PENERAPAN MODEL
CODEBOOK
UNTUK TRANSKRIPSI
SUARA KE TEKS DENGAN EKSTRAKSI CIRI
MEL-FREQUENCY CEPSTRUM COEFFICIENTS
(MFCC)
MEGGA DARA NINGGAR SUHARTO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Penerapan Model Codebook untuk Transkripsi Suara ke Teks dengan Ekstraksi Ciri Mel-Frequency Cepstrum Coefficients (MFCC) adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
MEGGA DARA NINGGAR SUHARTO. Penerapan Model Codebook untuk Transkripsi Suara ke Teks dengan Ekstraksi Ciri Mel-Frequency Cepstrum Coefficients (MFCC). Dibimbing oleh AGUS BUONO.
Seiring dengan perkembangan teknologi informasi, maka tuntutan manusia untuk memanfaatkan komputer guna mempermudah kehidupan sehari-hari juga makin bervariasi. Salah satunya adalah untuk membuat komputer mampu berkomunikasi secara alami dengan manusia. Penelitian ini menggunakan MFCC sebagai metode ekstraksi ciri dan codebook sebagai metode pengenalan pola untuk transkripsi suara ke teks. Teknik cluster yang digunakan pada penelitian ini adalah k-means. Data hasil MFCC diklasterkan menggunakan k-means, kemudian dibuat modelnya dengan metode codebook. Parameter MFCC yang digunakan adalah sampling rate 11 000 Hz, time frame 23.27 ms, overlapping 39%. Sebanyak 300 data suara berdurasi 5 detik dan berekstensi WAV digunakan sebagai data latih dan data uji untuk menemukan jumlah koefisien cepstral dan jumlah cluster yang menghasilkan akurasi tertinggi. Percobaan ini dilakukan dengan mengenali setiap suku kata pada 60 data uji dengan menggunakan 240 data latih. Hasil simulasi menunjukkan bahwa akurasi maksimum yang diperoleh adalah 98.3% pada koefisien cepstral 26 dan jumlah cluster 12.
Kata kunci : codebook, k-means, MFCC, transkripsi suara
ABSTRACT
MEGGA DARA NINGGAR SUHARTO. Application of Codebook Model for Voice to Text Transcription with Mel-Frequency Cepstrum Coefficients (MFCC) Feature Extraction.Supervised by AGUS BUONO.
The advancement of information technology has triggered various demands in utilizing computer. One of them is to make computers able to communicate naturally with humans. This study uses MFCC as a feature extraction method and codebook as a pattern recognition method for voice-to-text transcription. The clustering technique used in this study is k-means. Data obtained from MFCC are clustered using the k-means method, and the model for classification is constructed using the codebook method. The utilized MFCC parameters are sampling frequency 11 000 Hz, time frame 23.27 ms, overlapping 39%. 300 voice data in WAV files with 5 seconds of duration each, are used as the training data and test data to determine the number of cepstral coefficients and the number of cluster that can produce the highest accurancy. The experiment is conducted by recognizing each syllable in 60 the test data with 240 training data. Simulation result shows that the maximum accurancy obtained is 98.3% at 26 cepstral coefficients and 12 clusters.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
PENERAPAN MODEL
CODEBOOK
UNTUK TRANSKRIPSI
SUARA KE TEKS DENGAN EKSTRAKSI CIRI
MEL-FREQUENCY CEPSTRUM COEFFICIENTS
(MFCC)
MEGGA DARA NINGGAR SUHARTO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Penerapan Model Codebook untuk Transkripsi Suara ke Teks dengan Ekstraksi Ciri Mel-Frequency Cepstrum Coefficients (MFCC)
Nama : Megga Dara Ninggar Suharto NIM : G64114029
Disetujui oleh
Dr Ir Agus Buono, MSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian ini ialah pengenalan suara, dengan judul Penerapan Model Codebook untuk Transkripsi Suara ke Teks dengan Ekstraksi Ciri Mel-Frequency Cepstrum Coefficients (MFCC).
Terima kasih penulis ucapkan kepada:
1 Ayah, Ibu, Adik dan seluruh keluarga atas segala doa dan dukungan dalam pengerjaan karya ilmiah ini.
2 Bapak Dr Ir Agus Buono, MSi MKom selaku dosen pembimbing yang telah banyak memberi saran saat bimbingan.
3 Bapak Toto Haryanto, SKom MSi dan Ibu Karlisa Priandana, ST. M.Eng selaku dosen penguji atas kesediaannya sebagai penguji.
4 Tino Akbar mahasiswa ilkom angkatan 6 yang telah membantu selama pengumpulan data.
5 Teman-teman Ilkom alih jenis angkatan 6 khususnya teman-teman satu bimbingan yang senantiasa memberikan dukungan dan bantuan selama pengerjaan karya ilmiah ini.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 1
Manfaat Penelitian 1
Ruang Lingkup Penelitian 2
METODE 2
Lingkungan Pengembangan 3
Studi Literatur 3
Pengambilan Data Suara 3
Praproses 3
Pembagian Data Latih dan Data Uji 6
Pemodelan Codebook 7
Pengujian 8
Rancangan Percobaan 8
HASIL DAN PEMBAHASAN 9
Pengambilan Data Suara 9
Praproses 9
Pemodelan Codebook 10
Implementasi Sistem 10
Hasil dan Analisis Percobaan 11
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 13
DAFTAR PUSTAKA 13
DAFTAR TABEL
1 Data latih 6
2 Hasil akurasi dengan parameter jumlah cluster 12
3 Confusion matrix kesalahan dalam pengenalan suku kata pada koefisien 12 4 Persentase keberhasilan pengujian kata pada koefisien 12
DAFTAR GAMBAR
5 Tahapan proses penelitian 2
6 Alur praproses 3
7 Sinyal suara yang mengandung jeda dan silent 4
8 Diagram alur proses MFCC 4
9 Ilustrasi sebaran codebook (Marta 2013) 7
10 Ilustrasi perhitungan jarak data uji dengan sebuah codebook 8
11 Sinyal suara kata hama dari satu pembicara 9
12 Proses normalisasi sinyal suara (a) sebelum normalisasi, (b) sesudah
normalisasi 9
13 Proses segmentasi sinyal suara 10
14 Tampilan antarmuka proses pengenalan suku kata 10
15 Tampilan antarmuka proses akurasi penelitian 11
PENDAHULUAN
Latar Belakang
Seiring dengan perkembangan teknologi informasi, maka tuntutan manusia untuk memanfaatkannya guna mempermudah kehidupan sehari-hari juga makin bervariasi. Salah satunya adalah untuk membuat komputer mampu berkomunikasi secara alami dengan manusia. Secara umum, dalam berkomunikasi manusia menggunakan bahasa yang disampaikan dalam bentuk perkataan. Komunikasi digunakan oleh manusia untuk menciptakan dan menggunakan informasi tersebut agar dapat terhubung dengan lingkungannya dan orang lain (Brent dan Stewart 2006). Agar suatu informasi dapat dipahami, informasi tersebut harus disampaikan dengan baik agar tidak terjadi misinterpretasi dari informasi. Bagi manusia, mengenali suara bukanlah hal yang sulit untuk dilakukan lain halnya dengan komputer.
Hal inilah yang mendorong dikembangkannya penelitian dalam bidang suara, salah satunya transkripsi suara ke teks. Dalam proses transkripsi suara ke teks hal yang perlu diperhatikan adalah pengenalan kata. Pada proses tersebut, pengenalan kata digunakan untuk membandingkan suara masukan dengan data latih suara dan menghasilkan data suara yang paling cocok dengan cluster data latih suara tersebut.
Pada penelitian ini dibangun sebuah sistem yang dapat mendeteksi suara dan akan ditranskripsi ke teks. Secara sederhana kerja sistem ini dengan mencari ciri dari setiap suku kata dengan menggunakan mel frequency cepstrum coefficient (MFCC). MFCC digunakan pada sistem ini karena teknik MFCC telah banyak digunakan dalam berbagai bidang pemrosesan suara. Tujuan utama MFCC adalah meniru perilaku telinga manusia. Selain itu MFCC telah terbukti bisa merepresentasikan variasi dari gelombang suara (Do 1994). Setelah melakukan ekstraksi ciri, pada sistem ini akan digunakan codebook sebagai pengidentifikasi pola.
Pemilihan kedua metode ini berdasarkan penelitian yang dilakukan oleh Haryono (2013) dan Wisnudisastra dan Buono (2011) yang menggunakan codebook sebagai metode pengenalan pola dan MFCC sebagai metode ekstraksi ciri. Penelitian Haryono (2013) menghasilkan akurasi di atas 98.89%, sedangkan penelitian Wisnudisastra dan Buono (2011) menghasilkan akurasi 96%. Pemilihan MFCC sebagai metode ekstraksi ciri dan codebook sebagai metode identifikasi diharapkan dapat membantu pengguna sistem dalam mentranskripsi suara ke teks.
Tujuan Penelitian
Tujuan dari penelitian ini ialah:
1 Menerapkan MFCC sebagai metode ekstraksi ciri dan codebook sebagai metode indentifikasi pola untuk transkripsi suara ke teks.
2 Mengetahui akurasi transkripsi suara ke teks dengan ekstraksi ciri MFCC dan codebook sebagai metode identifiasi pola.
Manfaat Penelitian
2
Ruang lingkup dalam penelitian ini ialah: 1 Kata yang digunakan ialah kata bahasa Indonesia.
2 Difokuskan pada pengenalan suku kata, bukan pengenalan kalimat.
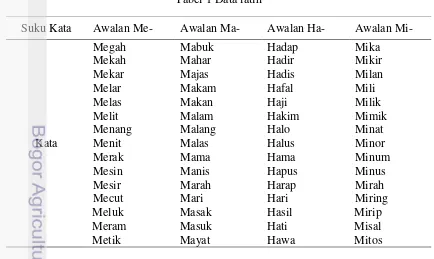
3 Menggunakan satu pembicara untuk pengambilan data latih (suara laki-laki usia ± 23 tahun).
4 Jumlah suku kata acuan ada empat berasal dari suku kata ME-, MA-, HA-, dan MI-. 5 Jumlah suku kata yang digunakan untuk acuan penelitian adalah dua suku kata. 6 Kata yang diujikan pada penelitian ini adalah hama, mama, maha, mimi, mami, dan
memi.
METODE
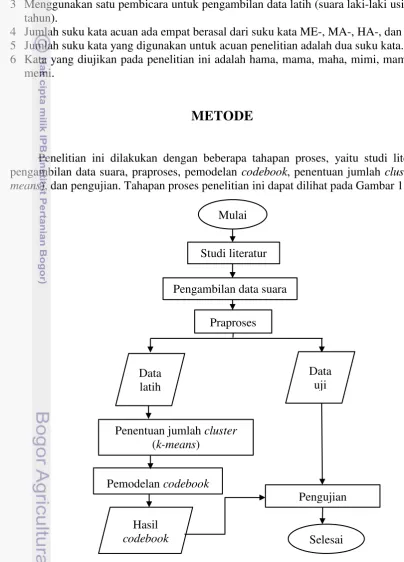
Penelitian ini dilakukan dengan beberapa tahapan proses, yaitu studi literatur, pengambilan data suara, praproses, pemodelan codebook, penentuan jumlah cluster (k-means), dan pengujian. Tahapan proses penelitian ini dapat dilihat pada Gambar 1.
3
Gambar 2 Alur praproses Lingkungan Pengembangan
Penelitian ini menggunakan perangkat keras dan perangkat lunak dengan spesifikasi sebagai berikut:
1 Perangkat Keras
Processor Intel Core 2 Duo CPU @ 2.10 GHz.
Memori 2 GB.
Harddisk 300 GB.
Keyboard dan mouse.
Monitor. 2 Perangkat Lunak
Sistem operasi Windows 8 Pro 64 bit.
Matlab 7.7.0 (R2008b).
Studi Literatur
Pada tahapan ini dilakukan pencarian dan pembelajaran tentang kebutuhan dalam penelitian ini. Hal-hal yang dibutuhkan antara lain tentang metode pengenalan pola codebook dan juga MFCC. Selain itu, hal-hal yang terkait dengan pengenalan suara akan dicari dan dipelajari untuk dijadikan referensi dalam penelitian ini.
Pengambilan Data Suara
Data yang digunakan dalam penelitian ini adalah data suara yang direkam oleh satu orang pembicara. Data suara yang direkam adalah suku kata berbahasa Indonesia dengan panjang suku kata yang direkam berjumlah dua suku kata. Banyaknya data suara yang direkam adalah sebanyak 300 data suara. Data suara direkam selama 5 detik, sampling rate 11 000 Hz, time frame 23.27 ms, overlap 39%, serta koefisien cepstral 13 dan 26 dengan ekstensi fail WAV.
Praproses
Tahapan ini mengolah setiap data suara yang telah direkam oleh pembicara. Alur dari tahapan ini dapat dilihat pada Gambar 2. Normalisasi dilakukan terhadap data suara agar nilai absolut maksimumnya menjadi |1|.
Segmentasi
Ekstraksi ciri MFCC Mel Cepstrum
4
Silent
Jeda
Silent
Selanjutnya dilakukan segmentasi karena data yang telah direkam merupakan data kotor yang mengandung blank dan jeda yang terdapat pada awal dan akhir suara seperti pada Gambar 3. Proses ini disebut pembersihan data (cutting silent). Tahap praproses selanjutnya adalah ekstraksi ciri sinyal suara yang menggunakan metode MFCC. MFCC telah banyak digunakan dalam berbagai bidang pemrosesan suara karena dapat mempresentasikan ciri sebuah sinyal suara (Do 1994). Dengan dilakukan ekstraksi ciri sinyal suara ditransformasikan ke dalam vektor-vektor ciri, dengan setiap vektornya merepresentasikan informasi yang terdapat pada beberapa frame. Selain itu, MFCC telah terbukti dapat merepresentasikan variasi dari gelombang suara (Do 1944).
Diagram alur proses MFCC dapat dilihat pada Gambar 4. Parameter yang digunakan dalam proses ini yaitu:
1 Input yang digunakan adalah data suara dengan ekstensi WAV. Sinyal suara yang digunakan telah melalui tahap pembersihan data.
2 Sampling rate yaitu banyaknya data yang akan diambil dalam satu detik.
3 Time frame adalah waktu yang dipakai untuk membagi data suara menjadi beberapa bagian frame.
4 Overlapping digunakan untuk mengurangi hilangnya informasi saat proses frame blocking.
5 Koefisien cepstral yaitu banyaknya koefisien cepstral yang diinginkan sebagai output.
Gambar 3 Sinyal suara yang mengandung jeda dan silent
Gambar 4 Diagram alur proses MFCC
Frame Blocking
Windowing FFT
5 Frame Blocking
Pada proses ini, sinyal suara dibagi menjadi beberapa frame. Setiap frame memilki N sample yang direpresentasikan dalam bentuk vektor. Frame-frame yang bersebelahan akan saling tumpang tindih (overlap). Hal ini dilakukan agar tidak ada sedikitpun sinyal yang hilang (deletion).
Windowing
Sinyal analog yang sudah diubah menjadi sinyal digital dibaca frame demi frame dan pada setiap frame-nya dilakukan windowing dengan fungsi window tertentu. Proses windowing bertujuan untuk meminimalisasi ketidakberlanjutan sinyal pada awal dan akhir setiap frame (Do 1994). Fungsi window yang dipakai adalah Hamming window yang dapat dilihat pada persamaan (1) (Do 1994):
w n - n - , 0nN-1 (1) Keterangan:
N = jumlah sampel pada setiap frame n = frame ke-n
w = fungsi Hamming window
Fast Fourier Transform (FFT)
Proses ini mengubah setiap frame dari domain waktu ke domain frekuensi. Hal ini dilakukan untuk mempermudah pemrosesan selanjutnya. Dengan algoritme FFT, kompleksitas menjadi rendah (Buono 2009). Dengan alasan inilah maka pada penelitian ini, transformasi Fourier yang digunakan adalah algoritme FFT. Algoritme FFT ditunjukkan oleh persamaan (2) (Do 1994):
n ∑ -
Persepsi manusia dalam frekuensi sinyal suara tidak mengikuti skala linear. Untuk setiap bunyi dengan frekuensi aktual f (dalam satuan Hz) nilai subyektif dari pitch-nya diukur dengan menggunakan skala mel. Skala mel-frequency adalah selang frekuensi linear di bawah 1000 Hz dan selang logaritmik untuk frekuensi di atas 1000 Hz. Satu relasi antara frekuensi bunyi (dalam Hz) dengan skala mel ditunjukkan pada persamaan (3) (Nilsson dan Ejnarsson 2002):
(3)
Mel-frequency wrapping umumnya dilakukan dengan menggunakan filterbank. Perhitungannya ditunjukkan pada persamaan (4) (Do 1994):
6
N = banyaknya data
Transformasi Kosinus (Discrete Cosine Transform)
Proses selanjutnya yaitu konversi log mel spectrum ke domain waktu. Hasilnya disebut mel frequency cepstrum coefficients. Representasi cepstral spectrum suara merupakan representasi property spectral local yang baik dari suatu sinyal untuk analisis frame. Mel spectrum coefficients dan logaritmanya berupa bilangan riil sehingga dapat dikonversikan ke domain waktu dengan menggunakan Discrete Cosine Transform (DCT). Proses DCT ditunjukkan pada persamaan (5) (Do 1994):
∑ (( - ) ) (5) Keterangan:
Cj = nilai koefisien C ke- j
j = jumlah koefisien cepstral i = jumlah wrapping
Xi = hasil mel-frequency pada frekuensi ke- i
Pembagian Data Latih dan Data Uji
7
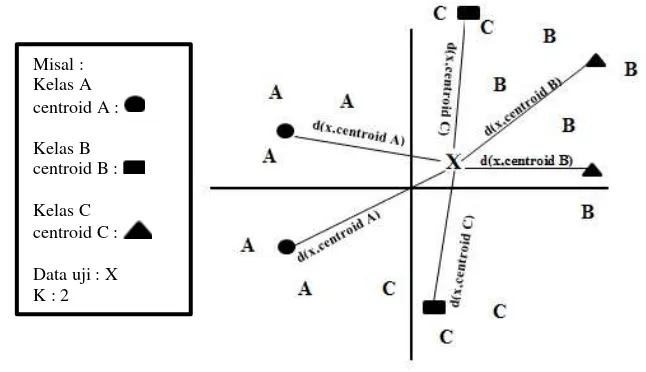
Pengenalan pola dengan codebook dilakukan untuk data latih setelah vektor ciri diperoleh dari proses MFCC. Codebook adalah kumpulan titik (vektor) yang mewakili distribusi suara dari suara tertentu dalam ruang suara. Setiap titik pada codebook dikenal sebagai codeword. Codebook merupakan cetakan yang dihasilkan suara setelah melakukan proses training. Setiap suara yang sudah direkam dibuat codebook yang terdiri atas beberapa codeword untuk merepresentasikan ciri suaranya. Codebook dibentuk dengan cara membentuk cluster semua vektor ciri yang dijadikan sebagai training set dengan menggunakan algoritme clustering. Algoritme clustering yang akan dipakai adalah k-means. Ilustrasi prinsip dasar pembuatan codebook dapat dilihat pada Gambar 5.
Langkah pertama yang dilakukan oleh algoritme ini adalah menentukan K-initial centroid, dengan k (jumlah cluster) adalah parameter spesifik yang ditentukan user, yang merupakan jumlah cluster yang diinginkan. Setiap titik atau objek kemudian ditempatkan pada centroid terdekat. Kumpulan titik atau objek pada tiap centroid disebut cluster.
Kemudian, langkah penempatan objek dan perubahan centroid diulangi sampai tidak ada objek yang berpindah cluster. Setiap suara yang masuk, akan dihitung jaraknya dengan codebook setiap kelas. Setelah itu, jarak setiap sinyal suara ke codebook dihitung sebagai jumlah jarak setiap frame sinyal suara tersebut ke setiap codeword yang ada pada codebook. Kemudian dipilih codeword dengan jarak minimum. Setelah itu, setiap sinyal suara yang masuk akan diidentifikasi berdasarkan jumlah dari jarak minimum tersebut. Perhitungan jarak dilakukan dengan menggunakan jarak euclid yang didefinisikan pada persamaan (6) (Buono dan Kusumoputro 2007):
deucl dean √∑ -
(6)
dengan x dan y adalah vektor yang ada sepanjang vector dimension (D).
Jika dalam sinyal suara input O terdapat T frame dan codewordk merupakan
masing-masing codeword yang ada pada codebook, jarak sinyal input dengan codebook dapat dirumuskan pada persamaan (7):
12
Tabel 2 Hasil akurasi dengan parameter jumlah cluster Koefisien Pada penelitian ini, pengujian yang paling baik dengan menggunakan koefisien cepstral 26 dan jumlah cluster 12. Parameter tersebut digunakan karena semakin kecil jumlah cluster yang digunakan semakin cepat proses pengujian terjadi. Tabel 3 menyajikan confusion matrix dari pengujian dengan menggunakan parameter seperti yang disebutkan sebelumnya, yaitu koefisien cepstral 26 dan jumlah cluster 12.
Tabel 3 Confusion matrix kesalahan dalam pengenalan suku kata pada koefisien cepstral 26 dengan jumlah cluster 12
Pada Tabel 4 diketahui banyak suku kata yang diujikan pada data latih yaitu 120 suku kata yang terdiri atas:
Suku kata me- sebanyak 10. Suku kata ma- sebanyak 50. Suku kata ha- sebanyak 20. Suku kata mi- sebanyak 40.
Dapat dilihat bahwa dengan menggunakan koefisien cepstral 26 dan jumlah cluster 12 hanya terjadi 2 kesalahan dalam pengenalan suku kata yaitu pada 1 suku kata ma teridentifikasi menjadi ha dan 1 suku kata ha teridentifikasi menjadi suku kata mi. Tabel 4 menyajikan hasil persentase keberhasilan dari kata yang diujikan.
Tabel 4 Persentase keberhasilan pengujian kata pada koefisien cepstral 26 dan jumlah cluster 12
Data uji Persentase (%) keberhasilan
13
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan, maka dapat disimpulkan bahwa: 1 Penelitian ini telah berhasil menerapkan metode pengenalan pola codebook dan
ekstraksi ciri MFCC dalam transkripsi suara ke teks.
2 Akurasi tertinggi yang dihasilkan 98.3% yang diperoleh pada koefisien cepstral 26 dengan jumlah cluster 12.
Saran
Saran untuk pengembangan selanjutnya yaitu:
1 Jumlah kata yang lebih banyak agar diperoleh suku kata yang lebih variatif. 2 Banyaknya suku kata di setiap perekaman kata lebih banyak dari 2 suku kata. 3 Pembicara yang melakukan perekaman lebih dari satu pembicara.
DAFTAR PUSTAKA
Buono A. 2009. Representasi nilai HOS dan model MFCC sebagai ekstraksi ciri pada aplikasi indentifikasi pembicara di lingkungan ber-noise menggunakan HMM. [disertasi]. Depok (ID): Program Studi Ilmu Komputer, Universitas Indonesia. Buono A, Kusumoputro B. 2007. Pengembangan model HMM berbasis maksimum lokal
menggunakan jarak Euclid untuk sistem identifikasi pembicara. Di dalam: Prosiding Workshop NACSIIT; 2007 Jan 29-30; Depok (ID). hlm 52.
Do MN. 1994. Digital Signal Processing Mini-Project: An Automatic Speaker Recognition System. Laussane (CH): Audio Visual Communications Laboratory, Swiss Federal Institute of Technology.
Haryono T. 2013. Pengembangan model codebook untuk konversi suara gitar ke tangga nada [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Marta A. 2013. Pembangunan metode codebook untuk identifikasi chord gitar dengan teknik ekstraksi ciri MFCC [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Nilsson M, Ejnarsson M. 2002. Speech recognition using hidden markov model: performance evaluation in noisy environment [tesis]. Karlskrona: Department of Telecommunications and Speech Processing, Blekinge Institute of Technology. Brent DR, Stewart LP. 2006. Communication and Human Behavior. Waipahu (US):
Allyn and Bacon
14
RIWAYAT HIDUP
Penulis dilahirkan di Sukabumi, Jawa Barat, Indonesia pada tanggal 16 September 1990. Penulis merupakan anak pertama dari dua bersaudara, dari pasangan Suharto, dan Tuti Ernawati, SE.
Penulis memulai pendidikan formal dari TK Nugraha 3 Bogor dan lulus pada tahun 1996, kemudian melanjutkan pendidikan di SD Negeri Polisi 4 Bogor dan lulus pada tahun 2001. Pendidikan menegah diselesaikan di SMP Negeri 5 Bogor dan lulus tahun 2005. Lalu, penulis melanjutkan pendidikan tingkat atas di SMA Negeri 2 Bogor dan lulus pada tahun 2008.