NTIFIKASI PEMBICARA DENGAN
PEMODELAN IDENTIFIKASI PEMBICARA DENGAN
MFCC SEBAGAI EKSTRAKSI CIRI DAN
SVM SEBAGAI PENGENALAN POLA
LUTHFAN ALMANFALUTHI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
*Dengan ini saya menyatakan bahwa tesis Pemodelan Identifikasi Pembicara Dengan MFCC Sebagai Ekstraksi Ciri Dan SVM Sebagai Pengenalan Pola adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Februari 2014
Luthfan Almanfaluthi NIM G651100354
*Pelimpahan hak cipta atas karya tulis dari penelitian kerja sama dengan pihak
RINGKASAN
LUTHFAN ALMANFALUTHI. Pemodelan Identifikasi Pembicara dengan MFCC sebagai Ekstraksi Ciri dan SVM sebagai Pengenalan Pola. Dibimbing oleh AGUS BUONO dan YANI NURHADRYANI.
Setiap hari manusia bertukar informasi dengan menggunakan media suara walaupun dapat juga bertukar informasi dengan media teks dan alat bantu semacamnya. Sinyal suara yang diucapkan setiap manusia memiliki karakter dan kualitas yang berbeda atau bersifat unik. Masyarakat Indonesia mempunyai beragam suku dan budaya, sehingga banyak permasalahan pola ucapan yang berbeda-beda untuk satu kata yang sama. Oleh karena permasalahan ini bisa menjadi problem dalam sistem identifikasi pembicara, sehingga perlu dikembangkan suatu sistem yang relatif lebih robust terhadap permasalahan intra-speaker variability dan noise. Sistem identifikasi pembicara lebih berfokus pada analisis dengan dua subsistem yaitu Feature Extractor (ekstraksi ciri) dan Pattern Recogniser (pengenalan pola). Mel-Frequency Cepstrum Coefficients (MFCC) adalah salah satu ekstraksi ciri yang sering digunakan untuk pemrosesan suara manusia karena menghitung koefisien cepstral dengan mempertimbangkan pendengaran manusia. Support Vector Machine (SVM) merupakan salah satu teknik klasifikasi data dengan proses pelatihan (supervised learning) yang mampu mengklasifikasikan multi class sehingga cocok untuk pengenalan lebih dari dua kelas.
Pengambilan data suara dilakukan dengan menggunakan alat mikrofon. Sumber suara diperoleh dari 10 orang pembicara dewasa dengan perbedaan jenis kelamin, umur dan suku yang masing-masing mengucapkan 50 kali kata
“KOMPUTER” yang hingga didapatkan 500 data suara. Durasi rekam yang
digunakan yaitu 2 detik dengan besar frekuensi rekam 16 KHz. Sebelum suara diproses maka melalui tahapan praproses yang terdiri atas penghapusan silence, normalisasi dan penambahan noise. Sinyal noise yang ditambahkan bersifat Gaussian dengan level 80 dB sampai dengan 0 dB. Pengenalan pola dengan menggunakan SVM menggunakan algoritma QP dan algoritma SMO. Pengujian fungsi Kernel diujicobakan untuk fungsi RBF, Quadratic dan Linear untuk masing-masing algoritma.
SUMMARY
LUTHFAN ALMANFALUTHI. Speaker Identification System Modeling Using MFCC as Feature Extraction and SVM as Pattern Recognition. Supervised by AGUS BUONO and YANI NURHADRYANI.
Everyday people exchange information using voice may also exchange information with the media texts and tools. Voice signal every human has the character and qualities of different or unique. Indonesia has a diverse ethnic, communities and cultures, many problems are for the same word has different pronunciation patterns. Because of this problem could be a problem in the speaker identification system, so it is necessary to develop a system that is relatively more robust to the problem of intra-speaker variability and noise. Speaker identification system is more focused on the analysis of the two subsystems, namely Feature Extractor and Pattern Recogniser. Mel-Frequency Cepstrum Coefficients (MFCC) is one of feature extraction that is often used for processing the human voice for calculating the cepstral coefficients with the consideration of human hearing. Support Vector Machine (SVM) is one of the classification techniques of data with the supervised learning that is able to classify the multi-class so it is suitable for the classification of more than two classes.
Data collection was performed using a microphone to record sound. Sound source was obtained from 10 adult speakers with differences in gender, age and ethnicity, which each speakers say 50 times the word "COMPUTER" so that obtained 500 data. Record duration is 2 seconds with a frequency of 16 KHz. Before data is processed, a preprocessing stage consisting of the elimination of silence, normalization and noise addition. Gaussian noise is added from the level of 80 dB to 0 dB. After the MFCC feature extraction is done, the next stage is SVM pattern recognition using QP and SMO algorithms. Kernel function tested for RBF, Linear, and Quadratic for each algorithm.
Pattern Recognition using Kernel quadratic function with a ratio of 90 : 10 for the test data that the original sound without noise, SMO algorithm produces accuracy of 97.0% and the accuracy of the system can maintain above 70% up to 40dB noise addition. The number of errors for all 10 speakers using the test data of the original sound without noise is at most the number 9 speakers (Male, 41 years old, Java). The processing time SMO algorithm is better than the QP algorithm. Future studies may be added to increase the accuracy of Noise Cancelling the voice data is contaminated by noise.
© Hak Cipta Milik IPB, Tahun 2014
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
PEMODELAN IDENTIFIKASI PEMBICARA DENGAN
MFCC SEBAGAI EKSTRAKSI CIRI DAN
SVM SEBAGAI PENGENALAN POLA
LUTHFAN ALMANFALUTHI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
Judul Tesis
Pemodelan Identifikasi Pembicara dengan MFCC sebagai Ekstraksi Ciri dan SVM sebagai Pengenalan Pola
PRAKATA
Puji dan syukur penulis panjatkan kehadirat Allah SWT, sholawat dan salam penulis haturkan kepada Nabi Muhammad SAW sehingga tesis ini dapat diselesaikan. Topik yang dipilih dalam penelitian ini adalah Pemodelan Identifikasi Pembicara dengan MFCC sebagai Ekstraksi Ciri dan SVM sebagai Pengenalan Pola.
Pada kesempatan ini penulis ingin menyampaikan ucapan terima kasih dan penghargaan kepada:
1. Bapak Dr Ir Agus Buono, MSi MKom dan Ibu Dr Yani Nurhadryani, SSi MT selaku pembimbing yang telah banyak memberikan waktu dan masukannya untuk tesis ini.
2. Bapak Dr Bib Paruhum Silalahi, MKom selaku dosen penguji atas saran yang membangun dalam tesis ini.
3. Dosen-dosen, Staf karyawan (Bapak Ruchyan dan Bapak Ficky) dan rekan-rekan Angkatan XII Pascasarjana Ilmu Komputer kelas khusus (Hafzal Hanief, Arif Purnomo, Muji Yuswanto, Firnas Nadirman, Darwinsyah, Erniyati dan Diana) atas semua bantuannya.
4. Keluarga (orang tua, saudara, istri dan anak-anak) yang tiada hentinya memberikan semangat, dukungan dan doanya kepada penulis.
5. Seluruh pihak yang telah membantu dalam penyelesaian tesis ini.
Penulis menyadari bahwa kesempurnaan hanya milik Allah SWT dan masih terdapat banyak kekurangan dalam penyusunan tesis ini. Penulis berharap semoga tesis ini dapat bermanfaat dan dapat dikembangkan di masa mendatang.
Bogor, Februari 2014
DAFTAR ISI
Ruang Lingkup Penelitian 3
2 TINJAUAN PUSTAKA 4
Prinsip Identifikasi Pembicara 4
Mel-Frequency Cepstrum Coefficients (MFCC) 4 Support Vector Machine (SVM) 6
3 METODOLOGI PENELITIAN 10
Kerangka Pemikiran 10
Pengambilan Data Suara 11
Praproses Data 11
Pemrosesan Data 14
4 HASIL DAN PEMBAHASAN 16
Praproses Data 16
Karakteristik Pembicara 16
Ekstraksi Ciri MFCC 17
Pengenalan Pola SVM dengan fungsi KernelLinear 17 Pengenalan Pola SVM dengan fungsi KernelQuadratic 18 Pengenalan Pola SVM dengan fungsi Kernel RBF 20
Jumlah error Pembicara 22
Perbandingan waktu proses algoritma SMO dengan QP 22
5 SIMPULAN DAN SARAN 23
DAFTAR PUSTAKA 24
LAMPIRAN 25
DAFTAR TABEL
1 Daftar 10 pembicara yang digunakan dalam penelitian 11 2 Pengujian pemilihan perbandingan data latih dan data uji 14 3 Jumlah error untuk setiap pembicara dengan data uji suara tanpa noise 22
DAFTAR GAMBAR
1 Sistem identifikasi pembicara 1
2 SVM dengan data terpisah secara linear 6
3 Fungsi Kernel memetakan data ke ruang vektor berdimensi lebih tinggi 8
4 Diagram alir penelitian 10
5 Tahapan penghapusan silence pada data suara 12
6 Tahapan normalisasi pada data suara 12
7 Perbandingan sinyal asli tanpa noise dan sinyal asli yang sudah
ditambahkan noise 80 dB, 60 dB, 40 dB, 20 dB, 10 dB dan 0 dB 14
8 Perbandingan jenis kelamin dengan FFT 16
9 Perbandingan keakuratan fungsi KernelLinear dengan menggunakan
rasio 90 : 10 17
10 Perbandingan keakuratan fungsi KernelLinear dengan menggunakan
rasio 75 : 25 18
11 Perbandingan keakuratan fungsi KernelLinear dengan menggunakan
rasio 60 : 40 18
12 Perbandingan keakuratan fungsi KernelQuadratic dengan menggunakan
rasio 90 : 10 19
13 Perbandingan keakuratan fungsi KernelQuadratic dengan menggunakan
rasio 75 : 25 19
14 Perbandingan keakuratan fungsi KernelQuadratic dengan menggunakan
rasio 60 : 40 20
15 Perbandingan keakuratan fungsi Kernel RBF dengan menggunakan
rasio 90 : 10 20
16 Perbandingan keakuratan fungsi Kernel RBF dengan menggunakan
rasio 75 : 25 21
17 Perbandingan keakuratan fungsi Kernel RBF dengan menggunakan
rasio 60 : 40 21
DAFTAR LAMPIRAN
1
1
PENDAHULUAN
Latar Belakang
Setiap hari manusia bertukar informasi dengan menggunakan media suara walaupun dapat juga bertukar informasi dengan media teks dan alat bantu semacamnya. Sinyal suara yang diucapkan setiap manusia memiliki karakter dan kualitas yang berbeda atau bersifat unik. Sinyal suara dipengaruhi banyak hal, seperti intra-speaker variability (dimensi artikularis pembicara, emosi, kesehatan, umur, jenis kelamin, dialek) dan noise (latar belakang suara lingkungan dan media transmisi) (Campbell 1997).
Reynold (2002) berpendapat bahwa suara dapat juga dikategorikan sebagai alat biometrik karena memiliki ciri-ciri sebagai berikut: alami, mudah diukur, tidak terlalu berubah seiring waktu atau kondisi fisik, tidak terlalu terganggu dengan adanya gangguan lingkungan, serta tidak mudah ditiru. Suara hampir memenuhi semua persyaratan biometrik, namun permasalahan yang timbul dari pemrosesan suara yaitu suara adalah bersifat multidimensi (linguistik, semantik, artikularis dan akustik).
Proses identifikasi dengan suara memiliki keuntungan secara ekonomis dibandingkan dengan identifikasi secara biometrik lainnya seperti identifikasi pada wajah, sidik jari, tanda tangan, retina dan lain-lain. Identifikasi dengan suara hanya membutuhkan alat tambahan berupa mikrofon dan kartu suara, sedangkan karakteristik lain membutuhkan alat tambahan seperti scanner. Hal ini dapat menekan sedikit biaya pengembangan sistem (Campbell 1997).
Sinyal suara manusia mempunyai tingkat variabilitas yang sangat tinggi. Suatu sinyal suara yang dikeluarkan oleh pembicara yang berbeda-beda menghasilkan pola ucapan yang berbeda-beda pula. Masyarakat Indonesia mempunyai beragam suku dan budaya, sehingga banyak permasalahan pola ucapan yang berbeda-beda untuk satu kata yang sama. Oleh karena permasalahan ini bisa menjadi problem dalam sistem identifikasi pembicara, sehingga perlu dikembangkan suatu sistem yang relatif lebih robust terhadap permasalahan intra-speaker variability dan noise. Sistem identifikasi pembicara lebih berfokus pada analisis dengan dua subsistem yaitu Feature Extractor (ekstraksi ciri) dan Pattern Recogniser (pengenalan pola) yang diilustrasikan oleh Gambar 1.
2
Mel-Frequency Cepstrum Coefficients (MFCC) adalah salah satu ekstraksi ciri yang sering digunakan untuk pemrosesan suara manusia, MFCC merupakan ekstraksi ciri yang menghitung koefisien cepstral dengan mempertimbangkan pendengaran manusia (Do 1994). Support Vector Machine (SVM) merupakan salah satu teknik klasifikasi data dengan proses pelatihan (supervised learning) yang mampu mengklasifikasikan multi class sehingga cocok untuk pengenalan lebih dari dua kelas.
Beberapa ekstraksi ciri untuk identifikasi pembicara yang lain yaitu Linear Predictive Coding, Perceptual Linear Prediction, dan Wavelet. Tujuan ekstraksi ciri adalah mengubah vektor suara yang dihasilkan dari digitalisasi yang memiliki vektor yang besar menjadi vektor ciri, tanpa menghilangkan karakteristik suara tersebut. Beberapa model pengenalan pola yang dapat digunakan untuk identifikasi pembicara yang lain yaitu Jarak Euclid, Distribusi Normal, Probabilistic Neural Network (PNN), dan Hidden Markov Model (HMM).
Penelitian sebelumnya yaitu Guiwen Ou dan Dengfeng Ke (2004), A.
Mezghani dan D. O’Shaughnessy (2005) dan M.M Homayounpour dan I. Rezaian
(2008) telah membuktikan bahwa MFCC baik untuk mengenali pola pada pembicara dan dapat digunakan untuk identifikasi pembicara. Agus Buono (2009) dalam desertasinya menggunakan 1D-MFCC mendapatkan hasil keakuratan 98.8% sedangkan dengan 2D-MFCC mendapatkan hasil keakuratan 99.9% pada sinyal suara tanpa noise. Sedangkan untuk pengenalan pola SVM pada sinyal suara sudah pernah dilakukan juga dan mendapatkan hasil yang menakjubkan yaitu Shi-Huang Chen dan Yu-Ren Luo (2009) menguji coba identifikasi pembicara menggunakan SVM dengan sumber 20 pria dan 20 wanita dari database Aurora-2. Mereka mengujinya tanpa noise pada tingkat 8000 Hz dan menghasilkan keakuratan 95.1%.
Tujuan Penelitian
Penelitian ini bertujuan membangun model sistem identifikasi pembicara dengan menerapkan MFCC sebagai ekstraksi ciri dan SVM sebagai pengenalan pola.
Manfaat Penelitian
Sistem identifikasi pembicara dapat digunakan untuk melakukan identifikasi seseorang melalui kata-kata yang diucapkan oleh pengguna sistem, sehingga sistem ini menghasilkan identitas pengguna sistem.
3
Ruang Lingkup Penelitian
Ruang lingkup penelitian secara singkat adalah sebagai berikut: 1. Sistem yang dikembangkan hanya dalam bentuk model sistem.
2. Identifikasi pembicara dilakukan melalui kata yang diucapkan pembicara bersifat text-dependent yang berarti telah disepakati sebelumnya dan akan digunakan seterusnya.
3. Sumber suara yang digunakan adalah 10 orang dewasa dengan perbedaan jenis kelamin, umur dan suku.
4. Penelitian ini dibatasi pada penanganan gangguan eksternal berupa noise, dan difokuskan pada Gaussian Noise yang berkisar dari 80 dB hingga 0 dB.
4
2
TINJAUAN PUSTAKA
Prinsip Identifikasi Pembicara
Identifikasi pembicara adalah proses mengklasifikasikan pembicara dari sejumlah suara pembicara yang diberikan, sebagai suatu keputusan yang terbaik. Dasar kerja sistem identifikasi pembicara yaitu mampu meniru kemampuan manusia dalam mengenal identitas seseorang melalui suara yang didengar, sehingga sistem identifikasi pembicara dapat dimasukan kedalam kelompok sistem kecerdasan buatan (Kusumadewi 2003).
Secara garis besar terdapat dua tahap proses yang dilibatkan untuk membangun suatu sistem identifikasi pembicara. Pertama, mendapatkan informasi spesifik atau nilai ciri dari suara yang diamati. Kedua, mengklasifikasikan suara melalui proses pencocokan nilai ciri suara yang diterima dengan nilai ciri suara acuan (basis data ciri suara) (Furui 1997).
Dari sudut pandang linguistik, terdapat dua metode yang dapat diterapkan untuk mengembangkan sistem identifikasi pembicara. Metode pertama disebut text-dependent, dan metode kedua disebut text-independent. Sistem identifikasi pembicara yang mengadopsi metode text-dependent, harus mengetahui dan menentukan terlebih dahulu teks yang akan diucapkan pembicara. Contoh penerapan metode text-dependent adalah pada pengucapan PIN (nomor identitas diri) yang digunakan sebagai kata kunci. Sistem identifikasi pembicara yang mengadopsi metode text-independent, tidak perlu menentukan teks apa yang harus diucapkan pembicara, sehingga pembicara bebas menentukan pilihan teks yang akan diucapkannya (Furui 1997).
Mel-Frequency Cepstrum Coefficients (MFCC)
Ekstraksi ciri adalah proses untuk menentukan vektor yang dapat digunakan sebagai penciri objek atau individu. Ciri yang biasa digunakan adalah koefisien cepstral. MFCC merupakan ekstraksi ciri yang menghitung koefisien cepstral dengan mempertimbangkan pendengaran manusia. MFCC memiliki tahapan yang terdiri atas (Do 1994):
1. Frame Blocking. Pada tahap ini sinyal suara continous speech dibagi ke
dalam beberapa frame serta dilakukan overlapping frame agar tidak kehilangan informasi.
2. Windowing. Merupakan salah satu jenis filtering untuk
5
penggunaan window Hamming cukup beralasan. Persamaan window Hamming adalah :
…(1) Keterangan: n = 0, .., N-1 (lebar frame)
3. Fast Fourier Transform (FFT). Tahapan selanjutnya adalah mengubah
tiap frame dari domain waktu ke dalam domain frekuensi. FFT adalah algoritme yang mengimplementasikan Discrete Fouries Transform (DFT). Hasil DFT adalah bilangan kompleks dengan persamaan 2 untuk mencari nilai real dan persamaan 3 untuk mencari nilai imaginer.
…(2)
…(3) Keterangan: N = jumlah data
k = 0, 1, 2, ..., �
x[i] = data pada titik ke-i
Proses selanjutnya ialah menghitung nilai magnitudo FFT. Magnitudo
dari bilangan kompleks = + adalah | | = √ + .
4. Mel-Frequency Wrapping. Persepsi sistem pendengaran manusia
terhadap frekuensi sinyal suara ternyata tidak hanya bersifat linear. Penerimaan sinyal suara untuk frekuensi rendah (< 1000 Hz) bersifat linear, sedangkan untuk frekuensi tinggi (> 1000 Hz) bersifat logaritmik. Skala ini disebut skala mel-frequency yang berupa filter. Pada persamaan 4 ditunjukkan hubungan skala mel dengan frekuensi dalam Hz:
…(4) Proses wrapping terhadap sinyal dalam domain frekuensi dilakukan menggunakan persamaan 5.
…(5)
6
Hi(k) = nilai tinggi pada filter i segitiga dan k frekuensi, dengan k = 0, 1 sampai N-1 jumlah magnitudo frekuensi
5. Cepstrum. Tahap ini merupakan tahap terakhir MFCC. Pada tahap ini
mel-frequency akan diubah menjadi domain waktu menggunakan Discrete Cosine Transform (DCT) dengan persamaan 6.
…(6)
Support Vector Machine (SVM)
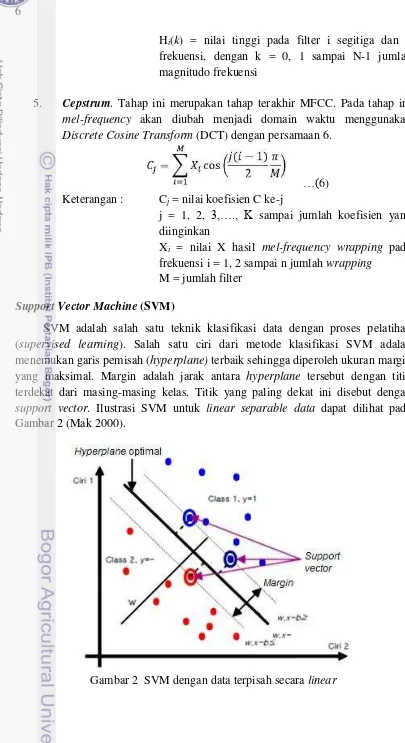
SVM adalah salah satu teknik klasifikasi data dengan proses pelatihan (supervised learning). Salah satu ciri dari metode klasifikasi SVM adalah menemukan garis pemisah (hyperplane) terbaik sehingga diperoleh ukuran margin yang maksimal. Margin adalah jarak antara hyperplane tersebut dengan titik terdekat dari masing-masing kelas. Titik yang paling dekat ini disebut dengan support vector. Ilustrasi SVM untuk linear separable data dapat dilihat pada Gambar 2 (Mak 2000).
7
Diberikan data pelatihan , , , , …., �, � , dimana ∈ ℜ�, ∈
{+1, −1}. Jika data terpisah secara linear seperti pada Gambar 2, maka akan berlaku fungsi diskriminan linear:
� = . – …(7)
dimana w adalah vektor bobot normal terhadap hyperplane, x adalah data yang diklasifikasi, dan b adalah bias. Hyperplane adalah garis u = 0. Margin antara dua
kelas adalah � =
‖�‖2. Margin dapat dimaksimalkan dengan menggunakan fungsi optimisasi Lagrangian seperti berikut:
…(8)
dengan memperhatikan sifat gradien:
dan
persamaan Lagrangian dapat dimodifikasi sebagai maksimalisasi L yang hanya mengandung � , persamaan berikut disebut juga Quadratic Programing (QP) yaitu sebagai berikut:
…(9)
dan dengan persamaan sebagai berikut:
…(10)
serta � adalah lagrange multiplier. Data yang berkorelasi dengan � yang positif disebut sebagai support vector.
8
…(11)
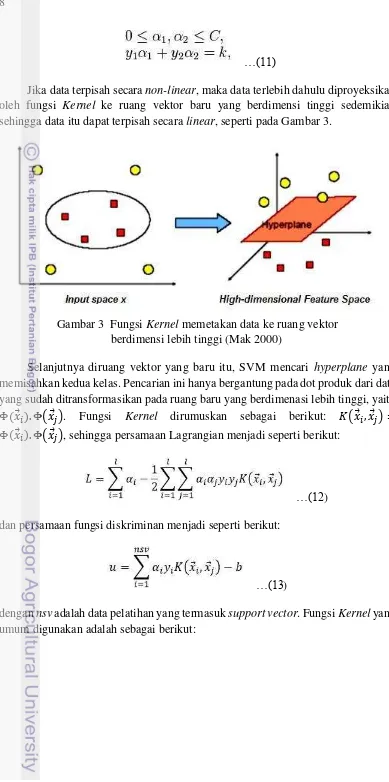
Jika data terpisah secara non-linear, maka data terlebih dahulu diproyeksikan oleh fungsi Kernel ke ruang vektor baru yang berdimensi tinggi sedemikian sehingga data itu dapat terpisah secara linear, seperti pada Gambar 3.
Gambar 3 Fungsi Kernel memetakan data ke ruang vektor berdimensi lebih tinggi (Mak 2000)
Selanjutnya diruang vektor yang baru itu, SVM mencari hyperplane yang memisahkan kedua kelas. Pencarian ini hanya bergantung pada dot produk dari data yang sudah ditransformasikan pada ruang baru yang berdimenasi lebih tinggi, yaitu
Φ ⃗ . Φ( ⃗ ). Fungsi Kernel dirumuskan sebagai berikut: �( ⃗ , ⃗ ) =
Φ ⃗ . Φ( ⃗ ), sehingga persamaan Lagrangian menjadi seperti berikut:
…(12)
dan persamaan fungsi diskriminan menjadi seperti berikut:
…(13)
9
Kernel Linear:
…(14)
Kernel Polynomial:
…(15)
Radial Basis Function (RBF):
10
3
METODOLOGI PENELITIAN
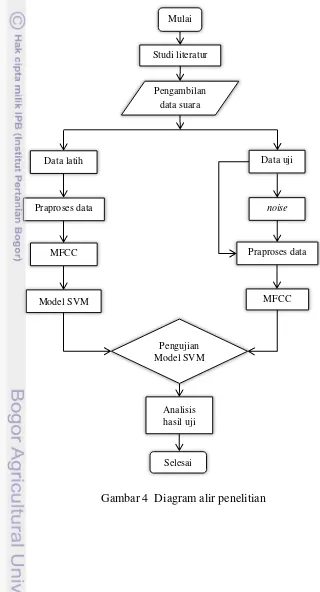
Kerangka Pemikiran
Kerangka pemikiran dalam membangun model simulasi pada penelitian ini dapat dituangkan dalam suatu diagram alir penelitian, disajikan pada Gambar 4 dibawah ini.
Gambar 4 Diagram alir penelitian
11
Pengambilan Data Suara
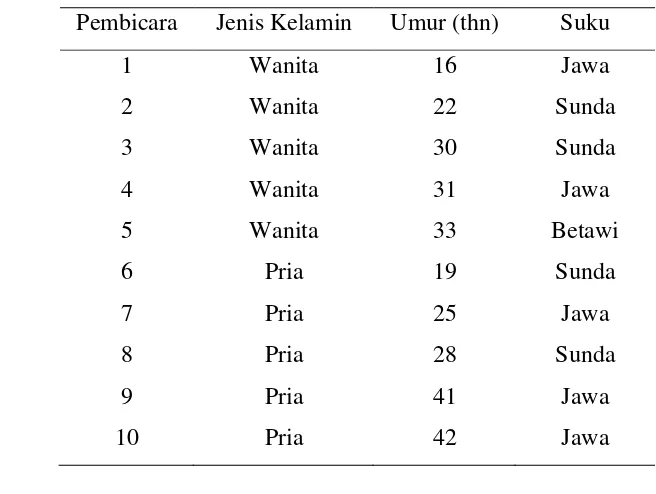
Pengambilan data suara dilakukan dengan merekam suara menggunakan alat mikrofon. Sumber suara diperoleh dari 10 orang pembicara dewasa dengan perbedaan jenis kelamin, umur dan suku yang masing-masing mengucapkan 50 kali kata “KOMPUTER” yang pengucapannya tidak dikontrol hingga didapatkan 500 data suara. Durasi rekam yang digunakan yaitu 2 detik dengan besar frekuensi rekam 16KHz dan data suara disimpan dalam format audio dengan ekstensi (*.wav).
Dalam hal intra-speaker variability (jenis kelamin, umur dan suku) maka pada tahap pengambilan data suara dari 10 orang pembicara didapatkan rentang umur yang beragam yaitu dari umur paling rendah 16 tahun dan paling tinggi umur 42 tahun. Sedangkan untuk jenis kelamin didapatkan lima orang berjenis kelamin wanita dan lima orang berjenis kelamin pria. Untuk perbedaan suku, didapatkan tiga suku yang berbeda yaitu empat orang bersuku sunda, lima orang dari suku jawa dan satu orang dari suku betawi. Karakteristik kesepuluh pembicara tersebut disajikan pada Tabel 1.
Tabel 1 Daftar 10 pembicara yang digunakan dalam penelitian
Pembicara Jenis Kelamin Umur (thn) Suku
1 Wanita 16 Jawa
12
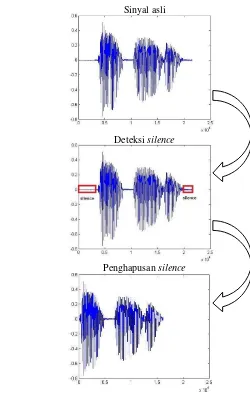
Gambar 5 Tahapan penghapusan silence pada data suara
Setelah penghapusan silence dilakukan, tahap selanjutnya adalah normalisasi sinyal suara. Prosesnya yaitu membagi sinyal dengan nilai mutlak simpangan maksimum, sehingga diperoleh sinyal dengan simpangan maksimum +1 atau -1. Ilustrasinya untuk proses normalisasi ini disajikan pada Gambar 6.
Gambar 6 Tahapan normalisasi pada data suara
Sebelum normalisasi
Sinyal asli
Deteksi silence
Penghapusan silence
13
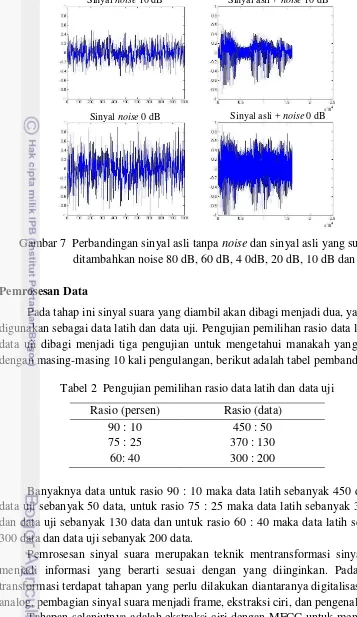
Sesuai dengan fokus dari penelitian ini yaitu untuk membangun model yang lebih bersifat robust terhadap noise, maka diperlukan sinyal noise yang akan mengkontaminasi sinyal asli. Sinyal noise yang ditambahkan bersifat Gaussian dengan level 80 dB, 70 dB, 60 dB, 50 dB, 40 dB, 30 dB, 20 dB, 10 dB dan 0 dB. Berikut ilustrasinya disajikan pada Gambar 7.
Sinyal asli tanpa noise
Sinyal noise 80 dB Sinyal asli + noise 80 dB
Sinyal noise 60 dB Sinyal asli + noise 60 dB
Sinyal noise 40 dB Sinyal asli + noise 40 dB
14
Gambar 7 Perbandingan sinyal asli tanpa noise dan sinyal asli yang sudah ditambahkan noise 80 dB, 60 dB, 4 0dB, 20 dB, 10 dB dan 0 dB
Pemrosesan Data
Pada tahap ini sinyal suara yang diambil akan dibagi menjadi dua, yaitu akan digunakan sebagai data latih dan data uji. Pengujian pemilihan rasio data latih dan data uji dibagi menjadi tiga pengujian untuk mengetahui manakah yang terbaik dengan masing-masing 10 kali pengulangan, berikut adalah tabel pembandingnya:
Tabel 2 Pengujian pemilihan rasio data latih dan data uji
Rasio (persen) Rasio (data)
90 : 10 450 : 50
75 : 25 370 : 130
60: 40 300 : 200
Banyaknya data untuk rasio 90 : 10 maka data latih sebanyak 450 data dan data uji sebanyak 50 data, untuk rasio 75 : 25 maka data latih sebanyak 370 data dan data uji sebanyak 130 data dan untuk rasio 60 : 40 maka data latih sebanyak 300 data dan data uji sebanyak 200 data.
Pemrosesan sinyal suara merupakan teknik mentransformasi sinyal suara menjadi informasi yang berarti sesuai dengan yang diinginkan. Pada proses transformasi terdapat tahapan yang perlu dilakukan diantaranya digitalisasi sinyal analog, pembagian sinyal suara menjadi frame, ekstraksi ciri, dan pengenalan pola.
Tahapan selanjutnya adalah ekstraksi ciri dengan MFCC untuk menentukan vektor yang dapat digunakan sebagai penciri objek atau individu tiap sinyal suara. Proses MFCC adalah Frame Blocking, Windowing, Fast Fourier Fransform,
Mel-Sinyal noise 10 dB Sinyal asli + noise 10 dB
15
Frequency Wrapping, dan Cepstrum. Pembagian sinyal suara digital menjadi beberapa frame adalah dengan membagi sinyal suara kedalam i frame dan dilakukan overlaping frame agar tidak kehilangan informasi. Setiap data suara dilakukan proses framing dimana masing-masing frame berukuran 40 ms dengan overlaping 50% dan menggunakan koefisien mel cepstrum 13 (Buono 2009). MFCC memiliki hasil berupa matriks ciri (n×k) dimana n adalah koefisien mel cepstrum yaitu 13 dan k adalah jumlah frame. Agar ukuran matriks sama untuk setiap suara yaitu berbentuk (n×1) untuk setiap suara, maka dilakukan proses perata-rataan koefisien pada setiap baris.
16
4
HASIL DAN PEMBAHASAN
Praproses data
Sebelum sinyal suara siap diolah dengan proses ekstraksi ciri maka sinyal suara dilakukan penghapusan silence pada bagian awal dan bagian akhir sehingga sinyal suara yang diolah adalah benar-benar sinyal suara yang diujikan. Pada tahap penghapusan silence terjadi pengurangan lebar data disetiap sinyal suara yaitu data suara sebelum dilakukan proses penghapusan silence adalah berjumlah 32000 data, didapatkan dari besarnya frekuensi rekam 16KHz dikalikan lamanya waktu rekam selama 2 detik. Setelah penghapusan silence maka lebar berkurang sehingga banyaknya data akan beragam besarnya bergantung pada besarnya silence yang dihapus.
Proses normalisasi juga dilakukan sebelum proses ekstraksi ciri agar besarnya amplitudo semua sinyal suara seragam yaitu maksimum +1 dan minimum -1. Sebenarnya proses normalisasi ini tidak berpengaruh pada ekstraksi ciri maupun proses pengenalan pola, namun normalisasi ini berguna untuk penyeragaman visual pada batas atas dan batas bawah.
Karakteristik Pembicara
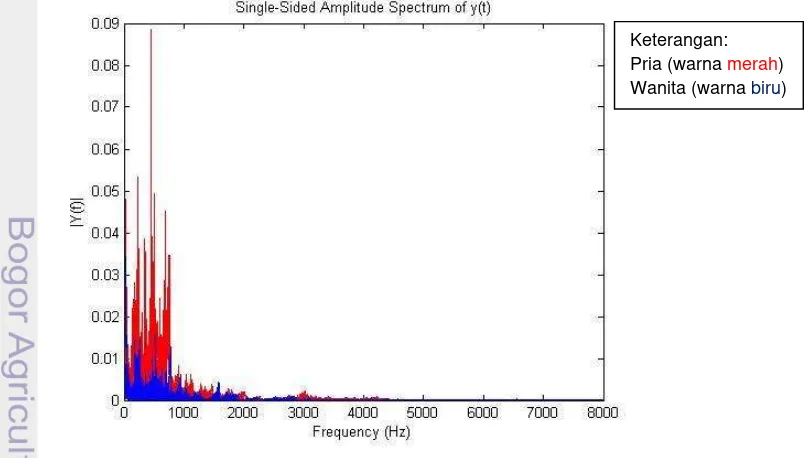
Perbandingan karakteristik pembicara dengan menggunakan Fast Fourier Transform (FFT) terhadap kesepuluh pembicara didapatkan yaitu untuk suara jenis kelamin pria lebih tinggi dibandingkan dengan suara jenis kelamin wanita, hal ini dapat dilihat pada Gambar 8.
Gambar 8 Perbandingan jenis kelamin dengan FFT
17
Ekstraksi Ciri MFCC
Setelah melakukan proses ekstraksi ciri menggunakan MFCC dilakukan proses perata-rataan untuk hasil ekstraksi ciri sehingga dihasilkan matriks ciri berukuran 13×k, dimana 13 didapatkan dari besarnya koefisien mel yang digunakan dan untuk vektor k bergantung dari banyaknya data yang diekstraksi. Dari percobaan empiris didapatkan bahwa kolom pertama hasil ekstraksi ciri MFCC harus dihapus untuk meningkatkan keakuratan sehingga matriks ciri yang digunakan berukuran 12×k.
Pengenalan Pola SVM dengan fungsi Kernel Linear
Pengenalan Pola menggunakan SVM dengan fungsi Kernel Linear untuk rasio 90 : 10 ditunjukan pada Gambar 9. Untuk data uji suara asli tanpa noise, algoritma QP menghasilkan keakuratan 96.8% sedangkan untuk algoritma SMO menghasilkan keakuratan 96.0% dan sistem masih dapat mempertahankan keakuratan diatas 70% sampai penambahan noise 40 dB.
Gambar 9 Perbandingan keakuratan fungsi KernelLinear dengan menggunakan rasio 90 : 10
18
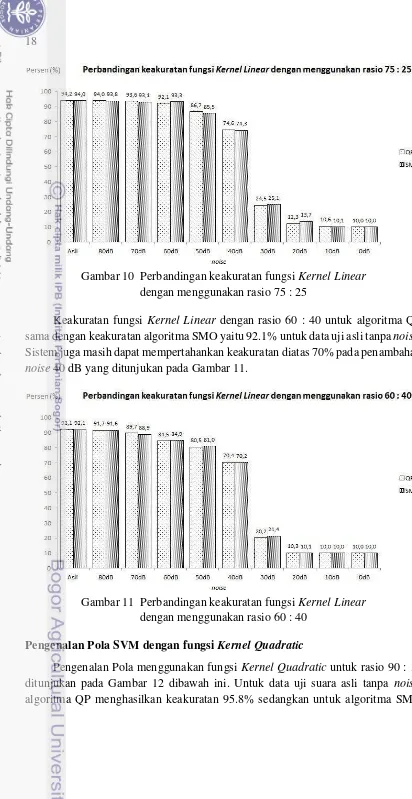
Gambar 10 Perbandingan keakuratan fungsi KernelLinear dengan menggunakan rasio 75 : 25
Keakuratan fungsi Kernel Linear dengan rasio 60 : 40 untuk algoritma QP sama dengan keakuratan algoritma SMO yaitu 92.1% untuk data uji asli tanpa noise. Sistem juga masih dapat mempertahankan keakuratan diatas 70% pada penambahan noise 40 dB yang ditunjukan pada Gambar 11.
Gambar 11 Perbandingan keakuratan fungsi KernelLinear dengan menggunakan rasio 60 : 40
Pengenalan Pola SVM dengan fungsi Kernel Quadratic
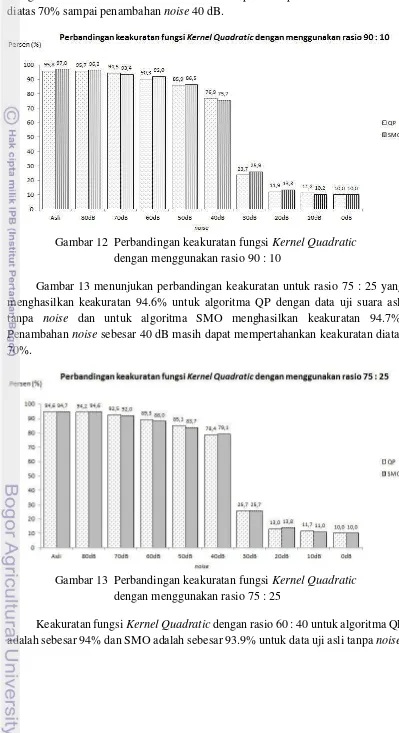
19
menghasilkan keakuratan 97.0% dan sistem dapat mempertahankan keakuratan diatas 70% sampai penambahan noise 40 dB.
Gambar 12 Perbandingan keakuratan fungsi KernelQuadratic dengan menggunakan rasio 90 : 10
Gambar 13 menunjukan perbandingan keakuratan untuk rasio 75 : 25 yang menghasilkan keakuratan 94.6% untuk algoritma QP dengan data uji suara asli tanpa noise dan untuk algoritma SMO menghasilkan keakuratan 94.7%. Penambahan noise sebesar 40 dB masih dapat mempertahankan keakuratan diatas 70%.
Gambar 13 Perbandingan keakuratan fungsi KernelQuadratic dengan menggunakan rasio 75 : 25
20
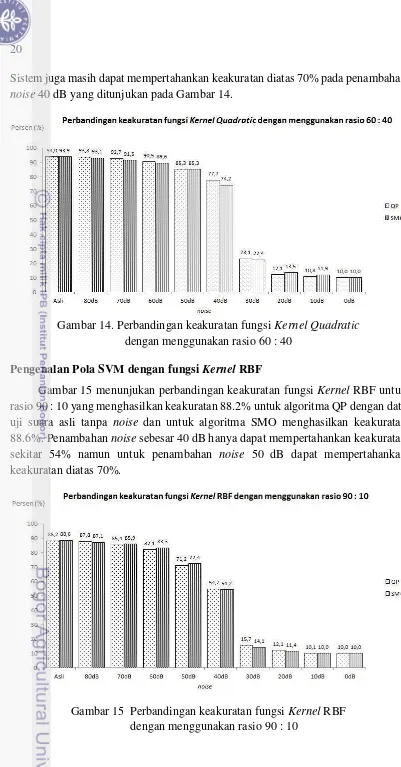
Sistem juga masih dapat mempertahankan keakuratan diatas 70% pada penambahan noise 40 dB yang ditunjukan pada Gambar 14.
Gambar 14. Perbandingan keakuratan fungsi KernelQuadratic dengan menggunakan rasio 60 : 40
Pengenalan Pola SVM dengan fungsi Kernel RBF
Gambar 15 menunjukan perbandingan keakuratan fungsi Kernel RBF untuk rasio 90 : 10 yang menghasilkan keakuratan 88.2% untuk algoritma QP dengan data uji suara asli tanpa noise dan untuk algoritma SMO menghasilkan keakuratan 88.6%. Penambahan noise sebesar 40 dB hanya dapat mempertahankan keakuratan sekitar 54% namun untuk penambahan noise 50 dB dapat mempertahankan keakuratan diatas 70%.
21
Keakuratan fungsi Kernel RBF dengan rasio 75 : 25 untuk algoritma QP adalah sebesar 82.3% dan SMO adalah sebesar 82.2% untuk data uji asli tanpa noise. Sistem masih dapat mempertahankan keakuratan diatas 70% pada penambahan noise 60 dB yang ditunjukan pada Gambar 16.
Gambar 16 Perbandingan keakuratan fungsi Kernel RBF dengan menggunakan rasio 75 : 25
Pengenalan Pola menggunakan fungsi Kernel RBF untuk rasio 60 : 40 ditunjukan pada Gambar 17 dibawah ini. Untuk data uji suara asli tanpa noise, algoritma QP menghasilkan keakuratan 78.3% sedangkan untuk algoritma SMO menghasilkan keakuratan 78.2% dan sistem dapat mempertahankan keakuratan diatas 70% pada penambahan noise 50 dB.
22
Jumlah error Pembicara
Banyaknya error untuk ke-10 pembicara menggunakan data uji suara asli tanpa noise ditunjukan pada Tabel 3. Jumlah error yang paling banyak untuk semua rasio adalah pembicara nomor 9 (Pria, 41 tahun, Jawa). Jumlah error yang paling sedikit untuk rasio 90 : 10 dan rasio 75 : 25 adalah pembicara nomor 10 (Pria, 42 tahun, Jawa) dengan masing-masing jumlah error yaitu 0 dan 6, sedangkan untuk rasio 60 : 40 adalah pembicara nomor 2 (Wanita, 22 tahun, Sunda) dengan jumlah error yaitu 5.
Tabel 3 Jumlah error untuk setiap pembicara dengan data uji suara tanpa noise
Pembicara Jumlah error Pembicara
Rasio 90 : 10 Rasio 75 : 25 Rasio 60 : 40
Perbandingan waktu proses algoritma SMO dengan QP
Algoritma SMO lebih baik dibandingkan dengan algoritma QP dalam waktu proses yang ditunjukan pada Gambar 18. Waktu proses algoritma SMO adalah yang paling baik dengan fungsi Kernel Quadratic yaitu 8.85 detik dan untuk algoritma QP waktu proses terbaik yaitu dengan fungsi Kernel RBF yaitu 861.18 detik. Sedangkan untuk waktu proses yang paling lama yaitu fungsi Kernel Quadratic menggunakan algoritma QP mencapai 1990.92 detik.
23
5
SIMPULAN DAN SARAN
SIMPULAN
Dari hasil dan pembahasan yang telah dilakukan, diperoleh simpulan sebagai berikut :
1. Pengenalan pola SVM dengan fungsi Kernel Quadratic menggunakan algoritma SMO menghasilkan hasil yang paling baik yaitu 97%.
2. Sistem masih dapat mempertahankan keakuratan diatas 70% pada penambahan noise 40 dB dan noise 50 dB.
3. Waktu proses algoritma SMO lebih baik dibandingkan dengan algoritma QP.
SARAN
Adapun saran yang dapat dilakukan untuk penelitian selanjutnya antara lain:
1. Menambahkan Noise Cancelling untuk menambahkan keakuratan pada data suara yang dikontaminasi noise.
2. Melakukan penambahan jumlah pembicara untuk melihat kinerja sistem dengan jumlah data yang lebih besar.
24
DAFTAR PUSTAKA
Buono A. 2009. Representasi Nilai HOS dan Model MFCC sebagai Ekstraksi Ciri pada Sistem Indentifikasi Pembicara di Lingkungan Ber-noise Menggunakan HMM. [disertasi]. Depok: Program Studi Ilmu Komputer, Universitas Indonesia.
Campbell JP. 1997. Speaker Recognition: A Tutorial. Proceedings of the IEEE Vol.85 No.9.
Chen S, Luo Y. 2009. Speaker Verification Using MFCC and Support Vector Machine.
Proceedings of the International MultiConference of Engineers and Computer
Scientists 2009 Vol I, Hong Kong.
Do MN. 1994. Digital Signal Processing Mini- Project: An Automatic Recognition
System. Audio Visual Communication Laboratory, Swiss Federal Institute of
Technology.
Furui S. 1997. Recent advances in speaker recognition. Pattern Recognition Letters 18: 859 – 872.
Homayounpour M, Rezaian I. 2008. Robust Speaker Verification Based on Multi Stage Vector Quantization of MFCC Parameters on Narrow Bandwidth Channels,
ICACT 2008, vol 1 : 336-340.
Jurafsky D, Martin JH. 2000. Speech and Language Processing: An Introduction to
Natural Language Processing, Computational Linguistic, and Speech Recognition.
New Jersey: Prentice Hall.
Kusumadewi S. 2003. Artificial Intelligence (Teknik dan Aplikasinya). Yogyakarta: Graha Ilmu.
Mak G. 2000. The Implementation of Support Vector Machine Using The Sequential
Minimal Optimization Algorithm. Master Degre. McGill University.
Mezghani A, O'Shaughnessy D. 2005. Speaker verification using a new representation based on a combination of MFCC and formants, Canadian Conference on
Electrical and Computer Engineering : 1461-1464.
Ou G, Ke, D. 2004. Text-independent speaker verification based on relation of MFCC components, International Symposium on Chinese Spoken Language Processing : 57-60.
Pelton GE. 1993. Voice Processing. Singapore: McGraw Hill.
Reynolds D. 2002. Automatic Speaker recognition Acoustics and Beyond. Tutorial note, MIT Lincoln Laboratory.
Srinivasamurthy N. 2006. Compression Algorithms for Distributed Classification with
Applications to Distributed Speech Recognition. A Dissertation Presented to the
25
26
27
28
29
30
31
32
33
34
35
37
RIWAYAT HIDUP
Penulis dilahirkan di Bandung pada tanggal 8 Juli 1984 sebagai anak kedua dari tiga bersaudara dari pasangan Abdul Mudjib dan Titi Melati. Penulis menempuh pendidikan Sarjana Strata Satu di Departemen Fisika, Fakultas MIPA, Institut Pertanian Bogor tahun 2002 melalui jalur Undangan Seleksi Masuk IPB (USMI). Penulis melanjutkan pendidikan Magister di Departemen Ilmu Komputer, Sekolah Pascasarjana, Institut Pertanian Bogor tahun 2010.