SISTEM PENDETEKSI PLAGIAT HARFIAH PADA
DOKUMEN TEKS BERBAHASA INDONESIA
DENGAN MEMANFAATKAN
MESIN PENCARI
FUAD DAVIRATMA HUSNI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Sistem Pendeteksi Plagiat pada Dokumen Teks Berbahasa Indonesia dengan Memanfaatkan Mesin Pencari adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2013
Fuad Daviratma Husni
ABSTRAK
FUAD DAVIRATMA HUSNI. Sistem Pendeteksi Plagiat Harfiah pada Dokumen Teks Berbahasa Indonesia dengan Memanfaatkan Mesin Pencari. Dibimbing oleh AHMAD RIDHA.
Mesin pencari dapat dimanfaatkan untuk mendeteksi plagiat karena mesin pencari adalah salah satu pintu gerbang untuk mendapatkan dokumen sumber plagiat. Penelitian ini bertujuan untuk membentuk korpus dokumen plagiat dan membuat sistem pendeteksi plagiat dengan memanfaatkan mesin pencari. Korpus dokumen plagiat dibuat dengan menyalin 1-3 dokumen sumber dan merestrukturisasi dokumen sumber dengan menerjemahkan bolak-balik menggunakan Google Translate. Korpus dokumen plagiat terdiri atas 100 dokumen. Teks diekstraksi menjadi segmen-segmen yang terdiri atas 4-20 kata. Segmen-segmen tersebut diboboti berdasarkan ada tidaknya kata dalam kamus dengan bobot lebih besar diberikan pada kata yang tidak ada dalam kamus. Penelitian ini berhasil mendeteksi 100% korpus dokumen plagiat dengan maksimal 31% segmen dokumen dan memanfaatkan mesin pencari Google, sedangkan dengan mesin pencari Bing, penggunaan hingga 40% segmen dokumen hanya berhasil mendeteksi 30% korpus dokumen plagiat. Hasil penelitian ini menunjukkan hasil deteksi plagiat tergantung pada kualitas hasil pencarian yang dilakukan mesin pencari.
Kata kunci: deteksi plagiat, mesin pencari, segmentasi
ABSTRACT
FUAD DAVIRATMA HUSNI. Literal Plagiarism Detection System for Indonesian Text Document Using Search Engine. Supervised by AHMAD RIDHA.
Search engines can be used to detect plagiarism because search engines are one of the gateways to get source documents. This research aims to establish a corpus of document plagiarism and develops a system that can detect plagiarism by utilizing search engines. The corpus is created by copying passages from 1-3 source documents and restructuring the source documents by translating back and forth with Google Translate. The corpus consists of 100 documents. The documents are extracted into segments consisting of 4-20 words. The segments will be weighted based on the words existence in Indonesian dictionary where words not found in dictionary are given higher weights. Using Google’s search engine, this study successfully detects 100% of the plagiarized documents using only a maximum of 31% segments. On the other hand, using Bing and 40% segment documents only detects 30% of the corpus. The results of this study show that the performance of online plagiarism detection depends on the quality of the search results provided by search engines.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
SISTEM PENDETEKSI PLAGIAT HARFIAH PADA
DOKUMEN TEKS BERBAHASA INDONESIA
DENGAN MEMANFAATKAN
MESIN PENCARI
FUAD DAVIRATMA HUSNI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Sistem Pendeteksi Dokumen Plagiat Harfiah pada Dokumen Teks Berbahasa Indonesia dengan Memanfaatkan Mesin Pencari Nama : Fuad Daviratma Husni
NIM : G64104002
Disetujui oleh
Ahmad Ridha, SKom MS Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan karya ilmiah ini. Topik pada penelitian ini adalah Pendeteksian Plagiat dengan Mesin Pencari.
Terima kasih penulis ucapkan kepada bapak Ahmad Ridha, SKom MS selaku pembimbing. Terima kasih juga penulis ucapkan kepada ayah, ibu, istri serta seluruh keluarga, atas segala doa dan kasih sayangnya.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 1
Ruang Lingkup Penelitian 2
METODE 2
Dokumen Uji 2
Praproses Dokumen 4
Segmentasi Dokumen 4
Pembobotan Segmen dan Pemeringkatan Segmen 5
Pencarian Online 6
Pencatatan dan Identifikasi Alamat 6
Ekstraksi Dokumen Sumber dan Dokumen Uji 7
Perhitungan Jarak 7
Perhitungan Akurasi 8
HASIL DAN PEMBAHASAN 8
Pembentukan Korpus Dokumen Uji 8
Praproses Dokumen Uji dan Dokumen Sumber 10
Segmentasi Dokumen 10
Pembobotan dan Pemeringkatan Segmen 11
Pencarian Online 11
Pencatatan dan Identifikasi Alamat 12
Perhitungan Jarak 13
Akurasi Deteksi Plagiat 14
SIMPULAN DAN SARAN 16
Simpulan 16
Saran 16
LAMPIRAN 17
DAFTAR TABEL
1 Nilai kesamaan kosinus dokumen uji dengan sumber plagiat 9
2 Hasil segmentasi dokumen uji 10
3 Hasil pencarian Google 11
4 Hasil pencarian Bing 12
5 Perbandingan hasil kesamaan kosinus maksimum dokumen uji dengan
cara identifikasi alamat dokumen sumber 12
6 Hasil rata-rata deteksi plagiat dengan 40% segmen dan mesin pencari
Google 13
7 Hasil rata-rata deteksi plagiat dengan 40% segmen dan mesin pencari
Bing 13
8 Waktu rata-rata pendeteksian plagiat dengan 40% segmen (detik)
dengan mesin pencari Google 15
9 Waktu rata-rata pendeteksian plagiat dengan 40% segmen (detik)
dengan mesin pencari Bing 15
DAFTAR GAMBAR
1 Aliran sistem deteksi plagiat 2
2 Metode penelitian 3
3 Penggunaan segmen sebagai kueri dan akurasi deteksi plagiat dengan
Google 14
DAFTAR LAMPIRAN
1 Dokumen uji 18
2 Rata-rata kesamaan dokumen uji dengan satu dokumen sumber 19 3 Rata-rata kesamaan dokumen uji dengan lebih dari satu dokumen
sumber 20
4 Hasil segmentasi dokumen uji dengan satu dokumen sumber 21 5 Hasil segmentasi dokumen uji dengan lebih dari satu dokumen sumber 22 6 Hasil deteksi plagiat dengan mesin pencari Google (dokumen uji jenis
hampir sama persis) 23
7 Hasil deteksi plagiat dengan mesin pencari Google (dokumen uji jenis
gabungan berbagai sumber) 24
8 Hasil deteksi plagiat dengan mesin pencari Google (dokumen uji jenis
sedikit bagian sumber) 25
9 Hasil deteksi plagiat dengan mesin pencari Google (dokumen uji jenis
restrukturisasi) 26
10 Hasil deteksi plagiat dengan mesin pencari Bing (dokumen uji jenis
hampir sama persis) 27
11 Hasil deteksi plagiat dengan mesin pencari Bing (dokumen uji jenis
gabungan berbagai sumber) 28
12 Hasil deteksi plagiat dengan mesin pencari Bing (dokumen uji jenis
13 Hasil deteksi plagiat dengan mesin pencari Bing (dokumen uji jenis
restrukturisasi) 30
14 Waktu deteksi plagiat dokumen uji jenis hampir sama persis dengan
mesin pencari Google (detik) 31
15 Waktu deteksi plagiat dokumen uji jenis gabungan beberapa sumber
dengan mesin pencari Google (detik) 32
16 Waktu deteksi plagiat dokumen uji jenis sedikit bagian sumber dengan
mesin pencari Google (detik) 33
17 Waktu deteksi plagiat dokumen jenis restrukturisasi dengan mesin
pencari Google (detik) 34
18 Waktu deteksi plagiat dokumen uji jenis hampir sama persis dengan
mesin pencari Bing (detik) 35
19 Waktu deteksi plagiat dokumen uji jenis gabungan beberapa sumber
dengan mesin pencari Bing (detik) 36
20 Waktu deteksi plagiat dokumen uji jenis sedikit bagian sumber dengan
mesin pencari Bing (detik) 37
21 Waktu deteksi plagiat dokumen jenis restrukturisasi dengan mesin
PENDAHULUAN
Latar Belakang
Kemajuan teknik mesin pencari memudahkan orang-orang dalam mencari apa yang mereka inginkan di internet. Di sisi lain, kesempatan untuk melakukan plagiat meningkat drastis jika orang-orang memanfaatkan mesin pencari dengan tidak semestinya. Skenario khas plagiat adalah seseorang melakukan pencarian di mesin pencari dan kemudian melakukan copy-paste tanpa memahami bahan yang diambil untuk menyelesaikan tugas mereka (Liu et al. 2007). Hal ini merupakan kesalahan yang sering dilakukan oleh orang-orang terutama saat waktu yang dimiliki untuk menyelesaikan tugas tinggal sedikit.
Keseriusan masalah plagiarisme di kalangan akademisi ditunjukkan oleh hasil penelitian Honig dan Bedi (2012) dengan memeriksa 279 makalah yang disajikan di International Management Division pada Academy of Management Conference 2009. Hasil penelitian menunjukkan bahwa 25% dari sampel merupakan hasil plagiarisme, dan lebih dari 13% menunjukkan plagiarisme yang signifikan.
Berdasarkan perilaku plagiator, plagiat dibagi menjadi dua bagian yaitu plagiat harfiah dan plagiat kecerdasan. Plagiat harfiah adalah yang umum dilakukan dan dalam praktiknya si plagiator tidak menghabiskan banyak waktu untuk melakukan plagiat, sedangkan plagiat kecerdasan adalah mengakui kontribusi orang lain sebagai kontribusi si plagiator. Plagiat harfiah terbagi atas plagiat sama persis, mendekati persis, dan restrukturisasi, sedangkan plagiat kecerdasan terbagi atas manipulasi teks, terjemah, dan adopsi ide (Alzahrani et al.
2011).
Plagiat harfiah dapat dideteksi dengan menggunakan sistem. Sistem untuk melakukan deteksi plagiat terdapat dua jenis, yaitu sistem pendeteksi online dan sistem pendeteksi offline (Mozgovoy 2006). Mozgovoy mengungkapkan bahwa sistem pendeteksi online masih sulit untuk dilakukan karena butuh banyak waktu dan perbandingan dokumen tetap dilakukan dengan sistem offline. Oleh sebab itu, penelitian ini bermaksud untuk membuat sistem pendeteksi plagiat harfiah online
menjadi lebih mudah. Adanya sistem pendeteksi plagiat dengan memanfaatkan mesin pencari diharapkan dapat menghemat waktu dan tenaga yang digunakan jika dibandingkan dengan pendeteksian plagiat secara manual menggunakan mesin pencari.
Tujuan Penelitian
Penelitian ini bertujuan:
1 Membentuk korpus dokumen plagiat harfiah untuk bahasa Indonesia
2 Membuat sistem pendeteksi plagiat harfiah untuk dokumen teks bahasa Indonesia dengan mesin pencari
2
Gambar 1 Aliran sistem deteksi plagiat Ruang Lingkup Penelitian
Ruang lingkup dari penelitian ini adalah 1 Bahasa yang digunakan adalah bahasa Indonesia 2 Jenis plagiat yang dideteksi adalah plagiat harfiah 3 Mesin pencari yang digunakan adalah Google dan Bing 4 Ekstraksi teks tidak memperhatikan format asli
METODE
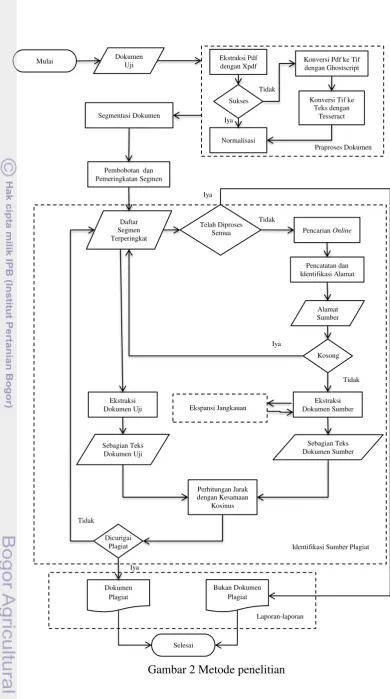
Penelitian Liu et. al. (2011) menggunakan suatu aliran deteksi plagiat yang dapat dilihat pada Gambar 1 untuk mendeteksi suatu dokumen plagiat. Aliran sistem pendeteksi plagiat pada penelitian Liu et al. (2011) diadopsi menjadi metode pada penelitian ini (lihat Gambar 2). Terdapat 4 proses inti dalam aliran tersebut, yaitu (a) ekstraksi segmen atau potongan kata dari dokumen uji (dokumen yang ingin diketahui plagiat atau tidak), (b) pemeringkatan segmen sesuai dengan bobotnya, (c) identifikasi sumber plagiat untuk menentukan apakah dokumen uji plagiat atau tidak, dan (d) ekspansi jangkauan sebagai pilihan proses dalam mendapatkan dokumen sumber yaitu dokumen yang dicurigai adalah dokumen sumber plagiat dari dokumen uji.
Dokumen Uji
3
Gambar 2 Metode penelitian
Segmentasi Dokumen
4
Praproses Dokumen
Pada tahap ini dilakukan ekstraksi teks dan normalisasi dokumen. Ekstraksi dokumen teks format PDF menggunakan aplikasi Xpdf (GCL 2011). Namun, ada pula dokumen yang tidak dapat diekstrak dengan Xpdf karena terproteksi. Jika dokumen terproteksi, maka dilakukan rekognisi karakter optik dengan cara mengkonversikan dokumen menjadi dokumen format TIFFmenggunakan aplikasi Ghostscript (ASI 2012) dan mengkonversikan dokumen format TIFF menjadi dokumen teks dengan aplikasi Tesseract-ocr. Aplikasi Tesseract-ocr adalah mesin rekognisi karakter optik yang dikembangkan di Google saat ini (Google 2011).
Penggunaan Ghostscript dilakukan dengan perintah “gs dBATCH
-dNOPAUSE -sDEVICE=tiffg4 -r600x600 -sPAPERSIZE=a4
-sOutputFile=namafilebaru.tif namafile.pdf”. Opsi dnopause dan
dbatch digunakan supaya interaksi dengan pengguna ditiadakan dan tidak berhenti saat akhir setiap halaman. Opsi sdevice dengan tiffg4 berarti dokumen dikonversikan menjadi jenis dokumen gambar TIFF hitam putih. Opsi r600x600 berarti resolusi dokumen gambar yang diinginkan adalah 600x600 dpi. Opsi spapersize dengan a4 berarti dokumen gambar dibuat seukuran kertas A4 (Artofcode 2002). Setelah dokumen berhasil dikonversikan menjadi dokumen gambar TIFF, dokumen gambar TIFF akan dikonversikan menjadi dokumen teks menggunakan Tesseract-ocr dan dapat diekstrak teksnya.
Daftar pustaka tidak termasuk teks yang diperiksa karena yang menjadi acuan dalam pemeriksaan plagiat adalah bagian sebelumnya. Daftar pustaka tidak disertakan karena dapat menyebabkan kesalahan saat melakukan deteksi plagiat. Dokumen dengan topik yang sama meskipun bukan plagiat dapat memiliki daftar pustaka yang mirip sehingga akan terdeteksi sebagai plagiat. Daftar pustaka
dihilangkan dengan cara memotong teks yang diawali “DAFTAR PUSTAKA” atau “REFERENSI” atau “BIBLIOGRAFI” pada 80% bagian akhir dokumen.
Pemilihan pemotongan pada 80% bagian akhir dokumen bertujuan untuk tidak memotong teks pada daftar isi yang dapat menghilangkan isi dokumen.
Tahap berikutnya adalah normalisasi dokumen teks. Langkah-langkah yang dilakukan adalah dengan membuang karakter selain tanda petik tunggal, titik, angka dan huruf, dan spasi yang lebih dari 1. Langkah-langkah ini dilakukan untuk mendapatkan teks dengan kata-kata tanpa ada simbol atau tanda baca lain selain titik. Tanda baca titik tidak dihilangkan karena diperlukan pada segmentasi dokumen.
Segmentasi Dokumen
Metode deteksi plagiat dengan pendekatan segmentasi diperkenalkan Liu et al. (2012) dengan alasan utama yaitu waktu yang dimiliki plagiator untuk memeriksa dan mengubah setiap kalimat dalam dokumen hanya sedikit. Oleh sebab itu, kalimat yang tidak diubah dapat dengan mudah diidentifikasi sebagai plagiat. Oleh sebab itu, cukup diambil beberapa bagian saja untuk diperiksa.
5 1 spasi. Batasan jumlah kata yang baik untuk segmen adalah 20 kata. Oleh sebab itu, jumlah kata maksimum yang diterima adalah 20 kata. Jumlah minimum kata yang diterima adalah 5 kata karena jumlah kata yang terlalu sedikit kurang baik untuk menemukembalikan dokumen yang relevan (Fathi 2012). Algoritme untuk mengimplementasikan aturan segmentasi dokumen adalah seperti berikut
1
AT = daftar teks yang dipisahkan ". " countAT = jumlah teks dalam AT
ctx = 0
for( ctx < countAT ){
array_kata = daftar kata pada array teks ke-'ctx' jumlah_kata = jumlah kata pada array_kata
if ( jumlah_kata > 20 ) {
daftar_segmen <- AT ke-[ctx] }
ctx = ctx + 1 }
Pembobotan Segmen dan Pemeringkatan Segmen
Pada penelitian ini dilakukan pembobotan kata yang berguna untuk pembobotan segmen. Pembobotan kata dilakukan dengan ketentuan sebagai berikut.
1 Kata yang terdapat di kamus diberikan nilai bobot 1 2 Kata yang berupa angka diberikan nilai bobot 1
3 Kata yang merupakan bahasa Indonesia dengan awalan “di” diberikan nilai
Kamus bahasa Indonesia yang digunakan pada penelitian ini adalah Kamus Besar Bahasa Indonesia edisi III. Ketentuan (1), (2), dan (3) hanya diberikan bobot 1 karena kata tersebut terdapat pada bahasa Indonesia. Ketentuan (2) dan (3) perlu dibuat terpisah dari ketentuan (1) karena pada kamus bahasa Indonesia tidak terdapat kata dengan awalan di. Ketentuan (4) dilakukan supaya semakin panjang kata yang tidak terdapat pada bahasa Indonesia, maka semakin tinggi bobotnya dan akan menjadikan kata tersebut lebih menentukan bobot segmen.
6
Pemeringkatan segmen perlu dilakukan karena tidak semua segmen perlu digunakan pada pencarian online. Penelitian Butakov dan Shcherbinin (2009) mendapatkan fakta bahwa 5% segmen cukup untuk menilai apakah suatu dokumen plagiat atau tidak. Penggunaan lebih dari 40% segmen tidak meningkatkan hasil pendeteksian dokumen plagiat. Oleh sebab itu, segmen yang digunakan pada penelitian ini dibatasi maksimal 40%.
Pencarian Online
Pencarian online adalah pencarian pada mesin pencari untuk mendapatkan daftar alamat serta cuplikan masing-masing hasil pencarian. Alamat serta cuplikan yang diambil maksimal 10 peringkat teratas pencarian. Pencarian online akan berhenti jika dokumen terdeteksi plagiat atau semua segmen yang ditetapkan sebagai kueri telah diproses namun dokumen belum terdeteksi plagiat. Pencarian
online dengan mesin pencari Google menggunakan True Google Search (Technofreak 2012), sedangkan pencarian online dengan mesin pencari Bing menggunakan Bing Search API (Microsoft 2012).
Pencarian online dengan mesin pencari mengambil hasil pencarian yang telah disesuaikan untuk negara Indonesia. Penyesuaian pada mesin pencari
Google menggunakan domain Indonesia yaitu “.co.id” sedangkan pada mesin
pencari Bing menggunakan parameter pasar Indonesia yaitu “en-ID”.
Pencatatan dan Identifikasi Alamat
Pencarian online akan menghasilkan daftar alamat dan cuplikan. Alamat dan cuplikan akan dicatat beserta segmen yang menjadi kueri. Selain itu, frekuensi kemunculan suatu alamat juga dicatat terpisah.
Identifikasi alamat adalah tahap untuk mendapatkan alamat dokumen yang harus diperiksa selanjutnya. Alamat diidentifikasi berdasarkan (1) frekuensi kemunculan suatu alamat dokumen (2) atau kemunculan kata segmen kueri pada cuplikan hasil pencarian online. Ketentuan (1) dilakukan dengan cara mendapatkan alamat yang telah tercatat lebih dari 1. Ketentuan (2) dilakukan dengan cara mendapatkan alamat yang cuplikannya memiliki minimal 70% kata pada kueri dan maksimal hanya 30% kata di cuplikan alamat tersebut yang tidak terdapat pada kueri. Ketentuan (1) dilakukan karena jika suatu alamat ada pada hasil pencarian dengan kueri berbeda maka dokumen pada alamat tersebut memiliki kemungkinan keterkaitan dengan dokumen uji, sehingga perlu dilakukan pemeriksaan. Ketentuan (2) dilakukan karena suatu cuplikan memiliki minimal 70% kata yang sama dan maksimal hanya 30% kata yang berbeda memiliki kemungkinan kesamaan yang tinggi. Oleh sebab itu, pemeriksaan tidak harus menunggu ketentuan (1) melainkan dapat langsung melakukan pemeriksaan antara dokumen uji dan dokumen sumber.
7 Ekspansi Jangkauan
Ekspansi jangkauan adalah tahap yang dilakukan ketika suatu alamat telah dirujuk sebelumnya. Sistem tidak perlu melakukan pengunduhan ulang untuk mendapatkan dokumen sumber yang mempengaruhi kecepatan proses deteksi. Ekstraksi dokumen sumber cukup mengambil dokumen yang telah diunduh sebelumnya jika alamat tersebut telah dirujuk.
Ekstraksi Dokumen Sumber dan Dokumen Uji
Setelah mendapatkan daftar alamat, dokumen pada daftar alamat akan diunduh dan diproses seperti dokumen uji untuk pengambilan teks. Selanjutnya dokumen sumber disegmentasi dengan aturan yang sama dengan dokumen uji.
Setiap segmen pada dokumen sumber akan diberikan bobot berdasarkan banyaknya kata pada kueri yang terdapat pada segmen dokumen sumber. Banyaknya kata yang sama tidak diperhatikan untuk pembobotan segmen. Segmen dengan bobot terbesar atau dengan kemunculan kata terbanyak akan dijadikan acuan untuk mengekstraksi sebagian teks dokumen sumber.
Sebagian teks dokumen sumber yang diambil adalah minimal 20 kata sebelum dan setelah segmen acuan serta segmen acuan tersebut. Pengambilan teks dilakukan dengan mengambil teks sebelum dan sesudahnya hingga memenuhi ketentuan minimal 20 kata atau hingga segmen terakhir yang tersedia jika tidak memenuhi ketentuan minimal 20 kata. Ekstraksi pada dokumen uji juga mengambil minimal 20 kata sebelum dan setelah segmen kueri serta segmen kueri. Pembatasan minimal 20 kata ini dilakukan supaya dapat mendeteksi suatu dokumen yang hanya memiliki sedikit teks plagiat.
Ekstraksi dokumen sumber dan dokumen uji menghasilkan dua teks yaitu sebagian teks dokumen uji dan sebagian teks dokumen sumber. Kedua teks ini akan menjadi penentu apakah dokumen uji memplagiat dokumen sumber.
Perhitungan Jarak
Langkah selanjutnya adalah membandingkan sebagian teks dokumen uji dan dokumen sumber. Metode untuk menghitung kesamaan sebagian teks dokumen menggunakan ukuran kesamaan kosinus dengan pembobotan yang dilakukan dengan aturan (Manning et al. 2009)
{
Asumsikan adalah bobot suatu kata pada suatu dokumen, sedangkan adalah frekuensi suatu kata pada suatu dokumen.
Perhitungan ukuran kesamaan kosinus pada penelitian ini dilakukan dengan rumus ukuran kesamaan kosinus (Manning et al. 2009)
sim d d ⃑⃑ d ⃑⃑ d | ⃑⃑ d || ⃑⃑ d |
8
⃑⃑ d ⃑⃑ d didefinisikan dengan ∑ ni dengan n adalah banyaknya kata unik pada dokumen uji dan dokumen sumber, adalah bobot kata pada dokumen uji dan adalah bobot kata pada dokumen sumber. Penyebut |⃑⃑ | didefinisikan dengan
√∑ ⃑⃑⃑⃑
.
Simbol ⃑⃑⃑⃑⃑⃑⃑⃑⃑⃑⃑ adalah kuadrat dari bobot suatu kata pada dokumen uji (d ) atau dokumen sumber (d ).
Pada sebagian dokumen teks uji dan sumber, terdapat 3 bagian yaitu (a) sebelum segmen acuan, (b) segmen acuan dan (c) setelah segmen acuan. Bagian-bagian ini akan digunakan dalam 3 perhitungan antara seBagian-bagian teks dokumen uji dan sumber. Perhitungan pertama membandingkan ketiga bagian tersebut. Perhitungan kedua membandingkan bagian pertama (a) dan kedua (b). Perhitungan ketiga membandingkan bagian kedua (b) dan ketiga (c). Jika di antara ketiga perbandingan tersebut mendapatkan hasil di atas 70%, dokumen uji dianggap plagiat terhadap dokumen sumber. Perhitungan jarak dilakukan dengan 3 perhitungan karena posisi segmen plagiat dapat berada di awal, akhir atau pertengahan teks dokumen uji.
Perhitungan Akurasi
Setelah seluruh dokumen uji diujicobakan, maka dilakukan proses perhitungan akurasi secara manual. Perhitungan akurasi dapat dilakukan dengan rumus:
akurasi ∑dokumen u i dengan klasi ikasi benar
∑dokumen u i 00%
Spesifikasi Perangkat Lunak dan Perangkat Keras
Perangkat lunak yang digunakan dalam pengembangan sistem adalah Net Beans IDE 7.2, Apache 2.2, PHP 5.3, dan MySqL 5.5. Perangkat keras yang digunakan dalam pengembangan sistem adalah Laptop HP 4430s dengan spesifikasi prosesor Intel Core i3-2330M 2.2 GHz dan Memori RAM 4GB, dan jaringan internet dengan penyedia layanan PT Indosat Mega Media.
HASIL DAN PEMBAHASAN
Pembentukan Korpus Dokumen Uji
9
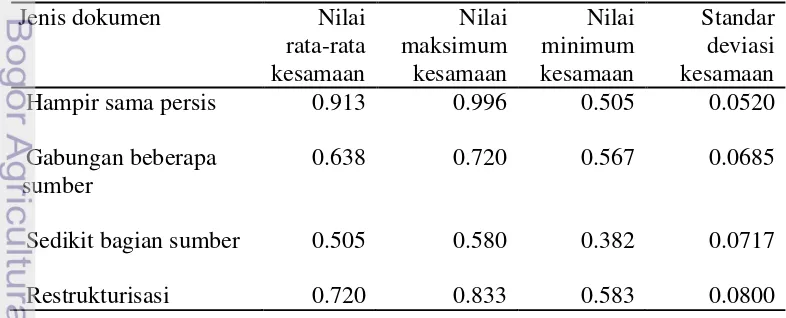
Tabel 1 Nilai kesamaan kosinus dokumen uji dengan sumber plagiat
Jenis dokumen Nilai
Sedikit bagian sumber 0.505 0.580 0.382 0.0717
Restrukturisasi 0.720 0.833 0.583 0.0800
Pembentukan korpus dokumen plagiat menghasilkan 100 dokumen. Untuk detailnya dapat dilihat pada Lampiran 1.
Pembentukan dokumen hampir sama persis dengan cara menyalin sebagian besar isi dokumen sumber. Pembentukan dokumen gabungan beberapa sumber dengan cara menyalin isi dari 2-3 dokumen berbeda. Pada dokumen jenis sedikit bagian sumber, dokumen dibentuk dengan menyalin beberapa paragraf dari dokumen sumber kemudian menggabungkannya dengan dokumen yang bukan plagiat. Dokumen bukan plagiat yang digunakan adalah dokumen teks yang dibentuk dan teruji bukan dokumen plagiat. Dokumen jenis restrukturisasi dibentuk dengan menyalin suatu dokumen sumber kemudian mengubah strukturnya menjadi berbeda dengan dokumen sumbernya.
Pembentukan dokumen jenis restrukturisasi memanfaatkan layanan Google Translate1. Hal ini dapat dilakukan karena ketika suatu teks diterjemahkan ke suatu bahasa lain dan kemudian diterjemahkan kembali ke bahasa aslinya pada Google Translate, hasil akhir tidak sama persis dengan teks awal. Sebagai contoh, terjemahan bolak-balik (Indonesia-Inggris dari “Strategi dalam dunia pemeliharaan di industri mulai mengarah pada predictive maintenance PdM ”
adalah “Strategi perawatan di dunia dalam industri mulai mengarah pada pemeliharaan predikti PDM ”. Perbedaan beberapa kata pada kalimat tersebut
dapat menghasilkan perbedaan signifikan pada pencarian di mesin pencari. Penggunaan teks awal pada contoh akan memberikan hasil alamat sumber aslinya pada mesin pencari, sedangkan penggunaan teks hasil restrukturisasi pencarian pada mesin pencari tidak mendapatkan hasil alamat sumber aslinya.
Jenis dokumen plagiat hampir sama persis memiliki rata-rata kemiripan yang paling tinggi dengan dokumen sumber, sedangkan plagiat dengan sedikit bagian sumber memiliki rata-rata kemiripan yang terendah (lihat Tabel 1). Hal ini karena pembentukan dokumen hampir sama persis hanya menulis ulang sumber dengan sedikit perubahan. Dokumen dengan jenis gabungan beberapa sumber mengambil dua atau tiga dokumen sebagai sumber plagiat, sehingga kemiripannya dengan suatu dokumen sumber plagiat secara spesifik menjadi turun. Dokumen dengan sedikit bagian dokumen hanya mengambil sedikit bagian dokumen yang kemudian digabungkan dengan dokumen bukan plagiat, sehingga rata-rata kemiripannya paling kecil. Dokumen jenis restrukturisasi memiliki rata-rata
10
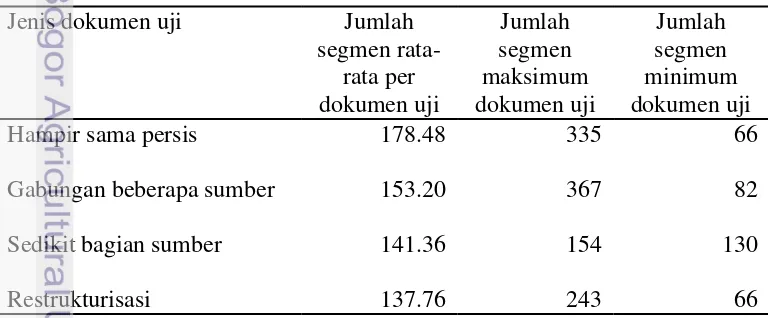
Tabel 2 Jumlah segmen hasil segmentasi dokumen uji
Jenis dokumen uji Jumlah
segmen
rata-Sedikit bagian sumber 141.36 154 130
Restrukturisasi 137.76 243 66
kemiripan yang cukup tinggi namun dengan nilai standar deviasi yang paling besar dibandingkan dengan yang lainnya. Hal ini menunjukkan bahwa dokumen jenis restrukturisasi lebih beragam daripada dokumen plagiat jenis lainnya. Untuk detail nilai kesamaan kosinus setiap dokumen uji dapat dilihat pada Lampiran 2 dan 3.
Praproses Dokumen Uji dan Dokumen Sumber
Tahap praproses dokumen dilakukan untuk mengekstraksi teks. Dokumen uji menggunakan dokumen jenis PDF, sedangkan dokumen sumber yang dapat diekstrak adalah dokumen jenis PDF dan dokumen jenis HTML. Pada dokumen uji tidak terdapat dokumen yang terproteksi karena pembentukan korpus dokumen uji tidak melakukan proteksi dokumen uji. Namun, dokumen sumber plagiat dapat berupa dokumen yang terproteksi sehingga harus dilakukan upaya untuk mendapatkan teks yaitu dengan menggunakan Ghostscript dan Tesseract.
Segmentasi Dokumen
Segmentasi dokumen uji menghasilkan jumlah segmen rata-rata untuk setiap jenis dokumen uji antara 141-179, maksimum 335 dan minimum 66 segmen (lihat Tabel 2). Detail jumlah segmen setiap dokumen uji dapat dilihat pada Lampiran 4 dan 5.
Jumlah segmen menentukan jumlah kueri yang digunakan pada pencarian
online. Segmen yang digunakan sebagai kueri dibatasi maksimal 40%, sehingga rata-rata setiap jenis dokumen memiliki daftar kueri antara 55-72 segmen.
11
Tabel 3 Hasil pencarian Google
Jenis dokumen
Rata-rata frekuensi pencarian
Rata-rata persentase jumlah segmen yang
digunakan
Hampir sama persis 2.72 1.79
Gabungan beberapa sumber 2.72 2.22
Sedikit bagian sumber 9.32 6.62
Restrukturisasi 8.04 6.68
Pembobotan dan Pemeringkatan Segmen
Pembobotan dan pemeringkatan yang dilakukan dinilai dari banyaknya kueri yang digunakan atau banyaknya pencarian yang dilakukan hingga suatu dokumen terdeteksi plagiat. Berdasarkan hasil deteksi dengan mesin pencari Google (lihat Tabel 3), rata-rata pencarian yang dilakukan adalah 5.7 kali pencarian. Hal ini menunjukkan bahwa aturan pembobotan segmen yang dilakukan sudah memberikan hasil yang baik karena penggunaan kueri dengan bobot tinggi dapat menemukan dokumen sumber plagiat. Penilaian pembobotan segmen yang dilakukan hanya berdasarkan hasil deteksi dengan mesin pencari Google karena dengan mesin pencari Google seluruh dokumen terdeteksi plagiat, sedangkan hasil deteksi dengan mesin pencari Bing tidak dapat dijadikan acuan karena tidak seluruh dokumen terdeteksi plagiat.
Pencarian Online
Pencarian online dilakukan selama daftar kueri yang digunakan masih belum diproses seluruhnya dan dokumen uji belum terdeteksi sebagai plagiat. Pencarian online dengan Google memerlukan rata-rata 2.72-9.32 kali pencarian (lihat Tabel 3) untuk setiap jenis dokumen, sedangkan pencarian online dengan Bing memerlukan rata-rata 38.28-49.04 kali pencarian (lihat Tabel 4). Pencarian dengan mesin pencari Google menggunakan rata-rata 1.79-6.68% segmen untuk setiap jenis dokumen. Pencarian terbanyak dengan mesin pencari Google terjadi pada suatu dokumen restrukturisasi yang menggunakan 27.27% segmen sebagai kueri, sedangkan pada mesin pencari Bing pada setiap jenis dokumen rata-rata menggunakan lebih dari 27% segmen.
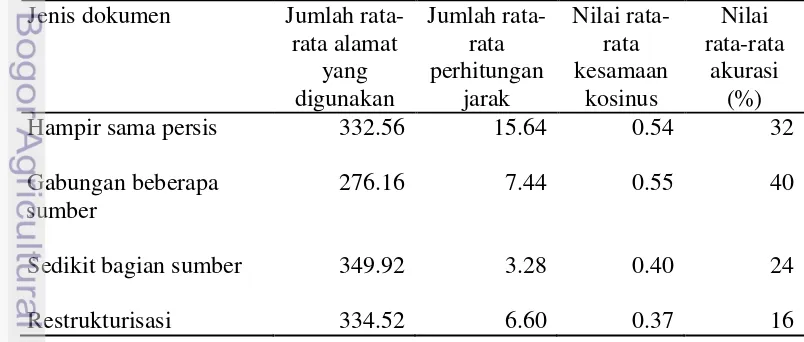
Tahap pencarian online menghasilkan alamat dan cuplikan untuk diidentifikasi apakah harus diperiksa. Setiap pencarian online mengambil maksimal 10 alamat teratas. Jumlah pencarian mempengaruhi banyaknya alamat yang dicatat. Oleh sebab itu, pada mesin pencari Google rata-rata alamat yang didapatkan lebih sedikit daripada mesin pencari Bing. Rata-rata alamat yang didapatkan pada mesin pencari Google hanya 31.37 (lihat Tabel 6), sedangkan rata-rata alamat yang didapatkan pada mesin pencari Bing sebanyak 323.29 (lihat
12
Tabel 4 Hasil pencarian Bing
Jenis dokumen
Rata-rata frekuensi pencarian
Rata-rata persentase jumlah segmen yang
digunakan
Hampir sama persis 49.04 27.92
Gabungan beberapa sumber 38.28 27.56
Sedikit bagian sumber 46.64 33.01
Restrukturisasi 45.52 34.79
Tabel 5 Perbandingan hasil kesamaan kosinus maksimum dokumen uji dengan cara identifikasi alamat dokumen sumber
Aturan identifikasi
diperoleh lebih dari 1
54 10 69
Cuplikan minimum 70% kata kueri, maksimum 30% bukan kata kueri
46 18 1
Pencatatan dan Identifikasi Alamat
Identifikasi alamat yang dilakukan dengan aturan pertama yaitu dengan memperhatikan apakah alamat telah diperoleh dari hasil pencarian sebelumnya atau frekuensi alamat lebih dari 1, merupakan aturan yang paling banyak digunakan (lihat Tabel 5). Meskipun demikian, aturan tersebut memberikan hasil dengan kesamaan kurang dari 0.7 terbanyak dengan 69 dokumen uji, sedangkan aturan kedua hanya memberikan 1 hasil yang kurang dari 0.7. Pada umumnya, semakin tinggi suatu alamat dokumen sumber didapatkan dari hasil pencarian, maka semakin besar kemungkinan dokumen sumber tersebut memiliki keterkaitan dengan dokumen uji. Namun, keterkaitan tersebut tidak berarti dokumen uji memplagiat dokumen sumber karena hal yang terkait dapat juga berupa pembahasan mengenai topik yang sama sehingga alamat dokumen sumber diperoleh lebih dari 1.
Aturan kedua lebih sedikit dilakukan karena tidak banyak hasil pencarian
13
Tabel 6 Hasil deteksi plagiat menggunakan 40% segmen dan mesin pencari Google
Jenis dokumen Jumlah rata-rata alamat
Tabel 7 Hasil deteksi plagiat menggunakan 40% segmen dan mesin pencari Bing Jenis dokumen Jumlah
rata-rata alamat merepresentasikan kesamaan kosinus namun sebatas untuk mendapatkan dokumen yang akan diuji.
Perhitungan Jarak
Perhitungan jarak deteksi plagiat dengan mesin pencari Google dilakukan rata-rata hanya 1.04 kali perhitungan (lihat Tabel 6), sedangkan dengan mesin pencari Bing dilakukan rata-rata 8.24 kali perhitungan (lihat Tabel 7). Kesamaan kosinus setiap jenis dokumen uji yang diperoleh deteksi plagiat dengan mesin pencari Google memperoleh nilai rata-rata antara 0.84-0.97, sedangkan dengan mesin pencari Bing hanya memperoleh 37.32-55.36. Nilai ini diperoleh dari nilai maksimum kesamaan kosinus yang diperoleh setiap dokumen uji.
14
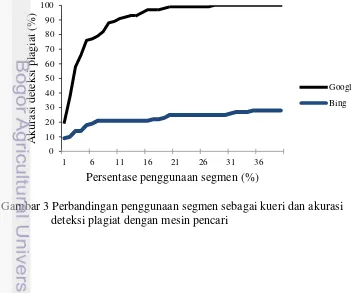
Gambar 3 Perbandingan penggunaan segmen sebagai kueri dan akurasi deteksi plagiat dengan mesin pencari
0
Persentase penggunaan segmen (%)
Bing
kata-kata pada dokumen uji jika dibandingkan dengan dokumen sumber. Jenis dokumen sedikit bagian sumber memiliki rata-rata kesamaan kosinus yang tinggi yaitu 0.99. Perhitungan jarak teks dokumen yang dilakukan dengan 3 cara membuat keberadaan teks yang bukan plagiat menjadi tidak terpengaruh terhadap hasil perhitungan jarak. Dokumen jenis hampir sama persis dan gabungan beberapa sumber memiliki rata-rata kesamaan kosinus yang tinggi dan tidak berbeda. Hasil ini menunjukkan bahwa banyaknya sumber tidak membuat dokumen lebih sulit untuk dideteksi.
Pada deteksi plagiat dengan mesin pencari Bing, kesamaan kosinus dihitung dari nilai terbesar ketika suatu dokumen dilakukan perhitungan jarak. Rendahnya nilai kesamaan kosinus dengan mesin pencari Bing disebabkan banyaknya dokumen yang hingga penggunaan 40% segmen tidak mendapatkan sumber plagiat.
Akurasi Deteksi Plagiat
Deteksi plagiat dengan 40% segmen teratas dan mesin pencari Google mendapatkan rata-rata hasil akurasi 100% (lihat Tabel 6). Namun, deteksi plagiat dengan mesin pencari Bing hanya mendapatkan rata-rata akurasi 28% (lihat Tabel 7). Akurasi tertinggi dengan mesin pencari Bing dihasilkan jenis dokumen gabungan beberapa sumber, sedangkan akurasi terendah dihasilkan jenis dokumen restrukturisasi.
15
Tabel 8 Waktu rata-rata pendeteksian plagiat dengan 40% segmen (detik) dengan mesin pencari Google
Jenis dokumen Waktu
rata-rata
Tabel 9 Waktu rata-rata pendeteksian plagiat dengan 40% segmen (detik) dengan mesin pencari Bing
Jenis dokumen Waktu
rata-rata
Pendeteksian dokumen plagiat dengan mesin pencari Google berhasil 100% mendeteksi seluruh dokumen plagiat dengan 28% segmen. Hasil ini sesuai dengan pernyataan Butakov dan Shcherbinin (2009) bahwa penggunaan lebih dari 40% segmen tidak meningkatkan tingkat akurasi deteksi plagiat (lihat Gambar 3). Pada pendeteksian dengan mesin pencari Bing, penggunaan 40% segmen pendeteksian hanya dapat mendeteksi 28% dari keseluruhan dokumen karena dokumen sumber belum terindeks pada mesin pencari.
16
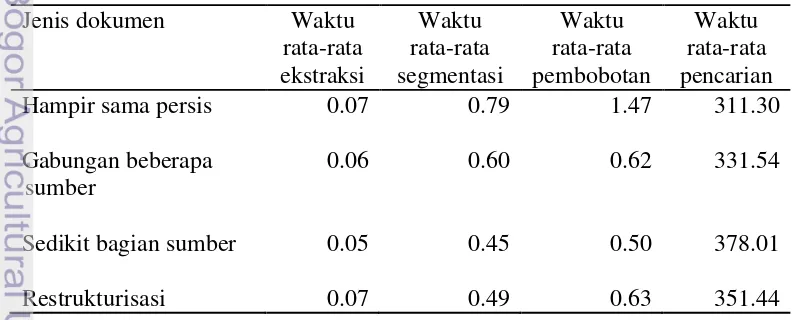
internet dapat saja berubah atau tidak dapat diakses. Detail waktu deteksi plagiat dengan mesin pencari Google dapat dilihat pada Lampiran 14, 15, 16 dan 17, sedangkan detail waktu deteksi plagiat dengan mesin pencari Bing dapat dilihat pada Lampiran 18, 19, 20 dan 21.
Hasil sistem pendeteksi online ini masih melalui tahap offline seperti yang diutarakan Mozgovoy (2006). Namun, otomatisasi sistem menunjukkan bahwa saat ini sistem pendeteksi online tidak lagi sulit untuk dilakukan.
Hasil yang diperoleh pada penelitian ini merupakan indikasi plagiat sebenarnya. Terdapat beberapa hal yang belum didukung oleh sistem, sehingga dapat membuat dokumen yang seharusnya bukan plagiat teridentifikasi sebagai dokumen plagiat seperti kutipan langsung. Kutipan langsung pada dokumen uji pasti akan sama persis dengan dokumen sumber, sehingga jika sistem membandingkan antara dokumen uji dan dokumen sumber maka akan terindikasi plagiat.
SIMPULAN DAN SARAN
Simpulan
Penelitian ini menghasilkan sistem pendeteksi dokumen plagiat untuk dokumen berbahasa Indonesia dengan memanfaatkan mesin pencari. Sistem ini berhasil mendeteksi seluruh korpus dokumen plagiat dengan mesin pencari Google. Namun, perlu dilakukan pemeriksaan manual untuk memastikan dokumen tersebut adalah dokumen plagiat.
Jika dokumen sumber dari dokumen plagiat belum terindeks pada mesin pencari, maka dokumen sumber tersebut tidak dapat dideteksi. Sebaliknya, jika dokumen sumber telah terindeks oleh mesin pencari, sistem ini dapat mendeteksi dokumen tersebut sebagai dokumen plagiat. Jadi, kualitas hasil sistem pendeteksi dokumen plagiat ini tergantung pada hasil pencarian yang dihasilkan oleh mesin pencari.
Saran
Beberapa saran untuk penelitian selanjutnya yaitu:
1 Menambahkan korpus dokumen uji berupa dokumen yang bukan plagiat untuk mendeteksi apakah suatu dokumen uji yang bukan plagiat dikategorikan dokumen plagiat.
17
DAFTAR PUSTAKA
Alzahrani S M, Salim N B, Abraham A. 2012. Understanding plagiarism linguistic patterns, textual features, and detection methods. Sys, Man, Cyber, Part C: Appl Rev. 42(2):133-249.doi:10.1109/TSMCC.2011.2134847. Artofcode. 2002. Details of Ghostscript output devices [internet]. [diunduh 2013
April 26]. Tersedia pada: http://pages.cs.wisc.edu/~ghost/doc/AFPL/8.00/ Devices.htm
[ASI] Artifex Software, Inc. c2012. Ghostscript [internet]. [diunduh 2013 April 24]. Tersedia pada: http://www.ghostscript.com/Ghostscript.html
Butakov S, Shcherbinin V. 2009. On the number of search queries required for internet plagiarism detection. Di dalam: Advanced Learning Technologies;
2009 Jul 15-17; Riga. Riga (LV): [IEEE]. Hlm 482-483.
Fathi S. 2012. Pembentukan passage dalam question answering system untuk dokumen bahasa Indonesia [skripsi]. Bogor (ID): Institut Pertanian Bogor. [GCL] Glyph & Cog, LLC. c2011. Xpdf: A PDF Viewer for X [internet].
[diunduh 2013 April 24]. Tersedia pada: http://www.foolabs.com/xpdf/ home.html
Google. c2011. Tesseract-ocr [internet]. [diunduh 2013 Maret 4]. Tersedia pada: https://code.google.com/p/tesseract-ocr/
Honig B, Bedi A. 2012. The fox in the hen house: a critical examination of plagiarism among members of the academy of management. Acad Manag Learn & Educ. 11(1):101–123.doi:10.5465/amle.2010.0084.
Liu Y, Zhang H, Chen T, Teng W . 2007. Extending Web Search for Online Plagiarism Detection. Di dalam: Information Reuse and Integration; 2007 Aug 13-15; Las Vegas. Las Vegas (US): [IEEE]. Hlm 164-169.
Manning C D, Raghavan P, Schütze H. 2009. An Introduction to Information Retrieval. Cambridge Univ Press (GB): Cambrigde.
Microsoft. c2012. Bing Search API [internet]. [diunduh 2013 April 10]. Tersedia pada: http://datamarket.azure.com/dataset/bing/search
Mozgovoy M. 006. Desktop tools or o fline plagiarism detection in computer
programs. Inform Educ. [Internet]. [diunduh 2013 Mar 16]; 5(1):97-112. Tersedia pada: http://www.mii.lt/informatics_in_education/pdf/INFE067. pdf
19 Lampiran 2 Rata-rata kesamaan dokumen uji dengan 1 dokumen sumber
20
Lampiran 3 Rata-rata kesamaan dokumen uji dengan lebih dari 1 dokumen sumber
Nama dokumen Kesamaan Kosinus
d2-130-132 68.18
d2-133-140 72.02
d2-143-148 71.96
d2-151-167 66.50
d2-153-142 69.13
d2-153-154 71.96
d2-165-154 65.06
d2-165-166 69.70
d2-168-146 65.32
d2-170-141 59.49
d3-106-144-137 63.64
d3-107-153-167 57.29
d3-129-146-151 66.11
d3-130-131-132 59.96
d3-130-134-142 65.33
d3-133-136-140 58.07
d3-140-139-168 62.93
d3-143-144-148 60.55
d3-151-167-128 60.52
d3-153-142-131 59.36
d3-153-154-165 63.94
d3-165-154-149 62.89
d3-166-167-170 61.57
d3-168-146-155 57.80
d3-170-141-143 56.65
tr2-130-132 62.44
tr2-133-140 65.19
tr2-143-148 62.15
tr2-151-167 58.26
tr2-153-142 61.22
tr2-153-154 63.30
tr2-165-154 60.28
tr2-165-166 63.66
tr2-168-146 58.98
21 Lampiran 4 Hasil segmentasi dokumen uji dengan suatu dokumen sumber
Nama dokumen Jumlah Segmen
106 325
Nama dokumen Jumlah Segmen
22
Lampiran 5 Hasil segmentasi dokumen uji dengan lebih dari 1 dokumen sumber
Nama dokumen Jumlah segmen
d2-130-132 148
d2-133-140 167
d2-143-148 132
d2-151-167 108
d2-153-142 127
d2-153-154 201
d2-165-154 90
d2-165-166 122
d2-168-146 100
d2-170-141 89
d3-106-144-137 372
d3-107-153-167 147
d3-129-146-151 267
d3-130-131-132 122
d3-130-134-142 371
d3-133-136-140 119
d3-140-139-168 197
d3-143-144-148 112
d3-151-167-128 108
d3-153-142-131 108
d3-153-154-165 169
d3-165-154-149 129
d3-166-167-170 148
d3-168-146-155 84
d3-170-141-143 134
tr2-130-132 133
tr2-133-140 159
tr2-143-148 129
tr2-151-167 100
tr2-153-142 121
tr2-153-154 195
tr2-165-154 91
tr2-165-166 116
tr2-168-146 94
23 Lampiran 6 Hasil deteksi plagiat dengan mesin pencari Google (dokumen uji
jenis hampir sama persis)
Nama dokumen Frekuensi Pencarian
Persentase penggunaan
segmen
Aturan identifikasi yang digunakan
Kesamaan kosinus
(%)
106 1 0.31 2 81.69
107 1 0.99 2 100.00
128 1 0.56 2 100.00
129 1 0.49 2 100.00
130 3 0.90 1 100.00
131 3 2.22 1 98.90
132 4 2.37 1 100.00
133 3 1.81 1 98.84
134 3 1.09 1 100.00
137 1 0.71 2 100.00
139 3 2.44 1 100.00
140 3 2.00 1 80.86
142 3 1.82 1 100.00
143 1 0.93 2 88.34
144 2 0.88 1 100.00
146 5 2.51 1 100.00
148 2 1.22 2 98.67
149 3 2.22 2 88.23
151 3 1.60 1 100.00
153 5 2.05 1 94.57
155 5 7.58 1 100.00
165 1 0.79 2 100.00
167 2 0.80 1 100.00
168 6 4.35 1 100.00
24
Lampiran 7 Hasil deteksi plagiat dengan mesin pencari Google (dokumen uji jenis gabungan berbagai sumber)
Nama dokumen Frekuensi Pencarian
Persentase penggunaan
segmen
Aturan identifikasi
yang digunakan
Kesamaan kosinus
(%)
d2-130-132 1 0.68 2 97.09
d2-133-140 3 1.82 1 98.37
d2-143-148 3 2.31 1 96.30
d2-151-167 4 3.70 1 97.31
d2-153-142 3 2.40 1 80.19
d2-153-154 4 2.01 1 100.00
d2-165-154 1 1.12 2 100.00
d2-165-166 1 0.82 2 100.00
d2-168-146 5 5.10 1 99.38
d2-170-141 10 11.36 2 84.16
d3-106-144-137 2 0.54 2 81.69
d3-107-153-167 1 0.68 2 100.00
d3-129-146-151 2 0.76 2 100.00
d3-130-131-132 3 2.48 2 98.99
d3-130-134-142 1 0.27 2 100.00
d3-133-136-140 4 3.36 1 99.09
d3-140-139-168 3 1.59 2 100.00
d3-143-144-148 5 4.50 1 100.00
d3-151-167-128 2 1.85 2 99.06
d3-153-142-131 3 2.78 1 100.00
d3-153-154-165 2 1.18 2 100.00
d3-165-154-149 2 1.56 2 100.00
d3-166-167-170 1 0.68 2 100.00
d3-168-146-155 1 1.22 2 100.00
25 Lampiran 8 Hasil deteksi plagiat dengan mesin pencari Google (dokumen uji
jenis sedikit bagian sumber)
Nama dokumen Frekuensi Pencarian
Persentase penggunaan
segmen
Aturan identifikasi
yang digunakan
Kesamaan kosinus
(%)
e-106 7 4.90 2 100.00
e-107 13 9.56 2 92.12
e-128 12 8.39 1 100.00
e-129 3 2.13 2 100.00
e-130 7 4.76 2 97.81
e-131 12 8.51 2 100.00
e-132 22 15.49 1 100.00
e-133 10 7.14 2 100.00
e-134 20 14.29 2 100.00
e-137 3 2.00 2 98.50
e-139 12 8.63 1 100.00
e-140 4 2.99 2 100.00
e-142 3 2.03 2 100.00
e-143 3 2.26 2 100.00
e-144 9 6.43 1 95.47
e-146 5 3.38 2 100.00
e-148 7 4.90 1 100.00
e-149 5 3.25 1 85.59
e-151 14 10.14 2 100.00
e-153 9 6.25 2 100.00
e-155 17 12.41 1 97.49
e-165 21 14.79 1 100.00
e-167 6 4.23 1 100.00
e-168 3 2.31 2 100.00
26
Lampiran 9 Hasil deteksi plagiat dengan mesin pencari Google (dokumen uji jenis restrukturisasi)
Nama dokumen Frekuensi Pencarian
Persentase penggunaan
segmen
Aturan identifikasi
yang digunakan
Kesamaan kosinus
(%)
tr-128 1 0.58 2 83.87
tr-131 2 1.55 2 82.85
tr-132 11 7.10 1 83.73
tr-133 6 3.61 1 78.38
tr-139 10 8.13 1 91.75
tr-140 3 2.13 1 85.09
tr-142 17 10.43 1 85.00
tr-143 9 8.26 1 79.10
tr-144 6 2.47 1 82.87
tr-146 5 2.60 2 89.92
tr-148 5 2.87 1 89.36
tr-149 3 2.29 1 78.50
tr-155 18 27.27 1 75.34
tr-165 5 4.27 1 81.96
tr-170 6 4.55 1 82.11
tr2-130-132 6 4.48 1 81.09
tr2-133-140 1 0.63 2 87.81
tr2-143-148 24 18.75 1 77.43
tr2-151-167 16 16.00 1 85.06
tr2-153-142 4 3.31 1 86.25
tr2-153-154 17 8.67 1 80.39
tr2-165-154 3 3.30 1 88.19
tr2-165-166 4 3.51 1 88.17
tr2-168-146 18 19.15 1 83.64
27 Lampiran 10 Hasil deteksi plagiat dengan mesin pencari Bing (dokumen uji jenis
hampir sama persis)
Nama dokumen Frekuensi Pencarian
Persentase penggunaan
segmen
Aturan identifikasi yang digunakan
Kesamaan kosinus
(%)
106 1 0.31 2 87.47
107 1 0.99 2 100.00
128 71 39.89 1 28.18
129 82 40.00 1 31.94
130 134 40.00 1 41.24
131 1 0.74 2 98.31
132 67 39.64 1 31.08
133 3 1.81 2 91.91
134 110 39.86 1 33.36
137 1 0.71 2 94.31
139 49 39.84 1 40.42
140 60 40.00 1 25.39
142 1 0.61 2 80.88
143 43 39.81 1 24.34
144 1 0.44 2 98.50
146 79 39.70 1 46.24
148 65 39.63 1 52.83
149 54 40.00 1 39.31
151 75 39.89 1 61.12
153 97 39.75 1 55.97
155 26 39.39 1 24.45
165 50 39.37 1 21.01
167 40 16.06 1 86.57
168 55 39.86 1 27.51
28
Lampiran 11 Hasil deteksi plagiat dengan mesin pencari Bing (dokumen uji jenis gabungan berbagai sumber)
Nama Frekuensi
Pencarian
Persentase penggunaan
segmen
Aturan identifikasi yang digunakan
Kesamaan kosinus
(%)
d2-130-132 59 39.86 1 32.02
d2-133-140 31 18.79 1 73.18
d2-143-148 52 40.00 1 34.67
d2-151-167 43 39.81 1 50.51
d2-153-142 3 2.40 1 76.49
d2-153-154 79 39.70 1 39.11
d2-165-154 31 34.83 1 72.49
d2-165-166 48 39.34 1 28.05
d2-168-146 39 39.80 2 37.97
d2-170-141 35 39.77 1 31.55
d3-106-144-137 2 0.54 2 87.47
d3-107-153-167 6 4.11 2 100.00
d3-129-146-151 105 39.77 1 32.35
d3-130-131-132 5 4.13 1 99.39
d3-130-134-142 9 2.47 2 98.54
d3-133-136-140 23 19.33 2 98.95
d3-140-139-168 75 39.68 1 29.48
d3-143-144-148 1 0.90 2 98.50
d3-151-167-128 43 39.81 1 10.53
d3-153-142-131 6 5.56 2 97.96
d3-153-154-165 67 39.64 1 11.90
d3-165-154-149 51 39.84 1 20.73
d3-166-167-170 59 39.86 1 54.22
d3-168-146-155 32 39.02 1 27.05
29 Lampiran 12 Hasil deteksi plagiat dengan mesin pencari Bing (dokumen uji jenis
sedikit bagian sumber)
Nama dokumen Frekuensi Pencarian
Persentase penggunaan
segmen
Aturan identifikasi yang digunakan
Kesamaan kosinus
(%)
e-106 7 4.90 2 92.69
e-107 9 6.62 2 100.00
e-128 57 39.86 1 27.87
e-129 56 39.72 - -
e-130 58 39.46 1 26.33
e-131 56 39.72 1 27.87
e-132 56 39.44 1 28.84
e-133 27 19.29 2 96.44
e-134 56 40.00 1 27.87
e-137 60 40.00 1 37.13
e-139 55 39.57 1 15.02
e-140 53 39.55 1 18.98
e-142 3 2.03 2 99.44
e-143 53 39.85 1 28.84
e-144 9 6.43 1 95.47
e-146 59 39.86 1 26.33
e-148 57 39.86 1 34.67
e-149 61 39.61 1 29.16
e-151 55 39.86 1 24.34
e-153 57 39.58 1 27.87
e-155 54 39.42 1 27.87
e-165 45 31.69 1 73.27
e-167 56 39.44 1 18.69
e-168 52 40.00 - -
30
Lampiran 13 Hasil deteksi plagiat dengan mesin pencari Bing (dokumen uji jenis restrukturisasi)
Nama Frekuensi
Pencarian
Persentase penggunaan
segmen
Aturan identifikasi yang digunakan
Kesamaan kosinus
(%)
tr-128 69 39.88 1 31.31
tr-131 51 39.53 1 24.52
tr-132 62 40.00 1 29.89
tr-133 7 4.22 1 83.25
tr-139 49 39.84 1 30.85
tr-140 56 39.72 1 39.35
tr-142 1 0.61 2 77.14
tr-143 43 39.45 1 17.89
tr-144 6 2.47 1 82.87
tr-146 76 39.58 1 48.54
tr-148 69 39.66 1 44.05
tr-149 52 39.69 1 27.58
tr-155 26 39.39 1 22.13
tr-165 46 39.32 1 24.40
tr-170 52 39.39 1 39.71
tr2-130-132 53 39.55 1 33.61
tr2-133-140 48 30.38 1 78.97
tr2-143-148 51 39.84 1 32.84
tr2-151-167 40 40.00 1 35.27
tr2-153-142 48 39.67 1 22.11
tr2-153-154 78 39.80 1 22.50
tr2-165-154 36 39.56 1 0.00
tr2-165-166 45 39.47 1 22.26
tr2-168-146 37 39.36 1 20.65
31 Lampiran 14 Waktu deteksi plagiat dokumen uji jenis hampir sama persis
dengan mesin pencari Google (detik)
Nama dokumen Ekstraksi Segmentasi Pembobotan Pencarian
106 0.08 1.33 0.85 5.88
107 0.04 0.27 0.73 5.42
128 0.05 0.36 0.82 4.97
129 0.05 0.83 0.76 6.07
130 0.08 0.99 1.43 8.32
131 0.05 0.63 0.35 6.37
132 0.06 0.33 0.54 11.96
133 0.05 0.47 0.62 7.90
134 0.07 1.18 0.96 8.84
137 0.05 0.51 0.44 3.30
139 0.05 0.29 0.31 8.91
140 0.05 0.53 0.53 25.23
142 0.05 0.36 0.49 10.04
143 0.05 0.39 0.41 5.00
144 0.06 0.93 1.02 7.52
146 0.06 0.35 0.60 10.26
148 0.06 0.46 0.49 5.46
149 0.05 0.61 0.98 9.36
151 0.05 0.48 0.99 6.51
153 0.06 0.77 0.58 9.44
155 0.04 0.17 0.50 11.85
165 0.05 0.35 0.74 3.76
167 0.07 0.45 1.80 7.46
168 0.04 0.48 0.77 13.65
32
Lampiran 15 Waktu deteksi plagiat dokumen uji jenis gabungan beberapa sumber dengan mesin pencari Google (detik)
Nama dokumen Ekstraksi Segmentasi Pembobotan Pencarian
d2-130-132 0.05 0.37 0.89 51.31
d2-133-140 0.05 0.29 0.57 33.34
d2-143-148 0.05 0.23 0.85 6.41
d2-151-167 0.04 0.26 0.62 8.31
d2-153-142 0.05 0.33 1.61 7.30
d2-153-154 0.06 0.52 0.50 10.01
d2-165-154 0.04 0.31 0.26 3.54
d2-165-166 0.05 0.40 0.32 5.54
d2-168-146 0.04 0.32 0.73 10.83
d2-170-141 0.04 0.22 0.23 16.73
d3-106-144-137 0.09 0.86 1.72 6.99
d3-107-153-167 0.05 0.28 0.54 6.03
d3-129-146-151 0.07 0.70 1.02 6.06
d3-130-131-132 0.04 0.36 0.31 6.20
d3-130-134-142 0.08 1.03 0.97 4.47
d3-133-136-140 0.05 0.40 0.40 37.70
d3-140-139-168 0.06 0.55 0.57 7.96
d3-143-144-148 0.05 0.29 0.41 12.28
d3-151-167-128 0.05 0.34 0.29 7.31
d3-153-142-131 0.05 0.20 0.30 8.45
d3-153-154-165 0.06 0.33 0.45 4.49
d3-165-154-149 0.05 0.25 0.48 7.06
d3-166-167-170 0.06 0.28 0.52 3.78
d3-168-146-155 0.04 0.34 0.26 4.58
33 Lampiran 16 Waktu deteksi plagiat dokumen uji jenis sedikit bagian sumber
dengan mesin pencari Google (detik)
Nama dokumen Ekstraksi Segmentasi Pembobotan Pencarian
e-106 0.17 0.66 1.04 11.78
e-107 0.05 0.39 0.58 18.43
e-128 0.05 0.39 0.43 17.50
e-129 0.05 0.49 0.50 5.74
e-130 0.05 0.60 0.66 13.21
e-131 0.05 0.41 0.36 16.06
e-132 0.05 0.32 0.60 28.60
e-133 0.05 0.26 0.73 15.85
e-134 0.05 0.50 0.42 30.61
e-137 0.05 0.28 0.80 6.31
e-139 0.05 0.35 0.44 19.34
e-140 0.05 0.32 0.54 6.99
e-142 0.05 0.32 0.49 7.13
e-143 0.05 0.39 0.68 6.05
e-144 0.05 0.32 0.49 55.24
e-146 0.05 0.40 0.50 219.20
e-148 0.05 0.82 0.41 33.30
e-149 0.05 0.51 0.45 17.56
e-151 0.05 0.36 0.61 156.01
e-153 0.05 0.64 0.50 51.08
e-155 0.05 0.45 0.40 23.41
e-165 0.05 0.42 0.35 36.17
e-167 0.05 0.81 0.51 10.46
e-168 0.05 0.24 0.67 4.72
34
Lampiran 17 Waktu deteksi plagiat dokumen jenis restrukturisasi dengan mesin pencari Google (detik)
Nama dokumen Ekstraksi Segmentasi Pembobotan Pencarian
tr-128 0.11 1.60 0.62 5.86
tr-131 0.04 0.27 0.48 9.30
tr-132 0.05 1.14 0.48 44.50
tr-133 0.05 0.42 0.85 16.01
tr-139 0.05 0.33 0.58 22.42
tr-140 0.05 0.50 0.75 14.22
tr-142 0.05 0.35 0.53 176.93
tr-143 0.05 1.01 0.42 55.18
tr-144 0.06 0.84 0.98 34.20
tr-146 0.06 1.47 0.66 15.26
tr-148 0.06 0.36 0.46 11.79
tr-149 0.05 0.54 0.62 10.82
tr-155 0.03 0.13 0.18 240.61
tr-165 0.05 0.20 0.71 11.50
tr-170 0.05 0.29 0.59 13.86
tr2-130-132 0.05 0.40 0.62 10.39
tr2-133-140 0.05 0.53 0.76 4.89
tr2-143-148 0.05 0.30 0.43 45.68
tr2-151-167 0.04 0.28 0.48 31.44
tr2-153-142 0.04 0.42 0.39 9.26
tr2-153-154 0.05 0.73 0.77 52.54
tr2-165-154 0.04 0.22 0.38 105.06
tr2-165-166 0.04 0.22 0.35 15.14
tr2-168-146 0.04 0.28 0.31 29.47
35 Lampiran 18 Waktu deteksi plagiat dokumen uji jenis hampir sama persis
dengan mesin pencari Bing (detik)
Nama dokumen Ekstraksi Segmentasi Pembobotan Pencarian
106 0.63 3.61 2.14 17.37
107 0.62 1.58 3.99 20.92
128 0.06 2.00 3.30 298.04
129 0.05 2.77 4.16 266.84
130 0.09 3.84 2.52 525.95
131 0.32 0.35 0.74 3.16
132 0.69 0.76 0.60 289.71
133 0.09 0.81 1.11 10.34
134 0.08 1.13 1.71 435.14
137 0.05 0.62 1.99 2.83
139 0.28 1.32 2.69 169.10
140 0.05 0.35 1.58 190.80
142 0.08 1.37 1.43 2.71
143 0.08 0.75 1.10 170.35
144 0.06 2.00 2.32 2.13
146 0.06 3.56 2.83 252.10
148 0.11 1.35 1.36 391.32
149 0.05 1.00 0.99 216.08
151 0.06 1.41 1.41 245.17
153 0.07 2.63 1.83 62.86
155 0.04 0.85 0.37 77.03
165 0.08 2.59 1.75 132.09
167 0.11 1.97 2.48 153.89
168 0.06 1.05 1.71 277.12
36
Lampiran 19 Waktu deteksi plagiat dokumen uji jenis gabungan beberapa sumber dengan mesin pencari Bing (detik)
Nama dokumen Ekstraksi Segmentasi Pembobotan Pencarian
d2-130-132 0.05 0.44 0.52 233.54
d2-133-140 0.06 0.40 0.62 177.86
d2-143-148 0.25 0.50 0.52 193.47
d2-151-167 0.05 0.32 0.30 129.83
d2-153-142 0.05 0.39 0.34 28.40
d2-153-154 0.08 0.87 0.70 281.76
d2-165-154 0.04 0.31 0.30 84.21
d2-165-166 0.05 0.48 0.53 185.97
d2-168-146 0.04 0.34 0.34 122.34
d2-170-141 0.04 0.28 0.27 185.18
d3-106-144-137 0.11 1.64 1.71 12.66
d3-107-153-167 0.07 0.28 0.72 24.82
d3-129-146-151 0.07 0.82 1.02 553.10
d3-130-131-132 0.04 0.24 0.53 22.37
d3-130-134-142 0.08 0.92 1.47 18.55
d3-133-136-140 0.04 0.27 0.42 66.06
d3-140-139-168 0.06 0.41 0.65 206.75
d3-143-144-148 0.05 0.23 0.27 1.84
d3-151-167-128 0.06 0.32 0.41 164.53
d3-153-142-131 0.05 0.42 0.58 12.57
d3-153-154-165 0.06 0.92 0.55 180.56
d3-165-154-149 0.05 0.94 0.51 139.28
d3-166-167-170 0.06 0.41 0.50 265.49
d3-168-146-155 0.04 0.18 0.21 169.59
37 Lampiran 20 Waktu deteksi plagiat dokumen uji jenis sedikit bagian sumber
dengan mesin pencari Bing (detik)
Nama dokumen Ekstraksi Segmentasi Pembobotan Pencarian
e-106 0.06 1.08 0.74 14.13
e-107 0.07 1.27 1.04 20.72
e-128 0.07 1.18 1.07 223.92
e-129 0.06 1.03 0.66 202.13
e-130 0.07 1.01 0.72 621.37
e-131 1.34 0.80 0.81 230.21
e-132 0.05 0.35 0.68 158.52
e-133 0.05 0.82 0.88 140.63
e-134 0.05 0.36 0.63 259.78
e-137 0.05 0.42 0.92 6.10
e-139 0.05 0.36 0.81 179.95
e-140 0.05 0.55 0.49 230.90
e-142 0.05 0.53 0.76 6.42
e-143 0.05 0.41 0.34 125.39
e-144 0.05 1.20 0.97 18.11
e-146 0.07 1.40 0.71 282.35
e-148 0.05 0.85 0.78 172.86
e-149 0.05 1.13 0.66 165.80
e-151 0.07 0.90 1.09 132.97
e-153 0.07 0.41 0.75 146.50
e-155 0.05 0.72 0.75 171.83
e-165 0.07 1.35 0.80 176.00
e-167 0.06 0.86 0.49 241.05
e-168 0.06 21.69 0.61 151.52
38
Lampiran 21 Waktu deteksi plagiat dokumen jenis restrukturisasi dengan mesin pencari Bing (detik)
Nama dokumen Ekstraksi Segmentasi Pembobotan Pencarian
tr-128 0.05 1.04 0.88 452.88
tr-131 0.05 0.75 0.98 276.31
tr-132 0.06 0.89 1.16 2592.31
tr-133 0.06 0.95 0.78 40.67
tr-139 0.06 0.68 0.87 208.25
tr-140 0.08 23.30 0.71 568.28
tr-142 0.06 0.93 0.84 2.18
tr-143 0.06 0.86 0.52 268.21
tr-144 0.07 1.82 1.67 35.22
tr-146 0.07 1.59 0.94 477.77
tr-148 0.07 0.73 0.87 650.47
tr-149 0.06 1.20 0.43 162.66
tr-155 0.04 0.28 0.19 88.87
tr-165 0.05 0.72 0.71 129.54
tr-170 0.06 0.65 0.44 301.55
tr2-130-132 0.06 0.76 0.58 238.46
tr2-133-140 0.08 23.32 0.89 153.21
tr2-143-148 0.09 0.39 0.92 246.19
tr2-151-167 0.04 1.78 0.75 135.02
tr2-153-142 0.08 0.75 0.87 174.66
tr2-153-154 0.06 1.27 1.79 964.75
tr2-165-154 0.04 0.41 0.86 147.31
tr2-165-166 0.05 0.55 0.49 144.28
tr2-168-146 0.04 0.53 0.41 261.75
39
RIWAYAT HIDUP
Penulis dilahirkan di Pangkalpinang, 11 Desember 1989 dari ayah Yadi dan ibu Sylvia Ratna Ningsih. Penulis merupakan anak pertama dari tiga bersaudara.
Penulis menempuh sekolah menengah atas di Sekolah Menengah Atas Negeri 1 Pemali. Selama masa sekolah menengah atas, penulis aktif dalam organisasi yaitu sebagai pengurus Organisasi Siswa Intra Sekolah dan Organisasi Siswa Intra Asrama. Pada tahun 2007 penulis lulus seleksi IPB Diploma melalui jalur Undangan Seleksi Masuk IPB. Penulis menyelesaikan pendidikan diplomanya pada tahun 2010 dengan tugas akhir berjudul “Pembangunan Website