PENERAPAN MEL-FREQUENCY CEPSTRUM COEFFICIENTS
(MFCC) SEBAGAI EKSTRAKSI CIRI PADA
TRANSKRIPSI SUARA KE TEKS DENGAN
SELF ORGANIZING MAPS (SOM)
TINO AKBAR
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Penerapan Mel-Frequency Cepstrum Coefficients (MFCC) sebagai Ekstraksi Ciri pada Transkripsi Suara ke Teks dengan Self Organizing Maps (SOM) adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Februari 2014 Tino Akbar NIM G64114024
ABSTRAK
TINO AKBAR. Penerapan Mel-Frequency Cepstrum Coefficients (MFCC) sebagai Ekstraksi Ciri pada Transkripsi Suara ke Teks dengan Self Organizing Maps (SOM). Dibimbing oleh AGUS BUONO.
Transkripsi suara ke teks adalah suatu teknik yang memungkinkan sebuah komputer untuk menerima input berupa kata yang diucapkan dan ditranskripsikan ke dalam sebuah teks. Tujuan penelitian ini adalah mengembangkan suatu sistem transkripsi suara ke teks dengan ekstraksi ciri MFCC dan pemodelan jaringan syaraf tiruan Self Organizing Maps (SOM). Data yang digunakan adalah data suara yang telah direkam dari satu pembicara yang mengucapkan 15 kata untuk data latih dan 5 kata untuk data uji. Masing-masing kata diulang hingga mencapai 240 data latih dan 50 data uji. Kemudian ciri data suara diekstraksi dengan sampling rate 11000 Hz, time frame 23.27 ms, overlap 0.39 ms, dan koefisien cepstral 13 untuk mendapatkan karakteristik dari sinyal suara dalam setiap frame. Percobaan dilakukan dengan mengenali tiap suku kata yang ada pada data uji. Hasil menunjukkan bahwa akurasi tertinggi yang diperoleh sebesar 95% pada kombinasi parameter epoch 10, 30, 50, 70, 90 dan 110, learning rate sebesar 0.5, penurunan learning rate 0.999, dan radius 0.
Kata kunci: ekstraksi fitur, Mel-Frequency Cepstrum Coefficients (MFCC), Self Organizing Map, pembicara tunggal, transkripsi
ABSTRACT
TINO AKBAR. Application of Mel-Frequency Cepstrum Coefficients (MFCC) for Extraction Feature in Voice Transcription to Text Using Self Organizing Map (SOM). Supervised by AGUS BUONO.
Transcripting voice to the text is a technique that enables a computer to receive spoken words as input. The purpose of this experiment is to develop a voice to text transcription system by extracting the characteristics of MFCC and artificial neural network of Self Organizing Maps (SOM). The data used are recorded from one speaker who pronounced is words 15 for training data and 5 words for testing data. In total, training and testing data consisted of 240 and 50 data respectively. Then the voice data are extracted with a sampling rate of 11000 Hz, 23.27 ms, 0.39 ms and a cepstral coefficient of 13 to obtain the characteristics of the speech signal in each frame. The experiment is conducted by identifying every syllable found in the experiment data. The highest accuration is 95% at epochs 10, 30, 50, 70, 90 and 110 with a learning rate of 0.5, a learning reduction rate of 0.999, and a radius of 0.
Key word: feature extraction, Mel-Frequency Cepstrum Coefficients (MFCC), Self Organizing Map (SOM), single speaker, transcription
Penguji:
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PENERAPAN MEL-FREQUENCY CEPSTRUM COEFFICIENTS
(MFCC) SEBAGAI EKSTRAKSI CIRI PADA
TRANSKRIPSI SUARA KE TEKS DENGAN
SELF ORGANIZING MAPS (SOM)
TINO AKBAR
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
Penguji:
1 Karlisa Priandana, ST MEng 2 Toto Haryanto, SKom MSi
Judul Skripsi : Penerapan Mel-Frequency Cepstrum Coefficients (MFCC) sebagai Ekstraksi Ciri pada Transkripsi Suara ke Teks dengan Self
Organizing Maps (SOM) Nama : Tino Akbar
NIM : G64114024
Disetujui oleh
Dr Ir Agus Buono, MSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir yang berjudul Penerapan Mel-Frequency Cepstrum Coefficient (MFCC) sebagai Ekstraksi Ciri pada Transkripsi Suara ke Teks dengan Self Organizing Maps (SOM).
Terima kasih penulis ucapkan kepada:
1 Keluarga tercinta yaitu Almarhum Ayahanda Soewery Syukri, Ibunda Wahyuningsih, Kakak Nadya Tamara, Hiko Rizky dan kekasih Nur Iqlima atas doa dan dukungannya.
2 Dosen pembimbing, Bapak Dr Ir Agus Buono, MSi MKom atas saran dan bimbingannya selama penelitian berlangsung.
3 Dosen penguji, Bapak Toto Haryanto, SKom MSi dan Ibu Karlisa Priananda, ST MEng selaku penguji.
4 Teman-teman satu bimbingan, Aren atas bantuannya, Ima dan teman-teman ILKOM 6 dan seluruh pihak yang membantu dalam penyelesaian penelitian ini.
Semoga karya ilmiah ini bermanfaat bagi mahasiswa Ilmu Komputer dan pembacanya.
Bogor, Februari 2014 Tino Akbar
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Tujuan Penelitian 1 Manfaat Penelitian 2Ruang Lingkup Penelitian 2
METODE 2
Pengumpulan Data 3
Normalisasi 3
Segmentasi 3
Ekstraksi Ciri Menggunakan MFCC 5
Penentuan Data Latih dan Data Uji 6
Pemodelan Self Organizing Maps (SOM) 7
Pengujian 8
Perhitungan Nilai Akurasi 8
Sensitivity dan Specificity 8
Lingkungan Pengembangan 9
HASIL DAN PEMBAHASAN 9
Pengumpulan Data 9
Ekstraksi Ciri dengan MFCC 9
Pemodelan Self Organizing Maps (SOM) 10
Percobaan Menggunakan Kombinasi Parameter SOM 10
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 13
DAFTAR PUSTAKA 14
DAFTAR TABEL
1 Data latih dalam penelitian 3
2 Jumlah data latih dan bobot 6
3 Jumlah data uji 7
4 Hasil percobaan SOM dengan radius 0 dan penurunan learning rate
0.999 11
5 Hasil percobaan SOM dengan radius 1 dan penurunan learning rate
0.999 11
DAFTAR GAMBAR
1 Diagram alur penelitian proses transkripsi suara ke teks 4
2 Contoh segmentasi kata 'Hama' 4
3 Alur blok diagram MFCC 5
4 Kohonen Self Organizing Maps 7
5 Grafik hasil percobaan SOM 12
6 Grafik performance sensitivity dan specificity pada transkripsi suara
ke teks 12
DAFTAR LAMPIRAN
1 Pengulangan data uji 15
2 Hasil percobaan sistem transkripsi suara ke teks 15
3 Klusterisasi data uji pada suku pertama 16
4 Perhitungan awalan HA- pada kata HAMA 17
5 Perhitungan awalan MA- pada kata MAMA, MAHA dan MAMI 17
6 Perhitungan awalan MI pada kata MIMI 17
7 Perhitungan awalan ME pada kata MEMI 17
8 Klusterisasi data uji pada suku kedua 18
9 Perhitungan akhiran MA pada kata HAMA dan MAMA 18
10 Perhitungan akhiran HA pada kata MAHA 18
11 Perhitungan akhiran MI pada kata MIMI dan MAMI 18 12 Rata-rata pada suku kata dengan Sensitivity dan Specificity 19
PENDAHULUAN
Latar Belakang
Suara adalah alat komunikasi yang digunakan antar manusia yang dilakukan saat bercakap-cakap. Perkembangan teknologi informasi semakin pesat dan dapat mempermudah pekerjaan manusia dalam kehidupan sehari-hari. Salah satu sistem otomatis adalah sistem yang membuat komputer dapat berkomunikasi dengan manusia. Pengenalan sebuah kata atau kalimat bukanlah hal yang sulit dilakukan oleh manusia karena kata atau kalimat yang digunakan sehari-hari sudah sering digunakan dalam kehidupan nyata. Selain sebagai alat komunikasi antar manusia, suara juga memiliki fungsi lain sebagai alat komunikasi dengan komputer (mesin). Salah satu contoh penerapan aplikasi yang telah menerapkan suara pada konversi suara digital sebagai alat komunikasi adalah menerapkan suara kepada mesin atau robot dalam bentuk perintah.
Penelitian ini memfokuskan pada transkripsi suara ke teks dalam bahasa Indonesia. Transkripsi suara ke teks adalah suatu teknik yang memungkinkan sebuah komputer untuk menerima input berupa kata yang diucapkan dan ditranskripsikan ke dalam sebuah teks. Untuk ekstraksi ciri dan pengenalan pola digunakan Mel Frequency Cepstrum Coefficients (MFCC) sebagai ekstraksi ciri dengan Self Organizing Maps (SOM).
Penelitian terkait sebelumnya menggunakan ekstraksi ciri Mel Frequency Cepstrum Coefficients (MFCC) dan pengenalan pola dengan Self Organizing Maps (SOM) pada penelitian berjudul Pengenalan Suara Nyanyian untuk Deteksi Lagu, hasil yang dicapai sistem untuk dapat mengenali suara nyanyian dengan tingkat akurasi yang didapatkan sebesar 99.6% (Pandu 2012). Pada penelitian terkait lainnya dengan membandingkan Wavelet dan MFCC sebagai ekstraksi ciri pada proses pengenalan fonem, penggunaan metode Wavelet Daubechies sebagai ekstraksi ciri pada pengenalan pola tidak lebih baik dari metode MFCC. Untuk Wavelet Daubechies mempunyai tingkat akurasi 36% sedangkan MFCC mencapai tingkat akurasi 100% (Taufani 2011). MFCC merupakan ekstraksi fitur yang umum digunakan pada pengolahan suara dan pengenalan pembicara (Buono et al 2011). Maka dari itu, penelitian ini akan mengimplementasikan MFCC sebagai ekstraksi ciri dengan Self Organizing Maps (SOM) pada transkripsi suara ke teks.
Tujuan Penelitian
Tujuan penelitian ini adalah:
1 Memodelkan jaringan syaraf tiruan yaitu Self Organizing Maps (SOM) untuk transkripsi suara ke teks.
2 Mengetahui akurasi transkripsi suara ke teks dengan ekstraksi ciri MFCC dan SOM sebagai metodenya.
2
Manfaat Penelitian
Penelitian ini dilakukan untuk memberikan informasi nilai akurasi dan mengetahui kinerja dari pemodelan dengan metode menggunakan jaringan syaraf tiruan Self Organizing Maps (SOM) dengan ekstraksi ciri MFCC dalam transkripsi suara ke teks.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah:
1 Kata-kata yang digunakan adalah kata dalam bahasa Indonesia 2 Jumlah pembicara dalam penelitian ini adalah satu
3 Kata acuan yang digunakan adalah MEMAHAMI
4 Kata yang dapat dikenali adalah potongan tiap suku kata pada kata acuan MEMAHAMI
5 Jumlah suku kata acuan ada empat yaitu ME-, MA-, HA- dan MI-. 6 Kata yang diujikan adalah hama, mama, maha, mimi dan mami
7 Jumlah suku kata yang digunakan pada perulangan suku kata pada kata acuan untuk penelitian ini adalah dua suku kata
8 Masing-masing 15 kata dari suku kata pada kata acuan ME-, MA-, HA- dan MI- yang digunakan untuk data latih dan bobot adalah sebagai berikut :
• 15 kata berawalan me- adalah megah, mekar, mekah, melar, melas, menang, menit, merak, mesin, mesir, melit, mecut, meluk, meram dan metik
• 15 kata berawalan ma- adalah mabuk, mahar, malas, majas, makam, makan, mama, mari, malang, main, marah, masuk, maling, malam dan manis
• 15 kata berawalan ha- adalah hama, halo, haji, hadir, hadis, hakim, halus, hati, hawa, hafal, hapus, harap, hadap, hari dan hasil
• 15 kata berawalan mi- adalah mika, mikir, milan, mili, mi lik, mimik, minat, minor, minum, minus, mirah, miring, mirip, misal dan mitos
METODE
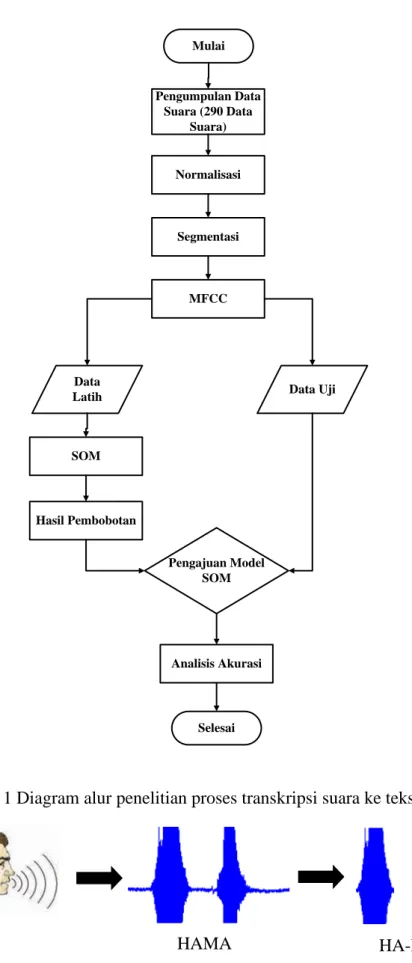
Penelitian ini dilakukan dengan beberapa tahapan, yaitu pengumpulan data, normalisasi, segmentasi, ekstraksi ciri dan pengenalan pola. Penelitian ini dilakukan dengan mengambil data suara dari satu orang dengan mengucapkan 15 kata berbeda dengan pengulangan sebanyak 4 kali untuk data latih dan bobot dan mengucapkan 5 kata dengan pengulangan sebanyak 10 kali untuk data uji. Bagian silence pada data suara akan dihapus. Setelah itu data suara akan dinormalisasi dan dilakukan segmentasi. Kemudian data akan diolah dengan proses MFCC. Data suara dibagi menjadi 3 yaitu data latih, data uji dan bobot. Untuk lebih jelas metode penelitian ini dapat dilihat pada Gambar 1.
3
Pengumpulan Data
Penelitian ini akan menggunakan data yang telah didigitalisasi dan direkam dari satu orang pembicara yang mengucapkan 15 kata dengan pengulangan sebanyak 4 kali dan mengucapkan 5 kata dengan pengulangan sebanyak 10 kali. Setiap suara direkam dengan rentang waktu 5 detik dengan sampling rate 11000 Hz dalam bentuk berekstensi WAV sehingga data yang dikumpulkan sebanyak 290 data suara. Hasil rekaman sebanyak 236 data suara dijadikan data latih, 4 data suara dijadikan data bobot dan 50 data suara dijadikan data uji. Kata yang digunakan untuk data latih dalam penelitian ini dapat dilihat pada Tabel 1.
Tabel 1 Data latih dalam penelitian
Awalan Me- Awalan Ma- Awalan Ha- Awalan Mi- Megah Mekar Mekah Melar Melas Menang Menit Merak Mesin Mesir Melit Mecut Meluk Meram Metik Mabuk Mahar Malas Majas Makam Makan Mama Mari Malang Main Marah Masuk Maling Malam Manis Hama Halo Haji Hadir Hadis Hakim Halus Hati Hawa Hafal Hapus Harap Hadap Hari Hasil Mika Mikir Milan Mili Milik Mimik Minat Minor Minum Minus Mirah Miring Mirip Missal Mitos Normalisasi
Normalisasi dilakukan dengan membagi nilai setiap frekuensi sinyal dengan absolute maksimum dari sebuah frekuensi sinyal suara. Tujuan normalisasi untuk menghasilkan amplitude maksimum dan minimum yang normal yaitu satu dan minus satu sehingga dapat menormalkan tingkat kekerasan suara.
Segmentasi
Tahapan ini membuat setiap suku kata dari kata yang direkam akan dipisahkan secara otomatis menggunakan Matlab. Potongan suku kata dari kata yang telah direkam hanya diambil suku kata pertama saja untuk data latih sedangkan potongan suku kata pertama dan suku kata kedua digunakan untuk data uji. Contoh hasil dari segmentasi yang dilakukan dapat dijelaskan pada Gambar 2.
4 Mulai Pengumpulan Data Suara (290 Data Suara) Normalisasi Segmentasi MFCC Data
Latih Data Uji
SOM Hasil Pembobotan Pengajuan Model SOM Analisis Akurasi Selesai
Gambar 1 Diagram alur penelitian proses transkripsi suara ke teks
HAMA HA-MA
5
Ekstraksi Ciri Menggunakan MFCC
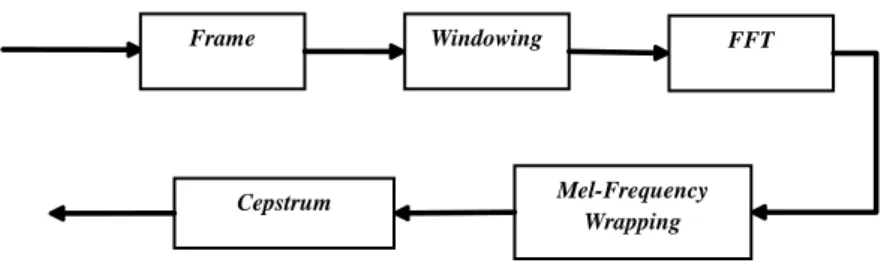
Tujuan ekstraksi ciri untuk mereduksi ukuran data suara tanpa mengubah karakteristik dari sinyal suara dalam setiap frame yang dapat digunakan sebagai penciri serta digunakan pada berbagai bidang pemrosesan suara, karena dianggap cukup baik dalam merepresentasikan ciri sebuah sinyal (Buono 2009). Ciri yang digunakan adalah koefisien Cepstral dengan mempertimbangkan pendengaran manusia. Gambar 3 menampilkan tahapan MFCC sebagai berikut (Do 1994):
1 Frame Blocking
Pada tahap ini dilakukan segmentasi frame dengan lebar tertentu yang saling overlapping frame. Tiap hasil frame direpresentasikan dalam sebuah vektor. Agar tidak kehilangan informasi (Do 1994).
2 Windowing
Merupakan salah satu jenis filtering frame dengan mengalikan frame dengan window yang digunakan. Windowing dilakukan untuk meminimalkan diskontinuitas (non-summary) sinyal pada bagian awal dan akhir sinyal suara. Penelitian suara banyak menggunakan Window Hamming karena kesederhanaan formulanya dan nilai kerja window. Persamaan Window Hamming dapat dituliskan sebagai berikut (Do 1994):
w(n)=0.54-0.46 cos �2πn
N-1� (1)
Keterangan : n = 0,…,N-1
3 Fast Fourier Transform (FFT)
FFT merupakan algoritme yang mengimplementasikan discrete fouries transform (DFT). DFT adalah mengubah tiap frame dari domain waktu ke domain frekuensi yang didefinisikan pada persamaan berikut (Do 1994) :
Xk=∑N-1n=0Xne-j2πkn/N , k = 0, 1, 2,…,N-1 (2) Keterangan :
Xk = magnitude frekuensi
Gambar 3 Alur blok diagram MFCC
Frame Windowing FFT
Mel-Frequency Wrapping Cepstrum
6
Xn = nilai sampel yang akan diproses , k = N/2 + 1
N = jumlah data , j = bilangan imajiner 4 Mel-Frequency Wrapping
Persepsi sistem pendengaran manusia terhadap sinyal suara ternyata tidak hanya bersifat linear (Buono 2009). Penerimaan sinyal suara untuk frekuensi rendah di bawah 1000 bersifat linear, sedangkan frekuensi tinggi di atas 1000 bersifat logaritmik. Skala inilah yang disebut skala mel-frequency berupa filter. Persamaan berikut dapat digunakan untuk perhitungan mel-frequency dalam frekuensi Hz (Buono 2009): Fmel=� 2595* log10 �1+ FHz 700� jika FHz>1000 FHz jika FHz ≤1000 (3) 5 Cepstrum
Cepstrum merupakan hasil mel-frequency yang diubah menjadi domain waktu menggunakan discrete cosine transform (DCT). Berikut persamaannya (Buono 2009) :
Cj= ∑ XiMi=1 cos�j�i-1� 2
π
M � (4)
Keterangan :
𝐶𝐶𝑗𝑗 = nilai koefisien C ke 𝑗𝑗
𝑗𝑗 = 1, 2, 3,… sampai koefisien yang diharapkan
Xi = nilai X hasil mel-frequency wrapping pada frekuensi i=1, 2 sampai n
jumlah wrapping 𝑀𝑀 = jumlah filter
Penentuan Data Latih dan Data Uji
Pada tahap ini, dilakukan pembagian data latih dan data uji. Pembagian masing-masing data tersebut adalah 236 untuk data latih, 50 untuk data uji dan 4 untuk bobot. Kemudian, data latih yang sudah dipilih akan dilakukan tahap pemodelan Self Organizing Maps (SOM) sebagai vektor input dan data bobot untuk bobot awal. Lebih detail banyaknya data latih dan data uji untuk masing-masing suku kata dapat dilihat pada Tabel 2 dan Tabel 3.
Tabel 2 Jumlah data latih dan bobot Suku kata Banyaknya kata
direkam
Suku kata yang
diambil Pengulangan Jumlah
Me- 15 kata 15 suku kata me- 4 kali 60
Ma- 15 kata 15 suku kata ma- 4 kali 60
Ha- 15 kata 15 suku kata ha- 4 kali 60
Mi- 15 kata 15 suku kata mi- 4 kali 60
Tabel 2 menunjukkan jumlah data latih dan bobot yang digunakan pada penelitian transkripsi suara ke teks. Total data latih yang digunakan sebanyak 236 dan bobot sebanyak 4 yang diambil dari data terakhir pada data latih.
7 Tabel 3 Jumlah data uji
Kata Banyaknya kata direkam
Suku kata yang
diambil Pengulangan Jumlah
Hama 1 kata ha- dan ma- 10 kali 10
Mama 1 kata ma- dan ma- 10 kali 10
Maha 1 kata ma- dan ha- 10 kali 10
Mimi 1 kata mi- dan mi- 10 kali 10
Mami 1 Kata ma- dan mi- 10 kali 10
Memi 1 Kata me dan mi- 10 kali 10
Tabel 3 menunjukkan jumlah data uji dan kata yang digunakan pada penelitian transkripsi suara ke teks. Total data uji yang digunakan sebanyak 50, dari banyaknya lima kata yang direkam dengan pengulangan 10 kali.
Pemodelan Self Organizing Maps (SOM)
Self Organizing Maps atau juga disebut topology preserving adalah topologi antara unit kluster. Metode ini merupakan salah satu model jaringan syaraf tiruan. Bobot vektor untuk tiap unit kluster berfungsi sebagai contoh dari input pola yang terkait dengan unit kluster tersebut. Selama proses pengenalan pola Self Organizing Maps, akan dipilih satu kluster sebagai winner dan kluster winner serta kluster tetangganya akan memperbaharui bobot kluster. Kluster winner ditentukan berdasarkan jarak minimal atau jarak terdekat dari bobotnya. Arsitektur dan model SOM dapat dilihat pada Gambar 4 (Fausett 1994).
Jika:
𝑤𝑤𝑖𝑖𝑗𝑗 = Bobot yang diambil dari data suara per suku kata
𝑥𝑥𝑖𝑖𝑗𝑗 = Vektor input dari data suara
R = Mengatur jarak topologi sekitarnya pada transkripsi suara ke teks yaitu 0,1 dan 2
8
D(j) = Perhitungan vektor masukan dan bobot yang sudah ditentukan J = Vektor input terdekat yang akan diambil (minimum)
𝑤𝑤𝑖𝑖𝑗𝑗(𝑏𝑏𝑏𝑏𝑏𝑏𝑏𝑏) = Bobot pemenang yang diperoleh pada saat pelatihan akan
diperbaharui
Maka algoritme pengelompokkan pola jaringan SOM adalah sebagai berikut (Fausett 1994):
0 Inisialisasi
• Bobot 𝑤𝑤𝑖𝑖𝑗𝑗 (Acak)
• Laju pembelajaran awal dan faktor penurunannya. • Bentuk dan jari-jari (=R) topologi sekitarnya.
1 Selama kondisi penghentian bernilai salah, lakukan langkah 2-7 2 Untuk setiap vektor masukan x, lakukan langkah 3-5
3 Hitung jarak Euclidean untuk semua j :
D(j) = ∑(𝑤𝑤𝑖𝑖𝑗𝑗 − 𝑥𝑥𝑖𝑖𝑗𝑗)2 (5) 4 Tentukan indeks J sedemikian hingga D(J) minimum
5 Untuk setiap unit j di sekitar J modifikasi bobot :
𝑤𝑤𝑖𝑖𝑗𝑗(𝑏𝑏𝑏𝑏𝑏𝑏𝑏𝑏) = 𝑤𝑤𝑖𝑖𝑗𝑗(𝑙𝑙𝑏𝑏𝑙𝑙𝑏𝑏) + 𝛼𝛼(𝑥𝑥𝑖𝑖 − 𝑤𝑤𝑖𝑖𝑗𝑗(𝑙𝑙𝑏𝑏𝑙𝑙𝑏𝑏) (6)
6 Modifikasi laju pembelajaran (learning rate) 7 Uji kondisi penghentian
Pengujian
Pengujian dilakukan pada data uji yang telah dinormalisasi dan disegmentasi lalu diekstraksi ciri dengan MFCC kemudian di-cluster dengan SOM menggunakan bobot dari data latih. Pengenalan kata untuk transkripsi suara ke teks suara yang masuk akan dilihat masuk ke kluster yang sesuai. Output yang akan dihasilkan berupa nilai akurasi yang didapat dan tulisan kata yang telah diucapkan.
Perhitungan Nilai Akurasi
Pengujian dilakukan pada data uji yang sudah disiapkan. Perhitungan dilakukan dengan membandingkan banyaknya hasil suku kata yang benar dengan suku kata yang diuji. Presentase tingkat akurasi akan dihitung dengan fungsi berikut :
Hasil=∑ suku kata yang benar
∑ suku kata yang diuji x 100% (7)
Sensitivity dan Specificity
Dari hasil pengujian yang dilakukan akan menghasilkan matriks konfusion yang selanjutnya akan diproses untuk menentukan nilai sensitivity dan specificity. Sensitivity mengukur presentase kejadian sebenarnya yang diidentifikasi sesuai dengan kelasnya. Specificity mengukur presentase kejadian untuk membedakan data yang bukan dari kelas x dari semua data selain kelas x. Berikut adalah rumus untuk menghitung sensitivity dan specificity (Novianti dan Purnami 2012) :
9 Sensitivity= Number of True Positive
Number of True Positive+Number of False Negative (8)
Specificity= Number of True Negative
Number of True Negative+Number of False Positive (9)
Keterangan :
• True Positive = Correctly Identified (diidentifikasi dengan benar) • False Positive = Incorrectly Identified (salah diidentifikasi) • True Negative = Correctly Rejected (ditolak dengan benar ) • False Negative = Incorrectly Rejected (salah ditolak )
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam penelitian ini adalah sebagai berikut :
1 Perangkat Keras
• Processor Intel(R) CoreTM 2 Duo CPU @1.83GHz.
• Memori 2.5GB. • Harddisk 100GB.
• Keyboard dan Mouse Optic. • Monitor.
2 Perangkat Lunak
• Sistem operasi Windows 7 Ultimate 64 bit • Matlab 7.7.0 (R2008b).
HASIL DAN PEMBAHASAN
Pengumpulan Data
Data suara yang digunakan pada penelitian ini telah didigitalisasi dan direkam dari satu pembicara dengan mengucapkan kata sebanyak 15 kata untuk data latih dan 5 kata untuk data uji. Kata direkam dengan rentang waktu 5 detik dengan sampling rate 11000 Hz dalam bentuk file berekstensi WAV. Jumlah data suara untuk data latih dan bobot yang direkam adalah sebanyak 240 data suara dari empat suku kata acuan masing-masing suara sebanyak 15 data suara. Sebanyak 50 data suara yang direkam akan dijadikan data uji dari kata yang diujikan yaitu hama, mama, maha, mimi, mami dan memi.
Ekstraksi Ciri dengan MFCC
Data suara yang telah direkam dinormalisasi dengan cara membagi nilai setiap frekuensi sinyal dengan absolute maksimum dari sebuah frekuensi sinyal suara untuk menghasilkan amplitudo maksimum dan minimum yaitu satu dan
10
minus satu, sehingga dapat menormalkan tingkat kekerasan suara. Data yang telah dinormalisasi akan dilakukan tahap segmentasi yaitu memisahkan potongan suku kata yang telah direkam. Potongan suku kata nya hanya diambil suku kata pertama saja, suku kata terakhir tidak digunakan.
Kemudian data suara diekstraksi ciri menggunakan MFCC, time frame yang digunakan sebesar 23.27, sampling rate 11000, overlap 0.39 serta koefisien cepstral 13. Proses ekstraksi ciri ini dilakukan tehadap data latih, data uji dan bobot. MFCC mengubah sinyal suara ke dalam sebuah matriks yang berukuran jumlah koefisien yang digunakan dikali dengan banyaknya frame suara yang terbentuk. Matriks yang dihasilkan menunjukkan ciri spectral dari sinyal suara. Data suara yang dihasilkan dari proses MFCC memiliki jumlah frame yang berbeda-beda.
Pemodelan Self Organizing Maps (SOM)
Tahap pemodelan SOM menentukan nilai parameter yang digunakan seperti epoch, learning rate, penurunan learning rate dan radius. Vektor masukan x diambil dari data latih dan bobot awal diambil dari data latih. Parameter awal dari algoritme SOM yang digunakan adalah :
• Learning rate : 0.1, 0.3, 0.5, 0.7, dan 0.9 • Penurunan learning rate sebesar, 0.999 • Ukuran lingkungan (R) : 0,1, dan 2
Bobot awal yang diambil dari data latih digunakan untuk melatih dengan pemodelan SOM. Selama proses pelatihan data latih maka bobot akan selalu terupdate. Kriteria pemberhentian algoritme SOM dalam penelitian ini adalah iterasi (epoch) dengan banyak iterasi: 10, 30, 50, 70, 90 dan 110. Dari berbagai kombinasi parameter awal dan iterasi, akan dipilih kluster yang bobot vektornya sesuai dengan pola masukan dipilih sebagai kluster pemenang sebagai kluster terbaik dan kluster pemenang serta kluster tetanggannya akan memperbaharui bobot kluster.
Percobaan Menggunakan Kombinasi Parameter SOM
Pada tahap pengujian ini dilakukan kombinasi parameter agar memperoleh perbandingan akurasi yang terbaik mana yang akan diperoleh. Percobaan yang sudah dilakukan yaitu pada percobaan SOM dengan radius 0 dan 1 dilakukan kombinasi parameter dengan learning rate sebesar 0.1, 0.3, 0.5, 0.7, 0.9, 0.001, 0.003, 0.005, 0.007 dan 0.009, nilai epoch 10, 30, 50, 70 dan 90 dan penurunan learning rate 0.999. Percobaan tersebut menghasilkan akurasi tertinggi sebesar 95% dengan nilai epoch 10, 30, 50, 70 dan 90, learning rate 0.5, penurunan learning rate 0.999 dan radius 0. Hasil percobaan pengujian SOM dengan radius 0 dan radius 1 dapat dilihat di Tabel 4 dan Tabel 5.
11 Tabel 4 Hasil percobaan SOM dengan radius 0 dan penurunan learning rate 0.999
Epoch Learning Rate
0.1 0.3 0.5 0.7 0.9 0.001 0.003 0.005 0.007 0.009 10 91% 91% 95% 93% 91% 52% 55% 57% 57% 59% 30 91% 42% 95% 93% 92% 55% 58% 68% 72% 77% 50 91% 42% 95% 93% 91% 57% 66% 75% 83% 84% 70 87% 42% 95% 94% 91% 57% 72% 83% 84% 85% 90 87% 41% 95% 94% 91% 58% 76% 83% 85% 85% Rata-rata 89% 52% 95% 93% 91% 56% 65% 73% 76% 78% Tabel 4 menunjukan hasil keluaran transkripsi suara ke teks dengan akurasi terbaik yang didapatkan pada percobaan sebelumnya yang dilakukan yaitu sebesar 95% dengan epoch 10, 30, 50, 70 dan 90, learning rate 0.5, ralpha 0.999 dan radius berjarak 0.
Tabel 5 Hasil percobaan SOM dengan radius 1 dan penurunan learning rate 0.999
Epoch Learning Rate
0.1 0.3 0.5 0.7 0.9 0.001 0.003 0.005 0.007 0.009 10 31% 18% 19% 12% 64% 48% 22% 8% 6% 4% 30 31% 18% 19% 19% 64% 22% 4% 2% 3% 4% 50 31% 17% 19% 15% 61% 8% 4% 2% 3% 4% 70 31% 17% 19% 15% 60% 6% 4% 2% 3% 6% 90 30% 15% 19% 16% 60% 3% 4% 1% 9% 27% Rata-rata 31% 17% 19% 15% 62% 17% 8% 3% 5% 9%
Tabel 5 menunjukkan akurasi terendah sebesar 1% dengan nilai epoch 90, learning rate 0.005, penurunan learning rate 0.999 dan radius berjarak 1. Gambar 5 menunjukkan grafik hasil akurasi dari beberapa percobaan kombinasi parameter dan Gambar 6 menunjukkan grafik performance sensitivity dan specificity pada transkripsi suara ke teks.
Pada Gambar 5 menunjukkan rata-rata hasil akurasi, transkripsi suara ke teks maksimum dan minimum memiliki akurasi yang paling baik yaitu 95% pada kombinasi parameter SOM radius berjarak 0. Dengan jarak radius bernilai nol menghasilkan akurasi terbaik tergantung dengan parameter yang dikombinasikan sehingga didapatkan akurasi tertinggi.
Percobaan yang sudah dilakukan (Tabel 4 dan 5) menunjukkan tingkat akurasi rata-rata pengenalan suara yang diucapkan dari 290 data suara. Dari percobaan penelitian yang diujikan terdapat hasil berbeda dari tiap penggalan suku kata yang didapatkan, karena adanya tingkat kemiripan tiap suku kata yang diujikan. Sebagai contoh, terjadi kesalahan sistem mengenali suku kata ‘ha’ dan ‘ma’. Untuk suku kata ‘ma’, ‘me’ dan ‘mi’ dapat dikenali sistem mencapai 100%. Akan tetapi untuk suku kata ‘ha’ sistem lebih sering mengenali ‘ma’ sehingga hasil teks yang dihasilkan seperti ‘hama’ menjadi ‘mama’ dan’maha’ menjadi ‘mama’. Kesalahan sistem dalam mentranskripsi suara ke teks terjadi pada suara hama5.wav, hama8.wav, hama9.wav dan maha1.wav. Hasil percobaan sistem dapat dilihat pada Lampiran 2.
12
Gambar 5 Grafik hasil percobaan SOM
Pada Gambar 6 menunjukkan sensitivity dan specificity pada kombinasi parameter SOM tertinggi yaitu epoch 10, 30, 50, 70,90 dan 110, learning rate 0.5, penurunan learning rate 0.999 dan radius 0. Kelas Me menunjukkan specificity dan sensitifity tertinggi yaitu 1, hal ini menunjukkan sensitifity data yang diidentifikasi masuk ke kelas Me adalah benar dan specificity tinggi untuk membedakan data yang bukan dari kelas Me dari semua data. Kelas Ha- menunjukkan sensitivity tertinggi sebesar 1. Hal ini menunjukkan sensitivity data yang diidentifikasi masuk ke kelas Ha adalah benar. Kemampuan kelas Ha kecil untuk membedakan data yang bukan dari kelas Ha dari semua data sehingga specificity yang didapat kelas HA sebesar 0.95.
Gambar 6 Grafik performance sensitivity dan specificity pada transkripsi suara ke teks 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 0,1 0,3 0,5 0,7 0,9 0,001 0,003 0,005 0,007 0,009
Parameter SOM Radius 0 Parameter SOM Radius 1
0,88 0,9 0,92 0,94 0,96 0,98 1 HA MI MA ME Sensitivity Specificity
13 Kelas Ma dan Mi menunjukkan sensitivity rendah yaitu sebesar 0.925 dan 0.98 ini menunjukkan kelas Ma- dan Mi- salah mengidentifikasi kelas lain sebagai kelasnya. Kemampuan kelas Ma dan Mi tinggi untuk membedakan data yang bukan dari kelas Ma dan Mi sehingga specificity yang didapatkan tinggi sebesar 1. Rata-rata pada suku kata dengan sensitivity dan specificity dapat dilihat di Lampiran 12.
SIMPULAN DAN SARAN
Simpulan
Penelitian ini telah berhasil dalam menerapkan Mel Frequency Cepstrum Coeffiicients (MFCC) dalam transkripsi suara ke teks dengan Self Oranizing Maps (SOM). Dari kombinasi parameter yang dilakukan menghasilkan akurasi tertinggi yaitu 95% pada kombinasi parameter dengan epoch 10, 30, 50, 70 dan 90, learning rate 0.5, penurunan learning rate 0.999 dan radius berjarak 0. Dan menghasilkan akurasi tertinggi sebesar 64% pada kombinasi parameter epoch 10 dan 30, learning rate 0.9, ralpha 0.999 dan radius berjarak 1.
Berdasarkan hasil percobaan yang dilakukan, nilai epoch semakin kecil dengan kombinasi learning rate semakin besar dan radius berjarak nol akan menghasilkan akurasi yang lebih tinggi dibandingkan dengan nilai epoch yang semakin besar dengan kombinasi learning rate semakin kecil dan radius berjarak satu dan dua akan menghasilkan akurasi lebih rendah. Ini menunjukkan bahwa penentuan nilai parameter sangat berpengaruh dalam mendapatkan hasil akurasi yang terbaik.
Saran
Penelitian ini memungkinkan untuk dikembangkan lebih lanjut Saran untuk pengembangan selanjutnya ialah:
1 Jumlah kata yang lebih banyak agar memperoleh suku kata yang lebih variatif 2 Jumlah pembicara yang lebih banyak
3 Akurasi terbaik didapatkan pada penelitian transkripsi suara ke teks dengan Self Organizing Maps (SOM) ini, akan tetapi dapat dicoba untuk suku kata yang digunakan lebih dari dua.
14
DAFTAR PUSTAKA
Buono A. 2009. Representasi Nilai HOS dan Model MFCC Sebagai Ekstraksi Ciri Pada Sistem Identifikasi Pembicara di Lingkungan Ber-Noise Menggunakan HMM [Disertasi]. Depok (ID): Program Pascasarjana, Universitas Indonesia. Buono A, Jatmiko W, Kusumoputro B. 2011. Mel-frequency cepstrum
coefficients as higher order statistics representation to characterize speech signal for speaker identification system in noisy environment using hidden Markov model. Di dalam: Mwasiagi JI, editor. Self Organizing Maps - Applications and Novel Algorithm Design. Rijeka (HR): Intech. hlm 189-206. doi: 10.5772/566.
Do MN. 1994. DSP Mini Project: An Automatic Recognition System. Audio Visual Communication Laboratory. Swiss Federal Institute of Technology. http://www.ifp.illinois.edu/~minhdo/teaching/speaker_recognition/
Fausett L. 1994. Fundamentals Of Neural Networks: Architectures, Algorithms, and Applications. New Jersey (US): Prentice Hall.
Novianti FA, Purnami SW. 2012. Analisis Diagnosis Pasien Kanker Payudara Menggunakan Regresi Logistik dan Support Vector Machine (SVM) Berdasarkan Hasil Mamografi. Jurnal Sains dan Seni. 1(1):D-147-D-152.
Pandu RS. 2012. Pengenalan suara nyanyian deteksi lagu menggunakan jaringan syaraf tiruan Self Organizing Map (SOM) [skripsi]. Bandung (ID): Jurusan Teknik Telekomunikasi, Fakultas Elektro dan Komunikasi, Institut Teknologi Telkom.
Taufani MF. 2011. Perbandingan pemodelan Wavelet dan MFCC sebagai Ekstraksi Ciri pada Pengenalan Fonem dengan Teknik Jaringan Syaraf Tiruan sebagai Classifier [skripsi]. Bogor (ID): Jurusan Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
15
Lampiran 1 Pengulangan data uji
Pengulangan Hama Mama Maha Mimi Mami Memi 1 Hama1 Mama1 Maha1 Mimi1 Mami1 Memi1 2 Hama2 Mama1 Maha2 Mimi2 Mami2 Memi2 3 Hama3 Mama1 Maha3 Mimi3 Mami3 Memi3 4 Hama4 Mama1 Maha4 Mimi4 Mami4 Memi4 5 Hama5 Mama1 Maha5 Mimi5 Mami5 Memi5 6 Hama6 Mama1 Maha6 Mimi6 Mami6 Memi6 7 Hama7 Mama1 Maha7 Mimi7 Mami7 Memi7 8 Hama8 Mama1 Maha8 Mimi8 Mami8 Memi8 9 Hama9 Mama1 Maha9 Mimi9 Mami9 Memi9 10 Hama10 Mama1 Maha10 Mimi10 Mami10 Memi10
Lampiran 2 Hasil percobaan sistem transkripsi suara ke teks
Nama File Hasil penggal kata Hasil Pengujian
hama1.wav ha-ma hama
hama2.wav ha-ma hama
hama4.wav ha-ma hama
hama4.wav ha-ma hama
hama5.wav ha-ma mama
hama6.wav ha-ma hama
hama7.wav ha-ma hama
hama8.wav ha-ma mama
hama9.wav ha-ma mama
hama10.wav ha-ma hama
mama1.wav ma-ma mama
mama2.wav ma-ma mama
mama3.wav ma-ma mama
mama4.wav ma-ma mama
mama5.wav ma-ma mama
mama6.wav ma-ma mama
mama7.wav ma-ma mama
mama8.wav ma-ma mama
mama9.wav ma-ma mama
mama10.wav ma-ma mama
maha1.wav ma-ha mama
maha2.wav ma-ha maha
maha3.wav ma-ha maha
maha4.wav ma-ha maha
maha5.wav ma-ha maha
maha6.wav ma-ha maha
16
maha8.wav ma-ha maha
maha9.wav ma-ha maha
maha10.wav ma-ha maha
mimi1.wav mi-mi mimi
mimi2.wav mi-mi mimi
mimi3.wav mi-mi mimi
mimi4.wav mi-mi mimi
mimi5.wav mi-mi mimi
mimi6.wav mi-mi mimi
mimi7.wav mi-mi mimi
mimi8.wav mi-mi mimi
mimi9.wav mi-mi mimi
mimi10.wav mi-mi mimi
mami1.wav ma-mi mami
mami2.wav ma-mi mami
mami3.wav ma-mi mami
mami4.wav ma-mi mami
mami5.wav ma-mi mami
mami6.wav ma-mi mami
mami7.wav ma-mi mami
mami8.wav ma-mi mami
mami9.wav ma-mi mami
mami10.wav ma-mi mami
memi1.wav me-mi memi
memi2.wav me-mi memi
memi3.wav me-mi memi
memi4.wav me-mi memi
memi5.wav me-mi memi
memi6.wav me-mi memi
memi7.wav me-mi memi
memi8.wav me-mi memi
memi9.wav me-mi memi
memi10.wav me-mi memi
Lampiran 3 Klusterisasi data uji pada suku pertama Suku Pertama Cluster 1
(HA) Cluster 2 (MI) Cluster 3 (MA) Cluster 4 (ME) Total HAMA = HA- 7 3 10 MAMA =MA- 10 10 MAHA = MA- 10 10 MIMI = MI- 10 10 MAMI = MA- 10 10 MEMI = ME- 10 10
17 Lampiran 4 Perhitungan awalan HA- pada kata HAMA
HA BUKAN HA HA 7 3 BUKAN HA 0 50 Sensitivity = TP / (TP + FN) = 7 / (7 + 0) = 1 Specificity = TN / (FP + TN) = 50 / (50 + 3) = 0.94
Lampiran 5 Perhitungan awalan MA- pada kata MAMA, MAHA dan MAMI
MA BUKAN MA MA 30 0 BUKAN MA 3 27 Sensitivity = TP / (TP + FN) = 30 / (30 + 3) = 0.90 Specificity = TN / (FP + TN) = 27 / (27 + 0) = 1
Lampiran 6 Perhitungan awalan MI pada kata MIMI
MI BUKAN MI MI 10 0 BUKAN MI 0 50 Sensitivity = TP / (TP + FN) = 10 / (10 + 0) = 1 Specificity = TN / (FP + TN) = 50 / (50 + 0) = 1
Lampiran 7 Perhitungan awalan ME pada kata MEMI
ME BUKAN ME ME 10 0 BUKAN ME 0 50 Sensitivity = TP / (TP + FN) = 10 / (10 + 0) = 1 Specificity = TN / (FP + TN) = 50 / (50 + 0) = 1
18
Lampiran 8 Klusterisasi data uji pada suku kedua Suku Kedua Cluster 1
(HA) Cluster 2 (MI) Cluster 3 (MA) Cluster 4 (ME) Total HAMA = MA- 10 10 MAMA = MA- 10 10 MAHA = HA- 8 1 1 10 MIMI = MI- 10 10 MAMI = MI- 10 10 MEMI = MI- 10 10
Lampiran 9 Perhitungan akhiran MA pada kata HAMA dan MAMA
MA BUKAN MA MA 20 0 BUKAN MA 1 39 Sensitivity = TP / (TP + FN) = 20 / (20 + 1) = 0.95 Specificity = TN / (FP + TN) = 39 / (39 + 0) = 1
Lampiran 10 Perhitungan akhiran HA pada kata MAHA
HA BUKAN HA HA 8 2 BUKAN HA 0 50 Sensitivity = TP / (TP + FN) = 8 / (8 + 0) = 1 Specificity = TN / (FP + TN) = 50 / (50 + 2) = 0.96
Lampiran 11 Perhitungan akhiran MI pada kata MIMI dan MAMI
MI BUKAN MI MI 30 0 BUKAN MI 1 29 Sensitivity = TP / (TP + FN) = 30 / (30 + 1) Specificity = TN / (FP + TN) = 29 / (29 + 0)
19
= 0.96 = 1
Lampiran 12 Rata-rata pada suku kata dengan Sensitivity dan Specificity Sensitifity Specificity
HA 1 0.95
MA 0.925 1
MI 0.98 1
20
RIWAYAT HIDUP
Penulis dilahirkan pada tanggal 17 Desember 1990 di Balikpapan. Penulis merupakan anak ketiga dari tiga bersaudara.
Tahun 2002 penulis lulus dari SD Negeri 085 Balikpapan, kemudian melanjutkan pendidikan di SMP PGRI 3 Bogor. Pada tahun 2005, penulis melanjutkan pendidikan di SMA Taruna Andigha Bogor dan lulus pada tahun 2008. Pada tahun yang sama penulis lulus seleksi masuk IPB melalui jalur Undangan Seleksi Masuk IPB. Pada tahun 2011 penulis lulus dari program Diploma Manajemen Informatika Institut Pertanian Bogor, pada tahun yang sama penulis melanjutkan pendidikan ke program studi Sarjana di Departemen Ilmu Komputer, Institut Pertanian Bogor, dengan memilih program studi Ilmu Komputer.