118
INISIALISASI PUSAT
CLUSTER
MENGGUNAKAN
ARTIFICIAL BEE
COLONY
PADA ALGORITMA
POSSIBILISTIC FUZZY C-MEANS
UNTUK SEGMENTASI CITRA
Amalia Nurani Basyarah, Chastine Fatichah2, Darlis Heru Murti3 Program Studi Teknik Informatika, Fakultas Teknologi Informasi,
Institut Teknologi Sepuluh Nopember
Email: [email protected], [email protected], [email protected]
ABSTRAK
PossibilisticFuzzy C-Means (PFCM) adalah algoritma clustering yang menggabungkan nilai keanggotaan Fuzzy C-Means (FCM) dan nilai kesesuaian Possibilistic C-Means (PCM) pada fungsi objektifnya. PFCM kemudian mengatur batasan pada nilai keanggotaan dan nilai kesesuaian sehingga dapat mengatasi masalah pada algoritma sebelumnya, yaitu sensitivitas pada noise dan coincidentcluster.Namun PFCM juga masih memiliki kelemahan, utamanya pada inisialisasi pusat clusterawal.Inisialisasi pusat cluster
yang kurang tepat akan mengakibatkan masalah local minima, sehingga hasil akhir cluster
tidak akan sesuai dengan karakteristik natural cluster yang ada. Untuk mengatasi masalah tersebut, beberapa penelitian mengenai inisialisasi pusat cluster menggunakan metode optimasi telah dilakukan.Salah satunya menggunakan Artificial Bee Colony (ABC).ABC adalah algoritma optimasi yang mengadopsi perilaku cerdas kawanan lebah. Kelebihan algoritma ABC dibandingkan dengan algoritma optimasi lainnya adalah penggunaan parameter kontrol yang lebih sedikit namun tetap memiliki hasil kinerja yang sama dan bahkan lebih baik dari algoritma lain. Oleh karena itu, pada penelitian ini diusulkan metode
clustering PFCM dengan inisialisasi pusat cluster menggunakan ABC untuk kasus segmentasi citra.Metode segmentasi citra yang diusulkan tersebut telah dievaluasi menggunakan SSIM (Structural Similarity Index) pada 30 citra dari 6 dataset yang berbeda.Berdasarkan hasil evaluasi diketahui ABC-PFCM memperoleh hasil yang lebih baik daripada PFCM.Hal ini ditandai dengan nilai rata-rata SSIM ABC-PFCM yang lebih tinggi daripada PFCM.Pada citra sintetis ABC-PFCM dan PFCM berturut-turut memperoleh rata-rata sebesar 0.9843 dan 0.9699. Selanjutnya, pada citra real, ABC-PFCM dan PFCM dengan berurutan memperoleh rata-rata SSIM 0.8113dan 0.7898.
Kata Kunci: artificial bee colony, clustering, optimasi, possibilistic fuzzy c-means, segmentasi.
ABSTRACT
PossibilisticFuzzyC-Means (PFCM) is one of clustering algorithm which combines membershipvalues of FuzzyC-Means andtypicality value of PossibilisticC-Means inits objective function. PFCM then arrange the limitation of membershipvalues and typicality value, so PFCM can overcome the deficiencies of previous algorithms, mainly in terms of sensitivity to noise and the coincident clusters. HoweverPFCMalsohas limitations, especially in theinitialization of cluster centers. Improperinitializationof cluster center will resultinlocalminimaproblems, thus the resultwouldnot beappropriateaccording to thenaturalcharacteristics ofthe existingcluster. To overcome this problem, someresearch oncluster centerinitializationusingoptimization methodshave been carried out. One of them is ArtificialBeeColony(ABC).ABC is one of optimization algorithm based on swarm intelligence which adopts the intelligent behavior of honey bee swarm. The
119 advantagesofABCalgorithmcomparedwithotheroptimizationalgorithmsisdespite its fewer
control parameter, ABC stillhavethe same
performanceandevenbetterresultsthanotheralgorithms. Therefore, this reserachproposedaclusteringmethodby takingadvantagesof PFCMwithoptimization of
clustercenterusingABCfor case studyof image segmentation.The proposed image segmentation methods have been evaluated using SSIM (Structural Similarity)Index on 30 images from 6 different datasets.The evaluation result shows that ABC-PFCM has better result, proventhat ABC-PFCM has higher SSIM values than PFCM. On synthetic images size, consecutively ABC-PFCM dan PFCM obtain a mean of 0.9843 and 0.9699. On real images ABC-PFCM can acquire a mean of 0.8113, whereas PFCM can only obtain 0.7898.
Keywords: artificial bee colony, clustering, optimization, possibilistic fuzzy c-means, segmentation.
1. Pendahuluan
Metode Possibilistic Fuzzy C-Means (PFCM) diusulkan oleh Pal dkk.(2005) [4], untuk memperbaiki kelemahan pada algoritma sebelumnya, yaitu Fuzzy Possibilistic C-Means
(FPCM). Pada FPCM, nilai keanggotaan
Fuzzy C-Means dan nilai kesesuaianPossibilistic C-Means
digabungkan dalam fungsi
objektifnya.Namun sayangnya FPCM masih memiliki kekurangan, yaitu pada nilai kesesuaian FPCM yang menjadi sangat kecil ketika dihadapkan pada
dataset yang besar.Untuk mengatasi masalah tersebut, PFCM menghilangkan batasan penjumlahan nilai kesesuaian (typicality value) pada FPCM dan tetap menggunakan batasan pada nilai keanggotaan (membership value). Penggabungan serta pengaturan batasan kedua nilai tersebut pada fungsi objektif
PossibilisticFuzzy C-Means (PFCM) membuat algoritma ini dapat mengatasi masalah dari algoritma Fuzzy C-Means
(FCM) dan PossibilisticC-Means (PCM), yaitu dalam hal sensitivitas pada noise
serta pencegahan terjadinya coincident cluster[2]. Namun PFCM juga masih memiliki kelemahan, utamanya pada inisialisasi pusat cluster awal[4].
Inisialisasi parameter dan pusat
cluster yang kurang tepat akan mengakibatkan masalah local minima, sehingga hasil akhir cluster tidak akan
tepat sesuai dengan karakteristik
naturalcluster yang ada. Untuk mengatasi masalah tersebut, beberapa penelitian telah menerapkan algoritma optimasi untuk mengatasi masalah inisialisasi parameter pada clustering. He dkk.[2] mengusulkan inisialisasi pusat clusterPossibilistic Fuzzy C-Means (PFCM) menggunakan Improved Particle Swarm Optimization (IPSO). Selain itu, Emary dkk.[1] juga melakukan penelitian mengenai optimasi pusat cluster
dari Possibilistic Fuzzy C-Means (PFCM) menggunakan metode Cuckoo Search. Dari kedua penelitian tersebut diperoleh hasil clustering yang lebih baik dibandingkan clustering tanpa optimasi pusat cluster.
Artificial Bee Colony (ABC) adalah algoritma optimasi berdasarkan
swarm intelligence yang diusulkan oleh Karaboga dan Basturk[3]. Penggunaan metode Artificial Bee Colony (ABC) untuk inisialisasi pusat cluster juga telah
dilakukan. Taherdangkoo
dkk.[6]mengusulkan segmentasi citra MR
otak menggunakan FCM dengan
inisialisasi pusat cluster menggunakan
120
algoritma optimasi lainnya adalah penggunaan parameter kontrol yang lebih sedikit dan tetap memiliki hasil kinerja yang sama dan bahkan lebih baik dari algoritma lain[3]. Oleh karena itu, pada penelitian ini akan diusulkan metode
clustering dengan mengambil kelebihan dari PossibilisticFuzzy C-Means(PFCM) dengan optimasiparameter pusat cluster
menggunakan Artificial Bee Colony
(ABC) untuk kasus segmentasi citra.
2. Tinjauan Pustaka
2.1 PossibilisticFuzzy C-Means (PFCM) PossibilisticFuzzy C-Means
(PFCM)[4]adalah algoritma
pengembangan dari Fuzzy Possibilistic C-Means [5] yang menggabungkan dasar-dasar dari Fuzzy C-Means dan
Possibilistic C-Means. Metode ini menganggap bahwa nilai keanggotaan (membership) yang diusulkan pada Fuzzy C-Means dan nilai kesesuaian (typicality) pada Possibilistic C-Means adalah dua hal yang penting untuk menghasilkan interpretasi data yang lebih baik.
Metode PossibilisticFuzzy C-Means (PFCM) melonggarkan batasan pada teorema nilai kesesuaian dan tetap menggunakan batasan penjumlahan pada teorema nilai keangggotaan[4]. Dengan penggabungan nilai keanggotaan dan nilai kesesuaian serta pengaturan batasan kedua nilai tersebut pada fungsi objektif
PossibilisticFuzzy C-Means (PFCM) membuat algoritma ini dapat mengatasi masalah dari algoritma Fuzzy C-Means
(FCM) dan PossibilisticC-Means (PCM), yaitu dalam hal sensitivitas pada noise
serta pencegahan terjadinya coincident cluster [4]. Berikut ini adalah fungsi objektif dari PossibilisticFuzzy C-Means
(PFCM): besarnya kecendrungan nilai keanggotaan dan nilai kesesuaian pada fungsi objektif.γiadalah nilai konstanta yang harus ditentukan oleh pengguna dengan syarat γi> 0. Nilai konstanta a danb
harus lebih besar daripada nol (𝑎> 0,𝑏> 0).Selanjutnya nilai m dan 𝜂 adalah nilai konstanta yang nilainya harus lebih besar dari 1 (𝑚> 1,𝜂 > 0).Berikut ini adalah persamaan untuk menghitung nilai keanggotaan (𝑢𝑖𝑘), nilai kesesuaian (𝑡𝑖𝑘) , dan pusat cluster(𝑣𝑖) pada
PossibilisticFuzzy C-Means (PFCM):
𝑢𝑖𝑘 = 𝐷𝐷𝑖𝑘𝐴 Persamaan (6) menunjukkan bahwa ketika
b diberi nilai yang tinggi dibanding a, maka nilai pusat clusterakan lebih dipengaruhi oleh nilai kesesuaian (𝑡𝑖𝑘) dibandingkan nilai keanggotaan (𝑢𝑖𝑘).
2.2 Artificial Bee Colony (ABC)
Artificial Bee Colony (ABC) adalah algoritma optimasi yang mengadopsi perilaku cerdas kumpulan lebah[3]. Pada algoritma ini, koloni lebah terbagi atas tiga kelompok, yaitu lebah pekerja (employed bees), lebah penunggu (onlookerbees), dan lebah penjelajah (scout) (Karaboga, 2005).Prosedur dasar dari algoritma Artificial Bee Colony
(ABC) adalah sebagai berikut (Akay dan Karaboga 2012, E. Cuevas dkk., 2013):
121 𝑥𝑗𝑚𝑎𝑥adalah nilai maksimal dan 𝑥𝑗𝑚𝑖𝑛
adalah nilai minimal dari parameter j.
2) Tahap Lebah Pekerja
Setelah proses inisialisasi, populasi sumber makanan (solusi) akan mengalami siklus berulang berupa proses pencarian dari lebah pekerja, lebah penunggu, dan lebah penjelajah. Pada tahap lebah pekerja, akan dibuat sumber makanan barudi sekitar posisi sumber makanan awal dengan persamaan sebagai berikut:
𝑣𝑖𝑗 = 𝑥𝑖𝑗 + 𝑖𝑗 𝑥𝑖𝑗 − 𝑥𝑘𝑗 (8)
dengan𝑘 ∈ 1,2,…,𝑆𝑁 dan 𝑗 ∈ 1,2,…,𝐷 adalah indeks yang dipilih secara acak dengan syarat nilai 𝑘 haruslah berbeda dari nilai i.𝑖𝑗adalah angka acak dengan rentang [-1,1].
Nilai fitness yang mewakili profitabilitas dari solusi tersebut akan dihitung untuk mengukur seberapa baik solusi yang dibuat.
𝑓𝑖𝑡𝑛𝑒𝑠𝑠𝑖 =
1
1+𝑓𝑖 𝑗𝑖𝑘𝑎𝑓𝑖 ≥0
1 +𝑎𝑏𝑠 𝑓𝑖 𝑗𝑖𝑘𝑎𝑓𝑖 < 0
(9)
𝑓𝑖adalah nilai dari fungsi objektif yang
akan diminimalkan. Selanjutnya proses
greedy selection akan dilakukan pada 𝑣𝑖dan 𝑥𝑖. Hasil terbaik di antara keduanya
akan dipilih berdasarkan nilai fitness yang mewakili jumlah nectar (kualitas solusi)𝑣𝑖dan 𝑥𝑖.
3) Tahap Lebah Penunggu
Pada tahap ini, setiap lebah penunggu akan memilih salah satu dari sumber makanan yang diusulkan oleh lebah pekerja tergantung pada nilai fitness dari sumber makanan yang telah dihitung oleh lebah pekerja. Probabilitas dari sumber
makanan yang akan dipilih dapat dihitung menggunakan persamaan berikut:
𝑝𝑖 = 𝑆𝑁𝑓𝑖𝑡𝑓𝑖𝑡𝑖 𝑛 𝑛=1
(10)
dengan𝑓𝑖𝑡𝑖 adalah nilai fitness dari sumber makanan yang berkaitan dengan nilai objektif (𝑓𝑖). Setelah proses tersebut selesai, lebah penunggu akan melakukan pencarian dan pemilihan kandidat sumber makanan baru di sekitar sumber makanan sebelumnya menggunakan persamaan (8). Setelah itu dilakukan pula greedy selection
antara solusi lama dan solusi baru.
Jika suatu sumber makanan tidak dapat ditingkatkan nilainya melalui jumlah
trial yang telah ditentukan (limit), maka sumber makanan tersebut akan dianggap sebagai sumber makanan yang tidak dapat dipakai lagi, atau akan ditinggalkan. Selanjutnya lebah pekerja atau lebah penunggu yang berkaitan dengan sumber makanan tersebut akan berubah menjadi lebah penjelajah.
4) Tahap lebah penjelajah
Lebah penjelajah akan melakukan eksplorasi dan membuat sumber makanan secara random berdasarkan persamaan (7).
3. Metodologi Penelitian
Pada penelitian ini, sistem yang dibangun terdiri atas konversi citra RGB ke Grayscale, optimasi pusat cluster center menggunakan metode Artificial Bee Colony (ABC), serta segmentasi citra
menggunakan metode
clusteringPossibilistic Fuzzy C-Mean
122
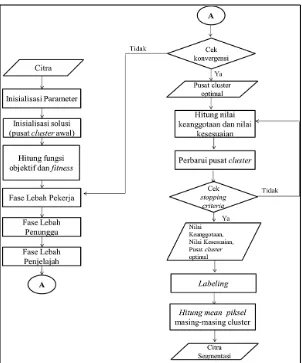
Gambar 1. Alur Proses Possibilistic Fuzzy C-Means (PFCM) dengan pusat cluster menggunakan Artificial Bee Colony (ABC).
3.1 Dataset
Keseluruhan citra pada penelitian ini diambil dari 6 dataset dimana tiap-tiap datasetnya terdiri atas lima citra yang dipilih secara acak, sehingga total citra yang digunakan adalah sebanyak 30 citra. Dataset yang digunakan terbagi atas dua jenis citra, yaitu citra sintetis dan citra real. Citra sintetis yang digunakan pada penelitan ini berjumlah 10 citra dan diambil dari dua dataset yang berbeda, yakni dataset Color Synthetic Image dan dataset sintetis Rectangle yang dibuat menggunakan aplikasi Adobe Photoshop. Selanjutnya, citra real yang digunakan berjumlah 20 citra.Citra real pada penelitian ini diperoleh dari empat dataset yang berbeda, yakni dataset Weizmann, dataset SIPI-misc, dataset Caltech-Leaves,
dan Caltech-Toys.Semua citra yang akan dijadikan data masukan awal untuk proses segmentasi akan diubah menjadi grayscale
terlebih dahulu, sebelum akhirnya akan menjadi masukan untuk proses segmentasi dan evaluasi citra hasil segmentasi.
3.2 Optimasi Pusat Cluster
Sebelum melakukan proses
segmentasi dengan metode
clusteringPossibilistic Fuzzy C-Means
(PFCM), cluster center yang akan digunakan dalam inisialisasi awal akan dioptimasi terlebih dahulu menggunakan
Artificial Bee Colony (ABC). Proses dari algoritma ini diawali dengan inisialisasi parameter ABC. Parameter-parameter yang diperlukan dalam algoritma ABC adalah jumlah populasi, limit, dan
123 penelitian ini, nilai parameter yang
digunakan, yaitu populasi = 10, limit = 100, serta MCN = 100 untuk citra real dan
MCN = 70 untuk citra sintetis.
Proses selanjutnya adalah inisialisasi solusi awal berupa cluster center secara random menggunakan persamaan (7). Solusi awal dalam penelitian ini adalah nilai clustercenter. Solusi awal tersebut akan dihitung nilai
fitnessnya menggunakan persamaan (9). Pada persamaan tersebut terdapat perhitungan fungsi objektif.Dalam metode yang diusulkan, fungsi objektif tersebut adalah fungsi objektif dari metode
Possibilistic Fuzzy C-Means
(PFCM).Proses selanjutnya adalah fase lebah pekerja. Pada fase lebah pekerja, untuk mengetahui solusi yang terbaik diantara keduanya. Setelah nilai fitness
dari masing-masing solusi diperoleh, selanjutnya akan dilakukan greedy selection. Jika nilai fitness solusi yang baru lebih baik dari yang lama 𝑓𝑖𝑡(𝑣𝑖) > telah ditemukan oleh lebah pekerja menggunakan persamaan (10).Setelah memilih salah satu solusi berupa cluster center terbaik, maka akan ditentukan
cluster center yang baru di sekitar cluster center yang lama menggunakan persamaan (9). Nilai fitness dari solusi baru tersebut kemudian dihitung kembali, lalu dilakukan pengecekan untuk membandingkan nilai
fitness solusi lama dan solusi baru atau disebut dengan proses greedy selection.
Pada fase lebah penjelajah, dilakukan pengecekan solusi cluster center
yang sudah tidak digunakan (abandoned
source). Jika ditemukan adanya
abandoned source, maka solusi tersebut akan diganti dengan solusi yang lain. Proses pencarian solusi berupa cluster center baru secara random tersebut dilakukan menggunakan persamaan (7). Pada penelitian ini hasil terakhir ABC adalah cluster center dengan nilai fitness
terbaik.
3.3 Segmentasi
Proses segmentasi dilakukan menggunakan algoritma Possibilistic Fuzzy C-Means (PFCM) dengan memanfaatkan cluster center yang telah dioptimasi oleh Artificial Bee Colony
(ABC). Pada proses ini setiap piksel gambar dikelompokkan menjadi sejumlah area sesuai dengan jumlah cluster yang diinisialisasikan di awal proses segmentasi. Proses awal dari algoritma PFCM dimulai dengan inisialisasi parameter yang digunakan. Pada penelitian ini nilai-nilai parameter PFCM adalah sebagai berikut: a = 1, b = 1, m= 1, dan
=1. Nilai keanggotaan (𝑢𝑖𝑘)dan nilai kesesuaian (𝑡𝑖𝑘)yang dihasilkanakan digunakan untuk memperbarui pusat
cluster. Pembaruan pusat cluster dihitung menggunakan persamaan (6).
Nilai keanggotaan (𝑢𝑖𝑘)dan nilai kesesuaian (𝑡𝑖𝑘)yang dihasilkanakan digunakan untuk memperbarui pusat
cluster. Pembaruan pusat cluster dihitung menggunakan persamaan (6). Pada akhir proses perhitungan, akan diperoleh nilai keanggotaan, nilai kesesuaian, serta pusat
clusterakhir. Setiap piksel akan dikelompokkan pada cluster sesuai dengan nilai keanggotaan dan nilai kesesuaian yang dimiliki oleh piksel tersebut.
3.4Evaluasi
Evaluasi dilakukan untuk mengetahui seberapa akurat hasil segmentasi.Evaluasi citra pada metode ini menggunakan
Structural Similarity Index
124
SSIM dan jumlah iterasi yang dihasilkan dilakukan pula evaluasi menggunakan metode statistik T-test.
4. Hasil dan Pembahasan
Data yang digunakan pada penelitian ini berjumlah 30 citra yang diambil dari 6 dataset yang berbeda-beda. Selain dataset sintetis Rectangle yang berjenis bit grayscale, kelima dataset lainnya berjenis RGB. Setiap citra yang digunakan berukuran 100x100 piksel. Proses uji coba dengan cara melakukan segmentasi masing-masing citra menggunakan metode yang diusulkan, yaitu ABC-PFCM kemudian dibandingkan dengan metode PFCM. Pada penelitian ini, proses uji coba dibedakan menjadi dua, yaitu uji coba pada citra sintetis dan uji coba pada citra real.Untuk citra real, pada
setiap metode dilakukan variasi jumlah
cluster yaitu c=2, c=3, c=4, c=5, dan c=6. Sedangkan pada citra sintetis, jumlah cluster masukan disamakan dengan jumlah segmen asli pada citra. Masing-masing variasi dilakukan 5 kali percobaan dan diambil nilai rata-rata SSIM dan jumlah iterasi dari kelima percobaan tersebut.Hasil segmentasi kemudian dievaluasi menggunakan metode SSIM.
4.1 Hasil Uji Coba Sintetis
Pada uji coba citra sintetis, nilai jumlah cluster center yang diujikan diatur sesuai dengan jumlah segmen pada citra. Total keseluruhan percobaan pada kedua dataset tersebut adalah 10 percobaan. Tabel 1 berikut ini menunjukkan nilai SSIM tertinggi tiap metode pada citra sintetis.
Tabel 1 Jumlah Nilai SSIM Tertinggi Metode ABC-PFCM dan PFCM pada Citra Sintetis
No Dataset Jumlah SSIM
Tertinggi
Jumlah SSIM Sama
ABC-PFCM PFCM
1. Synthetical Color Image 5 0 0
2. Rectangle 4 0 1
Total 9 0 1
Dari Tabel 1 di atas dapat diketahui
bahwa ABC-PFCM memperoleh 7
percobaan dengan nilai SSIM yang lebih tinggi dari PFCM, 1 percobaan dengan nilai SSIM ABC-PFCM yang lebih rendah, dan 2 percobaan dengan nilai SSIM yang sama dengan PFCM. Dengan demikian, dapat disimpulkan bahwa, untuk citra sintetis, ABC-PFCM memiliki hasil SSIM yang lebih baik daripada metode PFCM.
Selain perhitungan jumlah SSIM tertinggi kedua metode seperti yang ditunjukkan pada Tabel 3, dilakukan pula analisis hasil SSIM kedua metode secara statistik menggunakan paired sample t-test. Analisis menggunakan paired sample t-test ini dilakukan untuk mengetahui signifikansi perbedaan antara hasil SSIM
ABC-PFCM dan PFCM berdasarkan nilai rata-rata (mean) yang dihasilkan.
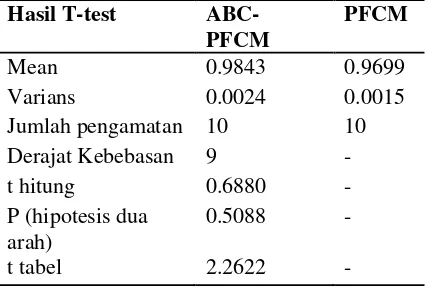
Tabel 2 Hasil paired sample t-test SSIM ABC-PFCM dan PFCM pada citra sintetis
Hasil T-test
ABC-PFCM
PFCM
Mean 0.9843 0.9699
Varians 0.0024 0.0015
Jumlah pengamatan 10 10
Derajat Kebebasan 9 -
t hitung 0.6880 -
P (hipotesis dua arah)
0.5088 -
125 Dari hasil tabel di atas dapat
diketahui bahwa metode ABC-PFCM memperoleh nilai rata-rata SSIM yang baik, ini ditandai dengan nilai rata-rata SSIM lebih tinggi daripada PFCM.Nilai SSIM yang terbaik adalah nilai SSIM yang bernilai 1 atau mendekati nilai 1.Dari tabel di atas, diketahui bahwa ABC-PFCM memperoleh nilai rata-rata SSIM yang lebih tinggi yaitu 0.9843, sedangkan PFCM hanya memperoleh nilai rata-rata sebesar 0.9699.
Selain itu, untuk signifikansi perbedaan hasil rata-rata kedua metode, dapat dilihat dari nilai t hitung dan t tabel.H0 atau hipotesis nol pada penelitian ini menyatakan tidak terdapat perbedaan yang signifikan antara nilai rata-rata kedua metode. Syarat diterimanya H0 adalah jika t hitung < t tabel atau jika t hitung > -t tabel. Sedangkan H1 adalah hipotesis alternatif yang menyatakan terdapat perbedaan yang signifikan antara nilai rata-rata kedua metode. Syarat diterimanya H1 adalah jika t hitung > t tabel atau jika t hitung < - t tabel. Dari hasil pada tabel di atas diketahui bahwa t hitung (0.6880) < t tabel (2.2622). Dengan demikian dapat disimpulkan bahwa meski nilai rata-rata SSIM ABC-PFCM lebih tinggi dari PFCM, namun kedua metode tersebut tidak memiliki perbedaan yang signifikan.
Selain nilai SSIM, penelitian ini juga melakukan pengamatan terhadap jumlah iterasi yang dihasilkan.Pengamatan jumlah iterasi dilakukan untuk melihat hubungan antara cluster center awal yang dihasilkan oleh kedua metode terhadap jumlah iterasi yang diperlukan untuk memenuhi stoppingcriteria. Stopping criteria pada uji coba ini adalah jika nilai selisih antara cluster center baru dan
cluster center lama telah mencapai nilai 0.001 atau jika telah mencapai batas iterasi maksimal, yaitu 100 iterasi.
Tabel 3 Hasil paired sample t-test jumlah iterasi ABC-PFCM dan PFCM pada citra sintetis
Hasil
ABC-PFCM
PFCM
Mean 5.08 20.52
Varians 51.851 216.526
Jumlah pengamatan 10 10
Derajat Kebebasan 9 -
t hitung -2.979 -
P (hipotesis dua arah) 0.015 -
t tabel 2.262 -
Dari hasil tabel di atas dapat diketahui bahwa ABC-PFCM memperoleh nilai rata-rata jumlah iterasi sebesar 5.08, sedangkan PFCM memperoleh nilai rata-rata sebesar 20.52. Dari hasil pada tabel di atas juga diketahui bahwa t hitung (-2.9789) < -t tabel (-2.2622). Sehingga dapat disimpulkan bahwa nilai rata-rata
ABC-PFCM dan PFCM, memiliki
perbedaan yang signifikan dengan nilai rata-rata jumlah iterasi ABC-PFCM lebih rendah dari PFCM.Nilai rata-rata jumlah iterasi yang lebih rendah tersebut berarti ABC-PFCM memerlukan iterasi yang lebih sedikit untuk sampai pada
stoppingcritera, dengan kata lain ABC-PFCM lebih efisien daripada ABC-PFCM.
4.2 Hasil Uji coba citra real
126
Tabel 4 Jumlah Nilai SSIM Tertinggi ABC-PFCM dan PFCM pada Citra Real
No Dataset Jumlah SSIM Tertinggi Jumlah
SSIM Sama
ABC-PFCM PFCM
1. Weizmann 14 5 6
2. Misc 10 2 13
3. Leaves 21 3 1
4. Toys 10 2 13
Total 52 14 5
Dari hasil pada tabel tersebut diatas, dapat ketahui bahwa jumlah nilai tertinggi SSIM ABC-PFCM lebih banyak daripada PFCM. Meski demikian, berdasarkan tabel di atas, ABC-PFCM juga banyak memiliki nilai SSIM yang sama dengan PFCM. Hal ini menandakan bahwa PFCM sebenarnya sudah memiliki performansi yang bagus pada citra real. Tabel 5 Hasil paired sample t-test ABC-PFCM dan ABC-PFCM pada citra real
Hasil
ABC-PFCM PFCM
Mean 0.8113 0.7898
Varians 0.0126 0.0114
Jumlah pengamatan 100 100
Derajat Kebebasan 99 -
t hitung 5.2702 -
P (hipotesis dua arah) 0.0000008 -
t tabel 1.9842 -
Dari hasil Tabel 5 di atas dapat diketahui bahwa ABC-PFCM memperoleh nilai rata-rata SSIM sebesar 0.8113, sedangkan PFCM hanya memperoleh nilai rata-rata sebesar 0.7898.Selain itu, untuk signifikansi perbedaan hasil rata-rata kedua metode, dapat dilihat dari nilai t hitung dan t tabel.Dari hasil pada tabel di atas dapat dilihat bahwa t hitung (5.2702) > t tabel (1.9842).Dengan demikian dapat disimpulkan bahwa kedua metode memiliki perbedaan yang signifikan pada hasil nilai rata-rata SSIM kedua ukuran citra real.
Selanjutnya, selain nilai SSIM, penelitian ini juga melakukan pengamatan terhadap jumlah iterasi yang dihasilkan kedua metode pada citra real.
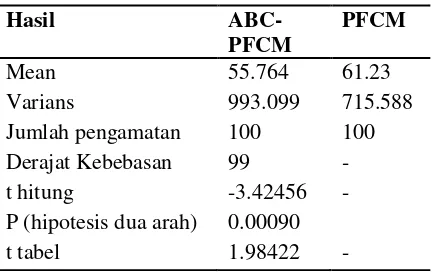
Tabel 6 Hasil paired sample t-test jumlah iterasi ABC-PFCM dan PFCM pada citra real
Hasil
ABC-PFCM
PFCM
Mean 55.764 61.23
Varians 993.099 715.588
Jumlah pengamatan 100 100
Derajat Kebebasan 99 -
t hitung -3.42456 -
P (hipotesis dua arah) 0.00090
t tabel 1.98422 -
Dari hasil Tabel 6 di atas dapat diketahui bahwa ABC-PFCM memperoleh nilai rata-rata jumlah iterasi sebesar 55.764, sedangkan PFCM memperoleh nilai rata-rata sebesar 61.23.Dari hasil pada tabel di atas dapat dilihat bahwa t hitung (-3.4246) < -t tabel (-1.9842). Sehingga dapat disimpulkan bahwa nilai rata-rata ABC-PFCM dan PFCM, memiliki perbedaan yang signifikan dengan nilai rata-rata jumlah ABC-PFCM lebih rendah dari PFCM. Nilai rata-rata jumlah iterasi yang lebih tersebut berarti ABC-PFCM memerlukan iterasi yang lebih sedikit untuk sampai pada
stoppingcritera, sehingga ABC-PFCM lebih efisien daripada PFCM.
127 Metode yang diusulkan, yaitu optimasi
cluster center PFCM menggunakan ABC (ABC-PFCM), mampu memperoleh hasil segmentasi yang lebih baik pada citra sintetis.Hal ini dibuktikan dengan nilai rata-rata SSIM ABC-PFCM yang lebih tinggi daripada PFCM.ABC-PFCM memperoleh rata-rata SSIM sebesar 0.9843, sedangkan PFCM hanya
memperoleh rata-rata sebesar
0.9699.Meski demikian, dari analisis t-test ditemukan bahwa perbedaan nilai rata-rata SSIM untuk citra sintetis tersebut tidak terlalu signifikan. Pada citra real, ABC-PFCM juga memperoleh hasil segmentasi yang lebih baik daripada PFCM, yaitu ABC-PFCM memperoleh nilai rata-rata SSIM sebesar 0.8113, sedangkan PFCM hanya memperoleh rata-rata sebesar 0.7898. Dari uji coba statistk t-test ditemukan bahwa kedua metode mempunyai perbedaan rata-rata SSIM yang signifikan.
6. Saran
Berdasarkan hasil yang didapatkan dari penelitian ini, ada beberapa saran yang diajukan untuk penelitian selanjutnya, yaitu: (1) Proses random awal
cluster center pada metode ABC-PFCM bisa lebih diefektifkan lagi menggunakan proses random yang lebih terukur. (2) Proses eksplorasi ABC-PFCM pada fase lebah penjelajah dapat ditingkatkan untuk menghindari kemungkinan terjadinya lokal optima.
Daftar Pustaka
[1] Emary, E., Zawbaa, H. M., Hassanien, A.E., Schaefer, G., dan Azar, A. T. (2014, July). Retinal vessel segmentation based on possibilistic fuzzy c-means clustering
optimised with cuckoo search. In Neural Networks (IJCNN), 2014 International Joint Conference on (pp. 1792-1796).IEEE.
[2]He, Y., Zhang, K., dan Sun, Z. (2014). APossibilistic Fuzzy C-means Clustering
Algorithm Based on Improved Particle Swarm Optimization. Journal of
Computational Information Systems, 10(18), 7845-7857.
[3]Karaboga, D., dan Basturk, B. (2007). A powerful and efficient algorithm for numerical function optimization: artificial bee colony (ABC) algorithm. Journal of global optimization, 39(3), 459-471. [4]Pal, N. R., Pal, K., Keller, J. M., dan Bezdek, J. C. (2005). A possibilistic fuzzy c-means clustering algorithm. Fuzzy Systems, IEEE Transactions on, 13(4), 517-530.
[5]Pal, N. R., Pal, K., dan Bezdek, J. C. (1997, July). A mixed c-means clustering model. In Fuzzy Systems, 1997., Proceedings of the Sixth IEEE International Conference on (Vol. 1, pp. 11-21). IEEE.
[6] Taherdangkoo, M., Yazdi, M., dan Rezvani, M. H. (2010, November). Segmentation of MR brain images using FCM improved by artificial bee colony (ABC) algorithm. In Information
Technology and Applications in Biomedicine (ITAB), 2010 10th IEEE International Conference on (pp. 1-5). IEEE.