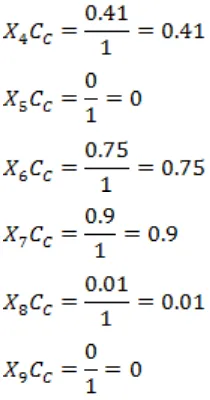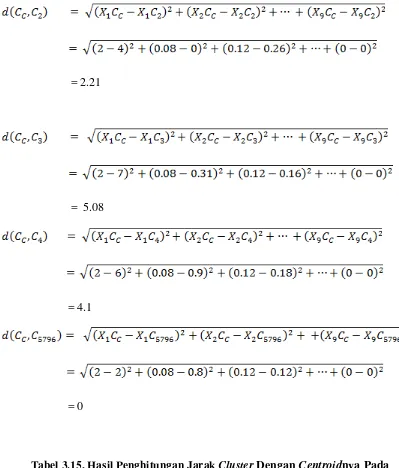METODE HIERARCHICAL K-MEANS UNTUK PENGELOMPOKAN DESA
TERTINGGAL DIPROVINSI SUMATERA UTARA
SKRIPSI
NANIEK BJ MATANARI
101402019
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
METODE HIERARCHICAL K-MEANS UNTUK PENGELOMPOKAN DESA TERTINGGAL DIPROVINSI SUMATERA UTARA
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Teknologi Informasi
NANIEK BJ MATANARI 101402019
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : METODE HIERARCHICAL K-MEANS UNTUK
PENGELOMPOKAN DESA TERTINGGAL DI PROVINSI SUMATERA UTARA
Kategori : SKRIPSI
Nama : NANIEK BJ MATANARI
NomorIndukMahasiswa : 101402019
Program Studi : S1 TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dedy Arisandi, S.T., M.Kom Dr. Syahril Efendi, S.Si.M.IT NIP19790831200912 1 002 NIP 19671110 199602 1 001
Diketahui/Disetujui oleh
Program Studi S1 TeknologiInformasi Ketua,
PERNYATAAN
METODE HIERARCHICAL K-MEANSUNTUK PENGELOMPOKAN DESA TERTINGGAL DIPROVINSI SUMATERA UTARA
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 23 Mei 2015
UCAPAN TERIMA KASIH
Puji dan syukur penulis sampaikan kehadirat Tuhan Yang Maha Esa atas berkat dan rahmat yang telah diberikan sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Teknologi Informasi Universitas Sumatera Utara.
Penulis mengucapkan banyak terimakasih kepada Bapak Dr. Syahril Efendi, S.Si., M.IT selaku dosen pembimbing pertama dan Bapak Dedy Arisandi, S.T., M.Kom selaku dosen pembimbing kedua yang telah membimbing, memberi kritik dan saran kepada penulis selama proses penelitian serta penulisan skripsi. Tanpa inspirasi serta motivasi dari kedua dosen pembimbing, tentunya penulis tidak akan mampu menyelesaikan skripsi ini. Penulis juga mengucapkan terimakasih kepada Ibu Sarah Purnamawati, ST., M.Sc. selaku dosen pembanding pertama dan Bapak Seniman, S.Kom., M.Kom. sebagai dosen pembanding kedua yang telah membantu memberikan kritik dan saran yang membantu penulis dalam pengerjaan skripsi ini. Ucapan terimakasih juga penulis tujukan pada semua dosen, pegawai serta staff pada program studi S1 Teknologi Informasi yang telah membantu dan membimbing penulis selama proses perkuliahan.
Penulis juga berterimakasih terutama kepada kedua orang tua penulis, Bapak Asi Matanari serta Ibu Dameria Siringoringo yang telah membesarkan penulis dengan sabar dan penuh kasih sayang. Penulis juga berterimakasih kepada adik-adik penulis Try Loren Matanari, Pascal S.H Matanaridan Daniel S Matanari serta seluruh anggota keluarga penulis yang namanya tidak dapat disebutkan satu per satu.
ABSTRAK
Salah satu masalah utama saat ini baik di negara-negara miskin, berkembang, maupun di negara-negara maju adalah kemiskinan. Kemiskinan merupakan awal dari timbulnya masalah-masalah social lainnya yang terkait erat dengan kualitas pendidikan, kriminalitas, kelaparan, dan sebagainya yang secara tidak langsung akan mengganggu ketahanan atau stabilitas negara. Beragam kebijakan pemerintah terkait dengan kemiskinan tentunya akan efektif jika kebijakan tepat mengarah pada faktor-faktor yang mempengaruhi kemiskinan itu sendiri. Sehingga akan dapat dirumuskan alternative kebijakan pengentasan kemiskinan yang lebih intensif dan tepat sasaran. Oleh sebab itu dilakukan pengelompokan desa dengan menggunakan algoritma hierarchical clustering dan k-means yang mampu mengolah data dan membangun model secara efisien dengan jumlah data yang besar. Variabel input untuk pengelompokkan desa tertinggal meliputi jarak kantor kepala desa terhadap kantor bupati, rasio jumlah sarana pendidikan per 100 penduduk, rasio jumlah sarana kesehatan per 100 penduduk, rasio jumlah tenaga kesehatan per 100 penduduk, jumlah minimarket, persentase keluarga pertanian, persentase keluarga pengguna listrik, persentase keluarga yang tinggal dibantaran sungai, dan rasio penderita gizi buruk per 1000 penduduk. Dari sistem yang dibangun diperlukan waktu ± 2 menit untuk proses iterasi centroid dan jarak clusternya untuk clustering 5797 data desa. Yang mana hasil yang diperoleh dengan penggunaan 5 cluster
adalah kelompok desa paling banyak berada di cluster 3 dengan banyak desa 4443 desa, kemudian diikuti oleh cluster 1 sebanyak 1264 desa, cluster 4 sebanyak 62 desa, kemudian cluster 2 dan 5 sebanyak 14 desa.
HIERARCHICAL K-MEANS METHODTO CLASSIFYTHE UNDERDEVELOPED VILLAGESINTHE PROVINCEOF NORTH SUMATERA
ABSTRACT
One of the main problem in poor, developing and even developed countries nowadays is
poverty. Poverty is the root to all other social problems related to education quality, crimes,
famine, etc, which will indirectly affect the national resilience or stability. Various
government policies related to the poverty will surely become more effective if those policies
are aiming directly at the cause of the poverty itself, so that government could find a more
intensive and 'right on target' alternative to alleviate poverty. Therefore, groupings were
done using Hierarchical Clustering and K-Means algorithm which are able to process data
and construct model efficiently even with a large amount of data. Input variable for
underdeveloped village grouping includes the distance between village chief's office and
regent's office, ratio of educational facilities per 100 residents, ratio of health facilities per
100 residents, ratio of health professionals per 100 residents, number of minimarket built,
farmer household percentage, power user household percentage, percentage of household
which live on riverbanks, and ratio of malnutrition per 1000 residents. Built system needs
approximately 2 minutes for centroid iteration process and the cluster distance for 5797
village data clustering. Result gained using 5 clusters is most village were in the cluster 3
with 4443 villages, followed by cluster 1 with 1264 villages, cluster 4 with 62 villages, then
cluster 2 and 5 both with 14 villages.
Keywords - clustering, algorithm, k-means, hierarchical, grouping, underdeveloped village,
Abstrak v
2.2 Penambangan Data (Data Mining) 8
2.2.1. Tahapan Data Mining 9
2.2.2.Pengelompokkan Data Mining 11
BAB 3 Analisis dan Perancangan Sistem 21
3.1 Data yang Digunakan 21
3.2Pemrosesan Data 22
3.3 Uji Coba Algoritma Hierachical dan K-Means 22
3.4 Analisis Sistem 54
BAB 4 Implementasi dan Pengujian Sistem 57
4.1 Implementasi Sistem 57
4.1.2. Implementasi Perancangan Antarmuka 57
4.2 Pengujian Sistem 71
4.2.1. Rencana Pengujian Sistem 71
4.2.2. Kasus dan Hasil Pengujian Sistem 72
BAB 5 Kesimpulan dan Saran 75
5.1 Kesimpulan 75
5.2 Saran 76
DAFTAR TABEL
Hal.
Tabel 2.1. Penelitian Terdahulu 19
Tabel 3.1. Pemberian Nama Cluster Pada Masing - Masing Data 25
Tabel 3.2. Matrik Perhitungan Jarak Cluster 31
Tabel 3.3. Matrik Perhitungan Jarak Cluster L(C0) = 0 dan m = 0 32 Tabel 3.4. Matrik Perhitungan Jarak Cluster L(C0/C1) =0.50 dan m = 1 32 Tabel 3.5. Matrik Perhitungan Jarak Cluster L(C3/ C4) = 1.30 dan m = 2 32 Tabel 3.6. Matrik Perhitungan Jarak Cluster L(C2/C3/ C4) = 2.07
dan m = 3 33
Tabel 3.7 Matrik Perhitungan Jarak Cluster L(C0/C1/C2/C3/ C4) = 0.74
dan m = 4 33
Tabel 3.8 Matrik Perhitungan Jarak Cluster L(C0/C1/C2/C3/ C4/ C5796) = 2.21
dan m = 5 33
Tabel 3.9 Anggota Cluster Baru yang Dibentuk 35
Tabel 3.10 Hasil Centroid Awal Masing – Masing Cluster 37 Tabel 3.11 Hasil Penghitungan Jarak Cluster Dengan Centroidnya 40 Tabel 3.12 Anggota Data Awal Masing-Masing Cluster 40
Tabel 3.14 Hasil Centroid Baru Masing – Masing Cluster 43 Tabel 3.15 Hasil Penghitungan Jarak Cluster Dengan Centroidnya Pada
Pengulangan I 46
Tabel 3.16 Anggota Data Baru Masing-Masing Cluster Pada Pengulangan I 47
Tabel 3.17 Anggota Cluster baru yang dibentuk 47
Tabel 3.18 Hasil Centroid Baru Masing – Masing Cluster SetelahPengulangan II 49 Tabel 3.19 Hasil Penghitungan Jarak Cluster Dengan Centroidnya Pada
Pengulangan II 52
Tabel 3.20 Anggota Data Baru Masing-Masing Cluster Pada Pengulangan II 53
Tabel 3.21 Hasil Akhir Proses Clustering 53
Tabel 4.1. Perhitungan Total Jarak Cluster Terhadap Centroidnya 67
Tabel 4.2. Perhitungan Jarak Rata-Rata Cluster 67
Tabel 4.3. Perhitungan Jarak Rata-Rata Cluster Terhadap Jumlah Rata-Rata 68 Tabel 4.4. Total JarakCluster Terhadap Semua Parameter 68
Tabel 4.5. Rencana Pengujian 71
DAFTAR GAMBAR
Hal. Gambar 2.1.BidangIlmu Data Mining (Pramudiono, 2006) 9
Gambar 2.2.Tahapan Data Mining (Fayyad, 1996) 11
Gambar 2.3. Dendogram Penggromboloan Berhierarki Dengan Prosedur
Agglomerative Dan Divisive (Izenman, 2008) 15
Gambar 2.4. Ilustrasi Prosedur Linkage dari Dua Cluster (Izenman, 2008) 17 Gambar 3.1. Print Screen Data Podes Sumatera Utara Tahun 2011 22 Gambar 3.2. Flowchart Algoritma Hierarchical Clustering dan K-Means 24
Gambar 3.3. Dendrogram Jarak Cluster 33
Gambar 3.4. Flowchart Hierarchical Clustering K-Means 54
Gambar 3.5. Flowchart Sistem 56
Gambar 4.1. Halaman Home 58
Gambar 4.2. Halaman Proses 58
Gambar 4.3. Halaman Proses Clustering 59
Gambar 4.4. Halaman Hasil Clustering 60
Gambar 4.5. Halaman Cek Cluster 63
Gambar 4.6. Halaman Proses Cek Cluster 64
Gambar 4.7. Halaman HasilCek Cluster 65
Gambar 4.8. Halaman Proses Gagal 66
Gambar 4.10. Perbandingan Cluster Menuju Maju Dengan Rata-Rata Cluster 69 Gambar 4.11. Perbandingan Cluster Sedang Dengan Rata-Rata Cluster 70 Gambar 4.12. Perbandingan Cluster Menuju Sedang Dengan Rata-Rata
Cluster 70
ABSTRAK
Salah satu masalah utama saat ini baik di negara-negara miskin, berkembang, maupun di negara-negara maju adalah kemiskinan. Kemiskinan merupakan awal dari timbulnya masalah-masalah social lainnya yang terkait erat dengan kualitas pendidikan, kriminalitas, kelaparan, dan sebagainya yang secara tidak langsung akan mengganggu ketahanan atau stabilitas negara. Beragam kebijakan pemerintah terkait dengan kemiskinan tentunya akan efektif jika kebijakan tepat mengarah pada faktor-faktor yang mempengaruhi kemiskinan itu sendiri. Sehingga akan dapat dirumuskan alternative kebijakan pengentasan kemiskinan yang lebih intensif dan tepat sasaran. Oleh sebab itu dilakukan pengelompokan desa dengan menggunakan algoritma hierarchical clustering dan k-means yang mampu mengolah data dan membangun model secara efisien dengan jumlah data yang besar. Variabel input untuk pengelompokkan desa tertinggal meliputi jarak kantor kepala desa terhadap kantor bupati, rasio jumlah sarana pendidikan per 100 penduduk, rasio jumlah sarana kesehatan per 100 penduduk, rasio jumlah tenaga kesehatan per 100 penduduk, jumlah minimarket, persentase keluarga pertanian, persentase keluarga pengguna listrik, persentase keluarga yang tinggal dibantaran sungai, dan rasio penderita gizi buruk per 1000 penduduk. Dari sistem yang dibangun diperlukan waktu ± 2 menit untuk proses iterasi centroid dan jarak clusternya untuk clustering 5797 data desa. Yang mana hasil yang diperoleh dengan penggunaan 5 cluster
adalah kelompok desa paling banyak berada di cluster 3 dengan banyak desa 4443 desa, kemudian diikuti oleh cluster 1 sebanyak 1264 desa, cluster 4 sebanyak 62 desa, kemudian cluster 2 dan 5 sebanyak 14 desa.
HIERARCHICAL K-MEANS METHODTO CLASSIFYTHE UNDERDEVELOPED VILLAGESINTHE PROVINCEOF NORTH SUMATERA
ABSTRACT
One of the main problem in poor, developing and even developed countries nowadays is
poverty. Poverty is the root to all other social problems related to education quality, crimes,
famine, etc, which will indirectly affect the national resilience or stability. Various
government policies related to the poverty will surely become more effective if those policies
are aiming directly at the cause of the poverty itself, so that government could find a more
intensive and 'right on target' alternative to alleviate poverty. Therefore, groupings were
done using Hierarchical Clustering and K-Means algorithm which are able to process data
and construct model efficiently even with a large amount of data. Input variable for
underdeveloped village grouping includes the distance between village chief's office and
regent's office, ratio of educational facilities per 100 residents, ratio of health facilities per
100 residents, ratio of health professionals per 100 residents, number of minimarket built,
farmer household percentage, power user household percentage, percentage of household
which live on riverbanks, and ratio of malnutrition per 1000 residents. Built system needs
approximately 2 minutes for centroid iteration process and the cluster distance for 5797
village data clustering. Result gained using 5 clusters is most village were in the cluster 3
with 4443 villages, followed by cluster 1 with 1264 villages, cluster 4 with 62 villages, then
cluster 2 and 5 both with 14 villages.
Keywords - clustering, algorithm, k-means, hierarchical, grouping, underdeveloped village,
BAB 1
PENDAHULUAN
Bab ini membahas tentang hal-hal yang menjadi latar belakang pembuatan tugas akhir, rumusan masalah, tujuan, batasan masalah, manfaat, metodologi penelitian serta sistematika penulisan tugas akhir.
1.1. Latar Belakang
Salah satu masalah utama saat ini baik di negara-negara miskin, berkembang, maupun di negara-negara maju adalah kemiskinan. Kemiskinan merupakan awal dari timbulnya masalah-masalah sosial lainnya yang terkait erat dengan kualitas pendidikan, kriminalitas, kelaparan, dan sebagainya yang secara tidak langsung akan mengganggu ketahanan atau stabilitas negara (Arisanti, 2011). Oleh karena itu pemerintah daerah di setiap negara berusaha untuk mengatasi masalah kemiskinan dengan beragam kebijakan-kebijakan, termasuk di Provinsi Sumatera Utara.
Penanganan masalah kemiskinan di Indonesia tertuang pada Rencana Pembangunan Jangka Menengah Nasional (RPJMN) Tahun 2010-2014. Dalam RPJMN 2010-2014 sasaran utama dalam pembangunan kesejahteraan rakyat di bidang ekonomi salah satunya adalah menurunkan tingkat kemiskinan menjadi 8-10 persen diakhir tahun 2014.
Beragam kebijakan pemerintah terkait dengan kemiskinan tentunya akan efektif jika kebijakan tepat mengarah pada faktor-faktor yang mempengaruhi kemiskinan itu sendiri. Sehingga akan dapat dirumuskan alternatif kebijakan pengentasan kemiskinan yang lebih intensif dan tepat sasaran.
Kabupaten Kutai Kartanegara. Yang mana penelitian tersebut menyimpulkan bahwa jumlah kelompok yang paling optimal adalah sebanyak 5 (lima) kelompok. Penelitian lain dilakukan oleh Angsoka Dewi, dkk yang menggunakan Algoritma Cluster Ensemble untuk pengelompokan desa perdesaan di Provinsi Riau. Penelitian ini menunjukkan bahwa algoritma pengelompokkan ensembel menghasilkan kelompok dengan kinerja yang lebih baik daripada pengelompokkan full kategorik dan full kontinu. Nilai rasio dari masing-masing algoritma yang diukur pada jumlah kelompok sama dengan 4 (empat) secara berturut-turut adalah 0,0072; 0,0904; dan 0,2679. Dengan pengelompokkan ensembel, desa perdesaan di Provinsi Riau dapat dikelompokkan menjadi 4 (empat) kelompok dan dapat mengidentifikasi 65 desa yang merupakan remote area. Nur’Aidah pada tahun 2014 juga melakukan penelitian menggunakan Agglomerative Spatial Hierarchical Clustering untuk Pengelompokan Daerah Tertinggal di Provinsi Daerah Istimewa Yogyakarta. Penelitian ini menghasilkan kesimpulan bahwa berdasarkan hasil perbandingan algoritma Spatial Hierarchical Clustering dapat mengelompokkan wilayah dalam letak geografis yang
berdekatan, sementara algoritma Hierarchical Clustering tidak.
Pengklasteran menurut Edi Satriyanto adalah suatu algoritma pengelompokkan berdasarkan ukuran kedekatan (kemiripan). Pengklasteran berbeda dengan group dimana group berarti kelompok yang sama kondisinya sedangkan klaster tidak harus sama akan tetapi pengelompokkannya berdasarkan pada kedekatan dari suatu karakteristik sampel yang ada.
Algoritma K-means merupakan algoritma clustering yang paling sederhana dan umum. Hal ini dikarenakan K-means mempunyai kemampuan mengelompokkan data dalam jumlah yang cukup besar dengan waktu komputasi yang relatif cepat dan efisien. Namun, K-means mempunyai mempunyai kelemahan yang diakibatkan oleh penentuan pusat awal cluster. Hasil cluster yang terbentuk dari algoritma K-means ini sangatlah tergantung pada inisiasi nilai pusat awal cluster yang diberikan. Hal ini menyebabkan hasil clusternya berupa solusi yang sifatnya local optimal. Untuk itu, maka K-means dikolaborasikan oleh algoritma hierarki untuk penentuan pusat awal cluster (Alfina, dkk., 2012).
Berbasis Arc View” yang mana pada pada hasil penelitian tersebut perwilayahan di provinsi Sumatera Selatan dibagi menjadi 7 kluster dan menghasilkan hasil klusterisasi dan analisis yang baik. Penelitian lain dilakukan oleh Tahta Alfina, dkk pada tahun 2012 dengan judul “Analisa Perbandingan Algoritma Hierarchical Clustering, K-means dan Gabungan Keduanya dalam Cluster Data (Studi kasus: Problem Kerja Praktek Jurusan Teknik Industri ITS)” yang mana hasil dari penelitian ini menghasilkan pengelompokan data yang lebih baik jika dibandingkan dengan K-Means dalam semua pengujian. Dalam studi kasus Problem Kerja Praktek Jurusan
Teknik Industri ITS, dari kombinasi hierarchical clustering dan K-means yang ada, kombinasi single linkage clustering dan K-means menghasilkan pengelompokan data yang terbaik dibandingkan dengan algoritma hierarki yang lainnya. Rendy Handoyo pada tahun 2014 juga melakukan penelitian dengan judul “Perbandingan Algoritma Clustering Menggunakan Algoritma Single Linkage Dan K - Means Pada Pengelompokan Dokumen” yang mana hasil dari penelitian ini adalah Algoritma Single Linkage memilliki performansi yang lebih baik dibandingkan dengan algoritma
K-means. Jumlah cluster memberikan pengaruh terhadap nilai silhouette dan Purity. Dan jumlah dokumen memberikan pengaruh terhadap nilai Silhouette Coefficient. Dan pada tahun 2007 Kohei Arai dan Ali Ridho Barakbah melakukan penelitian dengan judul “Hierarchical K-means: an algorithm for centroids initialization for K-means” yang mana penggunaan algoritma hierarchical k-means menghasilkan waktu komputasi yang lebih singkat dibandingkan dengan algoritma lain yang digunakan seperti Single Linkage, Centroid Linkage, Complete Linkage, Average Linkage, Fuzzy c-means,dan K-means using random init.
Berdasarkan latar belakang diatas, maka judul penelitian ini adalah “ALGORITMA HIERARCHICAL K-MEANS UNTUK PENGELOMPOKAN DESA TERTINGGAL DI PROVINSI SUMATERA UTARA”.
1.2. Rumusan Masalah
sehingga mempermudah pemerintah memberi kebijakan untuk menanggulangi masalah kemiskinan agar lebih tepat sasaran ?
1.3. Tujuan Penelitian
Mengelompokkan desa-desa tertinggal yang ada di provinsi Sumatera Utara dengan menggunakan algoritma hierarchical k-means sehingga dapat membantu pemerintah untuk memberi kebijakan untuk menanggulangi masalah kemiskinan di daerah tersebut.
1.4. Ruang Lingkup Penelitian
Ruang lingkup pada penelitian adalah :
1. Desa yang dikluster adalah desa-desa yang ada di provinsi Sumatera Utara.
2. Parameter yang digunakan variabel yang digunakan dalam penelitian ini hanya 9 variabel bertipe data kontinu dan pemilihan variabel diperoleh dari penelitian Husna (2011) yaitu :
1. Jarak kantor desa terhadap kantor bupati
2. Rasio jumlah sarana pendidikan per 100 penduduk. 3. Rasio jumlah sarana kesehatan per 100 penduduk. 4. Rasio jumlah tenaga kesehatan per 100 penduduk. 5. Jumlah minimarket.
6. Persentase keluarga pertanian. 7. Persentase keluarga pengguna listrik.
8. Persentase keluarga yang tinggal dibantaran sungai 9. Rasio penderita gizi buruk per 1000 penduduk
1.5. Manfaat Penelitian
Manfaat dari penelitian ini adalah :
1. Menambah pengetahuan penulis dalam bidang data mining khusunya clustering. 2. Membantu pengambilan keputusan oleh pemerintah terkait masalah kemiskinan
1.6. Metodologi Penelitian
Metodologi penelitian yang digunakan pada penelitian ini adalah sebagai berikut. 1. Studi Literatur
Pada tahap ini dilakukan studi kepustakaan yaitu proses mengumpulkan bahan referensi mengenai hierarchical clustering, k-means, data mining, dan daerah tertinggal dari berbagai buku, jurnal, artikel, dan beberapa sumber referensi lainnya.
2. Analisis
Pada tahap ini dilakukan analisis terhadap studi literatur untuk mendapatkan pemahaman mengenai algoritma hierarchical clustering dan k-means untuk menyelesaikan masalah pengelompokan desa tertinggal di Provinsi Sumatera Utara.
3. Perancangan
Pada tahap ini dilakukan perancangan arsitektur, pengumpulan data, pelatihan, dan perancangan antarmuka. Proses perancangan dilakukan berdasarkan hasil analisis studi literatur yang telah didapatkan.
4. Implementasi
Pada tahap ini dilakukan pengkodean program menggunakan PHP, javascript, dan MySQL
5. Pengujian
Pada tahap ini dilakukan pengujian aplikasi pengelompokan desa tertinggal yang telah dibuat guna memastikan aplikasi telah berjalan sesuai dengan yang diharapkan.
6. Dokumentasi dan Penyusunan Laporan
Pada tahap ini dilakukan dokumentasi hasil analisis dan implementasi algoritma hierarchical clustering dan k-means untuk melakukan pengelompokan desa
1.7. Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri dari lima bagian utama sebagai berikut: Bab 1: Pendahuluan
Bab ini berisi latar belakang, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metodologi penelitian, dan sistematika penulisan.
Bab 2: Landasan Teori
Bab ini berisi teori-teori yang digunakan untuk memahami permasalahan yang dibahas pada penelitian ini. Pada bab ini dijelaskan tentang penerapan algoritma hierarchical clustering dan k-means untuk pengelompokan desa tertinggal dan data-data
pendukungnya.
Bab 3: Analisis dan Perancangan Sistem
Bab ini berisi analisis dan penerapan hierarchical clustering dan k-means untuk pengelompokan desa tertinggal, serta perancangan seperti pemodelan dengan flowchart.
Bab 4: Implementasi dan Pengujian Sistem
Bab ini berisi pembahasan tentang implementasi dari analisis dan perancangan yang disusun pada Bab 3 dan pengujian apakah hasil yang didapatkan sesuai dengan yang diharapkan.
Bab 5: Kesimpulan Dan Saran
BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan algoritma hierarchical clustering dan k-means untuk pengelompokan desa tertinggal.
2.1. Daerah Tertinggal
Ketertinggalan (underdevelopment) bukan merupakan sebuah kondisi dimana tidak terdapat perkembangan (absence of development), karena pada dasarnya setiap manusia atau kelompok manusia akan berusaha untuk meningkatkan kualitas hidupnya walaupun itu hanya sedikit. Ketertinggalan adalah sebuah kondisi suatu wilayah dengan wilayah lainnya. Kondisi ini terjadi ketika perkembangan sosial manusia yang tidak sama dan bila dilihat dari sudut pandang ekonomi, sekelompok orang telah lebih maju dibandingkan kelompok orang lainnya (Rodney, 1997).
Ketertinggalan biasanya digambarkan dengan adanya eksploitasi, misalnya eksploitasi suatu negara oleh negara lainnya. Eropa merupakan negara yang mengeksploitasi negara-negara tertinggal di dunia. Ketertinggalan negara-negara tersebut adalah hasil dari kolonialisme, imperialisme, dan kapitalisme yang pernah terjadi di masa lalu. Keuntungan sumber daya yang terdapat di negara-negara tertinggal dihilangkan oleh Eksploitasi, baik itu sember daya alam, maupun sumber daya manusia. Ketertinggalan juga berkaitan dengan ketergantungan, yang mana ketergantungan yang terdapat pada negara atau daerah lain menyebabkan suatu daerah atau negara tidak dapat disebut mengalami pembangunan yang baik.
Pada umumnya di daerah tertinggal, tidak terdapat sektor ekonomi yang bisa membawa pertumbuhan secara besar, atau yang memiliki multiplier effect yang tinggi yang dapat memicu pertumbuhan (Edy, 2009).
Menurut Kepmen PDT nomor 1 tahun 2005 tentang Strategi Nasional Pembangunan Daerah Tertinggal, daerah tertinggal didefinisikan sebagai daerah kabupaten yang masyarakat dan wilayahnya relatif kurang berkembang dibandingkan dengan daerah lain dalam skala nasional. Sesuai dengan pengertian tersebut maka penetapan daerah tertinggal merupakan hal yang sangat relative karena merupakan hasil perbandingan dengan daerah lainnya. Untuk itu dalam penetapan daerah tertinggal digunakan data agregat tingkat kabupaten.
2.2. Penambangan Data (Data Mining)
Data mining merupakan pemilihan atau penggalian pengetahuan dari jumlah data yang banyak (Han dan Kamber, 2001). Data mining merupakan penemuan pengetahuan atau cara untuk menemukan pola yang tersembunyi pada data. Data mining adalah proses untuk analisis data dari perspektif yang berbeda dan diringkas menjadi informasi yang bermanfaat (Segall et al., 2008). Data mining adalah menganalisis secara otomatis dari data yang berjumlah besar atau kompleks untuk menemukan suatu pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaannya (Pramudiono, 2006).
Data mining adalah analisis meninjau sekumpulan data untuk menemukan suatu hubungan yang tidak diduga dan meringkas data secara berbeda dengan sebelumnya, yang bermanfaat dan dipahami oleh pemilik data (Larose, 2006). Maka dari itu, data mining adalah proses untuk analisis data dalam jumlah besar sehingga membentuk suatu pola yang menjadi informasi berguna.
Dari berbagai definisi yang telah disampaikan, berikut merupakan beberapa hal penting yang terkait dengan data mining:
1. Data mining adalah suatu proses otomatis yang dilakukan terhadap data yang telah ada.
3. Tujuan dari data mining adalah untuk mendapatkan hubungan atau pola yang kemungkinan memberikan indikasi bermanfaat.
Data mining merupakan suatu bidang ilmu yang telah lama ada. Kesulitan untuk mendefinisikan data mining salah satunya karena data mining mewarisi banyak aspek dan teknik dari berbaagai bidang ilmu yang sudah mapan terlebih dahulu. Dari Gambar 2.1 memperlihatkan bahwa data mining memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligence), machine learning, statictic, database, serta information retrieval (Pramudiono, 2006).
Gambar 2.1. Bidang Ilmu Data Mining (Pramudiono, 2006)
2.2.1. Tahapan Data Mining
1. Data Selection
Pemilihan (seleksi) data dilakukan dari suatu kumpulan data operasional, sebelum tahap penggalian informasi dalam KDD dimulai proses ini perlu dilakukan. Data hasil seleksi disimpan dalam suatu berkas, terpisah dari basis data operasional. 2. Pre-processing/Cleaning
Proses cleaning perlu dilakukan pada data yang menjadi fokus KDD sebelum proses data mining dapat dilakukan. Proses cleaning melingkupi antara lain membuang data yang memiliki duplikasi, data yang tidak konsisten diperiksa, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (typo), juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Proses transformasi pada data yang telah dipilih adalah Coding, sehingga sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining merupakan proses untuk mencari suatu pola atau informasi yang menarik dalam data yang terpilih dengan teknik atau metode tertentu. Data mining memiliki teknik, metode, atau algoritma dalam sangat bervariasi. Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/Evalution
Interpretation merupakan proses untuk menampilkan pola informasi yang
Gambar 2.2. Tahapan Data Mining (Fayyad, 1996)
2.2.2. Pengelompokan Data Mining
Berdasarkan tugas yang dapat dilakukan data mining dibagi menjadi beberapa kelompok, yaitu (Larose, 2006).
1. Deskripsi
Kadang kala peneliti menggambarkan suatu pola dan kecenderungan yang terdapat dalam data secara sederhana. Misalnya, petugas di TPS mungkin tidak mampu menemukan keterangan atau fakta bahwa calon yang tidak cukup profesional akan memiliki suara yang sedikit dalam suatu pemilihan. Deskripsi dari suatu pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi
Perbedaan dari estimasi dan klasifikasi adalah terletak pada variabel target estimasi yang lebih kearah numeric daripada kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi.
3. Prediksi
digunakan dalam klasifikasi dan estimasi dapat digunakan untuk prediksi (untuk keadaan yang tepat).
4. Klasifikasi
Klasifikasi terdapat target variabel kategori. Contoh pada penerapan klasifikasi dalam bisnis adalah menentukan suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan.
5. Clustering
Clustering adalah pengelompokan record, pengamatan dan membentuk kelas
objek-objek yang memiliki kemiripan. 6. Asosiasi
Tugas asosiasi pada data mining yaitu menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
2.3.Clustering
Clustering adalah suatu teknik analisis multivariate untuk menemukan suatu
kelompok-kelompok dari sekumpulan objek maupun individu berdasarkan karakteristik yang dimiliki. Tujuan objektif secara khusus dari teknik ini adalah untuk mengklasifikasikan sampel entitas (berupa individu/objek atau yang lainnya) yang berdasarkan kemiripan antara entitas menjadi sejumlah kelompok tertentu. Untuk cluster banyaknya suatu kelompok tidak ditentukan terlebih dahulu. Karena kelompok
(cluster) pada data pada diidentifikasi menggunakan teknik ini. Hasil cluster (kelompok) yang akan terbentuk diharapkan memiliki tingkat homogenitas internal yang tinggi dan heterogenitas eksternal yang tinggi pula. Hal pokok dalam analisis cluster adalah ukuran kemiripan antar objek. Metode pengukuran kemiripan pada
cluster yang biasa digunakan ada tiga yaitu kemiripan antar objek biasa diukur
menggunakan jarak (distance), kemiripan antar variabel (jika variabel yang diclusterkan) diukur menggunakan ukuran korelasi, dan asosiasi antar variabel.
Metode utama pada analisis cluster adalah metode hierarki (hierarchical clustering) dan metode tidak berhierarki/partisi (K-means clustering). Metode hierarki
pembagian (divisive). Metode tidak berhirarki disebut juga dengan metode penyekatan (partitioning / K-means method) dimana jumlah cluster yang ingin dibentuk sudah ditentukan sebelumnya.
2.3.1. Ukuran Kedekatan (Proximity)
Untuk mengukur kemiripan (similarity) ataupun ketidakmiripan (dissimilarity) antar objek digunakan ukuran jarak (distance) antar variabel tiap-tiap objek. Misalnya, xi, xj ϵ ℜr ketidakmiripan (dissimilarity) biasanya dipenuhi dengan properti seperti pada
persamaan (2.1) sebagai berikut:
Metode pengukuran jarak untuk menghitung ketidakmiripan sering menggunakan Euclidean distance, manhattan distance, dan canberra distance. (Izenman:2008, Everitt et.al. :2011). Euclidean dan manhattan distance adalah keluarga dari minkowski distance (minkowski dengan � = 2 adalah euclidean distance dan � = 1 adalah manhattan distance).
Jika Xi (xil ,.., xir )dan Xj (xjl ,.., xjr ) menunjukan dua poin dalam r . Lalu untuk mengukur jarak dapat dilakukan dengan cara sebagai berikut:
Euclidean:
(2.2)
(2.3)
Minkowski:
Canberra:
(2.5) Untuk ketidakmiripan yang digunakan ketika mengklasterkan variabel adalah ukuran koefisien korelasi
1 –koefisien korelasi :
Dimana 1≤ ≤ 1 adalah korelasi antara sepasang variabel Xi dan Xj, dan
(2.6)
jauh kedekatannya jika nilai koefisien korelasi mendekati nol (ρij ≈ 0). Maka ukuran ketidakmiripan antar variabel adalah 1- ρij.
Jika ada sebanyak n observasi, x1,…, xn ϵ ℜr, untuk perhitungan prosedur algoritma clustering berhirarki, maka terlebih dahulu hitung kedekatan antara observasi dan dibentuk dalam matriks kedekatan (proximity matrix)simetris (n X n) D (d )ij dimana d ij = d(X i ,X j) dan sepanjang diagonal matriks bernilai nol. Maka
ketika mengklasterkan variabel matriks kedekatan simetrik (r x r) D (d ij) dengan d ij 1 ijNur’aidah, 2014)
2.4. Hierarchical Clustering
Hierarchical clustering memiliki dua tipe metode yaitu agglomerative dan divisive. Agglomerative clustering atau disebut juga dengan metode “bottomup” karena dianggap setiap objek sebagai cluster tunggal kemudian cluster-cluster tersebut digabungkan sehingga hanya tersisa satu cluster saja. Divisive clustering juga disebut dengan metode ”top-down”. Pada metode divisive awalnya seluruh objek dianggap menjadi satu kesatuan cluster yang sama, kemudian dilakukan proses pemecahan cluster menjadi dua cluster dan seterusnya hingga setiap objek dianggap satu cluster
tunggal.
Proses pembentukan cluster pada hierarchical clustering digambarkan melalui diagram dua dimensi yang disebut dendrogram. Gambar 2.3 merupakan pembentukan cluster baik dengan prosedur agglomerative maupun divisive dalam bentuk dendrogram.
Prosedur yang sering digunakan dalam metode clustering berhierarki adalah prosedur agglomerative. Awalnya terdapat n anggota/observasi yang dianggap n cluster atau kelompok tunggal dan pada akhirnya menghasilkan satu cluster atau satu
kelompok yang berisi n anggota.
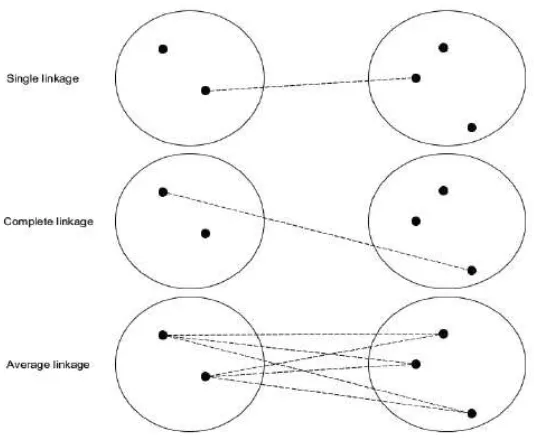
(farthest neighbor). Sedangkan average linkage menggunakan rata-rata jarak untuk menentukan jarak antar objek. Metode operasi penggabungan lainnya antara lain Ward’s minimal variance, centroid method, median method, dan average linkage wighted.
Gambar 2.3. Dendrogram penggerombolan berhierarki dengan prosedur
agglomerative dan divisive (Izenman, 2008)
Algoritma aglomerative hierarchical clustering dengan banyak objek adalah N secara umum adalah sebagai berikut (Izenman, 2008):
1. Diawali dengan N buah cluster yang mana dari setiap cluster merupakan entitas tunggal dengan sebuah matriks jarak (matriks kedekatan) berukuran N × N yang dituliskan .
3. Cluster X dan Y digabungkan menjadi suatu cluster baru yaitu cluster XY. Perbaharui ukuran matriks jarak menjadi (N – 1)×(N – 1). Penghitungan jarak antara cluster baru yang dibentuk dengan N-1 cluster yang telah ada, dapat dilakukan dengan berbagai metode penggabungan single linkage, complete linkage, average linkage ataupun yang lainnya. Dari persamaan (2.7) nilai dari jarak ketika cluster XY dan W digabungkan adalah jarak minimum antar cluster X dengan cluster W dan cluster X dengan cluster W. Dimana pada persamaan (2.7) merupakan bentuk matematis dari metode penggabungan single linkage. Dan persamaan (2.8) adalah bentuk matematis dari metode complete linkage jarak ketika cluster XY dan W digabungkan adalah jarak maksimum antar cluster X dengan cluster W dan cluster Y dengan cluster W. Sedangkan pada metode average linkage, jarak dua cluster merupakan rata-rata jarak dari keduanya, dapat
dilihat pada persamaan (2.8). Gambaran dari penentuan jarak dua buah cluster untuk metode single linkage, complete linkage, average linkage diilustrasikan pada gambar 2.4
(2.7)
(2.8)
(2.9)
Gambar 2.4 Ilustrasi prosedur linkage dari dua cluster (Izenman, 2008)
2.5. Algoritma K-Means
K-Means merupakan salah satu algoritma unsupervised learning yang paling sederhana untuk menyelesaikan masalah clustering. Prosedur ini dengan sederhana dan mudah mengklasifikasikan kumpulan data tertentu melalui jumlah cluster tertentu (k cluster) yang sebelumnya telah ditetapkan (MacQueen, 1967).
K-Means merupakan salah satu metode data clustering non hirarki yang mempartisi data ke dalam cluster sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok lain sehingga data yang berada dalam satu cluster/kelompok memiliki tingkat variasi yang kecil (Agusta, 2007).
Tujuan dari data clustering adalah meminimalisasikan objective function yang diset dalam proses clustering, yang pada umumnya berusaha meminimalisasikan variasi di dalam suatu cluster dan memaksimalkan variasi antar cluster.
Langkah awal, centroid dipilih secara acak dari k buah data. Lalu, dengan menggunakan Euclidean Distance dilakukan penghitungan jarak antara data dan centroid. Data ditempatkan dalam cluster yang terdekat, yang dihitung dari titik
tengah cluster. Jika semua data telah ditempatkan dalam cluster terdekat maka centroid baru akan ditentukan. Proses penentuan centroid dan penempatan data dalam
cluster diulangi sampai nilai centroid konvergen (centroid dari semua cluster tidak berubah lagi).
2.6. Penelitian Terdahulu
2
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Bab ini secara garis besar membahas analisis algoritma hierarchical clustering dan k-means pada sistem dan tahap-tahap yang dilakukan dalam perancangan sistem yang
akan dibangun.
3.1.Data yang Digunakan
Data yang digunakan dalam penelitian ini adalah data desa yang bersumber dari data desa pada pendataan Potensi Desa (PODES) tahun 2011 di provinsi Sumatera Utara. Setelah pengumpulan data lalu dilakukan analisa data sesuai dengan kebutuhan sistem. Analisis data dilakukan menggunakan algoritma hierarchical dan algoritma k-means. Total data yang digunakan 5797 data desa.
Pada saat petugas lapangan melakukan pendataan Podes, petugas mengisi data potensi desa yang merupakan data umum yang memberikan indikasi keberadaan potensi yang dimiliki oleh suatu wilayah. Yang mana data yang dikumpulkan berupa :
1. Potensi Desa/Kelurahan: kondisi sosial ekonomi penduduk, ketersediaan infrastruktur, dan pembangunan desa/kelurahan di seluruh Indonesia.
2. Potensi Kecamatan: fasilitas perlindungan sosial, situs/bangunan bersejarah, obyek wisata, prasarana transportasi, serta aparatur kecamatan.
3. Potensi Kabupaten/Kota: keberadaan pertambangan, industri, perhubungan, politik dan keamanan, serta aparatur kabupaten/kota.
4. Kualitas Infrastruktur Pendidikan: keberadaan dan kualitas sekolah negeri termasuk jumlah siswa, guru, kondisi ruangan dan sanitasi yang ada di sekolah tersebut.
Dari data umum tersebut terdapat 9 (Sembilan) variabel yang digunakan dalam penelitian. Gambar 3.1 merupakan contoh data Podes yang akan digunakan untuk pengelompokan desa tertinggal.
Gambar 3.1. Print Screen Data Podes Sumatera Utara Tahun 2011
3.2.Pemrosesan Data
Dalam mengolah data mining terdapat beberapa tahapan yang harus dilakukan sehingga data dapat digunakan secara maksimal. Tahapan tersebut merupakan bagian dari Knowledge Discovery in Database (KDD). Pada tahap ini dilakukan pembersihan data, yaitu membuang dan mengisi data missing values, sehingga dihasilkan data yang layak diperlukan pada proses pengelompokan desa.
3.3. Uji Coba dengan Algoritma Hierarchical Clustering dan K-means Clustering
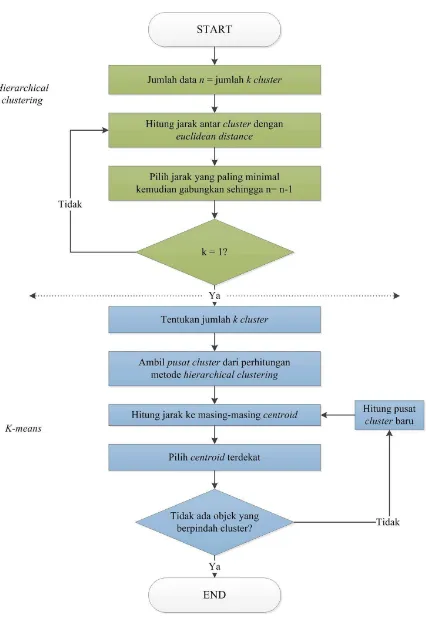
Pada tahapan ini pengelompokan data dilakukan menggunakan kombinasi dua algoritma clustering, yaitu hierarchical clustering dan k-means. Algoritma hierarchical clustering digunakan untuk menentukan pusat cluster (centroid). Yang mana pusat cluster yang diperoleh dari hierarchical clustering tersebut akan digunakan untuk proses pengelompokan data dengan menggunakan metode k-means.
Flowchart pada gambar 3.2. urutan pengerjaan penelitian dengan
menggunakan kombinasi dua algoritma clustering yakni hierarchical clustering dan k-means. Pada tahapan hierarchical clustering setiap data yang ada dianggap sebagai
Lalu dilanjutkan dengan menghitung jarak antar cluster yang menggunakan rumus clustering ini akan diperoleh sebuah gambar dendrogram yang akan menunjukkan urutan pengelompokan masing-masing anggota dalam cluster hingga menjadi satu cluster yang terbentuk.
Setelah tahapan hierarchical clustering selesai, kemudian dilanjutkan dengan metode k-means. Pada umumnya tahapan metode k-means diawali dengan penentuan jumlah k cluster yang akan dibentuk, lalu dilanjutkan dengan penentuan pusat awal cluster yang dilakukan secara random. Namun karena ini merupakan gabungan algoritma hierarchical clustering dan k-means maka penentuan pusat cluster untuk algoritma k-means ditentukan dengan mencari rata-rata dari data yang berada pada sebuah cluster hasil dari hierarchical clustering, yang mana data yang diambil adalah data dari banyak cluster yang ingin digunakan, sehingga pusat cluster pada algoritma k-means langsung dapat ditentukan. Jika dari hasil hierarchical clustering kita ingin menggunakan 5 cluster maka anggota tiap cluster diperoleh dari hasil proses hierarchical atau dapat dilihat dari dendrogram yang megelompokkan 5 cluster. Hal
Berikut adalah langkah – langkah pengelompokan data yang menggunakan algoritma hierarchical clustering dan k-means yang menggunakan sample data dari desa di Provinsi Sumatera Utara. Banyak data yang digunakan adalah banyak cluster yang digunakan.
Nama parameter yang digunakan akan diubah variabelnya sehinggal lebih memudahkan penulis dalam perhitungannya.
10.Jarak kantor kepala desa terhadap kantor bupati menjadi X1 11.Rasio jumlah sarana pendidikan per 100 penduduk menjadi X2 12.Rasio jumlah sarana kesehatan per 100 penduduk menjadi X3 13.Rasio jumlah tenaga kesehatan per 100 penduduk menjadi X4 14.Jumlah minimarket menjadi X5
15.Persentase keluarga pertanian menjadi X6 16.Persentase keluarga pengguna listrik menjadi X7
17.Persentase keluarga yang tinggal dibantaran sungai menjadi X8 18.Rasio penderita gizi buruk per 1000 penduduk menjadi X9
Tabel 3.1. Pemberian Nama Cluster Pada Masing - Masing Data
Desa
Jarak cluster C0 dengan cluster lainnya :
= 0
= 0.5
= 2.24
= 1.27
= 0.87
= 4.01
= 0.5
= 0
= 2.26
= 1.23
= 0.74
= 2.71
= 2.24
= 2.26
= 0
= 3.17
= 2.07
= 2.21
= 1.27
= 1.23
= 3.17
= 0
= 1.3
= 5.08
Jarak cluster C4 dengan cluster lainnya :
= 0.87
= 0.74
= 2.07
= 1.3
= 0
= 4.1
Jarak cluster C5796 dengan cluster lainnya :
= 4.01
= 4.04
= 2.21
= 5.08
= 4.1
= 0
Tabel 3.2. Matrik Perhitungan Jarak Cluster
Setelah di dapatkan tabel matrik seperti pada tabel 3.2 diatas selanjutnya cari sepasang cluster yang jaraknya paling dekat, dan gabungkan sehingga didapat sebuah cluster baru. Dari penggabungan ini maka banyak data akan menjadi n = n – 1. Lalu hitung jarak antara cluster yang baru dengan masing-masing cluster yang lainnya. Penghitungan jarak cluster baru ini menggunakan Single-Linkage pada persamaan (2.7).
Dari tabel matrik pada tabel 3.2 ditemukan pasangan jarak terdekat adalah C0
dan C1, dengan jarak = 0.5. Keduanya digabung menjadi Cluster tunggal yaitu C0/C1. Level
dari cluster baru adalah L(C0/C1) = 0.5 dan m = 1. Kemudian dihitung jarak dari objek
gabungan ini ke semua objek lainnya. Pada Clusterisasi singlelinkage, aturannya adalah jarak antara objek gabungan ke objek lainnya sama dengan jarak terpendek dari suatu anggota pada
Cluster ke yang lainnya di luar objek.
Setelah penggabungan C0 dan C1 maka akan terbentuk cluster baru yang mana proses pembentukannya adalah setelah C0/C1 tergabung maka dilihat kembali jarak antara C0/C1 dan C0/C1 = 0, dan pada pembentukan cluster C0/C1 dan C2 dilihat jarak mana yang lebih dekat antara C0 terhadap C2 atau C1 terhadap C2 . Karena yang paling dekat adalah 2.24 maka nilai selanjutnya yang diisi pada matrik C0/C1 dan C2 adalah 2.24 bukan 4.28. Lakukan hal ini dalam pembentukan matrik selanjutnya.
C0/C1/C2/C3/ C4 0 2.21
C5796 2.21 0
Tabel 3.8. Matrik Perhitungan Jarak Cluster L(C0/C1/C2/C3/ C4/ C5796) = 2.21 dan m = 5
Cluster (C
0/C1/C2/C3/ C4/ C5796)
(C0/C1/C2/C3/ C4/ C5796) 0
Setelah terbentuk 1 cluster besar yaitu C0/C1/C2/C3/C4/C5796 maka proses dalam algoritma hierarchical clustering telah selesai. Hasil dari proses ini akan ditampilkan dalam suatu dendrogram.
Gambar 3.3. Dendrogram Jarak Cluster
dilakukan. Pada kasus ini penulis ingin membentuk 3 cluster. Karena ingin membentuk 3 cluster maka anggota tiap cluster baru adalah adalah :
Cluster A : C0 dan C1
Cluster B : C2,C3 dan C4
Cluster C : C5796
Pengambilan pusat cluster (centroid) dilakukan dengan menghitung mean (rata-rata) pada masing-masing cluster dengan membagi jumlah data yang didapatkan untuk setiap clusternya. Adapun tujuan dari penghitungan ini adalah agar setiap cluster memiliki anggota data pada iterasi pertama. Untuk mencari mean (rata-rata) dengan menggunkan rumus berikut:
dimana :
: rata-rata dari data yang berada dalam satu cluster (centroid awal)
n : banyak data
Tabel 3.9. Anggota Cluster baru yang dibentuk
Cluster
baru Cluster
lama X1 X2 X3 X4 X5 X6 X7 X8 X9
CA C0 6 0.3 0.3 0.3 0 0.61 0.84 0 0
CB C2 4 0 0.26 0.78 0 0.91 0.06 0 0
CB C3 7 0.31 0.16 0.31 0 0.4 0.39 0.59 0
CB C4 6 0.09 0.18 0.26 0 0.78 0.02 0 0
…
CC C5796 2 0.08 0.12 0.41 0 0.75 0.90 0.01 0
Proses penghitungan nilai centroid awal pada masing-masing cluster sebagai berikut:
1. Nilai centroid awal pada cluster pertama (CA) :
3. Nilai centroid awal pada cluster ketiga (CC) :
Tabel 3.10. Hasil Centroid Awal Masing – Masing Cluster
Cluster X1 X2 X3 X4 X5 X6 X7 X8 X9
CA 6 0.19 0.17 0.19 0 0.51 0.73 0 0
CB 5.67 0.13 0.2 0.45 0 0.7 0.16 0.2 0
CC 2 0.08 0.12 0.41 0 0.75 0.9 0.01 0
Setelah hasil centroid awal dari setiap cluster didapat, selanjutnya dilakukan penghitungan jarak anggota cluster ke setiap centroidnya dengan menggunakan rumus euclidiance distance yakni persamaan (2.2). Hasil dari penghitungan jarak anggota
cluster dengan centroidnya akan berpengaruh pada penempatan setiap data ke cluster
yang telah ditentukan.
Jarak cluster CA dengan centroidnya:
= 0.25
= 0.25
= 2.23
= 0.77
= 4.02
Jarak cluster CB dengan centroidnya:
= 0.82
= 0.78
= 1.73
= 0.46
= 3.75
Jarak cluster CC dengan centroidnya:
= 4.01
= 4.04
= 2.21
= 4.1
= 0
Tabel 3.11. Hasil Penghitungan Jarak ClusterDengan Centroidnya
Cluster X1 X2 X3 X4 X5 X6 X7 X8 X9 dCA dCB dCC
Setelah melakukan penghitungan jarak centroid dengan masing-masing clusternya, selanjutnya adalah dilakukan pengelompokkan jarak terkecil disetiap
masing-masing cluster. Pada tabel 3.12 dapat dilihat bahwa jarak paling dekat pada C0 adalah 0.25 maka dari itu cluster C0 merupakan anggota dari cluster CA, demikian juga dengan cluster C1 jarak paling dekat adalah 0.25 sehingga cluster C1 merupakan anggota dari cluster CB. Demikian selanjutnya dengan jarak cluster yang lainnya. Untuk lebih jelasnya anggota data awal untuk masing-masing cluster baru akan disajikan pada Tabel 3.12 berikut:
Tabel 3.12. Anggota Data Awal Masing-Masing Cluster
Cluster dCA dCB dCC CA CB CC
C4 0.77 0.46 4.10 ok C5796 4.02 3.75 0 ok
Hasil dari tabel 3.12 diatas adalah hasil sementara, maka akan terjadi pengulangan (iterasi) pada proses k-means hingga tidak ada perpindahan pada setiap anggota cluster. Maka dari itu proses akan diulang kembali dari penentuan centroid baru dan menghitung kembali jarak antara cluster dan centroidnya.
Pengulangan pertama dilakukan dengan menggunakan data pada tabel 3.13 yang merupakan tabel yang anggota dari cluster baru telah terbentuk.
Tabel 3.13. Anggota Cluster baru yang dibentuk
Cluster
Proses penghitungan nilai centroid baru pada masing-masing cluster sebagai berikut:
2. Nilai centroid baru pada cluster kedua (CB) :
Adapun hasil dari centroid baru dari masing-masing cluster dapat dilihat pada Tabel 3.14 berikut:
Tabel 3.14. Hasil Centroid Baru Masing – Masing Cluster
Cluster X1 X2 X3 X4 X5 X6 X7 X8 X9
CA 6.33 0.23 0.17 0.23 0 0.47 0.62 0.2 0
CB 5 0.04 0.22 0.52 0 0.84 0.04 0 0
CC 2 0.08 0.12 0.41 0 0.75 0.90 0.01 0
Selanjutnya dilakukan penghitungan jarak anggota cluster ke setiap centroid barunya.
Jarak cluster CA dengan centroidnya:
= 0.46
= 2.52
= 0.82
= 0.79
= 4.36
Jarak cluster CB dengan centroidnya:
= 1.34
= 1.04
= 2.19
= 1.04
= 3.13
Jarak cluster CC dengan centroidnya:
= 4.01
= 2.21
= 5.08
= 4.1
= 0
Tabel 3.15. Hasil Penghitungan Jarak ClusterDengan Centroidnya Pada Pengulangan I
Cluster X1 X2 X3 X4 X5 X6 X7 X8 X9 dCA dCB dCC
Setelah melakukan penghitungan jarak centroid dengan masing-masing clusternya, selanjutnya adalah dilakukan pengelompokkan jarak terkecil disetiap
masing-masing cluster.
Tabel 3.16. Anggota Data Baru Masing-Masing Cluster Pada Pengulangan I
Cluster dCA dCB dCC CA CB CC
C0 0.49 1.34 4.01 ok
C1 0.46 1.32 4.04 ok
C2 2.52 1.04 2.21 ok
C3 0.82 2.19 5.08 ok
C4 0.79 1.04 4.10 ok
C5796 4.36 3.13 0.00 ok
Dari tabel 3.16 dapat dilihat bahwa telah terjadi perpindahan cluster pada C4 yang mana sebelumnya C4 adalah anggota dari cluster CB namun setelah pengulangan I (pertama) C4 telah berpindah ke cluster CA. Karena terjadi perpindahan maka pengulangan kembali dilakukan.
Tabel 3.17. Anggota Cluster baru yang dibentuk
Cluster
baru
Cluster
lama
X1 X2 X3 X4 X5 X6 X7 X8 X9
CA C0 6 0.30 0.30 0.30 0 0.61 0.84 0 0
CA C1 6 0.09 0.04 0.09 0 0.40 0.62 0 0
CB C2 4 0 0.26 0.78 0 0.91 0.06 0 0
CA C3 7 0.31 0.16 0.31 0 0.40 0.39 0.59 0
CA C4 6 0.09 0.18 0.26 0 0.78 0.02 0 0
…
CC C5796 2 0.08 0.12 0.41 0 0.75 0.90 0.01 0
Proses penghitungan nilai centroid baru pada masing-masing cluster sebagai berikut:
2. Nilai centroid baru pada cluster kedua (CB) :
3. Nilai centroid baru pada cluster ketiga (CC) :
Tabel 3.18. Hasil Centroid Baru Masing – Masing Cluster Setelah Pengulangan II
Cluster X1 X2 X3 X4 X5 X6 X7 X8 X9
CA 6.25 0.2 0.17 0.24 0 0.55 0.47 0.15 0
CB 4 0 0.26 0.78 0 0.91 0.06 0 0
Selanjutnya dilakukan penghitungan jarak anggota cluster ke setiap centroid barunya.
Jarak cluster CA dengan centroidnya:
= 0.51
= 0.42
= 2.39
= 0.9
= 4.28
Jarak cluster CB dengan centroidnya:
= 2.24
= 1.26
= 0
= 3.17
= 2.21
Jarak cluster CC dengan centroidnya:
= 4.01
= 4.04
= 2.21
= 5.08
= 0
Tabel 3.19. Hasil Penghitungan Jarak ClusterDengan Centroidnya Pada Pengulangan II
Setelah melakukan penghitungan jarak centroid dengan masing-masing clusternya, selanjutnya adalah dilakukan pengelompokkan jarak terkecil disetiap
masing-masing cluster.
Tabel 3.20. Anggota Data Baru Masing-Masing Cluster Pada Pengulangan II
Cluster dCA dCB dCC CA CB CC
Dari hasil yang ditampilkan tabel 3.20 menunjukkan bahwa tidak ada perpindahan cluster yang terjadi pada data pada saat pengulangan kedua dilakukan, ini artinya
dibutuhkan. Yang mana dari data tersebut dihasilkan kelompok data yang telah dibagi menjadi 3 cluster. Hasil dari pengelompokan ini dapat dilihat pada tabel 3.21 berikut :
Tabel 3.21. Hasil Akhir Proses Clustering
Nama
Bahasa pemrograman yang digunakan untuk membangun perancangan sistem adalah menggunakan bahasa pemograman PHP dan pembuatan database menggunakan mysql.
3.4.1. Perancangan Algoritma Hierarchical Clustering dan K-means
Gambar 3.4. FlowchartHierarchical Clustering K-Means (lanjutan)
3.4.2. Flowchart sistem
Flowchart sistem merupakan bagan yang menunjukkan alur kerja di dalam sistem
secara keseluruhan dan menjelaskan urutan dari prosedur-prosedur yang ada di dalam sistem. Dengan kata lain, flowchart ini merupakan deskripsi secara grafik dari urutan prosedur-prosedur yang terkombinasi yang membentuk suatu sistem (Agustina, 2012).
BAB 4
IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab ini akan dijelaskan tentang proses pengimplementasian algoritma hierarchical clustering dan k-means pada sistem, sesuai perancangan sistem yang
telah dilakukan di Bab 3 serta melakukan pengujian sistem yang telah dibangun.
4.1.Implementasi Sistem
Pada tahap ini, algoritma hierarchical clustering dan k-means akan diimplementasikan ke dalam sistem dengan menggunakan bahasa pemrograman PHP dan database MySQL sesuai perancangan yang telah dilakukan.
4.1.1. Spesifikasi Perangkat Keras dan Lunak yang Digunakan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk membangun sistem ini adalah sebagai berikut:
1. Prosesor Intel®CoreTM i5-2450M CPU 2.5 GHz. 2. Kapasitas hardisk 750 GB.
3. Memori RAM yang digunakan 4 GB.
4. Sistem operasi yang digunakan adalah Microsoft Windows 7 Home Premium. 5. Web server yang digunakan adalah XAMPP versi 3.2.1
6. Database MySQL versi 5.6.16
4.1.2. Implementasi Perancangan Antarmuka
Adapun implementasi perancangan antarmuka yang telah dilakukan sebelumnya pada sistem adalah:
a. Halaman Home
Gambar 4.1. Halaman Home
b. Halaman Proses
Halaman proses merupakan halaman yang berisi tentang tampilan awal dari proses clustering, yang mana user diminta untuk mengimputkan banyak cluster yang
ingin di bentuk dari data base yang telah ada. Dalam halaman proses sendiri terdapat beberapa button seperti proses clustering, hasil clustering, dan cek cluster.
Proses clustering akan ditampilkan ketika user memilih button “Proses Clustering”. Proses cluster yang ditampilkan adalah proses perubahan centroid awal hingga centroid akhir yang terbentuk serta jarak antar masing-masing clusternya dengan centroid-centroidnya.
Gambar 4.3. Halaman Proses Clustering
Proses iterasi tetap berlangsung hingga iterasi ke-17 yang mana pada saat iterasi tersebut data tidak lagi mengalami perpindahan cluster dari cluster yang
sebelumnya dengan perubahan centroid sebanyak 16 kali.
Setelah melihat tampilan proses clustering, user dapat melihat hasil cluster dengan memilih button “Hasil Clustering”. Pada tampilan hasil clustering dapat dilihat hasil cluster, keterangan warna cluster, dan menu sorting cluster. Pada hasil cluster ditampilkan semua nama desa beserta yang diikuti denganwarna
clusternya. Sedangkan pada keterangan warna ditampilkan bahwa setiap cluster
memiliki warna yang berbeda sehingga memudahkan user dalam membedakan tiap cluster dan diikuti dengan banyaknya anggota cluster. Untuk menu sorting cluster merupakan menu untuk menampilkan desa - desa anggota suatu cluster
sehingga lebih memudahkan user dalam melakukan pengelompokan.
Gambar 4.4. Halaman Hasil Clustering
Gambar 4.4. Halaman Hasil Clustering (lanjutan)
Gambar 4.4. Halaman Hasil Clustering (lanjutan)
Gambar 4.4. Halaman Hasil Clustering (lanjutan)
Selain menggunakan data yang ada dalam data base, user juga dapat mengelompokkan data yang berasal dari data diluar data base yang sudah tersimpan. Namun data yang diinputkan haruslah data berekstensi “.csv” dan mengikuti format data tanpa header nama field. Untuk melakukan proses ini user harus memilih button “Cek Cluster”.
Gambar 4.5. Halaman Cek Cluster (lanjutan)
Untuk melihat proses clustering seperti pada data sebelumnya, user juga harus memilih button “Proses Clustering”.
Gambar 4.6. Halaman Proses Cek Cluster (lanjutan)
Untuk melihat hasil cluster, user dapat memilih button “Hasil Clustering” seperti pada tampilan berikut.
Gambar 4.7. Halaman Hasil Cek Cluster
Gambar 4.8. Halaman Proses Gagal
Gambar 4.8. Halaman Proses Gagal (lanjutan)
Untuk melihat cluster berapa yang merupakan kategori desa tertinggal, penulis menggunakan rumus sendiri berdasarkan parameter yang digunakan karena belum ada ketetapan perhitungan untuk desa tertinggal itu sendiri.
Parameter yang digunakan adalah :
1. Jarak kantor kepala desa terhadap kantor bupati.
Jika jarak semakin jauh maka desa tersebut akan mendekati kategori desa tertinggal.
2. Rasio jumlah sarana pendidikan per 100 penduduk.
Jika rasio semakin tinggi maka desa tersebut akan menjauhi kategori desa tertinggal.
3. Rasio jumlah sarana kesehatan per 100 penduduk.
Jika rasio semakin tinggi maka desa tersebut akan menjauhi kategori desa tertinggal.
4. Rasio jumlah tenaga kesehatan per 100 penduduk.