PENDETEKSIAN KESAMAAN PADA DOKUMEN TEKS
MENGGUNAKAN KOMBINASI ALGORITMA
ENHANCED CONFIX STRIPPING
DAN
ALGORITMA
WINNOWING
SKRIPSI
ADE CHANIA SION SAGALA
091402044
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
PENDETEKSIAN KESAMAAN PADA DOKUMEN TEKS
MENGGUNAKAN KOMBINASI ALGORITMA
ENHANCED CONFIX STRIPPING
DAN
ALGORITMA
WINNOWING
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
ADE CHANIA SION SAGALA
091402044
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul : PENDETEKSIAN KESAMAAN PADA
DOKUMEN TEKS MENGGUNAKAN KOMBINASI ALGORITMA ENHANCED CONFIX STRIPPING DAN ALGORITMA WINNOWING
Kategori : SKRIPSI
Nama : ADE CHANIA SION SAGALA
Nomor Induk Mahasiswa : 091402044
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI (FASILKOM-TI) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, 29 Agustus 2014
Komisi Pembimbing:
Pembimbing 2 Pembimbing 1
Romi Fadillah Rahmat, B.Comp.Sc., M.Sc. Maya Silvi Lydia, B.Sc., M.Sc. NIP 19860303 201012 1 004 NIP 19740127 200212 2 001 Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
PERNYATAAN
PENDETEKSIAN KESAMAAN PADA DOKUMEN TEKS MENGGUNAKAN KOMBINASI ALGORITMA ENHANCED CONFIX STRIPPING
DAN ALGORITMA WINNOWING
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 29 Agustus 2014
UCAPAN TERIMA KASIH
Segala puji dan syukur penulis sampaikan kepada Tuhan Yesus yang telah memberikan berkat-Nya yang melimpah sehingga penulis dapat menyelesaikan skripsi ini dengan baik untuk memperoleh gelar Sarjana Teknologi Informasi, Program Studi S1 Teknologi Informasi Universitas Sumatera Utara.
Dengan segala kerendahan hati penulis ucapkan terima kasih kepada:
1. Ayah penulis, alm. Alfanus Februanto Sagala, S.H., ibu penulis, Chitra Dewi Siregar, dan adik penulis satu-satunya Milca Satriyani Sagala, A.md yang telah memberikan doa dan dukungan moral kepada penulis untuk menyelesaikan skripsi ini beserta keluarga besar yang telah turut mendoakan penulis.
2. Ibu Maya Silvi Lydia, B.Sc., M.Sc. dan Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc. selaku dosen pembimbing penulis yang telah meluangkan waktu, pikiran, saran, dan kritiknya untuk penulis dalam menyelesaikan skripsi ini.
3. Ibu Sarah Purnamawati, S.T., M.Sc dan Ibu Dr. Erna Budhiarti, M.IT. yang telah bersedia menjadi dosen penguji dan memberikan saran dan kritik yang membangun dalam penyelesaian skripsi ini.
4. Ketua dan Sekretaris Program Studi S1 Teknologi Informasi, Bapak M. Anggia Muchtar, S.T., MM.IT. dan Bapak Mohammad Fadly Syahputra, B.Sc., M.Sc.IT.
5. Seluruh dosen yang mengajar serta Ibu Delima dan Bang Faisal, sebagai staf Tata Usaha Program Studi Teknologi Informasi Universitas Sumatera Utara. 6. Sahabat-sahabat yang selalu mendukung dan memberi semangat kepada
penulis, Fida Elvi Anderia Sebayang, S.TI, Stella Maris Harefa, S.TI, Cynthia Arilla Sembiring, S.TI, Riska Vinesia Butarbutar, S.TI, Jihan Meutia Fauzen, S.TI, Annifa Iqramitha, S.TI, dan semua teman angkatan 2009.
7. Sahabat penulis Maria Fransiska Sinaga, S.T., Septina Veronika Bancin, S.KG, dan Dewi Tambunan yang selalu mendoakan dan memberi semangat.
8. Seluruh rekan kuliah sejawat yang tidak dapat disebutkan satu persatu.
ABSTRAK
Maraknya tindakan plagiarisme di dunia perkuliahan, baik plagiarisme dalam hal penyelesaian tugas maupun penyusunan karya ilmiah dapat mengurangi bahkan mematikan kreativitas seseorang dalam berkarya. Oleh karena itu, dibutuhkan sebuah aplikasi untuk mendeteksi tingkat kesamaan (similarity) sebuah dokumen teks dengan dokumen yang sudah ada. Penelitian ini menggunakan kombinasi dari algoritma Enhanced Confix Stripping (ECS) Stemmer untuk proses stemming teks yang dimasukkan dan algoritma Winnowing untuk menghitung tingkat kesamaannya (similarity) dengan dokumen dari database. Dengan ditentukannya nilai gram dan window pada perhitungan algoritma Winnowing, diharapkan dapat memudahkan user menggunakan aplikasi ini tanpa harus bingung menentukan nilai gram dan window-nya untuk menghasilkan nilai similarity yang akurat. Hasil pengujian menyimpulkan nilai kesamaan (similarity) sekitar 23-26% dengan percobaan 3 jurnal yang berkategori sama dengan jurnal pembanding. Dan untuk pendeteksian tanpa stemming menghasilkan tingkat kesamaan (similarity) sekitar 35-40% dengan jumlah jurnal dan kategori yang sama pula.
SIMILARITY DETECTION FOR TEXT DOCUMENTS USING COMBINATION OF ENHANCED CONFIX
STRIPPING STEMMER ALGORITHM AND WINNOWING ALGORITHM
ABSTRACT
The plethora of plagiarism in lecturing, such as for finishing projects or making scientific papers can diminish even stifle someone‟s creativity. Therefore, an application to detect a document for the similarity level of plagiarism with the existing one is needed. This research uses the combination of Enhanced Confix Stripping (ECS) Stemmer algorithm to stem the input text and Winnowing algorithm to numerate the similarity level with a document in database. The value of gram and window for the calculation of Winnowing algorithm are determined along with, so that it can abridge the user to use this application without being confused to determine the value of its gram and window to get an accurate similarity. The result concludes that the similarity is about 23-26% by three-same-category testing journals with the correlate journal in database. And the result of the nonstemming detection of similarity is about 35-40% with the same total of journals and category.
DAFTAR ISI
Halaman
PERSETUJUAN ii
PERNYATAAN iii
UCAPAN TERIMA KASIH iv
ABSTRAK v
ABSTRACT vi
DAFTAR ISI vii
DAFTAR TABEL ix
DAFTAR GAMBAR x
BAB 1 PENDAHULUAN 1
1.1. Latar Belakang 1
1.2. Rumusan Masalah 2
1.3. Batasan Masalah 3
1.4. Tujuan Penelitian 3
1.5. Manfaat Penelitian 3
1.6. Metodologi Penelitian 3
1.7. Sistematika Penulisan 4
BAB 2 TINJAUAN PUSTAKA 6
2.1. Plagiarisme 6
2.1.1. Pengertian Plagiarisme 6
2.1.2. Peraturan dan Hukum yang Mengatur Plagiarisme 8
2.2. Citasi 9
2.3. Algoritma Stemming Bahasa Indonesia 10 2.3.1. Algoritma Enhanced Confix Stripping Stemmer 11
2.4. Algoritma Winnowing 14
2.4.1. Rolling Hash 15
2.4.2. Tahapan Penerapan Algoritma Winnowing 16 2.4.3. Pengukuran Dan Persentase Similarity 17
2.5. Penelitian Terdahulu 18
BAB 3 ANALISIS DAN PERANCANGAN SISTEM 20
3.1. Analisis Data 20
3.1.1. Data Jurnal 20
3.1.2. Tabel Kata Dasar 21
3.1.3. Tabel Stoplist 21
3.2. Analisis Sistem 22
3.2.1. Proses Admin 22
a. Text Preprocessing 23
b. Penghapusan Stopwords 26
Halaman
3.2.2. Proses User 45
3.3. Perancangan Sistem 46
3.3.1. Arsitektur Umum (General Architecture) 46
3.3.2. Diagram Use Case 46
3.3.3. Realisasi Definisi Use Case 47
3.4. Perancangan Tampilan Antarmuka 49
3.4.1. Rancangan Halaman Utama User 49 3.4.2. Rancangan Halaman Hasil Pendeteksian 49 3.4.3. Rancangan Halaman Home Admin 50 3.4.4. Rancangan Halaman Profile Admin 51 3.4.5. Rancangan Halaman Edit Dictionary Admin 51 3.4.6. Rancangan Halaman Proses Stemming 52 3.4.7. Rancangan Halaman Nilai Hash dan Fingerprint 53
BAB 4 IMPLEMENTASI DAN PENGUJIAN 54
4.1. Implementasi Sistem 54
4.1.1. Spesifikasi Perangkat Keras Dan
Perangkat Lunak Yang Digunakan 54 4.1.2. Implementasi Perancangan Antarmuka 54
a. Tampilan Halaman Utama User 54
b. Tampilan Halaman Hasil Pendeteksian 55
c. Tampilan Halaman Home Admin 55
d. Tampilan Halaman Profile Admin 56 e. Tampilan Halaman Edit Dictionary Admin 56 f. Tampilan Halaman Proses Stemming 57 g. Tampilan Halaman Nilai Hash dan Fingerprint 57
4.2. Pengujian Sistem 58
4.2.1. Pengujian pada Proses yang Dilakukan Admin 58 4.2.2. Pengujian pada Proses yang Dilakukan User 60
4.2.3. Pengujian Kinerja Sistem 60
4.2.4. Hasil Pengujian Sistem 61
a. Hasil Pengujian Dengan Proses Stemming 61 b. Hasil Pengujian Tanpa Proses Stemming 62
BAB 5 KESIMPULAN DAN SARAN 64
5.1. Kesimpulan 64
5.2. Saran 64
DAFTAR PUSTAKA 65
LAMPIRAN A: Kode Program 68
DAFTAR TABEL
Halaman Tabel 2.1. Aturan Dasar Awalan - Akhiran Yang Berlaku 11
Tabel 2.2. Urutan Pengembalian Akhiran 11
Tabel 2.3. Aturan Pemenggalan Awalan Algoritma Stemmer
Nazief dan Adriani 11
Tabel 2.4. Aturan Pemenggalan Awalan Algoritma
Enhanced Confix Stripping Stemmer 13
Tabel 2.5. Penelitian Terdahulu 19
Tabel 3.1. Tabel Kategori 20
Tabel 3.2. Tabel Keyword 24
Tabel 3.3. Tabel Kata Dasar 21
Tabel 3.4. Tabel Stoplist 22
Tabel 3.5. Nilai Fungsi Hash Kalimat 1 31
Tabel 3.6. Nilai Fungsi Hash Kalimat 2 38
Tabel 3.7. Realisasi Definisi Use case 47
Tabel 4.1. Daftar Jurnal Uji 60
Tabel 4.2. Daftar Jurnal Pembanding 60
DAFTAR GAMBAR
Halaman
Gambar 3.1. Flowchart Proses Admin 25
Gambar 3.2. Flowchart Text Preprocessing 26
Gambar 3.3. Flowchart Penghapusan Stopwords 25
Gambar 3.4. Flowchart Stemming ECS 29
Gambar 3.5. Flowchart Proses User 45
Gambar 3.6. General Architecture 46
Gambar 3.7. Diagram Use case 47
Gambar 3.8. Rancangan Halaman Utama User 49
Gambar 3.9. Rancangan Halaman Hasil Pendeteksian 50
Gambar 3.10. Rancangan Halaman Home Admin 50
Gambar 3.11. Rancangan Halaman Profile Admin 51 Gambar 3.12. Rancangan Halaman Edit Dictionary Admin 52 Gambar 3.13. Rancangan Halaman Proses Stemming 52 Gambar 3.14. Rancangan Halaman Nilai Hash dan Fingerprint 53
Gambar 4.1. Tampilan Halaman Utama User 55
Gambar 4.2. Tampilan Halaman Hasil Pendeteksian 55
Gambar 4.3. Tampilan Halaman Home Admin 56
Gambar 4.4. Tampilan Halaman Profile Admin 56 Gambar 4.5. Tampilan Halaman Edit Dictionary Admin 57 Gambar 4.6. Tampilan Halaman Proses Stemming 57 Gambar 4.7. Tampilan Halaman Nilai Hash dan Fingerprint 58
ABSTRAK
Maraknya tindakan plagiarisme di dunia perkuliahan, baik plagiarisme dalam hal penyelesaian tugas maupun penyusunan karya ilmiah dapat mengurangi bahkan mematikan kreativitas seseorang dalam berkarya. Oleh karena itu, dibutuhkan sebuah aplikasi untuk mendeteksi tingkat kesamaan (similarity) sebuah dokumen teks dengan dokumen yang sudah ada. Penelitian ini menggunakan kombinasi dari algoritma Enhanced Confix Stripping (ECS) Stemmer untuk proses stemming teks yang dimasukkan dan algoritma Winnowing untuk menghitung tingkat kesamaannya (similarity) dengan dokumen dari database. Dengan ditentukannya nilai gram dan window pada perhitungan algoritma Winnowing, diharapkan dapat memudahkan user menggunakan aplikasi ini tanpa harus bingung menentukan nilai gram dan window-nya untuk menghasilkan nilai similarity yang akurat. Hasil pengujian menyimpulkan nilai kesamaan (similarity) sekitar 23-26% dengan percobaan 3 jurnal yang berkategori sama dengan jurnal pembanding. Dan untuk pendeteksian tanpa stemming menghasilkan tingkat kesamaan (similarity) sekitar 35-40% dengan jumlah jurnal dan kategori yang sama pula.
SIMILARITY DETECTION FOR TEXT DOCUMENTS USING COMBINATION OF ENHANCED CONFIX
STRIPPING STEMMER ALGORITHM AND WINNOWING ALGORITHM
ABSTRACT
The plethora of plagiarism in lecturing, such as for finishing projects or making scientific papers can diminish even stifle someone‟s creativity. Therefore, an application to detect a document for the similarity level of plagiarism with the existing one is needed. This research uses the combination of Enhanced Confix Stripping (ECS) Stemmer algorithm to stem the input text and Winnowing algorithm to numerate the similarity level with a document in database. The value of gram and window for the calculation of Winnowing algorithm are determined along with, so that it can abridge the user to use this application without being confused to determine the value of its gram and window to get an accurate similarity. The result concludes that the similarity is about 23-26% by three-same-category testing journals with the correlate journal in database. And the result of the nonstemming detection of similarity is about 35-40% with the same total of journals and category.
BAB 1
PENDAHULUAN
1.1.Latar Belakang
Tugas akhir merupakan kewajiban yang harus diselesaikan setiap mahasiswa yang ingin mendapatkan status kelulusan. Dalam teknik penulisan tugas akhir salah satu ciri utamanya adalah keasliannya. Setiap karya memiliki kekhasan penulisannya masing-masing tergantung karakter dari setiap penulis. Keaslian suatu karya dapat ditunjukkan pula dengan adanya copyright dari pemilik tulisan itu sendiri. (Sonneborn, 2011)
Dari penelitian yang dilakukan oleh Andrew Thompsett dan Jatinder Ahluwalia (2010) ada sekitar 89% mahasiswa yang setuju dan mengerti arti dari plagiarisme dalam dunia pendidikan, dan menyarankan agar materi tentang hal itu dijelaskan pada awal perkuliahan. Tetapi sekitar 65% mengaku bahwa mereka merasa bingung dengan pengertian plagiat, 59% diantaranya menyatakan bahwa mereka tidak diberi tutorial yang cukup untuk menghindari tindak plagiat dalam menyelesaikan tugas mereka.
Kerugian dari melakukan tindak plagiat adalah dapat mematikan kreativitas mahasiswa dalam berkarya. Mereka juga akan dikenakan sanksi/hukuman berupa peringatan dan pemberhentian secara tidak hormat atas status kemahasiswaannya.
Proses pendeteksian dapat dilakukan dengan mengurai isi dokumen menjadi string yang memiliki nilai dan dilakukan pencocokan dengan dokumen yang tersedia di dalam database. Beberapa penelitian sebelumnya, pendeteksian dilakukan dengan metode Latent Semantic Analysis (Alfarisi, 2011), algoritma Rabin-Karp (Nugroho, 2011), algoritma Smith-Waterman (Novanta, 2009), konsep Similarity dan algoritma Rabin-Karp (Salmuasih, 2013).
Dalam awal pendeteksian diperlukan proses stemming. Melakukan proses stemming berarti menghilangkan akhiran dari suatu kata. Proses ini sudah sering dilakukan dalam proses pencarian teks, aplikasi kamus, pengklasifikasian subjek dokumen perkantoran, dan mesin pencari (Asian, 2005). Berbeda dengan proses stemming peeada bahasa Inggris, proses stemming pada bahasa Indonesia lebih sulit dilakukan karena bahasa Indonesia mengenal imbuhan awalan (prefixes), sisipan (infixes), akhiran (suffixes), dan kombinasi awalan dan akhiran (confixes).
Penelitian proses stemming pada bahasa Indonesia telah dilakukan sebelumnya. Ada beberapa algoritma yang digunakan untuk melakukan stemming pada dokumen teks berbahasa Indonesia, seperti, algoritma Nazief dan Adriani (1996), algoritma Ahmad, Yussof, dan Sembok (1996), algoritma Vega (2001), algoritma Ariffin dan Setiono (2002), algoritma Confix Stripping oleh Jelita Asian, pengembangan algoritma Nazief dan Adriani (2007), algoritma Enhanced Confix Stripping Stemmer (2010).
Dalam penelitian yang akan dilakukan, algoritma Enhanced Confix Stripping Stemmer dipilih untuk proses penguraian teks dari imbuhannya. Untuk menghitung nilai kesamaan teks dengan dokumen dalam database digunakan algoritma Winnowing dengan teknik rolling hash. Algoritma Winnowing membuang seluruh pemakaian karakter yang tidak relevan, seperti, tanda baca, spasi, angka, dan karakter lainnya. Hanya karakter berupa huruf yang akan diproses ke tahap berikutnya (Purwitasari et al, 2010).
1.2.Rumusan Masalah
dokumen teks sehingga didapatkan perbandingan antara jurnal yang diuji user dan jurnal yang terdeteksi.
1.3.Batasan Masalah
Adapun batasan masalah dalam penelitian ini adalah:
1. Dokumen teks bahasa Indonesia yang digunakan dengan format Portable Document File (.pdf).
2. Portable Document File yang terkunci (secured) tidak dapat di-parsing dengan aplikasi ini.
3. Sumber „kata dasar‟ dari aplikasi ini diambil dari KBBI online.
4. Sumber dokumen karya ilmiah merupakan jurnal mahasiswa USU (data akses: repositori USU).
5. Nilai gram dan window pada perhitungan algoritma Winnowing ditentukan oleh penulis.
1.4.Tujuan Penelitian
Tujuan dari penelitian tugas akhir ini adalah mendeteksi kesamaan pada dokumen teks dengan mengombinasikan algoritma Enhanced Confix Stripping Stemmer dan algoritma Winnowing sehingga memperoleh tingkat akurasi yang lebih baik.
1.5.Manfaat Penelitian
Manfaat dari penelitian tugas akhir ini, antara lain:
1. Mengurangi adanya tindak plagiarisme pada mahasiswa dalam penyelesaian karya ilmiah.
2. Memudahkan dosen untuk mengecek tingkat plagiarisme yang dilakukan mahasiswa dalam menyelesaikan tugas akhirnya.
1.6.Metodologi Penelitian
1. Studi Literatur
Pada tahap ini, penulis mencari metode yang berbeda dari penelitian sebelumnya dan memahaminya, serta mencari referensi yang berkenaan dengan proses stemming pada dokumen teks, berupa pdf.
2. Desain Sistem
Pada tahap ini, penulis membuat flowchart system, use case, dan arsitektur umum dari sistem yang akan dibuat.
3. Pembuatan Sistem
Pada tahap ini, penulis mulai mengodekan sistem yang akan dibuat dengan bahasa pemrograman PHP dan database MySQL.
4. Pengujian Sistem
Pada tahap ini, penulis melakukan pengujian dari sistem yang telah dibuat. Pengujian akan menampilkan persentase tingkat plagiat dari dokumen yang di-input oleh user dan menampilkan dokumen yang kemungkinan besar sama dengan dokumen yang dimasukkan oleh user tersebut.
6. Dokumentasi
Pada tahap ini, penulis menyusun laporan terhadap sistem yang telah dibuat.
1.7.Sistematika Penulisan
Adapun bagian utama dari sistematika penulisan skripsi ini, yaitu: BAB 1. PENDAHULUAN
Bab ini berisikan latar belakang diangkatnya judul skripsi, perumusan masalah yang diambil, batasan-batasan masalahnya, tujuan, dan manfaat penelitian, metodologi penulisan, serta sistematika penulisan dari penyusunan skripsi ini.
BAB 2. TINJAUAN PUSTAKA
Bab ini menjelaskan mengenai landasan teori dan penelitian terdahulu.
BAB 3. ANALISIS DAN PERANCANGAN SISTEM
BAB 4. IMPLEMENTASI DAN PENGUJIAN
Bab ini menjelaskan implementasi dari analisis yang dilakukan dan pengujian terhadap sistem.
BAB 5. KESIMPULAN DAN SARAN
BAB 2
TINJAUAN PUSTAKA
2.1.Plagiarisme
2.1.1.Pengertian plagiarisme
Maxim Mozgovoy (2007) mengemukakan bahwa komputer jika dan hanya jika dapat mendeteksi plagiarisme apabila sejumlah dokumen dianggap mirip.
Plagiarisme merupakan proses pengambilan gagasan dari orang lain tanpa menyertakan citasi penulis asli. Hal ini dapat dicontohkan dengan menggunakan poin-poin umum atau mengutip beberapa kata dan mengubahnya dari tulisan asli tanpa menyebutkan sumber tulisan (Lancaster, 2003).
Berbagai pemicu untuk melakukan tindakan plagiat di dunia akademi didasarkan pada tiga faktor umum berikut (Lako, 2012):
1. Kecerobohan mahasiswa dan kelalaian dosen
Keinginan mahasiswa menyelesaikan skripsi, tesis, ataupun disertasinya secara instan tanpa bekerja keras dan mengikuti tahap penulisan ilmiah yang benar menjadikan karya ilmiah yang dikerjakan tidak sesuai standar. Di sisi lain, para dosen pembimbing tidak bekerja dengan maksimal. Beberapa hanya berorientasi pada hasil karya ilmiah semata, tanpa mau repot mengecek apakah karya ilmiah yang dihasilkan mahasiswanya terbebas dari tindak plagiarisme. 2. Desakan finansial (biasanya dilakukan oleh dosen)
3. Ketidakpuasan terhadap ketenaran produk dan diri sendiri Kasus ini banyak terjadi di kalangan penulis (dosen senior) yang selalu merasa kurang terkenal terhadap penelitian yang telah dilakukannya. Ketidakpuasannya dilakukan dengan melakukan plagiasi terhadap karya sendiri (autoplagiarism) dan plagiasi antarbahasa.
Sistem pendeteksian plagiarisme dapat diaplikasikan untuk jurnal, artikel, novel, essay, maupun bahasa pemrograman (Kurniawati & Wicaksana, 2008). Menurut Telepovska dan Gajdos (2010) aplikasi pendeteksian tersebut dapat mengunakan sistem lokal (terisolasi secara offline dan hanya menggunakan database individu) ataupun menggunakan sistem global (berjalan secara online dan menggunakan servis internet sehingga dokumen yang dicari lebih beragam).
Dari penelitian yang dilakukan Alzahrani et al (2012) ditemukan ada beberapa cara melakukan tindak plagiat, seperti:
1. Text Manipulation (Manipulasi Teks)
Plagiarisme dapat dilakukan dengan memanipulasikan teks asli sehingga menyamarkan isi dari teks duplikat. Hal ini dapat dilakukan dengan menyinonimkan ataupun mengantonimkan beberapa frase dari teks asli, mengubah pola kalimat asli, dan mereduksi kata-kata yang dianggap tidak penting.
2. Translation (Menerjemahkan)
Dengan menerjemahkan kalimat dari satu bahasa ke bahasa lain dianggap lebih efisien dalam melakukan tindakan plagiat. Tetapi harus dipertimbangkan kembali jika melakukan penerjemahan dengan google translate maupun secara manual, terkadang dapat menghasilkan terjemahan yang kurang tepat.
3. Idea Adoption (Mengadopsi Ide)
Cara ini sangat fatal dalam dunia pendidikan. Mengadopsi ide orang lain dapat dikatakan sebagai pencuri intelektual. Solusi untuk tindakan ini dapat dikembangkan dengan algoritma fuzzy.
proporsi/persentasi kata, kalimat, paragraf yang diplagiat. Sastroasmoro juga menyimpulkan plagiarisme ringan 0–29%, plagiarisme sedang 30–70%, plagiarisme berat atau total 71–100%. Keempat, berdasarkan pola plagiarisme, seperti plagiarisme kata demi kata (word for plagiarizing) dan plagiarisme mozaik.
2.1.2.Peraturan dan hukum yang mengatur plagiarisme
Menteri Pendidikan Indonesia telah mengeluarkan Peraturan Nomor 17 Tahun 2010 yang berisikan Pencegahan Dan Penanggulangan Plagiat Di Perguruan Tinggi. Di dalam Bab IV, Pasal 7, disebutkan bahwa:
(1) Pada setiap karya ilmiah yang dihasilkan di lingkungan perguruan tinggi harus dilampirkan pernyataan yang ditandatangani oleh penyusun bahwa:
a. Karya ilmiah tersebut bebas plagiat;
b. Apabila di kemudian hari terbukti terdapat plagiat dalam karya ilmiah tersebut, maka penyusunnya bersedia menerima sanksi sesuai ketentuan peraturan perundang-undangan.
(2) Pimpinan perguruan tinggi wajib mengunggah secara elektronik semua karya ilmiah mahasiswa/dosen/peneliti/tenaga kependidikan yang telah dilampiri pernyataan sebagaimana dimaksud pada ayat (1) melalui portal Garuda (Garba Rujukan Digital) sebagai titik akses tehadap karya ilmiah mahasiswa/dosen/peneliti/tenaga kependidikan Indonesia, atau portal lain yang telah ditetapkan oleh Direktur Jenderal Pendidikan Tinggi.
Peraturan Menteri Pendidikan Indonesia dimaksudkan agar setiap karya ilmiah yang dihasilkan dari dunia pendidikan Indonesia tidak mengandung aksi plagiat.
Seperti yang telah dijelaskan di awal, keaslian suatu karya, seperti karangan atau ciptaan merupakan suatu hal esensial dalam perlindungan hukum melalui hak cipta. Perlindungan hukum melalui hak cipta diberikan kepada karya pengarang, artis, musisi, programer, dan lainnya, yakni melindungi hak-hak pencipta dari tindakan peniruan dan mereproduksi tanpa izin (Purwaningsih, 2005).
Undang-Undang Hak Cipta Indonesia, menyatakan bahwa hak cipta merupakan hak yang dikhususkan bagi pencipta karya untuk mengumumkan atau memperbanyak ciptaannya maupun memberi izin untuk itu dengan tidak mengurangi pembatasan menurut peraturan perundangan yang berlaku. Menurut pasal 12 ayat 1, UU Hak Cipta, ciptaan yang dilindungi adalah ciptaan dalam bidang ilmu pengetahuan, seni, dan sastra, yang mencakup:
1. Buku, program komputer, pamflet, layout karya tulis yang diterbitkan dan semua hasil karya tulis lainnya;
2. Ceramah, kuliah, pidato, dan ciptaan lain yang sejenis dengan itu;
3. Alat peraga yang dibuat untuk kepentingan pendidikan dan ilmu pengetahuan; 4. Lagu atau musik dengan atau tanpa teks;
5. Drama atau drama musikal, tari koreografi, pewayangan, dan pantomime; 6. Seni rupa dalam segala bentuk (seni lukis, gambar, seni ukir, seni kaligrafi,
pahat, seni patung, kolase, dan seni terapan); 7. Arsitektur;
8. Peta; 9. Seni Batik; 10.Fotografi; 11.Sinematografi;
12.Terjemahan, tafsir, saduran, bunga rampai, database, dan karya lainnya.
Pelanggaran hak cipta terjadi apabila materi hak cipta digunakan tanpa izin dan harus ada kesamaan antara dua karya yang dibandingkan; jika seluruh atau sebagian dari karya yang telah dilindungi hak cipta telah dikopi. Dengan semakin meningkatnya kesadaran hukum yang berlaku atas kekayaan intelektual, diharapkan penyelesaian ganti rugi dapat diseimbangkan dengan tuntutan pidana. (Purwaningsih, 2005).
2.2.Citasi
Dengan dibuatnya citasi tidak akan mengurangi keaslian suatu karya, melainkan membantu para pembaca lainnya untuk membandingkan ide penulis dengan sumber citasi yang disebutkan. Citasi juga akan membantu membebaskan penulis dari tindak plagiarisme. Ada beberapa model citasi yang dapat diikuti oleh penulis karya ilmiah (dapat disesuaikan dengan instansi terkait), seperti (plagiarism.org):
a. Model Humaniora, terdiri dari: Chicago dan MLA (Modern Language Association)
b. Model Sains, terdiri dari: ACS (American Chemical Society), IEEE (Institute of Electrical and Electronics Engineers), NLM (National Library of Medicine), dan Vancouver (Biological Science)
c. Model Ilmu Sosial, terdiri dari: AAA (American Anthropological Association), APA (American Psychological Association), APSA (American Political Science Association), dan Legal
2.3.Algoritma Stemming Bahasa Indonesia
Stemming merupakan bagian dari proses Information Retrieval (IR), yang mengubah beberapa kata ke bentuk kata dasarnya sebelum dilakukan pengindeksan. Contoh, kata
dibaca, membaca, pembaca, akan diubah ke kata dasarnya, yaitu “baca” (Peng, 2007).
2.3.1.Algoritma enhanced confix stripping stemmer
Merujuk pada penelitian yang dilakukan oleh Andita Dwiyoga Tahitoe (2010) proses stemming untuk bahasa Indonesia dengan performa yang paling baik adalah dengan menggunakan algoritma Enhanced Confix Stripping (ECS) Stemmer. Algoritma ini merupakan pengembangan dari algoritma Confix Stripping (CS) Stemmer, dan berhasil mereduksi jumlah term pada algoritma Confix Stripping Stemmer hingga 32.66%, sedangkan pada awalnya Confix Stripping Stemmer hanya mampu mereduksi 30.95% term (Mahendra, 2008).
Berdasarkan penelitian Mahendra (2008), tahapan kerja algoritma Enhanced Confix Stripping Stemmer adalah sebagai berikut:
Tabel 2.1. Aturan Dasar Awalan - Akhiran Yang Berlaku Pasangan Awalan – Akhiran Yang Berlaku
Be – lah Be – an Me – i
Di – i Pe – i Te – i
Tabel 2.2. Urutan Pengembalian Akhiran
No Akhiran Tipe
1. -i, -kan, -an Derivation Suffixes (DS) 2. -ku, -mu, -nya Possessive Pronoun (PP) 3. -lah, -kah, -tah, -pun Inflectional Particle (P)
Tabel 2.3. Aturan Pemenggalan Awalan Algoritma Stemmer Nazief dan Adriani
Aturan Format Kata Pemenggalan
1 berV… ber-V… | be-r-V…
2 berCAP… ber-CAP… dimana C!=„r‟ & P!=‟er‟
3 berCAerV… ber-CaerV… dimana C!=‟r‟
4 belajar bel-ajar
5 beC1erC2… be-C1erC2… dimana C1!={„r‟ | „l‟}
6 terV… ter-V… | te-rV…
7 terCerV… ter-CerV… dimana C!=‟r‟
Tabel 2.3. Aturan Pemenggalan Awalan Algoritma Stemmer Nazief dan Adriani (lanjutan)
Aturan Format Kata Pemenggalan
9 teC1erC2… te-C1erC2… dimana C1!=‟r‟
10 me{l|r|w|y}V… me-{l|r|w|y}V…
11 mem{b|f|v}… mem-{b|f|v}…
12 mempe{r|l} mem-pe…
13 mem{rV|V}… me-m{rV|V}… | me-p{rV|V}…
14 men{c|d|j|z}… men-{c|d|j|z}…
15 menV… me-nV… | me-tV…
16 meng{g|h|q}… meng-{g|h|q}…
17 mengV… meng-V… | meng-kV…
18 menyV… meny-sV…
19 mempV… mem-pV… dimana V!=‟e‟
20 pe{w|y}V… pe-{w|y}V…
21 perV… per-V… | pe-rV…
23 perCAP… per-CAP… dimana C!=‟r‟ dan P!=‟er‟
24 perCAerV… per-CAerV… dimana C!=‟r‟
25 pem{b|f|V}… pem-{b|f|V}…
26 pem{rV|V}… pe-m{rV|V}… | pe-p{rV|V}…
27 pen{c|d|j|z}… pen-{c|d|j|z}…
28 penV… pe-nV… | pe-tV…
29 peng{g|h|q}… peng-{g|h|q}…
30 pengV… peng-V… | peng-kV…
31 penyV… peny-sV…
32 pelV… pe-lV… kecuali “pelajar” yang menghasilkan “ajar”
33 peCerV… per-erV… dimana C!={r|w|y|l|m|n}…
34 peCP… pe-CP… dimana C!={r|w|y|l|m|n} dan P!=‟er‟
1. Perhatikan Aturan Dasar pada Tabel 2.1., jika input kata sesuai dengan pasangan yang ada, maka lakukan penghilangan awalan terlebih dahulu. Jika tidak ada, maka penghilangan akhiran dilakukan terlebih dahulu.
2. Lakukan recording (penyusunan kembali kata-kata yang mengalami proses stemming berlebih) apabila diperlukan.
3. Lakukan loopPengembalianAkhiran.
4. Lakukan pengecekan apakah terdapat tanda hubung („-‟) yang menandakan input
kata tersebut adalah kata ulang. Jika benar, maka lakukan proses stemming pada potongan kata di sebelah kiri dan kanan tanda hubung. Apabila hasil stemming memberikan hasil yang sama, maka kata dasar dari kata ulang tersebut adalah hasil yang didapatkan.
Pada setiap langkah dilakukan proses pengecekan output stemming ke kamus data. Apabila ditemukan, maka proses berhenti.
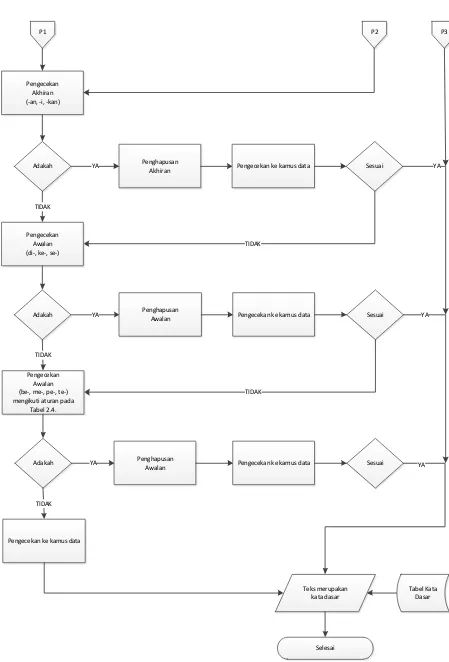
Proses loopPengembalianAkhiran bekerja seperti berikut:
1. Kembalikan seluruh awalan yang telah dihilangkan, sehingga menghasilkan model kata seperti: [DP+[DP+[DP]]] + Kata Dasar. Pemenggalan awalan dilanjutkan dengan proses pencarian di kamus.
2. Kembalikan akhiran sesuai urutan pada Tabel 2.2. Untuk setiap pengembalian, lakukan langkah 3) hingga 5) berikut. Khusus untuk akhiran “-kan”,
pengembalian pertama dimulai dengan “k”, lalu dilanjutkan dengan “an”.
3. Lakukan pengecekan ke kamus data. Apabila kata dasar ditemukan, proses dihentikan. Apabila gagal, maka lakukan proses pemenggalan awalan berdasarkan aturan pada Tabel 2.3.
4. Lakukan recording jika diperlukan.
5. Apabila pengecekan di kamus tetap gagal setelah recording, maka awalan-awalan yang telah dihilangkan dikembalikan lagi.
Tabel 2.4. Aturan Pemenggalan Awalan Algoritma Enhanced Confix Stripping Stemmer
Aturan Format Kata Pemenggalan
1 berV… ber-V… | be-r-V…
2 berCAP… ber-CAP… dimana C!=„r‟ & P!=‟er‟
3 berCAerV… ber-CAerV… dimana C!=‟r‟
4 belajar bel-ajar
5 beC1erC2… be-C1erC2… dimana C1!={„r‟ | „l‟}
6 terV… ter-V… | te-rV…
7 terCerV… ter-CerV… dimana C!=‟r‟
8 terCP… ter-CP… dimana C!=‟r‟ dan P!=‟er‟
9 teC1erC2… te-C1erC2… dimana C1!=‟r‟
10 me{l|r|w|y}V… me-{l|r|w|y}V…
11 mem{b|f|v}… mem-{b|f|v}…
12 mempe… mem-pe…
13 mem{rV|V}… me-m{rV|V}… | me-p{rV|V}…
14 men{c|d|j|s|z}… men-{c|d|j|s|z}…
15 menV… me-nV… | me-tV…
16 meng{g|h|q|k}… meng-{g|h|q|k}…
17 mengV… meng-V… | meng-kV… | (mengV-… jika V=‟e‟)
18 menyV… meny-sV…
19 mempA… mem-pA… dimana A!=‟e‟
Tabel 2.4. Aturan Pemenggalan Awalan Algoritma Enhanced Confix Stripping
Stemmer (lanjutan)
Aturan Format Kata Pemenggalan
21 perV… per-V… | pe-rV…
23 perCAP… per-CAP… dimana C!=‟r‟ dan P!=‟er‟
24 perCAerV… per-CAerV… dimana C!=‟r‟
25 pem{b|f|V}… pem-{b|f|V}…
26 pem{rV|V}… pe-m{rV|V}… | pe-p{rV|V}…
27 pen{c|d|j|z}… pen-{c|d|j|z}…
28 penV… pe-nV… | pe-tV…
29 pengC… peng-C…
30 pengV… peng-V… | peng-kV… | (pengV-… jika V=‟e‟)
31 penyV… peny-sV…
32 pelV… pe-lV… kecuali “pelajar” yang menghasilkan “ajar”
33 peCerV… per-erV… dimana C!={r|w|y|l|m|n}…
34 peCP… pe-CP… dimana C!={r|w|y|l|m|n} dan P!=‟er‟
35 terC1erC2… ter-C1erC2… dimana C1!=‟r‟
36 peC1erC2… pe-C1erC2… dimana C1!={r|w|y|l|m|n}
Pada Tabel 2.3. dan Tabel 2.4., simbol C merupakan konsonan, simbol V merupakan vokal, simbol A merupakan vokal atau konsonan, dan simbol P merupakan
partikel atau fragmen dari suatu kata, misalnya “er”. Dari kedua tabel dapat dilihat
beberapa perbedaan. Awalan yang diikuti huruf awal pada setiap kata dasar telah dikelompokkan menjadi kumpulan konsonan, vokal, atau partikel. Seperti, aturan no.29 pada awalan algoritma Stemmer Nazief dan Adriani, pemenggalan awalan
“peng-{g|h|q}” telah dikelompokkan menjadi “peng-C” pada awalan algoritma
Enhanced Confix Stripping Stemmer. Dan terdapat beberapa aturan tambahan pada algoritma ECS, yaitu aturan no. 35 dan no. 36.
2.4.Algoritma Winnowing
Salah satu algoritma yang digunakan untuk mendeteksi bentuk kesamaan pada dokumen teks adalah algoritma Winnowing. Pada dasarnya sistem pendeteksian haruslah memiliki 3 unsur utama yang harus dipenuhi, seperti (Schleimer et al, 2003):
1. Whitespace insensitivity, sistem pencocokan teks seharusnya tidak terpengaruh pada spasi, adanya huruf kapital, berbagai tanda baca, dan sebagainya;
3. Position independence, sistem seharusnya tidak bergantung pada posisi kata yang dicari sehingga apabila ditemukan kata yang terindeksi sama dengan posisi berbeda masih dapat dikenali;
Algoritma Winnowing dipilih karena algoritma ini sudah memenuhi unsur untuk proses pendeteksian. Implementasi dari algoritma Winnowing membutuhkan masukan berupa file teks dan menghasilkan keluaran berupa nilai hash yang disebut fingerprint (Purwitasari et al, 2011). Setiap kata yang terkandung dalam file teks diubah terlebih dahulu menjadi sebuah kumpulan nilai hash dengan teknik rolling hash. Nilai hash merupakan nilai numerik dari perhitungan ASCII untuk setiap karakter. Lalu kumpulan nilai hash yang disebut fingerprint tersebut digunakan untuk mendeteksi kemiripan antardokumen (Aziz et al, 2012).
2.4.1.Rolling hash
Teknik Rolling Hash pada awalnya digunakan pada algoritma Rabin-Karp. Setiap karakter di dalam dokumen teks diubah (encode) menjadi nilai array bilangan bulat, sehingga nilai masukan yang awalnya berupa karakter menjadi fungsi hash berupa angka. Untuk membandingkan dua string yang dianggap sama, maka setiap A[i] = B[i] dan membutuhkan waktu sebesar O(n). Panjang waktu yang dibutuhkan tergantung pada panjang iterasi elemen string yang dibandingkan (Cormen et al, 2009).
Menurut Cormen (2009), metode dasar untuk mencari perbandingan antara kedua string dokumen A dan B adalah:
a. Asumsikan dokumen A memiliki panjang elemen string p, dan dokumen B memiliki panjang q.
b. Lakukan hashing pada dokumen A untuk mendapatkan h(A) dengan waktu sebesar O(p).
c. Lakukan iterasi pada dokumen B dengan panjang elemen string p, dan bandingkan h(A) dengan waktu sebesar O(qp).
d. Jika nilai hash substring tidak cocok dengan h(A), bandingkan substring yang ada dengan A. Jika cocok, berhenti, jika tidak, lakukan kembali hingga ditemukan waktu sebesar O(p).
Contoh, lakukan hashing 5 substring pada kata “komputer”. Hash I: „kompu‟, hash II:
„omput‟, dan seterusnya. Dengan teknik rolling hash, maka didapatkan bahwa kedua
hash yang saling dibandingkan akan menghasilkan substring yang sama, yaitu:
„ompu‟ dan berlaku untuk perbandingan hasil hash berikutnya.
Digunakannya perhitungan operasi modulo agar tidak mempersulit sistem menghitung dalam jumlah banyak, selama nilai modulo yang digunakan tidak terlalu besar pula (Ellard, 1997).
Persamaan teknik rolling hash (Cormen, 2009) adalah sebagai berikut:
[ ] [ ] [ ] [ ]
[ ]
……… (1)
Untuk menghitung hash lanjutan, persamaannya adalah:
[ ] [ ] ……… (2)
Dimana:
b : Nilai bilangan basis (10) k : Nilai ASCII karakter h(k) : Nilai hash
m : Nilai bilangan prima (10007)
L : Banyaknya karakter yang di-hashing S(i) : Nilai hash awal
S(i+1) : Nilai hash berikutnya
2.4.2.Tahapan penerapan algoritma winnowing
Beberapa tahapan dalam penerapan algoritma Winnowing adalah sebagai berikut (Purwitasari et al, 2011):
1. Tahap Pertama: Membuang karakter yang tidak relevan seperti tanda baca, spasi, dan simbol-simbol lainnya.
2. Tahap Kedua: Membentuk rangkaian gram.
4. Tahap Keempat: Membentuk window yang terdiri dari nilai hash yang dihasilkan.
5. Tahap Kelima: Membentuk nilai fingerprint yang unik, dengan memilih nilai terendah dari setiap baris di dalam window.
2.4.3.Pengukuran dan persentase similarity
Perhitungan similaritas antardua dokumen diambil dari pemilihan nilai fingerprint hash terunik, seperti (Taufik, 2012):
……… (3)
Keterangan :
S : Similaritas
Nt : Total hash yang sama
Nx : Total substring pembanding
Ny : Total substring uji
Penilaian persentase similaritas antardua dokumen yang dibandingkan menurut A. Benny Mutiara & Sinta Agustina (2008) adalah sebagai berikut:
1. Kategori Nihil (0%)
Kedua dokumen tidak terindikasi plagiat karena benar-benar berbeda baik dari segi isi dan kalimat secara keseluruhan.
2. Kategori Sedikit Kesamaan (<15%)
Kedua dokumen hanya mempunyai sedikit kesamaan. 3. Kategori Plagiat Sedang (15-50%)
Kedua dokumen terindikasi plagiat tingkat sedang. 4. Kategori Mendekati Plagiarisme (>50%)
Hasil uji menunjukkan lebih dari 50%, dapat dikatakan bahwa dokumen yang diuji mendekati tingkat plagiarisme.
5. Kategori Plagiarisme (100%)
2.5.Penelitian Terdahulu
Aplikasi pendeteksian plagiat pada dokumen teks telah banyak dibuat sebelumnya. Dengan metode dan algoritma yang berbeda-beda didapatkan aplikasi dengan kelebihan dan kekurangannya masing-masing.
Alfarisi (2011) menyatakan hasil pengujian dari penelitian yang dilakukannya meggunakan metode Latent Semantic Analysis menghasilkan perbandingan yang lebih cepat karena pada metode LSA terdapat semantic space pada awal perbandingan. Dan algoritma Sherlock menghasilkan keakuratan perbandingan yang lebih tepat, tetapi waktu yang diperlukan lebih lama.
Penggabungan algoritma Smith-Waterman dengan pre-processing pada aplikasi yang telah dibuat oleh Novanta (2009) menghasilkan bobot terjadinya tindakan plagiat menjadi lebih akurat, dan menyebabkan bertambahnya waktu proses.
Purwitasari (2011) pada penelitiannya berhasil menemukan kesamaan nilai fingerprint pada 2 file yang dianggap sama (hasil copy-paste) dengan menggunakan algoritma Hashing (Winnowing) yang berbasis N-Gram.
Mahendra (2008) berhasil melakukan pengembangan pada algoritma Confix Stripping Stemmer dengan mereduksi jumlah term hingga 32.66%, sedangkan awalnya hanya mampu mereduksi 30.95%. Algoritma pengembangan tersebut selanjutnya dinamakan Enhanced Confix Stripping Stemmer.
Hasil dari penelitian Nugroho (2011) adalah penggunaan algoritma Rabin-Karp yang telah dimodifikasi menghasilkan akurasi nilai similarity yang relatif sama dengan penggunaan algoritma Rabin-Karp biasa, tetapi waktu prosesnya menjadi lebih baik. Dan penggunaan kgram yang semakin kecil menghasilkan akurasi similarity yang lebih baik daripada kgram yang lebih besar.
Tabel 2.5. Penelitian Terdahulu Nama
(Tahun) Judul Penelitian Keterangan Hasil
Alfarisi (2011)
Analisis Dan Perancangan Sistem Pendeteksi Kesamaan Dokumen Teks Menggunakan Metode Latent Semantic Analysis
-Awal perbandingan lebih cepat (LSA)
-Keakuratan perbandingan lebih tepat, tapi waktu lebih lama (Sherlock)
Audi Novanta (2009)
Pendeteksian Plagiarisme Pada Dokumen Teks Dengan Menggunakan Algoritma Smith-Waterman
Dengan pre-processing, bobot plagiat lebih akurat, tapi proses bertambah
Purwitasari (2011)
Deteksi Keberadaan Kalimat Sama Sebagai Indikasi Penjiplakan Dengan Algoritma Hashing Berbasis N-Gram.
- Algoritma Winnowing berhasil
menemukan lesamaan nilai fingerprint dua dokumen copy-paste
Mahendra (2008)
Enhanced Confix Stripping Stemmer And Ants Algorithm For Classifying News Document In Indonesian Language.
Perancangan Sistem Deteksi Plagiarisme Dokumen Teks Dengan Menggunakan Algoritma Rabin-Karp
- Waktu proses lebih baik
(Rabin-Karp modifikasi)
- Nilai kgram yang kecil = nilai
similarity yang lebih baik Salmuasih
(2013)
Perancangan Sistem Deteksi Plagiat Pada Dokumen Teks Dengan Konsep Similarity Menggunakan Algoritma Rabin Karp
- Nilai modulo berpengaruh
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
3.1.Analisis Data
Data yang digunakan untuk membangun aplikasi Pendeteksian Kesamaan Pada Dokumen Teks ini terdiri dari 3 tabel data utama, yaitu data jurnal, kata dasar, dan stoplist.
3.1.1.Data jurnal
Sumber jurnal dalam penelitian ini diperoleh dari jurnal mahasiswa USU (data akses: repositori USU). Jurnal yang digunakan sebanyak 625 buah. Dan sebagai bahan pengujian digunakan 20 jurnal dari prodi Teknologi Informasi dan Ilkom. Jurnal-jurnal tersebut dibagi atas 35 kategori.
Database untuk data jurnal dibagi atas 2 tabel, yaitu: a. Tabel Kategori
Tabel kategori merupakan tabel yang menyimpan data kategori dari beberapa jurnal. Tabel ini memiliki 2 field, yaitu id dan kategori. Rancangan tabel dapat dilihat pada Tabel 3.1.
Tabel 3.1. Tabel Kategori
id kategori
1 Agripet 2 Agrisol
3 Analisis Administrasi dan Kebijakan 4 Atrium
5 Bahasa dan Sastra (Logat) 6 Bearing
7 Ekonomi 8 Englonesian 9 Ensikom 10 Equality
id kategori
11 Etnomusikologi 12 Etnovisi
13 Harmoni Sosial
14 Info Kesehatan Masyarakat 15 Jurnal Biologi Sumatera 16 Jurnal Ekonom
17 Jurnal Manajemen Bisnis 18 Jurnal Teknologi Proses 19 Kerabat
Tabel 3.1. Tabel Kategori (lanjutan)
id kategori
21 Komunikasi Penelitian-MIPA 22 Komunikasi Penelitian-Rekayasa 23 Kultura
24 Majalah Kedokteran Nusantara 25 Pemberdayaan Komunitas 26 Peronema
27 Pustaha 28 Rufaidah
id kategori
29 Sains Kimia 30 Simetrika
31 Sistem Teknik Industri 32 Wahana Hijau
33 Wawasan 34 ILKOM
35 Teknologi Informasi
b. Tabel Keyword
Tabel keyword merupakan tabel yang menyimpan data dari proses stemming dan winnowing. Tabel ini memiliki 9 field, yaitu id, nama_file, teks_keyword, teks_tanpa_stemming, fingerprint_tanpa_stemming, hash_tanpa_stemming, fingerprint_keyword, hash_keyword, kategori. Tabel dapat dilihat pada Tabel 3.2.
3.1.2. Tabel kata dasar
Tabel kata dasar merupakan tabel yang menyimpan data kata dasar bahasa Indonesia yang bersumber dari KBBI online. Tabel ini memiliki 3 field, yaitu id_ktdasar, katadasar, dan tipe_katadasar. Rancangan tabel dapat dilihat pada Tabel 3.3.
Tabel 3.3. Tabel Kata Dasar
id_ktdasar katadasar tipe_katadasar
1 a Nomina
2 ab Nomina
… … …
28532 sesuai Partikel
28533 sei Nomina
3.1.3.Tabel stoplist
Tabel 3.4. Tabel Stoplist
id_ktdasar katadasar tipe_katadasar
1 a Nomina
2 ab Nomina
… … …
28532 sesuai Partikel
28533 sei Nomina
3.2.Analisis Sistem
Analisis sistem bertujuan untuk mengidentifikasi sistem yang akan diteliti. Proses analisis ini diperlukan sebagai dasar perancangan sistem. Pada penelitian ini, sistem dibagi atas 2 proses utama, yaitu proses yang dilakukan admin dan proses yang dilakukan user.
3.2.1.Proses admin
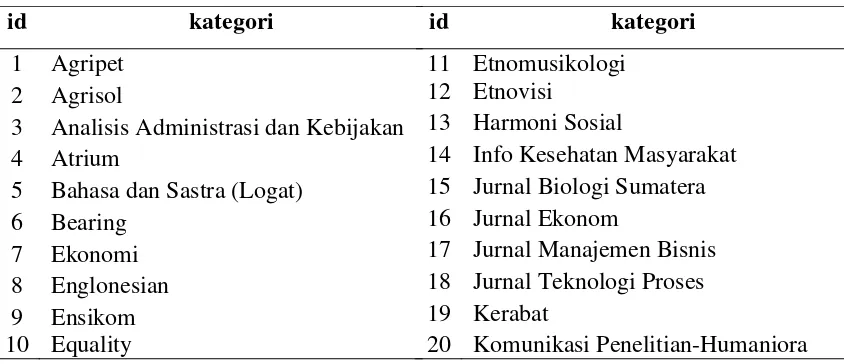
Tahapan proses yang dilakukan admin adalah sebagai berikut:
1. Masukkan dokumen pdf (jurnal) sebagai input dalam proses.
2. Sistem melakukan proses parsing pdf, dimana teks dalam pdf diurai mejadi kata per kata dan membentuk kalimat sesuai dengan isi pdf. Dalam hal ini, gambar dan tabel tidak dibaca, terkecuali teks dalam tabel hanya diuraikan saja. Dan pdf yang terkunci (secured) tidak dapat di-parsing oleh sistem. 3. Proses dilanjutkan dengan tahapan text preprocessing.
4. Setelah selesai tahapan text preprocessing, lalu sistem membagi 2 tahapan dalam sekali proses, yaitu penghapusan stopwords pada teks yang akan di-stemming dan tidak melakukan proses penghapusan stopwords pada teks tanpa stemming.
5. Selanjutnya sistem melakukan proses stemming. Untuk teks tanpa stemming, teks akan diproses ke tahap berikutnya. Tahapan stemming ini hanya diperuntukkan untuk teks berbahasa Indonesia. Apabila di dalam pdf tersebut terdapat beberapa teks berbahasa asing, maka proses stemming tidak berlaku untuk teks tersebut.
7. Tahapan selanjutnya, admin memilih kategori dari teks pdf yang telah diproses. Lalu sistem akan melakukan penyimpanan data berupa, nilai hash dan fingerprint, teks yang telah di-stemming, dan teks tanpa stemming beserta nilai hash dan fingerprint-nya ke dalam database.
Adapun bentuk flowchart dari tahapan yang dilakukan admin dapat dilihat pada Gambar 3.1.
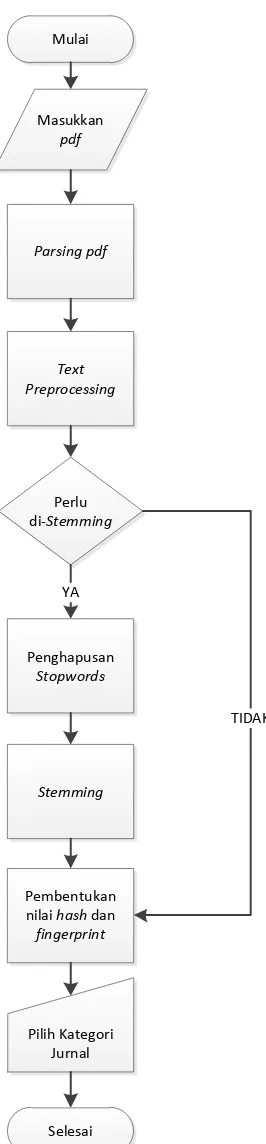
a. Text preprocessing
Text Preprocessing adalah beberapa proses yang akan dilalui sebelum teks di-stemming. Proses tersebut adalah sebagai berikut:
1. Masukkan teks dokumen yang telah di-parsing.
2. Mengubah keseluruhan teks menjadi huruf kecil (toLowerCase). 3. Menghapus beberapa karakter, angka, dan simbol.
4. Menghapus 2 kata yang tidak memiliki arti penting, seperti: oh, yg, ya, dan lainnya.
5. Pembentukan teks dokumen yang baru, yang akan dilanjutkan ke proses berikutnya.
24 Tabel 3.2. Tabel Keyword
Mulai
Masukkan pdf
Parsing pdf
Text Preprocessing
Penghapusan Stopwords
Stemming Perlu di-Stemming
Pembentukan nilai hash dan fingerprint
Pilih Kategori Jurnal
TIDAK YA
Selesai
Mulai
Masukkan teks yang telah
di-parsing
toLowerCase
Penghapusan karakter, angka, dan
simbol Penghapusan karakter, angka, dan
simbol
Penghapusan 2 kata Masukkan
teks yang telah
di-parsing
Array kata pembentuk
kalimat Mulai
Selesai
Gambar 3.2. FlowchartText Preprocessing
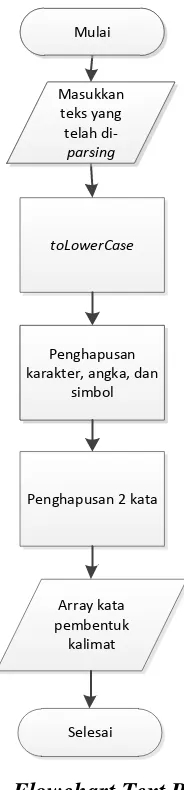
b. Penghapusan stopwords
Proses penghapusan stopwords adalah sebagai berikut:
1. Teks dokumen hasil proses text preprocessing dijadikan data masukan. 2. Setiap teks/kata dijadikan array kata dan dibandingkan dengan kata-kata
yang ada di tabel stoplist di dalam database.
3. Jika beberapa kata yang ada di database terdapat juga di array kata, maka kata tersebut akan dihapus dari array. Dan apabila di array tidak terdapat kata seperti yang ada di database, maka kata tersebut tidak dihapus. Dan array kata yang tersisa akan diproses ke tahap berikutnya.
Mulai
Masukkan teks hasil text preprocessing
Bentuk arrayKata dari setiap teks
Bandingkan setiap arrayKata dengan kata yang ada di tabel
stoplist
Kata dihapus dari arrayKata
Sesuai
YA TIDAK
Kata tidak dihapus dari
arrayKata
Sisa arrayKata
Selesai
Gambar 3.3. Flowchart Penghapusan Stopwords
c. Stemming enhanced confix stripping
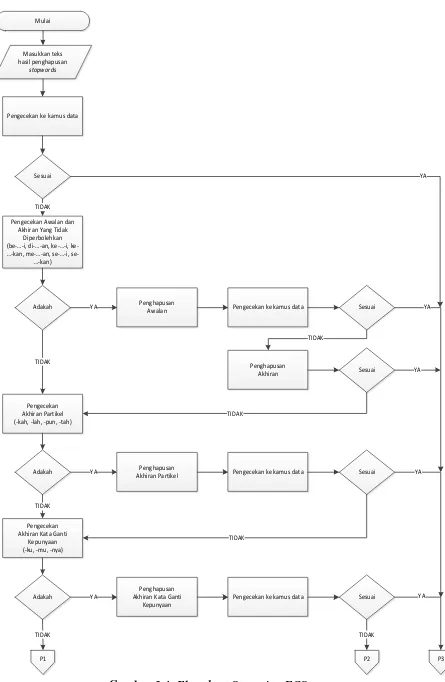
Proses stemming yang dilakukan sesuai dengan algoritma yang digunakan oleh penulis, yaitu algoritma Enhanced Confix Stripping Stemmer (Mahendra, 2008) dengan beberapa perubahan. Tahapan yang dilakukan algoritma ECS adalah sebagai berikut:
2. Setiap arrayKata akan dicek ke kamus data, yaitu ke tabel kata dasar yang ada di database. Jika terdapat arrayKata yang sama dengan kata dasar maka algoritma berhenti. Sebaliknya, jika arrayKata tidak sama dengan kata dasar maka proses stemming dilanjutkan.
3. Lakukan pengecekan aturan awalan dan akhiran yang tidak diperbolehkan (Prefix Disallowed Sufixes), seperti be-…-i, di-…-an, ke-…-i, ke-…-kan, me-…-an, se-…-i, se-…-kan.
4. Tahapan penghapusan awalan dan akhiran terdiri dari:
a. Penghapusan Inflection Suffixes (akhiran). Proses ini meliputi penghapusan particle (partikel) berupa …-kah, …-lah, …-pun, …-tah dan penghapusan possessive pronoun (kata ganti kepunyaan) berupa
…-ku, …-mu, …-nya.
b. Penghapusan Derivation Suffixes (akhiran). Proses ini menghapus
akhiran …-an, …-i, …-kan.
c. Penghapusan Derivation Prefixes (awalan). Proses ini meliputi penghapusan awalan be-…, di-…, ke-..., me-…, pe-…, se-…, dan te-… Penghapusan awalan di-…, ke-…, dan se-… dapat langsung dihapus. Dan penghapusan awalan be-…, me-…, pe-…, te-… mengikuti aturan pada Tabel 2.4.
5. Proses penghapusan awalan dan akhiran dimulai dari penghapusan akhiran lalu awalan.
6. Setiap melakukan proses penghapusan, kata dicek ke kamus data. Jika kata yang sudah mengalami penghapusan awalan/akhiran sudah sama dengan kata dasar, maka proses stemming dihentikan. Dan sebaliknya.
Pengecekan ke kamus data
Sesuai
Pengecekan Akhiran Partikel (-kah, -lah, -pun, -tah)
Adakah Penghapusan
Akhiran Partikel Pengecekan ke kamus data Sesuai
Pengecekan Akhiran Kata Ganti
Kepunyaan (-ku, -mu, -nya)
Adakah
Penghapusan Akhiran Kata Ganti
Kepunyaan
Pengecekan ke kamus data Sesuai TIDAK
YA
YA
TIDAK
TIDAK
YA YA
YA
TIDAK Pengecekan Awalan dan
Akhiran Yang Tidak Diperbolehkan (be-…-i, di-…-an, ke-…-i,
ke-…-kan, me-…-an, se-…-i,
se-…-kan) TIDAK
Adakah Penghapusan
Awalan Pengecekan ke kamus data
YA Sesuai
Penghapusan Akhiran
TIDAK
Sesuai
YA
YA
TIDAK
P1 P2
TIDAK
P3 Mulai
Masukkan teks hasilpenghapusan
stopwords
P1 P2 P3
Pengecekan Akhiran (-an, -i, -kan)
Adakah Penghapusan
Akhiran Pengecekan ke kamus data Sesuai
YA YA
TIDAK TIDAK
Pengecekan Awalan (di-, ke-, se-)
Adakah Penghapusan
Awalan Pengecekan ke kamus data Sesuai
YA YA
TIDAK TIDAK
Pengecekan Awalan (be-, me-, pe-, te-) mengikuti aturan pada
Tabel 2.4.
Adakah Penghapusan
Awalan Pengecekan ke kamus data Sesuai
YA YA
TIDAK
Pengecekan ke kamus data
Teks merupakan kata dasar
Tabel Kata Dasar
Selesai
d. Pembentukan nilai hash dan fingerprint
Untuk pembentukan nilai hash dan fingerprint, penulis menggunakan algoritma winnowing, seperti yang telah dijelaskan pada bab sebelumnya. Setiap kata yang terkandung dalam file teks diubah terlebih dahulu menjadi sebuah kumpulan nilai hash dengan teknik rolling hash. Nilai hash tersebut merupakan nilai numerik dari perhitungan ASCII untuk setiap karakter. Lalu kumpulan nilai hash yang terbentuk disebut fingerprint, yang digunakan untuk mendeteksi kemiripan antardokumen (Aziz et al, 2012).
Persamaan teknik rolling hash (Cormen, 2009) adalah sebagai berikut: [ ] [ ] [ ] [ ]
[ ] Penetuan nilai:
Gram : 10 Window : 5 Bil. Prima : 10007 Bil. Basis : 10
Perhitungan nilai hash dan pembentukan fingerprint dari kutipan kalimat yang diambil dari dokumen teks (pdf) yang akan dijadikan sample pembanding akan dijabarkan di bawah ini.
Contoh kalimat:
1. Pengaruh massa dan ukuran biji kelor pada proses penjernihan air (kalimat uji)
Pengaruh massa ukur biji kelor proses jernih air (sudah di-stemming)
2. Pengaruh berat dan ukuran biji kelor pada proses penjernihan air (kalimat pembanding)
Pengaruh berat ukur biji kelor proses jernih air (sudah di-stemming) Kalimat 1: Pengaruh massa ukur biji kelor proses jernih air
Pembentukan nilai Gram
pengaruhma | engaruhmas | ngaruhmass | garuhmassa | aruhmassau | ruhmassauk | uhmassauku | hmassaukur | massaukurb | assaukurbi | ssaukurbij | saukurbiji | aukurbijik | ukurbijike | kurbijikel | urbijikelo | rbijikelor | bijikelorp | ijikelorpr | jikelorpro | ikelorpros | kelorprose | elorproses | lorprosesj | orprosesje | rprosesjer | prosesjern | rosesjerni | osesjernih | sesjerniha | esjernihai | sjernihair
Pembentukan nilai fungsi hash kalimat 1 dapat dilihat pada Tabel 3.5. Tabel 3.5. Nilai Fungsi Hash Kalimat 1 H(pengaruhma | b=10 | k=10)
(ascii(p)* + ascii(e)* + ascii(n)* + ascii(g)* + ascii(a)* + ascii(r)* + ascii(u)* + ascii(h)* +
ascii(m)* + ascii(a)* ) mod 10007
(112* + 101* + 110* + 103* + 97* + 114* + 117* + 104* +
ascii(a)* + ascii(u)* +
ascii(k)* + ascii(u)* ) mod 10007
97* + 117* +
107* + 117* ) mod 10007 (117000000000 + 10400000000 + 1090000000 + 97000000 + 11500000 + 1150000 + 97000 + 11700 + 1070 + 117) mod 10007 = 128599759887 mod 10007 = 3027 (104000000000 + 10900000000 + 970000000 + 115000000 + 11500000 + 970000 + 117000 + 10700 + 1170 + 114) mod 10007 = 115997598984 mod 10007 = 7469 H(massaukurb | b=10 | k=10) (109000000000 + 9700000000 + 1150000000 + 115000000 + 9700000 + 1170000 + 107000 + 11700 + 1140 + 98) mod 10007 = 119975989938 mod 10007 = 5496 H(assaukurbi | b=10 | k=10) (97000000000 + 11500000000 + 1150000000 + 97000000 + 11700000 + 1070000 + 117000 + 11400 + 980 + 105) mod 10007 = 109759899485 mod 10007 = 1301 H(ssaukurbij | b=10 | k=10) (115000000000 + 11500000000 + 970000000 + 117000000 + 10700000 + 1170000 + 114000 + 9800 + 1050 + 106) mod 10007 = 127598994956 mod 10007 = 8145 (115000000000 + 9700000000 + 1170000000 + 107000000 + 11700000 + 1140000 + 98000 + 10500 + 1060 + 105) mod 10007 = 125989949665 mod 10007 = 8398 H(aukurbijik | b=10 | k=10)
Pembentukan nilai Fingerprint
[1098,0] [1301,5] [923,8] [779,10] [275,13] [577,18] [48,19] [909,24] [605,26]
Kalimat 2 : Pengaruh berat ukur biji kelor proses jernih air Pembentukan nilai Gram
pengaruhbe | engaruhber | ngaruhbera | garuhberat | aruhberatu | ruhberatuk | uhberatuku | hberatukur | beratukurb | eratukurbi | ratukurbij | atukurbiji | tukurbijik | ukurbijike | kurbijikel | urbijikelo | rbijikelor | bijikelorp | ijikelorpr | jikelorpro | ikelorpros | kelorprose | elorproses | lorprosesj | orprosesje | rprosesjer | prosesjern | rosesjerni | osesjernih | sesjerniha | esjernihai | sjernihair
Pembentukan nilai Hash
9091 | 2546 | 986 | 1347 | 9237 | 7450 | 6360 | 771 | 8565 | 5835 | 3864 | 509 | 226 | 4360 | 779 | 3965 | 6842 | 275 | 3000 | 5954 | 577 | 1728 | 3452 | 48 | 1752 | 4105 | 2924 | 909 | 979 | 6365 | 605 | 1607
Pembentukan Window
Array [0] : {9091 2546 986 1347 9237} Array [1] : {2546 986 1347 9237 7450} Array [2] : {986 1347 9237 7450 6360} Array [3] : {1347 9237 7450 6360 771} Array [4] : {9237 7450 6360 771 8565} Array [5] : {7450 6360 771 8565 5835} Array [6] : {6360 771 8565 5835 3864} Array [7] : {771 8565 5835 3864 509} Array [8] : {8565 5835 3864 509 226} Array [9] : {5835 3864 509 226 4360} Array [10] : {3864 509 226 4360 779} Array [11] : {509 226 4360 779 3965} Array [12] : {226 4360 779 3965 6842} Array [13] : {4360 779 3965 6842 275}
Array [14] : {779 3965 6842 275 3000} Array [15] : {3965 6842 275 3000 5954} Array [16] : {6842 275 3000 5954 577} Array [17] : {275 3000 5954 577 1728} Array [18] : {3000 5954 577 1728 3452} Array [19] : {5954 577 1728 3452 48} Array [20] : {577 1728 3452 48 1752} Array [21] : {1728 3452 48 1752 4105} Array [22] : {3452 48 1752 4105 2924} Array [23] : {48 1752 4105 2924 909} Array [24] : {1752 4105 2924 909 979} Array [25] : {4105 2924 909 979 6365} Array [26] : {2924 909 979 6365 605} Array [27] : {909 979 6365 605 1607} Pembentukan nilai Fingerprint
[986,0] [771,3] [509,7] [226,8] [275,13] [577,18] [48,19] [909,24] [605,26]
Nilai fingerprint-1 : [1098,0] [1301,5] [923,8] [779,10] [275,13] [577,18] [48,19] [909,24] [605,26]
Nilai fingerprint-2 : [986,0] [771,3] [509,7] [226,8] [275,13] [577,18] [48,19] [909,24] [605,26]
Nilai fingerprint yang sama: [275,13] [577,18] [48,19] [909,24] [605,26]
Penentuan nilai persentase Similarity (Taufik, 2012) adalah:
Benny Mutiara & Sinta Agustina (2008), kedua kalimat tersebut dikelompokkan dalam plagiat sedang (15-50%).
3.2.2.Proses user
Tahapan proses yang dilakukan user adalah sebagai berikut:
1. User memilih dan memasukkan dokumen teks (pdf) yang akan dideteksi. 2. Sistem melakukan proses parsing pdf dan menampilkannya di textarea
yang disediakan. Pdf yang terkunci (secured) tidak dapat di-parsing sistem. Oleh karena itu, user dapat memasukkan teks/isi pdf secara manual.
3. User memilih kategori dari jurnal yang dimasukkan.
4. Ketika user mengklik tombol proses, maka sistem akan melakukan tahapan 4-6 yang dilakukan pada proses admin.
5. Setelah menunggu beberapa saat, sistem akan menampilkan nama file pdf (jika dimasukkan), nilai kesamaan, lama proses yang dilakukan sistem, file yang dimasukkan (file uji), dan file yang memiliki nilai kesamaan paling tinggi sesuai kategori yang dipilih sebelumnya (file banding).
Adapun bentuk flowchart dari tahapan yang dilakukan user dapat dilihat pada Gambar 3.5.
Mulai
Masukkan pdf/teks
Parsing pdf
Menampilkan isi pdf ke dalam
textarea
TIDAK
Selesai
Pilih Kategori Jurnal
Text Preprocessing
Perlu di-Stemming Penghapusan Stopwords Stemming Pembentukan nilai hash dan fingerprint
Menampilkan nama file, nilai kedekatan, waktu proses, file uji,
dan file banding
YA
3.3.Perancangan Sistem
3.3.1.Arsitektur umum (general architecture)
Arsitektur umum merupakan desain arsitektur kasar dari sebuah sistem. Pada desain ini digambarkan bagaimana setiap proses berlangsung sehingga terbentuk sebuah sistem yang terorganisasi dengan baik. Rancangan arsitektur umum dari sistem dapat dilihat pada Gambar 3.6.
Hasil
User Admin
Text Preprocessing
Input Jurnal
Pilih Kategori Hapus Stopword
Stemming
Nilai Hash dan Fingerprint Proses
Pendeteksian
Berhasil Masuk Database
Enhanced Confix Stripping Stemmer
Enhanced Confix Stripping Stemmer
Winnowing
Winnowing Input Jurnal
Gambar 3.6. General Architecture
3.3.2.Diagram use case
Halaman
3.3.3.Realisasi definisi use case
Realisasi definisi use case dimaksudkan untuk menjelaskan setiap kegiatan yang dilakukan aktor dalam use case. Terdapat kegiatan use case include yang berarti aktor dapat melakukan kegiatan yang dituju arah panah. Dan kegiatan use case extend yang berarti aktor dapat melakukan kegiatan jika kondisi kegiatan sebelumnya sudah terpenuhi.
Tabel 3.7. Realisasi Definisi Use case
No Use case Deskripsi
1 Halaman Utama Menampilkan halaman utama dari sistem, digunakan oleh user dan admin
2 Proses Pendeteksian
Tabel 3.7. Realisasi Definisi Use case (lanjutan)
No Use case Deskripsi
3 Tampilan Hasil
Menampilkan hasil perbandingan jurnal yang dimasukkan user dengan jurnal yang terdeteksi dari database admin, waktu eksekusi, dan tingkat kesamaan jurnal, dapat digunakan user dan admin 4 Login Proses masuk ke sistem dan melakukan pengolahan
data, hanya digunakan oleh admin 5 Home Menampilkan halaman utama admin 6 Profile Admin Menampilkan data profil admin
7 Edit Dictionary Menampilkan halaman tabel database admin 8 Logout Proses keluar dari sistem hanya jika sudah login 9 Input Jurnal Proses memilih dan memasukkan jurnal ke
database
10 Hapus Stopword Proses menghapus stopwords dari jurnal yang dimasukkan
11 Stemming Proses stemming ECS terhadap jurnal 12 Tampilan Nilai Hash
dan Fingerprint
Menampilkan hasil perhitungan algoritma Winnowing
13 Pilih Kategori Proses pemilihan kategori jurnal 14 Database Masuk
Menampilkan pemberitahuan bahwa jurnal berhasil dimasukkan ke dalam database
15 Tampilan Profile
Admin Menampilkan data profil admin
16 Tabel Kata Dasar Menampilkan keseluruhan isi database dari tabel kata dasar
17 Tabel Kategori Menampilkan keseluruhan isi database dari tabel kategori
18 Tabel Keyword Menampilkan keseluruhan isi database dari tabel keyword
19 Tabel Stoplist Menampilkan keseluruhan isi database dari tabel stoplist
3.4.Perancangan Tampilan Antarmuka
Tampilan antarmuka dari sistem yang akan dirancang adalah desain awal dari interface sistem.
3.4.1.Rancangan halaman utama user
Pada halaman utama user akan ditampilkan tombol search file untuk memilih jurnal
yang akan dideteksi. Tombol “Tampilkan Isi” untuk menampilkan isi jurnal ke dalam
textarea di bawahnya. Textarea dapat diisi secara manual jika jurnal yang dideteksi terkunci (secured), tombol scroll down untuk memilih kategori jurnal, dan tombol
“Proses” untuk melakukan proses pendeteksian. Rancangan dapat dilihat pada Gambar
3.8.
Footer Footer
PENDETEKSIAN KESAMAAN PADA DOKUMEN TEKS
PENDETEKSIAN KESAMAAN PADA DOKUMEN TEKS
Logo USU
Masukkan File Anda
Masukkan File Anda Choose File
Tampilkan Isi
Pilih Kategori Jurnal Pilih Kategori Jurnal Kategori
Proses
Isi Jurnal
Isi Jurnal
Gambar 3.8. Rancangan Halaman Utama User
3.4.2.Rancangan halaman hasil pendeteksian
Pada halaman hasil pendeteksian akan ditampilkan nama file jurnal yang terdeteksi (pembanding) dari database, tingkat kesamaan (similarity), lamanya waktu proses, dan 2 kolom yang berisi jurnal yang diuji user dan jurnal yang terdeteksi. Terdapat
pula tombol “Home” untuk kembali ke halaman utama user. Rancangan dapat dilihat
Footer Footer
PENDETEKSIAN KESAMAAN PADA DOKUMEN TEKS
PENDETEKSIAN KESAMAAN PADA DOKUMEN TEKS
Logo USU
Nama File : Nama File :
Kedekatan : Kedekatan :
Waktu Proses : Waktu Proses :
Jurnal Yang Diuji
Jurnal Yang Diuji Jurnal Yang TerdeteksiJurnal Yang Terdeteksi
Home
Gambar 3.9. Rancangan Halaman Hasil Pendeteksian
3.4.3.Rancangan halaman home admin
Untuk masuk ke dalam halaman Home admin, seorang admin harus login terlebih dahulu. Pada halaman ini akan ditampilkan tombol search file untuk mengambil file
jurnal. Lalu tombol “Proses” untuk melanjutkan ke proses selanjutnya, dalam hal ini
proses selanjutnya adalah step1, yaitu mengambil teks dari pdf yang di-input. Rancangan dapat dilihat pada Gambar 3.10.
Footer Footer
PENDETEKSIAN KESAMAAN PADA DOKUMEN TEKS
PENDETEKSIAN KESAMAAN PADA DOKUMEN TEKS
Logo
USU Logout
Home Profile Admin Edit Dictionary
Masukkan File Anda
Masukkan File Anda Choose File
Proses