ANALISIS PERBANDINGAN ALGORITMA SUPPORT
VECTOR CLUSTERING (SVC) DAN K-MEDOIDS
PADA KLASTER DOKUMEN
TESIS
SUHADA
117038037
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
ANALISIS PERBANDINGAN ALGORITMA SUPPORT
VECTOR CLUSTERING (SVC) DAN K-MEDOIDS
PADA KLASTER DOKUMEN
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
SUHADA
117038037
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul Tesis : Analisis Perbandingan Algoritma Support Vector Clustering (SVC) Dan K-Medoids Pada Klaster Dokumen
Kategori : Tesis
Nama Mahasiswa : Suhada Nomor Induk Mahasiswa : 117038037
Program Studi : Magister (S2) Teknik Informatika
Fakultas : Ilmu Komputer Dan Teknologi Informasi Universitas Sumatera Utara
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dr. Marwan Ramli, M.Si Prof. Dr. Muhammad Zarlis
Diketahui/disetujui oleh
Program Studi Magister (S2) Teknik Informatika Ketua,
PERNYATAAN ORISINALITAS
ANALISIS PERBANDINGAN ALGORITMA SUPPORT
VECTOR CLUSTERING (SVC) DAN K - MEDOIDS
PADA KLASTER DOKUMEN
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan masing – masing telah disebutkan sumbernya.
Medan, 6 Juni 2013
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai Sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini:
Nama : Suhada
NIM : 117038037
Program Studi : Magister (S2) Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty free Right) atas tesis saya yang berjudul:
ANALISIS PERBANDINGAN ALGORITMA SUPPORT VECTOR CLUSTERING (SVC) DAN K-MEDOIDS
PADA KLASTER DOKUMEN
Beserta perangkat yang ada. Dengan Hak Bebas Royalti Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 6 Juni 2013
Telah diuji pada
Tanggal : 20 Juni 2013
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Muhammad Zarlis
Anggota : 1. Prof. Dr. Herman Mawengkang
2. Prof. Dr. Tulus
3. Dr. Marwan Ramli, M.Si
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap : Drs. Suhada
Tempat dan Tanggal Lahir : Pematangsiantar, 13 Mei 1958
Alamat Rumah : Jl. Batu Kapur No. 19 Pematangsiantar
E_Mail :
Instansi Tempat Bekerja : AMIK Tunas Bangsa Pematangsiantar
Alamat Kantor : Jl. Jend. Sudirman No. 2A Pematangsiantar
DATA PENDIDIKAN
SD : SD Negeri No.8 Pematangsiantar TAMAT : 1971
SMP : SMP Negeri 2 Pematangsiantar TAMAT : 1974
SMA : SMA Negeri 3 Pematangsiantar TAMAT : 1977
Strata-1 : FMIPA Fisika USU Medan TAMAT : 1987
KATA PENGANTAR
Assalamu’alaikum Wr. Wb.
Pertama-tama penulis panjatkan syukur Alhamdulillah kepada Allah SWT, berkat
rahmat dan kemurahanNya penulis dapat menyelesaikan tesis ini dengan judul Analisis
Perbandingan Algoritma Support Vector Clustering (SVC) Dan K-Medoids Pada Klaster
Dokumen.
Laporan tesis ini disusun dan diajukan untuk memenuhi persyaratan dalam
memperoleh gelar magister pada Program Pascasarjana FasilKom TI Universitas
Sumatera Utara.
Dalam penyelesaian tesis beserta penyusunan laporannya dapat berjalan dengan
lancar, tidak lepas dari dukungan berbagai pihak. Oleh karena itu, penulis mengucapkan
banyak terima kasih kepada:
Allah SWT yang senantiasa memberikan kemudahan dan kekuatan kepada
penulis dalam memahami dan mengamalkan ilmu-ilmu yang didapatkan selama ini.
Bapak Prof. Dr. dr. Syahril Pasaribu, DTM&H, M.Sc (CTM), Sp. A(K) selaku
Rektor Universitas Sumatera Utara, atas kesempatan yang diberikan kepada penulis untuk
mengikuti dan menyelesaikan pendidikan Program Magister.
Bapak Prof. Dr. Muhammad Zarlis, selaku Dekan FasilKom TI Universitas
Sumatera Utara, atas kesempatan yang diberikan kepada penulis untuk mengikuti dan
menyelesaikan pendidikan Program Magister pada Program Pascasarjana FasilKom TI
Universitas Sumatera Utara..
Bapak Prof. Dr. Muhammad Zarlis selaku Ketua Program Studi Magister Teknik
Informatika dan selaku dosen pembimbing utama yang dengan penuh perhatian telah
Bapak Muhammad Andri Budiman, S.T, M. Comp. Sc, M.EM selaku Sekretaris
Program Studi Magister Teknik Informatika.
Bapak Dr. Marwan Ramli, M.Si selaku pembimbing anggota yang dengan penuh
kesabaran menuntun dan membimbing penulis hingga selesainya penelitian ini.
Seluruh dosen serta civitas akademika pada Program Studi Magister Teknik
Informatika Program Pascasarjana FasilKom TI Universitas Sumatera Utara, yang telah
memberikan bekal ilmu dan pengetahuan selama penulis mengikuti kuliah di Universitas
Sumatera Utara.
Ketua Yayasan Muhammad Nasir AMIK Tunas Bangsa Pematangsiantar H.
Mauliyah Ahmad Ridwan Syah yang telah memberikan izin, bantuan moril dan materil
dan kesempatan kepada penulis untuk mengikuti pendidikan lanjutan pada program
Pascasarjana FasilKom TI Universitas Sumatera Utara.
Orangtua tercinta, almarhum ayahanda dan almarhum ibunda serta seluruh
keluarga yang senantiasa mendoakan dan memberikan dorongan kepada penulis.
Istri dan anak tercinta Nikma Siregar, Fanny Andhina dan Riyan Muhammad
yang selalu mendoakan, memberikan semangat dengan kasih, sabar dan bantuan selama
penulis mengikuti pendidikan. Budi baik ini tidak dapat dibalas, hanya diserahkan kepada
Allah SWT, Tuhan Yang Maha Esa. Sekali lagi terimakasih.
Rekan mahasiswa se-angkatan penulis program studi magister (S2) Teknik
Informatika Komputer FasilKom TI Universitas Sumatera Utara dan rekan sejawat di
AMIK Tunas Bangsa Pematangsiantar, yang telah banyak membantu penulis selama
mengikuti perkuliahan.
Direktur AMIK Tunas Bangsa, Bapak Rahmat Widia Sembiring, M.Sc.IT. yang
telah banyak membantu penulis dalam menyelesaikan tesis ini.
Bapak Prof. Dr. Opim Salim Sitompul yang telah banyak memberikan dorongan
kepada penulis untuk menyelesaikan tesis ini.
Semua pihak yang tidak dapat disebutkan satu-persatu, yang telah berperan serta
Penulis menyadari bahwa penulisan laporan tesis ini masih jauh dari
kesempurnaan baik dari segi materi yang dibahas maupun dari penulisannya. Untuk itu
saran dan kritik yang bersifat membangun sangat penulis harapkan.
Akhir kata penulis berharap semoga tesis beserta laporannya ini membawa
manfaat dan faedah bagi pembaca dan pihak-pihak yang berkepentingan, serta buat
penulis sendiri sebagai dharma bakti penulis kepada almamater.
Wassalamualaikum.Wr.Wb.
Medan, 6 Juni 2013 Penulis
ABSTRAK
Data dengan jumlah yang begitu besar berpotensi menghasilkan kesalahan dalam penyajian informasi. Pengolahan data dokumen juga menjadi isu penting pada saat ini. Seiring dengan meningkatkan jumlah data yang dikumpulkan dan disimpan dalam suatu database meningkat secara drastis. Data ini dapat berasal dari berbagai macam sumber seperti aplikasi financial, Enterprise Resource Management (ERM), Customer Relationship Management (CRM), dan lain-lain. Data-data tersebut jika di olah dapat digunakan untuk menunjang proses pengambilan keputusan.
Penelitian ini difokuskan kepada isu aplikasi metode data mining pada kasus pengelompokkan data (Clustering). Dengan terdapatnya jumlah data yang cukup besar memungkinkan peranan metode data mining dalam hal proses segmentasi melalui klastering yang dapat mengelompokkan data ke dalam beberapa kelompok (Klaster) yang diinginkan. Adapun metode data mining yang digunakan Support Vector Clustering (SVC) dan algoritma K-Medoids. Pengujian nya dilakukan dengan software Rapidminer. Hasilnya didapat untuk SVC berkisar 11:21 Menit dan K-Medoids berkisar 3:21 Menit.
ABSTRACT
Data with such a large number of potentially result in errors in the presentation of information. Data processing documents also become an important issue at this time. Along with the increasing amount of data collected and stored in a database increases drastically. This data can come from a variety of sources such as financial applications, Enterprise Resource Management (ERM), Customer Relationship Management (CRM), and others. These data if if can be used to support the decision-making process.
This study focused on the issue of application of data mining methods in the case of data classification (clustering). With the presence of a considerable amount of data possible role of data mining methods in the process of segmentation via clustering that can classify the data into groups (clusters) are desired. The data mining method used Support Vector Clustering (SVC) and K-Medoids algorithm. Her test is done with the software RapidMiner. The result obtained for 11:21 Minutes SVC ranges and K-Medoids range 3:21 Minutes.
DAFTAR ISI 2.5 Algoritma Support Vektor Clustering 14
2.6 Algoritma K-Medoids 15
2.7 Riset-Riset Terkait 16
2.8 Kontribuasi Riset 17
2.9 Analisa dan Interpretasi 17
BAB III METODE PENELITIAN 18
3.1. Pendahuluan 18
3.2 Lokasi dan Waktu Penelitian 18
3.3 Rancangan Penelitian 20
3.4 Flowchart Metodologi Penelitian 21 3.5 Perancangan Proses Klastering 23
BAB IV HASIL DAN PEMBAHASAN 24
4.2 Sampel Data Yang Bersumber Dari Berbagai Bidang Pendidikan AMIK Tunas Bangsa
Pematangsiantar 25
4.3 Proses Support Vector Clustering 25 4.4 Hasil Proses Support Vector Clustering 31
4.5 Proses K-Medoids 38
BAB V PENUTUP 53
5.1. Kesimpulan 53
5.2. Saran 53
DAFTAR PUSTAKA
ABSTRAK
Data dengan jumlah yang begitu besar berpotensi menghasilkan kesalahan dalam penyajian informasi. Pengolahan data dokumen juga menjadi isu penting pada saat ini. Seiring dengan meningkatkan jumlah data yang dikumpulkan dan disimpan dalam suatu database meningkat secara drastis. Data ini dapat berasal dari berbagai macam sumber seperti aplikasi financial, Enterprise Resource Management (ERM), Customer Relationship Management (CRM), dan lain-lain. Data-data tersebut jika di olah dapat digunakan untuk menunjang proses pengambilan keputusan.
Penelitian ini difokuskan kepada isu aplikasi metode data mining pada kasus pengelompokkan data (Clustering). Dengan terdapatnya jumlah data yang cukup besar memungkinkan peranan metode data mining dalam hal proses segmentasi melalui klastering yang dapat mengelompokkan data ke dalam beberapa kelompok (Klaster) yang diinginkan. Adapun metode data mining yang digunakan Support Vector Clustering (SVC) dan algoritma K-Medoids. Pengujian nya dilakukan dengan software Rapidminer. Hasilnya didapat untuk SVC berkisar 11:21 Menit dan K-Medoids berkisar 3:21 Menit.
ABSTRACT
Data with such a large number of potentially result in errors in the presentation of information. Data processing documents also become an important issue at this time. Along with the increasing amount of data collected and stored in a database increases drastically. This data can come from a variety of sources such as financial applications, Enterprise Resource Management (ERM), Customer Relationship Management (CRM), and others. These data if if can be used to support the decision-making process.
This study focused on the issue of application of data mining methods in the case of data classification (clustering). With the presence of a considerable amount of data possible role of data mining methods in the process of segmentation via clustering that can classify the data into groups (clusters) are desired. The data mining method used Support Vector Clustering (SVC) and K-Medoids algorithm. Her test is done with the software RapidMiner. The result obtained for 11:21 Minutes SVC ranges and K-Medoids range 3:21 Minutes.
BAB I
PENDAHULUAN
1.1 Latar Belakang
dalam pengklasteran data salah satu nya adalah dengan Data Mining (DM). Data Mining adalah proses pencarian pola dan relasi-relasi yang tersembunyi di data yang besar dengan tujuan untuk melakukan klasifikasi, estimasi, prediksi, klastering, deskripsi, dan visualisasi (Han dkk, 2001 dan Baskoro,2010).
Dengan meningkatnya pertumbuhan teknologi, jumlah data yang dikumpulkan dan disimpan dalam database semakin meningkat secara drastis, sehingga menimbulkan kesulitan dalam pengelompokkan data. Data-data tersebut, jika diolah dapat digunakan untuk menunjang pengambilan keputusan. Kita dapat mempelajari pola-pola dari data-data tersebut yang sering dikenal dengan pengenalan pola (pattern recognition), merupakan bagian dari data mining. Tujuan utama dari data mining untuk mendapatkan informasi dari data dengan cara mempelajari pola tersebut. Mengacu dari skema di atas penelitian ini fokus pada isu aplikasi metode data mining pada kasus pengelompokan data (clustering). Dengan terdapatnya jumlah data yang berskala besar memungkinkan peranan data mining, dalam hal proses segmentasi melalui klastering yang dapat mengelompokkan ke dalam beberapa kelompok (cluster) yang diinginkan. Untuk menyelesaikan permasalahan ini, metode yang digunakan adalah Support Vector Clustering (SVC) dan algoritma K-Medoids akan dibandingkan untuk melihat algoritma mana yang lebih cepat dalam mengklastering data sekaligus mengetahui jumlah hasil klasteringnya.
1.2 Perumusan Masalah
Permasalahan yang akan diselesaikan dalam penelitian ini adalah melakukan klastering dengan menggunakan metode Support Vector Clustering dan Algoritma K-Medoids (PAM) kemudian dilakukan analisis perbandingan tersebut dengan kedua metode tersebut, untuk mengetahui metode terbaik dalam klastering data judul tugas akhir mahasiswa berdasarkan database, jaringan dan web.
1.3 Ruang Lingkup Penulisan
1. Data yang digunakan di ambil dari judul tugas akhir mahasiswa Diploma 3 AMIK Tunas Bangsa Pematangsiantar berdasarkan Database, jaringan dan web.
2. Metode klastering yang digunakan metode Support Vector Clustering (SVC) dan K-Medoids (PAM) untuk yang hasil akan dibandingkan metode mana yang terbaik dalam pengklasteran dokumen tersebut.
1.4 Tujuan Penelitian
Tujuan dalam penelitian ini adalah :
1. Melakukan pengujian validitas metode yang akan digunakan untuk klastering.
2. Melakukan klastering dari data yang diperoleh dengan beberapa metode yang diusulkan.
3. Menghitung nilai variansi dalam klaster dan antar klaster pada tiap metode.
4. Membanding metode data mining yang digunakan sehingga didapatkan metode yang terbaik berdasarkan nilai variansi yang dihasilkan.
1.5 Manfaat Penelitian
Manfaat yang diperoleh dari penelitian ini adalah :
1. Diperoleh hasil klastering yang lebih optimal untuk data tugas akhir mahasiswa AMIK Tunas Bangsa Pematangsiantar yang didasarkan atas database, jaringan dan web.
BAB II
TINJAUAN PUSTAKA
2.1. Penambangan Data (Data Mining)
Penambangan data (Data Mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini tersembunyi dibalik data atau tidak diketahui secara manual (Iko Pramudiono, 2006). Proses untuk menggali nilai tambah dari sekumpulan data sering juga dikenal sebagai penemuan pengetahuan dari pangkalan data (Knowledge Discovery in Databases = KDD) yaitu tahap-tahap yang dilakukan dalam menggali pengetahuan dari sekumpulan data. Tahap-tahap yang dimaksud digambarkan seperti Gambar 2.1. berikut ini:
Gambar 2.1. Proses Menggali Pengetahuan Dari Pangkalan Data (Sumber; Han.J & Kember, 2006)
1. Data Selection
Pada proses ini dilakukan pemilihan himpunan data, menciptakan himpunan data target, atau memfokuskan pada subset variabel (sampel data) dimana penemuan akan melakukan. Hasil seleksi disimpan dalam satu berkas yang terpisah dari basis data operasional.
2. Pre-Processing
Pre-Processing dilakukan untuk membuang data yang tidak konsisten dan noise, duplikasi data,memperbaiki kesalahan data dan boleh juga diperkaya dengan data eksternal yang relevan.
3. Transformation
Proses ini mentransformasikan atau menggabungkan ke dalam data yang lebih tepat untuk melakukan proses mining dengan cara melakukan peringkasan.
4. Data Mining
Proses data mining yaitu proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik, metode atau algoritma tertentu.
5. Evaluasi
Proses untuk menterjemahkan pola-pola yang dihasilkan dari data mining. Mengevaluasi apakah pola atau informasi yang ditemukan bersesuaian atau bertentangan dengan fakta atau hipotesa sebelum nya.
himpunan data yang berukuran besar, output dari data mining dapat dipakai untuk memperbaiki pengambilan keputusan.
Pada dasarkan data mining berhubungan dengan analisis data dan penggunaan perangkat lunak untuk mencari pola dan kesamaan dalam sekelompok data. Ide dasarnya menggali sumber yang berharga dari tempat yang sama sekali tidak terduga, seperti perangkat lunak. Data mining mengekstrasi pola yang sebelumnya tidak terlihat atau tidak begitu jelas sehingga tidak terperhatikan sebelumnya. Analisis data mining berjalan pada data yang cenderung terus meningkat dan teknik terbaik yang digunakan kemudian berorientasi kepada data yang berukuran sangat besar untuk mendapatkan kesimpulan dan keputusan paling layak. Data mining memiliki beberapa sebutan antara lain yaitu : Knowledge Discovery (MiningI in Databases (KDD), ekstraksi pengetahuan (knowledge extraction), analisis data pola , kecerdasan bisnis (business intelligence).
Beberapa faktor yang mendukung perlunya data mining adalah : 1. Data telah mencapai jumlah dan ukuran yang sangat besar. 2. Telah dilakukan proses data warehousing.
3. Kemampuan komputasi yang semakin terjangkau. 4. Persaingan bisnis yang semakin ketat.
Secara sederhana data mining mengacu pada pengekstrakan suatu pengetahuan dari banyaknya data. Sehingga data mining dapat disebut secara tepat dengan data pengetahuan yang diambil dari data sangat besar. Mining itu sendiri berkarakteristik pada proses yang menemukan sekumpulan data kecil yang berharga dari sekian banyak data yang ada.
2.2 Klastering
2.2.1. Pengertian Klastering
”Klastering adalah proses pengelompokkan satu set benda-benda fisik atau abstrak ke dalam kelas objek yang sama” (Han and Kamber, 2006).
Baskoro (2010) menyatakan bahwa :
Klastering adalah satu diantara alat bantu pada data mining yang bertujuan untuk mengelompokkan objek-objek ke dalam klaster-klaster. Klaster adalah sekelompok atau sekumpulan objek-objek data yang similar satu sama lain dalam klaster yang sama dan disimilar terhadap objek-objek data yang berbeda klaster. Objek-objek yang akan dikelompokkan ke dalam satu atau lebih klaster sehingga objek-objek yang berada dalam suatu klaster akan mempunyai kesamaan yang tinggi antara satu dengan yang lainnya. Objek-objek dikelompokkan berdasarkan prinsip memaksimalkan kesamaan objek pada klaster yang sama dan memaksimalkan ketidaksamaan pada klaster yang berbeda. Kesamaan objek biasanya diperoleh dari nilai-nilai atribut yang menjelaskan objek data, sedangkan objek-objek data biasanya direpresentasikan sebagai sebuah titik dalam ruang multidimensi.
Klaster 1
Klaster 2 Outliners
Gambar 2.2 Contoh Klastering(Baskoro 2010)
Adapun tujuan dari data Klastering ini adalah untuk meminimalisasikan
objective function yang diset dalam proses Klastering, yang pada umumnya
berusaha meminimalisasikan variasi di dalam suatu Klaster dan
memaksimalisasikan variasi antar Klaster.
2.2.2. Metode Klastering.
Secara garis besar, terdapat beberapa metode clusterisasi data. Pemilihan metode clusterisasi bergantung pada tipe data dan tujuan clusterisasi itu sendiri. Metode-metode beserta algoritma yang termasuk didalamnya meliputi (Baskoro, 2010):
Sadaaki et. al. (2008) menyatakan :
Sebelum memutuskan berapa jumlah cluster yang akan dibentuk bahwa
terdapat dua pendekatan yang dapat digunakan yaitu :
a. supervised (jika jumlah cluster ditentukan).
b. unsupervised (jika jumlah cluster tidak ditentukan/alami).
2.3. Dokumen Klastering.
“Dokumen Klastering merupakan suatu teknik untuk mengelompokkan
dokumen-dokumen berdasarkan kemiripannya dengan tujuan mendapatkan sekumpulan
dokumen yang tepat” (Widyawati, 2010). Dokumen-dokumen tersebut dikelompokan
ke dalam klaster berdasarkan tingkat kemiripannya. Suatu klaster dapat dikatakan
bagus apabila tingkat kemiripan antar anggota klaster sangat tinggi dan tingkat Klaster 1
kemiripan antar klaster sangat rendah. Sedangkan kualitas suatu klasterdapat diukur
melalui kemampuannya dalam menemukan pola-pola yang tersembunyi.
Gambar 2.3. berikut ini menunjukkan contoh data yang akan dilakukan
klastering :
Gambar 2.3 Data Sebelum dilakukan proses pengelompokkan
Jika data dilakukan klastering (pengelompokkan) berdasarkan warna, maka
pengelompokkannya seperti yang terlihat pada gambar 2.4 :
Jika data dilakukan klastering berdasarkan bentuk, maka pengelompokkan
seperti terlihat gambar 2.5 :
Gambar 2.5 Pengelompokkan berdasarkan kesamaan bentuk
Pengelompokkan bisa juga bisa dilakukan dengan kesamaan jarak
Gambar 2.6 Pengelompokkan berdasarkan kesamaan jarak
Teknik analisis data yang bertujuan untuk mengelompokkan individu / objek
kedalam beberapa kelompok yang memiliki sifat berbeda antar kelompok, sehingga
Ukuran data yang bias digunakan adalah jarak euclidius (euiclidean) antara dua objek.
Jika objek pertama yang diamati adalah X =[ x1, x2, m, xp,]’ dan Y = [y1, y2,m, yp]’
adalah :
d(�+�) = √ ���=1(Xy−Yj) 2 ……….2.1 analisi klaster diukur dengan menggunakan nilai variance, variance digunakan
untuk mengukur nilai penyebarandari data-data hasil klastering. Pada dasarnya
variance pada klastering ada 2 yaitu variance dalam klaster (Vw) dan variance antar
klaster (Vb). klaster disebut ideal jika memiliki nilai Vw seminimal mungkin Vb
semaksimal mungkin.
Untuk menghitung nilai variance dari semua data setiap klaster digunakan
rumus :
Sedangkan untuk menghitung variance didalam klaster digunakan rumus
sebagai berikut :
1
1
Sedangkan untuk menghitung variance antar klaster digunakan rumus
sebagai berikut :
untuk mendapat nilai variance dari semua klaster dilakukan dengan cara
membagi nilai variance dalam klaster dengan variance antar klaster. Semakin kecil
nilai tersebut maka semakin klaster yang dihasilkan.
2.4. Support Vector Clustering (SVC)
Support vector clustering merupakan metode clustering dengan menggunakan probabilitas kepadatan titik memakai kernel jarak pada dimensi tinggi (Ben-hur et al, 2001 ) Dua tahapan dari SVC adalah pelatihan data untuk menentukan jarak dan pelabelan kluster.
Pada metode ini, data dipetakan ke dalam dimensi yang lebih tinggi dengan kernel jarak. Pada ruang dimensi yang baru, dilakukan kluster data terlihat sebagai bentuk bola. Untuk mendapatkan kluster data yang sesuai, dilakukan pencarian bentuk bola yang minimal (minimal sphere) .
Dimana merupakan fungsi transformasi non linear Xj dari dimensi rendah ke dimensi tinggi.
Sehingga persamaan diatas dapat diubah menjadi
………..2.5 Dimana :
a merupakan titik tengah bola minimal R merupakan radius bola minimal
Variabel slack untuk pinalty term bentuk bola yang tidak selalu ideal, dimana j
>= 0.
Untuk dapat menyelesaikan permasalah bola minimal, diperkenalkan Langrangian
……….2.6
Untuk setiap titik xj dengan $j =0 merupakan titik yang berada di permukaan atau di dalam bola. Dimana $j >=0 dan μj>=0 merupakan
Langrangian Multiplier yang bisa didapatkan dengan mengubah ke bentuk Dual problem (W):
………..2.7 Dengan konstrain
Dengan mengeset turunan dari Langrarian menghasilkan a=
Bola minimal yang telah didapat kemudian dipetakan kembali ke dimensi awal (rendah) dengan menjadi kontur yang secara eksplisit memperlihatkan bentuk kluster. Seluruh titik yang berada pada kontur tersebut diasosiasikan sebagai anggota kluster tersebut.
Ciri titik berada di dalam kontur adalah jarak titik tersebut dengan pusat kluster lebih kecil atau sama dengan radius bola.
……….2.8
……….2.9
Sehingga bentuk kluster dapat dilihat dengan melihat titik –titik support vector dari kluster tersebut. Untuk menentukan titik masuk ke kluster mana diperlukan pengujian jarak titik tersebut dengan titik yang lain. Misal terdapat titik i dan j maka i dan j termasuk dalam kluster yang sama jika jarak seluruh titik-titik antara i dan j dalam garis lurus lebih kecil atau sama dengan radius bola minima. Cara diatas mengharuskan dibuatnya matrik ketetanggan antar titik dimana Aij=1 jika titik i dan j terletak dalam 1 kluster dan Aij=0 jika i dan j tidak terletak dalam 1 kluster.
2.5. Algoritma Support Vector Clustering
1. Lakukan inisialisasi data.
2. Lakukan pencarian nilai beta melalui optimasi persamaan linear dual wolfe dengan konstrain 0< βj < C dan ∑βj=1
2.6. Algoritma K-Medoids
Pengelompokkan merupakan proses pengumpulan beberapa objek ke dalam
kelompok sehingga setiap objek dalam satu kelompok adalah mirip namun tidak
mirip dengan kelompok yang lain. Metode K-Means telah diketahui sehingga teknik
yang baik untuk pengelompokan. Namun, metode K-Means ini sensitive terhadap
adanya outlier, alternatifnya yang sering digunakan adalah metode K-Medoids
(Park dan Jun, 2009). K-Medoids ini mirip dengan K-Mean, namun yang menjadi
center klaster adalah datum, bukan mean data.
Park dan Jun (2009) menawarkan algoritma K-Medoids dimana menurut
penelitiannya algoritma ini menghasilkan kinerja yang baik dibandingkan K-Means
dan dengan waktu yang lebih cepat.
Algoritma K-Medoids tersebut adalah sebagai berikut :
1. Tahap pertama (pilih inisial medoid)
1-1 Hitung dij , jarak di antara setiap pasangan objek berdasarkan ukuran jarak
tertentu, misalnya Euclidean
��� = �∑��=1(��� − ���)2 = �(x� − x�)′(x�−x�) ( 2.10 )
dimana i=1,…..,n; j=1,…..,n dan p adalah banyak variable, serta V adalah matrik varian kovarian.
1-2 Hitung vj untuk setiap objek j dimana
�� = � ���
1-3 Urutkan vj dari terkecil ke terbesar. Pilih objek terkecil sebanyak k sebagai inisial medoid.
1-4 Hitung jarak setiap objek terhadap inisial medoid dan kelompok objek dalam k kelompok berdasarkan jarak minimal terhadap setiap medoid. 1-5 Hitung jumlah jarak dari semua objek ke medoid kelompoknya.
Cari medoid baru pada setiap kelompok dimana jarak antar objek minimal. Update medoid setiap kelompok yang ada dengan medoid yang baru.
3 Tahap Ketiga (menghubungkan objek pada medoid)
3-1 Hitung jarak semua objek ke setiap medoid dan dihasilkan kelompok baru berdasarkan jarak minimal.
3-2 Hitung jarak semua ke medoid kelompoknya. Jika jumlahnya sama dengan jumlah sebelumnya, hentikan algoritma. Jika tidak kembali ke tahap 2.
2.7. Riset-Riset Terkait
Terdapat beberapa riset yang telah dilakukan banyak peneliti berkaitan dengan
domain pendidikan, seperti yang akan dijelaskan dibawah ini :
1. Muchammad Juniarto (2009) menjelaskan bahwa metode SVC lebih baik
daripada K-Means dalam pengelompokkan data.
2. Kusrini (2001) menjelaskan bahwa algoritma data mining.
3. Jayanti Diah Basuki (2008) menjelaskan implementasi tentang algoritma
K-Medoids untuk Clustering dokumen teks.
4. Karhendana, A (2008) menjelaskan tentang pemanfaatan dokumen
2.8. Kontribusi Riset
Penelitian ini memberikan kontribuasi pada pemahaman tentang hubungan data tugas akhir mahasiswa AMIK Tunas Bangsa Pematangsiantar untuk mengetahui perbandingan ke dua algoritma yang mana yang lebih cepat dalam pengclasteran dokumen. Beberapa kemungkinan lain yang dianggap penting adalah bahwa perguruan tinggi dapat menggunakan informasi dalam hal pengelompokkan data di perguruan tinggi tersebut, untuk membuat agar dapat diketahui model algoritma mana yang lebih baik dalam pengklasteran dokumen.
2.9. Analisis dan Interpretasi
BAB III
METODOLOGI PENELITIAN
3.1. Pendahuluan
Tujuan dari penulisan tesis ini adalah untuk membuat pengelompokkan data dari tugas akhir mahasiswa dengan membandingkan kedua algoritma Support Vector Clustering dan algoritma K-Medoids untuk mengetahui algoritma mana yang lebih cepat dalam hal pengelompokkan data tugas akhir mahasiswa tersebut, dengan menggunakan software Rapidminer sebagai pedoman dalam pembuatan keputusan. Pada bagian ini kita mulai dengan menggambarkan studi kasus data mining untuk jumlah mahasiswa Diploma III di AMIK Tunas Bangsa Pematangsiantar dalam hal ini judul Tugas Akhir mahasiswa tersebut untuk diolah datanya.
Data yang telah dikumpulkan dari database bagian pendidikan di AMIK Tunas Bangsa Pematangsiantar dan mensurvei data tugas akhir tersebut diambil dari tahun 2007 sampai 2012. Instrumen penelitian yang digunakan harus mempunyai ukuran yang akurat, terperinci, bagaimana mendapatkan yang lebih baik dalam proses data mining yang digambarkan pada bagian sebelum pemrosesan data.
3.2. Lokasi dan Waktu Penelitian
Secara detail metodologi penelitian ini dirancang seperti diagram block berikut ini :
Gambar 3.1. Diagram Block Penelitian
3.2.1. Data Colection
Data tugas akhir mahasiswa diperoleh dari database AMIK Tunas Bangsa Pematangsiantar berjumlah 2020 dengan atribut sebagai berikut :
1. Nim 2. Nama
3. Tahun Akademik 4. Judul TA
5. Klasifikasi TA
Keseluruhan data yang diperoleh dibuat dalam tabel data (dapat dilihat pada Bab
4 (4.2))
3.2.2. Data Preprocessing
Data yang telah dikumpulkan dilakukan proses untuk mempersiapkan data inputan pada aplikasi SVC dan K-Medoids untuk proses klastering. Langkah-langkah dalam preprocessing data dilakukan sebagai berikut :
1. Data Cleaning
Proses data cleaning dilakukan untuk memastikan dalam tabel data tidak terdapat missing value, tidak konsisten dan atribut yang hilang. 2. Data Transformasi
Format data dibuat dalam bentuk Excel, akan dikonversi menjadi format XML sebagai inputan untuk aplikasi SVC dan K-Medoids.
3.2.3. Data Analisis (Clustering)
Data yang sudah dipersiapkan sebagai output dari preprocessing akan dianalisis oleh 2 metode klastering yakni : SVC dan K-Medoids.
3.2.4. Cluster Analisis
Hasil klaster yang diperoleh dari proses SVC dan K-Medoids diinterpretasikan untuk mendapatkan ferforma dari masing-masing klaster yang dihasilkan oleh SVC dan K-Medoids, kedua hasil klaster akan dibandingkan untuk melihat model klaster yang terbaik. Model klaster yang terbaik tersebut diperoleh dengan parameter yakni jumlah data pada setiap klaster, atribut data yang mudah dilihat dari setiap klaster yang terbentuk.
3.3. Rancangan Penelitian
Rancangan penelitian ini pertama kali dilakukan dengan pengamatan atau (observasi) untuk mempelajari data tugas akhir mahasiswa. Hasil pengamatan kemudian dibuat percobaan yang mendukung selanjutnya dilakukan eksperimen data dengan menggunakan algoritma Support Vector Clustering dan algoritma K-Medoids lalu membandingkan kedua algoritma tersebut untuk mendapatkan hasil klaster yang terbaik.
Hasil dari eksperimen data ini merupakan pengembangan dari ilmu pengetahuan yang nantinya dapat merupakan input bagi pemecahan masalah yang ada di lembaga pendidikan AMIK Tunas Bangsa Pematangsiantar.
Secara garis besar metodologi penelitian ini dilaksanakan adalah sebagai berikut :
1. Studi literature yang berkaitan dengan permasalahan dan teknik-teknik yang akan digunakan untuk analisis data bersumber dari journal-journal, buku-buku dan internet.
3. Pemeriksaan kelengkapan data dan pembersihan data-data yang tidak lengkap.
4. Melakukan proses data Preparation (Data Cleaning and Transformation) untuk persiapan sebagai input analisis data.
5. Pengujian dan analisis data menggunakan software Rapidminer yang ada.
6. Pendokumentasian proses dan hasil pengolahan data. 7. Perumusan kesimpulan.
8. Penulisan laporan dalam bentuk tesis.
3.4. Flowchart Metodologi Penelitian
Adapun proses metodologi penelitian untuk Support Vector Clustering dan K-Medoids dapat dilihat pada gambar 3.2 berikut ini :
Identifikasi Permasalahan
Penetapan Tujuan Penelitian
Studi Literatur :
- DataMining - SVC
- K-Medoids
Tahap Identifikasi Awal
Pengumpulan Data : Data Tugas Akhir
Pengolahan Data :
Proses Validasi Metode Klastering (K-Medoids dan SVC) Menggunakan Data TA
Pengolahan Data :
Proses klastering menggunakan data Tugas Akhir dengan metode
(K-Medoids dan SVC)
Gambar 3.2. Flowchart Metodologi Penelitian
Dalam metodologi penelitian jelas kelihatan bahwa tahap awal, tahap pengumpulan data dan tahap analisis dan kesimpulan, sehingga proses ini dapat memudahkan kita untuk menjalankan pengolahan-pengolahan dan pengumpulan datanya. Dalam hal ini metodologi penelitian yang diproses oleh SVC sangat membantu dalam penulisan tesis ini.
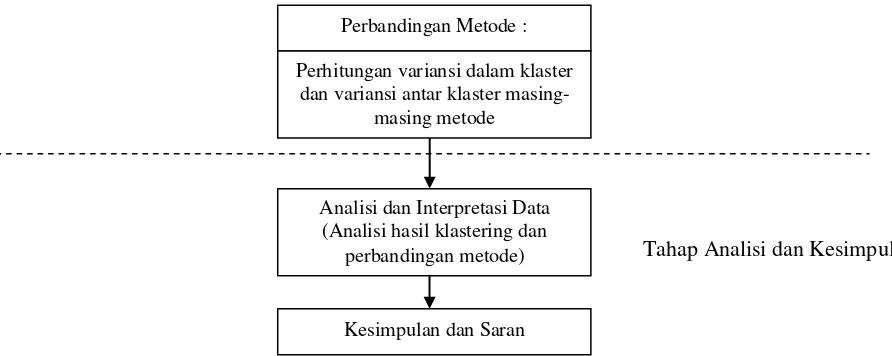
Perbandingan Metode :
Perhitungan variansi dalam klaster dan variansi antar klaster
masing-masing metode
Analisi dan Interpretasi Data (Analisi hasil klastering dan
perbandingan metode)
Kesimpulan dan Saran
3.5. Perancangan Proses Klastering.
Proses klastering seperti gambar 3.3. di bawah ini yang terdiri dari beberapa proses di antaranya proses klastering itu sendiri. Inputnya berupa teks dokumen (Tugas Akhir Mahasiswa AMIK Tunas Bangsa Pematangsiantar). Untuk mengelompokkan data yang didapat dari Tugas Akhir Mahasiswa AMIK Tunas Bangsa Pematangsiantar yaitu Tentang Web, Jaringan dan Database, dapat dilihat pada gambar 3.3 berikut ini :
Gambar 3.3. Proses Klastering dari SVC dan K-Medoid
Input Teks Dokumen
Preprocessing
Feature Selection
Clustering
SVC K-Medoids
Start
Clustering Teks Dokumen
Clustering Teks Dokumen
BAB IV
HASIL DAN PEMBAHASAN
4.1. Komunitas Rapidminer
Rapidminer (YALE) adalah perangkat lunak Open Source untuk knowledge discovery dan data mining. Rapidminer memiliki kurang lebih 400 prosedure (operator) data mining, termasuk operator masukan, output dan preprocessing dan visualisasi. Operator meta secara otomatis mengoptimalkan desain eksperimen dan pengguna tidak memerlukan waktu yang panjang untuk menentukan langkah dan parameter yang lebih panjang. Sejumlah besar teknik visualisasi dan kemungkinan untuk meletakkan breakpoints setelah masing-masing operator memberikan pandangan tentang keberhasilan desain anda bahkan untuk menjalankan percobaan.
Ribuan aplikasi data mining yang telah dikembangkan menggunakan Rapidminer dan banyak digunakan di dunia bisnis maupun penelitian.
Beberapa fitur dari Rapidminer antara lain : 1. Berlisensi gratis (open source)
2. Multiflatform karena deprogram dalam bahasa java
3. Internal data berbasis XML sehingga memudahkan pertukaran data eksperimen
4. Dilengkapi dengan scripting language untuk optomasi eksperimen 5. Memiliki GUI (Graphical User Interface), Command Line Mode (batch
Mode), dan java API yang dapat dipanggil dari program lain. 6. Dapat dikembangkan dengan menambahkan plugin dan ekstention 7. Fasilitas plotting untuk visualisasi, multidimensi dan model
4.2. Sampel Data Yang Bersumber Dari Bidang Pendidikan AMIK Tunas
Bangsa Pematangsiantar.
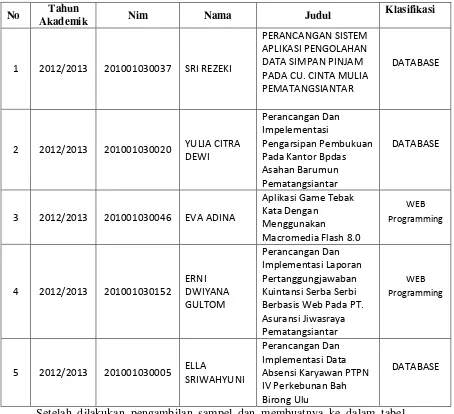
Data ini adalah data yang diambil dari bidang pendidikan AMIK Tunas Bangsa Pematangsiantar untuk contoh pengklasteran judul Tugas Akhir mahasiswa di AMIK Tunas Bangsa Pematangsiantar, diambil sampel dari 2020 judul, sampel tersebut dapat dilihat pada tabel 4.1 berikut ini :
Tabel 4.1 Sampel Data Tugas Akhir
No Tahun
Akademik Nim Nama Judul
Klasifikasi
1 2012/2013 201001030037 SRI REZEKI
PERANCANGAN SISTEM APLIKASI PENGOLAHAN DATA SIMPAN PINJAM PADA CU. CINTA MULIA PEMATANGSIANTAR
DATABASE
2 2012/2013 201001030020 YULIA CITRA DEWI
Perancangan Dan Impelementasi
Pengarsipan Pembukuan Pada Kantor Bpdas Asahan Barumun Pematangsiantar
DATABASE
3 2012/2013 201001030046 EVA ADINA
Aplikasi Game Tebak Kata Dengan
Menggunakan
Macromedia Flash 8.0
WEB Programming
4 2012/2013 201001030152
ERNI Kuintansi Serba Serbi Berbasis Web Pada PT. Asuransi Jiwasraya Pematangsiantar
WEB Programming
5 2012/2013 201001030005 ELLA
SRIWAHYUNI
Perancangan Dan Implementasi Data Absensi Karyawan PTPN IV Perkebunan Bah Birong Ulu
DATABASE
proses nantinya akan dibandingkan dengan melihat hasil pengklasteran melalui tampilan yang ada.
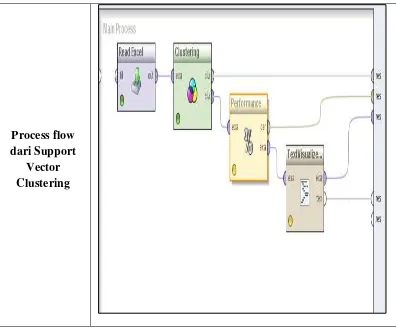
4.3. Proses Support Vector Clustering
Dalam proses SVC tampilan yang diperlihatkan dilayar menjadi pedoman untuk
mengetahui proses SVC dengan 4 tahapan yang dapat dilihat pada gambar 4.1 berikut ini
:
Process flow dari Support
Vector Clustering
Gambar 4.1. Tampilan dari Proses SVC dengan menggunakan Software
Dengan memasukkan data yang bersumber dari bidang pendidikan AMIK Tunas Bangsa pematangsiantar yang berjumlah 2020 judul Tugas Akhir mahasiswa, maka dapat dilihat tahap proses SVC yang dengan ini menggunakan software Rapidminer dengan 4 tahapan antara lain pengelompokan berdasarkan nim, nama, tahun masuk, dan judul Tugas Akhir dari mahasiswa, kemudian dilakukan pengujian sehingga menghasilkan 4 tahapan dari masing-masing gambar. Keterangan masing-masing gambar dapat dilihat pada halaman berikutnya.
Ringkasan
Operator ini membaca sebuah teladan dari file spreadsheet Excel.
Deskripsi
Operator ini dapat digunakan untuk memuat data dari spreadsheet Microsoft Excel. Operator ini mampu membaca data dari Excel 95, 97, 2000, XP, dan 2003. Pengguna harus menentukan mana dari spreadsheet di buku kerja harus digunakan sebagai tabel data. Tabel harus memiliki format sehingga setiap baris adalah contoh dan setiap kolom mewakili atribut. Harap dicatat bahwa baris pertama mungkin digunakan untuk nama atribut yang dapat ditunjukkan dengan parameter.
Masukan: Data file excel diatur, berupa Data Judul Tugas Akhir, yang bersumber Dari Database AMIK Tunas Bangsa Pematangsiantar.
Output: data set excel Yang Akan menjadi pengelompokkan Artikel Baru Support Vector Clustering
Ringkasan
Clustering dengan vektor dukungan
Deskripsi
Implementasi Support Vector Clustering berdasarkan {@ rapidminer.cite BenHur/etal/2001a}. Operator ini akan membuat atribut klaster jika belum ada.
Masukan
• Contoh set menampilkan: ExampleSetMetaData: # contoh: = 0; # atribut: 0
Keluaran
• Klaster Model:
• Berkelompok menjadi set parameter:
Parameter
• menambahkan atribut klaster: Menunjukkan jika id cluster dihasilkan sebagai atribut khusus yang baru. • tambahkan sebagai label: Jika nilai klaster
ditambahkan sebagai label.
• menghapus berlabel: Hapus contoh berlabel. • pts min: Jumlah minimal poin dalam setiap cluster. • Tipe kernel: The SVM Jenis kernel
• kernel gamma: The SVM parameter kernel gamma (radial).
• Gelar kernel: The SVM kernel Gelar parameter (polinomial).
• kernel b: The SVM parameter kernel b (saraf). • kernel cache: Ukuran cache untuk evaluasi kernel im MB
• konvergensi epsilon: Presisi pada kondisi KKT • max iterasi: Hentikan setelah ini banyak iterasi • p: Fraksi diperbolehkan outlier.
• r: Gunakan jari-jari ini bukan yang dihitung (-1 untuk radius dihitung).
• titik sampel nomor: Jumlah titik sampel virtual untuk memeriksa neighborship.
Ringkasan
Operator ini dapat digunakan untuk langsung menurunkan ukuran kinerja dari data tertentu atau nilai statistik.
Deskripsi
Operator ini dapat digunakan untuk memperoleh nilai tertentu dari contoh himpunan dan memberikan itu sebagai nilai kinerja yang dapat digunakan untuk tujuan optimasi.
Masukan
• Contoh set: yang didapat dari Example Set
Keluaran
• kinerja: • Contoh set:
Parameter
• Jenis kinerja: Menunjukkan cara bagaimana makro harus didefinisikan.
digunakan sebagai nilai makro.
• nama atribut: The Nama dari atribut dari mana data harus diturunkan.
• nilai atribut: Nilai atribut yang harus dihitung.
• Indeks contoh: Indeks contoh dari mana data harus diturunkan. Indeks negatif dihitung dari akhir set data. Penghitungan positif dimulai dengan 1, penghitungan negatif dengan -1.
• arah optimasi: Menunjukkan jika nilai kinerja harus diminimalkan atau dimaksimalkan.
Ringkasan
Visualisasi teks.
Deskripsi Masukan
• set contoh masukan
Keluaran
• set contoh keluaran
• Teks pelabuhan Visualizer
Parameter
text-atribut
Yang atribut harus digunakan untuk divisualisasikan? label-atribut
Yang atribut harus divisualisasikan sebagai label?
terlihat sebagai bentuk bola, untuk mendapatkan klaster data yang sesuai dilakukan pencarian bentuk bola yang minimal.
4.4. Hasil Proses SVC
Pada gambar 4.2 menunjukkan bahwa setelah dilakukan pengklasteran dengan menggunakan metode SVC didapat waktu berkisar 11:21 menit.
Meta data View
Proces sing time
Perfor
mance
Vector
Gambar 4.2. (Hasil klastering dengan proses SVC)
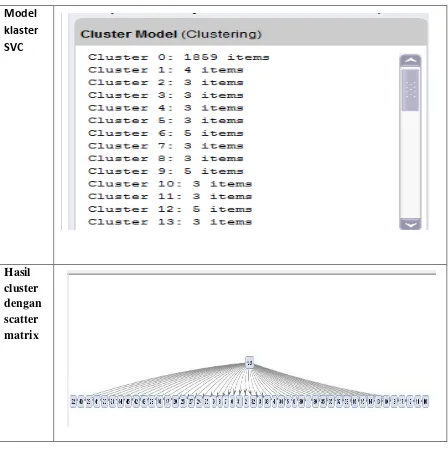
Pada proses dengan Support Vector Clustering (SVC) menunjukkan kecepatan pengklasteran data yakni judul tugas akhir mahasiswa AMIK Tunas Bangsa Pematangsiantar hasil klasteringnya didapat waktu 11:21 menit, dengan klaster yang lebih baik. Ini dapat dilihat pada gambar 4.2.1 berikut ini :
Model
klaster
SVC
Hasil cluster dengan scatter matrix
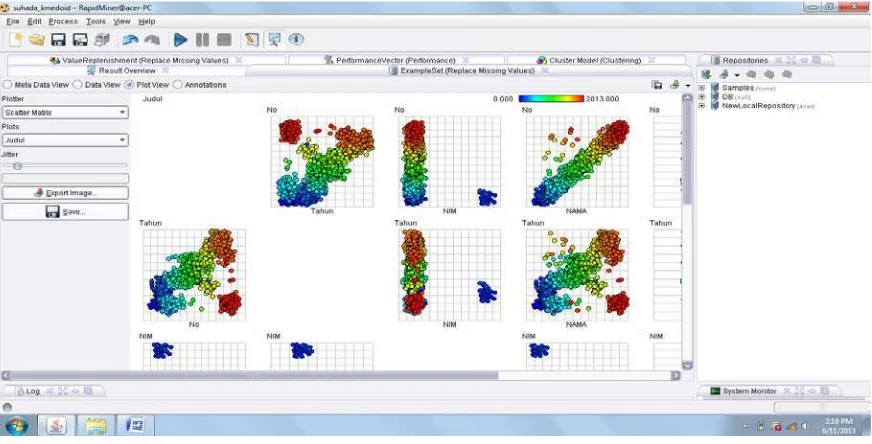
Pada pengklasteran menggunakan metode SVC diambil Scatter Matrix dan berdasarkan judul dapat dilihat pada gambar 4.3 berikut ini :
Gambar 4.3. Hasil klastering SVC berdasarkan judul dengan Scatter Matrix
Berikutnya adalah hasil klastering SVC berdasarkan klasifikasi dapat dilihat pada gambar 4.4. berikut ini :
Selanjutnya hasil klastering dari SVC berdasarkan Nim dapat dilihat pada gambar 4.5 sebagai berikut :
Gambar 4.5. Hasil klastering SVC berdasarkan Nim dengan Scatter Matrix
Kemudian dilanjutkan dengan pengklasteringan dengan SVC berdasarkan tahun akademik dapat dilihat pada gambar 4.6 berikut ini :
Untuk melihat hasil klastering baik proses SVC maupun proses K-Medoids ditemukan pengklasteran yang dapat dilihat pada tabel berikut :
Dari tabel diatas dapat dilihat jumlah daripada pengklasteran judul tugas akhir mahasiswa AMIK Tunas Bangsa Pematangsiantar dengan database berjumlah 1708 dan web programming berjumlah 311, selanjutnya dapat juga dilihat beberapa proses klaster berdasarkan judul dan klasifikasi, tahun, nim dan nama yang dapat dilihat pada gambar 4.7 berikut ini :
Gambar 4.8. Hasil klastering SVC didapat berdasarkan Tahun
4.5. Proses K-Medoids
Dalam proses K-Medoids tampilan yang diperlihatkan dilayar menjadi pedoman
untuk mengetahui proses K-Medoids dengan 4 tahapan yang dapat dilihat pada tampilan
berikut ini :
Process flow dari
K-medoids Clustering
Gambar 4.11. Tampilan dari Proses K-Medoids dengan menggunakan Software
Ringkasan
Operator ini membaca sebuah tampilan yang terbaik dari file spreadsheet Excel.
Deskripsi
Operator ini dapat digunakan untuk memuat data dari spreadsheet Microsoft Excel. Operator ini mampu membaca data dari Excel 95, 97, 2000, XP, dan 2003. Pengguna harus menentukan mana dari spreadsheet di buku kerja harus digunakan sebagai tabel data. Tabel harus memiliki format sehingga setiap baris adalah contoh dan setiap kolom mewakili atribut. Harap dicatat bahwa baris pertama mungkin digunakan untuk nama atribut yang dapat ditunjukkan dengan parameter.
Tabel data dapat ditempatkan di manapun pada lembar dan diperbolehkan mengandung instruksi sewenang-wenang format, baris kosong, dan kolom kosong. Nilai data yang hilang ditandai dengan sel kosong atau sel yang hanya berisi "?".
Masukan: Data file excel diatur, berupa Data Judul Tugas Akhir, diambil Dari database sebuah institusi Pendidikan
Output: data set excel Yang Akan di kelompokan Artikel Baru Support Vector Clustering
Parameter
• mengkonfigurasi Operator: Konfigurasi operator ini dengan cara Wizard.
• file excel: Nama dari file excel untuk membaca data dari.
lembar karena tidak mengandung data yang dapat digunakan.
• Kolom offset: Jumlah kolom untuk melewati di sisi kiri lembar karena tidak mengandung data yang dapat digunakan.
• baris pertama sebagai nama: Mengindikasikan jika baris pertama harus digunakan untuk nama-nama atribut.
• penjelasan: Peta nomor baris untuk nama penjelasan. • membaca tidak sesuai nilai-nilai sebagai missings: Nilai yang tidak cocok dengan mengetik nilai yang ditentukan dianggap sebagai missings.
• kumpulan data meta informasi data: Informasi meta data
• nama atribut telah didefinisikan: parameter menjelaskan apakah nama-nama atribut yang ditetapkan oleh pengguna secara manual atau yang dihasilkan oleh pembaca (nama generik atau baris pertama dari file)
Ringkasan
Clustering dengan k-medoids
deskripsi
Operator ini merupakan implementasi k-medoids. Operator ini akan membuat atribut klaster yang belum ada.
masukan
• Contoh set : ditampilkan: ExampleSetMetaData: # contoh: = 0; # atribut: 0
keluaran
• klaster Model:
• menjadi bagian yang berkelompok:
parameter
• menambahkan atribut klaster: Menunjukkan jika id cluster dihasilkan sebagai atribut khusus baru.
• tambahkan sebagai label: Jika nilai klaster ditambahkan sebagai label.
• menghapus berlabel: Hapus contoh berlabel. • k: Jumlah cluster yang harus terdeteksi.
• max berjalan: Jumlah maksimal berjalan K-Medoids dengan inisialisasi acak yang dilakukan.
• max optimasi langkah: Jumlah maksimal iterasi dilakukan untuk satu run K-Medoids.
• menggunakan pengacakan secara local : Menunjukkan jika pengacakan lokal harus digunakan.
• benih pengacakan lokal: Menentukan pengacakan lokal
• jenis ukuran: Jenis Ukuran • ukuran campuran: Pilih ukuran • ukuran nominal: Pilih ukuran • ukuran numerik: Pilih ukuran • perbedaan: Pilih divergence • Tipe kernel: Jenis kernel
• kernel gamma: Kernel parameter gamma. • kernel sigma1: Kernel Parameter sigma1. • kernel sigma2: Kernel Parameter sigma2. • kernel sigma3: Kernel Parameter sigma3. • Gelar kernel: Tingkat parameter kernel.
• kernel b: Kernel parameter b.
Ringkasan
Operator ini dapat digunakan untuk langsung
menurunkan ukuran kinerja dari data tertentu atau nilai statistik.
Deskripsi
Operator ini dapat digunakan untuk memperoleh nilai tertentu dari contoh himpunan dan memberikan itu sebagai nilai kinerja yang dapat digunakan untuk tujuan optimasi.
Masukan
• Contoh set: yang ditampilkan: ExampleSet
Keluaran
• Kinerja: • Contoh set:
Parameter
• Jenis kinerja: Menunjukkan cara bagaimana makro harus didefinisikan.
• Statistik: Statistik dari atribut tertentu yang harus digunakan sebagai nilai makro.
• nama atribut: Nama dari atribut dari mana data harus diturunkan.
diturunkan. Indeks negatif dihitung dari akhir set data. Penghitungan positif dimulai dengan 1, penghitungan negatif dengan -1.
• arah optimasi: Menunjukkan jika nilai kinerja harus diminimalkan atau dimaksimalkan.
Ringkasan
Visualisasi teks. Deskripsi
Masukan
• set contoh masukan
Keluaran
• set contoh keluaran • Teks tempat Visualizer
Parameter
text-atribut
Yang atribut harus digunakan untuk divisualisasikan? label-atribut
Hasil proses dari K-Medoids dapat dilihat kecepatan mengklaster data judul tugas akhir mahasiswa AMIK Tunas Bangsa Pematangsiantar memakan waktu 3,21 menit, sedangkan hasil klastering nya cukup memadai, yang dapat dilihat pada gambar
Metadat a View
Processi ng time
Centroid cluster model
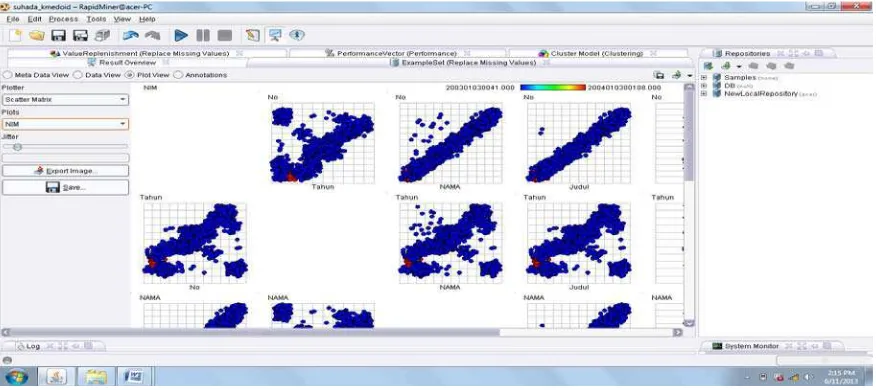
Pada pengklasteran menggunakan metode K-Medoids diambil Scatter Matrix dan berdasarkan judul dapat dilihat pada gambar 4.13 berikut ini :
Gambar 4.13. Hasil klastering K-Medoids berdasarkan judul dengan Scatter Matrix
Berikutnya adalah hasil klastering K-Medoids berdasarkan klasifikasi dapat dilihat pada gambar 4.14. berikut ini :
Selanjutnya hasil klastering dari K-Medoids berdasarkan Nim dapat dilihat pada gambar 4.15 sebagai berikut :
Gambar 4.15. Hasil klastering K-Medoids berdasarkan Nim dengan Scatter Matrix
Kemudian dilanjutkan dengan pengklasteringan dengan K-Medoids berdasarkan tahun akademik dapat dilihat pada gambar 4.16 berikut ini :
Untuk melihat hasil klastering baik proses SVC maupun proses K-Medoids ditemukan pengklasteran yang dapat dilihat pada tabel berikut :
Dari tabel diatas dapat dilihat jumlah daripada pengklasteran judul tugas akhir mahasiswa AMIK Tunas Bangsa Pematangsiantar dengan database berjumlah 1708 dan web programming berjumlah 311, selanjutnya dapat juga dilihat beberapa proses klaster berdasarkan judul dan klasifikasi, tahun, nim dan nama yang dapat dilihat pada gambar 4.17 berikut ini :
Gambar 4.18. Hasil klastering K-Medoids didapat berdasarkan Tahun
Gambar 4.20. Hasil klastering K-Medoids didapat berdasarkan Nama
Gambar 4.22. Hasil dari Klastering K-Medoids Dengan Sumbu-Y sebagai Nim dan Sumbu -X sebagai Judul
Gambar 4.24. Hasil dari Klastering K-Medoids Dengan Sumbu-Y sebagai Judul dan Sumbu-X sebagai Judul
Dari tampilan-tampilan yang telah ditunjukkan oleh gambar hasil proses SVC dan K-Medoids dapat dijelaskan bahwa :
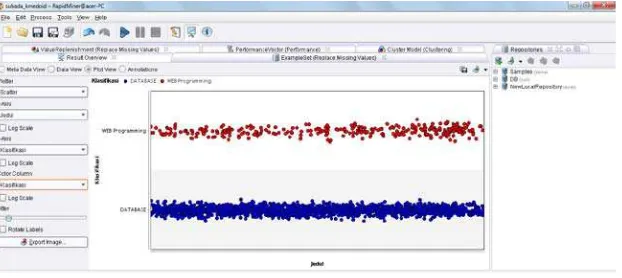
1. Pada pengklasteringan judul Tugas akhir mahasiswa AMIK Tunas Bangsa Pematangsiantar yang berjudul 2020 jelas kelihatan bahwa pengelompokkan terhadap database dan web programming masing-masing berjumlah 1708 untuk database dan 311 untuk web programming, karena jenis klasifikasi lain tidak ada diambil untuk Tugas akhir mahasiswa tersebut.
2. Pada pengklasteran dengan mengambil scatter sebagai pilihan dapat dilihat pada gambar 4.7 dengan hasil pengelompokkan database dan web programming. Ini berlaku untuk algoritma SVC dan K-Medoids.
BAB V
PENUTUP
5.1.Kesimpulan
1. Penelitian ini menggunakan data yang bersumber dari bidang Pendidikan di AMIK Tunas Bangsa Pematangsiantar yaitu judul Tugas Akhir mahasiswa dengan mengelompokkan berdasarkan database, web programming dan jaringan.
2. Hasil pengujian dengan menggunakan software Rapidminer didapat untuk SVC berkisar 11:21 menit dengan hasil pengelompokkan yang lebih baik, sedangkan dari K-Medoids didapat hasil pengklasteran berkisar antara 3,21 menit dengan hasil pengelompokkan yang cukup signifikan.
3. Setelah dilakukan pengklasteran dengan menggunakan software Rapidminer maka ditemukan hasil hanya dua klasifikasi yaitu database dan web programming. Database berjumlah 1708 judul sedangkan untuk web programming 311 judul dan untuk jaringan tidak ada.
5.2.Saran
Berdasarkan hasil penelitian yang telah dilakukan, maka penulis berharap penulis selanjutnya untuk :
1. Mencari lebih banyak lagi data dalam hal judul tugas akhir mahasiswa yang dikelompokkan berdasarkan klasifikasi misalnya database, web programming, jaringan, dan multimedia.
2. Untuk lebih detailnya penulisan selanjutnya dengan menggunakan algoritma klastering lainnya.
Daftar Pustaka
Aggarwal, C., Yu, P.S., Park, 2001, Outlier Detection for High Dimensional Data, SIGMOD, 2001.
Baskoro, H. (2010). Implementasi Algoritma K-Means Menggunakan Data Penyewaaan Alat Berat Untuk Melakukan Estimasi Nilai Outcome, Skripsi Program S1 Fakultas Ilmu Komputer, Universitas Pembangunan Nasional “Veteran” Jakarta.
Ben-Hur, D.Horn, H.Siegelmann, and V. Vapnik (2001), Support Vector Clustering.
Journal of Machine Learning Research 2, p 125- 137
Berry, M.J.A. dan Linoff G.S, 2004. Data Mining Techniques For Marketing , Sales, Customer Relationship Management, Second Edition, Wiley Publishing, Inc.
Han, J., & Kamber, M (2006). Data Mining Concepts adnd Techniques Second Edition. San Fransico : Morgan Kaufman Publisher.
Han, Michael dan Kamber, Micheline, 2001, “Data Mining Concepts and Techniques San Fransisco; Morgan Kaufmann Publishers,.
Iko Pramudiono, (2006), Apa itu Data Mining ? dalam
diakses tanggal 04 Mei 2013.
Jayanti Diah Basuki, 2008 “Implementasi Algoritma K-Medoids untuk Clustering Dokumen teks”,Skripsi Program S1 Ilmu Komputer Universitas Kristen Duta Wacana.
Kusrini & Lutfi, Emha Taufiq. (2009). Algoritma Data Mining. Yogyakarta : Penerbit Andi.
Lanzi, P., L., (2009). Clustering Partitioning Method. Diakses 01 Mei 2012, dari
Large, R., Dvornik, T., Hamilton, W., (2012), & Hess B. (n.d.). Data Mining For Facebook Cliques. Diakses 23 Februari 2012, dari
Mochammad Juniarto. , 2009 ”Implementasi Metode Support Vector Clustering untuk Pengklasteran Produk”, Institut Teknologi Sepuluh November.
Ogor Emmanuel. N, 2004, “Student Academic Performance : Monitoring and Evaluation Using Data Mining Techniques”. Fourth Congress of Electronics, Robotics and Automotive Mechanics.. I EEE Computer Socienty.
Parr Rud, O. (2001), Data Mining Cookbook. Modeling Data for Marketing , Risk and Customer Relationship Management. John Wiley & Sons, Inc.; .
Press, WH, Teukolsky, SA, Vetterling, WT, Flannery, BP (2007), “Section 2.6”, Numerical Recipes : The Art of Scientific Computing (3rd ed.), New York : Cambridge University Press, ISBN 978-0-521-88068-8
Saadaki M, Hidetomo I, Katsuhiro H. 2008. Algorithm for Fuzzy Clustering. Di dalam : Studies in Fuzziness and Soft Computing. ISSN : 1434-9922
Sajadin S, Embong. A., Hamza.M, Furqan.M, (2009)“Improving Student Academik Performance Using Data Mining Techniques”. The 5th IMTGT International Conference on Mathematic, Statistic and their Aplication (ICMSA), Bukit Tinggi Sumatera Utara.
Stephen D. Bay, Mark Scwabacher, (2003)Mining Distance Based Outliers in Near Linier Time with Randomization and a Simple Pruning Rule. In ACM SIGMOD.
Sudipto Guha, Rajew Rastogi, Kyuseok Shim, (1998)CURE: An efficient Clustering algorithm for large databases. In ACM SIGMOD Internation Conference on Management of Data,.
Tan. Pang-Ning, Steincbach. Michael, Kumar. Vipin, 2006, Introduction to Data Mining, Pearson Education Inc.
Wibisono, Y. (2012). Perbandingan Partition Around Medoids (PAM) dan K-Means Clustering Untuk Tweets. Diakses 23 Maret 2012, dari
Widyawati, N. (2010). Perbandingan Clustering Based On Frequent Word Sequence (CFWS) dan K-Means Untuk Pengelompokan Dokumen Berbahasa Indonesia. Skripsi. Bandung: Fakultas Pendidikan Matematika Dan Ilmu Pengetahuan Alam, Universitas Pendidikan Indonesia. [Tersedia]:
LAMPIRAN A
Data berikut adalah data Judul Tugas Akhir Mahasiswa AMIK Tunas Bangsa Pematangsiantar yang berjumlah 2020 judul (dalam lampiran ini hanya sampel) :
No Tahun NIM NAMA Judul Kasifikasi
1 2012/2013 201001030037 SRI REZEKI
PERANCANGAN SISTEM APLIKASI PENGOLAHAN DATA SIMPAN PINJAM PADA CU. CINTA MULIA
PEMATANGSIANTAR
DATABASE
2 2012/2013 201001030020 YULIA CITRA DEWI
Perancangan Dan Impelementasi Pengarsipan Pembukuan Pada Kantor Bpdas Asahan Barumun
Pematangsiantar
DATABASE
3 2012/2013 201001030046 EVA ADINA Aplikasi Game Tebak Kata Dengan Menggunakan Macromedia Flash 8.0
WEB Programming
4 2012/2013 201001030152 ERNI DWIYANA GULTOM
Perancangan Dan Implementasi Laporan Pertanggungjawaban Kuintansi Serba Serbi Berbasis Web Pada PT. Asuransi Jiwasraya Pematangsiantar
WEB Programming
5 2012/2013 201001030005 ELLA SRIWAHYUNI
Perancangan Dan Implementasi Data Absensi Karyawan PTPN IV Perkebunan Bah Birong Ulu
DATABASE
6 2012/2013 201001030034 RICHI FERNANDO SARAGIH
SISTEM INFORMASI PENDAFTARAN ANGGOTA BARU BERBASIS WEB DI KOPDIT CU. CINTA MULIA
WEB Programming
7 2012/2013 201001030032 NURWALIANI
Perancangan Dan Implementasi Pengolahan Data Anggaran Pengeluaran Pembangulan Di Kantor Camat Jorlang Hataran
DATABASE
8 2012/2013 201001030072 LAMRIA SIHOMBING
Perancangan Perencanaan Sistem Kerja Di Kantor Bpdas Asahan Barumun Pematangsiantar
DATABASE
9 2012/2013 201001030126 ANDRI YANTI
Perancangan Dan Implementasi Pendaftaran Pernikahan Online Pada Kantor Kementrian Agama
Pematangsiantar
WEB Programming
10 2012/2013 201001030096 RENGGA AMRISTHA
Perancangan Dan Impelementasi Data Penjualan Raskin Pada Kecamatan Siantar Marimbun Kelurahan Tong Marimbun
DATABASE
11 2012/2013 201001030185 RICKY REZZA FRIMA
Perancangan Dan Implementasi Daftar Piket Security Pada PPKS Marihat Pematangsiantar Dengan Menggunakan Visual Basic 6.0 Dan Daabase Mikrosoft SQL Server 2000
DATABASE
12 2012/2013 201002030010 JOANA PRATIWI
Perancangan Dan Implementasi Penerimaan Dan Pengeluaran Barang Pada PT. Perkebunan Nusantara IV Marihat
DATABASE
13 2012/2013 201001030021 ANDRIANSYAH RUKMAN
Perancangan Dan Implementasi Pengolahan Data Bkm(Bantuan Khusus Murid) Pada Smk Teladan
Pematangsiantar
DATABASE
14 2012/2013 201001030057 SRI RAHMAYANI
Sistem Informasi Masa Bebas Tugas (Mbt) Karyawan Yang Akan Pensiun Pada PTP. Nusantara IV (Persero) Unit Kebun Dolok Ilir
LAMPIRAN B
15 2012/2013 201001030323 NURHILMAN SIRAIT
Perancangan Dan Implementasi Konstruksi Pemasangan Pipa Di Perusahaan Daerah Air Minum ( PDAM )Tirtauli Pematangsiantar Menggunakan Bahasa Pemrograman Visual Basic 6.0 dan Database SQL Server 2000
DATABASE
16 2012/2013 201001030058 SUCI LESTARI
Perancangan Dan Implementasi Finishing Polis Pada PT. Asuransi Sinar Mas Pematangsiantar
DATABASE
17 2012/2013 201001030059 SURIANI
Sistem Informasi Penerimaan Surat Pengantar Kiriman Berbasis Web Pada PT. Kerta Gaya Pustaka Pematangsiantar
WEB Programming
18 2012/2013 201002030006 FITRIANI
Perancangan Dan Implementasi Dana Kredit Kontrak Pada Kopdit/ CU Cinta Mulia Pematangsiantar
DATABASE
19 2012/2013 201001030339 LUCY NOVITRI
Perancangan Dan Implementasi Sistem Informasi Pendaftaran Pasien Pada Rumah Sakit Vita Insani Dengan Menggunakan Macromedia Dreamweaver Mx2004 Dan Database Mysql
WEB Programming
20 2012/2013 201001030356 IDRIS MAYANDA
Sistem Informasi Pelaksanaan Kegiatan Instruktur Dan Daftar Data Kelulusan Peserta Pelatihan Pada Balai Latihan Kerja UKM Pematangsiantar
DATABASE
21 2012/2013 201001030052 MUTIARA LUBIS
Perancangan Dan Implementasi Penggajian Karyawan Pada Kantor Camat Siantar Barat Pematangsiantar Dengan Menggunakan Microsoft Visual Basic 6.0 Dan Database Sql Server 2000
DATABASE
22 2012/2013 201001030316 HERMAN SAPUTRA
Perancangan Dan Implementasi Sistem Data Pada Laka Pada Kantor Jasa Raharja Cabang Pematang Siantar Dengan Menggunakan Visual Basic 6.0 Dan SQL Server 2000
DATABASE
23 2012/2013 201001030030 KHOIROTUN NISYAH NASUTION
Peracangan Dan Implementasi Pendataan Penyandang Cacat Berat Di Kantor Camat Jorlanghataran Dengan Menggunakan Bahasa Pemrograman Visual Basic 6.0 Dan Data Base Sql Server2000
DATABASE
24 2012/2013 201001030022 ARFYAH YUSLINA
Perancangan Dan Implementasi Buku Tamu Pada Kantor Perwakilan Bank Indonesia Pematangsiantar
DATABASE
25 2012/2013 201001030038 SUYANTINI
Perancangan Dan Implementasi Penggajian Pegawai Pada Dinas Pendapatan Pengelolaan Keuangan Dan Aset Daerah Pematangsiantar
DATABASE
26 2012/2013 201001030004 DEWI MUSTIKA SARI
Perancangan Dan Implementasi Aplikasi Daftar Nilai Ujian Semester Pada Smk Satrya Budi Karang Sari
DATABASE
27 2012/2013 201001030027 ESTI RAHMADHANI UTAMI
Perancangan Program Sistem Pengingputan Data Pembuatan STNK CV. Apollo Motor Pematangsiantar
LAMPIRAN C
28 2012/2013 201001030159 MUHAMMAD NURSANDRI
Sistem Informasi Pendaftaran Siswa/ Siswi SMK PRAMAARTHA Dengan Menggunakan Microsoft Visual Basic 6.0 Dan Database Microsoft SQL Server 2000
DATABASE
29 2012/2013 201001030029 JULISAH
Perancangan Sistem Informasi Data Iventaris Pada Kantor Camat Jorlang Hataran Dengan Menggunakan Kambahasa Pemrograman Vb 6.0 Dan Data Base Sql Server 2000
DATABASE
30 2012/2013 201001030031 M. RISWANDI
Perancangan Dan Implementasi Pengolahan Data Pembayaran Uang Buku Smk Teladan Pematangsiantar
DATABASE
31 2012/2013 201001030053 NASTRIANI
Perancangan Dan Implementasi Pengolahan Data Piutang Harian Pada Kerta Pusaka (Kgp) Denagan Microsoft Vb 6.0. Dan My Sql Server Pematangsiantar
DATABASE
32 2012/2013 201001030033 OGI IMANUEL
Perancangan Sistem Informasi Pendataan Simpanan Pokok Dan Simpanan Wajib Pada Koperasi CU Cinta Mulia Pematangsiantar
DATABASE
33 2012/2013 201002030031 NURIDWAN
Perancangan Dan Implementasi Jurnal Khusus Pengeluaran Kas Pada Pembelian Buku Lembar Kerja Siswa Smk Swasta Al-Wasliyah 07 Dolok Batu Naggar,Kabupaten Simalungun Dengan Menggunakan Visual Basic For Application(Macro Excel)
DATABASE
34 NULL 2003010300004 Andri Kurniawan
SISTEM IFORMASI INVENTARISASI BERKAS PIUTANG NEGARA PADA KP2LN PEMATANGSIANTAR MENGGUNAKAN BAHASA PEMOGRAMAN VISUAL BASIC 6.0 DENGAN DATABASE SQL SERVER
DATABASE
35 NULL 2003010300005 Arif Rahman
PERANCANGAN DAN IMPLEMENTASI WEB PADA KANTOR PELAYANAN PIUTANG DAN LELANG NEGARA ( KP2LN ) PEMATANG SIANTAR DENGAN MENGGUNAKAN MACROMEDIA DREAMWEAVER MX
WEB Programming
36 NULL 2003010300007 Azhari Rufiandi Saragih
PERANCANGAN DAN IMPLEMENTASI WEB PADA PUSAT PENELITIAN KELAPA SAWIT ( PPKS) PEMATANG SIANTAR DENGAN MENGGUNAKAN MACROMEDIA DREAMWEAVER MX
WEB Programming
37 NULL 2003010300010 Daoni Sinaga
SISTEM INFORMASI INDISIPLINER MAHASISWA AMIK TUNAS BANGSA PEMATANGSIANTAR
MENGGUNAKAN BAHASA PEMOGRAMAN VISUAL BASIC 6.0
DATABASE
38 NULL 2003010300011 Dessi Anizar
SISTEM INFORMASI ADMINISTRASI KARYAWAN MUTASI PADA PTP. NUSANTARA IV KEBUN SIBOSUR MENGGUNAKAN BAHASA PEMROGRAMAN DELPHI 7.0 DENGAN DATABASE SQL SERVER 2000
LAMPIRAN D
39 NULL 2003010300013 Dewi Furi
Handayani
SISTEM INFORMASI PENDATAAN KARYAWAN PENSIUN PADA PTP. NUSANTARA IV UNIT KEBUN SIBOSUR MENGGUNAKAN BAHASA PEMROGRAMAN VISUAL BASIC 6.0 DENGAN DATABASE SQL SERVER 2000
DATABASE
40 NULL 2003010300015 Dina Maya Sari
SISTEM INFORMASI KEPEGAWAIAN PADA PT. TELEKOMUNIKASI INDONESIA, TBK DEVISI LONG DISTANCE RO PEMATANG SIANTAR DENGAN BAHASA PEMOGRAMAN BORLAND DELPHI 7 DAN MENGGUNAKAN DATABASE MICROSOFT ACCESS 2000
DATABASE
41 NULL 2003010300016 Edi Gunawan
PERANCANGAN DAN IMPLEMENTASI E - LEARNING PADA AMIK TUNAS BANGSA PEMATANGSIANTAR DENGAN MENGGUNAKAN MACROMEDIA DREAMWEVER MX 2004 DAN PHP
WEB Programming
42 NULL 2003010300018 Eva Novalina Tamba
SISTEM INFORMASI PELANGGARAN LALU LINTAS PADA POLRES PEMATANGSIANTAR DENGAN MENGGUNAKAN BAHASA PEMROGRAMAN DELPHI 7.0
DATABASE
43 NULL 2003010300022
Heppy Diana Malindan Tampubolon
SISTEM INFORMASI KEPEGAWAIAN PADA DINAS PU TOBA SAMOSIR MENGGUNAKAN BAHASA PEMROGRAMAN VISUAL BASIC 6.0 DAN DATABASE SQL SERVER
DATABASE
44 NULL 2003010300023 Iin Parlina
SISTEM INFORMASI PEGAWAI PADA PT. JAMSOSTEK KISARAN
MENGGUNAKAN BAHASA PEMROGRAMAN VISUAL BASIC 6.0 DENGAN DATABASE SQL SERVER
DATABASE
45 NULL 2003010300024 Ika Novasari
SISTEM INFORMASI ABSENSI PEGAWAI PADA PT. JAMSOSTEK KISARAN MENGGUNAKAN BAHASA PEMROGRAMAN VISUAL BASI 6.0 DENGAN DATABASE SQL SERVER
DATABASE
46 NULL 2003010300027 Joko Julianto
SISEM INFORMASI PENGHITUNGAN SMS PADA Q RADIO DENGAN PEMOGRAMAN VB 6.0 DENGAN SQL SERVER 2000
DATABASE
47 NULL 2003010300028 Juni Anggriani
SISTEM INFORMASI PENGGAJIAN PEGAWAI PADA PT. ASURANSI JIWASRAYA PERSERO PEMATANGSIANTAR DENGAN MENGGUNAKAN BAHASA PEMROGRAMAN VISUAL BASIC 6.0 DENGAN DATABASE SQL SERVER
DATABASE
48 NULL 2003010300029 Lili Chairani Situmorang
SISTEM INFORMASI TATA USAHA GUDANG PADA DIVISI URT PPKS UNIT USAHA MARIHAT MENGGUNAKAN BAHASA PEMROGRAMAN VISUAL BASIC 6.0 DENGAN DATABASE SQL SERVER