Nama Panggilan : Nando
Tempat/Tanggal Lahir : Pekan Baru/31 Oktober 1994 Jenis Kelamin : Laki – laki
Agama : Islam
Kewarganegaraan : Indonesia
Alamat Rumah :Dusun Kebon Randu III,Desa Anjatan Baru,Kecamatan Anjatan RT06/RW01
Alamat Sekarang : Tubagus Ismail Bawah Email : [email protected]
B. PENDIDIKAN FORMAL 2000 – 2006
Sekolah Dasar : SDN 3 Anjatan Baru 2006 – 2009
Sekolah Menengah Pertama : SMPN 1 Anjatan 2009 – 2012
Sekolah Menengah Kejuruan : SMKN 13 Bandng 2012 – Sekarang
Mahasiswa S-1 Jurusan Teknik Informatika, Universitas Komputer Indonesia
C. KESEHATAN
Tinggi Badan : 168 cm Berat Badan : 53 kg
D. PELATIHAN DAN SEMINAR
a. Kuliah Bersama 2012 “BERFIKIR CERDAS DI INFORMATIKA” : 1 Desember 2012
: 22 Juni 2015
E. RIWAYAT PEKERJAAN / PENGALAMAN BERORGANISASI a. Anggota LDK UMMI UNIKOM 2012 – 2014
b. Anggota GEMA PEMBEBASAN 2014 – 2015 c. Anggota HMIF UNIKOM 2014/2015
Demikian daftar riwayat hidup ini saya buat dengan sebenar – benarnya dalam keadaan sadar dan tanpa paksaan.
Bandung, 25 Agustus 2016
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
FERNANDO WINATA
10112740
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
KATA PENGANTAR
Puji dan syukur penulis ucapkan kepada Allah SWT atas rakhmat dan
karunia – Nya sehingga penulis dapat menyelesaikan tugas akhir dengan judul
IMPLEMENTASI METODE LATENT SEMANTIC ANALYSIS (LSA) PADA PERINGKAS TEKS OTOMATIS UNTUK ARTIKEL BERITA BERBAHASA INDONESIA.
Selama proses penulisan tugas akhir ini penulis menyadari bahwa penulis
banyak mendapati kendala, namun berkat berkah Allah SWT dan bantuan,
bimbingan serta kerjasama dari berbagai pihak, penulis dapat mengatasi berbagai
macam kendala yang dilalui selamat penulisan tugas akhir ini dan Alhamdulillah
penulis dapat menyelesaikan penulisan tugas akhir ini. Untuk itu, penulis ingin
menyampaikan terimakasih yang sebesar – besarnya kepada :
1. Allah SWT yang telah memberikan penulis rakhmat dan karunia – Nya
sehingga penulis dapat menyelesaikan tugas akhir ini.
2. Kedua orang tua penulis yang selalu memberikan dukungan dan bantuan
kepada penulis.
3. Ibu Ednawati Rainarli, S.Si., M.Si selaku pembimbing yang telah
membimbing penulis selama penulisan tugas akhir ini.
4. Bapak Eko Budi Setiawan, S.Kom., M.T selaku reviewer yang telah
memberikan masukan terhadap penelitian yang dilakukan penulis.
5. Bapak Alif Finanditha, S.Kom., M.T yang telah memberikan masukan
terhadap penelitian yang dilakukan penulis.
6. Rekan – rekan penulis yaitu Rismoyo Bayu, Rinaldy Nursalis, Sani
Saefurochman, Hilmi Abdul Aziz, Arief Budiman Eka Putra, Euaggelion
Seduse Maximus dan Ardiansyah yang selalu memberikan dukungan,
iv
7. Rekan – rekan penulis di IF-1 yang selalu memberikan dukungan serta
bantuan selama penulisan tugas akhir ini.
8. Semua pihak yang penulis tidak dapat sebutkan satu persatu yang telah
membantu penulis dalam penyelesaian tugas akhir ini.
Akhir kata, semoga tugas akhir ini dapat memberikan manfaat kepada para
pembaca.
Bandung, 25 Agustus 2016
v
ABSTRACT...ii
KATA PENGANTAR...iii
DAFTAR ISI...v
DAFTAR GAMBAR...viii
DAFTAR TABEL...x
DAFTAR SIMBOL...xii
vii
101
and Latent Semantic," Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Developement in Information Retrieval, pp. 19 - 25, 2001.
[2] Karel Jezek Josef Steinberger, "Using Latent Semantic Analysis in Text Summarization and Summary Evaluation," Proceedings of ISIM, pp. 93-100, 2004.
[3] Steve Renals, Jean Carletta Gabriel Murray, "Extractive Summarization of Meeting Recordings," 2005.
[4] Makbule Gulcin Ozsoy, Ilyas Cicekli, and Ferda Nur Alp, "Text Summarization of Turkish Texts Using Latent Semantic Analysis,"
Proceedings of the 23rd international conference on computational linguistics, pp. 869 - 876, 2010.
[5] Junta Zeniarja, Abu Salam Ardytha Luthfiarta, "Algoritma Latent Semantic Analysis (LSA) Pada Peringkas Dokumen Otomatis Untuk Proses Clustering Dokumen," Semantik, vol. 3, no. 1, pp. 61-68, 2013.
[6] Adiwijawa, Moch Arif Bijaksana Agung Triwibowo, "Penggunaan Metode Relevance Measure Dan Latent Semantic Analysis (LSA) Dalam Membuat Ikhtisar Dokumen Berita," 2010.
[7] Andre F.T. Martins Dipanjan Das, "A Survey on Automatic Text
Summarization," Literature Survey for the Language and Statistics II course at CMU, vol. 4, pp. 192 - 195, November 2007.
[8] J. Ilamathi, Nithya Vijayarani, "Preprocessing Techniques for Text Mining,"
International Journal of Computer Science and Communication Network, vol. 5, no. 1, pp. 7-16, 2015.
[10] M.F. Porter, "An Algorithm for Suffix Stripping," Program, vol. 4, no. 3, pp. 130 - 137, 1980.
[11] Fadillah Z Tala, "A Study of Stemming Effects on Information Retrieval in Bahasa Indonesia," 2003.
[12] Ledy Agusta, "Perbandingan Algoritma Stemming Porter dengan Algoritma Nazief & Adriani Untuk Stemming Teks Dokumen Bahasa Indonesia,"
Konferensi Nasional Sistem dan Informatika, pp. 192 - 201, 2009.
[13] Gregoria Ariyanti, "Dekomposisi Nilai Singular dan Aplikasinya," Prosiding Seminar Nasional Matematika dan Pendidikan Matematika (2010):”
Peningkatan Kontribusi Penelitian dan Pembelajaran Matematika dalam
Upaya Pembentukan Karakter Bangsa”, 2010.
[14] Manabu Okumura Takahiro Fukusima, "Text Summarization Challenge Text Summarization Evaluation in Japan," North American Association for
Computational Linguistics (NAACL2001), Workshop on Automatic Summarization, pp. 51 - 59, 2001.
[15] Karel Jezek Josef Steinberg, "Evaluation Measures for Text Summarization,"
Computing and Informatics, vol. 28, no. 2, pp. 251 - 275, 2009.
[16] MADCOMS, Kupas Tuntas Adobe Dreamweaver dengan Pemograman PHP & MySQL CS6. Madiun, Indonesia: ANDI, 2013.
[17] Viktor Pekar, Laura Hasler Constantin Orasan, "A Comparison of Summarisation Methods Based on Term Specificity Estimation,"
Proceedings of the Fourth International Language Resources and Evaluation
1.1. Latar Belakang
Dengan semakin pesatnya perkembangan teknologi maka kebutuhan untuk mendapatkan informasi semakin besar. Informasi sekarang bisa di dapatkan secara cepat dan mudah serta bisa di dapatkan kapan dan dimana saja melalui berbagai macam portal berita yang tersedia untuk memenuhi kebutuhan masyarakat akan informasi yang up to date dan real time, tetapi dari sekian banyak artikel berita yang disediakan oleh portal – portal berita tersebut tidak mempunyai ringkasan dan abstrak. Untuk mendapatkan informasi inti dari sebuah artikel berita, pembaca harus membaca keseluruhan artikel yang cukup memakan waktu, sehingga dibutuhkan sebuah alat bantu yang dapat menghasilkan ringkasan dari dokumen sumber secara otomatis dan akurat.
Peringkas teks otomatis merupakan sebuah alternatif yang dapat digunakan untuk menghasilkan ringkasan secara otomatis menggunakan bantuan komputer. Pada penerapannya terdapat banyak metode yang digunakan untuk menghasilkan ringkasan pada peringkas teks otomatis. Salah satu metode yang digunakan untuk menghasilkan ringkasan adalah metodeLatent Semantic Analysis
(LSA). Metode ini terinspirasi oleh metodeLatent Semantic Indexing (LSI) yang menerapkan Singular Value Decomposition (SVD) sebagai cara untuk memilih kalimat yang akan dijadikan sebagai kalimat ringkasan [1].
juga banyak bermunculan, seperti penggabungan metode LSA dengan metode
clustering dokumen untuk menghasilkan ringkasan pada multi document
berbahasa Indonesia [5] yang berhasil meningkatkan tingkat akurasi yang dihasilkan dari multi document dengan cara menggabungkan algoritma Latent Semantic Analysis dengan algoritma clustering dan pada penelitian lainnya digunakan metode Latent Semantic Analysis dan metode Relevance Measure
untuk meringkas dokumen tunggal berbahasa Indonesia [6] yang membuktikan bahwa metode Latent Semantic Analysis mempunyai tingkat akurasi ringkasan yang lebih tinggi dibanding dengan metodeRelevance Measure.
Dari penelitian yang menggunakan metode latent semantic analysis untuk menghasilkan ringkasan pada teks berbahasa Indonesia diketahui bahwa metode
latent semantic analysis yang digunakan adalah metode latent semantic analysis
awal yang belum dikembangkan. Penggunaan metode latent semantic analysis
yang lama tentu akan menghasilkan ringkasan dengan tingkat akurasi yang lebih rendah jika dibandingkan dengan akurasi ringkasan yang dihasilkan dari metode
latent semantic analysisyang telah dikembangkan.
Sebuah Peringkas teks otomatis diharapkan dapat membantu pembaca untuk mendapatkan informasi inti dari berita yang dibaca dengan lebih cepat. Penerapan Cross Method Latent Semantic Analysis pada peringkas teks otomatis dapat menghasilkan sebuah ringkasan yang lebih akurat dibanding dengan ringkasan yang dihasilkan metode latent semantic analysis biasa [4]. Oleh karena itu, penulis tertarik untuk mengambil pokok bahasan penelitian dengan judul “Implementasi Cross Method Latent Semantic Analysis Pada peringkas Teks Otomatis Untuk Artikel Berita Berbahasa Indonesia”.
1.2. Perumusan Masalah
Berdasarkan permasalahan yang telah di uraikan, maka maksud dari penelitian ini adalah untuk melakukan implementasi Cross Method Latent Semantic Analysispada peringkas teks otomatis.
Sedangkan tujuan dari penelitian ini adalah untuk mengetahui tingkat akurasi dari ringkasan yang dihasilkan dengan penerapan Cross Method Latent Semantic Analysis pada peringkas teks otomatis terhadap artikel berita berbahasa Indonesia.
1.4.Batasan Masalah
Untuk menghindari pembahasan yang meluas, maka penulis membatasi permasalahan sebagai berikut :
a. Dokumen yang di ringkas adalah artikel berita politik berbahasa Indonesia. b. Dokumen yang dimasukan kedalam peringkas teks otomatis diambil
menggunakan rich site summary (RSS) yang dimiliki portal berita viva.co.id yang merupakan salah satu portal berita dengan tingkat akses pengunjung tinggi.
c. Jumlah Berita yang ditampilkan oleh peringkas teks otomatis dari portal berita viva.co.id yang dapat dipilih oleh pengguna untuk di ringkas adalah 15 buah berita.
d. Dokumen yang di masukan ke dalam peringkas teks otomatis untuk di ringkas merupakan dokumen tunggal.
e. Hasil yang dihasilkan oleh peringkas teks otomatis adalah ringkasan.
f. Bahasa program yang akan digunakan adalah PHP hypertext preprocessor (PHP) dan MySQL sebagai pengolahandatabase.
g. Data stop words bahasa Indonesia yang digunakan diperoleh dari Kevin Bouge1.
h. Data kata dasar bahasa Indonesia yang digunakan diperoleh dari kateglo2 1https://sites.google.com/site/kevinbouge/stopwords-lists
penelitian kali ini penulis akan menggunakan metode penelitian deskriptif.
Metode penelitian deskriptif adalah suatu metode dimana setiap objek digambarkan secara jelas dan nyata sesuai dengan fakta. Metode yang digunakan selama penelitian di gambarkan pada gambar 1.1. di bawah:
Gambar 1.1 Metode Penelitian
Penjelasan metode penelitian yang digunakan pada gambar 1.1 adalah sebagai berikut :
a. Identifikasi Masalah
Berdasarkan latar belakang yang telah disebutkan, permasalahan yang dapat di identifikasi adalah kebutuhan masyarakat akan peringkas teks otomatis yang dapat menghasilkan ringkasan dengan cepat dan akurat. Serta penggunaan metode pada peringkas teks otomatis yang dapat menghasilkan ringkasan dengan tingkat akurasi tinggi.
b. Analisis Masalah
menggunakan metode LSA yang lama sedangkan metode LSA telah mengalami beberapa tahap pengembangan. Sehingga ringkasan yang dihasilkan oleh metode LSA yang lama memiliki tingkat akurasi yang lebih rendah jika dibandingkan dengan metode LSA yang telah dikembangkan. c. Pengambilan Hipotesis Awal
Dari hasil analisis masalah di atas dapat diambil sebuah hipotesis awal yaitu, untuk menghasilkan sebuah peringkas teks otomatis metode yang dapat digunakan adalah Cross Method Latent Semantic Analysis yang dapat menghasilkan sebuah ringkasan yang lebih akurat dibandingkan dengan metodelatent semantic analysisbiasa.
d. Studi Literatur
Pada tahap ini dilakukan studi terhadap literatur – literatur yang berkaitan dengan penelitian yang dilakukan seperti literature mengenai peringkas teks otomatis, proses pengolahan teks, dancross method latent semantic analysis, serta literature – literatur lain yang mendukung penelitian.
e. Perancangan Simulator
Pada tahap ini dilakukan proses perancangan peringkas teks otomatis. Proses perancangan terdiri dari proses analisis kebutuhan fungsional dan non fungsional dari peringkas teks otomatis yang akan dibangun, analisis data masukan, perancangan tampilan antar muka peringkas teks otomatis dan perancangan jaringan semantik.
f. Pembangunan Peringkas Teks Otomatis
Pada tahap ini dilakaukan pembangunan dari peringkas teks otomatis untuk teks berbahasa Indonesia. Dimulai dari tahap pembangunan interface
(TF-Pada tahapan ini, akan dilakukan proses pengujian terhadap peringkas teks otomatis yang telah di bangun untuk melihat apakah peringkas teks otomatis dapat berjalan dengan semestinya. Jika peringkas teks otomatis yang dibangun memiliki kekurangan maka akan kembali ke tahapan perancangan peringkas teks otomatis untuk melakukan analisis kesalahan yang mungkin terjadi pada saat pembangunan peringkas teks otomatis. Jika peringkas teks otomatis sudah dapat berjalan dengan semestinya maka akan masuk ke dalam tahapan pengujian metode.
h. Pengujian Metode
Dalam tahapan ini akan dilakukan pengujian terhadap Cross Method Latent Semantic Analysis untuk mengetahui hasil dari implementasi metode ini dalam peringkas teks otomatis. Jika dari tahapan ini memberikan hasil yang kurang baik maka akan kembali ke tahapan studi literatur untuk menganalisis kesalahan yang mungkin terjadi pada saat penerapan metode.
i. Analisis Hasil Ringkasan
Pada proses ini dilakukan analisis pada hasil ringkasan yang didapatkan dengan menggunakan metode Latent Semantic Analysis. Untuk proses analisis digunakan metode Precision,Recall serta metode F-Measure untuk mengetahui tingkat ke akuratan ringkasan yang dihasilkan dariCross Method Latent Semantic Analysis.
j. Pengambilan Kesimpulan
Pada tahap ini dilakukan pengambilan kesimpulan yang didapat dari hasil ringkasan yang dihasilkan oleh peringkas teks otomatis untuk teks berita berbahasa Indonesia.
1.6. Sistematika Penulisan
menjelaskan pokok – pokok pembahasannya.
BAB 2 LANDASAN TEORI
Pada bab ini akan menjelaskan mengenai teori – teori pendukung yang berhubungan dengan penelitian dan pembangunan peringkas teks otomatis.
BAB 3 ANALISIS KEBUTUHAN ALGORITMA
Dalam bab ini berisikan analisis dan perancangan dari peringkas teks otomatis yang akan dibangun. Proses analisis meliputi proses analisis masalah, analisis data masukan, analisis kebutuhan dari perangkat lunak yang akan dibangun,analisis tahap preprocessing dan analisis dari metode peringkasan yang digunakan dalam penelitian. Sedangkan pada proses perancangan peringkas teks otomatis akan di bahas mengenai proses perancangan basis data,tampilan antar muka dan jaringan semantic yang akan diterapkan pada peringkas teks otomatis.
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Dalam bab ini berisikan implementasi dari sistem yang telah dirancang untuk mengetahui keberhasilan dari pembangunan peringkas teks otomatis serta tingkat keberhasilan algoritma dalam menghasilkan sebuah ringkasan pada artikel berita berbahasa Indonesia. Pengujian pada peringkas teks otomatis dilakukan dengan menggunakan metode pengujian Precision, Recall dan F-Measure yang digunakan untuk mengukur tingkat akurasi dari ringkasan yang dihasilkan.
BAB 5 KESIMPULAN DAN SARAN
9 2.1. Peringkas Teks Otomatis
Ringkasan adalah sebuah teks yang dihasilkan dari sebuah dokumen atau lebih yang menyatakan informasi penting dari dokumen asli, dan sebuah ringkasan memiliki ukuran yang relatif lebih pendek dari dokumen asli [7]. Tujuan utama dari ringkasan adalah menghasilkan sebuah intisari atau informasi inti yang terdapat dalam dokumen asli dalam bentuk yang lebih kecil agar pembaca dapat mendapatkan informasi penting yang terdapat dalam dokumen dengan lebih cepat. Proses peringkasan teks secara otomatis sendiri merupakan proses peringkasan pada suatu dokumen dengan menggunakan bantuan komputer. 2.1.1. Pendekatan Peringkasan Teks Secara Otomatis
Terdapat dua buah pendekatan yang dilakukan untuk menghasilkan sebuah ringkasan secara otomatis yaitu :
a. Ekstraksi
Pada teknik ekstraksi, sistem menyalin unit-unit teks yang dianggap paling penting dari teks sumber menjadi ringkasan. Unit-unit teks yang disalin dapat berupa klausa utama, kalimat utama, atau paragraf utama tanpa ada penambahkan kalimat-kalimat baru yang tidak terdapat pada dokumen aslinya.
b. Abstraksi
Teknik abstraksi menggunakan metode linguistik untuk memeriksa dan menafsirkan teks dokumen menjadi ringkasan. Ringkasan teks tersebut dihasilkan dengan cara menambahkan kalimat-kalimat baru yang merepresentasikan intisari teks sumber ke dalam bentuk yang berbeda dengan kalimat-kalimat yang ada pada teks sumber.
menggunakan computer sebagai alat bantu untuk menghasilkan ringkasan dari dokumen asli.
2.2. Preprocessing
Preprocessing merupakan tahapan awal untuk menghasilkan sebuah ringkasan. Teks masukan yang akan di ringkas sebelumnya harus melalui tahap untuk membuang berbagai macam jenis noise atau kata – kata yang di anggap tidak penting dalam ringkasan yang masih terdapat pada teks masukan [8].
Dalam penerapan preprocessing terdapat beberapa tahap yang harus dilalui dimulai dari tahapan tokenisasi, penghilangan stop words sampai dengan tahapan stemming, selain tahapan itu juga biasanya di tambahkan beberapa tahapan lain untuk kasus tertentu seperi casefolding dan penghilangan kata yang jarang dimunculkan atau kata dengan frekuensi kemunculan yang kecil [9].
Proses preprocessing yang diterapkan pada penelitian ini meliputi beberapa macam tahap yaitu :
a. Pemecahan Kalimat
Pada tahapan ini teks masukan dipecah menjadi beberapa kalimat berdasarkan delimiter atau pemisah yang sudah ditetapkan. Pemisah tersebut adalah tanda titik(.),tanda seru(!) dan tanda Tanya(?).
b. CaseFolding
Pada tahapan ini dilakukan proses penyamaan case atau besar kecil dari setiap huruf yang terdapat pada teks masukan yang telah di pecah menjadi beberapa kalimat. Selain itu pada tahap ini juga di lakukakan proses pembuangan pada tanda baca,simbol dan angka yang terdapat pada data masukan.
c. Tokenizing
Pada tahapan ini teks masukan hasil dari proses casefolding dipecah kembali menjadi beberapa kalimat berdasarkan spasi yang terdapat pada kalimat hasil
d. Stop Words Removal
Pada tahapan ini dilakukan proses penghapusan stop words yang masih terdapat pada teks hasil dari proses tokenizing. Stopwords merupakan sebuah kata yang dianggap tidak terlalu penting dalam proses peringkasan atau kata yang tidak mempunyai arti dalam sebuah dokumen [10]. Contoh dari stop words dalam bahasa Indonesia adalah : dan,atau,jika dan sebagainya. Tujuan utama dilakukan tahap ini adalah untuk mengurangi dimensi dari teks masukan sehingga proses peringkasan dapat berjalan dengan lebih mudah [8].
c. Stemming
Stemming merupakan proses yang menyediakan pemetaan varian morfologi yang berbeda dari suatu kataker akar katanya dengan cara [11]. proses ini melakukan pemetaan dari penguraian berbagai bentuk kata baik itu prefix,
sufix, maupun gabungan antara prefix dan sufix (confix), menjadi bentuk kata dasarnya. Pada penelitian ini algoritma stemming yang digunakan adalah algoritma stemming Nazief dan Adriani
2.2.1. Algoritma Nazief dan Adriani
Algoritma Nazief dan Adriani merupakan algoritma stemming yang di gunakan untuk proses stemming terhadap teks berbahasa Indonesia [12]. Cara Kerja dari Algoritma ini adalah :
1. Di awal proses stemming dan setiap langkah yang selanjutnya dilakukan, lakukan pengecekan hasil proses stemming kata yang di-input-kan pada langkah tersebut ke kamus kata dasar. Jika kata ditemukan, berarti kata tersebut sudah berbentuk kata dasar dan proses stemming dihentikan. Jika tidak ditemukan, maka langkah selanjutnya dilakukan.
2. Hilangkan Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”). Jika berupa particles (“-lah”, “-kah”, “-tah” atau “-pun”) maka langkah ini diulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”, atau “- nya”), jika ada.
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “- k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke langkah 4.
4. Hilangkan derivation prefixes. a. Langkah 4 berhenti jika :
i. Terjadi kombinasi awalan dan akhiran yang terlarang.
ii. Awalan yang dideteksi saat ini sama dengan awalan yang dihilangkan sebelumnya.
iii. Tiga awalan telah dihilangkan.
b. Identifikasi tipe awalan dan hilangkan. Awalan terdiri dari dua tipe : i. Standar (“di-”, “ke-”, “se-”) yang dapat langsung dihilangkan dari
kata.
ii. Kompleks (“me-”, “be-”, “pe”, “te-”) adalah tipe-tipe awalan yang dapat bermorfologi sesuai kata dasar yang mengikutinya. Oleh karena itu, gunakan aturan pada Tabel 2.1 untuk mendapatkan hasil pemenggalan yang tepat.
c. Cari kata yang telah dihilangkan awalannya ini di dalam kamus kata dasar. Apabila tidak ditemukan, maka langkah 4 diulangi kembali. Apabila ditemukan, maka keseluruhan proses dihentikan.
5. Apabila setelah langkah 4 kata dasar masih belum ditemukan, maka proses
recoding dilakukan dengan mengacu pada aturan pada Tabel 2.1. Recoding
6. Jika semua langkah gagal, maka input kata yang diuji pada algoritma ini dianggap sebagai kata dasar.
Tabel 0.1 Aturan Pemenggalan Awalan Algortima Nazief dan Adriani
Aturan Format Kata Pemenggalan
1 berV … ber-V … | be-rV …
2 BerCAP … ber-CAP … dimana C!=”r” & P!=”er” 3 berCAerV … ber-CaerV … dimana C!=”r”
4 Belajar bel-ajar
5 BeC1erC2 … be-C1erC2 … dimana C1!={“r”|”l”}
6 terV … Ter-V … | te-rV …
7 terCerV … Ter-CerV …dimana C! = “r”
8 TerCP … Ter-CP … dimana C!=”r” dan P! =”er” 9 teC1erC2… Te-C1erC2 … dimana C1!=”r”
10 Me{l|r|w|y}V … Me-{l|r|w|y}V …
22 perCAP… Per-CAP… dimana C!=”r” dan P!=”er” 23 perCAerV … Per-CAerV … dimana C!=”r”
24 Pem{b|f|V} … Pem-{b|f|V} …
Aturan Format Kata Pemenggalan
A : huruf vokal atau konsonan
P : Partikel atau fragmen dari suatu kata, misalnya “er”
2.3. Algoritma Term Frequency – Inverse Document Frequency (TF-IDF) Metode Term Frequency-Inverse Document Frequency (TF-IDF) adalah cara pemberian bobot hubungan suatu kata (term) terhadap dokumen. Untuk dokumen tunggal tiap kalimat dianggap sebagai dokumen. Metode ini menggabungkan dua konsep untuk perhitungan bobot, yaitu Term frequency (TF) merupakan frekuensi kemunculan kata (t) pada kalimat (d). Document frequency
(DF) adalah banyaknya kalimat dimana suatu kata (t) muncul.
digunakan rumus untuk menghitung bobot (W) masing masing dokumen terhadap kata kunci dengan rumus yaitu :
(2.1) Keterangan:
d = dokumen ke-d
t = kata ke-t dari kata kunci
W= bobot dokumen ke-d terhadap kata ke-t
tf = banyaknya kata yang dicari pada sebuah dokumen IDF = Inversed Document Frequency dengan rumus :
IDF =
(2.2) D = total dokumen
df = banyak dokumen yang mengandung kata yang dicari 2.4. Latent Semantic Analysis
Latent Semantic Analysis (LSA) adalah suatu metode untuk mengekstrak sebuah tulisan dalam suatu dokumen dan kemudian mengaplikasikannya dalam perhitungan matematis. Penilaian dengan metode LSA lebih kepada kata-kata yang ada dalam tulisan tanpa memperhatikan urutan kata dan tata bahasa dalam tulisan tersebut, sehingga suatu kalimat yang dinilai adalah berdasarkan kata-kata kunci yang ada pada kalimat tersebut [8].
Metode ini terinspirasi dari penggunaan latent semantic indexing yang mengimplementaasikan metode singular value decomposition (SVD) untuk menghasilkan sebuah ringkasan. Terdapat 3 tahapan utama dalam proses menghasilkan ringkasan menggunakan metode ini, yaitu :
a. Pembuatan matriks
b. Singular value decomposition c. Ekstraksi kalimat ringkasan 2.4.1. Pembuatan matriks
n matriks dengan m atau baris matriks di ambil dari kalimat dari teks yang akan di ringkas, sedangkan n atau kolom matriks merupakan kata yang terdapat dalam teks yang telah diberi bobot dengan algoritma tf-idf.
2.4.2. Singular Value Decomposition
Setelah matriks di ciptakan maka tahap selanjutnya adalah mengubah matriks tersebut menjadi lebih kecil dengan menggunakan metode singular value decomposition (SVD). Suatu proses dekomposisi akan memfaktorkan sebuah matriks menjadi lebih dari satu matriks. Demikian halnya dengan Dekomposisi Nilai Singular (Singular Value Decomposition) atau yang lebih dikenal sebagai SVD, adalah salah satu teknik dekomposisi berkaitan dengan nilai singular (singular value) suatu matriks yang merupakan salah satu karakteristik matriks tersebut.Dekomposisi nilai singular matriks riil A mxn adalah faktorisasi.
(2.3) Dengan U matriks orthogonal m x m, V matriks orthogonal n x n dan S matriks diagonal m x n bernilai riil tak negatif yang disebut nilai-nilai singular. Dengan kata lain S = diag (σ1, σ2, … , σn ) terurut sehingga σ1 ≥ σ2 ≥ … ≥ σn .
Teorema tersebut juga menyatakan bahwa matriks Amxn dapat dinyatakan sebagai dekomposisi matriks yaitu matriks U, S dan V . Matriks S merupakan matriks diagonal dengan elemen diagonalnya berupa nilai-nilai singular matriks A, sedangkan matriks U dan V merupakan matriks-matriks yang kolom-kolomnya berupa vektor singular kiri dan vektor singular kanan dari matriks A untuk nilai singular yang bersesuaian.
2.4.3. Ekstraksi Ringkasan
Pada proses ini dilakukan tahap pemilihan kalimat yang akan di jadikan sebagai ringkasan. Kalimat yang dipilih diambil dari kalimat yang terdapat pada matriks VT. Kemudian dilakukan pemilihan kalimat yang akan di jadikan sebagai ringkasan berdasarkan kalimat yang mengandung bobot kata terbesar. Proses pemilihan diulang sebanyak jumlah kalimat yang terdapat dalam matriks.Contoh dari proses ekstraksi menggunakan metode ini adalah sebagai berikut.
2.5. Cross Method Latent Semantic Analysis
Cross method latent semantic analysis merupakan sebuah pegembangan dari metode latent semantic analysis yang telah ada sebelumnya. Metode ini dapat menghasilkan ringkasan dari teks masukan yang lebih akurat dibandingkan dengan metode latent semantic analysis yang sebelumnya [4]. Tahapan dari metode ini sebenarnya sama seperti metode latent semantic analysis sebelumnya yaitu dimulai dari tahap pembuatan matriks, singular value decomposition dan ekstraksi ringkasan.
Yang menjadi perbedaan metode ini dengan metode latent semantic analysis terdapat pada saat tahap ekstraksi ringkasan. Metode ini menggunakan nilai rata – rata (average) dan panjang(length) yang di ambil dari matriks VT dan matriks S. Nilai average diambil dari nilai rata – rata dari setiap bobot kata yang terdapat baris matriks VT. setelah ditemukan nilai rata – rata dari setiap kata yang terdapat pada matriks VT , langkah selanjutnya adalah mencocokan nilai rata-rata yang didapatkan pada setiap baris dengan nilai dari setiap kata yang terdapat pada baris tersebut. Jika ternyata nilai dari kata tersebut lebih rendah dari nilai rata-rata yang didapat, maka nilai kata tersebut di ubah menjadi nol(0). Tetapi jika tidak maka nilai dari kata tersebut tetap atau tidak diubah.
Setelah tahapan pencarian dan pencocokan nilai rata – rata telah dilakukan, tahap selanjutnya adalah menghitung length dari setiap baris dari matriks VT dengan rumus :
Baris - baris pada matriks atau kalimat - kalimat yang mempunyai nilai
length yang tinggi akan di jadikan sebagai ringkasan. 2.6. Metode Pengujian Hasil Ringkasan
Hasil ringkasan yang dihasilkan oleh peringkas teks otomatis selanjutnya harus melalui tahapan pengujian dan evaluasi untuk mengetahui tingkat akurasi dan ketepatan hasil ringkasan yang dihasilkan. Proses evaluasi hasil ringkasan dapat dikategorikan menjadi dua yaitu metode evaluasi intrinsik dan metode evaluasi ekstrinsik [10].
Pada proses evaluasi secara ekstrinsik, kualitas dari hasil ringkasan dilandaskan pada efek apakah hasil dari ringkasan dapat membantu pada kasus yang diberikan. Sedangkan pada proses evaluasi secara intrinsik, kualitas dari hasil ringkasan berdasarkan dari hasil analisis yang dilakukan pada ringkasan secara langsung. Pada kasus evaluasi intrinsik hasil ringkasan dibandingkan dengan dokumen asli, dari situ akan di analisis seberapa banyak ide utama pada dokumen asli yang terdapat pada hasil ringkasan dengan menyamakan hasil ringkasan dengan hasil ringkasan abstrak atau hasil ringkasan manual yang dilakukan oleh manusia [15].
Pada penelitian ini proses evaluasi yang akan digunakan adalah proses evaluasi secara intrinsik dengan menggunakan metode precision, recall dan f -measure . Nilai f - measure dihasikan berdasarkan nilai precision dan recall. Metode evaluasi ini merupakan metode evaluasi yang sering digunakan dalam proses evaluasi hasil ringkasan. Dalam metode intrinsik, precision dan recall
digunakan untuk mengukur kualitas ringkasan sistem dengan cara membandingkan ringkasan sistem dengan ringkasan manual (buatan manusia).
Precision adalah tingkat ketepatan hasil ringkasan yang dihasilkan peringkas teks otomatis sedangkan recall adalah tingkat keberhasilan ringkasan yang dihasilkan peringkas teks otomatis.Untuk menghitung nilai precision dan nilai recall
digunakan persamaan berikut [15]:
∑ ∑ (2.6)
Kalimat relevan adalah kalimat – kalimat ringkasan yang dihasilkan oleh peringkas teks otomatis yang sama dengan kalimat – kalimat ringkasan yang dihasilkan secara manual oleh manusia. Untuk mencari kalimat relevan digunakan persamaan berikut :
Kalimat relevan = (2.7)
Setelah diketahui nilai precision dan nilai recall, tahapan selanjutnya adalah menghitung nilai dari f – measure yang merupakan nilai yang digunakan untuk mengukur nilai akurasi dari ringkasan yang dihasilkan dengan menggunakan nilai yang dihasilkan pada perhitungan precision dan recall
sebelumnya, sehingga f-measure bisa juga disebut sebagai gabungan atau kombinasi nilai precision dan recall. F-measure dapat dicari dengan menggunakan persamaan berikut [12]:
(2.8) 2.7. PHP : Hypertext Prepocessor (PHP)
PHP adalah bahasa pemrograman script server-side yang didesain untuk pengembangan web. PHP disebut bahasa pemrograman server side karena PHP yang artinya dijalankan di server, kemudian hasilnya atau outputnya dikirim ke
client (browser) . Hal ini berbeda dibandingkan dengan bahasa pemrograman client-side seperti JavaScript yang diproses pada web browser (client).
Pada awalnya PHP merupakan singkatan dari Personal Home Page.
Sesuai dengan namanya, PHP digunakan untuk membuat website pribadi. Dalam beberapa tahun perkembangannya, PHP menjelma menjadi bahasa pemrograman web yang powerful dan tidak hanya digunakan untuk membuat halaman web sederhana, tetapi juga website populer yang digunakan oleh jutaan orang
21
BAB 3
ANALISIS KEBUTUHAN ALGORITMA
3.1. Analisis Masalah
Analisis masalah adalah suatu gambaran masalah yang diangkat dalam penelitian mengenai simulasi peringkas teks otomatis untuk dokumen tunggal berbahasa Indonesia. Analisis masalah ini menjelaskan proses identifikasi masalah serta evaluasi mengenai sistem peringkas teks otomatis dalam dokumen tunggal berbahasa Indonesia. Berdasarkan uraian pada latar belakang masalah, pada penelitian ini diketahui bahwa penerapan metode LSA yang telah dikembangkan pada peringkas teks otomatis belum di uji untuk meringkas dokumen tunggal berbahsa Indonesia. Oleh karena itu pada penelitian ini akan dibuat sebuah peringkas teks otomatis sebagai alat simulasi dari penerapan metode LSA pada peringkas teks otomatis untuk meringkas dokumen tunggal berbahasa Indonesia.
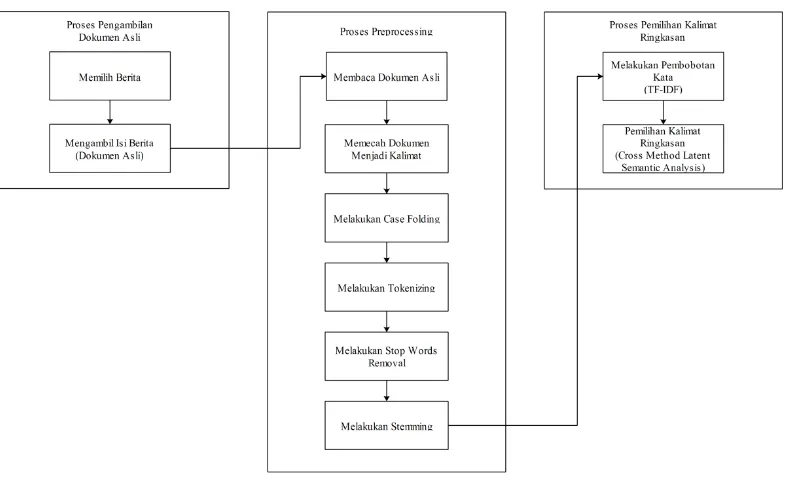
3.2. Analisis Proses
Peringkas teks otomatis yang dibangun mempunyai tiga tahapan proses yang dikerjakan yaitu tahap pengambilan dokumen asli, tahap preprocessing dan tahap pemilihan kalimat ringkasan. Tahapan pengambilan dokumen asli merupakan tahapan yang dilakukan untuk mengambil berita dari portal berita yang telah ditentukan untuk dijadikan sebagai berita yang akan di ringkas, tahapan
Gambar 3.1 Gambaran Umum Peringkas Teks Otomatis
3.2.1. Analisis Pengambilan Dokumen Asli
Analisis yang dilakukan pada pengambilan dokumen asli atau dokumen yang akan di ringkas dari peringkas teks otomatis yang dibangun ini menjelaskan proses - proses yang dilakukan untuk mendapatkan dokumen yang akan di ringkas. Data masukan yang digunakan dalam peringkas teks otomatis adalah data dari dokumen tunggal berita berbahasa Indonesia yang di ambil dari portal berita. Gambaran umum dari proses pemilihan dokumen asli atau dokumen yang akan di ringkas pada peringkas teks otomatis yang akan di bangun adalah :
1. User atau pengguna memilih judul berita yang akan di ringkas melalui daftar berita yang ditampilkan oleh peringkas teks otomatis.
2. Peringkas Teks Otomatis melakukan proses pengambilan isi atau konten dari berita yang telah dipilih oleh pengguna kemudian setelah itu peringkas teks otomatis akan melakukan tahapan preprocessing pada isi dari berita tersebut untuk menghilangkan noise didalamnya. Tahapan preprocessing terdiri dari tahap pemecahan kalimat, case folding, tokenizing, stop words removal dan
stemming yang akan dibahas pada analisis berikutnya.
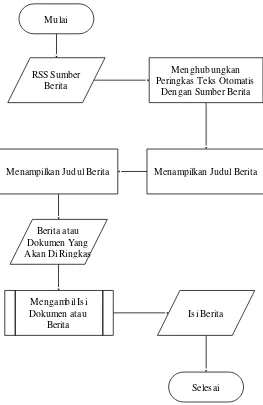
Gambar 3.2 Flowchart Pemilihan Dokumen Asli
Penjelasan dari gambar 3.2 diatas adalah a. RSS Sumber Berita
Alamat dari sumber berita atau portal berita yang akan dijadikan sebagai masukan untuk mengambil berita – berita yang terdapat pada portal berita tersebut.
b. Menghubungkan Peringkas Teks Otomatis Dengan Sumber Berita
Pada tahapan ini peringkas teks otomatis akan meminta daftar dari berita kepada portal berita atau sumber berita sesuai dengan alamat RSS sumber berita yang digunakan.
Mulai
Selesai
Menampilkan Judul Berita
Berita atau Dokumen Yang Akan Di Ringkas
Menghubungkan Peringkas Teks Otomatis
Dengan Sumber Berita
Mengambil Isi Dokumen atau
Berita RSS Sumber
Berita
Menampilkan Judul Berita
c. Menampilkan Judul Berita
Peringkas teks otomatis akan menampilkan daftar dari berita yang tersedia pada portal berita yang dapat pengguna pilih untuk di ambil ringkasannya. d. Memilih Berita Yang Akan Di Ringkas
Pada tahapan ini Pengguna memilih judul berita yang telah disediakan oleh peringkas teks otomatis dari sumber atau portal berita sebagai berita atau dokumen yang akan di ringkas.
e. Berita atau Dokumen Yang Akan Di Ringkas
Pada tahapan ini berita atau dokumen yang telah di pilih oleh pengguna akan dijadikan sebagai input atau masukan bagi peringkas teks otomatis. Masukan ini berupa keseluruhan dari halaman berita yang telah di pilih oleh pengguna.
f. Mengambil Isi Dari Berita atau Dokumen
Dokumen yang telah di masukan ke dalam peringkas teks otomatis akan di ambil isi nya yaitu isi berita yang terdapat pada dokumen tersebut karena pada saat dokumen dimasukan kedalam peringkas teks otomatis bukan hanya isi berita saja yang dimasukan tetapi keseluruhan dari halaman berita tersebut.
g. Isi Berita
Isi dari berita yang telah dipilih oleh pengguna.
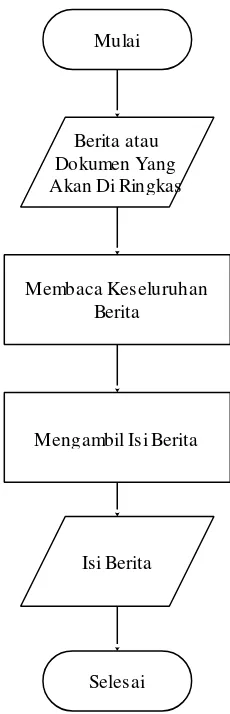
Gambar 3.3 Detil Proses Mengambil Isi Dokumen Atau Berita
Penjelasan dari gambar 3.2 diatas adalah
a. Berita Atau Dokumen Yang Akan Di Ringkas
Dokumen yang telah di pilih oleh pengguna akan dijadikan sebagai input
atau masukan bagi peringkas teks otomatis. Masukan ini berupa keseluruhan dari halaman berita yang telah di pilih oleh pengguna.
b. Membaca Keseluruhan Isi Berita
Pada tahapan ini berita yang telah dipilih oleh pengguna seelumnya di baca secara keseluruhan oleh peringkas teks otomatis dan di simpan ke dalam sebuah variabel sebagai penampung isi berita tersebut.
Mulai
Berita atau Dokumen Yang Akan Di Ringkas
Membaca Keseluruhan Berita
Mengambil Isi Berita
Isi Berita
c. Mengambil Isi Berita
Dokumen berita yang dipilih oleh pengguna tidak hanya berisi artikel berita saja tetapi seluruh informasi yang dimiliki oleh dokumen tersebut sama seperti pada saat dokumen tersebut ditampilkan pada portal berita seperti daftar rekomendasi berita lain, iklan dan sebagainya. Oleh karena itu pada saat pengambilan isi berita, informasi atau isi berita diambil berdasarkan tag yang menandakan bahwa tah tersebut memiliki artikel berita yang akan di ambil, sehingga keluaran dari proses ini hanya berupa isi dari artikel berita yang dipilih saja
d. Isi Berita
Isi dari berita yang telah dipilih oleh pengguna.
Sedangkan data atau kalimat yang akan digunakan untuk pengujian metode preprocessing dan metode pengambilan ringkasan ditunjukan oleh tabel 3.1 di bawah :
Tabel 3.1 Tabel Kalimat Pengujian
Kalimat Uji Tindak Pidana Korupsi.
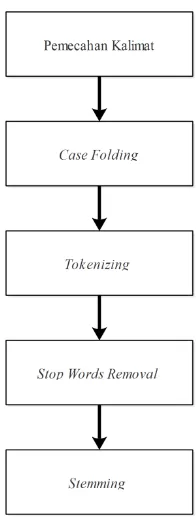
Korupsi merupakan tindakan kejahatan. Pelaku korupsi harus dihukum. 3.2.2. Analisis Preprocessing
Gambar 3.4 Tahapan Preprocessing
3.2.2.1.Pemecahan Data Masukan menjadi Kalimat
Gambar 3.5 Alur Pemecahan Kalimat
Penjelasan dari alur pemecahan data masukan menjadi kumpulan kalimat – kalimat dari alur gambar 3.5 diatas adalah sebagai berikut :
a. Data Masukan
Pada tahap ini dilkaukan proses pembacaan data RSS yang diambil dari portal sumber oleh peringkas teks otomatis.
b. Pemecahan data masukan menjadi kalimat
Pada tahap pemecahan data masukan menjadi kalimat – kalimat digunakan fungsi preg_split("delimiter", data_yang_akan_dipecah) dimana fungsi ini akan memecah atau memtong data yang dimasukan berdasarkan dengan
tuliskan dalam format regular expression pada saat pembangunan aplikasi. Format regular expression yang digunakan untuk delimiter adalah /[.?!]. c. Hasil Pemecahan kalimat
Keluaran dari proses pemecahan data masukan menjadi perkalimat dimasukan kedalam array.
Tabel 3.2 menampilkan hasil proses pemecahan dokumen menjadi kumpulan kalimat-kalimat sebagai berikut :
Tabel 3.2 Hasil Pemecahan Kalimat
No Kalimat
D1 Tindak Pidana Korupsi
D2 Korupsi merupakan tindakan kejahatan D3 Pelaku korupsi harus dihukum
3.2.2.2. Case Folding
Gambar 3.6 Alur Case Folding
Penjelasan dari alur case folding gambar 3.6 diatas adalah sebagai berikut : a. Data Hasil Pecah Kalimat
Pada proses ini dilakukan pembacaan terhadap array dari hasil proses pemecahan kalimat untuk dilakukan proses case folding.
b. Ubah kata menjadi huruf kecil
terdapat pada aray yang digunakan. Fungsi akhir yang digunakan dalam proses case folding adalah array_map("strtolower", variabel_pemecahan_kalimat);
c. Buang tanda baca
Pada tahap ini hasil dari proses penyamaan huruf menjadi huruf kecil diolah kembali untuk menghilangkan noise berupa tanda baca dan angka yang masih terdapat pada huruf. Pada proses ini digunakan fungsi preg_replace(“delimiter”, “ pengganti”,kata), delimiter yang digunakan adalah \d yang menandakan digit[0-9] dan \W yang menandakan simbol atau karakter yang tidak termasuk kedalam huruf dan pengganti merupakan karakter yang digunakan untuk mengganti karakter yang sesuai dengan delimiter, pada kasus ini digunakan spasi sebagai karakter pengganti. Dengan delimiter tersebut fungsi akan menghapus angka dan simbol yang terdapat pada kata yang dimasukan sebagai parameter.
d. Data Hasil Case Folding
Output atau keluaran dari proses case folding di masukan kedalam array. Hasil dari proses case folding yang dilakukan dapat dilihat pada tabel 3.3 di bawah:
Tabel 3.3 Hasil Case Folding
No Kalimat
D1 tindak pidana korupsi
D2 korupsi merupakan tindakan kejahatan D3 pelaku korupsi harus dihukum
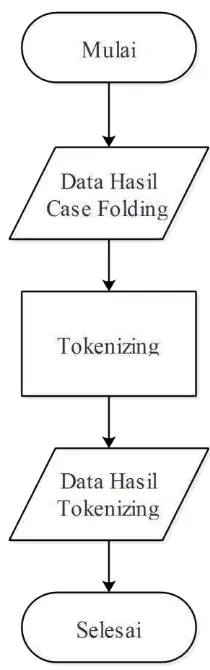
3.2.2.3. Tokenizing
Gambar 3.7 Alur Tokenizing
Penjelasan dari alur tokenizing gambar 3.7 diatas adalah sebagai berikut : a. Data Hasil Case Folding
Pada proses ini dilakukan pembacaan terhadap array dari hasil proses case folding untuk dilakukan proses tokenizing.
b. Tokenizing
c. Data Hasil Tokenizing
Output atau keluaran dari proses tokenizing di masukan kedalam array. Hasil dari proses tokenizing dapat dilihat pada tabel 3.4 dibawah ini :
Tabel 3.4 Hasil Proses Tokenizing
Kata Hasil Proses Tokenizing dihukum harus kejahatan korupsi korupsi korupsi merupakan pelaku pidana tindak tindakan
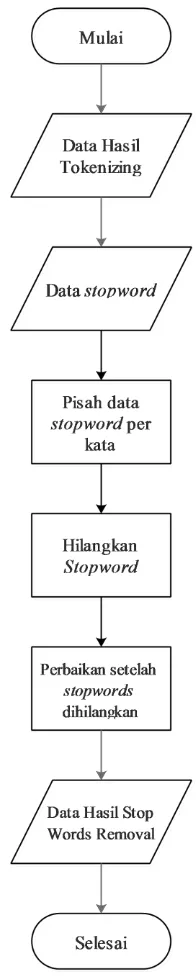
3.2.2.4. Stop Words Removal
Gambar 3.8 Alur Stop Words Removal
Penejelasan dari alur stop words removal yang ditunjukan pada gambar 3.8 diatas adalah sebagai berikut :
a. Data Hasil Tokenizing
Pada proses ini dilakukan pembacaan terhadap array dari hasil proses
b. Baca data stopwords
Pada tahap ini dilkaukan proses pembacaan data dengan format file .txt yang yang mengandung stop words yang akan digunakan dalam simulasi. Untuk proses pembacaan file pada peringkas teks otomatis digunakan fungsi file_get_contents("nama_file.txt") untuk membaca file bertipe txt yang akan digunakan peringkas teks otomatis.
c. Pisah data stopwords per kata
Pada tahap ini dilakukan proses pemisahan stopwords menjadi kata – kata dan memasukan stopwords kedalam variabel penampung bertipe array. Untuk pemisahan stopwrods menjadi kata – kata digunakan fungsi preg_split("delimiter", file_stopwords). Dimana fungsi ini akan memotong data yang terdapat pada file stopwords menjadi array berdasarkan delimiter
yang digunakan. Delimiter yang digunakan dalam format regular expression adalah \s yang menandakan karakter spasi.
d. Hilangkan Stop Words
Pada tahap ini dilakuka proses penghilangan stop words yang masih terdapat pada data hasil tokenizing. Fungsi yang digunakan dalam proses ini adalah array_diff(array1,array2), fungsi ini akan membandingkan array 1 dan array 2 yang telah dimasukan pada parameter fungsi tersebut. Perbandingan yang dilakukan adalah membandingkan kata / nilai yang sama yang terdapat pada kedua array tersebut kemudian fungsi ini akan menghapus kata/nilai yang terdapat pada array 1 yang mempunyai nilai yang sama dengan nilai yang terdapat pada array 2, kemudian nilai yang tidak dihapus pada array 1 akan dijadikan sebagai keluaran. Sehingga parameter yang digunakan dalam fungsi tersebut adalah array_diff(hasil_tokenizing,data_stopwords).
e. Perbaikan Setelah Stopwords Dihilangkan
kunci baru pada array yang terdapat pada parameter fungsi ini sehingga array tersebut akan memiliki nilai kunci yang tidak berlubang.
f. Data Hasil Stop Words Removal
Output atau keluaran dari proses stop words removal di masukan kedalam array.
Hasil dari proses stop words removal dapat dilihat pada tabel 3.5 dibawah : Tabel 3.5 Hasil Stop Words Removal
Kata Hasil Stop Words Removal dihukum kejahatan korupsi korupsi korupsi pelaku pidana tindak tindakan
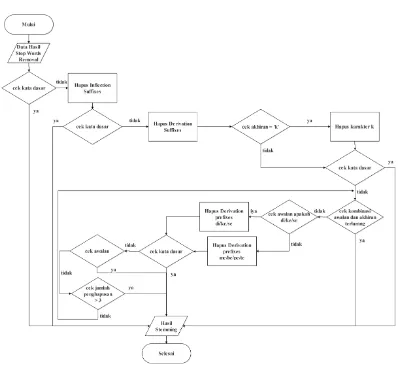
3.2.2.5.Stemming
Proses stemming yang dilakukan adalah untuk menentukan kata dasar yang terdapat dari sebuah kata yang telah melalui tahap paproses sebelumnya.
Gambar 3.9 Alur Stemming
Sedangkan penjelasan dari algoritma stemming Nazief dan Adriani yang digunakan adalah sebagai berikut:
a. Data Hasil Proses Stop Words Removal
Pada proses ini dilakukan pembacaan terhadap array dari hasil proses stop words removal untuk dilakukan proses stemming.
b. Cek Kata Dasar
c. Hapus Inflection Suffiixes
Hilangkan Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”). Pada tahap ini digunakan fungsi preg_match untuk cek apakah kata masukan mempunyai akhiran lah,kah,ku,mu, atau nya. Jika kata masukan mempunyai akhiran tersebut selanjutnya akhiran tersebut di hilangkan dengan menggunakan fungsi preg_replace.
d. Hapus Derivation Suffixes
Hilangkan Derivation Suffixes (“-i”, “-an”, “-kan). Pada tahap ini digunakan fungsi preg_match untuk cek apakah kata masukan mempunyai akhiran I,an atau kan. Jika kata masukan mempunyai akhiran tersebut selanjutnya akhiran tersebut di hilangkan dengan menggunakan fungsi preg_replace.
e. Hapus Derivation Prefixes
Hilangkan Derivation Prefixes (“-di”, “-ke”, “-se”,“-me”, “-be”, “-pe”,”-te”). Pada tahap ini digunakan fungsi preg_match untuk cek apakah kata masukan mempunyai awalan di,ke,se,me,be,pe atau te. Jika kata masukan mempunyai awalan tersebut selanjutnya akhiran tersebut di penggal dari kata asli dengan menggunakan fungsi preg_replace. Tetapi untuk kasus awalan me,be,pe,te pemenggalan kata yang dilakukan mengikuti aturan pemenggalan yang sudah ditentukan.
f. Hasil Stemming
Output atau keluaran dari proses stemming adalah kata yang telah melalui tahapan – tahapan di atas. Tetapi jika semua langkah gagal, maka input kata yang diuji pada algoritma ini dianggap sebagai kata dasar. Keluaran yang dihasilkan di masukan kedalam array.
Hasil dari proses stemming dapat dilihat pada tabel 3.6 dibawah Tabel 3.6 Hasil Proses Stemming
3.2.3. Analisis Metode Peringkasan
Pada analisis metode peringkasan akan dijelaskan proses peringkasan teks dengan metode pembobotan kata Term Frequency – Inverse Document Frequency
(TF-IDF) dan metode Latent Semantic Analysis untuk menghasilkan ringkasan. Alur dari proses peringkasan teks pada peringkas teks otomatis dapat dilihat pada gambar 3.10.
Gambar 3.10 Alur Peringkasan Teks
Sedangkan penjelasan dari gambar 3.10 diatas adalah sebagai berikut: a. Data hasil preprocessing
b. TF-IDF
Tahapan ini merupakan tahapan pembobotan kata dari data yang didapatkan pada tahap preprocessing. Untuk metode pembobotan kata yang digunakan adalah metode Term Frequency – Inverse Document Frequency (TF-IDF).
c. Pemilihan kalimat ringkasan (LSA)
Pada tahapan ini bobot dari kata yang telah di dapatkan akan diolah menggunakan Cross Method Latent Semantic Analysis untuk menentukan kalimat mana yang akan dijadikan sebagai ringkasan
d. Hasil Ringkasan
Merupakan tahap akhir atau output yang menghasilkan sebuah ringkasan dari artikel sumber
3.2.3.1.Algoritma TF-IDF
Pada tahapan ini akan dilakukan proses pembobotan pada setiap kata yang terdapat pada artikel yang akan diringkas. Adapun metode yang akan digunakan untuk menghasilkan bobot dari setiap kata adalah metode TF-IDF. Metode ini menghasilkan bobot dari sebuah kata berdasarkan dengan frekuensi kemunculan kata tersebut pada artikel dan berdasarkan kemunculan dari suatu kata pada dokumen lain [17].
Gambar 3.11 Alur Pembobotan Kata
Penjelasan dari gambar 3.11 di atas adalah sebagai berikut : a. Data Hasil Preprocessing
Pada proses ini dilakukan pembacaan terhadap array dari hasil tahap
b. Cari jumlah kalimat yang terdapat dalam dokumen
Pada tahap ini akan dicari jumlah dari kalimat yang terdapat dalam dokumen. Jumlah dokumen dilambangkan dengan variabel N dimana variabel ini menandakan jumlah dokumen yang akan diringkas. Tetapi karena proses peringkasan dilakukan pada dokumen tunggal maka nilai dari variabel N berubah menjadi jumlah kata yang akan diringkas yang terdapat pada dokumen tunggal. Untuk mendapatkan nilai dari N digunakan fungsi count() untuk menghitung jumlah dari kalimat yang telah dimasukan kedalam array, array yang digunakan adalah array hasil dari proses pemecahan kalimat sehingga pemanggilan fungsi akan seperti ini : count(variabel_hasil_pisah_kalimat).
c. Hitung Frekuensi kata dalam setiap dokumen (TF)
Pada tahap ini akan dilakukan perhitungan TF (Term Frequency) untuk menghitung frekuensi kemunculan dari suatu kata di dalam sebuah dokumen. Pada tahap ini digunakan fungsi array_count_values() dengan parameter masukan berupa array hasil proses stemming, sehingga pemanggilan fungsi akan seperti ini : array_count_values (variabel_hasil_stemming).
d. Hitung df setiap kata
Pada tahap ini akan dilakukan proses perhitungan df dari setiap kata. Df merupakan banyak dokumen yang mengandung kata yang akan di bobotkan. Tetapi karena dokumen yang akan hitung bobotnya merupakan dokumen tunggal maka df adalah banyak kalimat yang mengandung kata yang akan dibobotkan.
e. Hitung IDF setiap kata
IDF merupakan perhitungan jumlah dokumen yang mengandung sebuah term
yang dicari dari kumpulan dokumen yang ada. Untuk mencari nilai IDF digunakan persamaan (2.2).
f. Hitung weight atau bobot setiap kata
g. Hasil Pembobotan Kata
Keluaran yang dihasilkan dari tahap ini dimasukan kedalam array.
Hasil perhitungan nilai TF-IDF pada setiap term atau kata yang terdapat dalam dokumen uji yang digunakandapat dilihat pada tabel 3.7 dan tabel 3.8.
Tabel 3.7 Perhitungan Nilai TF-IDF
Kata yang
Tabel 3.8 Perhitungan Bobot kata (W)
3.3.3.2.Cross Method Latent Semantic Analysis
Setelah didapatkan bobot dari setiap kata menggunakan metode TF-IDF maka bobot yang didapatkan tersebut akan diolah untuk pemilihan kalimat ringkasan. Metode yang digunakan untuk proses ekstraksi ringkasan adalah Cross Method Latent Semantic Analysis. Perbedaan Cross Method Latent Semantic Analysis dengan Metode Latent Semantic Analysis pada umumnya terdapat pada tahapan ekstraksi kalimat ringkasan.Pada tahapan ekstraksi hasil ringkasan artikel diukur berdasarkan panjang/length vector baris yang dihasillkan dari perkalian antara matriks V dan matriks S . Tetapi nilai matriks V seelumnya di olah terlebih dahulu dengan cara mencari setiap nilai rata-rata yang terdapat pada setiap baris di matriks V. Kemudian setelah di dapatkan nilai rata-rata tersebut maka nilai setiap kolom didalam setiap baris yang mempunyai nilai lebih kecil dari pada nilai rata-rata dari setiap baris di ubah menjadi nol (0). Dalam metode Cross Latent Semantic Analysis terdapat 3 tahapan utama untuk menghasilkan ringkasan, yaitu: 1. Pembuatan matriks
2. Singular Value Decomposition
3. Penentuan Ringkasan
Gambar 3.12 Alur Metode Latent Semantic Analysis
a. Data Bobot Kata
Dalam tahap ini dilakukan pembacaan terhadap data dari hasil proses pembobotan kata. Data tersebut akan digunakan pada proses LSA.
b. Pembuatan Matriks
Keterangan :
Di = Kalimat ke-i dalam dokumen
Tabel 3.9 Lokasi Kata Dalam Kalimat
Kata D1 D2 D3
Setelah diketahui lokasi kata dalam kalimat, selanjutnya masukan weight atau bobot dari setiap kata sesuai dengan bobot yang dihasilkan dari tahap TF-IDF. Hasilnya dapat dilihat pada tabel 3.10 di bawah.
Tabel 3.10 Bobot Kata Dalam Kalimat
Kata D1 D2 D3
Maka di dapatkan matriks Amn sebagai berikut :
c. Singular Value Decomposition
Pada tahap ini dilakukan proses reduksi matriks menggunakan metode
Singular Value Decomposition. Dengan metode ini matriks A akan dipecah menjadi tiga buah matriks baru yaitu matriks U,S dan V. untuk memecah matriks A digunakan persamaan (2.3).Berikut ini adalah proses pembentukan matriks U,S dan V.
i. Membuat matriks V dan Transpose matriks V
Untuk mendapatkan nilai dari matriks V pertama cari nilai dari matriks ATA kemudian cari nilai eigenvector dari hasil perkalian tersebut karena kolom dari matriks V merupakan eigenvector dari matriks orthogonal ATA. Matriks V juga digunakan sebagai koordinat dari dokumen.
N = ATA.
Setelah itu cari determinan dari matriks V untuk menentukan nilai eigen untuk membangun matriks S dan eigenvector untuk membangun matriks V. Determinan dicari dengan rumus det(N-λI) = 0, dimana I merupakan matriks identitas. Berikut proses pencarian determinan dari matriks N:
Det [
Kemudian cari nilai dari eigenvector dari matriks N. eigenvector(x) merupakan solusi dari matriks (N-λI) untuk setiap nilai λyang ada di mana x ≠
Lakukan operasi eliminasi gauss pada matriks diatas seperti berikut
[
]
[
]
Dari matriks diatas dapat dihasilkan persamaan -0.124x1 + 0.124x2 = 0
-0.021X3 = 0
Dari persamaan terseut diketahui bahwa nilai x1 = x2 dan nilai x3 = 0, maka dapat diperoleh nilai x1 = 1 ,x2 = 1 dan x3 = 0, sehingga menghasilkan vector
[1,1,0]
Nilai eigen vector untuk
[
] [
]
=
[ ] [ ]
=
Lakukan operasi eliminasi gauss pada matriks diatas seperti berikut
[ ] -0.104R2 – 0.124R1 R2
[ ] R1 – 0.124R2 R1
[ ]
Dari matriks diatas dapat dihasilkan persamaan -0.104x1 = 0
0*X3 = 0
Dari persamaan tersebut diketahui bahwa nilai x1=0,x2=0 dan x3=1, sehingga menghasilkan vector [0,0,1]
Nilai eigenvector untuk
Lakukan operasi eliminasi gauss pada matriks diatas seperti berikut
[
]
R2-R1 R2
[
]
Dari matriks diatas dapat dihasilkan persamaan 0.124x1 + 0.124x2 = 0
0.228X3 = 0
Sehingga dihasilkan matriks V :
V = [
]
Setelah itu konversi matriks yang telah dibuat menjadi sebuah matriks orthogonal dengan menggunakan metode otornomalisasi gram-schmidt pada setiap kolom vektor matriks V.
= [1, -1, 0] - 0 * [0.707107, 0.707107, 0] – 0
Sehingga dari perhitungan di atas diketahui nilai vektor sebagai berikut
Sehingga dapat dibentuk matrik V :
V= [
]
Kemudian transposes matriks V sehingga didapatkan VT :
VT = [
]
ii. Membuat matriks S
Matriks S merupakan matriks diagonal dimana nilai dari matriks S didapatkan dari nilai singular value dari matriks ATA dengan urutan descending. Untuk mendapatkan nilai singular value pertama cari dulu eigenvalue dari matriks ATA. dari proses pencarian matriks V diatas diketahui bahwa matriks ATA memiliki eigenvalue yaitu 0.475,0.455 dan 0.227, kemudian cari akar dari
S1 = √ = 0.689 S2 = √ = 0.675 S3 = √ = 0.476
Sehingga didapatkan matriks S sebagai berikut :
S = [
]
iii.Membuat matriks U
Matriks U dapat dicari dengan menggunakan rumus U = AVS-1
U =
[
]
iv.Penentuan Ringkasan
Perbedaan dari penggunaan metode LSA umum dengan dengan metode LSA yang menggunakan metode cross terdapat pada tahapan ini. Jika pada metode LSA biasanya hasil ringkasan diambil dari nilai kesamaan antara query dengan koordinat dokumen (matriks VT),kemudian kalimat yang mempunyai nilai tingkat kesamaan terbesar dengan query dijadikan sebagai ringkasan. Tetapi pada metode Cross Latent Semantic Analysis parameter yang dijadikan penentu hasil ringkasan adalah length atau panjang dari baris kalimat dalam dokumen yang dihasilkan dari vector matriks VT dikalikan dengan baris vector matriks S dengan persamaan (2.4).
Tetapi sebelum dilakukan proses perhitungan length, dicari dahulu nilai rata – rata dari setiap kata yang terdapat pada setiap baris matriks VT. Kemudian kata yang mempunyai nilai lebih kecil daripada nilai rata – rata yang dihasilkan maka nilai dari kata tersebut diubah menjadi nol, jika nilai lebih besar atau sama dengan nilai matriks maka nilai dari kata tersebut tidak diubah.
Nilai rata – rata dari setiap baris adalah : avgD1 = avgD2 =
avgD3 =
Dari nilai rata – rata dari setiap baris matriks diatas terdapat nilai pada matriks VT yang memiliki nilai lebih kecil dari nilai rata-rata yang telah didapat, sehingga nilai yang lebih kecil tersebut di ubah menjadi 0. Hasil dari perubahan nlai pada matriks VT adalah sebagai berikut
VT = [
Kemudian setelah proses pengecekan nilai kata dengan nilai rata – rata dilakukan lanjutkan dengan proses perhitungan length dari setiap kolom matriks yang merepresentasikan kalimat dalam dokumen yang akan diringkas. Perhitungan dari length setiap kolom menggunakan rumus (2.5) adalah : Length 1 = √ 3,length 1 dan length 2. Sehingga susunan kalimat yang dijadikan sebagai hasil ringkasan dari contoh diatas adalah kalimat 3, kalimat 1 dan kalimat 2.
3.3. Spesifikasi Kebutuhan Perangkat Lunak
Spesifikasi kebutuhan perangkat lunak yang dibangun dibagi menjadi dua kebutuhan, yaitu kebutuhan nonfungsional dan fungsional. Spesifikasi kebutuhan fungsional dan nonfungsional dapat dilihat pada tabel 3.11dan 3.12 di bawah.
Tabel 3.11 Kebutuhan Fungsional
Kode Keterangan
SKPL-F-001 Aplikasi mampu membaca sebuah teks berita dengan tipe file .txt
SKPL-F-002 Aplikasi mampu melakukan proses preprocessing pemecahan kalimat pada data masukan.
SKPL-F-003 Aplikasi mampu melakukan proses preprocessingcase folding
pada data masukan.
SKPL-F-004 Aplikasi mampu melakukan proses preprocessingtokenizing
pada data masukan.
SKPL-F-005 Aplikasi mampu melakukan proses preprocessing menghapus
SKPL-F-006 Aplikasi mampu melakukan proses preprocessingstemming
pada data masukan.
SKPL-F-007 Aplikasi mampu menghasilkan ringkasan dari dokumen berita tunggal berbahasa Indonesia
Tabel 3.12 Kebutuhan Non Fungsional
Kode Keterangan
SKPL-NF-001 Peringkas teks otomatis dibangun berbasis web
SKPL-NF-002 Aplikasi yang dibangun dapat berjalan optimal pada browser
google chrome dan mozila firefox
SKPL-NF-003 Aplikasi ini dibangun dengan spesifikasi hardware yang memenuhi standar minimum kebutuhan.
SKPL-NF-004 Data yang digunakan untuk ringkasan dokumen adalah artikel berita yang diambil dari portal berita viva.co.id.
SKPL-NF-005 Data masukan yang diambil dengan menggunakan bantuan RSS yang disediakan oleh viva.co.id
3.4. Analisis Kebutuhan Non Fungsional
Analisis kebutuhan Non Fungsional menggambarkan kebutuhan dari luar yang diperlukan untuk menjalankan perangkat lunak yang dibangun. Analisis kebutuhan non fungsional yang dilakukan adalah Analisis Kebutuhan Perangkat Keras (Hardware), Analisis Kebutuhan Perangkat Lunak (Software) dan Analisis Perangkat Pikir (Brainware).
3.4.1. Analisis Kebutuhan Perangkat Keras (Hardware)
Kebutuhan Perangkat keras yang mendukung dalam pembangunan sistem peringkas teks otomatis ini adalah sebagai berikut :
1. Processor dual core atau lebih tinggi 2. RAM2048MB atau lebih tinggi
5. Keyboard 6. Mouse
3.4.2. Analisis Kebutuhan Perangkat Lunak (Software)
Analisis kebutuhan perangkat lunak (software) pada penelitian ini yang mendukung dalam sistem peringkas teks otomatis ini adalah sebagai berikut : 1. Sistem Operasi Window atau linux.
2. Bahasa Pemrograman PHP. 3. Web server XAMPP.
4. Code Editor SublimeText 3.
5. Web Browser Mozilla Firefox.
3.4.3. Analisis Kebutuhan Perangkat Pikir (Brainware)
Kebutuhan perangkat pikir (Brainware) yang dibahas dalam penelitian ini dikelompokkan menjadi tiga kategori yaitu user knowledge and experience, user jobs and tasks, dan user physical characteristic. Penjelasan untuk masing-masing kategori sebagai berikut:
1. Pengetahuan dan Pengalaman Pengguna (User Knowledge and Experience) Pengetahuan dan pengalaman pengguna yang di targetkan dalam pembangunan perangkat lunak ini dapat dilihat pada tabel 3.12 dibawah :
Tabel 3.13 Pengetahuan dan Pengalaman Pengguna
Aspek Pengguna
Education Level SMA sampai perguruan tinggi
(D3,S1,S2,S3)
Reading Level Sedang sampai tinggi
Computer Literacy Mempunyai pengalaman dalam
menggunakan komputer
Task Experience Rendah sampai tinggi
System Experience Rendah sampai tinggi
Use Of Other System tidak
Native Language or Culture Dominan bahasa Indonesia
2. Tugas dan Kebutuhan Pengguna (User Jobs and Tasks)
Tugas dan pekerjaan pengguna yang ditargetkan dalam pembangunan perangkat lunak ini dapat dilihat pada tabel 3.13 dibawah :
Tabel 3.14 Tugas dan Pekerjaan Pengguna
Aspek Pengguna
Frequency Of Use Continual
Primary Training Disediakan menu petunjuk
Task or Need Importance Sedang sampai tinggi
Task Structure Sedang sampai tinggi
Job Categories Tidak
Life Style tidak
3. Karakteristik Pengguna (User Physical Characteristic)
Karakter fisik pengguna yang ditargetkan dalam pembangunan perangkat lunak ini dapat dilihat pada tabel 3.14 dibawah:
Tabel 3.15 Karakteristik Pengguna
Aspek Pengguna
Handedness Keduanya dalam kondisi baik
Gender Laki – laki dan perempuan
Age 20 tahu ke atas
Disabilities Tidak cacat tubuh 3.5. Analisis Kebutuhan Fungsional
3.5.1. Diagram Konteks
Diagram konteks adalah suatu diagram yang menggambarkan ruang lingkup sistem peringkas teks dalam berita bahasa indonesia. Peringkas teks otomatis digambarkan dengan bulatan, sedangkan lingkungan diwakili oleh entitas luar yang digambarkan dengan persegi. Gambar 3.13 dibawah menggambarkan diagram konteks yang terdapat peringkas teks otomatis.
Gambar 3.13 Diagram Konteks
3.5.2. Data Flow Diagram (DFD) LV 1
Data flow diagram (DFD) level 1 berfungsi untuk menjelaskan aliran data yang terdapat di peringkas teks otomatis. Untuk data flow diagram (DFD) level 1 pada peringkas teks otomatis digambarkan pada gambar 3.14 dibawah :
Gambar 3.14 Data Flow Diagram Level 1
3.5.3. Data Flow Diagram(DFD) LV 2
Data flow diagram (DFD) Level 2 berfungsi untuk menjelaskan aliran data yang terdapat di peringkas teks otomatis. Untuk data flow diagram (DFD) level 2 pada peringkas teks otomatis digambarkan pada gambar 3.15 dibawah :
Gambar 3.15 Data Flow Diagram Level 2
3.5.4. Deskripsi Proses
Deskripsi proses digunakan untuk menggambarkan proses model aliran yang terdapat pada DFD. Spesifikasi proses dari DFD level 1 dan DFD level 2 yang telah dibuat dapat dijelaskan pada tabel 3.16 sampai tabel 3.26 dibawah:
2.
Data Kata Dasar Info Kata Dasar
Tabel 3.16 Deksripsi Proses Request Data Dokumen
Proses Keterangan
No Proses 1
Nama Proses Request Data Dokumen
Sumber Pengguna
Input Alamat Sumber
Output Alamat Sumber
Tujuan Meminta data berita yang dimiliki oleh portal berita Logika Proses 1. Pengguna menekan tombol pilih berita pada
peringkas teks otomatis
2. Peringkas teks otomatis akan meminta hubungan atau koneksi dengan portal berita 3. Portal berita akan memberikan alamat dari
sumber berita tersebut ke proses selanjutnya
Tabel 3.17 Deksripsi Proses Menampilkan Judul Dokumen
Proses Keterangan
No Proses 2
Nama Proses Menampilkan Judul Dokumen
Sumber Portal Berita
Input Data Dokumen
Output Judul Dokumen Ringkasan Alamat Dokumen Ringkasan