PENERAPAN ANALISIS GEROMBOL DATA TIDAK
LENGKAP DENGAN ALGORITMA KHUSUS PADA DATA
KESEJAHTERAAN RAKYAT PROVINSI ACEH
RAHMAWATI EKA HANDAYANI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul “Penerapan Analisis Gerombol Data Tidak Lengkap dengan Algoritma Khusus pada Data Kesejahteraan Rakyat Provinsi Aceh” adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, November 2016
Rahmawati Eka Handayani
RINGKASAN
RAHMAWATI EKA HANDAYANI. Penerapan Analisis Gerombol Data Tidak Lengkap dengan Algoritma Khusus pada Data Kesejahteraan Rakyat Provinsi Aceh. Dibimbing oleh ERFIANI dan UTAMI DYAH SYAFITRI.
Analisis gerombol merupakan teknik peubah ganda yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan kemiripan karakteristik yang dimilikinya (Mattjik dan Sumertajaya 2011). Semakin mirip dua objek, maka semakin besar kemungkinan dua objek tersebut untuk dikelompokkan dalam satu gerombol. Analisis gerombol secara umum memerlukan data yang lengkap. Permasalahan yang sering terjadi pada analisis gerombol adalah ditemukan kumpulan objek atau peubah dengan data tidak lengkap.
Secara umum penanganan data tidak lengkap pada analisis gerombol dapat dilakukan dengan tiga pendekatan. Pendekatan pertama adalah mengabaikan data yang tidak lengkap (marginalisasi). Kelemahan dari pendekatan ini adalah mengakibatkan kehilangan banyak informasi. Pendekatan kedua adalah menduga data yang tidak lengkap. Pendugaan data dilakukan dengan metode imputasi, yaitu menduga data tidak lengkap menggunakan angka nol, nilai median, nilai rata-rata, dan lainnya. Pendugaan dengan metode imputasi lebih sering digunakan dengan alasan lebih mudah dan sederhana (Safitri 2015). Kelemahan metode imputasi dikemukakan oleh Wagstaff dan Laidler (2005) yaitu hasil pendugaan dari metode imputasi tidak efisien karena memberikan informasi yang tidak berarti. Pendekatan ke tiga yaitu metode tanpa imputasi yang digunakan untuk mengatasi kelemahan dari metode imputasi. Beberapa penelitian yang mengembangkan metode tanpa imputasi antara lain. Wagstaff (2004) melakukan penelitian penggerombolanuntuk data tidak lengkap tanpa imputasi dengan pendekatan k-means soft constraints
(KSC). Matyja dan Simiński (2014) telah melakukan penelitian penggerombolan untuk data tidak lengkap dengan membandingkan metode imputasi, marginalisasi dan algoritma khusus penggerombolan. Beberapa algorima khusus penggerombolan yang digunakan seperti partial distance strategy (PDS), optimum completion strategy (OCS), serta nearest prototype strategy (NPS). PDS merupakan algoritma khusus penggerombolan data tidak lengkap tanpa imputasi, sedangkan metode OCS dan NPS merupakan algorima khusus penggerombolan data tidak lengkap dengan mengambil teknik imputasi di dalam proses iterasinya. Hasil perbandingan tersebut memperoleh kesimpulan bahwa metode algoritma khusus lebih unggul dalam menggerombolkan data tidak lengkap dibanding metode imputasi dan marginalisasi. Safitri (2015) telah mengkaji metode gerombol tanpa imputasi dengan membandingkan metode KSC dan metode PDS. Pada penelitian tersebut didapat kesimpulan bahwa metode PDS lebih unggul dibanding metode KSC.
Goals (MDGs), dan indikator kesejahteraan yang dipublikasikan oleh BPS dan BAPPENAS Provinsi Aceh tahun 2007 yang bekerjasama dengan instansi pemerintah lainnya.
Tujuan dari penelitian ini adalah mengelompokkan dan mengevaluasi hasil gerombol kabupaten/kota di Provinsi Aceh tahun 2006. Penggerombolan dilakukan berdasarkan indikator kesejahteraan rakyat. Metode Penggerombolan yang digunakan adalah metode OCS dan NPS. Evaluasi hasil penggerombolan dilakukan dengan dua cara yaitu menggunakan RMSSTD dan Pseudo F. Pada penelitian ini pseudo F tidak dapat digunakan untuk mengevaluasi hasil penggerombolan karena setiap jumlah gerombol memiliki penciri yang berbeda-beda. Hasil gerombol optimum dapat ditentukan berdasarkan hasil RMSSTD. Jumlah gerombol optimum yang diperoleh dari metode OCS yaitu 5 gerombol dengan nilai RMSSTD terkecil 0,6459. Pada metode NPS, jumlah gerombol dengan nilai RMSSD terkecil diperoleh sebanyak 6 gerombol dengan nilai RMSSTD yaitu 0,6057.
Penelitian Safitri (2015), menggunakan data yang sama untuk menangani data tidak lengkap dengan menggunakan metode PDS. Hasil penelitian tersebut diperoleh nilai RMSSTD terkecil yaitu pada jumlah gerombol 4 dengan nilai RMSSTD sebesar 0,7493. Nilai RMSSTD pada metode OCS dan NPS dengan jumlah gerombol 4, masing-masing memperoleh nilai sebesar 0,6989 untuk OCS dan 0,6983 untuk NPS. Berdasarkan hasil tersebut, menunjukkan bahwa metode OCS dan NPS memiliki nilai RMSSTD lebih kecil dari metode PDS. Secara keseluruhan metode OCS dan NPS lebih baik dari metode PDS pada penelitian Safitri (2015) dalam menangani data tidak lengkap.
.
SUMMARY
RAHMAWATI EKA HANDAYANI. The Application of Incomplete Data Cluster Analysis through Special Algorithm on Public's Welfare Data of Aceh Province. Supervised by ERFIANI and UTAMI DYAH SYAFITRI.
Cluster analysis is a multivariate technique in which grouping the objects based on similarity or dissimilarity of characteristics (Mattjik and Sumertajaya 2011). Cluster analysis requires complete data. Preprocessing is needed to overcome incomplete data. There are two techniques for preprocessing: marginalization and imputation. Disadvantage of marginalization approach is will cause in losing a lot of information. On other hand, imputation method is easier and simple, although it is in efficient because of providing non-significant information. Wagstaff (2004) conducted a research grouping to incomplete data without imputation with approach k-means soft constraints (KSC). Matyja and Simiński (2014) developed special clustering algorithm such as PDS, OCS, and NPS, and compared the results with marginalization and imputation. PDS is a special algorithm method of incomplete data pure without imputation, whereas the method of OCS and NPS are a special algorithm method of incomplete data with involving imputation in the process of iteration. Those three algorithm were better than marginalization and imputation. Safitri (2015) also discovered that PDS was better than KSC.
Data used in this research is secondary data which is the same data with Safitri’s research (2015). Variables are used from various sources, such as Long Term Development Plan (RPJP), the Millennium Development Goals (MDGs) and indicators of welfare published by BPS and Bappenas of Aceh Province in cooperation with other government agencies in 2007.
The purpose of this study was to clustering and evaluate the results of the group districts / cities in Aceh province in 2006. Grouping is done based on the indicators of people's welfare. Evaluation of the results of the grouping is done in two ways: using RMSSTD and Pseudo F. In this study pseudo F can not be used to evaluate the results of the grouping for each number of groups have a different identifier. The optimum group results can be determined based on the results RMSSTD.
In this research two methods : OCS and NPS were compered to overcome missing data in the dataset. Based on RMSSTD, the optimum cluster number was 5 for OCS and 6 for NPS. RMSSTD value of 4 clusters of PDS was higher than OCS and NPS. This means that OCS and NPS outperformed than PDS. In conclusion, the algorithm involving imputation is better than the algorithm without imputation.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah, dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika Terapan
PENERAPAN ANALISIS GEROMBOL DATA TIDAK
LENGKAP DENGAN ALGORITMA KHUSUS PADA DATA
KESEJAHTERAAN RAKYAT PROVINSI ACEH
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
PRAKATA
Puji dan syukur kehadirat Allah SWT yang telah melimpahkan rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan tesis yang berjudul “Penerapan Analisis Gerombol Data Tidak Lengkap dengan Algoritma Khusus pada Data Kesejahteraan Rakyat Provinsi Aceh”. Penulis menyadari, bahwa banyak pihak yang telah berpartisipasi dan membantu dalam menyelesaikan penulisan tesis ini.
Terima kasih penulis ucapkan kepada Ibu Dr. Ir. Erfiani, M.Si dan Ibu Dr. Utami Dyah Syafitri, M.Si selaku pembimbing atas kesediaan memberikan ide, kritik dan saran kepada penulis, dan terimakasih atas segala masukan, motivasi dan kesabaran dalam membimbing dan membagi ilmunya kepada penulis dalam penyusunan tesis ini. Terimakasih kepada Dr. Bagus Sartono, M.Si selaku penguji luar komisi pembimbing atas masukan yang diberikan. Ucapan terima kasih juga penulis sampaikan sebesar-besarnya kepada seluruh Dosen Departemen Statistika IPB yang telah mengasuh dan mendidik penulis selama di bangku kuliah hingga berhasil menyelesaikan studi, serta seluruh staf Departemen Statistika IPB atas bantuan, pelayanan, dan kerjasamanya selama ini.
Ucapan terima kasih yang tulus penulis ucapkan kepada kedua orangtuaku Bapak Shohibun dan Ibu Fadliyah serta kepada keempat adikku Ziki Ibadul Iman, Ukhti Mujahidah, Lutfi Qurotul A’yun dan Fadil Akmalul Azmi dan seluruh keluargaku yang selalu memberikan motivasi, dukungan, semangat serta do’a selama ini kepada penulis.
Terakhir tak lupa penulis juga menyampaikan terima kasih kepada seluruh mahasiswa Pascasarjana Departemen Statistika atas segala bantuan dan kebersamaannya selama menghadapi masa-masa terindah maupun tersulit dalam menuntut ilmu, serta semua pihak yang telah banyak membantu dan tak sempat penulis sebutkan satu per satu.
Penulis menyadari bahwa tesis ini masih terdapat kekurangan dan belum bisa dikatakan sempurnan. Penulis berharap tesis ini dapat memberikan manfaat bagi semua pihak.
Bogor, November 2016
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
TINJAUAN PUSTAKA 2
Analisis Gerombol 2
Penggerombolan Data Tidak Lengkap 3
Optimum Completion Strategy (OCS) 4
Nearest Prototype Strategy (NPS) 5
Root Mean Square Standard Deviation (RMSSTD) 6 Pseudo F Statistic 6
Biplot Analysis 7
METODE PENELITIAN 8
Data 8
Metode Analisis 9
HASIL DAN PEMBAHASAN 12
Analisis Gerombol Metode OCS 12
Analisis Gerombol Metode NPS 14
Perbandingan Hasil Gerombol PDS, OCS, dan NPS 16
Hasil Gerombol Metode OCS 16
Hasil Gerombol Metode NPS 19
SIMPULAN DAN SARAN 23
Simpulan 23
Saran 23
DAFTAR PUSTAKA 24
DAFTAR TABEL
1 Daftar peubah indikator kesejahteraan rakyat 9
2 Hasil RMSSTD metode OCS 12
3 Hasil Pseudo F pada metode OCS 13
4 Hasil RMSSTD metode NPS 14
5 Hasil Pseudo F pada metode NPS 15
6 Hasil RMSSTD metode OCS, NPS, dan PDS 16
7 Hasil penggerombolan kabupaten/kota di Provinsi Aceh pada metode OCS 17
8 Pusatgerombol metode OCS 17
9 Karakteristik gerombol metode OCS 18
10 Hasil penggerombolan kabupaten/kota di Provinsi Aceh pada metode NPS 20
11 Pusatgerombol metode NPS 20
12 Karakteristik gerombol metode NPS 22
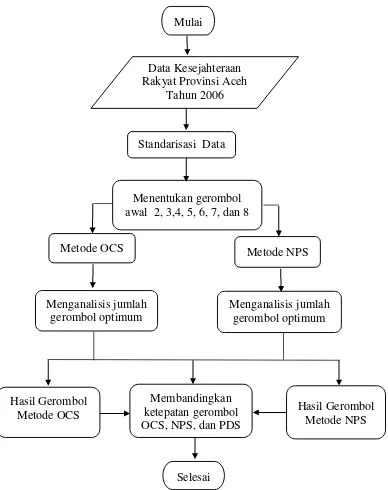
DAFTAR GAMBAR 1 Diagram alir penelitian 11
2 Grafik RMSSTD metode OCS 13
3 Grafik RMSSTD metode NPS 15
4 Biplot indikator kesejahteraan rakyat Provinsi Aceh Tahun 2006 dengan 5 gerombol pada metode OCS 18
1 PENDAHULUAN
Latar Belakang
Meningkatnya kesejahteraan rakyat yang adil dan merata merupakan tujuan dari pembangunan nasional Indonesia. Badan Koordinasi Keluarga Berencana Nasional (BKKBN) mengemukakan definisi keluarga sejahtera apabila keluarga dapat memenuhi kebutuhan anggotanya baik sandang, pangan, perumahan, kesehatan, sosial, dan agama serta mempunyai keseimbangan antara penghasilan keluarga dengan jumlah anggota keluarga. Berbagai program dan kegiatan pembangunan telah dilakukan pemerintah Indonesia guna mencapai tujuan tersebut. Suatu taraf kesejahteraan dapat dinilai melalui indikator-indikator yang terukur dari berbagai aspek pembangunan. Badan Pusat Statistika (BPS) mengembangkan Indikator Kesejahteraan Rakyat (INKERSRA) yang terdiri dari indikator dampak
(output indicators), indikator masukan (input indicators) dan indikator proses (process indicators). Indikator tersebut mencakup beberapa kelompok indikator sektoral, antara lain: kependudukan, pendidikan, kesehatan, gizi, konsumsi dan pengeluaran rumah tangga, ketenagakerjaan, dan perumahan.
Menurut penelitian Jasmina (2015), untuk mengukur tingkat kesejahteraan rakyat maka diperlukan data dan informasi yang akurat. Dalam rangka evaluasi kondisi yang ada, maka perlu dilakukan analisis untuk melihat pemerataan kesejahteraan rakyat tingkat kabupaten/kota. Salah satu analisis statistika yang dapat mengelompokkan suatu kabupaten/kota berdasarkan kriteria kesejahteraan rakyat adalah analisis gerombol. Permasalahan yang terjadi, banyak ditemukan dalam peubah kesejahteraan rakyat terdapat kabupaten/kota yang memiliki data tidak lengkap. Kabupaten/kota tersebut merupakan kabupaten/kota yang baru terbentuk (pemekaran), sehingga data pada kabupaten/kota tersebut menjadi tidak lengkap pada beberapa peubah.
2
optimal completion strategy (OCS), nearest prototype strategy (NPS). PDS merupakan algoritma khusus penggerombolan data tidak lengkap tanpa imputasi, sedangkan metode OCS dan NPS merupakan algoritma khusus data tidak lengkap dengan mengambil teknik imputasi di dalam proses iterasinya. Hasil perbandingan tersebut memperoleh kesimpulan bahwa algoritma khusus penggerombolan lebih unggul dalam menggerombolkan data tidak lengkap. Safitri (2015) telah mengkaji metode gerombol tanpa imputasi dengan membandingkan metode KSC dan metode PDS untuk menggerombolkan data tidak lengkap, dalam kesimpulannya menyatakan bahwa metode PDS lebih unggul dari metode KSC. Dalam penelitian ini digunakan algoritma khusus penggerombolan untuk menutupi kekurangan dari metode imputasi di teknik preprocessing. Metode yang digunakan yaitu metode OCS dan NPS yang diterapkan untuk menggerombolkan kabupaten/kota di Provinsi Aceh berdasarkan indikator kesejahteraan rakyat tahun 2006.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1. Mengelompokkan kabupaten/kota di Provinsi Aceh tahun 2006 berdasarkan peubah-peubah yang menentukan indikator kesejahteraan rakyat dengan metode penggerombolan OCS dan NPS.
2. Mengevaluasi hasil gerombol kabupaten/kota di Provinsi Aceh tahun 2006.
2 TINJAUAN PUSTAKA
Analisis Gerombol
Analisis gerombol merupakan teknik peubah ganda yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan kemiripan atau ketidakmiripan karakteristik yang dimilikinya. Karakteristik objek-objek dalam suatu gerombol memiliki tingkat kemiripan yang tinggi, sedangkan karakteristik antar objek pada suatu gerombol dengan gerombol lain memiliki tingkat kemiripan yang rendah. Dengan kata lain, keragaman dalam satu gerombol minimum sedangkan keragaman antar gerombol maksimum (Mattjik dan Sumertajaya 2011). Ukuran kemiripan atau ketidakmiripan antar objek yang digunakan biasanya ditunjukkan dengan menggunakan ukuran jarak. Pengukuran jarak yang dikenal yaitu jarak Euclid yang didefinisikan sebagai berikut:
2 1 1 2 ) (
K k jk ikij x x
d
Keterangan :
ij
d = jarak antara objek ke-i dan objek ke-j ik
x = nilai objek ke-i pada peubah ke-k jk
3
K = banyaknya peubah
Menurut Rencher (2002), terdapat dua metode sebagai pendekatan umum dalam analisis gerombol yaitu metode berhirarki dan metode tak berhirarki. Metode berhirarki digunakan untuk menggerombolkan pengamatan secara terstruktur berdasarkan kemiripan sifatnya dan gerombol yang diinginkan belum diketahui banyaknya. Metode ini dilakukan dengan dua pendekatan yaitu dengan penggabungan dan pemisahan. Penggabungan didapatkan dengan menggabungkan pengamatan atau gerombol secara bertahap sehingga pada akhirnya didapat hanya satu gerombol saja. Sedangkan dengan cara pemisahan dimulai dengan membentuk satu gerombol besar beranggotakan seluruh pengamatan. Gerombol besar tersebut kemudian dipisah menjadi gerombol yang kecil, sampai satu gerombol hanya beranggotakan satu pengamatan saja. Beberapa metode berhirarki yang sering digunakan yaitu metode pautan tunggal (single linkage), pautan lengkap (complete lingkage), pautan rataan (average linkage), dan pautan Ward.
Sedangkan metode tak berhirarki dimulai dengan menentukan terlebih dahulu jumlahgerombolyang diinginkan, sehingga sifat pengelompokannya tidak alamiah karena dikondisikan untuk jumlah penggerombolan tertentu. K-Means
adalah contoh umum metode tak berhirarki yang sering digunakan. Menurut Ben-Arieh et all. (2010), mengatakan bahwa keuntungan metode ini adalah kemudahan dalam implementasi dan lebih efisiensi, sementara kelemahannya adalah kesulitan dalam menentukan jumlah gerombol.
Penggerombolan Data Tidak Lengkap
Pada banyak kasus jika ditemukan data tidak lengkap, umumnya data diduga dengan menggunakan metode imputasi. Metode imputasi yang umum digunakan seperti imputasi dengan nilai konstan, angka nol, nilai acak, nilai median, nilai rata-rata, dan lainnya. Kekuarangan dari metode imputasi dikemukakan oleh Wagstaff dan Laidler (2005) yang menyatakan bahwa hasil pendugaan dari metode imputasi tidak efisien karena memberikan informasi yang tidak berarti. Oleh karena itu untuk menutupi kekurangan dari metode imputasi, diperlukan algoritma khusus penggerombolan untuk meningkatkan nilai-nilai yang tidak lengkap selama proses iterasi. Beberapa pendekatan yang dapat digunakan untuk menutupi kekurangan dari metode imputasi yaitu metode optimal completion Strategy (OCS) dan metode
nearest prototype strategy (NPS).
4
Optimal Completion Strategy (OCS)
Pendugaan data tidak lengkap pada metode OCS dilakukan pada setiap iterasi, sehingga dugaan data tidak lengkap menghasilkan nilai yang berbeda-beda pada setiap iterasi (Matyja dan Simiński 2014). Sebagai langkah awal, nilai dugaan ditetapkan dengan menggunakan nilai rata-rata sebagai nilai inisiasi.
Langkah selanjutnya dalam tahapan algoritma OCS adalah pembentukan titik awal pusat gerombol. Pembentukan pusat gerombol disesuaikan dengan jumlah gerombol yang ditentukan di awal. Selanjutnya mencari jarak dari suatu objek ke-i
ke pusat gerombol ke-c dan mengalokasikan objek ke dalam gerombol berdasarkan jarak minimun. Proses iterasi selanjutnya dalam metode OCS yaitu nilai-nilai yang tidak lengkap kemudian digantikan dengan memanfaatkan informasi centroid
gerombol dan nilai keanggotaan objek ke-i terhadap gerombol ke–c. Tahapan algoritma metode OCS adalah sebagai berikut:
1. Membagi objek-objek ke dalam c gerombol awal berdasarkan letak keadaan geografis.
2. Menentukan pusat gerombol ke-c dengan formula:
n i ci n i ik ci ck u x u c 1 2 1 2 ) ( ) ( Keterangan : ckc
= pusat gerombol ke-c berdasarkan peubah ke–k ciu = nilai keanggotan objek ke–i terhadap gerombolke–c,dengan
C c ci u 11∀ � ;
x
ik = item objek ke–i pada peubah ke-kn = banyaknya objek
3. Mencari jarak dari suatu objek ke-i ke pusat gerombol ke-c dengan menggunakan jarak euclid dengan formula:
K k ck ikci x c
d 1 2 ) ( Keterangan :
d
ci = jarak objek ke–i terhadap gerombolke-c K = banyaknya peubah4. Kemudian menentukan gerombol dari suatu objek ke dalam suatu gerombol berdasarkan jarak yang paling minimum
5 i C u c u x C c ci C
c ci ck
ik
,1
) ( ) ( 1 2 1 2
6. Memperbarui nilai keanggotaan objek ke-i terhadap gerombol ke-c dengan menggunakan formula sebagai berikut:
2 1
C c ci Ci ci d d u7. Ulangi langkah 1 hingga 6 dan berhenti sampai
( ) ( 1) 5
,10 | |
max ckr
r ck k c c c Keterangan :
r = iterasi
C = banyaknya gerombol
Nearest Prototype Strategy (NPS)
NPS merupakan modifikasi sederhana dari algoritma OCS. Dalam algoritma NPS nilai dari item data yang tidak lengkap kemudian diganti dengan nilai-nilai berdasarkan centroid gerombol yang memiliki derajat keanggotaan tertinggi (Matyja dan Simiński 2014). Iterasi yang digunakan dalam metode NPS sama dengan metode OCS pada awal iterasi. Tahapan algoritma NPS adalah sebagai berikut:
1. Membagi objek-objek ke dalam c gerombol awal berdasarkan letak keadaan geografis.
2. Menentukan pusat gerombol ke-c dengan formula:
n i ci n i ik ci ck u x u c 1 2 1 2 ) ( ) ( Keterangan :cck = pusat gerombol ke-c berdasarkan peubah ke–k
uci = nilai keanggotan objek ke–i terhadap gerombolke–c, dengan
C c ci u 11∀ � ;
x
ik = item objek ke–i pada peubah ke-kn = banyaknya objek
3. Mencari jarak dari suatu objek ke-i ke pusat gerombol ke-c dengan menggunakan jarak euclid dengan formula:
K k ck ikci x c
d
1
2
)
6
Keterangan :
d
ci = jarak objek ke–i terhadap gerombolke-cK = banyaknya peubah
4. Kemudian menentukan gerombol dari suatu objek ke dalam suatu gerombol berdasarkan jarak yang paling minimum
5. Mengganti nilai-nilai yang tidak lengkap dengan formula sebagai berikut: xik cck , dci = min{d11, d21 ... dci}
6. Memperbarui nilai keanggotaan objek ke-i terhadap gerombol ke-c dengan formula sebagai berikut:
2 1
C c ci Ci ci d d u7. Ulangi langkah 1 hingga 6 dan berhenti sampai
() ( 1) 5
,10 | |
max ckr
r ck k c c c Keterangan : r = iterasi
C = banyaknya gerombol
Root Mean Square Standard Deviation (RMSSTD)
RMSSTD merupakan indeks validasi yang bisa dijadikan tolak ukur dalam pengujian validitas kelompok yang bertujuan untuk mengevaluasi hasil kelompok yang terbaik. RMSSTD mengukur kehomogenan dari kelompok yang terbentuk (Halkidi et all. 2001). Formula yang digunakan sebagai berikut :
RMSSTD =
K k ck K k k i n c n x x ck 1 1 2 1 ) 1 ( ) ( Keterangan : ix = nilai objek ke-i
k
x = rata-rata peubah ke-k ck
n = banyaknya objek yang masuk ke dalam gerombol ke-c pada peubah ke-k
K = banyaknya peubah
Pseudo F Statistic
7 yang digunakan dalam analisis gerombol di setiap jumlah gerombol. Pseudo F dapat menggambarkan rasio keragaman antar gerombol dengan keragaman di dalam gerombol (Caliński dan Harabasz 1974). Peubah yang memiliki keragaman yang homogen dapat dilihat berdasarkan hasil nilai pseudo F yang tertinggi. Semakin besar nilai pseudo F maka semakin baik hasil penggerombolan yang dimiliki. Menurut Rencher (2002) formula yang digunakan dalam perhitungan pseudo F adalah:
ci c c ci c c c n n x x c cn x n x F ) /( ) / ( ) 1 /( ) / .. ) / ( ( 2 . 2 2 2 . Keterangan: 2 . cx = total nilai pada gerombol ke-c kuadrat
..
2
x = nilai total umum kuadrat
2
ci
x = nilai pada objek ke-i terhadap gerombol ke-c kuadrat
n = banyaknya objek
c = banyaknya gerombol
Analisis Biplot
Biplot adalah teknik statistik deskriptif yang dapat disajikan secara visual guna menyajikan secara simultan n objek pengamatan dan k peubah dalam ruang bidang datar, sehingga ciri-ciri peubah dan objek pengamatan serta posisi relatif antar objek pengamatan dengan peubah dapat dianalisis. Menurut Johnson dan Wichern (2007), biplot adalah representasi grafis dari informasi dalam sebuah n
dikali k matriks data yang mengacu pada dua jenis informasi yang terkandung dalam matriks data. Sedangkan menurut Rencher (2002), biplot adalah representasi dua dimensi dari matriks X, dengan menunjukkan suatu titik untuk masing-masing vektor n pengamatan bersama dengan titik untuk masing-masing peubah k. Informasi dalam baris berkaitan dengan objek dan yang di kolom berkaitan dengan informasi peubah. Biplot merupakan upaya membuat gambar di ruang berdimensi banyak menjadi gambar di ruang berdimensi dua. Pereduksian dimensi ini mengakibatkan menurunnya informasi yang terkandung dalam biplot.
Biplot merupakan teknik statistika deskriptif dimensi ganda yang mendasarkan pada penguraian nilai singular(SVD), dengan matriks X merupakan matriks yang terkoreksi terhadap rataannya yang kemudian dapat diuraikan sebagai berikut :
X = ULAT
U dan A adalah matriks dengan kolom ortonormal (UUT=AAT=I) dan L adalah matriks diagonal dengan yang unsur-unsur diagonalnya adalah akar dari akar ciri XTX yaitu
p
1 2 3 ... . Unsur –unsur diagonal matriks L ini disebut nilai singular matriks XTX dan kolom-kolom matriks AT adalah vektor
8
diagonalnya adalah 1 2 .... p . Misalkan matriks G=U �� dan matriks H=��−�A dengan besarnya 0 1, maka diperoleh persamaan:
X = U����−�AT = GHT
Matriks G adalah titik-titik koordinat dari n objek dan matriks H adalah titik koordinat dari k peubah. Menurut Mattjik dan Sumertajaya (2011), beberapa hal yang bisa diterangkan dari analisis biplot yaitu:
1. Kedekatan antar Objek
Dua objek yang memiliki karakteristik yang sama akan digambarkan sebagai dua titik dengan posisi yang berdekatan.
2. Keragaman Peubah
Peubah yang memiliki keragaman yang kecil digambarkan dengan vektor yang pendek, sedangkan keragaman yang besar digambarkan dengan vektor yang panjang.
3. Korelasi antar peubah
Dua peubah yang memiliki korelasi negatif akan memiliki sudut yang tumpul, sedangkan dua peubah yang memiliki korelasi yang positif akan memiliki sudut yang lancip.
4. Kedekatan objek dengan peubah
Suatu objek yang searah dengan vektor dari suatu peubah, maka dapat dikatakan bahwa objek tersebut memiliki nilai di atas rata-rata dari peubah tersebut. Sebaliknya, jika suatu peubah berlawanan dengan arah vektor sutau peubah, maka objek tersebut memiliki nilai di bawah rata-rata dari peubah tersebut.
2 METODE PENELITIAN
Data
9
Tabel 1 Daftar peubah indikator kesejahteraan rakyat
Peubah indikator kesejahteraan rakyat Simbol
Persentase laju pertumbuhan penduduk (%) X1
Kepadatan penduduk per km2 (jiwa) Angka beban ketergantungan (jiwa) Rata-rata lama sakit (bulan/ tahun)
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (%)
X2
X3
X4
X5
Pengeluaran rata-rata perkapita sebulan (Rp)
Persentase rumah tangga dengan luas lantai kurang dari 10 m2 (%)
X6
X7
Persentase rumah tangga dengan sumber air minum ledeng (%) X8
Persentase penduduk usia muda 0 – 14 tahun (%) X9
Persentase penduduk usia lanjut ≥ 65 tahun (%) X10
Metode Analisis
Tahapan analisis data yang dilakukan dalam penelitian ini sebagai berikut : 1. Menentukan gerombol awal kabupaten/kota Provinsi Aceh tahun 2006.
Jumlah gerombol optimum tidak diketahui dari awal, sehingga jumlah gerombol ditetapkan sebanyak 2, 3, 4, 5, 6, 7, dan 8 gerombol. Alokasi kabupaten/kota pada setiap gerombol ditentukan berdasarkan letak keadaan geografis Provinsi Aceh.
2. Menstandarisasikan data kesejahteraan rakyat Provinsi Aceh, karena perbedaan satuan pada peubah.
3. Menggerombolkan kabupaten/kota Provinsi Aceh tahun 2006 dengan metode OCS dan NPS.
3a. Metode penggerombolan dengan OCS dilakukan dengan tahapan berikut: (1) Membagi objek-objek ke dalam c gerombol awal.
(2) Tetapkan
x
ik
x
k, untuk r =1, jika xik data tidak lengkap.Keterangan:
ik
x
= item objek ke–i pada peubah ke-k r = iterasi(3) Masuk ke tahapan 2 sampai 4 algoritma OCS (4) Berhenti jika
() ( 1) 5
,
10 | |
max ckr
r ck k c c c Keterangan : ck
c = pusat gerombol ke-c berdasarkan peubah ke–k
(5) Selainnya r = r +1, perbarui nilai keanggotaan objek ke-i terhadap gerombol ke-c dengan menggunakan formula sebagai berikut:
2 1
C c ci Ci ci d d u Keterangan:10
dengan
C c ci u 1
1∀ � ;
d
ci = jarak objek ke–i terhadap gerombolke-c C = banyaknya gerombol(6) Menentukan xik dengan formula :
C i u c u x C c ci C
c ci ck
ik
1 , ) ( ) ( 1 2 1 1 + r 2, jika xik data tidak lengkap.
(7) Kembali ke langkah 3.
3b. Metode penggerombolan dengan NPS dilakukan dengan tahapan berikut: (1) Membagi objek-objek ke dalam c gerombol awal.
(2) Tetapkan
x
ik
x
k, untuk r =1, jika xik data tidak lengkap.(3) Masuk ke tahapan 2 sampai 4 algoritma NPS (4) Berhenti jika
() ( 1) 5
,
10 | |
max ckr
r ck k c c c
(5) Selainnya r = r +1, tentukan :
xik cckr +1, dci = min {d11, d21 ... dci}, jika xik data tidak lengkap.
(6) Memperbarui nilai keanggotaan objek ke-i terhadap gerombol ke-c
dengan menggunakan formula sebagai berikut:
2 1
C c ci Ci ci d d u(7) Kembali ke langkah 3.
4. Evaluasi terhadap hasil penggerombolan.
Evaluasi hasil gerombol dalam hal ini dilakukan dengan dua cara yaitu dengan
Root Mean Square Standard Deviation (RMSSTD) dan Pseudo F statistik
5. Intepretasi hasil penggerombolan dari hasil metode penggerombolan data tidak lengkap yang terbaik berdasarkan RMSSTD.
11
Diagram alir yang digunakan dalam penelitian ini adalah:
Gambar 1 Diagram alir penelitian Mulai
Data Kesejahteraan Rakyat Provinsi Aceh
Tahun 2006
Menentukan gerombol awal 2, 3,4, 5, 6, 7, dan 8
Metode NPS Metode OCS
Membandingkan ketepatan gerombol OCS, NPS, dan PDS Menganalisis jumlah
gerombol optimum
Menganalisis jumlah gerombol optimum
Selesai Standarisasi Data
Hasil Gerombol Metode NPS Hasil Gerombol
12
4 HASIL DAN PEMBAHASAN
Kabupaten/kota di Provinsi Aceh yang digunakan dalam penelitian ini yaitu sebanyak 23 kabupaten/kota. Kapubaten yang memiliki data tidak lengkap pada tahun 2006 yaitu Kabupaten Pidie Jaya dan Kabupaten Subulussalam. Kabupaten tersebut merupakan kabupaten hasil pemekaran pada awal tahun 2007. Beberapa peubah yang memiliki data tidak lengkap pada kabupaten tersebut antara lain pada peubah X3 : angka beban ketergantungan (jiwa), X4 : rata-rata lama sakit
(bulan/tahun), X6 : pengeluaran rata-rata perkapita sebulan (Rp), X7 : persentase
rumah tangga dengan luas lantai kurang dari 10 m2 (%), X
8 : persentase rumah
tangga dengan sumber air minum ledeng (%), X9 : persentase penduduk usia muda
0-14 tahun (%), dan X10 : persentase penduduk usia lanjut ≥ tahun (%).
Keseluruhan data yang digunakan dalam penelitian ini memiliki 8% data yang tidak lengkap.
Analisis Gerombol Metode OCS
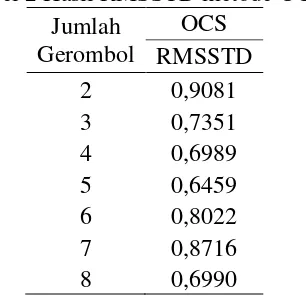
Penentuan jumlah gerombol yang optimum pada metode OCS dapat dilakukan menggunakan kriteria RMSSTD dan pseudo F. Hasil RMSSTD dapat mengevaluasi jumlah gerombol yang optimum secara kuantitatif berdasarkan hasil nilai RMSSTD yang terkecil. Jumlah gerombol yang memiliki RMSSTD terkecil menunjukkan bahwa jumlah gerombol tersebut memiliki keragaman yang lebih kecil dalam satu gerombol dibanding jumlah gerombol lainnya. Semakin kecil nilai RMSSTD semakin kecil keragaman dari gerombol yang terbentuk. Nilai RMSSTD yang tinggi menunjukkan gerombol yang terbentuk memiliki keragaman yang tinggi. Tabel 2. Menunjukkan hasil RMSSTD pada masing-masing jumlah gerombol dengan metode OCS. Berdasarkan Tabel 2. Jumlah gerombol 5 memiliki nilai RMSSTD lebih kecil dari jumlah gerombol lainnya. Hal tersebut menunjukkan bahwa jumlah gerombol 5 memiliki keragaman yang lebih kecil dalam satu gerombol dibanding jumlah gerombol lainnya.
Tabel 2 Hasil RMSSTD metode OCS Jumlah
Gerombol
OCS RMSSTD
2 0,9081
3 0,7351
4 0,6989
5 0,6459
6 0,8022
7 0,8716
8 0,6990
13
Gambar 2 Grafik RMSSTD metode OCS
Gambar 2. Menunjukkan bahwa semakin besar jumlah gerombol maka RMSSTD membentuk pola kubik dengan titik belok minimum pada jumlah gerombol 5. Sehingga jumlah gerombol lima merupakan jumlah gerombol yang optimum dalam menggerombolkan kabupaten/kota di Provinsi Aceh.
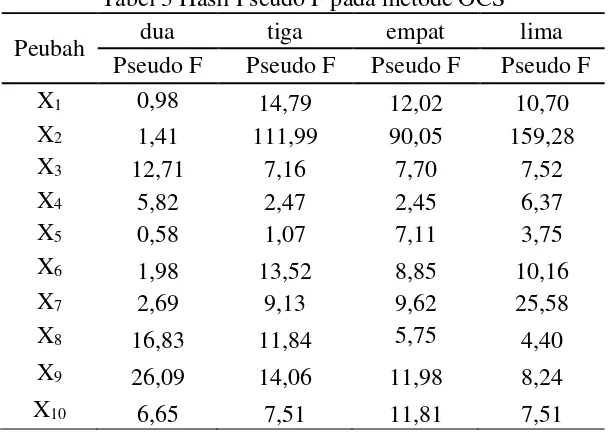
Pada penelitian ini, pseudo F digunakan untuk menunjukkan keragaman masing-masing peubah pada setiap jumlah gerombol. Jumlah gerombol dapat dicirikan oleh peubah dengan nilai pseudo F yang tinggi dibanding jumlah gerombol lainnya. Peubah yang memiliki nilai pseudo F tertinggi menunjukkan bahwa jumlah gerombol tersebut memiliki peubah dengan keragaman yang lebih kecil dibanding jumlah gerombol lainnya. Hal tersebut dapat memperlihatkan jumlah gerombol yang optimum untuk mendukung hasil RMSSTD. Berdasarkan grafik RMSSTD menunjukkan bahwa hasil nilai RMSSTD akan menurun sangat signifikan pada jumlah gerombol 2, 3, 4 dan 5, oleh karena itu perhitungan pseudo F di masing-masing peubah dilakukan pada jumlah gerombol 2, 3 ,4 dan 5. Tabel 3. Menunjukkan hasil pseudo F pada masing-masing peubah berdasarkan metode OCS.
Tabel 3 Hasil Pseudo F pada metode OCS
Peubah dua tiga empat lima
Pseudo F Pseudo F Pseudo F Pseudo F
X1 0,98 14,79 12,02 10,70
X2 1,41 111,99 90,05 159,28
X3 12,71 7,16 7,70 7,52
X4 5,82 2,47 2,45 6,37
X5 0,58 1,07 7,11 3,75
X6 1,98 13,52 8,85 10,16
X7 2,69 9,13 9,62 25,58
X8 16,83 11,84 5,75 4,40
X9 26,09 14,06 11,98 8,24
X10 6,65 7,51 11,81 7,51
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
0 1 2 3 4 5 6 7 8
R
MS
S
14
Berdasarkan Tabel 3. Hasil pseudo F dengan jumlah gerombol dua memiliki nilai pseudo F tertinggi pada peubah X3, X8, dan X9. Kemudian jumlah gerombol 3
memiliki nilai pseudo F tertinggi pada peubah X1 dan X6. Selanjutnya jumlah
gerombol empat memiliki nilai pseudo F tertinggi pada peubah X5 dan X10.
Kemudian jumlah gerombol lima memiliki nilai pseudo F tertinggi pada peubah X2,
X4, dan X7. Berdasarkan hasil perhitungan pseudo F pada masing-masing peubah,
setiap jumlah gerombol memiliki penciri yang berbeda-beda, sehingga pseudo F dalam penelitian ini tidak dapat digunakan untuk mengambil keputusan. Hasil jumlah gerombol yang optimum dapat dilihat berdasarkan hasil RMSSTD yaitu dengan jumlah gerombol lima.
Analisis Gerombol Metode NPS
Metode NPS merupakan algoritma khusus penggerombolan data tidak lengkap dengan teknik yang sama dengan metode OCS. Perbedaan dari metode OCS yaitu dalam menggantikan nilai yang tidak lengkap. Metode NPS menggantikan nilai yang tidak lengkap menggunakan pusat gerombol, berdasarkan jarak yang minimum. Evaluasi jumlah gerombol yang optimum pada metode NPS juga dapat dilihat dari hasil nilai RMSSTD dan pseudo F. Berikut merupakan hasil nilai RMSSTD pada masing-masing jumlah gerombol dengan metode NPS yang ditunjukkan pada Tabel 4.
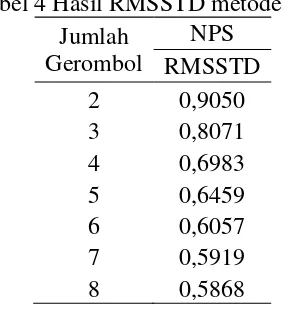
Tabel 4 Hasil RMSSTD metode NPS Jumlah
Gerombol
NPS RMSSTD
2 0,9050
3 0,8071
4 0,6983
5 0,6459
6 0,6057
7 0,5919
8 0,5868
Hasil RMSSTD pada Tabel 4. Menunjukkan bahwa semakin banyak jumlah gerombol hasil RMSSTD akan semakin kecil, namun pada jumlah gerombol enam sudah terlihat kovergen. Pada jumlah gerombol tujuh dan delapan perbedaan hasil RMSSTD dengan jumlah gerombol enam tidak jauh berbeda. Penurunan hasil nilai RMSSTD pada masing-masing jumlah gerombol pada metode NPS akan terlihat jelas pada grafik RMSSTD yang ditunjukkan pada Gambar 3.
15
Gambar 3 Grafik RMSSTD metode NPS
Jumlah gerombol yang optimum yaitu apabila setiap peubah yang digunakan memiliki keragam yang kecil dalam satu gerombol. Hal tersebut dapat ditunjukkan berdasarkan perhitungan pseudo F pada masing-masing peubah di setiap jumlah gerombol. Berdasarkan grafik RMSSTD pada Gambar 3. Menunjukkan bahwa jumlah gerombol mengalami penurunan yang signifikan pada jumlah gerombol 2, 3, 4, 5, dan 6. Dalam hal ini akan ditunjukkan hasil pseudo F di masing-masing peubah pada jumlah gerombol 2, 3, 4, 5, dan 6. Berikut merupakan hasil perhitungan pseudo F pada masing-masing peubah dengan metode NPS yang ditunjukkan pada Tabel 5.
Tabel 5 Hasil Pseudo F pada metode NPS
Peubah Dua Tiga Empat Lima Enam
Pseudo F Pseudo F Pseudo F Pseudo F Pseudo F
X1 0,98 0,46 12,02 10,7 8,59
X2 1,41 5,27 90,05 159,28 120,4
X3 14,14 19,01 7,78 7,66 6,33
X4 6,46 3,42 2,59 6,46 6,02
X5 0,58 0,15 7,11 3,75 2,95
X6 2,18 6,47 8,86 10,31 57,01
X7 2,95 33,51 9,71 25,66 19,73
X8 18,84 8,96 5,81 4,57 3,94
X9 29,48 20,8 12,05 8,4 6,3
X10 7,36 19,65 12,05 7,54 5,72
Berdasarkan Tabel 5. Hasil pseudo F dengan jumlah gerombol dua memiliki nilai pseudo F tertinggi pada peubah X4, X8, dan X9. Kemudian jumlah gerombol
tiga memiliki nilai pseudo F tertinggi pada peubah X3 dan X10. Selanjutnya jumlah
gerombol empat memiliki nilai pseudo F tertinggi pada peubah X1 dan X5.
Kemudian jumlah gerombol lima memiliki nilai pseudo F tertinggi pada peubah X2
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
1 2 3 4 5 6 7 8
R
MS
S
16
dan X7. Sedangkan jumlah gerombol enam memiliki nilai pseudo F tertinggi pada
peubah X6. Berdasarkan hasil perhitungan pseudo F pada masing-masing peubah,
setiap jumlah gerombol memiliki penciri yang berbeda-beda, sehingga hasil pseudo F pada metode NPS dalam penelitian ini tidak dapat digunakan untuk mengambil keputusan. Hasil jumlah gerombol yang optimum dari metode NPS dapat dilihat berdasarkan hasil RMSSTD yaitu dengan jumlah gerombol enam.
Perbandingan Hasil Gerombol PDS, OCS, dan NPS
Penelitian Safitri (2015), telah mengkaji metode gerombol murni tanpa imputasi dengan membandingkan metode KSC dan metode PDS menggunakan data simulasi dan data kesejahteraan rakyat Provinsi Aceh tahun 2006. Pada penelitian tersebut menyimpulkan bahwa metode PDS lebih baik dibanding metode KSC dalam menggerombolkan data tidak lengkap. Kemudian metode PDS diterapkan untuk menggerombolkan kabupaten/kota Provinsi Aceh tahun 2006 dengan 4 gerombol. Berdasarkan informasi tersebut, dalam penelitian ini akan dibandingkan metode yang terbaik dari OCS, NPS atau PDS dalam menggerombolkan kabupaten/kota di Provinsi Aceh tahun 2006 dengan 4 gerombol. Metode yang memiliki nilai RMSSTD yang terkecil maka dapat dikatakan bahwa metode tersebut dapat menghasilkan keragaman yang kecil dalam satu gerombol dibanding metode lainnya. Sehingga untuk mendapatkan metode yang terbaik yaitu dilihat berdasarkan hasil nilai RMSSTD pada masing-masing metode dengan jumlah gerombol empat. Hasil RMSSTD dapat dilihat pada Tabel 6.
Tabel 6 Hasil RMSSTD metode OCS, NPS, dan PDS Metode RMSSTD
OCS 0,6989
NPS 0,6983
PDS 0,7493
Hasil RMSSTD pada Tabel 5. Menunjukkan bahwa metode OCS dan NPS dengan jumlah gerombol empat memiliki nilai RMSSTD lebih kecil dibanding metode PDS. Berdasarkan hasil tersebut dapat dikatakan bahwa metode OCS dan NPS lebih baik dibanding metode PDS dalam menggerombolkan data tidak lengkap pada data kesejahteraan rakyat di Provinsi Aceh tahun 2006.
Hasil Gerombol Matode OCS
17 Tabel 7 Hasil penggerombolan kabupaten/kota di Provinsi Aceh pada
metode OCS
Gerombol Kabupaten/Kota
1 Sabang, Kota Langsa dan Lhokseumawe
2 Simeulue, Aceh Singkil, Aceh Tenggara, Aceh Timur, Aceh Tengah, Bireuen, Aceh Utara, Bener Merieh
3 Aceh Selatan, Aceh Barat, Aceh Barat Daya, Gayo Lues, Aceh Jaya, Subulussalam
4 5
Aceh Besar, Pidie, Aceh Tamiang, Nagan Raya, Pidie Jaya Banda Aceh
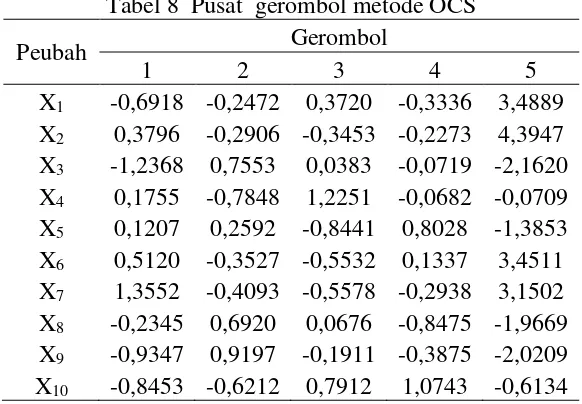
[image:31.595.166.457.284.486.2]Karakteristik dari masing-masing gerombol dapat dilihat berdasarkan pusat gerombol pada masing-masing peubah yang ditunjukkan pada Tabel 8.
Tabel 8 Pusat gerombol metode OCS
Peubah Gerombol
1 2 3 4 5
X1 -0,6918 -0,2472 0,3720 -0,3336 3,4889
X2 0,3796 -0,2906 -0,3453 -0,2273 4,3947
X3 -1,2368 0,7553 0,0383 -0,0719 -2,1620
X4 0,1755 -0,7848 1,2251 -0,0682 -0,0709
X5 0,1207 0,2592 -0,8441 0,8028 -1,3853
X6 0,5120 -0,3527 -0,5532 0,1337 3,4511
X7 1,3552 -0,4093 -0,5578 -0,2938 3,1502
X8 -0,2345 0,6920 0,0676 -0,8475 -1,9669
X9 -0,9347 0,9197 -0,1911 -0,3875 -2,0209
X10 -0,8453 -0,6212 0,7912 1,0743 -0,6134
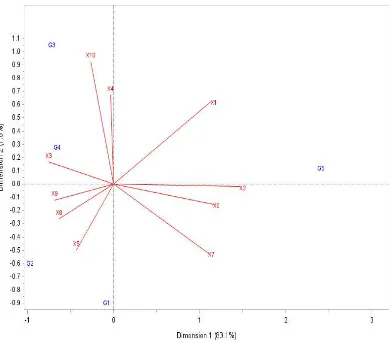
Selain menggunakan pusat gerombol dari masing-masing peubah, karakteristik kabupaten/kota pada setiap gerombol juga dapat dilihat secara visual dengan menggunakan analisis biplot. Hasil analisis biplot ditunjukkan pada Gambar 4.
Keragaman yang dapat dijelaskan dari hasil analisis biplot pada Gambar 4. yaitu sebesar 90,9% dengan dimensi pertama menjelaskan 83,1% dan dimensi kedua menjelaskan 7,8%. Hal tersebut juga menunjukkan bahwa terdapat 9,1% informasi yang hilang atau tidak dapat dijelaskan dari biplot.
18
Gambar 4 Biplot indikator kesejahteraan rakyat Provinsi Aceh Tahun 2006 dengan 5 gerombol pada metode OCS
Karakteristik kabupaten/kota di Provinsi Aceh yang dicirikan dari hasil biplot di masing-masing gerombol pada metode OCS ditunjukkan pada Tabel 9.
Tabel 9 Karakteristik gerombol metode OCS
Gerombol Karakteristik Gerombol
1
Pengeluaran rata-rata perkapita sebulan (X6) tinggi
Persentase rumah tangga dengan luas lantai kurang dari 10 m2 (X7 ) tinggi
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (X5) sedang
Persentase laju pertumbuhan penduduk (X1) rendah
Angka beban ketergantungan (X3) rendah
Persentase penduduk usia muda 0 – 14 tahun (X9) rendah
Persentase penduduk usia lanjut ≥ 65 tahun (X10) rendah
2
Angka beban ketergantungan (X3) tinggi
19
Gerombol Karakteristik Gerombol
2
Persentase rumah tangga dengan sumber air minum ledeng (X8)
tinggi
Persentase rumah tangga dengan sumber air minum ledeng (X8)
tinggi
Persentase penduduk usia muda 0 – 14 tahun (X9) tinggi
Kepadatan penduduk perkm2 (X2) rendah
Rata-rata lama sakit (X4) rendah
Pengeluaran rata-rata perkapita sebulan (X6) rendah
Persentase penduduk usia lanjut ≥ 65 tahun (X10) rendah
3
Angka beban ketergantungan (X3) tinggi
Rata-rata lama sakit (X4) tinggi
Persentase penduduk usia lanjut ≥ 65 tahun (X10) tinggi
Kepadatan penduduk perkm2 (X2) rendah
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (X5) rendah
Pengeluaran rata-rata perkapita sebulan (X6) rendah
Persentase rumah tangga dengan luas lantai kurang dari 10 m2 (X7 )
rendah
4
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (X5) tinggi
Persentase penduduk usia lanjut ≥ 65 tahun (X10) tinggi
Angka beban ketergantungan (X3) sedang
Persentase penduduk usia muda 0 – 14 tahun (X9) sedang
Persentase laju pertumbuhan penduduk (X1) rendah
Persentase rumah tangga dengan sumber air minum ledeng (X8)
rendah
5
Persentase laju pertumbuhan penduduk (X1) tinggi
Kepadatan penduduk perkm2 (X
2) tinggi
Pengeluaran rata-rata perkapita sebulan (X6) tinggi
Persentase rumah tangga dengan luas lantai kurang dari 10 m2 (X 7)
tinggi
Angka beban ketergantungan (X3) rendah
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (X5) rendah
Persentase rumah tangga dengan sumber air minum ledeng (X8)
rendah
Hasil Gerombol Metode NPS
20
Tabel 10 Hasil penggerombolan kabupaten/kota di Provinsi Aceh pada metode NPS
Gerombol Kabupaten/Kota
1 Sabang, Kota Langsa dan Lhokseumawe
2 Simeulue, Aceh Singkil, Aceh Tenggara, Aceh Timur, Aceh Tengah, Bireuen, Aceh Utara, Bener Merieh
3 Aceh Selatan, Aceh Barat, Aceh Barat Daya, Gayo Lues, Aceh Jaya, Subulussalam
4 5 6
Aceh Besar, Pidie, Aceh Tamiang, Nagan Raya, Pidie Jaya Banda Aceh
Aceh Barat Daya
[image:34.595.106.457.306.535.2]Karakteristik dari masing-masing gerombol dapat dilihat berdasarkan pusat gerombol pada masing-masing peubah yang ditunjukkan pada Tabel 11.
Tabel 11 Pusat gerombol metode NPS
Peubah Gerombol
1 2 3 4 5 6
X1 -0,6919 -0,2472 0,4676 -0,3336 3,4889 -0,1059
X2 0,3796 -0,2906 -0,3483 -0,2273 4,3947 -0,3305
X3 -1,2368 0,7553 0,1817 -0,0693 -2,162 -0,5611
X4 0,1755 -0,7848 0,9472 -0,0748 -0,0709 2,2784
X5 0,1207 0,2592 -0,9291 0,8028 -1,3853 -0,4189
X6 0,5120 -0,3527 -0,0168 0,1339 3,4511 -2,6463
X7 1,3552 -0,4093 -0,5003 -0,2937 3,1502 -0,7759
X8 -0,2345 0,6920 0,2862 -0,8474 -1,9669 -0,6344
X9 -0,9347 0,9197 -0,0645 -0,3867 -2,0209 -0,6896
X10 -0,8453 -0,6212 0,8209 1,0796 -0,6134 0,5699
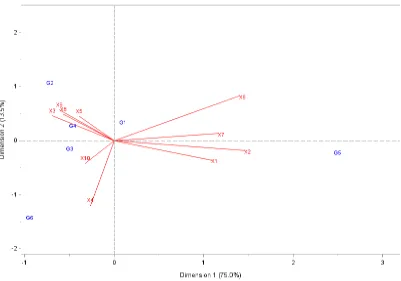
Selain menggunakan pusat gerombol dari masing-masing peubah, karakteristik kabupaten/kota pada setiap gerombol pada metode NPS juga dapat dilihat secara visual dengan menggunakan analisis biplot. Hasil analisis biplot ditunjukkan pada Gambar 5.
21
Gambar 5 Biplot indikator kesejahteraan rakyat Provinsi Aceh Tahun 2006 dengan 6 gerombol pada metode NPS
Karakteristik kabupaten/kota di Provinsi Aceh yang dicirikan dari hasil biplot
pada masing-masing gerombol dengan metode NPS ditunjukkan pada Tabel 12. Tabel 12 Karakteristik gerombol metode NPS
Gerombol Karakteristik Gerombol
1
Pengeluaran rata-rata perkapita sebulan (X6) tinggi
Persentase rumah tangga dengan luas lantai kurang dari 10 m2 (X 7)
tinggi
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (X5) sedang
Persentase laju pertumbuhan penduduk (X1) rendah
Angka beban ketergantungan (X3) rendah
Persentase penduduk usia lanjut ≥ 65 tahun (X10) rendah
2
Angka beban ketergantungan (X3) tinggi
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (X5) tinggi
Persentase rumah tangga dengan sumber air minum ledeng (X8)
tinggi Persentase penduduk usia muda 0 – 14 tahun (X9) tinggi
Kepadatan penduduk perkm2 (X2) rendah
Rata-rata lama sakit (X4) rendah
[image:35.595.110.515.472.738.2]22
Gerombol Karakteristik Gerombol
3
Angka beban ketergantungan (X3) tinggi
Rata-rata lama sakit (X4) tinggi
Persentase penduduk usia lanjut ≥ 65 tahun (X10) tinggi
Kepadatan penduduk perkm2 (X2) rendah
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (X5) rendah
Pengeluaran rata-rata perkapita sebulan (X6) rendah
Persentase rumah tangga dengan luas lantai kurang dari 10 m2 (X7 ) rendah
4
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (X5) tinggi
Persentase penduduk usia lanjut ≥ 65 tahun (X10) tinggi
Angka beban ketergantungan (X3) sedang
Persentase penduduk usia muda 0 – 14 tahun (X9) sedang
Persentase laju pertumbuhan penduduk (X1) rendah
Persentase rumah tangga dengan sumber air minum ledeng (X8)
rendah
5
Persentase laju pertumbuhan penduduk (X1) tinggi
Kepadatan penduduk perkm2 (X
2) tinggi
Pengeluaran rata-rata perkapita sebulan (X6) tinggi
Persentase rumah tangga dengan luas lantai kurang dari 10 m2 (X7) tinggi
Angka beban ketergantungan (X3) rendah
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (X5) rendah
Persentase rumah tangga dengan sumber air minum ledeng (X8)
rendah
Persentase penduduk usia muda 0 – 14 tahun (X9) rendah
6
Rata-rata lama sakit (X4) tinggi
Persentase penduduk usia lanjut ≥ 65 tahun (X10) sedang
Kepadatan penduduk perkm2 (X2) rendah
Pengeluaran rata-rata perkapita sebulan (X6) rendah
Persentase rumah tangga dengan luas lantai kurang dari 10 m2 (X7 ) rendah
23 5 SIMPULAN DAN SARAN
Simpulan
Berdasarkan hasil penggerombolan data tidak lengkap pada kabupaten/kota di Provinsi Aceh tahun 2006 dengan metode OCS dan NPS maka dapat disimpulkan sebagai berikut:
1. Pada penelitian ini, kriteria hasil penggerombolan dengan pseudo F tidak dapat digunakan untuk mengambil keputusan, dikarenakan masing-masing jumlah gerombol memiliki penciri yang berbeda-beda. Jumlah gerombol yang optimum dapat dinyatakan berdasarkan hasil RMSSTD.
2. Hasil penggerombolan dengan metode OCS lebih baik dari metode NPS dalam menggerombolkan kabupaten/kota di Provinsi Aceh tahun 2006. Hasil penggerombolan dengan metode OCS mendapatkan jumlah gerombol 5 sebagai jumlah gerombol yang optimum. Hal tersebut ditunjukkan dari hasil nilai RMSSTD terkecil yaitu pada jumlah gerombol 5.
3. Hasil RMSSTD dengan jumlah gerombol 4 menunjukkan bahwa metode OCS dan NPS lebih baik dibanding metode PDS dalam menggerombolkan data tidak lengkap pada data kesejahteraan rakyat di Provinsi Aceh tahun 2006.
Saran
24
DAFTAR PUSTAKA
Ben-Arieh D, Gullipalli DK, Wu C-H. 2010. DEA Analysis of Kansas Clinics with Sparse Data. Proceedings of the 2010 Industrial Engineering Research ConferenceA. Johnson and J.Miller,eds. Kansas. USA.
Caliński T, Harabasz J. 1974. A Dendrite Method for Cluster Analysis.
Communications in Statistics-theory and Method. 3(1): 1-27.
Halkidi M, Yannis B, Michalis V. 2001. On Clustering Validation Techniques.
Journal of Intelligent Information System 17(2/3):107-145. Netherlands. Jasmina D. 2015. Analisis Ketelantaran Lanjut Usia di Indonesia dengan Metode
Biplot dan Gerombol [Tesis]. Bogor: IPB.
Johnson RA, Wichern DW. 2007. Applied Multivariate Statistical Analysis. New Jersey (US): Pearson Prentice Hall. Ed ke-6.
Mattjik A, Sumertajaya IM. 2011. Sidik Peubah Ganda dengan Menggunakan SAS. Bogor (ID): IPB Press.
Matyja AA, Simiński K. 2014. Comparison of algorithms for clustering incomplete data.Journal Foundations of Computing and Decision Sciences 39 : 107–127. Rencher AC. 2002. Method of Multivariate Analysis. Canada: John Wiley dan Son,
Inc. Ed ke -2.
Safitri WD. 2015. Kajian Penggerombolan Data Tidak Lengkap dengan Algoritma Khusus Tanpa Imputasi [Tesis]. Bogor: IPB
Troyanskaya O, Cantor M, Sherlock G, Brown P, Hastie T, Tibshirani R, Botstein D, Altman RB. 2001. Missing value estimation methods for DNA microarrays. Journal Bioinformatics 17 : 520–525. USA.
Wagstaff K. 2004. Clustering with missing values: No imputation required. Proceedings of the Meeting of the International Federation of Classification Societies : 649–658. California.
25 RIWAYAT HIDUP
Penulis dilahirkan di Desa Pancasila, Kecamatan Natar, Kabupaten Lampung Selatan, pada tanggal 10 Desember 1991 dari bapak yang bernama Shohibun dan Ibu Fadliyah. Penulis merupakan anak sulung dari lima bersaudara. Penulis menyelesaikan pendidikan Taman Kanak-Kanak di TK Aisyiah Bustanul Athfal Desa Pancasila pada tahun 1997 dan lulus pada tahun 1998. Kemudian penulis melanjutkan pendidikan di Madrasah Ibtidayah Muhammadiyah (MIM) Pancasila dan lulus pada tahun 2004. Selanjutnya melanjutkan pendidikan Sekolah Menengah Pertama di SMP Muhammadiyah 3 Natar dan tamat pada tahun 2007. Penulis melanjutkan pendidikannya di jenjang SMA di Madrasah Aliyah (MA) Al-Fatah Natar dan lulus pada tahun 2010, kemudian penulis terdaftar sebagai mahasiswa jurusan Matematika Fakultas Matematika dan Ilmu Pengetahuan Universitas Lampung pada tahun 2010 melalui jalur Penelusuran Kemampuan Akademik dan Bakat (PKAB), dan menyelesaikannya pada tahun 2014. Pada tahun yang sama penulis menerima beasiswa Lembaga Pengelola Dana Pendidikan (LPDP) dan melanjutkan program master (S2) pada program studi Statistika Terapan di Pascasarjana IPB.