ANALISIS PEMANFAATAN DATA MINING DALAM PENENTUAN VARIABEL UNTUK PREDIKSI INDEKS PRESTASI
MAHASISWA MENGGUNAKAN METODE BACK-PROPAGATION NEURAL NETWORK
TESIS
Oleh FRIENDLY 087034030/TE
FAKULTAS TEKNIK
UNIVERSITAS SUMATERA UTARA MEDAN
ANALISIS PEMANFAATAN DATA MINING DALAM PENENTUAN VARIABEL UNTUK PREDIKSI INDEKS PRESTASI
MAHASISWA MENGGUNAKAN METODE BACK-PROPAGATION NEURAL NETWORK
TESIS
Untuk Memperoleh Gelar Magister Teknik dalam Program Studi Magister Teknik Elektro pada Fakultas Teknik Universitas Sumatera Utara
Oleh: FRIENDLY 087034030/TE
FAKULTAS TEKNIK
Telah Diuji pada
Tanggal: 18 November 2011
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Ir. Usman Baafai
Anggota : 1. Dr. Benny B. Nasution, Dipl.Ing, M.Eng 2. Fakhruddin Rizal Batubara, ST. MT 3. Prof. Dr. Opim S. Sitompul, M.Si 4. Prof. Dr. Tulus, M.Si
ABSTRAK
Penggunaan pengolahan data akademik secara elektronik memberikan kemudahan dalam administrasi. Data akademik ini juga sudah digunakan sebagai dasar pengambilan keputusan dan juga digunakan dalam penelitian. Penelitian ditujukan untuk dapat menganalisa informasi yang ada pada sehingga dapat diperoleh informasi yang baru dari data akademik yang ada. Salah satu penelitian yang memanfaatkan data akademik ini adalah penelitian mengenai prediksi indeks prestasi mahasiswa. Namun dengan beragamnya data sebagai variabel masukan prediksi indeks prestasi yang tersedia pada data akademik, prediksi indeks prestasi yang sudah dilakukan sebelumnya belum tentu dapat digunakan dengan data akademik yang lain dan menghasilkan prediksi yang baik.
Hal utama yang ingin dicapai adalah untuk mendapatkan suatu model dengan teknik data mining dengan menggunakan back propagation neural network yang dapat melakukan pembelajaran terhadap data yang ada dan menentukan variabel yang dapat dipergunakan dalam prediksi indeks prestasi mahasiswa. Model ini akan melakukan penentuan variabel dari data yang ada dan melakukan pengujian data variabel hasil penentuan. Data yang digunakan adalah data mahasiswa Fakultas MIPA, Fakultas Hukum dan Fakultas Teknik.
Hasil pengujian menunjukkan bahwa variabel yang dihasilkan berbeda berdasarkan data yang digunakan dan dari hasil pengujian diperoleh peningkatan persentasi prediksi dengan menggunakan penentuan variabel ini walaupun data mahasiswa pada Fakultas Teknik memiliki jumlah variabel yang lebih sedikit dibandingkan data Mahasiswa Fakultas MIPA dan Hukum.
ABSTRACT
The use of electronic academic data processing makes the administrative job easy. These academic data has also been used as the basis of decision making and when doing a research. The purpose of this study was to analyze existing information that the academic data available can result in new information. One of the researches
using these academic data is a study on prediction of students’ achievement index.
Yet, with the various data used as the input variables for prediction of achievement index found in the available academic data, the previously done prediction of achievement index cannot always be used together with the other academic data and produces good prediction.
The main thing to be achieved is to find out a model with data mining technique by using the back propagation neural network that can learn the data available and
determine the variables that can be used in predicting students’ achievement index.
This model will determine the variables from the available data and test the determined data variables. The data used in this study were the data of the students of Faculty of Mathematics and Natural Science, Faculty of Law and Faculty of Engineering.
The result of this study showed that the variables produced were different. Based on the data used and the result of the test done, it was found out that by using the determination of these variables, the percentage of prediction increased even though the data of students of Faculty of Engineering had less variables compared to the data of students of Faculty of Mathematics and Natural Science and Faculty of Law.
KATA PENGANTAR
Puji dan syukur kehadirat Tuhan Yang Maha Esa, atas berkat rahmat dan karunia-Nya sehinga penulis dapat menyelesaikan proposal tesis yang berjudul:
“Analisis Pemanfaatan Data Mining Dalam Penentuan Variabel Untuk Prediksi
Indeks Prestasi Mahasiswa Menggunakan Metode Back Propagation Neural Network”.
Pada kesempatan ini, penulis mengucapkan terima kasih kepada Bapak Prof. Dr. Ir. Usman Baafai, selaku ketua komisi pembimbing, Bapak Dr. Benny B. Nasution, Dipl. Ing, M.Eng dan Bapak Fakhruddin Rizal Batubara, ST. MT selaku anggota komisi pembimbing yang dengan penuh sabar, arif dan bijaksana memberikan bimbingan, dorongan, petunjuk serta arahan kepada penulis. Bapak Prof. Dr. Opim S. Sitompul, M.Sc, Bapak Prof. Dr. Tulus, M.Si, dan Bapak Soeharwinto ST, MT. selaku Pembanding utama yang telah memberikan kritik dan masukan terhadap tesis.
Teknik Elektro, untuk itu penulis mengucapkan terima kasih atas kontribusi dan bantuannya.
Penulis menyadari masih ada kekurangan dalam tulisan ini, namun penulis mengharapkan tulisan ini dapat memenuhi persyaratan yang diperlukan untuk suatu tesis dalam Program Studi Magister Teknik Elektro Fakultas Teknik Universitas Sumatera Utara.
Akhir kata penulis mengucapkan banyak terima kasih dan semoga tesis ini dapat berguna bagi kita semua.
Medan, November 2011 Hormat saya,
DAFTAR RIWAYAT HIDUP
Saya yang bertanda tangan di bawah ini,
Nama : Friendly
Tempat/Tanggal Lahir : Kisaran, 24 Agustus 1981 Jenis Kelamin : Laki-laki
Agama : Katolik
Bangsa : Indonesia
Alamat : Jl. Armada No. 2 Medan 20124
Menerangkan dengan sesungguhnya, bahwa:
PENDIDIKAN
1. Tamatan Teknik Elektro USU Tahun 2006
2. Tamatan SMK Negeri 2 Yogyakarta Tahun 1999
3. Tamatan SMP Swasta Panti Budaya Kisaran Tahun 1996 4. Tamatan SD Swasta Panti Budaya Kisaran Tahun 1993
PEKERJAAN
Demikian riwayat hidup ini saya buat dengan sebenarnya untuk dapat dipergunakan sebagaimana mestinya.
Medan, 18 November 2011 Tertanda,
DAFTAR ISI
Halaman
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... vii
DAFTAR TABEL ... ix
DAFTAR GAMBAR ... x
BAB 1 PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 5
1.3. Tujuan Penelitian ... 5
1.4. Manfaat Penelitian ... 5
1.5. Batasan Masalah ... 6
1.6. Metode Penelitian ... 6
1.7. Sistematika Pembahasan ... 7
BAB 2 TINJAUAN PUSTAKA ... 8
2.1. Data Mining ... 8
2.3. Mengaktifkan Jaringan Saraf Tiruan ... 13
2.4. Jaringan Syaraf Tiruan Back Propagation ... 15
BAB 3 METODE PENELITIAN ... 20
3.1. Rancangan Penelitian ... 20
3.2. Sumber Data ... 20
3.3. Instrumen Penelitian ... 21
3.4. Database SIA ... 21
3.5. Data mining ... 22
3.6. Perancangan Pengumpul Data ... 23
3.7. Pembobotan Data ... 25
3.8. Klasifikasi Data ... 28
BAB 4 HASIL DAN ANALISIS ... 46
4.1. Data Mining ... 46
4.2. Analisa Pengujian Dengan Data Mining ... 49
4.3. Pengujian Variabel ... 51
4.4. Analisa Hasil Pengujian Variabel ... 53
BAB 5 KESIMPULAN DAN SARAN ... 57
5.1. Kesimpulan ... 57
5.2. Saran ... 58
DAFTAR TABEL
Nomor Judul Halaman
1.1 Daftar Penelitian Terkait ... 4
3.1 Hasil Pembobotan ... 27
3.2 Penyusunan Kelas Dengan N=300 ... 33
3.3 Penyusunan Kelas Dengan N=500 ... 33
3.4 Penyusunan Kelas Dengan N=700 ... 33
3.5 Spesifikasi Daftar Hasil Pelatihan ... 40
3.6 Spesifikasi Tabel Daftar Hasil Pengujian ... 41
3.7 Hasil Penelitian Berdasarkan Nilai Pembelajaran [32] ... 43
4.1 Jumlah Neuron Rata-Rata Hasil Pelatihan Jaringan ... 47
4.2 Rangkuman Hasil Pelatihan ... 48
4.3 Hasil Pengujian Pelatihan Data VA ... 52
4.4 Hasil Pengujian Pelatihan Data VB ... 52
4.5 Hasil Pengujian Pelatihan Data VC ... 53
DAFTAR GAMBAR
Nomor Judul Halaman
2.1 Proses Data Mining [17] ... 9
2.2 Proses Pada Metode CRISP-DM [19] ... 11
2.3 Sebuah Jaringan Syaraf Tiruan Dengan 1 Lapisan Tersembunyi [23] ... 13
2.4 Fungsi Pengaktif ... 14
2.5 Pengaruh Pengaturan σ Pada Karakteristik Fungsi Sigmoid ... 15
2.6 Arsitektur JST Back Propagation ... 16
2.7 Hubungan Antara Bobot Pada JST ... 16
3.1 Diagram Aktivitas Pembobotan Data ... 26
3.2 Diagram Aktivitas Klasifikasi ... 28
3.3 Diagram Aktivitas Penyusunan Kelompok Variabel ... 30
3.4 Diagram Aktivitas Penyusunan Kelas ... 32
3.5 Diagram Aktivitas Pemanggilan Data ... 35
3.6 Arsitektur Jaringan Syaraf Tiruan ... 36
3.7 Diagram Aktivitas Penentuan Jumlah Neuron ... 39
ABSTRAK
Penggunaan pengolahan data akademik secara elektronik memberikan kemudahan dalam administrasi. Data akademik ini juga sudah digunakan sebagai dasar pengambilan keputusan dan juga digunakan dalam penelitian. Penelitian ditujukan untuk dapat menganalisa informasi yang ada pada sehingga dapat diperoleh informasi yang baru dari data akademik yang ada. Salah satu penelitian yang memanfaatkan data akademik ini adalah penelitian mengenai prediksi indeks prestasi mahasiswa. Namun dengan beragamnya data sebagai variabel masukan prediksi indeks prestasi yang tersedia pada data akademik, prediksi indeks prestasi yang sudah dilakukan sebelumnya belum tentu dapat digunakan dengan data akademik yang lain dan menghasilkan prediksi yang baik.
Hal utama yang ingin dicapai adalah untuk mendapatkan suatu model dengan teknik data mining dengan menggunakan back propagation neural network yang dapat melakukan pembelajaran terhadap data yang ada dan menentukan variabel yang dapat dipergunakan dalam prediksi indeks prestasi mahasiswa. Model ini akan melakukan penentuan variabel dari data yang ada dan melakukan pengujian data variabel hasil penentuan. Data yang digunakan adalah data mahasiswa Fakultas MIPA, Fakultas Hukum dan Fakultas Teknik.
Hasil pengujian menunjukkan bahwa variabel yang dihasilkan berbeda berdasarkan data yang digunakan dan dari hasil pengujian diperoleh peningkatan persentasi prediksi dengan menggunakan penentuan variabel ini walaupun data mahasiswa pada Fakultas Teknik memiliki jumlah variabel yang lebih sedikit dibandingkan data Mahasiswa Fakultas MIPA dan Hukum.
ABSTRACT
The use of electronic academic data processing makes the administrative job easy. These academic data has also been used as the basis of decision making and when doing a research. The purpose of this study was to analyze existing information that the academic data available can result in new information. One of the researches
using these academic data is a study on prediction of students’ achievement index.
Yet, with the various data used as the input variables for prediction of achievement index found in the available academic data, the previously done prediction of achievement index cannot always be used together with the other academic data and produces good prediction.
The main thing to be achieved is to find out a model with data mining technique by using the back propagation neural network that can learn the data available and
determine the variables that can be used in predicting students’ achievement index.
This model will determine the variables from the available data and test the determined data variables. The data used in this study were the data of the students of Faculty of Mathematics and Natural Science, Faculty of Law and Faculty of Engineering.
The result of this study showed that the variables produced were different. Based on the data used and the result of the test done, it was found out that by using the determination of these variables, the percentage of prediction increased even though the data of students of Faculty of Engineering had less variables compared to the data of students of Faculty of Mathematics and Natural Science and Faculty of Law.
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Mahasiswa sebagai produk universitas dapat memberikan gambaran keberhasilan pendidikan dan manajemen pendidikan yang berlangsung di dalamnya. Banyak hal dilakukan untuk menunjang terwujudnya pendidikan dan manajemen yang baik. Sistem informasi manajemen telah banyak dikembangkan untuk mendukung hal tersebut dengan pengumpulan dan penyimpanan data akademik secara elektronik.
Data akademik yang tersimpan dapat digunakan untuk menganalisa hubungan antar data yang ada seperti hubungan antara prestasi dan asal sekolah, prestasi dan asal daerah, jumlah mahasiswa berprestasi dan asal program studi, jarak kelulusan mahasiswa dengan diterima bekerjanya mahasiswa dan asal program studi, dan banyak hal lainnya. Data akademik ini dapat disajikan dalam bentuk tampilan grafik maupun persentasi. Penyajian data dengan model grafik dan persentasi cukup banyak digunakan untuk membantu mendukung pengambilan keputusan dan dapat digunakan untuk membantu memecahkan masalah yang mungkin atau sedang terjadi dalam kegiatan akademik, misalnya masalah menurunnya indeks prestasi mahasiswa.
2
diperhatikan dapat mengakibatkan mahasiswa drop-out. Apabila dosen wali diberikan perkiraan indeks prestasi yang mungkin diperoleh mahasiswa pada semester yang akan diambil, hal ini diharapkan dapat memberikan peringatan dini bagi mahasiswa.
Sejumlah penelitian telah dilakukan terkait dengan prediksi indeks prestasi kumulatif mahasiswa [1,2,3,4] dan memprediksi nilai mahasiswa [5,6,7]. Beberapa penelitian yang dilakukan dengan menggunakan artificial neural network sebagai metode pada data mining [1,4] untuk memprediksi IPK kelulusan menunjukkan hasil yang lebih baik dibandingkan metode lain yang pernah diteliti. Namun variabel yang digunakan dalam memprediksikan indeks prestasi mahasiswa tidak seragam pada masing-masing penelitian. Tidak semua penelitian tersebut dapat diimplementasikan pada institusi pendidikan lainnya [2,5,8,9]. Hal ini disebabkan karena perbedaan ketersediaan data yang dimiliki oleh setiap institusi pendidikan.
Terdapat kesamaan permasalahan pada beberapa penelitian di atas, yakni mengenai keseragaman dan pemilihan variabel. Berdasarkan penelitian-penelitian yang telah dilakukan sebelumnya, peneliti mencoba untuk memanfaatkan data mining untuk mengetahui kedekatan data yang terdapat dalam basis data yang tersedia terhadap indeks prestasi yang dicari. Dari hasil pengolahan data oleh data mining akan diperoleh variabel yang memiliki potensi untuk digunakan dalam prediksi indeks prestasi.
model dalam melakukan pemilihan variabel terlihat menjanjikan karena keefektifan
neural network sudah dicoba secara empiris [10]. Neural network telah berhasil diimplementasikan pada sejumlah pengklasifikasian di dunia nyata seperti pada pekerjaan industri, bisnis, dan ilmu pengetahuan [11]. Aplikasinya termasuk prediksi kebangkrutan, pengenalan tulisan, pengenalan ucapan, pemeriksaan produksi, pendeteksian kesalahan, diagnosa kesehatan, dan pemeringkatan yang terkait [10]. Menurut [12], artificial neural network merupakan alat data mining yang menjanjikan karena dapat memberikan metode kualitatif pada permasalahan umum yang membutuhkan perumusan secara statistik dan matematik yang sangat kompleks. Berdasarkan penelitian yang dilakukan oleh [13], bahwa algoritma back propagation
adalah algoritma yang terbaik sebab algoritma analisa klasifikasi bentuk kompleks dan algoritma pembelajaran dengan metode back propagation dirancang untuk mengurangi kesalahan antara hasil sebenarnya dan hasil yang diinginkan dari jaringan dengan suatu pola teratur [13]. Kombinasi dari data mining dan model neural network dapat sangat meningkatkan effisiensi dari metode data mining [14].
Meskipun telah dilakukan berbagai penelitian, namun metode yang digunakan dalam penelitian tidak dapat secara langsung diimplementasikan karena perbedaan data akademik yang digunakan dimana data tersebut belum tentu terdapat pada basis data di instansi lainnya.
4
Tabel 1.1 Daftar Penelitian Terkait
Penulis Judul Penelitian Pembahasan Tahun
Shaeela Ayesha Data Mining Model for
Pada kesimpulan dalam beberapa penelitian [2,5,8,9] dikemukakan beberapa hal seperti:
a. Terdapat kesamaan permasalahan pada beberapa penelitian di atas, yakni mengenai keseragaman dan pemilihan variabel
Dari rumusan kesimpulan yang diperoleh dari beberapa penelitian tersebut diperoleh bahwa antara satu model prediksi dengan model prediksi yang lain belum dapat dipastikan untuk dapat diimplementasikan dengan menggunakan database yang berbeda.
Apabila terdapat suatu model yang dapat melakukan penyeleksian data yang ada, maka penelitian tersebut diharapkan dapat diterapkan dengan menggunakan ketersediaan data yang berbeda.
1.2. Rumusan Masalah
Dibutuhkan suatu model penentuan variabel dari beberapa data yang berbeda sebagai masukan pada metode prediksi indeks prestasi mahasiswa menggunakan model neural network.
1.3. Tujuan Penelitian
Penelitian dilakukan untuk mendapatkan suatu model dengan menggunakan
back propagation neural network yang dapat melakukan pembelajaran terhadap data yang ada dan menentukan variabel yang dapat dipergunakan dalam prediksi indeks prestasi mahasiswa.
1.4. Manfaat Penelitian
6
1.5. Batasan Masalah
Berikut ini adalah hal-hal yang menjadi fokus pada penelitian:
a. Data yang digunakan adalah data mahasiswa USU semua program studi S-1 Fakultas Hukum, Teknik, dan MIPA, pemilihan didasarkan pada kelengkapan data.
b. Database yang digunakan adalah Mysql sesuai dengan database yang digunakan pada SIA USU.
c. Penyeleksian variabel pada data mining dengan menggunakan back propagation neural network.
d. Untuk melakukan prediksi indeks prestasi digunakan model back propagation neural network dimana model ini memberikan hasil prediksi yang lebih baik [4].
1.6. Metode Penelitian
Adapun metode penelitian yang dilakukan dalam penelitian ini meliputi: a. Studi literatur dari buku dan referensi, untuk menjadikan landasan dan
acuan bagi penelitian ini.
b. Menyusun algoritma data mining.
c. Membuat aplikasi yang memanfaatkan metode back propagation neural network untuk dapat dipergunakan dalam melakukan prediksi indeks prestasi mahasiswa.
1.7. Sistematika Pembahasan
Pada tulisan ini disusun sebanyak lima bab yang terdiri dari:
BAB I : PENDAHULUAN, berisi kerangka penelitian yaitu latar belakang, rumusan masalah, tujuan penelitian, batasan masalah, dan metode yang ditempuh;
BAB II : TINJAUAN PUSTAKA, memuat berbagai teori mengenai data mining dan back propagation neural network yang dijadikan landasan dalam melakukan penulisan dan perancangan;
BAB III : PERANCANGAN, berisi pemilihan variabel berdasarkan data yang ada, perancangan dalam membangun webservice dan aplikasi webservice dan perancangan back propagation neural network;
BAB IV : HASIL PERCOBAAN DAN ANALISIS, berisi analisis dari hasil prediksi dan perbandingan hasil prediksi terhadap data yang diperoleh;
BAB 2
TINJAUAN PUSTAKA
2.1. Data Mining
Data mining adalah kombinasi secara logis antara pengetahuan data, dan analisa statistik yang dikembangkan dalam pengetahuan bisnis atau suatu proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, tiruan dan machine-learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat bagi pengetahuan yang terkait dari berbagai database besar [15,16]. Data mining juga merupakan proses analisa yang dirancang untuk menelusuri data untuk mendapatkan bentuk konsisten dan hubungan yang sistematik antara variabel yang kemudian divalidasi dengan menggunakan sub set data yang baru [17].
Data mining sebagai bentuk dari penelusuran dengan analisis data, merupakan proses yang otomatis melakukan pengumpulan bentuk dan relasi dari sekumpulan data yang besar dibandingkan dengan melakukan percobaan hipotesa tanpa rumus [17], bahkan beberapa teknik data mining menggunakan metode validasi silang yang merupakan teknik sampling [18].
transformasi data untuk mengubah data mentah menjadi format yang dapat diproses oleh data mining, misalnya melalui filtrasi atau agregasi. Hasil transformasi data akan digunakan oleh analisis data untuk membangkitkan pengetahuan dengan menggunakan teknik seperti analisis statistik, machine learning, dan visualisasi informasi.
Gambar 2.1 Proses Data Mining [17]
Machine Learning adalah suatu area dalam kecerdasan buatan yang berhubungan dengan pengembangan teknik-teknik yang bisa diprogramkan dan belajar dari data masa lalu.
Data mining memiliki 4 tipe relasi [19] yakni:
a. Kelas, data dikelompokkan dalam kategori oleh pengguna,
10
d. Bentuk sekuensial, data digunakan untuk menentukan perilaku dan trend. Pengumpulan data yang digunakan dalam data mining dapat berupa pengambilan data secara langsung melalui hasil survey, basis data, maupun catatan yang dimasukkan secara manual. Pada pengambilan data menggunakan basis data, dapat dilakukan dengan mengakses sistem basis data maupun melaui perantaraan
webservice.
Salah satu prosedur data mining yang banyak digunakan dalam penelitian [6] terutama oleh peneliti dari beberapa perusahaan Eropa adalah Cross-Industry Standard Process for Data Mining (CRISP-DM) [19] [21]. Berdasarkan metode CRISP-DM, terdapat 6 proses data mining yakni:
a. Bussiness understanding
Proses ini fokus pada pemahaman dan perspektif bisnis proses dari suatu sistem.
b. Data Understanding
Proses ini fokus pada pembelajaran data yang ada, pengumpulan dan penyeleksian data.
c. Data Preparation
d. Modeling
Data yang telah terkumpulkan akan diproses pada tahap ini. Untuk mendapatkan hasil yang optimal, perlu dilakukan pengulangan proses data preparation.
e. Evaluation
Melakukan evaluasi terhadap hasil pemodelan, proses pemodelan dan dataset yang disiapkan sehingga tujuan penelitian dapat tercapai.
f. Deployment
Pada proses ini model telah dihasilkan. Proses ini umumnya bukan merupakan akhir dari data mining, namun proses ini dapat menjadi awal dari proses berikutnya.
Gambaran dari proses di atas dapat dilihat pada Gambar 2.2.
12
2.2. Neural Network
Neural network atau jaringan syaraf tiruan(JST) merupakan prosesor tersebar paralel yang sangat besar yang memiliki kecendrungan untuk menyimpan pengetahuan yang bersifat pengalaman dan membuatnya siap untuk digunakan [22].
Jaringan syaraf tiruan merupakan suatu sistem pemrosesan informasi yang mempunyai karakteristik menyerupai jaringan syaraf manusia. Jaringan syaraf tiruan tersusun dari sejumlah besar elemen yang melakukan kegiatan analog dengan fungsi-fungsi saraf biologis yang paling mendasar. Jaringan syaraf tiruan menyerupai otak manusia dalam dua hal [22]:
a. Pengetahuan diperoleh jaringan melalui proses belajar
b. Kekuatan hubungan antar sel syaraf yang dikenal sebagai bobot sinaptik digunakan untuk menyimpan pengetahuan
c. Jaringan syaraf tiruan dapat melakukan pembelajaran dari pengalaman sebelumnya, melakukan generalisasi, yakni dapat menghasilkan keluaran yang benar untuk input yang belum pernah dilatih sebelumnya, atas contoh-contoh yang diperolehnya dan mengabstraksi karakteristik masukan.
Sel syaraf adalah unit pemrosesan informasi yang merupakan dasar dari operasi jaringan saraf tiruan. Gambar 2.3 menunjukkan susunan dari sebuah jaringan syaraf tiruan dengan 1 lapisan tersembunyi. Terdapat tiga elemen dasar dari model neuron yaitu [22]:
b. Suatu penjumlah yang menjumlahkan sinyal-sinyal input yang diberi bobot oleh sinapsis syaraf yang sesuai
c. Fungsi aktivasi, yaitu fungsi yang digunakan untuk membatasi amplitudo keluaran dari setiap neuron.
Gambar 2.3 Sebuah Jaringan Syaraf Tiruan Dengan 1 Lapisan Tersembunyi [23] 2.3. Mengaktifkan Jaringan Saraf Tiruan
14
...(2.1) a.Fungsi Step b. Fungsi Sign
c.Fungsi Sigmoid d.Fungsi Linier Gambar 2.4 Fungsi Pengaktif
Fungsi sigmoid merupakan fungsi aktivasi yang umum digunakan dalam pelatihan jaringan syaraf tiruan [24,25]. Fungsi sigmoid didefenisikan sebagai berikut
Gambar 2.5 Pengaruh Pengaturan σ Pada Karakteristik Fungsi Sigmoid
Bila nilai σ mendekati 0, maka karakteristik fungsi sigmoid menyerupai fungsi
linier, dan bila nilai σ mendekati tak hingga, maka karakteristik fungsi sigmoid
menyerupai fungsi step.
2.4. Jaringan Syaraf Tiruan Back Propagation
16
Gambar 2.6 Arsitektur JST Back Propagation
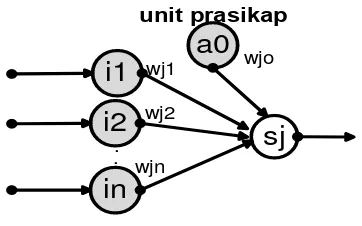
Pelatihan pada JST back propagation, umpan maju dilakukan dalam rangka perhitungan bobot sehingga pada akhir pelatihan akan diperoleh bobot-bobot yang baik. Hubungan antara bobot ini ditunjukkan seperti pada Gambar 2.7.
a0
Gambar 2.7 Hubungan Antara Bobot Pada JST
Selama proses pelatihan, bobot-bobot diatur untuk meminimumkan kesalahan yang terjadi. Sebagian besar pelatihan untuk jaringan umpan maju menggunakan gradien dari fungsi aktivasi untuk menentukan bagaimana mengatur bobot-bobot dalam rangka meminimumkan kinerja. Algoritma pelatihan standar back propagation
akan menggerakkan bobot dengan arah gradien negatif. Prinsip dasar dari algoritma
...(2.4)
... (2.5) ...(2.3) ...(2.2) Algoritma back propagation dengan fungsi aktivasi sigmoid adalah sebagai berikut:
a. Inisialisasi nilai bobot awal dengan menggunakan nilai acak yang cukup kecil, yakni antara 0 dan 1.
b. Berikan data masukan dan keluaran
c. Melakukan perhitungan keluaran. Perhitungan keluaran dilakukan dengan menggunakan persamaan sebagai berikut:
Bila X merupakan matriks data masukan dan merupakan matriks dari bobot neuron ke-h, dan bila Z merupakan nilai aktivasi neuron
tersembunyi terhadap setiap nilai masukan X yang berbanding lurus terhadap bobot. Defenisi X,W dan Z adalah sebagai berikut:
Nilai Z merupakan hasil dari fungsi:
18
...(2.6)
...(2.7)
...(2.9) ...(2.8) dan bila keluaran dari setiap layer tersembunyi adalah V, dimana
dan nilai keluaran Y didefenisikan sebagai:
dimana merupakan matriks bobot awal dari setiap neuron
tersembunyi, sehingga akan kita peroleh keluaran sebagai matriks
d. Penyesuaian bobot dilakukan dengan memanfaatkan algoritma rekursif, dimulai dari keluaran menuju ke lapisan tersembunyi pertama. Pengaturan bobot dilakukan dengan menggunakan persamaan:
Dimana:
= merupakan bobot dari titik tersembunyi i atau dari masukan ke titik j pada waktu t, atau merupakan keluaran dari titik i ataupun masukannya.
= merupakan perbaikan bobot antara lapisan tersembunyi dengan keluaran
= merupakan nilai kesalahan dari titik j e. Nilai kesalahan ditentukan oleh:
...(2.10) Dimana:
d = keluaran yang diinginkan
= hasil keluaran jaringan
f. Ada kalanya penambahan nilai momentum (α) dapat mempercepat proses pelatihan dan memperbaiki linieritas perubahan bobot. Nilai momentum memiliki rentang antara 0 dan 1. Penambahan nilai momentum didefenisikan dengan:
BAB 3
METODE PENELITIAN
3.1. Rancangan Penelitian
Penelitian ini menggunakan eksperimen laboratorium yaitu mengumpulkan data dari server database yang akan digunakan. Data dikumpulkan per mahasiswa. Data dari database akan diambil dan diberi pembobotan. Melakukan penyusunan algoritma data mining yang akan digunakan untuk mengambil data yang telah diberi pembobotan dan melakukan penyeleksian data berdasarkan kedekatan data tersebut dengan indeks prestasi. Dari variabel-variabel yang diperoleh, akan digunakan untuk mendapatkan data latihan pada metode back propagation neural network yang digunakan untuk melakukan prediksi indeks prestasi. Prediksi indeks prestasi yang diperoleh akan dibandingkan dengan data perolehan indeks prestasi mahasiswa pada semester berikutnya.
3.2. Sumber Data
3.3. Instrumen Penelitian 3.3.1 Perangkat keras
Penelitian ini menggunakan satu unit komputer terhubung ke jaringan local Unversitas Sumatera Utara yang mempunyai spesifikasi sebagai berikut:
a. Prosesor Intel(R) 2,7 GHz, b. Memori sebesar 2 GB,
c. Kapasitas penyimpanan sebesar 320 GB. 3.3.2 Perangkat lunak
Perangkat lunak yang digunakan pada penelitian ini adalah bahasa pemrograman C# dan menggunakan database mysql. Pemanfaatan bahasa pemrograman C# dikarenakan bahasa pemrograman ini memiliki fungsi
multithreading yang dapat membantu dalam perancangan aplikasi sehingga dalam proses pelatihan jaringan syaraf tiruan dapat dilakukan dengan cepat. Database mysql dipilih karena sesuai dengan database SIA dan banyak fasilitas yang diberikan dan cukup ringan sehingga proses penyimpanan dan pengambilan data tidak akan menjadi hambatan pada saat proses pelatihan berlangsung.
3.4. Database SIA
22
a. Tabel Induk
Tabel induk merupakan tabel yang mewakili entitas tertentu. Tabel induk digunakan untuk menyimpan informasi mahasiswa, pegawai, maupun dosen. Tabel yang berisikan daftar matakuliah juga termasuk dalam kategori ini. Tabel induk berisikan data yang jarang berubah.
b. Tabel Referensi
Tabel referensi berisikan data acuan. Data acuan merupakan data yang berisikan informasi terperinci yang menjelaskan data induk. Contoh data yang yang menjadi referensi adalah agama, asal SMA, kota, pekerjaan orang tua, pendidikan orang tua, penghasilan, program studi, dan lain sebagainya.
c. Tabel Transaksi
Tabel transaksi merupakan tabel yang berisikan informasi yang menggambarkan suatu bisnis proses ataupun aktifitas. Tabel transaksi akan terus bertambah secara periodik. Informasi yang terkandung di dalam tabel transaksi dapat merupakan kombinasi antara tanggal dan informasi dari tabel induk dan tabel referensi. Contoh data yang disimpan pada tabel transaksi seperti jadwal kelas, jadwal ujian, KRS mahasiswa, nilai, kegiatan mengajar dosen dan lain sebagainya.
3.5. Data mining
cukup memiliki kedekatan dengan nilai indeks prestasi, sehingga bila digunakan sebagai masukan pada prediksi indeks prestasi dapat memberikan nilai prediksi yang baik. Persiapan data dibagi menjadi pengumpul data, pembobotan data, penyusunan kelas data dan penyusunan variabel. Untuk proses data mining dilakukan dengan melakukan prediksi indeks prestasi dengan memanfaatkan data yang telah melalui proses persiapan data sebelumnya. Hasil data mining merupakan informasi kedekatan data variabel dengan data keluaran. Informasi ini akan dikelompokkan dan dilakukan pengujian dengan memanfaatkan jaringan syaraf tiruan untuk mengetahui apakah pengelompokan variabel dengan menggunakan data mining dapat dilakukan.
3.6. Perancangan Pengumpul Data
Sebuah tabel akan digunakan sebagai tempat penampungan keseluruhan variabel yang akan digunakan. Nilai masing-masing variabel akan disusun berdasarkan pembobotan. Karena tabel mahasiswa pada database sistem informasi akademik USU merupakan database ternormalisasi maka beberapa data akan menggunakan nilai referensi untuk memberikan nilai yang berbeda pada setiap data. Variabel yang akan digunakan untuk melakukan prediksi indeks prestasi berjumlah 16 yakni:
a. Asal Kota, b. Asal SMTA, c. Jumlah Saudara,
24
f. Pendidikan Terakhir Ayah, g. Pendidikan Terakhir Ibu, h. Pekerjaan Ayah,
i. Pekerjaan Ibu, j. Jumlah nilai A, k. Jumlah nilai B, l. Jumlah nilai C, m. Jumlah nilai D, n. Jumlah nilai E, o. Jumlah kehadiran, p. Persentasi kehadiran.
Data yang digunakan untuk pelatihan jaringan syaraf tiruan adalah data mahasiswa Fakultas Hukum dan MIPA semester ganjil 2008/2009, genap 2008/2009, dan ganjil 2009/2010 berjumlah 2300 sedangkan untuk pengujian digunakan data mahasiswa semester genap 2009/2010 dan ganjil 2010/2011. Untuk data pembanding digunakan data Fakultas Teknik semester ganjil 2008/2009, genap 2008/2009, ganjil 2009/2010, dan genap 2009/2010 berjumlah 2292 dan pengujian menggunakan data mahasiswa semester ganjil 2010/2011 dan genap 2010/2011. Variabel yang digunakan untuk data mahasiswa Fakultas Teknik berjumlah 14, yakni:
d. Jumlah Tanggungan Ortu, e. Jalur Masuk,
f. Pendidikan Terakhir Ayah, g. Pendidikan Terakhir Ibu, h. Pekerjaan Ayah,
i. Pekerjaan Ibu, j. Jumlah nilai A, k. Jumlah nilai B, l. Jumlah nilai C, m. Jumlah nilai D, n. Jumlah nilai E.
Data kehadiran dan persentasi kehadiran tidak terdapat pada database Fakultas Teknik.
3.7. Pembobotan Data
26
Gambar 3.1 Diagram Aktivitas Pembobotan Data
Mengambil Jumlah Variabel
Mengambil rekod variabel
Mengelompokkan nilai data pada variabel
Mengurutkan Kelompok Variabel
Mengambil Jumlah kelompok variabel
Mengambil Nilai kelompok variabel
Konversi Nilai Kelompok menjadi nilai bipolar
Terminasi
[Akhir Rekod]
[Akhir Rekod]
Algoritma pembobotan data adalah sebagai berikut:
a. Melakukan pemeriksaan data pada tabel variabel untuk memperoleh jumlah data yang tersedia.
b. Untuk setiap data variabel, data dikelompokkan berdasarkan nilai masing-masing variabel.
c. Untuk setiap pengelompokkan nilai variabel, diberikan pengurutan dari 0 sampai jumlah maksimum pengelompokan data.
d. Lakukan pemberian bobot untuk setiap data berdasarkan urutan data. e. Untuk setiap nilai bobot, dilakukan konversi menjadi nilai bipolar.
f. Untuk setiap kelompok data dengan nilai bobot yang sudah ditentukan, data variabel dikonversi menjadi nilai binner.
Dengan memanfaatkan algoritma pembobotan yang telah disusun, diperoleh data dengan pembobotan -1 dan 1. Hasil pembobotan beberapa data ditunjukkan pada Tabel 3.1.
Tabel 3.1 Hasil Pembobotan
28
3.8. Klasifikasi Data
3.8.1. Pemodelan Klasifikasi Data
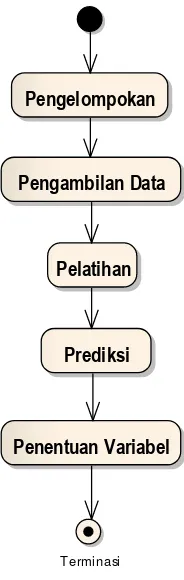
Klasifikasi data dilakukan dengan memanfaatkan kemampuan metode back propagation pada jaringan syaraf tiruan untuk melakukan prediksi indeks prestasi. Model klasifikasi akan terdiri dari 4 bagian yakni: bagian yang melaksanakan pengelompokan, bagian yang melaksanakan pengambilan data, bagian yang melakukan prediksi, dan bagian yang melakukan penentuan apakah variabel dapat dipergunakan sebagai data prediksi. Diagram aktivitas klasifikasi data dapat dilihat pada Gambar 3.2.
Gambar 3.2 Diagram Aktivitas Klasifikasi
Pengelompokan
Pengambilan Data
Prediksi
Penentuan Variabel
3.8.2. Pengelompokan
Bagian pengelompokan memiliki 2 bagian yakni bagian yang berfungsi untuk menyusun dan melakukan pengelompokan variabel yang akan menjadi masukan pada jaringan syaraf tiruan dan bagian yang menyusun kelas data. Pengelompokan variabel memiliki sub bagian yang melakukan penyusunan kelompok dan menyimpan informasi pengelompokan ke dalam database.
Informasi penyusunan kelompok yang disimpan tersebut memiliki 3 fungsi yakni:
a. Membedakan antara pengujian dengan pengelompokan kelas yang berbeda.
b. Mendapatkan variabel yang tepat pada saat pelatihan, pengklasifikasian dan penentuan variabel.
c. Pengujian dapat dilakukan dengan menggunakan data yang memiliki karakteristik yang sama dengan data pelatihan, pengklasifikasian dan penentuan variabel.
30
Gambar 3.3 Diagram Aktivitas Penyusunan Kelompok Variabel
Kelas data merupakan pengelompokan nilai keluaran (indeks prestasi) dari data prediksi. Masing-masing kelas data yang disusun akan memiliki satu buah objek jaringan syaraf tiruan yang dilatih berdasarkan data masukan. Untuk memperoleh kelas dilakukan perhitungan jumlah data. Proses penyusunan kelas diawali dengan mengambil jumlah data indeks prestasi yang seragam. Untuk mendapatkan kelas, maka data akan disusun berdasarkan pengelompokan nilai indeks prestasi yang seragam tersebut dengan minimal N jumlah data. Pada penelitian [4,5,27], umumnya data keluaran disusun dalam pengelompokan yang cukup sedikit dibawah 5
Ambil data variabel
Susun query pengambilan data
Simpan query ke database
buah kelas. Berdasarkan hal ini maka nilai N yang diujicobakan akan memiliki nilai 300,500 dan 700. Pemilihan jumlah ini digunakan karena jumlah data untuk pelatihan jaringan syaraf tiruan yang ada pada database sejumlah 2300, dimana dengan nilai ini akan diperoleh 7 buah kelas untuk N=300,4 buah kelas untuk N=500 dan 3 buah kelas untuk N=700. Setiap kelas memiliki informasi yakni: objek jaringan syaraf tiruan, indeks prestasi minimum, dan indeks prestasi maksimum.
32
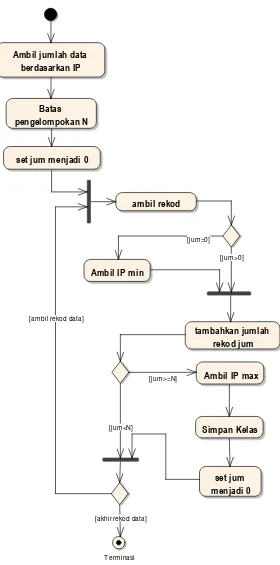
Gambar 3.4 Diagram Aktivitas Penyusunan Kelas
Ambil jumlah data berdasarkan IP
Batas pengelompokan N
set jum menjadi 0
ambil rekod
tambahkan jumlah rekod jum
Ambil IP max Ambil IP min
Simpan Kelas
set jum menjadi 0
Terminasi [akhir rekod data]
[jum>=N] [jum=0]
[jum<N] [ambil rekod data]
Hasil dari penyusunan kelas disimpan agar dapat dipergunakan pada saat melakukan pelatihan dan prediksi. Hasil penyusunan kelas dapat dilihat pada Tabel 3.2,3.3, dan 3.4:
Tabel 3.2 Penyusunan Kelas Dengan N=300 No. Ip Terkecil Ip Terbesar Jumlah
Tabel 3.3 Penyusunan Kelas Dengan N=500 No. Ip Terkecil Ip Terbesar Jumlah
1 0 2.42 501
2 2.43 2.83 503
3 2.84 3.14 506
4 3.15 4 790
Tabel 3.4 Penyusunan Kelas Dengan N=700 No. Ip Terkecil Ip Terbesar Jumlah
1 0 2.61 710
2 2.62 3.08 706
3 3.09 4 884
34
terakhir menunjukkan bahwa jumlah data yang nilai indeks prestasinya berada antara rentang kelas tersebut cukup besar.
3.8.3. Pengambilan Data
Pengambilan data memiliki fungsi untuk melakukan penyusunan kelas data yang akan menjadi masukan pada data pelatihan jaringan syaraf tiruan dan melakukan pengambilan data berdasarkan pengelompokan data. Bagian pengambilan data akan mengambil informasi pengelompokan variabel yang akan digunakan dari bagian pengelompokan data, kemudian mengambil data ke database.
Bagian pengambilan data juga harus dapat membedakan pengambilan data untuk data latihan dan pengambilan data untuk data uji coba. Perbedaan pengambilan data masukan pelatihan dan data uji coba adalah penyusunan data berdasarkan kelas. Untuk data yang digunakan sebagai data masukan untuk melatih objek jaringan syaraf tiruan, bagian pengambil data melakukan penyusunan query dengan informasi dari tiap kelas sebagai batasan pemanggilan data.
Gambar 3.5 Diagram Aktivitas Pemanggilan Data 3.8.4. Jaringan Syaraf Tiruan
Jaringan syaraf tiruan berfungsi untuk melakukan prediksi nilai indeks prestasi. Dengan memanfaatkan jaringan syaraf tiruan, akan ditentukan apakah suatu data dari variabel yang telah dikumpulkan dapat digunakan sebagai data untuk prediksi yang sebenarnya.
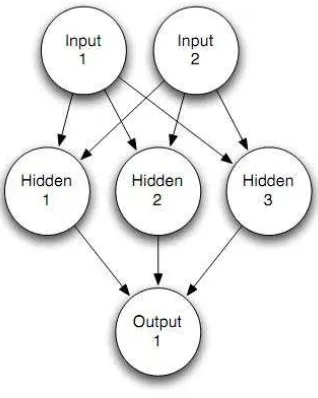
Perancangan jaringan syaraf tiruan dimulai dengan menentukan arsitektur jaringan syaraf tiruan yang akan dibuat. Dalam penelitian ini akan digunakan 1 layer
masukan, 1 layer tersembunyi, dan 1 layer keluaran. Arsitektur ini merupakan Ambil data variabel
Susun query pengambilan data
Simpan query ke database
36
...(3.2) ...(3.1) arsitektur yang umum digunakan dalam aplikasi dan penelitian [25,26]. Arsitektur jaringan dapat dilihat pada Gambar 3.6.
Gambar 3.6 Arsitektur Jaringan Syaraf Tiruan
Pemilihan fungsi aktifasi menjadi bagian yang penting dalam perancangan jaringan syaraf tiruan. Fungsi aktifasi untuk back propagation seharusnya memiliki karakteristik penting yakni: memiliki fungsi kontinu, derivatif dan bukan merupakan fungsi penurunan linier [29]. Peneliti memilih memanfaatkan fungsi sigmoid, karena fungsi sigmoid ini memenuhi karateristik yang disebutkan diatas, untuk menentukan aktifasi dari neuron. Fungsi sigmoid didefenisikan sebagai berikut
Dan fungsi derivatifnya adalah:
Agar jaringan syaraf tiruan dapat dipergunakan dalam prediksi, terlebih dahulu setiap neuron harus diberikan bobot. Pelatihan jaringan syaraf dimaksudkan untuk memberikan bobot tersebut yang akan dilakukan dengan menggunakan metode
back propagation. Algoritma pembelajaran dengan metode back propagation sesuai dengan algoritma yang telah dipaparkan pada Bab 2.4.
Dalam perancangan jaringan syaraf tiruan, jumlah neuron pada lapisan tersembunyi juga memiliki fungsi yang sangat berpengaruh. Jumlah neuron akan memberikan pengaruh pada kestabilan jaringan dan kestabilan perbandingan antara masukan dan keluaran [31]. Semakin banyak jumlah lapisan tersembunyi maka nilai bobot masing-masing neuron akan semakin kecil [31]. Jumlah lapisan tersembunyi ini juga memiliki pengaruh terhadap cepat lambatnya proses pelatihan dan prediksi dengan memanfaatkan jaringan syaraf tiruan tersebut. Semakin banyak jumlah lapisan tersembunyi maka semakin lama waktu yang diperlukan jaringan syaraf tiruan untuk melakukan pelatihan dan prediksi.
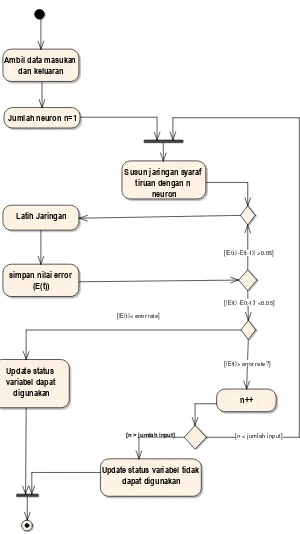
Penentuan jumlah neuron juga akan membantu mengoptimalkan waktu yang diperlukan untuk pelatihan dan prediksi dan juga membantu menurunkan tingkat kesalahan prediksi. Untuk menemukan jumlah hidden neuron yang tepat, akan digunakan algoritma sebagai berikut:
a. Melakukan pengambilan data masukan dan keluaran.
38
c. Ambil nilai error, simpan ke dalam array E(t) dimana t adalah jumlah iterasi saat ini.
d. Jika nilai |E(t)-E(t-1)| lebih besar dari 0.05, maka akan dilakukan pelatihan dengan nilai iterasi selanjutnya. Nilai 0.05 diambil untuk membatasi bahwa perubahan jaringan sudah stabil sehingga tidak akan terjadi perubahan yang signifikan jika dilakukan pelatihan selanjutnya. e. Jika nilai |E(t) - E(t-1)| lebih kecil dari 0.05, maka akan dilakukan
pengecekan apakah E(t) lebih kecil dari nilai error rate yang diberikan, jika lebih kecil, maka pelatihan dihentikan dan akan dilanjutkan dengan update status data variabel.
f. Bila nilai E(t) lebih besar dari error rate, maka akan dilakukan penambahan jumlah neuron pada lapisan tersembunyi dengan jumlah n=n+1 dan proses akan diulang kembali mulai dari langkah ke-2.
g. Bila jumlah n telah sama dengan jumlah masukan, maka pelatihan akan dihentikan, sesuai dengan penelitian yang dilakukan oleh [28,29] bahwa jumlah neuron yang optimum yang digunakan adalah jumlah antara jumlah keluaran yang diharapkan dan jumlah masukan yang diberikan pada jaringan syaraf tiruan yang dibentuk.
Gambar 3.7 Diagram Aktivitas Penentuan Jumlah Neuron
Jumlah neuron n=1
Susun jaringan syaraf tiruan dengan n
neuron
Latih Jaringan
simpan nilai error (E(t)) Ambil data masukan
dan keluaran
n++
Update status variabel tidak dapat digunakan Update status
variabel dapat digunakan
[|E(t)> error rate?] [|E(t) -E(t-1)| >0.05]
[|E(t)< error rate]
[n > j umlah input] [n < jumlah input]
40
Proses pelatihan ini akan menghasilkan sebuah network yang akan dipergunakan sebagai klasifikasi. Untuk melakukan penyeleksian data variabel, maka jaringan yang sudah dilatih akan disimpan dalam bentuk berkas. Berkas ini kemudian dapat dipergunakan untuk melakukan prediksi terhadap variabel yang telah dipersiapkan pada bagian klasifikasi. Proses pelatihan dilakukan untuk setiap kombinasi variabel data dan kombinasi kelas. Untuk setiap kombinasi, objek data akan disimpan dalam satu berkas. Variabel yang tidak memenuhi pada proses seleksi pertama ini tidak akan digunakan pada tahap selanjutnya.
Setiap hasil akhir proses penentuan jumlah neuron akan disimpan ke dalam tabel sehingga informasi bahwa data variabel dapat digunakan atau tidak dapat diketahui. Spesifikasi tabel disusun seperti pada Tabel 3.5.
Tabel 3.5 Spesifikasi Tabel Daftar Hasil Pelatihan
Nama Kolom Tipe Data Keterangan
preTrainId int(20) unsigned Id Primer
preTrainGroup bigint(20) unsigned
...(3.3) kemudian dilakukan pengambilan data yang akan digunakan sebagai data uji coba. Proses dilanjutkan dengan menyusun objek jaringan syaraf tiruan dari berkas, kemudian melakukan perhitungan bobot. Proses dilakukan secara berulang berdasarkan informasi yang disimpan pada hasil pelatihan. Nilai bobot akan menentukan apakah suatu jaringan tersebut memiliki nilai prediksi yang tepat atau tidak. Untuk setiap kelompok variabel dilakukan pelatihan data, dan akan dipilih salah satu jaringan yang dianggap tepat sesuai nilai bobot, dan informasi prediksi disimpan ke dalam tabel. Pada data yang disimpan diberikan informasi identitas data tabel variabel sehingga dapat digunakan untuk melakukan pencarian informasi jumlah kesalahan prediksi yang terjadi pada saat pengujian. Spesifikasi tabel disusun seperti pada Tabel 3.6.
Tabel 3.6 Spesifikasi Tabel Daftar Hasil Pengujian
Nama Kolom Tipe Data Keterangan
dbResultId int(10) unsigned Id Primer
dbResultTrainId int(10) unsigned dbResultAccuracy varchar(45) dbResultTryData varchar(45)
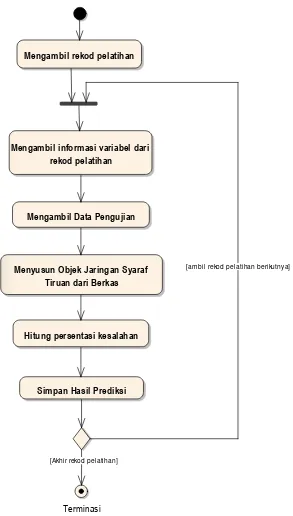
Proses prediksi akan dilakukan dalam perulangan untuk setiap data yang diambil berdasarkan pengelompokan variabel dan pengelompokan kelas keluaran data. Hasil prediksi indeks prestasi akan dibandingkan dengan perolehan indeks prestasi mahasiswa pada semester yang diprediksi. Perhitungan persentasi prediksi (E) dilakukan dengan menggunakan persamaan sebagai berikut:
42
Pada Gambar 3.8 digambarkan diagram aktivitas proses prediksi.
Gambar 3.8 Diagram Aktivitas Proses Prediksi Indeks Prestasi
Mengambil rekod pelatihan
Mengambil informasi variabel dari rekod pelatihan
Mengambil Data Pengujian
Menyusun Objek Jaringan Syaraf Tiruan dari Berkas
Hitung persentasi kesalahan
Simpan Hasil Prediksi
Terminasi
[Akhir rekod pelatihan]
Pada proses pelatihan jaringan diperlukan jumlah perulangan yang cukup banyak. Hal ini terkait dengan jumlah variabel yang akan diuji, jumlah data yang dipergunakan, jumlah iterasi dalam penentuan jumlah neuron, dan parameter-parameter yang digunakan dalam penentuan jumlah neuron. Karenanya akan dilakukan penggabungan antara pelatihan jaringan syaraf tiruan dan prediksi.
Parameter yang digunakan dalam melakukan pelatihan jaringan syaraf tiruan adalah nilai pembelajaran Lrate dan nilai sigmoid Asigmoid. Belum terdapat acuan
standar dalam pemilihan nilai pembelajaran dan nilai sigmoid. Pada penelitian yang dilakukan [30], dilakukan pengujian menggunakan beberapa nilai pembelajaran yang hasilnya ditunjukkan pada Tabel 3.7.
Tabel 3.7 Hasil Penelitian Berdasarkan Nilai Pembelajaran [32] Lrate Jumlah Pelatihan Persentase Akurasi
44
Berdasarkan hasil penelitian tersebut, maka digunakan nilai pembelajaran Lrate yakni 0.01, 0.05, 0.1 karena pada nilai pembelajaran tersebut, diperoleh jumlah pelatihan yang lebih sedikit dengan nilai persentasi akurasi yang cukup baik. Sedangkan nilai alpha sigmoid akan memberikan pengaruh terhadap jumlah pelatihan. Nilai alpha sigmoid yang umum digunakan dalam pengujian adalah 0.5,1,2 dimana nilai ini mewakili fungsi sigmoid, yakni nilai alpha sigmoid 0.5 memberikan karakteristik yang mendekati fungsi linier, nilai alpha sigmoid 1 memberikan karakteristik fungsi sigmoid, dan nilai alpha sigmoid 2 memberikan karakteristik mendekati fungsi step.
Adapun parameter yang akan digunakan dalam pelatihan jaringan syaraf tiruan dan prediksi adalah sebagai berikut:
a. Jumlah pengelompokan data N yakni 300,500,700 b. Nilai pembelajaran Lrate yakni 0.01, 0.05, 0.1
c. Nilai alpha sigmoid Asigmoid yang digunakan yakni 0.5,1, 2
persentasi prediksi dan S menginformasikan status apakah objek jaringan valid atau tidak.
3.8.5. Penentuan Variabel
Penentuan variabel berdasarkan pada valid atau tidaknya sebuah variabel sesuai dengan hasil pengujian penentuan jumlah neuron dan persentasi prediksi. Prediksi menggunakan data pengujian, dan setelah prediksi dilakukan, data hasil prediksi dibandingkan dengan hasil sebenarnya. Variabel yang memiliki persentasi prediksi tertinggi merupakan hasil dari bagian klasifikasi variabel ini dan akan digunakan untuk menentukan apakah model ini dapat digunakan untuk membantu dalam proses pemilihan variabel bila terdapat sejumlah variabel yang menurut pengamatan memiliki pengaruh yang cukup signifikan dalam memberikan prediksi yang lebih baik.
3.8.6. Pengujian Variabel
46
BAB 4
HASIL DAN ANALISIS
Pengujian dilakukan dengan mengunakan data yang diperoleh dari database SIA, yakni data mahasiswa Fakultas Hukum dan Fakultas MIPA. Kelengkapan data merupakan hal yang utama, sebab bila cukup banyak variabel yang akan digunakan dalam pengujian bernilai kosong, maka akan sangat mempengaruhi keakuratan hasil prediksi indeks prestasi mahasiswa. Pengaruh keakuratan prediksi indeks prestasi dapat membuat variabel yang diikutsertakan dalam klasifikasi tidak memiliki potensi untuk digunakan dalam menentukan indeks prestasi mahasiswa.
Keakuratan pengujian juga sangat dipengaruhi oleh parameter pembentukan jaringan. Parameter seperti nilai pembelajaran (Lrate) dan nilai alpha sigmoid Asigmoid
membantu menentukan kenaikan bobot dari setiap neuron yang menjadi penentu keluaran dari jaringan syaraf tiruan. Jumlah neuron yang ada juga sangat berpengaruh dalam memberikan prediksi yang baik.
4.1. Data Mining
Tabel 4.1 Jumlah Neuron Rata-Rata Hasil Pelatihan Jaringan
Dengan memperhatikan pembentukan kelas pada Tabel 3.2,3.3, dan 3.4, pada Tabel 4.1 ditunjukkan bahwa semakin sedikit jumlah keluaran, maka nilai kedekatan data antara masukan dan keluaran prediksi indeks prestasi dapat semakin baik, namun dengan semakin sedikitnya kelas keluaran indeks prestasi yang diprediksi, maka rentang indeks prestasi pada kelas menjadi cukup besar sehingga akan menurunkan ketelitian prediksi.
48
Tabel 4.2 Rangkuman Hasil Pelatihan
a. Dengan menggunakan Data Mahasiswa Fakultas MIPA dan Hukum
K Jumlah Jaringan Valid
b. Dengan menggunakan Data Mahasiswa Fakultas Teknik
4.2. Analisa Pengujian Dengan Data Mining
Pada pengujian dengan N=700 pada Tabel 4.2, kesemua pengujian menghasilkan jaringan yang valid. Hal ini menunjukkan bahwa kemungkinan valid jaringan pada N=700 cukup besar.
Untuk N=500, pada Tabel 4.2.a, tampak bahwa kedekatan data ditunjukkan dengan nilai yang bervariasi pada hasil pengujian. Pada pengujian dengan N=500, terdapat 8 variabel yang memiliki kedekatan data antara masukan dan keluaran yang lebih baik dimana dengan menggunakan variabel tersebut dapat menghasilkan 7 jaringan yang valid, sedangkan pada Tabel 4.2.b, terdapat 2 variabel yang pada pengujian dapat menghasilkan 8 jaringan yang valid.
Untuk N=300 pada pengujian dengan menggunakan data mahasiswa Fakultas MIPA dan Hukum, jumlah jaringan yang berhasil dibentuk sangat sedikit, bahkan terdapat 1 variabel yang hanya memiliki jumlah variabel yang valid hanya 2 yakni pada pengujian dengan menggunakan data variabel ke-7. Jumlah ini menunjukkan bahwa dengan sejumlah pengujian yang dilakukan kedekatan data antara masukan dan keluaran dari variabel ke-7 lebih sedikit dari variabel yang lain, sedangkan pada Tabel 4.2.b, dengan menggunakan data variabel ke-1 dan 2 jumlah jaringan valid lebih banyak dibandingkan bila menggunakan variabel lainnya.
50
a. Asal SMTA, b. Jumlah Saudara, c. Jumlah nilai A, d. Jumlah nilai B, e. Jumlah nilai C, f. Jumlah nilai D, g. Jumlah nilai E, h. Jumlah kehadiran.
Sedangkan dari hasil pengujian valid atau tidaknya sebuah jaringan dengan menggunakan data mahasiswa Fakultas Teknik, diperoleh variabel-variabel yang memiliki kedekatan data antara data variabel dan indeks prestasi mahasiswa sbb:
a. Asal Kota, b. Asal SMTA, c. Jumlah nilai A, d. Jumlah nilai D, e. Jumlah nilai E.
a. Asal Kota,
b. Jumlah Tanggungan Ortu, c. Jalur Masuk,
d. Pendidikan Terakhir Ayah, e. Pekerjaan Ayah,
f. Pekerjaan Ibu, g. Persentasi kehadiran.
Sedangkan dari hasil pengujian dengan menggunakan data mahasiswa Fakultas Teknik, variabel yang digunakan sebagai perbandingan pengujian adalah:
a. Jumlah nilai C, b. Jumlah nilai D. 4.3. Pengujian Variabel
Dari proses data mining diperoleh informasi variabel yang dapat digunakan berdasarkan analisa klasifikasi yang telah dipaparkan sebelumnya. Untuk memastikan apakah variabel yang diklasifikasikan memberikan hasil prediksi indeks prestasi yang baik, maka akan dilakukan pengujian dengan menggunakan penggabungan data variabel yang dikelompokkan diatas, yakni variabel dengan jumlah jaringan valid sebanyak 19 dan 18 untuk pengujian menggunakan data Fakultas MIPA dan Hukum, dan variabel dengan jumlah jaringan valid sebanyak 20 dan 19 untuk pengujian menggunakan data Fakultas Teknik.
52
melakukan perbandingan dengan nilai indeks prestasi sebenarnya, dan dilakukan perhitungan persentasi prediksi. Dari hasil pengujian dengan variabel yang masing-masing memperoleh jumlah jaringan valid sejumlah 19(VA) dan 18(VB) dengan menggunakan data Fakultas MIPA dan Hukum diperoleh data seperti Tabel 4.3 dan Tabel 4.4 dan pengujian dengan variabel yang masing-masing memperoleh jumlah jaringan valid sejumlah 20(VC) dan 19(VD) dengan menggunakan data Fakultas Teknik diperoleh data seperti Tabel 4.5 dan Tabel 4.6.
Tabel 4.3 Hasil Pengujian Pelatihan Data VA
Asigmoid Lrate
Tabel 4.4 Hasil Pengujian Pelatihan Data VB
Tabel 4.5 Hasil Pengujian Pelatihan Data VC
Tabel 4.6 Hasil Pengujian Pelatihan Data VD
Asigmoid Lrate
4.4. Analisa Hasil Pengujian Variabel
54
VC, dan Nn=50 untuk VD, sehingga proses pelatihan tidak dilanjutkan kembali. Jaringan yang valid dengan menggunakan data VA, ditunjukkan pada pelatihan N=500 dengan nilai Asigmoid=0.5 dan nilai Lrate 0.01,0.05, dan 0.1 dan dengan nilai Asigmoid=1 dan nilai Lrate 0.05 dan 0.1dan pada pelatihan dengan N=700, semua prediksi menunjukkan nilai yang cukup baik diatas 80%. Sedangkan dengan menggunakan data VD, jaringan yang valid ditunjukkan pada pelatihan N=500 dengan nilai Asigmoid=0.5 dan nilai Lrate 0.1 dan dengan nilai Asigmoid=2 dan nilai Lrate 0.05. Pada pelatihan dengan N=700 dengan menggunakan data yang sama diperoleh jaringan yang valid pada nilai Asigmoid=0.5 dan nilai Lrate 0.05, Asigmoid=1 dan nilai
Lrate 0.01 dan 0.05dan Asigmoid=2 dan nilai Lrate 0.05.
Pada pelatihan jaringan syaraf tiruan, rata-rata persentasi prediksi indeks prestasi jaringan syaraf tiruan yang valid dengan menggunakan data mahasiswa Fakultas MIPA dan Hukum adalah:
Rata-rata Persentasi Prediksi =
=
= 60.63834 %
Rata-rata Persentasi Prediksi =
=
= 64.66%
Setelah menggunakan variabel yang ditentukan dengan menggunakan model klasifikasi ini, diperoleh rata-rata persentasi prediksi indeks prestasi dengan menggunakan data Fakultas MIPA dan Hukum adalah:
Rata-rata Persentasi Prediksi =
=
= 81.589%
dan rata-rata persentasi prediksi indeks prestasi dengan menggunakan data mahasiswa Fakultas Teknik adalah:
Rata-rata Persentasi Prediksi =
=
= 79.9%
56
cukup besar pada nilai 47.19%. Hal ini menunjukkan bahwa data yang dipergunakan dalam pelatihan ini tidak memiliki keterkaitan antara data masukan dengan data keluaran yakni indeks prestasi mahasiswa. Namun pada pengujian variabel untuk kelompok variabel VD, terdapat 1 jaringan yang valid degan menggunakan nilai Asigmoid=2 dan nilai Lrate 0.05. Namun persentasi prediksi tidak menunjukkan peningkatan dari hasil pengujian sebelumnya.
BAB 5
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Berdasarkan hasil pengujian dan analisa penelitian ini diperoleh kesimpulan: a. Proses pemilihan, pengelompokan, dan pengklasifikasian sebagai proses dari
data mining ditunjukkan dalam pengujian ini memberikan hasil yang cukup memuaskan, dimana berdasarkan pengujian yang dilakukan, model pemilihan variabel dengan memanfaatkan data mining, dengan menggunakan jaringan syaraf tiruan bermetode pembelajaran back propagation memiliki kemampuan dalam melakukan pemilihan variabel.
58
5.2. Saran
Adapun saran untuk penelitian selanjutnya adalah:
a. Pada penelitian ini, hanya dilakukan pemilihan variabel dengan memanfaatkan jaringan syaraf tiruan dengan aktivasi sigmoid. Pada penelitian berikutnya dapat memanfaatkan beberapa metode aktivasi lainnya dapat diterapkan ke dalam metode ini.
b. Hasil pengujian menunjukkan bahwa jumlah kehadiran memiliki pengaruh yang cukup baik dimana pada pengujian dengan menggunakan data Fakultas MIPA dan Hukum lebih baik dibandingkan dengan pengujian dengan menggunakan data Fakultas Teknik, namun perlu dilakukan pengujian pada penelitian selanjutnya dengan menggunakan variabel lain seperti nilai TPA, TOEFL, IQ dan variabel yang menggambarkan kemampuan akademik mahasiswa lainnya.
c. Perlunya penelitian lebih lanjut mengenai efektivitas pemanfaatan metode jaringan syaraf tiruan ini sebagai bagian pemilih variabel pada data mining
DAFTAR PUSTAKA
[1] Joan L. Anderson, "Predicting Final CPA of Graduate School Students: Comparing Artificial Neural Networking and Simultaneous Multiple Regression," College and University, vol. 81, no. 4, pp. 19-29, 2006. [2] Cesar Vialardi, Javier Bravo, Leila Shafti, and Alvaro Ortigosa,
"Recommendation in Higher Education Using Data Mining Techniques,"
Educational Data Mining, 2009.
[3] Bijayananda Naik and Srinivasan Ragothaman, "Using Neural Netwroks to Predict MBA Student Success," College Student Journal, vol. 38, no. 1, pp. 143-149, 2004.
[4] Zaidah Ibrahim and Daliela Rusli, "Predicting Students Academic Performance: Comparing Artificial Neural Network, Decision Tree and Liniear Regresion,"
21st Anual SAS Malaysia Forum, September 2007.
[5] V.O. Oladokun, A.T. Adebanjo, and O.E. Charles-Owaba, "Predicting Students Academic Performance using Artificial Neural Network:A Case Study of an Engineering Course.," The Pacific Journal of Science and Technology, vol. 9, no. 1, May-June 2008.
[6] Qasem A. Al-Radaideh, Emad M. Al-Shawakfa, and and Mustafa I. Al-Najjar, "Mining Student Data Using Decision Trees," The 2006 International Arab Conference on Information Technology, 2006.
[7] K Nilakant. (2011, Februari) Application of Data Mining in Constraint Based Intelligent Tutoring System. [Online].
http://www.cosc.canterbury.ac.nz/research/reports/HonsReps/
[8] Stamos T. Karamouzis and Andreas Vrettos, "An Artificial Neural Network for PredictingStudent Graduation Outcomes," Proceedings of the World Congress on Engineering and Computer Science, October 2008.
60
Practices in Quantitative Methods.: Sage Publications, 2007, pp. 283-293. [10] Guoqiang Peter Zhang, "Neural Networks for Classification: A Survey," IEEE
Transactions On Systems, Man and Cybernetics, vol. 30, no. 4, NOVEMBER 2000.
[11] B.Widrow, D. E. Rumelhard, and M. A. Lehr, "Neural networks: Appllications in industry, business and science," Commun. ACM, vol. 37, pp. 93-105, 1994. [12] Dr. Yashpal Singh and Alok Singh Chauhan, "Neural Networka in Data
Mining," Journal of Theoretical and Applied Information Technology, vol. 5, no. 6, pp. 37-42, 2009.
[13] Mutasem Khalil Sari Alsmadi and Khairuddin Bin Omara, "Back Propagation Algorithm: The Best Algorithm Among the Multi-layer Perceptron Algorithm,"
IJCSNS International Journal of Computer Science and Network Security, vol. 9, p. 378, April 2009.
[14] Xianjun Ni, "Research of Data Mining Based on Neural Networks," World Academy of Science, Engineering and Technology 39, 2008.
[15] Therling K. (2011, Februari) An Introduction to Data Mining Discovering hidden value in your data warehouse. [Online].
http://www.thearling.com/text/dmwhite/dmwhite.htm
[16] M.H. Dunham, Data mining introductory and advanced topics. New Jersey, USA: Prentice Hall, 2003.
[17] Shuxiang Xu and Ling Chen, "A Novel Approach for Determining the Optimal
Number of Hidden Layer Neurons for FNN’s and Its Application in Data
Mining," International Conference on Information Technology and Applications 5th (ICITA 2008), 2008.
[18] Jiawei Han, Data Mining Concepts and Techniques. San Fransisco, USA: Morgan Kaufmann, 2006.
[19] Programming In Data Mining Industry. [Online].
[20] CRISP-DM. [Online]. http://www.crisp-dm.org/Process/index.htm [2011, Juni] [21] Nikhil R. Pal Jain and Lakhmi, Advanced Techniquesin Knowledge
Discoveryand Data Mining. London: Springer-Verlag, 2004.
[22] Simon Haykin, Neural Networks: A Comprehensive Foundation. New York, USA: Macmillan, 1994.
[23] David L. Poole and Alan K. Mackworth, Artificial Intelligence Foundations of
Computational Agents. Cambridge, United Kingdom: Cambridge University Press, 2010.
[24] L Fausett, Fundamentals of Neural Networks: Architecture. Englewood Cliffs: Prentice Hall, 1994.
[25] Monica Adya and Fred Collopy, "How Effective are Neural Networks at Forecasting and Prediction? A Review and Evaluation," in Journal of Forecasting J. Forecast. 17, 1998, pp. 481-495.
[26] Michal Rosen Zvi, Michael Biehl, and Ido Kanter, "Learnability of Periodic Activation Functions-General Results," in Physical Review E, 1998.
[27] Zhen Liu, German Florez, and Susan M. Bridges, "A Comparison Of Input Representations In Neural Networks: A Case Study In Intrusion Detection," in
Proceedings of the 2002 International Joint Conference on Neural Networks, 2002.
[28] Behrouz Minaei-Bidgoli, Deborah A. Kashy, Gerd Kortemeyer, and William F. Punch, "Predicting Student Performance: An Application Of Data Mining Methods With The Educational Web-based System Lon-Capa," ASEE/IEEE Frontiers in Education Conference, November 2003.
[29] Mehmet Yilmaz and Ersoy Arslan, "Effect of Increasing Number of Neurons Using Artificialneural Network to Estimate Geoid Heights," International Journal of the Physical Sciences, vol. 6, no. 3, pp. 529-533, February 2011. [30] Michael L. Nelson, Joan A. Smith, and Ignatio G. del Campo, "Efficient,
62
2006.
[31] Katsunari Shibata and Yusuke Ikeda, "Effect of number of hidden neurons on learning in large-scale layered neural networks," in ICROS-SICE International Joint Conference, Fukuoka, Japan, 2009, pp. 5008-5013.
Lampiran 1 Hasil Pengujian Dengan Menggunakan Data Mahasiswa Fakultas MIPA dan Hukum
Tabel 1 Hasil Pengujian Dengan N=300, Asigmoid =0.5
K
Lrate
0.01 0.05 0.1
Nn I E S Nn I E S Nn I E S
64
Tabel 2 Hasil Pengujian Dengan N=300, Asigmoid =1
K
Lrate
0.01 0.05 0.1
Nn I E S Nn I E S Nn I E S
Tabel 3 Hasil Pengujian Dengan N=300, Asigmoid =2
K
Lrate
0.01 0.05 0.1
Nn I E S Nn I E S Nn I E S
66
Tabel 4 Hasil Pengujian Dengan N=500, Asigmoid =0.5
K
Lrate
0.01 0.05 0.1
Nn I E S Nn I E S Nn I E S
Tabel 5 Hasil Pengujian Dengan N=500, Asigmoid =1
K
Lrate
0.01 0.05 0.1
Nn I E S Nn I E S Nn I E S