingkat akurasi yang cukup memuaskan yaitu 90.74% untuk metode Support Vector Machine dan 95.91% untuk metode Naïve Bayes Classifier.
Kata kunci: Analisis sentimen, Support Vector
Machine, Naïve Bayes Classifier, Cross Validation, Twitter, tweet
1.
PENDAHULUAN
Dewasa ini perkembangan pertelevisian Indonesia sangatlah pesat, sehingga banyak bermunculan acara-acara baru yang bervariasi. Mulai dari acara news, talk show, variety show hingga acara lawak atau komedi. Salah satu acara komedi adalah standup comedy, yaitu salah satu genre profesi melawak yang pelawaknya membawakan lawakannya di atas panggung seorang diri, dengan cara bermonolog mengenai suatu topik. Orang yang melakukan kegiatan ini disebut pelawak tunggal atau komik[1].
ketersediaan sentimen untuk acara standup comedy kompastv sangat melimpah, sehingga feedback yang disampaikan oleh followers dapat digunakan untuk mengukur analisis sentimen followers terhadap acara standup comedy di kompastv.
Permasalahan analisis sentimen adalah bagaimana melakukan klasifikasi sentimen pada data twitter yang hasilnya dapat dimanfaatkan untuk evaluasi mengenai kualitas suatu acara televisi. Penggunaan Support Vector Machine dan Naïve Bayes Classifier tersebut dikarenakan performasinya lebih baik untuk klasifikasi teks berbahasa Indonesia, sehingga analisis sentimen dapat diterapkan pada tweet bahasa Indonesia yang memiliki nilai subyektif[2].
2.
ANALISIS SENTIMEN PENGGUNA
TWITTER TERHADAP ACARA
STANDUP
COMEDY
DENGAN
MENGGUNAKAN
SUPPORT
VECTOR MACHINE DAN NAÏVE
BAYES CLASSIFIER
Kompastv merupakan sebuah stasiun televisi swasta yang memiliki program acara standup comedy, dan menggunakan Twitter sebagai salah satu sosial media untuk sarana promosi. Dengan adanya akun standup comedy kompastv dan jumlah postingan tweet yang banyak setiap harinya memungkinkan terdapat feedback dari penikmat acara standup comedy yang merupakan followers dari akun twitter tersebut, yang dapat dianggap sebagai ketersediaan sentimen yang dimanfaatkan untuk evaluasi kualitas program acara standup comedy kompastv.
Namun permasalahan pada analisis sentimen adalah bagaimana melakukan klasifikasi sentimen pada data twitter yang hasilnya dapat dimanfaatkan untuk evaluasi program acara standup comedy di kompastv.
2.1Analisis Sistem
Dalam mengimplementasikan metode
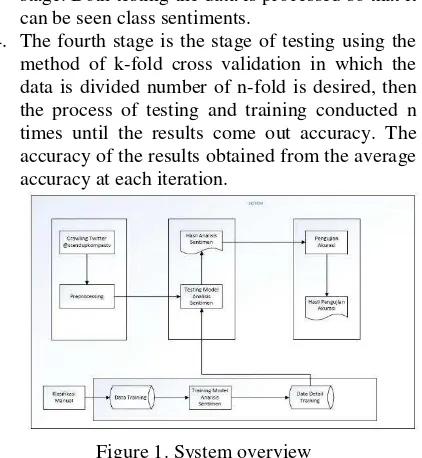
Support Vector Machine dan Naïve Bayes Classifier akan dibangun sebuah prototype dengan gambaran sistem yang akan tertera pada Gambar 1.
Sistem yang akan dibangun memiliki 4 tahap yaitu praproses, training data, testing, dan cross validation. Untuk penjelasan setiap tahap dapat dilihat sebagai berikut:
1. Tahap pertama adalah tahap mengambil data twitter dengan crawling menggunakan stream API, kemudian data tersebut dilakukan proses preprocessing yang merupakan tahap dimana data yang akan digunakan sebagai data testing dibersihkan dari noise atau dari hal yang tidak
mempunyai pengaruh dalam sentimen.
Preprocessing yang dilakukan dalam tahap ini antara lain: case folding, cleansing, stopword
removal, convert emoticon, convert negation, tokenizer.
2. Tahap yang kedua adalah tahap training data, pada tahap ini menggunakan dua data training, yaitu data training support vector machine dan data training naïve bayes, lalu kedua data training tersebut dilakukan tahap preprocessing dan diklasifikasikan secara manual kedalam empat kelas yaitu kelas relevan dan tidak relevan untuk data training support vector machine, dan kelas positif dan negatif untuk data training naïve bayes. Kemudian keempat kelas tersebut di simpan ke dalam database data training. Setelah itu tweet yang sudah diklasifikasikan secara manual dibuat model analisis sentimen yang nantinya akan disimpan kembali ke dalam database detail data training yang akan digunakan pada tahap testing sebagai model analisis sentimen.
3. Tahap yang ketiga yaitu tahap testing, pada tahap ini menggunakan data testing support vector machine dan data testing naïve bayes sebagai data masukan yang tentu saja sudah melalui tahap preprocessing. Kedua data testing tersebut diproses sehingga dapat dilihat kelas sentimennya.
4. Tahap keempat yaitu tahap pengujian
menggunakan metode k-fold cross
validation dimana data dibagi sejumlah n-fold yang diinginkan,kemudian proses testing dan training dilakukan sebanyak n kali sampai hasil akurasi keluar. Hasil akurasi tersebut didapat dari rata-rata akurasi pada setiap iterasi.
Gambar 1. Gambaran Sistem
2.2Analisis Data Masukan
Data masukan yang digunakan adalah data tweet dari akun twitter resmi StandUp KompasTv. Data tweet tersebut didapat dengan memanfaatkan fitur API (Application Interface) yang telah disediakan oleh twitter untuk mendapakan API key, dan access token yang nantinya digunakan untuk pengambilan data tweet. Data yang diambil adalah
data tweet yang mengandung kata
140 karakter. Contoh dari setiap tweet yang
mengandung sentimen pada akun
“@StandUpKompasTV” terdapat pada Gambar 2 dan Gambar 3.
Gambar 2. Tweet dengan sentimen positif
Gambar 3. Tweet dengan sentimen negatif
Data tweet yang diambil dari akun resmi Standup comedy kompastv masih berupa data mentah dan terdapat noise atau ciri-ciri yang tidak mempunyai pengaruh pada klasifikasi sentimen seperti link, “@”, stopword, hashtag yang ditandai dengan munculnya karakter “#”. Contoh tweet mentah tersebut ada pada Gambbar 4.
Gambar 4. Contoh data tweet
Selain itu, karateristik tweet yang dirasa mempunyai pengaruh pada penentuan sentimen adalah terdapat emoticon yang merupakan salah satu cara untuk mengekspresikan ungkapan persetujuan atau pertidaksetujuan pada suatu kalimat atau tweets. Contoh tweet mentah yang terdapat emoticon ada pada Gambar 5.
Gambar 5. Contoh data tweet dengan emoticon
Karakteristik tweet selanjutnya yaitu ada terdapat kata negasi yang perlu diperhatikan dalam analisis sentimen karena dapat merubah nilai sentimen suatu tweet. Kata yang bersifat negasi seperti “tidak”, “bukan”, “ga”, “jangan”, “nggak”, “tak”, “tdk”, dan “gak”. Contohnya kata“lelet” yang merupakan kata dengan sentimen negatif, karena di depan kata “lelet” terdapat kata negasi “tidak” maka sentimen dari gabungan kata tersebut adalah positif. Contoh tweet yang terdapat kata negasi ada padaGambar 6.
Gambar 6. Contoh data tweet dengan negasi
Agar data-data tweets tersebut dapat dimanfaatkan dengan baik untuk mengklasifikasikan
sentimen maka diperlukan proses preprocessing . Pada proses ini data tweet yang digunakan untuk data training data data testing dibersikan dari noise atau ciri-ciri yang tidak berpengaruh pada klasifikasi sentimen seperti link, “@”, “RT”, stopword, dan lain sebagainya. Gambaran proses preprocessing dapat dilihat pada Gambar 7.
Gambar 7. Tahapan Preprocessing
1. Case Folding
Pada proses case folding huruf besar atau uppercase yang terdapat pada tweet diubah menjadi lowercase atau huruf kecil.
2. Cleansing
Tweet yang terdapat pada akun resmi StandUp KompasTV memiliki berbagai komponen atau karakteristik tweet yang khas seperti “@” yang diidentifikasi sebagai komponen username, URL yang dikenal melalui operasi regular, hashtag yang menandakan kata sebagai topik yang sedang dibicarakan, dan “RT” yang diidentifikasi sebagai mengulang kembali tweet yang telah diposting. Komponen-komponen tersebut tidak memiliki pengaruh apapun terhadap sentimen, maka akan dibuang.
3. Stopword Removal
Data tweet yang sudah melalui proses sebelumnya masih mengandung kata yang dianggap tidak dapat memberikan pengaruh dalam menentukan suatu kategori sentimen. Kata-kata tersebut dimasukkan kedalam daftar stopword yang biasanya berupa kata ganti orang, kata ganti penghubung, pronomial penunjuk, dan lain sebagainya.
4. Convert Emoticon
[image:20.595.307.532.699.773.2]Convert emoticon adalah proses mengkonversikan emoticon kedalam string yang sesuai dengan ekspresi emoticon itu sendiri. Convert emoticon dilakukan karena pada data tweet yang diambil dari standup comedy kompastv terdapat emoticon yang merupakan salah satu cara mengekspresikan persetujuan atau pertidaksetujuan dalam suatu tweet. Hal ini dirasa mempunyai pengaruh terhadap pengklasifikasian sentimen, oleh karena itu convert emoticon digunakan.
Tabel 1. Konversi Emoticon[3]
Emoticon Konversi
>:] :-) :) :o) :] :3 :c) :> =] 8) =) :} :^)
esenang
>:D :-D :D &-D 8D x-D xD X-D XD =-D =D =-3 =3
etertawa
<><<><
D:< D: D8 D; D= DX v.v D-„: ehoror >:P :-P :P X-P x-p xp XP :-p :p =p
:-b :b
elidah
>:o >:O :-O :O o_O o.O 8-0 ekaget >:\ >:/ :-/ :-. :/ :\ =/ =\ :S ekesal
:| :-| edatar
5. Convert Negation
Convert negation merupakan proses konversi kata-kata negasi yang terdapat pada suatu tweet, karena kata negasi mempunyai pengaruh dalam merubah nilai sentimen pada suatu tweet. Kata negasi yang terdapat pada suatu tweet akan dihilangkan, dan diberikan penanda . Jika terdapat kata negasi makan akan disatukan dengan kata setelahnya. Kata-kata negasi tersebut meliputi kata “bkn”, “bukan”, “tida”, “tak”, “ga”, “enggak”, “g”, “jangan”, dan “tidak”.
6. Tokenizer
Pada proses tokenizer setiap kata pada tweet dipisahkan, pada proses ini tahap yang dilakukan adalah memisahkan setiap kata yang dipisahkan oleh spasi, selanjutnya bagian tweet yang memiliki karakter selain alphabet, angka, dan garis bawah akan dipecah sesuai posisi karakter tersebut dan bagian yang hanya memiliki satu karakter non alphabet dan angka akan dibuang .
2.3Pembobotan TF-IDF
Term weighting ialah proses memberikan bobot terhadap semua kata pada dokumen, metode Term weighting yang digunakan pada penelitian ini adalah TF IDF. Term frequency adalah salah satu metode pembobotan yang paling sederhana. Pada metode ini setiap term diasumsikan memiliki proporsi kepentingan sesuai dengan jumlah terjadinya (munculnya) term tersebut dalam dokumen. Persamaan TF adalah sebagai berikut:
Dimana TF(d,t) adalah frekuensi kemunculan term t pada dokumen d.
Inverse Document Frequency memperhatikan kemunculan term pada kumpulan dokumen. Pada metode ini, term yang dianggap bernilai adalah term yang jarang muncul pada kumpulan dokumen. Persamaan IDF adalah sebagai berikut:
Dimana df(t) adalah banyak dokumen yang mengandung term t. TF*IDF merupakan kombinasi metode TF dengan IDF. Sehingga persamaan TF*IDF adalah sebagai berikut:
2.4Support Vector Machine
Support Vector Machine (SVM) merupakan salah satu metode machine learning yang mengubah text menjadi data vector. Vector dalam penelitian ini memiliki dua komponen yaitu dimensi (word id) dan bobot. Konsep SVM dapat dijelaskan secara sederhana sebagai usaha mencari hyperplane terbaik yangberfungsi sebagai pemisah dua buah class pada input space[4]. Usaha untuk mencari lokasi hyperplane ini merupakan inti dari proses pembelajaran pada SVM. Klasifikasi pada SVM dibagi menjadi 2, yaitu linier dan nonlinier.
Dimulai dengan kasus klasifikasi secara linier,
fungsi ini dapat didefinisikan
sebagai.
Dengan
Atau
Input pada penelitian SVM terdiri dari poin-poin yang merupakan vektor dari angka-angka real data yang tersedia dinotasikan sebagai
sedangkan label masing-masing dinotasikan sebagai untuk i = 1, 2, …,1 dimana 1 adalah banyaknya data. Diasumsikan kedua kelas -1 (negatif) dan +1 (positif) dapat terpisah secara sempurna oleh hyperplane berdimensi d, yang didefinisikan,
Dengan
Sebuah pattern xi yang termasuk kelas -1 (sampel negatif) dapat dirumuskan sebagai pattern yang memenuhi pertidaksamaan:
Dengan
Sedangkan pattern xi yang termasuk kelas +1 (sampel positif):
Dengan
Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara hyperplane dan titik terdekatnya, yaitu .
2.5Klasifikasi dengan Naïve Bayes
Pada pengklasifikasian menggunakan naïve bayes dibagi kedalam 2 proses, yaitu proses training dan testing. Proses training digunakan untuk menghasilkan model analisis sentimen yang nantinya akan digunakan sebagai acuan untuk mengklasifikasikan sentiment dengan data testing atau data mentah yang baru. Berikut adalah algoritma klasifikasi sentimen menggunakan Naïve Bayes Classifier:
1. Proses Training
a. Hitung .
b. Hitung untuk setiap kata pada model.
2. Proses Testing
a. Hitung untuk setiap
b. Tentukan kategori dengan nilai maksimal.
Pemberian kategori dari sebuah dokumen dilakukan dengan memilih nilai c yang memiliki nilai p(C = ci| D = dj) maksimum, dan dinyatakan dengan:
(1)
Dimana :
adalah hasil perkalian dari probabilitas kemunculan semua kata pada dokumen dj.
adalah hasil probabilitas dari semua kategori pada data training.
Kategori c* merupakan kategori yang memiliki nilai p(C = ci | D = dj) maksimum. Nilai p(D = dj) tidak mempengaruhi perbandingan karena untuk setiap k ategori nilainya akan sama.
3.
IMPLEMENTASI DAN PENGUJIAN
3.1 Lingkungan Implementasi
Perangkat keras yang digunakan dalam proses perancangan dan implementasi sistem memiliki beberapa spesifikasi sebagai berikut:
1. Processor 2.13GHz 2. RAM 1024MB
3. Monitor dengan resolusi 1366x768 pixels 4. Keyboard
5. Mouse
Perangkat lunak yang digunakan dalam proses implementasi sistem ini adalah sebagai berikut: 1. Sistem Operasi Windows 8 Starter 32 bit 2. Bahasa pemograman PHP.
3. Web server XAMPP.
4. Code editor berupa SublimeText3Portable. 5. DBMS : MySQL 5.5.27
6. Web Browser: Google Chrome 34.0.1847.137
3.2 Impelementasi Antarmuka (Interface)
Pada sub-bab ini akan dijelaskan mengenai implementasi antar muka yang telah dirancang sebelumnya. Hasil perancangan antarmuka yang telah diimplementasikan adalah sebagai berikut:
Gambar 8. Antarmuka Crawling Tweet
[image:22.595.325.539.229.347.2]Gambar 8. merupakan antarmuka Crawling Tweet yang diimplementasikan dalam sistem. Tab ini berfungsi untuk crawling data tweet dari akun resmi standup comedy kompastv, yang nantinya akan digunakan sebagai data testing untuk diklasifikasikan kedalam beberapa kategori sentimen.
[image:22.595.311.525.461.587.2] [image:22.595.69.286.582.781.2] [image:22.595.319.526.668.802.2]Gambar 9. Antarmuka Preprocessing
Gambar 9. merupakan antarmuka
preprocessing yang berfungsi yang berfungsi untuk menampilkan hasil dari setiap preprocessing data testing sebelum data tersebut di klasfikasi, seperti case folding, cleansing, stopword removal, convert emoticon, convert negation, tokenizer.
Gambar 10. Antarmuka Support vector machine
Gambar 11. Antarmuka Naïve Bayes
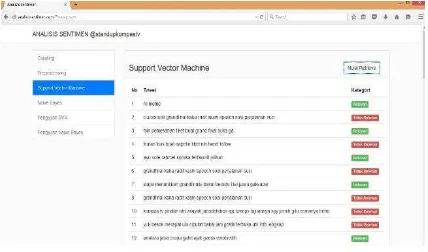
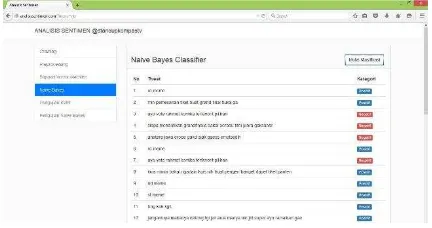
[image:23.595.77.284.200.310.2]Gambar 11. merupakan antarmuka naïve bayes yang berfungsi untuk menampilkan data tweet yang sudah diklasifikasi ke dalam kategori positif dan negatif. hasil testing atau hasil klasifikasi data testing, klasifikasi sentimen dari setiap tweet pada data testing didapat dari perhitungan naïve bayes yang sebelumnya telah melalui tahap preprocessing.
Gambar 12. Antarmuka Pengujian Support Vector Machine
[image:23.595.74.283.411.549.2]Gambar 12. merupakan antarmuka pengujian support vector menggunakan cross validation yang berfungsi untuk menguji performa klasifikasi dari sistem yang di bangun .
Gambar 13. Antarmuka Pengujian Naïve Bayes Classifier
Gambar 13. merupakan antarmuka pengujian naïve bayes menggunakan cross validation yang berfungsi untuk menguji performa klasifikasi dari sistem yang di bangun. Performa klasifikasi dapat dilihat dari hasil perhitungan akurasi dengan metode cross validation.
3.3 Pengujian Akurasi Sistem dengan Metode
10-fold cross validation
Jumlah data memegang peranan penting di dalam algoritma machine learning. Jumlah data yang sedikit (<100 instance) mungkin membuat algoritma machine learning tidak akurat. Algoritma machine learning merekomendasikan jumlah instance yang banyak (>1000 instance) namun data itu sendiri tidak mudah untuk diperoleh.
K-fold cross validation adalah teknik yang dapat digunakan apabila memiliki jumlah data yang terbatas (jumlah instance tidak banyak)[5]. K-fold cross validation merupakan salah satu metode yang digunakan untuk mengetahui rata-rata keberhasilan dari suatu sistem dengan cara melakukan perulangan dengan mengacak atribut masukan sehingga sistem tersebut teruji untuk beberapa atribut input yang acak. K-foldcross validation diawali dengan membagi data sejumlah n-fold yang diinginkan. Dalam proses cross validation data akan dibagi dalam n buah partisi dengan ukuran yang sama D1,D2,D3..Dn selanjutnya proses testing dan training dilakukan sebanyak n kali. Dalam iterasi ke-i partisi
Di akan menjadi data testing dan sisanya akan menjadi data training. Untuk penggunaan jumlah fold terbaik untuk uji validitas, dianjurkan menggunakan 10-fold cross validation dalam model.
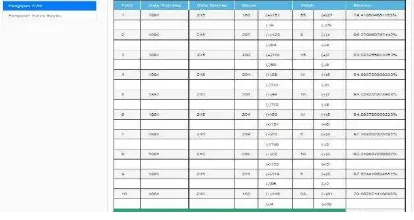
Skenario pengujian merupakan tahap penentuan pengujian yang dilakukan. Pengujian dilakukan untuk metode support vector machine dan naïve bayes. Pengujian dilakukan menggunakan metode k-cross validation dengan nilai k sebanyak 10 fold, pengujian ini bertujuan untuk mengetahui akurasi metode support vector machine dan naïve bayes classifier yang diterapkan pada analisis sentimen jika diuji dengan data training dan data testing yang berbeda. Tahap pengujian dengan menggunakan metode 10-fold cross validation membagi dataset yang awalnya berjumlah 1881 data akan dibagi menjadi 10 subset data untuk pengujian support vector machine. Sedangkan untuk naïve bayes classifier tahap pengujian dengan menggunakan metode 10-fold cross validation membagi dataset yang awalnya berjumlah 549 data akan dibagi menjadi 10 subset data. Pada fold pertama terdapat kombinasi 9 subset yang berbeda digabung dan digunakan sebagai data training, sedangkan 1 subset (sisa) digunakan sebagai data testing, selanjutnya proses training dan testing dilakukan sampai fold kesepuluh. Skenario uji akurasi dengan metode 10-fold cross validation dapat dilihat pada Tabel 2.
3.4 Hasil dan Analisis Pengujian
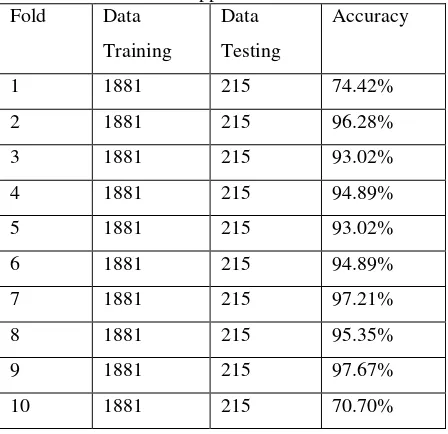
[image:24.595.309.528.87.421.2]Pada skenario uji dengan jumlah 10-fold cross validation dan iterasi yang dilakukan sebanyak 10 kali iterasi untuk support vector machine rata-rata yang dihasilkan yaitu 90.74%. Iterasi pertama pada fold pertama menggunakan 1881 data, proses training dan proses testing dilakukan sampai iterasi ke-10. Detail hasil dari akurasi pengujian skenario untuk support vector machine pada masing-masing foldnya dapat dilihat pada Tabel 3.
Tabel 3. Hasil Uji Stabilitas dengan 10-fold cross validation untuk support vector machine
Fold Data
Training
Data
Testing
Akurasi
1 1881 215 74.42%
2 1881 215 96.28%
3 1881 215 93.02%
4 1881 215 94.89%
5 1881 215 93.02%
6 1881 215 94.89%
7 1881 215 97.21%
8 1881 215 95.35%
9 1881 215 97.67%
10 1881 215 70.70%
Rata-rata akurasi 90.74%
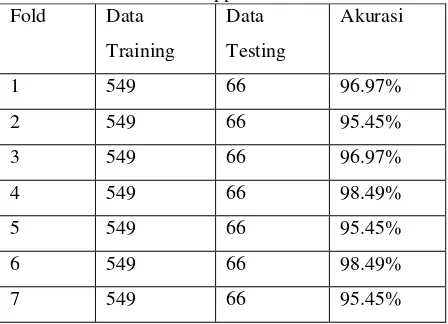
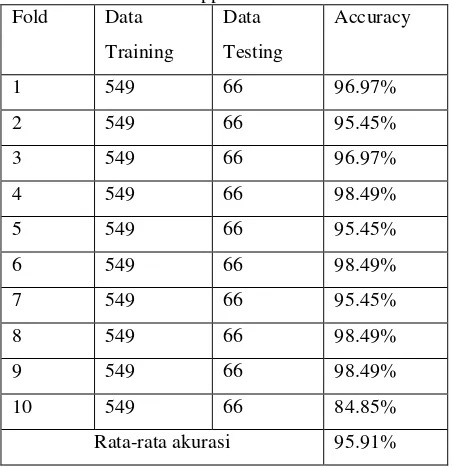
[image:24.595.66.290.234.465.2]Pada skenario uji dengan jumlah 10-fold cross validation dan iterasi yang dilakukan sebanyak 10 kali iterasi untuk naïve bayes rata-rata yang dihasilkan yaitu 95.91%. Iterasi pertama pada fold pertama menggunakan 549 data, proses training dan proses testing dilakukan sampai iterasi ke-10. Detail hasil dari akurasi pengujian skenario untuk naïve bayes pada masing-masing foldnya dapat dilihat pada Tabel 4.
Tabel 4. Hasil Uji Stabilitas dengan 10-fold cross validation untuk support vector machine
Fold Data
Training
Data
Testing
Akurasi
1 549 66 96.97%
2 549 66 95.45%
3 549 66 96.97%
4 549 66 98.49%
5 549 66 95.45%
6 549 66 98.49%
7 549 66 95.45%
8 549 66 98.49%
9 549 66 98.49%
10 549 66 84.85%
Rata-rata akurasi 95.91%
Tabel 3. mengindikasikan bahwa nilai akurasi pada tiap fold sudah sangat stabil. Percobaan pada fold ke-1 memperlihatkan hasil yang paling rendah diantara 9 fold lainnya yaitu 74.42%, sedangkan fold sisanya menghasilkan akurasi yang lebih besar dengan aurasi paling tinggi ada pada fold 1, 2, 3, 5, 7, dan 10. Sedangkan untuk Tabel 4. juga mengindikasikan bahwa nilai akurasi tiap fold sudah sangat stabil. Percobaan pada fold-10 memperlihatkan hasil yang rendah diantara 9 fold lainnya yaitu 84.85%. Jika dianalisis performa klasifikasi dengan Support Vector Machine dan Naïve Bayes yang dihasilkan sudah bisa dikatakan akurat, serta kinerja model klasifikasi sudah bisa dikatakan baik dengan melihat rata-rata akurasi dari setiap fold yang cukup besar yaitu 90.74% untuk support vector machine dan 95.91% untuk Naïve Bayes pada 10 fold cross validation dengan data training yang digunakan sebanyak 1881 data untuk support vector machine dan 549 data untuk naïve bayes, karena secara umum semakin besar data training maka akan semakin baik kinerja model klasifikasi suatu sistem.
4
PENUTUP
4.1Kesimpulan
Dari proses pengujian dan analisis yang telah dilakukan, kesimpulan yang dapat diambil antara lain:
Fold Data Subset
Fold 1
Training Testing
S2, S3, S4, S5, S6, S7 S8, S9, S10
S1 Fold
2
Training Testing
S1, S3, S4, S5, S6, S7 S8, S9, S10
S2 Fold
3
Training Testing
S1,S2, S4, S5, S6, S7 S8, S9, S10
S3 Fold
4
Training Testing
S1,S2, S3, S5, S6, S7 S8, S9, S10
S4 Fold
5
Training Testing
S1,S2, S3, S4, S6, S7 S8, S9, S10
S5 Fold
6
Training Testing
S1,S2, S3, S4, S5, S7, S8, S9, S10
S6 Fold
7
Training Testing
S1,S2, S3, S4, S5, S6, S8, S9, S10
S7 Fold
8
Training Testing
S1,S2, S3, S4, S5, S6, S7,S9, S10
S8 Fold
9
Training Testing
S1,S2, S3, S4, S5, S6, S7 , S10
S9 Fold
10
Training Testing
S1,S2, S3, S4, S5, S6, S7 S8, S9
[image:24.595.66.290.602.764.2]1. Metode Support Vector Machine dapat diterapkan pada analisis sentimen dalam retrieval data untuk mengelompokkan data relevan dan tidak relevan.
2. Metode Naïve Bayes Classifier dapat diterapkan pada analisis sentimen dalam mengklasifikasikan sentimen positif dan negatif.
3. Hasil pengujian stabilitas performa klasifikasi dengan menggunakan metode 10-fold cross validation menghasilkan akurasi yang cukup tinggi yaitu 90.74% untuk Support Vector Machine dan 95.91% untuk Naïve Bayes Classifier. Hal ini menunjukan bahwa kinerja model klasifikasi sudah bisa dikatakan baik dan stabil.
4.2Saran
Dari hasil pengujian , analisis dan kesimpulan yang telah dirumuskan, terdapat hal yang disarankan untuk penelitian selanjutnya, yaitu analisis sentimen pada penelitian ini belum memperhatikan semantic yaitu makna kata dan kalimat. Penelitian selanjutnya diharapkan dapat menggunakan makna kata dan kalimat untuk menentukan kategori sentimen pada suatu dokumen agar mendapatkan hasil yang lebih baik.
DAFTAR PUSTAKA
[1] [Online]. Available :
http://suc.metrotvnews.com/article/ensiklope dia/13.
[Accessed 12 Februari 2014].
[2] Ni Wayan Sumartini Saraswati,
“pps.unud.ac.id,” [Online]. Available:
www.pps.unud.ac.id/thesis/pdf_thesis/unud-209-236721286-tesis.pdf. [Accessed 10
Februari 2014]
[3] I. Sunni and D. H. Widyantoro, "Analisis Sentimen dan Ekstraksi Topik Penentu Sentimen pada Opini Terhdap Tokoh Publik," Jurnal Sarjana Institut Teknologi Bandung Bidang Elektro dan Informatika, vol. 1, pp. 200 - 206, 2012.
[4] Nugroho A.S., Arief Budi, and Dwi Handoko. 2003. Support Vector Machine Teori dan Aplikasinya dalam Bioinformatika, kuliah umum IlmuKomputer.Com.
[5]
R. Kohavi, "A study of Cross-Validation and Bootstrap for Accuracy Estimation andModelSelection,"1995.[Online].Available:http://ijcai.org/Past%20Pr
oceedings/IJCAI-95-VOL2/PDF/016.pdf.
SENTIMENT ANALYSIS ON TWITTER USER OF STANDUP COMEDY EVENT BY
USING SUPPORT VECTOR MACHINE AND NAÏVE BAYES CLASSIFIER
Rina Priyani
Informatic Engineering
–
Indonesian Computer University
Jl. Dipatiukur 112-114 Bandung
E-mail : [email protected]
ABSTRACT
One event is a standup comedy standup comedy KompasTV. The existence of an official account on twitter KompasTV standup comedy, allowing people who become followers of the account do feedback by responding to every posting a tweet from the account. Because of the availability of sentiment for a standup comedy show KompasTV very abundant, so the feedback submitted by followers can be used to measure sentiment analysis followers to standup comedy show in KompasTV. The number of tweets that get into standup comedy KompasTV twitter account can be used to determine the sentiment of followers to show KompasTV standup comedy, but in the delivery of these sentiments are sentiments which is not an opinion, and therefore before sentiment classified into positive and negative categories, a Data twitter should be separated into categories relevant and irrelevant by using Support Vector Machine. Once the data twitter entry into the relevant category, then the data twitter classified into positive and negative categories using the Naive Bayes classifier.
Problems sentiment analysis is how to classify sentiment into classes that have been determined. Furthermore, in order to overcome these problems is done by using a machine learning Support Vector Machine for separation of data relevant and irrelevant, and Naïve Bayes classifier for data classification positive and negative. The use of Support Vector Machine and Naïve Bayes classifier because performasinya better for Indonesian-language text, so the sentiment analysis can be applied to tweet which has a subjective value. From the test results by the method of 10-fold cross validation showed that both methods used have a satisfactory level of accuracy is 90.74% for the method of Support Vector Machine and 95.91% for the Naïve Bayes classifier method.
Keyword: Analisis sentimen, Support Vector
Machine, Naïve Bayes Classifier, Cross Validation, Twitter, tweet
1.
INTRODUCTION
Nowadays, the development of television Indonesia is very fast, so many emerging new events that varies. Ranging from news shows, talk shows, variety shows up comedy show or a comedy. One of standup comedy is comedy, a genre that is one profession that pelawaknya droll jokes brought on stage by myself, in a way monologue about a topic. People who do this activity called a stand-up comedy or comic [1].
One television that has a standup comedy show that KompasTV. Not just provide entertainment comedy with existing comics, KompasTV had several times held a talent show standup comedy, whose audition spread across Indonesia. Therefore enthusiastic people large enough to standup comedy, then KompasTV also have social media as a promotional tool standup comedy show, one that is twitter. Twitter is used KompasTV for displaying schedules standup comedy show that will be aired so that people can watch the event. The existence of standup comedy KompasTV official account on twitter, allowing people who become followers of the account do feedback by responding to each post a tweet from the account. Due to the availability of sentiment for a standup comedy show KompasTV very abundant, so the feedback given by the followers can be used to measure sentiment analysis followers to standup comedy show in KompasTV.
2.
SENTIMENT
ANALYSIS
ON
USER
OF
STANDUP
COMEDY
EVENT
BY
USING
SUPPORT VECTOR MACHINE AND
NAÏVE BAYES CLASSIFIER
KompasTV a private television station which has a standup comedy programs, and using Twitter as a social media for promotion. With the standup comedy KompasTV account and the number of posts a tweet that many every day there is feedback from the audience allows standup comedy show which is the followers of the twitter account, which can be considered as the availability of sentiment that is used for quality evaluation program KompasTV standup comedy.
But the problems in the sentiment analysis is how to classify sentiment on twitter of data that results can be used to evaluate programs in KompasTV standup comedy.
2.1Analysis System
In implementing the method of Support Vector Machine and Naïve Bayes classifier will be built a prototype with a description of the system which will be shown in Figure 1.
The system will be built has four stages: preprocessing, the data training, testing, and cross validation. For an explanation of each step can be seen as follows:
1. The first stage is the stage of retrieving data using twitter by crawling stream API, then the data is done preprocessing process which is the stage where the data will be used as a data testing cleared of noise or from something that has no influence on sentiment. Preprocessing is done in this phase include: case folding, cleansing, stopword removal, convert emoticons, convert negation, tokenizer.
2. The second stage is the stage of training the data, at this stage uses two training data, the training data support vector machine and the training data naïve Bayes, then the training data is done preprocessing stage and classified manually into four classes, namely classes relevant and irrelevant to training data support vector machine, and positive and negative grade for the training data naïve Bayes. Then all four classes are stored into a database of training data. After the tweets that have been classified manually created models sentiment analysis that will be saved back into the database detail the training data that will be used in the testing stage as sentiment analysis model.
3. The third stage is the stage of testing, at this stage using support vector machine testing of data and data testing naïve Bayes as a data input which of course is through the preprocessing
stage. Both testing the data is processed so that it can be seen class sentiments.
[image:27.595.316.527.90.319.2]4. The fourth stage is the stage of testing using the method of k-fold cross validation in which the data is divided number of n-fold is desired, then the process of testing and training conducted n times until the results come out accuracy. The accuracy of the results obtained from the average accuracy at each iteration.
Figure 1. System overview
2.2Analysis of Data Input
The input data used is the tweet from the official Twitter account standup KompasTV. Tweet data is obtained by utilizing the features of API (Application Interface) that has been provided by twitter for mendapakan API key, and access token that will be used for data retrieval tweet. The data is data taken tweets that contain the word "standupkompastv" tweet or data contained in the official account "StandUpKompasTV", the data can be considered to represent the sentiment of the user or standup KompasTV followers. Data in the form of a sentence with a maximum length of 140 characters. Examples of every tweet containing sentiment on account "StandUpKompasTV" contained in Figure 2 and Figure 3.
Figure 2. Tweets with positive sentiment
Figure 3. Tweets with negative sentiment
Tweet Data taken from the official account KompasTV Standup comedy is still a raw data and there is noise or traits that have no effect on sentiment classification as a link, "@", stopword, which is marked by the hashtag "#" character. Examples of such raw tweet exist in Figure 4.
In addition, the tweet perceived characteristics have an influence on the determination of the sentiment is there an emoticon that is one way to express approval or disapproval phrase in a sentence or tweets. Examples tweet existing of crude emoticons contained in Figure 5.
Figure 5. Example of data tweet with emoticons
Characteristics next tweet is no negation there is a word that needs to be considered in the analysis because the sentiment can change the sentiment of a tweet. The word is the negation as “tidak”, “bukan”, “ga”, “jangan”, “nggak”, “tak”, “tdk”, dan “gak”. For example the word “lelet” which is a word with negative sentiment, because in front of the word “lelet” there is a negation word “tidak” then the sentiment of the combined word is positive. Examples tweet contained a negation word is in Figure 6.
Figure 6. Example of data tweet with negation
Tweets so that the data can be put to good use to classify sentiment will require preprocessing process. In this process the data tweet that used for testing the data the data training data dibersikan of noise or traits that have no effect on sentiment classification as a link, "@", "RT", stopword, and so forth. Preprocessing process description can be seen in Figure 7.
Figure 7. Stages Preprocessing
1. Case Folding
In the case of folding process large or uppercase letters contained in a tweet converted to lowercase.
2. Cleansing
Tweet contained in the official account standup KompasTV has various components or characteristics tweet characteristic such as "@" are identified as components of usernames, URLs, known through the operation of regular, hashtag which marks the word as a topic that is being discussed, and "RT" are identified as repeat the tweet was posted. These components do not have any influence on the sentiment, it will be discarded.
3. Stopword Removal
Data tweets that have been through the previous process still contains words deemed unable to give effect to determine a category sentiment. The words are inserted into the stopword list which is usually in the form of personal pronouns, relative pronoun, pronomial pointer, and others.
4. Convert Emoticon
Convert emoticon is the process of converting emoticon into a string corresponding to the emoticon expression itself. Convert emoticons made because the tweet of data taken from standup comedy emoticon KompasTV there is one way of expressing approval or disapproval in a tweet. It is considered to have an influence on sentiment classification, therefore convert emoticons used.
Table 1. Conversion Emoticon[3]
Emoticon Conversion
>:] :-) :) :o) :] :3 :c) :> =] 8) =) :} :^)
ehappy
>:D :-D :D &-D 8D x-D xD X-D XD =-D =D =-3 =3
elaugh
>:] :-( :( :-c :c :-< :< :-[ :[ :{ <><<><
esad
D:< D: D8 D; D= DX v.v D-„: ehoror >:P :-P :P X-P x-p xp XP :-p :p =p
:-b :b
etongue
>:o >:O :-O :O o_O o.O 8-0 eshock >:\ >:/ :-/ :-. :/ :\ =/ =\ :S eangry
:| :-| eflat
5. Convert Negation
Convert negation is the process of converting the words of negation contained in a tweet, because the word negation have an influence in changing the value of sentiment in a tweet. Said negation contained in a tweet would be eliminated, and given marker. If there is a negation word will eat united with said afterwards. The words of negation include words “bkn”, “bukan”, “tida”, “tak”, “ga”, “enggak”, “g”, “jangan”, dan “tidak”.
6. Tokenizer
In the process tokenizer every word on the tweet is separated, in the process steps done is to separate each word separated by a space, the next part of tweets that have a character other than the alphabet, numbers, and the bottom line will be broken down according to the position the character and the part that has only one non-alphabetic and numeric characters will be discarded.
Term weighting is the process giving weight to every word in the document, the term weighting method used in this study is the TF IDF. Term frequency is one of the simplest methods of weighting. In this method, each term is assumed to have the proportion of interest in accordance with the number of occurrence (emergence) of the terms in the document. TF equation is as follows:
Where TF (d, t) is the frequency of occurrence of term t in document d.
Inverse Document Frequency attention to the appearance of the term in the document. In this method, a term that is considered valuable is the term that rarely appear in the document. IDF equation is as follows:
Where df (t) is many documents that contain the term t. TF * IDF is a combination of TF with the IDF. So the equation TF * IDF is as follows:
2.4Support Vector Machine
Support Vector Machine (SVM) is a machine learning method that converts text into vector data. Vector in this study has two components, namely the dimension (word id) and weights. SVM concepts can be explained simply as an attempt to find the best hyperplane which serves as a separator are two classes in the input space[4]. Attempt to find the location of this hyperplane is the core of the learning process on SVM. SVM classification is divided into two, namely linear and nonlinear.
Starting with the linear classification of cases, this function can be defined as.
with
Or
Input to the SVM research consists of the points which is a vector of real numbers available data is denoted as xi ∈R ^ d while each label is denoted as yi∈ {-1, + 1} for i = 1, 2, ..., 1 where 1 is the number of data. Both classes are assumed to -1 (negative) and +1 (positive) can be separated perfectly by hyperplane dimension d, which is defined,
with
A pattern xi which belongs to the class -1 (negative samples) can be formulated as a pattern that satisfies the inequality:
With
While the pattern that belongs to the class xi +1 (positive samples):
With
The margin can be found by maximizing the value of the distance between the hyperplane and the closest point, which is 1 / (∥w∥).
2.5Classification with Naive Bayes
In using the naïve Bayes classification is divided into two processes, namely the process of training and testing. The training process is used to produce a sentiment analysis model that will be used as a reference to classify sentiment data testing of new or raw data. Here is sentiment classification algorithms using Naïve Bayes Classifier:
1. Training
a. Calculate .
b. Calculate for each word on the
model. 2. Testing
a. Calculate for each
category
b. Determine the value category maximum.
Determination of the category of a document is done by choosing the value of c which has a value of p(C = ci| D = dj) maximum, and is expressed by:
(1)
Where :
is the product of the probability of occurrence of all words in the documentdj.
is the result of the probability of all categories in the training data.
Categoryc* is the category that has the value ofp(C = ci | D = dj) maximum. Value ofp(D = dj) does not affect the comparison because for each k value will be the same category.
3.
IMPLEMENTATION
AND TESTING
3.1 Environment Implementation
The hardware used in the design and implementation of the system has some specifications as follows:
1. Processor 2.13GHz 2. RAM 1024MB
3. Monitor 1366x768 pixels 4. Keyboard
5. Mouse
The software used in the implementation process of this system are as follows:
2. PHP programming language. 3. Web server XAMPP.
4. Code editor berupa SublimeText3Portable. 5. DBMS : MySQL 5.5.27
6. Web Browser: Google Chrome 34.0.1847.137
3.2
Implementation of Interfaces
In the sub-chapter will explain the implementation of the interface has been designed previously. Results of interface design that has been implemented is as follows:
Figure 8. Interface of Crawling Tweet
[image:30.595.70.284.226.390.2]Figure 8. Tweet Crawling is an interface that is implemented in the system. This tab serves for crawling the data tweet from the official account KompasTV standup comedy, which will be used as a data testing to be classified into several categories sentiment.
Figure 9. Interface of Preprocessing
Figure 9. a interface of preprocessing that serves that function for displaying the results of any testing preprocessing of data before the data is in klasfikasi, such as case folding, cleansing, stopword removal, convert emoticons, convert negation, tokenizer.
Figure 10. Interface of Support vector machine
Gambar 10. a interface of support vector machine that serves to display the data tweet that has been grouped into categories relevant and irrelevant.
Figure 11. Interface of Naïve Bayes
[image:30.595.310.526.233.347.2]Figure 11. a interface of naïve Bayes that serves to display the data tweet that has been classified into positive and negative categories. the results of testing or the results of testing data classification, sentiment classification of each tweet on the data obtained from the testing naïve Bayes calculations that had previously been through the preprocessing stage.
[image:30.595.86.296.498.614.2]Figure 12. Interface of Testing Support Vector Machine
[image:30.595.321.532.504.618.2] [image:30.595.315.525.697.817.2] [image:30.595.70.284.719.834.2]Figure 13. Interface of Testing Naïve Bayes Classifier
Figure 13. a interface of testing naïve using cross validation that serves to test the performance of the classification system in the wake. Performance classification can be seen from the calculation accuracy by cross validation method.
3.3 Accuracy Testing Method System with
10-fold cross validation
The amount of data plays an important role in machine learning algorithms. The amount of data bit (<100 instance) may make a machine learning algorithm is not accurate. Machine learning algorithms recommend the number of instances that many (> 1000 instance) but the data itself is not easy to obtain.
K-fold cross validation is a technique that can be used if it has a limited amount of data (number of instances not many) [5]. K-fold cross validation is one method used to determine the average success of a system by means of looping to randomize the input attributes that the system is tested for several attributes of random input. K-foldcross validation begins by dividing the data number of the desired n-fold. In the process of cross validation data will be divided into n partitions of the same size D1, D2, D3..Dn further testing and training processes carried out n times. In the i-th iteration will be a data partition in testing and the remainder will be the training data. To use the best fold number for validity, it is recommended to use 10-fold cross validation in the model.
Scenario testing is determining the stage of testing. Tests conducted for the method of support vector machine and naïve Bayes. Testing is done using k-cross validation with k values as much as 10 fold, this test aims to determine the accuracy of the method of support vector machine and naïve Bayes classifier that is applied to the analysis of sentiment when tested with the training data and testing the data differently. The testing phase using 10-fold cross validation divides the dataset which initially amounted to 1881 data will be divided into 10 subsets of data for testing support vector machine. As for the naïve Bayes classifier testing phase using 10-fold cross validation divides the dataset that originally numbered 549 data will be divided into 10 subsets of data. At first fold there
![Gambar 1. 1 Model Proses Waterfall[3]](https://thumb-ap.123doks.com/thumbv2/123dok/1208607.777915/13.595.157.449.115.285/gambar-model-proses-waterfall.webp)
![Tabel 1. Konversi Emoticon[3]](https://thumb-ap.123doks.com/thumbv2/123dok/1208607.777915/20.595.307.532.699.773/tabel-konversi-emoticon.webp)