SELEKSI FITUR DINAMIS UNTUK PASANGAN ATRIBUT
BERKORELASI TINGGI MENGGUNAKAN KOMPUTASI
PARALEL BERBASIS GRAPHICS PROCESSING UNIT
(GPU)
ASTRIED SILVANIE
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK
CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Seleksi Fitur Dinamis untuk Pasangan Atribut Berkorelasi Tinggi menggunakan Komputasi Paralel Berbasis Graphics Processing Unit (GPU) adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, November 2013
RINGKASAN
ASTRIED SILVANIE. Seleksi Fitur Dinamis untuk Pasangan Atribut Berkorelasi Tinggi menggunakan Komputasi Paralel Berbasis Graphic Processing Unit (GPU). Dibimbing oleh TAUFIK DJATNA dan HERU SUKOCO.
Seleksi fitur dengan fitur berkorelasi tinggi di dunia nyata harus dilakukan pada data dinamis. Hal ini karena penyisipan, penghapusan transaksi dan memperbarui terjadi terus menerus pada basis data. Transaksi ini membuat dimensi data menjadi sangat besar dalam jumlah record dan sejumlah fitur. Pertanyaannya adalah bagaimana kita melakukan seleksi fitur pada data yang sangat besar dan terus berubah ini. Masalah ini harus diselesaikan dan salah satu metode yang umum adalah untuk melakukan sampling dari basis data.
Dalam penelitian ini, metode random sampling digunakan untuk mengekstraksi sinopsis keseluruhan data dalam basis data. Algoritma reservoir digunakan untuk menginisialisasi sampel. Jenis sampel adalah backing sample terdiri atas identitas, nilai prioritas dan time stamp. Ketika ada perubahan dalam basis data, data lama dengan prioritas terendah dalam sampel akan diganti dengan yang baru. Sampel sebagai representasi dari basis data dipertahankan memiliki distribusi kelas yang sama dengan basis data menggunakan kullback leibler divergence. Semua teknik dan algoritma digabungkan dan diimplementasikan dalam bahasa SQL menggunakan MySQL 5.5. Sebagai hasilnya, proses pengambilan sampel mengambil sejumlah kecil baru data sebagai representasi dari database dengan distribusi kelas yang sama dengan basis data.
Proses sampling mengurangi dimensi dalam jumlah record dan diperlukan metode lain untuk mempercepat seleksi fitur pada jumlah fitur yang besar. Dalam penelitian ini, komputasi GPU paralel digunakan untuk mempercepat seleski fitur yang memiliki dimensi besar. Algoritma seleksi fitur akan dibagi menjadi dua sub masalah. Masalah ini adalah diskritasi dan komputasi geometri x-monotone. Algoritma paralel diterapkan untuk masing-masing sub-masalah sejauh tidak ada dependensi dan rekursif. Algoritma ditulis ke dalam program dengan bahasa C CUDA. Program dibagi menjadi dua fungsi kernel yaitu kernel diskritasi dan kernel x-monotone.
Uji coba dilakukan pada kumpulan data dengan tiga distribusi yaitu seimbang, miring negatif dan positif miring. Percepatan rata-rata yang paralel untuk satu pasang fitur adalah 1.5 kali untuk diskritasi dan 1.87 kali untuk x-monotone daripada sekuensial. Percepatan rata-rata yang paralel dapat mencapai 45, 190, 435, 780, 1225, 1770, 2415, 3160,4005, 4950 sepasang fitur adalah 8.2 kali daripada sekuensial. Akurasi diukur untuk setiap fungsi kernel dalam program CUDA. Kernel diskritasi memiliki akurasi 81.76% dan kernel x-monoton memiliki akurasi 85%. Seleksi fitur untuk 4950 pasangan dengan distribusi seimbang membutuhkan 0.85 detik. Perhitungan yang sama pada negatif miring dan miring positif adalah 1.66 dan 1.84 detik. Fakta-fakta ini menunjukkan perhitungan pada data dengan distribusi miring membutuhkan durasi yang lebih lama dari distribusi yang seimbang.
SUMMARY
ASTRIED SILVANIE. Dynamic Data mining for Highly Intercorrelated Feature Selection with Graphic Processing Unit Computing (GPU). Supervised by TAUFIK DJATNA and HERU SUKOCO.
Feature selection with correlated features in the real world should be performed on dynamic data. This is due to insertion, deletion and updating transactions occur continuously on the database. This transaction makes the dimension of data becomes very large in number of records and number of features. The question is how we do feature selection on very large data and is constantly changing. This problem should be solved and one common method is to perform the sampling on database.
In this research, random sampling method is used to extract the overall synopsis of the data in the database. The reservoir algorithm used to initialize the sample. Type of sample is backing sample composed of identities, priorities and time stamp. When there is a change in the database, the old data in the sample with the lowest priority will be replaced with a new one. Sample as a representation of the database has maintained the same class distribution using the kullback leibler divergence. All the techniques and algorithms are incorporated and implemented in the SQL language using MySQL 5.5. As a result, the sampling process of taking a small amount of new data as a representation of the database with the same class distribution database.
Sampling process reduces the dimension of the required number of records. We need other methods to speed up the feature selection on very large number of features. In this research, parallel GPU computing is used to speed up feature selection that have large dimensions. Feature selection algorithm is divided into two sub problems. This problem is discreetization and computational geometry x- monotone. Parallel algorithm is applied to each sub problem as long as no recursiveness and dependencies. The algorithm is written into the program with the CUDA C language. The program is divided into two, which are discreetization kernel function and x-monotone kernel function.
Tests performed on a data set with three distributions, which are balanced, negatively skewed and positively skewed. Average acceleration doing with parallel for one pair feature is 1.5 times to 1.87 times for discreetization and x-monotone rather than sequential. Average acceleration parallel for 45, 190, 435, 780, 1225, 1770, 2415, 3160, 4005, 4950 number of features pairs is 8.2 times faster than sequential. Accuracy was measured for each kernel function in CUDA programs. Discreetization kernel has accuracy of 81.76 % and an x-monotone kernel has accuracy of 85 %. Feature selection for 4950 pairs with a balanced distribution requires only 0.85 seconds. The same calculation on negative skewed and positive skewed is 1.66 and 1.84 seconds. These facts show the calculation on the data with skewed distribution requires a longer duration than a balanced distribution.
© Hak Cipta Milik IPB, Tahun 2013
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
SELEKSI FITUR DINAMIS UNTUK PASANGAN ATRIBUT
BERKORELASI TINGGI MENGGUNAKAN KOMPUTASI
PARALEL BERBASIS GRAPHICS PROCESSING UNIT
(GPU)
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2013
Judul Tesis : Seleksi Fitur Dinamis untuk Pasangan Atribut Berkorelasi Tinggi menggunakan Komputasi Paralel Berbasis Graphics Processing Unit (GPU)
Nama : Astried Silvanie NIM : G651110351
Disetujui oleh Komisi Pembimbing
Dr Taufik Djatna, STP Msi
Ketua
Diketahui oleh
Dr Heru Sukoco, SSi MT Anggota
Ketua Program Studi Ilmu Komputer
Dr Yani Nurhadryani, SSi MT
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MSc Agr
Tanggal Ujian: 13 September 2013
PRAKATA
Alhamdulillah saya panjatkan kepada Allah Subhanahu wa ta’ala atas semua ujian dan berkah yang telah diberikan selama penelitian ini dilakukan. Setiap ujian yang hadir telah membentuk pribadi saya menjadi lebih tabah dan kuat. Setiap masalah yang datang baik dari keluarga, keuangan, dan motivasi menyadarkan saya pentingnya kemampuan beradaptasi. Kegagalan hanyalah langkah menuju kesuksesan. So never give up, trust me i am an engineer !
Terima kasih penulis ucapkan kepada Bapak Dr Taufik Djatna, STP MSi dan Bapak Dr Heru Sukoco, Ssi MT selaku pembimbing. Terima kasih juga buat Dr Yani Nurhadryani, SSi MT selaku kaprodi ilmu komputer. Ungkapan terima kasih juga disampaikan kepada ibu, dan kedua adik tercinta yang selalu mendukung dalam keadaan sulit sekali pun. Ungkapan terima kasih tidak lupa disampaikan pada Neny Rosmawarni, Galih Sidik, Azima, Fajar, Elfira, Nina, Iwan, Arif, Gen-T 4 dan seluruh pihak yang tidak bisa disebutkan namanya satu persatu, atas segala doa dan bantuannya. Terima kasih pada seluruh rekan sekuliahan Pasca Sarjana IPB. Terima kasih buat ibu Nining.
Terima kasih pada Birone Lynch (my J B) atas petunjuknya di masalah data dinamis. Terima kasih pada Eric Brainville atas artikelnya mengenai bitonic merge sorting di internet. Thank you for Karen my Philippines sister. Thank you for my love Binti BrindAmour.
“Without engineer, Scientist is only philosopher talking about philosophy. Thank to God, I am both !”
Bogor, Desember 2013
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN ix
1 PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Ruang Lingkup 2
Manfaat Penelitian 3
2 METODE 3
Pengolahan terhadap data dinamis 3
Data mining terhadap data dinamis 3
Sampel 4
Inisialisasi Sampel 5
Kullback lieblerDivergence 6
Proses Pemasukan Data 7
Proses Penghapusan Data 8
Proses Pembaharuan Data 10
Cara Kerja 10
Paralelisasi pada seleksi fitur 11
Seleksi Fitur 11
Perancangan Teknik Paralel menggunakan GPU 15
Kernel Diskritasi 18
Kernel X-Monotone 21
Integrasi Aplikasi dan Kernel 24
Uji Coba 26
Perangkat keras dan perangkat lunak 27
3 HASIL DAN PEMBAHASAN 28
Implementasi dan Hasil Metode Data mining Dinamis 28 Implementasi dan Hasil Algoritme Paralel dan Komputasi GPU 30
4 SIMPULAN DAN SARAN 33
Simpulan 33
Saran 33
DAFTAR PUSTAKA 34
DAFTAR TABEL
1
Tampilan data di backing sample 4
2
Input dan output kernel diskritasi 19
3
Input dan output kernel x-monotone 22
4
Hasil uji coba sampling terhadap data dinamis berdasarkan jumlah transaksi, entropi dan nilai kullback liebler 29 5
Evaluasi kinerja untuk model pohon keputusan dari data dengan
distribusi seimbang dan tidak seimbang 30
6
Hasil uji coba komputasi paralel terhadap algoritme seleksi fitur
untuk satu pasangan fitur 30
7
Hasil uji coba perbandingan waktu eksekusi komputasi sekuensial dan paralel dengan berberapa jumlah pasangan fitur 31
DAFTAR GAMBAR
1
Sekilas mengenai proses seleksi fitur terhadap data dinamis 4 2
Inisialisasi backing sample 5
3
Kode sumber fungsi Kullback Liebler Divergence 6 4
Algoritme pemasukan data baru ke basis data 7
5
Algoritme penghapusan data dari basis data 9
6
Algoritme pembaharuan data di basis data 10
7
Diskritasi dengan multidimensional equi-depth histogram 12 8
Multidimensional equi-depth histogram yang tiap bucket dihitung jumlah record kelas target positif dan jumlah record target negatif 12 9
(a) area poligon tidak x-monotone; (b) area poligon x-monotone 12 10
Kalkulasi inner product untuk semua kolom 13
11
Komputasi botsum untuk semua kolom 13
12
13
Komputasi topsum untuk semua kolom 13
14
Komputasi top untuk semua kolom 14
15
Kalkulasi x-monotone 14
16
Kalkulasi convex hull 14
17
evaluasi area x monotone 15
18
Struktur memori CUDA dan cara kerja program CUDA 17 19
Rancangan program paralel untuk kasus seleksi fitur 18 20
Penentuan indeks pasangan fitur untuk tiap blok thread 18 21
Alokasi data dan kelas target ke tiap blok thread 19 22
Algoritme bitonic merge sort berdasarkan dua nilai data 20 23
Alokasi beberapa thread ke tiap bucket dari multidimensional equi-depth
histogram berukuran 3 x 3 20
24
Algoritme untuk menghitung jumlah record kelas target positif dan
negatif 21
25
Alokasi thread di tiap kolom untuk menghitung botsum, bot, topsum,
top secara paralel 22
26
Kalkulasi inner product untuk semua kolom secara paralel 22 27
Komputasi botsum semua kolom secara paralel 22
28
Komputasi bot untuk semua kolom secara paralel 22 29
Komput asi topsum untuk semua kolom secara paralel 23 30
Komputasi top untuk semua kolom secara paralel 23 31
Komput asi F-max untuk tiap kolom secara paralel 23 32
Komput asi nilai flatness secara paralel 24
33
Arsitektur aplikasi seleksi fitur 24
34
Alokasi ukuran data dinamis di kernel diskritasi 25 35
Pemanggilan kernel beserta jumlah blok thread, jumlah thread, ukuran
memori dinamis dan data 25
36
37
Data dengan distribusi seimbang 26
38
Data dengan distribusi miring positif 27
39
Data dengan distribusi miring negatif 27
40
Pohon keputusan setelah 1000 transaksi terjadi terhadap basis data 28 41
Pohon keputusan setelah 500 transaksi terjadi terhadap basis data 29 42
Grafik waktu eksekusi dari proses pemasukan data, eksekusi kernel dan
mengeluarkan hasil eksekusi 32
43
Grafik waktu eksekusi proses eksekusi kernel 32
DAFTAR LAMPIRAN
1
Data set Pima Indisan Diabetes 36
2
Data set acak mengikuti pola Pima Indisan Diabetes dengan distribusi
kelas seimbang 36
3
Data set acak mengikuti pola Pima Indisan Diabetes dengan distribusi
kelas miring positif 37
4
Data set acak mengikuti pola Pima Indisan Diabetes dengan distribusi
1 PENDAHULUAN
Latar Belakang
Seleksi fitur digunakan untuk memilih subset fitur yang relevan dengan mengidentifikasikan dan membuang sebanyak mungkin informasi yang redundan dan tidak relevan (Hall 2000; Alpaydin 2004). Hal ini dapat meningkatkan kinerja model prediksi dengan dengan mengurangi efek dari kutukan dimensi, meningkatkan kinerja generalisasi, mempercepat proses pembelajaran, dan meningkatkan model penterjemahan (Hoi 2012). Djatna dan Morimoto (2008a, 2008b) menyatakan pentingnya memperhitungkan interkorelasi antara dua fitur untuk menentukan kelas target. Mereka mengajukan algoritme seleksi fitur dengan memilih pasangan fitur berkorelasi tinggi yang sangat relevan untuk menentukan kelas target.
Penelitian mengenai seleksi fitur selama ini hanya digunakan dengan data yang statik. Di dunia nyata data selalu berubah seiring dengan waktu disebut data dinamis. Data dinamis terjadi karena transaksi pemasukan, penghapusan dan pembaharuan data secara terus menerus terhadap basis data. Transaksi ini membuat dimensi data menjadi semakin besar, baik dari jumlah fitur dan record. Menurut Nasereddin (2009) data dinamis mempunyai karakter terus menerus, tidak terbatas dan berkecepatan tinggi. Seleksi fitur terhadap data dimensi tinggi yang selalu berubah memerlukan waktu lebih lama. Hal ini karena dibutuhkan memindai ulang keseluruhan data setiap ada perubahan. Sehingga perlu digunakan metode yang tepat agar seleksi fitur terhadap data dinamis menjadi lebih efisien. Penelitian ini focus terhadap seleksi fitur yang diguankan untuk klasifikasi. Sehingga selain efesiensi perlu diperhatikan kinerja seleksi fitur terhadap model klasifikasi.
Metode sampel acak umum digunakan dalam penelitian-penelitian sebelum untuk data dinamis (Babcock 2002; Braverman et al. 2009; Byung-Hoon et al. 2007; Gemulla 2008; Gibbons 1997; Vitter 1985). Penelitian ini menggunakan sampel acak untuk mengekstrasi sinopsis dari basis data yang sangat besar. Algoritme reservoir digunakan untuk inisialisasi sampel (Vitter 1985). Backing sample merupakan teknik yang digunakan Gibbons (1997) untuk menjaga isi sampel selalu terbaharui. Proses pergantian data di sampel memilih sampel yang akan diganti berdasarkan nilai prioritas (Gemulla 2008). Semua teknik yang telah disebutkan sebelumnya dapat digunakan secara bersama untuk menghasilkan sampel acak yang selalu terbaharui.
2
dengan pengukuran distribusi menggunakan Kullback Liebler diharapkan dapat memperoleh sampel yang mirip dengan basis data.
Teknik pengambilan sampel hanya memperkecil data dalam jumlah record. Seleksi fitur Djanta dan Morimoto (2008a, 2008b) memeriksa semua kombinasi pasangan fitur yang mungkin. Jika data mempunyai dimensi fitur yang sangat besar akan menghasilkan jumlah pasangan yang sangat besar pula. Perlu dicarikan solusi untuk mempercepat komputasi seleksi fitur. Solusi untuk mepercepat komputasi adalah komputasi paralel. Komputasi paralel adalah penggunaan komputer paralel untuk mereduksi waktu yang dibutuhkan untuk menyelesaikan masalah komputasional tunggal (Quinn 2003). Komputasi paralel dapat menggunaka multi core Central Processing Unit (CPU) atau many core Graphic Processing Unit (GPU) mempunyai potensi yang besar untuk melakukan komputasi paralel. Secara arsitektur GPU mempunyai lebih banyak inti (core) dari CPU. Dalam penelitian Zhang et al. (2009, 2010, 2011) menggunakan komputasi paralel dengan GPU untuk mempercepat komputasi terhadap data berjumlah sangat besar. Menurut Che et al. (2008) GPU terbukti lebih cepat daripada komputasi paralel menggunakan CPU.
Penelitian ini menggunakan algoritme reservoir, backing sample, priority sampling, kullback liebler untuk mengambil sampel dari data dinamis. Sampel berukuran lebih kecil dari basis data tetapi terbaharui dan mirip dengan basis data. Seleksi fitur terhadap sampel lebih efisien karena dimensi baris lebih kecil. Komputasi paralel dengan GPU digunakan untuk mempercepat seleksi fitur terhadap data dengan dimensi fitur yang sangat tinggi.
Perumusan Masalah
Data di dunia nyata sangat dinamis sehingga seleksi fitur pada data statik tidak lagi ideal. Data yang dinamis secara terus menerus merubah isi dan dimensi data. Ukuran dimensi data adalah jumlah baris dan jumlah fitur. Proses seleksi fitur terhadap data dinamis ini perlu memindai ulang keseluruhan data. Hal ini memerlukan waktu dan terdapat kemungkinan data sudah berubah sebelum proses memindai ulang selesai. Perlu dirancang algoritme untuk mengekstrasi data dari data dinamis tersebut secara terus menerus dan perlu solusi untuk mempercepat proses data mining.
Tujuan Penelitian
1. Merancang algoritme untuk mengolah data yang dinamis.
2. Merancang algoritme paralel yang dapat mempercepat seleksi fitur dengan pasangan fitur berkorelasi tinggi.
3. Implementasi algoritme paralel dengan komputasi paralel berbasis graphic processing unit (GPU).
Ruang Lingkup
3
2. Algoritme seleksi fitur yang digunakan berdasarkan penelitian Djatna dan Morimoto (2008a, 2008b).
3. Komputasi paralel menggunakan GPU dengan compute capability 1.1.
Manfaat Penelitian
1. Pembuatan kerangka untuk pengolahan data mining dinamis.
2. Menyediakan alternatif metode untuk menyediakan penyelesaian data berdimensi tinggi dengan komputasi GPU.
3. Mempercepat proses seleksi fitur dalam data preprocessing.
2 METODE
Pengolahan terhadap data dinamis
Data mining terhadap data dinamis
Data dinamis adalah data yang selalu berubah atas proses pemasukan (insert), pembaharuan (update) dan penghapusan (delete) data. Ketiga transaksi ini membuat ukuran basis data semakin membesar dan tidak tetap. Data mining terhadap data dinamis harus dijalankan secara kontinu. Beberapa penelitian membahas data mining terhadap data dinamis (Babcock 2002; Braverman et al. 2009; Byung-Hoon et al. 2007; Gemulla 2008; Gibbons 1997; Vitter 1985). Mereka menggunakan metode sampling. Idenya adalah mengektrasi sinopsis dari basis data yang sangat besar ke dalam ukuran data yang lebih kecil disebut sampel. Sampel menjadi representasi dari basis data. Sampel ini yang akan menjadi data masukan bagi proses data mining. Penelitian ini berfokus pada data mining untuk klasifikasi dengan kelas target binary. Fitur predikator yang digunakan dalam penelitian ini adalah data bertipe numerik. Kelas target binary mempunyai dua nilai yaitu positif dan negatif. Sebagai representasi dari basis data, penting untuk menjaga kesamaan distribusi kelas antara sampel dan basis data. Alasannya adalah karena bentuk distribusi kelas mempunyai pengaruh pada model klasifikasi dan performa dari model klasifikasi (Chawla 2010; Haibo 2009; Jason 2007; Prati 2008; Tang 2005; Xinjian 2008). Hal ini tidak dibahas pada penelitian sebelum (Babcock 2002; Braverman et al. 2009; Byung-Hoon et al. 2007; Gemulla 2008; Gibbons 1997; Vitter 1985). Metode pengambilan sampel secara acak tidak menjamin kesamaan distribusi kelas antara basis data dan sampel. Penelitian ini menggunakan metode kullback liebler divergence untuk mengukur kesamaan distribusi kelas antara sampel dan basis data. Metode ini dibahas lebih lanjut pada bab lullback lieblerdivergence.
4
negative. Proses seleksi fitur tidak dilakukan pada keseluruhan data dalam basis data, tetapi hanya pada sampel. Sampel merupakan representasi dari keseluruhan basis data. Data di dalam sampel akan menjadi data yang diolah untuk proses seleksi fitur.
Gambar 1 Sekilas mengenai proses seleksi fitur terhadap data dinamis Sumber : www.shutterstock.com
Sampel
Basis data berisi seluruh data dianggap sebagai populasi dari sampel. Proses pengambilan sampel dilakukan dengan mengambil k record secara acak dari basis data yang akan dimasukkan ke dalam sampel dinotasikan sebagai S. Salah satu hal penting adalah menjaga sampel selalu terbaharui dengan menggunakan teknik pengambilan backing sampling seperti dalam penelitian Gibbons (1997). Backing sample berisi data sampel acak dari basis data dan selalu terbaharui dengan adanya transaksi penyisipan, penghapusan dan pembaharuan dalam basis data. Record mewakili tiap baris dalam basis data. Model backing sample terdiri atas k record dinotasikan sebagai
bs
=
{ }
e
i i= −1 k. Backing sample hanya menyimpan id record dinotasikanid
i, prioritas dinotasikanpriority
i dan timestamp dinotasikani
t
. Setiap record dalam backing sample mengandunge
i=
{ ,
id priority t
i i, }
i i= −1 k. Prioritas adalah nilai riil acak antara 0 dan 1 yang diberikan pada masing-masing record dalam sampel (Gemulla 2008). Ketika terjadi transaksi pemasukan dan penghapusan record terhadap basis data, salah satu record dalam sampel akan dihapus. Record yang dihapus dari sampel adalah record yang mempunyai prioritas terendah. Backing sample dalam basis data disimpan sebagai tabel seperti pada Tabel 1.Tabel 1 Tampilan data di backing sample
ID Priority TimeStamp
5
Inisialisasi Sampel
Pada saat awal backing sample kosong tanpa record. Algoritme reservoir sampling digunakan untuk mengambil k data secara acak dari basis data (Vitter 1985). Dalam penelitian ini, untuk inisalisasi sampel dibuat algoritme yang sejenis dengan reservoir sampling tetapi bedanya algoritme ini dapat mempertahankan kesamaan distribusi kelas antara basis data dan sampel. Gambar 2 di bawah ini menjelaskan logika dari proses pembentukan sampel pada saat inisialisasi.
/* ni as the counter of each class i
* currentPos as the position of record
* Pi as distribution of each class in database
*/
Declare ni.
Declare currentPos. Set ni to zero.
Set currentPos to zero. Calculate Pi.
WHILE NOT EOF DO
Generate an integer random number r with interval value 1 to t. Skip as much as r records.
currentPos = currentPos + r.
FOR i = 1 TO m DO
IF (ni/k) < Pi AND i == Class index currentPos record
THEN
Add record of currentPos from database to backing sample.
Increment ni.
BREAK FOR. END IF
END FOR END WHILE
IF sample size is not k THEN FOR i = 1 to m
IF (ni/k) < Pi THEN
w = (Pi – (ni/k)) * k
Sample_temp = select id from database
where id is not in sample and class index = i.
FOR j = 1 TO w
Add record of position j from sample_temp to backing sample.
Increment ni. END FOR
Sample_temp = null
END IF END FOR END IF
Gambar 2 Inisialisasi backing sample
6
membuat proses pelewatan dilakukan hanya (k+1) kali. Alasannya agar proses pelewatan tidak melebihi akhir dari tabel. Algoritme harus memindai ulang basis data jika jumlah sampel di bawah k record. Setelah proses ini sampel akan terdiri dari k record dan mempunyai distribusi kelas yang sama dengan basis data.
Kullback lieblerDivergence
Distribusi kelas dapat berbentuk seimbang (balance) dan tidak seimbang (imbalance). Sebuah dataset dengan distribusi kelas seimbang (balance) terjadi ketika persentase masing-masing kelas adalah (100/n), dimana n adalah jumlah kelas. Jika persentase tidak persis sama maka dataset ini disebut tidak seimbang (imbalance). Ketika distribusi kelas mempunyai secara signifikan condong pada kelas tertentu maka data disebut miring (skew).
Kullback liebler (KL) divergence adalah ukuran dalam statistik untuk menunjukkan seberapa dekat probabilitas distribusi p = {pi} adalah sebuah model
distribusi q = {qi}, di mana p adalah populasi dan q adalah sampel (Efren 2013). Penelitian ini menggunakan divergensi KL untuk mengukur persamaan distribusi kelas antara populasi dan sampel. Jika kita memiliki sebanyak l jumlah kelas target maka Kullback liebler divergence didefinisikan sebagai berikut:
2
1
( || ) log ( )
l
i
KL i
i i
p
D p q p
q =
=
∑
(1)
Jika i
i
mp p
np
= dan i
i
mq q
nq
= maka KL divergence dapat didefinisikan dalam rumus 1. Nilai i menunjukkan indeks kelas yaitu 1 dan 2 untuk kelas positif dan negatif. Nilai
i
mp adalah jumlah kelas i dalam populasi. Nilai i
mq adalah jumlah kelas i dalam sampel. Nilai npadalah jumlah record dalam populasi dan
ns
adalah jumlah record dalam sampel.2 1
( || ) log
i l i KL i i mp mp np
D p q
mq np nq = =
∑
(2)Perhitungan Kullback liebler divergence tersebut diimplementasikan dalam fungsi di MySQL (lihat Gambar 3). Fungsi ini akan dipanggil pada kode sql lainnya untuk menghitung nilai Kullback liebler divergence antara sampel dan basis data.
CREATE FUNCTION fKLDistance(p1 float, p2 float, q1 float, q2 float) RETURNS double
BEGIN
return ( (p1*flog2(p1/q1)) + (p2*flog2(p2/q2)) ); END
Gambar 3 Kode sumber fungsi Kullback Liebler Divergence
7
menjaga kemiripan distribusi kelas antara populasi dan sampel, nilai KL divergence harus mendekati nol. Logika dari proses penggunaan KL divergence untuk menjaga distribusi data adalah sebagai berikut :
i. Pemasukan record kelas j akan mengubah distribusi sebagai berikut : jika nilai KL divergence mendekati nol maka tidak perlu mengubah distribusi kelas di sampel. Kebalikannya, distribusi sampel harus diubah. Caranya adalah dengan menambah record kelas j dan menghapus record dari kelas lain di sampel.
' 1 1 1 i i i mp i j np p mp i j np + = + = ≠ + ' 1 1 i i i mq i k nq q mq i k nq + = = − ≠
(3)
ii. Penghapusan record kelas j akan mengubah distribusi sebagai berikut : Jika nilai KL divergence mendekati nol maka tidak perlu mengubah distribusi kelas di sampel. Kebalikannya, distribusi sampel harus diubah. Caranya adalah dengan menghapus record kelas k dan menambah record dari kelas lain di sampel.
' 1 1 1 i i i mp i j np p mp i j np − = − = ≠ − ' 1 1 i i i mq i k nq q mq i k nq − = = + ≠
(4)
Proses Pemasukan Data
Ketika masuk satu record baru untuk kelas j (newRecj) ke dalam basis data
akan terjadi salah satu dari beberapa aktivitas berikut :
• newRecj akan menggantikan record kelas j dengan prioritas terendah di
sampel.
• newRecj akan dimasukkan ke dalam sampel dan sampel akan menghapus satu
record kelas bukan j dengan prioritas terendah di sampel.
Algoritme di Gambar 4 menunjukkan detail logika untuk proses pemasukan data baru ke basis data.
/* c1 for class occurrence for positive class in database * c2 for class occurrence for negative class in database * d1 for class occurrence for positive class in sample * d2 for class occurrence for negative class in sample
* kl for Kullback Liebler divergence
* np for number of records in database * ns for number of records in sample
* i for the current class of new inserted record */
8
Declare c1,c2,d1,d2,kl,np,ns,i.
Set kl = fkl(c1/np, c2/np, d1/ns, d2/ns)
IF kl >= 0 AND kl <= 0.0001 THEN
Delete the lowest priority record from sample for class i. Insert new inserted record into sample.
ELSE
IF i is positive class THEN
Set d1 = d1 + 1. Set d2 = d2 – 1. ELSE
Set d1 = d1 – 1. Set d2 = d2 + 1. END IF
Set kl = fkl(c1/np, c2/np, d1/ns, d2/ns).
IF kl >= 0 AND kl <= 0.0001 THEN
Delete the lowest priority record from sample for class NOT i.
Insert a record from database wih the highest priority AND NOT in sample FOR class i.
ELSE
IF i is positive class THEN
Set d2 = d2 + 2 Set d1 = d1 - 2 ELSE
Set d2 = d2 – 2 Set d1 = d1 + 2 END IF
Set kl = fkl(c1/np, c2/np, d1/ns, d2/ns)
IF kl >= 0 AND kl <= 0.0001 THEN
Delete the lowest priority record from sample FOR class i.
Insert a record from database wih the highest priority AND NOT in sample FOR class NOT i.
END IF
END IF END IF
Gambar 4 Lanjutan Algoritme pemasukan data baru ke basis data
Proses Penghapusan Data
Ketika salah satu record kelas j (delRecj) di hapus dari basis data akan
terjadi salah satu dari beberapa aktivitas berikut :
• Satu record kelas j dengan prioritas terendah di sampel di hapus di ganti dengan record kelas j dengan prioritas tertinggi dari sampel.
9
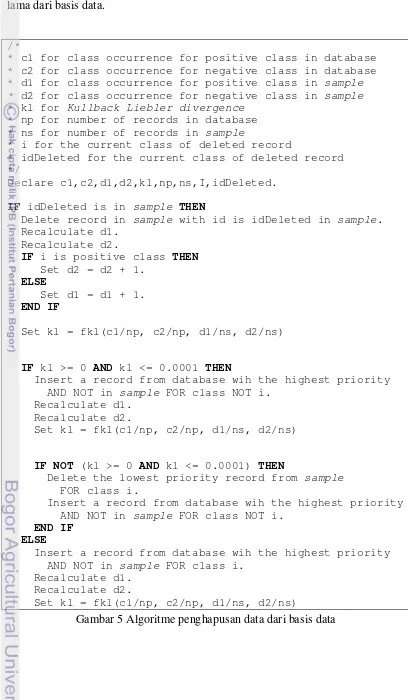
Algoritme di Gambar 5 menunjukkan detail logika untuk proses penghapusan data lama dari basis data.
/*
* c1 for class occurrence for positive class in database * c2 for class occurrence for negative class in database * d1 for class occurrence for positive class in sample * d2 for class occurrence for negative class in sample
* kl for Kullback Liebler divergence
* np for number of records in database * ns for number of records in sample
* i for the current class of deleted record
* idDeleted for the current class of deleted record */
Declare c1,c2,d1,d2,kl,np,ns,I,idDeleted.
IF idDeleted is in sample THEN
Delete record in sample with id is idDeleted in sample. Recalculate d1.
Recalculate d2.
IF i is positive class THEN
Set d2 = d2 + 1. ELSE
Set d1 = d1 + 1. END IF
Set kl = fkl(c1/np, c2/np, d1/ns, d2/ns)
IF kl >= 0 AND kl <= 0.0001 THEN
Insert a record from database wih the highest priority AND NOT in sample FOR class NOT i.
Recalculate d1. Recalculate d2.
Set kl = fkl(c1/np, c2/np, d1/ns, d2/ns)
IF NOT (kl >= 0 AND kl <= 0.0001) THEN
Delete the lowest priority record from sample FOR class i.
Insert a record from database wih the highest priority AND NOT in sample FOR class NOT i.
END IF
ELSE
Insert a record from database wih the highest priority AND NOT in sample FOR class i.
Recalculate d1. Recalculate d2.
Set kl = fkl(c1/np, c2/np, d1/ns, d2/ns)
10
IF NOT (kl >= 0 AND kl <= 0.0001) THEN
Delete the lowest priority record from sample FOR class NOT i.
Insert a record from database wih the highest priority AND NOT in sample FOR class i.
END IF END IF
ELSE
IF I is positive class THEN
Set d1 = d1 – 1 Set d2 = d2 + 1 ELSE
Set d1 = d1 + 1 Set d2 = d2 – 1 END IF
Set kl = fkl(c1/np, c2/np, d1/ns, d2/ns)
IF kl >= 0 AND kl <= 0.0001 THEN
Delete the lowest priority record from sample for class i.
Insert a record from database wih the highest priority AND NOT in sample FOR class NOT i.
ELSE
Delete the lowest priority record from sample for class NOT i.
Insert a record from database wih the highest priority AND NOT in sample FOR class i.
END IF END IF
Gambar 5 Lanjutan Algoritme penghapusan data dari basis data Proses Pembaharuan Data
Ketika terjadi pembaharuan terhadap salah satu data di dalam basis data maka record tersebut akan diperbaharui nilai prioritasnya. Gambar 6 menjelaskan logika dari proses tersebut.
/*
* idUpdated for current class of deleted record */
Declare idUpdated.
SET priority = Randomize() WHERE id = idUpdated
Gambar 6 Algoritme pembaharuan data di basis data Cara Kerja
11
menghitung log basis dua yang dibutuhkan pada kalkulasi Kullback Liebler divergence. Fungsi KL untuk menghitung nilai Kullback Liebler divergence. Trigger TR_Insert akan mendeteksi transaksi pemasukan data kemudian mengeksekusi kode program dalam trigger dan sp_insert. Trigger TR_delete akan mendeteksi transaksi penghapusan data kemudian mengeksekusi kode program dalam trigger dan sp_delete. Trigger TR_Update akan mendeteksi transaksi pemasukan data kemudian mengeksekusi kode program dalam trigger. Setiap informasi mengenai transaksi yaitu catatan waktu, nilai Kullback Liebler, jenis transaksi dan id record yang berubah disimpan dalam tabel log. Tabel log digunakan untuk melihat apakah teknik dan algoritme yang diterapkan berhasil menjaga keterbaharuan dan distribusi kelas target.
Paralelisasi pada seleksi fitur
Seleksi Fitur
Tujuan dari seleksi fitur adalah untuk memilih subset fitur-fitur yang relevan untuk membangun model prediksi efektif. Menurut Hall (2000) seleksi subset fitur adalah proses mengidentifikasikan dan membuang sebanyak mungkin informasi yang redundan dan tidak relevan. Menurut Djatna dan Morimoto (2008a, 2008b) di dunia nyata di antara fitur terdapat korelasi. Djatna dan Morimoto (2008a, 2008b) mengajukan algoritme yang menyeleksi pasangan fitur dengan interkorelasi tinggi dan juga mempunyai korelasi tinggi dengan kelas target.
Algoritme seleksi fitur dengan pasangan fitur berkorelasi tinggi (Djatna dan Morimoto 2008a, 2008b):
1) Jika basis data terdiri atas sekelompok fitur berjumlah fn maka dapat direpresentasikan
database=
{
f1,..., ffn}
(5) Maka dibuatkan kombinasi pasangan fitur tanpa perulangan sebanyak :
! 2!( 2) !
fn
fn− (6)
12
Gambar 7 Diskritasi dengan multidimensional equi-depth histogram
Gambar 8 Multidimensional equi-depth histogram yang tiap bucket dihitung jumlah record kelas target positif dan jumlah record target negatif
3) Djatna dan Morimoto (2008a, 2008b) menggunakan komputasi geometri untuk mencari pasangan fitur yang interkorelasinya tinggi. Mereka percaya jika dibentuk suatu area poligon yang disebut x-monotone maka pasangan fitur tersebut mempunyai interkorelasi yang tinggi. Area poligon x-monotone adalah area poligon yang tidak terpotong dengan garis vertikal. Contoh area poligon x-monotone dan bukan x-monotone dapat dilihat pada Gambar 9. Setiap pasangan fitur menghasilkan satu area poligon x-monotone.
(a) (b)
[image:30.595.80.470.70.842.2]13
Berikut ini dijelaskan secara ringkas logika algoritme x-monotone : i. Kalkulasi inner product (Θ) untuk tiap bucket di histogram.
FOR i = 1 to banyak_baris FOR j = 1 to banyak_kolom
, ,
. .
x Pi j y Pi j
θ θ
Θ = +
[image:31.595.108.516.47.833.2]END FOR END FOR
Gambar 10 Kalkulasi inner product untuk semua kolom x
θ
: stamp point x yθ : stamp point y
,
i j
P : jumlah record kelas target positif baris i kolom j
,
i j
N : jumlah record kelas target negatif baris i kolom j ii. Komputasi botsum untuk semua kolom.
FOR m = 1 TO banyak_kolom botsum(1) = 0
FOR S = 2 to N
botsum(s) = botsum(s-1)+Gs-1,m
END FOR END FOR
Gambar 11 Komputasi botsum untuk semua kolom N : jumlah baris multidimensional equi-depth histogram m : indeks kolom
1,
s m
G− : total inner product di kolom m dari baris pertama sampai baris s-1
iii. Komputasi bot untuk semua kolom.
FOR m = 1 TO banyak_kolom botm(1) = 1FOR s = 2 TO N
IF (botsum(S) < botsum(botm(s-1)))
botm(s) = s
ELSE
botm(s) = botm(s-1)
END IF
dBottomArr((s*dCelSize)+m) = botm(s)
END FOR END FOR
Gambar 12 Komputasi bot untuk semua kolom iv. Komputasi topsum untuk semua kolom.
FOR m = 1 TO banyak_kolom topsum(N) = 0
FOR S = N-1 to 1
topsum(s) = topsum(s+1)+Gs+1,m
END FOR END FOR
14
v. Komputasi top untuk semua kolom.
FOR m = 1 TO banyak_kolom topm(N) = N
FOR s = N-1 TO 1
IF (topsum(S) < topsum(topm(s+1)))
topm(s) = s
ELSE
topm(s) = topm(s+1)
END IF
dTopArr((s*dCelSize)+m) = topm(s)
[image:32.595.81.489.59.780.2]END FOR END FOR
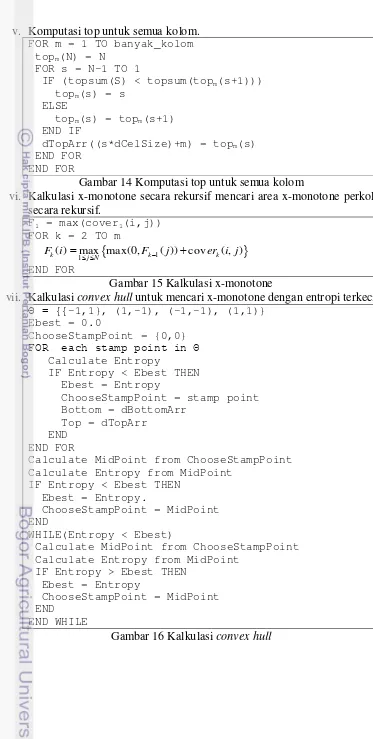
Gambar 14 Komputasi top untuk semua kolom
vi. Kalkulasi x-monotone secara rekursif mencari area x-monotone perkolom secara rekursif.
F1 = max(cover1(i,j))
FOR k = 2 TO m
{
}
1 1
( ) max max(0, ( )) cov ( , )
k k k
j N
F i = ≤ ≤ F− j + er i j
END FOR
Gambar 15 Kalkulasi x-monotone
vii. Kalkulasi convex hull untuk mencari x-monotone dengan entropi terkecil.
Θ = {{-1,1}, (1,-1), (-1,-1), (1,1)}
Ebest = 0.0
ChooseStampPoint = {0,0}
FOR each stamp point in Θ
Calculate Entropy
IF Entropy < Ebest THEN Ebest = Entropy
ChooseStampPoint = stamp point Bottom = dBottomArr
Top = dTopArr END
END FOR
Calculate MidPoint from ChooseStampPoint Calculate Entropy from MidPoint
IF Entropy < Ebest THEN Ebest = Entropy.
ChooseStampPoint = MidPoint END
WHILE(Entropy < Ebest)
Calculate MidPoint from ChooseStampPoint Calculate Entropy from MidPoint
IF Entropy > Ebest THEN Ebest = Entropy
ChooseStampPoint = MidPoint END
END WHILE
[image:32.595.92.465.75.814.2]15
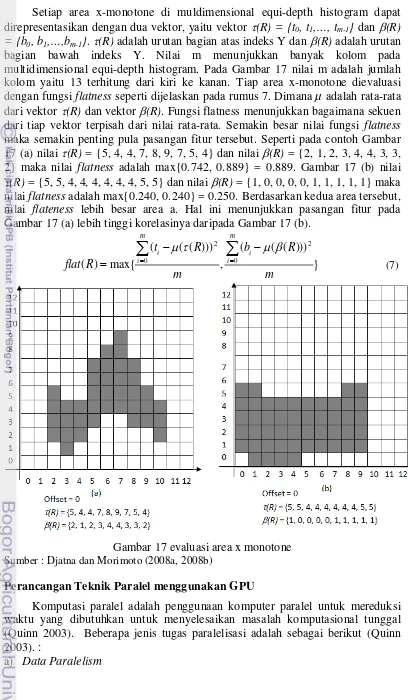
Setiap area x-monotone di muldimensional equi-depth histogram dapat direpresentasikan dengan dua vektor, yaitu vektor τ(R) = {t0, t1,…, tm-1} dan β(R)
= {b0, b1,…,bm-1}. τ(R) adalah urutan bagian atas indeks Y dan β(R) adalah urutan
bagian bawah indeks Y. Nilai m menunjukkan banyak kolom pada multidimensional equi-depth histogram. Pada Gambar 17 nilai m adalah jumlah kolom yaitu 13 terhitung dari kiri ke kanan. Tiap area x-monotone dievaluasi dengan fungsi flatness seperti dijelaskan pada rumus 7. Dimana µ adalah rata-rata dari vektor τ(R) dan vektor β(R). Fungsi flatness menunjukkan bagaimana sekuen dari tiap vektor terpisah dari nilai rata-rata. Semakin besar nilai fungsi flatness maka semakin penting pula pasangan fitur tersebut. Seperti pada contoh Gambar 17 (a) nilai τ(R) = {5, 4, 4, 7, 8, 9, 7, 5, 4} dan nilai β(R) = {2, 1, 2, 3, 4, 4, 3, 3, 2} maka nilai flatness adalah max{0.742, 0.889} = 0.889. Gambar 17 (b) nilai
τ(R) = {5, 5, 4, 4, 4, 4, 4, 4, 5, 5} dan nilai β(R) = {1, 0, 0, 0, 0, 1, 1, 1, 1, 1} maka nilai flatness adalah max{0.240, 0.240} = 0.250. Berdasarkan kedua area tersebut, nilai flateness lebih besar area a. Hal ini menunjukkan pasangan fitur pada Gambar 17 (a) lebih tinggi korelasinya daripada Gambar 17 (b).
2 2
0 0
( ( ( ))) ( ( ( )))
( ) max{ , }
m m
i i
i i
t R b R
flat R
m m
µ τ µ β
= =
− −
=
∑
∑
(7)Gambar 17 evaluasi area x monotone Sumber : Djatna dan Morimoto (2008a, 2008b)
Perancangan Teknik Paralel menggunakan GPU
Komputasi paralel adalah penggunaan komputer paralel untuk mereduksi waktu yang dibutuhkan untuk menyelesaikan masalah komputasional tunggal (Quinn 2003). Beberapa jenis tugas paralelisasi adalah sebagai berikut (Quinn 2003). :
[image:33.595.109.517.80.780.2]16
Beberapa tugas yang saling bebas mengerjakan operasi yang sama terhadap kumpulan data yang berbeda.
b) FunctionalParallelism
Beberapa tugas yang saling bebas mengerjakan operasi yang berbeda terhadap kumpulan data yang berbeda.
c) Pipelining
Komputasi ini mirip proses perakitan, di mana satu operasi terdiri atas beberapa bagian terhadap kumpulan data yang berbeda.
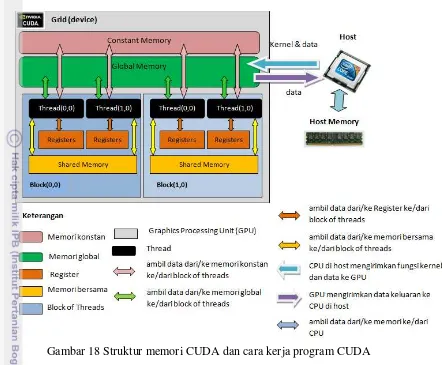
Komputasi paralel dapat dilakukan oleh computer dengan multi core CPU (Central Processing Unit) atau many core GPU (Graphics Processing Unit). Secara arsitektur GPU mempunyai lebih banyak inti (core) yang merupakan keunggulan daripada multi core CPU. NVIDIA sebagai salah satu vendor GPU merupakan perintis dalam komputasi paralel dengan GPU. CUDA (Compute Unit Device Architecture) adalah platform komput asi paralel dan model pemrograman yang diciptakan oleh NVIDIA.
17
18
Gambar 19 Rancangan program paralel untuk kasus seleksi fitur
Kernel Diskritasi
Kernel diskritasi mempunyai enam data masukan dan dua data keluaran. Tabel 1 menjelaskan masukan dan keluaran dari kernel diskritasi. Fungsi kernel diskritasi dijalankan oleh semua pasangan fitur untuk menghasilkan multidimensional equi-depth histogram. Semua pasangan fitur mengeksekusi proses diskritasi yang sama sehingga proses ini dilakukan secara paralel. Jumlah thread pada kernel diskritasi adalah jumlah pasangan fitur dikali jumlah record. Tiap pasangan fitur mempunyai thread sebanyak jumlah record. Kumpulan thread untuk tiap pasangan fitur dikelompokkan dalam satu blok thread. Seperti pada contoh Gambar 20, data yang diolah terdiri atas tiga fitur dan empat baris record. Fitur keempat adalah kelas target yang merupakan hasil klasifikasi. Tiga fitur akan menghasilkan tiga pasangan fitur berdasarkan rumus 6. Sehingga untuk kasus pada Gambar 21 kernel diskritasi akan mempunyai dua belas thread. Dua belas thread tersebut dibagi ke dalam tiga blok dengan tiap blok terdiri atas empat thread. Tiap blok thread mengeksekusi kernel untuk satu pasangan fitur.
19
Gambar 21 Alokasi data dan kelas target ke tiap blok thread Tabel 2 Input dan output kernel diskritasi
Data Jenis Keterangan
dData Input Data semua record untuk semua fitur yang diambil dari basis data. Data ini direpresentasikan dalam bentuk vektor baris (lihat Gambar 10).
dPairId input data indeks fitur yang akan menjadi pasangan fitur yang diolah oleh tiap blok thread. Gambar 9 terdapat 3 blok yang menentukan indeks pasangan fitur untuk mereka olah. Blok-0 pair id (0,1), blok-1 pair id (0,2) dan blok-2 pair id (1,2). Kombinasi indeks pasangan fitur dilakukan oleh host.
dTargetClass input Data kelas target untuk tiap record pasangan fitur. (lihat Gambar 10).
density input jumlah record untuk tiap bucket dalam histogram.
dCelSize input Jumlah bucket untuk membentuk histogram yang merupakan perkalian baris dan kolom dari histogram.
pairs input Jumlah kombinasi pasangan fitur.
dBucketPositif Output Total record di tiap bucket untuk kelas target positif dBucketNegatif output Total record di tiap bucket untuk kelas target negatif
[image:37.595.114.563.90.273.2]20
Scatter data for each BLOCK of THREAD
EACH BLOCK of THREAD
{
Receive portion to sort
Sort local data using an algorithm of preference
FOR( level = 1; level <= lg(P) ; level++ ) FOR ( j = 0; j<level; j++ )
partner = rank ^ (1<<(level-j-1));
Exchange data with partner
IF ((rank<partner) == ((rank & (1<<level)) ==0))
extract low values from local and received data (mergeLow)
ELSE
extract high values from local and received data (mergeHigh)
[image:38.595.42.485.54.541.2]END IF END FOR END FOR }
Gambar 22 Algoritme bitonic merge sort berdasarkan dua nilai data
Setelah proses pengurutan data dilakukan maka dilanjutkan dengan pembagian tiap record ke bucket. Tiap bucket menyimpan jumlah record kelas target positif dan jumlah record kelas target negative ke dalam dBucketPositif dan dBucketNegatif. Multidimensional equi-depth histogram terdiri atas dCelSize baris dan dCelSize kolom sehingga total bucket adalah dCelSize x dCelSize. Sebanyak dCelSize x dCelSize thread dipekerjakan untuk menghitung jumlah record. Jika dCelSize x dCelSize bernilai lebih kecil daripada jumlah record maka sejumlah (jumlah record - (dCelSize x dCelSize)) thread akan idle. Gambar 23 adalah contoh multidimensional equi-depth histogram berukuran 3 x 3 dan kepadatan 5 record tiap bucket. Satu thread menangani satu bucket sehingga terdapat sembilan thread pada Gambar 23. Thread bekerja secara paralel untuk menghitung lima record dalam tiap bucket. Gambar 24 menjelaskan logika untuk menghitung record tiap bucket.
[image:38.595.93.457.549.820.2]21
DECLARE dBucketPositif, dBucketNegatif for saving number of record for each class value.
IF (tid < gridSize)
{in parallel}
Determine the start position of data of each thread. pos = tid * density
FOR i := 1 TO density
{in parallel}
All threads check value of target class. IF SortedTargetClass[pos] is positif THEN
add dBucketPositif ELSE
add dBucketNegatif END IF
pos = pos + 1
END FOR END IF
Gambar 24 Algoritme untuk menghitung jumlah record kelas target positif dan negatif
Kernel X-Monotone
22
Tabel 3 Input dan output kernel x-monotone Parameter Jenis Keterangan
dBucketPositif Input Total record di tiap bucket untuk kelas target positif. dBucketNegatif Input Total record di tiap bucket untuk kelas target negatif. dTotalPositif Input Jumlah keseluruhan record dengan kelas target positif. dTotalNegatif Input Jumlah keseluruhan record dengan kelas target negatif. dCelSize Input Jumlah bucket untuk membentuk histogram yang
merupakan perkalian baris dan kolom dari histogram. dFlatness output Nilai fungsi flatness untuk tiap pasangan fitur seperti pada
rumus 6.
Gambar 25 Alokasi thread di tiap kolom untuk menghitung botsum, bot, topsum, top secara paralel
Berikut ini dijelaskan secara ringkas logika algoritme x-monotone :
i. Kalkulasi inner product (Θ) untuk tiap bucket dengan rumus sebagai berikut :
col = threadIdx.x row = threadIdx.y
tid = (row * dCelSize) + col
. .
x Ptid y Ptid
θ θ
Θ = +
Gambar 26 Kalkulasi inner product untuk semua kolom secara paralel ii. Komputasi botsum untuk semua kolom.
col = threadIdx.x row = threadIdx.y botsum(row) = 0 FOR S = 2 to N
pos = ((s-1) * dCelSize) + col
botsum((s * dCelSize)+col) = botsum(pos) + G(pos) END FOR
Gambar 27 Komput asi botsum semua kolom secara paralel iii. Komputasi bot untuk semua kolom.
col = threadIdx.x row = threadIdx.y bot(row) = 1
23
FOR s = 2 TO N
idx = bot(((s-1) * dCelSize)+col)
IF (botsum((s * dCelSize)+col) < botsum((idx * dCelSize)+col)
bot((s * dCelSize)+col) = s ELSE
bot((s * dCelSize)+col) = bot(((s-1) * dCelSize)+col)
END IF
dBottomArr((s*dCelSize)+m) = topm(s)
[image:41.595.109.518.74.599.2]END FOR
Gambar 28 Lanjutan Komputasi bot untuk semua kolom secara paralel iv. Komputasi topsum untuk semua kolom.
col = threadIdx.x row = threadIdx.y topsum(row) = 0 FOR s = N-1 to 1
pos = ((s+1) * dCelSize) + col
topsum((s * dCelSize)+col) = topsum(pos) + G(pos) END FOR
Gambar 29 Komputasi topsum untuk semua kolom secara paralel v. Komputasi top untuk semua kolom.
col = threadIdx.x row = threadIdx.y top(row) = row FOR s = N-1 TO 1
idx = bot(((s+1) * dCelSize)+col)
IF (topsum((s * dCelSize)+col) < topsum((idx * dCelSize)+col)
topm((s * dCelSize)+col) = s
ELSE
topm((s * dCelSize)+col) =
topm((((s+1)*dCelSize)+col))
END IF
dTopArr((s*dCelSize)+m) = topm(s)
END FOR
Gambar 30 Komputasi top untuk semua kolom secara paralel
vi. Komputasi F-max untuk membentuk area x-monotone dilakukan tiap kolom. Komputasi x-monotone kolom m memerlukan area x-monotone kolom m-1.
col = threadIdx.x row = threadIdx.y
tid = (row * dCelSize) + col
FOR idx = dBottomArr[tid] TO dTopArray[tid]
cover[tid] = innerProduct[(idx*dCelSize) + col] END FOR
24
IF (col == 1) THEN
F(col) = max(cover(col)) END IF
FOR k = 2 TO m
[image:42.595.55.488.6.842.2]F(k) = max(max(0,F(k-1))+cover(k))) END FOR
Gambar 31 Lanjutan Komputasi F-max untuk tiap kolom secara paralel vii. Kalkulasi convex hull
Kalkulasi ini memerlukan perulangan yang akan mencari area x-monotone dengan nilai entropi lebih rendah daripada nilai entropi terbaik saat ini. Kalkulasi ini tetap berjalan sekuensial karena perulangan bersifat heuristik.
viii. Pada kalkulasi fungsi flatness sesuai dengan rumus 7, perhitungan jarak dilakukan secara paralel seperti pada Gambar 32.
col = threadIdx.x
b[col] = pow( bottom[col] – mean_bottom, 2) t[col] = pow( top[col] – mean_top, 2)
Gambar 32 Komput asi nilai flatness secara paralel
Integrasi Aplikasi dan Kernel
Aplikasi ditulis dalam bahasa pemrograman Visual C++ edisi express 2008. Aplikasi terdiri atas program yang berjalan di host dan program yang berjalan di GPU. Gambar 33 menjelaskan struktur program aplikasi secara keseluruhan. Prototipe.cpp adalah program yang dijalankan di host, KernelSupport.cu adalah program yang dijalankan di GPU, KernelDiskritasi.h dan KernelXmonotone. adalah file header yang berisi kode program kernel yang dijalankan di GPU. Program prototipe.cpp akan memanggil KernelSupport.cu. Dalam KernelSupport.cu dieksekusi pemanggilan header KernelDiskritasi.h dan KernelXmonotone.h.
Gambar 33 Arsitektur aplikasi seleksi fitur
25
dinamis dalam program CUDA adalah memori bersama yang ukurannya tidak konstan dan ditentukan dari luar fungsi kernel.
[image:43.595.118.511.248.422.2]Berikut ini dijelaskan bagaimana memori bersama dinamis digunakan untuk data dinamis. Contoh yang diambil adalah alokasi memori bersama dinamis pada kernel diskritasi. Data yang ukurannya dinamis adalah dData, dTargetClass, dBucketPositif, dBucketNegatif (lihat Tabel 2). Pertama deklarasikan variabel untuk menyimpan ukuran seluruh data yang dinamis dalam hal ini variabel nSharedMem. Variabel ini diberikan nilai nol sebagai nilai inisialisasi. Alokasikan ukuran untuk memori dinamis dengan dengan aturan seperti rumus 8 dan 9. Kode sumber untuk alokasi ukuran data dinamis di kernel diskritasi dapat dilihat pada Gambar 34.
Jika data bukan array maka :
nSharedMemory=ukuranTipeData (8)
Jika data berupa array maka :
1
totalItem
length
nSharedMemory length ukuranTipeData =
=
∑
× (9)int nSharedMem; nSharedMem = 0;
nSharedMem += 2 * (totalRecord * sizeof(float)); nSharedMem += totalRecord * sizeof(int);
nSharedMem += 2 * (gridSize * sizeof(int)); nSharedMem += 2 * (gridSize * sizeof(int));
Gambar 34 Alokasi ukuran data dinamis di kernel diskritasi
Memori bersama dinamis nSharedMem dimasukkan ke kernel dengan perintah seperti pada Kode sumber 3. Ukuran memori bersama dinamis dialokasikan untuk tiap blok thread. Sehingga jika jumlah blok sebanyak blocksPerGrid maka total memori bersama keseluruhan yang digunakan program adalah blocksPerGrid x nSharedMem. Berikut ini penjelasan elemen dari Gambar 35 :
• diskritasi : kernel.
• blocksPerGrid : jumlah blok thread.
• threadsPerBlock : jumlah thread dalam blok thread.
• nSharedMem : ukuran memori dinamis dalam byte.
diskritasi<<<blocksPerGrid,threadsPerBlock, nSharedMem>>> ( dData, dPairId, dTargetClass, dSorted,
dBucketYes, dBucketNo, dTotalYes,
dTotalNo,totalRecord, celSize, density, totalFitur);
Gambar 35 Pemanggilan kernel beserta jumlah blok thread, jumlah thread, ukuran memori dinamis dan data
26
Baris berikutnya mengalokasikan memori dinamis ke beberapa variabel dengan cara menggunakan pointer.
extern __shared__ float s[]; dAtt1 = s; dAtt2 = &dAtt1[totalRecord];
sorted = (int *)&dAtt2[totalRecord]; yes = &sorted[totalRecord];
no = &yes[gridSize]; tYes = &no[gridSize]; tNo = &tYes[gridSize];
Gambar 36 Pengambilan memori bersama dinamis untuk tiap variable di dalam blok
Uji Coba
Dalam proses klasifikasi di data mining membangun model yang akurat sangat penting. Tipe klasifikasi supervised learning mempelajari bagaimana membangun model dari data yang telah ada. Metrik seleksi fitur yang khas seperti information gain akan bias terhadap pemilihan fitur untuk kelas minor jika distribusi kelas target miring (Tang 2005). Penelitian ini menggunakan data set dari Pima Indian Diabetes (lihat Lampiran 1) dan data yang dibangkitkan secara acak. Tiga data dibentuk secara acak dengan bentuk distribusi kelas seimbang (lihat Lampiran 2), miring negatif (lihat Lampiran 3) dan miring positif (lihat Lampiran 4). Pembentukan data ini dilakukan dengan membangkitkan nilai acak untuk fitur dan kelas target mengikuti pola dari Pima Indian Diabetes data set. Tiap fitur pada data set Pima Indian Diabetes dihitung jumlah minimum dan maksimum. Nilai fitur dibangkitkan acak dengan rentang di antara nilai minimum dan maksimum tiap fitur.
_ (min( ) max( ))
i i i
f =random between f − f (9) Berikut ini dijelaskan lebih rinci proses pembentukan tipe data :
1. Data seimbang (balanced data)
Gambar 37 Data dengan distribusi seimbang Sumber : (http://www.mathsisfun.com/data/skewness.html)
Distribusi kelas di dalam data membentuk distribusi normal dan tidak miring. Jumlah data untuk tiap nilai kelas secara imbang dibagi dua. Bagian pertama bernilai positif dan bagian kedua bernilai negatif.
27
Gambar 38 Data dengan distribusi miring positif Sumber : (http://www.mathsisfun.com/data/skewness.html)
Data yang miring ke kanan atau dikenal juga positive skewed data, memiliki ekor panjang dan meluas ke kanan. Jumlah data secara proposional dibagi untuk tiap kelas. Sebanyak k1 data mempunyai nilai kelas target bernilai positif dan sebanyak k2 mempunyai kelas target bernilai negatif. Dibentuk data dengan jumlah data untuk nilai k1 lebih banyak k2.
3. Distribusi miring negatif (negative skewed data)
Gambar 39 Data dengan distribusi miring negatif Sumber : http://www.mathsisfun.com/data/skewness.html
Data yang miring ke kiri atau dikenal juga negative skewed data, memiliki ekor panjang dan meluas ke kanan. Jumlah data secara proposional dibagi untuk tiap kelas. Sebanyak k1 data mempunyai nilai kelas target bernilai positif dan sebanyak k2 mempunyai kelas target bernilai negatif. Dibentuk data dengan jumlah data untuk nilai k2 lebih banyak k1.
Perangkat keras dan perangkat lunak
Perangkat lunak yang digunakan dalam penelitian ini adalah :
- Database Management System MySql 5.5 (Oracle 2012) - Visual C++ 2008 Express Edition (Microsoft)
- Compute Unit Device Architecture C (NVIDIA) - NetBeans 7.2 dan Java (Oracle 2013)
28
3 HASIL DAN PEMBAHASAN
Implementasi dan Hasil Metode Data mining Dinamis
[image:46.595.84.533.277.727.2]Dengan menggunakan metode sampling, kita tidak perlu menelusuri ulang seluruh basis data. Nilai prioritas berlaku pada setiap record dalam sampel digunakan untuk memilih record dengan nilai prioritas terendah. Prioritas random sampling dan backing sampling terbukti mampu mempertahankan data diperbaharui dalam sampel. Nilai catatan waktu (time stamp) selalu terbaharui dan id baru muncul dalam sampel. Sampel adalah sebagai masukan proses klasifikasi . Weka adalah perangkat lunak yang digunakan untuk melakukan klasifikasi yang menghasilkan model pohon keputusan sebagai pengklasifikasi. Gambar 40 dan Gambar 41 menunjukkan bahwa pohon keputusan setelah 500 transaksi dan 1000 transaksi berbeda. Alasannya adalah bahwa isi dalam sampel selalu terbaharui saat transaksi baru terjadi. Hal ini menunjukkan bahwa teknik dan algoritme yang diterapkan dapat membuat isi sampel terbaharui .
29
Gambar 41 Pohon keputusan setelah 500 transaksi terjadi terhadap basis data
Telah dilakukan beberapa kali pengujian atas pengaruh nilai kullback liebler terhadap menjaga kesamaan distribusi kelas target. Diujikan berbagai nilai kullback liebler dengan rentang 0.0-0.1, 0.0-0.01, 0.0-0.001, dan 0.0-0.0001. Nilai kullback liebler dengan nilai rentang 0.0 s/d 0.0001 jauh lebih baik untuk menjaga kesamaan distribusi kelas. Nilai minimal 1.022937113 x 10-6 dan nilai maksimum 6.1507380451 x 10-5. Pada Tabel 4 nilai entropi basis data dan sampel sama sampai ketelitian satu digit. Hal ini menunjukkan bahwa distribusi kelas antara sampel dan basis data serupa.
Tabel 4 Hasil uji coba sampling terhadap data dinamis berdasarkan jumlah transaksi, entropi dan nilai kullback liebler
Jumlah transaksi
Ukuran data (MB)
Nilai entropi populasi
Nilai entropi sampel
Kullback Liebler Divergence
100 0.02 9.48742 x 10-1 9.5001 x 10-1 8.286449884 x 10-6 200 0.04 9.63099 x 10-1 9.61338 x 10-1 2.1078238206 x 10-5 300 0.06 9.70841 x 10-1 9.71179 x 10-1 1.022937113 x 10-6 400 0.08 9.93117 x 10-1 9.94169 x 10-1 4.3754822400 x 10-5 500 0.1 9.99912 x 10-1 9.99989 x 10-1 3.6685582018 x 10-5 600 0.12 0.999944 x 10-1 9.99901 x 10-1 6.268978723 x 10-6 700 0.14 9.95797 x 10-1 9.95141 x 10-1 2.3935101126 x 10-4 800 0.16 9.89157 x 10-1 9.90723 x 10-1 6.1507380451 x 10-5 900 0.18 9.9022 x 10-1 9.90723 x 10-1 1.6752503143 x 10-5 1000 0.2 9.89603 x 10-1 9.89396 x 10-1 1.049382945 x 10-6
[image:47.595.109.513.464.643.2]30
model data tidak seimbang memiliki 30,3 % untuk tingkat TN dan 69.7 % untuk tingkat FP. Ini berarti bahwa model ini hanya benar melakukan klasifikasi sebesar 30.3% untuk kelas negatif dan 60.7% dari kelas negatif salah klasifikasi sebagai kelas positif. Dengan cara lain, model data seimbang memiliki 94.2 % untuk tingkat TP dan 5,8 % untuk tingkat FN. Ini berarti bahwa model ini dengan benar dapat mengklasifikasikan 94.2 % untuk kelas positif dan hanya 5.8 % dari kelas positif salah klasifikasi. Kesimpulannya model data distribusi seimbang baik sebagai predikator untuk kelas positif karena memiliki jumlah record yang lebih besar dari keseluruhan record. Kelas negatif sebagai kelas dengan jumlah record sedikit, cenderung salah klasifikasi oleh model ini. Berdasarkan Tabel 4 diklasifikasikan secara benar 80.5 % kelas positif dan 73.4 % kelas negatif. Model ini melakukan kesalahan klasifikasi sebanyak 19.5 % kelas positif dan 26.6 % kelas negatif. Nilai ROC untuk data seimbang adalah 0.844 dan 0.622 untuk data tidak seimbang. Ini berarti secara keseluruhan, kinerja model klasifikasi lebih baik dengan distribusi kelas yang seimbang.
Tabel 5 Evaluasi kinerja untuk model pohon keputusan dari data dengan distribusi seimbang dan tidak seimbang
Seimbang Tidak seimbang TP rate (%) 80.5 94.2 TN rate (%) 73.4 30.3 FP rate (%) 26.6 69.7 FN rate (%) 19.5 5.8 ROC 0.824 0.622
Implementasi dan Hasil Algoritme Paralel dan Komputasi GPU
Pada uji coba pertama komputasi diskritasi data dan komputasi x-montone diujikan terhadap satu pasang fitur untuk melihat perbandingan percepatan dan akurasi antara sekuensial dan paralel. Hasil uji coba terhadap tiap kernel di komputasi GPU dapat dilihat pada Tabel 6. Rata-rata percepatan untuk kernel diskritasi dan xmonotone adalah 1.5 kali dan 1.87 kali. Hasil ini masih dianggap kurang maksimal dan perlu diterapkn optimalisai kode program untuk kernel dan pengalokasian maksimal untuk tiap thread. Akurasi yang dicapai untuk kernel diskritasi dan x-monotone adalah 81.69 % dan 83.76 %. Ditemukan indikasi penyebab masalah dalam kasus akurasi yaitu :
1. Pengurutan terhadap indeks menghasilkan nilai data yang tepat tetapi nilai indeks data tidak terurut dengan baik.
2. Perbedaan perhitungan terhadap nilai desimal dengan presisi tinggi pada perhitungan entropi.
Tabel 6 Hasil uji coba komputasi paralel terhadap algoritme seleksi fitur untuk satu pasangan fitur
Kernel Data Akurasi
rata-rata
Percepatan rata-rata
Diskritasi Pima Indian Diabetes 81.69 % 1.5 kali X-Monotone Pima Indian Diabetes, Data
acak
31
[image:49.595.112.508.219.406.2]Pada uji coba kedua, komputasi diskritasi data dan x-montone diujikan terhadap lebih dari satu pasang fitur (lihat Tabel 7). Terlihat jelas rata-rata percepatan untuk komputasi paralel terhadap komputasi sekuensil yaitu 8.2 kali. Hal ini membuktikan jika data semakin banyak akan ideal untuk komputasi paralel.
Tabel 7 Hasil uji coba perbandingan waktu eksekusi komputasi sekuensial dan paralel dengan berberapa jumlah pasangan fitur
Jumlah pasangan fitur
Rata-rata waktu komputasi sekuensial
Rata-rata waktu komputasi
paralel
Percepatan
45 112 12,67 8,84
190 318,33 41,63 7,65
435 679 80,45 8,44
780 1168,67 144,70 8,08
1225 1818 216,06 8,41
1770 2517,33 307,58 8,18
2415 3577 421,42 8,49
3160 4591 548,75 8,37
4005 5765 690,86 8,34
4950 7139,33 848,79 8,41
Uji coba ketiga dilakukan pada jumlah pasangan fitur sejumlah 45, 190, 435, 780, 1225, 1770, 2415, 3160, 4005 dan 4950 pasang fitur untuk melihat kinerja CUDA dalam mengatasi jumlah data ratusan dan ribuan. Dilakukan dua jenis uji coba dengan cara pengukuran waktu eksekusi berbeda. Tujuannya untuk melihat kinerja komputasi paralel menangani pasangan fitur jika skala semakin besar. Uji coba pertama dilakukan pengukuran waktu eksekusi hanya untuk eksekusi fungsi kernel. Uji coba kedua dilakukan pengukuran waktu eksekusi untuk proses pemasukan data (load data), eksekusi fungsi kernel, dan pengeluaran hasil (unload data). Gambar grafik untuk keduanya dapat dilihat pada Gambar 42 dan Gambar 43. Kedua uji coba diterapkan pada jenis distribusi negative skewed memakan waktu lebih lama daripada positive skewed dan balance data. Kedua grafik menunjukkan kalkulasi tercepat adalah pada balance data. Proses seleksi fitur secara paralel untuk 4950 pasangan fitur pada data balanced data, positive skewed dan negative skewed adalah 0.85 detik, 1.66 detik dan 1.84 detik. Waktu yang diperlukan untuk proses pemasukan dan pengeluaran data pada jumlah pasangan fitur sebanyak 4950 adalah 32.28, 32.97 dan 31.33 mili detik untuk tipe data balance data, positive skewed dan negative skewed. Rata-rata hanya diperlukan 31.85 milidetik untuk proses pemasukan dan pengeluaran data dan hal ini tidak begitu signifikan.
32
selama 1.84 detik. Sehingga perubahan data dinamis dalam kurun waktu dua detik dapat diakomodasi oleh seleksi fitur secara paralel.
[image:50.595.90.467.72.792.2]Gambar 42 Grafik waktu eksekusi dari proses pemasukan data, eksekusi kernel dan mengeluarkan hasil eksekusi
33
4 SIMPULAN DAN SARAN
Simpulan
Pada pengolahan data dinamis menggunakan priority random sampling, backing sampling dan kullback divergence, disimpulkan beberapa hal. Random sampling dengan prioritas dan backing sampling salah satu teknik yang bisa diterapkan untuk data mining dinamis. Kedua teknik ini dapat mengekstrasi synopsis data dari keseluruhan isi basis data. Interval kullback liebler antara 0 sampai dengan 0.0001 adalah nilai yang ideal untuk menjaga distribusi kelas yang sama antara sampel dan populasi. Bentuk kemiringan antara sampel dan populasi secara signifikan serupa. Sebagai transaksi baru terjadi, konten dalam backing sampling akan selalu terbaharui. Akurasi klasifikasi sampel lebih baik jika model dihasilkan dari data dengan distribusi seimbang.
Komputasi paralel menggunakan GPU dapat mempercepat proses komputasi daripada sekuensial. Pengujian pertama akurasi menunjukkan hasil 83.76 % pada kernel x-monotone dan untuk kernel diskritasi hanya mencapai 81.69 %. Rata-rata percepatan untuk kernel diskritasi dan x-monotone adalah 1.5 kali dan 1.87 kali dengan uji coba eksekusi hanya pada satu pasangan fitur saja. Pengujian kedua dilakukan pada lebih dari satu pasangan fitur. Hasil uji coba kedua menunjukkan kecepatan komputasi paralel lebih terlihat signifikan ketika pasangan fitur semakin banyak. Hal ini terjadi karena komputasi sekuensial untuk lebih dari satu pasang fitur harus melakukan perulangan. Komputasi paralel untuk jumlah