PENDETEKSIAN WARNA UNTUK
MEMBANTU PENDERITA BUTA WARNA
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
Disusun Oleh:
Marcel Eka Putra
10110076
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
NIM : 10110076
Tempat/Tanggal Lahir : Bandung, 2 Januari 1990 Jenis Kelamin : Pria
Agama : Islam
Alamat Lengkap : Kp. Cipatat, Ujung berung Bandung RT/RW. 003/004 Kel. Ciporeat Kec. Cilengkrang.
Nomor Telepon
Pendidikan Formal
: 089622028425
1998-2004 : SD Santa Maria Santo Yusuf Bandung 2004-2007 : SMP Providentia Bandung
2007-2010 : SMA Negeri 7 Bandung
2010-2014 : Program Strata 1 (S1) Program Studi Teknik Informatika Fakultas Teknik dan Ilmu Komputer Universitas
Komputer Indonesia Bandung
v
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... xii
DAFTAR SIMBOL ... xiv
DAFTAR LAMPIRAN ... xvii
BAB 1 PENDAHULUAN ... 1
1.1. Latar Belakang Masalah ... 1
1.2. Identifikasi Masalah ... 2
1.3. Maksud dan Tujuan ... 2
1.4. Batasan Masalah... 3
1.5. Metodologi Penelitian ... 3
1.5.1. Metode Pengumpulan Data ... 3
1.5.2. Metode Pembangunan Perangkat Lunak ... 4
1.6. Sistematika Penulisan... 5
BAB 2 LANDASAN TEORI ... 7
2.1. Definisi Warna ... 7
2.1.1. Model Warna RGB ... 7
2.1.2. Model Warna CIE XYZ ... 8
2.1.3. Model Warna CIE LUV ... 9
2.1.4. Model Warna Munsell ... 9
2.2. Pengertian Clustering ... 10
2.2.1. Kategori Clustering ... 10
2.3. Algoritma K-Means ... 11
2.4. Algoritma Genetika... 12
2.4.1. Stuktur Umum Algoritma Genetik ... 13
vi
2.4.7. Parameter Genetik ... 17
2.5. Fast Genetic K-means Algorithm ... 19
2.5.1. Inisialisasi ... 21
2.5.2. Nilai Fitness ... 21
2.5.3. Seleksi ... 22
2.5.4. Mutasi ... 22
2.6. Operator Sobel ... 23
2.7. Konsep Dasar Analisis Sistem ... 24
2.7.1. OOP (Object Oriented Programming) ... 24
2.7.2. Kelas (Class) ... 25
2.7.3. Objek (Object) ... 25
2.7.4. Abstraksi (Abstract) ... 25
2.7.5. Enkapsulasi (Encapsulation) ... 26
2.7.6. Polimorfisme (Polymorphism) ... 26
2.7.7. Inheritans (Inheritance) ... 26
2.7.8. UML (Unified Modelling Language) ... 27
2.7.9. Use Case Diagram ... 27
2.7.10. Conceptual Diagram ... 28
2.7.11. Sequence Diagram ... 28
2.7.12. Collaboration Diagram ... 29
2.7.13. State Diagram ... 29
2.7.14. Activity Diagram ... 29
2.7.15. Class Diagram ... 29
2.7.16. Object Diagram ... 30
2.7.17. Component Diagram ... 30
2.7.18. Deployment Diagram ... 30
2.8. IDE yang Digunakan. ... 30
vii
3.1. Analisis Masalah ... 33
3.2. Analisis Sistem ... 34
3.3. Analisis Data Masukkan ... 35
3.4. Analisis Metode/Algoritma ... 36
3.5. Analisis Kompleksitas Algoritma ... 109
3.6. Analisis Kebutuhan Perangkat Lunak ... 111
3.6.1. Analisis Kebutuhan Non-Fungsional ... 111
3.6.2. Analisis Kebutuhan Fungsional ... 113
3.6.2.1.Use Case Diagram ... 114
3.6.2.2.Skenario Use Case ... 114
3.6.2.3.Activity Diagram ... 117
3.6.2.4.Sequence Diagram ... 123
3.6.2.5.Class Diagram ... 131
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 133
4.1. Implementasi Sistem ... 133
4.1.1. Implementasi Perangkat Keras ... 133
4.1.2. Implementasi Perangkat Lunak ... 133
4.1.3. Implementasi Aplikasi ... 134
4.1.4. Implementasi Antarmuka ... 134
4.2. Pengujian Black Box ... 140
4.2.1. Skenario Pengujian Black Box ... 140
4.2.2. Kasus dan Hasil Pengujian ... 140
4.2.2.1.Input Citra ... 140
4.2.2.2.Input Jumlah Kromosom ... 140
4.2.2.3.Input Rasio Mutasi ... 141
4.2.2.4.Input Iterasi K-Means ... 141
4.2.3. Kesimpulan Hasil Pengujian Black Box ... 142
4.3. Pengujian Kuesioner ... 142
4.3.1. Skenario Pengujian Kuesioner ... 142
4.3.2. Kasus dan Hasil Pengujian ... 143
viii
BAB 5 KESIMPULAN DAN SARAN ... 177
5.1. Kesimpulan ... 177
5.2. Saran ... 177
179 Yogyakarta: Andi Publisher.
[2] Sunar Prasetyono Dwi (2013). Tes Buta Warna untuk Segala Tujuan. Yogyakarta: Saufa.
[3] Yi Lu, Shiyong Lu, Farshad Fotouhi, Youping Deng, Susan Brown , “FGKA: A Fast Genetic K-means Algorithm”, Discourse Processes, 2004.
[4] Suyanto, ST., Msc. (2008). Evolutionary Computation - Komputasi Berbasis Evolusi dan Genetika. Bandung: Informatika.
[5] Supriyono, R. (2010). Desain Komunikasi Visual. Yogyakarta: Andi Publisher.
[6] Rosa A. S, M. S. (2013). Rekayasa Perangkat Lunak Terstruktur dan Berorientasi Objek. Bandung: Informatika Bandung.
[7] Sianipar, R. H. (2014). Pemrograman C#. Bandung: Informatika Bandung. [8] Hermawati, F. A. (2013). Pengolahan Citra Digital. Yogyakarta: Andi Publisher. [9] K. Venkatalakshmi, P. Anisha Praisy, R. Maragathavalli, S. Mercy Shalinie (2007),
Multispectral Image Clustering Using Enhanced Genetic k-Means Algorithm, Information Technology Journal 6 (4) : 554-560.
[10]Wiharto, Y.S. Palgunadi, Muh Aziz Nugroho (2013), Analisis Penggunaan Algoritma Genetika untuk Perbaikan Jaringan Syaraf Tiruan Radial Basis Function, ISSN: 2089-9815.
iii
Segala puji bagi Allah yang telah melimpahkan karunia-Nya serta atas ijin dan cinta-Nya lah dapat terselesaikan skripsi ini yang berjudul
“IMPLEMENTASI ALGORITMA K-MEANS PADA PENDETEKSIAN
WARNA CITRA UNTUK MEMBANTU PENDERITA BUTA WARNA”
dengan segala kekurangan, kelebihan dan keterbatasannya. Keberhasilan penyusun dalam menyelesaikan tugas akhir ini tidak lepas dari peran serta berbagai pihak yang telah memberikan sumbangan pikiran, bimbingan, serta dorongan semangat pada penulis.
Penyusun menyadari sepenuhnya bahwa dalam tugas akhir yang penyusun buat masih sangat jauh dari kesempurnaan. Hal ini tiada lain disebabkan oleh keterbatasan waktu, pengetahuan dan pengalaman yang penulis miliki. Penulis ingin mengucapkan terima kasih yang sebesar – besarnya kepada yang terhormat dan tercinta :
1. Ibunda tercinta Yulia Tandean dan Ayahanda tercinta Okkey Haruman Widjaja yang dengan tulus selalu mendoakan, memberikan dorongan moril dan materil, perhatian, dukungan sepenuhnya dan kasih sayang yang tidak ternilai.
2. Ibu Nelly Indriani W, S.Si., M.T., selaku dosen pembimbing yang telah meluangkan waktunya untuk membimbing dan memberikan masukan-masukan dalam penulisan skripsi ini.
3. Bapak Andri Heryandi, S.T., M.T., selaku dosen penguji yang telah memberikan saran serta kritiknya dalam penyusunan skripsi ini.
4. Ednawati Rainarli, S.Si., M.Si., selaku dosen penguji yang telah memberikan masukan dan kritiknya terhadap penyusunan skripsi ini. 5. Kepada sahabat – sahabatku, seluruh mahasiswa Teknik Informatika
iv
7. Ibu Dian Dharmayanti S.T. selaku dosen wali IF – 2 2010 yang telah membantu dalam kelancaran dari berbagai permasalahan mengenai perkuliahan.
8. Bapak Irawan Afrianto S.T., M.T. selaku Ketua Program Studi Teknik Informatika Fakultas Teknik dan Ilmu Komputer UNIKOM.
9. Kepada pihak – pihak yang tidak sempat disebutkan satu persatu, semua memiliki andil yang sangat besar atas perjuangan saya. Terima kasih yang sebesar – besarnya.
Akhri kata, penulis berharap semoga laporan bisa sangat berguna dan bermanfaat bagi penulis dan pembaca. Semoga segala jenis bantuan yang telah diberikan kepada penulis mendapat balasan dari Allah SWT. Amin.
Bandung, 18 Agustus 2014
1
PENDAHULUAN
1.1. Latar Belakang Masalah
Clustering [1] merupakan sebuah metode unsupervised learning (tanpa supervisi) yang membagi sekumpulan data menjadi kelompok-kelompok atau
cluster berdasarkan kemiripan atribut di antara data-data tersebut. Metode
clustering disebut sebagai metode tanpa supervisi dikarenakan sifatnya yang mampu membagi sekumpulan data yang besar dan tanpa memiliki label menjadi sebuah ataupun beberapa kelompok tanpa perlu mengetahui karakteristik apa yang membuat data tersebut menjadi anggota dari salah satu kelompok.
K-Means [1] merupakan sebuah metode clustering yang bersifat efisien dan cepat dalam mengelompokkan data akan tetapi K-Means tidak terlalu efektif jika dilihat secara output dari proses pengelompokkannya. Hal ini dikarenakan K-Means hanya mengelompokkan data yang mengarah pada lokal optimum saja sehingga pengelompokkan data yang dihasilkan oleh K-Means seringkali kurang akurat. Berdasarkan hasil studi literatur K-Means dapat dioptimalkan dengan algoritma genetika yang merupakan algoritma yang baik dalam mendekati global optimum yang disebut dengan Fast Genetic K-Means Algorithm [3]. Dengan algoritma genetika hasil pengelompokkan dari K-Means akan menjadi lebih fit dan secara otomatis dapat meningkatkan akurasi pengelompokkan warna. Akan tetapi kekurangan dari algoritma FGKA adalah mahalnya biaya komputasi untuk mendekati kondisi konvergen.
warna dikategorikan sebagai penyakit yang tidak dapat diobati karena buta warna merupakan penyakit yang disebabkan oleh faktor keturunan yaitu kekurangan satu atau lebih sel kerucut pada mata.
Pendeteksian warna merupakan suatu usaha dalam membantu penderita buta warna dalam mengenali warna dengan mengimplementasikan algoritma K-Means yang dapat dioptimalkan oleh algoritma genetika (FGKA) pada teknologi komputer. Aplikasi ini bekerja dengan cara melakukan pengelompokkan warna pada citra yang dipilih oleh pengguna penderita buta warna melalui sistem kemudian melakukan penandaan tepi oleh operator sobel.
1.2. Rumusan Masalah
Berdasarkan latar belakang masalah yang telah diuraikan di atas, yang menjadi titik permasalahan dalam penelitian ini adalah adanya kebutuhan akurasi yang tinggi dan waktu pengelompokkan yang relatif cepat dalam pengelompokkan warna yang dilakukan pada sistem pendeteksian warna yang dapat meningkatkan ketepatan pendeteksian batas-batas tepi objek berwarna terdeteksi.
1.3. Maksud dan Tujuan
Berdasarkan judul yang diambil, maka maksud dari penulisan tugas akhir ini adalah untuk mengetahui akurasi dan efisiensi algoritma K-Means dengan pengoptimalan oleh algoritma genetika (FGKA) pada pendeteksian warna yang dapat digunakan dalam membantu penderita buta warna.
Sedangkan tujuan yang akan dicapai dalam penelitian ini adalah menemukan kombinasi parameter inputan yang terbaik sehingga dapat meningkatkan performansi dan optimasi berdasarkan efektifitas dan efisiensi pengelompokkan warna yang dilakukan pada sistem pendeteksian warna dengan mengimplementasikan algoritma clustering Fast Genetic K-Means Algorithm
1.4. Batasan Masalah
Dalam penelitian ini terdapat beberapa batasan yang perlu diperhatikan, antara lain :
1. Pendeteksian warna hanya dapat dilakukan pada objek dengan keadaan intensitas cahaya yang baik dan tidak gelap.
2. Aplikasi pendeteksian warna dibangun untuk membantu penderita buta warna parsial dan total.
3. Data yang dikelompokkan oleh algoritma clustering berupa warna yang memiliki atribut RGB (Red, Green, dan Blue).
4. Citra inputan sistem berupa file citra yang telah tersedia di direktori komputer yang berekstensi JPG, JPEG, PNG, dan BMP ataupun hasil capture foto oleh
webcam.
5. Citra inputan sistem berukuran 400 x 350 piksel. 6. Perangkat lunak yang dibangun berbasis desktop. 7. Perangkat lunak yang dihasilkan adalah prototype.
1.5. Metodologi Penelitian
Dalam pembuatan skripsi ini menggunakan metode penelitian deskriptif yang menggambarkan fakta-fakta dan informasi secara sistematis, aktual, dan akurat. Metode penelitian ini memiliki dua tahapan penelitian, yaitu sebagai berikut :
1.5.1. Metode Pengumpulan Data
1.5.2. Metode Pembangunan Perangkat Lunak
Dalam perancangan tugas akhir ini penulis menggunakan metode
Prototype. Prototype model adalah salah satu metode pengembangan perangkat lunak dimana pengembang dan pengguna dapat saling berinteraksi selama proses pembuatan sistem. Proses pada prototyping dapat dijelaskan sebagai berikut : 1. Pengumpulan kebutuhan
Developer dan klien bertemu dan menentukan tujuan umum dari sistem pendeteksian warna yang ditujukan pada penderita buta warna parsial dan total.
2. Perancangan
Perancangan dilakukan setelah developer bertemu dengan klien. Sistem akan dibangun sesuai dengan kebutuhan klien yang dapat saling berinteraksi ketika proses perancangan.
3. Pemodelan
Setelah dilakukan perancangan yang melibatkan pengguna untuk terus berinteraksi, dilakukan pemodelan yang dapat digunakan pengguna sebagai panduan untuk menggunakan perangkat lunak.
4. Konstruksi
Setelah dilakukan pemodelan, pembangunan perangkat lunak dilakukan sesuai dengan model yang telah dibuat sebelumnya.
5. Evaluasi prototype
Gambar 1.1 Siklus Model Prototype [6]
1.6. Sistematika Penulisan
Sistematika penulisan penelitian ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB I. PENDAHULUAN
Menguraikan tentang latar belakang masalah yang dihadapi, menentukan maksud dan tujuan, dan batasan masalah, yang kemudian diikuti dengan metodologi penelitian, serta sistematika penulisan.
BAB II. LANDASAN TEORI
Membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis permasalahan. Landasan teori yang dimaksud mencakup penjelasan mengenai pengertian warna, pengertian clustering, algoritma k-means, algoritma genetika, algoritma FGKA, dan operator sobel.
BAB III. ANALISIS DAN KEBUTUHAN
metode yang diimplementasikan terhadap sistem. Dan pemodelan sistem menggunakan OOP (Object Oriented Programming).
BAB IV. IMPLEMENTASI DAN PENGUJIAN SISTEM
Merupakan tahapan yang dilakukan dalam penelitian secara garis besar sejak dari tahap persiapan sampai penarikan kesimpulan dan kaidah yang diterapkan dalam penelitian. Termasuk menentukan metode pengujian yang akan dipergunakan dalam pengujian sistem yang akan dibangun.
BAB V. KESIMPULAN DAN SARAN
7
LANDASAN TEORI
2.1. Definisi Warna
Warna [5] merupakan elemen terpenting pada sebuah objek berupa citra dimana elemen warna sangat dipengaruhi oleh intensitas cahaya. Warna sendiri dapat dilihat oleh indera penglihatan manusia dikarenakan adanya pantulan cahaya pada suatu permukaan benda dan dipengaruhi oleh pigmen yang terdapat pada permukaan benda tersebut.
Pada sebuah citra digital, warna dapat dibagi menjadi beberapa model warna yang digambarkan pada sistem koordinat berdimensi tiga. Model warna yang umum dipakai adalah RGB (digunakan pada monitor), CMY (digunakan pada printer berwarna), YIQ (digunakan pada siaran televisi berwarna), HSV, CIEXYZ, CIE LUV, CIE Lab, dan Munsell. Model warna dibedakan berdasarkan sistem koordinat maupun gamut warna.
2.1.1. Model Warna RGB
2.1.2. Model Warna CIE XYZ
Berbagai macam warna dapat dihasilkan melalui pencahayaan warna merah, hijau dan biru. Kurva pencocokan warna r(λ), g(λ), dan b(λ) menggambarkan angka dari RGB yang dibutuhkan untuk mencocokkan warna dengan panjang gelombang dominan λ. Hal terpenting adalah kurva merah r(λ) adalah tidak eksis pada 438 nm hingga 546 nm atau dikatakan negatif pada kurva tersebut, yang berarti bahwa warna pada daerah tersebut tidak dapat diproduksi melalui kombinasi positif dari R, G dan B.
Pada tahun 1931 Komisi Internationale de L’ Eclairge (CIE) membahas masalah bobot negatif dalam model warna RGB. Komisi ini mendefinisikan tiga primari baru yang disebut sebagai X, Y dan Z [5] untuk menggantikan RGB. Pencocokan warna kurva x(λ), y(λ), dan z(λ) menggambarkan angka dari XYZ yang dibutuhkan untuk mencocokkan warna dengan panjang gelombang dominan λ. Kurva ini dirancang untuk menjadi kombinasi linear dari r(λ), g(λ), dan b(λ). Tidak satu pun dari x(λ), y(λ), ataupun z(λ) negatif dalam kisaran 380nm hingga 780nm, yang berarti setiap warna dapat diproduksi dengan kombinasi positif X, Y dan Z.
2.1.3. Model Warna CIE LUV
Masalah yang timbul pada model warna CIE XYZ [5] adalah kurangnya keseimbangan perseptual warna. Warna yang memiliki jarak yang sama antara satu sama lain secara perseptual tidak selalu berjarak sama. Oleh karena alasan tersebut pada tahun 1967, CIE mengusulkan model warna CIE LUV. CIE LUV merupakan sebuah model warna yang memiliki perseptual warna dengan jarak yang sama.
2.1.4. Model Warna Munsell
Model warna Munsell [5] diusulkan pada tahun 1898 oleh Albert H. Munsell yang kemudian direvisi kembali pada tahun 1943 oleh Optical Society of America untuk lebih mendekati keseimbangan warna. Warna pada model warna Munsell ditentukan dengan menggunakan tiga dimensi elemen yaitu hue, kroma (chroma), dan nilai (value) seperti pada gambar 2.2.
Gambar 2.2. Model warna Munsell [7]
Hue mengacu pada identifikasi keunikan warna yang digambarkan oleh
BG, B, PB, P, dan RP). Setiap bagian tersebut dapat dibagi kembali menjadi sepuluh subbagian sesuai dengan kehalusan hue yang dibutuhkan.
Nilai (value) mengacu pada tingkat kecerahan atau kegelapan warna yang dapat dibagi menjadi sebelas bagian (penomoran dimulai dari 0 hingga 10). Untuk warna yang gelap memiliki nilai yang rendah sedangkan warna yang cerah memiliki nilai yang tinggi.
Kroma (chroma) mendefinisikan kekuatan atau kelemahan warna. Chroma diukur dalam langkah-langkah yang bernomor dimulai dari angka 1. Warna lemah memiliki nilai kroma yang rendah sedangkan warna yang kuat memiliki nilai kroma yang tinggi. Kroma bernilai nol adalah warna abu-abu sehingga nilai nol pada kroma dapat diabaikan.
2.2. Pengertian Clustering
Salah satu metode yang diterapkan dalam pendeteksian warna adalah
clustering. Clustering [1] merupakan sebuah metode yang membagi data ke dalam grup-grup yang mempunyai obyek yang karakteristiknya sama. Garcia-Molina et al. menyatakan clustering adalah mengelompokkan item data ke dalam sejumlah kecil grup sedemikian sehingga masing-masing grup mempunyai sesuatu persamaan yang esensial.
Clustering adalah metode data mining yang unsupervised yang berarti tidak ada satu atributpun yang digunakan untuk memandu proses pembelajarannya sehingga seluruh atribut input diperlakukan sama
2.2.1. Kategori Clustering
Clustering [1] dapat dibagi kedalam dua kelompok, yaitu hierarchical dan
partitional clustering. Partitional Clustering disebutkan sebagai pembagian obyek-obyek data ke dalam kelompok yang tidak saling overlap sehingga setiap data berada tepat di satu cluster. Hierarchical clustering adalah sekelompok
1. Partitioning algorithms: algoritma dalam kelompok ini membentuk bermacam partisi dan kemudian mengevaluasinya dengan berdasarkan beberapa kriteria.
2. Hierarchy algorithms: pembentukan dekomposisi hirarki dari sekumpulan data menggunakan beberapa kriteria.
3. Density-based: pembentukan cluster berdasarkan pada koneksi dan fungsi densitas.
4. Grid-based: pembentukan cluster berdasarkan pada struktur multiple-level granularity
5. Model-based: sebuah model dianggap sebagai hipotesa untuk masing-masing
cluster dan model yang baik dipilih diantara model hipotesa tersebut.
2.3. Algoritma K-Means
K-means [1] merupakan salah satu metode clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster. Metode ini mempartisi data ke dalam cluster sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karateristik yang berbeda di kelompokan ke dalam cluster yang lain. Secara umum algoritma dasar dari K-Means adalah sebagai berikut :
1. Tentukan jumlah cluster
2. Alokasikan data ke dalam cluster secara random
3. Hitung centroid/rata-rata dari data yang ada di masing-masing cluster
4. Alokasikan masing-masing data ke centroid/rata-rata terdekat
5. Kembali ke Step 3, apabila masih ada data yang berpindah cluster atau apabila perubahan nilai centroid ada yang di atas nilai threshold yang ditentukan.
Distance space digunakan untuk menghitung jarak antara data dan
... (2.1)
dimana,
dij= jarak euclidean antara data dan centroid
xik = data
xjk = centroid/titik pusat cluster
p = dimensi data k = jumlah centroid
2.4. Algoritma Genetika
Algoritma Genetika [4] adalah algoritma pencarian heuristik yang didasarkan atas mekanisme evolusi biologis. Keberagaman pada evolusi biologis adalah variasi dari kromosom antar individu organisme. Variasi kromosom ini akan mempengaruhi laju reproduksi dan tingkat kemampuan organisme untuk tetap hidup. pada dasarnya ada 4 kondisi yang sangat mempengaruhi proses evaluasi yaitu :
1. kemampuan organisme untuk melakukan reproduksi
2. keberadaan populasi organisme yang bisa melakukan reproduksi 3. keberagaman organisme dalam suatu populasi
4. perbedaan kemampuan untuk survive
Individu yang lebih kuat (fit) akan memiliki tingkat survival dan tingkat reproduksi yang lebih tinggi jika dibandingkan dengan individu yang kurang fit. Pada kurun waktu tertentu (sering dikenal dengan istilah generasi), populasi secara keseluruhan akan lebih banyak memuat organisme yang fit.
2.4.1. Stuktur Umum Algoritma Genetik
Pada algoritma ini [4] teknik pencarian dilakukan sekaligus atas sejumlah solusi yang mungkin yang dikenal dengan populasi. Individu yang terdapat dalam satu populasi disebut istilah kromosom. Kromosom ini merupakan suatu solusi yang masih berbentuk simbol. Populasi awal dibangun secara acak, sedangkan populasi berikutnya merupakan hasil evolusi kromosom-kromosom melalui iterasi yang disebut dengan istilah generasi. Pada setiap generasi, kromosom akan melalui proses evaluasi dengan menggunakan alat ukur yang disebut dengan fungsi fitness.
Nilai fitness dari suatu kromosom akan menunjukkan kualitas kromosom dalam populasi tersebut. Generasi berikut dikenal dengan istilah anak (offspring) terbentuk dari gabungan 2 kromosom generasi sekarang yang bertindak sebagai induk (parent) dengan menggunakan operator penyilangan (crossover). Selain operator penyilangan, suatu kromosom juga dapat dimodifikasi dengan menggunakan operator mutasi.
Populasi generasi yang baru dibentuk dengan cara menyeleksi nilai fitness
dari kromosom induk (parent) dan nilai fitness dari kromosom anak (offspring), serta menolak kromosom-kromosom yang lainnya sehingga ukuran populasi (jumlah kromosom dalam suatu populasi) konstan. Setelah melalui beberapa generasi, maka algoritma ini akan konvergen ke kromosom terbaik.
2.4.2. Algoritma Genetika Komponen-komponen Utama
Ada 6 komponen utama dalam algoritma genetika [4], yaitu : 1. Teknik Penyandian
2. Prosedur Inisialisasi
Ukuran populasi tergantung pada masalah yang akan dipecahkan dan jenis operator genetika yang akan diimplementasikan. Setelah ukuran populasi ditentukan, kemudian harus inisialisai terhadap kromosom yang terdapat pada populasi tersebut. Inisialisasi kromosom dilakukan secara acak, namun demikian harus tetap memperhatikan domain solusi dan kendala permasalahan yang ada.
3. Fungsi Evaluasi
Ada 2 hal yang harus dilakukan dalam melakukan evaluasi kromosom, yaitu: evaluasi fungsi objektive (fungsi tujuan) dan konversi fungsi objektive kedalam fungsi fitness. Secara umum, fungsi fitness diturunkan dari fungsi objektive dengan nilai tidak negatif. Apabila ternyata fungsi objektive memiliki nilai negatif, maka perlu ditambahkan suatu konstanta C agar nilai fitness yang terbentuk menjadi tidak negatif.
4. Seleksi
Seleksi ini bertujuan untuk memberikan kesempatan reproduksi yang lebih besar bagi anggota populasi yang paling fit.
5. Operator Genetika
Ada 2 operator genetika, yaitu:
a. Operator untuk melakukan rekombinasi, yang terdiri dari: rekombinasi bernilai biner (crossover).
b. Mutasi. mutasi bernilai biner
6. Penentuan parameter
Yang disebut parameter disini adalah parameter kontrol algoritma genetika, yaitu: ukuran populasi (popsize), peluang crossover (Pc), dan peluang
a) Untuk permasalahan yang memiliki solusi cukup besar, De Jong merekomendasikan untuk nilai parameter kontrol:
(popsize; Pc; Pm) = (50; 0,6; 0,001)
b) Bila rata-rata fitness setiap generasi digunakan sebagai indikator, maka Grefenstette merekomendasikan:
(popsize; Pc; Pm) = (30; 0,95; 0,01)
c) Bila fitness dari individu terbaik dipantau pada setiap generasi, maka usulannya adalah:
(popsize; Pc; Pm) = (80; 0,45; 0,01)
Ukuran populasi sebaiknya tidak lebih kecil dari 30, untuk sembarang jenis permasalahan.
2.4.3. Istilah-istilah dalam algoritma genetik
Algoritma genetik [4] merupakan algoritma pencarian yang bekerja berdasarkan mekanisme seleksi alam dan genetika. Pada genetika, kromosom terdiri dari gen-gen. Tiap gen mempunyai sifat tertentu (allele), dan posisi tertentu (locus). Satu atau lebih kromosom bergabung membentuk paket genetik yang disebut genotif. Interaksi genotif dengan lingkungannya disebut fenotif. Pada algoritma genetik, kromosom berpadanan dengan string dan gen dengan karakter. Setiap karakter mempunyai posisi (locus) dan arti tertentu (allele). Satu atau lebih string bergabung membentuk struktur (genotif), dan apabila struktur tersebut
di-decode-kan akan diperoleh salah satu alternative solusi (fenotif). Tabel 2.1 Tabel susunan gen ilmu genetik
Ilmu genetik Algoritma genetik
Kromosom String
Gen Karakter
Allele Nilai karakter
Locus Posisi dalam individu
Genotif Struktur
2.4.4. Operator Genetik
Operator genetik [4] digunakan untuk mengkombinasikan (modifikasi) individu dalam aliran populasi untuk menghasilkan individu pada generasi berikutnya. Ada tiga operator genetik yaitu , crossover dan mutasi.
2.4.5. Crossover
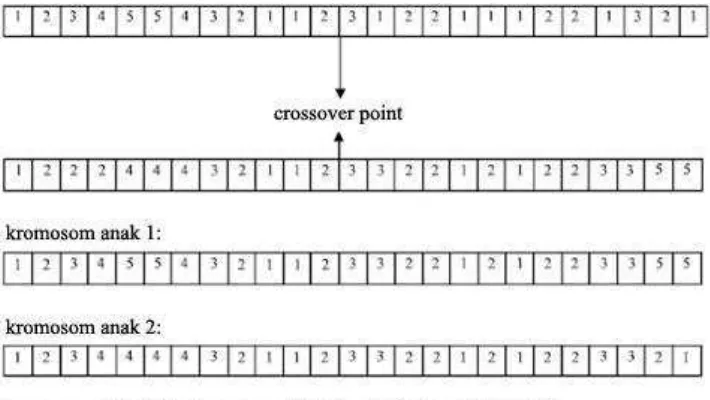
Pada crossover [4] akan dipilih secara acak dua individu dan tempat pertukaran, dimana kromosom yang ditandai diantara kedua tempat pertukaran akan bertukar tempat satu sama lain. Proses crossover akan membangkitkan offspring baru dengan mengganti sebagian informasi dari parents (orang tua atau induk).
Tujuan dari proses crossover adalah untuk menambahkan keanekaragaman individu dalam populasi dengan mengawinkan individu-individu pada populasi sehingga menghasilkan keturunan berupa individu-individu baru untuk ditempatkan pada populasi selanjutnya. Ada beberapa tipe crossover, antara lain : 1. One-cut-point-crossover
Pada tipe ini, akan dibuat satu titik crossover dimana individu yang dihasilkan akan diambil dari bilangan biner parent pertama dari awal sampai titik
crossover dan sisanya dari parent kedua seperti pada gambar 2.3. Algoritmanya adalah :
a. Memilih site secara random dari parent pertama
b. Isi disebelah kanan site pada parent pertama ditukar dengan parent kedua untuk menghasilkan offspring.
Contoh : Parent 1 Parent 2
Offspring 1 Offspring 2
Gambar 2.3. Contoh single pointcrossover [7]
0 1 1 0 1 0 1 1
1 1 0 0 0 1 1 1
0 1 1 0 0 1 1 1
2. Order-based crossover
Pada tipe ini, offspring yang dihasilkan hanya satu hasil dari kombinasi kedua parent yang dapat dilihat pada gambar 2.4.
Contoh :
Parent 1 Offspring Parent 2
Gambar 2.4. Contoh Order Based Crossover [7]
2.4.6. Mutasi
Mutasi [4] menciptakan individu baru dengan melakukan modifikasi satu atau lebih gen dalam individu yang sama. Mutasi berfungsi untuk menggantikan gen yang hilang dari populasi selama proses seleksi serta menyediakan gen yang tidak ada dalam populasi awal. Sehingga mutasi akan meningkatkan variasi populasi. Shif mutation diperlihatkan pada gambar 2.5 dan dilakukan dengan cara :
1. Menentukan dua site secara random
2. Site pertama ditempatkan ke site kedua, untuk selanjutnya digeser ke kiri seperti terlihat pada gambar berikut.
Parent 1 2 3 4 5 6 7 8 Offspring 1 2 7 4 5 6 3 8
Gambar 2.5. Contoh Shift Mutation [7]
2.4.7. Parameter Genetik
Parameter-parameter genetik [4] berguna dalam pengendalian operator-operator genetik. Pemilihan penggunaan nilai-nilai parameter genetik sangat berpengaruh terhadap kinerja algoritma genetik dalam menyelesaikan suatu masalah. Parameter-parameter genetik yang digunakan antara lain :
1 2 3 4 5 6 7 8
2 4 5 3 1 6 7 8
1. Ukuran populasi
Ukuran popolasi mempengaruhi ukuran efektivitas dan kinerja algoritma genetik. Tidak ada aturan yang pasti tentang berapa nilai ukuran populasi. Apabila ukuran populasi kecil berarti hanya tersedia sedikit pilihan untuk crossover dan sebagian kecil dari domain solusi saja yang dieksplorasi untuk setiap generasinya. Sedangkan apabila terlalu besar, kinerja algoritma genetik akan menurun. Penelitian menunjukan ukuran populasi besar tidak mempercepat pencarian solusi. Disarankan ukuran populasi berkisar antara 20 – 30.
2. Jumlah generasi
Jumlah generasi berpengaruh terhadap banyaknya iterasi yang akan dikerjakan dan domain solusi yang akan dieksplorasi untuk setiap generasinya. Semakin besar jumlah generasi berarti semakin banyak iterasi yang dilakukan, dan semakin besar solusi yang dieksplorasi. Sedangkan semakin kecil jumlah generasinya, maka akan semakin kecil iterasi yang akan dilakukan, dan semakin kecil pula solusi yang dieksplorasi untuk tiap generasinya.
3. Probabilitas crossover (Pc)
Probabilitas crossover akan mengendalikan operator crossover dalam setiap generasi dalam populasi yang mengalami crossover. Semakin besar nilai probabilitas crossover, akan semakin cepat struktur individu baru terbentuk ke dalam populasi. Sedangkan apabila nilai probabilitas crossover terlalu besar, individu yang merupakan kandidat solusi terbaik mungkin akan dapat hilang lebih cepat pada generasi selanjutnya. Disarankan nilai probabilitas crossover berkisar antara 80 % - 95 %.
4. Probabilitas mutasi (Pm )
Probabilitas mutasi akan mengendalikan operator mutasi pada setiap generasi. Peluang mutasi yang digunakan biasanya lebih kecil daripada peluang
peluang mutasi dibuat lebih kecil untuk setiap generasi. Disarankan nilai probabilitas mutasi kecil berkisar antara 0.5 % - 1 %.
2.5. FastGenetic K-Means Algorithm
Fast Genetic K-Means Algorithm (FGKA) [3] merupakan pengembangan dari Genetic K-means Algorithms (GKA) yang diusulkan oleh Yi Lu pada tahun 2004. Algoritma ini selalu mampu menghasilkan konvergensi pada global optimal. FGKA mampu menghindari lokal optimal akan tetapi FGKA berjalan 20 kali lebih cepat dibandingkan GKA.
Algoritma GKA sangat baik dalam menemukan optimasi global akan tetapi membutuh waktu yang cukup besar dalam mencapai kondisi konvergensi akibat adanya operator genetika crossover. Crossover sangat mahal secara biaya komputasi untuk mendapatkan kromosom yang valid (kromosom dengan cluster
tidak kosong) dan bahkan terkadang dapat menghasilkan kromosom yang tidak valid seperti yang diperlihatkan pada gambar 2.6. Kromosom 1 sebagai hasil
crossover adalah contoh yang valid karena memiliki setiap cluster pada alel-alel nya tetapi kromosom 2 adalah contoh yang tidak valid karena cluster 5 tidak memiliki anggota pada kromosom tersebut.
FGKA memproses satu populasi yang merupakan kumpulan Z solusi, dimana Z adalah sebuah parameter yang dimasukkan oleh pengguna. Masing-masing solusi dinamakan kromosom, yang dikodekan dengan string a1 a2,... aN dengan panjang N, dimana ai dinamakan gen yang berisi nilai {1,2,...,K} yang merepresentasikan nomor dari cluster yang merupakan memiliki gen tersebut. Sebagai contoh a1 a2 a3 a4 a5 = “33212” mengkodekan 5 data dimana data X1 dan X2 milik cluster 3 dan X3 dan X5 milik cluster 2 dan X4 milik cluster 1.
String yang tidak legal merepresentasikan sebuah solusi di mana terdapat
cluster yang tidak mempunyai anggota. Sebagai contoh, jika jumlah K = 3, string a1 a2 a3 a4 a5 = “23232” tidak legal karena cluster 1 tidak mempunyai anggota. Untuk sebuah kemungkinan solusi Sz= a1 a2 ... aN , maka e(Sz), dinamakan legality ratio adalah angka yang menunjukkan jumlah cluster yang tidak punya anggota dalam Sz dibagi dengan K. Sehingga kita dapat mengatakan Sz adalah legal jika e(Sz) = 1, selainnya adalah tidak legal.
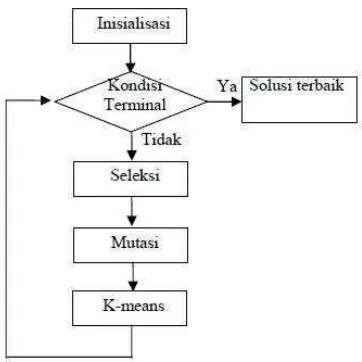
Gambar 2.7. Alir Algoritma FGKA
2.5.1. Inisialisasi
Tahap inisialisasi [3] adalah membangkitkan populasi awal P0 yang berisi Z solusi, dimana Z adalah parameter yang ditentukan oleh pengguna. Masing-masing gen dalam kromosom menunjukkan nomor cluster yang dipilih secara random dengan distribusi uniform dalam jangkauan {1, ..., K}. Dari inisialisasi awal ini dimungkinkan didapatkannya string yang tidak legal. Untuk populasi awal string yang tidak legal dihindari, artinya dalam populasi awal harus didapatkan string yang legal. Apabila string yang tidak legal dapat dimasukkan dalam FGKA, maka sebagian besar solusi yang tidak legal dengan memberikan nilai TWCV yang tinggi dan nilai fitness yang rendah sehingga sebuah solusi yang tidak legal akan mempunyai probabilitas yang rendah untuk bertahan. Kompleksitas dari proses inisialisasi awal ini adalah O(Z).
2.5.2. Nilai Fitness
Permasalahan clustering [3] terdiri dari N gen yang merepresentasikan N data(obyek). Tujuan dari algoritma FGKA adalah membagi N data ke dalam K
cluster, dimana cluster yang baik adalah cluster yang memiliki anggota dengan jarak total yang kecil terhadap masing-masing centroidcluster. Itu berarti cluster
Variation (TWCV) yang rendah dan disebut sebagai masalah minimasi. Untuk mengkonversi masalah minimasi menjadi masalah maksimasi perlu dilakukan
inverse terhadap TWCV dalam mencari nilai fitness suatu cluster dengan rumusan:
... (2.2)
Dimana CON adalah konstanta yang bernilai 1. Konstanta ini disertakan ke dalam persamaan untuk menangani kasus ketika nilai dari TWCV adalah nol. Jika TWCV bernilai nol dan tidak adanya konstanta CON maka nilai fitness akan menjadi ∞ (tidak terhingga).
2.5.3. Seleksi
Seleksi [3] dilakukan dengan maksud untuk menemukan pusat cluster
global dengan mereduksi nilai dari TWCV setiap kromosom. Pada seleksi dilakukan operator elitism yang merupakan operator yang membiarkan kromosom dengan nilai fitness terbaik selalu dipertahankan.
Kromosom dengan nilai fitness terbaik sebagai hasil seleksi oleh operator elitism akan dibandingkan dengan nilai fitness kromosom-kromosom generasi berikutnya yang telah mengalami mutasi. Kromosom hasil pengkopian ini akan diurutkan ke dalam serangkaian kromosom pada generasi berikutnya sehingga kromosom dengan nilai fitness terburuk pada generasi berikutnya tidak akan bertahan. Dengan operator elitism ini maka populasi di dalam generasi terbaru akan memiliki serangkaian solusi Z kromosom yang merupakan kandidat-kandidat kromosom dengan nilai fitness terbaik.
2.5.4. Mutasi
dilakukan mutasi pada setiap kromosom Z selain kromosom terbaik pada setiap generasi tertentu sesuai dengan frekuensi mutasi yang ditetapkan. Untuk melakukan mutasi perlu dilakukannya pemeriksaan probabilitas dari suatu data Xij pada kromosom Zi yang didapatkan secara random.
... (2.3)
Dimana tot_min merupakan jarak terkecil antara alel yang berada dalam cluster
data Xij dan pusat cluster data Xij.
Jika Pm adalah 1 maka nilai dari alel terpilih akan dipetakan terhadap pusat cluster yang secara acak dipilih. Kemudian jika Pm adalah 0 maka kromosom tersebut tidak perlu dilakukan mutasi.
Mutasi ini didefinisikan sebagai berikut:
1. Xij dipilih secara random, hal ini bertujuan untuk mencapai optimal pada wilayah global.
2. Probabilitas dari Xij akan besar ketika jarak antara alel tersebut dengan pusat cluster adalah besar. Ini dimaksudkan agar pusat cluster baru yang terbentuk akibat mutasi tidak berjarak terlalu berdekatan atau bahkan merupakan nilai dari pusat cluster yang sudah eksis.
2.6. Operator Sobel
Operator Sobel [8] merupakan sebuah teknik deteksi tepi yang sederhana dan memiliki tingkat komputasi yang cepat dan akurat. Pada umumnya operator ini digunakan untuk citra grayscale. Operator Sobel dapat digambarkan dengan dua buah matriks berukuran 3 x 3 seperti pada gambar 2.8.
Matriks operator sobel dapat merespon tepian maksimal hingga 45º. Kedua matriks tersebut dapat diterapkan pada citra secara terpisah, baik untuk mendapatkan tepian horizontal maupun tepian vertikal. Kedua matriks ini juga dapat dikombinasikan untuk mendapatkan hasil gradient gabungan dengan menggunakan persamaan :
... (2.4)
atau dengan persamaan
... (2.5)
2.7. Konsep Dasar Analisis Sistem
Adapun konser dasar analisis sistem adalah sebagai berikut:
2.7.1. OOP (Object Oriented Programming)
OOP (Object Oriented Programming) atau yang dikenal dengan Pemrograman Berorientasi Objek merupakan paradigma pemrograman yang berorientasikan kepada objek. Semua data dan fungsi di dalam paradigma ini dibungkus ke dalam kelas-kelas atau objek-objek. Model data berorientasi objek dikatakan dapat memberi fleksibilitas yang lebih, kemudahan mengubah program, dan digunakan luas dalam teknik piranti lunak skala besar. Lebih jauh lagi, pendukung OOP mengklaim bahwa OOP lebih mudah dipelajari bagi pemula dibanding dengan pendekatan sebelumnya, dan pendekatan OOP lebih mudah dikembangkan dan dirawat.
untuk mengambilnya. Pada kasus tersebut seorang manager tidak harus mengetahui bagaimana cara mengambil data tersebut tetapi manager bisa mendapatkan data tersebut melalui objek petugas administrasi. Jadi untuk menyelesaikan suatu masalah dengan kolaborasi antar objek-objek yang ada karena setiap objek memiliki deskripsi tugasnya sendiri. Pemrograman orientasi-objek menekankan konsep berikut:
2.7.2. Kelas (Class)
Kelas [6] merupakan kumpulan atas definisi data dan fungsi-fungsi dalam suatu unit untuk suatu tujuan tertentu. Sebagai contoh 'Class of dog' adalah suatu unit yang terdiri atas definisi-definisi data dan fungsi-fungsi yang menunjuk pada berbagai macam perilaku/turunan dari anjing. Sebuah Class adalah dasar dari modularitas dan struktur dalam pemrograman berorientasi objek. Sebuah Class
secara tipikal sebaiknya dapat dikenali oleh seorang non-programmer sekalipun terkait dengan domain permasalahan yang ada, dan kode yang terdapat dalam sebuah Class sebaiknya (relatif) bersifat mandiri dan independen (sebagaimana kode tersebut digunakan jika tidak menggunakan OOP). Dengan modularitas, struktur dari sebuah program akan terkait dengan aspek-aspek dalam masalah yang akan diselesaikan melalui program tersebut. Cara seperti ini akan menyederhanakan pemetaan dari masalah ke sebuah program ataupun sebaliknya.
2.7.3. Objek (Object)
Objek [6] membungkus data dan fungsi bersama menjadi suatu unit dalam sebuah program komputer. Objek merupakan dasar dari modularitas dan struktur dalam sebuah program komputer berorientasi objek.
2.7.4. Abstraksi (Abstract)
berkomunikasi dengan objek lainnya dalam sistem, tanpa mengungkapkan bagaimana kelebihan ini diterapkan. Proses, fungsi atau metode dapat juga dibuat abstrak, dan beberapa teknik digunakan untuk mengembangkan sebuah pengabstrakan.
2.7.5. Enkapsulasi (Encapsulation)
Enkapsulasi [6] memastikan pengguna sebuah objek tidak dapat mengganti keadaan dalam dari sebuah objek dengan cara yang tidak layak. Hanya metode dalam objek tersebut yang diberi ijin untuk mengakses keadaannya. Setiap objek mengakses interface yang menyebutkan bagaimana objek lainnya dapat berinteraksi dengannya. Objek lainnya tidak akan mengetahui dan tergantung kepada representasi dalam objek tersebut.
2.7.6. Polimorfisme (Polymorphism)
Polimorfisme [6] tidak bergantung kepada pemanggilan subrutin, bahasa orientasi objek dapat mengirim pesan. Metode tertentu yang berhubungan dengan sebuah pengiriman pesan tergantung kepada objek tertentu di mana pesa tersebut dikirim. Contohnya, bila sebuah burung menerima pesan "gerak cepat", dia akan menggerakan sayapnya dan terbang. Bila seekor singa menerima pesan yang sama, dia akan menggerakkan kakinya dan berlari. Keduanya menjawab sebuah pesan yang sama, namun yang sesuai dengan kemampuan hewan tersebut. Ini disebut polimorfisme karena sebuah variabel tunggal dalam program dapat memegang berbagai jenis objek yang berbeda selagi program berjalan, dan teks program yang sama dapat memanggil beberapa metode yang berbeda di saat yang berbeda dalam pemanggilan yang sama. Hal ini berlawanan dengan bahasa fungsional yang mencapai polimorfisme melalui penggunaan fungsi kelas-pertama.
2.7.7. Inheritans (Inheritance)
yang sudah ada objek-objek ini dapat membagi (dan memperluas) perilaku mereka tanpa harus mengimplementasi ulang perilaku tersebut (bahasa berbasis-objek tidak selalu memiliki inheritas).
2.7.8. UML (Unified Modelling Language)
UML (Unified Modeling Language) [6] adalah bahasa spesifikasi standar untuk mendokumentasikan, menspesifikasikan, dan membangun sistem. Unified Modeling Language (UML) adalah himpunan struktur dan teknik untuk pemodelan desain program berorientasi objek (OOP) serta aplikasinya. UML adalah metodologi untuk mengembangkan sistem OOP dan sekelompok perangkat
tool untuk mendukung pengembangan sistem tersebut. UML mulai diperkenalkan oleh Object Management Group, sebuah organisasi yang telah mengembangkan model, teknologi, dan standar OOP sejak tahun 1980-an. Sekarang UML sudah mulai banyak digunakan oleh para praktisi OOP.
UML merupakan dasar bagi perangkat (tool) desain berorientasi objek dari IBM. UML adalah suatu bahasa yang digunakan untuk menentukan, memvisualisasikan, membangun, dan mendokumentasikan suatu sistem informasi. 25 UML dikembangkan sebagai suatu alat untuk analisis dan desain berorientasi objek oleh Grady Booch, Jim Rumbaugh, dan Ivar Jacobson. Namun demikian UML dapat digunakan untuk memahami dan mendokumentasikan setiap sistem informasi. Penggunaan UML dalam industri terus meningkat. Ini merupakan standar terbuka yang menjadikannya sebagai bahasa pemodelan yang umum dalam industri peranti lunak dan pengembangan system. UML menyediakan 10 macam diagram untuk memodelkan aplikasi berorientasi objek, yaitu:
2.7.9. Use Case Diagram
berada di luar sistem. Diagram ini menunjukkan fungsionalitas suatu sistem atau kelas dan bagaimana sistem tersebut berinteraksi dengan dunia luar.
Use-case diagram dapat digunakan selama proses analisis untuk menangkap requirement sistem dan untuk memahami bagaimana sistem seharusnya bekerja. Selama tahap desain, use case diagram berperan untuk menetapkan perilaku (behavior) sistem saat diimplementasikan. Dalam sebuah model mungkin terdapat satu atau beberapa use-case diagram. Kebutuhan atau
requirements system adalah fungsionalitas apa yang harus disediakan oleh sistem kemudian didokumentasikan pada model use-case yang menggambarkan fungsi sistem yang diharapkan (use case), dan yang mengelilinginya (aktor), serta hubungan antara aktor dengan use case (use case diagram) itu sendiri.
2.7.10.Conceptual Diagram
Sebuah diagram konseptual [6] merupakan representasi visual dari cara di mana konsep-konsep abstrak terkait. Hal ini digunakan sebagai bantuan dalam memvisualisasikan proses atau sistem tingkat tinggi melalui serangkaian garis yang unik dan bagan. Diagram konseptual secara luas digunakan dalam segala bidang seperti bisnis, ilmu pengetahuan, dan manufaktur.
2.7.11.Sequence Diagram
Sequence Diagram [6] menggambarkan interaksi antar objek di dalam dan di sekitar sistem (termasuk pengguna, display, dan sebagainya) berupa message yang digambarkan terhadap waktu. Sequence Diagram terdiri atar dimensi vertikal (waktu) dan dimensi horizontal (objek-objek yang terkait).
2.7.12.Collaboration Diagram
Collaboration diagram [6] yaitu diagram yang mengelompokkan pesan pada kumpulan diagram sekuen menjadi sebuah diagram. Dalam diagram tersebut terdapat method yang dijalankan antara objek yang satu dan objek lainnya. Di diagram kolaborasi ini, objek harus melakukan sinkronisasi pesan dengan serangkaian pesan-pesan lainnya. Collaboration Diagram lebih menekankan kepada peran setiap objek dan bukan pada waktu penyampaian pesan.
2.7.13.State Diagram
State Diagram [6] adalah diagram untuk menggambarkan behavior, yaitu perubahan state di suatu Class berdasarkan event dan pesan yang dikirimkan dan diterima oleh Class tersebut. Setiap diagram state hanya boleh memiliki satu start state (initial state) dan boleh memiliki satu atau lebih dari satu stop states (final state).
2.7.14.Activity Diagram
Activity Diagram [6] memiliki pengertian yaitu lebih fokus kepada menggambarkan proses bisnis dan urutan aktivitas dalam sebuah proses. Dipakai pada business modeling untuk memperlihatkan urutan aktifitas proses bisnis. Memiliki struktur diagram yang mirip flowchart atau data flow diagram pada perancangan terstruktur. Memiliki pula manfaat yaitu apabila kita membuat diagram ini terlebih dahulu dalam memodelkan sebuah proses untuk membantu memahami proses secara keseluruhan. Dan activity dibuat berdasarkan sebuah atau beberapa use case pada use case diagram.
2.7.15.Class Diagram
Class diagram [6] adalah sebuah Class yang menggambarkan struktur dan penjelasan Class, paket, dan objek serta hubungan satu sama lain seperti
2.7.16.Object Diagram
Objek diagram [6] adalah diagram yang memberikan gambaran struktur model sebuah sistem, dalam kurun waktu tertentu. Diagram objek yang berasal dari diagram kelas sehingga diagram objek tergantung pada diagram kelas. Objek Diagram, kadang-kadang disebut sebagai diagram instance sangat mirip dengan diagram kelas. Seperti diagram kelas object diagram juga menunjukkan hubungan antara obyek, tetapi object diagram menggunakan contoh-contoh dunia nyata.
Object diagram digunakan untuk menunjukkan bagaimana sistem akan terlihat seperti pada waktu tertentu. Karena ada data yang tersedia di objek-objek diagram sering digunakan untuk menjelaskan hubungan yang kompleks antara objek.
2.7.17.Component Diagram
Component diagram [6] adalah diagram UML yang menampilkan komponen dalam system dan hubungan antara mereka. Pada component View, akan difokuskan pada organisasi fisik system. Pertama, diputuskan bagaimana kelas-kelas akan diorganisasikan menjadi kode pustaka. Kemudian akan dilihat bagaimana perbedaan antara berkas eksekusi, berkas dynamic link library (DDL), dan berkas runtime lainnya dalam system.
2.7.18.Deployment Diagram
Deployment Diagram [6] adalah diagram yang menggambarkan detail bagaimana komponen disebar kedalam infrastruktur sistem, dimana komponen akan terletak (pada mesin, node, server atau piranti keras apa), bagaimana
kemampuan jaringan pada lokasi tersebut, spesifikasi server, dan hal-hal lain yang bersifat fisikal.
2.8. IDE yang Digunakan
Sebuah IDE, atau secara bebas dapat diterjemahkan sebagai Lingkungan Pengembangan Terpadu, setidaknya memiliki fasilitas:
a. Editor, yaitu fasilitas untuk menuliskan kode sumber dari perangkat lunak. b. Compiler, yaitu fasilitas untuk mengecek sintaks dari kode sumber kemudian
mengubah dalam bentuk binari yang sesuai dengan bahasa mesin.
c. Linker, yaitu fasilitas untuk menyatukan data binari yang beberapa kode sumber yang dihasilkan compiler sehingga data-data binari tersebut menjadi satu kesatuan dan menjadi suatu program komputer yang siap dieksekusi. d. Debuger, yaitu fasilitas untuk mengetes jalannya program, untuk mencari
bug/kesalahan yang terdapat dalam program.
Sampai tahap tertentu IDE modern dapat membantu memberikan saran yang mempercepat penulisan. Pada saat penulisan kode, IDE juga dapat menunjukan bagian-bagian yang jelas mengandung kesalahan atau keraguan.
2.8.1. Microsoft Visual Studio
Microsoft Visual Studio [7] merupakan sebuah perangkat lunak lengkap (suite) yang dapat digunakan untuk melakukan pengembangan aplikasi, baik itu aplikasi bisnis, aplikasi personal, ataupun komponen aplikasinya, dalam bentuk aplikasi console, aplikasi Windows, ataupun aplikasi Web. Visual Studio mencakup kompiler, SDK, Integrated Development Environment (IDE), dan dokumentasi (umumnya berupa MSDN Library). Kompiler yang dimasukkan ke dalam paket Visual Studio antara lain Visual C++, Visual C#, Visual Basic, Visual Basic .NET, Visual InterDev, Visual J++, Visual J#, Visual FoxPro, dan Visual SourceSafe.
Visual Studio kini telah menginjak versi Visual Studio 9.0.21022.08, atau dikenal dengan sebutan Microsoft Visual Studio 2008 yang diluncurkan pada 19 November 2007, yang ditujukan untuk platform Microsoft .NET Framework 3.5. Versi sebelumnya, Visual Studio 2005 ditujukan untuk platform .NET Framework
177
KESIMPULAN DAN SARAN
Pada bab ini akan dikemukakan kesimpulan yang diperoleh dari pembahasan bab-bab sebelumnya serta saran untuk perbaikan dan pengembangan sistem yang lebih lanjut.
5.1. Kesimpulan
Berdasarkan hasil analisis dan pengujian yang telah dilakukan terhadap algoritma FKGA dalam melakukan pengelompokkan warna pada sistem pendeteksian warna untuk membantu penderita buta warna maka dapat diambil kesimpulan bahwa semakin besar jumlah kromosom maka semakin besar pula kemungkinan FGKA dalam mencapai konvergensi pada global optima. Namun perlu adanya pertimbangan pada nilai rasio mutasi, semakin rendah nilai rasio mutasi maka semakin sulit FGKA dalam mencapai optimasi global. Iterasi K-Means menjadi penyebab mahalnya biaya komputasi FGKA dalam mencapai konvergensi. Dan untuk melakukan peningkatan performansi dan optimasi algoritma FGKA dalam melakukan pengelompokkan warna dibutuhkan kombinasi parameter inputan yang terbaik sesuai dengan hasil pengujian yaitu dengan jumlah kromosom sebanyak 6 kromosom, rasio mutasi bernilai 7 dan iterasi KMO dilakukan hingga 2 iterasi.
5.2. Saran
Untuk lebih meningkatkan kinerja dari sistem yang dibuat, maka diusulkan beberapa saran sebagai berikut :
1. Perlu adanya otomatisasi sistem dalam menentukan jumlah centroid
warna yang lebih efisien, dan untuk citra yang memiliki kompleksitas warna tinggi akan memiliki akurasi pendeteksian warna yang lebih optimal.
2. Perlu adanya usaha dalam meningkatkan efisiensi pengelompokkan warna oleh operator K-Means pada algoritma FGKA. Dengan usaha tersebut maka waktu pengelompokkan warna dalam setiap iterasi operator K-Means yang dilakukan oleh setiap kromosom pada suatu generasi FGKA dapat diminimalkan.
3. Untuk kasus pendeteksian warna secara real-time seperti pada sistem berbasis
Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033
Teknik Informatika – Universitas Komputer Indonesia Jl. Dipatiukur 112-114 Bandung
E-mail : [email protected]
ABSTRAK
K-Means merupakan salah satu algoritma
clustering dimana setiap bagian
pengelompokkannya diwakili oleh rata-rata dari anggota kelompoknya. K-Means mempunyai kelemahan pada inisialisasi titik pusat cluster yang bersifat random sehingga seringkali menyebabkan terjebaknya pada optimasi lokal sehingga hasil pengelompokannya tidak optimal. Pada kasus pengelompokkan warna sistem pendeteksian warna hal tersebut dapat berakibat pada kurang tepatnya hasil pendeteksian warna. Berdasarkan permasalahan tersebut maka diperlukan sebuah algoritma sebagai solusi yang dapat meningkatkan hasil clustering menuju optimasi global. Fast
Genetic K-Means Algorithm (FGKA) merupakan
sebuah algoritma clustering yang menggabungkan efisiensi algoritma K-Means dan kekuatan algoritma Genetika.
Dalam penelitian ini dilakukan sejumlah percobaan terhadap algoritma FGKA dengan melakukan kombinasi parameter inputan berupa jumlah kromosom, rasio mutasi, dan juga iterasi K-Means Operator (KMO). Kombinasi parameter FGKA yang optimal didapatkan pada penelitian ini sehingga dapat meningkatkan akurasi pendeteksian warna dengan waktu pengelompokkan warna yang paling efisien. mengelompokkan data akan tetapi K-Means tidak terlalu efektif jika dilihat secara output dari proses pengelompokkannya. Hal ini dikarenakan K-Means hanya mengelompokkan data yang mengarah pada lokal optimum saja sehingga pengelompokkan data yang dihasilkan oleh K-Means seringkali kurang akurat. Berdasarkan hasil studi literatur K-Means dapat dioptimalkan dengan algoritma genetika yang merupakan algoritma yang baik dalam mendekati
global optimum yang disebut dengan Fast Genetic K-Means Algorithm [3]. Dengan algoritma genetika hasil pengelompokkan dari K-Means akan menjadi lebih fit dan secara otomatis dapat meningkatkan akurasi pengelompokkan warna. Akan tetapi kekurangan dari algoritma FGKA adalah mahalnya biaya komputasi untuk mendekati kondisi konvergen.
Buta warna [2] merupakan salah satu kelainan atau penyakit pada indra penglihatan manusia yang menyebabkan ketidakmampuan penderitanya dalam mengenali setiap warna (buta warna total) ataupun warna tertentu saja (buta warna parsial). Pada kasus buta warna parsial, buta warna dapat dibagi menjadi beberapa golongan yaitu buta warna protanopia, buta warna deuteranopia, dan buta warna tritanopia dimana setiap golongan buta warna tersebut memiliki kekurangan dalam mengenali warna yang berbeda. Pada dunia medis sampai saat ini buta warna dikategorikan sebagai penyakit yang tidak dapat diobati karena buta warna merupakan penyakit yang disebabkan oleh faktor keturunan yaitu kekurangan satu atau lebih sel kerucut pada mata.
Pendeteksian warna merupakan suatu usaha dalam membantu penderita buta warna dalam mengenali warna dengan mengimplementasikan algoritma K-Means yang dapat dioptimalkan oleh algoritma genetika (FGKA) pada teknologi komputer. Aplikasi ini bekerja dengan cara melakukan pengelompokkan warna pada citra yang dipilih oleh pengguna penderita buta warna melalui sistem kemudian melakukan penandaan tepi oleh operator sobel.
1.1 Warna
Warna [5] merupakan elemen terpenting pada sebuah objek berupa citra dimana elemen warna sangat dipengaruhi oleh intensitas cahaya. Warna sendiri dapat dilihat oleh indera penglihatan manusia dikarenakan adanya pantulan cahaya pada suatu permukaan benda dan dipengaruhi oleh pigmen yang terdapat pada permukaan benda tersebut.
HSV, CIEXYZ, CIE LUV, CIE Lab, dan Munsell. Model warna dibedakan berdasarkan sistem koordinat maupun gamut warna.
1.2 Model Warna RGB
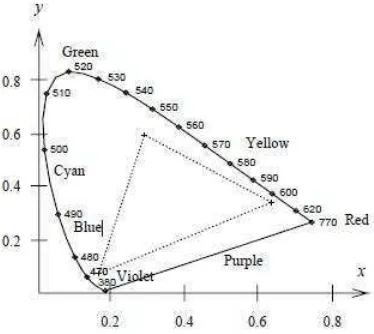
Model warna RGB [5] digunakan oleh kebanyakan monitor berwarna. Monitor berwarna dapat menghasilkan 16 juta warna berbeda berdasarkan perpaduan warna dari ketiga chanel warna RGB yaitu merah, hijau dan biru. Gamut dari monitor berwarna RGB seringkali digambarkan sebagai unit kubus sehingga warna monitor sepenuhnya dikombinasikan oleh warna merah jenuh, kuning, hijau, cyan, biru, dan magenta. Pada sudut-sudut kubus terdapat warna hitam dan putih dimana secara diagonal menjadi degradasi warna putih menuju keabu-abuan hingga menjadi hitam. Sesuai dengan kromatisitas triad, gamut monitor dapat digambarkan sebagai segitiga kromatisitas tapal kuda yang dapat dilihat pada gambar 1.
Gambar 1 Kromatisasi warna
1.3 Algoritma K-Means
K-means [1] merupakan salah satu metode
clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih
cluster. Metode ini mempartisi data ke dalam cluster
sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karateristik yang berbeda di kelompokan ke dalam cluster yang lain. Secara umum algoritma dasar dari K-Means adalah sebagai berikut :
1) Tentukan jumlah cluster
2) Alokasikan data ke dalam cluster secara random 3) Hitung centroid/rata-rata dari data yang ada di
masing-masing cluster
4) Alokasikan masing-masing data ke centroid /rata-rata terdekat
ditentukan.
1.4 Distance Space
Distance space digunakan untuk menghitung jarak antara data dan centroid. Adapun persamaan yang dapat digunakan salah satunya yaitu Euclidean Distance Space. Euclidean distance space sering digunakan dalam perhitungan jarak, hal ini dikarenakan hasil yang diperoleh merupakan jarak terpendek antara dua titik yang diperhitungkan. Adapun persamaannya adalah sebagai berikut :
(1)
1.5 Fast Genetic K-Means Algorithm (FGKA)
Fast Genetic K-Means Algorithm (FGKA) [3] merupakan pengembangan dari Genetic K-means Algorithms (GKA) yang diusulkan oleh Yi Lu pada tahun 2004. Algoritma ini selalu mampu menghasilkan konvergensi pada global optimal. FGKA mampu menghindari lokal optimal akan tetapi FGKA berjalan 20 kali lebih cepat dibandingkan GKA.
Algoritma GKA sangat baik dalam menemukan optimasi global akan tetapi membutuh waktu yang cukup besar dalam mencapai kondisi konvergensi akibat adanya operator genetika crossover.
Crossover sangat mahal secara biaya komputasi untuk mendapatkan kromosom yang valid (kromosom dengan cluster tidak kosong) dan bahkan terkadang dapat menghasilkan kromosom yang tidak valid seperti yang diperlihatkan pada gambar 2. Kromosom 1 sebagai hasil crossover
adalah contoh yang valid karena memiliki setiap
cluster pada kromosomnya tetapi kromosom 2
Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033
Gambar 2 Operator crossover pada GKA
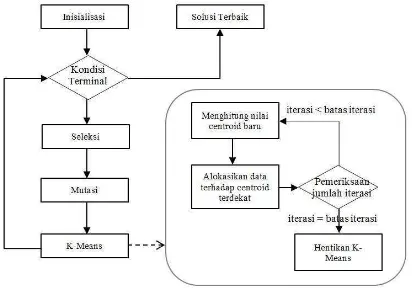
Pada Gambar 3 diilustrasikan diagram alir algoritma FGKA. Algoritma dimulai dari fase inisialisasi, dimana pada fase ini dibangkitkan populasi awal P0. Populasi dalam generasi berikutnya Pi+1 didapatkan menggunakan operator genetika dari populasi sebelumnya Pi. Evolusi akan berhenti jika kondisi akhir telah dicapai yaitu pada saat setiap kromosom memiliki angka fitness yang konvergen pada suatu generasi. Operator genetika yang digunakan dalam algoritma FGKA ini adalah : seleksi, mutasi dan operator K-means.
Gambar 3 Diagram alir FGKA
1.5.1 Inisialisasi
Tahap inisialisasi [3] adalah membangkitkan populasi awal P0 yang berisi Z solusi, dimana Z adalah parameter yang ditentukan oleh pengguna. Masing-masing gen dalam kromosom menunjukkan nomor cluster yang dipilih secara random dengan distribusi uniform dalam jangkauan {1, ..., K}. Dari inisialisasi awal ini dimungkinkan didapatkannya string yang tidak legal. Untuk populasi awal string yang tidak legal dihindari, artinya dalam populasi awal harus didapatkan string yang legal. Apabila string yang tidak legal dapat dimasukkan dalam FGKA, maka sebagian besar solusi yang tidak legal dengan memberikan nilai TWCV yang tinggi dan nilai fitness yang rendah sehingga sebuah solusi yang tidak legal akan mempunyai probabilitas yang rendah untuk bertahan. Kompleksitas dari proses inisialisasi awal ini adalah O(Z).
1.5.2 Nilai Fitness
Permasalahan clustering [3] terdiri dari N gen yang merepresentasikan N data(obyek). Tujuan dari algoritma FGKA adalah membagi N data ke dalam K cluster, dimana cluster yang baik adalah cluster
yang memiliki anggota dengan jarak total yang kecil terhadap masing-masing centroid cluster. Itu berarti
cluster yang memiliki nilai fitness yang tinggi akan memiliki nilai Total Within-Cluster Variation
(TWCV) yang rendah dan disebut sebagai masalah minimasi. Untuk mengkonversi masalah minimasi menjadi masalah maksimasi perlu dilakukan inverse
terhadap TWCV dalam mencari nilai fitness suatu cluster dengan rumusan:
(2) Dimana CON adalah konstanta yang bernilai 1. Konstanta ini disertakan ke dalam persamaan untuk menangani kasus ketika nilai dari TWCV adalah nol. Jika TWCV bernilai nol dan tidak adanya konstanta CON maka nilai fitness akan menjadi ∞ (tidak
terhingga).
1.5.3 Seleksi
Seleksi [3] dilakukan dengan maksud untuk menemukan pusat cluster global dengan mereduksi nilai dari TWCV setiap kromosom. Pada seleksi dilakukan operator elitism yang merupakan operator yang membiarkan kromosom dengan nilai fitness
terbaik selalu dipertahankan.
Kromosom dengan nilai fitness terbaik sebagai hasil seleksi oleh operator elitism akan dibandingkan dengan nilai fitness kromosom-kromosom generasi berikutnya yang telah mengalami mutasi. Kromosom hasil pengkopian ini akan diurutkan ke dalam serangkaian kromosom pada generasi berikutnya sehingga kromosom dengan nilai fitness
terburuk pada generasi berikutnya tidak akan bertahan. Dengan operator elitism ini maka populasi di dalam generasi terbaru akan memiliki serangkaian solusi Z kromosom yang merupakan kandidat-kandidat kromosom dengan nilai fitness terbaik.
1.5.4 Mutasi
Mutasi [3] digunakan untuk menghindari optimum lokal dan membuat pusat cluster untuk mendekati optimum global secara menyebar. Karena sifat inisialisasi yang acak, pusat cluster tidak akan tepat pada tahap awal sehingga dilakukan mutasi pada setiap kromosom Z selain kromosom terbaik pada setiap generasi tertentu sesuai dengan rasio mutasi yang ditetapkan. Untuk melakukan mutasi perlu dilakukannya pemeriksaan probabilitas dari suatu data Xij pada kromosom Zi yang didapatkan secara random.
Jika Pm adalah 1 maka nilai dari alel terpilih akan dipetakan terhadap pusat cluster yang secara acak dipilih. Kemudian jika Pm adalah 0 maka kromosom tersebut tidak perlu dilakukan mutasi.
Mutasi ini didefinisikan sebagai berikut:
1) Xij dipilih secara random, hal ini bertujuan untuk mencapai optimal pada wilayah global.
2) Probabilitas dari Xij akan besar ketika jarak antara alel tersebut dengan pusat cluster adalah besar. Ini dimaksudkan agar pusat cluster baru yang terbentuk akibat mutasi tidak berjarak terlalu berdekatan atau bahkan merupakan nilai dari pusat cluster yang sudah eksis.
1.6 Operator Sobel
Operator Sobel [6] merupakan sebuah teknik deteksi tepi yang sederhana dan memiliki tingkat komputasi yang cepat dan akurat. Pada umumnya operator ini digunakan untuk citra grayscale. Operator Sobel dapat digambarkan dengan dua buah matriks berukuran 3 x 3 seperti pada gambar 4.
Gambar 4 Matriks operator sobel
Matriks operator sobel dapat merespon tepian maksimal hingga 45º. Kedua matriks tersebut dapat diterapkan pada citra secara terpisah, baik untuk mendapatkan tepian horizontal maupun tepian vertikal. Kedua matriks ini juga dapat dikombinasikan untuk mendapatkan hasil gradient
gabungan dengan menggunakan persamaan: sistem pendeteksian warna yang bertujuan untuk membantu penderita buta warna untuk dapat memilah warna dari suatu objek citra yang didapatkan dengan melakukan capture foto melalui kamera perangkat komputer ataupun melakukan
browse terhadap citra yang telah eksis pada direktori hardisk komputer.
Citra inputan yang telah didapatkan oleh sistem komputer kemudian akan melalui tahap pre-proccessing dengan melakukan penskalaan citra menjadi ukuran 400 x 350 piksel. Tahap ini diharapkan dapat mereduksi beban proses sistem
kemudian sistem mengelompokkan warna citra sekaligus menurunkan dimensi warna citra menjadi sejumlah titik pusat cluster K yang didefinisikan oleh pengguna sistem. Setelah warna citra berhasil dikelompokkan ke dalam setiap titik pusat cluster, maka setiap nilai titik pusat cluster adalah warna-warna terdeteksi pada citra yang dapat dipilih oleh pengguna sistem untuk kemudian dilakukan pendeteksian tepi pada setiap anggota cluster
terpilih. Pendeteksian tepi dilakukan untuk memperjelas informasi warna yaitu batas-batas tepian objek berwarna yang dibutuhkan oleh pengguna sistem. Gambaran umum sistem pendeteksian warna dapat dilihat pada gambar 5.
Gambar 5 Gambaran umum sistem
2.2 Use Case Diagram
Use case diagram menggambarkan
fungsionalitas yang diharapkan dari sebuah sistem. Yang ditekankan adalah “apa” yang diperbuat oleh sistem, dan bukan “bagaimana”. Sebuah use case
![Gambar 1.1 Siklus Model Prototype [6]](https://thumb-ap.123doks.com/thumbv2/123dok/1295243.790897/17.595.200.418.119.270/gambar-siklus-model-prototype.webp)
![Gambar 2.1. Kromatisasi warna CIE [5]](https://thumb-ap.123doks.com/thumbv2/123dok/1295243.790897/20.595.192.436.475.695/gambar-kromatisasi-warna-cie.webp)
![Gambar 2.2. Model warna Munsell [7]](https://thumb-ap.123doks.com/thumbv2/123dok/1295243.790897/21.595.210.418.419.593/gambar-model-warna-munsell.webp)
![Gambar 2.3. Contoh single point crossover [7]](https://thumb-ap.123doks.com/thumbv2/123dok/1295243.790897/28.595.163.518.605.717/gambar-contoh-single-point-crossover.webp)
![Gambar 2.4. Contoh Order Based Crossover [7]](https://thumb-ap.123doks.com/thumbv2/123dok/1295243.790897/29.595.155.464.525.574/gambar-contoh-order-based-crossover.webp)