IMPLEMENTASI
HYBRID PARALLELIZATION
PADA
ALGORITME
GLOBAL PAIRWISE ALIGNMENT
ERWANSYAH ADRIANTAMA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Implementasi Hybrid Parallelization pada Algoritme Global Pairwise Alignment adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, September 2015
Erwansyah Adriantama
ABSTRAK
ERWANSYAH ADRIANTAMA. Implementasi Hybrid Parallelization pada Algoritme Global Pairwise Alignment. Dibimbing oleh WISNU ANANTA KUSUMA.
Algoritme pairwise alignment (PA) merupakan salah satu metode yang umum digunakan dalam penjajaran sekuens. PA terbagi menjadi 2 jenis yaitu
global pairwise alignment (GPA) dan local pairwise alignment. Perkembangan teknologi yang semakin pesat menyebabkan ukuran data sekuens bertambah besar sehingga pemrosesan data tersebut akan memakan waktu yang sangat lama apabila hanya dikerjakan dalam satu prosesor. Oleh karena itu, suatu metode pemrosesan paralel dibutuhkan untuk mempersingkat waktu komputasi. Penelitian ini bertujuan mempercepat algoritme GPA menggunakan skema partisi data
blocked columnwise dengan menggunakan metode hybrid parallelization. Hybrid parallelization dilakukan dengan menggabungkan metode sistem memori terdistribusi dengan sistem memori bersama. Hasil penelitian menunjukkan nilai
speedup pada percobaan menggunakan 2, 3, dan 4 komputer masing-masing adalah 5.3, 6.9, dan 7.77 pada ukuran data 16000 pasang basa dan nilai efisiensi berturut-turut adalah 66%, 58%, dan 49%. Kinerja terbaik dicapai menggunakan 4 komputer, sedangkan skalabilitas memori terbaik diperoleh menggunakan 2 komputer.
Kata kunci: hybrid parallelization, memori bersama, memori terdistribusi, pairwise alignment, pemrosesan paralel
ABSTRACT
ERWANSYAH ADRIANTAMA. Implementation of Hybrid Parallelization on Global Pairwise Alignment Algorithm. Supervised by WISNU ANANTA KUSUMA.
Pairwise alignment (PA) algorithms is a method frequently used in sequence alignment. PA is divided into two kinds, i.e., global pairwise alignment (GPA) and local pairwise alignment. Rapid technology development produces huge sequence data. It will be time consuming if it is done by single processor. Therefore, it is necessary to use a parallel processing method to shorten the computation time. This research aims to accelerate GPA algorithm using blocked columnwise data partition scheme using hybrid parallelization. Hybrid parallelization is formed by combining distributed memory parallelization with shared memory parallelization. The results of this research showed the values of speedup using 2, 3, and 4 computers were 5.3, 6.9, and 7.77 respectively at the size of 16 000 base pair long sequence data, and the efficiency values were 66%, 58%, dan 49%, respectively. The best performance is obtained by using 4 computers, meanwhile the best memory scalability is obtained by using 2 computers.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
IMPLEMENTASI
HYBRID PARALLELIZATION
PADA
ALGORITME
GLOBAL PAIRWISE ALIGNMENT
ERWANSYAH ADRIANTAMA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Implementasi Hybrid Parallelization pada Algoritme Global Pairwise Alignment
Nama : Erwansyah Adriantama NIM : G64110069
Disetujui oleh
DrEng Wisnu Ananta Kusuma, ST MT Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Agustus 2014 ini ialah bioinformatika, dengan judul Implementasi Hybrid Parallelization pada Algoritme Global Pairwise Alignment.
Terima kasih penulis ucapkan kepada:
1 Ayah dan ibu, Yuswan Farmanta dan Erny Emalia, yang telah memberikan doa, dukungan, dan kasih sayang kepada penulis.
2 Bapak Wisnu Ananta Kusuma selaku pembimbing yang telah memberi banyak arahan kepada penulis.
3 Ibu Karlina Khiyarin Nisa dan Ibu Husnul Khotimah selaku penguji yang telah memberikan banyak masukan.
4 Bapak Auriza Akbar yang banyak memberikan saran dalam pembuatan algoritme.
5 Teman–teman Ilmu Komputer 48 yang telah mendukung saya dalam penyelesaian tugas akhir ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, September 2015
DAFTAR ISI
DAFTAR TABEL vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Tahapan Penelitian 2
Lingkungan Pengembangan 5
HASIL DAN PEMBAHASAN 5
Implementasi Algoritme Hybrid Parallelization 5
Verifikasi Kebenaran Algoritme 8
Evaluasi Kinerja 9
SIMPULAN DAN SARAN 12
Simpulan 12
Saran 12
DAFTAR PUSTAKA 12
DAFTAR GAMBAR
1 Tahapan penelitian 3
2 Skema hybrid parallelization pada partisi blocked columnwise 4
3 Pseudocode program GPA sekuensial (Akbar et al. 2015) 6
4 Pseudocode algoritme GPA dengan metode hybrid parallelization 6
5 Matriks inisialisasi menggunakan 4 komputer 7
6 Ilustrasi perhitungan matriks pada baris 1 kolom 1 7
7 Matriks perhitungan algoritme GPA 8
8 Ilustrasi komunikasi data antar komputer 8
9 Perbandingan waktu eksekusi 9
10 Perbandingan speedup 10
11 Perbandingan efisensi 10
PENDAHULUAN
Latar Belakang
Penjajaran sekuens adalah cara untuk mengurutkan sekuens dari DNA, RNA atau protein untuk mengidentifikasi kemiripan pada tiap sekuensnya. Ada beberapa metode yang terdapat dalam penjajaran sekuens, salah satunya pairwise alignment. Algoritme pairwise alignment (PA) merupakan algoritme yang hanya dapat menjajarkan dua buah sekuens. Algoritme ini sangat efisien dalam perhitungan dan sering dipakai untuk metode yang tidak memerlukan presisi yang tinggi. PA menggunakan teknik pemrograman dinamis untuk memperoleh hasil penjajaran optimal dengan kompleksitas O(n2), dengan n merupakan panjang sekuens, dengan asumsi kedua panjang sekuens sama (Akbar et al. 2015). Algoritme PA sendiri terbagi menjadi dua jenis, yaitu global pairwise alignment
(GPA) (Needleman dan Wunsch 1970) dan local pairwise alignment (Smith dan Waterman 1981). Perbedaan dari kedua algoritme ini adalah pemberian nilai negatif, apabila terdapat nilai negatif pada local pairwise alignment, nilai tersebut akan diubah menjadi nol.
Perkembangan teknologi DNA sequencer yang semakin pesat, menyebabkan data yang akan diproses semakin besar. Salah satu solusi untuk mengatasi pertumbuhan data yang semakin besar adalah dengan mempercepat waktu komputasi dengan komputasi paralel. Komputasi paralel adalah metode mempercepat suatu proses dengan menggunakan banyak pemroses.
Paralelisasi PA telah beberapa kali dilakukan, seperti CudaSW (Liu et al.
2013), ParAlign (Rognes 2001) dan paralelisasi menggunakan memori bersama dengan beberapa skema partisi oleh Akbar et al. (2015). Penelitian Akbar et al.
(2015) menggunakan empat skema partisi untuk dibandingkan yaitu, row-wise, antidiagonal, blocked-columnwise, dan blocked-columnwise loop unrolling
dengan penjadwalan manual. Hasil dari penelitian tersebut membuktikan bahwa skema blocked-columnwise loop unrolling dengan penjadwalan manual merupakan skema yang memiliki efisiensi tertinggi.
Paralelisasi dengan sistem memori terdistribusi menggunakan pustaka
message passing interface (MPI) sangat memungkinkan menggunakan skema
2
Perumusan Masalah
Berdasarkan dari latar belakang dapat dirumuskan masalah dalam penelitian ini adalah bagaimana cara memparalelkan algoritme GPA dengan menggunakan metode hybrid parallelization dan apakah hasil paralel tersebut akan lebih efisien daripada hasil paralel dengan menggunakan sistem memori bersama.
Tujuan Penelitian
Tujuan dari penelitian ini adalah melakukan akselerasi pada algoritme GPA dengan menggunakan hybrid parallelization antara memori terdistribusi dan memori bersama serta menghitung speedup dan efisiensi dari algoritme GPA yang diakselerasi.
Manfaat Penelitian
Penelitian ini diharapkan dapat menghasilkan algoritme paralel dengan kinerja yang tinggi sehingga dapat mengurangi waktu komputasi penjajaran sekuens menggunakan algoritme GPA secara signifikan.
Ruang Lingkup Penelitian
Penelitian ini menitikberatkan pada paralelisasi algoritme GPA dengan skema blocked column-wise menggunakan sistem memori terdistribusi dan skema
row-wise menggunakan sistem memori bersama yang dikembangkan oleh Akbar
et al. (2015). Paralelisasi dilakukan dengan menggunakan standar OpenMP pada sistem memori bersama dan message passing interface (MPI) pada sistem memori terdistribusi. Data yang digunakan dibangkitkan secara acak dengan jumlah 1000, 2000, 4000, 8000, dan 16 000 pasang basa.
METODE
Tahapan Penelitian
Penelitian ini dibagi menjadi tiga tahapan utama, yaitu implementasi algoritme, verifikasi kebenaran algoritme, dan evaluasi kinerja. Pada implementasi algoritme dilakukan penerapan skema hybrid parallelization
3
Algoritme hybrid parallelization diimplementasikan pada 3 percobaan, yaitu paralelisasi dengan menggunakan 2, 3, dan 4 komputer. Masing-masing percobaan tersebut akan dihitung waktu eksekusi, speedup, dan besar efisensi.
Implementasi algoritme hybrid parallelization
Global pairwise alignment merupakan algoritme yang digunakan untuk mengukur kemiripan 2 rangkaian DNA. Algoritme ini menerapkan prinsip
dynamic programming dengan kompleksitas n2. Perhitungan skor pada setiap sel matriks GPA dilihat dari skor tertinggi dari 3 kemungkinan arah penjajaran yaitu atas, kiri dan diagonal. Skor atas dan kiri dihitung dengan mengurangi skor GAP
dan skor pada sel tersebut. Skor diagonal dihitung dengan melihat similarity pada kedua residu DNA yang disejajarkan. Apabila kedua residu sama, maka skor ditambahkan dengan skor MATCH, sedangkan apabila tidak sama, maka skor ditambahkan dengan skor MISMATCH.
Implementasi paralel dilakukan dengan menggabungkan dua metode yaitu, memori terdistribusi dan memori bersama. Standar pada sistem memori terdistribusi menggunakan MPI dengan memakai pustaka MPICH2, sedangkan pada sistem memori bersama menggunakan OpenMP. Skema yang digunakan adalah skema blocked columnwise yang dikembangkan oleh Akbar et al. (2015). Meskipun efisiensi dan speedup terbaik diperoleh dari skema blocked columnwise
dengan loop unrolling, implementasi skema tersebut sulit diimplementasikan. Desain paralelisasi menggunakan Foster’s design methodology yang terdiri dari empat tahapan yaitu partitioning, communication, agglomeration, dan mapping
(Quinn 2003). Berikut penjelasan masing-masing tahapan Foster’s design methodology pada algoritme paralel ini.
1 Partitioning
Pada tahapan ini, dilakukan pembagian data dan komputasi menjadi bentuk yang lebih sederhana atau dapat disebut sebagai task. Jumlah kolom matriks GPA pada tahap ini akan dibagi sesuai dengan banyaknya komputer yang digunakan, sedangkan jumlah baris akan dibagi berdasarkan jumlah
thread yang ada pada tiap komputer yang digunakan. Sehingga tiap komputer tidak harus mengerjakan semua kolom.
2 Communication
Penentuan komunikasi antar task dilakukan pada tahap ini. Komunikasi antar komputer pemroses data dilakukan dengan menggunakan MPI_Send dan MPI_Recv. Komunikasi melibatkan thread yang mengerjakan baris i pada prosesor k dengan thread yang mengerjakan baris i pada prosesor sebelumnya (k-1) dan prosesor sesudahnya (k+1). Tiap-tiap prosesor akan mengirimkan data pada kolom terakhirnya ke kolom pertama prosesor sesudahnya.
Gambar 1 Tahapan penelitian
Implementasi algoritme hybrid
parallelization
Verifikasi kebenaran
4
3 Agglomeration
Tahapan ini dilakukan penggabungan task untuk mengatur beban kerja pada tiap pemroses data. Tiap komputer pada skema ini akan mendapatkan jumlah data sebanyak m×n/p dengan m dan n adalah panjang dua sekuens yang digunakan dan p adalah banyak komputer pemroses data yang digunakan.
4 Mapping
Tahapan ini dilakukan penyerahan task pada tiap-tiap komputer. Komputer ke-k akan menerima data dengan panjang kolom (k×n/p)+1 sampai kolom (k+1)×n/p dengan baris sebanyak m, dengan m dan n adalah panjang data sekuens pertama dan kedua serta p adalah jumlah komputer. Data tersebut akan diolah per baris oleh masing-masing thread yang terdapat dalam masing-masing komputer secara rowwise. Gambar 2 menunjukan skema partisi yang akan digunakan pada 3 komputer dan 4 thread.
Verifikasi kebenaran algoritme
Verifikasi kebenaran algoritme dilakukan dengan membandingkan data hasil algoritme GPA yang sudah diparalelkan dengan metode hybrid dengan hasil algoritme sekuensial dari penelitian Akbar et al. (2015) sebagai pembanding hasil yang valid. Verifikasi dilakukan dengan menggunakan data berjumlah 1000, 2000, 4000, 8000, dan 16000 pasang basa.
Evaluasi kinerja
Evaluasi kinerja dilakukan dengan membandingkan waktu eksekusi,
speedup dan efisiensi dengan jumlah komputer yang beragam dan dengan hasil komputasi algoritme sekuensialnya. Waktu eksekusi diambil dari rata-rata waktu eksekusi program dengan sepuluh kali pengulangan. Perhitungan nilai speedup
dan efisiensi masing-masing dilakukan menggunakan Persamaan 1 dan 2 (Grama
et al. 2003).
S= TpTs
Gambar 2 Skema hybrid parallelization pada partisi blocked columnwise Komputer 1 Komputer 2 Komputer 3
Th
rea
d
5
E= S P
Nilai speedup (S) didapatkan dari hasil bagi antara waktu eksekusi sekuensial (Ts) dengan waktu eksekusi paralel (Tp). Efisiensi (E) didapat dengan membagi speedup (S) dengan jumlah prosesor (P). Dalam penelitian ini jumlah prosesor adalah jumlah keseluruhan thread yang dipakai dalam setiap percobaan.
Speedup terbesar akan dibandingkan dengan program algoritme GPA sistem memori bersama dengan menggunakan blocked-columnwise dengan penjadwalan manual dan loop unrolling hasil penelitian Akbar et al. (2015) pada lingkungan dan data yang sama.
Efisiensi pada penelitian ini menggunakan jumlah thread sebagai pembagi karena data yang diproses secara paralel dilakukan dengan memaksimalkan tiap thread pada setiap core komputer. Alasan menggunakan jumlah thread sebagai pembagi adalah karena hybrid parallelization menggunakan library OpenMP yang memparalelkan data antar-thread.
Lingkungan Pengembangan
Spesifikasi perangkat keras yang digunakan pada penelitian ini adalah empat buah komputer dengan CPU Intel Core i5-3470 3.30 GHz dengan 4 core
CPU dengan masing-masing core memiliki 1 thread dan memiliki RAM 4 GB, serta OS Ubuntu 13.10 “Saucy Salamander”. Perangkat lunak yang digunakan adalah Sublime text 2.0.2, GCC compiler dengan OpenMP, dan library MPICH2
HASIL DAN PEMBAHASAN
Pembahasan dimulai dengan penjelasan bagaimana implementasi dari algoritme hybrid parallelization, kemudian dilanjutkan dengan verifikasi kebenaran algoritme dan diakhiri dengan membandingkan nilai efisiensi dan
speedup. Berikut adalah hasil dan pembahasan dari penelitian ini.
Implementasi Algoritme Hybrid Parallelization
Algoritme sekuensial yang dipakai dalam penelitian ini merupakan algoritme GPA sekuensial dari hasil penelitian Akbar et al. (2015). Gambar 3 merupakan pseudocode dari algoritme sekuensial. Mengacu pada Gambar 3,
pseudocode yang memiliki bagian looping akan diparalelkan. Implementasi
hybrid parallelization dimulai dengan mengaktifkan fungsi thread pada pustaka MPI menggunakan MPI_Init_thread dengan value MPI_MULTIPLE agar semua
thread dapat melakukan komunikasi antar prosesor. Berikutnya kolom matriks GPA dibagi menjadi blok-blok berdasarkan jumlah komputer pemroses yg tersedia. Pembagian blok kolom untuk pengerjaan dengan memori terdistribusi dilakukan secara manual.
6
Penentuan kolom pertama (jfirst) dilakukan dengan rumus (rank×n/p)+ 1 dan penentuan kolom terakhir (jlast) dilakukan dengan rumus (rank+1)×n/p
dengan rank adalah tag tiap komputer pemroses data, n adalah panjang sekuens DNA kedua dan p adalah jumlah keseluruhan komputer pemroses data. Ketika data sudah diterima pada setiap komputer, data tersebut akan dikerjakan secara paralel antar-thread dengan sistem memori bersama secara row-wise. Apabila data tersebut sudah mencapai jlast, data akan dikirim oleh thread ke prosesor
If not first processor
MPI_Recv(Scorei,jfirst-1 , source processor, source thread) // receive data
EndIf
diag =Scorei-1,j-1+SIMILARITY(Xi, Yj)
up =Scorei-1,j+ GAP
left = Scorei, j-1+ GAP
EndFor
If not last processor
MPI_Send(Scorei,jlast, destination processor, destination thread) EndIf
EndFor
$OMP Parallel End Return Score
Gambar 4 Pseudocode algoritme GPA dengan metode hybrid parallelization diag = Scorei-1,j-1 + SIMILARITY (Xi,Yj)
diag =Score i-1,j-1+SIMILARITY(Xi, Yj)
up =Scorei-1,j+ GAP
left = Scorei, j-1+ GAP
+
Return Score
Gambar 3 Pseudocode program GPA sekuensial (Akbar et al. 2015)
7
Algoritme pada Gambar 4 memiliki beberapa subproses, yaitu inisialisasi matriks, perhitungan skor, dan komunikasi antar komputer pemroses.
1 Inisialisasi matriks
Proses ini akan membentuk matriks kosong sebagai matriks inisiliasi sesuai dengan jumlah thread dan komputer yang akan digunakan dalam paralelisasi. Kolom matriks (i) akan dibagi sesuai dengan jumlah komputer yang dipakai dan baris matriks (j) akan dibagi secara merata sebanyak jumlah
thread pada setiap komputer. Gambar 5 mengilustrasikan inisialisasi matriks dengan menggunakan 4 komputer dengan masing-masing komputer memiliki 4
thread.
2 Perhitungan skor pada matriks
Perhitungan skor dimulai dengan mengisi skor awal pada baris dan kolom GAP di matriks. Untuk setiap sel berikutnya skor akan dihitung dengan menggunakan Persamaan 3.
Score i,j= MAX{
diag =Scorei-1,j-1+SIMILARITY(Xi, Yj)
up =Scorei-1,j+ GAP
left = Scorei, j-1+ GAP
Nilai SIMILARITY ditentukan dengan melihat kecocokan dari potongan sekuens DNA yang akan disejajarkan. Jika kedua potongan tersebut sama, maka nilai SIMILARITY akan diisi dengan menggunakan nilai MATCH, jika berbeda, maka nilai diisi dengan menggunakan nilai MISMATCH. Nilai
MATCH, MISMATCH, dan GAP masing-masing adalah 1, -1, dan -3. Gambar 6 dan Gambar 7 memperlihat proses perhitungan skor pada matriks GPA.
Komputer 1 Komputer 2 Komputer 3 Komputer 4
GAP G G C T T T G C
Gambar 5 Matriks inisialisasi menggunakan 4 komputer
(3)
Gambar 6 Ilustrasi perhitungan matriks pada baris 1 kolom 1
diag = Scorei-1,j-1 + SIMILARITY (Xi,Yj)
8
3 Komunikasi data antar komputer
Data pada kolom pertama satu komputer menerima data dari kolom terakhir komputer sebelumnya. Hal tersebut diketahui sebagai komunikasi antar komputer. Gambar 8 merupakan ilustrasi dari komunikasi yang terjadi pada dua komputer.
Verifikasi Kebenaran Algoritme
Implementasi algoritme GPA yang digunakan telah diuji konsistensinya dengan membandingkan hasil dengan algoritme GPA sekuensial yang dipakai pada penelitian Akbar et al. (2015). Pengujian dilakukan dengan data yang memiliki ukuran yang berbeda, yaitu dengan panjang 1000, 2000, 4000, 8000, dan 16 000 pasang basa. Seperti yang terlihat pada Tabel 1, semua keluaran algoritme
hybrid parallelization yang dihasilkan serupa dengan algoritme sekuensial. Dapat disimpulkan bahwa implementasi algoritme hybrid parallelization 100% sesuai dengan algoritme sekuensial.
Komputer 1 Komputer 2 Komputer 3 Komputer 4
GAP G G A T T T G C
Gambar 7 Matriks perhitungan algoritme GPA
Tabel 1 Perbandingan hasil algoritme Data (bp) Skor algoritme
hybrid
9
Evaluasi Kinerja
Analisis waktu eksekusi rata-rata
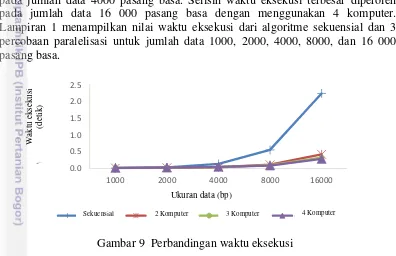
Analisis waktu eksekusi dilakukan dengan mengambil waktu rata-rata pada 10 kali pengujian pada jumlah penggunaan komputer yang berbeda. Perhitungan waktu eksekusi menggunakan fungsi MPI_Wtime. Gambar 9 menunjukkan bahwa algoritme hybrid parallelization yang diterapkan pada 3 percobaan menunjukan pengurangan waktu eksekusi yang signifikan dibanding algoritme sekuensial pada ukuran data lebih dari 4000 pasang basa.
Pengujian pada data berjumlah 1000 pasang basa belum menunjukan perbedaan waktu eksekusi yang signifikan. Hal tersebut ditunjukan oleh selisih waktu eksekusi antara algoritme sekuensial dengan 3 percobaan paralelisasi yang bernilai di bawah 0.1 detik. Selisih waktu eksekusi mulai mengalami peningkatan pada jumlah data 4000 pasang basa. Selisih waktu eksekusi terbesar diperoleh
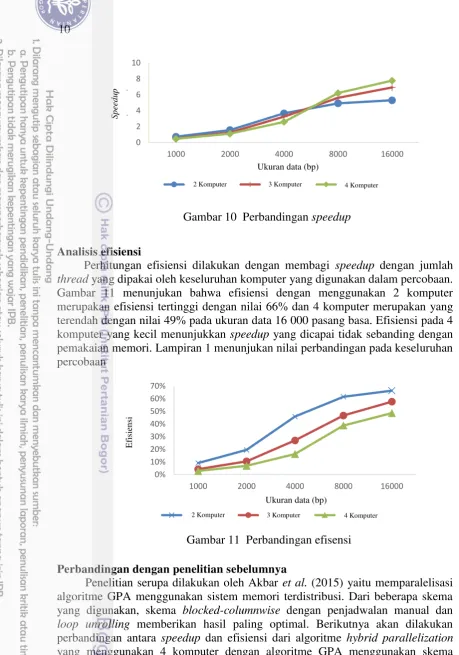
Analisis speedup dilakukan dengan membandingkan jumlah pemakaian komputer pada proses paralel. Seperti yang terlihat pada Gambar 10, speedup
tertinggi dicapai dengan menggunakan 4 komputer dengan nilai 7.77 pada 16 000 pasang basa, sedangkan pada ukuran data yang sama, yang terendah dicapai menggunakan 2 komputer dengan nilai 5.30. Hal ini disebabkan beban masing-masing komputer yang besar sehingga menghasilkan speedup yang kecil. Percobaan menggunakan 4 komputer menunjukan peningkatan speedup yang signifikan pada jumlah data 4000 pasang basa sampai 8000 pasang basa yang disebabkan oleh waktu komunikasi yang lebih besar dibanding waktu eksekusi pada data dibawah 4000 pasang basa. Lampiran 1 menampilkan perbandingan
speedup tiap percobaan.
Gambar 9 Perbandingan waktu eksekusi
0.0
Sekuensial 2 Komputer 3 Komputer 4 Komputer
W
10
Analisis efisiensi
Perhitungan efisiensi dilakukan dengan membagi speedup dengan jumlah
thread yang dipakai oleh keseluruhan komputer yang digunakan dalam percobaan. Gambar 11 menunjukan bahwa efisiensi dengan menggunakan 2 komputer merupakan efisiensi tertinggi dengan nilai 66% dan 4 komputer merupakan yang terendah dengan nilai 49% pada ukuran data 16 000 pasang basa. Efisiensi pada 4 komputer yang kecil menunjukkan speedup yang dicapai tidak sebanding dengan pemakaian memori. Lampiran 1 menunjukan nilai perbandingan pada keseluruhan percobaan
Perbandingan dengan penelitian sebelumnya
Penelitian serupa dilakukan oleh Akbar et al. (2015) yaitu memparalelisasi algoritme GPA menggunakan sistem memori terdistribusi. Dari beberapa skema yang digunakan, skema blocked-columnwise dengan penjadwalan manual dan
loop unrolling memberikan hasil paling optimal. Berikutnya akan dilakukan perbandingan antara speedup dan efisiensi dari algoritme hybrid parallelization
yang menggunakan 4 komputer dengan algoritme GPA menggunakan skema
blocked-columnwise dengan penjadwalan manual dan loop unrolling. Perbandingan speedup dan efisiensi dilakukan pada penggunaan 4 komputer
Gambar 11 Perbandingan efisensi
0%
2 komputer 3 komputer 4 komputer
Ef
isien
si
Ukuran data (bp)
Gambar 10 Perbandingan speedup
0
2 komputer 3 komputer 4 komputer
2 Komputer 3 Komputer 4 Komputer
S
11 karena percobaan menggunakan 4 komputer mengalami penurunan waktu eksekusi yang terbesar dibanding algoritme GPA sekuensial.
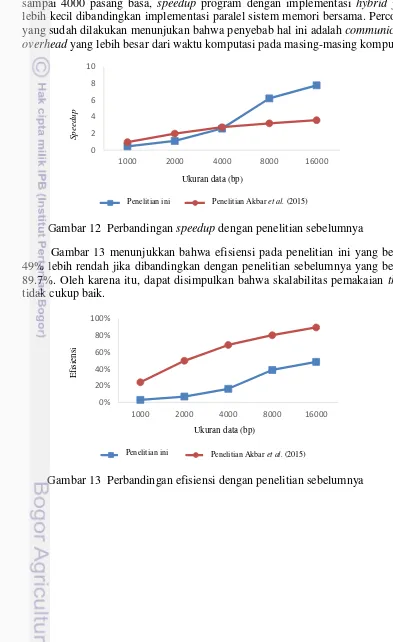
Gambar 12 memperlihatkan peningkatan speedup yang signifikan dari penelitian ini yang bernilai 7.77 jika dibandingkan dengan penelitian sebelumnya yang bernilai 3.59 pada ukuran data 16 000 pasang basa. Hal ini menunjukkan bahwa kinerja pada program hasil penelitian ini cukup baik. Pada data 1000 sampai 4000 pasang basa, speedup program dengan implementasi hybrid justru lebih kecil dibandingkan implementasi paralel sistem memori bersama. Percobaan yang sudah dilakukan menunjukan bahwa penyebab hal ini adalah communication overhead yang lebih besar dari waktu komputasi pada masing-masing komputer.
Gambar 13 menunjukkan bahwa efisiensi pada penelitian ini yang bernilai 49% lebih rendah jika dibandingkan dengan penelitian sebelumnya yang bernilai 89.7%. Oleh karena itu, dapat disimpulkan bahwa skalabilitas pemakaian thread
tidak cukup baik.
Gambar 13 Perbandingan efisiensi dengan penelitian sebelumnya
0%
Penelitian ini Penelitian Akbar et al. (2015)
Gambar 12 Perbandingan speedup dengan penelitian sebelumnya
0
Penelitian iniPenelitian ini Penelitian Akbar et al. (2015)Penelitian Akbar et al. (2015)
12
SIMPULAN DAN SARAN
Simpulan
Penelitian ini berhasil menerapkan hybrid parallelization antara sistem memori bersama dan sistem memori terdistribusi dengan skema blocked-columnwise. Speedup yang dihasilkan pada penelitian ini pada percobaan 2, 3, dan 4 komputer masing-masing adalah 5.3, 6.9, dan 7.77 pada ukuran data 16 000 pasang basa. Nilai speedup terbaik dari ketiga percobaan dua kali lipat lebih besar dari nilai speedup terbaik dari penelitian Akbar et al. (2015) yang sebesar 3.59. Hasil efisiensi setiap percobaan tergolong kecil yaitu 66%, 58%, dan 49%. Nilai efisiensi pada percobaan yang memiliki speedup terbaik justru jauh lebih rendah dari efisiensi terbaik dari penelitan Akbar et al. (2015) yang sebesar 89.7% pada ukuran data 16 000 pasang basa. Penyebab hal ini adalah ongkos komunikasi antar komputerterlalu besar, sehingga menyebabkan penurunan efisiensi.
Saran
Saran untuk penelitian selanjutnya untuk mengembangkan algoritme ini dengan menggunakan hybrid paralelization menggunakan sistem memori terdistribusi dengan GPU, menambahkan gap extension pada data dan penggunaan data yang lebih besar. Diharapkan hal tersebut dapat meningkatkan hasil speedup dan efisensi pemrosesan paralel. Perbaikan pada skema pembagian data juga dapat mengatasi masalah komunikasi antar komputer.
DAFTAR PUSTAKA
Akbar AR, Sukoco H, Kusuma WA. 2015. Comparison of data partitioning schema of parallel pairwise alignment on shared memory system.
TELKOMNIKA. 13(2):694. doi: 10.12928/telkomnika.v13i2.1415.
Grama A, Gupta A, Karypis G, Kumar V. 2003. Introduction to Parallel Computing. Ed ke-2. Edinburgh (GB): Benjamin/Cummings.
Liu Y, Wirawan A, Schmidt B. 2013. CUDASW++ 3.0: accelerating Smith-Waterman protein database search by coupling CPU and GPU SIMD instructions. BMC Bioinformatics. 14(1):117.
Needleman SB, Wunsch CD. 1970. A general method applicable to the search for similarities in the amino acid sequence of two protein. Journal of Molecular Biology. 48(3):443-453. doi:10.1016/0022-2836(70)90057-4.
Quinn MJ. 2003. Parallel Programming in C with MPI and OpenMP. New York (US): McGraw-Hill.
Rognes T. 2001. ParAlign: a parallel sequence alignment algorithm for rapid and sensitive database searches. Nucleic Acids Research. 29(7):1647–1652.
13 Lampiran 1 Hasil eksekusi program penelitian
Data 1000 bp Waktu eksekusi (detik) Pengulangan Sekuensial 2
komputer
Data 2000 bp Waktu eksekusi (detik)
14
Data 4000 bp Waktu eksekusi (detik) Pengulangan Sekuensial 2
komputer
Data 8000 bp Waktu eksekusi (detik) Pengulangan Sekuensial 2
15
Data 16000 bp Waktu eksekusi (detik) Pengulangan Sekuensial 2
komputer
3 komputer
4 komputer
1 2.246 0.418 0.329 0.275
2 2.246 0.417 0.327 0.274
3 2.246 0.424 0.325 0.273
4 2.246 0.423 0.338 0.270
5 2.246 0.420 0.331 0.271
6 2.246 0.425 0.330 0.276
7 2.246 0.425 0.332 0.284
8 2.246 0.429 0.330 0.272
9 2.246 0.428 0.335 0.271
10 2.246 0.424 0.271 0.424
Waktu rata-rata 2.246 0.423 0.325 0.289
Speedup 5.305 6.917 7.773
Efisiensi 66% 58% 49%
16