Fian Setiyaningsih_Risqia Fadhilah S Page 1 RINGKASAN PRAKTIKUM METODE STATISTIKA II KELAS A LABORATORIUM KOMPUTASI STATISTIKA DAN MATEMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS GADJAH MADA
Dosen Pengampu : Dr. Herni Utami, M.Si. Asisten Praktikum :
Fian Setiyaningsih (15843) Risqia Fadhilah Syahrir (15849)
ANOVA SATU ARAH
ANOVA Satu Arah adalah uji mean yang dilakukan untuk populasi, dengan , memerlukan prosedur yang sedikit berbeda dengan uji mean untuk 1 atau 2 populasi.
ANOVA Satu Arah melibatkan satu faktor yang diduga mempengaruhi variabel respon.
Contoh :
Misalkan kita akan melihat perbedaan efek 4 bahan bakar yang berbeda terhadap jarak tempuh . Diambil 20 sampel mobil dengan spesifikasi yang sama (sampel 5 mobil per bahan bakar)
Pembahasan :
Berdasarkan contoh di atas, diduga faktor bahan bakar mempengaruhi variabel respon yaitu jarak tempuh mobil . Diketahui . Pada kasus ini k adalah banyaknya jenis bahan bakar. Diketahui pula
Asumsi dalam ANOVA Satu Arah :
Data sampel dari populasi berdistribusi normal (Parametrik)
Jika data tidak berdistribusi normal, maka akan digunakan metode statistika nonparametrik. (akan dibahas pada bagian Statistika Non-Parametrik)
o Hipotesis
H0 : Data berdistribusi normal H1 : Data tidak berdistribusi normal Tingkat Signifikansi
Statistik Uji
Untuk memakai Shapiro-Wilk, memakai Kolmogorov Smirnov
P-value ... = ...
P-value ... = ...
P-value ... = ...
Fian Setiyaningsih_Risqia Fadhilah S Page 2 Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
Data sampel dari populasi mempunyai variansi yang relatif sama (p-value lihat tabel Tests of Homogeneity of Variances)
Data sampel yang diambil dari populasi memiliki variansi yang relatif sama. o Hipotesis
H0 : Semua populasi memiliki variansi yang relatif sama H1 : Variansi populasi tidak sama
Tingkat Signifikansi
Statistik Uji
P-value = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
Data bersifat independen antar satu populasi dengan populasi yang lain*
*untuk asumsi independen, biasanya sudah terpenuhi jika data sampel diambil secara acak.
UJI ANOVA SATU ARAH (p-value lihat tabel ANOVA)
o Hipotesis
H0 : Semua populasi memiliki rata-rata yang relatif sama H1 : Ada populasi yang memiliki rata-rata yang berbeda Tingkat Signifikansi
Statistik Uji
P-value = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
Fian Setiyaningsih_Risqia Fadhilah S Page 3 UJI MULTIPLE COMPARISON ANALYSIS (lihat tabel Multiple Comparisons)
o Hipotesis
H0 : tidak ada perbedaan yang signifikan antara ... dengan ... H1 : ada perbedaan yang signifikan antara ... dengan ... Tingkat Signifikansi
Statistik Uji
P-value = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
CONTOH SOAL ANOVA SATU ARAH
Data berikut merupakan data beberapa bungkus rokok yang terjual di sebuah pasar swalayan pada 8 hari yang dipilih secara random ;
Cap
A B C D E
21 35 45 32 45
35 12 60 53 29
32 27 33 29 31
28 41 36 42 22
14 19 31 40 36
47 23 40 23 29
25 31 43 35 42
38 20 48 42 30
a. Lakukan uji asumsi normalitas dan kesamaan variansi terhadap data tersebut! b. Dengan nilai α= 0,05, tentukan apakah secara rata-rata pasar swalayan yang
menjual kelima merk rokok di atas berhasil menjual rokok sama banyaknya? c. Jika terdapat perbedaan, lakukan uji MCA dan cap rokok manakah yang terjual
Fian Setiyaningsih_Risqia Fadhilah S Page 4 ANOVA DUA ARAH
Hampir sama dengan ANOVA Satu Arah, yaitu ANOVA Dua Arah adalah uji mean yang dilakukan untuk populasi, dengan
Bedanya adalah, ANOVA Dua Arah melibatkan dua faktor yang diduga mempengaruhi variabel respon.
Contoh :
Misalkan kita ingin mengetahui apakah perbedaan metode belajar dan kelompok belajar berpengaruh terhadap nilai mahasiswa. Diuji 4 metode dengan 3 kelompok belajar sehingga didapat 12 kombinasi perlakuan . Diambil 3 sampel untuk masing-masing kombinasi perlakuan.
Pembahasan :
Berarti dari contoh di atas, diduga faktor metode belajar dan kelompok belajar mempengaruhi variabel respon yaitu nilai mahasiswa. Diketahui . Kemudian level faktor metode belajar = 4 ; level faktor kelompok belajar = 3.
Asumsi dalam ANOVA Dua Arah :
Data sampel berdistribusi normal (Parametrik)
Hampir sama dengan ANOVA Satu Arah. Namun dalam ANOVA Dua Arah ini dilakukan Uji Kenormalan untuk masing-masing faktor.
o Hipotesis
H0 : Data berdistribusi normal H1 : Data tidak berdistribusi normal Tingkat Signifikansi
Statistik Uji
Untuk memakai Shapiro-Wilk, memakai Kolmogorov Smirnov
P-value ... = ...
P-value ... = ...
P-value ... = ... Dan seterusnya... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
Fian Setiyaningsih_Risqia Fadhilah S Page 5 Data sampel mempunyai variansi yang relatif sama
Hampir sama dengan ANOVA Satu Arah. Namun dalam ANOVA Dua Arah ini dilakukan Uji Kesamaan Variansi untuk masing-masing faktor.
o Hipotesis
H0 : Semua populasi memiliki variansi yang relatif sama H1 : Variansi populasi tidak sama
Tingkat Signifikansi
Statistik Uji
P-value = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
Data bersifat independen antar satu populasi dengan populasi yang lain*
*untuk asumsi independen, biasanya sudah terpenuhi jika data sampel diambil secara acak.
UJI ANOVA DUA ARAH (Interaksi)
o Hipotesis
H0 : tidak ada interaksi antara faktor ... dan faktor ... H1 : ada interaksi antara faktor ... dan faktor ... Tingkat Signifikansi
Statistik Uji
P-value = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
*Jika H0 pada Uji ANOVA Dua Arah tidak ditolak (tidak terdapat interaksi), maka dilakukan Uji Efek Faktor untuk masing-masing faktor.
UJI EFEK FAKTOR
o Hipotesis
H0 : tidak ada efek faktor ... H1 : ada efek faktor ... Tingkat Signifikansi
Fian Setiyaningsih_Risqia Fadhilah S Page 6 Statistik Uji
P-value = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
*Jika H0 pada Uji Efek Faktor ditolak (terdapat efek faktor), maka untuk mengetahui perbedaan rata-rata, dilakukan UJI MCA (Multiple Comparison Analysis).
UJI MULTIPLE COMPARISON ANALYSIS (lihat tabel Multiple Comparisons)
o Hipotesis
H0 : tidak ada perbedaan yang signifikan antara ... dengan ... H1 : ada perbedaan yang signifikan antara ... dengan ... Tingkat Signifikansi
Statistik Uji
P-value = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
Fian Setiyaningsih_Risqia Fadhilah S Page 7 CONTOH SOAL ANOVA DUA ARAH
Tiga varietas kentang hendak dibandingkan hasilnya. Percobaannya hendak dilaksanakan dengan menggunakan 12 petak yang seragam di masing-masing 4 lokasi yang berbeda. Di setiap lokasi setiap varietas dicobakan pada 3 petak yang ditentukan secara acak. Hasilnya, dalam kwintal per petak, adalah sebagai berikut:
Lokasi
Varietas Kentang
A B C
1
16 20 22
19 24 17
12 18 14
2
17 24 26
10 18 19
13 22 21
3
9 12 10
12 15 5
5 11 8
4
14 21 19
8 16 15
11 14 12
a) Analisis apa yang digunakan untuk kasus di atas? Mengapa?
b) Apakah terdapat perbedaan produksi kentang?Lakukan analisis lengkap namun singkat padat jelas !
Fian Setiyaningsih_Risqia Fadhilah S Page 8 ANALISIS REGRESI LINEAR SEDERHANA
Analisis yang dilakukan antara variabel independen (prediktor) dan variabel dependen (respon) dimana prediktor diasumsikan mempengaruhi variabel respon secara linear.
Analisis Regresi Linear Sederhana melibatkan satu variabel independen yang diduga mempengaruhi variabel respon.
Tujuan dilakukan Analisis Regresi Linear Sederhana:
Mengetahui bentuk hubungan antara variabel dependen (biasa dilambangkan dengan “Y”) dan variabel independen (
Melakukan prediksi nilai variabel dependen (Y) bila diketahui nilai variabel independen (
Contoh :
Misalkan kita ingin mengetahui apakah lama tidur berpengaruh terhadap nilai mahasiswa. Diambil 60 sampel mahasiswa S1 Statistika semester 4 yang kemudian didata lama tidurnya dan juga IP-nya.
Pembahasan :
Berarti dari contoh di atas, diduga faktor lama tidur (yang disebut sebagai prediktor) mempengaruhi nilai mahasiswa (variabel respon)
Asumsi dalam Analisis Regresi Linear Sederhana :
Data Variabel Dependen berdistribusi normal o Hipotesis
H0 : Data variabel dependen (...) berdistribusi normal H1 : Data variabel dependen (...) tidak berdistribusi normal Tingkat Signifikansi
Statistik Uji
Untuk memakai Shapiro-Wilk, memakai Kolmogorov Smirnov
P-value ... = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
Linearitas
Fian Setiyaningsih_Risqia Fadhilah S Page 9 Kenapa harus linear? Karena kita melakukan Analisis Regresi Linear , jadi sesuai dengan nama analisis yang kita lakukan, bahwa asumsi Linear ini memegang peranan penting. Karena jenis Analisis Regresi itu banyak (tidak hanya Linear saja)
Contoh Interpretasi Linearitas
Karena titik-titik berada di sekitar garis lurus menaik, maka bisa disimpulkan bahwa terdapat hubungan linear positif antara variabel independen (...) dengan variabel dependen (...) UNTUK LINEAR POSITIF, atau
Karena titik-titik berada di sekitar garis lurus menurun, maka bisa disimpulkan bahwa terdapat hubungan linear negatif antara variabel independen (...) dengan variabel dependen (...) UNTUK LINEAR NEGATIF
Jika dilihat bahwa titik-titik cenderung tidak berada di sekitar garis lurus menaik/menurun maka terdapat hubungan linear positif/negatif yang lemah. Contoh interpretasinya untuk yang lemah :
Karena titik-titik cenderung berada di sekitar garis lurus menaik, maka bisa disimpulkan bahwa terdapat hubungan linear positif yang lemahantara variabel independen (...) dengan variabel dependen (...) UNTUK LINEAR POSITIF LEMAH, atau
Karena titik-titik cenderung berada di sekitar garis lurus menurun, maka bisa disimpulkan bahwa terdapat hubungan linear negatif yang lemahantara variabel independen (...) dengan variabel dependen (...) UNTUK LINEAR NEGATIF LEMAH
Setelah asumsi terpenuhi, maka kita akan melakukan Uji Kelayakan Model Regresi (Uji Overall) dan Uji Kelayakan Konstanta beserta Koefisien Variabel Independen (Uji Parsial)
UJI OVERALL
o Hipotesis
H0 : model regresi tidak layak digunakan H1 : model regresi layak digunakan Tingkat Signifikansi
Statistik Uji
P-value ... = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
Fian Setiyaningsih_Risqia Fadhilah S Page 10 UJI PARSIAL
Uji Konstanta
o Hipotesis
H0 : konstanta tidak layak digunakan H1 : konstanta layak digunakan Tingkat Signifikansi
Statistik Uji
P-value ... = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
Uji Variabel Independen
o Hipotesis
H0 : variabel independen (...) tidak layak digunakan H1 : variabel independen (...) layak digunakan Tingkat Signifikansi
Statistik Uji
P-value ... = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
*Jika Variabel Independen tidak signifikan pada Analisis Regresi Linear Sederhana, maka otomatis model regresi tersebut tidak terpakai karena variabel independennya hanya satu-satunya yang tidak mungkin dikeluarkan.
Namun, jika konstanta tidak signifikan pada Analisis Regresi Linear Sederhana maka konstanta bisa dikeluarkan dan model masih bisa digunakan asalkan variabel independennya signifikan.
Interpretasi Model Summary
R = besarnya hubungan antara variabel dan
Artinya variabel independen erat dengan variabel dependen sebesar ... % Catatan
Nilai R
Fian Setiyaningsih_Risqia Fadhilah S Page 11 R2 = variasi dalam variabel yang dapat diterangkan oleh
variabel (dalam persen, jangan dibulatkan)
Artinya sebesar (nilai R2 dalam persen) variabel dependen dapat diterangkan oleh variabel independen, dan (100% - nilai R2 dalam persen) sisanya diterangkan oleh variabel lain.
Semakin besar nilai R2 maka semakin besar variabel dependen yang dipengaruhi oleh variabel independen (model semakin baik)
Adjusted R2 = besarnya koreksi terhadap R2 Artinya nilai koreksi R2 yang didapat sebesar ...
Standard Error of Estimate = besarnya variasi dalam model* *Semakin besar, maka semakin buruk karena errornya makin besar.
Interpretasi Model Regresi Contoh
Maka interpretasinya adalah :
Setiap kenaikan satu satuan variabel independen maka akan mengakibatkan kenaikan dari sebesar satuan dengan menganggap variabel lain konstan.
Jika tandanya negatif ‘-‘
maka interpretasinya :
Setiap kenaikan satu satuan variabel independen maka akan mengakibatkan penurunan dari sebesar satuan dengan menganggap variabel lain konstan.
ANALISIS REGRESI LINEAR GANDA
Analisis Regresi Linear Ganda melibatkan lebih dari satu variabel independen yang diduga mempengaruhi variabel respon. ( )
Tujuan dilakukan Analisis Regresi Linear Ganda :
Mengetahui bentuk hubungan antara variabel dependen (biasa dilambangkan dengan “Y”) dan variabel independen ( ,
Melakukan prediksi nilai variabel dependen (Y) bila diketahui nilai variabel independen ( , p > 1
Contoh :
Fian Setiyaningsih_Risqia Fadhilah S Page 12 Pembahasan :
Berdasarkan contoh di atas, diduga faktor Penguasaan Kosa Kata, Pemahaman Tema, Pengetahuan Tata Bahasa (prediktor) mempengaruhi Kemampuan Menulis Siswa SMA (variabel respon).
Asumsi dalam Analisis Regresi Linear Ganda :
Data Variabel Dependen (respon) berdistribusi normal o Hipotesis
H0 : Data variabel dependen (...) berdistribusi normal H1 : Data variabel dependen (...) tidak berdistribusi normal
Tingkat Signifikansi
Statistik Uji
Untuk memakai Shapiro-Wilk, memakai Kolmogorov Smirnov
P-value ... = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
Linearitas
Harus ada hubungan linear antara variabel dependen dengan variabel independen , bisa linear positif ataupun linear negatif.
Kenapa harus linear? Karena kita melakukan Analisis Regresi Linear , jadi sesuai dengan nama analisis yang kita lakukan, bahwa asumsi Linear ini memegang peranan penting. Karena jenis Analisis Regresi itu banyak (tidak hanya Linear saja)
Contoh Interpretasi Linearitas
Karena titik-titik berada di sekitar garis lurus menaik, maka bisa disimpulkan bahwa terdapat hubungan linear positif antara variabel independen (...) dengan variabel dependen (...) UNTUK LINEAR POSITIF, atau
Karena titik-titik berada di sekitar garis lurus menurun, maka bisa disimpulkan bahwa terdapat hubungan linear negatif antara variabel independen (...) dengan variabel dependen (...) UNTUK LINEAR NEGATIF
Jika dilihat bahwa titik-titik cenderung tidak berada di sekitar garis lurus menaik/menurun maka terdapat hubungan linear positif/negatif yang lemah. Contoh interpretasinya untuk yang lemah :
Fian Setiyaningsih_Risqia Fadhilah S Page 13 independen (...) dengan variabel dependen (...) UNTUK LINEAR POSITIF LEMAH, atau
Karena titik-titik cenderung berada di sekitar garis lurus menurun, maka bisa disimpulkan bahwa terdapat hubungan linear negatif yang lemahantara variabel independen (...) dengan variabel dependen (...) UNTUK LINEAR NEGATIF LEMAH
Setelah asumsi terpenuhi, maka kita akan melakukan Uji Kelayakan Model Regresi (Uji Overall) dan Uji Kelayakan Konstanta beserta Koefisien Variabel Independen (Uji Parsial)
UJI OVERALL
o Hipotesis
H0 : model regresi tidak layak digunakan H1 : model regresi layak digunakan Tingkat Signifikansi
Statistik Uji
P-value ... = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
... UJI PARSIAL
Uji Konstanta
o Hipotesis
H0 : konstanta tidak layak digunakan H1 : konstanta layak digunakan Tingkat Signifikansi
Statistik Uji
P-value ... = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
Uji Variabel Independen
o Hipotesis
H0 : variabel independen (...) tidak layak digunakan H1 : variabel independen (...) layak digunakan Tingkat Signifikansi
Fian Setiyaningsih_Risqia Fadhilah S Page 14 Statistik Uji
P-value ... = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
*Jika Variabel Independen tidak signifikan pada Analisis Regresi Linear Ganda, maka variabel independen yang tidak signifikan dengan P-value terbesar dikeluarkan terlebih dahulu, lalu dilakukan analisis regresi linear ganda ulang tanpa variabel independen yang dikeluarkan tersebut (diulangnya tidak perlu dari Uji Normalitas dan Linearitas, cukup mulai dari Uji Overall)
Namun, jika konstanta tidak signifikan pada Analisis Regresi Linear Ganda maka konstanta dikeluarkan terakhir (yaitu sesudah semua variabel independen signifikan).
Interpretasi Model Summary
R = besarnya hubungan antara variabel dan
Artinya variabel independen erat dengan variabel dependen sebesar ... % Catatan
Nilai R
Jika nilai R > 0,5 = hubungan erat linear positif Jika nilai R < -0,5 = hubungan erat linear negatif
R2 = variasi dalam variabel yang dapat diterangkan oleh variabel (dalam persen, jangan dibulatkan)
Artinya sebesar (nilai R2 dalam persen) variabel dependen dapat diterangkan oleh variabel independen, dan (100% - nilai R2 dalam persen) sisanya diterangkan oleh variabel lain.
Semakin besar nilai R2 maka semakin besar variabel dependen yang dipengaruhi oleh variabel independen (model semakin baik)
Adjusted R2 = besarnya koreksi terhadap R2 Artinya nilai koreksi R2 yang didapat sebesar ...
Standard Error of Estimate = besarnya variasi dalam model* *Semakin besar, maka semakin buruk karena errornya makin besar.
Interpretasi Model Regresi Contoh
Maka interpretasinya adalah :
Fian Setiyaningsih_Risqia Fadhilah S Page 15
Jika tandanya negatif ‘-‘
maka interpretasinya :
Setiap kenaikan satu satuan variabel independen maka akan mengakibatkan penurunan
dari sebesar satuan dengan menganggap variabel lain konstan. Contoh Soal Analisis Regresi Linear Ganda
Ingin diketahui apakahPenguasaan Kosa Kata, Pemahaman Tema, Pengetahuan Tata Bahasa memengaruhi Kemampuan Menulis Siswa SMA?
No
Penggunaan Kosa Kata
Pemahaman Tema
Pengetahuan Tata Bahasa
Kemampuan Menulis
1 8 10 20 6
2 8 12 21 7
3 7 12 21 6
4 9 14 23 7
5 8 15 24 7
6 8 8 20 6
7 9 15 22 7
8 6 8 18 5
9 7 20 26 8
10 9 18 28 8
11 6 10 16 5
12 5 7 15 4
13 10 22 30 9
14 9 12 19 6
15 10 15 20 7
a) Apakah uji asumsi terpenuhi?
Fian Setiyaningsih_Risqia Fadhilah S Page 16 ANALISIS DATA KATEGORIK
Pembagian Data
1) Data Kuantitatif (dipaparkan dalam bentuk angka-angka) a. Interval (misal Frekuensi Kunjungan)
Data yang selain mengandung unsur penamaan dan urutan (order) juga memiliki sifat interval (selang). Intervalnya tetap. Dapat diukur perbedaan karakteristik antar individu.
Contoh
Frekuensi Kunjungan : 1 kali 2 kali b. Rasio (misal Berat Badan)
Mempunyai semua karakteristik yang dimiliki skala nominal,ordinal, dan interval. Kelebihannya adalah skala rasio ini punya nilai nol empiris absolut. Merupakan perbandingan satu individu atau objek tertentu dengan lainnya. Contoh
Berat badan sebelum diet : 70 kg Berat badan sesudah diet : 60 kg
Berat sebelum : Berat sesudah diet = 70 : 60 = 7 : 6
2) Data Kualitatif (disajikan dalam bentuk kata-kata yang mengandung makna) a. Nominal (misal Jenis Kelamin)
Data yang hanya mengandung unsur penamaan saja atau dapat diartikan sebagai lambang saja.
Contoh
Jenis Kelamin : Laki-laki = 1 Perempuan = 2 b. Ordinal (misal Jenjang Pendidikan)
Data yang selain mengandung unsur penamaan juga memiliki unsur urutan (order), ciri dari data ini disusun berdasarkan urutan yang logis dan sesuai dengan besarnya karakteristik yang dimiliki.
Contoh
Jenjang Pendidikan : SD = 1
SMP = 2
SMA = 3
Perguruan Tinggi = 4
Jika dalam analisis terdapat expected count < 5 = lihat p-value fisher
Fian Setiyaningsih_Risqia Fadhilah S Page 17 Macam – Macam Uji Hipotesis dalam Analisis Data Kategorik Tabulasi Silang
Uji Homogenitas
Sampel berasal dari populasi yang berbeda (2 populasi)
Tujuan : Mengetahui hubungan homogen proporsi populasi 1 dan populasi 2
Variabel B
Variabel A B Bc Jumlah
A a b n1= a + b
Ac c d n2 = c + d
Jumlah m1 = a + c m2= b + d n = n1 + n2
Sebelum melakukan penelitian, ditentukan terlebih dahulu besarnya sampel n1 dan n2 .
Keterangan
n1 = jumlah sampel yang mewakili populasi 1 n2 = jumlah sampel yang mewakili populasi 2
o Hipotesis
H0 : P1 = P2 (populasi 1 dan populasi 2 homogen) H1 : P1 ≠ P2 (populasi 1 dan populasi 2 tidak homogen) Tingkat Signifikansi
Statistik Uji
P-value ... = ... Daerah Kritik
H0 ditolak jika P-value < Kesimpulan
...
Contoh
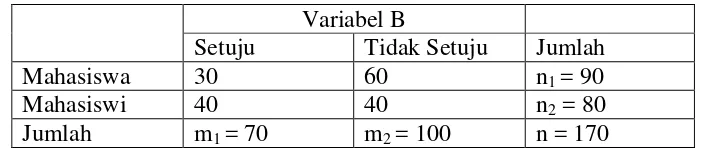
Dua sampel random dari 90 orang mahasiswa (n1) dan 80 orang mahasiswi(n2). Dan kepada mereka ditanyakan, apakah mereka setuju atau tidak setuju dengan lurah wanita. Didapat 30 mahasiswa dan 40 mahasiswi setuju dengan lurah wanita.
Pembahasan
Dari contoh ini, dapat dilihat bahwa terdapat 2 populasi yaitu populasi mahasiswa dan populasi mahasiswi. Dari masing-masing populasi, diambil sampel yaitu sebesar n1 (sampel dari populasi mahasiswa) = 90 dan sebesar n2 (sampel dari mahasiswi) =80. Lalu setelah ditanyakan pendapatnya, diperoleh :
Fian Setiyaningsih_Risqia Fadhilah S Page 18 m2 (sampel dari mahasiswa dan mahasiswi yang tidak setuju terhadap lurah
wanita)
= (90-30) mahasiswa + (80-40) mahasiswi = 60 + 40 = 100 orang
n = n1 + n2 = m1 + m2= 90 + 80 = 70 + 100 = 170
Jika dibentuk tabel kontingensi 2x2 maka akan didapat : Variabel B
Setuju Tidak Setuju Jumlah
Mahasiswa 30 60 n1 = 90
Mahasiswi 40 40 n2 = 80
Jumlah m1 = 70 m2 = 100 n = 170
Setelah didapatkan tabel kontingensi, kita dapat melakukan Uji Homogenitas.
o Hipotesis
H0 : P1 = P2 (populasi mahasiswa dan populasi mahasiswi homogen dalam pendapatnya mengenai lurah wanita)
H1 : P1 ≠ P2 (populasi mahasiswa dan populasi mahasiswi tidak homogen dalam pendapatnya mengenai lurah wanita)
*Uji Homogenitas tidak perlu menghitung ukuran asosiasi seperti RR/OR. Ukuran asosiasi adalah derajat hubungan antara variabel exposure dengan variabel disease
Uji Independensi
Sampel berasal dari 1 populasi. Uji Independensi lebih sering dipakai pada mata kuliah khusus Analisis Data Kategorik (bisa diambil pada semester genap)
o Hipotesis
H0 : P[AB]= P[A]P[B](tidak ada hubungan antara variabel exposure dan variabel disease)
H1 : P[AB]≠ P[A]P[B](ada hubungan antara variabel exposure dan variabel disease)
[image:18.595.121.473.181.257.2]Dalam Uji Independensi ini, terdapat 3 desain penelitian. Desain penelitian ini membedakan penggunaan OR/RR.
Fian Setiyaningsih_Risqia Fadhilah S Page 19 Prospektif
Pada studi ini, banyaknya subjek dalam tiap kelompok exposure, dan ditetapkan oleh peneliti sebelum studi dimulai. Subjek kemudian diamati secara prospektif untuk melihat seberapa banyak yang menjadi disease dan tidak menjadi disease .
Ukuran Asosiasi yang digunakan adalah Relative Risk (RR)
Contoh :
Misalkan akan dilakukan penelitian untuk mengetahui hubungan antara kebiasaan merokok dengan kanker paru – paru. Sekarang dipilih 150 pria umur 40 tahun ke atas dengan kebiasaan merokok dan 140 pria umur 40 tahun ke atas yang tidak memiliki kebiasaan merokok , kemudian 10 tahun lagi peneliti akan menanyakan responden tersebut apakah mereka terkena kanker paru atau tidak.
Pembahasan
Dari contoh ini, dapat dilihat bahwa sampel diambil dari 1 populasi yaitu populasi pria umur 40 tahun ke atas. Namun, populasi pria umur 40 tahun ke atas ini dikelompokkan berdasarkan kebiasaan merokok mereka, jadi akan didapat sampel :
pria umur 40 tahun ke atas dengan kebiasaan merokok yang akan masuk ke nE ,
sampel pria umur 40 tahun ke atas yang tidak memiliki kebiasaan merokok yang akan masuk ke nNE .
Didapatkan nE = 150 dan nNE = 140. Lalu 10 tahun kemudian, ditanyakan apakah mereka positif kanker paru, maka akan didapatkan :
nD(total pria umur 40 tahun ke atas yang terkena kanker paru) nND(total pria umur 40 tahun ke atas yang tidakterkena kanker paru)
n = nE+ nNE= 150 + 140 = 290
Contoh interpretasi untuk RR
Fian Setiyaningsih_Risqia Fadhilah S Page 20 Retrospektif
Pada studi ini, peneliti memilih subjek yang memiliki disease dan tanpa disease . Kemudian diselidiki riwayatnya untuk mengetahui berapa banyak yang ter-expose dan yang tidak.
Ukuran Asosiasi yang digunakan adalah Odds Ratio (OR)
=
Contoh :
Peneliti ingin mengetahui hubungan antara kebiasaan merokok ibu hamil dengan kemungkinan bayi lahir dengan berat kurang dari 2500 gram (Berat Bayi Lahir Rendah) , kemudian peneliti pergi ke suatu puskesmas dan menanyakan kepada 70 ibu yang memiliki bayi BBLR dan menanyakan juga kepada 60 ibu yang memiliki bayi yang berat lahirnya normal . Lalu ditanyakan, apakah dulu saat hamil Ibu itu memiliki kebiasaan merokok.
Pembahasan
Dari contoh ini, dapat dilihat bahwa sampel diambil dari 1 populasi yaitu populasi bayi lahir. Namun, populasi bayi lahir ini dikategorikan menurut berat badan saat lahir. Jadi akan didapat sampel bayi yang berat lahirnya rendah yang dikategorikan ke dalam nD , dan juga bayi yang berat lahirnya normal yang dikategorikan ke dalam nND. Didapatkan nD = 70 dan nND= 60. Setelah didapatkan data banyakknya nD dan nND, ingin diketahui apakah penyebab berat bayi lahir rendah apakah dikarenakan ibu yang merokok ketika hamil atau tidak. Dengan demikian ditanyakan kepada Ibu-Ibu tersebut apakah mereka dulu waktu hamil memiliki kebiasaan merokok atau tidak. Kemudian diperoleh
nE(total ibu yang waktu hamil dulunya memiliki kebiasaan merokok)
nNE(total ibu yang waktu hamil dulunya tidak memiliki kebiasaan merokok)
n = nD + nND= 70 + 60 = 130
Contoh interpretasi untuk OR
Fian Setiyaningsih_Risqia Fadhilah S Page 21 Cross-sectional
Pada studi ini, subjek diklasifikasi menurut dua variabel yaitu dan yang diukur pada saat yang sama.
Ukuran Asosiasi yang digunakan adalah Relative Risk (RR) atau Odds Ratio (OR)
Dalam studi ini, banyaknya sampel (n) ditentukan terlebih dahulu sebelum melakukan penelitian.
Contoh :
Dua ratus enam puluh tiga mahasiswa yang makan siang di kantin ditanya apakah mereka sakit perut atau tidak. Jawaban mereka diklasifikasi menurut apakah mereka makan pakai sambal atau tidak.
Pembahasan
Dari contoh ini, dapat dilihat bahwa sampel diambil dari 1 populasi yaitu populasi mahasiswa yang makan siang di kantin sebanyak 263 mahasiswa. Pada saat yang bersamaan, akan ditanya apakah mereka sakit perut atau tidak dan juga ditanyakan apakah mereka makan pakai sambal atau tidak.
n = 263 mahasiswa
Digunakan uji homogenitas, jika :
Terdapat dua populasi
Tujuan penelitian adalah untuk mengetahui apakah populasi 1 dan populasi 2 homogen atau tidak.
Digunakan uji independensi, jika :
Tujuan penelitian adalah untuk mengetahui ada tidaknya hubungan antara variabel exposure dengan variabel disease.
Fian Setiyaningsih_Risqia Fadhilah S Page 22 STATISTIKA NON-PARAMETRIK
Dipakai saat terdapat asumsi yang diperlukan dalam uji Parametrik tidak terpenuhi.
Ciri – ciri :
Distribusi tidak diketahui
Karena distribusinya tidak diketahui, juga berarti bahwa tidak berdistribusi normal Biasanya data berskala nominal dan ordinal (tetapi bukan berarti bahwa data yang
berskala interval dan rasio tidak bisa memakai Statistika Non-Parametrik) Sehingga, sebenarnya skala pengukuran dan jenis data tidak terlalu berarti Jumlah data kecil
Dilakukan untuk :
Data Independen (dikoding saat input ke SPSS) 2 sampel : Uji Mann-Whitney
k sampel : Uji Kruskal-Wallis ,
Data Dependen(tidak dikoding, inputnya per kolom yaitu per populasi) 2 sampel : Uji Tanda (Sign Test) , Uji Wilcoxon Signed Rank
*lebih akurat kalau memakai Uji Wilcoxon Signed Rank dibanding Uji Tanda
k sampel : Uji Friedman, Uji Q-Cochran‟s ,
Uji Mann-Whitney
Menguji signifikansi hipotesis antara 2 sampel independen. Oleh karena independen maka 2 sampel tersebut ukurannya bisa berbeda.
Jika asumsi distribusi normal dan kesamaan variansi semuanya terpenuhi maka memakai Uji 2 Mean Populasi Independen seperti yang sudah dipelajari di Metode Statistika I. Namun, jika salah satu uji asumsi saja sudah tidak terpenuhi maka langsung memakai Statistika Non-Parametrik untuk 2 Populasi Independen yaitu Uji Mann-Whitney.
o Hipotesis
H0 : = (tidak ada perbedaan rata-rata untuk sampel yang berasal dari 2 populasi tersebut)
Fian Setiyaningsih_Risqia Fadhilah S Page 23 Uji Kruskal-Wallis
Menguji signifikansi hipotesis antara sampel independen dan karena independen berarti sampel tersebut ukurannya bisa berbeda. ( )
Jika asumsi distribusi normal dan kesamaan variansi semuanya terpenuhi maka memakai Uji Mean Populasi Independen yaitu ANOVA SATU ARAH yang sudah dipelajari pada bab awal Metode Statistika II. Namun, jika salah satu uji asumsi saja sudah tidak terpenuhi maka langsung memakai Statistika Non-Parametrik untuk Populasi Independen yaitu Uji Kruskal-Wallis.
Asumsi dalam Kruskall-Wallis
Sampel berasal dari populasi-populasi independen
Sampel diambil secara random dari populasi masing-masing
Karena data sampel diambil secara random, maka asumsi sampel berasal dari populasi independen terpenuhi.
Data diukur minimal dalam skala ordinal
o Hipotesis
H0 : = = ... = (tidak ada perbedaan rata-rata untuk sampel yang berasal dari populasi tersebut)
H1 : ada yang tidak sama, (ada perbedaan rata-rata untuk sampel yang berasal dari populasi tersebut)
Uji Wilcoxon Signed Rank
Hanya untuk data bertipe interval atau rasio.
Menguji signifikansi hipotesis untuk 1 sampel yang dikenai 2 perlakuan.
Jika asumsi distribusi normal dan uji korelasi*semuanya terpenuhi maka memakai Uji 2 Mean Populasi Dependen seperti yang sudah dipelajari di Metode Statistika I. Namun, jika asumsi normalitas tidak terpenuhi maka langsung memakai Statistika Non-Parametrik untuk 2 Populasi Dependen yaitu Uji Wilcoxon Signed Rank.
*Uji Korelasi sebenarnya tidak wajib dilakukan untuk Asumsi 2 Mean Populasi Dependen, ada yang memakai Uji Korelasi, namun ada juga yang tidak memakai Uji Korelasi, semuanya tergantung pada yang sudah anda pelajari di kelas sebelumnya.
o Hipotesis
Fian Setiyaningsih_Risqia Fadhilah S Page 24 Uji Friedman
Menguji signifikansi hipotesis antara 1 sampel yang dikenai perlakuan ( dependen) dan karena dependen berarti ukurannya harus sama untuk setiap perlakuan,
Jika asumsi distribusi normal dan kesamaan variansi semuanya terpenuhi maka memakai Uji Mean Populasi Dependen yaitu ANOVA DUA ARAH yang sudah dipelajari pada bab awal Metode Statistika II. Namun, jika salah satu uji asumsi saja sudah tidak terpenuhi maka langsung memakai Statistika Non-Parametrik untuk Populasi Dependen yaitu Uji Friedman.
o Hipotesis
H0 : populasi-populasi dalam suatu blok identik
H1 : sekurang-kurangnya salah satu perlakuan cenderung menghasilkan nilai-nilai yang lebih besar dibanding sekurang-kurangnya salah satu perlakuan yang lain.
Kesalahan Umum dalam Tugas/Kuis/Laprak
Jangan lupa mengenai tanda koma dan juga tanda titik, ada SPSS yang menginterpretasikan koma dengan tanda „,‟ , ada juga yang menginterpretasikan dengan koma dengan tanda „.‟ . Kenali SPSS yang anda pakai untuk mengerjakan analisis. Karena salah tanda dari awal bisa menyebabkan kesalahan TOTAL dalam pengerjaan analisis.
Jangan bulatkan semua nilai yang tertera pada output SPSS, tuliskan sesuai dengan output SPSS. Kemarin cukup banyak yang membulatkan nilai P-value dan ada juga yang membulatkan nilai Standard Error of Estimate di Model Summary.
Karena P-value = 0,000 yang tertera pada output SPSS itu berbeda dengan 0
Karena nilai Standard Error misal 10,081563 yang tertera pada output SPSS itu berbeda dengan 10,082 ataupun 10,08156. Di statistika, 10,081563 itu berbeda dengan 10,081561 yang walaupun jika dibulatkan sama-sama 10,08156.
“In statistics, 0,00000000000000001 does matter ”
Jangan lupa untuk mendefinisikan setiap yang anda tulis , khususnya dalam Analisis Regresi Linear.
Saat menulis uji inferensi, harus lengkap yaitu mencakup : “Hipotesis, Tingkat Signifikansi, Statistik Uji, Daerah Kritik, serta Kesimpulan” . jangan lupakan walaupun hanya 1 bagian .
Saat membuat kesimpulan, jangan hanya menulis ya atau tidak , namun tuliskan secara lengkap yaitu variabel ...signifikan atau variabel ... tidak signifikan.
Fian Setiyaningsih_Risqia Fadhilah S Page 25 Saat menulis interpretasi, pastikan itu singkat,padat, namun mencakup total dan jelas. Tuliskan interpretasi itu agar orang yang awam akan statistika juga bisa mengerti analisis anda.
Telitilah dalam bekerja, ikuti semua instruksi dan format penulisan yang tertera dalam permasalahan yang akan dianalisis.
PENUTUP
Semoga ringkasan ini dapat digunakan dengan sebaik mungkin, diharapkan dengan adanya ringkasan ini bisa lebih memudahkan praktikan dalam memahami materi Praktikum Metode Statistika 2 Kelas A. Kami menyadari bahwa masih banyak kekurangan dalam ringkasan ini, sehingga diharapkan praktikan dapat mencari referensi pembelajaran lain yang ada pada buku ataupun internet yang relevan. Kami mohon maaf jika selama praktikum ini kami banyak kesalahan baik itu salah perbuatan maupun salah kata, juga apabila kami terlalu cepat menjelaskan materi praktikum. Tetap semangat dan jangan pernah kenyang dalam belajar, jalan masih panjang dan semoga kita bisa bertemu lagi pada kesempatan selanjutnya!!
Tertanda, Asisten Praktikum Metode Statistika 2 Kelas A :
Fian Setiyaningsih (15843) Risqia Fadhilah Syahrir (15849)