Fakultas Ilmu Komputer
Universitas Brawijaya 1958
Pengelompokkan Kondisi Komputer pada Bank X di Seluruh Indonesia Menggunakan Metode K-Medoids Clustering
Muthia Maharani1, Dian Eka Ratnawati2, Bayu Rahayudi3
Program Studi Teknologi Informasi, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Bank X merupakan salah satu bank negeri terbesar di Indonesia. Berjalannya proses perbankan hingga proses operasional Bank X yang berlangsung setiap hari selama 24 jam, dibutuhkan komputer dengan kualitas yang sangat baik. Sehingga proses peremajaan komputer harus selalu dilakukan. Banyaknya jumlah komputer di Bank X membuat proses peremajaan komputer menjadi salah satu pengeluaran terbesar Bank X. Selain itu, di berbagai unit kerja pada Bank X, proses peremajaan komputer juga masih belum efektif untuk dilakukan. Dari permasalahan ini, maka akan dilakukan penelitian berupa pengelompokkan kondisi komputer pada Bank X di seluruh Indonesia menggunakan metode K-Medoids Clustering.pPenelitian ini dilakukan untuk mengelompokkan komputer mana saja yang sangat perlu, cukup perlu, dan belum perlu dilakukan peremajaan komputer. Hasil dari pengelompokkan menggunakan 3 cluster adalah terdapat 237 data berada pada cluster 0 dengan kondisi belum perlu untuk dilakukan peremajaan, 126 data berada pada cluster 1 dengan kondisi sangat perlu untuk dilakukan peremajaan, dan 769 data berada pada cluster 2 dengan kondisi masih cukup baik namun perlu untuk tinjau kembali karena cukup perlu untuk dilakukan peremajaan komputer. Untuk pengujian menggunakan silhouette coefficient, percobaan dengan 2 cluster merupakan pengelompokkan yang paling baik karena memiliki silhouette score yang paling tinggi, yaitu sebesar 0,624684967. Lalu dilakukan juga pengujian terhadap jumlah data dimana 90% dari data aslinya merupakan presentase minimal jumlah data untuk hasil yang akurat. Hasil dari penelitian akan diberikan kepada Bank X sebagai rekomendasi untuk mengetahui komputer apa saja yang perlu untuk dilakukan peremajaan sehingga dapat ditindaklanjuti dengan lebih cepat.
Kata kunci: K-Medoids Clustering, Silhouette Coefficient, peremajaan komputer Abstract
Bank X is one of the largest public banks in Indonesia. With the banking process running up to the operational process of Bank X which run every day for 24 hours, a very good quality computer is needed.
So the process of upgrading computer must always be done. The large number of computers at Bank X makes the process of upgrading computers is one of Bank X's biggest expenses. Other than that, in several work units at Bank X, the process of upgrading computer is still not effective. From these problems, the research will be conducted in the form of grouping computer conditions at Bank X all over Indonesia using the K-Medoids Clustering method. This research was conducted to classify which computers are really need, need enough, and which computers do not need to upgrade. The results of this grouping are that there are 237 computer in cluster 0 no need to upgrade, 126 computer are in cluster 1 with a very need to upgrade, and 769 computer are in cluster 2 with condition good enough but need to be reviewed because it is quite necessary to do a computer upgrade. For testing using the Silhouette Coefficient, clustering with 2 clusters is the best because it has the highest silhouette score, which is 0.624684967. And also the test for amount of data which showed that 90% of the original data was the minimum presentation for data amount for accurate results. The results of the research will be given to Bank X as a recommendation to find out which computers need to be upgraded so that they can be followed up more quickly.
Keywords: K-Medoids Clustering, Silhouette Coefficient, computer upgrade
1. PENDAHULUAN
Bank X merupakan salah satu bank negeri terbesar di Indonesia. Bank X sudah berdiri sejak tahun 1998 dan hingga kini kesuksesannya masih terus berkibar. Karena sebagai salah satu bank terbesar dengan cabang yang sudah tersebar di seluruh Indonesia, Bank X tidak bisa hidup tanpa teknologi. Dengan berjalannya proses perbankan hingga proses operasional Bank X yang berlangsung setiap hari selama 24 jam, dibutuhkan sumber daya teknologi yang sangat baik untuk mendukung seluruh pekerjaan Bank X. Salah satu teknologi yang paling mendasar namun sangat penting dan sangat diperlukan untuk menunjang aktivitas Bank X yaitu komputer.
Pada Bank X, terdapat salah satu tim yang berjalan di bawah Grup IT Infrastructure, yaitu Tim Desktop. Pekerjaan Tim Desktop berfokus kepada mendistribusikan, mengecek, dan merawat seluruh komputer milik Bank X yang tersebar di seluruh Indonesia. Banyaknya jumlah komputer di Bank X membuat proses perawatan dan pergantian komputer menjadi salah satu pengeluaran terbesar Bank X. Pengeluaran ini tidak dapat dihindari karena perawatan dan pergantian komputer wajib dilakukan pada Bank X. Selain itu, di berbagai unit kerja pada Bank X, proses perawatan dan pergantian komputer juga masih belum efektif untuk dilakukan.
Sehingga sampai saat ini, cenderung lebih banyak komputer-komputer lama dan memiliki performa tidak maksimal yang digunakan di beberapa unit kerja. Hal-hal seperti ini jika dibiarkan maka akan merugikan tim Desktop dan Bank X sendiri karena akan dibutuhkan waktu dan biaya yang lebih besar lagi jika proses peremajaan tidak dilakukan secara efektif.
Dari permasalahan tersebut, maka Tim Desktop ingin melakukan evaluasi seluruh komputer yang digunakan pada Bank X. Cara melakukan evaluasi ini yaitu dengan menandai apakah suatu komputer sudah perlu untuk dilakukan peremajaan atau belum perlu. Selain membantu dalam segi biaya dan terhindar dari komputer yang semakin rusak, peremajaan komputer juga akan meningkatkan kinerja Bank X. Karena kondisi komputer yang tidak baik juga akan mempengaruhi kinerja Bank X.
Dengan memanfaatkan data mining, maka penulis akan membantu Tim Desktop untuk mengidentifikasikan kondisi komputer sehingga dapat memudahkan Tim Desktop untuk
melakukan peremajaan komputer. Tujuan dilakukannya pengelompokkan yaitu untuk memudahkan dalam mengidentifikasikan kondisi komputer yang akan diremajakan berdasarkan kemiripan karakteristik dari setiap komputer. Pengelompokkan seluruh komputer akan dilakukan menggunakan metode K- Medoids Clustering. Metode K-Medoids Clustering merupakan metode pengelompokkan pengembangan variasi dari metode K-Means clustering. Jika K-Means clustering menggunakan nilai rata-rata, metode ini menggunakan salah satu objek sebagai medoid untuk dijadikan pusat cluster pada setiap clusternya (Kaur et al., 2014). Cara ini membuat metode K-Medoids menyempurnakan metode K- Means untuk mengurangi sensitivitas dengan penggunaan nilai yang besar (Park & Jun, 2009).
Penelitian Juninda, Mustasim dan Andri (2019) meneliti mengenai pengelompokkan penyakit berdasarkan penyakit tertentu di Pekanbaru, Riau menggunakan metode K- Medoids clustering. Penelitian ini menghasilkan 4 cluster dengan nilai pengujian DBI sebesar 0,043. Hasil tersebut menunjukkan bahawa algoritma K-Medoids dapat melakukan pengelompokan penyakit dengan baik. Lalu terdapat penelitian Soni dan Patel (2017) melakukan perbandingan antara metode K- Means dengan K-Medoids menggunakan 150 dataset yang didapatkan dari UCI Machine Learning Repository. Hasil yang didapatkan yaitu K-Medoids memiliki hasil akurasi lebih tinggi yaitu 92% dibandingkan dengan K-Means yang sebesar 88,7%. Dari beberapa penelitian terdahulu yang disebutkan serta penggunaan data yang besar pada penelitian ini menjadikan K-Medoids Clustering sebagai metode yang akan digunakan untuk mengelompokkan kondisi komputer di Bank X seluruh Indonesia.
2. LANDASAN KEPUSTAKAAN 2.1. Kajian Pustaka
Penelitian Simamora, Furqon dan Priyambadha (2017) menggunakan K-Medoids Clustering untuk meneliti pengelompokkan data kejadian Tsunami yang disebabkan oleh gempa bumi. Hasil yang didapatkan oleh penelitian ini yaitu sebuah sistem untuk melakukan pengelompokkan dataset tsunami. Lalu dari hasil pengujiannya, jumlah cluster yang terbaik untuk proses clustering dari penelitian ini yaitu 2 cluster. Lalu berdasarkan pengujian terhadap
sampel data acak, hasil yang didapatkan yaitu presentase 90% menjadi presentase pengambilan sampel data minimal.
Penelitian selanjutnya yaitu oleh Juninda, Mustasim dan Andri (2019) yang meneliti mengenai analisis pengelompokkan penyakit berdasarkan penyakit tertentu di Pekanbaru, Riau menggunakan K-Medoids Clustering. Hasil yang diperoleh pada penelitian ini yaitu didapatkan 4 cluster sebagai jumlah pengelompokan yang paling terbaik untuk mengelompokkan penyakit karena jumlah cluster 4 memiliki nilai pengujian Devies Bouildien Indeks (DBI) sebesar 0,043.
Penelitian terakhir oleh Asmiatun, Wakhidah, dan Putri (2019) menggunakan metode K-Medoids Clustering untuk mengelompokkan kondisi jalanan di kota Semarang. Hasil dari penelitian ini yaitu didapatkan 4 cluster dengan tingkat kondisi jalan baik, sedang, rusak ringan, dan rusak berat.
Namun hasil pengujian menunjukkan bahwa 2 cluster merupakan jumlah cluster yang paling baik.
2.2. Komputer
Komputer merupakan teknologi berupa perangkat elektronik yang dapat menerima dan menjalankan perintah, mengolah data menjadi informasi, menjalankan program yang tersimpan di dalam memori, dan bekerja secara otomatis menggunakan aturan tertentu (Haryono, 2003).
Komputer diciptakan untuk memudahkan pekerjaan manusia seperti mengurangi proses menulis secara manual, menyimpan data yang banyak dan besar, menampilkan berbagai informasi serta visual yang menarik, serta kemudahan yang lainnya. Sistem komputer memiliki tiga komponen utama antara lain hardware (perangkat keras), software (perangkat lunak) dan brainware (sumber daya manusia) (Haryono, 2003).
2.3. K-Medoids
K-Medoids Clustering adalah metode pengelompokkan yang merupakan pengembangan dari metode K-Means clustering.
Metode ini menyempurnakan K-Means clustering yang sensitif terhadap noise dan outlier karena objek dengan nilai yang besar kemungkinan akan menghasilkan hasil yang menyimpang dari distribusi data (Kaur et al., 2014). Tahapan perhitungan metode K-Medoids (Pramesti et al., 2017) adalah:
1. Inisiasi pusat cluster secara acak sebanyak k (jumlah cluster).
2. Alokasikan setiap data (objek) ke cluster terdekatnya menggunakan perhitungan jarak setiap objek yang ada pada setiap cluster dengan kandidat medoid baru.
3. Lakukan kembali nomer 1 dengan kembali menetapkan medoid baru pada data secara acak, lalu hitung jarak seperti langkah nomer 2.
4. Menghitung total simpangan (S) dengan cara mengurangi nilai total distance baru dan nilai total distance lama. Jika S < 0, maka tukar objek dengan data pada cluster sehingga dibentuk objek baru yang akan menjadi medoid baru.
5. Ulangi kembali tahapan pada langkah 3 dan 4 hingga S > 0 dan sudah tidak ada perubahan pada medoid lagi, sehingga terbentuk cluster dan anggota setiap cluster nya.
2.4. Silhouette Coefficient
Silhouette Coefficient adalah teknik pengujian untuk memastikan kualitas dari penempatan suatu objek ke dalam suatu cluster (Shoolihah et al., 2017). Teknik ini menghitung jarak rata-rata antar objek dalam satu cluster (Handoyo et al., 2014). Langkah-langkah menghitung nilai Silhouette Coefficient (Rousseeuw, 1987) adalah :
1. Mencari nilai 𝑎(𝑖) yaitu perbedaan rata-rata jarak objek ke-i dengan semua objek yang berada di clusternya.
2. Mencari nilai 𝑑(𝑖, 𝐶) yaitu perbedaan rata- rata jarak objek ke-i dengan semua objek yang terdapat di cluster lain.
3. Mencari nilai 𝑏(𝑖) yaitu nilai paling minimum dari hasil d(i, C).
4. Dari hasil diatas, dapat dihitung nilai silhouette coefficient menggunakan persamaan 1.
𝑆(𝑖) = 𝑏(𝑖)−𝑎(𝑖)
max{𝑎(𝑖),𝑏(𝑖)} (1)
Dan juga dapat dihitung menggunakan persamaan 2.
𝑆(𝑖) = {
1 −𝑎(𝑖)𝑏(𝑖), 𝑖𝑓 𝑎(𝑖) < 𝑏(𝑖), 0, 𝑖𝑓 𝑎(𝑖) = 𝑏(𝑖)
𝑏(𝑖)
𝑎(𝑖)− 1, 𝑖𝑓 𝑎(𝑖) > 𝑏(𝑖).
(2)
Dimana :
𝑆(𝑖) : Silhouette Coefficient.
𝑎(𝑖) : perbedaan rata-rata jarak objek ke-i terhadap semua objek yang terdapat di clusternya.
𝑏(𝑖) : nilai minimum dari perbedaan rata-rata jarak objek ke-i terhadap semua objek yang terdapat di cluster lain.
3. METODOLOGI PENELITIAN
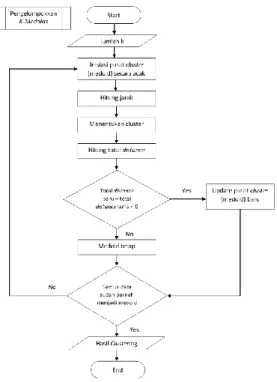
Penelitian ini merupakan non- implementatif analitik. Tahapan penelitian yang dilakukan pertama kali mencakup pengumpulan data dari perusahaan. Data yang sudah dikumpulkan dipelajari, dianalisa serta dibandingkan dengan teori yang revelan dengan permasalahan yang diangkat. Dari hasil penelitian ini, maka dapat ditarik kesimpulan serta diberikan saran untuk penelitian selanjutnya. Alur pelaksanaan dari penelitian ini tertuang pada Gambar 1.
Gambar 1 Metodologi Penelitian
4. IMPLEMENTASI
Selanjutnya yaitu mengimplementasikan rancangan ke dalam bahasa python. Proses implementasi sistem pengelompokkan kondisi komputer PT Bank X di seluruh Indonesia dengan K-Medoids Clustering menggunakan bahasa pemrograman python pada google colaboratory. Data yang digunakan sebagai input atau dataset yaitu informasi komputer Bank X di seluruh Indonesia berjumlah 1132 dengan atribut Device Name, OS Name, RAM, Processor, Harddisk Size, Application Error, System Manufacturer, dan umur komputer.
Tahapan-tahapan proses pada sistem pengelompokkan kondisi komputer Bank X adalah :
1. Memasukkan dataset berupa file .csv.
2. Data yang sudah dimasukkan akan dinormalisasi untuk dapat melakukan perhitungan selanjutnya.
3. Setelah data dinormalisasi, selanjutnya melakukan pengelompokkan data menggunakan algoritma K-Medoids.
4. Mengeluarkan hasil akhir data dengan cluster pada setiap data dan hasil pengelompokkan tersebut disimpan dalam bentuk excel.
5. Dari hasil pengelompokkan tersebut, maka akan dilakukan proses validasi terhadap kualitas kelompok dengan menghitung Silhouette Coefficient lalu mengeluarkan nilai Silhouette Coefficientnya.
Gambar 2 Diagram Alir Sistem
Proses utama pada sistem yang dibangun yaitu pengelompokkan menggunakan algoritma K-Medoids. Proses K-Medoids dimulai dari memasukkan jumlah cluster, lalu dilanjutkan dengan inisiasi medoid acak. Hasil akhir proses pengelompokkan akan ditampilkan sebagai output dari sistem saat proses perhitungan selesai. Gambar 3 merupakan flowchart dari algoritma K-Medoids Clustering.
Gambar 3. Flowchart K-Medoids
Implementasi sistem dilakukan menggunakan 3 cluster. Gambar 4, 5 dan 6 merupakan hasil output dari sistem berupa medoid final, cluster, dan nilai silhouette score dari percobaan 3 cluster.
Gambar 4 Medoid Awal dan Medoid Akhir
Gambar 5 Hasil Clustering Dalam Bentuk Array
Gambar 6 Hasil Silhouette Score
Hasil pengelompokkan yaitu 237 data berada pada cluster 0 dengan kondisi sangat baik, 126 data berada pada cluster 1 dengan kondisi sangat perlu untuk dilakukan peremajaan komputer, dan 769 data berada pada cluster 2 dengan kondisi masih cukup baik namun perlu untuk tinjau kembali karena cukup perlu untuk
dilakukan peremajaan komputer. Serta hasil silhouette coeffient pada cluster dan pusat medoid tersebut yaitu sebesar 0,336096777.
5. PENGUJIAN
Pada penelitian ini akan dilakukan 2 cara pengujian terhadap sistem menggunakan Silhouette Coefficient, antara lain:
1. Pengujian terhadap jumlah cluster Pengujian ini dilakukan untuk mengetahui cluster berapa yang paling baik digunakan pada sistem ini menggunakan data informasi komputer pada Bank X di seluruh Indonesia.
2. Pengujian terhadap jumlah data Pengujian ini dilakukan untuk mengetahui jumlah data paling sedikit yang akan dijadikan sebagai presentase minimal data untuk penggunaan sistem ini menggunakan beberapa jumlah data acak dari data informasi komputer pada Bank X di seluruh Indonesia.
6. ANALISIS
Dari implementasi serta pengujian yang dilakukan, maka didapatkan beberapa analisis berdasarkan hasil dari pengujian. Tabel 1 dan Gambar 7 merupakan hasil pengujian terhadap jumlah cluster.
Tabel 1 Hasil Pengujian Terhadap Jumlah Cluster
No. Jumlah Cluster Silhouette Score
1 2 0,624684967
2 3 0,400928286
3 4 0,338191992
4 5 0,267086080
5 6 0,272290757
6 7 0,295107831
7 8 0,293849029
8 9 0,311852482
9 10 0,327818766
Gambar 7 Hasil Pengujian Terhadap Jumlah Cluster 0
0.2 0.4 0.6 0.8
2 3 4 5 6 7 8 9 10
H A S I L P E N G U J I A N T E R H A D A P J U M L A H C L U S T E R
Silhouette Score
Dari seluruh percobaan yang dilakukan, percobaan yang memiliki silhouette score paling tinggi yaitu ada pada percobaan menggunakan 2 cluster sebesar 0,624684967. Hasil pengujian ini bisa beragam karena jarak antara data satu dengan data lainnya cukup jauh, serta pusat medoid yang dapat berubah-ubah sehingga menghasilkan pengelompokkan dengan silhouette score sangat beragam.
Lalu, didapatkan kesimpulan bahwa jumlah cluster yang sedikit akan menghasilkan silhouette score yang lebih tinggi. Rata-rata jarak antar data pada cluster akan semakin kecil saat jumlah clusternya sedikit, dan juga rata-rata jarak antar cluster akan semakin besar. Sehingga akan menghasilkan silhouette score yang besar.
Sebaliknya pun juga seperti itu.
Hasil pengujian yang sudah dilakukan belum bisa dijadikan sebagai hasil yang paling baik karena K-Medoids memiliki sifat mengambil data acak sebagai medoid, sehingga tidak menutup kemungkinan bahwa terdapat kombinasi serta jumlah medoid yang lebih baik daripada yang sudah diujikan.
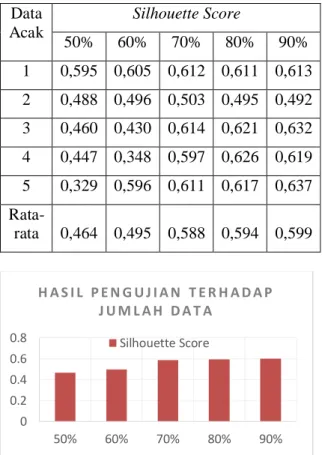
Tabel 2 dan Gambar 8 merupakan hasil pengujian terhadap jumlah data.
Tabel 2 Hasil Pengujian Terhadap Jumlah Data
Data Acak
Silhouette Score
50% 60% 70% 80% 90%
1 0,595 0,605 0,612 0,611 0,613 2 0,488 0,496 0,503 0,495 0,492 3 0,460 0,430 0,614 0,621 0,632 4 0,447 0,348 0,597 0,626 0,619 5 0,329 0,596 0,611 0,617 0,637 Rata-
rata 0,464 0,495 0,588 0,594 0,599
Gambar 8 Hasil Pengujian Terhadap Jumlah Data
Dari pengujian tersebut, maka dapat dilihat
bahwa nilai Silhouette Coefficient terus naik.
Sehingga, rata-rata nilai Silhouette Coefficient terbaik jatuh kepada presentasi 90% sebesar 0,5993454 dan nilai terendah yaitu 50% sebesar 0,4642272. Dari hasil percobaan pengujian terhadap jumlah data ini, dapat disimpulkan bahwa semakin kecil jumlah data yang digunakan, maka silhouette scorenya juga menjadi kecil. Karena jika data yang digunakan semakin sedikit, maka kemiripan antar data pada dataset juga menjadi berkurang. Sehingga, jumlah data dengan presentasi 90% dari data asli menjadi presentasi minimal pengambilan sampel data untuk hasil yang lebih akurat.
7. PENUTUP
Dari hasil implementasi serta pengujian yang sudah dilakukan, maka kesimpulan yang didapatkan antara lain:
1. Metode K-Medoids Clustering merupakan salah satu metode pengelompokkan yang dapat digunakan untuk pengelompokkan data informasi komputer pada Bank X di seluruh Indonesia. Implementasi K-Medoids clustering menggunakan data komputer Bank X di seluruh Indonesia sebanyak 1132 data dimulai dari menginput data pada form upload yang sudah dibuat, lalu data di normalisasi. Setelah itu dilakukan proses pengelompokkan menggunakan K-Medoids. Hasil dari pengelompokkan ini akan dieksport dalam bentuk file excel dan file inilah yang akan diserahkan kepada pihak Bank X. Sistem juga akan menampilkan nilai silhouette score untuk melihat kualitas dari pengelompokkan.
2. Hasil dari percobaan K-Medoids Clustering menggunakan 3 cluster yaitu terdapat 237 data berada pada cluster 0 dengan kondisi belum perlu untuk dilakukan peremajaan, 126 data berada pada cluster 1 dengan kondisi sangat perlu untuk dilakukan peremajaan komputer, dan 769 data berada pada cluster 2 dengan kondisi masih cukup baik namun perlu untuk tinjau kembali karena cukup perlu untuk dilakukan peremajaan komputer. Untuk pengujian menggunakan Silhouette Coefficient, percobaan dengan 2 cluster merupakan pengelompokkan yang paling baik
0 0.2 0.4 0.6 0.8
50% 60% 70% 80% 90%
H A S I L P E N G U J I A N T E R H A D A P J U M L A H D A T A
Silhouette Score
karena memiliki silhouette score yang paling tinggi, yaitu sebesar 0,624684967. Lalu dilakukan juga pengujian terhadap jumlah data dimana dimana 90% dari data aslinya merupakan presentase minimal jumlah data untuk hasil yang akurat.
8. SARAN
Dari penelitian yang sudah dilakukan, maka didapatkan beberapa saran dari penulis sebagai masukan untuk penelitian selanjutnya yang berkaitan dengan penelitian ini, antara lain:
1. Dapat dibuat sistem yang lebih baik berbentuk aplikasi maupun sistem lainnya serta ditambahkan beberapa fitur untuk sistem pengelompokkan kondisi komputer pada PT Bank X di seluruh indonesia agar lebih mudah untuk digunakan oleh berbagai kalangan.
2. Dapat dilakukan penelitian lanjut mengenai pengelompokkan kondisi komputer pada PT Bank X di seluruh Indonesia menggunakan metode yang lainnya untuk perbandingan dengan metode K-Medoids Clustering.
3. Dapat dilakukan penelitian lebih lanjut mengenai pemilihan medoid pada K- Medoids Clustering yang lebih baik agar medoid yang sudah terpilih menjadi medoid yang paling baik sehingga hasil clusteringnya akan lebih akurat.
9. DAFTAR PUSTAKA
Asmiatun, S., Wakhidah, N., & Putri, A. N.
(2019). Penerapan Metode K-Medoids Untuk Pengelompokkan Kondisi Jalan Di Kota Semarang. JATISI (Jurnal Teknik Informatika Dan Sistem Informasi), 6(2), 171–180.
https://doi.org/10.35957/jatisi.v6i2.193 Handoyo, R., Rumani, R., & Nasution, S. M.
(2014). Perbandingan Metode Clustering Menggunakan Metode Single Linkage Dan K-Means Pada Pengelompokan Dokumen. JSM STMIK Mikroskil.
Haryono, N. (2003). Ringkasan Materi Kuliah Pengantar Informatika. 1–27.
Juninda, T., Mustasim, & Andri, E. (2019).
Penerapan Algoritma K-Medoids untuk
Pengelompokan Penyakit di Pekanbaru Riau. Seminar Nasional Teknologi Informasi, Komunikasi Dan Industri, 11(1), 42–49.
Kaur, N. K., Kaur, U., & Singh, D. (2014). K- Medoid Clustering Algorithm- A Review.
International Journal of Computer Application and Technology.
Park, H. S., & Jun, C. H. (2009). A simple and fast algorithm for K-medoids clustering.
Expert Systems with Applications, 36(2 PART 2), 3336–3341.
https://doi.org/10.1016/j.eswa.2008.01.03 9
Pramesti, D. F., Lahan, Tanzil Furqon, M., &
Dewi, C. (2017). Implementasi Metode K- Medoids Clustering Untuk
Pengelompokan Data. Jurnal
Pengembangan Teknologi Informasi Dan Ilmu Komputer, 1(9), 723–732.
https://doi.org/10.1109/EUMC.2008.4751 704
Rousseeuw, P. J. (1987). Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20(C), 53–65.
https://doi.org/10.1016/0377- 0427(87)90125-7
Shoolihah, A.-M., Furqon, M. T., & Widodo, A. W. (2017). Implementasi Metode Improved K-Means untuk
Mengelompokkan Titik Panas Bumi.
Jurnal Pengembangan Teknologi
Informasi Dan Ilmu Komputer (J-PTIIK) Universitas Brawijaya, 1(11), 1270–1276.
Simamora, D. A. S., Furqon, M. T., &
Priyambadha, B. (2017). Clustering Data Kejadian Tsunami Yang Disebabkan Oleh Gempa Bumi Dengan Menggunakan Algoritma K-Medoids. Jurnal
Pengembangan Teknologi Informasi Dan Ilmu Komputer, 1(8), 635–640.
Soni, K. G., & Patel, A. (2017). Comparative Analysis of K-means and K-medoids Algorithm on IRIS Data. 13(5), 899–906.