SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana Program Strata Satu Jurusan Teknik Informatika
Fakultas Teknik dan Ilmu Komputer
Oleh:
RIKI HIDAYAT
10108371
PROGRAM STUDI S1
JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
i
PENCARIAN INFORMASI BUKU DI PERPUSTAKAAN
DAERAH BANDUNG PROVINSI JAWA BARAT
Oleh:
RIKI HIDAYAT
10108371
Berdasarkan hasil wawancara terhadap beberapa pengunjung perpustakaan dapat disimpulkan bahwa untuk mencari informasi buku hanya sedikit pengunjung yang sudah mengetahui identitas dari buku yang akan dicari. Akan tetapi, kebanyakan pengunjung justru tidak mengetahui informasi sedikitpun mengenai identitas buku yang akan dicari melainkan hanya mengetahui gambaran akan kebutuhan informasi yang dibutuhkan terhadap buku. Atas dasar permasalahan tersebut perlu dikembangkan sistem pencarian informasi buku yang dapat menemukan informasi buku sesuai dengan kebutuhan pengunjung secara dinamis. Maksud dinamis dalam penelitian ini adalah masukan terhadap sistem tidak hanya terpaku kepada identitas buku seperti judul, pengarang, penerbit, dan lain-lain, melainkan gambaran kebutuhan pengunjung terhadap buku. Selain itu, pengunjung juga bisa menentukan relevan atau tidaknya informasi buku sebagai
feedback untuk sistem agar sistem bisa menemukan informasi buku yang lebih relevan menurut pengunjung.
ii
buku dapat mempermudah pengunjung untuk mencari informasi buku yang
dibutuhkan. Selain itu, metode vector space model dan support vector machines
dapat diimplementasikan untuk membangun sistem pencarian informasi buku.
iii
BOOK INFORMATION RETRIEVAL AT LOCAL LIBRARY
BANDUNG WEST JAVA PROVINCE
By: RIKI HIDAYAT
10108371
Based on interview results with some library visitors can be concluded that in order to find information book, only a few visitors who already know about book identity which they want to seacrch. However, most visitors didn’t know about book identity which they want to search but they only know about description of information book as their needed. Depend on that problem need to build a information book retrieval system that can find information book as visitors need dynamically. Dynamically in this research mean that inputs to the system not only book identity such as title, author, publisher, etc., but also description of book information as visitors need. Moreover, visitor can judgement
book information by relevan or not as a feedback for system then system can retrieve book information more relevan.
This research, build information retrieval book system. The objective in this research is to find a book information as visitors need. This system build by implementing methods vector space model and support vector machines.
iv
Keyword : information retrieval book system, vector space model, support vector
v
Assalammu alaikum Wr. Wb.
Alhamdulillahi Rabbil alamiin, segala puji dan syukur penulis panjatkan kepada Allah SWT, karena dengan izin-Nya dan setitik ilmu pengetahuan yang diberikan
kepada mahluk-Nya, penulis dapat menyelesaikan laporan tugas akhir ini dengan
judul “IMPLEMENTASI METODE SUPPORT VECTOR MACHINES UNTUK PENCARIAN INFORMASI BUKU DI PERPUSTAKAAN DAERAH BANDUNG PROVINSI JAWA BARAT”. Adapun tujuan dari
penyusunan skripsi ini adalah untuk memenuhi salah satu syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika, Universitas Komputer Indonesia.
Penulis sangat menyadari kekurangan yang ada pada laporan ini. Kekurangan ini dikarenakan keterbatasan penulis dalam hal ilmu pengetahuan dan pemahaman penulisan laporan. Akan tetapi, penulis berusaha menyusun laporan ini sebaik yang penulis bisa dengan segenap kemampuan dan usaha yang penulis bisa.
Selama menulis laporan tugas akhir ini, penulis telah mendapatkan banyak sekali bimbingan dan bantuan dari berbagai pihak yang telah dengan segenap hati dan keikhlasan yang penuh membantu dan membimbing penulis dalam menyelesaikan laporan ini. Dengan kesadaran hati, penulis ucapkan terima kasih kepada :
1. Tuhan Yang Maha Esa yang telah memberikan kesehatan dan kesempatan kepada penulis dalam menyelesaikan skripsi ini dan juga ata semua keindahan, kemudahan, dan berjuta hikmah yang melahirkan semangat
jiwa.
2. Orang tua penulis yang telah memberikan segenap perhatian, cinta dan
vi
bersedia meluangkan waktu, tenaga dan pikirannya serta memberikan pengarahan dan pengalaman dalam penyusunan skripsi yang berguna bagi penulis.
5. Ibu Teti yang telah menerima penulis untuk melakukan penelitian tugas akhir di Badan Perpustakaan dan Kearsipan Daerah juga memberikan informasi-informasi yang dibutuhkan penulis dalam penyusunan skripsi.
6. Bapak Andri Heryandi, M.T., selaku dosen wali yang telah mengajarkan
ilmunya selama penulis kuliah di Universitas Komputer Indonesia.
7. Bapak dan Ibu dosen IF UNIKOM yang telah membagi ilmunya selama penulis duduk dibangku kuliah.
vii
ABSTRACT ... III KATA PENGANTAR ... V DAFTAR ISI ... VII DAFTAR GAMBAR ... XI DAFTAR TABEL ... XIV DAFTAR SIMBOL ... XVI DAFTAR LAMPIRAN ... XIX
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Identifikasi Masalah ... 4
1.3 Maksud dan Tujuan ... 4
1.4 Batasan Masalah ... 5
1.5 Metodologi Penelitian ... 5
1.6 Sistematika Penulisan ... 7
BAB 2 TINJAUAN PUSTAKA ... 9
2.1 Tinjauan Perusahaan ... 9
2.1.1 Sejarah Badan Perpustakaan dan Kearsipan Daerah ... 9
2.1.2 Profil Perpustakaan ... 10
2.1.3 Visi Misi dan Tujuan Perpustakaan ... 11
A. Visi Perpustakaan ... 11
viii
2.1.6 Deskripsi Jabatan ... 14
A. Tugas Kepala ... 14
B. Tugas Sekretaris ... 15
C. Tugas Bidang Pengembangan Bahan Pustaka ... 15
D. Tugas Bidang Layanan ... 16
E. Tugas Bidang Pembinaan ... 16
F. Tugas Subbidang layanan dan otomasi perpustakaan ... 17
2.2 Information Retrieval (IR) ... 17
2.2.1 Prilaku Pengguna ... 18
2.2.2 View Dokumen ... 19
2.2.3 Arsitektur Sistem IR ... 19
2.2.4 Stemming ... 20
2.2.5 Pembuatan Index... 22
2.3 Vector Space Model (VSM) ... 24
2.3.1 Indexing ... 26
2.3.2 Normalisasi ... 27
2.4 Ukuran Kemiripan ... 27
2.5 Peningkatan Kualitas Pencarian ... 28
2.6 Support Vector Machines (SVM) ... 29
2.6.1 Formulasi Matematis ... 32
2.6.2 Metode Kernel ... 36
2.7 MySQL ... 37
2.8 PHP ... 39
2.9 Cascading Style Sheets (CSS) ... 41
ix
2.12.2 Sequence Diagram ... 44
2.12.3 Activity Diagram ... 44
2.12.4 Class Diagram ... 44
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 43
3.1 Analisis Sistem ... 43
3.1.1 Analisis Masalah ... 43
3.1.2 Analisis Sistem yang sedang berjalan ... 43
3.1.3 Analisis Kebutuhan Data ... 46
3.1.4 Analisis Metode ... 46
3.1.4.1 Analisis Vector Space Model (VSM) ... 58
3.1.4.2 Analisis Support Vector Machines (SVMs) ... 68
3.1.5 Analisis Kebutuhan Non-Fungsional ... 78
3.1.5.1 Analisis Kebutuhan Perangkat Keras ... 78
3.1.5.2 Analisis Kebutuhan Perangkat Lunak ... 79
3.1.5.3 Analisis Kebutuhan Pengguna ... 79
3.1.6 Analisis Kebutuhan Fungsional ... 81
3.1.6.1 Use Case Diagram ... 81
3.1.6.2 Definisi Aktor ... 83
3.1.6.3 Activity Diagram ... 84
3.1.6.4 Seqeunce Diagram ... 104
3.1.6.5 Class Diagram ... 135
3.2 Perancangan Sistem ... 138
3.2.1 Perancangan Antarmuka ... 138
3.2.1.1 Perancangan Antarmuka Pengunjung ... 138
x
3.2.3.2 Method Pencarian Data Buku ... 154
3.2.3.3 Method Pencarian Data Buku Lebih Lanjut ... 155
3.2.3.4 Method Optimisasi Sistem Pencarian ... 155
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... 115
4.1 Implementasi Sistem ... 115
4.1.1 Implementasi Perangkat Keras ... 115
4.1.2 Implementasi Perangkat Lunak ... 115
4.1.3 Implementasi Basis Data ... 116
4.1.4 Implementasi Kelas... 117
4.1.5 Implementasi Antarmuka ... 117
4.2 Pengujian Sistem ... 118
4.2.1 Rencana Pengujian Aplikasi ... 118
4.2.1.1 Kasus dan Hasil Pengujian ... 119
4.2.1.2 Kesimpulan Hasil Pengujian ... 131
4.2.2 Pengujian Beta ... 131
4.2.2.1 Hasil Pengujian Beta ... 132
4.2.2.2 Kesimpulan Hasil Pengujian Beta ... 133
BAB 5KESIMPULAN DAN SARAN ... 135
5.1 Kesimpulan ... 135
5.2 Saran ... 135
1
1.1 Latar Belakang Masalah
Berdasarkan hasil pengamatan, perpustakaan menjadi tempat sumber informasi dan rekreasi sehingga dapat dinikmati oleh banyak orang. Salah satu perpustakaan yang ada di daerah Bandung yaitu perpustakaan yang dikelola oleh Badan Perpustakaan dan Kearsipan Daerah (BAPUSIPDA). Saat ini jumlah buku di perpustakaan daerah sudah mencapai kurang lebih 180.000 eksemplar per tanggal 18 April 2012. Meskipun dari sekian banyaknya jumlah buku yang ada di perpustakaan tersebut tetap masih belum bisa memenuhi kebutuhan masyarakat. Hal ini dapat membuat seseorang ketika mencari buku dengan cara datang langsung ke perpustakaan menjadi tidak efektif.
Berdasarkan hasil wawancara terhadap beberapa pengunjung perpustakaan dapat disimpulkan bahwa untuk mencari informasi buku hanya sedikit pengunjung yang sudah mengetahui identitas buku (judul, pengarang, subjek, dan lain-lain) yang akan dicari. Akan tetapi kebanyakan pengunjung yang hendak mencari buku justru tidak mengetahui informasi sedikitpun mengenai identitas buku yang akan dicari melainkan hanya mengetahui gambaran akan kebutuhannya mengenai informasi yang dibutuhkan terhadap buku. Sistem pencarian yang ada di perpustakaan tidak dapat memecahkan solusi untuk permasalahan yang sudah dipaparkan sebelumnya karena masukan terhadap sistem masih sangat yaitu identitas buku. Atas dasar permasalahan tersebut perlu dikembangkan sistem pencarian informasi buku yang dapat menemukan informasi buku sesuai dengan gambaran kebutuhan pengunjung secara dinamis.
Untuk mengimplementasikan teknik pencarian yang dapat menjadi solusi untuk permasalahan yang sudah dipaparkan sebelumnya maka diperlukan
untuk mencari dokumen-dokumen yang relevan dengan masukan terhadap sistem berupa query (deskripsi kebutuhan terhadap dokumen yang dibutuhkan)[3].
A. B. Manwar, dkk[27] telah berhasil mengimplementasikan sistem IR dengan menggunakan metode Vector Space Model (VSM). Oleh karena itu, dalam penelitian ini digunakan metode VSM agar sistem IR yang akan diterapkan dalam sistem pencarian informasi buku bisa direalisasikan.
Metode VSMdigunakan untuk mengukur kemiripan antara dokumen dengan
query. Pada model ini, query dan dokumen dianggap sebagai vektor-vektor pada ruang n-dimensi[1]. Akan tetapi, ukuran kemiripan suatu dokumen yang dinilai oleh sistem belum tentu sama dengan yang dinilai oleh pengguna[11]. Oleh karena itu, sistem perlu mengklasifikasi ulang data-data buku yang akan ditampilkan ke pengunjung. Mengacu pada penelitian Thorsten Joachim[2], dapat disimpulkan bahwa terdapat persamaan mendasar tujuan dari kasus Thorsten Joachim[2] dengan kasus yang sedang diteliti yaitu mengklasifikasikan dokumen kedalam kategori yang sudah ditetapkan dengan menggunakan metode Support
Vector Machines (SVMs).
Dari uraian tersebut maka penelitian yang akan dilakukan adalah,
“Implementasi Metode Support Vector Machines untuk Pencarian Informasi Buku di Perpustakaan Daerah Bandung Provinsi Jawa Barat”.
1.2 Identifikasi Masalah
Dari pemaparan latar belakang masalah, maka masalah tersebut dapat dirumuskan dalam suatu rumusan masalah yaitu bagaimana membangun sistem pencarian informasi buku yang dapat menemukan informasi buku sesuai dengan kebutuhan pengunjung dan dinamis di perpustakaan daerah provinsi Jawa Barat.
1.3 Maksud dan Tujuan
buku sesuai dengan kebutuhan pengunjung dan dinamis di perpustakaan daerah provinsi Jawa Barat dengan menerapkan metode VSM dan SVMs.
Sistem pencarian informasi buku yang akan dibangun bertujuan untuk mempermudah melakukan pencarian informasi buku dengan menggunakan query
(kebutuhan pembaca terhadap buku) sebagai masukan terhadap sistem dan keluaran dari sistem berupa identitas buku dan deskripsi buku. Hasil penelitian ini diharapkan mampu memecahkan masalah pengunjung perpustakaan untuk mencari buku yang sesuai dengan kebutuhan meskipun tidak mengetahui identitas buku yang dicari.
1.4 Batasan Masalah
Adapun ruang lingkup yang akan dibahas sangatlah luas, untuk itu diperlukan batasan masalah sebagai berikut :
1. Sistem yang akan dibangun merupakan pengembangan dari http://www.bapusipda.jabarprov.go.id.
2. Sistem yang dibangun adalah sistem pencarian informasi buku yang ada di perpustakaan daerah Bandung provinsi Jawa Barat.
3. Informasi yang diberikan sistem yaitu berupa identitas buku (judul, penulis dan golongan) dan deskripsi buku.
4. Sistem digunakan oleh dua kategori pengguna yaitu operator dan pengunjung situs.
5. Data buku yang digunakan yaitu data buku yang ditulis dalam bahasa Indonesia dan bahasa Inggris.
6. Sistem akan dibangun menggunakan bahasa pemrograman PHP dan
Database Management System MySQL.
1.5 Metodologi Penelitian
1.5.1 Metode Pengumpulan Data
Metodologi penelitian yang digunakan dalam pengumpulan data yang
berkaitan dengan penyusunan tugas akhir dan pembuatan sistem pencarian ini adalah :
1. Studi Kepustakaan
Mencari informasi yang berhubungan dengan permasalahan yang akan dibahas dengan bersumber pada buku-buku serta bacaan lain yang kiranya dapat membantu menyelesaikan pembangunan aplikasi.
2. Studi Dokumentasi
Mengumpulkan informasi mengenai data yang diperlukan agar lebih mudah untuk didefinisikan dan dirumuskan pada permasalahan yang ada.
3. Wawancara
Mengajukan pertanyaan kepada pengunjung mengenai data-data yang dibutuhkan untuk mencari informasi buku dan mengajukan pertanyaan kepada pustakawan mengenai prilaku pengunjung pada saat mencari buku.
1.5.2 Metode Pembangunan Perangkat Lunak
Pembangunan Sistem pencarian ini menggunakan metodologi waterfall yang meliputi beberapa proses diantaranya :
1. Requirements Definition: Mengumpulkan kebutuhan secara lengkap
kemudian kemudian dianalisis dan didefinisikan kebutuhan yang harus dipenuhi oleh program yang akan dibangun. Fase ini harus dikerjakan secara lengkap untuk bisa menghasilkan desain yang lengkap.
2. System and Software Design: Desain dikerjakan setelah kebutuhan selesai dikumpulkan secara lengkap.
3. Implementation and Unit Testing: desain program diterjemahkan ke dalam kode-kode dengan menggunakan bahasa pemrograman yang sudah ditentukan. Program yang dibangun langsung diuji baik secara unit.
5. Operation and Maintenance: mengoperasikan program dilingkungannya dan melakukan pemeliharaan, seperti penyesuaian atau perubahan karena
adaptasi dengan situasi sebenarnya.
Requirements Definition
System and Software Design
Implementation and Unit Testing
Integration and System Testing
Operation and Maintenance
Gambar 1.1 Waterfall menurut Ian Sommerville[4]
1.6 Sistematika Penulisan
Sistematika penulisan proposal penelitian ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas
akhir ini adalah sebagai berikut :
1. BAB 1 PENDAHULUAN
Menguraikan tentang latar belakang permasalahan, mencoba merumuskan inti permasalahan yang dihadapi, menentukan tujuan dan kegunaan penelitian, yang kemudian diikuti dengan pembatasan masalah, asumsi, serta sistematika penulisan.
2. BAB 2 TINJAUAN PUSTAKA
Berisi tentang segala hal yang berkaitan dengan perusahaan tempat
dilakukannya penelitian serta membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal
yang berguna dalam proses analisis permasalahan serta tinjauan terhadap penelitian-penelitian serupa yang telah pernah dilakukan sebelumnya termasuk sintesisnya.
Pada BAB ini di uraikan, tinjauan perusahaan, information retrieval,
vector space model, ukuran kemiripan, peningkatan kualitas pencarian,
support vector machines, MySQL, PHP, Cascading Style Sheet(CSS), xampp, adobe dreamweaver, dan unified modelling language.
3. BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Menganalisis masalah terhadap sistem yang akan dibangun, analisis penggunaan metode Stemming, Vector Space Model, dan Support Vector
Machines untuk penyelesaian masalah serta menganailis kebutuhan
fungsional dan non fungsional. Hasil analisis tersebut kemudian akan digunakan untuk melakukan perancangan antarmuka dan jaringan semantik.
Pada BAB ini di uraikan, analisis sistem, analisis masalah, analisis, sistem yang sedang berjalan, analisis kebutuhan data, analisis proses, analisis kebutuhan non-fungsional, analisis kebutuhan fungsional, perancangan sistem, antarmuka pengunjung, antarmuka operator, dan jaringan semantik
4. BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi hasil implementasi dari hasil analisis dan perancangan yang telah dibuat disertai juga dengan hasil pengujian dari sistem yang dibangun.
implementasi SVM, dan pengujian sistem disertai kesimpulan hasil pengujian.
5. BAB 5 KESIMPULAN DAN SARAN
Pada BAB ini akan dibahas mengenai kesimpulan dari keseluruhan
masalah yang telah dibahas pada bab sebelumnya dan dilengkapi dengan
saran-saran yang dapat dijadikan masukan dalam melakukan penulisan
tugas akhir.
9
BAB 2
TINJAUAN PUSTAKA
2.1Tinjauan Perusahaan
2.1.1Sejarah Badan Perpustakaan dan Kearsipan Daerah
Secara historis, lembaga perpustakaan daerah ditingkat Provinsi Jawa Barat yang saat ini menjadi Badan Perpustakaan dan Kearsipan Daerah Provinsi Jawa Barat, sebelumnya mengalami beberapa kali perubahan nama.
Sebagai cikal bakalnya bernama Perpustakaan Negara yang berdiri pada tanggal 23 Mei 1956, dibentuk berdasarkan Surat Keputusan Mentri Pendidikan Pengajaran dan Kebudayaan nomor 29103/s di 19 provinsi, salah satunya yaitu
Bandung yang berlokasi di Jalan Diponegoro serta induk organisasinya adalah Biro Perpustakaan dan Pembinaan Buku. Setelah terbit Surat Keputusan Menteri Pendidikan dan Kebudayaan nomor 095/1967 tanggal 6 Desember 1967,
ditetapkan bahwa lembaga perpustakaan merupakan induk organisasi perpustakaan negara, kemudian berdasarkan Surat Keputusan Menteri Pendidikan dan Kebudayaan nomor 079/1975 induk organisasi perpustakaan negara menjadi Pusat Pembinaan Perpustakaan.
Empat tahun kemudian, tepatnya tanggal 29 Mei 1979 Menteri Pendidikan dan Kebudayaan mengeluarakan Surat Keputusan nomor 095/1979 tentang Penetapan Pengalihan Nama Perpustakaan Negara Menjadi Perpustakaan Wilayah, sementara induk organisasinya masih Pusat Pembinaan Perpustakaan.
Setelah terbitnya keputusan presiden nomor 50 tahun 1997 tentang Perpustakaan Nasional Republik Indonesia, maka selaras pasal 16(1) nama
perpustakaan daerah Jawa Barat berubah lagi menjadi Perpustakaan Nasional Provinsi Jawa Barat, sedangkan induk organsasinya masih Perpustakaan
Nasional Republik Indonesia.
Dengan berlakunya Undang-undang nomor 22 Tahun 1999, pada tahun 2001 Perpustakaan Nasional Provinsi Jawa Barat yang pada awalnya merupakan instansi vertikal perpustakaan nasional Republik Indonesia yang berada di ibukota provinsi dilimpahkan kepada pemerintah Provinsi Jawa Barat.
Kemudian tanggal 12 April 2002, berdasarkan peraturan daerah nomor 6 dibentuk Badan Perpustakaan Daerah Jawa Barat sebagai salah satu lembaga teknis daerah Pemerintah Provinsi Jawa Barat dalam bidang perpustakaan.
Selanjutnya Badan Perpustakaan Daerah Provinsi Jawa Barat yang semula berdiri sendiri sebagai lembaga teknis daerah pemerintah Provinsi Jawa Barat bidang perpustakaan mulai 19 November 2008 mengalami perubahan lagi menjadi Badan Perpustakaan dan Kearsipan Daerah berdasarkan peraturan daerah Provinsi Jawa Barat nomor 22 tahun 2008 tentang organisasi dan tata kerja inspektorat, Badan Perencanaan Pembangunan Daerah, lembaga teknis daerah dan satuan polisi pamong praja Provinsi Jawa Barat (lembaran daerah tahun 2008 nomor 21 seri D, tambahan lembaran daerah nomor 56).
2.1.2 Profil Perpustakaan
Adapun profil dari Badan Perpustakaan dan Kearsipan Daerah adalah sebagai berikut :
1. Nama perpustakaan : Badan Perpustakaan dan Kearsipan Daerah
2. Alamat perpustakaan : Jln. Soekarno Hatta no. 629 Bandung
3. No telp : 022 7310435
4. No fax : 022 7301408
2.1.3Visi Misi dan Tujuan Perpustakaan
A. Visi Perpustakaan
Perpustakaan dan kerasipan sebagai sumber informasi yang handal menuju masyarakat jawa barat cerdas.
B. Misi Perpustakaan
1. Meningkatkan pembinaan dan pengembangan lembaga perpustakaan
dan kearsipan
2. Meningkatkan profesionalisme dan kompetensi SDM pengelola
perpustakaan dan kearsipan.
3. Mengembangkan budaya baca masyarakat guna mewujudkan
masyarakat belajar (learning society).
4. Mengembangkan budaya sadar arsip.
5. Mengembangkan, mengelola, dan melestarikan bahan perpustakaan dan
arsip sebagai khasanah informasi dan pengetahuan.
6. Menyelenggarakan layanan perpustakaan dan kearsipan berbasis
teknologi informasi dan komunikasi.
C. Tujuan Perpustakaan
Memberikan layanan kepada pemustaka, meningkatkan pemberdayaan dan kegemaran membaca, serta memperluas wawasan dan pengetahuan untuk mencerdaskan kehidupan bangsa.
2.1.4Tugas Pokok dan Fungsi
pokok melaksanakan perumusan dan pelaksanaan kebijakan daerah bidang perpustakaan dan kearsipan daerah berdasarkan asas otonomi, dekonsentrasi,
dan tugas pembantuan.
Dalam menyelenggarakan tugas pokok tersebut, Badan Perpustakaan dan
Kearsipan Daerah Provinsi Jawa Barat mempunyai fungsi sebagai berikut :
1. Penyelenggaraan perumusan dan penetapan kebijakan teknis bidang perpustakaan dan kearsipan daerah.
2. Penyelenggaraan pemberian dukungan atas penyelenggaraan pemerintahan daerah bidang perpustakaan dan kearsipan daerah.
2.1.5 Struktur Organisasi
Gambar 2.1 Struktur Organisasi Badan Perpustakaan dan Kearsipan Daerah
2.1.6Deskripsi Jabatan
Pembagian tugas dalam suatu instansi /lembaga/perusahaan/organisasi sangat penting, supaya terjadi keharmonisan dalam mencapai suatu tujuan.
A. Tugas Kepala
1. Memimpin, mengatur, membina dan mengendalikan pelaksanaan tugas pokok dan fungsi badan.
2. Menetapkan kebijaksanaan teknis perancangan pengolahan perpustakaan.
3. Menetapkan program kerja dan rencana kegiatan perpustakaan.
4. Menyelenggarakan fasilitas dalam bidang perpustakaan meliputi pengembangan bahan pustaka, layanan dan pembinaan.
5. Memberikan saran, pertimbangan dan rekomendasi sebagai bahan pengambilan kebijakan gubernur.
B. Tugas Sekretaris
1. Mengkoordinasikan penyusunan program, evaluasi dan pelaporan tugas badan.
2. Melaksanakan pengaturan pengelolaan administrasi kepegawaian.
3. Mengkoordinasikan pengaturan pengelolaan administrasi keuangan rutin.
4. Melaksanakan pengelolaan urusan rumah tangga dan perlengkapan.
5. Mengkoordinasikan penyusunan perencanaan strategis dan laporan akuntabilitas kinerja kerja.
6. Melaksanakan pembinaan kelembagaan dan ketatalaksanaan pada unit
kerja badan dilingkungan badan.
7. Melaksanakan perumusan bahan rancangan pendokumentasian perundang undangan, pengelolaan perpustakaan dan hubungan masyarakat.
8. Melaksanakan pengendalian administrasi keuangan belanja rutin.
10.Melaksanakan koordinasi dengan unit kerja terkait.
11.Melaksanakan evaluasi dan pelaporan.
C. Tugas Bidang Pengembangan Bahan Pustaka
1. Melaksanakan perumusan program kerja Bidang Pengembangan Bahan Pustaka.
2. Melaksanakan fasilitas kegiatan pengembangan bahan pustaka.
3. Melaksanakan perumusan bahan koordinasi dalam pelaksanaan kegiatan pengembangan literatur sekunder.
4. Melaksanakan perumusan bahan koordinasi dalam pelaksanaan kegiatan pengembangan bahan pustaka.
5. Melaksanakan koordinasi dengan unit kerja terkait.
6. Melaksanakan evaluasi pelaporan.
D. Tugas Bidang Layanan
1. Melaksanakan rencana dan program kerja.
2. Melaksanakan fasilitasi kegiatan layanan perpustakaan.
3. Melaksanakan perumusan bahan koordinasi dalam pelaksanaan kegiatan layanan perpustakaan.
4. Melaksanakan perumusan bahan koordinasi dalam pelaksanaan kegiatan otomasi perpustakaan.
5. Melaksanakan perumusan bahan koordinasi dalam dalam pelaksanaan
preservasi bahan pustaka.
6. Melaksanakan koordinasi dengan unit kerja terkait.
7. Melaksanakan evaluasi pelaporan.
E. Tugas Bidang Pembinaan
2. Melaksanakan fasilitasi kegiatan pembinaan.
3. Melaksanakan penyusunan bahan koordinasi dalam pelaksanaan
kegiatan pembinaan.
4. Melaksanakan penyusunan bahan koordinasi dalam pelaksanaan
kegiatan pembinaan sumber daya manusia.
5. Melaksanakan penyusunan bahan koordinasi dalam pelaksanaan kegiatan pembinaan kelembagaan perpustakaan.
6. Melaksanakan penyusunan bahan koordinasi dalam pelaksanaan kegiatan kajian perpustakaan.
7. Melaksanakan koordinasi dengan unit kerja terkait.
8. Menyelenggarakan evaluasi dan pelaporan.
F. Tugas Subbidang layanan dan otomasi perpustakaan
1. Sub bidang layanan dan otomasi perpustakaan mempunyai tugas pokok melaksanakan penyusunan bahan kebijakan teknis dan fasilitasi otomasi perpustakaan.
2. Melaksanakan pengelolaan pangkalan data perpustakaan, pembinaan dan pengembangan otomasi perpustakaan, dan pengelolaan internet.
2.2Information Retrieval (IR)
IR atau Pencarian Informasi dapat didefinisikan sebagai upaya untuk menemukan materi (biasanya dokumen) yang bersifat tidak terstruktur (biasanya teks) yang memenuhi kebutuhan informasi dari jumlah data yang sangat besar (biasanya disimpan dalam komputer).
Tujuan dari sistem IR adalah memenuhi kebutuhan informasi pengguna dengan me-retrieve semua dokumen yang mungkin relevan, pada waktu yang
sama me-retrieve sesedikit mungkin dokumen yang tidak relevan.Sistem IR yang baik memungkinkan pengguna menentukan secara cepat dan akurat apakah isi
dari dokumen yang diterima memenuhi kebutuhannya. Agar representasi dokumen lebih baik, dokumen-dokumen dengan topik atau isi yang mirip dikelompokkan bersama-sama [13].
Keefektifan dari temu kembali informasi yang diinginkan tergantung pada dua hal mendasar yaitu perilaku pengguna dan logical view dari sistem temu kembali.
2.2.1Prilaku Pengguna
Dalam sistem IR, pengguna menterjemaahkan kebutuhan informasinya ke dalam bentuk kata query, dengan query ini maka sistem akan melakukan pencarian ke dalam kumpulan dokumen. Kualitas informasi yang dihasilkan dari sistem IR, secara langsung dipengaruhi dua hal yaitu penyajian dokumen secara logikal oleh sistem dan prilaku pengguna, prilaku pengguna maksudnya adalah berhubungan dengan kegiatan pengguna menentukan query yang sesuai dengan informasi yang diinginkan. Interaksi antara pengguna dengan sistem IR melalui aktifitas yang berbeda dapat digambarkan seperti dibawah ini.
Database IR
Retrieve
Browsing
2.2.2 View Dokumen
Sistem basis data saat ini memungkinkan menyimpan representasi
dokumen dalam bentuk koleksi keseluruhan kata-kata yang dikandungnya. Dalam hal ini dikatakan bahwa sistem IR mengadopsi full text logical view.
Dengan banyaknya dokumen yang harus diproses, maka akan semakin besar kapaistas database yang diperlukan. Full text merupakan penampakan paling lengkap dari suatu dokumen tetapi penggunaannya membutuhkan biaya komputasi tinggi.
Untuk mengatasi hal tersebut, sistem harus dapat mereduksi kata yang disimpan dan mentransformasi logical view dari full text menjadi bentuk indeks. Hal ini dilakukan dengan meng-eliminasi stoplist (kata-kata yang terlalu umum seperti kata sandang, kata sambung, kata ganti, dll) dan melakukan proses stemming (pengubahan bentuk imbuhan ke bentuk dasar). Lebih jauh lagi adalah penggunaan metode-metode kompresi teks.
[image:32.595.98.477.447.698.2]2.2.3 Arsitektur Sistem IR
Secara garis besar arsitektur sistem IR diperlihatkan pada gambar II.2. Ada dua pekerjaan yang ditangani oleh sistem ini, yaitu melakukan pre-processing
terhadap database dan kemudian menerapkan metode tertentu untuk menghitung kedekatan (relevansi atau similarity) antara dokumen di dalam database yang
telah dipreprocess dengan query pengguna. Pada tahapan preprocessing, sistem yang berurusan dengan dokumen semi-structured biasanya memberikan tag tertentu pada term-term atau bagian dari dokumen; sedangkan pada dokumen tidak terstruktur proses ini dilewati dan membiarkan term tanpa imbuhan tag. Query yang dimasukkan pengguna dikonversi sesuai aturan tertentu untuk mengekstrak term-term penting yang sejalan dengan termterm yang sebelumnya telah diekstrak dari dokumen dan menghitung relevansi antara query dan dokumen berdasarkan pada term-term tersebut. Sebagai hasilnya, sistem mengembalikan suatu daftar dokumen terurut descending (ranking) sesuai nilai kemiripannya dengan query pengguna [15].
Setiap dokumen (termasuk query) direpresentasikan menggunakan model
bag-of-words yang mengabaikan urutan dari kata-kata di dalam dokumen, struktur sintaktis dari dokumen dan kalimat. Dokumen ditransformasi ke dalam
suatu “tas“ berisi kata-kata independen. Term disimpan dalam suatu database pencarian khusus yang ditata sebagai sebuah inverted index. Index ini merupakan konversi dari dokumen asli yang mengandung sekumpulan kata ke dalam daftar kata yang berasosiasi dengan dokumen terkait dimana kata-kata tersebut muncul.
Algoritma Nazief & Adriani sebagai algoritma stemming untuk teks berbahasa Indonesia yang memiliki kemampuan prosentase keakuratan (presisi) lebih baik dari algoritma lainnya. Algoritma ini sangat dibutuhkan dan menentukan dalam proses IR dalam dokumen Indonesia[24].
2.2.4Stemming
contoh, kata bersama, kebersamaan, menyamai, akan distem ke root word-nya
yaitu “sama”. Proses stemming pada teks ber Bahasa Indonesia berbeda dengan
stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris, proses yang diperlukan hanya proses menghilangkan sufiks. Sedangkan pada teks berbahasa
[image:34.595.93.490.226.729.2]Indonesia, selain sufiks, prefiks, dan konfiks juga dihilangkan[24].
2.2.5Pembuatan Index
Pembuatan index dari koleksi dokumen merupakan tugas pokok pada
tahapan preprocessing di dalam IR. Kualitas index mempengaruhi efektifitas dan efisiensi sistem IR [16]. Index dokumen adalah himpunan term yang
menunjukkan isi atau topik yang dikandung oleh dokumen. Index akan membedakan suatu dokumen dari dokumen lain yang berada di dalam koleksi. Ukuran index yang kecil dapat memberikan hasil buruk dan mungkin beberapa item yang relevan terabaikan. Index yang besar memungkinkan ditemukan banyak dokumen yang relevan tetapi sekaligus dapat menaikkan jumlah dokumen yang tidak relevan dan menurunkan kecepatan pencarian [11].
Pembuatan inverted index harus melibatkan konsep linguistic processing yang bertujuan mengekstrak term-term penting dari dokumen yang direpresentasikan sebagai bag-ofwords. Ekstraksi term biasanya melibatkan dua operasi utama berikut [15]:
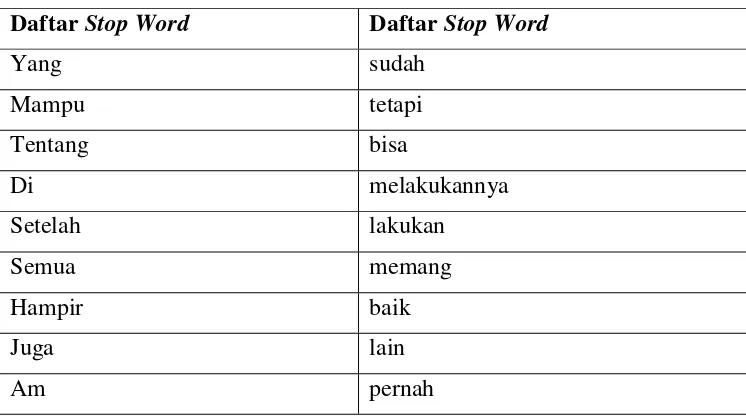
1. Penghapusan stop-words. Stop-word didefinisikan sebagai term yang tidak berhubungan (irrelevant) dengan subyek utama dari database meskipun kata tersebut sering kali hadir di dalam dokumen. Contoh beberapa daftar
[image:35.595.142.515.529.739.2]stop-word.
Tabel 2.1 Daftar Stop-word
Daftar Stop Word Daftar Stop Word
Yang sudah
Mampu tetapi
Tentang bisa
Di melakukannya
Setelah lakukan
Semua memang
Hampir baik
Juga lain
Antara setiap
Dan untuk
Ada dari
Seperti mendapatkan
Jadi punya
Karena telah
Of Mr
Mrs …, dll
Stop-words termasuk pula beberapa kata tertentu yang didefinisikan terkait dengan topik database, misal pada database yang menampung daftar karya tulis (paper) penelitian terkait dengan heart diseases, maka kata heart dan disease sebaiknya dihapus.
2. Salah satu teknik untuk meningkatkan performa sistem IR adalah pencarian
berdasarkan variasi morfologi kata. Salah satu contohnya untuk kata ‟siap‟
akan lebih mudah dikenali dalam suatu dokumen yang besar dibandingkan
kata „mempersiapkan‟. Stemming digunkan untuk mencari kata dasar dari bentuk berimbuhan, misalkan untuk kata lari, pelari, berlari, dilarikan, melarikan, semuanya akan dihitung menjadi satu term dengan frekuensi lima, bukan menjadi lima term berbeda dengan frekuensi masing-masing satu.
2.3Vector Space Model (VSM)
VSM adalah model sistem temu balik informasi yang mengibaratkan masing-masing query dan dokumen sebagai sebuah vektor n-dimensi. Tiap dimensi pada vektor tersebut diwakili oleh satu term. Term yang digunakan biasanya berpatokan kepada term yang ada pada query, sehingga term yang ada pada dokumen tetapi tidak ada pada query biasanya diabaikan.
dokumen. Tahap kedua yaitu pembobotan dari term yang sudah di-indeks untuk meningkatkan kualitas pencarian. Tahap terkahir, rangking dokumen berdasarkan
tingkat kemiripan antara query dengan dokumen[8].
Pada Vector Space Model ini :
1 Vocabulary merupakan kumpulan semua term berbeda yang tersisa dari dokumen setelah preprocessing dan mengandung t termindex. Term-term ini membentuk suatu ruang vektor.
2 Setiap term i di dalam dokumen atau query j, diberikan suatu bobot (weight) bernilai real wij.
3 Dokumen dan query diekspresikan sebagai vektor t dimensi dj = (w1, w2, ...,
wtj) dan terdapat n dokumen di dalam koleksi, yaitu j = 1, 2, ..., n.
Contoh dari model ruang vektor tiga dimensi untuk dua dokumen D1 dan D2, satu query pengguna Q1, dan tiga term T1, T2 dan T3 diperlihatkan pada gambar 2.5.
Gambar 2.5 Vector Space Model[15]
Dalam model ruang vektor, koleksi dokumen direpresentasikan oleh matriks
ditentukan. Nilai nol berarti bahwa term tersebut tidak hadir di dalam dokumen[15].
Gambar 2.6 Matriks Term Document 2.3.1 Indexing
Pengindeksan / indexing dilakukan untuk mendapatkan bobot dari setiap term dalam dokumen. Penghitungan bobot tersebut dilakukan dengan melakukan perhitungan terhadap Term Frequency (Tf) dan Document
Frequency (Df) dari tiap term yang terdapat di koleksi dokumen, nilai Df selanjutnya akan diproses menjadi nilai Inverse Document Frequency (Idf) yang akan digunakan dalam perhitungan bobot term[12].
Keberhasilan dari model VSM ini ditentukan oleh skema pembobotan terhadap suatu term baik untuk cakupan lokal maupun global, dan faktor normalisasi [20]. Pembobotan lokal hanya berpedoman pada frekuensi munculnya term dalam suatu dokumen dan tidak melihat frekuensi kemunculan
term tersebut di dalam dokumen lainnya. Pendekatan dalam pembobotan lokal yang paling banyak diterapkan adalah term frequency (tf) meskipun terdapat skema lain seperti pembobotan biner, augmented normalized tf, logaritmik tf dan logaritmik alternatif.
Idf dapat ditentukan dengan menggunakan rumus:
(1)
Idf = inverse document frequency
d = total dokumen
df = jumlah dokumen yang mengandung term
Bobot dari setiap term dapat dihitung dengan rumus w = tf * idf
2.3.2Normalisasi
Faktor normalisasi digunakan untuk menormalkan vektor dokumen sehingga proses retrieval tidak terpengaruh oleh panjang dari dokumen. Normalisasi ini diperlukan karena dokumen panjang biasanya mengandung perulangan term yang sama sehingga menaikkan frekuensi term (tf). Dokumen panjang juga mengandung banyak term yang berbeda sehingga menaikkan ukuran kemiripan antara query dengan dokumen tersebut, meningkatkan peluang di-retrievenya dokumen yang lebih panjang.
Normalisasi yang digunakan adalah normalisasi kosinus. Berdasarkan [22] rumus normalisasi kosinus yaitu :
(2)
Dengan W adalah bobot dari query dan dokumen.
2.4Ukuran Kemiripan
Model ruang vektor dan pembobotan tf-idf digunakan untuk merepresentasikan nilai numerik dokumen sehingga kemudian dapat dihitung
kedekatan antar dokumen. Semakin dekat dua vektor di dalam suatu VSM maka semakin mirip dua dokumen yang diwakili oleh vektor tersebut. Kemiripan antar dokumen dihitung menggunakan suatu fungsi ukuran kemiripan (similarity
measure). Ukuran ini memungkinkan perankingan dokumen sesuai dengan
Cosine Similarity tidak hanya digunakan untuk menghitung normalisasi panjang dokumen tapi juga menjadi salah satu ukuran kemiripan yang
popular[21]. Ukuran ini menghitung nilai kosinus sudut antara dua vektor. Jika terdapat dua vektor dokumen d dan query q, serta t term diekstrak dari koleksi
dokumen maka nilai kosinus antara d dan q didefinisikan sebagai [15] :
2.5Peningkatan Kualitas Pencarian
Rancangan dasar dari sistem IR dapat ditingkatkan untuk menaikkan presisi dan recall serta memperbaiki matriks term-document. Isu pertama sering diselesaikan menggunakan mekanisme relevance feedback. Beberapa term
ditambahkan ke dalam query awal agar dapat menemukan dokumen yang lebih relevan. Relevance feedback dapat dikerjakan secara manual maupun otomatis. Pada pendekatan manual, pengguna mengidentifikasi dokumen yang relevan dan
term baru dipilih secara manual atau otomatis. Pada pendekatan otomatis, dokumen relevan diidentifikasi menggunakan dokumen top-ranked, kemudian
term-term baru dipilih secara otomatis.
Takashi Onoda, dkk dalam penelitianya yang berjudul Relevance
Feedback Document Retrieval using Support Vector Machines, telah berhasil melakukan peningkatan kualitas pencarian dengan memodifikasi vektor query.
Gambar dibawah ini menjelaskan konsep Relevance Feedback untuk meningkatkan kualitas pencarian.
Gambar 2.7 Skema Umpan Balik dalam Pencarian Dokumen[9]
2.6Support Vector Machines (SVM)
Support Vector Machines (SVM) adalah suatu teknik yang relatif baru (1992) untuk melakukan prediksi, baik dalam kasus klasifikasi maupun regresi, yang sangat populer belakangan ini. SVM berada dalam satu kelas dengan
Artificial Neural Network (ANN) dalam hal fungsi dan kondisi permasalahan yang bisa diselesaikan. Keduanya masuk dalam kelas supervised learning. Baik para ilmuwan maupun praktisi telah banyak menerapkan teknik ini dalam menyelesaikan masalah-masalah nyata dalam kehidupan sehari-hari. Baik dalam masalah gene expression analysis, finansial, cuaca hingga di bidang kedokteran. Terbukti dalam banyak implementasi, SVM memberi hasil yang lebih baik dari ANN, terutama dalam hal solusi yang dicapai. ANN menemukan solusi berupa
local optimal sedangkan SVM menemukan solusi yang global optimal. Tidak heran bila solusi ANN dari setiap training selalu berbeda. Hal ini disebabkan solusi local optimal yang dicapai tidak selalu sama. SVM selalu mencapi solusi yang sama untuk setiap running. Dalam teknik ini, SVM berusaha untuk
menemukan hyperplane (pemisah/classifier) yang optimal yang bisa memisahkan dua set data dari dua kelas yang berbeda.
g(x) := sgn(f(x)) dengan f(x) = wT x + b
(4)
Dimana x, w ∈ Rn dan b ∈ R. Masalah klasifikasi ini bisa dirumuskan sebagai berikut: kita ingin menemukan set parameter (w, b) sehingga f (xi) =< w,x > + b=
yi untuk semua i.
Dalam teknik SVM berusaha menemukan fungsi hyperplane terbaik diantara fungsi yang tidak terbatas jumlahnya untuk memisahkan dua macam obyek. Hyperplane terbaik adalah hyperplane yang terletak di tengah-tengah antara dua set obyek dari dua kelas. Mencari hyperplane terbaik ekuivalen dengan memaksimalkan margin atau jarak antara dua set obyek dari kelas yang berbeda. Jika wx1 + b = +1 adalah hyperplane-pendukung (supporting hyperplane) dari
kelas +1 (wx1 + b = +1) dan wx2 + b = -1 hyperplane-pendukung dari kelas -1
(wx2 + b = -1) margin antara dua kelas dapat dihitung dengan mencari jarak antara
kedua hyperplane-pendukung dari kedua kelas. Secara spesifik, margin dihitung
dengan cara berikut (wx1 + b = +1) - (wx2 + b = -1) => w(x1–x2) = 2 => ( (x1 – x2)) = . Gambar 2.8 memperlihatkan bagaimana SVM bekerja untuk
menemukan suatu fungsi pemisah dengan margin yang maksimal. Untuk membuktikan bahwa memaksimalkan margin antara dua set obyek akan meningkatkan probabilitas pengelompokkan secara benar dari data testing. Pada dasarnya jumlah fungsi pemisah ini tidak terbatas banyaknya. Misalkan dari
jumlah yang tidak terbatas ini kita ambil dua saja, yaitu f1(x1) dan f2(x2). Fungsi f1
mempunyai margin yang lebih besar dari pada fungsi f2.Setelah menemukan dua
fungsi ini, sekarang suatu data baru masuk dengan keluaran −1. Kita harus
mengelompokkan apakah data ini ada dalam kelas −1 atau +1 menggunakan
fungsi pemisah yang sudah kita temukan. Dengan menggunakan f1, kita akan
kelompokkan data baru ini di kelas −1 yang berarti kita benar
mengelompokkannya. Sekarang coba kita gunakan f2, kita akan menempatkannya
memperbesar margin bisa meningkatkan probabilitas pengelompokkan suatu data secara benar.
Gambar 2.8 Mencari Fungsi Pemisah Optimal yang dapat Memisahkan Data Secara Linear[29]
2.6.1 Formulasi Matematis
Secara matematika, formulasi problem optimisasi SVM untuk kasus
klasifikasi linier di dalam primal space adalah
Subject to
yi (wxi + b) ≥ 1, i = 1,…., n
(5)
dimana xi adalah data input, yi adalah keluaran dari data xi, w, b adalah
parameter-parameter yang kita cari nilainya. Formulasi di atas bertujuan meminimalkan fungsi tujuan (obyektif function) dari persamaan(5) atau
memaksimalkan kuantitas atau wTw dengan memperhatikan pembatas yi
(wxi + b) ≥ 1. Bila output data yi = +1, maka pembatas menjadi (wxi + b) ≥ 1.
Sebaliknya bila yi = -1, pembatas menjadi (wxi + b) ≤ -1.
Di dalam kasus yang tidak feasible (infeasible) dimana beberapa data mungkin tidak bisa dikelompokkan secara benar, formulasi matematikanya menjadi berikut :
ti
Subject to
yi (wxi + b) + ti ≥ 1, ti ≥ 0, i = 1,…., l
(6)
dimana ti adalah variabel slack. Dengan formulasi ini kita ingin memaksimalkan
margin antara dua kelas dengan meminimalkan . Formulasi ini berusaha
meminimalkan kesalahan klasifikasi (misclassification error) yang dinyatakan dengan adanya variabel slack ti, secara bersamaan formulasi tersebut
memaksimalkan margin . penggunaan variabel slack ti adalah untuk
mengatasi kasus ketidaklayakan (infeasibility) dari pembatas (constraints) yi (wxi
tersebut. Untuk meminimalkan nilai ti ini, kita berikan pinalti dengan
menerapkan konstanta ongkos C. Vektor w tegak lurus terhadap fungsi pemisah:
wx + b = 0. Konstanta b menentukan lokasi fungsi pemisah relatif terhadap titik asal.
Problem (3) adalah programa nonlinear. Ini bisa dilihat dari fungsi tujuan (objective function) yang berbentuk kuadrat. Untuk menyelesaikannya, secara komputasi agak sulit dan perlu waktu lebih panjang. Untuk membuat masalah ini lebih mudah dan efisien untuk diselesaikan, masalah ini bisa kita transformasikan ke dalam dual space. Untuk itu, pertama kita ubah problem (6) menjadi fungsi Lagrangian :
(7)
dimana variabel non-negatif αi, dinamakan lagrange multiplier. Solusi dari problem optimisasi dengan pembatas seperti di atas ditentukan dengan mencari saddle point dari fungsi Lagrangian J(w, b, α). Fungsi ini harus diminimalkan terhadap variabel w dan b dan harus dimaksimalkan terhadap variabel α. Kemudian kita cari turunan pertama dari fungsi J(w, b, α) terhadap variabel w
dan b dan kita samakan dengan 0. Dengan melakukan proses ini, kita akan mendapatkan dua kondisi optimalitas berikut:
Kondisi 1 :
Kondisi 2 :
(8)
Penerapan kondisi optimalitas 2 pada fungsi Lagrangian (7) akan menghasilkan
(9)
Menurut duality theorem [26]:
1 Jika problem primal mempunyai solusi optimal, maka problem dual juga akan mempunyai solusi optimal yang nilainya sama
2 Bila wo adalah solusi optimal untuk problem primal dan αo untuk problem dual, maka perlu dan cukup bahwa wo solusi layak untuk problem primal
dan
Setelah itu, jabarkan persamaan (4) sebagai berikut:
(10)
Menurut kondisi optimalitas ke dua dalam (9), term ketiga sisi sebelah kanan dalam persamaan di atas sama dengan 0. Dengan memakai nilainilai w di (8),
maka didapat
(11)
maka persamaan 7 menjadi :
(12)
(13)
Subject to
0 ≤ αi, i = 1, ..l,
Dengan dot product xixj sering diganti dengan simbol K. K adalah matrik
kernel. Formulasi (10) adalah quadratic programming (QP) dengan pembatas (constraint) linier. Melatih SVM ekuivalen dengan menyelesaikan problem
convex optimization. Karena itu solusi dari SVM adalah unik (dengan asumsi bahwa k adalah positive definite) dan global optimal. Ambil,
(14)
Fungsi pemisah optimal adalah
(15)
dimana ,i =1,..l adalah solusi optimal dari problem (13) dan dipilih
sehingga yif(xi) = 1 untuk sembarang i dengan C > > 0. Data xi dimana > 0
dinamakan support vector dan menyatakan data training yang diperlukan untuk mewakili fungsi keputusan yang optimal. Dalam gambar 1, sebagai contoh, 3 titik berwarna putih menyatakan support vector. Untuk mengatasi masalah ketidaklinieran (nonlinearity) yang sering terjadi dalam kasus nyata, kita bisa menerapkan metode kernel. Metode kernel memberikan pendekatan alternatif dengan cara melakukan mapping data x dari input space ke feature space F
melalui suatu fungsi sehingga . Karena itu suatu titik x
2.6.2 Metode Kernel
Banyak teknik data mining atau machine learning yang dikembangkan
dengan asumsi kelinieran. Sehingga algorithma yang dihasilkan terbatas untuk kasus-kasus yang linier. Karena itu, bila suatu kasus klasifikasi memperlihatkan
ketidaklinieran, algorithma seperti perceptron tidak bisa mengatasinya. Secara umum, kasus-kasus di dunia nyata adalah kasus yang tidak linier. Sebagai contoh, perhatikan Gambar 3. Data ini sulit dipisahkan secara linier. Metode kernel [5] adalah salah satu untuk mengatasinya. Dengan metoda kernel suatu data x di input space dimapping ke feature space F dengan dimensi yang lebih
tinggi melalui map sebagai berikut . Karena itu data x di input
space menjadi (x) di feature space.
Sering kali fungsi (x) tidak tersedia atau tidak bisa dihitung. tetapi dot
product dari dua vektor dapat dihitung baik di dalam input space maupun di feature space. Dengan kata lain, sementara (x) mungkin tidak diketahui, dot
product < (x1), (x2) > masih bisa dihitung di feature space. Untuk bisa
memakai metoda kernel, pembatas (constraint) perlu diekspresikan dalam bentuk dot product dari vektor data xi. Sebagai konsekuensi, pembatas yang
menjelaskan permasalahan dalam klasifikasi harus diformulasikan kembali
sehingga menjadi bentuk dot product. Dalam feature space ini dot product < . > menjadi < (x1), (x2)‟ >. Suatu fungsi kernel, k(x, x‟), bisa untuk menggantikan
dot product < (x1), (x2)‟ > Kemudian di feature space, kita bisa membuat
Gambar 2.10 Mapping Data dari Input Space ke Feature Space[29]
Fungsi kernel yang biasanya dipakai dalam literatur SVM [7]:
1. Linear : xTx,
2. Polynomial : (xTx + 1)p,
3. Radial basis function :
4. Tangent hyperbolic (sigmoid) : tanh(βxTxi + β1), dimana β, β1 €R
Fungsi kernel yang legitimate diberikan oleh Teori Mercer [6] dimana fungsi itu harus memenuhi syarat: kontinus dan positive definite. Lebih mudah
menemukan fungsi kernel daripada mencari map seperti apa yang tepat untuk
melakukan mapping dari input space ke feature space. Pada penerapan metode kernel, tidak perlu tahu map apa yang digunakan untuk satu per satu data, tetapi lebih penting mengetahui bahwa dot produk dua titik di feaure space bisa digantikan oleh fungsi kernel.
2.7MySQL
Tidak sama dengan proyek-proyek seperti Apache, dimana perangkat lunak dikembangkan oleh komunitas umum, dan hak cipta untuk kode sumber
dimiliki oleh penulisnya masing-masing, MySQL dimiliki dan disponsori oleh sebuah perusahaan komersial Swedia MySQL AB, dimana memegang hak cipta
hampir atas semua kode sumbernya. Kedua orang Swedia dan satu orang Finlandia yang mendirikan MySQL AB adalah: David Axmark, Allan Larsson, dan Michael "Monty" Widenius.
MySQL memiliki beberapa keistimewaan, antara lain :
1. Portabilitas. MySQL dapat berjalan stabil pada berbagai sistem operasi seperti Windows, Linux, FreeBSD, Mac Os X Server, Solaris, Amiga, dan masih banyak lagi.
2. Perangkat lunak sumber terbuka. MySQL didistribusikan sebagai perangkat lunak sumber terbuka, dibawah lisensi GPL sehingga dapat digunakan secara gratis.
3. Multi-user. MySQL dapat digunakan oleh beberapa pengguna dalam waktu yang bersamaan tanpa mengalami masalah atau konflik.
4. 'Performance tuning', MySQL memiliki kecepatan yang menakjubkan dalam menangani query sederhana, dengan kata lain dapat memproses lebih banyak SQL per satuan waktu.
5. Ragam tipe data. MySQL memiliki ragam tipe data yang sangat kaya, seperti signed / unsigned integer, float, double, char, text, date, timestamp, dan lain-lain.
6. Perintah dan fungsi. MySQL memiliki operator dan fungsi secara penuh yang mendukung perintah Select dan Where dalam perintah (query).
8. Skalabilitas dan pembatasan. MySQL mampu menangani basis data dalam skala besar, dengan jumlah rekaman (records) lebih dari 50 juta dan 60 ribu
tabel serta 5 milyar baris. Selain itu batas indeks yang dapat ditampung mencapai 32 indeks pada tiap tabelnya.
9. Konektivitas. MySQL dapat melakukan koneksi dengan klien menggunakan protokol TCP/IP, Unix soket (UNIX), atau Named Pipes (NT).
10.Lokalisasi. MySQL dapat mendeteksi pesan kesalahan pada klien dengan menggunakan lebih dari dua puluh bahasa. Meski pun demikian, bahasa Indonesia belum termasuk di dalamnya.
11.Antar muka. MySQL memiliki antar muka (interface) terhadap berbagai aplikasi dan bahasa pemrograman dengan menggunakan fungsi API (Application Programming Interface).
12.Klien dan peralatan. MySQL dilengkapi dengan berbagai peralatan (tool)yang dapat digunakan untuk administrasi basis data, dan pada setiap peralatan yang ada disertakan petunjuk online.
13.Struktur tabel. MySQL memiliki struktur tabel yang lebih fleksibel dalam menangani ALTER TABLE, dibandingkan basis data lainnya semacam PostgreSQL ataupun Oracle.
2.8PHP
PHP berawal dari skrip Perl/CGI yang dibuat oleh seorang pengembang
perangkat lunak bernama Rasmus Lerdorf untuk menghitung jumlah pengunjung
homepage-nya. Karena banyaknya pengunjung yang meminta skrip tersebut,
Lerdorf akhirnya membagi-bagikan skrip buatannya yang diberi nama Personal
Home Page (PHP).
Ada tiga macam penggunaan PHP:
1. Server-side scripting. Ini merupakan jenis penggunaan yang paling banyak
dilakukan pengguna PHP. Untuk menggunakannya, dibutuhkan tiga hal: PHP
parser, aplikasi web server yang terkoneksi dengan instalasi PHP, dan aplikasi
web browser.
2. Command line scripting. Pada penggunaan PHP jenis ini hanya dibutuhkan PHP parser.
3. Pembuatan aplikasi berbasis desktop. Pada penggunaan PHP jenis ini, dibutuhkan ekstensi tambahan PHP-GTK.
PHP memiliki empat kelebihan utama yang menarik minat banyak pengguna. Kelebihan utama PHP tersebut diringkas dalam 4P berikut:
1. Practicality. PHP dibuat dengan menitikberatkan pada kepraktisan. Hasilnya, PHP adalah bahasa pemrograman minimalis, dilihat dari segi kebutuhan pengguna dan kebutuhan sintaks.
2. Power. PHP memiliki banyak kemampuan, mulai dari kemampuan untuk
terhubung dengan basis data, membuat halaman web dinamis, membuat dan memanipulasi berkas gambar, Flash dan PDF, berkomunikasi dengan bermacam protokol seperti IMAP dan POP3, dan masih banyak lagi.
3. Possibility. PHP dapat menyediakan lebih dari satu solusi untuk suatu masalah
4. Price. PHP selalu dirilis kepada publik tanpa ada batasan untuk penggunaan,
modifikasi, atau redistribusi.
2.9Cascading Style Sheets (CSS)
CSS adalah sebuah bahasa style sheet (lembar gaya) yang digunakan untuk mengatur tampilan dokumen yang ditulis dalam bahasa markup. CSS Level 1
CSS1 diberi status rekomendasi penuh oleh W3C yang juga mengatur spesifikasi CSS. Saat ini ada tiga level CSS, yaitu CSS Level 1 (Recommendation), CSS
Level 2 (Recommendation), dan CSS Level 2 Revision 1 (Candidate
Recommendation). Penggunaan CSS paling banyak untuk memformat halaman
web yang ditulis dengan HTML dan XHTML. Walau demikian, CSS dapat dipergunakan untuk bahasa markup lain seperti SVG dan XUL.
2.10 XAMPP
XAMPP merupakan singkatan dari X (empat operating system apapun) Apache, MySQL, PHP, Perl. XAMPP merupakan tool yang menyediakan paket perangkat lunak ke dalam satu buah paket. Dalam paketnya sudah terdapat Apache (web server), MySQL (database), PHP (server side scripting), Perl, FTP server, phpMyAdmin dan berbagai pustaka bantu lainnya. Dengan menginstall XAMPP maka tidak perlu lagi melakukan instalasi dan konfigurasi web server Apache, PHP dan MySQL secara manual. XAMPP akan menginstalasi dan mengkonfigurasikannya secara otomatis.
2.11 Adobe Dreamweaver CS5
Dreamweaver merupakan sebuah aplikasi untuk merancang pembuatan
website. Dreamweaver dibuat oleh perusahaan Macromedia sehingga dinamakan Macromedia Dreamweaver. Sejak Macromedia diakuisisi Adobe Inc., namanya berubah menjadi Adobe Dreamweaver. Versi pertama Dreamweaver dibawah
Adobe adalah CS5, mengikuti versi rilisnya yang dipaketkan dalam Adobe Creative Suite 5.
dengan berbagai fasilitas yang dimiliki Dreamweaver seperti tag auto-completionuntuk penulisan kode HTML. Format yang didukung Dreamweaver
juga cukup lengkap, mulai dari HTML, JavaScript, CSS, sampai XML.
2.12 Unified Modelling Language (UML)
UML adalah bahasa spesifikasi standar untuk mendokumentasikan, menspesifikasikan, dan membangun sistem perangkat lunak.
UML adalah himpunan struktur danteknik untuk pemodelan desain program berorientasi objek (OOP) serta aplikasinya. UML adalah metodologi untuk mengembangkan sistem OOP dan sekelompok perangkat tool untuk mendukung pengembangan sistem tersebut UML mulai diperkenalkan oleh Object Management Group, sebuah organisasi yang telah mengembangkan model, teknologi, dan standar OOP sejak tahun 1980-an. Sekarang UML sudah mulai banyak digunakan oleh para praktisi OOP. UML merupakan dasar bagi perangkat (tool) desain berorientasi objek dari IBM.
UML adalah suatu bahasa yang digunakan untuk menentukan, memvisualisasikan, membangun, dan mendokumentasikan suatu sistem informasi. UML dikembangkan sebagai suatu alat untuk analisis dan desain berorientasi objek oleh Grady Booch, Jim Rumbaugh, dan Ivar Jacobson.Namun demikian UML dapat digunakan untuk memahami dan mendokumentasikan setiap sistem informasi.Penggunaan UML dalam industri terus meningkat. Ini merupakan
standar terbuka yang menjadikannya sebagai bahasa pemodelan yang umum dalam industri peranti lunak dan pengembangan sistem.
UML menyediakan 10 macam diagram untuk memodelkan aplikasi berorientasi objek, yaitu:
1. Use CaseDiagram untuk memodelkan proses bisnis.
3. Sequence Diagram untuk memodelkan pengiriman pesan (message) antar objek.
4. Collaboration Diagram untuk memodelkan interaksi antar objek.
5. State Diagram untuk memodelkan perilaku objek di dalam sistem.
6. Activity Diagram untuk memodelkan perilaku userdan objek di dalam sistem.
7. Class Diagram untuk memodelkan struktur kelas.
8. Objek Diagram untuk memodelkan struktur objek.
9. Component Diagram untuk memodelkan komponen objek.
10.Deployment Diagram untuk memodelkan distribusi aplikasi.
Berikut akan dijelaskan 4 macam diagram yang paling sering digunakan dalam pembangunan aplikasi berorientasi objek, yaitu use case diagram, sequence diagram, collaboration diagram, dan class diagram.
2.12.1 Use Case Diagram
Use case diagram digunakan untuk memodelkan bisnis proses berdasarkan
perspektif pengguna sistem. Use case diagram terdiri atas diagram untuk use
case dan actor. Actor merepresentasikan orang yang akan mengoperasikan atau orang yang berinteraksi dengan sistem aplikasi.
Use case merepresentasikan operasi-operasi yang dilakukan oleh actor.
Use case digambarkan berbentuk elips dengan nama operasi dituliskan
didalamnya. Actor yang melakukan operasi dihubungkan dengan garis lurus ke
use case.
2.12.2 Sequence Diagram
2.12.3 Activity Diagram
Activity diagram adalah representasi grafis dari alur kerja tahapan aktifitas. Diagram ini mendukung pilihan tindakan, iterasi dan concurrency. Pada pemodelan UML, activity diagram dapat digunakan untuk menjelaskan bisnis
dan alur kerja operasional secara step-by-step dari komponen suatu sistem.
Activity diagram menunjukkan keseluruhan dari aliran kontrol.
2.12.4 Class Diagram
43
3.1Analisis Sistem
3.1.1 Analisis Masalah
Dilihat dari sistem yang sedang berjalan saat ini sistem pencarian yang berlaku masih manual, dimana pengunjung perpustakaan harus mencari buku satu per satu dengan atau tanpa bertanya ke pustakawan untuk mendapatkan informasi buku yang dibutuhkan. Pada saat mencari buku, sedikit pengunjung sudah mengetahui judul dan pengarang dari buku yang akan dicari, akan tetapi
kebanyakan pengunjung perpustakaan justru tidak tahu identitas buku yang akan dicari seperti judul, pengarang, penerbit, dan lain-lain yang hendak dicari.
Permasalahan pada penelitian ini adalah sulitnya mencari buku yang sesuai kebutuhan jika tidak mengetahui informasi sedikitpun mengenai identitas buku yang dibutuhkan sehingga menyebabkan lamanya proses pencarian buku jika harus menganalisis satu per satu buku di perpustakaan.
Oleh karena itu dibutuhkan sistem yang dapat melakukan proses pencarian berdasarkan representasi kebutuhan dari pencari buku kedalam query. Dengan kata lain, sistem yang dibangun dapat menghitung ukuran kemiripan antara dokumen dengan query. Akan tetapi, ukuran kemiripan suatu dokumen yang
dinilai oleh sistem belum tentu sama dengan yang dinilai oleh pengguna[11]. Oleh karena itu, sistem perlu mengklasifikasi ulang dokumen-dokumen yang akan ditampilkan ke pengguna.
3.1.2 Analisis Sistem yang sedang berjalan
kebutuhan pengunjung terhadap buku lebih jelas, jika sudah cukup jelas maka pustakawan merekomendasikan kepada pengunjung untuk mencari buku dilokasi
yang disebutkan oleh pustakawan atau pustakawan turut mencari buku yang dibutuhkan pengunjung.
Proses pencarian yang sudah dijelaskan sebelumnya, memiliki banyak kekurangan, seperti :
1. Keterbatasan pengetahuan pustakawan mengenai informasi buku yang terdaftar di perpustakaan,
2. Proses pencarian membutuhkan waktu yang sangat lama.
Namun proses pencarian ini juga memiliki kelebihan yaitu tingkat keakuratan yang cukup tinggi, karena baik pengunjung atau pustakawan yang melakukan pencarian, sama-sama menganalisis buku satu per satu dari mulai judul hingga isi buku.
Pengunjung Pustakawan
[Penjelasan Kebutuhan Cukup Jelas] [Penjelasan Kebutuhan
Masih Kurang Jelas] Bertanya atau
Menjelaskan Mengenai Informasi Buku yang Dibutuhkan
Mendengarkan Pertanyaan atau Penjelasan Kebutuhan
Pengunjung
Meminta Pengunjung Untuk Menjelaskan Lebih Detail Mengenai
Kebutuhan Buku Memberikan Informasi
Mengenai Lokasi Buku yang Dimaksud
3.1.3 Analisis Kebutuhan Data
Sistem yang akan dibangun merupakan sistem pencarian buku untuk
perpusatakaan daerah. Sebuah sistem pencarian hanya dapat melakukan proses pencarian jika tempat untuk pencarian ada, dan tempat pencarian tersebut adalah
identitas buku, dalam penelitian ini data yang dibutuhkan berupa judul, pengarang dan deskripsi. Oleh karena itu, untuk menunjang pembangungan sistem ini, dibutuhkan identitas (judul dan pengarang) dan deskripsi buku yang sudah terdaftar di perpustakaan.
Berdasarkan hasil analisis dari data buku sebanyak 60 data buku dari berbagai golongan, maka diperoleh karakteristik teks dari data buku yang perlu diperhatikan adalah sebagai berikut :
a. Bahasa
Terdapat beragam bahasa yang digunakan dalam buku yang ada di perpustakaan. Pada penelitian ini data buku yang digunakan merupakan data buku dengan teks berbahasa indonesia dan bahasa inggris.
b. Deskripsi Buku
Untuk mendapatkan deskripsi buku, dapat dilihat dari cover belakang buku. Alternatif lain yang bisa dijadikan deskripsi buku yaitu kata pengantar atau daftar isi dari data buku.
c. Jenis Kata
Terdapat beragam jenis kata yang ada data buku, yaitu :
1.kata sesuai EYD,
2.kata yang biasa digunakan sehari-hari,
3.kata berimbuhan, dan
4.kata dasar.
3.1.4 Analisis Metode
Proses pencarian dapat digunakan oleh pengunjung untuk melakukan proses pencarian informasi buku dan lihat deskripsi dari buku itu sendiri. Proses
pencarian dalam penelitian ini adalah proses pencarian dinamis, dimana pengguna juga dapat menentukan sesuai atau tidak nya query dengan informasi
buku yang ditampilkan dari hasil pencarian, setelah itu sistem akan mengklasifikasikan seluruh data buku yang terdapat dalam database kedalam kategori relevan dan tidak relevan. Data buku yang ditampilkan adalah data buku yang masuk dalam kategori relevan.
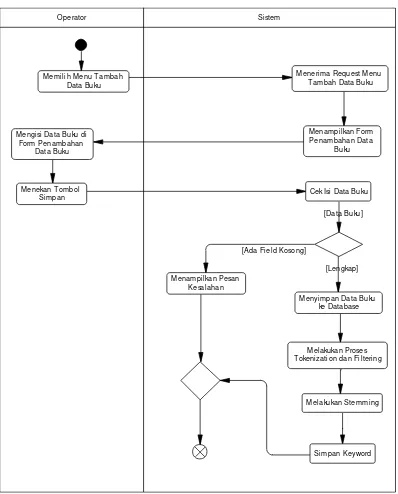
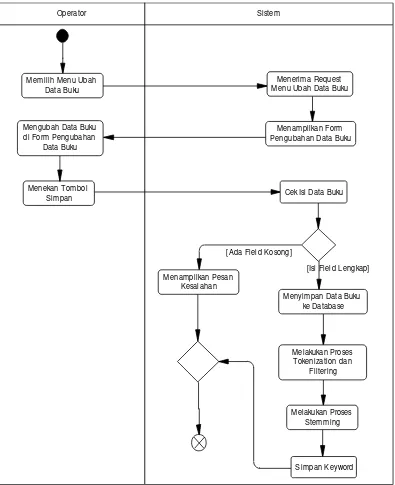
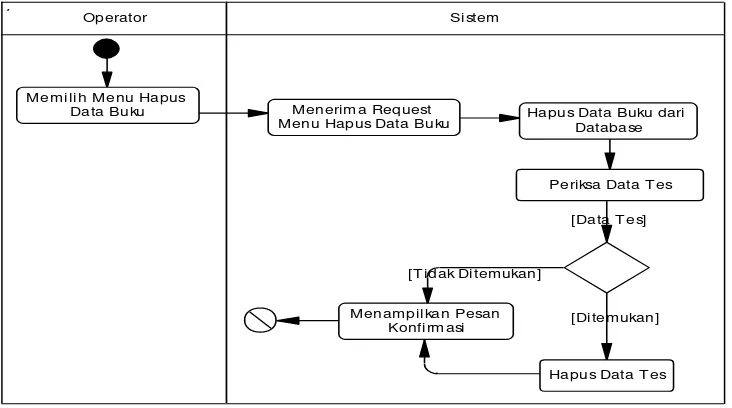
Proses pengolahan data, khusus digunakan oleh operator untuk melakukan proses pengolahan (tambah, ubah, lihat detail, cari, dan hapus) data buku, pengolahan (tambah dan ubah) data golongan, dan melakukan optimisasi pada sistem pencarian.
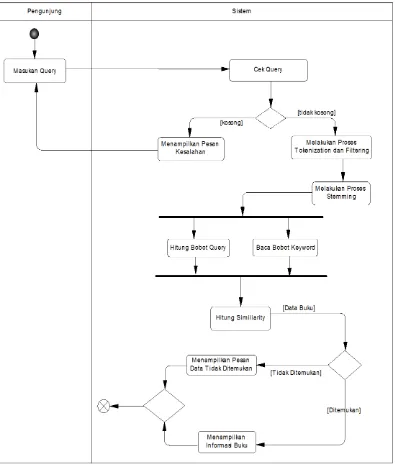
Berikut dibawah ini adalah gambar dari aktivitas sistem pencarian informasi buku :
Pengunjung Sistem
Masukkan Query
Cek Data Buku yang Relevan
Mencari dan Memberi Peringkat Data Buku Berdasarkan Ukuran Kemiripan
Menampilkan Maksimal 10 Informasi Buku dengan Ukuran Kemiripan Tertinggi
Menampilkan Informasi Buku Hasil Klasifikasi
Mengklasifikasi Seluruh Data Buku Berdasarkan Hasil Cek Pengunjung
Terdapat pula sub proses untuk menunjang proses-proses yang sudah diajabarkan sebelumnya, yaitu:
3.1.4.1Analisis Vector Space Model (VSM) A. Analisis Tokenizing
Tokenizing adalah proses pemotongan string input berdasarkan tiap kata yang menyusunya serta membedakan karakter-karakter tertentu yang dapat diperlakukan sebagai pemisah kata atau bukan. Tahapan ini juga menghilangkan karakter-karakter tertentu seperti tanda baca dan mengubah semua katake bentuk huruf kecil (lower case).
Karakter-karakter yang akan dihapus atau dianggap sebagai pemisah kata,
dapat dilihat di tabel 3.1.
Tabel 3.1 Karakter yang akan Dihapus
Karakter
! ~ + \
@ & = /
# * { “
$ ( } „
% ) [ :
^ - ] ;
` - | .
, < > ?
Tabel 3.2 Ilustrasi Tokenizing
No. Isi Hasil Tokenizing
D1 Bersama Buku Pintar TOEFL ini, Anda bisa benar-benar pintar menguasai TOEFL dalam waktu singkat! bersama buku pintar toefl ini anda bisa benar pintar menguasai dalam waktu singkat
D2 Haji adalah sebuah ibadah yang menuntut pengorbanan total para pelakunya. haji adalah sebuah ibadah
![Gambar 2.3 Arsitektur Sistem IR [25]](https://thumb-ap.123doks.com/thumbv2/123dok/1234039.783156/32.595.98.477.447.698/gambar-arsitektur-sistem-ir.webp)
![Gambar 2.4 Flow Chart Algoritma Nazief & Adriani [23]](https://thumb-ap.123doks.com/thumbv2/123dok/1234039.783156/34.595.93.490.226.729/gambar-flow-chart-algoritma-nazief-adriani.webp)