i Skripsi
Diajukan untuk Memenuhi Persyaratan Memperoleh Gelar Sarjana Komputer (S.Kom)
Oleh: SRI WULAN NIM : 206091004077
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
ii Skripsi
Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Komputer
Fakultas Sains dan Teknologi
Universitas Islam Negeri Syarif Hidayatullah Jakarta
Oleh : SRI WULAN NIM. 206091004077
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
v
DENGAN INI SAYA MENYATAKAN BAHWA SKRIPSI INI BENAR-BENAR HASIL KARYA SENDIRI YANG BELUM PERNAH DIAJUKAN SEBAGAI SKRIPSI ATAU KARYA ILMIAH PADA PERGURUAN TINGGI ATAU LEMBAGA MANAPUN.
Jakarta, Maret 2011
vi
1. Otak, pikiran, jiwa dan organ-organ yang ada dalam tubuh dan diri ini. Selamat atas kerja kerasnya. Ingatlah bahwa tak akan berhenti kita hingga kita melangkah ke jannah-Nya karna hidup ini bukan untuk hidup, hidup juga bukan untuk mati, tapi hidup untuk yang Maha Hidup.
vii
dan karunia-Nya dalam memberikan jalan dan kemudahan kepada penulis hingga tugas akhir ini dapat terselesaikan dengan baik. Shalawat dan salam memang pantas tercurah kepada Nabi Muhammad SAW, keluarga, serta para sahabat-sahabatnya yang menjadi panutan dan inspirasi bagi penulis.
Dalam hal ini, penulis mencoba untuk melakukan suatu penelitian dengan topik judul ”Analisis Penerapan String Matching dalam Komparasi Data Kepesertaan Jaminan Kesehatan (JAMKESMAS)”. Topik ini merupakan tugas
akhir yang diambil penulis guna memenuhi syarat untuk memperoleh gelar Sarjana Komputer (S.Kom) Teknik Informatika Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta.
Adapun dalam penyelesaian tugas akhir ini, penulis ingin menyampaikan terima kasih sebesar-besarnya kepada pihak-pihak yang telah membantu dalam penyelesaian pembuatan aplikasi dan penyusunan tugas akhir, antara lain kepada yang terhormat :
1. Bapak DR. Syopiansyah Jaya Putra, M.Sis selaku Dekan Fakultas Sains dan Teknologi yang telah memberikan suatu komitmen, dorongan, dan program pendidikan sesuai kebutuhan mahasiswanya.
viii
4. Bapak Swasetyo Yulianto selaku Dosen Pembimbing Lapangan yang telah memberikan bimbingan, masukan, serta berbagi ilmu pengetahuan dalam penyusunan sehingga penulis dapat menyelesaikan tugas akhir ini.
5. Seluruh anggota keluarga tercinta yang senantiasa mendoakan dan memberikan dukungan selama menjalankan masa perkuliahan.
6. Rekan-rekan seperjuangan, teman–teman Software Enginering dan seluruh kawan-kawan jurusan Teknik Informatika yang memberikan motivasi serta informasi kepada penulis. Mari kita sukses bersama.
7. Seluruh pihak yang telah membantu dan namanya tidak dapat disebutkan satu persatu. Terima kasih atas doa dan bimbingannya, Semoga Allah SWT membalas segala kebaikan yang telah diberikan kepada penulis.
Akhir kata, penulis memohon maaf atas berbagai hal keliru yang diperbuat selama masa penyelesaian tugas akhir ini, kritik dan saran yang membangun sangat diharapkan demi menambah pengetahuan dalam kepenulisan dan semoga tugas akhir ini dapat bermanfaat bagi pengembangan selanjutnya. Amiin
Jakarta, Maret 2011
ix
Dalam pencocokan string (string matching), penggunaan algoritma yang tepat
dapat memberikan hasil penelusuran yang tepat pula dan sesuai keinginan
pengguna. Dalam tugas akhir ini, penulis akan menganalisa penerapan algoritma
string matching yang terdiri atas inexact string matching (fuzzy string macthing)
menggunakan approximate string matching (dilihat dari segi penulisan) dan exact
string matching menggunakan brute force string matching pada data nama orang
(peserta) jamkesmas. Data yang digunakan dalam pencocokan string dalam
menerapkan algoritma string matching merupakan data yang akan dikomparasikan
untuk mendapatkan kecocokan data yang berasal dari dua database. Hasil analisa
fuzzy string matching dalam komparasi data kepesertaan ini akan diaplikasikan
menggunakan PHP dan MySQL, dengan menggunakan fase pengembangan
sistem RAD (Rapid Application Deveplopment). Hasil penerapan string matching
dalam tugas akhir ini menunjukkan bahwa penerapan fuzzy string matching
mampu menangani bentuk nama orang (peserta) yang bervariasi bentuk
penulisannya dan exact string matching tidak mampu mencocokan data nama
yang variatif bentuk kepenulisannya. Pengujian fuzzy string matching dalam
komparasi data kepesertaan ini menghasilkan persentasi kecocokan data peserta
yang sama besar dengan exact string matching.
Kata kunci : String Matching, Fuzzy String Matching (Approximate), Exact String Matching (Brute Force), komparasi data, dan RAD.
Kepesertaan JAMKESMAS
x
HALAMAN LUAR ... i
HALAMAN DALAM ... ii
LEMBAR PENGESAHAN PEMBIMBING ... iii
LEMBAR PENGESAHAN UJIAN ... iv
LEMBAR PERNYATAAN ... v
LEMBAR PERSEMBAHAN ... vi
KATA PENGANTAR ... vii
ABSTRAK ... viii
DAFTAR ISI ... ix
DAFTAR GAMBAR ... xiii
DAFTAR TABEL ... xv
DAFTAR ISTILAH ... xvi
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 4
1.3 Batasan Masalah ... 4
1.4 Metode Penelitian ... 5
1.5 Tujuan dan Manfaat Penelitian ... 6
xi
2.1.2 Ciri-ciri dan Sifat Algoritma ... 10
2.2 Logika Fuzzy ... 14
2.3 String Matching ... 15
2.3.1 Definisi String Matching ... 15
2.2.2 Kerangka Kerja String Matching ... 16
2.3.3 Kerangka Pikir String Matching ... 16
2.3.3 Macam Algoritma String Matching ... 18
2.4 Exact String Matching ... 18
2.5 Inexact String Matching (Fuzzy String Matching) ... 25
2.6 Karakteristik Nama ... 28
2.7 Normalisasi Nama ... 29
2.8 Sistem Basis Data ... 32
2.9 SQL ... 33
2.10 MySQL ... 34
2.11 Fungsi String MySQL ... 35
2.12 Aplikasi ... 35
2.13 Metode Pengembangan Sistem ... 34
2.13.1. Definisi Pengembangan Sistem ... 34
2.13.2. Macam-macam Metode Pengembangan Sistem ... 34
xii
3.1 Metode Pengumpulan Data ... 44
3.2 Metode Komparatif ... 45
3.3 Metode Pengembangan Sistem ... 46
3.4 Alasan Penggunaan RAD ... 48
3.5 Keunggulan dan Kelemahan RAD ... 49
BAB IV PENGEMBANGAN SISTEM 4.1 Metode Komparatif ... 50
4.1.1 Analisis String Matching ... 50
4.1.1.1 Exact String Matching ... 51
4.1.1.2 Normalisasi String ... 55
4.1.1.3 Inexact String Matching ... 63
4.2 Fase Perencanaan Syarat-syarat ... 68
4.2.1 Tujuan Informasi ... 53
4.2.2 Syarat Kebutuhan/Informasi ... 53
4.3 Perancangan Sistem ... 67
4.3.1 Perancangan Proses ... 67
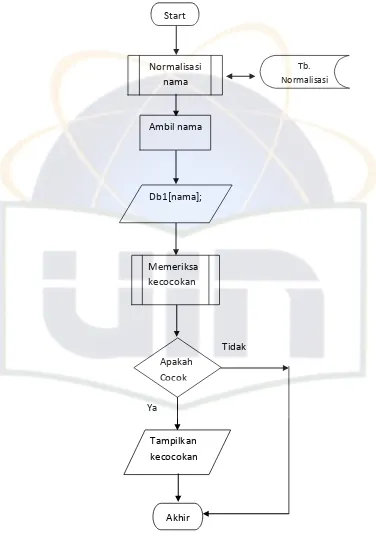
4.3.1.1 Algoritma Exact String Matching ... 67
4.3.1.2 Proses Kecocokan ... 68
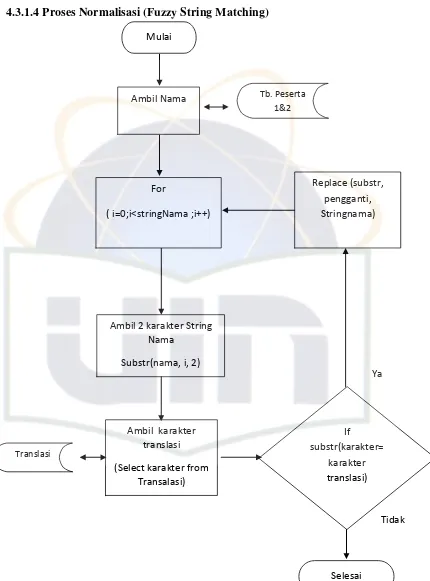
4.3.1.2 Algoritma Inexact String Matching ... 69
xiii
4.5 Implementasi ... 90 4.4.1 Pengenalan Sistem ... 90 4.4.1 Pengujian Sistem ... 91
BAB IV PENUTUP
5.1 Kesimpulan ……….. 104
5.2 Saran …..……….. 106
DAFTAR PUSTAKA ………. 107
xiv
Gambar 4.1 Proses Similarity Function ... 59
Gambar 4.2 Flowchart Exact String Matching ... 66
Gambar 4.3 Flowchart Kecocokan ... 67
Gambar 4.4 Flowchart Fuzzy String Matching ... 68
Gambar 4.5 Flowchart Normalisasi String Nama ... 69
Gambar 4.6 Rancangan Tampilan Exact String Matching ... 85
Gambar 4.7 Rancangan Tampilan Inexact String Matching ... 86
Gambar 4.8 Form Masukan Exact ... 88
Gambar 4.9 Form Masukan Inexact ... 89
Gambar 4.10 Tampilan Output Kecocokan ... 89
Gambar 4.11 Uji 1 ... 90
Gambar 4.12 Hasil Uji 1 ... 91
Gambar 4.13 Uji 2 ... 91
Gambar 4.14 Hasil Uji 2 ... 92
Gambar 4.15 Uji 3 ... 92
Gambar 4.16 Hasil Uji 3 ... 93
Gambar 4.17 Uji 4 ... 93
Gambar 4.18 Hasil Uji 4 ... 94
Gambar 4.19 Uji 5 ... 94
xv
Gambar 4.24 Hasil Uji 7 ... 97
Gambar 4.25 Uji 8 ... 97
Gambar 4.26 Hasil Uji 8 ... 98
Gambar 4.27 Uji 9 ... 98
Gambar 4.28 Hasil Uji 9 ... 99
Gambar 4.29 Uji 10 ... 99
Gambar 4.30 Hasil Uji 10 ... 100
Gambar 4.31 Uji 11 ... 100
Gambar 4.32 Hasil Uji 11 ... 101
Gambar 4.33 Uji 12 ... 101
xvi
Table 2.1 Simbol-simbol Flowchart ... 14
Table 2.2 Damerau Variasi Nama ... 30
Table 4.2 Contoh Variasi Penamaan ... 53
Table 4.3 Translasi Q-gram ... 59
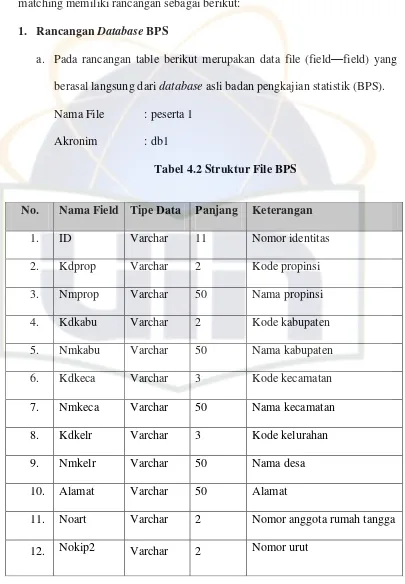
Table 4.4 Struktur File BPS ... 71
Table 4.5 Struktur File Translasi Db1 ... 73
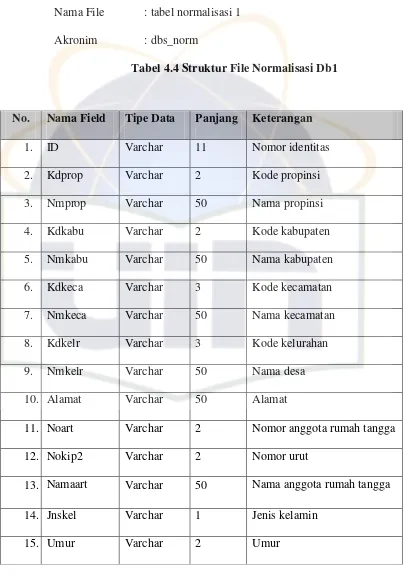
Table 4.6 Struktur File Normalisasi Db1 ... 75
Table 4.7 Struktur File Peserta Askes ... 76
Table 4.8 Struktur File Translasi Db2 ... 80
Table 4.9 Struktur File Normalisasi Db2 ... 85
Table 4.10 Kecocokan Field Kedua Database ... 85
xvii String Suatu kumpulan karakter
Pattern Sekumpulan string yang dicari pada teks.
Database Suatu kumpulan data atau informasi yang kompleks dimana data tersebut disusun menjadi beberapa kelompok dengan tipe data yang sejenis, dimana setiap datanya saling berhubungan satu sama lain atau dapat berdiri sendiri, sehingga mudah diakses.
Boolean Segala hal dapat diekspresikan dalam istilah binary (0 atau 1, hitam atau putih, ya atau tidak),
Fuzzy Logic Pendekatan yang membantu dalam menjelaskan
1 1.1. Latar Belakang Masalah
Dewasa ini kemajuan yang sangat pesat di bidang teknologi, terutama teknologi informasi komputer, mendorong munculnya inovasi baru dalam penyajian informasi untuk memenuhi kebutuhan informasi. Penyajian data atau informasi baik berupa subjek maupun objek dalam suatu perusahaan atau lembaga memerlukan adanya suatu database. Database adalah suatu kumpulan data atau informasi yang kompleks dimana, data tersebut disusun menjadi beberapa kelompok dengan tipe data yang sejenis, dimana setiap datanya saling berhubungan satu sama lain atau dapat berdiri sendiri, sehingga mudah diakses.
data yang berbeda. Perbedaan ini tentunya didasarkan karena perbedaan metode, teknik, serta perbedaan waktu pengambilan data maupun berbagai masalah teknis dilapangan yang dihadapi oleh masing-masing instansi. Perbedaan jumlah data dari dua instansi ini merupakan permasalahan bagi pengelola jamkesmas dalam menggunakan database penduduk miskin untuk penjaminan kesehatan secara menyeluruh dikarenakan akan berdampak pada keakurasian data penduduk miskin dilapangan serta mengakibatkan adanya sejumlah warga miskin yang tidak terdata maupun terdata lebih dari satu. Maka dari itu diperlukan suatu metode pencocokan untuk mencari kecocokan data diantara kedua database tersebut, yang mana tiap penduduknya memiliki data identitas yang bervariatif, sehingga tujuan dari penjaminan kesehatan dapat memadai atau terpenuhi.
Metode pencocokan string (string matching) yang merupakan bagian dalam proses pencarian string memegang peranan penting untuk mendapatkan dokumen yang sesuai dengan kebutuhan informasi. Pencocokan string (string matching) secara garis besar dapat dibedakan menjadi dua yaitu pencocokan
string secara eksak/sama persis (exact string matching) dan pencocokan string berdasarkan kemiripan (inexact string matching/fuzzy string matching). Fuzzy string matching (inexact string matching) merupakan pencocokan string yang
matching) dan berdasarkan kemiripan ucapan (phonetic string matching).
Dalam permasalahan ini penulis menggunakan fuzzy string matching proses pendekatan secara kemiripan penulisan (approximate) serta brute force yang mewakili algoritma exact string matching. Adapun dalam pencocokan ini, penulis lebih berpusat terhadap analisa string nama peserta, dikarenakan nama orang (peserta) merupakan string yang memiliki aneka ragam bentuk penulisan dalam satu pengucapan nama orang dalam pemasukan data peserta. Misalnya dalam permasalahan ini suatu string nama orang memiliki suatu bentuk pola huruf penulisan yang variatif tapi memiliki cara pengucapan yang sama dalam satu nama orang, sehingga diperlukan suatu aturan serta analisa yang tepat untuk menganalisa permasalahan mengenai pencocokan data string nama orang.
Berdasarkan uraian permasalahan tersebut, maka penulis mengambil suatu judul “Analisis Penerapan String Matching dalam Komparasi Data Kepesertaan Jaminan Kesehatan Masyarakat (JAMKESMAS) ” pada
tugas akhir (skripsi) ini.
1.2. Rumusan Masalah
Berpijak dari uraian yang telah dikemukakan pada latar belakang masalah, dapat dirumuskan masalah yang akan diteliti dalam hal ini adalah :
b. Bagaimana penerapan inexact string matching dan exact string matching dalam pencocokan data nama orang (peserta).
c. Bagaimana jumlah kesesuaian (kecocokan) data antar kedua database dalam penerapan string matching.
1.3. Batasan Masalah
Adapun yang diteliti dalam hal tugas akhir ini mencakup :
1. Analisis dan penerapan algoritma string matching (Brute Force dan Approximate) dalam penyelesaian pencocokan database dalam komparasi data kepesertaan.
2. Menggunakan sample data BPS dan ASKES yang diambil pada wilayah Bangka Belitung .
3. Mengaplikasikan algoritma string matching menggunakan PHP sebagai bahasa pemrograman dan MySQL sebagai database server.
1.4. Metode Penelitian
Untuk mendapat data dan fakta yang sebenarnya dalam menguraikan masalah pada penelitian ini, maka penulis merumuskan cara yang tepat dalam memecah permasalahan yang ada dengan :
1. Metode Pengumpulan data
dokumentasi. Metode dokumentasi adalah tehnik pengumpulan data yang dilakukan dengan membaca dan mempelajari buku, dokumen, jurnal serta literatur yang berkaitan dengan objek penelitian (Arikunto, 2006 : 231). Pengumpulan data ini penulis lakukan dengan cara mengunjungi perpustakaan maupun melalui artikel-artikel web online.
2. Metode Pengembangan Sistem
Metodologi yang digunakan pada pengembangan sistem penerapan algoritma string matching dalam komparasi data penamaan ini adalah metodologi pengembangan sistem RAD (Rapid Aplication Development) Kendall & Kendall, yang meliputi:
a. Fase perencanaan syarat-syarat : melakukan identifikasi terhadap kebutuhan informasi untuk memecahkan permasalahan dan menganalisa metode yang tepat guna memberikan solusi untuk mencapai tujuan dan syarat-syarat informasi.
b. Fase design : merancang proses-proses yang terjadi pada sistem program, database, maupun antarmuka (interface) aplikasi yang hendak dibangun.
c. Fase konstruksi : membangun aplikasi yang dibuat dengan cara pengkodean program.
1.5. Tujuan dan Manfaat Penelitian Tujuan dari penelitian ini yakni :
a. Mendapatkan kecocokan data peserta antar kedua database.
b. Menganalisis pencocokan string (string matching) nama orang dalam komparasi data kepesertaan.
c. Agar dapat diaplikasikan dalam berbagai permasalahan pencocokan komparasi data nama orang (peserta).
Penelitian ini diharapkan dapat bermanfaat :
a. Bagi Pengguna : Menyelesaikan permasalahan perbedaan data rujukan kepesertaan jamkesmas yang akurat dengan lebih cepat, efisien, dan murah.
b. Bagi Penulis : Memberikan pengetahuan tentang penerapan algoritma string matching dalam analisis bentuk penulisan nama orang (peserta) dan komparasi data peserta.
c. Bagi Universitas : Sebagai wahana dalam mengembangkan kemampuan mahasiswa/i dalam penyusunan tugas akhir.
1.6. Sistematika Penulisan
Secara garis besar, tugas akhir ini terbagi menjadi 5 bab, yaitu : BAB I : PENDAHULUAN
masalah, batasan masalah, tujuan, manfaat serta metodologi penelitian dan sistematika penulisan dalam tugas akhir ini. BAB II : LANDASAN TEORI
Dalam bab ini penulis akan menjelaskan secara detail teori-teori relevan yang digunakan dan mendasari dalam analisa penelitian ini. Bab ini terdiri atas teori pendukung, pengertian serta penjabaran yang dapat dijadikan sebagai suatu landasan teori analisa dari penelitian terhadap penerapan string matching dalam komparasi data kepesertaan.
BAB III : METODOLOGI PENELITIAN
Dalam bab ini penulis mencoba memaparkan mengenai metodologi yang digunakan selama menganalisa tentang penerapan fuzzy string matching dan exact string matching, pengembangan sistem yang digunakan, langkah (fase) kerja pengembangan sistem .
BAB IV : PENGEMBANGAN SISTEM
BAB V : PENUTUP
9 BAB II
LANDASAN TEORI
Dalam proses menyelesaikan penelitian ini penulis mendapatkan berbagai teori, konsep, serta berbagai uraian-uraian yang relevan terhadap objek penelitian dari berbagai referensi sehingga dapat dijadikan acuan pendukung penulis dalam pelaksanaan penelitian ini. Dalam bagian ini penulis mencoba menjelaskan teori-teori yang mendukung dalam menganalisa serta menerapkan algoritma string matching dalam penyelesaian kasus permasalahan komparasi data kepesertaan.
2.1. Konsep Algoritma 2.1.1. Definisi Algoritma
Menurut, Munir (2001:4) Algoritma adalah urutan langkah-langkah logis penyelesaian masalah yang disusun secara sistematis, sedangkan menurut Kamus Besar Bahasa Indonesia (1976:30) algoritma adalah urutan logis pengambilan putusan untuk pemecahan masalah.
Adapun definisi algoritma meliputi (Suarga, 2004 : 1) :
1. Teknik penyusunan langkah-langkah penyelesaian masalah dalam bentuk kalimat dengan jumlah kata terbatas, tetapi tersusun secara logis dan sistematis.
Kata algoritma sendiri diadaptasi dari nama ilmuwan muslim Abu Ja’far
Muhammad ibn Musa Al-Khawarizmi (780-847 M) yang banyak menghasilkan karya dalam bidang matematika, disamping karya-karyanya dalam bidang lainnya seperti geografi dan musik (Wahid, 2004 : 1).
2.1.2. Ciri – ciri dan Sifat Algoritma
Donald E. Knuth (1973), menyatakan bahwa ada beberapa ciri-ciri algoritma, yaitu :
a. Algoritma mempunyai awal dan akhir. Suatu algoritma harus berhenti setelah mengerjakan serangkaian tugas atau dengan kata lain suatu algoritma harus memiliki langkah yang terbatas.
b. Setiap langkah harus didefinisikan dengan tepat sehingga tidak memiliki arti ganda.
c. Memiliki masukan atau kondisi awal. d. Memiliki keluaran atau kondisi akhir.
e. Algoritma harus efektif; bila dikuti dengan benar-benar akan menyelesaikan persoalan.
a. Input : suatu algoritma memiliki input atau kondisi awal sebelum algoritma dilaksanakan dan bisa berupa nilai-nilai pengubah yang diambil dari himpunan khusus.
b. Output : suatu algoritma akan menghasilkan output setelah dilaksanakan, atau algoritma akan mengubah kondisi awal menjadi kondisi akhir, dimana nilai output diperoleh dari nilai input yang telah diproses melalui algoritma.
c. Definiteness : langkah-langkah yang dituliskan dalam algoritma terdefinisi dengan jelas sehingga mudah dilaksanakan oleh pengguna algoritma.
d. Finiteness : suatu algoritma harus memberi kondisi akhir atau output setelah melakukan sejumlah langkah yang terbatas jumlahnya untuk setiap kondisi awal atau input yang diberikan.
e. Effectiveness : setiap langkah dalam algoritma bisa dilaksanakan dalam suatu selang waktu tertentu sehingga pada akhirnya member solusi sesuai yang diharapkan.
f. Generality : langkah-langkah algoritma berlaku untuk setiap himpunan input yang sesuai dengan persoalan yang akan diberikan, tidak hanya untuk himpunan tertentu.
Algoritma sebagai langkah-langkah pemecahan masalah dapat dituliskan dengan berbagai cara , yaitu (Wahid, 2004 : 9) :
Penulisan algoritma dengan uraian deskriptif menggunakan bahasa yang biasa digunakan sehari-hari.
2. Algoritma pseudecode adalah algoritma yang dituliskan dalam kode-kode yang disepakati dan mempunyai urutan-urutan tertentu. Kode-kode ini dapat dikembangkan sendiri asalkan arti dari setiap Kode-kode disepakati bersama.
3. Bagan alir (flowchart)
Flowchart (bagan alir dokumen) adalah penggambaran secara grafik dari langkah-langkah dan urutan-urutan prosedur dari suatu program ( Jogiyanto Hartono : 1989).
Berikut ini adalah simbol-simbol yang digunakan dalam bagan alir dokumen menurut Marshall B. Romney ( 2004 ; 198 ) :
Tabel 2.1 Simbol-simbol Flowchart
Simbol Keterangan
Dokumen
Dokumen atau laporan : dokumen tersebut dapat dipersiapkan dengan tulisan tangan, atau di cetak dengan komputer.
Input/output
Fungsi input atau output apa pun di dalam bagan alir program. Juga dipergunakan untuk mewakili jurnal dan buku besar dalam bagan alir dokumen.
On-page
connector
akan menghindari garis-garis yang saling silang di satu halaman.
Off-page
connector
Suatu penanda masuk dari, atau keluar ke, halaman lain.
Proses manual
Pelaksanaan pemrosesan yang dilaksanakan secara manual.
Anotasi
Komentar deskriptif tambahan atau catatan penjelasan untuk klarifikasi.
File
File dokumen secara manual disimpan dan ditarik kembali; huruf yang ditulis di dalam simbol menunjukkan urutan pengaturan file secara
N = numeris, A = alfabetis, D = berdasar tanggal.
Pemrosesan dengan Komputer
Keputusan
Langkah pengambilan keputusan; dipergunakan dalam sebuah program komputer bagan alir untuk memperlihatkan pembuatan cabang ke jalan alternative.
Arus dokumen atau proses
Arah pemrosesan atau arus dokumen; arus yang normal berada dibawah dan mengarah ke kanan.
Terminal
Titik awal, akhir, atau pemberhentian dalam suatu proses atau program; juga dipergunakan untuk menunjukkan adanya pihak eksternal.
Disk Magnetic
Data disimpan secara permanen di dalam disk magnetis, dipergunakan untuk file utama ( master file ) dan database.
Sumber : Mulyadi, Sistem Akuntansi, 2001
2.2. Logika Fuzzy
Logika Fuzzy adalah peningkatan logika boolean yang berhadapan dengan konsep kebenaran sebagian. Di mana logika klasik menyatakan bahwa segala hal dapat diekspresikan dalam istilah binary (0 atau 1, hitam atau putih, ya atau tidak), logika fuzzy menggantikan kebenaran boolean dengan tingkat kebenaran (Kusumadewi, 2004).
Kusumadewi dan Purnomo (2004), pendekatan metode fuzzy dapat membantu dalam menjelaskan ketidakpastian batas antara satu kriteria dengan kriteria lainnya, yang disebabkan oleh adanya penilaian manusia terhadap sesuatu secara kumulatif. Teori ini dapat digunakan untuk membantu menyelesaikan permasalahan dalam ketidakpastian penulisan nama orang.
2.3. Pencocokan String (StringMatching)
2.3.1. Definisi StringMatching
Menurut Black (dalam Syaroni dan Munir, 2004:1) string adalah susunan dari karakter-karakter (angka, alphabet, atau karakter yang lain) dan biasanya direpresentasikan sebagai struktu data array. String dapat berupa kata, frase, atau kalimat. Sedangkan string matching menurut Black (dalam syaroni dan munir, 2004:1) diartikan sebagai sebuah permasalahan untuk menemukan pola susunan karakter string didalam string lain atau bagian dari isi teks. String matching dalam bahasa Indonesia dikenal dengan istilah pencocokan string (Munir dalam Hadiati, 2007:1).
2.3.2. Kerangka Kerja String Matching
Persoalan pencarian string dirumuskan sebagai berikut (Munir, 2004 : 1) Diberikan :
1. Sebuah teks (text), yaitu sebuah (long) stringyang panjangnya n karakter.
2. Pattern, yaitu sebuah string dengan panjang m.
Dengan sebuah nilai karakter (m < n) yang akan dicari dalam teks. Dalam algoritma pencocokan string, teks diasumsikan berada di dalam memori, sehingga bila kita mencari string di dalam sebuah arsip, maka semua isi arsip perlu dibaca terlebih dahulu kemudian disimpan di dalam memori. Jika pattern muncul lebih dari sekali di dalam teks, maka pencarian hanya akan memberikan keluaran berupa lokasi pattern ditemukan pertama kali.
2.3.3. Kerangka Pikir String Matching
Algoritma string matching dapat diklasifikasikan menjadi 3 bagian menurut arah pencariannya, yakni (Charras, 1997 : 12).
1. From left to right
Dari arah yang paling alami, dari kiri ke kanan, yang merupakan arah untuk membaca. Algoritma yang termasuk kategori ini adalah algoritma brute force, algoritma knuth moris Pratt.
Dari arah kanan ke kiri, arah yang bisanya menghasilkan hasil terbaik secara partikal. Algoritma yang termasuk kategori ini adalah algoritma boyer-moore.
3. In a specific order
Dari arah yang ditentukan secara spesifik oleh algoritma tersebut, arah ini menghasilkan hasil terbaik secara teoritis. Algoritma yang termasuk kategori ini adalah algoritma colossi dan algoritma crochemore-perrin.
Beberapa konsep string matching antara lain:
1. Approximate string matching, yaitu sebuah pencarian terhadap pola-pola string (mengandung beberapa proses yaitu mengitung jumlah karakter yang berbeda, penyisipan dan penghapusan karakter) sehingga mendekati pola atau pattern dari string yang dicari. Dari wikipedia didefinisikan sebagai sebuah teknik untuk mencari sebuah pola yang mendekati string dari sebuah kumpulan teks.
2.3.4. Macam Algoritma String Matching
Secara garis besar string matching dibedakan menjadi dua (Binstock & Rex dalam Syaroni & Munir, 2004 : 2), yaitu:
1. Exact string matching
2. Inexact string matching atau Fuzzy string matching.
2.4. Exact String Matching
Exact string matching, merupakan pencocokan string secara tepat dengan
susunan karakter dalam string yang dicocokkan memiliki jumlah maupun urutan karakter dalam string yang sama. Bagian algoritma ini bermanfaat jika pengguna ingin mencari string dalam dokumen yang sama persis dengan string masukan.
Beberapa algoritma exact string matching yang mengemuka antara lain :
1. Brute Force
Analisis dengan metoda Brute Force adalah membandingkan karakter per karakter sampai ditemukannya pola yang dicari dari awal string sampai dengan akhir string (Sagita, 2006 :1 ).
Dengan asumsi bahwa teks berada di dalam array T[1..n] dan pattern berada di dalam arrayP[1..m], maka algoritma brute force pencocokan string adalah sebagai berikut:
a. Mula-mula pattern P dicocokkan pada awal teks T.
sampai:semua karakter yang dibandingkan cocok atau sama (pencarian berhasil), atau dijumpai sebuah ketidakcocokan karakter (pencarian belum berhasil).
c. Bila pattern P belum ditemukan kecocokannya dan teks T belum habis, geser pattern P satu karakter ke kanan dan ulangi langkah 2.
Kekuatan dan Kelemahan Metode Brute Force. (Munir, 2004:6) a. Kekuatan:
1) Metode brute force dapat digunakan untuk memecahkan hampir sebagian besar masalah (wide applicability).
2) Metode brute force sederhana dan mudah dimengerti. 3) Metode brute force menghasilkan algoritma yang layak
untuk beberapa masalah penting seperti pencarian, pengurutan, pencocokan string, perkalian matriks.
4) Metode brute force menghasilkan algoritma baku (standard) untuk tugas-tugas komputasi seperti penjumlahan/perkalian n buah bilangan, menentukan elemen minimum atau maksimum di dalam tabel (list). b. Kelemahan:
1) Metode brute force jarang menghasilkan algoritma yang mangkus.
3) Tidak sekontruktif/sekreatif teknik pemecahan masalah lainnya.
Berikut ini adalah pseudecode dari algoritma brute force :
2. Knuth Morris Pratt
Algoritma KMP dikembangkan oleh D. E. Knuth, bersama-sama dengan J. H. Morris dan V. R. Pratt. (Munir, 2004 : 8) Dengan algoritma KMP procedure PencocokanString(input P : string, T : string, n, m : integer,output idx : integer)
{ Masukan: pattern P yang panjangnya m dan teks T yang panjangnya n. Teks T direpresentasika sebagai string (array of character)
Keluaran: lokasi awal kecocokan (idx) }
Deklarasi i : integer
ketemu : boolean Algoritma:
i 0
ketemu false
while (i n-m) and (not ketemu) do j 1
while (j m) and (Pj = Ti+j ) do j j+1
endwhile
{ j > m or Pj Ti+j }
if j = m then{ kecocokan string ditemukan } ketemu true
else
i i+1 {geser pattern satu karakter ke kanan teks } endif
endfor
{ i > n – m or ketemu } if ketemu then
idx i+1 else
waktu pencarian dalam pencocokan pattern dan teks dapat berkurang dikarenakan algoritma ini melakukan sejumlah pergeseran lebih jauh sesuai dengan informasi ketidakcocokan string antara teks dan pattern.
Dalam Algoritma Knuth-Morris-Pratt (KMP), untuk setiap karakter yang dibandingkan kita bisa memutuskan apakah berhasil atau gagal. Algoritma KMP membangun sebuah mesin automata yang status-statusnya adalah status dari string yang sedang kita cari dan setiap status memiliki fungsi berhasil dan gagal. Berhasil artinya status akan bergerak lebih mendekat ke status akhir dan gagal artinya status bisa jadi semakin jauh atau tetap terhadap status akhir. Kita akan mendapatkan sebuah karakter dari text saat kita berhasil dalam membandingkan dan akan me-reuse karakter bila kita gagal (Sagita : 3).
Berikut ini adalah pseudecode dari algoritma brute force :
procedure KMPsearch(input m, n : integer, input P : array[1..m] ofchar, input T : array[1..n] ofchar, output idx : integer)
{ Mencari kecocokan pattern P di dalam teks T dengan algoritma Knuth-Morris-Pratt. Jika ditemukan P di dalam T, lokasi awal kecocokan disimpan di dalam peubah idx.
Masukan: pattern P yang panjangnya m dan teks T yang panjangnya n.
Teks T direpresentasika sebagai string (array of character) Keluaran: posisi awal kecocokan (idx). Jika P tidak ditemukan, idx = -1.
}
Deklarasi i, j : integer ketemu : boolean
b : array[1..m] ofinteger
procedure HitungPinggiran(input m : integer, P : array[1..m] ofchar, output b : array[1..m] ofinteger)
3. Algoritma Boyer Moore
Algoritma boyer-moore adalah algoritma yang mempertimbangkan string matching dengan efisiensi tinggi dari aplikasi. Algoritma ini melakukan
pencocokan karakter yang dimulai dari kanan ke kiri (Purwanto, 2008).
Algoritma Boyer-Moore dipublikasikan oleh Robert S. Boyer, dan J. Strother Moore pada tahun 1977. Tidak seperti dua algoritma sebelumnya, algoritma Boyer-Moore memulai mencocokkan karakter dari sebelah kanan pattern. Ide dibalik algoritma ini adalah bahwa dengan memulai
Algoritma:
HitungPinggiran(m, P, b) j 0
i 1
ketemu false
while (i n and not ketemu) do while((j > 0) and (P[j+1] T[i])) do j b[j]
endwhile
if P[j+1]=T[i] then j j+1
endif
if j = m then ketemu true else
i i+1 endif endwhile if ketemu then
idx i-m+1 { catatan: jika indeks array dimulai dari 0, maka idx i-m }
pencocokan karakter dari kanan, dan bukan dari kiri, maka akan lebih banyak informasi yang didapat (Boyer). Jadi kita bisa melompati atau tidak melakukan perbandingan-perbandingan karakter yang diprediksikan akan gagal. Karakter paling kanan pada pola merupakan karakter pertama yang akan dicocokkan dengan teks.
Sehingga prinsip dasar dari algoritma Boyer-Moore ini yakni : 1. Pembacaan karakter dari kanan ke kiri.
2. Preprocessing dimana terdapat kondisi bad karakter preprocessing dan good suffix preprocessing.
2.5. Inexact string matching (fuzzy String Matching)
Fuzzy string matching merupakan pencocokan string secara samar,
maksudnya pencocokan string dimana string yang dicocokkan memiliki kemiripan dimana keduanya memiliki susunan karakter yang berbeda (mungkin jumlah atau urutannya) tetapi string-string tersebut memiliki kemiripan baik kemiripan tekstual/penulisan (approximate string matching) atau kemiripan ucapan (phonetic string matching). Metoda fuzzy string matching diarahkan untuk mencari nilai dari beberapa string yang mendekati
dan tidak hanya mengasilkan cocok atau tidak cocok (Syaroni dan Munir, 2004 : 2).
Konsep Fuzzy String Matching. (Dewanto : 2007)
2. Melakukan pencarian terhadap string yang sama dan juga string yang mendekati dengan string lain yang terkumpul dalam sebuah penampung atau kamus.
3. Kunci dari konsep pencarian ini adalah bagaimana memutuskan bahwa sebuah string yang dicari memiliki kesamaan dengan string tertampung di kamus, meskipun tidak sama persis dalam susunan karakternya. Untuk memutuskan ‘kesamaan’ ini dipergunakan sebuah fungsi yang
diistilahkan sebagai similarity function. Fungsi ini akan bertugas memutuskan string hasil pencarian jika ditemukan string hasil pendekatan (aproksimasi).
Inexact string matching masih dibagi menjadi dua yaitu : (Binstock & Rex dalam Syaroni & Munir, 2004 : 2)
1. Approximate stringmatching
Approximate string matching adalah pencocokan string berdasarkan
kemiripan penulisan (jumlah karakter,susunan karakter dalam dokumen). Tingkat kemiripan ditentukan dengan jauh tidaknya beda penulisan dua buah string yang dibandingkan tersebut dan nilai tingkat kemiripan ini ditentukan oleh pemrogram (programmer).
2. Phonetic String Matching
Phonetic String Matching adalah pencocokan string dengan dasar
kemiripan dari segi pengucapannya meskipun ada perbedaan penulisan dua string yang dibandingkan tersebut. Contoh step dengan steb dari tulisan berbeda tetapi dalam pengucapannya mirip sehingga dua string tersebut dianggap cocok. Contoh yang lain adalah step, dengan steppe, sttep, stepp, stepe. Dalam pembagiannya beberapa algoritma phonetic
string matching antara lain : soundex, metaphone, caverphone, phonex, NYSIIS, Jaro-Winkler, dan lain-lain. (Syaroni dan Munir, 2004)
Dalam penerapan kedua algoritma tersebut, sebenarnya phonetic string matching dapat dimanfaatkan untuk approximate string matching dengan batasan dua string yang dicocokkan masih memiliki kemiripan ucapan. Phonetic string matching sering juga dimanfaatkan untuk approximate string matching karena phonetic string matching lebih mudah diimplementasikan. Phonetic string matching banyak digunakan dalam bahasa Inggris karena dalam bahasa Inggris terdapat perbedaan antara penulisan dan pengucapan. Hal itupun terjadi pada bentuk penamaan Indonesia.
2.6. Karakteristik Nama
dipakai untuk mengenali sekelompok atau hanya sebuah benda dalam konteks yang unik maupun yang diberikan. Nama manusia umumnya terbagi kepada nama depan dan nama keluarga (marga), contohnya Ali Wijaya, di mana Ali adalah nama depan sedangkan Wijaya adalah marganya. Meskipun begitu, ada pula budaya-budaya yang tidak mengenal konsep tersebut. Ada pula nama panggilan yang merupakan nama khusus yang digunakan dalam bersosialisasi.
Ada banyak cara untuk menyusun suatu nama, tergantung dari budaya setempat dan bahasa setempat dan biasanya merupakan kombinasi dari
1. nama pemberian/nama depan (unik untuk setiap anak).
2. nama keluarga (unik untuk setiap keturunan dari garis laki-laki
3. nama tengah (untuk membedakan nama pemberian yang sama dari satu keluarga)
4. nama akhir (nama pemberian yang diletakkan setelah nama depan) 5. nama ayah
6. nama ibu
7. nama gadis (nama keluarga ibu sebelum menikah) 8. nama keluarga kakek dari ayah (=nama keluarga)
9. nama keluarga nenek dari ayah (=nama gadis nenek dari ayah) 10.nama keluarga kakek dari ibu (=nama gadis ibu)
11.nama keluarga nenek dari ibu (=nama gadis nenek dari ibu) 12.nama baptis
14.nama pekerjaan (biasanya di Eropa/Amerika) 15.nama warna (biasanya di Eropa/Amerika)
Daftar ini hanya sebagian kecil dari variasi yang mungkin terbentuk.
2.7. Normalisasi nama
Sebuah nama dapat memiliki banyak variasi dalam berbagai bahasa, biasanya untuk membuat suatu nama menjadi unik, orang juga membuat variasi mereka sendiri terhadap suatu nama yang telah ada. Nama-nama yang umum dipakai biasanya diturunkan dari nama orang-orang terkenal pada zaman dahulu, atau nama yang memiliki makna khusus (kata-kata yang indah, profesi orangtua, nama bunga, dan lain-lain).
[image:44.595.109.520.157.700.2]Dengan demikian, Penulisan dan cara pengucapan nama sangat tergantung kepada bahasa yang digunakan. Damerau (1964 : 171-176) menunjukkan setidaknya ada empat kejadian yang mengakibatkan variasi pada nama.
Tabel 2.2 Damerau Variasi Nama
Jenis Nama Dasar Variasi
Variasi pada nama tersebut, secara umum juga terjadi pada penamaan Indonesia. Sehingga dapat disimpulkan bahwa sifat bentuk penulisan dan pengucapan penamaan orang, adalah:
1. Memiliki bentuk cara penulisan yang bervariasi dalam satu nama orang.
2. Tidak memiliki standar penulisan nama yang baku. 3. Ketidakpastian (kekaburan) dalam bentuk penulisan.
4. Beberapa nama yang penulisannya berbeda, memiliki cara pengucapan yang sama.
Oleh karena itu, berdasarkan referensi studi yang dilakukan oleh Karhendana dalam studinya normalisasi string untuk optimasi phonetic string matching dalam menangani data nama orang didapatkan bahwa perlu adanya suatu langkah normalisasi sebelum dilakukan langkah pencocokan string dalam penamaan Bahasa Indonesia. Hal ini dilakukan untuk mendapatkan bentuk normal dari suatu bentuk penamaan Indonesia untuk meningkatkan akurasi algoritma pencocokan string dalam string nama orang.
Adapun secara umum normalisasi bertujuan, yaitu : 1. Untuk menghilangkan kerangkapan data.
2. Untuk mengurangi kompleksitas.
3. Untuk mempermudah pemodifikasian data
Proses normalisasi secara garis besar terbagi menjadi beberapa tahap, yaitu : (Karhendana : 2002)
2. Eliminasi duplikasi karakter
Tahap yang paling penting dalam proses normalisasi adalah translasi Q-gram. Q-gram adalah susunan beberapa huruf yang berurutan. translasi q-gram dilakukan dengan mengubah susunan huruf tersebut menjadi q-gram lain yang lebih sederhana. Tahap eliminasi duplikasi karakter dilakukan dengan menghilangkan karakter-karakter berurutan yang sama. Kebanyakan duplikasi karakter ini muncul setelah langkah normalisasi Q-gram. (Karhendana : 2002)
2.8. Sistem Basis Data
Database adalah kumpulan informasi yang disimpan di dalam komputer secara sistematik dan terstruktur sehingga dapat diperiksa menggunakan suatu program komputer untuk memperoleh informasi dari basis data tersebut.
Menurut Fathansyah (1999 : 2), basis data dapat diartikan sebagai suatu himpunan kelompok data (arsip) yang saling berhubung, diorganisasi sedemikian rupa agar kelak dapat dimanfaatkan kembali dengan cepat dan mudah.
A. Alasan Perlunya Database
1. Basis data merupakan salah satu komponen penting dalam system informasi, karena merupakan dasar dalam menyediakan informasi. 2. Basis data menentukan kualitas informasi : akurat, tepat pada
3. Basis data mengurangi duplikasi data (data redudancy).
4. Dengan mengaplikasikan basis data hubungan data dapat ditingkatkan.
5. Basis data dapat mengurangi pemborosan tempat simpanan luar.
B. Bahasa Basis Data
Bahasa basis data terdiri atas :
1. Data Definition Language (DDL), merujuk pada kumpulan perintah yang dapat digunakan untuk mendefinisikan objek – objek basis data, seperti membuat sebuah tabel basis data atau indeks primer atau sekunder.
2. Data Manipulation Language (DML), mengacu pada kumpulan perintah yang dapat digunakan untuk melakukan manipulasi data, seperti penyimpanan data ke suatu tabel, kemudian mengubahnya dan menghapusnya atau hanya sekedar menampilkannya kembali.
C. Manfaat Basis Data
Secara lebih lengkap, pemanfaatan basis data dilakukan untuk memenuhi sejumlah tujuan (objektif) seperti berikut
a. Kecepatan dan kemudahan (Speed) b. Efisiensi ruang penyimpanan (Space) c. Keakuratan (Accuracy)
e. Kelengkapan (Completeness) f. Keamanan (Security)
g. Kebersamaan pemakaian (Share sability)
2.9. SQL (Structured Query Language)
SQL adalah bahasa yang digunakan untuk berkomunikasi dengan database. Menurut ANSI (American National Standards Institute), bahasa ini
merupakan standar untuk relational database management systems (RDBMS).
Bahasa SQL memiliki struktur yang mudah dipahami karena perintah – perintahnya pada dasarnya dibuat dari bahasa Inggris. Sehingga kita dapat melakukan perintah – perintah SQL ke dalam database, yaitu :
a. Memasukkan atau menambah record baru ke dalam database. b. Mengeksekusi query database
c. Mengambil data dari database d. Mengubah record pada database e. Menghapus record pada database
Perintah SQL dapat diketik dengan huruf besar atau kecil (non case sensitive). Setelah selesai mengetik perintah di MySQL harus diakhiri dengan
2.10. MySQL
MySQL adalah sebuah server database buatan T.c.X Data Konsultan AB SQL multiuser dan multi-threaded.
Beberapa keistimewaan MySQL:
1. API Languange (Application Programming Interface). Aplikasi database MySQL dapat ditulis dengan bahasa pemrograman C, Perl, PHP, dan lain-lain.
2. Large Tabel. MySQL menyimpan masing-masing tabel dalam database seperti file, terpisah dalam directori database.
3. Speed and Durability. MySQL lebih cepat 3-4 kali dari database komersial lain.
4. MySQL mudah untuk dikendalikan dan tidak membutuhkan database administrator proffesional untuk menginstall MySql.
5. MySQL adalah database relasional yang bersifat open source dan gratis.
6. Tersedia dibanyak platform (tersedia berbagai versi untuk berbagai sistem operasi).
7. Memiliki sistem sekuriti yang cukup baik dengan verifikasi host. 8. Mendukung ODBC untuk sistem operasi Microsoft Windows.
9. Tidak membutuhkan ruang harddisk yang besar untuk aplikasinya, dan mudah digunakan pada database server.
2.11. Fungsi String MySQL
Fungsi atau function adalah kata atau teks SQL yang mempunyai kegunaan khusus untuk mengolah suatu data, sedangkan string adalah rangkaian karakter, angka, dan symbol-simbol lainnya. Banyak fungsi string yang disediakan MySQL untuk memanipulasi data string sehingga memudahkan pengolahan data.
2.12. Aplikasi
Menurut Daryanto (2004:347), aplikasi adalah Software atau perangkat lunak yang dibuatuntuk menyelesaikan masalah-masalah khusus. Sedangkan menurut Jogiyanto (2004 : 4), aplikasi merupakan program yang berisikan perintah-perintah untuk melakukan pengolahan data. Jadi aplikasi secara umum adalah suatu proses dari cara manual yang ditransformasikan ke komputer dengan membuat sistem atau program agar data diolah lebih berdaya guna secara optimal, sedangkan menurut Kristanto (2004 : 1), software adalah instruksi (program komputer) yang ketika dijalankan
menyediakan fungsi dan tampilan yang diinginkan, struktur data yang memberikan kesempatan program untuk memanipulasi informasi dan dokumen yang mendeskripsikan operasi dan pengaturan program.
Didalam sebuah program aplikasi terbagi menjadi 2 bagian: ( Santosa, 2004)
1. Bagian Antarmuka –> Berupa tampilan untuk pemasukan data (input) dan untuk keluaran data (Output)
2. Bagian Aplikasi –> bagian yang berfungsi untuk menghasilkan informasi berdasar olahan data yang sudah dimasukkan oleh pengguna lewat algoritma yang diisyaratkan oleh aplikasi tersebut. Adapun dalam analisa penerapan fuzzy string matching ini aplikasi yang dibuat termasuk kedalam kategori bagian aplikasi.
2.13. Metode Pengembangan Sistem 2.13.1.Definisi Pengembangan Sistem
Menurut Govindaraju (2006:2) pengembangan sistem adalah aktifitas untuk menghasilkan sistem informasi berbasis komputer untuk menyelesaikan persoalan organisasi untuk memanfaatkan kesempatan yang timbul, sehingga sesuai dengan kasus permasalahan.
2.13.2.Macam-macam Metode Pengembangan Sistem 1. Model Siklus Kehidupan Klasik
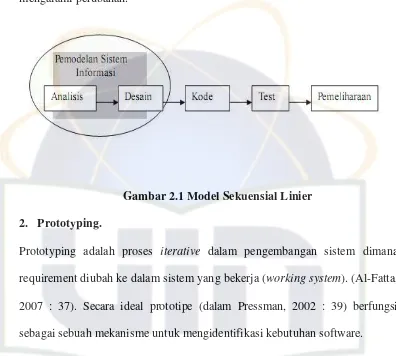
pengujian, dan pemeliharaan (Pressman : 1977). Model ini juga sering disebut dengan model air terjun.
Tahapan-tahapan Model Sekuensial Linier : 1. Rekayasa dan Pemodelan Sistem/Informasi
Karena perangkat lunak merupakan bagian dari suatu sistem maka langkah pertama dimulai dengan membangun syarat semua elemen sistem dan mengalokasikan ke perangkat lunak dengan memperhatikan hubungannya dengan manusia, perangkat keras dan database.
2. Analisis Kebutuhan Perangkat Lunak
Proses menganalisis dan pengumpulan kebutuhan sistem yang sesuai dengan domain informasi tingkah laku, unjuk kerja, dan antar muka (interface) yang diperlukan.
3. Desain
Proses desain akan menerjemahkan syarat kebutuhan ke sebuah perancangan perangkat lunak yang dapat diperkirakan sebelum dibuat coding.
4. Pengkodean (Coding)
Pengkodean merupakan proses menerjemahkan desain ke dalam suatu bahasa yang bisa dimengerti oleh komputer.
5. Pengujian
6. Pemeliharaan
[image:53.595.112.508.177.533.2]Perangkat lunak yang sudah disampaikan kepada pelanggan pasti akan mengalami perubahan.
Gambar 2.1 Model Sekuensial Linier 2. Prototyping.
Prototyping adalah proses iterative dalam pengembangan sistem dimana requirement diubah ke dalam sistem yang bekerja (working system). (Al-Fatta, 2007 : 37). Secara ideal prototipe (dalam Pressman, 2002 : 39) berfungsi sebagai sebuah mekanisme untuk mengidentifikasi kebutuhan software. Tahapan-tahapan dalam Prototyping adalah sebagai berikut:
1. Pengumpulan kebutuhan
Pelanggan dan pengembang bersama-sama mendefinisikan format seluruh perangkat lunak, mengidentifikasikan semua kebutuhan, dan garis besar sistem yang akan dibuat.
2. Membangun prototyping
3. Evaluasi protoptyping
Evaluasi ini dilakukan oleh pelanggan apakah prototyping yang sudah dibangun sudah sesuai dengan keinginann pelanggan. Jika sudah sesuai maka langkah 4 akan diambil. Jika tidak prototyping direvisi dengan mengulangi langkah 1, 2 , dan 3.
4. Mengkodekan sistem
Dalam tahap ini prototyping yang sudah di sepakati diterjemahkan ke dalam bahasa pemrograman yang sesuai
5. Menguji sistem
Pengujian ini dilakukan dengan White Box, Black Box, Basis Path, pengujian arsitektur dan lain-lain
6. Evaluasi Sistem
Pelanggan mengevaluasi apakah sistem yang sudah jadi sudah sesuai dengan yang diharapkan .Juka ya, langkah 7 dilakukan; jika tidak, ulangi langkah 4 dan 5.
7. Menggunakan sistem
Perangkat lunak yang telah diuji dan diterima pelanggan siap untuk digunakan.
3. Rapid Application Development (RAD).
menggunakan pendekatan konstruksi berbasis komponen. Sehingga apabila kebutuhan dipahami dengan baik, maka system fungsional yang utuh dapat diselesaikan dalam waktu kira-kira 60-90 hari.
Menurut Martin (dalam Kendall & Kendall, 2007 ; 237) Pendekatan RAD meliputi fase-fase:
1. Fase Perencanaan Kebutuhan (Requirement Planning).
Fase dimana pengguna tingkat tinggi memutuskan fungsi apa saja yang harus difiturkan oleh aplikasi tersebut.
2. Desain (Design Workshop)
Fase dimana pengguna diminta membahas aspek-aspek desain non teknis dari sistem, dengan bimbingan penganalisis.Karena tingginya sifat interaktif, fase ini sering digabungkan dengan fase konstruksi pada workshop desain RAD.
3. Fase Konstruksi
Pada fase ini setiap desain yang diciptakan dalam fase sebelumnya selanjutnya ditingkatkan untuk dilakukan pengkodean system.Kemudian setelah tahap ini selesai dilakukan uji kemampuan untuk mendapatkan komentar, dan revisi dari pengguna tingkat tinggi.
4. Fase Implementasi
4. Object Oriented Analysis Design (OOAD)
OOAD adalah metode pengembangan sistem yang lebih menekankan pada objek dibandingkan dengan data atau proses. Ada beberapa ciri khas dari pendekatan ini yaitu object, Inheritance dan object class. Objek adalah abstraksi dari benda nyata dimana data dan proses diletakkan bersama untuk memodelkan struktur dan perilaku dari objek dunia nyata. Objek class adalah sekumpulan objek yang berbagi struktur yang sama dan perilaku yang sama. Inheritance adalah properti yang muncul ketika tipe entitas atau objek class disusun secara hirarki dan setiap tipe entitas atau objek class menerima atau mewarisi atribut dan metode dari pendahulunya (Al Fatta, 2007: 38).
2.14. Unit Testing
Pengujian sistem perangkat lunak atau (software testing) adalah bagian dari suatu siklus yang melibatkan verifikasi apakah suatu unit yang dikembangkan telah memenuhi kebutuhan sistem (syarat-syarat informasi) yang didefinisikan pada tahapan sebelumnya.
Unit testing terdiri dari :
1. Pengujian Black Box
Black box testing adalah pengujian fungsional yang merupakan
hasil dari unit itu sesuai dengan proses bisnis yang diinginkan. Jika ada unit yang tidak sesuai outputnya maka untuk meneyelesaikannya, diteruskan pada pengujian white box (Al Fatta, 2007 : 172).
2. Pengujian White Box
Pengujian white box (structural testing) merupakan pengujian yang diturunkan dari pengetahuan struktur dan implementasi perangkat lunak. Pengujian structural biasanya diterapkan untuk unit program yang relative kecil seperti subrutin atau operasi yang terkait dengan suatu objek. Sebagaimana ditunjukan oleh namanya, penguji dapat menganalisis kode dan menggunakan pengetahuan mengenai struktur komponen untuk menurunkan data uji. Pengetahuan mengenai algoritma yang digunakan untuk implementasi beberapa fungsi dapat dipakai untuk mengidentifikasi partisi ekuivalensi lebih lanjut (Sommerville, 2003: 91).
2.15. Studi Sejenis
Untuk penelitian skripsi yang dilakukan, berikut ini adalah referensi tinjauan penelitian algoritma string matching dari dua buah skripsi dan jurnal-jurnal yang digunakan sebagai studi literature penulis diantaranya adalah :
didapatkan pada penelitian ini yakni algoritma boyer-moore memerlukan waktu yang lebih cepat dalam pencocokan dibandingkan knuth morris-pratt dan brute force tetapi boyer- moore tidak dapat melakukan pencocokan string untuk karakter ASCII data yang ada pada berkas komputer.
Endang Hastriana (2010). Perbandingan algoritma string matching knuth morris-pratt dengan boyer moore horspool pada simulasi pengenalan sidik
jari. Teknik Informatika Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah, Jakarta. Tujuan penelitian yang dibahas dalam tugas akhir ini merupakan penelitian yang dilakukan terhadap perbandingan algoritma knuth morris-pratt dan boyer moore pada suatu simulasi pengenalan sidik jari dengan menggunakan Borland Delphi melalui tahap model pengembangan sistem RAD. Hasil dari penelitian ini didapatkan bahwa boyer moore-horspool menghasilkan pencocokan yang lebih cepat dibanding knuth
morris-pratt karena boyer moore horspool melakukan pergeseran yang lebih jauh daripada knuth morris-pratt.
Mokhamad Syaroni dan Rinaldi Munir (2004). Pencocokan string berdasarkan kemiripan ucapan (phonetic string matching) dalam Bahasa Inggris. Tujuan penelitian yang dibahas dalam topik penelitian ini merupakan pembahasan dan analisis kemampuan tiga algoritma phonetic string matching yaitu algoritma soundex, metaphone, dan caverphone dari segi fonetik Bahasa Inggris. Hasil analasis kemampuan phonetic string matching algoritma soundex, metaphone, dan caverphone, menunjukkan bahwa kemampuan
Bernardino Madaharsa Dito Adiwidya (2009). Algoritma levensthein dalam pendekatan approximate string matching. Tujuan penelitian yang dibahas dalam topik penelitian ini merupakan pencarian jumlah operasi string dalam approximate string matching yang diperlukan untuk mentransformasikan suatu string menjadi string lain menggunakan pendekatan algoritma levenshtein. Hasil yang didapatkan pada penelitian ini disimpulkan bahwa levenshtein merupakan algoritma yang diperlukan untuk mencari perbedaan- perbedaan string yang ada pada operasi approximate dengan kompleksitas O(n2).
Anggy Sagita., dkk (2006). Analisa algoritma pencocokan string. Tujuan penelitian yang dibahas dalam topik penelitian ini merupakan suatu analisis algoritma staightforward matching dengan menggunakan brute force, knuth-morris-pratt, dan boyer-moore pada pencarian string dalam sekumpulan teks.
Hasil yang didapatkan yakni bahwa algoritma yang dianalisis pada penelitian ini hanya dapat menangani permasalahan string yang bersifat exact.
beberapa kekurangan masih muncul jika data yang dikirimkan bukan kode yang ada pada kamus sistem.
Berdasarkan penelitian yang dijabarkan diatas, maka penulis menjadikan penelitian-penelitian sebelumnya sebagai referensi studi sejenis untuk proses penelitian pada tugas akhir ini. Adapun penelitian-penelitian sebelumnya belumlah melakukan suatu penelitian analisis penerapan string matching menggunakan inexact string matching secara approximate string matching dan exact string matching secara brute force string matching pada suatu
44
Untuk mendapat data dan fakta yang sebenarnya dalam menguraikan masalah pada komparasi data untuk mendapatkan kecocokan data ini, maka penulis merumuskan cara yang tepat dalam memecahkan permasalahan yang terangkum dalam suatu rangkaian metodologi penelitian mengacu pada penelitian sebelumnya maupun referensi teori yang mendasari.
3.1. Metode Pengumpulan Data
Berkaitan dengan hal tersebut, penulis melakukan metode pengumpulan data. Pengumpulan data adalah prosedur yang sistematis dan standar untuk perolehan data yang diperlukan. Data yang dikumpulkan merupakan teori-teori yang telah berkembang dalam bidang ilmu yang berhubungan, dan teknik-teknik yang digunakan oleh peneliti sebelumnya. Metode pengumpulan data yang digunakan dalam hal ini adalah :
1. Metode Dokumentasi
2. Wawancara
Wawancara adalah teknik pengumpulan data yang dilakukan dengan Bapak Swasetyo Yulianto pada Desember 2010 di Badan Pengkajian dan Penelitian Teknologi guna mendapatkan informasi permasalahan yang dihadapi dalam pengelolaan data kepesertaan JAMKESMAS.
3.2. Metode Komparatif
3.3. Metode Pengembangan Sistem
Dalam pengembangan sistem yang dilaksanakan pada penerapan algoritma string matching dalam komparasi data kepesertaan ini penulis menggunakan model pengembangan RAD yang meliputi : (Kendall & Kendall, 2007:237)
1. Fase Perencanaan Syarat-syarat.
Dalam tahapan ini penulis merencanakan tujuan dan berbagai syarat-syarat dalam memenuhi kebutuhan sistem (aplikasi) dalam penyelesaian permasalahan kecocokan data kepesertaan ini. Menetukan syarat-syarat informasi salah satunya adalah menetukan data-data yang diperlukan dan menganalisa metode yang tepat guna memberikan solusi untuk mencapai tujuan, yakni dengan cara :
a. Mendefinisikan Masalah, adalah tahap untuk menentukan masalah apa yang harus diselesaikan dengan menggunakan sistem aplikasi yang akan dibangun. Hal ini dilakukan guna menentukan syarat-syarat informasi.
b. Menentukan kebutuhan syarat informasi untuk memecahkan permasalahan dan menganalisa metode yang tepat. Dalam menyelesaikan permasalahan komparasi data untuk mendapatkan kecocokan string data kepesertaan ini, penulis melakukan penyelesaian dengan menggunakan dua macam algoritma string matching yakni : 1. Exact String Matching
membuktikan dan menguji kehandalan algoritma ini dalam menyelesaikan permasalahan yang ada.
2. Fuzzy String Matching
Dalam hal ini penulis menggunakan algoritma approximate string matching untuk membuktikan serta menguji kehandalan algoritma
ini dalam meyelesaikan permasalahan yang ada.
Analisis algoritma string matching dalam komparasi data penamaan ini akan dijelaskan pada sub bab.
2. Fase Perancangan.
Dalam fase ini penulis melakukan perancangan terhadap pengaplikasian metode exact string matching dan fuzzy string matching, serta merancang aplikasi yang hendak dibuat atau dibangun guna menguji keefektifan metode algoritma dalam menyelesaikan permasalahan yang ada. Kegiatan yang dilakukan dalam tahap perancangan atau desain ini meliputi (Ladjamudin, 2005: 39):
a. Desain proses, meliputi desain tentang proses-proses apa saja yang dibutuhkan oleh sistem.
b. Desain basis data, merupakan desain tabel-tabel yang dibutuhkan dalam pengolahan data. Table-tabel ini akan diimplementasikan kedalam bentuk database, yang menggunakan program MySQL.
3. Fase Konstruksi.
Dalam fase ini penulis melakukan konstruksi aplikasi setelah melakukan fase perancangan aplikasi dengan cara pengkodean. Tools program yang digunakan dalam sistem penerapan algoritma string matching ini menggunakan PHP sebagai bahasa pemrograman dan MySQL sebagai database server.
4. Fase Implementasi.
Dalam fase ini penulis melakukan implementasi terhadap aplikasi yang dibangun guna menguji seberapa besar kemampuan metode fuzzy string matching dan exact string matching yang digunakan dalam menyelesaikan
permasalahan yang ada. Pengujian ini berguna agar penulis dapat mengetahui secara keseluruhan mengenai kesesuaian, efektifitas dan efisiensi penerapan algoritma string matching terhadap tujuan yang ingin dicapai, yang mana hal ini sangat berguna sebagai bahan kesimpulan dalam menilai akurasi kecocokan dalam menyelesaikan permasalahan pencocokan string komprasi data kepesertaan. Metode pengujian yang digunakan dalam pengujian sistem adalah metode pengujian white box pada pengujian sistem aplikasi yang dibangun.
3.4. Alasan Penggunaan RAD
1. Prinsip model pengembangan RAD yang waktunya cepat dan singkat dalam tiap langkah metode pengerjaannya .
2. Memudahkan dalam tiap-tiap langkah kerja karena adanya modularisasi pengerjaan.
3. Aplikasi yang dirancang dan dibangun hanya dipergunakan untuk mengimplementasikan metode algoritma yang dipilih guna menguji keefektifan algoritma dalam menyelesaikan permasalahan yang ada ssehingga tidak memerlukan tahap pemeliharaan.
4. Sangat cocok diterapkan pada aplikasi berskala kecil. Hal ini sesuai dengan aplikasi yang dibuat dalam penerapan metode algoritma string matching.
3.5. Keunggulan dan Kelemahan RAD a. Keunggulan:
1. Waktu pengembangan yang lebih singkat dan cepat jika kebutuhan dan batasan proyek diketahui.
2. Biaya yang relatif lebih murah atau rendah. b. Kelemahan:
1. Tidak cocok untuk proyek skala besar.
2. Hanya baik digunakan pada proyek penelitian yang dapat dimodularisasi.
50
Dalam melaksanakan penerapan string matching dalam komparasi data kepesertaan, penulis telah melalui berbagai tahap-tahapan metode penelitian hingga mencapai hasil dari tujuan yang hendak dicapai. Dalam bab ini penulis menjabarkan hal-hal yang dilakukan penulis selama penyelesaian penelitian ini, sesuai dengan metodologi penelitian yang dirujuk penulis.
4.1. Metode Komparatif
Dalam tahap komparatif ini penulis melakukan suatu proses analisis dalam penerapan string matching untuk komparasi data kepesertaan JAMKESMAS yang dilakukan dalam membandingkan dua data yang terdapat pada dua instansi yakni BPS dan ASKES. Data yang dibandingkan dalam komparasi data untuk mendapatkan kecocokan data ini merupakan data yang berasal dari wilayah Propinsi Bangka Belitung.
4.1.1. Analisis Algoritma String Matching
bentuk penulisan dalam satu nama orang, hal ini menunjukan bahwa string nama orang adalah hal yang bersifat kabur atau samar yang mana sesuai dengan prinsip logika fuzzy. Untuk menguatkan alasan dan sebagai parameter (ukuran) dalam pemilihan algoritma tersebut maka penulis kemudian juga menggunakan algoritma exact string matching.
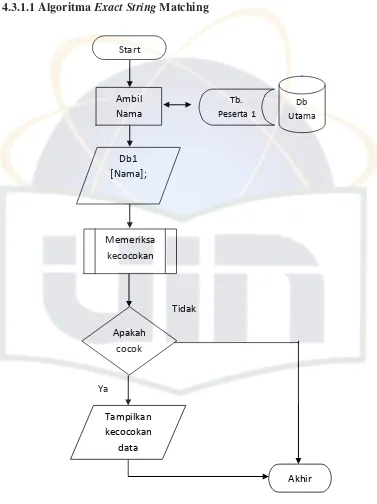
4.1.1.1Exact String Matching
Berdasarkan studi literatur yang dilakukan maka penulis memilih menggunakan algoritma brute force untuk diterapkan dalam komparasi data kepesertaan. Exact string matching merupakan algoritma yang digunakan penulis untuk menjadikan parameter (ukuran) dalam penggunaan algoritma inexact string matching.
Teknik Pencocokan pada Algoritma brute force :
1 2 3 4 5 6 1 2 3 4 5 6
1 … … … … 6
R A H M A T
R I Y A D I
E F E N D I
R A T I N A
S U M I N A
1 … … … … 6
E F E N D Y
J U N I A R
H A R T I N
H U S N A H
R E N A T A
Y U N I A R
2. Mencocokan kesamaan teks dengan membaca karakter sebelah kiri string yang berindeks-1 pada masing-masing database.
a. Bila karakter pada record masing-masing database memiliki kesamaan, maka pencocokan string akan berpindah kearah kanan karakter string selanjutnya, hingga akhir dari string tersebut.
b. Sedangkan bila karakter yang dicocokan tidak memiliki kesamaan antar karakter pada masing-masing database maka string tersebut tidak kembali dicocokan (dinyatakan tidak cocok).
1 … … … … 6
R A H M A T
R E N I T A
T U M I N I
R I Y A D I
S U M I N A
1 … … … … 6
T U M I N I
J U N I A R
H A R T I N
H U S N A H
R E L I T A
1 … … … … 6
R E N I T A
E F E N D I
1 … … … … 6
E F E N D Y
R E L I T A
1 … … … …
E F E N D I
1 … … … … 6
E F E N D Y
1 … … … … 6
E F E N D Y
1 … … … … 6
E F E N D I
1 … … … … 6
E F E N D I
1 … … … … 6
Dengan contoh perumpamaan diatas dapat disimpulkan bahwa menggunakan algoritma brute force string matching (Exact String Matching) dalam pencocokan string data nama orang merupakan metode pencocokan string yang hanya mengambil string nama yang sama persis dengan string masukan atau string yang dibandingkan. Sehingga algoritma ini belum mampu untuk menangani, seperti:
1. Adanya kemungkinan perbedaan ejaan dalam input data nama. 2. Bentuk penaaman orang (peserta) yang variatif.
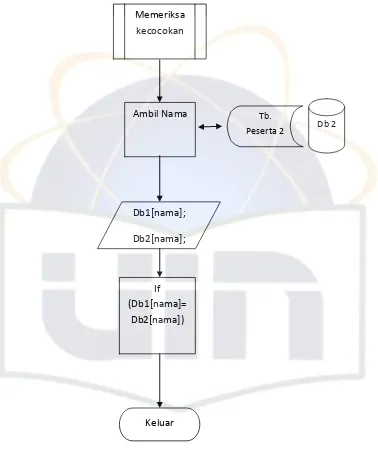
4.1.1.2 Normalisasi String
Sebelum melangkah kedalam algoritma string matching diperlukan suatu proses normalisasi string nama untuk mencapai keakuratan fuzzy string matching. Normalisasi string dalam data nama peserta adalah suatu proses untuk mendapatkan similarty function pada algoritma fuzzy string matching. Similarity function adalah suatu fungsi yang menentukan kesamaan data string yang dicocokan. Similarity function didapatkan dari normalisasi string penamaan sesuai dengan aturan translasi Q-gram maupun eliminasi duplikasi karakter setelah dilakukannya translasi Q-gram. Proses normalisasi ini dilakukan guna membentuk suatu nama orang (peserta) yang memiliki keteraturan bentuk penamaan sehingga dapat mengurangi variasi bentuk penamaan.
Proses normalisasi secara garis besar terbagi menjadi beberapa tahap, yaitu: 1. Translasi q-gram.
2. Eliminasi duplikasi karakter
Dalam menormalisasikan string, penulis melakukan translasi q-gram yang bertujuan untuk mendapatkan aturan tetap dari bentuk suatu karakter yang ada dalam data nama orang. Oleh karena itu dalam melakukan translasi q-gram, penulis melakukan pengambilan sampel data nama peserta untuk mendapatkan sebaran nama yang tetap terhadap bentuk karakter penamaan orang dan melakukan pendekatan statistic untuk memperkecil ambiguitas dari pemakaian bentuk string penamaan orang agar mangetahui translasi karakter yang sering muncul.
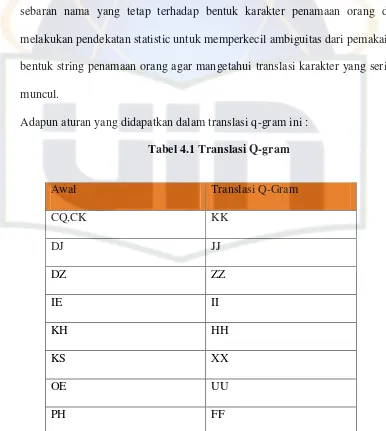
[image:73.595.111.497.302.733.2]Adapun aturan yang didapatkan dalam translasi q-gram ini : Tabel 4.1 Translasi Q-gram
Awal Translasi Q-Gram
CQ,CK KK
DJ JJ
DZ ZZ
IE II
KH HH
KS XX
OE UU
Pengambilan q-gram (urutan karakter) pada aturan translasi ini ditetapkan dengan asumsi keunikan dan tingginya tingkat kemunculan q-gram pada suatu string nama orang.
Berdasarkan hal diatas, melangkah pada tahap selanjutnya yakni melakukan eliminasi duplikasi karakter. Hal ini dilakukan terhadap suatu karakter yang berulang pada translasi q-gram. Sehingga didapatkan bentuk normal dari suatu karakter penamaan dalam data string nama orang.
Dalam penerapan normalisasi untuk mendapatkan similarity function maka dilakukan suatu penghitungan perbedaan jumlah karakter dari data string pada masing-masing database dengan cara melakukan operasi-operasi seperti operasi penghapusan, penyisipan, maupun penggantian pada data string
V F
SJ SY
SY SS
TJ CC
DY DI
BH,CH,DH,GH,JH,SH,TH,ZH BB,CC,DD,GG,JJ,SS,TT,ZZ AA,BB, CC, DD, EE, FF, GG,
HH, II, JJ, KK, LL, MM, NN, OO, PP, QQ, RR, SS, TT, UU, VV, WW, XX, YY, ZZ