KLASIFIKASI SUARA DENGAN EKSTRAKSI CIRI MEL FREQUENCY CEPSTRAL COEFFICIENTS MENGGUNAKAN MACHINE LEARNING
Skripsi
Dwi Prasetya Candra 11160940000067
PROGRAM STUDI MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
ii
KLASIFIKASI SUARA DENGAN EKSTRAKSI CIRI MEL FREQUENCY CEPSTRAL COEFFICIENTS MENGGUNAKAN MACHINE LEARNING
Skripsi
Diajukan Kepada
Universitas Islam Negeri Syarif Hidayatullah Jakarta Fakultas Sains dan Teknologi
Untuk Memenuhi Salah Satu Persyaratan dalam Memperoleh Gelar Sarjana Matematika (S.Mat)
Oleh:
Dwi Prasetya Candra 11160940000067
PROGRAM STUDI MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
iii
PERNYATAAN
DENGAN INI SAYA MENYATAKAN BAHWA SKRIPSI INI BENAR-BENAR HASIL KARYA SENDIRI YANG BELUM PERNAH DIAJUKAN SEBAGAI SKRIPSI ATAU KARYA ILMIAH PADA PERGURUAN TINGGI ATAU LEMBAGA MANAPUN
Jakarta, 27 Juni 2021
Dwi Prasetya Candra
iv
LEMBAR PENGESAHAN
Skripsi berjudul “Klasifikasi Suara Dengan Ekstraksi Ciri Mel Frequency Cepstral Coefficients Menggunakan Machine Learning” yang ditulis oleh Dwi Prasetya Candra, NIM 11160940000067 telah diuji dan dinyatakan lulus dalam sidang Munaqosah Fakultas Sains dan Teknologi UIN Syarif Hidayatullah Jakarta pada Selasa, 27 April 2021. Skripsi ini telah diterima sebagai salah satu syarat untuk memperoleh gelar sarjana strata satu (S1) Program Studi Matematika.
Menyetujui,
Pembimbing I Pembimbing II
Taufik Edy Sutanto, M.Sc.Tech., Ph.D Muhammad Manaqib, M.Sc NIP. 19790530 200604 1002 NIP. 19910605 202012 1013
Penguji I Penguji II
Muhaza Liebenlito, M.Si Mohamad Irvan Septiar Musti, M.Si
NIDN. 2003098802 NUP. 9920113224
Mengetahui,
Dekan Fakultas Sains dan Teknologi Ketua Program Studi Matematika
Ir. Nashrul Hakiem, S.Si., M.T., Ph.D Dr. Suma’inna, M.Si NIP. 197106082005011005 NIP. 1979120807012015
v
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini :
Nama : Dwi Prasetya Candra
NIM : 11160940000067
Program Studi : Matematika Fakultas Sains dan Teknologi
Demi pengembangan ilmu pengetahuan, saya menyetujui untuk memberikan Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Free Right) kepada Program Studi Matematika Fakultas Sains dan Teknologi UIN Syarif Hidayatullah Jakarta atas karya ilmiah saya yang berjudul:
“Klasifikasi Suara Dengan Ekstraksi Ciri Mel Frequency Cepstral Coefficients Menggunakan Machine Learning”
beserta perangkat yang dipelukan (bila ada). Dengan Hak Bebas Royalti Non-Ekslusif ini, Program Studi Matematika Fakultas Sains dan Teknologi UIN Syarif Hidayatullah Jakarta berhak menyimpan, mengalihmedia/formatkan mengelolanya dalam bentuk pangkalan data (data base), mendistribusikannya, dan menampilkan/mempublikasikannya di internet dan media lain untuk kepentingan akademis tanpa perlu meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilik Hak Cipta. Segala bentuk tuntuan hokum yang timbul atas pelanggaran Hak Cipta karya ilmiah ini menjadi tanggungjawab saya sebagai penulis.
Demikian pernyataan ini yang saya buat dengan sebenarnya. Dibuat di Tangerang Selatan
Pada tanggal : 27 Juni 2021 Yang membuat pernyataan
vi
PERSEMBAHAN DAN MOTTO
Puji Syukur atas Kehadirat Allah SWT dalam hidup, atas izin dan berkat-Nya penulis mampu menyelesaikan skripsi ini.
Sholawat beriringan salam tercurahkan kepada Nabi Muhammad SAW
Skripsi ini penulis persembahkan untuk kedua orangtua beserta keluarga yang telah memberikan doa dan dukungan yang begitu luar biasa.
Skripsi ini juga dipersembahkan untuk yang terkasih, teman-teman.
MOTTO
vii ABSTRAK
Dwi Prasetya Candra, Klasifikasi Suara Dengan Ekstraksi Ciri Mel Frequency Cepstral Coefficients Menggunakan Machine Learning, dibawah bimbingan Taufik Edy Sutanto, M.Sc.Tech., Ph.D dan Muhammad Manaqib, M.Sc. Dewasa ini, dalam perkembangan teknologi informasi yang semakin pesat, sinyal suara digunakan untuk melakukan pengiriman dan penerimaan data salah satunya yaitu pengenalan suara. Dalam pengenalan suara, variabilitas suara manusia yang beraneka ragam membuat pola suara yang dihasilkan berbeda-beda dan beragam pula. Hal ini dapat mempengaruhi mesin pembelajaran menjadi kurang optimal untuk mengenali pola suara/ucapan. Selain itu, noise yang dihasilkan juga akan mempengaruhi mesin dalam mengenali ucapan. Oleh karenanya peneliti mengusulkan penelitian menggunakan metode ekstraksi ciri Mel Frequency Cepstral Coefficients untuk mendapatkan pola suara dengan Machine Learning yang digunakan yaitu Random Forest Classifier, K-Nearest Neighbor dan Support Vector Machine untuk membuat model pengenalan pola suara. Data yang digunakan adalah 150 data rekaman pengucapan kalimat tayyibah. Pada pembuatan model, optimasi parameter model dilakukan dengan menggunakan Grid Search CV. Dalam penelitian ini diperoleh hasil evaluasi model terbaik yaitu Support Vector Machine dengan akurasi yang dihasilkan sebesar 93,3%. Penelitian ini merupakan salah satu bentuk integrasi antara ilmu pengetahuan dengan keislaman.
Kata Kunci : Grid Search Cross Validation, Mel Frequency Ceptrals Coefficients , K-Nearest Neighbour, Random Forest Classifier , Support Vector Machine
viii ABSTRACT
Dwi Prasetya Candra, Voice Classficication with Feature Extraction of Mel Frequency Cepstral Coefficients Using Machine Learning, under the guidance of Taufik Edy Sutanto, M.Sc.Tech., Ph.D and Muhammad Manaqib, M.Sc. Nowadays, in the increasingly rapid development of information technology, voice signals are used to transmit and receive data. One of them is voice recognition. In voice recognition, the diverse variability of the human voice makes the sound patterns produced are different and varied. This can affect machine learning to be less than optimal for recognizing speech patterns. Also, the resulting noise will affect the engine in recognize speech. Therefore, the researcher proposes a study using the Mel Frequency Cepstral Coefficients feature extraction method to obtain sound patterns with machine earning which is used by the Random Forest Classifier, K-Nearest Neighbors, and Support Vector Machine to create a model of speech recognition. The data used are 150 recorded data on the pronunciation of the Tayyibah sentence. In modeling, the optimization of model parameters is using the CV Grid Search. From this research, the results of the evaluation of the best model are the Support Vector Machine with the resulting accuracy of 93.3%. This research is the one of a form of integration between science and Islam.
Keywords: Grid Search Cross Validation, Mel Frequency Ceptrals Coefficients , K-Nearest Neighbors, Random Forest Classifier , Support Vector Machine
ix
KATA PENGANTAR
Assalamualaikum Wr. Wb.
Alhamdulillahirabbil ‘alamin, puji dan syukur penulis panjatkan kepada Allah SWT yang telah memberikan nikmat, berkat, rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan penelitian ini. Shalawat serta salam senantiasa penulis curahkan kepada junjungan Nabi Muhammad SAW beserta keluarga, para sahabat dan para pengikutnya.
Penulis menyelesaikan penelitian ini untuk memperoleh gelar sarjana Matematika. Dalam penyusunan, peneliti tidak luput dari kesulitan, hambatan dan rintangan. Namun, banyak pihak-pihak yang memberikan doa, dukungan, bantuan, motivasi dan memberikan semangat sehingga penelitian ini dapat terselesaikan. Oleh karena itu peneliti mengucapkan terima kasih kepada :
1. Bapak Ir. Nashrul Hakiem, S.Si., M.T., Ph.D selaku Dekan Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta 2. Ibu Dr. Summa’inna, M.Si., selaku Ketua Program Studi Matematika
Fakultas Sains dan Teknologi UIN Syarif Hidayatullah Jakarta dan Ibu Irma Fauziah M.Sc., selaku Sekretaris Program Studi Matematika Fakultas Sains dan Teknologi UIN Syarif Hidayatullah Jakarta.
3. Bapak Taufik Edy Sutanto, M.Sc.Tech., Ph.D., selaku pembimbing I dan Bapak Muhammad Manaqib, M.Sc., selaku pembimbing II atas ilmu dan arahannya selama penyusunan skripsi ini hingga akhirnya dapat terselesaikan.
4. Bapak Muhaza Liebenlito, M.Si., selaku Penguji I dan Bapak M. Irvan Septiar Musti, S.Si., M.Si., Selaku Penguji II, terima kasih atas kritik dan sarannya kepada penulis serta ketersediaan waktunya untuk menguji seminar hasil dan sidang skripsi.
x
5. Mama, Mas Adit, Mbak Atry dan Arka yang tiada henti-hentinya memberikan doa, dukungan, semangat dan motivasi hingga peneliti akhirnya mampu menyelesaikan skripsi ini
6. Andre Reva Utama, Bilal Adji Zaelani, Putriana Ramaida dan Theresa yang selalu menjadi tempat untuk berbagi keluh kesah selama penyusunan skripsi ini.
7. Teman-teman yaitu Eti Hartati S, Nia Karunia Dewi, Amellia Andrisa Alpa, Nabilla Sina dan Nurul Jannah yang selalu hadir di segala suka dan duka selama kuliah hingga akhir.
8. Teman-teman Matematika 2016 UIN Syarif Hidayatullah Jakarta yang tidak dapat penulis sebutkan satu persatu.
9. Seluruh pihak yang secara langsung maupun tidak langsung telah membantu, mendukung serta mendoakan penulis dalam penyelesaian skripsi ini. Meski tidak tertulis namun tidak mengurangi rasa cinta dan terima kasih dari penulis.
Penulis menyadari bahwa masih ada kesalahan dalam penyusunan skripsi ini. Maka dari itu penulis mengharapkan kritik dan saran yang membangun supaya menjadi bahan perbaikan bagi peneliti selanjutnya. Penulis juga berharap penelitian ini bermanfaat bagi siapapun yang membacanya.
Wassalamualaikum Wr.Wb
Ciputat, 27 April 2021
xi DAFTAR ISI
PERNYATAAN ... iii
LEMBAR PENGESAHAN ... iv
LEMBAR PERNYATAAN ... v
PERSEMBAHAN DAN MOTTO ... vi
ABSTRAK ... vii
ABSTRACT ... viii
KATA PENGANTAR ... ix
DAFTAR ISI ... xi
DAFTAR TABEL... xiii
DAFTAR GAMBAR ... xiv
BAB I PENDAHULUAN ... 1 1.1 Latar Belakang... 1 1.2 Rumusan Masalah ... 4 1.3 Batasan Masalah ... 4 1.4 Tujuan Penelitian ... 5 1.5 Manfaat Penelitian ... 5
BAB II LANDASAN TEORI ... 6
2.1 Pemrosesan Sinyal Digital ... 6
2.2 Transformasi Fourier ... 6
2.3 Transformasi Fourier Diskrit ... 8
2.4 Machine Learning ... 8
2.5 Random Forest Classifier ... 8
2.6 K-Nearest Neighbors ... 10
2.7 Support Vector Machine ... 11
2.8 Soft Margin SVM ... 16
2.9 Optimasi Parameter ... 17
BAB III METODOLOGI PENELITIAN ... 19
3.1 Desain Penelitian ... 19
3.2 Pengambilan Data ... 20
3.3 Pre-Processing Data ... 20
3.4 Ekstraksi Ciri dengan Mel Frequency Cepstrals Coefficients ... 22
xii
3.4.2 Frame Blocking ... 24
3.4.3 Windowing... 25
3.4.4 Fast Fourier Transform ... 27
3.4.5 Mel Filter Bank ... 29
3.4.6 Discrete Cosinus Transform ... 33
3.4.7 Cepstral Liftering ... 35
BAB IV HASIL DAN PEMBAHASAN... 37
4.1 Representasi Data Suara ... 37
4.2 Hasil Ekstraksi Ciri Suara Menggunakan MFCC ... 40
4.3 Optimasi Parameter pada Machine Learning ... 43
4.4 Hasil Klasifikasi dan Evaluasi Model ... 45
BAB V PENUTUP ... 48
5.1 Kesimpulan ... 48
5.2 Saran ... 49
DAFTAR PUSTAKA ... 50
xiii
DAFTAR TABEL
Tabel 2.1 Confusion Matrix ... 17
Tabel 3.1 Nilai sinyal audio... 21
Tabel 3.2 Hasil Pre-emphasis ... 23
Tabel 3.3 Hasil Frame Blocking ... 25
Tabel 3.4 Hasil Windowing ... 26
Table 3.5 Hasil FFT ... 28
Tabel 3.6 Hasil perhitungan kepadatan spektral energi ... 29
Tabel 3.7 Nilai Mel-Frequency ... 31
Tabel 3.8 Nilai Frekuensi ... 31
Tabel 3.9 Nilai bin ... 32
Tabel 3.10 Hasil Filter Bank ... 32
Tabel 3.11 Hasil Konversi ke Satuan dB... 33
Tabel 3.12 Hasil Discrete Cosinus Transform ... 34
Tabel 3.13 Hasil Cepstral Liftering ... 35
Tabel 4.1 Hasil Konversi File Suara “Alhamdulillah” ... 38
Tabel 4.2 Hasil Ekstraksi Ciri MFCC Data Suara “Alhamdulillah” ... 41
Tabel 4.3 Hasil Ekstraksi Ciri MFCC Data Suara “Assalamualaikum” ... 41
Tabel 4.4 Dataset Hasil Ekstraksi Ciri MFCC dan Label Kata ... 43
xiv
DAFTAR GAMBAR
Gambar 1.1 Speech Recognition System [2] ... 1
Gambar 1.2 Proses pengenalan suara [3]... 2
Gambar 2.1 Skema pemrosesan sinyal digital [8]. ... 6
Gambar 2.2 Analisis Fourier [9] ... 7
Gambar 2.3 Contoh hyperplane dua dimensi ... 12
Gambar 3.1 Diagram Alur Penelitian (1) ... 19
Gambar 3.2 Diagram Alur Penelitian (2) ... 20
Gambar 3.3 Contoh Waveplot ... 21
Gambar 3.4 Tahapan ekstraksi ciri MFCC ... 22
Gambar 3.5 Plot hasil tahap pre-emphasis ... 24
Gambar 3.6 Pembingkaian ... 24
Gambar 4.1 Contoh pelabelan file suara ... 37
Gambar 4.2 Folder file suara ... 38
Gambar 4.3 Plot hasil konversi data suara pada setiap kata ... 39
Gambar 4.4 Plot data suara hasil ektraksi dengan MFCC ... 42
Gambar 4.5 Parameter terbaik Random Forest ... 44
Gambar 4.6 Parameter terbaik KNN ... 44
Gambar 4.7 Parameter Terbaik Hasil SVM... 44
Gambar 4.8 Hasil akurasi data traning menggunakan parameter terbaik ... 45
Gambar 4.9 (a) Hasil Confusion Matrix KNN ... 46
1 BAB I PENDAHULUAN
Pada bab ini, penulis akan menjelaskan mengenai gambaran umum pelaksanaan penelitian yang mencakup latar belakang, rumusan masalah, batasan masalah, tujuan penelitian dan manfaat penelitian. Hal tersebut akan dijelaskan secara berurutan pada bab ini.
1.1 Latar Belakang
Dewasa ini, perkembangan teknologi infromasi menjadi sangat pesat. Setiap peralatan teknologi saat ini menggunakan sinyal untuk melakukan pengiriman dan penerimaan data. Salah satu sinyal yang digunakan dalam mengirim dan menerima data adalah sinyal suara. Sinyal suara adalah sebuah sinyal yang merambat dengan frekuensi dan amplitudo tertentu. Sinyal suara juga merupakan sebuah sinyal analog yang memerlukan pemrorsesan lebih lanjut untuk dapat dimanfaatkan [1]. Salah satu contoh penggunaan sinyal suara dalam aspek kehidupan manusia adalah pengenalan suara.
Gambar 1.1 Speech Recognition System [2]
Pengenalan suara atau yang dikenal dengan Automatic Speech Recognition (ASR) adalah pengembangan teknik dan sistem pembelajaran pada mesin atau
2
komputer untuk dapat menerima masukan berupa kata maupun kalimat yang diucapkan. Teknologi ini memungkinkan sebuah mesin pembelajaran untuk dapat mengenali dan memahami kata atau kalimat yang diucapkan dengan cara merubah kata atau kalimat tersebut kedalam sebuah gelombang suara (sinyal suara), lalu sinyal suara tersebut akan diubah ke dalam bentuk digital untuk kemudian dilakukan pencocokan sinyal tersebut dengan suatu pola tertentu yang telah tersimpan pada mesin pembelajaran. Gambar 1.2 berikut merupakan proses pengenalan suara.
Gambar 1.2 Proses pengenalan suara [3]
Secara garis besar, proses pengenalan suara ini adalah mula-mula sinyal suara manusia yang diterima oleh microphone dan simpan dalam file, kemudian dilakukan pemrosesan suara dengan membaca data suara dari file rekaman untuk diubah dari sinyal analog menjadi sinyal digital. Setelah didapat data sinyal dalam bentuk digital kemudian dilakukan ekstraksi ciri untuk mendapatkan data latih dan uji yang nantikan digunakan untuk membuat model klasifikasi dan akhitnya akan diperoleh hasil pengamatan.
Pada tahap klasifikasi, variabilitas sinyal suara berpengaruh pada proses pengenalan suara. Sinyal suara manusia memiliki variabilitas yang sangat tinggi. Hal ini dapat dilihat dari variasi pengucapan baik dari segi bahasa maupun kata yang berbeda-beda yang mana hal tersebut akan menghasilkan pola ucapan yang berbeda-beda pula. Semakin bervariasi bahasa dan kata dapat mengakibatkan penerjemahan makna dari sinyal suara menjadi semakin kompleks dan dapat mempengaruhi dalam ketepatan mesin pembelajaran untuk melakukan klasifikasi dalam proses pengenalan suara. Belum lagi ditambah dengan masalah akurasi yang rendah karena sinyal suara yang rentan terhadap noise pada suara. Oleh karena itu diperlukan metode-metode yang dapat melakukan ekstraksi ciri pada data suara untuk menangani hal tersebut.
3
Salah satu metode yang dapat digunakan untuk mengesktraksi ciri atau pola sinyal pada data suara adalah Mel- Frequency Cepstral Coefficients (MFCC). MFCC merupakan salah satu metode yang banyak digunakan dalam speech technology baik dalam pengenalan suara maupun pengenalan speaker [4]. Metode ini melakukan ekstraksi ciri untuk mendapatkan cepstral coefficients dan frame yang nantinya dapat digunakan dalam pemrosesan pengenalan suara agar memiliki ketepatan yang lebih baik. Metode ini juga merupakan metode feature extraction yang melakukan proses konversi suatu sinyal suara menjadi sebuah parameter atau vektor data. Keunggulan dari MFCC yaitu mampu menangkap karakteristik atau informasi-informasi penting yang terkandung dalam sinyal suara dan mampu menghasilkan data seminimal mungkin tanpa menghilangkan informasi-informasi penting yang ada didalam suatu sinyal suara [4].
Penelitian dengan menggunakan ekstraksi ciri sinyal suara dengan MFCC telah dilakukan sebelumnya oleh Totok Chamidy pada tahun 2016 untuk pemrosesan suara dalam mengklasifikasi kata Arabic pada penutur Indonesia [5]. Pada penelitian tersebut menggunakan metode Hidden Markov Model (HMM) untuk melakukan klasifikasi. Dalam penelitian tersebut diperoleh akurasi sebesar 82,2 %. Risanuri Hidayat, dkk pada tahun 2019 juga melakukan ekstraksi ciri dengan MFCC untuk mengenali suara kata khusus dalam percakapan Bahasa Indonesia [6]. Dalam penelitiannya, metode klasifikasi yang digunakan adalah Support Vector Machine (SVM). Dalam melakukan pengenalan khusus dalam percakapan Bahasa Indonesia dengan MFCC dan SVM tersebut diperoleh hasil nilai F1-score diatas 87% untuk setiap kelas kata yang ditentukan. Selain itu Akhmad Anggoro, dkk. juga melakukan penelitian dengan ekstraksi ciri menggunakan MFCC pada tahun 2020 untuk mengenali suara dengan artikulasi P [7]. Pada penelitian tersebut, peneliti menggunakan metode klasifikasi K-Nearest Neighbor dengan akurasi terbaik yang dihasilkan sebesar 76% yaitu pada kata atap.
Pada penelitian ini, peneliti menggunakan data primer yaitu data suara berupa file rekaman suara pengucapan kalimat tayyibah oleh penutur Indonesia. File rekaman suara pengucapan kalimat tayyibah digunakan sebagai data dalam penelitian ini sebagai karena sebagai bentuk integrasi antara ilmu pengetahuan
4
dengan keislaman. Selain itu, di dalam Islam sangat dianjurkan bagi setiap Muslim untuk selalu berkata yang baik (thayyib) seperti dalam firman Allah dalam surat Al Isra ayat 53 :
ُنَسْحَأ َيِه يِتَّلا اوُلوُقَي يِداَبِعِل ْلُق َو Artinya : “Dan katakanlah kepada hamha-hamba-Ku: “Hendaklah mereka mengucapkan perkataan yang lebih baik (benar)”.
Dalam penelitian ini, hal-hal yang membedakannya dengan penelitian-penelitian terdahulu adalah terdapat pada penggunaan data suara yang digunakan oleh peneliti dan penggunaan beberapa machine learning untuk membuat model klasifikasi pada data hasil ekstraksi ciri MFCC.
1.2 Rumusan Masalah
Berdasarkan latar belakang penelitian tersebut, maka perumusan masalahnya adalah sebagai berikut:
1. Bagaimana cara melakukan ekstraksi ciri dengan MFCC?
2. Bagaimana performa data hasil ekstraksi MFCC pada beberapa machine learning?
1.3 Batasan Masalah
Batasan masalah yang ditentukan dalam penelitian ini adalah sebagai berikut:
1. Data yang digunakan adalah data primer berupa file suara rekaman pengucapan kalimat tayyibah oleh penutur Indonesia yang direkam dengan frekuensi sampel 441 KHz, channel Stereo dan resolusi 32-bit(float) dengan durasi rata-rata 1 detik serta berbentuk *wav.
2. Kalimat-kalimat tayyibah yang ditentukan sebagai kelas dalam klasifikasi pada penelitian ini adalah Astaghfirullah, Alhamdulilah, Assalamualaikum, Subhanalah dan Wa’alaikumsalam.
3. Machine learning yang digunakan dalam penelitian ini adalah Random Forest Classifier, K-Nearest Neighbor, dan Support Vector Machine.
5 1.4 Tujuan Penelitian
Berdasarkan rumusan masalah yang diberikan, maka tujuan penelitian ini adalah sebagai berikut:
1. Mengetahui cara ekstrasi ciri dengan menggunakan MFCC
2. Mengetahui peforma data hasil ekstraksi ciri MFCC pada beberapa machine learning.
1.5 Manfaat Penelitian
Melalui penelitian ini diharapkan dapat turut berkontribusi dalam ilmu pengetahuan sebagai referensi mengenai ekstraksi ciri suara dengan MFCC pada beberapa machine learning dan sebagai bentuk pengintegrasian antara ilmu pengetahuan dengan keislaman. Selain itu, diharapkan juga untuk kedepannya penelitian ini dapat diterapkan ke dalam pengembangan teknologi berbasis pengenalan suara lainnya.
6 BAB II
LANDASAN TEORI
2.1 Pemrosesan Sinyal Digital
Pemrosesan sinyal digital (Digital Signal Processing) adalah suatu teknik, perhitungan dan algoritma untuk memanipulasi sebuah sinyal yang diperoleh dari data sensor yang kemudian dilakukan pengubahan ke dalam bentuk digital [8]. Salah satu bidang yang memerlukan permrosesan sinyal digital adalah pengenalan suara. Skema pemrosesan sinyal digital adalah seperti pada gambar 2.1 berikut.
Gambar 2.1 Skema pemrosesan sinyal digital [8].
Berdasarkan gambar 2.1, suara yang diperoleh akan melalui analog filter dan akan diubah menjadi digital signal pada proses analog-to-digital conversion (ADC). Suara yang telah diubah kedalam bentuk digital akan melalui proses digital signal processing (DSP) kemudian diubah ke dalam bentuk analog pada proses digital-to-analog (DAC). Namun dalam implementasinya tidak semua pemrosesan sinyal digital harus melalui proses ADC dan DAC. Salah satunya adalah dalam pengenalan suara, dimana tidak diperlukan proses DAC karena sistem cukup hanya mengenali suara yang didapatkan dan diubah ke dalam bentuk teks.
2.2 Transformasi Fourier
Joseph Fourier mengemukakan bahwa sebuah fungsi periodik dapat direpresentasikan dengan cara mengkombinasikan penjumlahan tak hingga dari fungsi sinus dan cosinus dimana yang kemudian representasi ini kemudian dikenal sebagai Deret Fourier [9]. Deret fourier kemudian mengalami perkembangan
7
menjadi bentuk yang lebih umum sehingga dapat diterapkan pada fungsi non periodik yang kemudian dikenal sebagai transformasi fourier.
Sebuah fungsi biasanya digambarkan dalam domain waktu, artinya yang dilakukan pengukuran dalam fungsi tersebut adalah waktu dimana misalkan sebuah fungsi digambarkan pada sumbu simetri dengan sumbu x mewakili waktu dan sumbu y mewakili nilai pada waktu t tertentu (nilai amplitudonya). Namun pada aplikasinya ini bukan merupakan representasi yang terbaik karena ada banyak kasus sebuah informasi khusus yang tersembunyi terletak pada nilai frekuensinya. Dengan adanya analisis fourier maka hal tersebut dapat diatasi yakni dengan mentransformasikan representasi waktu-amplitudo menjadi representasi frekuensi-amplitudo dimana sumbu x akan mewakili nilai frekuensi dan sumbu y mewakili nilai amplitudonya seperti pada gambar 2.2 berikut.
Gambar 2.2 Analisis Fourier [9]
Transformasi fourier miliki sifat reversible dimana suatu fungsi dapat ditransformasikan ke dalam domain yang memuat informasi frekuensi-amplitudo (domain frekuensi) dan dapat diinversikan kembali ke domain yang memuat informasi waktu-amplitudo (domain waktu) namun tidak bisa didapatkan secara bersamaan. Bentuk dari Transformasi Fourier adalah sebagai berikut.
𝑓(𝑤) = 1 2𝜋∫ 𝑓(𝑥)𝑒 𝑖𝑤𝑥𝑑 ∞ −∞ (2.1) Dengan: 𝑓(𝑤) : Transformasi Fourier 𝑓(𝑥) : Isyarat periodis
8 2.3 Transformasi Fourier Diskrit
Transformasi Fourier Diskrit merupakan model transformasi fourier yang dikenakan pada fungsi diksrit dan hasilnya juga diskrit [9]. Misalkan 𝑓(𝑥) periodik, di asumsikan N merupakan bagian-bagian yang diukur dari 𝑓(𝑥) yang diambil pada interval 0 ≤ 𝑥 ≤ 2𝜋 dengan jarak yang teratur dari titik-titik
𝑥𝑘 = 2𝜋𝑘
𝑁 , 𝑘 = 0, 1, … , 𝑁 − 1 (2.2)
Maka transformasi fourier diskrit dapat didefinisikan dengan :
𝑓𝑗 = ∑ 𝑓𝑘𝑒𝑖𝑗𝑥𝑘, 𝑓𝑘 = 𝑓(𝑥𝑘), 𝑗 = 0, … , 𝑁 − 1 𝑁−1
𝑘=0
(2.3)
Persamaan 2.3 tersebut akan menghasilkan spectrum frekuensi dari sebuah sinyal dan dinamakan sebagai Transformasi Diskrit 1 dimensi dan banyak digunakan dalam pengolahan sinyal digital.
2.4 Machine Learning
Machine Learning atau pembelajaran mesin merupakan pendekatan dalam kecerdasan buatan yang banyak digunakan untuk menggantikan, atau menirukan perilaku manusia dalam menyelesaikan masalah atau melakukan sesuatu secara otomatis (otomatisai) [10]. Yang menjadi ciri khas pada machine learning adalah terdapatnya proses pelatihan, pembelajaran atau training. Selain itu, pada machine learning terdapat dua aplikasi didalamnya yaitu klasifikasi dan prediksi. Klasifikasi merupakan metode pada machine learning yang digunakan oleh mesin untuk melakukan pemilahan atau mengelompokkan objek berdasarkan ciri tertentu sebagaimana manusia membedakan antara dua objek. Prediksi merupakan aplikasi dalam machine learning yan digunakan untuk melakukan penerkaan atau menerka keluaran suatu data masukan berdasarkan data yang telah dipelajari dalam training.
2.5 Random Forest Classifier
Random Forest merupakan metode ensemble yang digunakan untuk meningkatkan akurasi pada metode klasifikasi dengan cara mengkombinasikan
9
metode klasifikasi [11] . Pada metode random forest ini diawali dengan menggunakan teknik dasar data mining yaitu decision tree dimana data input dimasukkan pada bagian atas (root) lalu akan turun ke bagian bawah (leaf) untuk dilakukan penentuan data input tersebut masuk ke dalam kelas yang mana [12]. Random Forest juga merupakan metode pengklasifikasian yang terdiri dari kumpulan pengklasifikasian pohon berstruktur dengan masing-masing pohon memberikan unit suara untuk kelas yang paling popular pada input x [13]. Dapat dikatakan bahwa pada random forest terdiri dari sekumpulan decision tree (pohon keputusan) dimana kumpulan decision tree tersebut kemudian digunakan untuk mengklasifikasi data ke suatu kelas.
Misalkan data training berukuran n dengan d peubah penjelas, maka tahapan penyusunan dan pendugaan Random Forest dapat dituliskan secara sederhana sebagai berikut [14].
a. Tahapan bootstrap dimana dilakukan penarikan contoh acak dengan pemulihan berukuran n dari data training.
b. Tahap random sub-setting dimana pada tahap ini dilakukan penyusunan pohon berdasarkan data tersebut, namun pada setiap proses pemisahan pilih secara acak jumlah variabel peubah (m) < d peubah penjelas dan dilakukan pemisahan terbaik.
c. Mengulangi langkah a-b sebanyak k kali sehingga akan diperoleh sejumlah k pohon acak.
d. Melakukan pendugaan gabungan berdasarkan k buah pohon acak tersebut.
Dalam hal ini, pada setiap kali pembentukan pohon, kandidat peubah penjelas yang digunakan dalam pemisahan bukanlah semua peubah penjelas namun hanya sebagian saja sehingga akan dihasilkan pohon tunggal dengan bentuk yang berbeda beda dengan harapan antar kumpulan pohon tunggal tersebut memiliki korelasi yang kecil.
Random forest terdiri dari kumpulan pohon keputusan. Pohon keputusan ini dimulai dengan menghitung nilai entropy sebagai penentu tingkat ketidakmurnian
10
atribut dan nilai informasi gain. Nilai entropy dapat dihitung dengan menggunakan persamaan 2.4 sebagai berikut [14].
𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑌) = − ∑ 𝑝(𝑐|𝑌) log2𝑝(𝑐|𝑌) (2.4)
Dengan :
Y : Himpunan Kasus
𝑝(𝑐|𝑌) : proporsi nilai Y terhadap kelas c
Setelah diperoleh nilai entropy, maka dapat dihitung nilai information Gain menggunakan persamaan 2.5 sebagai berikut [14].
𝐺𝑎𝑖𝑛(𝑌, 𝑎) = 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑌) − ∑ 𝑣 ∈ 𝑉𝑎𝑙𝑢𝑒𝑠(𝑎)|𝑌𝑣|
|𝑌𝑎|𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑌) (2.5) Dengan :
𝐺𝑎𝑖𝑛(𝑌, 𝑎) : Nilai Infromation Gain
𝑉𝑎𝑙𝑢𝑒𝑠(𝑎) : Semua nilai yang mungkin dalam himpunan kasus a.
𝑌𝑣 : Subkelas dari Y dengan kelas v yang berhubungan dengan kelas a
𝑌𝑎 : Semua nilai yang sesuai dengan a
2.6 K-Nearest Neighbors
K-Nearest Neighbors (KNN) merupakan salah satu metode mesin pembelajaran yang digunakan untuk mengambil keputusan dengan mengklasifikasi data masukan baru berdasarkan jarak terdekat dengan data nilai [15]. KNN akan mengklasifikasikan objek berdasarkan data pembelajarannya yang memiliki jarak paling dekat dengan objek tersebut dimana data pembelajaran tersebut akan diproyeksikan ke dalam ruang berdimensi banyak yang masing-masing dimensi merepresentasikan fitur dari data [16].
11
Pada KNN, kedekatan didefinisikan dalam jarak metric seperti jarak Euclidean dimana dapat dicari dengan menggunakan persamaan 2.6 berikut [15].
𝐷𝑥𝑦 = √∑ (𝑥𝑖− 𝑦𝑖)2 𝑛 𝑖=1 (2.6) Dengan : 𝐷𝑥𝑦 : Jarak keterdekatan 𝑥 : data training 𝑦: data testing
𝑛 : jumlah atribut individi antaraa 1 s.d n
Langkah-langkah yang digunakan untuk menyelesaikan masalah dengan menggunakan algoritma K-Nearest Neighbors adalah pertama dengan menentukan parameter jumlah tetangga paling dekat (k), kemudian menghitung kuadrat jarak Euclid dengan menggunakan persamaan 2.6 diatas pada masing-masing objek terhadap data sampel yang diberikan, lalu akan diketahui objek-objek dengan jarak Euclid yang paling kecil dan mengurutkannya. Lalu mengumpulkan kategori Y (Klasifikasi Nearest Neighbor) dan menggunakan kategori tersebut yang paling dominan untuk memprediksi.
2.7 Support Vector Machine
Konsep dasar dari metode SVM adalah mentranformasi data ke ruang yang berdimensi lebih tinggi dan menemukan fungsi pemisah (hyperplane) terbaik. Hyperplane terbaik adalah fungsi pemisah yang terletak di tengah-tengah antara dua macam set obyek dari dua kelas. Untuk mencari hyperplane terbaik yaitu dengan memaksimalkan margin atau jarak antara dua set obyek (pattern) dari kelas yang berbeda. Pattern yang dekat dengan hyperplane ini disebut support vector.
Diasumsikan data merupakan linearly separable data. Misalkan data dinyatakan dalam (𝑥𝑖, 𝑦𝑖) dimana 𝑖 = 1, 2, 3, … , 𝑛. 𝑥𝑖 = [𝑥𝑖1, 𝑥𝑖2, 𝑥𝑖3, … , 𝑥𝑖𝑗]
12
adalah vektor baris dari fitur ke-𝑖 diruang dimensi ke-𝑗 dan 𝑦𝑖 adalah label dari 𝑥𝑖 yang didefinisikan sebagai 𝑦𝑖 ∈ {+1, −1}, maka kedua kelas dapat dipisahkan secara linier oleh hyperplane.
Pada gambar 2.3, hyperplane ditunjukkan dengan garis lurus yang berwarna biru. Data yang berbentuk lingkaran dan berada diatas hyperplane adalah kelas +1 dan yang berbentuk persegi dan berada dibawah hyperplane adalah kelas -1.
Gambar 2.3 Contoh hyperplane dua dimensi
Persamaan hyperplane dapat didefinisikan seperti pada persamaan 2.7. 𝑓(𝑥) = 𝑤 ∙ 𝑥 + 𝑏 (2.7)
Dengan:
𝑤 : parameter bobot 𝑥 : vektor input 𝑏 : bias
Dari persamaan 2.7 tersebut maka hyperplane pendukung dari kelas +1 dapat dinyatakan dengan persamaan 𝑤 ∙ 𝑥 + 𝑏 = +1 dan pattern yang memenuhi persamaan tersebut merupakan pattern kelas +1. Begitupula hyperplane pendukung dari kelas -1 dapat dinyatakan dalam persamaan 𝑤 ∙ 𝑥 + 𝑏 = −1 dan pattern yang memenuhi persamaan terserbut merupakan pattern kelas -1. Oleh karena itu, secara spesifik margin dapat dihitung dengan mencari nilai tengah dari kedua jarak kelas seperti pada persamaan 2.8.
𝑀𝑎𝑟𝑔𝑖𝑛 =1 2(( 𝑤 ||𝑤||, 𝑥 +) − ( 𝑤 ||𝑤||, 𝑥 −))
13 =1 2( 1 − 𝑏 ||𝑤|| − ( −1 − 𝑏 ||𝑤|| )) =1 2( 1 + 1 ||𝑤||) = 1 ||𝑤||, ||𝑤|| ≠ 0 (2.8)
Pada setiap kelas harus diberikan batasan pada data dari masing-masing kelas agar tidak masuk kedalam margin, batasan yang ditambahkan adalah sebagai berikut.
𝑤 ∙ 𝑥 + 𝑏 ≤ −1, 𝑗𝑖𝑘𝑎 𝑦 = −1 (2.9) 𝑤 ∙ 𝑥 + 𝑏 ≥ +1, 𝑗𝑖𝑘𝑎 𝑦 = +1 (2.10)
Atau persamaan 2.9 dan 2.10 dapat ditulis ke dalam bentuk persamaan 2.11 sebagai berikut:
𝑦𝑖(𝑤 ∙ 𝑥𝑖+ 𝑏) − 1 ≥ 0, ∀ 1 ≤ 𝑖 ≤ 𝑛, 𝑖 ∈ 𝑁 (2.11)
Untuk memaksimalkan nilai margin ekuivalen dapat dilakukan dengan meminimumkan ||𝑤||2. Oleh karena itu, secara sistematis, formulasi problem optimisasi SVM dapat ditulis dalam persamaan 2.12.
max 𝑚𝑎𝑟𝑔𝑖𝑛 = min1 2||𝑤|| 2 Dengan kendala: (2.12) 𝑦𝑖(𝑤 ∙ 𝑥𝑖+ 𝑏) − 1 ≥ 0, ∀ 1 ≤ 𝑖 ≤ 𝑛, 𝑖 ∈ 𝑁
Untuk menyelesaikan permasalahan pada persamaan 2.12, maka kita ubah permasalahan tersebut menjadi fungsi Lagrangian sebagai berikut.
min 𝐿𝑝(𝑤, 𝑏, 𝛼) = 1 2||𝑤|| 2 − ∑ 𝛼𝑖[𝑦𝑖(𝑤 ∙ 𝑥𝑖+ 𝑏) − 1] 𝑛 𝑖=1 (2.13) Dengan:
𝐿𝑝 : fungsi Lagrangian (primal problem)
14
Solusi dari permasalahan optimisasi seperti diatas ditentukan dengan mencari saddle points dari fungsi Lagrangian (𝐿𝑝). Fungsi ini harus diminimalkan terhadap variabel 𝑤, 𝑏, dan dimaksimalkan pada variabel 𝛼. Oleh karena itu, akan dicari turunan pertama dari persamaan 2.13 terhadap variabel 𝑤 dan 𝑏 dan disamakan dengan nol sebagai berikut [17]:
1. Turunan pertama 𝐿𝑝 terhadap 𝑤 : 𝜕 𝜕𝑤𝐿𝑝(𝑤, 𝑏, 𝛼) = 0 ∂ 𝜕𝑤( 1 2||𝑤|| 2 − ∑ 𝛼𝑖[𝑦𝑖(𝑤 ∙ 𝑥𝑖+ 𝑏)] − ∑ 𝛼𝑖 𝑛 𝑖=1 𝑛 𝑖=1 ) = 0
Maka akan diperoleh :
𝑤 − ∑ 𝛼𝑖𝑦𝑖𝑥𝑖= 0 𝑛 𝑖=1 𝑤 = ∑ 𝛼𝑖𝑦𝑖𝑥𝑖 𝑛 𝑖=1 (2.14)
2. Turunan pertama 𝐿𝑝 terhadap 𝑏 : 𝜕 𝜕𝑏𝐿𝑝(𝑤, 𝑏, 𝛼) = 0 ∂ 𝜕𝑏( 1 2||𝑤|| 2 − ∑ 𝛼𝑖[𝑦𝑖(𝑤 ∙ 𝑥𝑖+ 𝑏)] − ∑ 𝛼𝑖 𝑛 𝑖=1 𝑛 𝑖=1 ) = 0
Maka akan diperoleh :
∑ 𝛼𝑖𝑦𝑖 𝑛
𝑖=1
= 0 (2.15)
Persamaan 2.14 dan 2.15 diatas merupakan kondisi optimalisasi pada fungsi Lagrangian . Apabila problem primal (𝐿𝑝) memiliki solusi optimal maka problem dual (𝐿𝑑) juga akan memiliki solusi optimal yang sama dan apabila 𝑤0 adalah solusi problem primal dan 𝛼0 adalah solusi problem dual, maka cukup bahwa 𝑤0 solusi layak untuk problem primal [17]. Untuk mendapatkan problem dual, substiusi
15
persamaan 2.14 dan 2.15 pada persamaan 2.13 sehingga diperoleh persamaan 2.16 seperti berikut 𝑚𝑎𝑘𝑠 𝐿𝑑(𝛼) = ∑ 𝛼𝑖 𝑛 𝑖=1 −1 2∑ ∑ 𝛼𝑖𝑦𝑖𝛼𝑗𝑦𝑗(𝑥𝑖∙ 𝑥𝑗) 𝑛 𝑗=1 𝑛 𝑖=1 (2.16) Dengan kendala, ∑ 𝛼𝑖𝑦𝑖= 0 𝑛 𝑖=1 , 𝛼𝑖 ≥ 0
Nilai 𝛼 didapatkan dari hasil perhitungan substitusi kendala pada persamaan 2.16. Nilai 𝛼 ini dgunakan untuk mencari nilai 𝑤. Setiap titik data selalu terjadi 𝛼𝑖= 0. Titik-titik dengan 𝛼𝑖= 0 tidak akan ada dalam perhitungan untuk mencari nilai 𝑤 dan tidak berperan dalam melakukan prediksi data baru. Data lain dengan 𝛼𝑖> 0 disebut support vector [18].
Dalam SVM terdapat beberapa fungsi kernel yang dapat digunakan seperti linier, polynomial, RBF dan sigmoid. Fungsi kernel ini digunakan untuk mentranformasi data ke ruang yang memiliki dimensi lebih tinggi. Dalam penelitian ini fungsi kernel yang diujikan adalah kernel linier : 𝐾(𝑥𝑖, 𝑥𝑗) = (𝑥𝑇∙ 𝑥), sehingga untuk mencari nilai 𝑏 dapat dilakukan dengan mensubstitusi 2.14 ke 2.7 dan mensubtisuikan hasilnya dengan 𝑦𝑖𝑓(𝑥𝑖) = 1 dan diperoleh persamaan sebagai berikut [18]: 𝑏 = 1 𝑁𝑠∑ (𝑦𝑖− ∑ 𝑎𝑚𝑦𝑚𝑥𝑚 𝑇 ∙ 𝑥 𝑖 𝑠 𝑖=1 ) 𝑖∈𝑆 (2.17) Dengan :
𝑁𝑠 : banyaknya support vector
Setelah nilai 𝛼, 𝑤 dan 𝑏 telah ditemukan, fungsi pemisah optimal dapat ditentukan dengan persamaan:
𝑔(𝑥) = 𝑠𝑖𝑔𝑛(𝑓{𝑥}) = 𝑠𝑖𝑔𝑛(𝑤 ∙ 𝑥 + 𝑏) (2.18)
16 2.8 Soft Margin SVM
Pada dasarnya, prinsip kerja dari metode SVM adalah mencari fungsi pemisah (hyperplane) terbaik untuk dapat memisahkan kelas yang berbeda. Dalam beberapa kasus yang sering terjadi di dunia nyata, data yang dijumpai merupakan data yang tidak dipisahkan secara linear. Oleh karena itu, dibutuhkan soft margin classifier untuk mengatasi hal tersebut yaitu dengan mengklasifikasi sebagian besar data dengan benar dan memberikan kemungkinan kesalahan di sekitar batas pemisah. [19]. Dalam hal ini maka batas pemisah harus diubah agar lebih fleksibel dengan cara menambahkan variabel slack 𝜉 dimana 𝜉 > 0 pada setiap batas pemisah, sehingga batas pemisahnya berubah menjadi 𝑥𝑖+ 𝑏 ≥ 1 − 𝜉 untuk kelas +1 dan 𝑥𝑖+ 𝑏 ≤ −1 + 𝜉 untuk kelas -1. Variabel slack ini dapat meminimalkan kesalahan klasifikasi dengan memungkinkan suatu titik berada pada pad kondisi misklasifikasi sehingga rumus yang digunakan untuk mencari hyperplane terbaik adalah sebagai berikut.
max 𝑚𝑎𝑟𝑔𝑖𝑛 = min1 2||𝑤|| 2 + 𝐶 ∑ 𝜉𝑖 𝑛 𝑖=1 𝑠. 𝑡 𝑦𝑖(𝑤. 𝑥𝑖+ 𝑏) ≥ 1 − 𝜉𝑖
C merupakan parameter yang menentukan besar penalti akibat kesalahan dalam klasifikasi data [20].
Selanjutnya,persamaan primal problem akan berubah menjadi:
min 𝐿𝑝(𝑤, 𝑏, 𝛼) = 1 2||𝑤|| 2 + 𝐶 ∑ 𝜉𝑖 𝑛 𝑖=1 − ∑ 𝛼𝑖[𝑦𝑖(𝑤 ∙ 𝑥𝑖+ 𝑏) − 1 + 𝜉𝑖] − ∑ 𝜇𝑖𝜉𝑖 𝑛 𝑖=1 𝑛 𝑖=1 (2.18)
Pengubahan Langrange primal ke dalam dual problem , menghasilkan formula yang sama dengan kasus untuk data yang dapat dipisah secara linear sehingga
17
pencarian hyperplane terbaik dilakukan dengan cara yang hampir sama tetapi dengan nilai 𝛼𝑖adalah 0 ≥ 𝛼𝑖 ≥ 𝐶.
2.9 Optimasi Parameter
Grid Search Cross Vadiation adalah salah satu proses yang dilakukan untuk mengidentifikasi hyper-parameter terbaik dalam klasifikasi sehingga dapat memprediksi data yang tidak diketahui secara akurat [21]. Hyper-parameter merupakan parameter yang ditentukan tanpa proses uji atau dapat dikatakan sebagai parameter yang tidak ditentukan oleh mesin [18].
Pada Grid Search Cross Validation ini dilakukan berbagai kombinasi nilai hyper-parameter yang dimasukkan kemudian hyper-paramater yang memiliki akurasi terbaik akan dipilih dan digunakan untuk melatih SVM pada seluruh data. Pada kernel linear Support Vector Machine (SVM) hanya ada satu parameter penting yang perlu dioptimalkan yaitu C. Pada kernel RBF dan Sigmoid terdapat dua parameter yang perlu dioptimalkan yaitu C dan gamma, sedangkan pada kernel Polynomial terdapat tiga parameter yang perlu dioptimalkan yaitu C, gamma dan degree.
2.10 Evaluasi Model
Evaluasi model digunakan untuk mengetahui seberapa baik model dapat melakukan klasifikasi suatu kelas. Salah satu cara yang sering digunakan dalam melakukan evaluasi model adalah dengan menggunakan confusion matrix. Confusion matrix adalah sebuah matrix dari prediksi yang akan dibandingkan dengan kelas asli dari inputan atau dengan kata lain berisikan nilai actual dan prediksi pada klasifikasi seperti pada tabel 2.1.
Tabel 2.1 Confusion Matrix
Confusion Matrix
Kelas Prediksi Positif Negatif
18 Kelas
Sebenarnya
Negatif FN TN
Dari tabel 2.1 diatas, evaluasi dan validasi hasil dari model dapat dihitung menggunakan rumus akurasi, precision dan recall seperti pada persamaan-persamaan berikut [22]: Akurasi = TP + TN TP + FP + FN + TN (2.19) Precision = TP TP + FP (2.20) Recall = TP TP + FN (2.21) Dimana :
TP (True Positive) : Jumlah data positif yang terklasifikasi benar. TN (True Negative) : Jumlah data negative yang terklasifikasi benar. FP (False Positive) : Jumlah data positif yang terklasifikasi salah. FN (False Negative) : Jumlah data negative yang terklasifikasi salah.
19 BAB III
METODOLOGI PENELITIAN
Bab ini menjelaskan metode dan tahap-tahapan yang digunakan dalam penelitian. Metode yang digunakan pada penelitian ini yaitu metode Mel Frequency Cepstrum Coefficients (MFCC) untuk ekstraksi ciri dari data file suara dan metode Support Vector Machine (SVM) untuk klasifikasi suara. Pada Bab ini juga akan dijelaskan bagaimana alur penelitian.
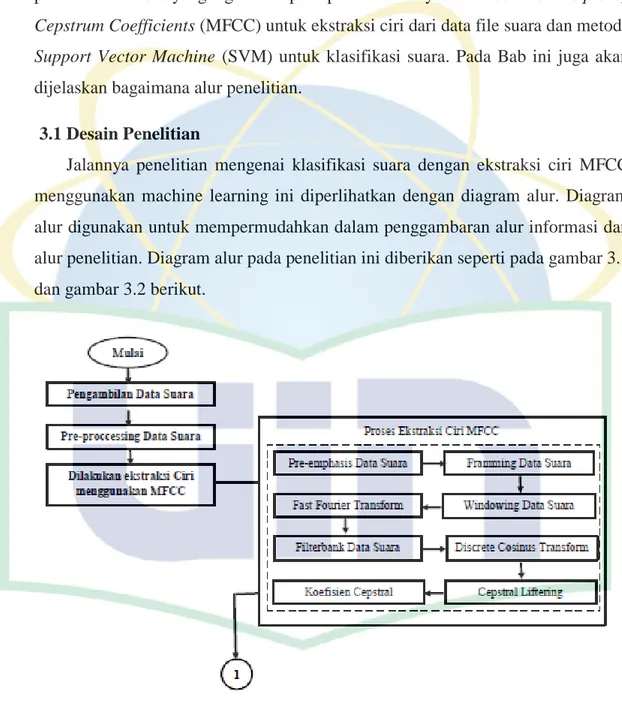
3.1 Desain Penelitian
Jalannya penelitian mengenai klasifikasi suara dengan ekstraksi ciri MFCC menggunakan machine learning ini diperlihatkan dengan diagram alur. Diagram alur digunakan untuk mempermudahkan dalam penggambaran alur informasi dan alur penelitian. Diagram alur pada penelitian ini diberikan seperti pada gambar 3.1 dan gambar 3.2 berikut.
20
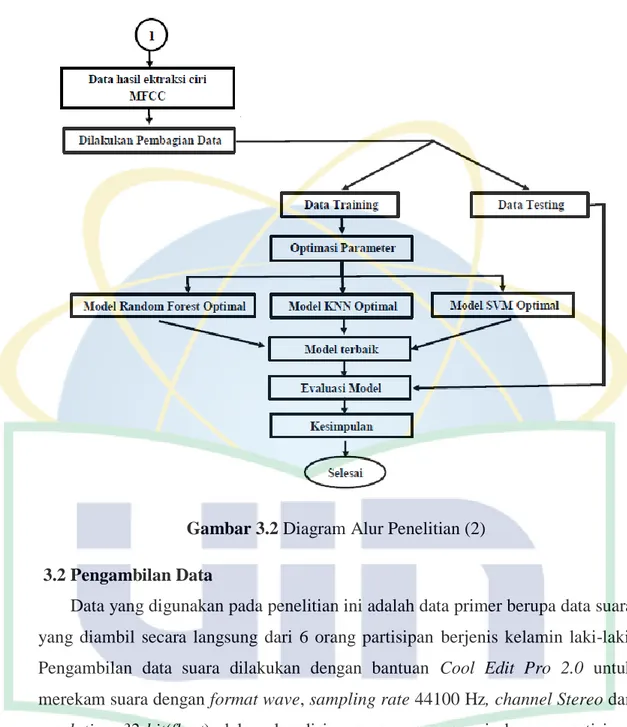
Gambar 3.2 Diagram Alur Penelitian (2) 3.2 Pengambilan Data
Data yang digunakan pada penelitian ini adalah data primer berupa data suara yang diambil secara langsung dari 6 orang partisipan berjenis kelamin laki-laki. Pengambilan data suara dilakukan dengan bantuan Cool Edit Pro 2.0 untuk merekam suara dengan format wave, sampling rate 44100 Hz, channel Stereo dan resolution 32-bit(float) dalam kondisi ruangan yang sunyi dengan partisipan berjarak 30 cm dari microphone. Pengambilan suara dilakukan sebanyak masing-masing 5 kali perulangan terhadap 5 kata yang telah dipersiapkan sebelumnya.
3.3 Pre-Processing Data
Sebelum dilakukan ekstraksi ciri dengan MFCC, file suara hasil pengambilan data yang berformat *wav akan dilakukan proses preprocessing yaitu pembacaan data menggunakan tools pada SciPy [23] dimana file suara yang berupa signal
21
analog akan diubah ke dalam bentuk digital seperti yang ditunjukkan dengan waveplot pada gambar 4.3 berikut.
Gambar 3.3 Contoh Waveplot
Dari proses pembacaan ini akan diperoleh dua buah nilai yaitu data sample yang dari file audio dan sampling ratenya. Pada proses ini, peneliti hanya mengambil data satu detik pertama dari setiap file audio. Jumlah data yang diperoleh dari setiap file audio dapat dihitung dengan mengalikan sampling rate dengan waktu dalam satuan detik, sehingga jumlah data yang diperoleh adalah 44100 × 1 = 44100 data berupa nilai sinyal audio seperti pada tabel 3.1.
Tabel 3.1 Nilai sinyal audio Frame ke-(n) Nilai sinyal (y)
0 −0,00655079
1 −0,01246232
2 −0,01002897
… …
22
3.4 Ekstraksi Ciri dengan Mel Frequency Cepstrals Coefficients
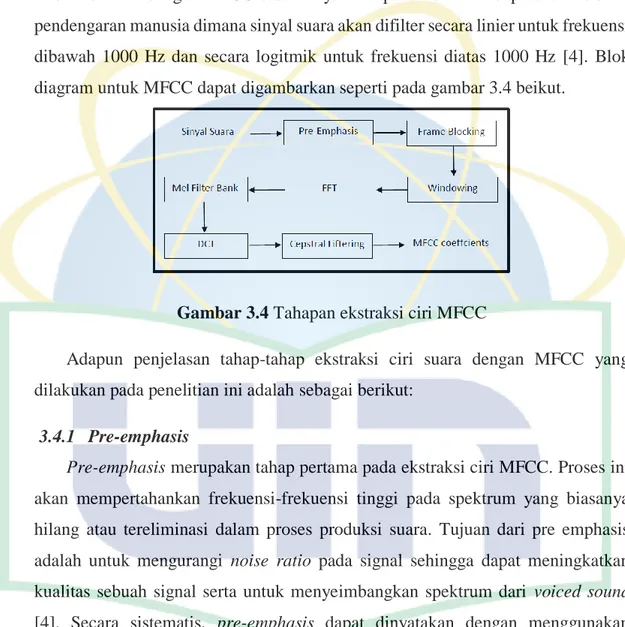
Setelah file suara melalui proses pre processing dan diperoleh data sebanyak 44100 data, maka langkah selanjutnya adalah ekstraksi ciri menggunakan MFCC. Ekstraksi Fitur dengan MFCC sebenarnya merupakan bentuk adaptasi dari sistem pendengaran manusia dimana sinyal suara akan difilter secara linier untuk frekuensi dibawah 1000 Hz dan secara logitmik untuk frekuensi diatas 1000 Hz [4]. Blok diagram untuk MFCC dapat digambarkan seperti pada gambar 3.4 beikut.
Gambar 3.4 Tahapan ekstraksi ciri MFCC
Adapun penjelasan tahap-tahap ekstraksi ciri suara dengan MFCC yang dilakukan pada penelitian ini adalah sebagai berikut:
3.4.1 Pre-emphasis
Pre-emphasis merupakan tahap pertama pada ekstraksi ciri MFCC. Proses ini akan mempertahankan frekuensi-frekuensi tinggi pada spektrum yang biasanya hilang atau tereliminasi dalam proses produksi suara. Tujuan dari pre emphasis adalah untuk mengurangi noise ratio pada signal sehingga dapat meningkatkan kualitas sebuah signal serta untuk menyeimbangkan spektrum dari voiced sound [4]. Secara sistematis, pre-emphasis dapat dinyatakan dengan menggunakan persamaan 3.1 sebagai berikut [24]
y(n) = s(n) − α s(n − 1) (3.1) Dengan :
y(n): signal hasil pre-emphasis s(n): signal sebelum pre-emphasis
23 s : signal
Misalkan dalam hal ini, konstanta filter pre-emphasis yang digunakan adalah 0,97 maka perhitungan dalam tahap pre-emphasis dengan menggunakan persamaan 3.1 adalah sebagai berikut:
𝑦[0] = −0,00655079
𝑦[1] = 𝑦[1] − 0,97(𝑦[0])
𝑦[1] = (−0,01246232) − 0,97(−0,00655079)
𝑦[1] = −0,006108059
Dengan menggunakan perhitungan yang sama dilakukan pada data yang lain hingga data ke 44099, maka akan diperoleh data seperti pada tabel 3.2.
Tabel 3.2 Hasil Pre-emphasis
Frame ke-(n) Hasil Pre-emphasis (y(n))
0 -0,00655079 1 -0,00610806 2 0,00205948 … … 44098 -0,00258835 44099 0,00925169
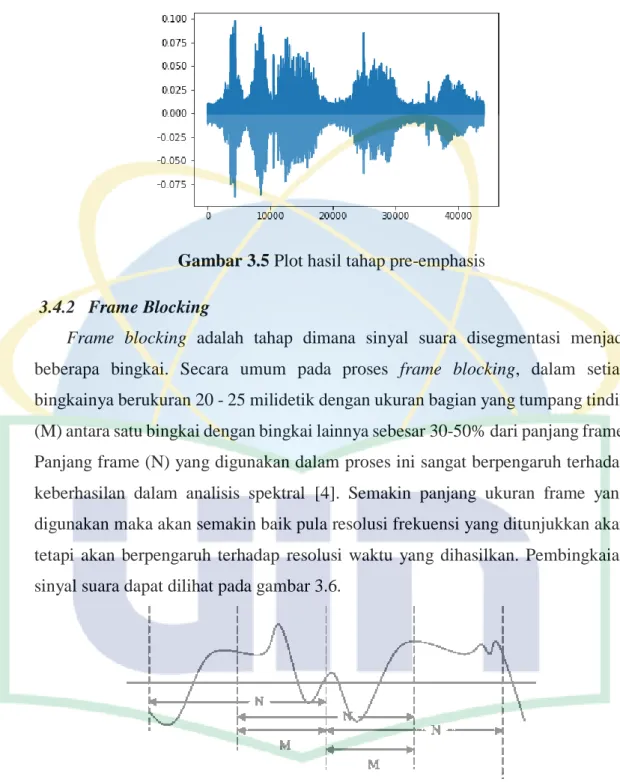
Apabila dilakukan plotting pada data hasil tahap pre-emphasis ini, maka akan menghasilkan plot seperti pada gambar 3.5 berikut.
24
Gambar 3.5 Plot hasil tahap pre-emphasis
3.4.2 Frame Blocking
Frame blocking adalah tahap dimana sinyal suara disegmentasi menjadi beberapa bingkai. Secara umum pada proses frame blocking, dalam setiap bingkainya berukuran 20 - 25 milidetik dengan ukuran bagian yang tumpang tindih (M) antara satu bingkai dengan bingkai lainnya sebesar 30-50% dari panjang frame. Panjang frame (N) yang digunakan dalam proses ini sangat berpengaruh terhadap keberhasilan dalam analisis spektral [4]. Semakin panjang ukuran frame yang digunakan maka akan semakin baik pula resolusi frekuensi yang ditunjukkan akan tetapi akan berpengaruh terhadap resolusi waktu yang dihasilkan. Pembingkaian sinyal suara dapat dilihat pada gambar 3.6.
Gambar 3.6 Pembingkaian
Misalkan pada pembingkaian ini, data akan dibingkai dengan ukuran 25 milidetik dengan ukuran tumpang tindih antara satu bingkai dengan bingkai lainnya sebesar 15 milidetik atau stridenya sebesar 10 milidetik, sehingga data hasil pembingkaiannya akan menjadi seperti pada tabel 3.3 berikut.
25
Tabel 3.3 Hasil Frame Blocking
0 1 2 … 1101 0 -0,006511 -0,006108 0,002059 … 0,002708 1 0,005582 -0,003729 0,002659 … 0,004971 2 0,003670 -0,003189 0,001461 … 0,010851 3 0,000910 -0,008175 0,005923 … -0,004884 4 0,008611 0,002250 0,006720 … 0,007614 … … … … … … 97 0,002569 -0,002152 0,003431 … -0,001270 3.4.3 Windowing
Windowing merupakan tahap pembobotan pada setiap frame yang telah terbentuk pada proses sebelumnya dengan menggunakan fungsi window [5]. Windowing ini dilakukan untuk mengurangi kesenjangan atau discontinuitas signal setalah proses frame blocking. Persamaan yang digunakan dalam proses windowing adalah sebagai berikut [25] :
x(n) = xi(n)w(n), n=0, 1, 2, … , N (3.2) Dengan :
x(n) : Nilai signal hasil windowing xi(n) : Nilai signal dari frame signal ke-i w(n) : Fungsi window
N : Frame size
Terdapat beberapa fungsi window yang dapat digunakan yaitu Rectangular Window, Hamming Window dan Hanning Window. Fungsi window yang sering digunakan dalam pengenalan suara adalah hamming window karena dapat menghasilkan slidelobe yang tidak terlalu tinggi dan noise yang tidak terlalu besar [4]. Secara sistematis, hamming window dapat didefiniskan dalam bentuk persamaan 3.3 sebagai berikut [5]
w(n) = 0,54 − 0,46 cos ( 2πn
26
Misalkan dalam penelitian, fungsi window yang digunakan adalah hamming window maka fungsi window ke-n dari data sinyal dengan hamming window dapat dihitung dengan menggunakan persamaan 3.3. Perhitungan fungsi window data sinyal ke-n nya adalah sebagai berikut.
𝑤(0) = 0,54 − 0,46 cos ( 2𝜋(0) (1102 − 1)) 𝑤(0) = 0,54 − 0,46 cos(0)
𝑤(0) = 0,08
Setelah diperoleh nilai fungsi window ke-n dari data sinyal, kemudian persamaan 3.2 digunakan untuk menghitung hasil windowing 𝑥(𝑛). Hasil windowing 𝑥(𝑛) dapat dihitung dengan mengalikan nilai sinyal dari frame sinyal ke- n (y(n)) dengan fungsi window-nya w(n). Proses perhitungan windowing adalah sebagai berikut.
𝑥(0) = 𝑦(0) × 𝑤(0)
= (−0,006551) × 0,08
𝑥(0) = −0,0052408
Dengan melakukan proses yang sama pada setiap nilai sinyal di setiap frame-nya, maka akan diperoleh data seperti yang ditunjukkan pada tabel 3.4.
Tabel 3.4 Hasil Windowing
0 1 2 3 … 1101 0 -0,000524 -0,000489 0,000165 0,000262 … 0,000217 1 0,000447 -0,000298 0,000213 0,000595 … 0,000398 2 0,000294 -0,000255 0,000117 -0,000170 … 0,000868 3 0,000073 -0,000654 0,000474 -0,000135 … -0,000391 … … … … …
27
98 0,000206 -0,000172 0,000275 0,000081 … -0,000102
3.4.4 Fast Fourier Transform
Fast Fourier Transform (FFT) merupakan pengembangan dari Discrete Fourier Transform (DFT) yang bertujuan untuk mengkonversi sinyal digital dari domain waktu ke domain frekuensi [24]. Dalam proses FFT ini, setiap frame N sampel akan diubah dari domain waktu ke domain frekuensi.
Proses Fast Fourier Transform dilakukan dengan mengimplementasikan Discrete Fourier Transform (DFT) dengan menggunakan persamaan 3.4 sebagai berikut [24]: S(k) = ∑ x(n)e−j2πnkN N−1 n=0 (3.4) Dengan :
S(k) : Hasil Perhitungan Fast Fourier Transform ke-k x(n) : Hasil perhitungan windowing ke-n
k : Indeks dari frekuensi (0, 1, 2, …, N) N : Jumlah sampel yang akan diproses
Misalkan dalam penelitian, banyaknya nilai yang dihitung pada tahap FFT adalah 512 (N=512), maka proses perhitungan pada proses Fast Fourier Transform adalah sebagai berikut.
𝑆(𝑘) = ∑ 𝑥(𝑛)𝑒−𝑗2𝜋𝑛𝑘𝑁 𝑁−1 𝑛=0 𝑠(0) = ∑ 𝑥(𝑛) 𝑒−𝑗2𝜋𝑛(0)512 512−1 𝑛=0 𝑠(0) = (−0.000524)𝑒−𝑗2𝜋(0)(0)512 + (−0.000489)𝑒 −𝑗2𝜋(1)(0) 512 + (0.000165)𝑒−𝑗2𝜋(2)(0)512 + (−0.000262)𝑒 −𝑗2𝜋(3)(0) 512 + (−0.000475)𝑒−𝑗2𝜋(4)(0)512 + ⋯ + (−0.002138232)𝑒 −𝑗2𝜋(511)(0) 512
28 𝑠(0) = 0.001075
Perhitungan ini dilakukan pada semua data sinyal pada setiap bingkai sehingga akan diperoleh data sinyal seperti pada tabel 3.5.
Table 3.5 Hasil FFT 0 1 2 3 4 … 512 0 0,001075 0,001126 0,001079 0,001402 0,007659 … 0,001126 1 0,003982 0,003868 0,003613 0,004600 0,007403 … 0,003868 2 0,000960 0,000996 0,001475 0,001794 0,011700 … 0,000996 3 0,032617 0,032814 0,033325 0,035334 0,047100 … 0,032814 … … … … … 98 0,026522 0,036273 0,036536 0,056927 0,177834 … 0,036273
Setelah diperoleh nilai FFT seperti pada tabel 3.5 diatas, nilai tersebut digunakan untuk menghitung kepadatan spektral energi. Kepadatan spektral energi ini akan digunakan untuk memetakan nilai FFT ke filter bank yang akan digunakan pada tahap berikutnya. Banyaknya nilai FFT yang digunakan untuk menghitung kepadatan spektral energi adalah 512
2 + 1 = 257 data pada setiap bingkainya. Kepadatan spektral energi dapat dihitung dengan membagi hasil kuadrat nilai FFT dengan N=512. Penghitungan kepadatan spektral energi (𝑃𝑘) adalah sebagai berikut. 𝑃0 = ||0.001075|| 2 512 = 0.000000002257 𝑃1 =||0.001126|| 2 512 = 0.000000002476
Dengan formula dan proses penghitungan yang sama pada setiap data sinyal hasil FFT pada setiap bingkainya, maka akan diperoleh nilai kepadatan spektral energi seperti pada tabel 3.6.
29
Tabel 3.6 Hasil perhitungan kepadatan spektral energi
0 1 2 … 256 0 0,00000000225 0,00000000247 0,00000000227 … 0,00000129181 1 0,00000003096 0,00000002921 0,00000002549 … 0,00000126531 2 0,00000000180 0,00000000193 0,00000000628 … 0,00000288914 3 0,00000207781 0,00000210309 0,00000216907 … 0,00000001779 … … … … … … 98 0,00000137390 0,00000256981 0,00000260721 … 0,00000014789
3.4.5 Mel Filter Bank
Filter bank adalah salah satu filter yang digunakan untuk mengetahui ukuran energy dari frequency band tertentu dalam sinyal suara [4]. Untuk mengetahui ukuran energi yang tersedia pada setiap titik, nilai frekuensi yang terdapat pada spektrum FFT harus dipetakan ke dalam Mel scale dengan bantuan triangular filter bank. Dalam pemataan ini, Mel scale akan memiliki jarak yang bersifat linier pada frekuensi dibawah 1 KHz dan logaritmik pada frekuensi diatas 1 KHz.
Persamaan 3.5 digunakan untuk menghitung mel scale sehingga dapat diperoleh nilai terendah dan tertinggi frekuensi suara dalam mel frequency dan membagikannya ke dalam N filter bank [4].
Mel(f) = 2595 × Log10(1 + f
700) (3.5) Dengan:
Mel(f) : Fungsi Mel scale f : Frekuensi
Filter bank dapat dibuat setelah nilai terendah dan tertinggi dari frekuensi telah dibagi ke dalam N filter bank dengan jarak yang sama. Filter bank pertama berawal dari titik pertama, berpuncak pada titik kedua dan akan kembali pada titik ketiga [8]. Persamaan 3.6 digunakan untuk menghitung nilai koefisien filter bank yang nantinya digunakan dalam penyusunan filter bank yang dibutuhkan [26].
30 H(m − 1, k) = { 0 k < f(m − 1) 2(k − f(m − 1)) f(m) − f(m − 1) f(m − 1) ≤ k < f(m) 2(f(m + 1) − k) f(m + 1) − f(m) f(m) ≤ k < f(m + 1) 0 k > f(m + 1) (3.6) Dengan :
H(m − 1, k): koefisien filter bank k : Indeks FFT yang ingin disaring
m : Indeks filterbank yang ingin digunakan
Filter bank bertujuan untuk menentukan ukuran energi suatu frekuensi-frekuensi tertentu, namun pada MFCC, penerapan filter bank harus dilakukan pada frekuensi domain dengan melakukan konvolusi representasi dalam melakukan filter terhadap sinyal. Konvolusi dapat dilakukan dengan mengalikan antara spektrum sinyal dari hasil proses FFT dan koefisien filter bank [27]. Secara sistematis dapat dituliskan seperti pada persamaan 3.7 berikut :
Ym= ∑ S(k) ∙ H(m − 1, k) N−1
k=0
(3.7)
Dengan:
S(k) : Magnitute spectrum pada frekuensi k H(m − 1, k) : Koefisien filterbank
Misalkan dalam penelitian, hasil dari tahap FFT yang berupa nilai kepadatan energy maka nilai tersebut akan disaring menggunakan mel scale dengan bantuan triangular filter bank. Hal ini dilakukan untuk mengetahui energi yang tersedia pada setiap titiknya. Persamaan 3.5 digunakan untuk menghitung nilai frekuensi terendah dan tertinggi dalam nilai mel frequency dan membaginya dalam N filter bank. Penghitungan nilai frekuensi terendah dan tertinggi tersebut adalah sebagai berikut.
𝑚𝑒𝑙(𝑓) = 2595 𝑙𝑜𝑔10(1 + 𝑓 700)
𝑚𝑒𝑙(𝑓(0)) = 2595 log10(1 + 0
31 𝑚𝑒𝑙(𝑓(22050)) = 2595 log10(1 +
22050
700 ) = 3923.33732
Setelah diperoleh nilai terendah dan tertinggi, maka nilai mel frequency dapat dihitung dengan membagi rentang nilai dari frekuensi terendah sampai dengan tertinggi sebanyak Nfilt+2 nilai. Pada penelitian ini, nilai filter bank yang digunakan adalah 40 (Nfilt=40) sehingga akan diperoleh nilai seperti pada tabel 3.7.
Tabel 3.7 Nilai Mel-Frequency Mel ke-n Nilai Mel-Frequency
0 0
1 95.69115419
2 191.38230838
… …
41 3923.33732174
Kemudian apabila tabel 3.7 diubah dari skala mel ke skala frekuensi maka akan diperoleh nilai seperti pada tabel 3.8.
Tabel 3.8 Nilai Frekuensi Frekuensi ke-n Nilai Frekuensi
0 0
1 62.03206123
2 129.56123192
… …
41 22050
Setelah diperoleh nilai frekuensi pada tabel 3.8, kemudian akan dilakukan penghitungan nilai fft bin untuk menghitung koefisien filter banknya. Nilai fft bin
32
dapat dihitung dengan cara mengalikan (NFFT +1) dengan nilai frekuensi ke-n dibagi sampling ratenya sehingga akan diperoleh nilai fft bin seperti pada tabel 3.9.
Tabel 3.9 Nilai bin
Nilai bin ke-m Nilai bin (f(m))
0 0 1 0 2 1 3 2 … … 41 256
Dari tabel terlihat bahwa bank filter terakhir berakhir pada nilai bin 256 yang sesuai dengan sampling rate 44100 Hz dengan ukuran FFT 512 titik. Persamaan 3.6 digunakan untuk menghitung koefisien filter bank sehingga akan diperoleh nilai koefisien filter bank untuk kemudian dilakukan perhitungan filter bank terhadap data sinyal yang diperoleh pada proses FFT sebelumnya dengan menggunakan persamaan 3.7 sehingga akan menghasilkan nilai seperti pada tabel 3.10.
Tabel 3.10 Hasil Filter Bank
0 1 2 … 39 0 0,0000000022577 0,000000002475 0,00000000227 … 0,000340 1 0,0000000309622 0,000000029219 0,00000002549 … 0,000206 2 0,0000000018016 0,000000001936 0,00000000425 … 0,000435 3 0,0000020778100 0,000002103090 0,00000216907 … 0,000435 … … … … … … 97 0,0000013739010 0,000002569841 0,00000260721 … 0,000268
33
Untuk menyederhanakan nilai pada tabel 3.11 maka dilakukan konversi kedalam satuan dB, sehingga akan dihasilkan nilai sinyal hasil filter bank pada tabel 3.12.
Tabel 3.11 Hasil Konversi ke Satuan dB
0 1 2 … 39 0 -172,926448 -172,126871 -172,866759 … -69,364986 1 -150,183360 -150,686496 -151,869575 … -73,720279 2 -174,886693 -174,260372 -167,431016 … -67,239966 3 -113,647885 -113,542844 -113,274516 … -69,364140 … … … … … … 97 -117,240890 -111,801875 -111,676455 … -71,442216
3.4.6 Discrete Cosinus Transform
Discrete Cosine Transform (DCT) merupakan langkah terakhir ekstraksi ciri dengan MFCC. Konsep dasar DCT adalah mendekorelasikan mel spectrum untuk menghasilkan representasi yang baik dari property spektral lokal. Pada tahap ini, nilai Mel spectrum dalam frequency domain akan di konversi ke dalam time domain dengan tujuan untuk mendapatkan nilai koefisiennya. Proses DCT dapat dinyatakan dalam persamaan 3.8 berikut [28].
C(k) = 2 ∑ x(n)cosπ(2n + 1)k 2N N−1
n=0
, 0 ≤ k ≤ N − 1 (3.8)
Dimana 𝐶(𝑘). 𝑓 dengan nilai 𝑓 :
𝑓 = { 1 4𝑁, 𝑘 = 0 1 √2𝑁, 𝑙𝑎𝑖𝑛𝑛𝑦𝑎 (3.9) Dengan :
x(n) : Keluaran dari proses filterbank N : Jumlah Koefisien yang diharapkan
34
Misalkan pada tahap ini koefisien yang diharapkan berjumlah 40 atau N=40, maka untuk menghitung nilai koefisiennya digunakan persamaan 3.8 dengan perhitungan sebagai berikut.
𝐶(0) = 2 ∑ 𝑥𝑛cos
𝜋(2𝑛 + 1)(0) 2𝑁 40−1
𝑛=0
= 2[−172,926448 cos(0) + (−172,126871 cos(0)) + (−163,311273 cos(0)) + ⋯ + (−69,364986 cos(0))]
= (−9032,69)
Karena 𝑘 = 0, maka 𝐶(0) × 1
√4𝑁 sehingga akan diperoleh nilai :
𝐶(0) = (−9032,69) × 1
√4(40)= −714,097
Lakukan proses perhitungan yang sama pada setiap nilai menggunakan persamaan 3.8 sehingga data nilai koefisien cepstralnya menjadi seperti pada tabel 3.12.
Tabel 3.12 Hasil Discrete Cosinus Transform
0 1 2 … 39 0 -714,097120 -107,673741 12,145802 … 1,957463 1 -701,332981 -99,798005 19,200615 … 0,541048 2 -708,564274 -127,767051 -3,826132 … 5,240449 3 -629,659580 -36,147501 39,700246 … 5,629582 4 -618,710043 -48,497531 5,026668 … -0,854742 … … … … … … 97 -617,961087 -21,923429 52,979713 … -7,586914
35
3.4.7 Cepstral Liftering
Proses cepstral liftering ini adalah proses akhir dalam mengekstraksi fitur dengan MFCC. Cepstral liftering merupakan sebuah teknik yang digunakan untuk meminimalisasi sensitivitas dari koefisien cepstral yang dihasilkan dari tahapan utama dalam ekstraksi ciri menggunakan MFCC. Proses ini berfungsi untuk meningkatkan kualitas pengenalan suara. Proses cepstral liftering dapat dinyatakan dalam persamaan 3.10 berikut [4].
w[n] = {1 + L sinsin (
nπ
L)} (3.10) Dengan:
L : Jumlah koefisien cepstral n : Indeks dari koefisien cepstral
Misalkan dalam penelitian, jumlah cepstral coefficients yang digunakan adalah 11 atau L=11 dengan data yang digunakan dari hasil DCT berjumlah 12 data saja. Maka perhitungan untuk menentukan hasil cepstral liftering dengan menggunakan persamaan 3.10 adalah sebagai berikut.
𝑛[0] = −714,097120 𝑤[1] = 1 +11 2 sin ( 1𝜋 11) = 2,549529063 𝑛[1] = 𝑐[1] × 𝑤[1] = (−274,038820)
Setelah dilakukan perhitungan yang sama pada setiap nilai koefisien cepstral maka akan diperoleh nilai koefisien cepstral hasil filtering seperti pada tabel 3.13. Nilai ini yang nantinya akan digunakan sebagai data set pada tahap klasifikasi.
Tabel 3.13 Hasil Cepstral Liftering
0 1 2 … 11
36 1 -701,332981 -254,437913 76,294113 … 6,091423 2 -708,564274 -325,745809 -15,203228 … -2,111476 3 -629,659580 -92,159104 157,749899 … -4,390836 4 -618,710043 -123,645865 19,973589 … 0,631582 … … … … … 97 -617,961087 -55,894421 210,516187 … -14,450155
37 BAB IV
HASIL DAN PEMBAHASAN
Pada bab ini penulis akan menjelaskan mengenai pelabelan data suara, representasi hasil konversi semua data suara dari bentuk analog ke digital, hasil ekstraksi ciri menggunakan MFCC pada sinyal suara yang telah dikonversi. Lalu akan ditunjukkan hasil optimasi parameter pada model untuk menentukan model yang paling optimal dan akan ditunjukkan pula hasil evaluasi model menggunakan confusion matrix.
4.1 Representasi Data Suara
Data/file suara yang sebelumnya diperoleh dari pengambilan suara secara langsung terhadap 6 orang partisipan menggunakan bantuan Cool Edit Pro 2.0 dilakukan proses pelabelan. Data/file suara akan diberi label sesuai dengan label yang telah ditentukan sebelumnya. Pemberian label pada file suara dilakukan dengan mengganti nama file suara sesuai dengan label kata yang diucapkan dalam suara tersebut dan ditambah dengan urutan nomor file seperti pada gambar 4.1.
38
File suara yang telah diberi label akan dikelompokkan dalam satu folder dengan nama folder sesuai dengan label kata yang telah ditentukan sebelumnya seperti pada gambar 4.2. Hal ini dilakukan agar mempermudah pada tahap pembacaan file dan pelabelan pada saat pemograman selanjutnya.
Gambar 4.2 Folder file suara
Sebelum dilakukan ekstraksi ciri suara menggunakan MFCC, file rekaman suara yang diperoleh dari pengambilan langsung dan sudah dilakukan pelabelan, harus melalui tahap preproccessing. Dimana 30 file suara dari setiap folder berdasarkan labelnya akan diubah dari bentuk analog ke bentuk digital dengan menggunakan tools SciPy [23]. Perintah yang digunakan untuk mengonversi file suara rekaman dari bentuk analog ke bentuk digital menggunakan tool SciPy adalah sebagai berikut.
sample_rate, signal = scipy.io.wavfile.read(f) signal = signal[0:int(1*sample_rate), 0]
Dari perintah tersebut akan dihasilkan dua buah nilai yakni nilai sampling rate dan hasil konversi dari file suara. Hasil konversinya hanya diambil data untuk satu detik pertama dari file suara sehingga akan diperoleh 44100 nilai hasil konversi dari setiap file suara seperti pada tabel 4.1.
Tabel 4.1 Hasil Konversi File Suara “Alhamdulillah”
0 1 2 3 … 44099
0 0,00402 0,00378 -0,00006 0,00423 … -0,00365 1 -0,00065 0,00269 -0,00199 0,00021 … 0,24189
39 2 0,02584 0,01591 0,027233 0,01371 … 0,00376 3 -0,00828 0,00020 -0,00174 -0,00598 … 0,00353 4 -0,00004 -0,00940 0,00232 -0,00587 … 0,00846 … … … … … 29 -0,00729 -0,00561 0,00376 -0,00576 … -0,00134
Apabila dilakukan plotting pada masing-masing kelas kata pada semua data suara maka akan diperoleh hasil plot seperti pada gambar 4.3 berikut:
![Gambar 1.1 Speech Recognition System [2]](https://thumb-ap.123doks.com/thumbv2/123dok/2283477.3566129/15.893.139.756.286.983/gambar-speech-recognition-system.webp)
![Gambar 1.2 Proses pengenalan suara [3]](https://thumb-ap.123doks.com/thumbv2/123dok/2283477.3566129/16.893.137.761.280.885/gambar-proses-pengenalan-suara.webp)
![Gambar 2.1 Skema pemrosesan sinyal digital [8].](https://thumb-ap.123doks.com/thumbv2/123dok/2283477.3566129/20.893.139.761.281.872/gambar-skema-pemrosesan-sinyal-digital.webp)