PERBANDINGAN METODE PENGENALAN POLA SUARA
MENGGUNAKAN
CODEBOOK
DAN
PROBABILISTIC
NEURAL NETWORK
BERDASARKAN
KISARAN USIA DAN JENIS KELAMIN
ARRY RINALDY PRATAMA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Perbandingan Metode Pengenalan Pola Suara Menggunakan Codebook Dan Probabilistic Neural Network Berdasarkan Kisaran Usia Dan Jenis Kelamin adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Mei 2013
Arry Rinaldy Pratama
ABSTRAK
ARRY RINALDY PRATAMA. Perbandingan Metode Pengenalan Pola Suara Menggunakan Codebook dan Probabilistic Neural Network Berdasarkan Kisaran Usia dan Jenis Kelamin. Dibimbing oleh TOTO HARYANTO.
Sinyal Suara dapat digunakan untuk mengidentifikasi seorang pembicara termasuk kisaran usia dan jenis kelamin berdasarkan perbedaan karakteristik frekuensi. Penelitian ini membandingkan dua metode pengenalan pola suara yaitu
Codebook dan Probabilistic Neural Network (PNN). Dalam penelitian ini, kelompok usia dibagi menjadi tiga yaitu anak-anak untuk usia 8 sampai 11 tahun, remaja untuk usia 12 sampai 21 tahun dan dewasa untuk usia 22 sampai 50 tahun. Setiap kelompok usia dibedakan berdasarkan jenis kelamin, sehingga terdapat enam kelompok data. Penelitian ini menggunakan 600 data suara yang mewakili 6 kelompok data. MFCC digunakan sebagai metode ekstraksi ciri sedangkan K-means digunakan sebagai teknik pengklasteran. Beberapa parameter yang penting dalam proses MFCC adalah jumlah koefisien cepstral, overlap, dan time frame. Nilai overlap dan time frame yang digunakan adalah 0.5 dan 40 ms; sedangkan nilai koefisien cepstral yang diujicobakan untuk menghasilkan akurasi terbaik dalam penelitian ini adalah 13, 20, dan 26. Perbandingan pengenalan model suara dibangun dari tiga proporsi yang berbeda untuk data latih dan data uji (25%:75%, 50%:50%, 75%:25%). Hasil penelitian menunjukkan bahwa rata-rata akurasi yang diperoleh dengan metode Codebook adalah sebesar 97.20% sedangkan akurasi PNN adalah sebesar 95.17%.
Kata kunci: codebook, K-means, Mel Frequency Cepstral Coefficients (MFCC), Probabilistic Neural Network
ABSTRACT
ARRY RINALDY PRATAMA. Comparison Voice Identification Method Using Codebook and Probabilistic Neural Network Based on Age Range and Gender. Supervised by TOTO HARYANTO.
Voice signal be used to identify a speaker, including the age range and gender based on the difference of its frequency characteristic. This research compares two method of voice identification namely codebook and probability neural network (PNN) in recognizing the age range and gender of the speaker. In this research, the age range is divided into three categories namely children (8-11 years old), teenagers (12-17 years old) and adults (30-50 years old). Each age category is divided based on gender, so that there are six categories in total. This research utilized 600 voice data representing the total six categories. MFCC is used as a method of feature extraction, whereas K-means is used as the clustering method. Several important parameters in the MFCC process are the number of cepstral coefficients, overlap, and time frame. The overlap and time frame values are 0.5 and 40 ms, respectively; whereas the chosen cepstral coefficients to produce the maximum accuracy are 13, 20, and 26. The comparison of voice identification is constructed from three different proportions of training data and testing data (25%:75%, 50%:50%, 75%:25%). It is shown that the accuracy of codebook method is 97.20% whereas that of PNN is 95.17%.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
PERBANDINGAN METODE PENGENALAN POLA SUARA
MENGGUNAKAN
CODEBOOK
DAN
PROBABILISTIC
NEURAL NETWORK
BERDASARKAN
KISARAN USIA DAN JENIS KELAMIN
ARRY RINALDY PRATAMA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN INSTITUT PERTANIAN BOGOR
Judul Skripsi: Perbandingan Metode Pengenalan Pola Suara Menggunakan
Codebook dan Probabilistic Neural Network Berdasarkan Kisaran Usia dan Jenis Kelamin
Nama : Arry Rinaldy Pratama NIM : G64104064
Disetujui oleh
Toto Haryanto, SKom, MSi Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen Ilmu Komputer
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wata’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Maret 2012 ini ialah ekstraksi ciri dan pengenalan pola, dengan judul Perbandingan Metode Pengenalan Pola Suara Menggunakan Codebook dan Probabilistic Neural Network Berdasarkan Kisaran Usia dan Jenis Kelamin.
Terima kasih penulis ucapkan kepada Bapak Toto Haryanto SKom, MSi selaku pembimbing yang telah memberikan arahan dan saran selama penelitian ini berlangsung, serta kepada Bapak Dr Ir Agus Buono MSi, MKom dan Bapak Aziz Kustiyo SSi, MKom selaku penguji untuk penelitian ini. Ungkapan terima kasih juga disampaikan kepada orang tua, kakak, serta seluruh keluarga atas segala doa dan kasih sayangnya.
Penulis menyadari bahwa masih terdapat kekurangan dalam penulisan skripsi ini. Semoga karya ilmiah ini bermanfaat.
Bogor, Mei 2013
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 1
Manfaat Penelitian 1
Ruang Lingkup Penelitian 2
METODE PENELITIAN 2
Pengambilan data suara 3
Praproses 3
Data latih dan data uji 4
Ekstraksi Ciri dengan MFCC 5
Pengenalan Pola dengan Codebook 7
Pengenalan Pola dengan Probabilistic Neural Network 8
Pengujian 9
Lingkungan Pengembangan Sistem 9
HASIL DAN PEMBAHASAN 10
Pengumpulan Data 10
Ekstraksi Ciri dengan MFCC 10
Pemodelan Codebook 10
Pemodelan Probabilistic Neural Network 11
Hasil Pengujian 11
Analisa Percobaan 15
Akurasi model dengan suara diluar data pelatihan 18
SIMPULAN DAN SARAN 18
Simpulan 18
Saran 18
DAFTAR PUSTAKA 20
DAFTAR TABEL
1 Perbandingan keakurasian pada kelompok anak laki-laki dengan
codebook dan PNN 12
2 Perbandingan keakurasian pada kelompok anak perempuan dengan
codebook dan PNN `12
3 Perbandingan keakurasian pada kelompok remaja laki-laki dengan
codebook dan PNN 13
4 Perbandingan keakurasian pada kelompok remaja perempuan dengan
codebook dan PNN 14
5 Perbandingan keakurasian pada kelompok dewasa laki-laki dengan
codebook dan PNN 14
6 Perbandingan keakurasian pada kelompok dewasa perempuan dengan
codebook dan PNN 15
7 Rata-rata akurasi kisaran usia dan jenis kelamin dari setiap studi kasus 16
8 Rata-rata akurasi kisaran usia dan jenis kelamin dari setiap studi kasus
berdasarkan koefisien 16
9 Rata-rata akurasi kisaran usia dan jenis kelamin dari setiap studi kasus
berdasarkan proporsi data latih 17
10 Confusion matrix untuk metode codebook 17
11 Confusion matrix untuk metode PNN
12 Akurasi model dengan suara diluar data pelatihan dengan metode
codebook 18
13 Akurasi model dengan suara diluar data pelatihan dengan metode PNN 19
DAFTAR GAMBAR
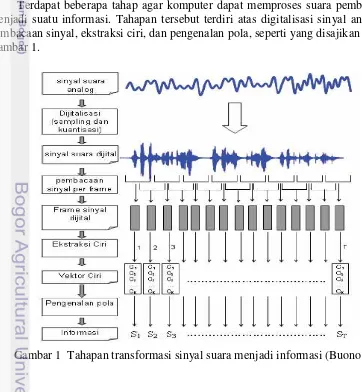
1 Tahapan transformasi sinyal suara menjadi informasi 2
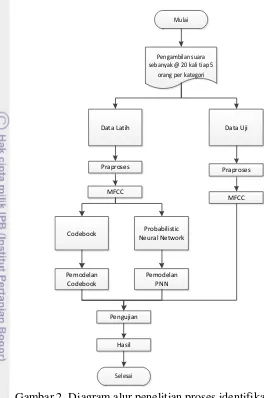
2 Diagram Alur Penelitian Proses Identifikasi Suara 4
3 Proses penghapusan silence dan normalisasi suara 4
4 Pemisahan data suara pada model pengenalan jenis kelamin dan kisaran
usia 5
5 Diagram alur MFCC 5
6 Ilustrasi sebaran Codebook 7
7 Struktur PNN 9
8 Contoh hasil MFCC dengan cepstral coefficient bernilai 26 dan nilai k
30 10
PENDAHULUAN
Latar Belakang
Komputer merupakan salah satu produk yang berperan penting dalam perkembangan teknologi digital. Komputer dapat dimanfaatkan untuk keperluan komunikasi, memperoleh informasi, penyimpanan data, keamanan, bahkan untuk hiburan. Pada saat manusia berbicara mengeluarkan energi yang sering disebut sinyal suara. Sinyal suara merupakan gelombang longitudinal (berupa sinyal analog) yang tercipta dari tekanan udara yang berasal dari paru-paru yang berjalan melewati lintasan suara menuju mulut dan rongga hidung dengan bentuk artikulator yang senantiasa berubah. Sehingga sinyal analog harus diubah terlebih dahulu menjadi sinyal digital yang nantinya akan dimasukkan ke komputer melalui microphone agar dapat digunakan sebagai akses untuk berkomunikasi dengan komputer melalui bahasa sehari-hari.
Pemrosesan sinyal suara merupakan teknik mentransformasi sinyal suara menjadi informasi yang berarti sesuai dengan yang diinginkan (Buono 2009). Banyak metode yang dapat diterapkan untuk proses pengenalan sinyal suara, di antaranya probabilistic neural network (PNN), codebook, hidden Markov model
(HMM), dan lainnya. Pada penelitian ini dilakukan perbandingan akurasi dari pengenalan pola suara dengan metode codebook dan probabilistic neural network. Perbandingan metode ini dilakukan karena terdapat penelitian tentang pengembangan probabilistic neural network pada pengenalan kisaran usia dan jenis kelamin berbasis suara yang telah dilakukan oleh Fransiswa (2010) dengan akurasi rata-rata 91.26%.
Pada penelitian ini untuk mengenali setiap jenis suara, diperlukan pengenalan ciri dari setiap suara tersebut. Setiap jenis suara diproses untuk diekstraksi ciri dari suara tersebut. Ekstraksi ciri yang digunakan adalah mel-frequency cepstrum coefficient (MFCC), yang dapat merepresentasikan sinyal lebih baik dibandingkan dengan linear prediction ceptrum coefficient (LPCC) dan teknik lainnya (Buono 2009).
Tujuan Penelitian
Penelitian ini bertujuan untuk membandingkan hasil yang didapat dari metode pengenalan suara menggunakan codebook dan PNN, dengan MFCC sebagai ekstraksi ciri, agar komputer dapat mengetahui kelompok umur dan jenis kelamin pembicara melalui mikrofon.
Manfaat Penelitian
2
usia maupun jenis kelamin pembicara, dan untuk sebagai data acuan pada penelitian berikutnya.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah:
1 Perbandingan hasil akhir atau tingkat akurasi antara metode codebook dan PNN.
2 Kata yang digunakan ialah “awas ada bom” sebagai input sinyal suara. Kata tersebut dipilih karena tidak mengandung diftong dengan susunan vokal-konsonan berturut-turut dan memiliki lebih dari satu suku kata sehingga memiliki variasi warna suara yang diucapkan dengan format WAV (Fransiswa 2010).
3 Kelompok usia dibagi menjadi anak-anak memiliki kisaran usia antara 8 tahun sampai 11 tahun, remaja antara 12 tahun sampai 21 tahun, dan dewasa antara 22 tahun sampai 50 tahun (IDAI 2009).
METODE PENELITIAN
Terdapat beberapa tahap agar komputer dapat memproses suara pembicara menjadi suatu informasi. Tahapan tersebut terdiri atas digitalisasi sinyal analog, pembacaan sinyal, ekstraksi ciri, dan pengenalan pola, seperti yang disajikan pada Gambar 1.
3 1 Perekaman suara yang berupa sinyal analog diubah menjadi sinyal digital melalui proses sampling dan kuantisasi. Sampling adalah proses pengambilan nilai setiap jangka waktu tertentu. Nilai ini menyatakan amplitudo volume suara pada saat itu. Hasilnya adalah sebuah vektor yang menyatakan nilai-nilai hasil sampling. Panjang vektor data ini tergantung pada panjang atau lamanya suara yang didigitalisasikan serta sampling rate yang digunakan pada proses digitalisasinya. Sampling rate adalah banyaknya nilai yang diambil setiap detik. Sampling rate yang biasa digunakan adalah 8000 Hz dan 16000 Hz (Jurafsky dan Martin 2000). Hubungan antara panjang vektor data yang dihasilkan dengan sampling rate dan panjangnya data suara yang didigitalisasikan dapat dinyatakan secara sederhana sebagai berikut:
S = Fs T S = panjang vektor
Fs = sampling rate yang digunakan (Hertz)
T = panjang suara (detik)
Proses selanjutnya adalah kuantisasi, yaitu menyimpan nilai amplitudo ini ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky dan Martin 2000).
2 Tahap pembacaan sinyal, sinyal digital dipartisi menjadi beberapa frame yang saling tumpang tindih untuk menghindari kehilangan informasi.
3 Ekstraksi ciri dilakukan untuk setiap frame sehingga didapatkan vektor ciri. 4 Pengenalan pola dilakukan untuk setiap vektor ciri sehingga diperoleh
informasi yang diinginkan.
Sistem pengenalan kata suara dapat diwujudkan melalui suatu program dengan menggunakan perangkat lunak MATLAB R2008b. Pembuatan program dibagi menjadi beberapa tahap sesuai diagram alur penelitian yang ditunjukkan pada Gambar 2.
Pengambilan Data Suara
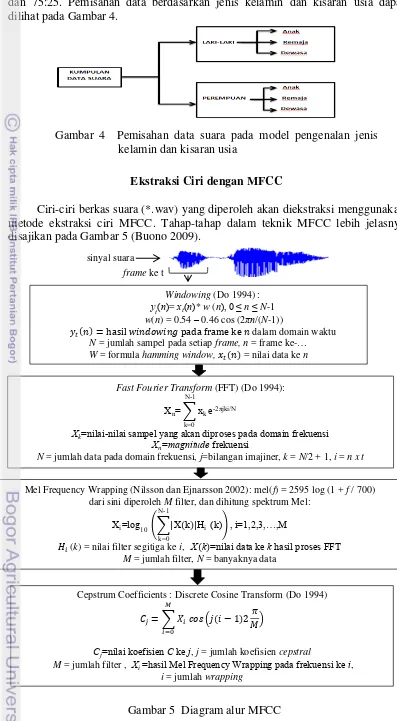
Data suara yang digunakan pada penelitian ini menggunakan 6 jenis suara yang berbeda, yaitu anak perempuan, anak laki-laki, wanita remaja, pria remaja, pria dewasa dan wanita dewasa. Masing-masing kelompok suara diambil contoh suara dari 5 orang, setiap kata dilakukan perekaman sebanyak 20 kali selama 2 detik dengan sampling rate 11000 Hz.
Praproses
4
Mulai
Pengambilan suara sebanyak @ 20 kali tiap 5
orang per kategori
Data Latih Data Uji
MFCC
MFCC
Codebook Probabilistic Neural Network
Pemodelan PNN
Pengujian
Hasil
Selesai
Pemodelan Codebook
Praproses Praproses
Data Latih dan Data Uji
Setiap pembicara, kata yang diucapkan ialah “awas ada bom” yang digunakan untuk pelatihan. Kalimat tersebut diucapkan oleh enam orang dari setiap kelompok sebanyak 20 kali. Data tersebut dibagi menjadi data latih dan data uji. Proporsi pembagian data latih berbanding data uji sebesar 25:75, 50:50,
Gambar 2 Diagram alur penelitian proses identifikasi suara
Gambar 3 Proses penghapusan silence dan normalisasi suara
5 dan 75:25. Pemisahan data berdasarkan jenis kelamin dan kisaran usia dapat dilihat pada Gambar 4.
Ekstraksi Ciri dengan MFCC
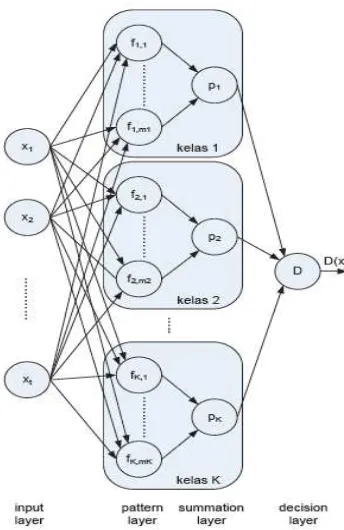
Ciri-ciri berkas suara (*.wav) yang diperoleh akan diekstraksi menggunakan metode ekstraksi ciri MFCC. Tahap-tahap dalam teknik MFCC lebih jelasnya disajikan pada Gambar 5 (Buono 2009).
Gambar 5 Diagram alur MFCC
Gambar 4 Pemisahan data suara pada model pengenalan jenis
Cepstrum Coefficients : Discrete Cosine Transform (Do 1994)
Cj=nilai koefisien C ke j, j = jumlah koefisien cepstral N = jumlah sampel pada setiap frame, n = frame ke-… W = formula hamming window, � = nilai data ke n
Xn= xk N-1
k=0
e-2 jki/N
Xk=nilai-nilai sampel yang akan diproses pada domain frekuensi
Xn=magnitude frekuensi
Fast Fourier Transform (FFT) (Do 1994):
N = jumlah data pada domain frekuensi, j=bilangan imajiner, k = N/2 + 1, i = n x t
Xi=log10 X k Hi N-1
k=0
(k) , i=1,2,3,…,M
Mel Frequency Wrapping (Nilsson dan Ejnarsson 2002): mel(f) = 2595 log (1 + f / 700) dari sini diperoleh M filter, dan dihitung spektrum Mel:
6
Teknik MFCC sebagai ekstraksi ciri dan teknik parameterisasi sinyal suara telah banyak digunakan pada berbagai bidang area pemrosesan suara. Teknik ini berbasis power spectrum dalam domain frekuensi sebagai penentu ciri sinyal suara. Berdasarkan Gambar 5, sinyal dibaca dari frame ke frame dengan nilai
overlap tertentu lalu dilakukan windowing untuk setiap frame. Kemudian, transformasi Fourierdilakukan untuk mengubah dimensi suara dari domain waktu ke domain frekuensi. Dari hasil transformasi Fourier, spektrum mel dihitung menggunakan sejumlah filter yang dibentuk untuk mengikuti persepsi sistem pendengaran manusia yang bersifat linear. Proses ini dikenal dengan mel frequency wrapping. Koefisien MFCC merupakan hasil transformasi kosinusdari
spectrum mel tersebut dan dipilih koefisien cepstral. Transformasi kosinus berfungsi untuk mengembalikan dari domain frekuensi ke domain waktu.
Frame Blocking
cepstral akan dicoba sebesar 13, 20 dan 26.
Windowing
Sinyal analog yang sudah diubah menjadi sinyal digital dibaca frame demi
frame dan pada setiap frame-nya dilakukan windowing dengan fungsi window
tertentu. Proses windowing bertujuan untuk meminimalisasi ketidakberlanjutan sinyal pada awal dan akhir setiap frame (Do 1994). Dengan pertimbangan kesederhanaan formula dan nilai kinerja window, maka penggunaan window
Hamming cukup beralasan (Buono 2009). Transformasi Fourier
Analisis Fourier muncul dari paper yang ditulis oleh Jean Baptiste Joseph Fourier (1768-1830) yang di-review oleh Joseph Louise Louis Lagrange (1736-1813) dan Pierre Simon de Laplace (1749-1827). Analisis ini merupakan suatu teknik matematika untuk mendekomposisi sinyal menjadi sinyal-sinyal sinusoidal. Untuk dapat melihat perbedaan sinyal suara yang berbeda-beda, harus dilihat dari domain frekuensi karena kalau dilihat dari domain waktu perbedaanya sulit terlihat. Untuk itu, sinyal suara yang berada pada domain waktu diubah ke domain frekuensi dengan Fast Fourier Transform (FFT). Dengan algoritme FFT, kompleksitas menjadi rendah (Buono 2009). Dengan alasan inilah maka pada penelitian ini, transformasi Fourier yang digunakan adalah algoritme FFT.
Mel Frequency Wrapping
7 Transformasi Kosinus (Discrete Cosine Transform)
Langkah terakhir yaitu mengonversi log mel spectrum ke domain waktu. Hasilnya disebut MFCC. Representasi cepstral spectrum suara merupakan representasi properti spectral lokal yang baik dari suatu sinyal untuk analisis
frame. Mel spectrum coefficients dan logaritmanya berupa bilangan riil sehingga dapat dikonversikan ke domain waktu dengan menggunakan discrete cosine transform (DCT).
Pengenalan Pola dengan Codebook
Pengenalan pola dengan codebook dilakukan untuk data latih, setelah vektor ciri diperoleh dari proses MFCC. Codebook adalah kumpulan titik (vektor) yang mewakili distribusi suara dari suara tertentu dalam ruang suara. Setiap titik pada
codebook dikenal sebagai codeword. Codebook merupakan cetakan yang dihasilkan suara setelah melakukan proses training. Setiap suara yang sudah direkam dibuat codebook yang terdiri dari beberapa codeword untuk merepresentasikan ciri suaranya.
Codebook dibentuk dengan cara membentuk cluster semua vektor ciri yang dijadikan sebagai training set dengan menggunakan algoritme clustering. Algoritme clustering yang akan dipakai adalah K-means. Langkah pertama yang dilakukan oleh algoritma ini adalah menentukan K-initial centroid, dengan K adalah parameter spesifik yang ditentukan pengguna, yang merupakan jumlah
cluster yang diinginkan. Setiap titik atau objek kemudian ditempatkan pada
centroid terdekat. Kumpulan titik atau objek pada tiap centroid disebut cluster. Kemudian langkah penempatan objek dan perubahan centroid diulangi sampai tidak ada objek yang berpindah cluster. Gambar 6 merupakan ilustrasi sebaran data suara di sekitar codebook.
Gambar 6 Ilustrasi sebaran codebook
Setiap suara yang masuk, akan dihitung jaraknya dengan codebook setiap kelas. Kemudian jarak setiap sinyal suara ke codebook dihitung sebagai jumlah jarak setiap frame sinyal suara tersebut ke setiap codeword yang ada pada
8
minimum tersebut. Perhitungan jarak dilakukan dengan menggunakan jarak Euclid yang didefinisikan sebagai berikut (Buono dan Kusumoputro, 2007):
deuclidean (x,y) = (xi - yi)2 i=1
x dan y adalah vektor yang ada sepanjang vector dimention (D). Jika dalam sinyal suara input O terdapat T frame dan codewordk merupakan masing-masing
codeword yang ada pada codebook, jarak sinyal input dengan codebook dapat
Data uji digunakan sebagai input data. Input data tersebut diidentifikasikan dengan pattern layer yang dirumuskan pada Persamaan 1.
= ∏
(
)
Pada penelitian ini metode PNN akan diimplementasikan dengan empat
layer sebagai berikut :
1 Input layer: merupakan layer dimana vektorpada penelitian ini akan dijadikan sebagai input.
2 Pattern layer: digunakan untuk menghitung jarak antara nilai input data suara atau vektor dengan nilai dari setiap anggota kelas dengan perhitungan berdasarkan Persamaan 1. Penelitian ini terdapat 6 buah kelas yang akan digunakan.
3 Summation layer: perhitungan peluang antara vektor dengan tiap kelasdengan menggunakan persamaan sebagai berikut :
P x = 1
2 d2 h1h2…hdn
∑ni=1 fi(x)
4 Decision layer: Hasil peluang P(x) pada setiap kelas akan dibandingkan pada
9
Pengujian
Pengujian dilakukan pada MFCC data uji dengan data latih menggunakan metode codebook dan metode PNN. Setiap data yang diuji, akan dilihat dari suara yang teridentifikasi dari 6 kelas suara. Sistem otomatis ini akan mengklasifikasikan suara masuk ke kelas yang sesuai. Output yang akan dihasilkan berupa hasil suara yang dikelompokkan berdasarkan umur dan jenis kelamin.. Tingkat akurasi sistem akan dihitung untuk mengevaluasi hasil penelitian. Persentase tingkat akurasi dihitung dengan rumus sebagai berikut:
Hasil akurasi = jumlah suara yang benarjumlah suara yang diuji × 100
Lingkungan Pengembangan Sistem
Lingkungan pengembangan adalah kumpulan fasilitas yang diperlukan dalam melaksanakan penelitian, baik berupa perangkat keras maupun perangkat lunak. Pada penelitian ini lingkungan pengembangan yang digunakan adalah sebagai berikut:
Perangkat lunak: Windows 7 Ultimate, MATLAB R2008b, Audacity 1.3
10
HASIL DAN PEMBAHASAN
Pengumpulan Data
Suara dari masing-masing jenis kelamin dan kategori umur direkam selama 2 detik dan disimpan ke dalam file WAV. Seluruh data suara berjumlah 600 data. Data tersebut diambil berdasarkan 6 kelompok dan setiap kelompok diwakili oleh 5 orang yang melakukan perekaman suara setiap pembicara sebanyak 20 kali.
Ekstraksi Ciri dengan MFCC
Proses MFCC pada penelitian ini menggunakan fungsi pada auditory toolbox Matlab. Fungsi MFCC tersebut didapat dari Buono (2012). Dari semua data yang diperoleh akan dilakukan ekstraksi ciri MFCC. Parameter yang dibutuhkan pada proses MFCC ini yaitu sampling rate, time frame, overlap, dan
cepstral coefficient. Sampling rate yang digunakan sebesar 11000 Hz selama dua detik, time frame sebesar 40ms, overlap sebesar 50%, dan pada penelitian ini digunakan cepstral coefficient yang telah diujikan sebelumnya yaitu 13 (Suhartono 2007), 20 (Do 1994), dan 26 (Buono 2009), sehingga ketiga koefisien tersebut dapat dibandingkan tingkat akurasinya. Gambar 8 menunjukkan contoh hasil MFCC yang dilakukan pada cepstrals coefficient bernilai 26 dengan nilai k
30.
Pemodelan Codebook
Tahap pemodelan codebook dengan menggabungkan setiap data latih pada masing- masing kategori suara. Data yang digunakan merupakan data latih yang sudah merupakan ciri dari setiap kategori suara yang diperoleh dari tahap MFCC. Setelah data digabungkan kemudian dilakukan proses clustering dengan menggunakan K-means. Data yang sudah diklasterkan merupakan gabungan koefisien dari setiap data latih. Jumlah k yang digunakan adalah 30.
Gambar 8 Contoh hasil MFCC dengan cepstrals coefficient
11 Pemodelan Probabilistic Neural Network
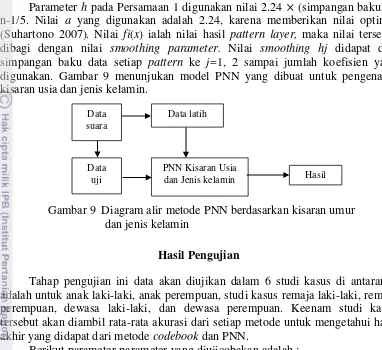
Parameter h pada Persamaan 1 digunakan nilai 2.24 (simpangan baku) n-1/5. Nilai a yang digunakan adalah 2.24, karena memberikan nilai optimal (Suhartono 2007). Nilai fi(x) ialah nilai hasil pattern layer, maka nilai tersebut dibagi dengan nilai smoothing parameter. Nilai smoothing hj didapat dari simpangan baku data setiap pattern ke j=1, 2 sampai jumlah koefisien yang digunakan. Gambar 9 menunjukan model PNN yang dibuat untuk pengenalan kisaran usia dan jenis kelamin.
Hasil Pengujian
Tahap pengujian ini data akan diujikan dalam 6 studi kasus di antaranya adalah untuk anak laki-laki, anak perempuan, studi kasus remaja laki-laki, remaja perempuan, dewasa laki-laki, dan dewasa perempuan. Keenam studi kasus tersebut akan diambil rata-rata akurasi dari setiap metode untuk mengetahui hasil akhir yang didapat dari metode codebook dan PNN.
Berikut parameter-parameter yang diujicobakan adalah : 1 Time frame sebesar 40 ms
2 Overlap 0.50
3 Jumlah koefisien cepstral 13, 20, dan 26
4 Jumlah klaster pada k-means 30 pada codebook
5 Komposisi data latih dan data uji 25:75, 50:50, dan 75:25 Studi kasus anak laki-laki
Studi kasus anak laki-laki dengan metode codebook, tingkat akurasi terbaik sebesar 100% yang terjadi pada seluruh koefisien, hanya saja tidak terjadi pada semua data latih. Tingkat akurasi terkecil sebesar 96% yang terjadi pada koefisien 13 dengan data latih 25% dan pada koefisien 20 dan 26 pada data latih 75%. Metode PNN, tingkat akurasi terbaik sebesar 100% yang terjadi pada koefisien 20 dan 26 dengan data latih 50% dan 75%. Tingkat akurasi terkecil sebesar 92% yang terjadi pada koefisien 13 dengan data latih 25%. Detail perbandingan akurasi pada codebook dan PNN untuk studi kasus anak laki-laki dapat dilihat pada Tabel 1.
12
Hasil yang didapat dari akurasi codebook dan PNN studi kasus anak laki-laki adalah 98.14% untuk codebook dan 97.11% untuk PNN, hasil codebook lebih baik dibandingkan PNNpada studi anak laki-laki. Tabel 1 terlihat bahwa proporsi data 50% dapat menghasilkan akurasi yang stabil baik pada kedua metode, karena terjadi keseimbangan jumlah data pada data latih dan data uji.
Studi kasus anak perempuan
Studi kasus anak perempuan menggunakan metode codebook, tingkat akurasi yang paling baik sebesar 100% terjadi pada semua koefisien dengan data latih 75%. Nilai akurasi minimum terjadi pada koefisien 13 dan data latih 25% mencapai 92%. Metode PNN, tingkat akurasi yang paling baik sebesar 100% terjadi pada koefisien 13 dengan data latih 75%. Nilai akurasi minimum terjadi pada koefisien 20 dan data latih 25% mencapai 93.33%. Detail perbandingan akurasi pada codebook dan PNN untuk studi kasus anak perempuan dapat dilihat pada Tabel 2.
Hasil yang didapat dari akurasi codebook dan PNN pada studi kasus anak perempuan adalah sebesar 97.11% untuk codebook dan 96.81% untuk PNN. Hasil
codebook lebih baik dibandingkan PNN pada studi anak perempuan. Pada Tabel 2 menunjukan bahwa metode codebook memiliki hasil akurasi yang stabil terjadi pada koefisien 26, dan pada metode PNN hasil akurasi yang stabil terjadi pada koefisien 13. Penggunaan proporsi data latih 75% pada codebook dan PNN mampu menghasilkan akurasi yang sangat baik. Oleh karena itu,
Tabel 1 Perbandingan keakurasian pada kelompok anak laki-laki dengan codebook dan PNN
13 pengidentifikasian selanjutnya untuk kasus anak perempuan disarankan menggunakan data latih 75%. Hal ini terjadi karena proporsi data latih pada lebih besar dibandingkan dengan data uji, sehingga penciri suara dari studi anak kasus perempuan mampu mengindentifikasi secara baik.
Studi kasus remaja laki-laki
Studi kasus remaja laki-laki dengan metode codebook, tingkat akurasi yang terbaik terjadi pada setiap koefisien dengan data latih 50% sebesar 100%, dan akurasi terkecil sebesar 80% terjadi pada koefisien 20 dengan data latih 25%. Metode PNN, tingkat akurasi pada koefisien 20 dan 26 yang terbaik terjadi pada data latih 75% sebesar 100%, untuk akurasi terkecil sebesar 84% terjadi pada koefisien 13 dengan data latih 25%. Detail perbandingan akurasi pada codebook
dan PNN untuk studi kasus remaja laki-laki dapat dilihat pada Tabel 3.
Koef remaja laki-laki menghasilkan rata-rata akurasi sebesar 95.26% untuk codebook
dan 95.47% untuk PNN, hasil PNN lebih baik dibandingkan codebook pada studi remaja laki-laki. Pada Tabel 3 menunjukan bahwa, metode codebook memiliki hasil akurasi yang stabil terjadi pada koefisien 13 dan 26, dan pada metode PNN hasil akurasi yang stabil terjadi pada koefisien 20. Terlihat bahwa koefisien sangat mempengaruh dari setiap metode. Hanya saja untuk proporsi data latih 50% pada
codebook mampu menghasilkan akurasi yang sangat baik dan PNN menghasilkan akurasi yang stabil pada data latih 75%.
Studi kasus remaja perempuan
Studi kasus remaja perempuan dengan menggunakan codebook, tingkat akurasi yang terbaik terjadi pada setiap koefisien dengan data latih 75% sebesar 100%, dan akurasi terkecil sebesar 81.33% terjadi pada koefisien 20 dengan data latih 25%. Metode PNN, tingkat akurasi pada koefisien 20 yang terbaik terjadi pada data latih 75% sebesar 100 %, untuk akurasi terkecil sebesar 88% terjadi pada koefisien 13 dengan data latih 25%. Detail perbandingan akurasi pada
codebook dan PNN untuk studi kasus remaja perempuan dapat dilihat pada Tabel 4.
14 remaja perempuan menghasilkan rata-rata akurasi sebesar 94.67% untuk codebook
dan 94.74 % untuk PNN, hasil PNN lebih baik dibandingkan codebook pada studi remaja perempuan. Tabel 4 menunjukan bahwa metode codebook memiliki hasil akurasi yang stabil terjadi pada koefisien 13, dan pada metode PNN hasil akurasi yang stabil terjadi pada koefisien 26. Terlihat bahwa koefisien sangat mempengaruh dari setiap metode. Hanya saja untuk proporsi data latih 75% pada
codebook mampu menghasilkan akurasi yang sangat baik dan PNN menghasilkan akurasi yang stabil pada data latih 50%.
Studi kasus dewasa laki-laki
Studi kasus dewasa laki-laki dengan menggunakan codebook, tingkat akurasi terbaik terjadi pada koefisien 13 dengan semua data latih sebesar 100%, dan akurasi terkecil sebesar 98% terjadi pada koefisien 20 dengan data latih 50%. Metode PNN, tingkat akurasi pada koefisien 13 yang terbaik terjadi pada data latih 50% sebesar 98.66%, untuk akurasi terkecil sebesar 81.33% terjadi pada koefisien 26 dengan data latih 25%. Detail perbandingan akurasi pada codebook
dan PNN untuk studi kasus remaja perempuan dapat dilihat pada Tabel 5.
Koef
Hasil yang didapat dari akurasi codebook dan PNN pada studi kasus dewasa laki-laki menghasilkan rata-rata akurasi sebesar 99.48% untuk codebook dan 89.7% untuk PNN, hasil codebook lebih baik dibandingkan PNN pada studi dewasa laki-laki. Studi kasus ini terlihat bahwa codebook mampu dengan baik mengenali suara dewasa laki-laki dengan perbedaan akurasi yang cukup siginifikan dibanding PNN. Tabel 5 menunjukan bahwa metode codebook
Tabel 4 Perbandingan keakurasian pada kelompok remaja perempuan dengan codebook dan PNN
15 memiliki hasil akurasi yang sangat baik terjadi pada koefisien 13, dan hal yang serupa terjadi pada metode PNN hasil akurasi yang stabil terjadi pada koefisien 13. Hanya saja pada metode PNN akurasi yang didapat kurang baik dibandingkan dengan codebook pada studi kasus ini. Penggunaan proporsi data latih 75% pada
codebook maupun PNN mampu menghasilkan akurasi yang baik dan stabil .
Studi kasus dewasa perempuan
Studi kasus dewasa perempuan menggunakan codebook, tingkat akurasi sempurna terjadi pada koefisien 26 dengan semua data latih sebesar 100%, dan akurasi terkecil sebesar 96% terjadi pada koefisien 13 dengan data latih 25%. Metode PNN, tingkat akurasi maksimal terjadi pada koefisien 20 dan 26 sebesar 100% dengan data latih 75%, untuk akurasi terkecil sebesar 92% terjadi pada koefisien 13 dengan data latih 75%.
. Detail perbandingan akurasi pada codebook dan PNN untuk studi kasus remaja perempuan dapat dilihat pada Tabel 6.
Koef
Hasil yang didapat dari akurasi codebook dan PNN pada studi kasus dewasa perempuan menghasilkan rata-rata akurasi sebesar 99.11% untuk codebook dan 96.29% untuk PNN, hasil codebook lebih baik dibandingkan PNN pada studi dewasa perempuan. Tabel 6 menunjukan bahwa metode codebook memiliki hasil akurasi yang sangat baik terjadi pada koefisien 26, dan hal yang berbeda dengan dengan studi kasus laki-laki dewasa, pada PNN teerjadi akurasi yang stabil terjadi pada koefisien 26. Penggunaan proporsi data latih 75% pada codebook maupun PNNmampu menghasilkan akurasi yang baik dan stabil. Akurasi yang didapatkan oleh metode codebook lebih baik dibandingkan dengan metode PNN.
Analisis Percobaan
Hasil yang didapat dari keenam studi kasus yang diujikan pada pengenalan kisaran usia dan jenis kelamin terdapat dua hasil akurasi yang berbeda antara
codebook dan PNN dengan rata-rata akurasi dari setiap studi kasus yang didapat ditunjukan pada Tabel 7.
16
Studi Kasus Codebook PNN
Anak Laki-Laki 98.14% 97.99%
Anak Perempuan 97.11% 96.81%
Remaja Laki-Laki 95.26% 95.47%
Remaja Perempuan 94.67% 94.74%
Dewasa Laki-Laki 99.48% 89.70%
Dewasa Perempuan 99.11% 96.29%
Rataan 97.20% 95.17%
Terlihat rata-rata akurasi yang terdapat pada Tabel 7, maka dapat disimpulkan metode codebook menghasilkan akurasi yang lebih baik dari metode PNN pada studi kasus anak perempuan, dewasa laki-laki, dan dewasa perempuan. Penggunaan metode PNN menghasilkan akurasi yang lebih baik dari codebook
pada studi kasus anak laki-laki, remaja laki-laki, dan remaja perempuan. Data yang diberikan pada Tabel 7, maka diperoleh akurasi secara keseluruhan untuk setiap metode yang diujikan sebesar 97.20% untuk metode codebook dan 95.17% untuk metode PNN.
Hasil rata-rata akurasi metode codebook yang didapat lebih tinggi dibandingkan dengan hasil yang didapat oleh PNN dengan selisih 2.03%. Hal ini disebabkan adanya perbedaan akurasi yang didapat dari setiap studi kasus. Studi kasus merupakan kelas-kelas yang terdapat pada penelitian ini. Selain itu akurasi juga dipengaruhi dari koefisien, proporsi data latih dan data uji yang digunakan.
Rata-rata akurasi berdasarkan koefisien dalam metode codebook
menghasilkan akurasi paling baik cenderung dengan koefisien 13, hal ini dapat disimpulkan bahwa metode codebook dengan penggunaan koefisien lebih besar atau semakin banyak fitur yang digunakan cenderung memperkecil hasil akurasi. Penggunaan metode PNN akurasi paling baik terdapat pada koefisien 20, terlihat bahwa metode PNN memerlukan fitur atau ciri yang lebih banyak dibandingkan dengan codebook untuk mendapatkan hasil akurasi yang baik. Rata-rata akurasi berdasarkan koefisien bisa dilihat pada Tabel 8.
Koefisien Codebook PNN
13 97.92% 93.99%
20 96.30% 97.00%
26 97.60% 94.51%
Rata-rata akurasi dari proporsi data latih dan data uji baik codebook
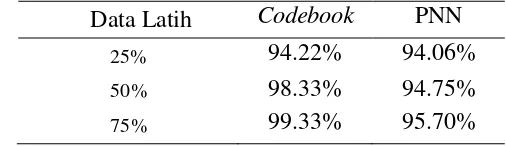
maupun PNN didapat akurasi terbaik dengan proporsi data latih sebesar 75%. Hal ini terjadi karena pada proporsi data latih 75%, jumlah data latih lebih besar dibandingkan dengan data uji, sehingga akurasi yang dihasilkan lebih baik dibandingkan dengan 25% dan 50%. Rata-rata akurasi berdasarkan proporsi data latih bisa dilihat pada Tabel 9.
Tabel 7 Rata-rata akurasi kisaran usia dan jenis kelamin dari setiap studikasus
17
Data Latih Codebook PNN
25% 94.22% 94.06%
50% 98.33% 94.75%
75% 99.33% 95.70%
Analisis Kesalahan
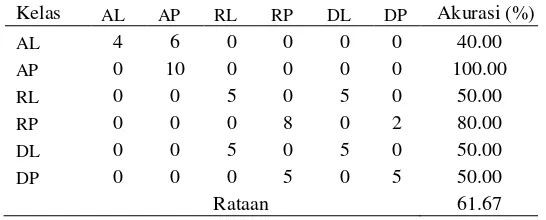
Terlihat dari pembahasan di atas bahwa pengenalan suara berdasarkan kisaran usia dan jenis kelamin menggunakan metode codebook dan PNN, analisa kesalahan untuk metode codebook dengan koefisien 20 dengan data latih 25% mampu menghasilkan hasil rata- rata akurasi yang kurang baik. Berikut confusion matrix untuk metode codebook dengan koefisien 20 dan data latih 25% pada tabel 10.
Kelas AL AP RL RP DL DP Akurasi(%)
AL 75 0 0 0 0 0 100
AP 5 70 0 0 0 0 93.33
RL 0 5 60 0 10 0 80.00
RP 0 9 0 61 0 0 81.33
DL 0 0 1 0 74 0 98.67
DP 0 0 0 0 0 75 100
Rataan 92.21
Tabel di atas menjelaskan bahwa metode codebook mampu dengan baik mengidentifikasi suara pada kelompok anak laki-laki dan dewasa laki-laki, dan kurang baik pada kelompok remaja laki-laki dan remaja perempuan. Terdapat kesalahan pengidentifikasian suara paling banyak pada kelompok remaja baik laki-laki maupun perempuan.
Analisis kesalahan untuk metode PNN dengan koefisien 13 dengan data latih 25% mampu menghasilkan rata-rata kurang baik dari koefisien yang lainnya. Berikut confusion matrix untuk metode PNN dengan koefisien 13 dan data latih 25% pada Tabel 11.
Tabel 9 Rata-rata akurasi kisaran usia dan jenis kelamin dari setiap studikasus berdasarkan proporsi data latih
18 mengidentifikasi suara pada kelompok anak laki-laki, remaja laki-laki, remaja perempuan, dan dewasa perempuan. Terlihat pada kelompok anak perempuan dan dewasa laki-laki, metode PNN terdapat kesalahan dalam pengidentifikasian. Terdapat satu suara pada anak perempuan yang teridentifikasi pada suara anak laki-laki, hal ini terjadi karena adanya tumpang tindih antara rentang frekuensi kelompok suara satu dengan kelompok suara lainnya.
Akurasi model dengan suara diluar data pelatihan
Pengujian data di luar data latih dengan menggunakan metode codebook
untuk koefisien 13 dan data latih 75% diperoleh akurasi model umum model sebesar 61.67%. Data yang diujikan sebanyak 10 data untuk setiap kelompoknya. Data tersebut memiliki akurasi maksimum pada kelompok anak perempuan dan akurasi minimum pada kelompok anak laki-laki. Data akurasi model untuk suara di luar data latih dapat dilihat pada Tabel 12.
Kelas AL AP RL RP DL DP Akurasi (%) scenario yang sama dengan metode codebook diperoleh rata-rata akurasi yang sama dengan metode codebook sebesar 61.67%. Akurasi dari setiap kelompok suara untuk akurasi maksimum dan akurasi minimum mendapatkan hasil yang sama dengan metode codebook. Data akurasi model untuk suara di luar data latih dapat dilihat pada Tabel 13.
Tabel 11 Confusion matrix untuk metode PNN
19
codebook maupun PNN menghasilkan hasil akurasi yang sama yaitu sebesar 61.67%. Suara yang tidak teridentifikasi dengan benar disebabkan adanya tumpang tindih antara frekuensi setiap kelompok pembicaranya dan terdapat noise yang cukup besar pada saat perekaman suara. Hal ini dapat mengubah karakteristik suara sehingga model tidak dapat mengidentifikasi dengan benar.
SIMPULAN DAN SARAN
Simpulan
Penelitian ini menunjukkan bahwa nilai-nilai parameter sangat mempengaruhi akurasi sistem. Metode codebook mempunyai hasil akurasi yang lebih baik dibandingkan dengan metode PNN. Hasil yang didapat untuk pengenalan kisaran usia dan jenis kelamin, metode codebook menghasilkan rata-rata akurasi sebesar 97.20% dan 95.17% untuk PNN. Terlihat akurasi yang didapat oleh metode codebook lebih besar dari metode PNN sebesar 2.03% pada penelitian ini, hal ini disebabkan karena pengaruh perbedaan dari koefisien, dan proporsi data latih dan data uji. Setiap metode baik codebook maupun PNN mempunyai komposisi nilai parameter yang berbeda untuk mengenali sebuah suara secara baik.
Saran
Penelitian ini memungkinkan untuk dikembangkan lebih baik lagi, saran untuk pengembangan selanjutnya ialah:
1 Menambahkan data pembicara pada setiap kelompok, sehingga sesuai dengan standar jumlah data statistik, yang berjumlah 30 orang pada setiap kelompoknya (Mattjik 2006). Penambahan data pembicara diharapkan meningkatkan tingkat akurasi pengenalan terutama pada pengenalan kisaran usia remaja.
2 Menggunakan rata-rata dan membandingkan nilai magnitudo kurva FFT pada setiap kelompok suara tanpa melalui proses MFCC.
20
DAFTAR PUSTAKA
Buono A. 2009. Representasi nilai HOS dan model MFCC sebagai ekstraksi ciri pada sistem identifikasi pembicara di lingkungan ber-noise menggunakan HMM [disertasi]. Depok (ID): Universitas Indonesia.
Buono A, Kusumoputro B. 2007. Pengembangan model HMM berbasis maksimum lokal menggunakan jarak Euclid untuk sistem identifikasi pembicara. Di dalam: Prosiding pada Workshop NACSIIT; 2007 Jan 29-30;
Depok (ID), hlm 52.
Do MN. 1994. Digital signal processing mini-project: an automatic recognition system. Laussane (CH): Federal Institute of Technology.
Fransiswa RR. 2010. Pengembangan model probabilistic neural network (PNN) pada pengenalan kisaran usia dan jenis kelamin berbasis suara [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Ganchev T. 2005. Speaker recognition [disertasi]. Patras (GR): University of Patras.
[IDAI] Ikatan Dokter Anak Indonesia. 2009. Overview adolescent health problems and services[Internet]. [diakses 2013 Apr 12]. Dapat diunduh pada http: //www.idai.or.id/remaja/artike.asp?q=200994155149.
Jurafsky D, Martin JH. 2000. Speech And Language Processing an Introduction to Natural Language Processing, Computational Linguistic, and Speech Recognition. New Jersey (US): Prentice Hall.
Mattjik AA. 2006. Perancangan Percobaan dengan Aplikasi SAS dan Minitab. Bogor (ID): IPB Press.
Nilsson M, Ejnarsson M. 2002. Speech recognition using hidden markov model: performance evaluation in noisy environment [tesis]. Karlskrona (SE): Blekinge Institute of Technology.
Suhartono MN. 2007. Pengembangan model identifikasi pembicara dengan
21