1 Latar Belakang Masalah
Burung adalah anggota kelompok hewan bertulang (vertebrata) yang memiliki bulu dan sayap. Jenis-jenis burung begitu bervariasi, mulai dari burung kolibri yang kecil hingga burung unta yang tingginya melebihi orang. Diperkirakan jenis burung yang terdapat didunia yaitu sekitar 8.800 hingga 10.200 spesies, dan sekitar 1650 jenis burung diantaranya ditemukan di Indonesia. Burung dapat dibagi dua macam yaitu diantaranya burung hias dan burung berkicau. Di Indonesia burung berkicau merupakan salah satu jenis burung yang paling diminati, hal tersebut dapat dilihat semakin banyaknya masyarakat yang memulai hobinya dalam memelihara burung dan juga lomba-lomba suara kicauan burung yang sering dan rutin diselenggarakan pada setiap kota. Oleh karena itu dibutuhkannya suatu kemudahan bagi para penghobi burung dalam mengidentifikasikan jenis suara burung berkicau terutama pada jenis burung yang memiliki karakteristik bentuk dan warna yang hampir sama. Suara merupakan salah satu bidang biometrik yang saat ini semakin berkembang. Pada penelitian sebelumnya yang dilakukan oleh Risha Annisa, Bambang Hidayat, dan Inung Wijayanto klasifikasi jenis suara burung menggunakan metode Wavelet Packet Decomposition dan Jaringan Syaraf Tiruan
rata-rata persentase pengenalan tertinggi terhadap pengujian dengan data rekam hanya mencapai 68,5% dan pengenalan tertinggi terhadap pengujian secara real time mencapai 58% [2].
Dalam penelitian ini metode yang akan digunakan untuk membangun sistem identifikasi jenis burung yaitu menggunakan metode Mel Frequency Cepstrum Coefficients (MFCC) untuk ekstraksi sinyal suara dan untuk identifikasi dibantu dengan menggunakan metode klasifikasi Jaringan Syaraf Tiruan Self Organizing Maps. Metode Mel Frequency Cepstrum Coefficients digunakan karena memiliki beberapa kelebihan diantaranya mampu menangkap informasi penting dalam sinyal suara, menghasilkan data seminimal mungkin tanpa menghilangkan informasi-informasi yang ada dan mereplikasikan organ pendengaran manusia dalam melakukan persepsi terhadap sinyal suara [3]. Hal ini dibuktikan pada penelitian sebelumnya untuk verifikasi suara orang dengan menggunakan metode MFCC didapatkan akurasi paling tinggi yaitu sekitar 93,254% [4].
Berdasarkan uraian diatas maka pada penelitian yang dilakukan ini, dengan mengimplementasikan metode Mel-Frequency Cepstrum Coefficients (MFCC) dan metode Jaringan Syaraf Tiruan Self Organizing Maps diharapkan dapat menghasilkan keakuratan yang lebih optimal dan waktu yang lebih cepat pada pengolahan suara digital terhadap identifikasi jenis suara burung, yang mana dapat membantu para masyarakat yang memulai hobinya dalam memelihara burung untuk mengidentifikasi jenis burung berdasarkan suaranya dengan lebih akurat dan cepat.
Identifikasi Masalah
Berdasarkan latar belakang masalah dan apa yang telah diuraikan di atas, maka dapat diidentifikasikan suatu masalah yaitu:
1. Diperlukannya perbandingan akurasi antar metode untuk memilih pemrosesan ekstraksi ciri dan klasifikasi yang tepat pada identifikasi jenis suara burung berkicau.
Maksud dan Tujuan
burung berkicau dan Jaringan Syaraf Tiruan Self Organizing Maps dalam identifikasi jenis burung.
Adapun tujuan yang ingin dicapai dalam penelitian ini, yaitu:
1. Mengimplementasikan dan mengukur tingkat akurasi metode Mel-Frequency Cepstrum Coefficients dan Jaringan Syaraf Tiruan Self Organizing Maps dalam identifikasi jenis suara burung berkicau.
Batasan Masalah
Terdapat beberapa batasan permasalahan yang dapat dirumuskan agar pembahasan masalah dapat lebih terarah dan terperinci sesuai dengan tujuan yang diharapkan dari penelitian ini. Adapun batasan-batasan masalah tersebut diantaranya adalah:
1. Sample suara kicau burung yang direkam dan disimpan dalam file berformat
wave (*.wav).
2. Jenis suara burung yang dianalisa berjumlah 7 jenis burung berkicau yang memiliki sub jenisnya diantaranya termasuk jenis burung Perkutut, Murai Batu, Kenari, Kacer, Kolibri, Jalak dan Glatik.
3. Jumlah sample suara yang akan dianalisis adalah 30 sample suara per subjenis sehingga jumlah sample suara keseluruhan yaitu 510 sample. 4. Sinyal suara memiliki frekuensi sampling 44100 Hz dan beresolusi 16 bit. 5. Proses ekstraksi ciri pada suara burung menggunakan metode Mel
Frequency Cepstral Coefficient (MFCC).
6. Proses identifikasi jenis burung menggunakan metode Jaringan Syaraf Tiruan Self Organizing Maps.
Metodologi Penelitian
Metode Pengumpulan Data
Metode pengumpulan data diperoleh secara langsung dari objek penelitian. Tahapan pengumpulan data yang digunakan yaitu:
a. Studi Literatur
Studi literatur yang dilakukan adalah dengan mempelajari berbagai literatur seperti buku, artikel, e-book, website, jurnal, dan sumber-sumber yang berkaitan dengan burung, metode MFCC dan Jaringan Syaraf Tiruan Self Organizing Maps untuk membantu dalam penelitian yang dilakukan. Studi literatur juga diperlukan untuk mendapatkan informasi penelitian-penelitian sebelumnya tentang metode dan sistem yang telah diterapkan.
b. Studi Lapangan
Studi ini dilakukan dengan mengunjungi tempat yang memiliki data yang dibutuhkan yaitu pada tempat perlombaan kicau burung dan pasar burung Sukahaji dengan pengumpulan data dilakukan secara langsung.
Metode Pembangunan Perangkat Lunak
Metode yang digunakan untuk pembangunan perangkat lunak dalam penelitian ini yaitu menggunakan linear sequential model atau sering disebut juga dengan waterfall model. Model ini adalah model klasik yang melakukan pendekatan secara sistematis, berurutan dalam membangun software karena melalui turunan dari satu fase ke fase yang lainnya. Tahap-tahap utama dari model ini yaitu [5]:
1. Requirements Analysis and Definition
Tahap ini berisi perencanaan, batasan dan tujuan sistem ditentukan melalui konsultasi dengan user sistem. Persyaratan ini kemudian didefinisikan secara rinci dan berfungsi sebagai spesifikasi sistem. Dan tahap perencanaan yang dilakukan adalah dengan memodelkan pemrograman terstruktur menggunakan (DFD) Data Flow Diagram, dan menerapkan metode Mel-Frequency Cepstrum Coefficient dan Jaringan Syaraf Tiruan
2. System and Software Design
Tahap design merupakan tahap perancangan dan menentukan arsitektur desain program dari pembangunan aplikasi identifikasi jenis suara burung. 3. Implementation and Unit Testing
Setelah tahap perancangan sistem selanjutnya dilakukan konversi rancangan sistem ke dalam kode-kode bahasa pemrograman Matlab. 4. Integration and System Testing
Unit program atau program individual diintegrasikan dan pengujian aplikasi dilakukan untuk memastikan keakuratan dan performansi dalam pengidentifikasian suara jenis burung sesuai dengan persyaratan dan desainnya. Setelah pengujian sistem, perangkat lunak dikirim kepada target
user.
5. Operation and Maintenance
Biasanya (walaupun tidak seharusnya), ini merupakan fase siklus hidup yang paling lama. Sistem diinstall dan dipakai. Pemeliharaan mencakup koreksi dari berbagai error yang tidak ditemukan pada tahap-tahap terdahulu, perbaikan atas implementasi unit sistem dan pengembangan pelayanan sistem, sementara persyaratan-persyaratan baru ditambahkan.
Requirements Definition
System and Software design
Implementation and unit testing
Integration and system testing
Operation and Maintenance
Sistematika Penulisan
Sistematika penulisan laporan skripsi penelitian ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan laporan skripsi ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi penjelasan mengenai latar belakang masalah, identifikasi masalah, maksud dan tujuan, batasan masalah, metodologi penelitian serta sistematika penulisan.
BAB II LANDASAN TEORI
Bab ini berisi tentang pembahasan mengenai landasan teori yang digunakan dalam pembangunan aplikasi identifikasi jenis burung melalui suara kicauan burung, yaitu menyangkut Voice Recognition, metode Mel Frequency Cepstrum Coefficient (MFCC), metode Jaringan Syaraf Tiruan Self Organizing Maps, teori pemodelan perangkat lunak terstruktur.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi tentang pembahasan mengenai analisis dan kebutuhan algoritma pada aplikasi identifikasi jenis burung melalui suara burung berkicau, analisis masalah, analisis bagaimana penerapan algoritma Mel Frequency Cepstrum Coefficients dan Jaringan Syaraf Tiruan Self Organizing Maps pada perangkat lunak yang dibangun, analisis studi kasus, analisis kebutuhan non fungsional, analisis kebutuhan fungsional, perancangan sistem dan analisis jaringan semantik. BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Menjelaskan mengenai implementasi dari hasil analisis dan perancangan perangkat lunak aplikasi identifikasi jenis suara burung yang telah dibangun dan disertai dengan kasus dan hasil pengujian aplikasi.
BAB V KESIMPULAN DAN SARAN
7 Kecerdasan Buatan
Kecerdasan Buatan (Artificial Intelligence atau AI) didefinisikan sebagai kecerdasan yang ditunjukkan oleh suatu entitas buatan. Sistem seperti ini umumnya dianggap komputer. Kecerdasan diciptakan dan dimasukkan kedalam suatu mesin (komputer) agar dapat melakukan pekerjaan seperti yang dapat dilakukan manusia [6].
Definisi Kecerdasan Buatan
Kecerdasan buatan merupakan salah satu bagian ilmu komputer yang membuat agar mesin (komputer) dapat melakukan pekerjaan seperti dan sebaik yang dilakukan oleh manusia. Pada awal diciptakannya, komputer hanya difungsikan sebagai alat hitung saja. Namun seiring dengan perkembangan zaman, maka peranan komputer semakin mendominasi kehidupan umat manusia. Komputer tidak lagi hanya digunakan sebagai alat hitung, lebih dari itu komputer diharapkan dapat diberdayakan untuk mengerjakan segala sesuatu yang bisa dikerjakan manusia.
Agar komputer bisa bertindak seperti dan sebaik manusia, maka komputer juga harus diberi bekal pengetahuan dan mempunyai kemampuan untuk menalar. Untuk itu pada Artificial Intelligence (AI) akan mencoba untuk memberikan beberapa metoda untuk membekali komputer dengan kedua komponen tersebut agar komputer bisa menjadi mesin yang pintar.
Pengertian kecerdasan buatan dapat dipandang dari berbagai sudut pandang, antara lain :
a. Sudut pandang kecerdasan
Kecerdasan buatan akan membuat mesin menjadi „cerdas‟ (mampu berbuat seperti apa yang dilakukan oleh manusia).
b. Sudut pandang penelitian
Kecerdasan buatan adalah suatu studi bagaimana membuat agar komputer dapat melakukan sesuatu sebaik yang dikerjakan oleh manusia.
c. Sudut pandang bisnis
Kecerdasan buatan adalah kumpulan peralatan yang sangat powerful dan metodologis dalam menyelesaikan masalah-masalah bisnis.
d. Sudut pandang pemrograman
Kecerdasan buatan meliputi studi tentang pemrograman simbolik, penyelesaian masalah (problem solving) dan pencarian (searching).
Untuk membuat aplikasi kecerdasan buatan ada 2 bagian utama yang sangat dibutuhkan, yaitu :
1. Basis Pengetahuan (Knowledge Base), berisi fakta-fakta, teori, pemikiran dan hubungan antara satu dengan lainnya.
2. Motor Inferensi (Inference Engine), yaitu kemampuan menarik kesimpulan berdasarkan pengalaman.
Kecerdasan Buatan dan Kecerdasan Ilmiah
Kecerdasan alamiah adalah kecerdasan yang dimiliki oleh manusia. Jika dibandingkan dengan kecerdasan buatan, ada beberapa keuntungan kecerdasan buatan dibanding kecerdasan alamiah, yaitu [6]:
1. Lebih permanen
Kecerdasan alamiah akan cepat mengalami perubahan. Hal ini dimungkinkan karena sifat manusia yang pelupa. Kecerdasan buatan tidak akan berubah sepanjang sistem komputer dan program tidak diubah.
2. Memberikan kemudahan dalam duplikasi dan penyebaran
Mentransfer pengetahuan manusia dari satu orang ke orang lain membutuhkan proses yang sangat lama dan keahlian itu juga tidak akan pernah dapat diduplikasi dengan lengkap. Oleh karena itu, jika pengetahuan terletak pada suatu sistem komputer, pengetahuan tersebut dapat disalin dari komputer tersebut dan dapat dipindahkan dengan mudah ke komputer yang lain.
3. Relatif lebih murah dari kecerdasan alamiah
Menyediakan layanan komputer akan lebih mudah dan lebih murah dibandingkan dengan harus mendatangkan seseorang untuk mengerjakan sejumlah pekerjaan dalam jangka watu yang sangat lama.
4. Konsisten dan teliti
Hal ini disebabkan karena kecerdasan buatan adalah bagian dari teknologi komputer. Sedangkan kecerdasan alami akan senantiasa berubah-ubah.
5. Dapat didokumentasi
Keputusan yang dibuat oleh komputer dapat didokumentasi dengan mudah dengan cara melacak setiap aktivitas dari sistem tersebut. Kecerdasan alami sangat sulit untuk direproduksi.
Sedangkan keuntungan kecerdasan alamiah dibanding kecerdasan buatan, yaitu:
1) Bersifat lebih kreatif.
Kemampuan untuk menambah ataupun memenuhi pengetahuan itu sangat melekat pada jiwa manusia. Pada kecerdasan buatan, untuk menambah pengetahuan harus dilakukan melalui sistem yang dibangun.
2) Dapat melakukan proses pembelajaran secara langsung, sementara AI harus mendapatkan masukan berupa simbol dan representasi.
3) Fokus yang luas sebagai referensi untuk pengambilan keputusan, sebaiknya AI menggunakan fokus yang sempit.
Komputer dapat digunakan untuk mengumpulkan informasi tentang objek, kegiatan (events), proses dan dapat memproses sejumlah besar informasi dengan lebih efisien dari yang dapat dikerjakan manusia. Namun disisi lain, manusia dengan menggunakan insting dapat melakukan hal yang sulit diprogram pada komputer, yaitu kemampuan mengenali (recognize) hubungan antara hal-hal tersebut, menilai kualitas dan menemukan pola yang menjelaskan hubungan tersebut.
Hubungan Kecerdasan Buatan Dengan Pengenalan Suara
Pemahaman Ucapan/Suara (Speech/Voice Understanding), adalah teknik agar komputer dapat mengenali dan memahami bahasa ucapan. Proses ini mengijinkan seseorang berkomunikasi dengan komputer dengan cara berbicara kepadanya.
Istilah “pengenalan suara” mengandung arti bahwa tujuan utamanya adalah
mengenai kata yang diucapkan tanpa harus tahu artinya, di mana bagian itu
merupakan tugas “pemahaman suara”.
MFCC (Mel Frequency Cepstrum Coefficient)
MFCC (Mel Frequency Cepstrum Coefficients) merupakan salah satu metode yang banyak digunakan dalam bidang speech technology, baik speaker recognation
1 Mampu untuk menangkap karakteristik suara yang sangat penting bagi pengenalan suara. Atau dengan kata lain, mampu menangkap informasi-informasi penting yang terkandung dalam sinyal suara.
2 Menghasilkan data seminimal mungkin tanpa menghilangkan informasi-informasi penting yang ada.
3 Mengadaptasi organ pendengaran manusia dalam melakukan persepsi terhadap sinyal suara.
Perhitungan yang dilakukan MFCC menggunakan dasar dari perhitungan short-term analysis. Hal ini dilakukan mengingat sinyal suara yang bersifat
quasistationary. Pengujian yang dilakukan untuk periode waktu yang cukup pendek (sekitar 0 sampai 10 milidetik) akan menunjukan karakteristik sinyal suara yang
stationary. Tetapi bila dilakukan dalam periode waktu yang lebih panjang karakteristik sinyal suara akan terus berubah sesuai dengan kata yang diucapkan.
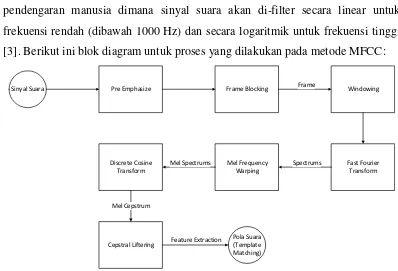
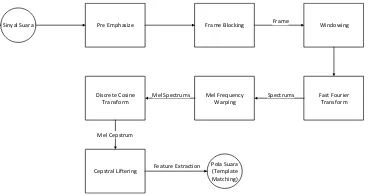
MFCC feature extraction sebenarnya merupakan adaptasi dari sistem pendengaran manusia dimana sinyal suara akan di-filter secara linear untuk frekuensi rendah (dibawah 1000 Hz) dan secara logaritmik untuk frekuensi tinggi [3]. Berikut ini blok diagram untuk proses yang dilakukan pada metode MFCC:
Sinyal Suara Pre Emphasize Frame Blocking Windowing
Fast Fourier Transform Mel Frequency
Warping Discrete Cosine
Transform
Cepstral Liftering
Pola Suara (Template Matching)
Frame
Spectrums Mel Spectrums
Mel Cepstrum
Feature Extraction
Gambar 2.2 Blok Diagram Alur Proses MFCC
Konversi Analog Menjadi Digital
komputer, semua sinyal yang dapat diproses oleh komputer hanyalah sinyal discrete
atau sering dikenal dengan istilah digital signal. Agar sinyal natural dapat diproses oleh komputer kita harus dapat mengubah data sinyal continue menjadi discrete. Hal itu dapat melalui tiga proses, diantaranya adalah proses sampling data, proses kuantisasi, dan proses pengkodean.
Proses sampling adalah suatu proses untuk mengambil data sinyal continue
untuk setiap periode tertentu. Dalam melakukan proses sampling data, berlaku aturan Nquist, yaitu bahwa frekuensi sampling (sampling rate) minimal harus dua kali lebih tinggi dari frekuensi maksimum yang akan disamplingkan. Jika sinyal sampling kurang dari dua kali frekuensi maksimum sinyal yang akan disampling, maka akan timbul efek aliasing. Aliasing adalah suatu efek dimana sinyal yang dihasilkan memiliki frekuensi yang berbeda dengan sinyal aslinya,
Proses kuantisasi adalah proses untuk membulatkan nilai data kedalam bilangan-bilangan tertentu yang telah ditentukan terlebih dahulu. Semakin banyak level yang dipakai maka semakin akurat pula data sinyal yang disimpan tetapi akan menghasilkan ukuran data yang besar dan proses lama.
Proses pengkodean adalah proses pemberian kode untuk tiap tiap data sinyal yang telah terkuantisasi berdasarkan level yang ditempati.
Gambar 2.3 Sinyal Sinus
Pre-Empasis
Pre-emphasis dilakukan untuk memperbaiki signal dari gangguan noise, sehingga dapat meningkatkan tingkat akurasi dari proses feature extraction. Default dari nilai alpha yang digunakan dalam proses pre-emphasis filtering adalah 0,9.
Bentuk yang paling umum digunakan dalam pre-emphasis filter adalah sebagai berikut:
= − � − (2.1)
Dimana 0.9 ≤ α ≤ 1.0 dan α € R, formula diatas dapat diimplementasikan
sebagai filter order differentiator, sebagai berikut
[ ] = [ ] − � [ − ] (2.2)
Keterangan:
y[n] = signal hasil pre-emphasis filter s[n] = signal sebelum pre-emphasis filter
Frame Blocking
Hasil perekaman suara merupakan sinyal analog yang berada dalam domain waktu yang bersifat variant time, yaitu suatu fungsi yang bergantung waktu. Oleh karena itu sinyal tersebut harus dipotong-potong dalam slot-slot waktu tertentu agar dapat dianggap invariant. Setiap potongan sinyal suara tersebut disebut frame.
Untuk menghitung jumlah frame digunakan rumus:
� �ℎ � � = − / + (2.3)
Keterangan: I = Sample rate
N = Sample point (Sample rate * waktu framing (s)) M = N/2
Gambar 2.5 Framing
Windowing
Fungsi window yang paling sering digunakan dalam aplikasi speaker recognation adalah Hamming Window. Fungsi ini menghasilkan sidelobe level yang tidak terlalu tinggi (kurang lebih -43dB) selain itu noise yang dihasilkan pun tidak terlalu besar (kurang lebih 1.36 BINS).
Window Hamming:
�ℎ� = . − . cos [�−� ] ≤ ≤ − (2.4)
Keterangan:
Wham(n) = Window Hamming
n = Sinyal ke [1 ... n]
N = Sample Point
Gambar 2.6 Window Hamming
Fast Fourier Transform
FFT (Fast Fourier Transform) adalah teknik perhitungan cepat dari DFT. FFT adalah DFT dengan teknik perhitungan yang cepat dengan memanfaatkan sifat periodikal dari transformasi fourier. Perhatikan definisi dari FFT:
� = ∑� − � �/�
Atau dapat dituliskan dengan:
� = ∑ cos � �� − ∑� sin � /
= �
= (2.6)
Untuk melihat nilai hasil FFT digunakan rumus:
| � | = [ + ] / (2.7)
Mel Frequency Warping (FilterBank)
Mel Frequency Warping umumnya dilakukan dengan menggunakan filterbank. Filterbank menggunakan representasi konvolusi dalam melakukan filter terhadap sinyal. Konvolusi dapat dilakukan dengan melakukan multiplikasi antara spektrum sinyal dengan koeffisien filterbank.
Berikut ini adalah rumus yang digunakan dalam perhitungan filterbank.
�[ ] = ∑� [ ]
= [ ] (2.8)
Keterangan:
N = jumlah magnitude spectrum
S[j] = magnitude spectrum pada frekuensi j
Hi[j] = koefisien filterbank pada frekuensi j (1 ≤ i ≤ M)
M = jumlah channel dalam filterbank
Dimana Hi= ��
⁄
Discrete Cosine Transform
Proses ini merupakan langkah akhir dari feature extraction. Hasil dari DCT ini adalah fitur-fitur yang dibutuhkan untuk melakukan proses analisa terhadap pengenalan suara tersebut. Menggunakan rumus:
= ∑ = cos[ − �] (2.9)
Keterangan:
Sk = keluaran dari proses filterbank pada indeks k
K = jumlah koefisien yang diharapkan
sangatlah berguna dalam menentukan end point dari suatu suku kata maupun kata. Hal ini disebabkan karena pada end point dari suatu suku kata maupun kata mempunyai energi yang lebih rendah daripada point-point.
Cepstral Liftering
Cepstral, hasil dari proses utama MFCC feature extraction, memiliki beberapa kelemahan. Low-order dari cepstral coefficients sangat sensitif terhadap
spectral slope, sedangkan bagian high order-nya sangat sensitif terhadap noise. Oleh karena itu, maka cepstral liftering menjadi salah satu standar teknik yang diterapkan untuk meminimalisasi sensitifitas tersebut.
Cepstral liftering dapat dilakukan dengan mengimplementasikan fungsi window terhadap cepstral features.
�[ ] = { + sin � } (2.10)
Keterangan:
L = jumlah cepstral coefficients
n= index dari cepstral coefficients
Cepstral liftering menghaluskan spektrum hasil dari main processor sehingga dapat digunakan lebih baik untuk pattern matching.
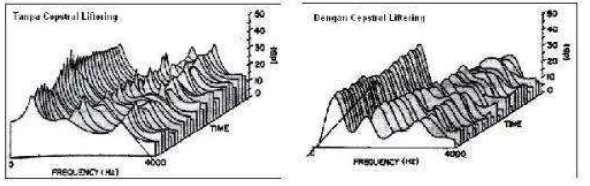
Gambar 2.7 Perbandingan Spectrum dengan dan Tanpa Cepstral liftering
Berdasarkan gambar diatas dapat dilihat bahwa pola spektrum setelah dilakukannya cepstral liftering lebih halus daripada spektrum yang tidak melalui tahap cepstral liftering. Dalam beberapa jurnal dikatakan bahwa cepstral liftering
Jaringan Syaraf Tiruan
Jaringan saraf tiruan (JST) adalah sistem pemrosesan informasi yang memiliki karakteristik mirip dengan jaringan saraf biologi. Hal ini menyerupai kerja otak dalam dua hal yaitu [7]:
1. Pengetahuan diperoleh oleh jaringan melalui suatu proses belajar,
2. Kekuatan hubungan antar sel saraf yang dikenal dengan bobot sinapsis digunakan untuk menyimpan pengetahuan.
JST merupakan sebuah model komputasi dari otak manusia yang mampu melakukan perhitungan, pengenalan, pengamatan serta pengambilan keputusan. Jaringan syaraf tiruan memanfaatkan struktur pengolahan paralel atas sejumlah pengolah sederhana dan hubungan antar pengolah tersebut. Dalam jaringan syaraf tiruan, terdapat elemen pengolah yang merupakan model dari neuron. Setiap hubungan elemen pengolah menentukan kemampuan JST. Seperti halnya jaringan saraf biologis, JST juga memiliki kemampuan untuk belajar dan beradaptasi terhadap masukan-masukannya. JST tidak perlu diprogram secara eksplisit, karena JST dapat belajar dari beberapa contoh pelatihan. Secara umum proses pembelajaran pada jaringan syaraf tiruan dibagi menjadi dua macam, yaitu:
1. Belajar dengan pengawasan (Supervised Learning)
Pada metode supervised learning jaringan diberikan vektor target yang harus dicapai sebagai dasar untuk mengubah hubungan interkoneksi atau bobot pada jaringan. Contoh jaringan yang belajar dengan pengawasan adalah Backpropagation dan Perceptron.
2. Belajar Tanpa Pengawasan (Unsupervised Learning)
Adaptive Resonance Theory 2 (ART 2), Self Organizing Map (SOM), dan Learning Vektor Quantization (LVQ).
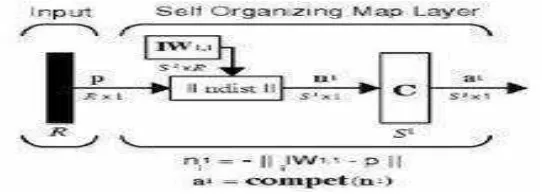
Jaringan Syaraf Tiruan Self Organizing Maps (SOM)
JST Kohonen - SOM merupakan salah satu model JST yang menggunakan metode unsupervised learning, yaitu mempelajari distribusi himpunan pola-pola tanpa informasi kelas. Jaringan ini terdiri dari dua lapisan (layer), yaitu lapisan input dan lapisan output. Setiap neuron dalam lapisan input terhubung dengan setiap neuron pada lapisan output. Setiap neuron dalam lapisan output merepresentasikan kelas (cluster) dari input yang diberikan.
Prinsip kerja dari algoritma SOM adalah pengurangan node-node tetangganya (neighbor), sehingga pada akhirnya hanya ada satu node output yang terpilih (winner node). Pertama kali yang dilakukan adalah melakukan inisialisasi bobot untuk tiap-tiap node dengan nilai random. Setelah diberikan bobot random, maka jaringan diberi input sejumlah dimensi node/neuron input (10x10). Setelah input diterima jaringan, maka jaringan mulai melakukan perhitung jarak vektor yang didapatkan dengan menjumlah selisih/jarak antara vektor input dengan vektor bobot.
Pada jaringan ini, suatu lapisan yang berisi neuron-neuron akan menyusun dirinya sendiri berdasarkan input nilai tertentu dalam suatu kelompok yang dikenal dengan istilah cluster. Selama proses penyusunan diri, cluster yang memiliki vector bobot paling cocok dengan pola input (memiliki jarak yang paling dekat) akan terpilih sebagai pemenang. Neuron yang menjadi pemenang beserta neuron-neuron tetangganya akan memperbaiki bobot-bobotnya. Berikut ilustrasi arsitektur JST SOM:
Bobot vektor-vektor contoh berfungsi sebagai penentu kedekatan antara vektor tersebut dengan masukan yang diberikan. Selama proses pengaturan, vektor contoh pada saat itu paling dekat dengan masukan akan muncul sebagai pemenang, kemudian vektor pemenang dan vektor-vektor sekitarnya akan dimodifikasi bobotnya.
Dalam JST SOM, neuron target tidak diletakkan dalam sebuah baris seperti layaknya model jaringan syaraf tiruan yang lain. Neuron target diletakkan dalam dua dimensi yang bentuk/topologinya dapat diatur.
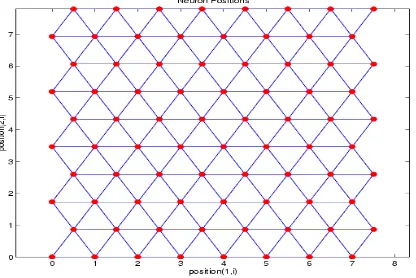
Ada tiga macam topologi yang dapat dibentuk yaitu [7]: 1. Gridtop
Dalam gridtop neuron disusun dalam array dua dimensi dengan bentuk persegi.
Gambar 2.9 Topologi Gridtop
2. Hextop
Dalam hextop neuron disusun dalam array dua dimensi dengan bentuk heksagonal.
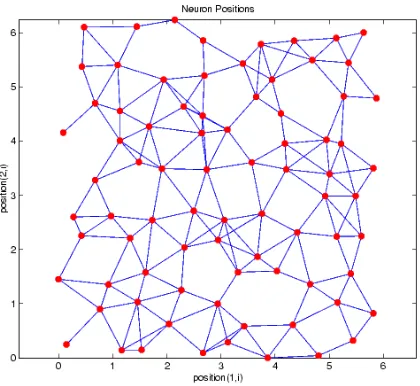
3. Randtop
Dalam randtop neuron disusun dalam array dua dimensi dengan susunan acak.
Gambar 2.11 Topologi Randtop
Jarak antara Neuron (Fungsi Jarak)
Dalam SOM, perubahan bobot tidak hanya dilakukan pada bobot garis yang terhubung ke neuron pemenang saja, tetapi juga pada bobot garis ke neuron-neuron di sekitarnya. neuron di sekitar neuron pemenang ditentukan berdasarkan jaraknya dari neuron pemenang. Ada 4 macam definisi jarak antara 2 neuron yaitu [7]:
1. Jarak Euclidean distance (Euclidist)
Jarak Euclidean distance adalah jarak antara 2 titik dalam posisi berbeda yang biasa kita kenal. Misal (x1,y1) dan (x2,y2) adalah koordinat 2 neuron, maka jarak kedua neuron tersebut didefinisikan sebagai:
2. Jarak Persegi (Boxdist)
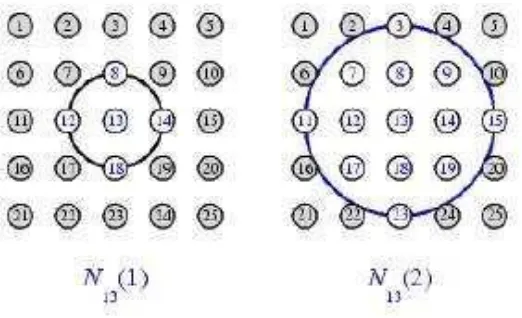
Gambar 2.12 Boxdist pada topologi Gridtop
Jarak persegi adalah jarak langsung antara neuron pemenang dengan neuron tetangganya secara langsung. Sebagai contoh apabila topologi neuron adalah gridtop, maka paling banyak terdapat 8 buah neuron tetangga dengan boxdist=1, dan terdapat paling banyak 16 tetangga jika boxdist=2. Jika neuron pemenang terletak di pinggir maka hanya ada 5 neuron tetangga dengan boxdist=1.
3. Jarak Link (Linkdist)
Jarak link adalah jumlah langkah yang dibutuhkan untuk menuju neuron tersebut. Jika dalam jaringan SOM menggunakan topologi gridtop dengan linkdist=1, berarti hanya neuron-neuron yang berhubungan langsung dengan neuron pemenang saja yang diubah bobotnya (jumlah neuron tetangga=4). Jika linkdist=2 maka jumlah neuron tetangga=12.
4. Jarak Manhattan (mandist)
Jarak Manhattan antara vector x (x1,x2,...,xn) dan vector y (y1,y2,...,yn) didefinisikan sebagai:
� (� − ) = ∑ | − | = (2.12)
Jika x=(x1,x2) dan y=(y1,y2) menyatakan koordinat neuron yang dibentuk melalui topologi tertentu, maka jarak Manhattan antara neuron x dan y adalah
� = | − | + | − | (2.13)
Basis Data
Sistem basis data adalah sistem terkomputerisasi yang tujuan utamanya adalah memelihara data yang sudah diolah atau informasi dan membuat informasi tersedia saat dibutuhkan . Pada intinya basis data adalah media untuk menyimpan data agar dapat diakses dengan mudah dan cepat [8]. Untuk basis data yang digunakan dalam Matlab yaitu berformat *.mat.
Analisis Terstruktur
Pengertian Analisis Terstruktur
Pemrograman terstruktur adalah konsep atau paradigma atau sudut pandang pemrograman yang membagi-bagi program berdasarkan fungsi-fungsi atau prosedur-prosedur yang dibutuhkan program komputer. Modul-modul biasanya dibuat dengan mengelompokan fungsi-fungsi dan prosedur-prosedur yang diperlukan sebuah proses tertentu.
Perangkat Pemodelan Analisis Terstruktur
Perangkat Pemodelan Analisis Terstruktur adalah alat bantu pemodelan yang digunakan untuk menggambarkan hasil pelaksanaan Analisis Terstruktur. Perangkat Analisis Terstruktur antara lain adalah [8]:
1) Diagram Konteks
Diagram konteks adalah diagram yang terdiri dari suatu proses dan menggambarkan ruang lingkup suatu sistem. Diagram konteks merupakan level tertinggi dari DFD yang menggambarkan seluruh input ke sistem atau output
dari sistem. Ia akan memberi gambaran tentang keseluruhan sistem. Dalam diagram konteks hanya ada satu proses. Tidak boleh ada store dalam diagram konteks. Diagram konteks berisi gambaran umum (secara garis besar) sistem yang akan dibuat. Secara kalimat, dapat dikatakan bahwa diagram konteks ini berisi siapa saja yang memberi data (dan data apa saja) ke sistem, serta kepada siapa saja informasi (dan informasi apa saja) yang harus dihasilkan sistem. 2) Diagram Aliran Data atau Data Flow Diagram (DFD)
Diagram untuk menggambarkan aliran data dalam sistem, sumber dan tujuan data, proses yang mengolah data tersebut, dan tempat penyimpanan datanya. Keuntungan dari diagram arus data adalah memungkinkan pengembangan sistem dari level yang paling tinggi dan memecah menjadi level yang lebih rendah. Beberapa simbol yang digunakan DFD adalah sebagai berikut :
a) Entitas Luar (External Entity)
Suatu yang berada diluar sistem, tetapi ia memberikan data ke dalam sistem atau memberikan data dari sistem, disimbolkan dengan suatu kotak notasi.
External Entity tidak termasuk bagian dari sistem. Bila sistem informasi dirancang untuk suatu bagian lain yang masih terkait menjadi external entity. b) Proses (Process)
masukan serta menghasilkan satu atau beberapa data kelurahan. Proses sering juga disebut bubble.
c) Arus Data (Data Flow)
Arus data merupakan tempat mengalirnya informasi dan digambarkan dengan garis yang menghubungkan komponen dari sistem. Arus data ditunjukan dengan arah panah dan garis diberi nama atas arus data yang mengalir. Arus data ini mengalir diantara proses, data store dan menunjukan arus data dari data yang berupa masukan untuk sistem atau hasil proses sistem.
d) Simpanan Data (Data Store)
Simpanan data merupakan tempat penyimpanaan data yang ada dalam sistem.
Data store dapat disimbolkan dengan dua garis sejajar atau dua garis dengan salah satu sisi samping terbuka. Proses dapat mengambil data dari atau memberikan data ke simpanan data (database).
3) Kamus Data (Data Dictionary)
Merupakan suatu tempat penyimpanan (gudang) dari data dan informasi yang dibutuhkan oleh suatu sistem informasi. Kamus data digunakan untuk mendeskripsikan rincian dari aliran data atau informasi yang mengalir dalam sistem, elemen-elemen data, file maupun basis data (tempat penyimpanan) dalam DFD.
Rekayasa Perangkat Lunak
Rekayasa perangkat lunak (software engineering) merupakan pembangunan dengan menggunakan prinsip atau konsep rekayasa dengan tujuan menghasilkan perangkat lunak yang bernilai ekonomi, dipercaya dan bekerja secara efisien menggunakan mesin. Rekayasa perangkat lunak lebih fokus pada praktik pengembangan perangkat lunak dan mengirimkan perangkat lunak yang bermanfaat bagi pengguna. Rekayasa perangkat lunak fokus pada bagaimana membangun perangkat lunak yang memenuhi kriteria berikut:
1. Dapat terus dipelihara setelah perangkat lunak selesai dibuat seiring berkembangnya teknologi dan lingkungan.
3. Efisien dari segi sumber daya dan penggunaan. 4. Kemampuan untuk dipakai sesuai dengan kebutuhan.
Pekerjaan yang terkait dengan rekayasa perangkat lunak dapat dikategorikan menjadi tiga buah kategori umum tanpa melihat area dari aplikasi, ukuran proyek atau kompleksitas perangkat lunak yang akan dibangun, yaitu:
1. Fase Pendefinisian (Definition Phase)
Fase pendefinisian fokus pada “what” yang artinya harus mencari tahu atau
mengidentifikasi informasi apa yang harus diproses, seperti apa fungsi dan performansi yang diinginkan, seperti apa prilaku sistem yang diinginkan, apa kriteria validasi yang dibutuhkan untuk mendefinisikan sistem.
2. Fase Pengembangan (Development Phase)
Fase pengembangan fokus pada “how” yang artinya selama tahap
pengembangan perangkat lunak seorang perekayasa perangkat lunak (software engineer) berusaha untuk mendefinisikan bagaimana data diinstrukturkan dan bagaimana fungsi-fungsi yang dibutuhkan diimplementasikan, bagaimana tampilan karakter antarmuka, bagaimana desain ditranslasikan ke dalam bahasa pemrograman dan bagaimana pengujian dijalankan.
3. Fase Pendukung (Support Phase)
Fase pendukung fokus pada perubahan yang terasosiasi pada perbaikan kesalahan (error), adaptasi yang dibutuhkan pada lingkungan perangkat lunak yang terlibat dan perbaikan yang terjadi akibat perubahan kebutuhan pengguna. Fase pendukung terdiri dari empat tipe perubahan antara lain:
a. Koreksi (Correction), yaitu pemeliharaan dengan melakukan perbaikan terhadap kecacatan perangkat lunak.
b. Adaptasi (Adaptation), yaitu merupakan tahap untuk memodifikasi perangkat lunak guna mengakomodasi perubahan lingkungan luar dimana perangkat lunak dijalankan.
d. Pencegahan (Prevention), pencegahan atau sering disebut juga dengan rekayasa ulang sistem (software reengineering) harus dikondisikan untuk mempu melayani kebutuhan yang diinginkan pemakainya.
Perangkat Lunak Pendukung
Adapun perangkat lunak pendukung yang digunakan dalam implementasi metode di aplikasi pengenalan dan identifikasi suara burung berkicau sebagai berikut :
MATLAB
Matlab dikembangkan sebagai bahasa pemograman sekaligus alat visualisasi, yang menawarkan banyak kemampuan untuk menyelesaikan berbagai kasus yang berhubungan langsung dengan disiplin ilmu matematika. Matlab dibangun dari bahasa induknya yaitu bahasa C, namun tidak dapat dikatakan sebagai varian dari bahasa C, karena dalam sintak maupun cara kerjanya sama sekali berbeda dari bahasa C. Namun dengan hubungan langsungnya dengan bahasa C, Matlab memiliki kelebihan-kelebihan dari bahasa C bahkan mampu berjalan pada semua platform Sistem Operasi tanpa mengalami perubahan sintak sama sekali. Bahasa ini mengintegrasikan kemampuan komputasi, visualisasi dan pemograman dalam sebuah lingkungan yang tunggal dan mudah digunakan. Matlab memberikan sistem interaktif yang menggunakan konsep array/matrik sebagai standar variabel elemennya tanpa membutuhkan pendeklarasian array seperti pada bahasa lainnya.
Matlab dikembangkan oleh MathWorks, yang pada awalnya dibuat untuk memberikan kemudahan mengakses data matrik pada proyek LINPACK dan EISPACK. Selanjutnya menjadi sebuah aplikasi untuk komputasi matrik. Dari sejak awal dipergunakan, matlab memperoleh masukan ribuan pemakai. Dalam lingkungan pendidikan ilmiah menjadi alat pemrograman standar bidang matematika, rekayasa dan keilmuan terkait. Dan dalam lingkungan industri dapat menjadi pilihan paling produktif untuk riset, pengembangan dan analisa [9].
Pengujian Perangkat Lunak
sedang diuji. Pengujian perangkat lunak juga memberikan pandangan mengenai perangkat lunak secara obyektif dan independen, yang bermanfaat dalam operasional bisnis untuk memahami tingkat risiko pada implementasinya. Teknik-teknik pengujian mencakup, namun tidak terbatas pada, proses mengeksekusi suatu
bagian program atau keseluruhan aplikasi dengan tujuan untuk menemukan “bug”
perangkat lunak. Bug merupakan suatu kesalahan desain pada suatu perangkat keras komputer atau perangkat lunak komputer yang menyebabkan peralatan atau program itu tidak berfungsi semestinya. Bug umumnya lebih umum dalam dunia perangkat lunak dibandingkan dengan perangkat keras [10].
Pengujian perangkat lunak merupakan suatu tahapan penting dalam pembangunan perangkat lunak. Pengujian dilakukan dengan cara mengevaluasi konfigurasi perangkat lunak yang terdiri dari spesifikasi kebutuhan, deskripsi perancangan, dan program yang dihasilkan. Hasil evaluasi kemudian dibandingkan dengan hasil uji yang diharapkan. Jika ditemukan kesalahan, maka perbaikan perangkat lunak harus dilakukan untuk kemudian diuji kembali.
Pengujian perangkat lunak adalah proses menjalankan dan mengevaluasi sebuah perangkat lunak secara manual maupun otomatis untuk menguji apakah perangkat lunak sudah memenuhi persyaratan atau belum, atau untuk menentukan perbedaan antara hasil yang diharapkan dengan hasil sebenarnya. Peksanaan pengujian perangkat lunak biasanya disesuaikan dengan metodologi pembangunan perangkat lunak yang digunakan.
Pengujian dikatakan berhasil apabila pengujian yang dilakukan memiliki probabilitas tinggi untuk menemukan kesalahan yang belum pernah ditemukan sebelumnya.
Teknik Pengujian
Teknik pengujian yang dapat digunakan dalam menguji perangkat lunak sebagai berikut :
a. Pengujian White Box
Secara sekilas dapat diambil kesimpulan white box testing merupakan petunjuk untuk mendapatkan program yang benar secara 100%.
Penggunaan metode pengujian white box dilakukan untuk :
1) Memberikan jaminan bahwa semua jalur independen suatu modul digunakan minimal satu kali
2) Menggunakan semua keputusan logis untuk semua kondisi true atau false 3) Mengeksekusi semua perulangan pada batasan nilai dan operasional pada
setiap kondisi.
4) Menggunakan struktur data internal untuk menjamin validitas jalur keputusan.
Persyaratan dalam menjalankan strategi White Box Testing sebagai berikut: 1) Mendefinisikan semua alur logika
2) Membangun kasus untuk digunakan dalam pengujian 3) Mengevaluasi semua hasil pengujian
4) Melakukan pengujian secara menyeluruh b. Pengujian Black Box :
Pengujian black box digunakan untuk menguji fungsi-fungsi khusus dari perangkat lunak yang dirancang. Pada teknik ini, kebenaran perangkat lunak yang diuji hanya dilihat berdasarkan keluaran yang dihasilkan dari data atau kondisi masukan yang diberikan untuk fungsi yang ada tanpa melihat bagaimana proses untuk mendapatkan keluaran tersebut. Dari keluaran yang dihasilkan, kemampuan program dalam memenuhi kebutuhan pemakai dapat diukur sekaligus dapat diiketahui kesalahan-kesalahannya.
Beberapa jenis kesalahan yang dapat diidentifikasi : 1) Fungsi tidak benar atau hilang
2) Kesalahan antar muka
3) Kesalahan pada struktur data (pengaksesan basis data) 4) Kesalahan inisialisasi dan akhir program
101
Berdasarkan pembahasan analisis, perancangan, implementasi hingga tahap pengujian maka dapat ditarik kesimpulan serta saran untuk implementasi metode MFCC (Mel-Frequency Cepstrum Coefficients) dalam identifikasi jenis suara burung berkicau.
Kesimpulan
Berdasarkan hasil implementasi dan pengujian yang didapat dalam penelitian serta telah disesuaikan dengan tujuan penelitian, maka dipeloreh kesimpulan sebagai berikut:
1. Penerapan metode MFCC (Mel-Frequency Cepstrum Coefficients) dan klasifikasi JST SOM berhasil diimplementasikan dalam identifikasi jenis suara burung berkicau dan didapatkan hasil akurasi sebesar 85,625% untuk kasus jenis burung yang sama sedangkan untuk kasus jenis burung yang masing-masing memiliki subjenis dengan karakteristik yang hampir sama dapat mendeteksi suara dengan tingkat akurasi sebesar 48,824% sehingga dapat disimpulkan sistem dengan menggunakan metode MFCC sebagai ekstraksi ciri dapat mengidentifikasi jenis burung lebih baik untuk kasus jenis burung dan sample yang sama dengan penelitian yang dilakukan sebelumnya yaitu burung perkutut, burung kenari, burung cucak ijo dan burung cucak rawa.
Saran
Berikut adalah saran yang dapat dilakukan untuk pengembangan dari penelitian yang telah dilakukan:
1. Mengembangkan aplikasi identifikasi jenis suara burung secara real time. 2. Menambah jumlah sample suara pelatihan dan pengujian lebih banyak agar
didapatkan hasil akurasi yang lebih optimal.
MFCC (Mel-Frequency Cepstrum Coefficients) dan Jaringan Syaraf Tiruan
Self Organizing Maps.
Nama : Fakhrizal Ahadiat
Tempat / tanggal lahir : Bandung / 07 Januari 1993
Jenis Kelamin : Laki-laki
Status : Belum Menikah
Agama : Islam
Alamat : Jln. Muararajeun Lama No 133A/144E,
Bandung
Tlp Genggam (HP) : +628561178932
Email : [email protected]
B. Pendidikan Formal
1998 – 2004 : SD Negeri 1 Ciluncat, Bandung 2004 – 2007 : SMPN 1 Soreang, Bandung
2007 – 2010 : SMKN 1 Katapang, Bandung
2010 – 2016 : Universitas Komputer Indonesia Bandung
C. Pendidikan Non-Formal
2009 – 2010 : Ganesha Operation
UNIKOM BANDUNG
2011 – 2012 : Anggota FUNCO (Comic Community)
UNIKOM BANDUNG
2008 – 2009 : Anggota Karate Indonesia SMKN 1
Katapang E. Kemampuan
Mampu bekerja sendiri dan berkerjasama secara tim.
Menguasai Office; Ms.Word, Ms.Excel, Ms.Power Point, Ms.Access,
Ms.Visio, Ms.Project.
Menguasai Pemograman; Bahasa C#, PHP, Java, MySQL.
PSD (Photoshop Design), CDR (Corel Draw), AI (Adobe Ilustrator).
F. Pengalaman Kerja
Bekerja di PT. Telkom Bandung
Periode : 2009 Status : Magang Posisi : Divisi IT
Bekerja di PT. Padjadjaran Mitra
Periode : Juli 2013 – November 2013 Status : Magang
Bandung, 24 Februari 2016
SKRIPSI
Diajukan Untuk Menempuh Ujian Akhir Sarjana
FAKHRIZAL AHADIAT
10110655
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
v
vi
vii
103
BERDASARKAN SUARA KICAU BURUNG MENGGUNAKAN WAVELET PACKET DECOMPOSITION DAN JARINGAN SYARAF
TIRUAN SELF ORGANIZING MAP,” 2012.
[2] F. AN, “PENGENALAN PENGUCAP TAK BERGANTUNG TEKS DENGAN METODE VEKTOR QUANTIZATION (VQ) MELALUI
EKSTRAKSI LINEAR PREDICTIVE CODING,” 2004.
[3] A. D. Andriana, “PERANGKAT LUNAK UNTUK MEMBUKA APLIKASI PADA KOMPUTER DENGAN PERINTAH SUARA MENGGUNAKAN
METODE MEL FREQUENCY CEPSTRUM COEFFICIENTS,” Jurnal
Ilmiah Komputer dan Informatika (KOMPUTA), vol. 2, no. 1, pp. 21-26, 2013.
[4] D. Putra dan A. Resmawan, “Verifikasi Biometrika Suara Menggunakan
Metode MFCC dan DTW,” Lontar Komputer, vol. 2, no. 1, pp. 8-21, 2011.
[5] I. Sommerville, Software Engineering (9th Edition), USA: Pearson Education, 2011.
[6] S. Kusumadewi, Artificial Intelligent (Teknik dan Aplikasinya), Yogyakarta: Graha Ilmu, 2003.
[7] A. Hermawan, Jaringan Saraf Tiruan Teori dan Aplikasi, Yogyakarta: Andi, 2006.
[8] R. A.S dan M. Shalahuddin, Rekayasa Perangkat Lunak Terstruktur dan Berorientasi Objek, Bandung: Informatika, 2013.
[9] G. A. Away, The Shortcut of MATLAB Programming, Bandung: Informatika Bandung, 2006.
BURUNG BERKICAU
Fakhrizal Ahadiat
Teknik Informatika – Universitas Komputer Indonesia Jl. Dipatiukur 112-114 Bandung
E-mail : [email protected]
ABSTRAK
Burung adalah anggota kelompok hewan bertulang (vertebrata) yang memiliki bulu dan sayap. Di Indonesia burung berkicau merupakan salah satu jenis burung yang paling diminati, hal tersebut dapat dilihat semakin banyaknya masyarakat yang memulai hobinya dalam memelihara burung dan lomba-lomba suara kicauan burung yang sering dan rutin diselenggarakan pada setiap kota. Oleh karena itu dibutuhkannya suatu kemudahan bagi para penghobi burung dalam mengidentifikasikan jenis suara burung berkicau terutama pada jenis burung yang memiliki karakteristik bentuk dan warna yang hampir sama.
Pada penelitian sebelumnya yang dilakukan oleh Risha Annisa, Bambang Hidayat, dan Inung Wijayanto klasifikasi jenis suara burung menggunakan metode Wavelet Packet
Decomposition dan Jaringan Syaraf Tiruan SOM
dengan jumlah sample sebanyak 4 jenis burung didapatkan akurasi dalam identifikasi sebesar 83,13%. Pada penelitian dan penyusunan tugas akhir ini untuk identifikasi jenis suara burung menggunakan metode Mel-Frequency Cepstrum Coefficients dan Jaringan Syaraf Tiruan SOM.
Berdasarkan hasil dari pengujian dapat disimpulkan bahwa metode MFCC dan Jaringan Syaraf Tiruan SOM dapat mendeteksi jenis suara burung dengan tingkat akurasi sebesar 85,625% untuk kasus jenis burung yang sama sedangkan untuk kasus jenis burung yang masing-masing memiliki subjenis dengan karakteristik yang hampir sama dapat mendeteksi suara dengan tingkat akurasi sebesar 48,824% sehingga dapat disimpulkan sistem dengan menggunakan metode MFCC sebagai ekstraksi ciri dapat mengidentifikasi jenis burung lebih baik untuk kasus jenis burung yang sama dengan penelitian yang dilakukan sebelumnya..
Kata Kunci : Burung Berkicau, Ekstraksi Ciri, MFCC, Jaringan Syaraf Tiruan SOM.
1. PENDAHULUAN 1.1Latar Belakang Masalah
Burung adalah anggota kelompok hewan bertulang (vertebrata) yang memiliki bulu dan sayap. Jenis-jenis burung begitu bervariasi, mulai dari burung kolibri yang kecil hingga burung unta yang tingginya melebihi orang. Diperkirakan jenis burung yang terdapat didunia yaitu sekitar 8.800 hingga 10.200 spesies, dan sekitar 1650 jenis burung diantaranya ditemukan di Indonesia. Burung dapat dibagi dua macam yaitu diantaranya burung hias dan burung berkicau. Di Indonesia burung berkicau merupakan salah satu jenis burung yang paling diminati, hal tersebut dapat dilihat semakin banyaknya masyarakat yang memulai hobinya dalam memelihara burung dan juga lomba-lomba suara kicauan burung yang sering dan rutin diselenggarakan pada setiap kota. Oleh karena itu dibutuhkannya suatu kemudahan bagi para penghobi burung dalam mengidentifikasikan jenis suara burung berkicau terutama pada jenis burung yang memiliki karakteristik bentuk dan warna yang hampir sama.
Suara merupakan salah satu bidang biometrik yang saat ini semakin berkembang. Pada penelitian sebelumnya yang dilakukan oleh Risha Annisa, Bambang Hidayat, dan Inung Wijayanto klasifikasi jenis suara burung menggunakan metode Wavelet Packet Decomposition dan Jaringan Syaraf Tiruan
Self Organizing Maps dengan jumlah sample
sebanyak 4 jenis burung didapatkan akurasi dalam identifikasi sebesar 83,13% [1] dikarenakan masih memiliki kekurangan dalam proses identifikasi jenis suara burung salah satunya yaitu belum dapat membedakan ciri suara pada 2 macam jenis burung diantaranya suara burung cucak ijo dan cucak rawa. Oleh karena itu maka dibutuhkannya perbandingan antar metode pemrosesan agar dapat memilih metode yang tepat untuk proses ekstraksi dan identifikasi jenis suara burung berkicau. Sementara penelitian lain dibidang biometrik suara yaitu dilakukan oleh Angga Setiawan, Achmad Hidayatno dan R. Rizal Isnanto dengan judul pengenalan pengucap tak bergantung teks menggunakan metode
tertinggi terhadap pengujian secara real time mencapai 58% [2].
Dalam penelitian ini metode yang akan digunakan untuk membangun sistem identifikasi jenis burung yaitu menggunakan metode Mel
Frequency Cepstrum Coefficients (MFCC) untuk
ekstraksi sinyal suara dan untuk identifikasi dibantu dengan menggunakan metode klasifikasi Jaringan Syaraf Tiruan Self Organizing Maps. Metode Mel Frequency Cepstrum Coefficients digunakan karena memiliki beberapa kelebihan diantaranya mampu menangkap informasi penting dalam sinyal suara, menghasilkan data seminimal mungkin tanpa menghilangkan informasi-informasi yang ada dan mereplikasikan organ pendengaran manusia dalam melakukan persepsi terhadap sinyal suara [3]. Hal ini dibuktikan pada penelitian sebelumnya untuk verifikasi suara orang dengan menggunakan metode MFCC didapatkan akurasi paling tinggi yaitu sekitar 93,254% [4].
Berdasarkan uraian diatas maka pada penelitian yang dilakukan ini, dengan mengimplementasikan metode Mel-Frequency Cepstrum Coefficients (MFCC) dan metode Jaringan Syaraf Tiruan Self
Organizing Maps diharapkan dapat menghasilkan
keakuratan yang lebih optimal dan waktu yang lebih cepat pada pengolahan suara digital terhadap identifikasi jenis suara burung, yang mana dapat membantu para masyarakat yang memulai hobinya dalam memelihara burung untuk mengidentifikasi jenis burung berdasarkan suaranya dengan lebih akurat dan cepat.
1.2Maksud dan Tujuan
Maksud dari penelitian yang dilakukan adalah untuk mengimplementasikan metode Mel-Frequency Cepstrum Coefficients dalam ekstrasi ciri sinyal suara burung berkicau dan Jaringan Syaraf Tiruan Self Organizing Maps dalam identifikasi jenis burung.
Adapun tujuan yang ingin dicapai dalam penelitian ini, yaitu:
1. Mengimplementasikan dan mengukur tingkat akurasi metode Mel-Frequency Cepstrum Coefficients dan Jaringan Syaraf Tiruan Self Organizing Maps dalam identifikasi jenis suara burung berkicau.
2. TEORI DASAR
Kecerdasan Buatan (Artificial Intelligence atau AI) didefinisikan sebagai kecerdasan yang ditunjukkan oleh suatu entitas buatan. Sistem seperti ini umumnya dianggap komputer. Kecerdasan diciptakan dan dimasukkan kedalam suatu mesin (komputer) agar dapat melakukan pekerjaan seperti yang dapat dilakukan manusia [6].
Pemahaman Ucapan/Suara (Speech/Voice Understanding), adalah teknik agar komputer dapat mengenali dan memahami bahasa ucapan. Proses ini mengijinkan seseorang berkomunikasi dengan komputer dengan cara berbicara kepadanya. Istilah “pengenalan suara” mengandung arti bahwa tujuan utamanya adalah mengenai kata yang diucapkan tanpa harus tahu artinya, di mana bagian itu merupakan tugas “pemahaman suara”.
2.2 MFCC
MFCC (Mel Frequency Cepstrum Coefficients) merupakan salah satu metode yang banyak digunakan dalam bidang speech technology, baik speaker recognation maupun speech recognation. Metode ini digunakan untuk melakukan feature extraction, sebuah proses yang mengkonversikan sinyal suara menjadi beberapa parameter. Keunggulan dari metode ini adalah:
1 Mampu untuk menangkap karakteristik suara yang sangat penting bagi pengenalan suara. Atau dengan kata lain, mampu menangkap informasi-informasi penting yang terkandung dalam sinyal suara.
2 Menghasilkan data seminimal mungkin tanpa menghilangkan informasi-informasi penting yang ada.
3 Mengadaptasi organ pendengaran manusia dalam melakukan persepsi terhadap sinyal suara.
MFCC feature extraction sebenarnya merupakan adaptasi dari sistem pendengaran manusia dimana sinyal suara akan di-filter secara linear untuk frekuensi rendah (dibawah 1000 Hz) dan secara logaritmik untuk frekuensi tinggi [3]. Berikut ini blok diagram untuk proses yang dilakukan pada metode MFCC:
Sinyal Suara Pre Emphasize Frame Blocking Windowing
Fast Fourier
Gambar 1 Blok Diagram Alur Proses MFCC
2.2.1 Pre-emphasize
Pre-emphasize dilakukan untuk memperbaiki
signal dari gangguan noise, sehingga dapat
Keterangan:
y[n] = signal hasil pre-emphasis filter s[n] = signal sebelum pre-emphasis filter
2.2.2 Frame Blocking
Hasil perekaman suara merupakan sinyal analog yang berada dalam domain waktu yang bersifat variant time, yaitu suatu fungsi yang bergantung waktu. Oleh karena itu sinyal tersebut harus dipotong-potong dalam slot-slot waktu tertentu agar dapat dianggap invariant. Setiap potongan sinyal suara tersebut disebut frame.
Untuk menghitung jumlah frame digunakan rumus:
Fungsi window yang paling sering digunakan dalam aplikasi speaker recognation adalah Hamming Window. Fungsi ini menghasilkan sidelobe level yang tidak terlalu tinggi (kurang lebih -43dB) selain itu noise yang dihasilkan pun tidak terlalu besar (kurang lebih 1.36 BINS).
Window Hamming: N = Sample Point
2.2.4 Fast Fourier Transform (FFT)
Proses windowing menghasilkan spektrum suara dalam domain waktu, untuk tidak terjadi kesalahan dalam proses warping path maka spektrum domain waktu dirubah menjadi sinyal frekuensi dengan menggunakan proses Fast Fourier Transform.
FFT (Fast Fourier Transform) adalah teknik perhitungan cepat dari DFT. FFT adalah DFT dengan teknik perhitungan yang cepat dengan memanfaatkan sifat periodikal dari transformasi fourier. Perhatikan definisi dari FFT:
� = ∑� − � �/�
= (4)
Atau dapat dituliskan dengan:
∑ = sin � / (5)
Untuk melihat nilai hasil FFT digunakan rumus: | � | = [ + ] / (6)
2.2.5 Mel Frequency Warping (FilterBank)
Magnitude hasil dari proses Fast Fourier Transform (FFT) selanjutnya akan melalui tahap
Filterbank. Filterbank ini bertujuan untuk
mengetahui ukuran energi pada Frequency Bandwith dalam signal suara. Langkah pertama yang dilakukan yaitu mencari nilai koefisien filterbank.
Berikut ini adalah rumus yang digunakan dalam perhitungan filterbank.
�[ ] = ∑� [ ]
= [ ] (7)
Keterangan:
N = jumlah magnitude spectrum
S[j] = magnitude spectrum pada frekuensi j Hi[j] = koefisien filterbank pada frekuensi j
(1 ≤ i ≤ M)
M = jumlah channel dalam filterbank Dimana Hi= ��
⁄
2.2.6 Discrete Cosine Transform (DCT)
Proses ini merupakan langkah akhir dari feature extraction. Hasil dari DCT ini adalah fitur-fitur yang dibutuhkan untuk melakukan proses analisa terhadap pengenalan suara tersebut. Menggunakan rumus:
= ∑ = cos[ − �] (8)
Keterangan:
Sk = keluaran dari proses filterbank pada indeks k
K = jumlah koefisien yang diharapkan
2.2.7 Cepstral Liftering
Cepstral, hasil dari fungsi DCT sebenarnya sudah merupakan hasil akhir dari proses feature extraction tetapi memiliki beberapa kelemahan. Low-order dari cepstral coefficients sangat sensitif terhadap spectral slope, sedangkan bagian high order-nya sangat sensitif terhadap noise. Oleh karena itu, maka cepstral liftering menjadi salah satu standar teknik yang diterapkan untuk meminimalisasi sensitifitas tersebut.
Cepstral liftering dapat dilakukan dengan
mengimplementasikan fungsi window terhadap cepstral features.
�[ ] = { + sin � } (9) Keterangan:
learning, yaitu mempelajari distribusi himpunan pola-pola tanpa informasi kelas. Jaringan ini terdiri dari dua lapisan (layer), yaitu lapisan input dan lapisan output. Setiap neuron dalam lapisan input terhubung dengan setiap neuron pada lapisan output. Setiap neuron dalam lapisan output merepresentasikan kelas (cluster) dari input yang diberikan. Berikut ilustrasi arsitektur JST SOM:
Gambar 2 Arsitektur JST-SOM
Dalam JST SOM, neuron target tidak diletakkan dalam sebuah baris seperti layaknya model jaringan syaraf tiruan yang lain. Neuron target diletakkan dalam dua dimensi yang bentuk/topologinya dapat diatur.
Ada tiga macam topologi yang dapat dibentuk yaitu [7]:
1. Gridtop
Dalam gridtop neuron disusun dalam array dua dimensi dengan bentuk persegi.
Gambar 3 Topologi Gridtop
2. Hextop
Dalam hextop neuron disusun dalam array dua dimensi dengan bentuk heksagonal.
Gambar 4 Topologi Hextop
3. Randtop
Dalam randtop neuron disusun dalam array dua dimensi dengan susunan acak.
Gambar 5 Topologi Randtop
3 ANALISIS
3.1 Deskripsi Umum Sistem
Pada bagian ini menjelaskan deskripsi umum sistem yang akan dibangun dan tentang metode yang akan diterapkan pada sistem. Dalam sistem identifikasi suara burung terdapat beberapa tahapan. Adapun tahapan sistem tersebut dapat dilihat pada gambar 6:
Burung Rekaman suara burung
Identifikasi JST - SOM
Gambar 6 Deskripsi Umum Sistem
Penjelasan dari gambar diatas adalah sebagai berikut:
1. Tahapan pertama pada sistem ini yaitu suara burung direkam menggunakan handphone dengan suara rekam berdurasi 3 detik kemudian suara rekaman burung tersebut disimpan ke komputer agar suara yang diinputkan dapat diolah oleh sistem.
2. Pre-processing
Tahapan ini yaitu mengubah suara dari sinyal analog menjadi sinyal digital dengan melalui tahapan konversi sinyal, akuisisi data, denoising, normalisasi dan tahapan Remove Silent/Cropping.
3. Analisis Ekstraksi Ciri MFCC (Mel-Frequency Cepstral Coefficients)
Tahapan ini yaitu merupakan tahapan yang paling penting dalam pembangunan sistem identifikasi yaitu proses pengekstraksian sinyal suara yang sudah dikonversi menjadi sinyal digital. Proses ekstraksi ciri ini dilakukan sebanyak dua kali yaitu pada tahap latih suara dan tahap uji suara. Tahapan analisis ekstraksi ciri MFCC terdiri dari 7 proses yaitu Pre Emphasize, Frame Blocking, Windowing, Fast Fourier Transform, Mel Frequency Warping,
Discrete Cosine Transform, dan Cepstral
Organizing Maps terdiri dari dua bagian yaitu pada data latih dan data uji. Pada proses data latih dilakukan proses untuk menentukan rentang kelas pada JST-SOM. Hasil tersebut akan digunakan untuk identifikasi jenis burung yang telah disesuaikan terlebih dahulu dengan kelas yang telah dihasilkan oleh JST-SOM yang dilatih.
3.2 Analisis Algoritma
Penelitian ini menggunakan metode ekstraksi ciri suara Mel-Frequency Cepstrum Coefficients (MFCC) dan metode Jaringan Syaraf Tiruan Self Organizing Maps dalam hal identifikasi. Dalam sistem ini tahap analisis dikhususkan dalam proses ekstraksi suara dan identifikasi suara burung berkicau, bagan pengenalan secara utuh dapat dilihat di gambar 7.
Gambar 7 Gambaran Alur Proses Latih Suara (a) dan Proses Uji Suara (b)
3.3 Analisis Pre-Processing 3.3.1 Denoising
Proses ini diperlukan untuk menghilangkan noise yang tidak diinginkan yang ikut terbawa pada proses perekaman sehingga data suara yang menjadi masukan untuk diekstraksi cirinya memiliki kualitas yang lebih baik.
3.3.2 Normalisasi
Proses ini bertujuan untuk menyamakan amplitude dari setiap suara burung yang direkam oleh sistem sehingga berada dalam rentang -1 dan +1. Penyamaan amplitude maksimum ini dilakukan karena level atau power yang dihasilkan subjek sample pada setiap perekaman tidak pasti sama. Sehingga untuk meminimalisasi perbedaan power digunakan proses normalisasi amplitude.
untuk meningkatkan akurasi sistem. Proses ini dilakukan dengan mencari nilai standar deviasi dari sinyal suara. Nilai standar deviasi tersebut dihitung berdasarkan rumus berikut:
= − ∑= − ̅ ⁄ (10)
Untuk standar nilai deviasi ditetapkan yaitu 0.01 Nilai sinyal yang lebih kecil dari nilai standar deviasi sinyal suara akan dianggap sebagai daerah silent. Setelah didapatkan daerah silent, dicari indeks maksimum dan minimum dari daerah silent tersebut dengan tujuan memotong daerah silent dari indeks minimum sampai daerah maksimum tersebut. Dengan demikian, daerah silent yang dipotong adalah daerah awal dan akhir dari sinyal suara. Berikut gambaran konsep dari Pre-processing:
Denoising Normalisasi Remove Silence
(Cropping)
Preprocessing
Gambar 8 Konsep Kerja Preprocessing
3.4Analisis MFCC
Metode Mel-Frequency Cepstrum Coefficients (MFCC) ini menggunakan beberapa parameter yang akan berperan penting dalan menentukan tingkat keberhasilan pengenalan signal suara. Berikut ini adalah keseluruhan proses MFCC feature extraction:
Mulai
3.5Analisis Identifikasi Jaringan Syaraf Tiruan Self Organizing Maps
JST-Topologi yang dipakai untuk identifikasi jenis burung pada penelitian ini yaitu menggunakan Topologi Gridtop, Hextop dan Randtop. Fungsi jarak yang digunakan adalah Euclidean Distance, Box Distance dan Manhattan Distance dengan jumlah epoch yaitu 150, 200, 250 dan 300.
Gambar 10 Posisi Bobot Latih JST-SOM Suara Burung
Gambar diatas adalah contoh hasil dari latih JST-SOM pada ekstraksi suara burung dengan jumlah epoch 150, topologi gridtop dan fungsi jarak yang digunakan adalah euclidean distances. Dari hasil tersebut untuk pencocokkan hasil ekstraksi pada proses pengujian diambil dengan cara mengambil nilai hasil uji yang lebih dekat dengan salah satu neuron hasil latih. Ketika salah satu neuron latih dipilih sebagai neuron yang paling cocok dengan nilai hasil uji maka neuron latih lainnya dibuang.
4 IMPLEMENTASI DAN PENGUJIAN 4.1Implemetansi Perangkat Keras
Perangkat keras yang digunakan untuk mengimplementasikan sistem dapat dilihat pada tabel 1.
Tabel 1 Spesifikasi Perangkat Keras
No. Perangkat Keras Spesifikasi
1. Prosesor intel i3 2.30 GHz
2 Monitor Monitor 14” 1366 x
768 (32Bit) (60Hz)
3 VGA 512Mb
4 Memori (RAM) 2GB
5 Keyboard dan Mouse Standard
6 Speaker Standard
4.2Implementasi Perangkat Lunak
Perangkat lunak yang digunakan untuk membangun dan mengimplementasikan sistem dapat dilihat pada tabel 2.
Tabel 2 Spesifikasi Perangkat Lunak
No. Perangkat Lunak Spesifikasi
1 Sistem Operasi Windows 7, 8, dan 8.1
3 Bahasa
Pemograman Matlab
4.3Pengujian Performansi
Dalam klasifikasi JST-SOM parameter yang mempengaruhi adalah topologi, fungsi jarak, dan pengulangan tiap vektor ciri atau epoch yang digunakan. Topologi yang digunakan dalam klasifikasi adalah Gridtop, Hextop, dan Randtop. Fungsi Jarak yang digunakan adalah Euclidean Distance, Box Distance, Manhattan Distance, dan Link Distance. Sedangkan jumlah epoch yang digunakan adalah 150, 200, 250, dan 300. Berikut adalah parameter yang digunakan dalam perhitungan akurasi sistem:
a. Akurasi
Akurasi adalah ukuran ketepatan sistem dalam mengenali input yang diberikan sehingga menghasilkan keluaran yang benar. Secara matematis, persamaan yang dapat dituliskan :
b. Error
Error adalah tingkat kesalahan sistem dalam hal mengenali input yang diberikan pada sistem terhadap jumlah data secara keseluruhan. Secara matematis, persamaan yang dapat dituliskan:
4.3.1Kasus Pengujian dengan Jumlah Sample 240
Berikut merupakan pengujian berdasarkan jenis burung dan jumlah data yang sama dengan penelitian yang dilakukan sebelumnya yaitu menggunakan 4 jenis suara burung. Rekaman yang digunakan adalah suara burung perkutut, suara burung kenari, suara burung cucak ijo, dan suara burung cucak rawa. Pada pengujian sistem ekstraksi ciri yang digunakan yaitu MFCC dan klasifikasinya yaitu JST-SOM. JST-SOM dilatih terlebih dahulu dengan menggunakan 20 data latih pada setiap masing-masing burung sehingga jumlah data suara latih terdiri dari 80 data. Untuk pengujiannya data yang digunakan yaitu 40 data uji yang berbeda dengan data latih pada masing-masing burung sehingga jumlah data yang diujikan yaitu 160 data.
1. Hasil Pengujian Penelitian Sebelumnya
Tabel 3 Hasil Akurasi Pengujian Pada Penelitian Sebelumnya
Jenis Gridtop Hextop Randtop
M M M
Hasil akurasi yang didapatkan oleh penelitian sebelumnya yaitu sebesar 83,13% terjadi pada jumlah epoch 200, topologi Randtop dan fungsi jarak Box.
2. Hasil Pengujian Metode MFCC
Tabel 4 Hasil Akurasi Pengujian dengan Menggunakan Metode MFCC
Jenis
Gridtop Hextop Randtop
Eu
Hasil akurasi yang didapatkan dengan menggunakan metode MFCC yaitu sebesar 85,625% terjadi pada jumlah epoch 150, topologi Randtop dan fungsi jarak Euclidean.
4.3.2Kasus Pengujian dengan Jumlah Sample 510
Berikut merupakan pengujian dengan menggunakan 7 jenis suara burung yang masing-masing burung memiliki sub jenisnya sehingga jumlah keseluruhan jenis burung yaitu 17 subjenis. Rekaman yang digunakan adalah subjenis dari suara burung perkutut, suara burung kenari, suara burung jalak, suara burung gelatik, suara burung kolibri, suara burung kacer dan suara burung murai batu. Pada pengujian sistem ekstraksi ciri yang digunakan yaitu MFCC dan klasifikasinya yaitu JST-SOM. JST-SOM dilatih terlebih dahulu dengan
digunakan yaitu 20 data uji yang berbeda dengan data latih pada masing-masing burung sehingga jumlah data yang diujikan yaitu 340 data.
Tabel 5 Hasil Akurasi Pengujian dengan Menggunakan 510 Sample
Jenis
Gridtop Hextop Randtop
Eu
Hasil akurasi yang didapatkan dengan menggunakan metode MFCC yaitu sebesar 48,824% terjadi pada jumlah epoch 150, topologi Gridtop dan fungsi jarak Box.
5 PENUTUP 5.1 Kesimpulan
![Gambar 1.1 Model Waterfall [5]](https://thumb-ap.123doks.com/thumbv2/123dok/1336209.795428/5.595.148.485.481.725/gambar-model-waterfall.webp)