PENDETEKSIAN KATA DENGAN MFCC SEBAGAI EKSTRAKSI
CIRI DAN CODEBOOK SEBAGAI PENGENALAN POLA
MOHAMMAD LUTHFI SYAFRUL
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENDETEKSIAN KATA DENGAN MFCC SEBAGAI EKSTRAKSI
CIRI DAN CODEBOOK SEBAGAI PENGENALAN POLA
MOHAMMAD LUTHFI SYAFRUL
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
MOHAMMAD SYAFRUL LUTHFI. Word Detection Using MFCC as Feature Extraction and Codebook as Pattern Recognition. Supervised by AGUS BUONO.
Word detection is the process of identifying words spoken by someone. It is useful for communication between computers and humans. MFCC technique was used to extract features from voice signal and compare it to the sound signal in the database. Codebook is the process of producing small characteristic vectors was used to match unknown words to words in the database. The purpose of this research was to quantify detection accuracy of spoken words and compare 16 codewords and 32 codewords. The experiment produced an average detection accuracy of 98%. We conclude that detection using MFCC and codebook can achieve good performance. And the performance of the 16 codewords is better than 32 codewords for word detection.
Penguji:
Judul skripsi : Pendeteksian Kata dengan MFCC sebagai Ekstraksi Ciri dan Codebook sebagai Pengenalan Pola
Nama : Mohammad Luthfi Syafrul NIM : G64076044
Menyetujui, Dosen Pembimbing
Dr Ir Agus Buono, MSi MKom NIP. 196607021993021001
Mengetahui,
Ketua Departemen Ilmu Komputer
Dr Ir Agus Buono, MSi MKom NIP. 196607021993021001
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhanahu Wa Ta’ala atas segala cinta dan kasih sayang-Nya sehingga karya ilmiah ini berhasil diselesaikan. Shalawat serta salam penulis sampaikan kepada junjungan kita Nabi Muhammad Shalallahu ‘alaihi wasallam atas teladan beliau sebagai motivasi. Tema yang dipilih dalam penelitian ini adalah penerapan metode pendeteksian kata dengan MFCC dan codebook, dengan judul pendeteksian kata dengan MFCC sebagai metode ekstraksi ciri dan codebook sebagai metode pengenalan pola. Penelitian dilakukan sejak Juni 2009 sampai dengan Juli 2013.
Pembuatan karya ilmiah berjalan baik karena banyak pihak yang membantu dan mendukung, karena itu penulis ingin menyampaikan ucapan terima kasih kepada:
1 Ayah dan Ibu untuk doa, kasih sayang, dan semangat kepada saya.
2 Bapak Agus Buono selaku dosen pebimbing atas waktu, bimbingan, dan saran yang diberikan.
3 Seluruh dosen pengajar dan civitas akademika Departemen Ilmu Komputer FMIPA IPB. 4 Zehan Novalia yang selalu memberikan dukungan dan semangat.
5 Kakak dan adik saya yang selalu memberikan semangat. 6 Teman-teman di Ilkom IPB.
7 Teman-teman di Warnet Benet.
8 Seluruh staf Biro Hukum Kementerian PPN/Bappenas.
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu selama penyelesaian karya ilmiah ini yang tidak dapat disebutkan satu per satu. Semoga karya ilmiah ini bermanfaat bagi para pembacanya.
Bogor, Juli 2013
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 13 November 1987 dari ayah Syafrul Sikumbang dan Ibu Yusniar Jalal. Penulis adalah putra kedua dari tiga bersaudara.
Penulis lulus dari SMA Negeri 21 Jakarta pada tahun 2004 dan pada tahun yang sama penulis melanjutkan pendidikan Diploma 3 di Program Studi Elektronika dan Teknologi Komputer, Institut Pertanian Bogor, dan lulus pada tahun 2007.
DAFTAR ISI
Halaman
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN Latar belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA Bunyi dan Sinyal ... 1
Sampling dan Kuantisasi ... 2
Ekstraksi Ciri Sinyal Suara ... 2
Pengenalan Pola dengan Codebook... 4
K-Means Clustering ... 4
METODOLOGI Pengambilan Data Suara ... 5
Praproses ... 5
Data Latih dan Data Uji ... 5
Proses Ekstraksi Ciri dan Codebook ... 6
Pengujian... 6
Dokumentasi ... 6
HASIL DAN PEMBAHASAN Pemisahan Kata ... 6
Ekstraksi Ciri dan Codebook ... 6
Pengujian Sistem Deteksi Kata ... 7
KESIMPULAN DAN SARAN Kesimpulan ... 9
Saran ... 9
DAFTAR PUSTAKA ... 9
LAMPIRAN ... 11
DAFTAR TABEL
Halaman
1 Akurasi pendeteksian kata ... 7
2 Akurasi pendeteksian kata pada kombinasi kata “komputer hidup sekarang” dengan 16 codeword ... 7
3 Akurasi pendeteksian kata pada kombinasi kata “IPB fakultas MIPA ilmu komputer” dengan 16 codeword ... 7
4 Akurasi pendeteksian kata pada kombinasi kata “departemen komputer jurusan teknologi komputer” dengan 16 codeword ... 8
5 Akurasi pendeteksian kata pada kombinasi kata “komputer hidup sekarang” dengan 32 codeword ... 8
6 Akurasi pendeteksian kata pada kombinasi kata “IPB Fakultas MIPA ilmu komputer” dengan 32 codeword ... 8
7 Akurasi pendeteksian kata pada kombinasi kata “departemen komputer jurusan teknologi komputer” dengan 32 codeword ... 8
DAFTAR GAMBAR
Halaman 1 Diagram pengolahan suara ... 12 Sinyal analog ... 2
3 Sinyal diskret ... 2
4 Diagram alur MFCC ... 2
5 Ilustrasi penggunaan codebook ... 4
6 Diagram alur penelitian ... 5
7 Proses pemisahan kata ... 7
8 Akurasi pendeteksian kata ... 7
9 Akurasi pendeteksian kombinasi kata... 8
10 Akurasi pendeteksian kombinasi kata dengan 16 codeword dan 32 codeword ... 9
DAFTAR LAMPIRAN
Halaman 1 Sistem pendeteksian kata ... 122 Akurasi pendeteksian kata dari kombinasi kata “komputer hidup sekarang” dengan 16 codeword ... 12
3 Akurasi pendeteksian kata dari kombinasi kata “komputer hidup sekarang” dengan 32 codeword ... 12
4 Akurasi pendeteksian kata dari kombinasi kata “IPB fakultas MIPA ilmu komputer” 16 codeword ... 13
5 Akurasi pendeteksian kata dari kombinasi kata “IPB fakultas MIPA ilmu komputer” 32 codeword ... 13
6 Akurasi pendeteksian kata dari kombinasi kata “departemen komputer jurusan teknologi komputer” dengan 16 codeword ... 14
7 Akurasi pendeteksian kata dari kombinasi kata “departemen komputer jurusan teknologi komputer” dengan 32 codeword ... 14
1
PENDAHULUAN
Latar BelakangSetiap ucapan oleh manusia memiliki artikulasi yang berbeda-beda. Perbedaan itulah yang dapat menginformasikan kepada pendengar untuk mengetahui kata-kata yang diucapkan oleh pembicara.
Cara pendeteksian kata yang dilakukan oleh komputer sama dengan cara pendengar yang mendapatkan informasi yang diucapkan oleh pembicara. Salah satu contoh aplikasi dari pendeteksian kata yaitu sebagai pencarian menggunakan suara. Pendeteksian kata juga dapat digunakan sebagai kata sandi dalam sistem keamanan (biometric security), pengoperasian komputer menggunakan perintah suara, maupun penekanan tombol telepon dengan suara.
Tahap-tahap yang harus dilewati agar komputer dapat memproses apa yang kita katakan sebagai suatu instruksi atau informasi. Tahap-tahap tersebut terdiri dari digitalisasi sinyal analog, standardisasi suara, penghapusan sinyal suara, pemisahan sinyal suara menjadi sinyal suara yang berupa kata, ekstraksi ciri, dan pengenalan pola untuk klasifikasi.
Pada penelitian ini diimplementasikan sistem pendeteksian kata untuk mengukur akurasi dari setiap kata dengan menggunakan metode Mel Frequency Cepstrum Coefficients
(MFCC) sebagai ekstraksi ciri dan codebook
sebagai pengenalan pola. Penelitian ini juga pernah dilakukan oleh Fazriah (2012) yang mengidentifikasi akurasi pembicara dengan menggunakan metode yang sama, sedangkan pada penelitian ini yang diidentifikasi adalah kata yang terdapat dalam kombinasi kata yang diucapkan oleh pembicara.
Tujuan
Penelitian ini bertujuan untuk mengembangkan sistem pendeteksian kata dengan MFCC sebagai ekstraksi ciri dan
codebook sebagai metode pengenalan polanya agar komputer dapat mengetahui kata yang diucapkan oleh pembicara melalui
microphone dan dapat mendeteksi kata yang terdapat dalam kombinasi kata.
Ruang Lingkup
Ruang lingkup pada penelitian ini adalah: 1 Penelitian difokuskan pada tahapan
pemodelan pendeteksian kata yang diucapkan oleh manusia melalui
microphone.
2 Penelitian ini menggunakan Mel Frequency Cepstrum Coefficients (MFCC) sebagai metode ekstraksi ciri dan
codebook sebagai metode pengenalan pola.
3 Uji kinerja dilakukan untuk menghitung tingkat akurasi pendeteksian kata terhadap
input kata yang diberikan.
TINJAUAN PUSTAKA
Bunyi dan SinyalBunyi adalah gelombang longitudinal yang merambat melalui suatu media. Media atau zat perantara ini dapat berupa zat cair, padat, atau gas. Kebanyakan suara adalah merupakan gabungan berbagai sinyal. Suara murni secara teoritis dapat dijelaskan dengan kecepatan osilasi atau frekuensi yang diukur dalam Hertz (Hz) dan amplitudo, sedangkan pengukuran kedalaman atau intensitas bunyi dalam diukur dalam decibel (dB).
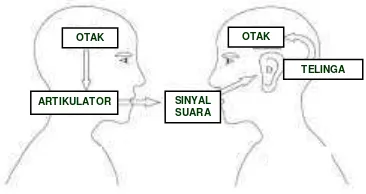
Beberapa tahap dilalui untuk mendapatkan suatu informasi dari suara, dimulai dari otak pembicara yang memikirkan formula kata yang akan diucapkan, kemudian diikuti dengan mekanisme berbicara pada manusia melalui kerjasama hidung dan paru-paru yang menyuplai udara, lidah, bibir dan mulut sebagai artikulator sehingga keluar suara yang merambat melalui media udara, diterima oleh telinga pendengar, kemudian dikirimkan ke otak yang diterjemahkan menjadi suatu informasi (Nilsson dan Ejnarsson 2002). Gambar 1 memberikan ilustrasi tahapan pengolahan suara pada manusia.
Gambar 1 Diagram pengolahan suara Sedangkan sinyal adalah kuantitas fisik yang bervariasi seiring waktu atau variabel bebas lainnya yang menyimpan suatu informasi (Roberts 2004). Secara matematika suatu sinyal dirumuskan sebagai fungsi dari satu atau lebih peubah bebas.
Berdasarkan peubah bebas waktu (t) sinyal dibedakan menjadi dua jenis yaitu:
OTAK
ARTIKULATOR SINYAL SUARA
2
a Sinyal analog
Sinyal analog adalah suatu besaran yang berubah dalam waktu dan atau dalam ruang dan yang mempunyai semua nilai untuk setiap nilai waktu (dan atau setiap nilai ruang). Sinyal analog sering disebut sinyal kontinyu untuk menggambarkan bahwa besaran itu mempunyai nilai yang kontinyu (tak terputus). Contoh grafik sinyal analog disajikan pada Gambar 2.
Gambar 2 Sinyal analog
Sedangkan contoh fungsi sinyal analog:
x(t) = sin (πt), dengan 0 < t < ∞ dengan
x(t) = sinyal analog pada setiap waktu
t = waktu (detik) b Sinyal diskret
Sinyal diskret merupakan suatu besaran yang berubah dalam waktu dan atau dalam ruang dan yang mempunyai nilai pada suatu titik-titik waktu tertentu. Jarak setiap titik waktu bisa saja berbeda-beda, namun untuk kemudahan penurunan sifat matematikanya biasanya jarak antar-titik waktu adalah sama. Contoh grafik sinyal diskret dapat dilihat pada Gambar 3.
Gambar 3 Sinyal diskret
Sinyal diskret ini dapat dibangkitkan dengan cara sampling atau dengan cara mengkumulatifkan sinyal analog dalam suatu selang waktu (Fazriah 2012).
Sampling dan Kuantisasi
Sampling adalah pengamatan sinyal waktu kontinyu (sinyal analog) pada suatu waktu tertentu sehingga diperoleh sinyal waktu diskret. Nilai ini menyatakan amplitudo suara. Hasilnya adalah sebuah vektor yang menyatakan nilai-nilai hasil sampling. Panjang vektor data tergantung panjang atau lamanya suara digitasi dan sampling rate yang digunakan pada proses digitasi. Sampling rate
sendiri adalah banyaknya nilai yang diambil setiap detik. Sampling rate yang biasanya
digunakan adalah 8000 Hz sampai 16000 Hz. Hubungan antara panjang vektor data yang dihasilkan dengan sampling rate dan panjangnya data suara yang didigitasi dapat dinyatakan dengan:
S = Fs * T
dengan
S = panjang vektor Fs = sampling rate (Hertz)
T = panjang suara (detik)
Setelah melalui tahap sampling proses digitalisasi suara selanjutnya adalah kuantisasi. Kuantisasi adalah tahap menyimpan nilai amplitudo ke dalam representasi nilai 8 bit atau 16 bit (Susanto 2006).
Ekstraksi Ciri Sinyal Suara
Ekstraksi ciri merupakan proses menentukan suatu nilai atau vektor yang dapat dipergunakan sebagai penciri objek atau individu. Pada pemrosesan suara, ciri yang biasa dipergunakan adalah nilai koefisien
cepstral dari sebuah frame. Salah satu teknik ekstraksi ciri sinyal suara yang umum dan menunjukan kinerja baik adalah teknik MFCC yang menghitung koefisien cepstral dengan mempertimbangkan persepsi sistem pendengaran manusia terhadap frekuensi suara. Teknik MFCC digunakan karena dapat mempresentasikan sinyal lebih baik dibandingkan dengan LPC, LPCC dan yang lainnya dalam pengenalan suara (Buono et al. 2008).
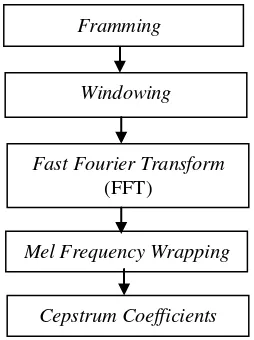
Teknik MFCC sebagai ekstraksi ciri telah banyak digunakan pada berbagai bidang area pemrosesan suara. Gambar 4 menyajikan tahapan teknik MFCC dalam mengekstraksi sinyal suara.
Gambar 4 Diagram alur MFCC t
Framming
Windowing
Fast Fourier Transform
(FFT)
Mel Frequency Wrapping
3
Pada tahapan framming sinyal dibaca dari
frame ke frame dengan nilai overlap tertentu, lalu dilakukan windowing untuk setiap frame
kemudian dilakukan transformasi Fourier untuk mengubah dimensi suara dari domain waktu ke domain frekuensi. Dari hasil transformasi Fourier selanjutnya dihitung spektrum mel menggunakan sejumlah filter yang dibentuk sedemikian sehingga jarak antar pusat filter adalah konstan pada ruang frekuensi mel. Skala mel dibentuk untuk mengikuti persepsi sistem pendengaran manusia yang bersifat linear. Proses ini dikenal dengan Mel Frequency Wrapping. Koefisien MFCC merupakan hasil tranformasi kosinus dari spektrum mel tersebut dan dipilih K koefisien. Tranformasi kosinus berfungsi untuk mengembalikan dari domain frekuensi ke domain waktu (Do 1994).
Tahap-tahap dalam teknik MFCC lebih jelas lagi yakni sebagai berikut:
a Frame Blocking
Untuk keperluan pemrosesan, sinyal analog yang sudah melalui proses sampling
dan kuantisasi (digitalisasi suara) dibaca dari
frame demi frame dengan lebar tertentu yang saling tumpang tindih (overlap). Panjang
frame biasanya 5 sampai 100 milisecond
dengan overlap antar-frame yang berurutan sebanyak 0, 25, 50 atau 75%. Proses ini dikenal dengan frame blocking.
b Windowing
Setiap frame mengandung satu unit informasi, sehingga barisan frame akan menyimpan suatu informasi yang lengkap dari sebuah sinyal suara. Untuk itu, distorsi
antar-frame harus diminimalisasi. Salah satu teknik untuk meminimalkan distorsi antar frame
adalah melakukan proses filtering pada setiap
frame. Secara umum proses filtering ada dua yaitu untuk memisahkan sinyal dari berbagai
noise serta untuk menjernihkan sinyal dari adanya distorsi.
Ada beberapa jenis filter yang dapat digunakan di antaranya Moving Average,
Single Pole, Windowing, Chebyshev, FIR
Custom, dan Iterative Design. Pada penelitian kali ini jenis filter yang digunakan yaitu
Windowing dikarenakan pemrosesan sinyal yang akan dilakukan dalam domain frekuensi.
Proses windowing dilakukan pada setiap
frame untuk meminimalisasi sinyal tak kontinyu pada awal dan akhir masing-masing
frame (Mustofa 2007). Window dinyatakan sebagai w(n),0 ≤ n ≤ N-1, dengan N adalah jumlah sampel dalam masing-masing frame,
x(n) adalah sinyal input dan hasil windowing
adalah y(n).
y(n)= x(n)* w(n), 0 ≤ n≤ N-1
dengan
y(n) = hasil windowing
x(n) = sinyal input w(n) = window n = frame
N = jumlah sampel dalam masing-masing
frame
Fungsi window sendiri terdiri atas beberapa jenis yaitu Daniell, Hamming, Parzen, Pierstly, dan Sasaki yang memiliki formula yang berbeda-beda. Dengan pertimbangan kesederhanaan formula maka penggunaan window Hamming cukup beralasan.
c Tranformasi Fourier (Fourier Transform)
Perbedaan sinyal suara yang berbeda-beda dilihat dari domain frekuensi karena jika dilihat dari domain waktu sulit terlihat perbedaannya. Untuk itu dari sinyal suara yang berada pada domain waktu diubah ke domain frekuensi dengan Fast Fourier Transform (FFT). FFT merupakan suatu algoritme untuk mengimplementasikan Transformasi Fourier Diskret. Perubahan dari domain waktu ke domain frekuensi disebut dengan persamaan analisis yang dapat ditulis sebagai berikut:
∑
-10 =
1
-=
2 -= N kk
e
n
0,1,2,...,
N
X
X
n πkn/N,
dengan
Xk = deretan aperiodik dengan nilai N
N = jumlah sampel
d Mel Frequency Wrapping
Studi psikofisik menunjukkan bahwa persepsi manusia terhadap frekuensi sinyal suara tidak berupa skala linier. Oleh sebab itu, untuk setiap nada dengan frekuensi aktual f
(dalam Hertz) tinggi subjektifnya diukur dengan skala mel (melody). Skala mel-frequency adalah selang frekuensi di bawah 1000Hz dan selang logaritmik untuk frekuensi di atas 1000Hz sehingga pendekatan tersebut dapat digunakan menghitung mel-frequency
4
)]
,
(
jarak
1
=
[
=
min
=
)
,
(
Jarak
∑
,.., 2 , 1 i∀ k
S
t
C
iT
t
S
C
id i2 i1 3d 32 31 2d 22 21 1d 12 11 C C C C C C C C C C C C C
Td T2 T1 3d 32 31 2d 22 21 1d 12 11 f f f f f f f f f f f f Se Tranformasi Kosinus (Discrete Cosine Transform)
Langkah terakhir yaitu mengkonversikan log mel spectrum ke domain waktu. Hasilnya disebut mel frequency cepstrum coefficients.
Representasi cepstral spektrum suara merupakan representasi property spectral local yang baik dari suatu sinyal untuk analisis frame. Mel spectrum coefficients dan logaritmanya berupa bilangan riil, sehingga dapat dikonversikan ke domain waktu dengan menggunakan Discrete Cosine Transform
(DCT) (Do 1994).
Pengenalan Pola dengan Codebook
Pengenalan pola merupakan bidang dalam pembelajaran pada ilmu komputer dan dapat diartikan sebagai "tindakan mengambil data mentah dan bertindak berdasarkan klasifikasi data", salah satu aplikasinya adalah pengenalan suara. Pengenalan pola itu sendiri khususnya berkaitan dengan langkah pengkelasan.
Beberapa metode pengenalan pola yaitu
codebook, jaringan syaraf tiruan, probabilistic neural network, dan hidden markov model. Pada penelitian ini metode yang digunakan adalah metode codebook. Codebook adalah kumpulan titik (vektor) yang mewakili distribusi suara dari sebuah kata tertentu dalam ruang suara. Setiap titik dari codebook
dikenal sebagai codeword. Setiap kata yang sudah direkam dibuat codebook yang terdiri dari beberapa codeword untuk merepresentasikan ciri suara dari kata tersebut (Do 1994).
Prinsip dasar dalam penggunaan
codebook adalah setiap suara yang masuk akan dihitung jaraknya ke setiap codebook yang telah dibuat. Kemudian jarak setiap sinyal suara ke codebook dihitung sebagai jumlah jarak setiap frame sinyal suara tersebut ke setiap codeword yang ada pada
codebook. Kemudian dipilih codeword
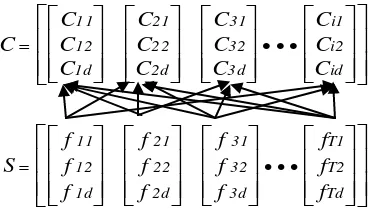
dengan jarak minimum. Setelah itu setiap sinyal suara yang masuk akan diidentifikasi berdasarkan jumlah dari jarak minimum tersebut. Prinsip penggunaan codebook diilustrasikan pada Gambar 5, dengan Codebook dinyatakan dengan C, codeword dengan Cid, sinyal suara baru dengan S, dan panjang frame dalam sinyal S dengan fTd.
Gambar 5 Ilustrasi penggunaan codebook
Perhitungan jarak dilakukan dengan menggunakan jarak euclidean yang dapat dirumuskan sebagai berikut :
dengan
C = codebook S = sinyal suara baru
Ci = codeword ke-i
St = frame sinyal suara baru ke-t
k = codeword
T = panjang frame dalam sinyal suara baru
K-Means Clustering
K-Means merupakan salah satu metode data clustering non-hierarkis yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster/kelompok. Metode ini mempartisi data ke dalam cluster/kelompok sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu
cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok yang lain.
Data clustering menggunakan metode K-Means yang secara umum dilakukan dengan algoritme dasar sebagai berikut :
1 tentukan jumlah cluster;
2 alokasikan data ke dalam cluster secara random;
3 hitung centroid/rata-rata dari data yang ada di masing-masing cluster;
4 alokasikan masing-masing data ke
centroid/rata-rata terdekat;
5 kembali ke tahap 3, apabila masih ada data yang berpindah cluster atau apabila perubahan nilai pada objective function
5
METODOLOGI
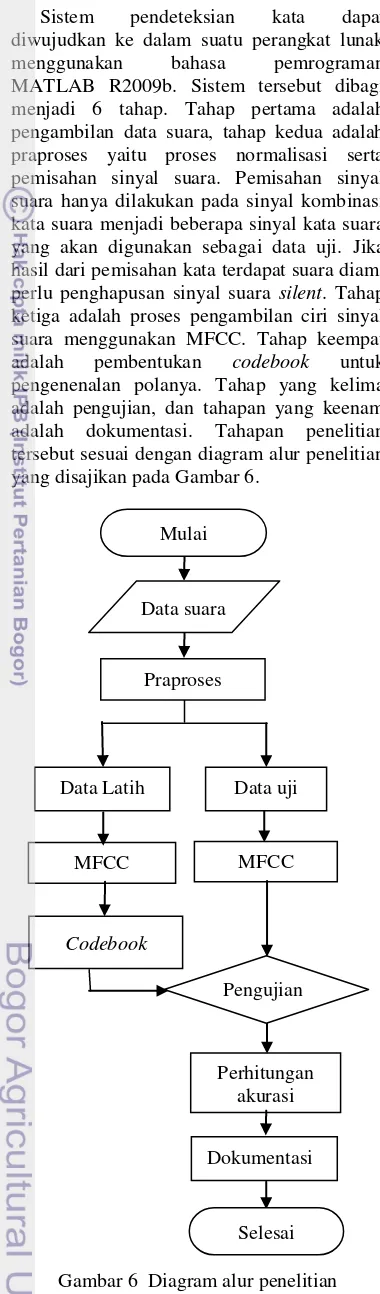
Sistem pendeteksian kata dapat diwujudkan ke dalam suatu perangkat lunak menggunakan bahasa pemrograman MATLAB R2009b. Sistem tersebut dibagi menjadi 6 tahap. Tahap pertama adalah pengambilan data suara, tahap kedua adalah praproses yaitu proses normalisasi serta pemisahan sinyal suara. Pemisahan sinyal suara hanya dilakukan pada sinyal kombinasi kata suara menjadi beberapa sinyal kata suara yang akan digunakan sebagai data uji. Jika hasil dari pemisahan kata terdapat suara diam, perlu penghapusan sinyal suara silent. Tahap ketiga adalah proses pengambilan ciri sinyal suara menggunakan MFCC. Tahap keempat adalah pembentukan codebook untuk pengenenalan polanya. Tahap yang kelima adalah pengujian, dan tahapan yang keenam adalah dokumentasi. Tahapan penelitian tersebut sesuai dengan diagram alur penelitian yang disajikan pada Gambar 6.
Gambar 6 Diagram alur penelitian
Pengambilan Data Suara
Data suara yang digunakan pada penelitian ini adalah 10 macam kata dengan setiap kata dilakukan perekaman sebanyak 60 kali, dengan kata yang digunakan yaitu “komputer”, “hidup”, “sekarang”, “IPB”, “fakultas”, “MIPA”, “departemen”, “jurusan”, “ilmu”, dan “teknologi"; dan 3 macam kombinasi kata yang dilakukan perekaman sebanyak 20 kali, dengan kombinasi kata yang digunakan adalah “komputer hidup sekarang”, “IPB fakultas MIPA ilmu komputer”, dan “departemen komputer jurusan teknologi komputer”, dengan setiap perekaman menggunakan sampling rate 11000Hz. Dengan demikian, data yang dihasilkan adalah 660 rekaman data.
Terdapat perbedaan pada rentang waktu perekaman yaitu untuk pengambilan suara setiap kata, rentang waktu yang digunakan selama 1.5 detik, sedangkan untuk kombinasi kata rentang waktu perekaman selama 1.5 detik dikalikan banyaknya kata pada kombinasi kata tersebut. Hal ini dilakukan karena memerlukan waktu perekaman yang lebih lama.
Praproses
Data suara tersebut harus melalui tahap praproses terlebih dahulu. Tahapan praproses terdiri dari normalisasi sinyal suara, penghapusan silent dan pemisahan sinyal suara. Setiap data suara memiliki nilai range
amplitudo yang berbeda-beda sehingga data suara perlu dinormalisasi terlebih dahulu dengan cara membagi setiap nilai dengan nilai maksimum pada data masing-masing suara agar didapat range nilai amplitudo suara yang sama.
Langkah berikutnya adalah penghapusan
silent yang berfungsi untuk penghapusan bagian suara „diam‟ yang terdapat pada awal dan akhir perekaman suara. Pada tahapan pemisahan sinyal suara hanya dilakukan pada sinyal kombinasi kata suara menjadi beberapa sinyal kata suara. Hasil dari pemisahan sinyal suara tersebut terdapat suara diam diawal atau di akhir sinyal kata, oleh karena itu perlu dilakukan hapus silent kembali, sehingga dihasilkan sinyal yang digunakan untuk data uji.
Data Latih dan Data Uji
Data suara yang digunakan untuk pelatihan yaitu 10 macam kata dengan perulangan setiap kata sebanyak 60 kali sehingga menghasilkan 600 sinyal kata suara.
MFCC MFCC
Codebook
Data Latih Data uji
6
Untuk data pengujian perlu dilakukan pemisahan kata dari kombinasi kata menjadi beberapa kata supaya mempermudah saat pendeteksian kata. Oleh sebab itu, 3 kombinasi kata yang dilakukan perulangan 20 kali menghasilkan 260 sinyal suara.
Proses Ekstraksi Ciri dan Codebook
Data suara yang direkam dan dihapus
silent-nya masih terlalu besar jika diproses untuk pengenalan pola sehingga perlu dilakukan proses ekstraksi ciri. Ekstraksi ciri merupakan proses menentukan suatu nilai atau vektor yang dapat dipergunakan sebagai penciri objek. Pada pemrosesan suara, ciri yang biasa digunakan adalah nilai koefisien
cepstral dari sebuah frame.
Metode ekstraksi ciri yang digunakan pada pada penelitian ini yaitu MFCC. Dengan MFCC, ukuran data yang dihasilkan tidak besar tanpa menghilangkan ciri atau informasi setiap data suara.
Pengujian
Penelitian ini hanya mengamati banyak kata yang terdeteksi dengan baik oleh sistem dan perbedaan pemakaian 16 codebook
dengan 32 codebook.
Dokumentasi
Tahap terahir dari penelitian ini adalah dokumentasi. Data yang didapat dari pengujian dapat dianalisis untuk menempatkan kata yang teridentifikasi dengan tepat dan perbedaan antara pemakaian 16
codebook dan 32 codebook. Dengan demikian diharapkan penggunaan yang tepat akan membuat sistem bekerja secara optimal.
HASIL DAN PEMBAHASAN
Setelah sistem dipersiapkan dan sudah berjalan dengan baik, selanjutnya adalah tahapan pengambilan data untuk data latih dan data uji, pemisahan data suara pada data suara yang akan diujikan, kemudian dilakukan ekstraksi ciri dengan metode MFCC dan
codebook sebagai pengenalan polanya. Pembahasan dari hasil penelitian ini mencakup akurasi pendeteksian dari setiap kata dan akurasi pendeteksian kata menggunakan 16 codeword dan 32 codeword.
Pemisahan Kata
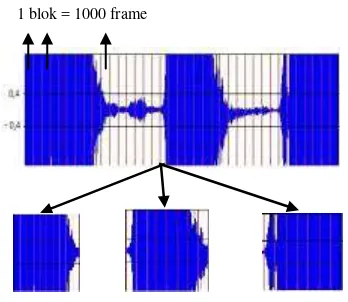
Tahapan pemisahan kata dimulai dengan pengujian setiap blok, yang terdiri atas 1000
frame. Blok frame pertama diuji dengan
amplitudo 0.04 dan -0.04. Apabila terdapat sinyal yang melebihi 0.04 atau kurang dari -0.04, blok tersebut merupakan bagian dari sinyal suara yang digunakan, akan tetapi jika tidak ada yang melebihi 0.04 atau kurang dari -0.04 maka blok tersebut bukan merupakan sinyal suara yang digunakan.
Pengujian tersebut dilakukan pada blok
frame selanjutnya secara berurutan hingga blok yang bukan merupakan sinyal suara. Gabungan blok yang merupakan sinyal suara merupakan 1 buah sinyal suara kata, sedangkan blok yang bukan merupakan sinyal suara akan dihilangkan atau dihapus. Proses tersebut dilakukan kembali setelah terdapat blok frame yang merupakan sinyal suara hingga seluruh sinyal suara, dan menghasilkan beberapa sinyal suara berupa kata. Proses pemisahan kata yang dijelaskan tersebut dapat dilihat pada Gambar 7.
Gambar 7 Proses pemisahan kata Hasil dari tahapan pemisahan kata masih terdapat suara diam di awal dan di akhir blok
frame. Oleh sebab itu, perlu dilakukan penghapusan silent agar sinyal suara yang akan digunakan untuk proses ekstraksi ciri hanya sinyal suara berupa kata.
Ekstraksi Ciri dan Codebook
Pada tahap MFCC, sinyal suara diubah ke dalam suatu matriks yang berukuran jumlah koefisien yang digunakan dikali dengan banyaknya frame suara yang terbentuk. Terdapat 5 parameter yang harus diinput untuk semua data yaitu input suara,
sampling rate, time frame, overlap, dan jumlah cepstral coefficient. Pemilihan nilai untuk time frame adalah 23.7 ms, overlap
50%, dan jumlah koefisien cepstral sebanyak 13 koefisien. Matriks ini menunjukkan ciri
spectral dari sinyal suara.
7
Pada tahap codebook, data yang digunakan adalah data latih yang sudah berupa ciri dari setiap kata yang telah diperoleh pada tahap sebelumnya. Jumlah codeword yang digunakan pada tahap ini yaitu 16 codeword
dan 32 codeword.
Pengujian Sistem Deteksi Kata
Pengujian pada penelitian ini menggunakan 10 kata yaitu “komputer”, “hidup”, “sekarang”, “IPB”, “fakultas”, “MIPA”, “ilmu”, “departemen”, “jurusan”, dan “teknologi”. Kata-kata tersebut didapat dari hasil pemisahan kata menggunakan 3 kombinasi kata yaitu “komputer hidup sekarang”, “IPB fakultas MIPA ilmu komputer”, dan “departemen komputer jurusan teknologi komputer”, dengan setiap kombinasi kata dilakukan perulangan pengambilan suara yang sama sebanyak 20 kali untuk data uji. Selanjutnya, setiap kombinasi kata tersebut perlu melalui proses pemisahan kata sehingga menjadi beberapa kata.
Perhitungan jarak euclidean dilakukan antara ciri dari setiap kata pada data uji dengan 16 codeword atau 32 codeword yang dihasilkan dari data latih, kemudian nilai terendah dari jarak tersebut dideteksi sebagai kata yang benar. Tabel 1 memperlihatkan hasil akurasi pendeteksian kata yang sudah melalui seluruh tahapan penelitian.
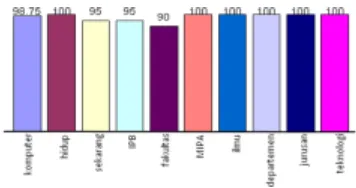
Tabel 1 Akurasi pendeteksian kata
Kata Akurasi
Komputer 99%
Hidup 100%
Sekarang 95%
IPB 95%
Fakultas 90%
MIPA 100%
Ilmu 100%
Departemen 100%
Jurusan 100%
Teknologi 100%
Rata-rata 98%
Dari hasil pengujian tersebut, akurasi kata terendah terdapat pada kata “fakultas” dengan akurasi 90%. Rata-rata dari akurasi seluruh kata adalah 98%. Berdasarkan hasil tersebut dapat dikatakan pendeteksian kata pada penelitian ini mendapatkan akurasi yang baik.
Grafik akurasi pendeteksian kata disajikan pada Gambar 8. Hasil akurasi antar-kata tidak jauh berbeda sehingga dapat dikatakan sample
kata yang digunakan dapat dideteksi oleh sistem dengan baik.
Gambar 8 Akurasi pendeteksian kata Tabel 1 menyajikan akurasi dari setiap kata. Akurasi pendeteksian kata yang sangat baik dengan hasil 100% terdapat pada kata “hidup”, “MIPA”, “ilmu”, “departemen”, “jurusan”, dan “teknologi”. Untuk kata komputer ditempatkan pada 3 kombinasi kata dengan urutan posisi kata yang berbeda yaitu
“komputer hidup sekarang” dengan
“komputer” terdapat pada posisi pertama, “IPB fakultas MIPA ilmu komputer” dengan “komputer” terdapat pada posisi kata kelima, dan “departemen komputer jurusan teknologi komputer” dengan “komputer” terdapat pada posisi kata kedua dan kelima. Hasil rata-rata persentase akurasi pendeteksian kata “komputer” yaitu 99%. Pengujian kata “komputer” tersebut dimaksudkan untuk mengetahui akurasi pendeteksian kata apabila kata yang sama ditempatkan pada posisi kombinasi yang berbeda.
Tabel 2 Akurasi pendeteksian kata pada kombinasi kata “komputer hidup sekarang” dengan 16 codeword
Kata Akurasi
Komputer 95%
Hidup 100%
Sekarang 95%
Rata-rata 97%
Tabel 3 Akurasi pendeteksian kata pada kombinasi kata “IPB fakultas MIPA
ilmu komputer” dengan 16
codeword
Kata Akurasi
IPB 95%
Fakultas 90%
MIPA 100%
Ilmu 100%
Komputer 100%
8
Tabel 4 Akurasi pendeteksian kata pada
kombinasi kata “departemen
komputer jurusan teknologi komputer” dengan 16 codeword
Kata Akurasi
Departemen 100%
Komputer 100%
Jurusan 100%
Teknologi 100%
Komputer 100%
Rata-rata 100%
Tabel 2 menunjukkan bahwa kombinasi “komputer hidup sekarang” dengan hasil akurasi adalah 97%. Akurasi tersebut didapat dengan perekaman data uji sebanyak 20 kali. Setiap kata yang telah melalui proses pemisahan kata mendapatkan hasil akurasi “komputer” = 95%, “hidup” = 100%, dan “sekarang” = 95%. Tabel 3 dengan kombinasi “IPB fakultas MIPA ilmu komputer” memiliki akurasi 97%, dan hasil setiap kata dari kombinasi tersebut adalah “IPB” = 95%, “fakultas” = 90%, “MIPA” = 100%, “ilmu” = 100%, dan “komputer” = 100%. Tabel 4 dengan kombinasi kata “departemen komputer jurusan teknologi komputer” mendapatkan hasil akurasi sebesar 100%, dengan rincian kata “departemen” = 100%, “komputer” posisi pertama = 100%, “jurusan” = 100%, “teknologi” = 100%, dan “komputer” posisi kelima = 100%.
Hasil akurasi dari setiap kombinasi kata di atas menjelaskan bahwa banyaknya kata dalam kombinasi kata tidak mempengaruhi hasil akurasi kombinasi kata. Hal tersebut digambarkan pada Gambar 9, akurasi dari setiap kombinasi kata dengan kombinasi kata pertama dengan 3 kata, kombinasi kedua dengan 5 kata dan kombinasi kata ketiga dengan 5 kata menghasilkan akurasi yang tidak jauh berbeda.
Gambar 9 Akurasi pendeteksian kombinasi kata.
Gambar 9 menjelaskan tidak adanya perbedaan akurasi deteksi yang jauh dari setiap kombinasi kata. Sesuai hasil grafik
tersebut pendeteksian terbaik pada kombinasi ketiga yaitu “departemen komputer jurusan teknologi komputer” dengan akurasi pendeteksian sebesar 100%. Hasil pendeteksian dari seluruh kombinasi terdapat kesalahan pendeteksian sebesar 2.2%, maka dapat dikatakan akurasi kombinasi kata adalah baik.
Pengujian kombinasi kata pada Tabel 2, 3, dan 4 menggunakan 16 codeword masih terdapat kesalahan pendeteksian sebesar 2.2%, maka perlu pembanding dengan menggunakan 32 codeword untuk mengetahui akurasi pendeteksian kata yang lebih baik. Agar perbandingan antar-codeword akurat, data uji yang digunakan pada penelitian 32 codeword
sama dengan data uji yang digunakan pada 16
codeword. Dapat dilihat pada Tabel 5, 6, dan 7 menunjukkan hasil akurasi dari setiap kata dan kombinasi kata dengan menggunakan 32
codeword.
Tabel 5 Akurasi pendeteksian kata pada kombinasi kata “komputer hidup sekarang” dengan 32 codeword
Kata Akurasi
Komputer 95%
Hidup 100%
Sekarang 90%
Rata-rata 95%
Tabel 6 Akurasi pendeteksian kata pada kombinasi kata “IPB fakultas MIPA
ilmu komputer” dengan 32
codeword
Kata Akurasi
IPB 95%
Fakultas 80%
MIPA 100%
Ilmu 100%
Komputer 100%
Rata-rata 95%
Tabel 7 Akurasi pendeteksian kata pada kombinasi kata “departemen komputer jurusan teknologi komputer” dengan 32 codeword
Kata Akurasi
Departemen 100%
Komputer 100%
Jurusan 100%
Teknologi 100%
Komputer 100%
9
Pada data akurasi yang disajikan pada tabel-tabel tersebut, hasil akurasi kata dengan menggunakan 16 codeword lebih baik dibandingkan dengan menggunakan 32
codeword. Selain hal tersebut, 32 codeword
banyak memerlukan waktu pengujian yang lebih lama. Gambar 10 memperlihatkan hasil akurasi perbandingan antara 16 codeword
dengan 32 codeword dari 3 kombinasi kata.
Gambar 10 Akurasi pendeteksian kombinasi kata dengan 16 codeword dan 32 codeword.
Kombinasi kata “komputer hidup
sekarang” akurasi yang dihasilkan dengan 16 codeword yaitu 97% dan 32 codeword yaitu 95%, perbedaan hasil tersebut terdapat pada kata “sekarang”, sedangkan pada kombinasi kata “IPB Fakultas MIPA Ilmu Komputer” akurasi pada 16 codeword yaitu 97% dan pada 32 codeword adalah 95%. Pengujian terakhir yaitu pada kombinasi kata “departemen komputer jurusan teknologi komputer” mendapat hasil yang sama dengan menggunakan 16 codeword dan 32 codeword
sebesar 100%. Berdasarkan pengujian yang dilakukan, dapat dikatakan pendeteksian kata menggunakan 16 codeword lebih baik dibandingkan dengan menggunakan 32
codeword.
KESIMPULAN DAN SARAN
KesimpulanBerdasarkan hasil analisis yang dilakukan pada penelitian ini, kesimpulan yang diperoleh adalah sebagai berikut:
1 Teknik MFCC dengan metode pengenalan pola menggunakan codebook
telah berhasil diimplementasikan dalam mengenali kata dengan rata-rata persentase adalah 98%.
2 Penelitian ini telah berhasil mengembangkan sistem pendeteksian kata yang memiliki jeda waktu pengucapan kata.
3 Pendeteksian kata dengan teknik MFCC dengan metode codebook sebagai pengenalan polanya lebih baik menggunakan 16 codeword dibandingkan dengan 32 codeword.
4 Posisi kata yang terdapat di dalam kombinasi kata tidak mempengaruhi akurasi pengenalan kata.
Saran
Untuk terus mengembangkan penelitian ini, ada beberahal yang dapat dilakukan saran sebagai berikut:
1 Penelitian ini dapat menjadi dasar bagi pengembangan sistem pencarian dengan menggunakan suara.
2 Dapat dilakukan pengembangan sistem dengan teknik berbeda sehingga menghasilkan akurasi pendeteksian kata yang lebih baik.
3 Dapat dikembangkan untuk membangun sistem pendeteksian kata dengan menambahkan imbuhan kata.
4 Dapat dilakukan pengembangan sistem pendeteksian kata tanpa atau dengan sedikit jeda waktu pengucapan antar-kata.
DAFTAR PUSTAKA
Buono A, Ramadhan A, Ruvinna. 2008. Pengenalan kata berbahasa Indonesia dengan hidden markov model (HMM) menggunakan Baum-Welch. Jurnal Ilmiah Ilmu Komputer, (6): 2.
Do MN. 1994. DSP (digital signal processing) mini project: An automatic speaker recognition system [internet]. http://ifp.illinois.edu/~minhdo/teaching/ speake_recognition/speaker_recognition. doc [15 Jun 2009].
Fazriah. 2012. Identifikasi pembicara dengan MFCC sebagai ekstraksi ciri dan
codebook untuk pengenalan pola [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Mustofa A. 2007. Sistem pengenalan penutur dengan metode mel-frequency wrapping. Jurnal Teknik Elektro, 7(2):88-92. Nilsson M, Ejnarsson M. 2002. Speech
recognition using hidden markov model [tesis]. Sweden: Blekinge Institute of Technology.
10
11
12
Lampiran 1 Sistem pendeteksian kata
Lampiran 2 Akurasi pendeteksian kata dari kombinasi kata “komputer hidup sekarang” dengan 16
codeword
Data Latih
Data Uji Komputer Hidup Sekarang MIPA
Komputer 19 0 0 1
Hidup 0 20 0 0
Sekarang 1 0 19 0
Lampiran 3 Akurasi pendeteksian kata dari kombinasi kata “komputer hidup sekarang” dengan 32
codeword
Data Latih
Data Uji Komputer Hidup Sekarang Fakultas
Komputer 19 0 0 1
Hidup 0 20 0 0
13
Lampiran 4 Akurasi pendeteksian kata dari kombinasi kata “IPB fakultas MIPA ilmu komputer” dengan16 codeword
Lampiran 5 Akurasi pendeteksian kata dari kombinasi kata “IPB fakultas MIPA ilmu komputer” dengan 32 codeword
Data Latih
Data Uji IPB Fakultas MIPA Ilmu Komputer Hidup
IPB 19 0 0 0 0 1
Fakultas 0 18 0 0 2 0
MIPA 0 0 20 0 0 0
Ilmu 0 0 0 20 0 0
Komputer 0 0 0 0 20 0
Data Latih
Data Uji IPB Fakultas MIPA Ilmu Komputer Hidup
IPB 19 0 0 0 0 1
Fakultas 0 16 0 0 4 0
MIPA 0 0 20 0 0 0
Ilmu 0 0 0 20 0 0
14
Lampiran 6 Akurasi pendeteksian kata dari kombinasi kata “departemen komputer jurusan teknologi komputer” dengan 16 codeword
Data Latih
Data Uji Departemen Komputer Jurusan Teknologi Komputer
Departemen 20 0 0 0 0
Komputer 0 20 0 0 0
Jurusan 0 0 20 0 0
Teknologi 0 0 0 20 0
Komputer 0 0 0 0 20
Lampiran 7 Akurasi pendeteksian kata dari kombinasi kata “departemen komputer jurusan teknologi komputer” dengan 32 codeword
Data Latih
Data Uji Departemen Komputer Jurusan Teknologi Komputer
Departemen 20 0 0 0 0
Komputer 0 20 0 0 0
Jurusan 0 0 20 0 0
Teknologi 0 0 0 20 0