S
PERBAND
SEBAGAI E
PROBABIL
FAKULT
NDINGAN M
EKSTRAKS
BILISTIC NEU
DEP
LTAS MATE
INS
METODE W
KSI CIRI PA
EURAL NET
AYU GU
EPARTEMEN
EMATIKA D
NSTITUT PE
B
WAVELET D
I PADA PENGE
ETWORK (PN
GUSTIAWA
EN ILMU KOM
A DAN ILMU
PERTANIAN
BOGOR
2011
DAUBECHI
GENALAN F
PNN) SEBAGA
ATI
KOMPUTER
U PENGETA
N BOGOR
HIES DAN M
FONEM DE
GAI CLASSI
R
TAHUAN AL
MFCC
ENGAN
IFIER
PERBANDINGAN METODE WAVELET DAUBECHIES DAN MFCC
SEBAGAI EKSTRAKSI CIRI PADA PENGENALAN FONEM DENGAN
PROBABILISTIC NEURAL NETWORK (PNN) SEBAGAI CLASSIFIER
AYU GUSTIAWATI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
AYU GUSTIAWATI. The comparison of Wavelet Daubechies and MFCC methods as feature extraction for phoneme recognition with Probabilistic Neural Netowork (PNN) as classifier. Under the direction of AGUS BUONO.
Nowadays, the development of telecommunication research is rapidly increasing. One of the research is in sound area. Sound is a way for human to interact with computers, known as word recogniser. Word recogniser is a part of voice recogniser that make the computers possible to receive input from word that pronounced. Word that pronounced contain phonemes that arranged into sentence. Voice recognition technology can recognise and understand words that pronounce by digitalising it, and tuning the digital signal with certain pattern that has been saved in a hardware. The result from this word identification will be displayed into printed word. This research will compare between Wavelet Daubechies and MFCCas identity extraction on word recognition with (PNN) as pattern identifier. PNN is a pattern identifier that has high accuracy. The comparison between trained data and tested data in research is 75% : 25%. Tested data that has been used was vary, such as: testing with increase the noise (pure noise) and data with noise increasing from 30dB, 20dB and 10dB. The result from this research is that the identity extraction by using MFCC is much better than with Wavelet Daubechies. From the pure original data (without noise increasing) the accuracy is 92.3% and in data with noise increasing 30dB, noise 20dB and noise 10dB the accuracy is 50.96%, 26.92% and 19.23%.
Judul : Perbandingan Metode Wavelet Daubechies dan MFCC sebagai Ekstraksi Ciri pada Pengenalan Fonem dengan Probabilistic Neural Network (PNN) sebagai Classifier Nama : Ayu Gustiawati
NRP : G64086034
Menyetujui :
Pembimbing
Dr. Ir. Agus Buono, M.Si, M.Kom NIP 19660702 199302 1 001
Mengetahui : Ketua Departemen
Dr. Ir. Sri Nurdiati, M.Sc NIP.19601126 198601 2 001
PRAKATA
Puji dan Syukur penulis ucapkan kepada Allah SWT yang telah memberikan rahmat dan hidayah-Nya sehingga skripsi dengan judul Perbandingan Metode Wavelet Daubechies dan MFCC sebagai Ekstraksi Ciri pada Pengenalan Fonem dengan Probabilistic Neural Network (PNN) sebagai
Classifier dapat diselesaikan. Penelitian ini dilaksanakan mulai Agustus 2010 sampai dengan Maret 2011, bertempat di Departemen Ilmu Komputer.
Penulis mengucapkan terima kasih kepada semua pihak yang telah membantu sehingga skripsi ini dapat diselesaikan, diantaranya :
1. Papa dan Mama terkasih atas dukungan, doa, dan kasih sayangnya kepada penulis.
2. Bapak Dr. Ir. Agus Buono, M.Si, M.Kom selaku pembimbing atas waktu, saran, dan bimbingan yang telah diberikan.
3. Sidik yang selalu sabar memberikan dukungan waktunya.
4. Kak Nisa, Panji dan Beni yang telah membantu memberikan ilmu dan waktunya.
5. Teman - teman seperjuangan di Ekstensi ILKOM dan semua pihak yang tidak dapat penulis sebutkan satu persatu yang telah membantu penulis dalam menyelesaikan penelitian ini.
Akhirnya penulis berharap semoga skripsi ini dapat bermanfaat bagi semua pihak yang membutuhkan. Amin.
Bogor, April 2011
RIWAYAT HIDUP
Penulis dilahirkan di Padang, Propinsi Sumatera Barat, pada tanggal 24 Agustus 1987. Penulis merupakan anak tunggal, pasangan Bapak Amril dan Ibu Yusni.
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... vi
DAFTAR TABEL ... vi
DAFTAR LAMPIRAN ... vii
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup ... 1
Manfaat ... 1
TINJAUAN PUSTAKA ... 1
Sinyal ... 1
Sinyal Suara ... 1
Speech Recognition ... 2
Digitalisasi Gelombang Suara ... 2
Noise ... 2
White Gaussian Noise ... 3
Fonem ... 3
Wave ... 3
Wavelet ... 4
Wavelet Daubechies ... 4
Mel-Frequency Cepstrum Coefficients (MFCC) ... 5
Probabilistic Neural Network (PNN) ... 6
METODOLOGI PENELITIAN ... 6
Kerangka Pemikiran ... 6
Data Suara ... 6
Penghapusan Silent ... 7
Normalisasi ... 7
Segmentasi Sinyal ... 7
Data Latih dan Data Uji ... 7
Ekstraksi Ciri (Wavelet dan MFCC) ... 8
Perata-rataan Hasil MFCC dan Wavelet ... 8
Pemodelan PNN ... 8
Pengujian Model PNN ... 8
Perhitungan Nilai Akurasi ... 8
Lingkup Pengembangan Sistem ... 8
HASIL DAN PEMBAHASAN... 8
Sinyal Suara Asli (Tanpa Penambahan Noise) ... 10
Wavelet Daubechies Orde 4 (db4) ... 10
MFCC ... 10
Perbandingan Wavelet Daubechies Orde 4 (Db4) dengan MFCC pada Suara Asli ... 11
Sinyal Suara dengan Penambahan Noise ... 11
Daubechies Orde 4 (db4) dengan Penambahan Noise 30dB ... 11
Wavelet Daubechies Orde 4 (db4) dengan Penambahan Noise 20dB ... 12
Wavelet Daubechies orde 4 (db4) dengan Penambahan Noise 10dB ... 12
Perbandingan Wavelet Daubechies dengan Penambahan Noise 30dB, 20dB, 10dB ... 12
MFCC dengan Penambahan Noise 30dB ... 12
MFCC dengan Penambahan Noise 20dB ... 13
MFCC dengan Penambahan Noise 10dB ... 13
Perbandingan MFCC dengan Penambahan Noise 30dB, 20dB, 10dB ... 13
Halaman
KESIMPULAN DAN SARAN ... 14
Kesimpulan ... 14
Saran ... 14
DAFTAR PUSTAKA ... 14
DAFTAR GAMBAR
Halaman
1 Sinyal suara ... 2
2 Tanpa Noise ... 3
3 White Gaussian Noise 30dB ... 3
4 White Gaussian Noise 20dB ... 3
4 White Gaussian Noise 10dB ... 3
6 Diagram Blok MFCC ... 5
7 Struktur PNN ... 6
8 Diagram Alur Penelitian ... 7
9 Pemotongan Silent ... 7
10 Segmentasi Sinyal ... 7
11 Penghapusan Silent ... 8
13 Data Uji Tanpa Penambahan Noise ... 9
14 Data Uji yang Ditambahkan Noise 30dB ... 10
15 Data Uji yang Ditambahkan Noise 20dB ... 10
16 Data Uji yang Ditambahkan Noise 10dB ... 10
17 Grafik Tingkat Akurasi Suara Asli dengan Wavelet Daubechies Masing-Masing Fonem ... 10
18 Grafik Tingkat Akurasi Suara Asli dengan MFCC Masing-Masing Fonem ... 11
19 Grafik Perbandingan Tingkat Akurasi Suara Asli dengan Wavelet Daubechies dan MFCC Masing-Masing Fonem ... 11
20 Perbandingan Tingkat Akurasi Suara Asli dengan Wavelet Daubechies dan MFCC ... 11
21 Grafik Tingkat Akurasi Suara dengan Noise 30 dB Menggunakan Wavelet Daubechies Masing-Masing Fonem ... 11
22 Grafik Tingkat Akurasi Suara dengan Noise 20dB Menggunakan Wavelet Daubechies Masing-Masing Fonem ... 12
23 Grafik Tingkat Akurasi Suara dengan Noise 10dB Menggunakan Wavelet Daubechies Masing-Masing Fonem ... 12
24 Grafik Perbandingan Tingkat Akurasi Menggunakan Wavelet Daubechies terhadap Suara Asli dan Suara dengan Penambahan Noise 30dB, 20dB, dan 10dB... 12
25 Grafik Tingkat Akurasi Suara dengan Noise 30dB Menggunakan MFCC Masing-Masing Fonem ... 13
26 Grafik Tingkat Akurasi Suara dengan Noise 20dB Menggunakan MFCC Masing-Masing Fonem ... 13
27 Grafik Tingkat Akurasi Suara dengan Noise 10dB Menggunakan MFCC Masing-Masing Fonem ... 13
28 Grafik Perbandingan Tingkat Akurasi Menggunakan MFCC terhadap Suara Asli dan Suara dengan Penambahan Noise 30dB, 20dB, dan 10dB ... 13
29 Grafik Perbandingan Tingkat Akurasi Wavelet Daubechies dan MFCC terhadap Suara Asli dan Suara dengan Penambahan Noise 30dB, 20dB, dan 10dB... 14
DAFTAR TABEL Halaman 1 Segmentasi Fonem ... 7
DAFTAR LAMPIRAN
Halaman
Lampiran 1 Hasil Pendeteksian Masing-Masing Fonem untuk Wavelet Daubechies ... 17
Lampiran 2 Matriks Confusion Wavelet Daubechies ... 18
Lampiran 3 Hasil Pendeteksian Masing-Masing Fonem untuk MFCC ... 19
Lampiran 4 Matriks Confusion MFCC ... 20
Lampiran 5 Hasil Pendeteksian Masing-Masing Fonem untuk Wavelet Daubechies dengan Penambahan Noise 30dB ... 21
Lampiran 6 Matriks Confusion Wavelet Daubechies dengan Penambahan Noise 30dB ... 22
Lampiran 7 Hasil Pendeteksian Masing-Masing Fonem untuk Wavelet Daubechies dengan Penambahan Noise 20dB ... 23
Lampiran 8 Matriks Confusion Wavelet Daubechies dengan Penambahan Noise 20dB ... 24
Lampiran 9 Hasil Pendeteksian Masing-Masing Fonem untuk Wavelet Daubechies dengan Penambahan Noise 10dB ... 25
Lampiran 10 Matriks Confusion Wavelet Daubechies dengan Penambahan Noise 10dB ... 26
Lampiran 11 Hasil Pendeteksian Masing-Masing Fonem untuk MFCC dengan Penambahan Noise 30dB ... 27
Lampiran 12 Matriks Confusion MFCC dengan Penambahan Noise 30dB ... 28
Lampiran 13 Hasil Pendeteksian Masing-Masing Fonem untuk MFCC dengan Penambahan Noise 20dB ... 29
Lampiran 14 Matriks Confusion MFCC dengan Penambahan Noise 20dB ... 30
Lampiran 15 Hasil Pendeteksian Masing-Masing Fonem untuk MFCC dengan Penambahan Noise 10dB ... 31
PENDAHULUAN Latar Belakang
Perkembangan penelitian di dunia telekomunikasi sangat pesat beberapa tahun terakhir ini. Salah satunya adalah penelitian di bidang suara. Suara adalah salah satu cara manusia untuk berinteraksi dengan komputer, dikenal dengan istilah pengenalan kata. Pengenalan kata merupakan bagian dari pengenalan suara yang memungkinkan komputer untuk menerima masukan berupa kata yang diucapkan. Kata yang diucapkan terdiri dari fonem-fonem yang menyusun sebuah kata. Teknologi pengenalan suara memungkinkan suatu perangkat untuk mengenali dan memahami kata-kata yang diucapkan dengan cara digitalisasi kata dan mencocokkan sinyal digital dengan suatu pola tertentu yang tersimpan dalam suatu perangkat. Hasil dari identifikasi kata yang diucapkan ditampilkan dalam bentuk tulisan.
Berbagai sistem pengenalan suara atau yang dapat disebut juga Automatic Speech
Recognition (ASR) telah banyak dikembangkan
di berbagai negara dengan berbagai bahasa. Beberapa sistem pengenalan suara yang telah dikembangkan (Ruvinna 2008) :
• Spoken Dialoque System, sistem yang dapat melakukan dialog singkat guna mendapatkan informasi tertentu. Seperti pada seorang customer service, pengguna hanya perlu menjawab ‘ya’ atau ‘tidak’ untuk mendapatkan informasi tertentu.
• Speed Dialing System, sistem yang dapat mengenali sebuah nama atau ID seseorang dan mencarinya dalam buku telepon untuk segera dihubungi. Pengguna tidak perlu mencari nomor telepon seseorang, biasanya dalam telepon selular, untuk dapat menghubungi seseorang, pengguna tidak perlu mencari nomor telepon orang tersebut. Namun cukup dengan menyebutkan nama atau ID orang yang akan dihubungi dan sistem secara otomatis menghubunginya.
• Speech to Text Translation System, sistem yang secara otomatis mengetikkan kata-kata yang diucapkan pengguna.
Oleh karena itu, penulis melakukan penelitian dengan membandingkan metode
Wavelet Daubechies dan MFCC sebagai
ekstraksi ciri pada pengenalan kata dengan
Probabilistic Neural Network (PNN) sebagai pengenalan pola. PNN merupakan salah satu
jenis pengenalan pola yang memiliki akurasi cukup tinggi (Suhartono MN 2007).
Tujuan Penelitian
Penelitian ini bertujuan membandingkan metode Wavelet Daubechies dan MFCC sebagai ekstraksi ciri pada pengenalan fonem dengan PNN untuk mendapatkan informasi tingkat akurasi.
Ruang Lingkup
Ruang lingkup dari penelitian ini antara lain:
1. Kata yang digunakan terdiri atas sebelas kata yaitu coba, fana, gajah, jaya, malu, pacu, quran, tip-x, visa, weda, dan zakat.
2. Masing-masing kata direkam oleh satu orang pembicara sebanyak 16 kali dalam waktu satu detik, time frame 30 ms, overlap
50%, dan sampling rate 12000Hz.
3. Penelitian ini terbatas pada pengenalan fonem tunggal (bukan pengenalan kata atau kalimat).
4. Segmentasi untuk masing-masing fonem dilakukan secara manual.
5. Ekstraksi ciri yang digunakan adalah pemodelan Wavelet Daubechies dan MFCC.
6. Metode yang digunakan pada penelitian ini adalah Probabilistic Neural Network (PNN).
7. Kata yang diucapkan berbahasa Indonesia.
Manfaat
Manfaat dari penelitian ini antara lain :
1. Menambah pustaka penelitian pengenalan fonem menggunakan metode Wavelet
Daubechies dan MFCC dengan
Probabilistic Neural Network (PNN).
2. Memberikan informasi tingkat akurasi pengenalan fonem menggunakan metode
Wavelet Daubechies dan MFCC dengan
Probabilistic Neural Network (PNN).
TINJAUAN PUSTAKA Sinyal
Menurut Proakis JG & Manolakis DG (2007), sinyal adalah suatu besaran fisik yang berubah terhadap variabel waktu, ruang atau variabel independen lainnya.
Sinyal Suara
Efek dari getaran tersebut menyebabkan tekanan udara ke lubang vokal dengan frekuensi getaran yang bervariasi, pada akhirnya melalui bibir dan lubang hidung keluar tekanan gelombang sinyal suara.
Menurut Proakis JG & Manolakis DG (2007), sinyal suara dihasilkan dengan memaksa udara melewati pita suara. Generasi sinyal biasanya diasosiasikan dengan sebuah sistem yang merespon stimulus. Sistem itu terdiri atas pita suara dan saluran suara, yang disebut juga dengan rongga suara. Stimulus yang berkombinasi dengan sistem tersebut disebut dengan sumber sinyal. Contoh sinyal suara dapat dilihat pada Gambar 1.
Gambar 1 Sinyal suara (Proakis JG & Manolakis DG 2007)
Speech Recognition
Speech recognition adalah proses konversi sebuah sinyal akustik, yang berasal dari mikrofon atau telepon, menjadi satu atau sekumpulan kata. Pengenalan suara merupakan masalah besar dan sulit untuk dipecahkan, karena terdapat faktor-faktor tidak tetap yang terkait dengan sebuah sinyal. Beberapa faktor tidak tetap tersebut di antaranya ialah (Zue V, Cole R, & Ward W 2007) :
• Phonetic variabilities, atau yang biasa dikenal sebagai homofon, dimana terdapat dua kata atau lebih yang memiliki penulisan berbeda namun pengucapannya sama, contohnya: bang dengan bank.
• Acoustic variabilities, yang dapat terjadi karena perbedaan lingkungan tempat berbicara.
• Within-speaker variabilities, yang dapat terjadi karena kondisi fisik dari pembicara yang dapat disebabkan oleh emosi yang sedang dirasakan.
• Across-speaker variabilities, hal ini dapat terjadi karena perbedaan logat atau cara pengucapan seseorang.
Speech recognition didasarkan pada
digitalisasi suatu bentuk gelombang yang sesuai dengan data yang digunakan kemudian
diekstraksi dengan menggunakan teknik praproses yang sesuai. Setelah itu data diproses untuk mendapatkan representasi dari sinyal suara (Al-Akaidi 2004).
Digitalisasi Gelombang Suara
Menurut Pelton GE (1993), digitalisasi merupakan proses mengubah sinyal analog menjadi sinyal digital. Sinyal suara yang direkam menggunakan mikrofon akan dikonversi menjadi sinyal analog. Sinyal analog memiliki karakter kontinyu dalam ruang waktu dan amplitudo.
Proses digitalisasi terdiri atas dua tahap yaitu sampling dan kuantisasi. Sampling
merupakan pengambilan nilai pada setiap jangka waktu tertentu yang akan menghasilkan suatu nilai vektor. Panjang nilai vektor yang dihasilkan tergantung dari panjangnya sinyal suara yang didigitalisasi dan sampling rate yang digunakan. Sampling rate adalah banyaknya nilai yang diambil tiap detik. Sampling rate
yang biasanya digunakan pada pengenalan suara yaitu 8000Hz – 16000Hz. Setelah tahap
sampling maka proses selanjutnya adalah proses kuantisasi. Kuantisasi merupakan proses menyimpan nilai amplitudo ini ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky & Martin 2007). Hubungan panjang vektor yang dihasilkan, sampling rate dan panjang data suara yang digitalisasi dinyatakan dengan persamaan 1.
S = Fs x T (1)
Keterangan:
S = panjang vektor
Fs = sampling rate yang digunakan (Hertz) T = panjang suara (detik)
Noise
Noise dari berbagai jenis membuat sebuah pengenalan menjadi lebih sulit. Deteksi pengenalan suara tanpa noise jauh lebih mudah dibandingkan dengan suara yang ditambahkan
noise. Penambahan noise sendiri akan
mengakibatkan sejumlah tingkat kesalahan dalam pendeteksian (Jurafsky & Martin 2007). Ukuran noise dapat dilihat pada persamaan 2.
(2)
Keterangan : = sinyal asli
= sinyal dengan noise
White Gaussian Noise
White noise didefinisikan sebagai suatu urutan nilai random berkorelasi. White noise
adalah “wideband” dimana semua frekuensi sama. Pembuatan white noise, tidak mempedulikan bagaimana kemungkinan nilai-nilai amplitudo didistribusikan (Smith 2010).
Gaussian noise merupakan ide dari white noise yang disebabkan oleh fluktuasi pada sinyal. Gaussian noise adalah white noise
dengan distribusi normal (McAndrew 2004).
White gaussian noise dibutuhkan untuk digital signal processing atau identifikasi sistem dari
digital signal processing (Donadio M 1992). Sinyal tanpa noise dan sinyal dengan penambahan white gaussian noise 30dB, 20dB, dan 10dB dapat dilihat pada Gambar 2, Gambar 3, Gambar 4 dan Gambar 5.
Gambar 2 Tanpa Noise
Gambar 3 White Gaussian Noise 30dB
Gambar 4 White Gaussian Noise 20dB
Gambar 4 White Gaussian Noise 10dB
Fonem
Menurut Resmiwati (2009), fonem adalah satuan bunyi terkecil yang mampu menunjukkan kontras warna. Fonem dapat dibagi menjadi empat bagian yaitu:
1. Fonem vokal, merupakan bunyi ujaran akibat adanya udara yang keluar dari paru-paru tidak terkena hambatan atau halangan. Jumlah fonem vokal ada lima yaitu: a, i, u, e, dan o.
2. Fonem konsonan, merupakan bunyi ujaran akibat adanya udara yang keluar dari paru-paru mendapatkan hambatan atau halangan. Jumlah fonem konsonan ada 21 buah yaitu: b, c, d, f, g, h, j, k, l, m, n, p, q, r, s, t, v, w, x, y, dan z.
3. Fonem vokal rangkap, merupakan gabungan dua fonem vokal yang menghasilkan bunyi rangkap, yaitu : ai, au, dan ai.
4. Fonem konsonan rangkap, merupakan gabungan dua buah konsonan, yaitu : ny, ng, kh, dan sy.
Wave
Fourier merupakan analisis wave. Perluasan sinyal atau fungsi wave berdasarkan sinusoids
telah terbukti sangat berguna dalam bidang matematika, science, dan teknik mesin khususnya periodik, waktu yang tidak berlainan (time-invariant), atau fenomena ketidakseimbangan (Burrus et al. 1998).
Wavelet
Wavelet adalah sebuah “small wave” yang energinya terkonsentrasi dalam waktu untuk analisis transien, ketidakseimbangan atau fenomena yang berubah-ubah terhadap waktu (Burrus et al. 1998). Wavelet ditunjukkan pertama kali sebagai dasar pendekatan baru untuk pemrosesan sinyal dan analisis yang disebut teori multiresolusi. Teori multiresolusi berkaitan dengan analisis dan representasi sinyal atau citra pada lebih dari satu resolusi. Hasil pendekatan teori multiresolusi yakni fitur yang tidak terdeteksi pada suatu resolusi dapat terdeteksi pada resolusi lain (Gonzalez & Woods 2002).
Secara umum transformasi wavelet kontinyu dituliskan,
(s, ) = f(t) s,t (x) dt (3)
dimana s,t (x)= !"# (4)
dan s, disebut dengan parameter skala dan translasi. Menurut Burrus et al. (1998), teori wavelet didasari oleh pembangkitan sejumlah tapis (filter) dengan menggeser dan menskala suatu wavelet berupa tapis pelewat tengah (band-pass filter). Penambahan skala wavelet akan meningkatkan durasi waktu, mengurangi lebar bidang (bandwidth) dan menggeser frekuensi pusat ke nilai frekuensi yang lebih rendah. Sebaliknya pengurangan skala menurunkan durasi waktu, menambah lebar bidang dan menggeser frekuensi ke nilai frekuensi yang lebih tinggi. Menurut McAndrew 2004 yang dirujuk pada Oktabroni I N 2008, wavelet dapat digunakan untuk mengurangi noise, deteksi tepi, dan kompresi citra. Wavelet Daubechies Wavelet Daubechies secara historis berasal dari sistem Haar. Wavelet Daubechies ini merupakan karya gemilang dari Ingrid Daubechies . h0 2 + h1 2 + h2 2 + h3 2 = 1 (5)
h0 h2 + h1h3 2 = 0 (6)
h3 - h2 + h1 – h0 = 0 (7) 0h3 - 1h2 + 2h1 – 3h0 = 0 (8)
Persamaan (4, 5, 6, dan 7) merupakan empat persamaan dengan empat bilangan yang tidak diketahui yaitu h0, h1, h2, dan h3. Persamaan tersebut pertama kalinya diperkenalkan dan diselesaikan oleh Ingrid Daubechies, ditunjukkannya bahwa persamaan-persamaan ini mempunyai penyelesaian tunggal. $ % & '() * + , - (9)
$ %' '() * + , - (10)
$ %' & '() * + , - (11)
$. % '() * + , - (12)
Matriks Transformasi ditemukan oleh Ingrid Daubechies yang memungkinkan melalui suatu sinyal dari resolusi 2j ke resolusi 2j+1. Untuk menyederhanakannya, matriks ini disebut matriks DAUB. c j = H c j+1 (13)
d j = G c j+1 (14)
Pada persamaan (13) dan (14) dimana H berkaitan dengan suatu filter low pass dan G berkaitan dengan filter high pass. H dan G disebut filter konjugasi kuadratur. / 0 1 $ ,2 0 (15)
3 0 1 ,2 0 (16)
Dari persamaan (15) dan (16), dapat dibentuk suatu matriks transformasi yang mempunyai elemen-elemen h(n) dan g(n). Dapat dihitung dengan persamaan g(n) = (-1)n h((2N-1)-n). Jika N = 2 maka akan diperoleh: g(0) = h(3); (17)
g(1) = -h(2); (18)
g(2) = h(1); (19)
g(3) = -h(0); (20)
Umumnya Wavelet Daubechies ditulis dengan “dbN” dengan N menunjukkan orde.
Daubechies ditopang secara kompak oleh induk wavelet dan fungsi skala dalam interval {0,2N-1} dengan N bilangan bulat 1 dan mempunya sifat sebagai berikut (Agustini 2006) :
1. Fungsi mempunyai sejumlah tertentu momen nol yaitu,
4 5"77 16 5 85 (22) untuk k = 0, 1, 2, …, N-1
2. Supp 9 0, 2N-1 dan Supp 9 1-N, N 3. Fungsi konjugasi kuadratur mempunyai
bentuk dekomposisi H (filter lowpass) dan
G (filter highpass) berhingga yang
memungkinkan untuk mengoptimalkan perhitungan koefisien wavelet dengan algoritma dekomposisi dari S. Mallat.
Mel-Frequency Cepstrum Coefficients (MFCC)
MFCC didasarkan pada variasi yang telah diketahui dari jaringan kritis telinga manusia terhadap frekuensi. Filter dipisahkan secara linear pada frekuensi rendah dan logaritmik pada frekuensi tinggi. Hal ini dilakukan untuk menangkap karakteristik penting dari sinyal suara (Do Mn 1995). Diagram blok MFCC dapat dilihat pada Gambar 6 (Buono 2009).
! " #
$ %&'$ %( ) * + , $ - ./ /%0 $ * . " 1 . "# ! 2 %0
3 4 $ *! 5 6 2 ..
3
7 8 0
9 9 & 9
:* -!- - ; < ;*: < 3*:
Gambar 6 Diagram Blok MFCC (Buono2009)
Tahapan MFCC yaitu :
1. Frame blocking
Frame blocking merupakan tahapan untuk membagi sinyal suara kedalam frame-frame
yang terdiri atas Nsample.
2. Windowing
Windowing dilakukan dengan cara
meminimalisasikan distorsi mengunakan
window untuk memperkecil sinyal hingga mendekati nol pada awal dan akhir tiap
frame. Jika window didefinisikan sebagai
w(n), 0 n N-1, dengan N adalah banyaknya sampel tiap frame. Window yang biasanya digunakan adalah window hamming karena kesederhanaan formulanya yang dapat dilihat pada persamaan 23 dan persamaan 243.
Y1(n) = x1(n)w(n), 0 n N-1 (23)
w(n)=0.54 – 0.46 cos (2 n/N-1) (24)
3. FastFourier Transform (FFT)
Tahapan ini bertujuan untuk mengonversi tiap frame dengan N sample dari time domain menjadi frekuency domain. FFT merupakan algoritme yang mengimplementasikan Discrete Fourier Transfom (DFT) yang didefinisikan pada persamaan 25.
: ?"1@ ;1<" =>1 +? (25) dengan
k=0,1,2,…,N-1
4. Mel Frequency Wrapping
Persepsi manusia terhadap frekuensi sinyal suara tidak berupa skala linear. Oleh karena itu, untuk setiap nada dengan frekuensi aktual f (dalam Hertz), tinggi subjektifnya diukur dengan skala mel. Skala mel-frequency adalah selang frekuensi di bawah 1000Hz dan selang logaritmik untuk frekuensi di atas 1000Hz. Perhitungan mel-frequency dapat dilihat pada persamaan 26 dan 27.
mel(f) = 2595 * log10 (1 + f / 700) (26)
:A ?"1@ B; 2 B/A 2 (27)
Keterangan : i = 1, 2, 3,…M
H(k) = nilai filter segitiga ke-i
5. Cepstrum
Tahapan ini bertujuan untuk mengonversi
mel frequency ke domain waktu
(DCT) yang dapat dilihat pada persamaan berikut :
C> DA@ :AEFG H> A" D=I (28) Keterangan :
C> = nilai koefisien C ke j
j = jumlah koefisien yang diharapkan :A = hasil mel-frequency wrapping pada
frekuensi i = 1, 2,….n jumlah
wrapping
M = jumlah filter
Probabilistic Neural Network (PNN)
Menurut Ganchecv (2005), PNN untuk klasifikasi, mapping, dan associative memory
diperkenalkan pertama kali oleh Specht tahun 1988. PNN diformulasikan ke dalam four-layer neural network yang sudah terlatih. Secara umum PNN dapat dituliskan,
J K M)NL M O HK"KPM I
P@L (29)
Keterangan :
k = fungsi kernel, dimana
k = QRL S"LQTQ (30)
e = 2,17 h = parameter
Struktur PNN terdiri atas empat layer, dapat dilihat pada Gambar 7.
Gambar 7 Struktur PNN (Ganchev 2005)
1. Input layer, berfungsi sebagai input data pada PNN.
2. Pattern layer, berfungsi menghitung jarak antara nilai input data suara dengan nilai pola dari tiap anggota kelas. Nilai hasil
pattern layer dapat ditunjukkan pada
persamaan berikut :
U ; V>@ 2 W!X" !ZXYX[ (31)
Keterangan:
d = banyaknya data pada pattern layer
xi = input data uji ke-j
xij = pattern ke-i data ke-j
hj = smoothing parameter
( x simpangan baku ke-j x n 1/5) i = 1, 2 sampai n
j = i, 2 sampai
n = banyaknya pattern pada satu kelas
3. Summation Layer, menghasilkan peluang
untuk satu kelas yang didapat dari penjumlahan patternlayer. Hasilnya dibagi dengan (2 )d/2hih2...hdn. Nilai hih2...hdn adalah nilai smoothing dari kelas tersebut. Persamaan untuk menghitung peluang tersebut adalah :
(32)
Keterangan:
hih2...hdn = nilai smoothing dari kelas
(fi(x)) = pattern layer
4. Decision Layer (Output Layer),
membandingkan hasil peluang pada setiap kelas kemudian input data dimasukkan dalam kelas yang memiliki nilai peluang terbesar.
METODOLOGI PENELITIAN Kerangka Pemikiran
Penelitian ini dilakukan dengan pengambilan sebelas kata. Masing-masing kata direkam sebanyak 16 kali dari satu orang pembicara. Kemudian, dilakukan proses penghapusan silent. Selanjutnya, data suara tersebut diolah dengan Wavelet Daubechies dan MFCC sebagai ekstraksi cirinya.
Data yang sudah diolah dibagi menjadi dua kelompok yaitu, data latih dan data uji. Kemudian, data latih dimodelkan dengan menggunakan PNN. Adapun langkah-langkah dalam proses pengenalan kata ini dapat dilihat pada Gambar 8.
Data Suara
Peng S biasa prose terku men P suar tiap seca Ilust Gam Data latih Ektraksi ciri (MFCC dan Wavlelet)
Perata -rataan
Model PNN
Gambar 8 D
enghapusan Sile
Silent merupa asanya terdapat oses perekaman rkumpul meru engandung silent
Pada proses in ara dengan men p suara. Peng cara manual den ustrasi pemotong ambar 9. Gambar silent Mulai Penghapusan silent Pengambilan data suara E ( Perhitungan nilai akurasi Selesai Normalisasi Segmentasi Pe Pengujian model PNN
Diagram Alur P
ent
pakan bagian at pada saat a an suara. Da rupakan suara
ent.
ini dilakukan pe enghilangkan s
nghapusan silen
engan menggun ngan silent dap
r 9 Pemotongan
Data uji
Ektraksi ciri (MFCC dan Wavlelet)
Perata -rataan
r Penelitian
n “diam” yan awal dan akh Data suara yan ra kotor yan
pembersihan dat
silent dari tiap
ilent dilakuka unakan Audacity
apat dilihat pad
an Silent silent ang khir ang ang data iap-kan ity. ada Norma Nor range masing cara m maksim memili dan min Segmen Seg sinyal Proses dengan didapat Ilustrasi pada G “c” Fon dilihat Tabel 1 Kat cob fana gaja jaya mal pac tip-visa wed zaka Data L Pen dilakuk fonem Setelah teratas dijadik latih da yang d
noise (
noise
ditamb malisasi
ormalisasi bertu nilai amplitud ng suara. Norm
membagi set simum pada mas miliki amplitudo sa
inus satu untuk
entasi Sinyal egmentasi adal
l suara dibagi-ses segmentasi
an menggunak at 26 fonem d rasi segmentasi
Gambar 10.
“ o”
Gambar 10 S
onem-fonem y at pada Tabel 1.
l 1 Segmentasi F
Kata Fo oba /c/, /o/ ana /f/, /a/ jah /g/, /a/, aya /j/, /a/ malu /m/, /a acu /p/, /a/
-x /t/, /i/ isa /v/, /i/ eda /w/, /e kat /z/, /a/,
Latih dan Data engambilan da ukan dengan car m kedalam k
ah dikelompokk as dari masing-m ikan data latih d dan data uji ya digunakan yait (data asli) dan 30dB, 20dB, bahkan adalah W
rtujuan untuk m udo yang sama
rmalisasi dilaku setiap nilai de
asing-masing su o satu untuk nila uk nilai minimum
alah tahap dim -bagi berdasar si dilakukan sec akan Audacity
dari masing-m si sinyal suara d
“b”
Segmentasi Sin
yang disegme
si Fonem
Fonem /o/, /b/, /a/ /a/, /n/, /a/ /, /j/, /a/, /h/ /a/, /y/, /a/ /a/, /l/, /u/ /a/, /c/, /u/
/i/, /p/, /x/ /i/, /s/, /a/ /e/, /d/, /a/
/, /k/, /a/, /t/
ata Uji
data latih dan ara mengelompo kelasnya ma kkan sebanyak masing kelas d dan data uji. P yaitu 75% : 25 aitu data tanpa an data dengan B, dan 10dB.
White Gaussian
mendapatkan a dari masing-kukan dengan
dengan nilai suara sehingga ilai maksimum
um.
dimana setiap sarkan fonem.
secara manual
ity sehingga masing suara. a dapat dilihat
“a”
inyal
entasi dapat
an data uji pokkan semua asing-masing. ak 16 fonem diambil untuk . Proporsi data 25%. Data uji a penambahan n penambahan . Noise yang
Ekstraksi Ciri (Wavelet dan MFCC)
Ekstraksi ciri merupakan proses untuk menentukan satu nilai atau vektor yang dipergunakan sebagai penciri objek. Tujuan utamanya adalah mereduksi ukuran data tanpa mengubah karakteristik dari sinyal suara. Ciri yang biasa dipergunakan adalah nilai koefisien
cepstral dari sebuah frame. Tahapan dari proses ini yaitu framing, windowing, fast fourier transform dan transformasi wavelet daubechies, mel-frequency wrapping, dan cepstrum.
Data suara yang telah disegmentasi selanjutnya dilakukan proses framing. Tiap
frame berukuran 30 ms, overlap 50%, dan 13 koefisien mel cepstrum. Pada transformasi
wavelet pengenalan fonem yang diproses akan mengalami penurunan fitur. Wavelet yang digunakan adalah Wavelet Daubechies (db4) satu level. Hasil dari matriks ekstraksi ciri ini merupakan masukan untuk pembelajaran pada PNN.
Perata-rataan Hasil MFCC dan Wavelet Proses ini bertujuan untuk menyamakan ukuran matriks untuk tiap suara pada masing-masing baris sehingga terbentuk ukuran matriks n×1. Hasil dari ekstraksi ciri MFCC dan wavelet
yaitu matriks ciri n×k, n adalah koefisien dan k adalah jumlah frame.
Pemodelan PNN
Hasil dari perata-rataan MFCC dan wavelet
selanjutnya dapat digunakan untuk membangun pemodelan PNN. Input data yang digunakan pada proses ini mempunyai ukuran matriks 13xN. Input data tersebut diidentifikasikan dengan pattern layer pada Persamaan 30. Parameter h pada Persamaan 30 digunakan nilai 1,14 × (simpangan baku) × n-1/5. Nilai UA ; ialah nilai hasil pattern layer ke i, dimana i=1, 2 sampai banyaknya observasi pada satu kelas. Setelah memperoleh selisih jarak antara nilai data input dengan data pada pattern layer, maka nilai tersebut dibagi dengan nilai smoothing parameter. Nilai smoothing $> didapat dari simpangan baku data setiap pattern ke j=1, 2 sampai jumlah koefisien yang digunakan.
Pengujian Model PNN
Pengujian model PNN ini dilakukan dengan cara memasukkan data uji (matriks n×1) ke dalam tiap kelas untuk mendapatkan nilai peluang. Perhitungan pada pengujian setiap kelas menggunakan Persamaan 31, sehingga nilai peluang p(x) diperoleh dari setiap kelas pada pengujian model PNN. Nilai peluang terbesar dari satu kelas merupakan hasil akhir
dari tahapan ini. Perbandingan data latih dan data uji adalah 75% : 25%.
Perhitungan Nilai Akurasi
Perhitungan nilai akurasi bertujuan untuk mengetahui hasil tingkat akurasi dari pengujian model PNN pada pengenalan fonem. Pada tahap ini kita bisa melihat fonem-fonem mana saja yang berhasil dikenali dengan baik dan fonem-fonem yang mungkin tidak bisa dikenali sama sekali. Selain itu kita juga bisa mengetahui metode mana yang lebih tinggi akurasinya. Perhitungan tingkat akurasi dapat dilihat pada persamaan berikut :
(33)
Lingkup Pengembangan Sistem
Perangkat keras yang digunakan pada penelitian ini berupa komputer notebook dengan spesifikasi:
• Intel Core2 Duo processor 1,3 GHz
• Memori DDR3 4 GB
• Harddisk 320 GB
Perangkat lunak yang digunakan yaitu :
• Sistem Operasi : Microsoft Xp
• Matlab 7.1
• Audacity 1.3
HASIL DAN PEMBAHASAN Data suara yang telah direkam pada frekuensi 12000Hz diperoleh sebanyak 176 kata untuk selanjutnya dilakukan penghapusan silent. Proses ini bertujuan untuk menghilangkan bagian silent yang terdapat pada awal dan akhir dari suara. Penghapusan silent dapat dilihat pada Gambar 11.
Data suara yang sudah dibersihkan disegmentasi per fonem tunggal. Semua fonem dikelompokkan per huruf agar lebih mudah diproses. Jumlah dari tiap fonem dapat dilihat pada Tabel 2.
Gambar 11 Penghapusan Silent
Tabel 2 Jumlah Tiap Fonem
Fonem Jumlah Fonem Jumlah
/a/ 224 /n/ 32
/b/ 16 /o/ 16
/c/ 32 /p/ 32
/d/ 16 /q/ 16
/e/ 16 /r/ 16
/f/ 16 /s/ 16
/g/ 16 /t/ 32
/h/ 16 /u/ 48
/i/ 32 /v/ 16
/j/ 32 /w/ 16
/k/ 16 /x/ 16
/l/ 16 /y/ 16
/m/ 16 /z/ 16
Akan tetapi penelitian ini hanya memilih 16 fonem dari jumlah masing-masing fonem yang ada. Hal ini dikarenakan jumlah fonem /a/ yang terlalu banyak yang menyebabkan fonem /a/ akan dominan untuk dikenali. Setelah didapat 16 fonem kemudian data tersebut dibagi menjadi data latih dan data uji dengan proporsi 75% : 25% untuk selanjutnya diekstraksi ciri dan dimodelkan menggunakan PNN.
Struktur PNN pada penelitian ini dapat dilihat pada Gambar 12. Input layer merupakan
input data yang berjumlah 13 sesuai banyaknya jumlah koefisien yang digunakan. Masing-masing kelas pada pattern layer berjumlah 12 sesuai banyaknya observasi yang digunakan. Pada layer ini dihitung jarak antara nilai input data dengan nilai pola dari tiap anggota kelas. Hasil dari pattern layer ini akan dijumlahkan dengan hasil dari pattern layer lainnya yang satu kelas. Proses ini terjadi pada summation layer. Pada summation layer diperoleh nilai terbesar untuk suatu kelas. Summation layer berjumlah 26 kelas sesuai jumlah kelas yang ada. Hasil dari summation layer tiap-tiap kelas dibandingkan pada decision layer berdasarkan nilai peluang terbesar sehingga input data dapat dikenali sebagai kelas tertentu.
Gambar 12 Implementasi Struktur PNN
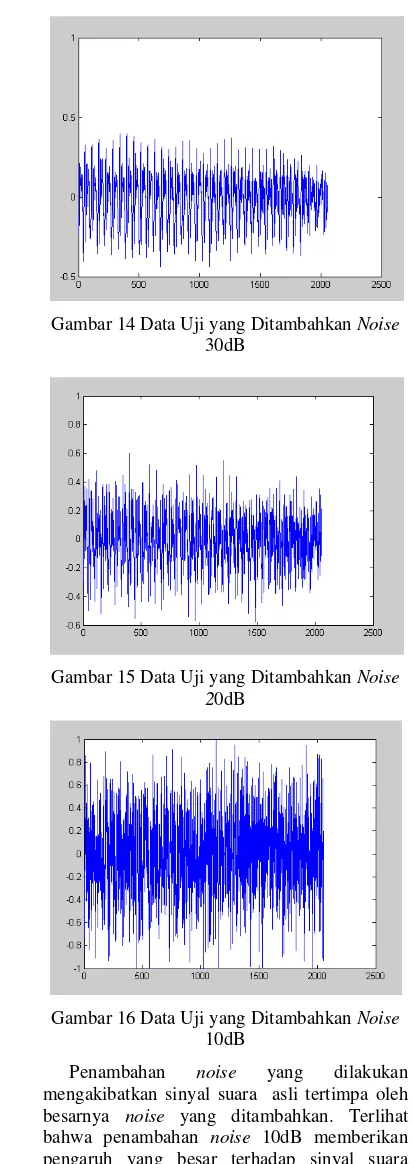
Pengujian yang dilakukan meliputi data uji asli (tanpa penambahan noise) dan data uji yang ditambahkan noise 30dB, 20dB, dan 10dB. Untuk mendapatkan hasil akurasi yang baik pengujian dilakukan secara berulang kali dengan mengombinasikan data latih dan data uji dari masing-masing fonem. Data uji tanpa penambahan noise dan data uji yang ditambahkan noise 30dB, 20dB, dan 10dB untuk fonem /a/ dapat dilihat secara berturut-turut pada Gambar 13, Gambar 14, Gambar 15, dan Gambar 16.
Gambar 14 Data Uji yang Ditambahkan Noise
30dB
Gambar 15 Data Uji yang Ditambahkan Noise 20dB
Gambar 16 Data Uji yang Ditambahkan Noise
10dB
Penambahan noise yang dilakukan mengakibatkan sinyal suara asli tertimpa oleh besarnya noise yang ditambahkan. Terlihat bahwa penambahan noise 10dB memberikan pengaruh yang besar terhadap sinyal suara dibandingkan dengan penambahan noise 20dB dan 30dB. Ini mengakibatkan sinyal suara akan sulit dikenali sesuai besarnya noise yang ditambahkan.
Sinyal Suara Asli (Tanpa Penambahan Noise)
Penelitian sinyal suara asli dilakukan dengan dua proses ekstraksi ciri yaitu wavelet dan MFCC. Induk wavelet yang digunakan adalah
Wavelet Daubechies orde 4 (db4).
Wavelet Daubechies Orde 4 (db4)
Pengujian dengan ekstraksi ciri Wavelet
Daubechies memperoleh akurasi sebesar
32.69% untuk keseluruhan fonem. Grafik tingkat akurasi suara asli dengan Wavelet Daubechies untuk masing-masing fonem dapat dilihat pada Gambar 17. Dapat dilihat bahwa akurasi yang dihasilkan belum memuaskan dimana masih terdapat fonem-fonem yang belum bisa dikenali. Fonem yang belum bisa dikenali di antaranya fonem /d/, /j/, /l/, /n/, /r/, /s/, /v/, /w/ dan /x/. Selain itu juga terdapat dua fonem yang dikenali cukup baik dengan akurasi di atas 70%, yaitu fonem /e/, /o/, /p/, /q/, /u/ dan /z/. Hasil pendeteksian masing-masing fonem untuk Wavelet Daubechies dan matriks
confusion dapat dilihat pada Lampiran 1 dan Lampiran 2. Fonem yang paling dominan terdeteksi pada metode wavelet daubechies
menggunakan data asli adalah fonem /e/.
Gambar 17 Grafik Tingkat Akurasi Suara Asli dengan Wavelet Daubechies Masing-Masing
Fonem
MFCC
Gambar 18 Grafik Tingkat Akurasi Suara Asli dengan MFCC Masing-Masing Fonem
Fonem yang memperoleh tingkat akurasi 100% sebanyak 20 fonem yaitu /b/, /d/, /e/, /f/, /g/, /h/, /j/, /l/, /m/, /n/, /o/, /p/, /r/, /s/, /u/, /v/, /w/, /x/, /y/, dan /z/. Fonem yang memperoleh tingkat akurasi 75% berturut-turut yaitu berturut-turut yaitu /a/, /c/, /i/, dan /q/. Fonem yang memperoleh tingkat akurasi 50 yaitu fonem /k/ dan /t/. Hasil pendeteksian masing-masing fonem untuk MFCC dan matriks
confusion dapat dilihat pada Lampiran 3 dan Lampiran 4.
Perbandingan Wavelet Daubechies Orde 4 (Db4) dengan MFCC pada Suara Asli
Perbandingan Wavelet Daubechies dan MFCC untuk semua fonem dapat dilihat pada Gambar 19. Terdapat empat fonem yang tidak dikenali pada pengujian yang menggunakan ekstraksi ciri Wavelet Daubechies sedangkan jika menggunakan MFCC fonem-fonem tersebut dapat dikenali semua.
Gambar 19 Grafik Perbandingan Tingkat Akurasi Suara Asli dengan Wavelet Daubechies
dan MFCC Masing-Masing Fonem
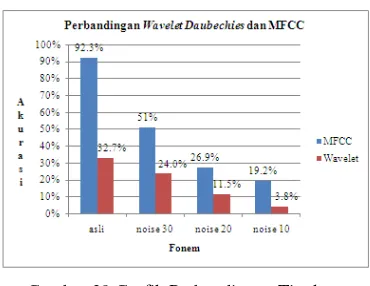
Gambar 20 menunjukkan perbandingan
Wavelet Daubechies dan MFCC secara
keseluruhan. Terlihat bahwa ekstraksi ciri menggunakan MFCC memperoleh akurasi yang cukup baik sebesar 92.3% dengan selisih mencapai 59.61% jika dibandingkan dengan
Wavelet Daubechies.
Gambar 20 Perbandingan Tingkat Akurasi Suara Asli dengan Wavelet Daubechies dan
MFCC
Sinyal Suara dengan Penambahan Noise
Noise yang ditambahkan pada penelitian ini adalah noise 30dB, 20dB, dan 10dB dengan ekstraksi ciri Wavelet Daubechies dan MFCC.
Daubechies Orde 4 (db4) dengan Penambahan Noise 30dB
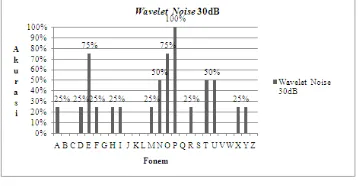
Grafik tingkat akurasi suara dengan noise
30dB menggunakan Wavelet Daubechies untuk masing-masing fonem dapat dilihat pada Gambar 21. Akurasi yang diperoleh dengan pengujian menggunakan ekstraksi ciri Wavelet
Daubechies untuk penambahan noise 30dB
adalah 24.03% untuk keseluruhan fonem.
Akurasi dengan penambahan noise 30dB menurun sebesar 8.66% dibandingkan dengan suara asli. Pada pengujian dengan penambahan
noise 30dB terdapat tiga fonem yang
mempunyai akurasi di atas 70% yaitu fonem /e/, /o/ dengan akurasi 75% dan fonem /p/ dengan akurasi 100%. Hasil pendeteksian masing-masing fonem untuk Wavelet Daubechies
dengan penambahan noise 30dB dan matriks
confusion dapat dilihat pada Lampiran 5 dan Lampiran 6. Fonem yang paling dominan terdeteksi pada penambahan noise 30dB yaitu fonem /e/.
Gambar 21 Grafik Tingkat Akurasi Suara dengan Noise 30 dB Menggunakan Wavelet
Wavelet Daubechies Orde 4 (db4) dengan Penambahan Noise 20dB
Akurasi yang diperoleh dengan pengujian menggunakan ekstraksi ciri Wavelet
Daubechies untuk penambahan noise 20dB
adalah 12.5% untuk keseluruhan fonem. Akurasi dengan penambahan noise 20dB menurun sebesar 11.53% dari penambahan
noise 30dB dan 20.19% dari suara asli. Pada penambahan noise 20dB masih terdapat fonem-fonem yang belum dikenali yaitu fonem-fonem /a/, /b/, /d/, /f/, /g/, /h/, /j/, /k/, /n, /q/, /r/, /s/, /t/, /v/, /w/, /x/, /y/, dan /z/ sedangkan fonem yang memperoleh akurasi 100% hanya hanya fonem /p/.
Grafik tingkat akurasi suara dengan noise
20dB menggunakan Wavelet Daubechies untuk masing-masing fonem dapat dilihat pada Gambar 22. Hasil pendeteksian masing-masing fonem untuk Wavelet Daubechies dengan penambahan noise 20dB dan matriks confusion
dapat dilihat pada Lampiran 7 dan Lampiran 8. Fonem yang paling dominan terdeteksi pada penambahan noise 20dB yaitu fonem /l/.
Gambar 22 Grafik Tingkat Akurasi Suara dengan Noise 20dB Menggunakan Wavelet
Daubechies Masing-Masing Fonem
Wavelet Daubechies orde 4 (db4) dengan Penambahan Noise 10dB
Pengujian dengan ekstraksi ciri Wavelet
Daubechies untuk penambahan noise 10dB
memperoleh akurasi sebesar 3.84% untuk keseluruhan fonem. Grafik tingkat akurasi suara dengan noise 10dB menggunakan
Wavelet Daubechies untuk masing-masing
fonem dapat dilihat pada Gambar 23. Akurasi dengan penambahan noise 10dB menurun sebesar 20.19% dari penambahan noise 30dB, 8.66% dari penambahan noise 20%, dan 28.85% dari suara asli.
Hasil pendeteksian masing-masing fonem untuk Wavelet Daubechies dengan penambahan
noise 10dB dan matriks confusion dapat dilihat pada Lampiran 9 dan Lampiran 10. Fonem yang paling dominan terdeteksi pada penambahan
noise 10dB yaitu fonem /o/. Ini dikarenakan
dengan penambahan noise 10dB membuat fonem-fonem yang diujikan menyerupai fonem /p/.
Gambar 23 Grafik Tingkat Akurasi Suara dengan Noise 10dB Menggunakan Wavelet
Daubechies Masing-Masing Fonem
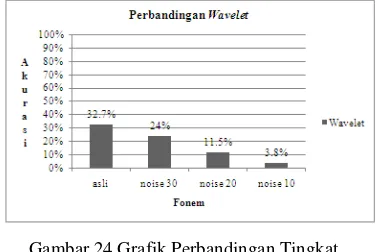
Perbandingan Wavelet Daubechies dengan Penambahan Noise 30dB, 20dB, 10dB
Tingkat akurasi perbandingan noise pada ekstraksi ciri Wavelet Daubechies dapat dilihat pada Gambar 24. Tingkat akurasi pada data suara asli lebih bagus dibandingkan dengan data suara dengan penambahan noise. Penambahan
noise pada penggunaan ekstraksi ciri Wavelet
Daubechies tidak terlalu berpengaruh
dibandingkan dengan suara asli (tanpa noise). Ini disebabkan wavelet dapat digunakan untuk mengurangi noise yang ditambahkan. Pada Gambar 24 terlihat semakin kecil noise yang ditambahkan semakin kecil tingkat akurasi pengenalan fonem, sedangkan jika semakin besar noise yang ditambahkan, akan semakin besar tingkat akurasi pengenalan fonemnya.
Gambar 24 Grafik Perbandingan Tingkat Akurasi Menggunakan Wavelet Daubechies
terhadap Suara Asli dan Suara dengan Penambahan Noise 30dB, 20dB, dan 10dB
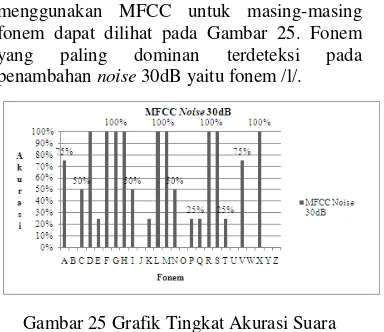
menggunakan MFCC untuk masing-masing fonem dapat dilihat pada Gambar 25. Fonem yang paling dominan terdeteksi pada penambahan noise 30dB yaitu fonem /l/.
Gambar 25 Grafik Tingkat Akurasi Suara dengan Noise 30dB Menggunakan MFCC
Masing-Masing Fonem
Hal ini membuktikan penambahan noise
30dB jauh lebih baik dari pada penambahan
noise 20dB dan 10dB. Hasil pendeteksian masing-masing fonem untuk MFCC dengan penambahan noise dan matriks confusion dapat dilihat pada Lampiran 11 dan Lampiran 12.
MFCC dengan Penambahan Noise 20dB Akurasi yang diperoleh dengan pengujian menggunakan ekstraksi ciri MFCC untuk penambahan noise 20dB hanya mencapai 26.92% untuk keseluruhan fonem. Akurasi dengan penambahan noise 20dB menurun sebesar 24.04% dibandingkan dengan penambahan noise 30dB dan 65.38% jika dibandingkan dengan suara asli. Pada penambahan noise 20dB terdapat lima fonem yang memperoleh akurasi 100% yaitu fonem /a/, /d/, /l/, /m/, dan /s /. Fonem yang paling dominan terdeteksi pada penambahan noise
10dB yaitu fonem /l/. Grafik tingkat akurasi suara dengan noise 20dB menggunakan MFCC untuk masing-masing fonem dapat dilihat pada Gambar 26. Hasil pendeteksian masing-masing fonem untuk MFCC dengan penambahan noise
20dB dan matriks confusion dapat dilihat pada Lampiran 13 dan Lampiran 14.
Gambar 26 Grafik Tingkat Akurasi Suara dengan Noise 20dB Menggunakan MFCC
Masing-Masing Fonem
MFCC dengan Penambahan Noise 10dB Pengujian dengan ekstraksi ciri MFCC untuk penambahan noise 10dB memperoleh akurasi sebesar 19.23% untuk keseluruhan fonem. Grafik tingkat akurasi suara dengan
noise 10dB menggunakan MFCC untuk
masing-masing fonem dapat dilihat pada Gambar 27.
Gambar 27 Grafik Tingkat Akurasi Suara dengan Noise 10dB Menggunakan MFCC
Masing-Masing Fonem
Pada Gambar 27 terlihat hanya delapan fonem yang dapat dikenali. Fonem tersebut di antaranya fonem /a/, /d/,/m/ dengan akurasi 100%, /l/, /p/, /s/ dengan akurasi 50%, dan /i/, /j/ dengan akurasi 25%. Hasil pendeteksian masing-masing fonem untuk MFCC dengan penambahan noise 10dB dan matriks confusion
dapat dilihat pada Lampiran 15 dan Lampiran 16. Fonem yang paling dominan terdeteksi pada penambahan noise 10dB yaitu fonem /a/.
Perbandingan MFCC dengan Penambahan Noise 30dB, 20dB, 10dB
Tingkat akurasi perbandingan noise pada ekstraksi ciri MFCC dapat dilihat pada Gambar 28.
Gambar 28 Grafik Perbandingan Tingkat Akurasi Menggunakan MFCC terhadap Suara
Asli dan Suara dengan Penambahan Noise
30dB, 20dB, dan 10dB
41.34% , 65.38% jika dibandingkan dengan penambahan noise 20dB dan mencapai 73.07% jika dengan penambahan noise 10dB.
Perbandingan Wavelet Daubechies dan MFCC antara Data Asli dan Data dengan Penambahan Noise 30dB, 20dB, 10dB
Tingkat akurasi perbandingan Wavelet Daubechies dan MFCC antara data asli dan data dengan penambahan noise 30dB, 20dB, dan 10dB dapat dilihat pada Gambar 29.
Gambar 29 Grafik Perbandingan Tingkat Akurasi Wavelet Daubechies dan MFCC terhadap Suara Asli dan Suara dengan Penambahan Noise 30dB, 20dB, dan 10dB
Akurasi menggunakan MFCC lebih tinggi dibandingkan dengan menggunakan Wavelet Daubechies yaitu sebesar 92.3%. Pada Gambar 29 dapat dilihat ekstraksi ciri menggunakan
Wavelet Daubechies memperoleh akurasi
kurang dari 50%. Hal ini menunjukkan ekstraksi ciri dengan Wavelet Daubechies tidak jauh lebih baik dari pada ekstraksi ciri dengan MFCC.
KESIMPULAN DAN SARAN Kesimpulan
Berdasarkan penelitian yang dilakukan, didapatkan kesimpulan sebagai berikut :
1. Ekstraksi ciri menggunakan MFCC pada pengenalan fonem jauh lebih baik dibandingkan dengan menggunakan Wavelet
Daubechies. Pada data asli (tanpa
penambahan noise) diperoleh akurasi sebesar 92.3% dan pada data yang ditambahkan noise 30dB, 20dB, dan 10dB akurasi yang diperoleh secara berturut-turut adalah 50.96%, 26.92%, dan 19.23%.
2. Akurasi data suara yang ditambahkan noise
30dB lebih tinggi dari pada akurasi data suara yang ditambahkan noise 20dB dan
noise 10dB. Ini mengakibatkan adanya
kemunduran tingkat akurasi. Oleh karena
itu, dapat disimpulkan jika semakin kecil
noise yang ditambahkan pada fonem maka akan semakin banyak jumlah fonem yang dapat dikenali (akurasi tinggi). Jika semakin besar noise yang ditambahkan pada fonem maka akan semakin sedikit jumlah fonem yang dapat dikenali (akurasi rendah).
Saran
Penelitian ini masih banyak kekurangan yang memungkinkan dilakukan pengembangan lebih lanjut. Beberapa saran yang dapat ditambahkan diantaranya :
1. Penelitian ini dapat dikembangkan ke arah pengenalan kata atau bahkan pengenalan kalimat.
2. Penggunaan kata yang lebih bervariasi serta menambah jumlah kata yang digunakan untuk data uji dan data latih.
3. Penambahan jumlah pembicara dan menggunakan dua atau lebih dalam pengucapan.
4. Segmentasi yang dilakukan tidak lagi secara manual (auto-correlation ).
DAFTAR PUSTAKA
Agustini K. 2006. Perbandingan Metode Transformasi Wavelet Sebagai Praproses Pada Sistem Identifikasi Pembicara. [Tesis]. Bogor : Sekolah Pasca Sarjana, Institut Pertanian Bogor.
Al-Akaidi M. 2004. Fractal Speech Processing. Cambridge University Press.
Buono A. 2009. Representasi Nilai HOS dan Model MFCC Sebagai Ekstraksi Ciri Pada
Sistem Identifikasi Pembicara di
Lingkungan Ber-Noise Menggunakan HMM.
[Disertasi]. Depok: Program Pascasarjana, Universitas Indonesia.
Burrus C.S, Gopinath RA, & Gou H. (1998).
Introduction to Wavelets and Wavelet Transforms A Primer. International Edition, Prentice-Hall International, Inc.
Donadio MB. 1992. How To Geberate White Gaussian Noise. http://www.dspguru.com/ds p/howtos/how-to-generate-white-gaussian-noise [diakses 12 Maret 2011].
Donoho DL, et al. 2003. Locally Stationary Covariance And Signal Estimation With Macrotiles. [Jurnal]. IEE Transaction On Signal Processing, Vol. 51 No. 3.
Laboratory Department of Computer and Electrical Engineering University of Patras.
Gonzalez RC, Woods RE. 2002. Digital Image Processing, Second Edition. New Jersey: Prentice Hall.
Jurafsky D, Martin JH. 2007. Speech And Language Processing: An Introduction To
Natural Language Processing,
Computational Linguistics, And Speech Recognition. New Jersey : Prentice Hall.
McAndrew A. 2004. An Introduction to Digital Image Processing with Matlab. School of Computer Science and Mathematics Victoria University of Technology.
Pelton GE. 1993. Voice Processing. New York: McGraw-Hill, Inc.
Proakis JG, Manolakis D. 2007. Digital Signal Processing : Principles, Algorithms, and Applications. New Jersey : Pearson Prentice Hall.
Resmiwati NUE. 2009. Pengenalan Kata Berbahasa Indonesia dengan Menggunakan
Hidden Markov Models Berbasiskan Fonem.
[Skripsi]. Bogor: Departemen Ilmu Komputer, FMIPA, Institut Pertanian Bogor.
Ruvinna. 2008. Pengenalan Kata Berbahasa Indonesia Dengan Hidden Markov Model (Hmm) Menggunakan Algoritme Baum-Welch. [Skripsi]. Bogor : Departemen Ilmu Komputer, FMIPA, Institut Pertanian Bogor.
Smith JO. 2010. Spectral Audio Signal Processing. Center for Computer Research in Music and Acoustics (CCRMA) Department of Music, Stanford University, Stanford, California 94305 USA.
Suhartono MN. 2007. Pengembangan Model
Identifikasi Pembicara Dengan
Probabilistic Neural Network. [Skripsi]. Bogor : Departemen Ilmu Komputer, FMIPA, Institut Pertanian Bogor.
Lampiran 1 Hasil Pendeteksian Masing-Masing Fonem untuk Wavelet Daubechies
Sinyal Terditeksi /a/ 1 21 5 21 /b/ 19 25 2 26 /c/ 23 3 12 16 /d/ 13 5 12 23 /e/ 5 5 21 5 /f/ 6 17 17 6 /g/ 22 7 24 22 /h/ 1 13 5 8
/i/ 19 9 9 1 /j/ 23 14 23 2 /k/ 11 8 3 10
/l/ 25 16 25 5 /m/ 5 13 1 18 /n/ 1 5 1 5 /o/ 15 21 15 15 /p/ 16 16 16 16 /q/ 17 7 17 17
/r/ 1 13 21 5 /s/ 4 7 22 13 /t/ 14 20 10 8 /u/ 21 5 21 21 /v/ 25 7 19 23 /w/ 13 14 5 25 /x/ 12 5 1 1 /y/ 12 1 25 5 /z/ 26 26 26 26
Keterangan :
Lampiran 2 Matriks Confusion Wavelet Daubechies
a b c d e f g h i j k l m n o p q r s t u v w x y z a 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 b 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 c 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 0 d 0 0 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 1 0 0 0 e 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 f 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 g 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 h 1 0 0 0 5 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0
i 1 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 j 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 2 0 0 0 k 0 0 1 0 0 0 0 1 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 l 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 2 0 m 1 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0
Lampiran 3 Hasil Pendeteksian Masing-Masing Fonem untuk MFCC
Sinyal Terditeksi /a/ 1 1 1 8 /b/ 2 2 2 2 /c/ 7 3 3 3 /d/ 4 4 4 4 /e/ 5 5 5 5 /f/ 6 6 6 6 /g/ 7 7 7 7 /h/ 8 8 8 8 /i/ 9 16 9 9 /j/ 10 10 10 10 /k/ 20 11 20 11 /l/ 12 12 12 12 /m/ 13 13 13 13 /n/ 14 14 14 14 /o/ 15 15 15 15 /p/ 16 16 16 16 /q/ 19 17 17 17 /r/ 18 18 18 18 /s/ 19 19 19 19 /t/ 20 9 9 20 /u/ 21 21 21 21 /v/ 22 22 22 22 /w/ 23 23 23 23 /x/ 24 24 24 24 /y/ 25 25 25 25 /z/ 26 26 26 26
Keterangan :
Lampiran 4 Matriks Confusion MFCC
Lampiran 5 Hasil Pendeteksian Masing-Masing Fonem untuk Wavelet Daubechies dengan Penambahan Noise 30dB
Sinyal Terditeksi /a/ 1 21 5 15 /b/ 23 23 19 23 /c/ 23 19 19 16 /d/ 13 23 4 12 /e/ 5 5 1 5 /f/ 17 17 26 6 /g/ 13 22 24 22 /h/ 8 1 12 13
/i/ 25 9 16 1 /j/ 9 14 23 23 /k/ 25 12 20 10
/l/ 25 16 25 5 /m/ 5 13 1 18 /n/ 14 5 14 5 /o/ 15 21 15 15 /p/ 16 16 16 16 /q/ 10 7 22 20
/r/ 25 1 5 18 /s/ 22 23 22 21 /t/ 13 20 9 20 /u/ 21 5 25 21 /v/ 19 5 19 19 /w/ 5 5 5 5 /x/ 12 24 15 1 /y/ 12 1 25 1 /z/ 3 3 23 23
Keterangan :
Lampiran 6 Matriks Confusion Wavelet Daubechies dengan Penambahan Noise 30dB
Lampiran 7 Hasil Pendeteksian Masing-Masing Fonem untuk Wavelet Daubechies dengan Penambahan Noise 20dB
Sinyal Terditeksi /a/ 12 5 5 21 /b/ 4 16 23 3 /c/ 7 3 24 10 /d/ 12 15 25 18 /e/ 15 5 5 21 /f/ 25 25 7 17 /g/ 15 18 12 21 /h/ 1 12 5 12
/i/ 9 21 16 1 /j/ 24 4 12 16 /k/ 19 13 25 10
/l/ 15 12 24 5 /m/ 5 13 1 18 /n/ 24 21 5 21 /o/ 15 5 24 15 /p/ 16 16 16 16 /q/ 12 3 19 23
/r/ 14 15 5 12 /s/ 22 16 25 12 /t/ 24 21 18 7 /u/ 21 12 9 24 /v/ 16 21 19 12 /w/ 21 15 5 15 /x/ 1 5 1 15 /y/ 9 12 15 4 /z/ 24 24 21 5
Keterangan :
Lampiran 8 Matriks Confusion Wavelet Daubechies dengan Penambahan Noise 20dB
Lampiran 9 Hasil Pendeteksian Masing-Masing Fonem untuk Wavelet Daubechies dengan Penambahan Noise 10dB
Sinyal Terditeksi /a/ 15 15 16 16 /b/ 15 21 9 19 /c/ 24 15 15 9 /d/ 16 20 1 24 /e/ 15 24 24 5 /f/ 20 9 12 12 /g/ 24 13 20 20 /h/ 9 21 9 24
/i/ 21 16 16 3 /j/ 3 25 15 9 /k/ 3 25 25 9 /l/ 20 25 12 24 /m/ 5 13 1 18 /n/ 15 4 25 16 /o/ 15 5 24 5 /p/ 21 25 24 24 /q/ 24 21 25 4
/r/ 15 12 1 24 /s/ 23 7 15 4 /t/ 15 4 24 9 /u/ 15 24 3 5 /v/ 25 24 24 4 /w/ 15 15 1 18 /x/ 15 9 5 15 /y/ 19 24 15 9 /z/ 14 9 15 21
Keterangan :
Lampiran 10 Matriks Confusion Wavelet Daubechies dengan Penambahan Noise 10dB
Lampiran 11 Hasil Pendeteksian Masing-Masing Fonem untuk MFCC dengan Penambahan Noise
30dB
Sinyal Terditeksi /a/ 1 1 1 8 /b/ 10 10 10 10 /c/ 12 7 3 3 /d/ 4 4 4 4 /e/ 12 5 12 12 /f/ 6 6 6 6 /g/ 7 7 7 7 /h/ 8 8 8 8 /i/ 20 20 9 9 /j/ 9 5 12 12 /k/ 9 10 10 11
/l/ 12 12 12 12 /m/ 13 13 13 13 /n/ 14 14 13 13 /o/ 10 10 10 10 /p/ 16 20 20 20 /q/ 19 10 17 20 /r/ 18 18 18 18 /s/ 19 19 19 19 /t/ 4 9 20 4 /u/ 12 12 12 12 /v/ 22 22 22 16 /w/ 12 12 12 12 /x/ 24 24 24 24 /y/ 12 12 12 12 /z/ 12 12 13 13
Keterangan :
Lampiran 12 Matriks Confusion MFCC dengan Penambahan Noise 30dB
Lampiran 13 Hasil Pendeteksian Masing-Masing Fonem untuk MFCC dengan Penambahan Noise
20dB
Sinyal Terditeksi /a/ 1 1 1 1 /b/ 10 10 10 10 /c/ 10 16 16 7 /d/ 4 4 4 4 /e/ 12 12 12 12 /f/ 6 10 9 7 /g/ 1 1 10 1 /h/ 1 1 1 1
/i/ 20 16 9 9 /j/ 20 12 12 12 /k/ 20 4 10 1
/l/ 12 12 12 12 /m/ 13 13 13 13 /n/ 13 13 13 13 /o/ 10 10 10 10 /p/ 20 20 16 16 /q/ 19 10 10 9
/r/ 9 16 7 1 /s/ 19 19 19 19 /t/ 1 20 20 10 /u/ 12 12 12 12 /v/ 9 9 9 16 /w/ 12 12 13 12 /x/ 1 1 1 24 /y/ 12 12 12 12 /z/ 5 12 13 13
Keterangan :
Lampiran 14 Matriks Confusion MFCC dengan Penambahan Noise 20dB
Lampiran 15 Hasil Pendeteksian Masing-Masing Fonem untuk MFCC dengan Penambahan Noise
10dB
Sinyal Terditeksi /a/ 1 1 1 1 /b/ 1 10 4 1 /c/ 1 16 16 16 /d/ 4 4 4 4 /e/ 1 1 1 1 /f/ 9 1 7 1 /g/ 1 1 1 1 /h/ 1 1 1 1 /i/ 20 16 20 9 /j/ 9 1 1 10 /k/ 9 1 1 1
/l/ 12 12 1 1 /m/ 13 13 13 13 /n/ 1 1 1 1 /o/ 1 1 1 1 /p/ 9 20 16 16 /q/ 4 1 1 9
/r/ 1 9 16 1 /s/ 9 9 19 19 /t/ 1 16 16 1 /u/ 1 1 12 12 /v/ 9 9 9 9 /w/ 1 1 1 1 /x/ 1 1 1 1 /y/ 1 1 1 1 /z/ 1 10 1 10
Keterangan :
Lampiran 16 Matriks Confusion MFCC dengan Penambahan Noise 10dB
ABSTRACT
AYU GUSTIAWATI. The comparison of Wavelet Daubechies and MFCC methods as feature extraction for phoneme recognition with Probabilistic Neural Netowork (PNN) as classifier. Under the direction of AGUS BUONO.
Nowadays, the development of telecommunication research is rapidly increasing. One of the research is in sound area. Sound is a way for human to interact with computers, known as word recogniser. Word recogniser is a part of voice recogniser that make the computers possible to receive input from word that pronounced. Word that pronounced contain phonemes that arranged into sentence. Voice recognition technology can recognise and understand words that pronounce by digitalising it, and tuning the digital signal with certain pattern that has been saved in a hardware. The result from this word identification will be displayed into printed word. This research will compare between Wavelet Daubechies and MFCCas identity extraction on word recognition with (PNN) as pattern identifier. PNN is a pattern identifier that has high accuracy. The comparison between trained data and tested data in research is 75% : 25%. Tested data that has been used was vary, such as: testing with increase the noise (pure noise) and data with noise increasing from 30dB, 20dB and 10dB. The result from this research is that the identity extraction by using MFCC is much better than with Wavelet Daubechies. From the pure original data (without noise increasing) the accuracy is 92.3% and in data with noise increasing 30dB, noise 20dB and noise 10dB the accuracy is 50.96%, 26.92% and 19.23%.
PENDAHULUAN Latar Belakang
Perkembangan penelitian di dunia telekomunikasi sangat pesat beberapa tahun terakhir ini. Salah satunya adalah penelitian di bidang suara. Suara adalah salah satu cara manusia untuk berinteraksi dengan komputer, dikenal dengan istilah pengenalan kata. Pengenalan kata merupakan bagian dari pengenalan suara yang memungkinkan komputer untuk menerima masukan berupa kata yang diucapkan. Kata yang diucapkan terdiri dari fonem-fonem yang menyusun sebuah kata. Teknologi pengenalan suara memungkinkan suatu perangkat untuk mengenali dan memahami kata-kata yang diucapkan dengan cara digitalisasi kata dan mencocokkan sinyal digital dengan suatu pola tertentu yang tersimpan dalam suatu perangkat. Hasil dari identifikasi kata yang diucapkan ditampilkan dalam bentuk tulisan.
Berbagai sistem pengenalan suara atau yang dapat disebut juga Automatic Speech
Recognition (ASR) telah banyak dikembangkan
di berbagai negara dengan berbagai bahasa. Beberapa sistem pengenalan suara yang telah dikembangkan (Ruvinna 2008) :
• Spoken Dialoque System, sistem yang dapat melakukan dialog singkat guna mendapatkan informasi tertentu. Seperti pada seorang customer service, pengguna hanya perlu menjawab ‘ya’ atau ‘tidak’ untuk mendapatkan informasi tertentu.
• Speed Dialing System, sistem yang dapat mengenali sebuah nama atau ID seseorang dan mencarinya dalam buku telepon untuk segera dihubungi. Pengguna tidak perlu mencari nomor telepon seseorang, biasanya dalam telepon selular, untuk dapat menghubungi seseorang, pengguna tidak perlu mencari nomor telepon orang tersebut. Namun cukup dengan menyebutkan nama atau ID orang yang akan dihubungi dan sistem secara otomatis menghubunginya.
• Speech to Text Translation System, sistem yang secara otomatis mengetikkan kata-kata yang diucapkan pengguna.
Oleh karena itu, penulis melakukan penelitian dengan membandingkan metode
Wavelet Daubechies dan MFCC sebagai
ekstraksi ciri pada pengenalan kata dengan
Probabilistic Neural Network (PNN) sebagai pengenalan pola. PNN merupakan salah satu
jenis pengenalan pola yang memiliki akurasi cukup tinggi (Suhartono MN 2007).
Tujuan Penelitian
Penelitian ini bertujuan membandingkan metode Wavelet Daubechies dan MFCC sebagai ekstraksi ciri pada pengenalan fonem dengan PNN untuk mendapatkan informasi tingkat akurasi.
Ruang Lingkup
Ruang lingkup dari penelitian ini antara lain:
1. Kata yang digunakan terdiri atas sebelas kata yaitu coba, fana, gajah, jaya, malu, pacu, quran, tip-x, visa, weda, dan zakat.
2. Masing-masing kata direkam oleh satu orang pembicara sebanyak 16 kali dalam waktu satu detik, time frame 30 ms, overlap
50%, dan sampling rate 12000Hz.
3. Penelitian ini terbatas pada pengenalan fonem tunggal (bukan pengenalan kata atau kalimat).
4. Segmentasi untuk masing-masing fonem dilakukan secara manual.
5. Ekstraksi ciri yang digunakan adalah pemodelan Wavelet Daubechies dan MFCC.
6. Metode yang digunakan pada penelitian ini adalah Probabilistic Neural Network (PNN).
7. Kata yang diucapkan berbahasa Indonesia.
Manfaat
Manfaat dari penelitian ini antara lain :
1. Menambah pustaka penelitian pengenalan fonem menggunakan metode Wavelet
Daubechies dan MFCC dengan
Probabilistic Neural Network (PNN).
2. Memberikan informasi tingkat akurasi pengenalan fonem menggunakan metode
Wavelet Daubechies dan MFCC dengan
Probabilistic Neural Network (PNN).
TINJAUAN PUSTAKA Sinyal
Menurut Proakis JG & Manolakis DG (2007)