Peringkasan Teks Otomatis Secara Ekstraktif Pada Artikel Berita Kesehatan Berbahasa Indonesia Dengan Menggunakan Metode Latent Semantic Analysis
Teks penuh
Gambar
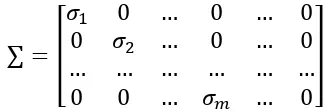

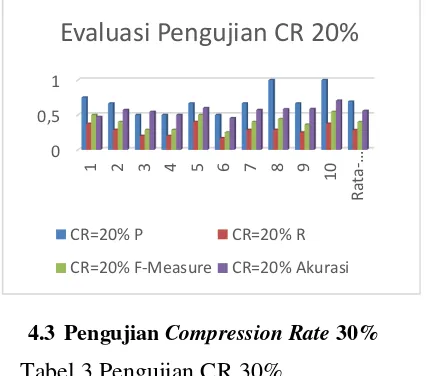
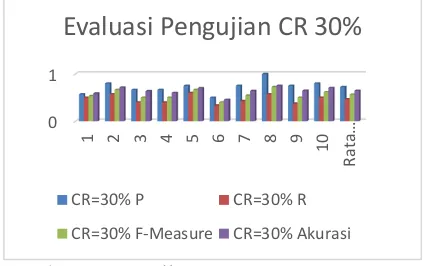
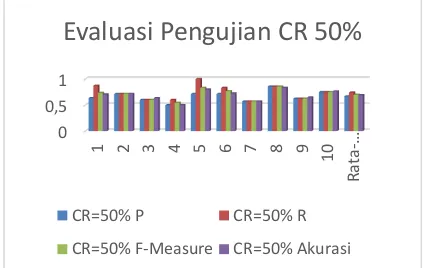
Dokumen terkait
Pengujian yang dilakukan pada sistem adalah melihat hasil ringkasan teks berita yang. menggunakan term frequency inverse
preprocessing dilakukan pada keseluruhan isi dari dokumen yang akan di ringkas untuk menghilangkan noise yang masih terdapat di dalamnya, sedangkan tahap pemilihan
Permasalahan dibatasi pada proses peringkasan teks otomatis yang telah dikembangkan yaitu menggunakan metode Maximum Marginal Relevance (MMR). Inputan teks yang
Review dilakukan terhadap berbagai teknik text summarization yang pernah digunakan pada penelitian-penelitian di bidang peringkasan teks berbahasa indonesia, baik
PERINGKASAN TEKS BERITA SECARA OTOMATIS MENGGUNAKAN TERM FREQUENCY INVERSE DOCUMENT FREQUENCY
online berskala nasional dan lokal dengan judul “Implementasi Metode Maximum Marginal Relevance pada Peringkasan Teks Otomatis
Peringkasan teks khususnya berita dapat digunakan untuk mendapatkan intisari dari teks berita tanpa membaca keseluruhan teks.. Oleh karena itu, dapat dikembangkan
Oleh karenanya, studi ini berfokus pada peringkasan teks artikel berita Bahasa Indonesia dengan menerapkan metode Latent Semantic Analysis LSA dan SVD menggunakan pendekatan Steinberger
