PERBANDINGAN W
EKSTRAKSI CIRI P
DEP
FAKULTAS MATE
INS
WAVELET DAUBECHIES DAN MFCC SEBA
PADA PENGENALAN FONEM BERDASAR
DISTRIBUSI NORMAL
NI WAYAN SUDARMI
PARTEMEN ILMU KOMPUTER
EMATIKA DAN ILMU PENGETAHUAN AL
NSTITUT PERTANIAN BOGOR
BOGOR
2011
BAGAI
RKAN
PERBANDINGAN WAVELET DAUBECHIES DAN MFCC SEBAGAI
EKSTRAKSI CIRI PADA PENGENALAN FONEM BERDASARKAN
DISTRIBUSI NORMAL
NI WAYAN SUDARMI
G64086010
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
NI WAYAN SUDARMI. Comparison between Wavelet Daubechies and Mel-frequency Cesptral Coeffisient (MFCC) with Feature Extraction Using Normal Distribution for Phoneme Recognition. Under the supervised of AGUS BUONO.
Speech recognition is speech to text transcription. Speech to text transcription system is a system used to convert a voice signal from a microphone into a single or a set of words. Most research of speech to text transcription used technique which every word in corpus is modeled. It is not effective if we want to develop a large vocabulary speech recognition system which number of words in corpus are more than one thousand words. Therefore, this research developed phoneme recognition with early stage in speech recognition.
This research used some stage proces, those are take data, feature extraction, and feature matching. Normal Distribution (Gaussian) is used for feature matching, Wavelet Daubechies and MFCC is used for feature extraction. Corpus on this research consist of 11 words in Indonesian which each word recorded 20 times, 15 times for data training and 5 times for data testing. This research used 13 cepstral coefficients. Phonemes are generated from the segmentation process, and then mhu and sigma be calculated to generate the model. This case produced 26 models. The best accuracy is 90% generated by feature extraction MFCC and 46.92% generated by the Wavelet Daubechies.
Judul Skripsi : Perbandingan Wavelet Daubechies dan MFCC sebagai Ekstraksi Ciri pada Pengenalan Fonem Berdasarkan Distribusi Normal
Nama : Ni Wayan Sudarmi
NRP : G64086010
Menyetujui: Pembimbing,
Dr. Ir. Agus Buono, M.Si., M.Kom.
NIP. 19660702 199302 1 001
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc.
NIP. 19601126 198601 2 001
PRAKATA
Puji syukur penulis panjatkan kepada Tuhan Yang Maha Esa yang telah melimpahkan rahmat dan karunia yang tak terbatas sehingga penulis dapat menyelesaikan tugas akhir ini.
Penulis menyadari bahwa keberhasilan penyelesaian tugas akhir ini tidak terlepas dari pihak-pihak yang telah banyak membantu. Oleh karena itu, penulis sampaikan terima kasih kepada Bapak Dr. Ir. Agus Buono, M. Si., M. Kom. sebagai pembimbing yang selalu sabar dalam memberikan arahan dan saran selama penyelesaian tugas akhir ini, serta Bapak Aziz Kustiyo, S.si, M.Kom. dan Bapak Mushthofa, S. Kom., M. Sc. yang telah bersedia menjadi moderator dan penguji dalam seminar dan sidang penulis.
Penulis ucapkan terima kasih kepada seluruh keluarga khususnya orang tua penulis yang tiada henti-hentinya memberikan doa, dukungan, pendidikan dan kepercayaan penuh atas apa yang penulis kerjakan hingga saat ini, juga kepada adik-adikku yang selalu memberikan keceriaan, semangat, dan dukungan selama ini. Kepada teman-teman Ekstensi Ilkom angkatan 3 penulis ucapkan terima kasih karena telah memberikan keceriaan dan persahabatannya. Kepada Yuliana Suri, Rahim Rasyid dan Herman A. yang bersedia menjadi pembahas dalam seminar tugas akhir penulis ucapkan terima kasih. Kemudian penulis sampaikan terima kasih kepada seluruh staf dan karyawan Departemen Ilmu Komputer, teman-teman Ekstensi Ilkom serta seluruh pihak lainnya yang tidak dapat disebutkan satu persatu.
Penulis menyadari bahwa dalam penelitian ini masih terdapat kekurangan, sehingga kritik dan saran yang membangun penulis harapkan dari semua pihak. Semoga penelitian ini dapat bermanfaat.
Bogor, Maret 2011
RIWAYATHIDUP
Penulis dilahirkan pada tanggal 17 Juli 1984 di Lampung. Penulis merupakan anak pertama dari dua bersaudara pasangan Nyoman Arta dan Nengah Kundri.
DAFTAR ISI
Halaman
DAFTAR TABEL ... vii
DAFTAR GAMBAR ... vii
DAFTAR PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA ... 1
Fonem ... 1
Akuisisi Data Sinyal Suara ... 1
Ekstraksi Ciri ... 2
Frame Blocking dan Windowing ... 2
Fast Fourier Transform (FFT) ... 2
Mel Frequency Wrapping ... 3
Cepstrum ... 3
Wavelet ... 3
Transformasi Wavelet Diskret ... 4
Transformasi Wavelet Daubenchies ... 5
Distribusi Normal ... 5
METODE PENELITIAN ... 6
Pengambilan Data ... 7
Praproses ... 7
Pembagian Data ... 7
Ekstraksi Ciri Sinyal ... 7
Pemodelan ... 8
Pencocokan Model ... 8
Pengujian ... 9
HASIL DAN PEMBAHASAN... 9
Praproses ... 9
Hasil Pengujian dengan MFCC ... 9
Hasil Pengujian dengan Wavelet Daubechies ... 9
Hasil Pengujian MFCC dan Wavelet Daubechies dengan Noise ... 11
KESIMPULAN DAN SARAN... 11
Kesimpulan ... 11
Saran ... 11
DAFTAR TABEL
Halaman
1 Tabel koefisien db4 ... 5
2 Daftar Fonem dalam Penelitian ... 6
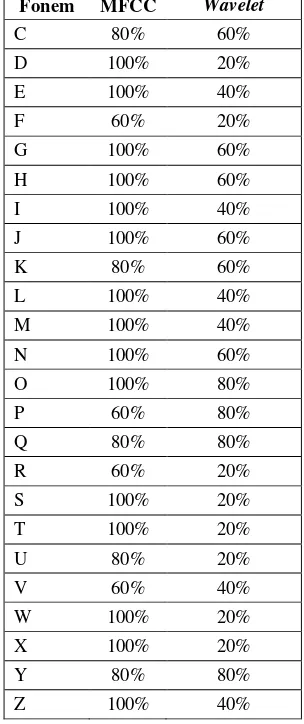
3 Akurasi Nilai Perbandingan MFCC dan Wavelet ... 10
4 Pengujian Data Uji dengan Noise ... 11
DAFTAR GAMBAR Halaman 1 Grafik hubungan frekuensi dengan skala mel ... 3
2 Dekomposisi Wavelet 3 Tingkat ... 4
3 Bank Filter Daubechies ... 5
4 Proses Pengenalan Fonem ... 6
5 Diagram Proses Ekstraksi Ciri MFCC dan Wavelet ... 7
6 Diagram proses pemodelan ... 8
7 Grafik Hasil Pengujian dengan Ekstraksi Ciri MFCC ... 9
8 Grafik Hasil Pengujian dengan Ekstraksi Ciri Wavelet ... 9
9 Grafik Hasil Pengujian dengan Ekstraksi Ciri MFCC dan Wavelet ... 10
10 Grafik Hasil Pengujian Data Uji ... 10
11 Grafik Hasil Pengujian Data Latih ... 10
PENDAHULUAN
Latar Belakang
Perkembangan teknologi informasi dapat
mempermudah pekerjaan manusia dalam
kehidupan sehari-hari. Pekerjaan manusia secara manual dapat digantikan dengan sistem otomatis. Salah satu sistem otomatis adalah sistem yang dapat membuat komputer mampu berkomunikasi dengan manusia. Dalam proses komunikasi ini diperlukan tahap konversi suara ke teks (speech to text transcription).
Konversi suara ke teks, berawal dari pengenalan berbasiskan fonem Berbasis fonem diterapkan karena, jika berbasiskan kata, yang mana setiap kata yang terdapat dalam kamus
kata dimodelkan dengan suatu teknik
pemodelan. Hal ini mengakibatkan kurang efektifnya sistem apabila akan dikembangkan untuk sistem pengenalan kata yang bersifat
large vocabulary yang mana kata yang terdapat dalam kamus kata berjumlah sangat besar. Oleh karena itu, di dalam penelitian ini akan dikembangkan suatu sistem pengenalan fonem yang merupakan tahap awal dari pengenalan kata.
Tahap awal pengenalan fonem dilakukan dengan praproses pada sinyal suara. Praproses merupakan proses penghapusan silent, normalisasi dan segmentasi manual. Data fonem yang dihasilkan dari praproses, dilanjutkan dengan pembuatan template untuk membangun model pengenalan fonem. Dengan demikian, komputer diharapkan mampu menerjemahkan ucapan ke dalam bentuk teks yang diucapkan. Teks yang dihasilkan merupakan gabungan dari beberapa fonem. Dengan demikian, sebelum ke tahap konversi suara ke teks diperlukan tahap pengenalan fonem.
Data yang digunakan adalah sinyal suara manusia yang direkam dari satu pembicara. Digunakan sinyal suara sebagai masukan karena merupakan salah satu karakteristik fisiologis manusia yang unik. Suara juga sebagai sistem biometrik dan lebih efisien dibandingkan dengan biometrik yang lain.
Penelitian ini membandingkan konsep
berbasiskan transformasi Fourier dan
transformasi Wavelet. Transformasi Wavelet
diskret yang digunakan berbasis orthogonal yaitu Daubechies. Menurut (Agustini 2006) Daubechies merupakan tipe Wavelet yang memberikan tingkat pengenalan paling tinggi dibandingkan dengan Symlets dan Coiflets.
Distribusi Normal digunakan sebagai
pencocokan pola.
Tujuan
Penelitian ini bertujuan memberikan informasi nilai akurasi. Selain itu, juga membandingkan antara transformasi Fourier
dan transformasi Wavelet sebagai ekstraksi
ciri, pada pengenalan fonem dengan
Distribusi Normal sebagai pencocokan pola.
Ruang Lingkup
Ruang lingkup penelitian ini adalah :
1. Penelitian difokuskan pada pemodelan pengenalan fonem, bukan pengenalan kata atau kalimat.
2. Fonem yang digunakan sebanyak 26
fonem dari /a/ sampai /z/.
3. Teks yang diucapkan berbahasa Indonesia. 4. Penelitian ini menerapkan transformasi
Fourier dan transformasi Wavelet jenis orthogonal Daubechies sebagai ekstraksi ciri dengan orde 4 pada level 1.
5. Penelitian ini menerapkan Distribusi Normal sebagai pengenalan pola.
6. Data sinyal suara pada penelitian ini menggunakan satu pembicara.
7. Implementasi sistem pengenalan kata menggunakan software MATLAB 7.7.
TINJAUAN PUSTAKA
Fonem
Fonem merupakan satuan bunyi terkecil yang mampu menunjukkan kontras makna (KBBI). Fonem dibagi menjadi dua, yaitu:
1. Fonem vokal merupakan bunyi ujaran akibat adanya udara yang ke luar dari paru-paru yang tidak terkena hambatan atau halangan. Jumlah fonem vokal ada lima yaitu: a, i, u, e, dan o.
2. Fonem konsonan merupakan bunyi ujaran akibat adanya udara yang ke luar dari paru-paru mendapatkan hambatan atau halangan. Jumlah fonem konsonan ada 21 buah yaitu: b, c, d, f, g, h, j, k, l, m, n, p, q, r, s, t, v, w, x, y, dan z.
Akuisisi data suara digital
Secara konsepsi, konversi analog to digital (A/D), melalui tiga tahapan proses yaitu: (Proakis dan Manolakis 1996)
a) Proses sampling
Sampling merupakan pengambilan nilai-nilai (sampling rate) dari sinyal kontinu pada setiap jangka waktu (T) yang ditentukan, sehingga sinyal yang awalnya kontinu berubah menjadi diskret.
Menurut (Buono 2009) bahwa, karena sinyal analog dapat direpresentasikan sebagai penjumlahan dari gelombang sinus dengan amplitudo, frekuensi dan fase yang berbeda. Dengan demikian, nilai sampling rate yang dapat menangkap semua komponen sinyal
haruslah minimal dua kali frekuensi
maksimum yang ada dalam sinyal. Nilai
sampling rate sebesar Fs = 2 Fmax disebut sebagai Nyquist rate.
Aturan teori Nyquist menyatakan bahwa frekuensi sinyal paling sedikit dua kali frekuensi sinyal yang akan di-sampling
(sinyal analog) dan merupakan batas
minimum dari frekuensi sample (Fs). Lebih
besar tentunya lebih baik, karena
menggambarkan sinyal aslinya.
Sampling rate yang digunakan pada pengenalan suara adalah 8000 Hz sampai dengan 16000 Hz (Jurafsky dan Martin 2000). Hubungan antara panjang vektor data yang dihasilkan, sampling rate dan panjang data suara yang didigitalisasikan dinyatakan berdasarkan persamaan 1:
S = Fs× T (1)
Keterangan: S = panjang vektor
Fs = sampling rate yang digunakan (Hertz) T = panjang suara (detik)
b) Kuantisasi
Kuantisasi merupakan konversi nilai amplitudo yang bersifat kontinu menjadi nilai diskret. Proses ini menyimpan nilai-nilai simpangan sinyal menjadi representasi nilai 8 bit atau 16 bit (Jurafsky dan Martin 2000).
c) Pengkodean
Pengkodean merupakan pemberian
bilangan biner pada setiap level kuantisasi.
Ekstraksi Ciri
Tujuan ekstraksi ciri untuk mereduksi ukuran data tanpa mengubah karakteristik dari sinyal suara dalam setiap frame yang dapat digunakan sebagai penciri. Ekstraksi ciri didapat dari mengonversikan bentuk sinyal
suara ke dalam bentuk representasi secara parameter (Agustini 2006). Ekstraksi ciri MFCC menghitung koefisien cepstral dengan mempertimbangkan pendengaran manusia. MFCC didasarkan pada variasi frekuensi batas pendengaran manusia yaitu sekitar 20 Hz -20000 Hz. Tahapan MFCC adalah sebagai berikut (Do 1994):
1. Frame Blocking dan Windowing
2. Fast Fourier Transform (FFT) 3. Mel FrequencyWrapping
4. Cepstrum
Frame Blocking dan Windowing
Frame blocking merupakan segmentasi
frame dengan lebar tertentu yang saling tumpang tindih atau suara digital yang telah diakuisisi dengan durasi tertentu. Tiap-tiap hasil
frame direpresentasikan dalam sebuah vektor. Proses frame blocking mengakibatkan terjadi distorsi (ketidakberlanjutan sinyal) antar frame. Dengan demikian, untuk meminimalisasi distorsi tersebut dilakukan proses windowing. Proses windowing yaitu proses filtering tiap
frame dengan cara mengalikan setiap frame
tersebut dengan fungsi window tertentu yang ukurannya sama dengan frame.
Frame windowing bertujuan meminimalkan diskontinuitas (non-stationary) sinyal pada bagian awal dan akhir sinyal suara. Tahap
pembuatan window menggunakan fungsi
window Hamming. Window Hamming dapat dituliskan dengan persamaan 2 (Do 1994).
d(u) = 0.54 + 0.46 cos
✂✁☎✄✝✆
✞✠✟☛✡☞✝✌ (2)
Dalam hal ini, u = 0,1,…,N-1 dan N
merupakanjumlah samples tiap frame. Menurut (Buono 2009), fungsi window Hamming memiliki nilai J(bias) dan V(varian) moderat. Selain itu, window Hamming juga memiliki nilai mean squared error (MSE) berada ditengah-tengah dibanding dengan filter yang lain serta memiliki kesederhaan rumus. Oleh sebab itu, maka fungsi window Hamming ini digunakan.
Fast Fourier Transform (FFT)
Fast fourier transformation (FFT) bertujuan mendekomposisi sinyal menjadi sinyal sinusoidal, dan terdiri atas dua unit, yaitu unit real dan unit imajiner. FFT digunakan untuk analisis frekuensi, sehingga mempermudah pemrosesan suara karena sesuai dengan pendengaran manusia. FFT adalah
algoritme yang mengimplementasikan
merupakan transformasi setiap frame dengan N
sample dari domain waktu ke domain frekuensi yang didefinisikan pada persamaan 3 berikut (Do 1994).
✍✏✎✒✑✔✓✖✕✘✗✂✙✛✚✢✜☎✣✝✤☎✥✧✦✒★
✩
✪✬✫✢✭
✮✝✯✢✰ ✱✧✲✴✳
Keterangan:
N = banyaknya segmen sekuen Xk = nilai data ke k
n = 0,1,2,3,…,N-1 dan k= 0,1,2,3,…,N-1 j = ✵✷✶✹✸
Secara umum Xn adalah bilangan yang kompleks. Hasil dari tahap ini disebut dengan spektrum sinyal atau periodogram.
Mel FrequencyWrapping
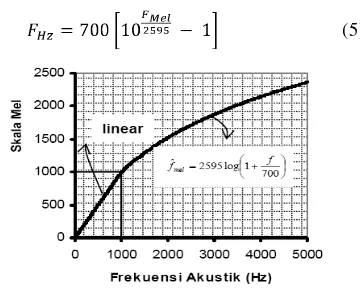
Proses wrapping menghitung nilai mel-frequency dengan sejumlah filter yang saling overlap. Filter yang digunakan berbentuk segitiga dengan tinggi satu pada ruang frekuensi mel. Skala mel digunakan untuk mengikuti persepsi pendengaran manusia yang dikenal dengan Mel Wrapping (Buono 2009).
Berdasarkan studi psikologi, telinga
manusia mempunyai persepsi terhadap
frekuensi suara secara tidak linear pada frekuensi di atas 1000 Hz. Persamaan berikut dapat digunakan untuk perhitungan mel-frequency pada frekuensi ✺ dalam satuan
hertz (Nilsson dan Ejnarsson 2002).
✻✽✼✿✾✴❀✘❁
❂✢❃✬❄✂❅✽❄✹❆✘❇❈✴❉✬❊☛❋❍●❏■✹❑ FHz
700▲✏▼❖◆◗P✂❘
FHz ❙❯❚✢❱✛❱✬❱
FHz❲❨❳◗❩✂❬ FHz❭❯❪✢❫✛❫✬❫ (4)
Dari persamaan 4, FHz adalah frekuensi akustik, maka nilai frekuensi FHz sebagai fungsi dari skala mel adalah:
❴✂❵✂❛❝❜❡❞☛❢☛❢❝❣✐❤☛❥✴❦♠❧✽♥✐♦ ♣☎qsr☎q t✈✉❏✇
(5)
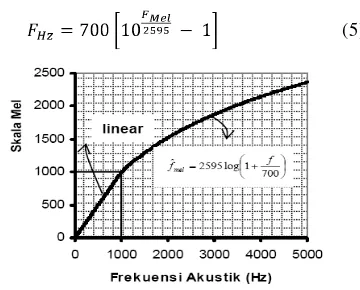
Gambar 1 Grafik hubungan frekuensi dengan skala mel (Buono 2009).
Pada Gambar 1 terlihat bahwa untuk frekuensi rendah, filter yang digunakan menggunakan skala linear, sehingga lebarnya konstan. Dilain pihak, untuk frekuensi tinggi (>1000 Hz), filter dibentuk dengan skala logaritma.
M filter selanjutnya digunakan untuk
menghitung nilai mel-frequency atau
wrapping pada persamaan 6 berikut:
①③②✏④⑥⑤⑦✴⑧✬⑨✧⑩✘❶❸❷❺❹✧❻❽❼✐❾✛❿✢➀➁➃➂s➄☎➅✛➆ ➇✠➈✢➉
➊✝➋✂➌ ➍ ➎✧➏✂➐
Dengan i=1,2,3…,M (M adalah jumlah filter
segitiga) dan Hi(k) adalah nilai filter segitiga ke i untuk frekuensi akustik sebesar k. Untuk N adalah banyaknya data, sedangkan X(k) merupakan nilai data ke k hasil dari proses FFT.
Cepstrum
Cepstrum merupakan hasil mel frequency
yang diubah menjadi domain waktu
menggunakan discrete cosine transform (DCT) dengan persamaan 7 (Do 1994):
➑✧➒❨➓→➔↔➣➙↕
➛
➜➝☛➞➠➟➢➡✢➤➦➥➨➧✠➩➭➫◗➯➳➲✴➵✢➸➻➺
➼ ➽ ➾✧➚❏➪
dengan j=1,2,3,…,K (K adalah jumlah koefisien yang diiginkan dan M = jumlah
filter, sedangkan Xi adalah nilai data ke i hasil proses mel frequensy wrapping .
Wavelet
Wavelet dapat dibentuk dari satu fungsi (x) dikenal sebagai “motherWavelet” dalam suatu interval berhingga. Wavelet merupakan gelombang singkat (small wave) yang energinya terkonsentrasi pada suatu selang
waktu untuk memberikan kemampuan
analisis transien, ketidakstasioneran, atau fenomena berubah terhadap waktu (time varying). Karakteristik dari Wavelet antara lain adalah berosilasi singkat, translasi (pergeseran), dan dilatasi (skala) (Burrus et al. 1998).
Wavelet memiliki banyak famili, dibedakan berdasarkan pada bank filter yang digunakan. Famili Wavelet terdiri atas biorthogonal Wavelet, Meyer Wavelet, Morlet
Wavelet, Shanon Wavelet, dan masih banyak lainnya. Wavelet Daubechies merupakan
famili orthogonal Wavelet hasil
Transformasi Wavelet menunjukkan frekuensi waktu yang baik untuk lokalisasi properti dan alat yang tepat untuk analisis sinyal diskontinu (non stationary) (Krishnan 1994). Wavelet merupakan fungsi variabel
real t, diberi notasi t dalam ruang fungsi L²(R). Fungsi ini dihasilkan oleh parameter penskala (dilatasi) dan penggeseran (translasi) dari sebuah fungsi tunggal (induk) yang dinyatakan dalam persamaan (Burrus et al. 1998) :
a,b(t) = a-1/2 ➶➘➹➷➴✂➬
➮ ➱ ; a>0,b
✃❒❐ (8)
fungsi pada persamaan (8) dikenalkan pertama kali oleh Grossman dan Morlet, dengan a,b ❮Ï❰ dan a 0, a merupakan parameter penskala dan b adalah parameter translasi.
j,k(t) = a j/2
(2jt-k) ; j,k Ð Z (9)
fungsi pada persamaan (9) dikenalkan pertama kali oleh Daubechies.
keterangan:
a = parameter penskala dan a 0 2j = parameter dilatasi
k = parameter waktu atau lokasi ruang
Wavelet berdasarkan pada pembangkitan sejumlah tapis (filter) dengan cara mengeser dan menskala mother Wavelet berupa tapis pelewat tengah (band-pass filter). Dengan demikian diperlukan pembangkit filter. Penambahan dan pengurangan skala akan mempengaruhi durasi waktu, lebar bidang (bandwith) dan nilai frekuensi (Burrus et al. 1998).
Transformasi Wavelet dapat dibedakan menjadi dua, yaitu continous wavelet transform
(CWT) dan discrete wavelet transform (DWT). Fungsi yang digunakan dalam transformasi CWT dan DWT diturunkan dari motherWavelet
melalui translasi/ pergeseran dan
penskalaan/dilatasi. Transformasi Wavelet
kontinu mempunyai dua kelemahan yaitu
redudancy dan ketidakpastian (impracticality) (Mallat 1999). Masalah tersebut dapat diselesaikan dengan mendiskretkan parameter penskala dan penggeseran.
Transformasi Wavelet Diskret
Transformasi Wavelet merupakan teknik pemrosesan sinyal multiresolusi. Proses
transformasi Wavelet dilakukan dengan
mengkonvolusi sinyal dengan data tapis (filter) atau dengan proses perata-rataan dan pengurangan secara berulang, yang sering disebut dengan metode filter bank. Prinsip
dasar dari DWT adalah bagaimana cara mendapatkan representasi waktu dan skala dari sebuah sinyal menggunakan teknik filter
digital dan operasi sub-sampling.
Transformasi Wavelet diskret bertujuan mengurangi redundansi yang terjadi pada transformasi Wavelet kontinu. Transformasi
Wavelet diskret menganalisis suatu sinyal dengan skala yang berbeda.
Sebuah sinyal dilewatkan dalam dua filter
DWT yaitu highpass filter dan lowpass filter
agar frekuensi dari sinyal tersebut dapat
dianalisis. Pembagian sinyal menjadi
frekuensi tinggi dan frekuensi rendah dalam proses highpass filter dan lowpass filter
disebut sebagai dekomposisi. Proses
dekomposisi ini dapat melalui satu atau lebih tingkatan. Dekomposisi satu tingkat ditulis dengan ekspresi matematika pada persamaan 10 dan 11.
Ñ☛Ò✧Ó✐Ô❏Õ✝Ö➢×✠ØÙ✬Ú③ÛÝÜßÞ✘àá✽â✐ãåä➨æ✢çéèëê❸ì
í î♠ï✢ð✴ñ
ò✠ó➷ôõ✝ö➘ö✴ô➭÷ø✬ù❒úÝûýü➙þÿ✁✄✂✆☎✞✝✠✟☛✡✌☞✁✍
✎
✏✒✑✓✑✕✔
Dalam hal ini y[k] tinggi dan y[k] rendah adalah hasil dari highpass filter dan lowpass filter, x[n] merupakan sinyal asal, h[n] adalah
highpassfilter, dan g[n] adalah lowpassfilter.
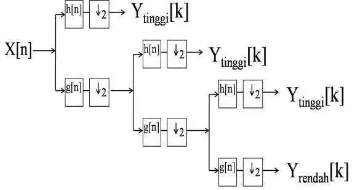
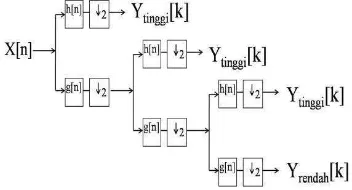
Contoh ilustrasi dekomposisi dipaparkan
pada Gambar 2 dengan menggunakan
dekomposisi tiga tingkat. Pada Gambar 2 y[k] tinggi dan y[k] rendah yang merupakan hasil dari highpass filter dan lowpass filter, y[k] tinggi disebut sebagai koefisien DWT. y[k] tinggi merupakan detail dari informasi sinyal, sedangkan y[k] rendah merupakan taksiran kasar dari fungsi penskalaan. Dengan menggunakan koefisien DWT ini maka dapat dilakukan proses inverse discrete wavelet transform (IDWT) untuk merekonstruksi menjadi sinyal asal.
Gambar 2 Dekomposisi Wavelet 3 tingkat.
berada pada akhir dekomposisi dengan sebelumnya meng – upsample oleh 2 ( 2) melalui highpass filter dan lowpass filter.
Proses rekonstruksi ini sepenuhnya
merupakan kebalikan dari proses dekomposisi
sesuai dengan tingkatan pada proses
dekomposisi. Dengan demikian, persamaan rekonstruksi pada masing-masing tingkatan dapat ditulis sebagai berikut:
✖✘✗✙✁✚✜✛✣✢✥✤✧✦✩★✫✪✬✮✭✮✭✯✪✱✰✲✴✳✄✵✆✶✞✷✜✸✺✹✣✻✽✼✴✾❀✿
❁
❂✽❃✒❄❆❅❈❇❊❉●❋✩❍■✴❏▲❑◆▼✞❖✜P✺◗❙❘✠❚✴❯▲❱ ❲✒❳✠❨❬❩
Transformasi Wavelet Daubechies
Wavelet Daubechies secara historis berasal dari sistem Haar ditulis sebagai ‘dbN’ dengan N menunjukkan orde dengan 2 koefisien (db2) memiliki scaling function dengan koefisien low-pass sebagai berikut (Burrus et al. 1998).
❭✯❪✞❫✒❴✁❵❜❛❀❝◆❞✩❡ ❢❊❣✴❤ ✐
❥✯❦✫❧♥♠✁♦q♣sr◆t✩✉ ✈❊✇✴① ②
③✯④✞⑤✒⑥✁⑦q⑧s⑨◆⑩✩❶ ❷❊❸✴❹ ❺
❻✯❼❽●❾✁❿❜➀❀➁◆➂✩➃ ➄❊➅✴➆
Dengan h(n) merupakan koefisien low-pass.
Nilai koefisien high-pass fungsi Wavelet dengan N=2 atau berorde 2 adalah
g0 = h3 , g1 = -h2, g2 = h1, g3 = -h0, dengan g= high-pass dan h = low-pass.
Ingrid Daubechies telah mengklasifikasikan koefisien secara numerik untuk N=4 atau berorde 4 pada Tabel 1(Burrus et al. 1998).
Tabel 1 Tabel koefisien db4.
Low fass Koefisien
N = 4 h(0) 0.230377813309
h(1) 0.714846570553
h(2) 0.630880077679
h(3) -0.027983769417
h(4) -0.187034811719
h(5) 0.030841381836
h(6) 0.032883011667
h(7) -0.010597401785
bank filter Wavelet Daubechies dengan 4 koefisien dapat dilihat pada Gambar 3 untuk n<0 dan n>4 nilai h(n)=0.
h
0h
1h
2h
30 0 0
g
0g
1g
2g
30 0 0
0 0 h
0h
1h
2h
30
0 0 g
0g
1g
2g
30
Gambar 3 Bank filter Daubechies.
Tahapan ekstraksi ciri menggunakan transformasi Wavelet yaitu:
a) Frame Blocking dan Windowing
b) Discrete Wavelet Transform (DWT) menggunakan Daubechies
c) Mel FrequencyWrapping
d) Cepstrum
Distribusi Normal
Distribusi Normal sering disebut sebaran
Gauss. Penulisan notasi dari peubah acak yang berdistribusi normal umum adalah
N(x;µ , 2), artinya peubah acak X
berdistribusi normal umum dengan mean µ dan varians 2. Peubah acak X yang berdistribusi normal dengan mean µ dan
varians 2 disingkat X~N(µ , 2).
Peubah acak X dikatakan berdistribusi normal umum, jika dan hanya jika fungsi densitasnya berbentuk seperti pada persamaan 13 (Herrhyanto dan Gantini 2009).
➇➉➈✧➊✴➋➍➌➏➎ ➐✴➑
➒ ➓ ➔➣→❬↔ ↕✫➙➜➛
➝♥➞✮➟ ➠➡➤➢ µ
➥✮➦➣➧ (13)
Dengan - <X< , - <µ < , - < 2< , dalam hal ini X merupakan data yang digunakan sebagai data uji, µ merupakan nilai rata-ratadari data latih.
Distribusi Normal (Gauss) multivariate
N( , ) didefinisikan sebagai:
➨➩✒➫➭✮➯➳➲ ➵
➸✞➺✒➻✕➼❆➽➾ ➚ ➪➶
➹ ➘❆➴♥➷➮➬❈➱◆✃
❐ ❒❮Ï❰ µÐ✧Ñ Ò♥Ó✓ÔÕÏÖ µ×▲Ø✆Ù✫Ú✒Û●Ü
Untuk kasus satu dimensi, disederhanakan menjadi:
Ý♥Þ✯ß▲à✴áãâ ä
å✱æ✯ç➮è✕é
ê
ë●ì✯í î✩ïñð
ò ó✱ôöõ
µ÷
ø ù✠ú➣û ü➣ý✽þ✕ÿ
ciri, µ adalah nilai rata-ratadari data latih dan merupakan nilai matriks kovarian dari data latih.
Matriks kovarian didapat dengan
menghitung nilai rata-rata dari data latih. Nilai rata-rata yang didapat selanjutnya dikurangi dengan matriks awal, dikali dengan matriks transform hasil pengurangan dan dibagi dengan banyak data. Misalkan, matriks data latih dengan banyak data 3, berukuran
mxn dengan m = 3 (banyaknya baris) dan n = 2 (banyaknya kolom), maka matriks kovarian yang dihasilkan berukuran 2x2. Berikut Langkah - langkah menghitung matriks kovarian dan rata-rata dari matriks A:
1. Menghitung nilai rata-rata dari matriks A untuk menghasilkan matriks B.
✂✁
✄✆☎✞✝✠✟☛✡
☞✞✌✠✍☛✎
✏✒✑✔✓✖✕✘✗
, ✙✛✚✢✜✣✥✤✧✦✩★✫✪
2. Mengurangi matriks rata-rata dengan matriks A
✬✮✭✰✯✲✱✳✵✴✷✶✹✸✻✺ ✼✩✽✿✾✹❀✻❁✒❂
❃❅❄❇❆❈✵❉✷❊●❋✻❍ ■✩❏✿❑●▲☛▼❖◆
P❘◗❇❙❚✵❯❲❱✹❳✒❨ ❩✩❬❪❭✹❫❵❴✫❛
3. Menghitung nilai kovarian
❜✘❝❖❞❢❡✫❣❖❤✐❡❖❥❧❦❧♠✮♥❵♦q♣✮r❖s✩t✈✉✩✇✻①③②⑤④❘⑥❢⑦⑨⑧✵⑩
❶❢❷✫❸☛❹⑨❷❢❺❼❻✘❽❢❾❿❽
Dalam hal ini, A1t merupakan transform
dari matriks A1, Bt merupakan transform
dari matriks B, dan Ct merupakan
transform dari matriks C.
METODE PENELITIAN
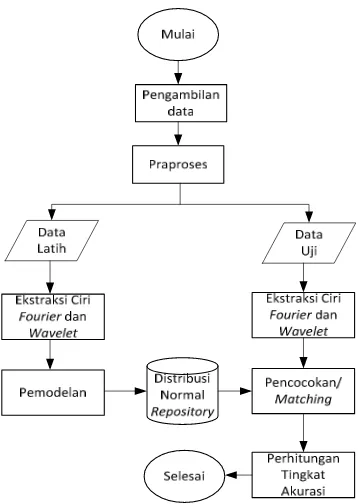
Penelitian ini dilakukan dengan beberapa tahapan, yaitu pengambilan data, pemodelan (feature extraction), dan pengenalan (feature matching). Feature extraction merupakan proses mengekstraksi data hasil akuisisi sehingga dihasilkan data yang berdimensi lebih kecil. Feature matching merupakan prosedur aktual mencocokkan pola dan membandingkan fitur ekstraksi suara yang dimasukkan dengan salah satu dari himpunan pembicara (Agustini 2006). Proses pengenalan fonem dapat dilihat pada Gambar 4.
Gambar 4 Proses pengenalan fonem.
Pengambilan Data
Data yang digunakan dalam penelitian ini adalah data dari sebelas kata (coba, fana, gajah, jaya, malu, pacu, quran, tip-x, visa, weda, dan zakat). Pemilihan kata dilakukan untuk memenuhi jumlah keseluruhan fonem yaitu sebanyak 26 fonem.
Letak fonem dalam suatu kata tidak
berpengaruh terhadap error rate yang
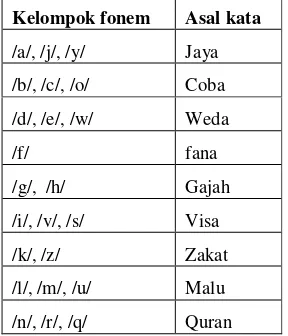
dihasilkan. Letak fonem pada awal kata tidak selalu memberikan nilai error rate yang kecil, begitupun pada fonem yang terletak pada tengah maupun akhir kata (Resmiwati 2009). Daftar fonem dari kata yang digunakan dalam penelitian ini dapat dilihat pada Tabel 2.
Tabel 2 Daftar fonem dalam penelitian.
Kelompok fonem Asal kata
/a/, /j/, /y/ Jaya
/b/, /c/, /o/ Coba
/d/, /e/, /w/ Weda
/f/ fana
/g/, /h/ Gajah
/i/, /v/, /s/ Visa
/k/, /z/ Zakat
/l/, /m/, /u/ Malu
Kelompok fonem Asal kat
/p/ Pacu
/t/, /x/ Tip-x
Data berasal dari satu pemb masing kata direkam seban pengulangan sehingga data yan sebanyak 520 data suara. Pen dilakukan dengan mengguna (banyaknya bit yang diproses pe sebesar 16 bit sampling rate seb dan disimpan dalam file bere Proses perekaman dilakukan di untuk mengurangi noise dari lin
Praproses
Pengenalan 26 fonem pada dilakukan beberapa tahapan yai
1. Penghapusan silent dan norm Penghapusan silent d suara yang disimpan hanya rekaman suara. Normalisa dengan membagi nilai se sinyal dengan absolute m sebuah frekuensi sinyal
normalisasi untuk
amplitudo maksimum dan m normal yaitu satu dan sehingga dapat menorm kekerasan suara.
2. Segmentasi sinyal
Data hasil penghapusa normalisasi dilakukan segm manual sehingga dihasilkan sebelas kata yang direkam sebanyak 20 kali pengula demikian jumlah total dat dihasilkan sebanyak 520 da fonem.
Pembagian Data
Pembagian data dibagi bagian, yaitu data pelatihan dengan proporsi 75% untuk 25% untuk data uji. Menurut dengan menggunakan metode HMM pembagian data den 75%:25% lebih baik dibuat dengan 50%:50% dan 25%:75%
Ekstraksi Ciri Sinyal
Data fonem hasil segmenta dilakukan ekstraksi ciri deng
transformasi Fourier dan
Wavelet Daubechies (db4) p Ekstraksi ciri dilakukan untu
ata
mbicara, masing-anyak 20 kali ang dikumpulkan engambilan data nakan bit rate
per satuan waktu) sebesar 12000 Hz erekstensi WAV. di tempat hening lingkungan.
da penelitian ini aitu:
ormalisasi dilakukan agar ya yang terdapat isasi dilakukan setiap frekuensi maksimum dari l suara. Tujuan menghasilkan n minimum yang n minus satu, malkan tingkat
san silent dan gmentasi secara an 26 fonem dari masing-masing langan. Dengan ata fonem yang data dari seluruh
i menjadi dua n dan pengujian data latih dan ut Buono (2009) de MFCC dan engan proporsi at perbandingan 5%.
ntasi selanjutnya ngan pemodelan n transformasi pada level 1. tuk menentukan
nilai vektor yang digunakan seba dengan dimensi yang lebih kecil d
frame-nya sehingga diharapk mempercepat waktu pengenalan fo
Dalam penggunaannya, fungsi
Wavelet memerlukan beberapa para 1. Input, merupakan sinyal tanpa
yang akan dianalisis ekstraksi ci 2. Sampling rate yaitu banyakny akan diambil dalam satu detik. 3. Time frame lamanya waktu yan dalam satu frame dalam miliseko 4. Overlap yaitu overlapping yan
antara satu frame dan frame sela 5. Cepstral coeffisient yaitu
koefisien cepstrum yang diingin
output.
6. Level yaitu banyaknya tahapan yang digunakan pada fungsi DW
MFCC yang diimplementasi
sistem ini merupakan fun
dikembangkan oleh Stanley pada Alur proses MFCC dan Wavelet
pada Gambar 5.
Penjelasan tahapan dari ek MFCC dan DWT yaitu:
a) Frame Blocking dan Windowin
Penelitian ini menggunakan pa pada lebar waktu 30 ms dan menyimpan data sebanyak 360 d antar frame 50%. Windowing m Hamming window dengan panja sama dengan panjang frame yaitu
Gambar 5 Diagram proses ekst MFCC dan Wavelet.
b) Transformasi Wavelet Daubec
Data yang terbagi dalam be hasil dari frame blocking dan wind
setiap fonem dilakukan proses d dengan menggunakan transforma
bagai penciri, l dalam setiap
pkan dapat
fonem.
si MFCC dan arameter yaitu: pa noise suara cirinya. nya data yang
ang diinginkan ekon.
ang diinginkan elanjutnya. u banyaknya
ginkan sebagai
n dekomposisi WT.
asikan dalam fungsi yang a tahun 1998. dapat dilihat
ekstraksi ciri
ing
panjang frame
n tiap frame
data, overlap
menggunakan njang window
tu 360 sample.
straksi ciri
echies
bentuk frame ndowing pada
Hasil dekomposisi menghasil koefisien (koefisien detail dan p
Algoritme 1 adalah untuk me detail dan perkiraan pada p dekomposisi (Agustini 2006).
Algoritme 1: Proses multiple dek
Input: sinyal yang akan di-filt
Tahap 1: Pilih filter yang a sebagai low-pass f pass filter.
Tahap 2: Sinyal input di-fi low-pass filter filter.
Tahap 3: Hasil Low-pass high-pass frekuens selanjutnya dila
downsampling.
Tahap 4: Low-pass frekuens selanjutnya kemba Tahap 5: Dilakukan terus
berhenti pada diharapkan.
Output: Low-pass frekuensi p ditentukan.
Analisis data transform dilakukan dengan mendekomp
sinyal ke dalam kompo
frekuensi yang berbeda-beda masing-masing komponen frek dapat dianalisis sesuai d resolusinya atau level dekom ini seperti proses filtering, domain waktu dilewatkan ke d
filter dan low pass filter untu komponen frekuensi tinggi rendah.
Proses dekomposisi berda Nyquist. Aturan Nyquist mengatakan bahwa frekuen
sample harus kurang atau setengah dari frekuensi samplin
itu maka, diambil frekuensi sa
frekuensi sampling dalam sub
pada dekomposisi Wavelet.
c) Mel -Frequency Wrapping
Dengan menggunakan al disarankan oleh Davis dan Me untuk membentuk M filter. Dar sudah dibentuk, selanjutny
wrapping terhadap sinyal. N
yang diharapkan didapat
transformasi kosinus.
silkan koefisien-n perkiraakoefisien-n).
encari koefisien proses multiple
ekomposisi.
filter
akan digunakan
s filter dan
high-filter ke dalam dan high-pass
s frekuensi dan nsi pada tahap 2, ilakukan proses
nsi hasil tahap 3 bali ke tahap 2. s menerus dan
level yang
si pada level yang
rmasi Wavelet
posisikan suatu ponen-komponen da. Selanjutnya rekuensi tersebut dengan skala mposisinya. Hal , sinyal dalam dalam high pass
tuk memisahkan i dan frekuensi
dasarkan aturan salah satunya ensi komponen sama dengan
ling. Oleh sebab
sample /2 dari
subsample oleh 2
algoritme yang ermelstein 1980 ari M filter yang tnya dilakukan Nilai koefisien t dari hasil
Pemodelan
Hasil ekstraksi ciri satu sinyal d hasil berupa matrikss ciri n×k, n ad
frame dan k adalah koefisien. dilakukan perata-rataan koefisien baris, sehingga setiap satu data siny matriks berukuran 1×k. Jumlah dat satu fonem ada 15 data, maka matriks berukuran 15×k, dengan k
koefisien. Matriks 15×k yang dih satu fonem kemudian dihitung nila
sigma untuk fonem tersebut. Kum
mean dan sigma dari fonem /a/ inilah yang digunakan sebagai m
tahap pencocokan. Contoh a
pemodelan untuk menghitung nila
sigma dari satu fonem dapat d Gambar 6.
Gambar 6 Diagram proses pem
Variabel n pada Gambar 6 m banyaknya frame yang dihas masing-masing sinyal. Banyak jum
dihasilkan pada proses eks
bergantung pada panjang pende hasil segmentasi. Variabel x da koefisien nilai hasil penggabung yang diperoleh dari hasil rata-rata.
Pencocokan Model
Model yang dihasilkan p
pemodelan selanjutnya
pencocokan. Pencocokan dilaku data uji yang telah disiapkan s
Penerapan Distribusi Norma
multivariate N( , ) digunak pencocokan model.
l data memiliki adalah jumlah . Kemudian n pada setiap nyal dihasilkan ata latih untuk ka dihasilkan
k banyaknya ihasilkan dari ilai mean dan umpulan Nilai /a/ sampai /z/ model untuk alur proses ilai mean dan dilihat pada
emodelan.
menunjukkan asilkan pada jumlah n yang kstraksi ciri deknya sinyal dan y adalah ngan matriks ta.
Pengujian
Pengujian dilakukan pada data uji yang telah dipersiapkan. Setiap data uji dilihat apakah data tersebut terindentifikasi pada fonem yang semestinya. Presentase tingkat akurasi dihitung dengan fungsi berikut:
➀☛➁q➂✒➃✆➄✩➅➇➆➉➈➋➊③➌➥➉➦➋➧③➨➍➏➎✘➐✖➑➓➒❵➔➣→❼↔❵↕➛➙✖➜✵➝➟➞➣➠➢➡➛➤➩➏➫✘➭✖➯➓➲❵➳➣➵❼➸❵➺➛➻✖➼✥➽➋➾➚✖➪➶➾ ➹➴➘❖➷❢➷❢➬ (16)
HASIL DAN PEMBAHASAN
Praproses
Penelitian ini, data yang digunakan sebanyak 390 data latih dan 130 data uji. Data tersebut selanjutnya dilakukan praproses yaitu penghapusan silent, normalisasi, dan segmentasi manual. Dengan demikian, tahap praproses menghasilkan 26 fonem dari fonem /a/ sampai /z/. Masing-masing fonem memiliki 15 data latih dan 5 data uji. Setelah dilakukan praproses, dilanjutkan dengan proses ekstraksi ciri pada semua data dengan menerapkan MFCC dan
Wavelet Daubechies.
Pada proses ekstraksi ciri dengan MFCC terdapat beberapa parameter yaitu, input suara,
sampling rate, time frame, overlap, cepstral coefficient. Parameter ekstraksi ciri Wavelet
Daubechies sama dengan parameter pada MFCC hanya ditambah satu parameter lagi yaitu level. Data latih merupakan data hasil praproses dan ekstraksi ciri yang sudah dibuatkan model terlebih dulu. Pemodelan dilakukan dengan menghitung nilai mean dan
sigma dari masing-masing fonem dengan 13 koefisien.
Karena keterbatasan data latih yang digunakan penelitian ini menerapkan 13 koefisien. Jika koefisien yang digunakan lebih dari 13 maka nilai sigma ( ) yang dihasilkan mendekati singular. Hal ini terjadi karena memiliki nilai determinan yang sangat kecil hingga mencapai 1e-128, oleh sistem dianggap sama dengan nol. Dengan demikian, akan
mengakibatkan Distribusi Normal yang
diperoleh bernilai infinitif atau NaN (not a number).
Jumlah data latih yang digunakan
mempunyai bobot yang sama untuk setiap kelasnya. Hal ini dilakukan, karena jika salah satu ada yang dominan akan berpengaruh terhadap nilai akurasi. Karena kelas yang dominan akan selalu mendominasi.
Hasil Pengujian dengan MFCC
Hasil pengujian fonem dengan ekstraksi ciri MFCC dan Distribusi Normal terhadap masing-masing fonem dapat dilihat pada Gambar 7. Pada grafik terlihat bahwa fonem yang dapat dikenali dengan baik oleh sistem ada 17 fonem. Fonem /a/,/b/, /d/, /e/, /g/, /h/, /i/, /j/, /l/, /m/, /n/, /o/, /s/, /t/, /w/, /x/, dan /z/ mencapai 100%. Akan tetapi, fonem /f/, /p/, /r/, /v/ kurang baik dikenali karena akurasinya hanya mencapai 60%. Namun demikian, untuk fonem /c/, /k/, /q/, /u/, dan /y/ lumayan baik dapat dikenali dengan akurasinya mencapai 80%.
Gambar 7 Grafik hasil pengujian dengan ekstraksi ciri MFCC.
Hasil Pengujian dengan Wavelet
Daubechies
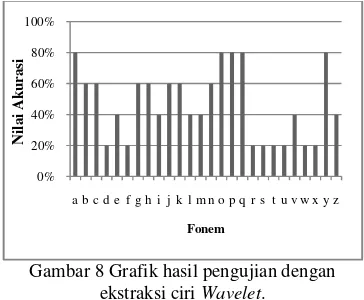
Hasil pengujian fonem dengan ekstraksi ciri
Wavelet Daubechies terhadap masing-masing fonem dapat dilihat pada Gambar 8. Pada grafik terlihat bahwa fonem kurang dapat dikenali dengan baik oleh sistem. Fonem /a/, /b/, /c/, /g/, /h/, /j/, /k/, /n/, /o/, /p/, /q/, /y/ dapat dikenali di atas 50% dan untuk fonem lainnya hanya bisa dikenali kurang dari 50%.
Gambar 8 Grafik hasil pengujian dengan ekstraksi ciri Wavelet.
Pada Gambar 9 terlihat bahwa pengujian fonem dengan ekstraksi ciri MFCC memiliki
0% 20% 40% 60% 80% 100%
a b c d e f g h i j k l m n o p q r s t u v w x y z
N
il
a
i
A
k
u
ra
si
Fonem
0% 20% 40% 60% 80% 100%
a b c d e f g h i j k l m n o p q r s t u v w x y z
Fonem
N
il
a
i
A
k
ur
a
kinerja yang cukup baik dibandingkan dengan ekstraksi ciri Wavelet. Hal ini, pada grafik terlihat bahwa dengan MFCC terdapat 25 fonem nilai akurasinya berada di atas grafik Wavelet. Akan tetapi, dari 26 fonem kecuali untuk fonem /p/ nilai akurasi MFCC berada di bawah
Wavelet. Nilai akurasi untuk fonem /p/ dengan MFCC sebesar 60%, sedangkan pada Wavelet
mencapai 80%. Jadi Wavelet di atas MFCC sebesar 20% hanya untuk fonem /p/.
Gambar 9 Grafik hasil pengujian dengan ekstraksi ciri MFCC danWavelet.
Gambar 10 Grafik hasil pengujian data uji.
Berdasarkan Tabel 3 dan Gambar 10 terlihat bahwa akurasi nilai perbandingan antara MFCC dan Wavelet menunjukkan perbedaan yang sangat signifikan. Rata-rata nilai akurasi MFCC memiliki keunggulan dibandingkan dengan
Wavelet sebesar 43,08% dari seluruh fonem. Untuk MFCC akurasi rata-rata sebesar 90% sedangkan Wavelet jauh di bawah MFCC dengan rata-rata akurasinya hanya mencapai 46,92%.
Tabel 3 Akurasi nilai perbandingan MFCC dan
Wavelet.
Fonem MFCC Wavelet
A 100% 80%
B 100% 60%
Fonem MFCC Wavelet
C 80% 60%
D 100% 20%
E 100% 40%
F 60% 20%
G 100% 60%
H 100% 60%
I 100% 40%
J 100% 60%
K 80% 60%
L 100% 40%
M 100% 40%
N 100% 60%
O 100% 80%
P 60% 80%
Q 80% 80%
R 60% 20%
S 100% 20%
T 100% 20%
U 80% 20%
V 60% 40%
W 100% 20%
X 100% 20%
Y 80% 80%
Z 100% 40%
Berdasarkan Gambar 11 terlihat bahwa hasil pengujian sangat baik, ketika menggunakan data latih sebagai data uji. Hal ini terlihat pada grafik bahwa, rata-rata nilai akurasi MFCC dan
Wavelet cukup tinggi dengan rata-rata akurasi 100% untuk MFCC dan 99,74% untuk
Wavelet. Jadi, pengujian dengan data latih MFCC lebih baik dibanding dengan Wavelet
dengan selisih sebesar 0,26%.
Gambar 11 Grafik hasil pengujian data latih. 0%
20% 40% 60% 80% 100%
a b c d e f g h i j k l m n o p q r s t u v w x y z
Fonem
MFCC WAVELET
N
il
a
i
A
k
ur
a
si
90.00%
46.92%
0% 20% 40% 60% 80% 100%
MFCC WAVELET
N
il
a
i
A
k
ur
a
si
Ekstraksi Ciri
100.00% 99.74%
0% 20% 40% 60% 80% 100%
MFCC WAVELET
N
il
a
i
A
k
ur
a
si
Hasil pengujiaan akan mengalami penurunan, jika menggunakan data uji dan
Wavelet sebagai ekstrasi ciri. Hal ini dijelaskan dari perbedaan selisih nilai akurasi pengujian dengan data uji mengalami peningkatan yang cukup signifikan. Nilai awal selisih antara MFCC dan Wavelet 0,26% dengan data latih dan meningkat menjadi 43,08% dengan data uji. Maka berdasarkan selisih nilai akurasi, MFCC lebih baik dibanding dengan Wavelet dalam pengenalan fonem untuk sinyal tanpa gangguan.
Penerapan ekstraksi ciri Wavelet baik, jika masih dalam ruang lingkup data latih yang diujikan untuk pengenalan fonem. Hasil akurasi pengenalan fonem kurang baik, ketika menggunakan data uji yang baru. Terlihat dari rata-rata pengujian dengan data uji pada
Wavelet hanya mencapai 46,92% dan meningkat 99,74% dengan data latih.
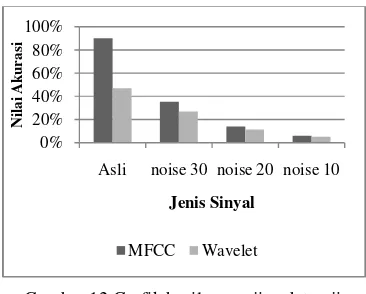
Hasil Pengujian MFCC dan Wavelet dengan
Noise
Penelitian ini dicoba dengan menambahkan
noise pada data uji sebesar 10 dB, 20 dB, dan 30 dB. Pemilihan noise 10 dB, 20 dB, dan 30 dB karena berdasarkan fakta empiris, bahwa
noise 20 dB mulai terasa pengaruhnya terhadap sinyal suara (Buono 2009). Oleh karena itu, digunakan noise di bawah dan di atas 20 dB untuk mengetahui kehandalan model yang sudah dibuat, jika sinyal uji diberi gangguan. Sinyal noise yang digunakan bersifat gaussian dengan menggunakan paket Matlab melalui instruksi AWGN(sinyal asli,level noise).
Tabel 4 Pengujian data uji dengan noise.
Sinyal MFCC Wavelet
Asli 90,0% 46,9%
noise 30 35,4% 26,9%
noise 20 13,8% 11,5%
noise 10 6,2% 5,4%
Berdasarkan Tabel 4 dapat disimpulkan,
bahwa model yang dibangun dengan
menerapkan MFCC sebagai ekstraksi ciri, jika data uji ditambah noise, maka tidak dapat mengenali dengan baik dan hasil akurasinya mengalami penurunan. Namun demikian, nilai akurasi MFCC mengalami penurunan, akan tetapi akurasi MFCC selalu berada di atas
Wavelet. Lebih jelasnya hasil akurasi yang didapat dapat dilihat pada Gambar 12. Pada grafik terlihat bahwa baik MFCC maupun
Wavelet dengan menambahkan noise hasil akurasi mengalami penurunan.
Gambar 12 Grafik hasil pengujian data uji dengan noise.
Perbedaan hasil pengujian yang sangat signifikan antara MFCC dan Wavelet, mungkin disebabkan oleh MFCC dalam mengekstraksi sinyal suara bersifat low noise sehingga teknik MFCC relatif lebih baik untuk sinyal tanpa
noise. Selain itu, MFCC juga didasarkan pada perbedaan frekuensi yang dapat ditangkap oleh
telinga manusia sehingga mampu
merepresentasikan sinyal suara sebagaimana manusia merepresentasikan.
KESIMPULAN DAN SARAN
Kesimpulan
Penelitian ini menghasilkan, bahwa ekstraksi ciri MFCC lebih baik 43,08% dibandingkan dengan Wavelet untuk sinyal tanpa noise. Rata-rata akurasi MFCC dengan data uji tanpa noise sebesar 90% untuk semua pengenalan fonem. Penerapan MFCC baik digunakan ketika data uji tidak ada gangguan dengan pemodelan Distribusi Normal. Nilai akurasi MFCC kurang baik, jika data uji ditambah dengan gangguan (noise).
Ekstraksi ciri Wavelet masih baik dalam pengenalan fonem, jika menggunakan data latih sebagai data uji dengan akurasi sebesar 99,74%. Pada kasus ini, penerapan Wavelet Daubechies kurang baik, jika pengujian dilakukan pada data uji dengan akurasi rata-rata 46,92% dan kurang baik juga ketika ditambah noise.
Saran
Penelitian ini memungkinkan untuk
dikembangkan lebih baik lagi, saran untuk pengembangan selanjutnya ialah:
1. Penelitian mengenai pengenalan fonem ini
masih sangat memungkinkan untuk
dikembangkan lebih lanjut ke tahap
pengenalan kata, dengan melakukan
0% 20% 40% 60% 80% 100%
Asli noise 30 noise 20 noise 10
Jenis Sinyal
MFCC Wavelet
N
il
a
i
A
k
ur
a
segmentasi secara otomatis menggunakan metode auto corelation.
2. Menggunakan jumlah kata yang bervariasi sehingga dapat mewakili untuk tiap fonem yang berada di depan, tengah, dan belakang untuk menghasilkan sistem yang lebih akurat.
3. Pengembangan dengan menggunakan
jumlah pembicara yang lebih banyak yang bersifat speaker independent.
4. Analisis lebih lanjut mengenai penyebab akurasi yang kurang bagus pada Wavelet
baik sebelum maupun sesudah diberikan
noise.
5. Analisis penyebab MFCC yang turun drastis sesudah diberi noise dan memberikan solusi kesalahan pada proses pengenalan fonem.
DAFTAR PUSTAKA
Agustini, Ketut. 2006. Perbandingan Metode Transformasi Wavelet sebagai Praproses pada Sistem Identifikasi Pembicara. [Tesis]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Buono, Agus. 2009. Representasi Nilai HOS dan Model MFCC sebagai Ekstraksi Ciri pada Sistem Identifikasi Pembicara di
Lingkungan Ber-Noise Menggunakan
HMM. [Disertasi]. Depok: Fakultas Ilmu Komputer, Universitas Indonesia.
Burrus, C.S. Gopinath R.A., dan Guo, H. 1998.
Introduction to Wavelets and Wavelet Transforms A Primer, International Edition.
Prentice-Hall International, Inc.
Do MN. 1994. Digital Signal Processing Mini-Project: An Automatic recognition System. Audio Visual Communication Laboratory, Swiss Federal Institute of Technology, Switzerland.
Herryhyanto, Nar, dan Gantini, Tuti. 2009.
Pengantar Statistika Matematis. Yrama Widya, Bandung.
Jurafsky D, Martin JH. 2000. Speech and Language Processing an Introduction to Natural Language Processing, Computational Linguistic, and Speech Recognition. New Jersey: Prentice Hall.
Krishnan, M, Neophytou, CP, dan Prescott, G.
1994. Wavelet Transform Speech
Recognition Using Vector Quantization, Dynamic Time Warping and Artificial
Neural Networks, Center for Excellence in Computer Aided Systems Engineering and
Telecommunications dan Information
Sciences Laboratory 2291 Irving Hill Drive, Lawrence, KS 66045.
Mallat, Stephane. 1999. A Wavelet Tour of Signal Processing. Second Edition, Academic Press 84 Theobald’s Road, London WClX 8RR, UK.
Nilsson, M, dan Ejnarsson, M. 2002. Speech Recognition using Hidden Markov Model : Kinerjance Evaluation in Noisy Environment. Master Thesis, Departement
Of Telecomunications and signal
Processing, Blekinge Institute of technologi, Sweden.
Proakis, L. R., dan Manolakis, D. G. 1996.
Digital Signal Processing. Principles, Algorithm, and Aplication. Edisi ke tiga, Prentice Hall, New Jersey.
Resmiwati, Narcayaning U. D. 2009.
Pengenalan Kata Berbahasa Indonesia
dengan Menggunakan Hidden Markov
Models Berbasiskan Fonem. [Skripsi]. Bogor : Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
PERBANDINGAN W
EKSTRAKSI CIRI P
DEP
FAKULTAS MATE
INS
WAVELET DAUBECHIES DAN MFCC SEBA
PADA PENGENALAN FONEM BERDASAR
DISTRIBUSI NORMAL
NI WAYAN SUDARMI
PARTEMEN ILMU KOMPUTER
EMATIKA DAN ILMU PENGETAHUAN AL
NSTITUT PERTANIAN BOGOR
BOGOR
2011
BAGAI
RKAN
PERBANDINGAN WAVELET DAUBECHIES DAN MFCC SEBAGAI
EKSTRAKSI CIRI PADA PENGENALAN FONEM BERDASARKAN
DISTRIBUSI NORMAL
NI WAYAN SUDARMI
G64086010
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
NI WAYAN SUDARMI. Comparison between Wavelet Daubechies and Mel-frequency Cesptral Coeffisient (MFCC) with Feature Extraction Using Normal Distribution for Phoneme Recognition. Under the supervised of AGUS BUONO.
Speech recognition is speech to text transcription. Speech to text transcription system is a system used to convert a voice signal from a microphone into a single or a set of words. Most research of speech to text transcription used technique which every word in corpus is modeled. It is not effective if we want to develop a large vocabulary speech recognition system which number of words in corpus are more than one thousand words. Therefore, this research developed phoneme recognition with early stage in speech recognition.
This research used some stage proces, those are take data, feature extraction, and feature matching. Normal Distribution (Gaussian) is used for feature matching, Wavelet Daubechies and MFCC is used for feature extraction. Corpus on this research consist of 11 words in Indonesian which each word recorded 20 times, 15 times for data training and 5 times for data testing. This research used 13 cepstral coefficients. Phonemes are generated from the segmentation process, and then mhu and sigma be calculated to generate the model. This case produced 26 models. The best accuracy is 90% generated by feature extraction MFCC and 46.92% generated by the Wavelet Daubechies.
PENDAHULUAN
Latar Belakang
Perkembangan teknologi informasi dapat
mempermudah pekerjaan manusia dalam
kehidupan sehari-hari. Pekerjaan manusia secara manual dapat digantikan dengan sistem otomatis. Salah satu sistem otomatis adalah sistem yang dapat membuat komputer mampu berkomunikasi dengan manusia. Dalam proses komunikasi ini diperlukan tahap konversi suara ke teks (speech to text transcription).
Konversi suara ke teks, berawal dari pengenalan berbasiskan fonem Berbasis fonem diterapkan karena, jika berbasiskan kata, yang mana setiap kata yang terdapat dalam kamus
kata dimodelkan dengan suatu teknik
pemodelan. Hal ini mengakibatkan kurang efektifnya sistem apabila akan dikembangkan untuk sistem pengenalan kata yang bersifat
large vocabulary yang mana kata yang terdapat dalam kamus kata berjumlah sangat besar. Oleh karena itu, di dalam penelitian ini akan dikembangkan suatu sistem pengenalan fonem yang merupakan tahap awal dari pengenalan kata.
Tahap awal pengenalan fonem dilakukan dengan praproses pada sinyal suara. Praproses merupakan proses penghapusan silent, normalisasi dan segmentasi manual. Data fonem yang dihasilkan dari praproses, dilanjutkan dengan pembuatan template untuk membangun model pengenalan fonem. Dengan demikian, komputer diharapkan mampu menerjemahkan ucapan ke dalam bentuk teks yang diucapkan. Teks yang dihasilkan merupakan gabungan dari beberapa fonem. Dengan demikian, sebelum ke tahap konversi suara ke teks diperlukan tahap pengenalan fonem.
Data yang digunakan adalah sinyal suara manusia yang direkam dari satu pembicara. Digunakan sinyal suara sebagai masukan karena merupakan salah satu karakteristik fisiologis manusia yang unik. Suara juga sebagai sistem biometrik dan lebih efisien dibandingkan dengan biometrik yang lain.
Penelitian ini membandingkan konsep
berbasiskan transformasi Fourier dan
transformasi Wavelet. Transformasi Wavelet
diskret yang digunakan berbasis orthogonal yaitu Daubechies. Menurut (Agustini 2006) Daubechies merupakan tipe Wavelet yang memberikan tingkat pengenalan paling tinggi dibandingkan dengan Symlets dan Coiflets.
Distribusi Normal digunakan sebagai
pencocokan pola.
Tujuan
Penelitian ini bertujuan memberikan informasi nilai akurasi. Selain itu, juga membandingkan antara transformasi Fourier
dan transformasi Wavelet sebagai ekstraksi
ciri, pada pengenalan fonem dengan
Distribusi Normal sebagai pencocokan pola.
Ruang Lingkup
Ruang lingkup penelitian ini adalah :
1. Penelitian difokuskan pada pemodelan pengenalan fonem, bukan pengenalan kata atau kalimat.
2. Fonem yang digunakan sebanyak 26
fonem dari /a/ sampai /z/.
3. Teks yang diucapkan berbahasa Indonesia. 4. Penelitian ini menerapkan transformasi
Fourier dan transformasi Wavelet jenis orthogonal Daubechies sebagai ekstraksi ciri dengan orde 4 pada level 1.
5. Penelitian ini menerapkan Distribusi Normal sebagai pengenalan pola.
6. Data sinyal suara pada penelitian ini menggunakan satu pembicara.
7. Implementasi sistem pengenalan kata menggunakan software MATLAB 7.7.
TINJAUAN PUSTAKA
Fonem
Fonem merupakan satuan bunyi terkecil yang mampu menunjukkan kontras makna (KBBI). Fonem dibagi menjadi dua, yaitu:
1. Fonem vokal merupakan bunyi ujaran akibat adanya udara yang ke luar dari paru-paru yang tidak terkena hambatan atau halangan. Jumlah fonem vokal ada lima yaitu: a, i, u, e, dan o.
2. Fonem konsonan merupakan bunyi ujaran akibat adanya udara yang ke luar dari paru-paru mendapatkan hambatan atau halangan. Jumlah fonem konsonan ada 21 buah yaitu: b, c, d, f, g, h, j, k, l, m, n, p, q, r, s, t, v, w, x, y, dan z.
Akuisisi data suara digital
PENDAHULUAN
Latar Belakang
Perkembangan teknologi informasi dapat
mempermudah pekerjaan manusia dalam
kehidupan sehari-hari. Pekerjaan manusia secara manual dapat digantikan dengan sistem otomatis. Salah satu sistem otomatis adalah sistem yang dapat membuat komputer mampu berkomunikasi dengan manusia. Dalam proses komunikasi ini diperlukan tahap konversi suara ke teks (speech to text transcription).
Konversi suara ke teks, berawal dari pengenalan berbasiskan fonem Berbasis fonem diterapkan karena, jika berbasiskan kata, yang mana setiap kata yang terdapat dalam kamus
kata dimodelkan dengan suatu teknik
pemodelan. Hal ini mengakibatkan kurang efektifnya sistem apabila akan dikembangkan untuk sistem pengenalan kata yang bersifat
large vocabulary yang mana kata yang terdapat dalam kamus kata berjumlah sangat besar. Oleh karena itu, di dalam penelitian ini akan dikembangkan suatu sistem pengenalan fonem yang merupakan tahap awal dari pengenalan kata.
Tahap awal pengenalan fonem dilakukan dengan praproses pada sinyal suara. Praproses merupakan proses penghapusan silent, normalisasi dan segmentasi manual. Data fonem yang dihasilkan dari praproses, dilanjutkan dengan pembuatan template untuk membangun model pengenalan fonem. Dengan demikian, komputer diharapkan mampu menerjemahkan ucapan ke dalam bentuk teks yang diucapkan. Teks yang dihasilkan merupakan gabungan dari beberapa fonem. Dengan demikian, sebelum ke tahap konversi suara ke teks diperlukan tahap pengenalan fonem.
Data yang digunakan adalah sinyal suara manusia yang direkam dari satu pembicara. Digunakan sinyal suara sebagai masukan karena merupakan salah satu karakteristik fisiologis manusia yang unik. Suara juga sebagai sistem biometrik dan lebih efisien dibandingkan dengan biometrik yang lain.
Penelitian ini membandingkan konsep
berbasiskan transformasi Fourier dan
transformasi Wavelet. Transformasi Wavelet
diskret yang digunakan berbasis orthogonal yaitu Daubechies. Menurut (Agustini 2006) Daubechies merupakan tipe Wavelet yang memberikan tingkat pengenalan paling tinggi dibandingkan dengan Symlets dan Coiflets.
Distribusi Normal digunakan sebagai
pencocokan pola.
Tujuan
Penelitian ini bertujuan memberikan informasi nilai akurasi. Selain itu, juga membandingkan antara transformasi Fourier
dan transformasi Wavelet sebagai ekstraksi
ciri, pada pengenalan fonem dengan
Distribusi Normal sebagai pencocokan pola.
Ruang Lingkup
Ruang lingkup penelitian ini adalah :
1. Penelitian difokuskan pada pemodelan pengenalan fonem, bukan pengenalan kata atau kalimat.
2. Fonem yang digunakan sebanyak 26
fonem dari /a/ sampai /z/.
3. Teks yang diucapkan berbahasa Indonesia. 4. Penelitian ini menerapkan transformasi
Fourier dan transformasi Wavelet jenis orthogonal Daubechies sebagai ekstraksi ciri dengan orde 4 pada level 1.
5. Penelitian ini menerapkan Distribusi Normal sebagai pengenalan pola.
6. Data sinyal suara pada penelitian ini menggunakan satu pembicara.
7. Implementasi sistem pengenalan kata menggunakan software MATLAB 7.7.
TINJAUAN PUSTAKA
Fonem
Fonem merupakan satuan bunyi terkecil yang mampu menunjukkan kontras makna (KBBI). Fonem dibagi menjadi dua, yaitu:
1. Fonem vokal merupakan bunyi ujaran akibat adanya udara yang ke luar dari paru-paru yang tidak terkena hambatan atau halangan. Jumlah fonem vokal ada lima yaitu: a, i, u, e, dan o.
2. Fonem konsonan merupakan bunyi ujaran akibat adanya udara yang ke luar dari paru-paru mendapatkan hambatan atau halangan. Jumlah fonem konsonan ada 21 buah yaitu: b, c, d, f, g, h, j, k, l, m, n, p, q, r, s, t, v, w, x, y, dan z.
Akuisisi data suara digital
Secara konsepsi, konversi analog to digital (A/D), melalui tiga tahapan proses yaitu: (Proakis dan Manolakis 1996)
a) Proses sampling
Sampling merupakan pengambilan nilai-nilai (sampling rate) dari sinyal kontinu pada setiap jangka waktu (T) yang ditentukan, sehingga sinyal yang awalnya kontinu berubah menjadi diskret.
Menurut (Buono 2009) bahwa, karena sinyal analog dapat direpresentasikan sebagai penjumlahan dari gelombang sinus dengan amplitudo, frekuensi dan fase yang berbeda. Dengan demikian, nilai sampling rate yang dapat menangkap semua komponen sinyal
haruslah minimal dua kali frekuensi
maksimum yang ada dalam sinyal. Nilai
sampling rate sebesar Fs = 2 Fmax disebut sebagai Nyquist rate.
Aturan teori Nyquist menyatakan bahwa frekuensi sinyal paling sedikit dua kali frekuensi sinyal yang akan di-sampling
(sinyal analog) dan merupakan batas
minimum dari frekuensi sample (Fs). Lebih
besar tentunya lebih baik, karena
menggambarkan sinyal aslinya.
Sampling rate yang digunakan pada pengenalan suara adalah 8000 Hz sampai dengan 16000 Hz (Jurafsky dan Martin 2000). Hubungan antara panjang vektor data yang dihasilkan, sampling rate dan panjang data suara yang didigitalisasikan dinyatakan berdasarkan persamaan 1:
S = Fs× T (1)
Keterangan: S = panjang vektor
Fs = sampling rate yang digunakan (Hertz) T = panjang suara (detik)
b) Kuantisasi
Kuantisasi merupakan konversi nilai amplitudo yang bersifat kontinu menjadi nilai diskret. Proses ini menyimpan nilai-nilai simpangan sinyal menjadi representasi nilai 8 bit atau 16 bit (Jurafsky dan Martin 2000).
c) Pengkodean
Pengkodean merupakan pemberian
bilangan biner pada setiap level kuantisasi.
Ekstraksi Ciri
Tujuan ekstraksi ciri untuk mereduksi ukuran data tanpa mengubah karakteristik dari sinyal suara dalam setiap frame yang dapat digunakan sebagai penciri. Ekstraksi ciri didapat dari mengonversikan bentuk sinyal
suara ke dalam bentuk representasi secara parameter (Agustini 2006). Ekstraksi ciri MFCC menghitung koefisien cepstral dengan mempertimbangkan pendengaran manusia. MFCC didasarkan pada variasi frekuensi batas pendengaran manusia yaitu sekitar 20 Hz -20000 Hz. Tahapan MFCC adalah sebagai berikut (Do 1994):
1. Frame Blocking dan Windowing
2. Fast Fourier Transform (FFT) 3. Mel FrequencyWrapping
4. Cepstrum
Frame Blocking dan Windowing
Frame blocking merupakan segmentasi
frame dengan lebar tertentu yang saling tumpang tindih atau suara digital yang telah diakuisisi dengan durasi tertentu. Tiap-tiap hasil
frame direpresentasikan dalam sebuah vektor. Proses frame blocking mengakibatkan terjadi distorsi (ketidakberlanjutan sinyal) antar frame. Dengan demikian, untuk meminimalisasi distorsi tersebut dilakukan proses windowing. Proses windowing yaitu proses filtering tiap
frame dengan cara mengalikan setiap frame
tersebut dengan fungsi window tertentu yang ukurannya sama dengan frame.
Frame windowing bertujuan meminimalkan diskontinuitas (non-stationary) sinyal pada bagian awal dan akhir sinyal suara. Tahap
pembuatan window menggunakan fungsi
window Hamming. Window Hamming dapat dituliskan dengan persamaan 2 (Do 1994).
d(u) = 0.54 + 0.46 cos
✂✁☎✄✝✆
✞✠✟☛✡☞✝✌ (2)
Dalam hal ini, u = 0,1,…,N-1 dan N
merupakanjumlah samples tiap frame. Menurut (Buono 2009), fungsi window Hamming memiliki nilai J(bias) dan V(varian) moderat. Selain itu, window Hamming juga memiliki nilai mean squared error (MSE) berada ditengah-tengah dibanding dengan filter yang lain serta memiliki kesederhaan rumus. Oleh sebab itu, maka fungsi window Hamming ini digunakan.
Fast Fourier Transform (FFT)
Fast fourier transformation (FFT) bertujuan mendekomposisi sinyal menjadi sinyal sinusoidal, dan terdiri atas dua unit, yaitu unit real dan unit imajiner. FFT digunakan untuk analisis frekuensi, sehingga mempermudah pemrosesan suara karena sesuai dengan pendengaran manusia. FFT adalah
algoritme yang mengimplementasikan
merupakan transformasi setiap frame dengan N
sample dari domain waktu ke domain frekuensi yang didefinisikan pada persamaan 3 berikut (Do 1994).
✍✏✎✒✑✔✓✖✕✘✗✂✙✛✚✢✜☎✣✝✤☎✥✧✦✒★
✩
✪✬✫✢✭
✮✝✯✢✰ ✱✧✲✴✳
Keterangan:
N = banyaknya segmen sekuen Xk = nilai data ke k
n = 0,1,2,3,…,N-1 dan k= 0,1,2,3,…,N-1 j = ✵✷✶✹✸
Secara umum Xn adalah bilangan yang kompleks. Hasil dari tahap ini disebut dengan spektrum sinyal atau periodogram.
Mel FrequencyWrapping
Proses wrapping menghitung nilai mel-frequency dengan sejumlah filter yang saling overlap. Filter yang digunakan berbentuk segitiga dengan tinggi satu pada ruang frekuensi mel. Skala mel digunakan untuk mengikuti persepsi pendengaran manusia yang dikenal dengan Mel Wrapping (Buono 2009).
Berdasarkan studi psikologi, telinga
manusia mempunyai persepsi terhadap
frekuensi suara secara tidak linear pada frekuensi di atas 1000 Hz. Persamaan berikut dapat digunakan untuk perhitungan mel-frequency pada frekuensi ✺ dalam satuan
hertz (Nilsson dan Ejnarsson 2002).
✻✽✼✿✾✴❀✘❁
❂✢❃✬❄✂❅✽❄✹❆✘❇❈✴❉✬❊☛❋❍●❏■✹❑ FHz
700▲✏▼❖◆◗P✂❘
FHz ❙❯❚✢❱✛❱✬❱
FHz❲❨❳◗❩✂❬ FHz❭❯❪✢