Abstrak—Segmentasi citra merupakan suatu metode
partisi terhadap citra menjadi beberapa bagian yang homogen berdasarkan kemiripan tertentu. Proses segmentasi sangat penting karena hasil segmentasi mempengaruhi hasil dari proses yang akan dilakukan selanjutnya seperti pengenalan pola. Dalam pengenalan pola, algoritma Fuzzy C-Means (FCM) sering digunakan untuk meningkatkan kekompakan dari daerah karena validitas pengelompokannya. Namun, dalam implementasi FCM sering menemui kesulitan dalam menentukan inisialisasi cluster dan jumlah cluster yang tepat. Kesulitan dalam melakukan inisialisasi dapat mempengaruhi kualitas segmentasi citra. Oleh karena itu, dibutuhkan suatu metode hybrid yang tepat untuk permasalahan penentuan inisialisasi cluster dan jumlah cluster pada FCM. Pada artikel ini, metode hybrid yang digunakan untuk mengatasi masalah penentuan inisialisasi cluster dan jumlah cluster pada FCM adalah histogram thresholding. Metode hybrid dari histogram
thresholding dan Fuzzy C-Means terdiri dari dua modul, yaitu
modul histogram thresholding dan modul FCM. Modul histogram thresholding digunakan untuk menghasilkan inisialisasi cluster dan jumlah cluster yang digunakan pada modul FCM. Metode ini memiliki nilai evaluasi kuantitatif yang kecil dan rata-rata error color kurang dari 0.08%.
Kata Kunci—Cluster Centroid, Fuzzy C-Means, Histogram Thresholding, segmentasi citra berwarna.
I. PENDAHULUAN
EGMENTASI citra berwarna merupakan proses partisi terhadap citra menjadi beberapa bagian yang homogen berdasarkan kriteria kemiripan tertentu. Hasil dari segmentasi citra berwarna akan digunakan untuk proses klasifikasi citra maupun proses identifikasi objek. Proses segmentasi sangat penting karena hasil segmentasi dapat mempengaruhi hasil dari proses yang dilakukan selanjutnya. Oleh karena itu, diperlukan algoritma yang dapat menghasilkan segmentasi citra yang baik. Dalam pengenalan pola, algoritma Fuzzy C-Means (FCM) sering digunakan untuk meningkatkan kekompakan dari warna karena validitas pengelompokannya. Namun, dalam melakukan implementasi terhadap FCM sering mengalami kesulitan dalam menentukan cluster awal dan jumlah cluster awal yang tepat. Kesulitan dalam menentukan jumlah cluster awal dapat mempengaruhi daerah yang tersegmentasi dan kesulitan
untuk menentukan cluster awal dapat mempengaruhi kekompakan cluster serta akurasi pengelompokan[1]. Sehingga diperlukan suatu metode hybrid yang tepat untuk digunakan pada FCM. Dengan metode hybrid tepat maka akan didapatkan cara melakukan penentuan cluster awal dan jumlah cluster dalam proses FCM.
Pada artikel ini, diusulkan metode yang dapat menentukan
cluster awal dan jumlah cluster dalam metode FCM untuk
segmentasi citra berwarna. Metode yang digunakan adalah histogram thresholding Fuzzy C-Means. Metode tersebut terdiri dari dua modul, yaitu modul histogram thresholding dan modul FCM. Modul histogram thresholding merupakan metode yang digunakan untuk menghasilkan cluster awal dan jumlah cluster awal yang digunakan pada modul FCM. Sedangkan modul FCM merupakan metode yang digunakan untuk meningkatkan kekompakan dari kelompok untuk mendapatkan label yang dioptimalkan dengan menggunakan
cluster dari anggota setiap cluster.
II. METODEPENELITIAN
Secara umum, metode Histogram Thresholding
Fuzzy-Means memiliki beberapa tahapan. Tahap tersebut
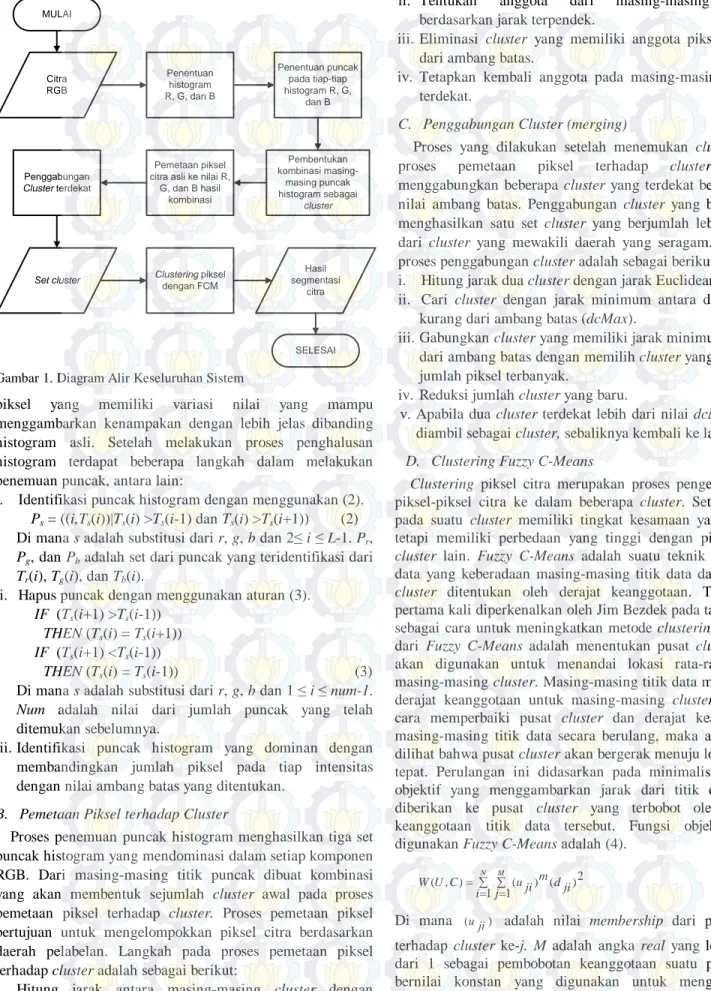
ditunjukkan pada Gambar 1.
A. Penemuan Puncak Histogram
Histogram dari suatu citra dapat menghasilkan deskripsi global tentang informasi citra. Histogram juga digunakan sebagai dasar penting dari pendekatan statistik dalam pengolahan citra[2]. Kunci dari model partisi pada histogram adalah suatu proses menemukan dan menghapus puncak dalam kurva histogram. Salah satu algoritma yang digunakan untuk menemukan puncak histogram dijelaskan pada [1].
Dalam metode pencarian puncak histogram, pertama dilakukan penghalusan terhadap histogram masing-masing komponen dengan menggunakan (1).
(1)
S adalah substitusi dari nilai r, g, dan b. WindowSize
merupakan ambang batas yang ditentukan oleh pengguna. Penghalusan terhadap histogram berguna untuk menyeleksi
Implementasi Histogram Thresholding Fuzzy
C-Means untuk Segmentasi Citra Berwarna
Risky Agnesta Kusuma Wati, Diana Purwitasari, Rully SoelaimanTeknik Informatika, Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember (ITS) Jl. Arief Rahman Hakim, Surabaya 60111 Indonesia
e-mail: [email protected]
S
windowSize i s i s i s i s i s i Ts()=( ( −2)+ ( −1)+ ()+ ( +1)+ ( +2))piksel yang memiliki variasi nilai yang mampu menggambarkan kenampakan dengan lebih jelas dibanding histogram asli. Setelah melakukan proses penghalusan histogram terdapat beberapa langkah dalam melakukan penemuan puncak, antara lain:
i. Identifikasi puncak histogram dengan menggunakan (2).
Ps = ((i,Ts(i))|Ts(i) >Ts(i-1) dan Ts(i) >Ts(i+1)) (2)
Di mana s adalah substitusi dari r, g, b dan 2≤ i ≤ L-1. Pr,
Pg, dan Pb adalah set dari puncak yang teridentifikasi dari
Tr(i), Tg(i), dan Tb(i).
ii. Hapus puncak dengan menggunakan aturan (3).
IF (Ts(i+1) >Ts(i-1))
THEN (Ts(i) = Ts(i+1))
IF (Ts(i+1) <Ts(i-1))
THEN (Ts(i) = Ts(i-1)) (3)
Di mana s adalah substitusi dari r, g, b dan 1 ≤ i ≤ num-1.
Num adalah nilai dari jumlah puncak yang telah
ditemukan sebelumnya.
iii. Identifikasi puncak histogram yang dominan dengan membandingkan jumlah piksel pada tiap intensitas dengan nilai ambang batas yang ditentukan.
B. Pemetaan Piksel terhadap Cluster
Proses penemuan puncak histogram menghasilkan tiga set puncak histogram yang mendominasi dalam setiap komponen RGB. Dari masing-masing titik puncak dibuat kombinasi yang akan membentuk sejumlah cluster awal pada proses pemetaan piksel terhadap cluster. Proses pemetaan piksel bertujuan untuk mengelompokkan piksel citra berdasarkan daerah pelabelan. Langkah pada proses pemetaan piksel terhadap cluster adalah sebagai berikut:
i. Hitung jarak antara masing-masing cluster dengan masing-masing piksel dengan jarak Euclidean.
ii. Tentukan anggota dari masing-masing cluster
berdasarkan jarak terpendek.
iii. Eliminasi cluster yang memiliki anggota piksel kurang dari ambang batas.
iv. Tetapkan kembali anggota pada masing-masing cluster terdekat.
C. Penggabungan Cluster (merging)
Proses yang dilakukan setelah menemukan cluster pada proses pemetaan piksel terhadap cluster adalah menggabungkan beberapa cluster yang terdekat berdasarkan nilai ambang batas. Penggabungan cluster yang berdekatan menghasilkan satu set cluster yang berjumlah lebih sedikit dari cluster yang mewakili daerah yang seragam. Langkah proses penggabungan cluster adalah sebagai berikut:
i. Hitung jarak dua cluster dengan jarak Euclidean. ii. Cari cluster dengan jarak minimum antara dua cluster
kurang dari ambang batas (dcMax).
iii. Gabungkan cluster yang memiliki jarak minimum kurang dari ambang batas dengan memilih cluster yang memiliki jumlah piksel terbanyak.
iv. Reduksi jumlah cluster yang baru.
v. Apabila dua cluster terdekat lebih dari nilai dcMax maka diambil sebagai cluster, sebaliknya kembali ke langkah 1.
D. Clustering Fuzzy C-Means
Clustering piksel citra merupakan proses pengelompokan
piksel-piksel citra ke dalam beberapa cluster. Setiap piksel pada suatu cluster memiliki tingkat kesamaan yang tinggi, tetapi memiliki perbedaan yang tinggi dengan piksel pada
cluster lain. Fuzzy C-Means adalah suatu teknik clustering
data yang keberadaan masing-masing titik data dalam suatu
cluster ditentukan oleh derajat keanggotaan. Teknik ini
pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981 sebagai cara untuk meningkatkan metode clustering. Konsep dari Fuzzy C-Means adalah menentukan pusat cluster yang akan digunakan untuk menandai lokasi rata-rata untuk masing-masing cluster. Masing-masing titik data mempunyai derajat keanggotaan untuk masing-masing cluster. Dengan cara memperbaiki pusat cluster dan derajat keanggotaan masing-masing titik data secara berulang, maka akan dapat dilihat bahwa pusat cluster akan bergerak menuju lokasi yang tepat. Perulangan ini didasarkan pada minimalisasi fungsi objektif yang menggambarkan jarak dari titik data yang diberikan ke pusat cluster yang terbobot oleh derajat keanggotaan titik data tersebut. Fungsi objektif yang digunakan Fuzzy C-Means adalah (4).
(4)
Di mana ( jiu ) adalah nilai membership dari piksel ke-i terhadap cluster ke-j. M adalah angka real yang lebih besar dari 1 sebagai pembobotan keanggotaan suatu piksel dan bernilai konstan yang digunakan untuk mengendalikan pembagian nilai membership. Dji adalah jarak antara piksel
ke-i terhadap cluster ke-j.
∑ = ∑= = N M i j dji m ji u C U W 1 1 2 ) ( ) ( ) , ( MULAI Citra RGB Penentuan histogram R, G, dan B Penentuan puncak pada tiap-tiap histogram R, G, dan B
Set cluster Clustering piksel
dengan FCM Hasil segmentasi citra SELESAI Pembentukan kombinasi masing-masing puncak histogram sebagai cluster Pemetaan piksel citra asli ke nilai R,
G, dan B hasil kombinasi Penggabungan
Cluster terdekat
Dari proses sebelumnya maka didapatkan set cluster yang digunakan pada proses Fuzzy C-Means. Dalam artikel ini penentuan cluster dan jumlahnya dilakukan secara otomatis dari proses sebelumnya. Algoritma Fuzzy C-Means yang digunakan adalah sebagai berikut:
i. Tentukan input yang berupa citra asli dengan N merupakan jumlah piksel.
ii. Tentukan cluster awal dan jumlah cluster.
iii. Tentukan sistem penghentian iterasi (ɛ merupakan nilai positif yang kecil).
iv. Tentukan jumlah iterasi awal q = 0. v. Hitung U(q) menurut C(q) dengan (5).
(5)
Di mana m merupakan pangkat pembobotan dengan nilai lebih dari 1. xi merupakan piksel ke-i pada citra,
1≤j≤ M.
vi. Hitung C(q+1) menurut U(q) dengan (6).
(6)
Di mana cj merupakan pusat cluster. uji merupakan nilai
keanggotaan cluster. N adalah jumlah piksel citra. m adalah pangkat pembobotan dengan nilai lebih dari 1. xi
merupakan piksel ke-i pada citra dan 1≤ j ≤ M.
vii. Pembaruan terhadap U(q+1) sesuai dengan C(q+1) pada (5). viii. Bandingkan U(q+1) dengan U(q). Apabila ||U(q+1)–U(q)||≤ɛ maka dilakukan penghentian iterasi. Jika tidak, q=q+1, dan mengulangi Langkah 5 sampai 7 hingga ||U(q+1)–
U(q)||>ɛ.
III. UJICOBADANEVALUASI
Uji coba dalam artikel ini dilakukan dengan menggunakan lima citra berwarna yang berasal dari database Berkeley. Masing-masing citra berukuran 289x193. Dalam uji coba digunakan pengujian berdasarkan nilai kualitas cluster (VPC)
serta nilai evaluasi kuantitas segmentasi (F(I)).
A. Evaluasi Kualitas Cluster (VPC)
Evaluasi kualitas cluster pada Fuzzy C-Means (FCM) dapat dilakukan dengan berbagai cara salah satunya dengan menggunakan fungsi evaluasi yang diusulkan oleh Bezdek[3]. Fungsi evaluasi tersebut berfungsi sebagai tolok ukur kuantitatif yang dapat digunakan untuk mengevaluasi kualitas cluster. Fungsi evaluasi Bezdek ditunjukkan dengan pada (7).
(7)
N merupakan jumlah piksel pada citra, M adalah jumlah cluster, dan uji merupakan nilai keanggotaan piksel terhadap
masing-masing cluster. Fungsi ini digunakan untuk mengukur ketidakjelasan dari hasil pengelompokan dan nilai
VPC dengan rentang antara 0 sampai 1. Dengan fungsi
tersebut, sebuah algoritma pengelompokan yang bagus menghasilkan nilai VPC yang lebih besar.
B. Evaluasi Kuantitatif Segmentasi Citra
Dalam mengevaluasi hasil segmentasi citra nyata maupun citra yang disintesis, serta mengevaluasi hasil baik lokal maupun global, salah satu fungsi yang dapat digunakan adalah fungsi yang diusulkan oleh Liu dan Yang[4]. Fungsi tersebut secara langsung maupun tidak langsung menggabungkan tiga dari empat kriteria heuristik yang disarankan oleh Haralick dan Shapiro untuk mengevaluasi hasil segmentasi tanpa harus mengatur nilai-nilai ambang batas untuk sifat subjektif dari luas daerah, bentuk atau homogenitas[5]. Kreteria yang dimaksudkan antara lain, daerah harus seragam dan homogen, daerah interior harus sederhana tanpa banyak detail citra, dan daerah yang berdekatan harus menunjukkan nilai yang berbeda secara signifikan untuk karakteristik yang seragam. Fungsi penghitungan evaluasi kuantitatif segmentasi citra yang diusulkan oleh Liu dan Yang ini ditunjukkan dengan (8).
(8)
N merupakan jumlah piksel citra, M adalah jumlah cluster,
dan Mi adalah jumlah piksel dari daerah yang ke-i. e2 adalah
jumlah jarak Euclidean dari vektor antara citra asli dan masing-masing piksel pada daerah citra segmentasi. Hasil segmentasi citra yang baik ditunjukkan dengan nilai evaluasi kuantitas yang rendah.
C. Hasil Uji Coba
Uji coba pada metode histogram thresholding Fuzzy
C-Means dilakukan pada citra berwarna statis yang diambil
secara acak dari database Berkeley [BSDS300]. Uji coba dilakukan untuk mengetahui parameter yang mempengaruhi hasil segmentasi dan perbandingan metode histogram
thresholding Fuzzy C-Means dibandingkan dengan cara random. Hasil pengujian menunjukkan nilai evaluasi
kuantitatif segmentasi citra (F(I)). Semakin kecil nilai F(I) maka segmentasi yang dihasilkan semakin baik. Hasil pengujian parameter ambang batas proses penggabungan
cluster ditunjukkan pada Tabel 1. Dari hasil tersebut
menunjukkan perbedaan nilai ambang batas menyebabkan hasil segmentasi yang dihasilkan berbeda. Hal itu ditunjukkan dengan nilai F(I) yang dihasilkan berbeda pada ketiga ambang batas. Pengujian terhadap ambang batas
region ditunjukkan pada Tabel 2. Dari hasil tersebut
menunjukkan bahwa dari ketiga nilai ambang batas region yang digunakan menghasilkan segmentasi yang berbeda ditunjukkan dengan nilai F(I) yang berbeda. Pengujian terhadap windowSize ditunjukkan pada Tabel 3. Hasil tersebut menunjukkan ketiga nilai windowSize menghasilkan jumlah
cluster yang berbeda. Selain itu, nilai F(I) yang dihasilkan
∑ = − − − = M k m k c i x j c i x ji u 1 1 2 2 || || 2 || || 1 N N i M j u ji PC V ∑ = ∑= = 1 1 2 ∑ = = M i M i e M N i F 1 2 1000 1 ) ( ∑ = ∑ = = N i m ji u N i ji u j c xi m 1 ) ( 1 ) (
Tabel 1.
Hasil perbandingan segmentasi citra berdasarkan ambang batas penggabungan cluster (merging).
No. Nama Citra
Ambang Batas Merging Jumlah Cluster Waktu (menit) F(I) 1 227092.bmp 20 14 40 18,90 2 28 14 21 30,85 3 38 12 16 29,53 4 189080.bmp 20 12 33 70,24 5 28 8 23 144,93 6 38 5 17 239,66 Tabel 2.
Hasil perbandingan segmentasi citra berdasarkan ambang batas region. No. Nama Citra
Ambang Batas Region Jumlah Cluster Waktu (menit) F(I) 1 227092.bmp 0,006N 15 25 20,70 2 0,007N 14 40 18,90 3 0,008N 13 15 23,75 4 189080.bmp 0,006N 12 33 70,24 5 0,007N 11 30 77,70 6 0,008N 11 45 77,70 Tabel 3.
Hasil perbandingan segmentasi citra berdasarkan nilai windowSize. No. Nama Citra windowSize Jumlah
Cluster Waktu (menit) F(I) 1 227092.bmp 3 14 40 18,90 2 6 14 42 18,90 3 9 14 41 18,90 4 189080.bmp 3 12 33 70,24 5 6 12 13 63,97 6 9 6 10 187,78 Tabel 4.
Hasil perbandingan segmentasi citra berdasarkan ambang batas identifikasi puncak yang dominan.
No. Nama Citra Threshold Cluster Jumlah (menit) Waktu F(I) 1 227092.bmp 100 14 42 18,90 2 120 14 40 18,90 3 140 13 40 26,99 4 189080.bmp 100 12 28 52,51 5 120 12 13 63,97 6 140 12 12 62,04 Tabel 5.
Hasil perbandingan segmentasi citra berdasarkan ukuran piksel citra. No. Nama Citra Ukuran Citra Jumlah
Cluster Waktu (menit) F(I) 1 227092.bmp 230x154 12 38 20,81 2 289x193 14 40 18,90 3 320x214 13 42 36,64 4 189080.bmp 230x154 8 16 95,43 5 289x193 12 28 52,51 6 320x214 10 26 73,06
oleh ketiga windowSize berbeda karena hasil segmentasi yang dihasilkan ketiga windowSize berbeda. Pengujian ambang batas proses identifikasi puncak dominan ditunjukkan pada Tabel 4. Pengujian tersebut menunjukkan dari ketiga ambang batas yang digunakan menghasilkan jumlah cluster yang berbeda sehingga hasil segmentasi yang dihasilkan juga berbeda. Perbedaan segmentasi citra berbeda ditunjukkan dengan nilai F(I) yang berbeda pada ketiga nilai ambang batas. Pengujian terhadap ukuran piksel citra ditunjukkan pada Tabel 5. Dari ketiga ukuran piksel citra yang digunakan menunjukkan perbedaan nilai F(I). Semakin kecil ukuran
piksel citra maka nilai F(I) semakin kecil. Semakin keci ukuran piksel citra maka waktu komputasi yang diperlukan juga semakin kecil.
Perbandingan hasil penentuan inisialisasi cluster dan jumlah cluster pada Fuzzy C-Means menggunakan metode hitogram thresholding dibandingkan cara random ditunjukkan pada Tabel 6. Dari hasil uji coba menunjukkan bahwa rata-rata error color dari metode histogram
thresholding lebih kecil dibandingkan dengan cara random.
Dari data uji coba menghasilkan rata-rata error color terbesar Tabel 6.
Hasil perbandingan inisialisasi cluster secara random dengan inisialisasi berdasarkan metode histogram thresholding.
No. Nama Citra Jumlah
Cluster Keterangan Rata-rata Error Color F(I) 1 189080.bmp 12 HTFCM 8,62 52,51 2 11 Random 10,10 71,27 3 12 Random 11,18 55,29 4 13 Random 11,12 54,60 5 353013.bmp 8 HTFCM 13,98 37,61 6 7 Random 16,07 28,67 7 8 Random 14,11 35,03 8 9 Random 13,84 29,53 Tabel 7.
Hasil perbandingan cluster hasil sebelum dan sesudah penggabungan cluster (merging).
No. Nama Citra Keterangan Jumlah Cluster Rata-rata Error Color F(I) 1 227092.bmp Merging 13 8,62 18,90 2 Non merging 26 8,93 20,25 3 189080.bmp Merging 11 13,98 52,51 4 Non merging 22 14,27 58,13 (a) (b) (c) (d)
Gambar 2. Hasil uji coba (a) Citra asli 227092.bmp, (b) Citra segmentasi 227092.bmp, (c) Citra asli 189080.bmp, dan (d) Citra segmentasi 189080.bmp.
adalah 0,07%. Selain itu, dari hasil evaluasi kuantitatif menunjukkan nilai evaluasi kuantitatif yang dihasilkan metode histogram thresholding juga kecil. Hasil kualitas
cluster yang dihasilkan metode tersebut lebih dari 0.5
sehingga kualitas cluster yang dihasilkan juga baik. Hasil segmentasi citra menggunakan metode histogram
thresholding Fuzzy C-Means ditunjukkan pada Gambar 2.
Pengujian hasil segmentasi juga dilakukan dengan menggunakan cluster hasil sebelum proses merging maupun setelah merging. Hasil dari uji coba tersebut ditunjukkan pada Tabel 7. Hasil menunjukkan bahwa jumlah cluster yang dihasilkan pada proses sebelum merging lebih banyak dibandingkan dengan hasil setelah merging. Waktu komputasi yang diperlukan untuk cluster sebelum merging lebih banyak dibandingkan dengan cluster setelah merging. Dari hasil segmentasi yang dihasilkan menunjukkan bahwa
cluster hasil proses setelah merging memberikan hasil
segmentasi yang lebih baik dibandingkan cluster sebelum
merging. Hal itu ditunjukkan dengan nilai F(I) cluster setelah merging lebih kecil dibandingkan dengan cluster sebelum merging.
IV. KESIMPULAN
Metode hybrid yang dapat digunakan pada Fuzzy C-Means dalam melakukan penentuan inisialisasi cluster dan jumlah
cluster adalah histogram thresholding. Metode histogram thresholding Fuzzy C-Means memberikan kemudahan dalam
penentuan inisialisasi cluster dan penentuan jumlah cluster pada proses Fuzzy C-Means. Hal ini dikarenakan pada metode histogram thresholding Fuzzy C-Means penentuan iniasilaisasi cluster dan jumlah cluster sudah didapatkan secara otomatis melalui proses histogram thresholding. Selain itu, penentuan inisialisasi cluster dan jumlah cluster menggunakan histogram thresholding menghasilkan citra segmentasi yang lebih baik dibandingkan dengan penentuan secara random. Hal tersebut ditunjukkan berdasarkan nilai evaluasi kuantitatif segmentasi yang didapatkan lebih kecil dibandingkan penentuan secara random. Rata-rata error
color yang dihasilkan pada metode histogram thresholding Fuzzy C-Means kurang dari 0,08%.
Hasil segmentasi citra menggunakan metode histogram
thresholding Fuzzy C-Means dipengaruhi oleh nilai ambang
batas region, ambang batas proses penggabungan cluster, nilai windowSize, nilai ambang batas proses identifikasi puncak yang dominan, dan ukuran piksel citra. Selain itu,
cluster hasil proses sebelum dan setelah merging memberikan
hasil segmentasi yang berbeda pula. Jumlah cluster sebelum
merging lebih banyak dibandingkan dengan cluster setelah merging. Dari hasil segmentasi menunjukkan bahwa cluster
setelah merging menghasilkan segmentasi yang lebih baik dibandingkan cluster sebelum merging. Hal tersebut ditunjukkan dengan nilai F(I) pada cluster setelah merging lebih kecil dibandingkan cluster sebelum merging.
DAFTARPUSTAKA
[1] Tan, K. S., & Mat Isa, N. A. 2011. “Color Image Segmentation Using Histogram Thresholding - Fuzzy C-Means Hybrid Approach”. Pattern
Recognition 44, 1-15.
[2] Cheng, H., Jiang, X., Sun, Y., & Wang, J. 2001. “Color Image Segmentation: Advances and Prospects”. Pattern Recognition 34, 2259-2281.
[3] Pal, N. R., & Bezdek, J. C. 1995. “On Cluster Validity for the Fuzzy C-Means Model”. IEEE Transactions on Fuzzy Systems, Vol. 3 No. 3. [4] Liu, J., & Yang, Y.-H. 1994. “Multiresolution Color Image
Segmentation”. Pattern Analysis and Machine Intelligence 16, 7. [5] Borsotti, M., Campadelli, P., & Schettini, R. 1998. “Quantitative
Evaluation of Color Image Segmentation Result”. Pattern Recognition