ABSTRACT
FAKHRI MAHATHIR. Plagiarism Detection System on Indonesian Language Text Documents Using ROUGE-N, ROUGE-L, and ROUGE-W. Under direction of AHMAD RIDHA.
Plagiarism is a serious problem in education. This research uses ROUGE-N (N = 3 or trigrams), ROUGE-L, and ROUGE-W (with weighted function f(x2)) at the sentence level to detect plagiarism on Indonesian language text documents. This research aim to obtain a suitable preprocessing for each method of assessment. The preprocessing includes stopword removal and stemming. This research uses clipping based on recall, precision, and f-measure. Analysis is restricted to preprocessing and calculation method used in each assessment method. Stemming improves ROUGE-N, while stopword removal negatively effects ROUGE-N. ROUGE-L and ROUGE-W performs well with f-measure clipping. ROUGE-W is better without stemming.
SISTEM PENDE
BERBAHASA
ROUG
DEP
FAKULTAS MATEM
INSTI
DETEKSI PLAGIAT PADA DOKUME
A INDONESIA MENGGUNAKAN ME
UGE-N, ROUGE-L DAN ROUGE-W
FAKHRI MAHATHIR
EPARTEMEN ILMU KOMPUTER
TEMATIKA DAN ILMU PENGETAHU
INSTITUT PERTANIAN BOGOR
BOGOR
2011
EN TEKS
METODE
ABSTRACT
FAKHRI MAHATHIR. Plagiarism Detection System on Indonesian Language Text Documents Using ROUGE-N, ROUGE-L, and ROUGE-W. Under direction of AHMAD RIDHA.
Plagiarism is a serious problem in education. This research uses ROUGE-N (N = 3 or trigrams), ROUGE-L, and ROUGE-W (with weighted function f(x2)) at the sentence level to detect plagiarism on Indonesian language text documents. This research aim to obtain a suitable preprocessing for each method of assessment. The preprocessing includes stopword removal and stemming. This research uses clipping based on recall, precision, and f-measure. Analysis is restricted to preprocessing and calculation method used in each assessment method. Stemming improves ROUGE-N, while stopword removal negatively effects ROUGE-N. ROUGE-L and ROUGE-W performs well with f-measure clipping. ROUGE-W is better without stemming.
SISTEM PENDETEKSI PLAGIAT PADA DOKUMEN TEKS
BERBAHASA INDONESIA MENGGUNAKAN METODE
ROUGE-N, ROUGE-L, DAN ROUGE-W
FAKHRI MAHATHIR
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Sistem Pendeteksi Plagiat pada Dokumen Teks Berbahasa Indonesia Menggunakan Metode ROUGE-N, ROUGE-L, dan ROUGE-W
Nama : Fakhri Mahathir NRP : G64052291
Menyetujui Pembimbing
Ahmad Ridha, S.Kom, MS NIP. 19800507 200501 1 001
Mengetahui Ketua Departemen
Dr. Ir. Sri Nurdiati, M.Sc NIP. 19601126 198601 2 001
PRAKATA
Alhamdulillahi Rabbil ‘Alamin, puji dan syukur penulis panjatkan kepada Allah Subhanahu Wata'ala atas curahan rahmat dan hidayah-Nya sehingga tugas akhir yang berjudul Sistem Pendeteksi Plagiat pada Dokumen Teks Berbahasa Indonesia Menggunakan Metode ROUGE-N, ROUGE-L, dan ROUGE-W dapat diselesaikan. Penelitian ini dilaksanakan mulai September 2010 sampai dengan Juni 2011, bertempat di Departemen Ilmu Komputer.
Penulis mengucapkan terima kasih kepada semua pihak yang telah membantu penulis dalam menyelesaikan tulisan akhir ini, antara lain kepada Mama Diah, Om Cholid, Om Daus, Tante Vivi, Papa, Nenek, Tante Tina, atas cinta kasih, bimbingan, dan iringan doa yang tak ternilai. Kepada adik-adikku, Riri, Titi, dan Nia atas motivasi serta canda tawa yang diberikan. Kepada Trien Marlisa atas kasih sayang yang tidak ternilai serta dukungan yang tak hentinya. Ucapan terima kasih dan penghargaan yang setinggi-tingginya kepada Bapak Ahmad Ridha, S.Kom, MS selaku pembimbing atas bimbingan dan arahan yang diberikan, tidak hanya mengenai tugas akhir ini tetapi juga tentang kehidupan secara luas, Bapak Sony Hartono Wijaya S.Kom, M.Kom dan Ibu Dr. Ir. Sri Nurdiati, M.Sc selaku dosen penguji yang telah memberikan saran dan kritik yang membangun kepada penulis. Tidak lupa kepada semua dosen pengajar yang telah mendidik, membina, serta mengajar penulis selama menjadi civitas akademika Departemen Ilmu Komputer. Kepada Pak Sholeh dan Pak Pendi yang telah banyak direpotkan oleh penulis semasa pekuliahan hingga saat seminar maupun sidang.
Selanjutnya, penulis ingin mengucapkan terima kasih kepada Wawan, Makinun, Rofiq, Hengky, Gaos, Mizan, Fahmilu, Hasyim, Andi, Wolvy, Ardy, Zai, Diyan, Windy dan Pak Udin, atas kebersamaan dalam mengarungi masa-masa sebagai mahasiswa di Institut Pertanian Bogor. Juga terima kasih kepada Dika dan Isa yang telah bersedia menjadi pembahas.
Penulis menyadari bahwa penelitian ini masih jauh dari kesempurnaan. Besar harapan penulis bahwa apa yang telah dikerjakan dapat memberikan manfaat bagi semua pihak, khususnya untuk para peneliti yang berminat melanjutkan dan menyempurnakan penelitian ini.
Bogor, Juni 2011
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 4 Agustus 1987 dari ayah bernama M. Salim Bajri dan ibu bernama Alm. Anita Zahida. Penulis merupakan anak pertama dari empat bersaudara.
Selama masa sekolah menengah, penulis aktif dalam organisasi dan kegiatan ekstrakurikuler, di antaranya ROHIS dan Taekwondo. Pada tahun 2005 penulis menamatkan sekolah menengah di Sekolah Menengah Atas Negeri (SMAN) 113 Jakarta. Pada tahun yang sama penulis lulus seleksi masuk IPB melalui jalur Undangan Seleksi Masuk IPB (USMI). Pada Tahun 2006, penulis diterima di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
iv
DAFTARISIHalaman
DAFTAR TABEL ... v
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA ... 1
Plagiat... 1
ROUGE ... 2
ROUGE-N ... 2
ROUGE-L ... 2
ROUGE-W ... 2
Gaussian(Sebaran Normal) ... 3
Bayesian Classifier ... 3
Naïve Bayes Classifier ... 4
Gaussian Naïve Bayes Classifier ... 4
Koefisien Korelasi Pearson ... 4
Fingerprint Based ... 4
String-Matching Based ... 4
Tree-Matching Based ... 4
METODE PENELITIAN ... 4
Korpus ... 4
Perhitungan Jarak ... 5
Perhitungan Korelasi ... 6
Praproses ... 6
Klasifikasi Naïve Bayes ... 6
Perhitungan Akurasi ... 6
HASIL DAN PEMBAHASAN... 7
Pemilihan Data Uji dan Data Latih ... 7
Perhitungan Akurasi ... 7
Akurasi ROUGE-N ... 7
Akurasi ROUGE-L ... 9
Akurasi ROUGE-W ... 11
Akurasi ROUGE-N pada 3-FoldCross-Validation ... 13
Akurasi ROUGE-L pada 3-FoldCross-Validation ... 14
Akurasi ROUGE-W pada 3-FoldCross-Validation ... 15
KESIMPULAN DAN SARAN... 17
Kesimpulan ... 17
Saran ... 17
DAFTAR PUSTAKA ... 17
v
DAFTAR TABELHalaman
1 Distribusi dokumen ... 5
2 Distribusi dokumen kategorisasi ulang ... 5
3 Kombinasi hasil yang mungkin ... 6
4 Rata-rata korelasi calon data latih empat kategori ... 7
5 Rata-rata korelasi calon data latih dua kategori ... 7
6 Hasil akurasi empat kategori dengan ROUGE-N ... 7
7 Hasil akurasi dua kategori dengan ROUGE-N ... 8
8 Korelasi antara praproses dan akurasi pada data empat kategori ROUGE-N ... 8
9 Korelasi antara teknik clipping dan akurasi pada data empat kategori ROUGE-N ... 9
10 Korelasi antara praproses dan akurasi pada data dua kategori ROUGE-N ... 9
11 Korelasi antara teknik clipping dan akurasi pada data dua kategori ROUGE-N ... 9
12 Hasil akurasi empat kategori dengan ROUGE-L ... 9
13 Hasil akurasi dua kategori dengan ROUGE-L ... 10
14 Korelasi antara praproses dan akurasi pada data empat kategori ROUGE-L ... 10
15 Korelasi antara teknik clipping dan akurasi pada data empat kategori ROUGE-L ... 10
16 Korelasi antara praproses dan akurasi pada data dua kategori ROUGE-L ... 11
17 Korelasi antara teknik clipping dan akurasi pada data dua kategori ROUGE-L ... 11
18 Hasil akurasi empat kategori dengan ROUGE-W... 11
19 Hasil akurasi dua kategori dengan ROUGE-W ... 11
20 Korelasi antara praproses dan akurasi pada data empat kategori ROUGE-W ... 12
21 Korelasi antara teknik clipping dan akurasi pada data empat kategori ROUGE-W ... 12
22 Korelasi antara praproses dan akurasi pada data dua kategori ROUGE-W ... 12
23 Korelasi antara teknik clipping dan akurasi pada data dua kategori ROUGE-W ... 13
24 Rata-rata akurasi ROUGE-N untuk dua kategori pada 3-fold cross-validation ... 13
25 Korelasi antara rata-rata akurasi dan praproses ROUGE-N dengan data dua kategori pada 3-fold cross-validation ... 13
26 Korelasi antara rata-rata akurasi dan teknik clipping ROUGE-N dengan data dua kategori pada 3-fold cross-validation ... 13
27 Rata-rata akurasi ROUGE-N untuk empat kategori pada 3-fold cross-validation ... 14
28 Korelasi antara rata-rata akurasi dan praproses ROUGE-N dengan data empat kategori pada 3-fold cross-validation ... 14
29 Korelasi antara rata-rata akurasi dan teknik clipping ROUGE-N dengan data empat kategori pada 3-fold cross-validation ... 14
30 Rata-rata akurasi ROUGE-L untuk dua kategori pada 3-fold cross-validation ... 14
31 Korelasi antara rata-rata akurasi dan praproses ROUGE-L dengan data dua kategori pada 3-fold cross-validation ... 14
32 Korelasi antara rata-rata akurasi dan teknik clipping ROUGE-L dengan data dua kategori pada 3-fold cross-validation ... 15
33 Rata-rata akurasi ROUGE-L untuk empat kategori pada 3-fold cross-validation ... 15
34 Korelasi antara rata-rata akurasi dan praproses ROUGE-L dengan data empat kategori pada 3-fold cross-validation ... 15
35 Korelasi antara rata-rata akurasi dan teknik clipping ROUGE-L dengan data empat kategori pada 3-fold cross-validation ... 15
36 Rata-rata akurasi ROUGE-W untuk dua kategori pada 3-fold cross-validation ... 16
37 Korelasi antara rata-rata akurasi dan praproses ROUGE-W dengan data dua kategori pada 3-fold cross-validation ... 16
38 Korelasi antara rata-rata akurasi dan teknik clipping ROUGE-W dengan data dua kategori pada 3-fold cross-validation ... 16
39 Rata-rata akurasi ROUGE-W untuk empat kategori pada 3-fold cross-validation ... 16
40 Korelasi antara rata-rata akurasi dan praproses ROUGE-W dengan data dua kategori pada 3-fold cross-validation ... 16
vi
DAFTAR GAMBARHalaman
1 Contoh clipped unigram. ... 2
2 Algoritme ROUGE-W. ... 3
3 Kurva normal. ... 3
4 Algoritme string-matching based. ... 4
5 Metode penelitian. ... 5
DAFTAR LAMPIRAN Halaman 1 Data empat kategori ... 22
2 Data dua kategori ... 23
3 Daftar stopword (Ridha 2002) ... 24
4 Data 3-fold cross-validation ... 25
5 Akurasi ROUGE-N untuk data empat kategori pada data latih 60% data uji 40% ... 26
6 Akurasi ROUGE-N untuk data dua kategori pada data latih 60% data uji 40% ... 27
7 Akurasi ROUGE-L untuk data empat kategori pada data latih 60% data uji 40% ... 28
8 Akurasi ROUGE-L untuk data dua kategori pada data latih 60% data uji 40% ... 29
9 Akurasi ROUGE-W untuk data empat kategori pada data latih 60% data uji 40% ... 30
10 Akurasi ROUGE-W untuk data dua kategori pada data latih 60% data uji 40% ... 31
11 Akurasi ROUGE-N untuk data dua kategori pada 3-fold cross-validation dengan data latih fold 1 dan 2 ... 32
12 Akurasi ROUGE-N untuk data dua kategori pada 3-fold cross-validation dengan data latih fold 1 dan 3 ... 33
13 Akurasi ROUGE-N untuk data dua kategori pada 3-fold cross-validation dengan data latih fold 2 dan 3 ... 34
14 Akurasi ROUGE-N untuk data empat kategori pada 3-fold cross-validation dengan data latih fold 1 dan 2 ... 35
15 Akurasi ROUGE-N untuk data empat kategori pada 3-fold cross-validation dengan data latih fold 1 dan 3 ... 36
16 Akurasi ROUGE-N untuk data empat kategori pada 3-fold cross-validation dengan data latih fold 2 dan 3 ... 37
17 Akurasi ROUGE-L untuk data dua kategori pada 3-fold cross-validation dengan data latih fold 1 dan 2 ... 38
18 Akurasi ROUGE-L untuk data dua kategori pada 3-fold cross-validation dengan data latih fold 1 dan 3 ... 39
19 Akurasi ROUGE-L untuk data dua kategori pada 3-fold cross-validation dengan data latih fold 2 dan 3 ... 40
20 Akurasi ROUGE-L untuk data empat kategori pada 3-fold cross-validation dengan data latih fold 1 dan 2 ... 41
21 Akurasi ROUGE-L untuk data empat kategori pada 3-fold cross-validation dengan data latih fold 1 dan 3 ... 42
22 Akurasi ROUGE-L untuk data empat kategori pada 3-fold cross-validation dengan data latih fold 2 dan 3 ... 43
23 Akurasi ROUGE-W untuk data dua kategori pada 3-fold cross-validation dengan data latih fold 1 dan 2 ... 44
24 Akurasi ROUGE-W untuk data dua kategori pada 3-fold cross-validation dengan data latih fold 1 dan 3 ... 45
vii
26 Akurasi ROUGE-W untuk data empat kategori pada 3-fold cross-validationdengan data latih fold 1 dan 2 ... 47 27 Akurasi ROUGE-W untuk data empat kategori pada 3-fold cross-validation
dengan data latih fold 1 dan 3 ... 48 28 Akurasi ROUGE-W untuk data empat kategori pada 3-fold cross-validation
1 PENDAHULUAN
Latar Belakang
Plagiat merupakan salah satu masalah serius dalam dunia pendidikan. Semakin bertambahnya penggunaan dan publikasi data elektronik pada dekade terakhir memudahkan dilakukannya plagiat dari material yang sudah ada (Van Zijl & Hoffmann 2005). Plagiat dalam bahasa sehari-hari disebut dengan mencontek. Dalam Kamus Besar Bahasa Indonesia (KBBI) edisi keempat tahun 2008, plagiat diartikan sebagai “pengambilan karangan (pendapat dan sebagainya) orang lain dan disiarkan sebagai karangan (pendapat dan sebagainya) sendiri.” Pelaku tindakan plagiat disebut plagiator.
Pendeteksian plagiat dapat dilakukan secara manual menggunakan bantuan manusia atau secara semi-otomatis menggunakan sistem komputer. Saat ini pendeteksian secara manual merupakan cara yang paling akurat dalam mendeteksi plagiat. Kelemahan dari cara ini adalah sangat menghabiskan tenaga, waktu, serta tidak konsisten karena dipengaruhi faktor emosional manusia. Oleh karena itu, selama dekade terakhir para akademisi berusaha mengembangkan sebuah sistem komputer untuk mendeteksi plagiat dengan tingkat akurasi yang mendekati sistem manual.
Dalam perkembangannya, sistem pendeteksi plagiat melahirkan berbagai macam teknik. Dari berbagai macam teknik yang telah diterapkan, sistem pendeteksi plagiat dapat dikelompokkan menjadi tiga kelompok, yaitu, fingerprint based, string-matching based, dan tree-matching based (Mozgovoy 2006).
Salah satu teknik yang termasuk kelompok string-matching based adalah Recall-Oriented Understudy for Gisting Evaluation (ROUGE). Pada awal kemunculannya, ROUGE digunakan untuk mengevaluasi hasil rangkuman (Lin 2004). ROUGE juga telah diterapkan pada sistem pendeteksi plagiat dalam bahasa Inggris yang penggunaannya dikombinasikan dengan WordNet (Chen et al. 2010). ROUGE memiliki empat jenis metode penilain: ROUGE-N,
ROUGE-L, ROUGE-W, dan ROUGE-S.
Keempat metode ROUGE menghasilkan nilai masing-masing tanpa terkait satu sama lain. ROUGE menggunakan perhitungan recall, precision, dan f-measure dengan modifikasi clipping yang ada pada penelitian Papineni et al. (2002) untuk setiap metodenya.
Penelitian ini mencoba menggunakan metode penilaian ROUGE-N (N = 3 atau trigram), ROUGE-L, dan ROUGE-W yang
masing-masing metode diaplikasikan pada tingkat kalimat.
Tujuan
Tujuan dari penelitian ini adalah:
1. Menerapkan metode penilaian ROUGE-N (N = 3), ROUGE-L, dan ROUGE-W untuk mendeteksi plagiat dokumen teks berbahasa Indonesia.
2. Memperoleh praproses yang baik untuk masing-masing metode penilaian ROUGE-N (N = 3), ROUGE-L, dan ROUGE-W ketika diterapkan pada dokumen teks berbahasa Indonesia.
Ruang Lingkup
Beberapa lingkup penelitian ini meliputi: 1. Metode yang digunakan adalah ROUGE-N
(N = 3), ROUGE-L, dan ROUGE-W dengan perhitungan recall, precision, dan f-measure yang dimodifikasi clipping (Papineni et al. 2002).
2. Praproses yang digunakan pada setiap metode adalah penghilangan stopword dan stemming.
3. Bahasa yang digunakan adalah bahasa Indonesia.
4. Algoritme stemming yang digunakan adalah algoritme pada penelitian Adriani et al. (2007) dan algoritme pada penelitian Iqbal (2010).
5. Dokumen korpus yang digunakan berjenis plaintext.
TINJAUAN PUSTAKA Plagiat
Plagiat adalah “pengambilan karangan (pendapat dan sebagainya) orang lain dan disiarkan sebagai karangan (pendapat dan sebagainya) sendiri” (KBBI 2008). Pelaku tindakan plagiat disebut plagiator. Menurut Jayapa (2007), pada umumnya ada beberapa tipe plagiat, antara lain:
• Copy-paste. Menyalin semua yang tertulis pada sumber.
2 • Translated. Merupakan terjemahan dari
sumber lain tanpa mencantumkan referensi sumber.
• Artistic. Mengubah media yang digunakan, misalnya teks, gambar, dan video.
• Idea. Menggunakan ide unik orang lain. • Code. Menggunakan kode program orang
lain tanpa izin atau mencantumkan sumber. ROUGE
ROUGE adalah sebuah teknik untuk mengevaluasi rangkuman yang dibuat oleh mesin. ROUGE ditemukan oleh Chin-Yew Lin pada tahun 2004. Di dalamnya terdapat empat jenis metode penilaian: ROUGE-N, ROUGE-L, ROUGE-W, dan ROUGE-S. Tiga dari empat penilaian tersebut digunakan pada Document Understanding Conference (DUC) 2004, konferensi evaluasi rangkuman berskala besar yang disponsiri National Institute of Standards and Technology (NIST) (Lin 2004).
ROUGE-N
Dikatakan oleh Lin (2004), ROUGE-N adalah recall n-gram antara kandidat rangkuman dan referensi rangkuman dengan gram terkecil adalah sebuah kata. Rumus recall pada temu kembali informasi adalah:
relevan ditemukembalikan relevan
Pada ROUGE-N, yang bertindak sebagai {relevan} adalah n-gram pada kalimat referensi rangkuman, sedangkan yang bertindak sebagai {ditemukembalikan} adalah n-gram pada kalimat kandidat rangkuman. Pada ROUGE-N, digunakan teknik clipping yang ada pada penelitian Papineni et al. (2002) untuk menghitung {relevan} ∩ {ditemukembalikan}.
ROUGE-N dilakukan pada tingkat kalimat. Bila Ai adalah kalimat pada referensi rangkuman dan Bj kalimat pada kandidat rangkuman, maka jarak antar kalimat menggunakan perhitungan recall, precision, dan f-measure pada ROUGE-N (ROUGE-N = 3) adalah:
Clipped trigram
Count trigram
Clipped trigram
Count trigram
1
Contoh clipped dapat dilihat pada Gambar 1. Jika β > 1 maka pengaruh recall dalam perhitungan lebih besar, jika β < 1 maka pengaruh precision dalam perhitungan lebih besar, dan jika β = 1 maka pengaruh recall dan precision sama besar. Untuk menghitung jarak antar dokumen digunakan rumus:
∑ maks
jumlah kalimat
Gambar 1 Contoh clipped unigram. ROUGE-L
ROUGE-L adalah salah satu metode penilaian pada ROUGE yang menggunakan Longest Common Subsequence (LCS) pada tingkat kalimat. ROUGE-L memandang kalimat dalam rangkuman sebagai suatu deretan kata. Jika X dan Y adalah sebuah deretan yang memiliki panjang masing-masing m dan n, maka LCS(X,Y) adalah panjang maksimal dari sub-deretean yang ada pada X maupun Y. Perhitungannya sebagai berikut (Lin 2004):
! "#$ %, '(
! "#$ %, ')
! 1 ! !
! !
Pada DUC, ditetapkan nilai β yang besar ( >= 8). Untuk menghitung jarak antar dokumen digunakan rumus:
∑ maks "
jumlah kalimat
ROUGE-W
ROUGE-W merupakan perluasan dari sistem penilaian ROUGE-L. ROUGE-W menambahkan pembobotan setiap urutan yang berdempetan. Sebagai contoh, diberikan tiga buah deretan X, Y1, dan Y2:
X: [saya suka makan nasi goreng kambing] Y1: [saya suka makan nasi uduk tanah abang]
Kalimat Kandidat: yang yang yang yang yang Kalimat Referensi:
orang yang makan nasi yang basi
3 Y2: [saya suka minum susu dan makan nasi]
Berdasarkan contoh di atas, nilai LCS(X,Y1) = LCS(X,Y2). Bagaimanapun, Y1 terlihat lebih baik dibandingkan dengan Y2, karena memiliki kesamaan urutan yang berdempetan. ROUGE-W menyimpan panjang kesamaan urutan yang berdempetan untuk dimasukkan dalam sistem penilaiannya (Lin 2004).
Fungsi pembobotan digunakan saat terdapat LCS yang berdempetan, yaitu dengan cara memasukkan panjang kesamaan urutan yang berdempetan ke dalam suatu fungsi pembobotan. Kemudian seluruh hasil pembobotan dijumlahkan, ini yang menjadi nilai Weighted Longest Common Subsequence (WLCS) pada tingkat kalimat. Algoritme ROUGE-W dapat dilihat pada Gambar 2. Perhitungan jarak pada tingkat kalimat menggunakan metode ROUGE-W adalah:
* ! +,-.+ panjang kata/"#$ , 0
* ! +,-.+ panjang kata/"#$ , 0
* ! 1 * ! * ! * ! * !
Untuk menghitung jarak antar dokumen digunakan rumus:
∑ maks /
jumlah kalimat
Gambar 2 Algoritme ROUGE-W.
Gaussian(Sebaran Normal)
Sebaran normal adalah sebaran peluang kontinu yang paling penting dalam bidang statistika. Grafiknya, yang disebut kurva normal, adalah kurva yang berbentuk genta seperti pada Gambar 3 (Walpole 1982).
Suatu peubah acak kontinu X yang memilki sebaran berbentuk genta seperti dalam Gambar 3 disebut peubah acak normal. Persamaan bagi sebaran peluang peubah acak normal ini bergantung pada dua parameter µ dan σ, yaitu nilai tengah dan simpangan bakunya (Walpole 1982).
Gambar 3 Kurva normal.
Bila X adalah suatu peubah acak normal dengan nilai tengah µ dan ragam σ2, maka persamaan kurva normalnya adalah (Walpole 1982):
) 1|3, 4 1
√2748 ,9:;<=>? @:
Dengan π= 3.14159… dan e= 2.71828… Bayesian Classifier
Bayesian classifier merupakan sebuah pendekatan untuk memodelkan peluang hubungan antara himpunan atribut dan kelas variabel tersebut. Implementasi dari Bayesian classifier, yaitu naïve Bayes classifier dan Bayesian belief network. (Tan et al. 2006).
Peluang bersama dan bersyarat untuk X dan Y dapat dilihat pada formula berikut (Tan et al. 2006):
%|' '|% A % %|' A '
Dari formula itu, dapat diperoleh teorema Bayes:
'|% %|' A '%
Variabel X pada teorema Bayes menunjukkan serangkaian atribut, sedangkan variabel Y menunujukkan variabel kelas. P(Y|X) merupakan peluang bersyarat yang juga dikenal sebagai posterior probability terhadap Y, sedangkan P(Y) merupakan prior probability (Tan et al. 2006).
1 FOR(h=1;h≤m;h++)
2 FOR(i=h;i≤m;i++)
3 FOR(j=batas;j≤n;j++) 4 IF(xi=yj)
5 k++;
6 batas=j+1; 7 break; 8 ELSE
9 weight=weight+f(k); 10 k=0;
11 ENDFOR 12 IF(k>0)
13 weight=weight+f(k); 14 k=0;
15 IF(weight>max) 16 max=weight; 17 ENDFOR
4 Naïve Bayes Classifier
Naïve Bayes classifier menduga kelas peluang bersyarat dengan mengasumsikan atribut secara kondisi bebas, jika diberi label kelas y (Tan et al. 2006). Naïve Bayes adalah salah satu algoritme pembelajaran induktif yang paling efesien dan efektif dalam bidang machine learning dan data mining. Tujuan dari algoritme pembelajaran adalah membangun sebuah pengklasifikasi (classifier) menggunakan satu set contoh data latih yang memiliki atribut kelas (Zhang 2004).
Diasumsikan E adalah sebuah contoh data yang memiliki nilai atribut (x1,x2,,…,xn), dengan xi adalah nilai dari atribut Xi , sedangkan C adalah variabel kelas dan c adalah nilai dari variabel C. Menurut aturan Bayes, peluang contoh data E = (x1,x2,,…,xn) sebagai kelas c adalah:
B C| B |C B CB
Naïve Bayes classifier mengasumsikan semua atribut adalah bebas sehingga
B |C B 1-, 1 , , … , 1E|C F B 1 |C E
G-B C| B C ∏ B 1 |CBE
G-Dalam proses pengklasifikasian, nilai p(E) adalah sama untuk sebuah data E. Naïve Bayes classifier dapat didefinisikan sebagai berikut:
#EI JKL(J1 B C F B 1 |C
E
G-Gaussian Naïve Bayes Classifier
Gaussian naïve Bayes classifier adalah naïve Bayes classifier yang menggunakan
sebaran normal (Gaussian) untuk
memperkirakan B 1 |C jika nilai atribut 1 adalah kontinu (Bouckaert 2004). Untuk setiap kelas c dan 1 adalah atribut data, B 1 |C ) 1 |3M, 4M dengan
) 1|3, 4 √ NO- 81B P -;Q,RO @ S.
Koefisien Korelasi Pearson
Korelasi Pearsonmengukur hubungan antara dua variabel X dan Y, yang memberikan nilai antara 1 dan -1. Jika korelasi mendekati 1 berarti semakin baik hubungan antara dua variabel, dan sebaliknya. Rumus korelasi Pearsonadalah (Walpole 1982):
K ∑EG- % %T ' 'T
U∑E % %T
G- U∑EG- ' 'T
Fingerprint Based
Ide utama pada fingerprint based adalah membuat fingerprint untuk semua koleksi dokumen. Pada sistem pendeteksi plagiat fingerprint based, setiap fingerprint mengandung atribut numerikal yang merepresentasikan struktur dari dokumen. Jika fingerprint antara dua dokumen sangat dekat, maka dapat dicurigai salah satunya merupakan hasil plagiat (Mozgovoy 2006).
String-Matching Based
Pada dasarnya, string-matching based bekerja menurut algoritme pada Gambar 4. Metode string-matching based membandingkan dokumen dengan memandangnya sebagai strings (Mozgovoy 2006).
Gambar 4 Algoritme string-matching based. Tree-Matching Based
Metode tree-matching based memandang dokumen sebagai suatu struktur. Oleh karena itu, tree-matching based lebih cocok dipakai untuk mendeteksi plagiat pada source program komputer karena memiliki aturan struktur yang sama (Mozgovoy 2006). Untuk diterapkan pada bahasa alami, dokumen yang dibandingkan harus memiliki aturan struktur yang sama.
METODE PENELITIAN
Metodologi yang digunakan pada penelitian ini terdiri atas beberapa tahap. Tahapan-tahapan tersebut dapat dilihat pada Gambar 5.
Korpus
Korpus pada penelitian ini merupakan korpus teks bahasa Inggris berjenis plaintext hasil penelitian Clough dan Stevenson (2009) yang diterjemahkan ke dalam Bahasa Indonesia. Korpus tersebut dibuat khusus untuk pengembangan dan evaluasi sistem pendeteksi plagiat dokumen teks. Korpus berjumlah 100 dokumen yang terdiri dari 5 dokumen asli dan 95 dokumen yang memiliki tingkatan plagiat. Masing-masing dokumen asli memiliki topik yang berbeda. Korpus penelitian Clough dan Stevenson (2009) terbagi menjadi empat tingkatan plagiat dokumen, yaitu:
1 FOR EACH collection file F
5
Gambar 5 Metode penelitian.
1. Near copy. Seluruh isi disalin dari teks aslinya, tetapi tidak semua isi pada teks asli disalin.
2. Light revision. Isi diambil dari teks aslinya dengan mengubah kata dan frase dengan
sinonimnya, mengubah struktur kalimat serta mengubah urutan kalimat.
3. Heavy revision. Isi diambil dari teks aslinya dengan mengubah kata dan frase dengan sinonimnya, mengubah struktur kalimat, mengubah urutan kalimat, memecah satu kalimat menjadi dua atau lebih kalimat serta menggabungkan dua atau lebih kalimat menjadi satu kalimat.
4. Non-plagiarised. Isi diambil dari bahan kuliah, buku teks, dan ditulis menggunakan tata bahasa yang berbeda.
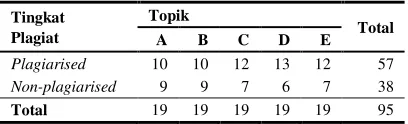
Jika dihubungkan antara tingkatan plagiat korpus dan definisi tipe plagiat pada Jayapa 2008, near copy dapat dikatakan sama dengan tipe plagiat copy-paste sedangkan light revision dan heavy revision merupakan perluasan dari paraphrasing. Distribusi asli dokumen berdasar tingkatan plagiat dan topiknya dapat dilihat pada Tabel 1 dan Lampiran 1.
Tabel 1 Distribusi dokumen
Tingkat Plagiat
Topik
Total
A B C D E
Near copy 4 3 3 4 5 19
Light revision 3 3 4 5 4 19 Heavy revision 3 4 5 4 3 19 Non-plagiarised 9 9 7 6 7 38
Total 19 19 19 19 19 95
Pada penelitian ini juga dilakukan pengategorian ulang menjadi dua kategori, plagiarised dan non-plagiarised. Kategori plagiarised merupakan penggabungan dari kategori near copy, light revision, dan heavy revision. Distribusi dokumen setelah dikategorikan ulang dapat dilihat pada Tabel 2 dan Lampiran 2.
Tabel 2 Distribusi dokumen kategorisasi ulang
Tingkat Plagiat
Topik
Total
A B C D E
Plagiarised 10 10 12 13 12 57 Non-plagiarised 9 9 7 6 7 38
Total 19 19 19 19 19 95
Untuk berikutnya, 95 dokumen yang memiliki tingkatan plagiat tersebut akan disebut sebagai dokumen kandidat.
Perhitungan Jarak
6 Perhitungan yang digunakan untuk ketiga
metode tersebut adalah recall, precision, dan f-measure dengan modifikasi clipping yang ada pada penelitian Papineni et al. (2002). Untuk berikutnya recall, precision, dan f-measure yang dimodifikasi clipping hanya disebut recall, precision, dan f-measure.
Pada ROUGE-N, n-gram yang digunakan adalah trigram (N = 3) dan pada ROUGE-W digunakan fungsi pembobotan f(x2). Nilai β yang digunakan untuk masing-masing penilaian pada penelitian ini adalah 1.
Perhitungan Korelasi
Dengan menggunakan korelasi Pearson dihitung nilai korelasi antara jarak dokumen terhadap dokumen asli dan tingkatan plagiat dokumen untuk masing-masing topik. Nilai tingkatan plagiat untuk empat kategori adalah near copy = 4, light revision = 3, heavy revision = 2, dan non-plagiarised = 1. Untuk dua kategori, nilai tingkatan plagiatnya adalah plagiarised = 2 dan non-plagiarised = 1.
Lalu dari lima topik yang ada pada korpus, baik yang empat kategori maupun yang dua kategori, dipilih tiga kombinasi topik yang memiliki nilai rata-rata korelasi tertinggi untuk kemudian dijadikan data latih (60% data) dan dua topik sisanya dijadikan data uji (40% data). Praproses
Yang dimaksud dengan praproses adalah perlakuan terhadap korpus sebelum dilakukannya proses penilaian. Praproses yang digunakan dalam penelitian ini adalah sebagai berikut:
a. Stemming
Mengubah setiap kata pada dokumen menjadi kata dasarnya. Algoritme stemming yang digunakan adalah:
• Algoritme stemming pada penelitian Adriani et al. (2007).
• Algoritme stemming pada penelitian Iqbal (2010).
b. Penghilangan Stopword
Seringkali, kata yang paling sering muncul pada dokumen bukanlah kata yang mewakili isi dokumen tersebut dan tidak dapat digunakan dalam proses temu kembali informasi. Kata-kata seperti ini disebut dengan stopword, dan pada umumnya tidak ikut dimasukkan ke dalam indeks (Baeza-Yates & Ribeiro-Neto 1999). Daftar stopword yang digunakan adalah stopword
pada penelitian Ridha (2002) yang dapat dilihat pada Lampiran 3.
Dengan mengombinasi praproses dengan perhitungan clipping, dapat dilihat pada Tabel 3 ada enam kombinasi hasil yang mungkin dilakukan dalam perhitungan jarak. Tiap kombinasi terdiri dari perhitungan recall, precision dan f-measure. Karena terdapat tiga metode yang digunakan, maka total terdapat 6 x 3 = 18 kombinasi hasil.
Tabel 3 Kombinasi hasil yang mungkin
No. Praproses
Stem Stop
1. x x 2. √(A) x 3. √(I) x 4. x √ 5. √(A) √ 6. √(I) √
(A) adalah stemmer Adriani, (I) adalah stemmer Iqbal
Klasifikasi Naïve Bayes
Pada tahap ini digunakan Gaussian naïve Bayes classifier. Ide penggunaan naïve Bayes classifier didapat dari penelitian Chong et al. pada tahun 2010. Saat pelatihan, data latih dihitung nilai rata-rata dan standar deviasinya untuk tiap tingkatan plagiat. Kemudian saat pengujian, jarak dokumen asli dengan dokumen yang memiliki tingkatan plagiat untuk masing-masing topik adalah satu-satunya atribut data dan merupakan atribut kontinu.
Perhitungan Akurasi
Tingkat akurasi dalam mengklasifikasi data uji dihitung untuk tiap tingkatan plagiat dan keseluruhan data uji. Tingkat akurasi tiap tingkatan plagiat diperoleh dengan perhitungan:
JVWKJXY ∑
data uji benar diklasifikasi pada tingkatan plagiat ∑data ujipada tingkatan
plagiat
x 100%
Dan tingkat akurasi keseluruhan diperoleh dengan perhitungan:
akurasi
∑benar diklasifikasidata uji
7 Untuk mencari seberapa besar pengaruh tiap
praproses dan teknik clipping, korelasinya dengan tingkat akurasi dapat dihitung dengan asumsi:
• Penggunaan stopword bernilai 1, jika tidak bernilai 0.
• Penggunaan stemming bernilai 1, jika tidak bernilai 0.
• Penggunaan stemming Iqbal (2010) bernilai 1 dan stemming Adriani (2007) bernilai 0. • Penggunaan recall bernilai 1, jika tidak
bernilai 0.
• Penggunaan precision bernilai 1, jika tidak bernilai 0.
• Penggunaan f-measure bernilai 1, jika tidak bernilai 0.
HASIL DAN PEMBAHASAN
Pemilihan Data Uji dan Data Latih
Untuk setiap kombinasi topik calon data latih, dihitung rata-rata korelasi perhitungan recall, precision, dan f-measure-nya.
Tabel 4 Rata-rata korelasi calon data latih empat kategori
Kombinasi Topik Calon Data Latih
Rata-rata Korelasi
Task a, Task b, Task c 0.748 Task a, Task b, Task d 0.790 Task a, Task b, Task e 0.834 Task a, Task c, Task d 0.784 Task a, Task c, Task e 0.831
Task a, Task d, Task e 0.861
Task b, Task c, Task d 0.717 Task b, Task c, Task e 0.772 Task b, Task d, Task e 0.809 Task c, Task d, Task e 0.803
Tabel 5 Rata-rata korelasi calon data latih dua kategori
Kombinasi Topik Calon Data Latih
Rata-rata Korelasi
Task a, Task b, Task c 0.737 Task a, Task b, Task d 0.764
Task a, Task b, Task e 0.810
Task a, Task c, Task d 0.744 Task a, Task c, Task e 0.792 Task a, Task d, Task e 0.808 Task b, Task c, Task d 0.712 Task b, Task c, Task e 0.762 Task b, Task d, Task e 0.782 Task c, Task d, Task e 0.763
Untuk data empat kategori, nilai rata-rata korelasi terbesar ada pada komposisi task a, task d, dan task e, yaitu 0.861 (lihat Tabel 4). Pada data dua kategori, nilai rata-rata korelasi terbesar ada pada komposisi task a, task b, dan task e, yaitu 0.810 (lihatTabel 5).
Perhitungan Akurasi Akurasi ROUGE-N
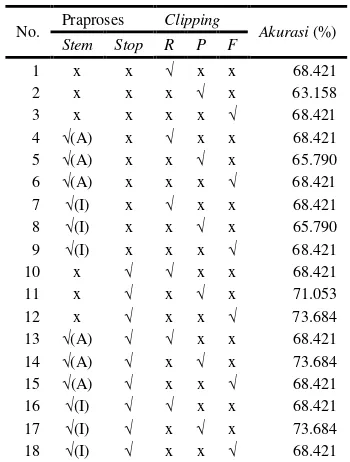
Hasil akurasi untuk data empat kategori, nilai akurasi tertinggi adalah sebesar 78.947%, sedangkan nilai akurasi terendah adalah sebesar 68.421% (lihatTabel 6). Nilai akurasi tertinggi terjadi pada semua kombinasi yang tidak menyertakan penghilangan stopword dalam praprosesnya. Nilai akurasi terendah terjadi saat kombinasi terdiri atas penghilangan stopword, tanpa stemming, dan menggunakan perhitungan f-measure. Untuk detilnya dapat dilihat pada Lampiran 5.
Tabel 6 Hasil akurasi empat kategori dengan ROUGE-N
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x x √ x x 78.947 2 x x x √ x 78.947 3 x x x x √ 78.947 4 √(A) x √ x x 78.947 5 √(A) x x √ x 78.947 6 √(A) x x x √ 78.947 7 √(I) x √ x x 78.947 8 √(I) x x √ x 78.947 9 √(I) x x x √ 78.947 10 x √ √ x x 71.053 11 x √ x √ x 71.053 12 x √ x x √ 68.421 13 √(A) √ √ x x 76.316 14 √(A) √ x √ x 73.684 15 √(A) √ x x √ 71.053 16 √(I) √ √ x x 76.316 17 √(I) √ x √ x 73.684 18 √(I) √ x x √ 71.053
8 Ketika dihitung rata-rata akurasinya, untuk
data empat kategori, kombinasi yang praprosesnya menyertakan penghilangan stopword memiliki rata-rata akurasi 72.515%, sedangkan praproses yang tanpa menyertakan penghilangan stopword memiliki rata-rata akurasi 78.947%. Terlihat bahwa rata-rata akurasi kombinasi yang praprosesnya tanpa menyertakan penghilangan stopword lebih besar dibandingkan dengan kombinasi yang praprosesnya menyertakan penghilangan stopword. Hal ini juga terjadi pada data dua kategori, rata-rata akurasi kombinasi yang praprosesnya tanpa menyertakan penghilangan stopword (92.105%) lebih besar dari praproses yang menyertakan penghilangan stopword (88.304%).
Tabel 7 Hasil akurasi dua kategori dengan ROUGE-N
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x x √ x x 92.105 2 x x x √ x 92.105 3 x x x x √ 92.105 4 √(A) x √ x x 92.105 5 √(A) x x √ x 92.105 6 √(A) x x x √ 92.105 7 √(I) x √ x x 92.105 8 √(I) x x √ x 92.105 9 √(I) x x x √ 92.105 10 x √ √ x x 86.842 11 x √ x √ x 86.842 12 x √ x x √ 84.211 13 √(A) √ √ x x 89.474 14 √(A) √ x √ x 89.474 15 √(A) √ x x √ 89.474 16 √(I) √ √ x x 89.474 17 √(I) √ x √ x 89.474 18 √(I) √ x x √ 89.474
Hasil akurasi data empat kategori, kombinasi yang praprosesnya menggunakan stemming memiliki rata-rata akurasi 76.316%, sedangkan praproses yang tanpa menggunakan stemming memiliki rata-rata akurasi 74.561%. Terlihat rata-rata akurasi kombinasi yang praprosesnya menggunakan stemming lebih besar dibandingkan dengan kombinasi yang praprosesnya tanpa menggunakan stemming. Hal ini juga terjadi pada data dua kategori, rata-rata akurasi kombinasi yang praprosesnya menggunakan stemming (90.789%) lebih besar dibandingkan dengan kombinasi yang praprosesnya tanpa menggunakan stemming (89.035%).
Hasil akurasi data empat kategori, kombinasi yang praprosesnya menggunakan stemming Iqbal (2010) memiliki rata-rata akurasi 73.392%, sedangkan praproses yang menggunakan stemming Adriani (2007) memiliki rata-rata akurasi 73.489%. Terlihat rata-rata akurasi stemming Adriani (2007) sedikit lebih besar dibandingkan dengan stemming Iqbal (2010). Namun pada data dua kategori, rata-rata akurasinya sama, yaitu sebesar 90.789%.
Nilai rata-rata akurasi yang menggunakan perhitungan recall, precision, dan f-measure pada data empat kategori adalah berturut-turut 73.587%, 73.567%, dan 74.196% sedangkan pada data dua kategori adalah 90.351%, 89.912%, dan 89.912%. Terlihat pada data empat kategori, perhitungan f-measure memiliki tingkat akurasi tertinggi. Namun pada data dua kategori, perhitungan recall yang memiliki akurasi tertinggi.
Jika acuan dalam memilih kombinasi yang optimal adalah rata-rata nilai akurasi untuk tiap praproses dan jenis perhitungan, kombinasi untuk mencapai akurasi optimal ROUGE-N pada data empat kategori terdiri atas tanpa penghilangan stopword, dengan stemming Adriani (2007), dan dengan perhitungan f-measure. Untuk data dua kategori, kombinasi yang optimal terdiri atas tanpa penghilangan stopword, menggunakan stemming Adriani (2007), dan perhitungan recall. Secara keseluruhan, baik untuk data empat kategori maupun dua kategori, ROUGE-N optimal ketika kombinasi praproses terdiri atas tanpa penghilangan stopword dan menggunakan stemming Adriani (2007).
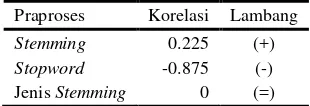
Korelasi antara praproses dan akurasi untuk data empat kategori dapat dilihat pada Tabel 8. Terlihat bahwa penghilangan stopword membawa pengaruh negatif dengan nilai korelasi -87.5%, sedangkan penggunaan stemming membawa pengaruh positif dengan nilai korelasi 22.5%. Jenis stemming yang digunakan tidak memberikan pengaruh karena nilai korelasinya yang nol.
Tabel 8 Korelasi antara praproses dan akurasi pada data empat kategori ROUGE-N
Praproses Korelasi Lambang
Stemming 0.225 (+)
Stopword -0.875 (-) Jenis Stemming 0 (=)
9 Tabel 9. Terlihat bahwa f-measure membawa
pengaruh negatif dengan nilai korelasi -22.5%. Sebaliknya, recall dan precision membawa pengaruh positif dengan nilai korelasi berturut-turut 19.7%, dan 2.8%.
Tabel 9 Korelasi antara teknik clipping dan akurasi pada data empat kategori ROUGE-N
Clipping Korelasi Lambang
Recall 0.197 (+)
Precision 0.028 (+)
F-measure -0.225 (-)
Korelasi antara praproses dan akurasi untuk data dua kategori dapat dilihat pada Tabel 10. Terlihat bahwa penghilangan stopword membawa pengaruh negatif, dan pengaruhnya cukup kuat dengan nilai korelasi -83%. Penggunaan stemming membawa pengaruh positif dengan nilai korelasi 36.1%. Jenis stemming yang digunakan tidak berpengaruh pada saat ini.
Tabel 10 Korelasi antara praproses dan akurasi pada data dua kategori ROUGE-N
Praproses Korelasi Lambang
Stemming 0.361 (+)
Stopword -0.830 (-) Jenis Stemming 0 (=)
Korelasi antara teknik clipping dan akurasi untuk data dua kategori dapat dilihat pada Tabel 11. Terlihat bahwa f-measure membawa pengaruh negatif dengan nilai korelasi -9%. Sebaliknya, recall dan precision membawa pengaruh postif dengan nilai korelasi berturut-turut 4.5%, dan 4.5%.
Tabel 11 Korelasi antara teknik clipping dan akurasi pada data dua kategori ROUGE-N
Clipping Korelasi Lambang
Recall 0.045 (+)
Precision 0.045 (+)
F-measure -0.090 (-)
Jika acuan dalam memilih kombinasi yang optimal adalah korelasi antara nilai akurasi dan praproses maupun teknik clipping, kombinasi untuk mencapai akurasi optimal ROUGE-N pada data empat kategori terdiri atas pengunaan stemming, tanpa penghilangan stopword dan dengan perhitungan recall. Begitu juga ntuk data dua kategori, kombinasi yang optimal terdiri atas pengunaan stemming, tanpa
penghilangan stopword dan dengan perhitungan recall.
Akurasi ROUGE-L
Pada hasil akurasi untuk data empat kategori, nilai akurasi tertinggi adalah sebesar 73.684%, sedangkan nilai akurasi terendah adalah sebesar 63.158% (lihat Tabel 12). Nilai akurasi tertinggi terjadi pada kombinasi 12, 14, dan 17 pada Tabel 12. Ketiga kombinasi tertinggi tersebut menyertakan penghilangan stopword dalam praprosesnya, dua di antaranya menggunakan perhitungan recall dan praproses stemming. Nilai akurasi terendah terjadi saat kombinasi terdiri atas tanpa penghilangan stopword, tanpa stemming, dan menggunakan perhitungan precision. Untuk detilnya dapat dilihat pada Lampiran 7.
Tabel 12 Hasil akurasi empat kategori dengan ROUGE-L
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x x √ x x 68.421 2 x x x √ x 63.158 3 x x x x √ 68.421 4 √(A) x √ x x 68.421 5 √(A) x x √ x 65.790 6 √(A) x x x √ 68.421 7 √(I) x √ x x 68.421 8 √(I) x x √ x 65.790 9 √(I) x x x √ 68.421 10 x √ √ x x 68.421 11 x √ x √ x 71.053 12 x √ x x √ 73.684 13 √(A) √ √ x x 68.421 14 √(A) √ x √ x 73.684 15 √(A) √ x x √ 68.421 16 √(I) √ √ x x 68.421 17 √(I) √ x √ x 73.684 18 √(I) √ x x √ 68.421
Hasil akurasi data dua kategori, nilai akurasi tertinggi adalah sebesar 94.737%, sedangkan nilai akurasi terendah adalah sebesar 86.842% (lihat Tabel 13). Nilai akurasi tertinggi terjadi saat kombinasi terdiri atas penghilangan stopword, tanpa stemming, dan menggunakan perhitungan f-measure. Nilai akurasi terendah terjadi pada kombinasi 2 dan 8 pada Tabel 13. Untuk detilnya dapat dilihat pada Lampiran 8.
10 akurasi 67.251%. Terlihat bahwa rata-rata
akurasi kombinasi yang praprosesnya menyertakan penghilangan stopword lebih besar dibandingkan dengan kombinasi yang praprosesnya tanpa menyertakan penghilangan stopword. Hal ini juga terjadi pada data dua kategori, rata-rata akurasi kombinasi yang praprosesnya menyertakan penghilangan stopword (92.398%) lebih besar dari praproses yang tanpa menyertakan penghilangan stopword (88.012%).
Tabel 13 Hasil akurasi dua kategori dengan ROUGE-L
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x x √ x x 89.474 2 x x x √ x 86.842 3 x x x x √ 92.105 4 √(A) x √ x x 89.474 5 √(A) x x √ x 89.474 6 √(A) x x x √ 92.105 7 √(I) x √ x x 92.105 8 √(I) x x √ x 86.842 9 √(I) x x x √ 92.105 10 x √ √ x x 92.105 11 x √ x √ x 92.105 12 x √ x x √ 94.737 13 √(A) √ √ x x 92.105 14 √(A) √ x √ x 92.105 15 √(A) √ x x √ 92.105 16 √(I) √ √ x x 92.105 17 √(I) √ x √ x 92.105 18 √(I) √ x x √ 92.105
Pada data empat kategori, kombinasi yang praprosesnya menggunakan stemming maupun yang tidakmenggunakan stemming, sama-sama memiliki rata-rata akurasi sebesar 68.860%. Kesamaan rata-rata akurasi antara kombinasi yang praprosesnya menggunakan stemming dan kombinasi yang tanpa stemming juga terjadi pada data dua kategori, yaitu sebesar 91.228%.
Hasil akurasi data empat kategori, kombinasi yang praprosesnya menggunakan stemming Iqbal (2010) maupun yang menggunakan stemming Adriani (2007), sama-sama memiliki rata-rata akurasi sebesar 68.860%. Kesamaan rata-rata akurasi antara kombinasi yang praprosesnya menggunakan stemming Iqbal (2010) dan kombinasi yang menggunakan stemming Adriani (2007) juga terjadi pada data dua kategori, yaitu sebesar 91.228%.
Nilai rata-rata akurasi yang menggunakan perhitungan recall, precision, dan f-measure pada data empat kategori adalah berturut-turut
68.421%, 68.860%, dan 69.298% sedangkan pada data dua kategori adalah 91.228%, 89.912%, dan 92.544%. Terlihat pada data empat kategori, perhitungan f-measure memiliki tingkat akurasi tertinggi, begitu juga pada data dua kategori.
Jika acuan dalam memilih kombinasi yang optimal adalah rata-rata nilai akurasi untuk tiap praproses dan jenis perhitungan, kombinasi untuk mencapai akurasi optimal ROUGE-L pada data empat kategori terdiri atas penghilangan stopword dan perhitungan f-measure. Kombinasi yang sama juga berlaku untuk data dua kategori.
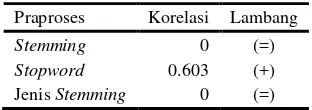
Korelasi antara praproses dan akurasi untuk data empat kategori dapat dilihat pada Tabel 14. Terlihat bahwa penghilangan stopword membawa pengaruh positif dengan nilai korelasi 60.3%. Pemilihan jenis stemming yang digunakan dan penggunaan stemming tidak memberikan pengaruh karena nilai korelasinya yang nol.
Tabel 14 Korelasi antara praproses dan akurasi pada data empat kategori ROUGE-L
Praproses Korelasi Lambang
Stemming 0 (=)
Stopword 0.603 (+) Jenis Stemming 0 (=)
Korelasi antara teknik clipping dan akurasi untuk data empat kategori dapat dilihat pada Tabel 15. Terlihat bahwa f-measure membawa pengaruh positif dengan nilai korelasi 11.6%. Sebaliknya, recall membawa pengaruh negatif dengan nilai korelasi sebesar -11.6%. Precision tidak membawa pengaruh karena nilai korelasi yang nol.
Tabel 15 Korelasi antara teknik clipping dan akurasi pada data empat kategori ROUGE-L
Clipping Korelasi Lambang
Recall -0.116 (-)
Precision 0 (=)
F-measure 0.116 (+)
11 Tabel 16 Korelasi antara praproses dan akurasi
pada data dua kategori ROUGE-L
Praproses Korelasi Lambang
Stemming 0 (=)
Stopword 0.596 (+) Jenis Stemming 0 (=)
Korelasi antara teknik clipping dan akurasi untuk data dua kategori dapat dilihat pada Tabel 17. Terlihat bahwa f-measure membawa pengaruh positif dengan nilai korelasi 47.4%. Sebaliknya, precision membawa pengaruh negatif dengan nilai korelasi sebesar -47.4%. Recall tidak membawa pengaruh apa-apa karena nilai korelasinya yang nol.
Tabel 17 Korelasi antara teknik clipping dan akurasi pada data dua kategori ROUGE-L
Clipping Korelasi Lambang
Recall 0 (=)
Precision -0.474 (-)
F-measure 0.474 (+)
Jika acuan dalam memilih kombinasi yang optimal adalah korelasi antara nilai akurasi dan praproses maupun teknik clipping, kombinasi untuk mencapai akurasi optimal ROUGE-L pada data empat kategori terdiri atas penghilangan stopword dan dengan perhitungan f-measure. Untuk data dua kategori, kombinasi yang optimal terdiri atas dengan penghilangan stopword dan dengan perhitungan f-measure. Akurasi ROUGE-W
Hasil akurasi untuk data empat kategori, nilai akurasi tertinggi adalah sebesar 76.316%, sedangkan nilai akurasi terendah adalah sebesar 63.158% (lihatTabel 18). Nilai akurasi tertinggi terjadi saat kombinasi terdiri atas tanpa penghilangan stopword, tanpa stemming, dan menggunakan perhitungan f-measure. Nilai akurasi terendah terjadi pada kombinasi 14 dan 17 pada Tabel 18. Untuk detilnya dapat dilihat pada Lampiran 9.
Hasil akurasi data dua kategori, nilai akurasi tertinggi adalah sebesar 92.105%, sedangkan nilai akurasi terendah adalah sebesar 81.579% (lihat Tabel 19). Nilai akurasi tertinggi terjadi pada kombinasi 3, 6, 9, 12, 15, dan 18 pada Tabel 19. Delapan kombinasi tersebut memilki kesamaan pada jenis perhitungan yang digunakan, yaitu f-measure. Nilai akurasi terendah terjadi pada kombinasi 1, 2, 14, dan 17
pada Tabel 19. Untuk detilnya dapat dilihat pada Lampiran 10.
Tabel 18 Hasil akurasi empat kategori dengan ROUGE-W
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x X √ x x 68.421 2 x X x √ x 71.053 3 x X x x √ 76.316 4 √(A) X √ x x 68.421 5 √(A) X x √ x 73.684 6 √(A) X x x √ 73.684 7 √(I) X √ x x 68.421 8 √(I) X x √ x 71.053 9 √(I) X x x √ 73.684 10 x √ √ x x 71.053 11 x √ x √ x 68.421 12 x √ x x √ 73.684 13 √(A) √ √ x x 71.053 14 √(A) √ x √ x 63.158 15 √(A) √ x x √ 71.053 16 √(I) √ √ x x 71.053 17 √(I) √ x √ x 63.158 18 √(I) √ x x √ 73.684
Tabel 19 Hasil akurasi dua kategori dengan ROUGE-W
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x x √ x x 81.579 2 x x x √ x 81.579 3 x x x x √ 92.105 4 √(A) x √ x x 84.211 5 √(A) x x √ x 84.211 6 √(A) x x x √ 92.105 7 √(I) x √ x x 84.211 8 √(I) x x √ x 84.211 9 √(I) x x x √ 92.105 10 x √ √ x x 89.474 11 x √ x √ x 86.842 12 x √ x x √ 92.105 13 √(A) √ √ x x 89.474 14 √(A) √ x √ x 81.579 15 √(A) √ x x √ 92.105 16 √(I) √ √ x x 86.842 17 √(I) √ x √ x 81.579 18 √(I) √ x x √ 92.105
12 menyertakan penghilangan stopword lebih besar
dibandingkan dengan kombinasi yang praprosesnya menyertakan penghilangan stopword. Hal ini juga terjadi pada data dua kategori, rata-rata akurasi kombinasi yang praprosesnya tanpa menyertakan penghilangan stopword (88.304%) lebih besar dari praproses yang menyertakan penghilangan stopword (86.257%).
Hasil akurasi data empat kategori, kombinasi yang praprosesnya menggunakan stemming memiliki rata-rata akurasi 70.175%, sedangkan praproses yang tanpa menggunakan stemming memiliki rata-rata akurasi 71.491%. Terlihat rata-rata akurasi kombinasi yang praprosesnya tanpa menggunakan stemming lebih besar dibandingkan dengan kombinasi yang praprosesnya menggunakan stemming. Hal ini juga terjadi pada data dua kategori, rata-rata akurasi kombinasi yang praprosesnya tanpa menggunakan stemming (87.281%) lebih besar dibandingkan dengan kombinasi yang praprosesnya menggunakan stemming (87.061%).
Hasil akurasi data empat kategori, kombinasi yang praprosesnya menggunakan stemming Iqbal (2010) maupun yang menggunakan stemming Adriani (2007), sama-sama memiliki rata-rata akurasi sebesar 70.175%. Namun pada data dua kategori, kombinasi yang menggunakan stemming Adriani (2007) sebesar 92.398%, lebih besar dari praproses yang menggunakan stemming Iqbal (2010) sebesar 88.012%.
Nilai rata-rata akurasi yang menggunakan perhitungan recall, precision, dan f-measure pada data empat kategori adalah berturut-turut 69.737%, 68.421%, dan 73.684% sedangkan pada data dua kategori adalah 85.965%, 83.333%, dan 92.105%. Terlihat pada data empat kategori, perhitungan f-measure memiliki tingkat akurasi tertinggi, begitu juga pada data dua kategori.
Jika acuan dalam memilih kombinasi yang optimal adalah rata-rata nilai akurasi untuk tiap praproses dan jenis perhitungan, kombinasi untuk mencapai akurasi optimal ROUGE-W pada data empat kategori terdiri atas tanpa penghilangan stopword, tanpa stemming, dan menggunakan perhitungan f-measure. Kombinasi yang sama juga berlaku untuk data dua kategori. Secara keseluruhan, baik untuk data empat kategori maupun dua kategori, ROUGE-W optimal ketika kombinasi praproses terdiri atas tanpapenghilangan stopword, tanpa
stemming, dan menggunakan perhitungan f-measure.
Korelasi antara praproses dan akurasi untuk data empat kategori dapat dilihat pada Tabel 20. Terlihat bahwa penggunaan stemming dan penggunaan stopword membawa pengaruh negatif dengan nilai korelasi berturutturut -18.1% dan -30%. Jenis stemming yang digunakan tidak memberikan pengaruh karena nilai korelasi yang nol.
Tabel 20 Korelasi antara praproses dan akurasi pada data empat kategori ROUGE-W
Praproses Korelasi Lambang
Stemming -0.181 (-)
Stopword -0.300 (-) Jenis Stemming 0 (=)
Korelasi antara teknik clipping dan akurasi untuk data empat kategori dapat dilihat pada Tabel 21. Terlihat f-measure membawa pengaruh positif dengan nilai korelasi 63.4%. Sebaliknya, recall dan precision membawa pengaruh negatif dengan nilai korelasi berturut-turut -18.1%, dan -45.3%.
Tabel 21 Korelasi antara teknik clipping dan akurasi pada data empat kategori ROUGE-W
Clipping Korelasi Lambang
Recall -0.181 (-)
Precision -0.453 (-)
F-measure 0.634 (+)
Korelasi antara praproses dan akurasi untuk data dua kategori dapat dilihat pada Tabel 22. Terlihat bahwa penggunaan stemming membawa pengaruh negatif sebesar -2.5%. Dalam penggunaan jenis stemming, penggunaan stemming Iqbal (2010) membawa pengaruh negatif sebesar -5.4%. Penggunaan stopword membawa pengaruh positif dengan nilai korelasi 20.9%.
Tabel 22 Korelasi antara praproses dan akurasi pada data dua kategori ROUGE-W
Praproses Korelasi Lambang
Stemming -0.025 (-)
Stopword 0.209 (+) Jenis Stemming -0.054 (-)
13 Sebaliknya, recall dan precision membawa
pengaruh negatif dengan nilai korelasi berturut-turut -19.7%, dan -64.1%.
Tabel 23 Korelasi antara teknik clipping dan akurasi pada data dua kategori ROUGE-W
Clipping Korelasi Lambang
Recall -0.197 (-)
Precision -0.641 (-)
F-measure 0.838 (+)
Jika acuan dalam memilih kombinasi yang optimal adalah korelasi antara nilai akurasi dan praproses maupun teknik clipping, kombinasi untuk mencapai akurasi optimal ROUGE-W pada data empat kategori terdiri atas tanpa penghilangan stopword, tanpa stemming dan dengan perhitungan f-measure. Untuk data dua kategori, kombinasi yang optimal terdiri atas denganpenghilangan stopword, tanpa stemming dan perhitungan f-measure.
Akurasi ROUGE-N pada 3-Fold Cross -Validation
Untuk data dua kategori, rata-rata akurasi ROUGE-N ketika dilakukan 3–fold cross-validation dapat dilihat pada Tabel 24. Untuk detilnya dapat dilihat pada Lampiran 11, 12, dan 13.
Tabel 24 Rata-rata akurasi ROUGE-N untuk 2 Kategori pada 3-fold cross-validation
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x x √ x x 91.633
2 x x x √ x 90.491
3 x x x x √ 90.491
4 √(A) x √ x x 92.675
5 √(A) x x √ x 91.566
6 √(A) x x x √ 90.491 7 √(I) x √ x x 92.675
8 √(I) x x √ x 91.566
9 √(I) x x x √ 90.491
10 x √ √ x x 90.591
11 x √ x √ x 90.524
12 x √ x x √ 92.641
13 √(A) √ √ x x 90.591
14 √(A) √ x √ x 90.491
15 √(A) √ x x √ 92.641
16 √(I) √ √ x x 90.591
17 √(I) √ x √ x 90.491
18 √(I) √ x x √ 92.641
Korelasi antara praproses dan rata-rata akurasi dapat dilihat pada Tabel 25. Terlihat bahwa penggunaan stopword membawa
pengaruh negatif dengan nilai korelasi -5.2%. Sebaliknya, penggunaan stemming membawa pengaruh positif dengan nilai korelasi 17.7%. Jenis stemming yang digunakan tidak memberikan pengaruh karena nilai korelasi yang nol.
Tabel 25 Korelasi antara rata-rata akurasi dan praproses ROUGE-N dengan data dua kategori pada 3-fold cross-validation
Praproses Korelasi Lambang
Stemming 0.177 (+)
Stopword -0.052 (-) Jenis Stemming 0 (=)
Korelasi antara teknik clipping dan rata-rata akurasi untuk data dua kategori dapat dilihat pada Tabel 26. Terlihat f-measure dan recall membawa pengaruh positif dengan nilai korelasi berturut-turut 20.8% dan 12.7%. Sebaliknya, precision membawa pengaruh negatif dengan nilai korelasi sebesar -33.5%. Tabel 26 Korelasi antara rata-rata akurasi dan
teknik clipping ROUGE-N dengan data dua kategori pada 3-fold cross-validation
Clipping Korelasi Lambang
Recall 0.127 (+)
Precision -0.335 (-)
F-measure 0.208 (+)
Jika acuan dalam memilih kombinasi yang optimal adalah korelasi antara rata-rata akurasi dan praproses maupun teknik clipping, kombinasi untuk mencapai akurasi optimal ROUGE-N pada data dua kategori terdiri atas tanpa penghilangan stopword, menggunakan stemming dan dengan perhitungan f-measure.
Untuk data empat kategori, rata-rata akurasi ROUGE-N ketika dilakukan 3–fold cross-validation dapat dilihat pada Tabel 27. Untuk detilnya dapat dilihat pada Lampiran 14, 15, dan 16.
Korelasi antara praproses dan rata-rata akurasi dapat dilihat pada Tabel 28. Terlihat bahwa penggunaan stemming dan penggunaan stopword membawa pengaruh negatif dengan nilai korelasi berturut-turut -27.3% dan -12.3%. Penggunaan stemming Iqbal (2010) juga membawa pengaruh negatif sebesar -29.8%.
14 recall membawa pengaruh positif dengan nilai
korelasi berturut-turut 48.3% dan 3.7%. Sebaliknya, f-measure membawa pengaruh negatif dengan nilai korelasi sebesar -51.9%. Tabel 27 Rata-rata akurasi ROUGE-N untuk
empat kategori pada 3-fold cross-validation
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x x √ x x 65.255
2 x x x √ x 65.155
3 x x x x √ 63.038
4 √(A) x √ x x 64.214
5 √(A) x x √ x 65.222
6 √(A) x x x √ 65.155
7 √(I) x √ x x 64.214
8 √(I) x x √ x 64.147
9 √(I) x x x √ 65.155
10 x √ √ x x 64.247
11 x √ x √ x 66.297
12 x √ x x √ 63.105
13 √(A) √ √ x x 64.214
14 √(A) √ x √ x 65.222
15 √(A) √ x x √ 63.105
16 √(I) √ √ x x 64.214
17 √(I) √ x √ x 64.147
18 √(I) √ x x √ 62.030
Tabel 28 Korelasi antara rata-rata akurasi dan praproses ROUGE-N dengan data empat kategori pada 3-fold cross-validation
Praproses Korelasi Lambang
Stemming -0.123 (-)
Stopword -0.273 (-) Jenis Stemming -0.298 (-)
Jika acuan dalam memilih kombinasi yang optimal adalah korelasi antara rata-rata akurasi dan praproses maupun teknik clipping, kombinasi untuk mencapai akurasi optimal ROUGE-N pada data empat kategori terdiri atas tanpa penghilangan stopword, tanpa
menggunakan stemming dan dengan
perhitungan precision.
Tabel 29 Korelasi antara rata-rata akurasi dan teknik clipping ROUGE-N dengan data empat kategori pada 3-fold cross-validation
Clipping Korelasi Lambang
Recall 0.037 (+)
Precision 0.483 (+)
F-measure -0.519 (-)
Akurasi ROUGE-L pada 3-Fold Cross -Validation
Untuk data dua kategori, rata-rata akurasi ROUGE-L ketika dilakukan 3–fold cross-validation dapat dilihat pada Tabel 30. Untuk detilnya dapat dilihat pada Lampiran 17, 18, dan 19.
Tabel 30 Rata-rata akurasi ROUGE-L untuk 2 Kategori pada 3-fold cross-validation
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x x √ x x 90.524
2 x x x √ x 81.116
3 x x x x √ 93.683
4 √(A) x √ x x 91.566
5 √(A) x x √ x 82.157
6 √(A) x x x √ 93.683 7 √(I) x √ x x 90.524
8 √(I) x x √ x 82.157
9 √(I) x x x √ 93.683
10 x √ √ x x 90.558
11 x √ x √ x 84.207
12 x √ x x √ 90.558
13 √(A) √ √ x x 90.558
14 √(A) √ x √ x 82.124
15 √(A) √ x x √ 91.599 16 √(I) √ √ x x 89.516
17 √(I) √ x √ x 82.157
18 √(I) √ x x √ 90.558
Korelasi antara praproses dan rata-rata akurasi dapat dilihat pada Tabel 31. Terlihat bahwa penggunaan stopword dan penggunaan stemming membawa pengaruh negatif dengan nilai korelasi berturut-turut -9% dan -0.9%. Penggunaan stemming Iqbal (2010) juga membawa pengaruh negatif sebesar -5.7%. Tabel 31 Korelasi antara rata-rata akurasi dan
praproses ROUGE-L dengan data dua kategori pada 3-fold cross-validation
Praproses Korelasi Lambang
Stemming -0.009 (-)
Stopword -0.09 (-) Jenis Stemming -0.057 (-)
15 Tabel 32 Korelasi antara rata-rata akurasi dan
teknik clipping ROUGE-L dengan data dua kategori pada 3-fold cross-validation
Clipping Korelasi Lambang
Recall 0.341 (+)
Precision -0.959 (-)
F-measure 0.618 (+)
Jika acuan dalam memilih kombinasi yang optimal adalah korelasi antara rata-rata akurasi dan praproses maupun teknik clipping, kombinasi untuk mencapai akurasi optimal ROUGE-L pada data dua kategori terdiri atas tanpa penghilangan stopword, tanpa
menggunakan stemming dan dengan
perhitungan f-measure.
Untuk data empat kategori, rata-rata akurasi ROUGE-L ketika dilakukan 3–fold cross-validation dapat dilihat pada Tabel 33. Untuk detilnya dapat dilihat pada Lampiran 20, 21, dan 22.
Tabel 33 Rata-rata akurasi ROUGE-L untuk empat kategori pada 3-fold cross-validation
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x x √ x x 62.063
2 x x x √ x 53.696
3 x x x x √ 66.263
4 √(A) x √ x x 61.022
5 √(A) x x √ x 53.696
6 √(A) x x x √ 66.297
7 √(I) x √ x x 61.022
8 √(I) x x √ x 54.772
9 √(I) x x x √ 65.222
10 x √ √ x x 61.089
11 x √ x √ x 54.704
12 x √ x x √ 63.172
13 √(A) √ √ x x 62.097
14 √(A) √ x √ x 53.696
15 √(A) √ x x √ 60.013 16 √(I) √ √ x x 60.013
17 √(I) √ x √ x 54.738
18 √(I) √ x x √ 60.013
Korelasi antara praproses dan rata-rata akurasi dapat dilihat pada Tabel 34. Terlihat bahwa penggunaan stopword dan penggunaan stemming membawa pengaruh negatif dengan nilai korelasi berturut-turut -18.9% dan -8.6%. Penggunaan stemming Iqbal (2010) juga membawa pengaruh negatif sebesar -2.1%.
Korelasi antara teknik clipping dan rata-rata akurasi untuk data empat kategori dapat dilihat
pada Tabel 35. Terlihat bahwa f-measure dan recall membawa pengaruh positif dengan nilai korelasi berturut-turut 63.8% dan 26.1%. Sebaliknya, precision membawa pengaruh negatif dengan nilai korelasi sebesar -89.9%. Tabel 34 Korelasi antara rata-rata akurasi dan
praproses ROUGE-L dengan data empat kategori pada 3-fold cross-validation
Praproses Korelasi Lambang
Stemming -0.086 (-)
Stopword -0.189 (-) Jenis Stemming -0.021 (-)
Tabel 35 Korelasi antara rata-rata akurasi dan teknik clipping ROUGE-L dengan data empat kategori pada 3-fold cross-validation
Clipping Korelasi Lambang
Recall 0.261 (+)
Precision -0.899 (-)
F-measure 0.638 (+)
Jika acuan dalam memilih kombinasi yang optimal adalah korelasi antara rata-rata akurasi dan praproses maupun teknik clipping, kombinasi untuk mencapai akurasi optimal ROUGE-L pada data empat kategori terdiri atas tanpa penghilangan stopword, tanpa
menggunakan stemming dan dengan
perhitungan f-measure.
Akurasi ROUGE-W pada 3-Fold Cross -Validation
Untuk data dua kategori, rata-rata akurasi ROUGE-W ketika dilakukan 3–fold cross-validation dapat dilihat pada Tabel 36. Untuk detilnya dapat dilihat pada Lampiran 23, 24, dan 25.
Korelasi antara praproses dan rata-rata akurasi dapat dilihat pada Tabel 37. Terlihat bahwa penggunaan stopword dan penggunaan stemming membawa pengaruh negatif dengan nilai korelasi berturut-turut -6.8% dan -2.3%. Penggunaan stemming Iqbal (2010) juga membawa pengaruh negatif sebesar -1.5%.
16 Tabel 36 Rata-rata akurasi ROUGE-W untuk 2
Kategori pada 3-fold cross-validation
No. Praproses Clipping Akurasi (%) Stem Stop R P F
1 x x √ x x 89.483
2 x x x √ x 77.923
3 x x x x √ 91.532
4 √(A) x √ x x 88.407
5 √(A) x x √ x 76.848
6 √(A) x x x √ 91.532
7 �