NNGKASAN
SIT1 NURHANIFAH. Pencarian Infomiasi dengan Metode Trigraiir (Trigrrriil Method air Scr~rrliiil~ Ii~foneatioi~). Dibinlbing oleh MEUTIIIA RACMMANIAI-I, JULIO ADISANTOSO, dan TlSYO IIARYONO.
Untuk nielicari suatu informasi yang berbasis teks biasanya dibutuhkan atribut-atribut tertenlu, dalam ha1 ini judul, nama peneliti, penerbit, dali tahun terbit. Untuk rekord berisi teks seperti judul dokmnc~~, abstrak atau ri~igkasan suatu dokumen, identifikasi yang digunakan adalah kata kunci atau kata indeks dari suatu dokumen. Pada saat jumlah kata yang dipunyai seniakin banyak, proses temu kenlbali yarig dilakukan akan nienlbutulikan waktu yang cukup lama, juga media penyinipanan di komputer. Pada pelielitiali ilii Ii~vertedfile digunakan sebagai tempat lnenyimpali sekumpulan dokumen yalig dicirikali olcli sekunipulan istilah. Sedangkan algoritnie trigranl dipakai sebagai algoritme untuk menieriksa istilali dalaln qlleiy yang mirip dengan istilah dalam basisdata.
Tugas Akhir ini bertujuan untuk menginiplementasikan Sistem Temu-Kembali (lnformnlion Retrivrrl Systeiit) dalam bentuk liypertext, yang dikenal sebagai loco1 search eirgiire. Implementasi dilakukan nielalui pengukuran kinerja recall-precisioir dan kecfektifan algoritnie frigrairl, deligan menggunakan liilai tl~rcsl~old yang berbeda-beda untuk mengetahui istilah mana yang dianggap sesuai dengan quoy.
) \
.'
8PENCARIAN INFORMASI DENGAN METODE
TRIGRAM
SIT1 NURHANIFAH
JURUSAN ILMU KOMPUTER
PAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
' '
\
BOGOR
Maka nikmat Tuhan kamu manakah yang kamu dustakan? (QSAR-Rahman, 55 : 55)
Saya bartgga dertgan rnarnaltku Yartg ~neirgajariku,
Bukarr dengarr kata-kafa, fetapi deitgart perbuatan Yang rirengajariku,
Perut bole11 kosang, tetapi fidak deitgan kepala dart ltati Yarrg ntertgajariku,
Sekecil apapurt suatu kesentpatart, pasli disifu ada harapan Yatrg nrerrgajariku,
Tiada kata terakhir dalam berjuarrg uittuk meinperolelr sesuatu yartg lebilt baik
Karya ilmiah ini Hani perscmbahkan unluk
) \
.'
8PENCARIAN INFORMASI DENGAN METODE
TRIGRAM
SIT1 NURHANIFAH
JURUSAN ILMU KOMPUTER
PAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
' '
\
BOGOR
NNGKASAN
SIT1 NURHANIFAH. Pencarian Infomiasi dengan Metode Trigraiir (Trigrrriil Method air Scr~rrliiil~ Ii~foneatioi~). Dibinlbing oleh MEUTIIIA RACMMANIAI-I, JULIO ADISANTOSO, dan TlSYO IIARYONO.
Untuk nielicari suatu informasi yang berbasis teks biasanya dibutuhkan atribut-atribut tertenlu, dalam ha1 ini judul, nama peneliti, penerbit, dali tahun terbit. Untuk rekord berisi teks seperti judul dokmnc~~, abstrak atau ri~igkasan suatu dokumen, identifikasi yang digunakan adalah kata kunci atau kata indeks dari suatu dokumen. Pada saat jumlah kata yang dipunyai seniakin banyak, proses temu kenlbali yarig dilakukan akan nienlbutulikan waktu yang cukup lama, juga media penyinipanan di komputer. Pada pelielitiali ilii Ii~vertedfile digunakan sebagai tempat lnenyimpali sekumpulan dokumen yalig dicirikali olcli sekunipulan istilah. Sedangkan algoritnie trigranl dipakai sebagai algoritme untuk menieriksa istilali dalaln qlleiy yang mirip dengan istilah dalam basisdata.
Tugas Akhir ini bertujuan untuk menginiplementasikan Sistem Temu-Kembali (lnformnlion Retrivrrl Systeiit) dalam bentuk liypertext, yang dikenal sebagai loco1 search eirgiire. Implementasi dilakukan nielalui pengukuran kinerja recall-precisioir dan kecfektifan algoritnie frigrairl, deligan menggunakan liilai tl~rcsl~old yang berbeda-beda untuk mengetahui istilah mana yang dianggap sesuai dengan quoy.
I'ENCARIAN INFORMAS1 DENGAN METODE
TRIGRAM
Ka~ya Ilmial~
scbagai salah satu syarat unluk me~iipe~.oleli gela~ Sarjana Ko~iipulcr
Pada Program Studi Ilmu Kompoter
JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT I'ERTANIAN BOGOR
Judul : Pencarian Infonnasi dengan Metode Trigrarn
Nama : Siti Nurhanifah
NRP
: GO6495028Menyetujui,
~ A J \ ,
-
,
11. Meuthia Rachmaniah. MSc Pen~bin~bing I
Drs. Tisyo Hawono, MLS Pembimbing 111
RIWAYAT HIDUP
Penulis dilahirkan di Garut pada tanggal 8 Deselnber 1975 sebagai anak ketujuh dari sembilan bersaudara, anak dari pasangan Bapak Enccp Sacf I-lidayat dan (Alm) Ibu Euis Sili Djubaedah.
PRAKATA
AlI~atnd~rliNaahirrobil'alamitt.
Baoyak karunia yang penulis rasakan sebagai curahan kasili sayang yang Alloh oia~vojala berikan, dalam menyelesaikan Kalya llmiah ini yang berjudul "Pencarian Informasi dengan Metode 7'rigronlX maupun dalam masa-masa pendakian pada perkulialian di Jurusan Ilmu Komputcr IPB. Dan rasa terima kasili yang dalam ingin penulis saliipaikan kepada :
I . (Alm) Mamah dalottl kmrotigan, Bapak, keluarga besar di Garut, Bandar Lampung, Bogor, dan Cimahi atas do'a, nasehat dan kasih sayang.
2. Ibu Ir. Meutliia Rachmaniah, MSc sebagai pembimbing pertama. 3. Bapak Ir. Julio Adisantoso, MKom sebagai pembimbing kedua.
4. Bapak Drs. Tisyo I-laryono, MLS sebagai pembimbing ketiga. 5 . Ibu R. Rusmini sebagai pembimbing tcknis di PUSTAKA
6.
Bapak Dr. Ir. Kudang Boro Seminar sebagai pcmbimbing akadcmik scwaktu penulis kuliali.7.
Seluruh staf pengajar di IPB, kliususnya di Jurusan Ilmu Komputer IPB.8, Ibu dan bapak pegawai tata usalia dan perpustakaan Jurusan Ilmu Komputer dan Jurusan Statistik II'B. 9. Lutbfi, Dien, Degi, Fani, Widodo, Lida, Rina, Dhanin, lsti (Kom 32), Erwin, Riyadi, Risoa, Fitri dan
Tuti Kla(Kon1 33) sebagai teman-teman Ilkom"' yang telah banyak membantu, mendukung dan membesarkan hati.
10. Seseorang di Palangkaraya yang sedang nlelaksaoakan tugas, yakin kita tidak bersatu, Okeli?
11. Pak "Lurah", Mas Hamed, Kang Af di Jakarta, dan seseorang di IPTN.
12. Para penghuni Ex Risaga K' Pinie, K' Delia, K' Neuncuk, K' Eci. K' Ani, K' Ticna, K' Indah, Ncng Titin, Neng Elly, Teh Lia dan Mbak Yami yalig selalu menyayangi, meskipun sudah pisah. Tak lupa untuk adikku sayang Anne dan Mira di Bandung serld Nitta di Garut 'kotr alivays stltile".
13. Dan seniua yang telah iiiemberikati jalan terang yang memungkinkan penulis nienyusun K a ~ y a Ilmiah ini dengan penuh semangat, tetapi tidak sempat penulis sebutkan satu persatu.
Zajak~rtt~~rllal~i Kl~oeroti Kalsiir.
Bogor, Juni 2001
DAFTAR IS1
DAFTAR GAMBAR
...
DAFTAR LAMPIRAN...
PENDAHULUAN...
Latar Belakang
...
Tujuan...
TINJAUAN PUSTAKA ....
. .Metode Pencarian
...
Iitverted File...
Algoritme n-gram...
Ukuran Kinerja...
Hyperrat Markup Laitguage (HTML)...
METODOLOGI PENELITIAN
...
.
.
...
Pengambilan Data...
Cara Kerja Algoritme Trigraiil... .
.
.
.
...
Penenhlan Nilai Ambang (T/~resholri)
...
Perangkat lunak dan keras...
Algoritme Progran~Pencarian Q~reiy...
Percobaan...
Pengukuran Kinerja Recall- Precisio~t....
...
HASIL DAN PEMBAHASAN
Keefektifan Algoritme Trigrain
... .
.
...
Kinerja Sistem berdasarkan Recall-Pvecision...
...
Kelebil~an Sistem
...
Kelemahan Sistem
KESIMPULAN DAN SARAN
...
Kesimpulan...
Saran...
...
DAFTAR PUSTAKA
DAFTAR GAMBAR
[image:11.599.66.544.60.813.2]1
.
Implenientasi Ir~ver!ed. .
File dellgan menggunakan Sorted Array...
2...
.
2 Grafik Recall-Precrslort 3...
3.
Diagram Alur Program Algoritme Trigrant 5...
....
4.
Grafik Perbandingan Recall-Precision pada Tltreshold 0.2 0.5.
.
7DAPTAR LAMPIRAN
Halamall 1.
Tampilan Awal Local Searcll Erlgirze...
.
.
.
...
102 . Tampilan antar muka sebagai F o ~ m isian user
...
103
.
Tampilan Hasil Query pada Tlt~eshold 0.2...
104
.
Hasil Percobaan Keefektifan Algorihne Trigrarrt pada Tl~resl~olri 0.2...
115
.
Hasil Percobaan Keefektifan Algorihne Trigram pada T/~reshold 0.3...
.
.
.
...
116
.
Hasil Percobaan Keefektifan Algorilnle Trigram pada Tlrreshold 0.4...
12PENDAHULUAN
Latar Belakang
Pengembangan sistem informasi elektronik dimulai pada sekitar 1940. Sistem temu-kembali informasi (ir$ormation retrieval Syste~n) secara otomatis pada awalnya dikembangkan untuk membantu mengatur literatur ilmu pengetahuan yang jumlahnya banyak. Kantor-kantor, pemsahaan dan perpustakaan telah menggunakan sistem temu-kembali informasi untuk mengakses buku-buku, koran, majalah, jumal, dan dokumen lainnya. Sistem ini mengolah dokumen-dokumen yang terorganisasi dalam record pada berkas Vile) dan mengelola pemintaan (request) i~~fotmasi, kemudian mengembalikamya dalam berkas tertentu sebagai tanggapan terhadap permintaan tersebut (Frakes & Baeza-Yates, 1992).
Kebutuhan informasi bagi user dan jumlah dokumen yang banyak menuntut sistem temu- kembali informasi untuk bekerja secara efisien. Berdasarkan lokasi sumber data, Local Searclt Engine memanfaatkan internet sebagai penghubung sistem temu-kembali informasi yang ada di dalamnya dengan user.
Salah satu algoritme temu-kembali infomiasi nntuk membandingkan kesamaan string adalah rr-
grants yang membandingkan humf pada kata taopa memperhatikan bahasa yang digunakan. Semakin banyak n-gra~ris yang sama muncul pada kedua string, maka dikatakan semakin mirip. Ada dua parameter yang dapat dipilih ketika memakai metode ini, yaitu ( I ) panjang 11-graets dan (2) spasi tamballan. Untuk parameter panjang 11-grants, trigram dan digram memperoleh hasil yang paling baik dalam pangambilan kata-kata yang niirip pada setiap kata (Pfeifer el nl., 1996).
Sebena~nya penelitian mengeiiai sistem temu- kembali infomasi telah dilakukan oleh Fittiyanti (1997). Pada kalya ilmiah tersebut implementasi sistem temu-ken~bali infomlasi bertumt-tumt
dapat diakses melalui internet dalam bentuk Itypcrtext dengan menggunakan metode trigram.
TINJAUAN PUSTAKA
Metode Pencarian
Beberapa metode yang dapat diterapkan untuk pencarian data diantaranya pencarian berumtan (sequential searchi~tg). Cara kerja metode iiii adalah melakukan pembacaan data yang akan dicari dan dibandingkan satu per satu dengan data pertama sampai data terakhir secara bemmtan, sehingga data tersebut ditemukan atau tidak ditemukan. Pada saat data yang dicari telah ditemukan, maka proses pencarian dapat langsung dihentikan. Jika data yang dicari belum ditemukan maka pencarian tems dilakukan sampai selumh data dibandingkan. Dalam kasus terbumk, untuk vektor dengan N buah elemen hams dilakukan pencarian sebanyak N kali pula (Stinson, 1985).
Metode yang kedua adalah pencarian pada tabel yang sudah diumtkan (sorting table senrclting), yaitu mencari suatu unsur dari suatu tabel, setiap unsur dari tabel tersebut mempunyai seknmpulan nilai yang disebut atribut. Salah satu dari atribut ini disebut kata kunci atau nama yang digunakan untuk menentukan unsur tersebut (Slamet at a1.,1990).
Metode yang terakhir adalah pencarian bemmtan berindeks (indexed scquerrlirrl searcltirrg). Data yang akan diproses dalam suatu tabel sudah diumtkan menumt suatu urutan tertentu dari key. Metode ini melakukan pengindeksan terhadap teks dan dapat digunakan untuk meningkatkan kecepatan pencarian. Ukuran indeks biasanya proporsional dengan ukuran basisdata dan waktu pencarian sublinear terhadap ukuran teks, contohnya inverter1 jile (Frakes&Baeza-Yates, 1992).
meneeunakan o ~ c r a t o r boolcan. sistem ~eringkat, -
....
.,-
dan sumber Gata dalam Bahasa indoiisia, x"vcrtcdl'ile
sedangkan pada penelitian ini melakukan Inverledjile adalah daftar yang diuiutkan olch implenlentasi sistem temu-kembali ke dalam istilah, dimana setiap istilah mempunyai bentuk lrypertext dengan menggunakan metode Ilubungan ke atau
Iebih
dOkumen Yaiig...:....-...
mengandung istilah. Fungsi irtvertedfilc adalahuntuk ii~emperbaiki efisieusi pencarian dengan
Tujuau beberapa ukuran jarak yang biasanya diperlukan
Tujuan penelitian ini a ~ a l a h untuk bcrkas teks yang besar. Ada dua algoritmc mengimpleme?tasikan sistem temll-kembali pencarian untuk irtverte(1 file, yaitu pencarian
untuk mencari suatu dokumen yang istilah dan algoritme possible search. Algoritme
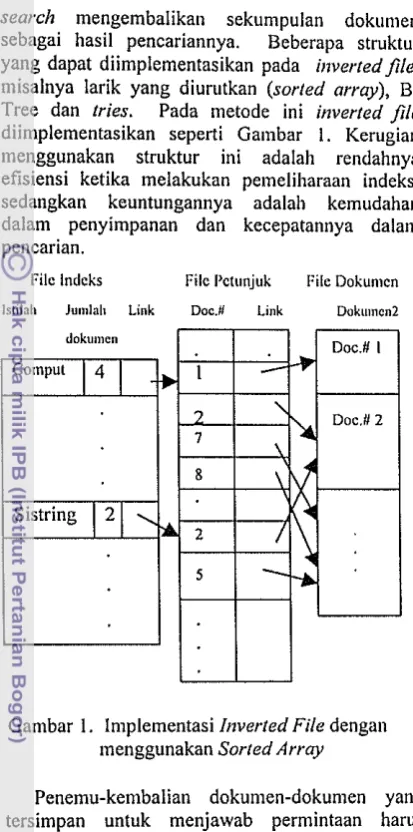
search mengembalika~i sekumpulan dokumen sebagai hasil pencariannya. Beberapa struktur yang dapat diimplementasikan pada irtvertedfile, misalnya larik yang diurutkan (sorted array), B- Tree dan tries. Pada metode ini inverted file diimplementasikan seperti Ga~nbar 1. Kerugian menggunakan struktur ini adalah rendahnya efisiensi ketika melakukan pe~neliharaan indeks, sedangkan keuntungannya adalah kemudahan dalam penyimpanan dan kecepatannya dalam pencarian.
Filc Indcks Filc I'cu~njuk File Dokunicn
IslilsL Junllvl! Link Doc.# Link Ooku1nen2
Jika c adalah banyaknya substring yalig sania antara ti dan mk, maka ukuran kesamaan antara T dan M dapat dihitung dengan menggunakan koefisien dice sebagai berikut :
[image:13.595.74.281.81.498.2]Jika I = 3, maka algoritme di atas dinamakan algoritme trigram. Sebagai contoh istilali COMBINING dalam dokumen dibandingkan dengan istilah COMBINE dala~n query, algoritme di atas dapat diterangkan sebagai berikut :
Gambar I. lmplementasi irzverted File dengall ~nenggunakan Sorted Array
Penemu-kembalian dokumen-dokumen yang tersimpan untuk menjawab permintaan harus berdasarkan penentuan ukuran kesamaan antara query dan iten? yang disimpan dan penga~nbilan itcal-item yang dapat dibuktikan cukup mirip dengan query. Padalial dokunien-dokumcn yang disimpan dan informasi yang diminta dapat tidak terstruktur dan keputusan penemu-kembaliannya tergantulig pada teks yang berliubungan.
Algoritme n-gram
Misalkan T adalah sebuah istilah dalam dokumen dengan panjang n karakter dan disimpan sebagai larik yang mengandung substring t, dengan panjang I, untuk i = 1,2
,...,
n+l-
1 (Angell, 1982 dalam Waliyudin). Misalkan M adalah istilah dalam q~rerj.\dengan panjang n' karakter dan disilnpan sebagai larik yang mengandung substring mk dengan panjang I, untuk k = 1,2,...,
n'+
I+
1.1. Kata COMBINING terdiri dari 11 substring, yaitu : $$C, $CO, COM, OMB, MBI, BIN, INI, NIN, ING, NG$. G$$.
2. Kata COMBINE terdiri atas 9 substring, yaitu : $$C, $CO, COM, OMB, MBI, BIN,
INE, NE$, E$$.
3. Jumlah substring yang sama
G yaitu
: $$C, $CO, COM, OMB, MBI, BIN.4. Memakai rumus koefisien dice maka didapatkan nilai koefisien dice 0.60
Jika nilai tersebut merupakan nilai terbesar dari koefisien dice untuk setiap pasangan istilali dala~n dokumen dan istilah dalam query, maka COMBINING adalah istilah dalam dokumen yang mirip dengan istilah COMBINE dalam qvmy. Ulturan Kinerja
Untuk mengukur kinerja sistem temu-kembali informasi dilakukan dcngan melihat perbandingan banyaknya dokumen yang terambil dari sekumpulan dokumen pada saat query diterapkan. Dokumen terambil merupakan kumpulan dokumen yang menjadi keluaran sistem, yang ~iierupakan subset dari koleksi dokumcn. Menurut Salton (1989) recall-precisior~ adalah metode yang digunakan untuk mcngukur ofektivitas temu-kembali.
Recall merupakan ukuran banyaknya dokumen-dokumen yang relevan yang terambil dari kumpulan dokumen pada saat qtrery diterapkan. RecaN didefinisikan sebagai berikut :
Jurnlah doku~iic~i rclcvan tcrambil
R=
Ju~iilali kcsclurulian dokumen rclcvan dalam basisdata
sangat menentukan dalam meniunculkan hasil query yang relevan. Jika nilai ambang terlalu besar, nlaka hasil query yang ditampilkan aka11 benar-benar dekat dengan query yang diterapkan dan ada kemungkinan istilah yang diharapkan tidak ditampilkan. Jika nilai ambang terlalu kecil, niaka hasil query yang ditampilkan selain istilah yang dekat juga akan mencakup istilah-istilali yang jauh dari query yang diterapkan. Nilai ambang dinyatakan dengan selang bilangan nyata antara 0 dan 1 ([O,l])sedangkan [0,0] diberikan untuk istilali yang tidak mirip atau tidak relevan.
Dalani penelitian ini, penentuan nilai ambang untuk masing-masing istilali dalam dokumen menggunakan interval. Tujuan penggunaan interval ini adalah untuk mengetahui tingkat recall dan precision yang optinium. Nilai ambang yang digunakan berada pada selang [0.2
-
0.51. Dari keempat nilai ambang ini akan diambil suatu nilai recall-precision yang kinerjanya optimum.Perangkat lunak d a n Perangkat keras
Pembuatan program pada saat mengembangkan sistem ini dilakukan dengan menggunakan sisteni operasi Windows 95. , Perangkat lunak yang
digunakan adalah Persortal Web Server (PWS), HTML, VB-Scripf untuk program aplikasi ASP, MS Access 97 untuk basisdata, pen~olahan gambar
Pengukuran Kinerja Recall-Precisio~~
Pengukuran kinerja recirll dan precisiorr didasarkan pada tingkat relevansi yang tcrdiri atas dua macam yaitu : Relevan (R) dan Tidak Relevan (TR). Sedangkan proses pengukuran kinerjanya dijelaskan sebagai berikut:
.
Anggap nilai recall telah diketaliui, yaitu terdiri dari 0.1 sampai 1.0..
Hasil keluaran program yaitu berupa dokunien-dokumen yang terambil diliitung jumlaluya. Nomor urut dokumen-dokunien menjadi acak sesuai dengan hasil keluaran program. Kemudian dicari dokumen- dokumen relevan dan dokumen-dokumen yang tidak rclevan..
Setelah selesai maka nilai precisio~r dapat diliitung, sesuai dengan rumus perliitungan precision pada lialaman 3.Pengukuran kinerja berdasarkan waktu proses dilakukan pada saat implementasi program temu- kenibali informasi. Waktu proses dimulai saat pengguna memasukan query dan berakhir ketika dokumen-dokumen telah terambil. Waktu proses diliitung dalam satuan detik. Pada penelitian ini waktu proses tidak diperhitungkan.
dengan Adobe Photoshop 5.0. ~ n 6 k hubuigan ke
server basisdata dilakukan nielalui ODBC (Operr
HASIL DAN PEMBAHASAN
Data Base Cortnectivity). Sedangkan perangkatkeras, yang digunakan Personcrl Cosrpurer (PC) dengan prosesor 486DX, RAM 16 MB dan kapasitas ltarddisk 540 MB.
Algoritrne Program Pencarian Qrrery
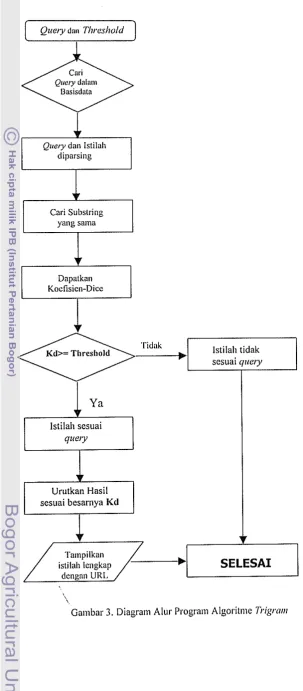
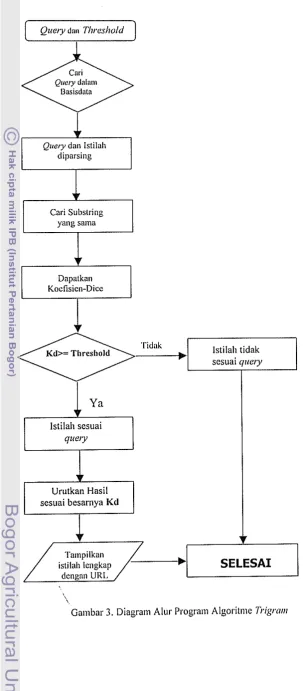
Secara unium algoritnie program pencarian qtrery dapat digambarkan seperi diagram alur pada Gambar 3.
Percobaan
Tujuan percobaan ini adalah untuk niengetnhui kinerja algorime frigrarrt, dengan memasukkan satu istilab dalam query dan nilai flrresholil yang berbeda-beda. Akan dilihat apakah metode tersebut niemberikan perkiraan istilah yang cukup baik untuk berbagai variasi qrrery. Junllah query yang diterapkan sebanyak 20 dengan nilai ambang berada pada selang [0.2
-
0.51. Lampiran 1 sampai 3 adalah tampilan awal, salah satu contoh query yang diujicoba seaa hasilnya.\.
Lampiran 4 sanlpai 7 menunjukkan hasil percobaan keefektifan algorihne frigru~r~ dengan irlverled file untuk masing-masing nilai fl~resl~olil. Pada Lampiran ini kolom pertama adalah nomor query, kolom kedua adalah qtrery, kolom ketiga adalah jumlah dokumen terambil dan kolom keempat adalah daftar varian istilah yang ditampilkan untuk masing-masing query. Perkiraan istilah dalam basisdata yang diniunculkan adalah istilah-istilah yang mempunyai koefisien dice yang melampaui atau sama dcngan nilai flrreshol~i yatig telah ditentukan.
1
Query don Tl?resl~old]
diparsing
Cnri Substring
Dapatkan Kocfisico-Dicc
f
Istilah sesuai
qtcery
1
Urutkan Hasil
sesuai besarnya Kd
Tampilkan istilab le~igkap
dcngnn URL
[image:16.595.71.375.76.768.2]\.
Gambar 3. Diagram Alur Program Algoritme Pigroar
..---"r/ ..
nilai tersebut dapat memperluas proses pencarian istilah dalam basisdata. Meskipun hasil q u e ~ y yang ditampilkan selain istilah yang dekat juga akan mencakup istilah-istilah yang jauh dari qiroy yang diterapkan. Misalnya bila menerapkan nilai tltreshold 0.2 atau 0.3.
Keefektifan Algoritme Trigran]
Banyaknya istilah yang dimunculkan tergantung pada banyaknya istilah dalam basisdata yang mempunyai koefisien dice tinggi, atau dengan kata lain istilah tersebut dianggap semakin mirip. Besarnya nilai lltresltol(1 telah ditentukan untuk bisa memunculkan istilah dengan mengacu pada satu atau lebih doku~nen yang terambil.
Untuk nilai tltreshold 0.2 istilah dan jumlah dokumen yang terambil dari basisdata cukup banyak, berbeda pada saat nilai tltresl~old 0.3 diterapkan untuk q u a y yang sama. Terjadi perbedaan jumlah dokumen dan istilah yang terambil dari basisdata. Yaitu ketika query ke 7
sampai 20 diterapkan kecuali untuk query ke 13,15,16, dan 17 jumlah dokumen dan istilah yang terambil sama banyak. Penggunaan nilai tltresl~old 0.4 dan 0.5, istilah yang dimunculkan benar-benar dekat dengan yang diinginkan. Ketika istilah tersebut mengacu pada dokumen yang memuat istilah-istilab yang didapatkan, dokumen tersebut nlempakan dokumen yang relevan yang telah ditentukan sebelumnya. Pemilihan qtrery yang digunakan sangat berpengaruli terhadap banyak sedikitnya istilah yang ditemu-kembalikan.
Besarnya nilai tl~reshold yang digunakan memberikan pengamh pada nilai rata-rata precision sehingga menghasilkan nilai yang tinggi. Seperti yang diuraikan sebelumnya pemilihan nilai tl~reshold ini dianggap sebagai formula yang cocok dan dapat memperluas proses pencarian, dengan hasil percobaan yang didapatkan menunjukkan bahwa dari keempat nilai tltresltold tersebut menggambarkan penggunaan algoritme trigrartl mempunyai kinerja yang cukup baik.
Keefektifan didefinisikan sebagai presentase istilah yang terseleksi dari senlua istilah yang diperiksa. Berdasarkan jumlah varian istilah yang terambil maka algoritme wigram dengall inverted jile memperlihatkan kinerja terbaik pada nilai fhreshold 0.2. Untuk nilai tltresltold 0.5 juga memperlihatkan kinerja yang baik karena nilai rata-rata precisiort yang dillasilkan tinggi, dan varian yang terambil lebih mendekati istilah yang dicari.
\.
Secara umum algoritme lrigrarn mempunyai kinerja yang cukup baik dalam menyeleksi istilah dalam query dengan istilah dalam basisdata, sepanjang istilah yang diharapkan terdapat dalam basisdata.
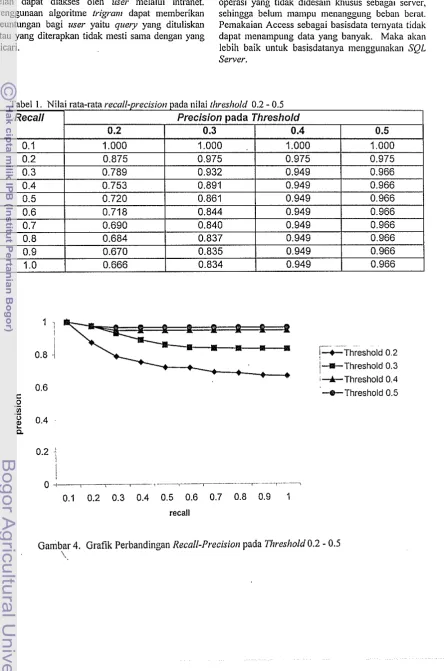
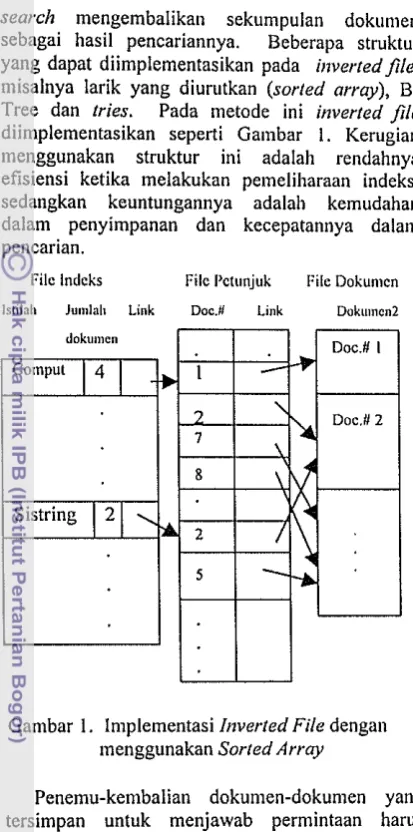
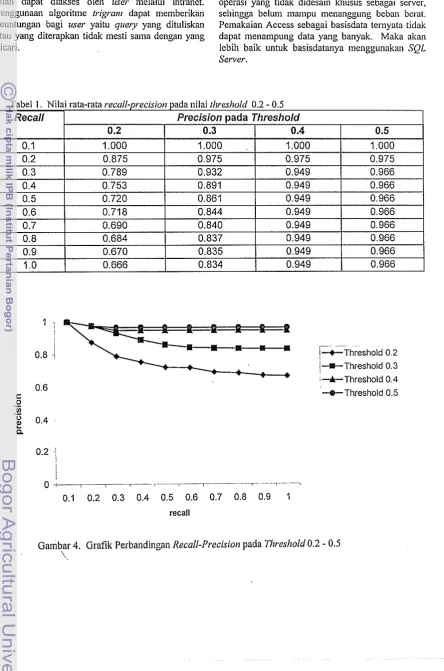
Kinerja Sistem berdasarkan Recall-Prccisio~l Kinerja sistem temu-kenlbali informasi dianalisis berdasarkan nilai Recall-Precision untuk setiap pemilihan nilai lhresslrold. Nilai rata-rata recall-precision untuk masing-masing nilai llrresltold dicantumkan pada Tabel 1. Utituk memperjelas perbedaan nilai precision pada setiap tingkat recall untuk masing-masing nilai tl~reshold direpresentasikan dalam Gambar 4.
Grafik pada Gambar 4 secara jelas menampilkan perbedaan kinerja setiap nilai tl~reskold. Ada dua buah grafik pada Gambar 4 ini yang memiliki nilai precisiorl menurun bersan~aan dengan bertambahnya nilai recall, yaitu grafik untuk nilai tl~resshold 0.2 dan nilai thresl~old 0.3. Hal ini terjadi karena pada saat query-query diterapkan jumlah dokumen yang terambil dalam basisdata banyak. Sedangkan untuk grafik pada nilai ihreshold 0.5 memiliki tingkat persiciort yaug tinggi dari nilai tl~resltold yang laimya. Disebabkan pada saat query diterapkan jumlah dokumen yang terambil dalam basisdata lebih mendekati istilah yang dicari atau diinginkan. Meskipun jumlah istilah yang mempunyai nilai koefisien dice lebih besar atau sama dengan nilai tltreshold yang terdapat dalam basisdata junllahnya sedikit. Masalah lain adalah adanya istilah yang me'mpunyai dokumen yang sania dengan istilah lain.
Jumlah dokumen yang ditampilkan pada nilai ~Itreshold 0.4 relatif sama dengan nilai tltreshold 0.5, perbedaannya terjadi pada saat q u e ~ y 13 diterapkan. Pada nilai tltreshold 0.4 jumlah dokumen yang terambil 3 buah, sedangkan pada nilai ~ltresl~old 0.5 hanya 2 buah dokumen yang terambil.
Kelebil~arl Sisterr~ K c l e n ~ a l ~ a ~ l Sistcrn
Sistein dapat bekerja sesuai dengan harapan, Sistem ini inasih menggunakan PWS yang yakni sejauh i~ii dapat ditampilkao oleh browser, dan bekerja pada Windows 95/98 yang ~nerupakaii sistein telah dapat diakses oleli user nielalui intranet. operasi yang tidak didesain kliusus sebagai server, Penggunaan algorit~ne irigra~ir dapat ~iierilberikan sehingga belurn mampu menanggung beban berat. keuntungan bagi zrser yaitu qtle~y yang dituliskan Pernakaian Access sebagai basisdata ternyata tidak atau yang diterapkan tidak rnesti saina dengall yang dapat rnenampung data yang banyak. Maka altan
dicari. lebili baik untuk basisdatariya inenggunakan SQL
Server.
Tabel I. Nilai rata-rata recall-precision pada nilai rl?r.es/lold 0.2
-
0.5R e c a l l Precision pada Threshold
0.2
I
0.3I
0.4I
0.5
0 i 7.. , ..~~ ?--.
_
. /. -- .~. v- .' '.0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall
[image:18.595.74.519.121.793.2]ICESIMPULAN DAN SARAN
I(esi1npu1a11
Pada prinsipnya, penemu-kenibalian dokumen-dokunlen yang tersimpan untuk menjawab pernlintaan hams berdasarkan penentuan ukuran kesamaan antara query dan iterrr yang disimpan dan pengambilan itenr-iteirr yang dapat dibuktikan cukup mirip dengan query.
Berdasarkan jumlah varian istilali yang teranibil, algorit~ne trigram dengan irlverterl file memberikan kinerja yang baik pada penieriksaan istilali dalam basisdata. Keefektifan algoritme ini niernberikan kinerja terbaik pada nilai tlzreshold 0.2 selain itu pada nilai threslrold 0.5 juga nlemperliliatkan kinerja yang baik karena nilai rata- rata precisiort yang dihasilkan tinggi, dan varian yang tera~nbil lebih niendekati istilali yang dicari nielalui query atau benar-benar dekat de~igan yang diinginkan. Naniun untuk mengetahui tingkat recall yang opti~nuni tidak dapat disajikan, karena tingkat precision tidak pernah berada pada selang
Fitriyanti, M. 1997. Perigenibangan Temu- Kenibali Infol-niasi dengan Menginiplenientasikan Operasi Boolean, Sistem Peringkat, Perbaikan qrre,y dan
Pemanfaatan Tesaurus. Skripsi. Fakultas Ilmu Komputer, Universitas Indonesia, Depok.
Frakes, W. B. & R. Raeza-Yates. 1992. Iifor?nuliort Retrievnl : Data Strricf~tre &
Algoritlrnzs. Prentice IJall, New Jersey. Pfeifer, U., T. Poerscll & N. F u l ~ r . 1996.
Retrieval 8ffectiveness of Proper Nrrrrte Seurcl~ Melltods. Irfornrntiorz Pmcessir~g cE Marmgcrizeirt. 32: 667-679.
Salton, G . 1989. Arrtorrzafic Text Processirrg : Tlze
Trrn~sforrrrntior~. Aitalysis, roril Reaievttl of
Irfo,?r~ntiorr by Corripzrler. Addison Wesley Publishing Company, Canada.
nilai 0.5
-
O.G. ~ i n g k a t precisiorr~ pada 11asipenelitian ini berada diatas nilai 0.6. Slamet, S. I.S., FX. Nursalim., C. II. Makaliwe
& W. C. Wibolvo. 1990. Petlnantar
Saran St~uktur Data. PT Elex Media Kompu~indo,
Faktor yang sangat penting dalam ten~u-kemnbali Jakarta. informasi adalah ukuran kinerja sistem yaitu waktu
proses dall relevallsi yang diberikan sesuai dengan Stinson, D. R. 1985. An ltrf,url~rctiorr to fhe kebutuhan. Secara unium algoritn~e frigrarrr <lesigrr arrd Arralysis Algorifhazs. Winnipeg, nienlberikan kineria yang cukup baik untuk sisteln . . . Canada.
temu-kembali informasi.
perlu dilakukall pula percobaan dengall nlencari Wal~yudin, A. 1999. Algoritme Trigram untuk altelnatif algorihiie lain misalnya 4-gram untuk nlengoreksi Ejaan. Skripsi. Jurusan llmu niengetahui kineria yang lebili baik. Selain itu perlu . . - Komputer FMIPA IPB, Bogor.
dilakukan penyusunan suatu shxktur irrvertedfile, misalnya B-Tree dan fries untuk n~endapatkan tingkat recall yang optimum.
Sesuai dengan kelemahan yang masili ada sebaiknya dalam peniilihan basisdata menggunakan basisdata yaug dapat menampung data yang banyak misalnya SQL Swver.
DAPTAR PUSTAIOI.
Lampiran 1. Tampila11 awal LocnlSenrrh EngLre
orrmlru,w Pusat Perpustakaan dan Pcnrcbaran ~ c k n o l o p i peeanban
.
c s m r fw aorrcvnuraf obrarr and yachrolwv oaremtoatroo* O W Y I
I n f o r m a ~ l m c n ~ c n a l S ~ I ~ r ~ l ~ Tuyasdan Funosl Sbuktur o r g a ~ s a s ~
P,.-IMI ~ c ~ n l n l r d n , ~ I ~ D U I A ~ ~ W Y , iesk br~drunclim ' m d w.om%tiolrd ~ r v c l w r
Lampiran 2. Tan~pilan Antar Muka sebagai Form Isian User
Lampiran 3. Tanlpilan Hasil Q u e ~ y pada Tltresl~old 0,2
I
SEARCHING RESULTAuUloi:Rudy Emysno u l d DidiekH.Ooenldi
Klyvord: Ppolenlld roronvlhuok m.di% go* m c o s i v l d
I
0, .
.
ICombinc 4 ICombining. Glycinct
- 0 . . I
y,, D;vclop~nc~~l 2 Ue\clopo~cnt. D:velops~cntol I
Q~ Q, Q~
n. -2
Q~ Q,
n.
lnbrccding Varietas Resislanr Effects Soil Oxis01 Gossypium
5
3
I 1 5 4 2
3
Inbred, Intercropping Variety
Rcsislant, Rcsponsc. Ricc Effect, Eficicncy Soil
Q ~ ,
Q ~ ,
Q ~ ,
Q~~
Q , ~
Q , ~
q19
oln
Interaction Nilrogcn Gcnotypc Phosphate Phosphoru~ Mcdia Cocoa Rcsponse
3
3
5
3
3
I I
4
Intcraclion, Inoculation Nitrogen
Gcnolypc
Phosphate, Pl~osphorus I'hosphorus, Pl~ospl~atc Mcdia
Lampiran 1. Tampila11 awal LocnlSenrrh EngLre
orrmlru,w Pusat Perpustakaan dan Pcnrcbaran ~ c k n o l o p i peeanban
.
c s m r fw aorrcvnuraf obrarr and yachrolwv oaremtoatroo* O W Y I
I n f o r m a ~ l m c n ~ c n a l S ~ I ~ r ~ l ~ Tuyasdan Funosl Sbuktur o r g a ~ s a s ~
P,.-IMI ~ c ~ n l n l r d n , ~ I ~ D U I A ~ ~ W Y , iesk br~drunclim ' m d w.om%tiolrd ~ r v c l w r
Lampiran 2. Tan~pilan Antar Muka sebagai Form Isian User
Lampiran 3. Tanlpilan Hasil Q u e ~ y pada Tltresl~old 0,2
I
SEARCHING RESULTAuUloi:Rudy Emysno u l d DidiekH.Ooenldi
Klyvord: Ppolenlld roronvlhuok m.di% go* m c o s i v l d
I
0, .
.
ICombinc 4 ICombining. Glycinct
- 0 . . I
y,, D;vclop~nc~~l 2 Ue\clopo~cnt. D:velops~cntol I
Q~ Q, Q~
n. -2
Q~ Q,
n.
lnbrccding Varietas Resislanr Effects Soil Oxis01 Gossypium
5
3
I 1 5 4 2
3
Inbred, Intercropping Variety
Rcsislant, Rcsponsc. Ricc Effect, Eficicncy Soil
Q ~ ,
Q ~ ,
Q ~ ,
Q~~
Q , ~
Q , ~
q19
oln
Interaction Nilrogcn Gcnotypc Phosphate Phosphoru~ Mcdia Cocoa Rcsponse
3
3
5
3
3
I I
4
Intcraclion, Inoculation Nitrogen
Gcnolypc
Phosphate, Pl~osphorus I'hosphorus, Pl~ospl~atc Mcdia
PENDAHULUAN
Latar Belakang
Pengembangan sistem informasi elektronik dimulai pada sekitar 1940. Sistem temu-kembali informasi (ir$ormation retrieval Syste~n) secara otomatis pada awalnya dikembangkan untuk membantu mengatur literatur ilmu pengetahuan yang jumlahnya banyak. Kantor-kantor, pemsahaan dan perpustakaan telah menggunakan sistem temu-kembali informasi untuk mengakses buku-buku, koran, majalah, jumal, dan dokumen lainnya. Sistem ini mengolah dokumen-dokumen yang terorganisasi dalam record pada berkas Vile) dan mengelola pemintaan (request) i~~fotmasi, kemudian mengembalikamya dalam berkas tertentu sebagai tanggapan terhadap permintaan tersebut (Frakes & Baeza-Yates, 1992).
Kebutuhan informasi bagi user dan jumlah dokumen yang banyak menuntut sistem temu- kembali informasi untuk bekerja secara efisien. Berdasarkan lokasi sumber data, Local Searclt Engine memanfaatkan internet sebagai penghubung sistem temu-kembali informasi yang ada di dalamnya dengan user.
Salah satu algoritme temu-kembali infomiasi nntuk membandingkan kesamaan string adalah rr-
grants yang membandingkan humf pada kata taopa memperhatikan bahasa yang digunakan. Semakin banyak n-gra~ris yang sama muncul pada kedua string, maka dikatakan semakin mirip. Ada dua parameter yang dapat dipilih ketika memakai metode ini, yaitu ( I ) panjang 11-graets dan (2) spasi tamballan. Untuk parameter panjang 11-grants, trigram dan digram memperoleh hasil yang paling baik dalam pangambilan kata-kata yang niirip pada setiap kata (Pfeifer el nl., 1996).
Sebena~nya penelitian mengeiiai sistem temu- kembali infomasi telah dilakukan oleh Fittiyanti (1997). Pada kalya ilmiah tersebut implementasi sistem temu-ken~bali infomlasi bertumt-tumt
dapat diakses melalui internet dalam bentuk Itypcrtext dengan menggunakan metode trigram.
TINJAUAN PUSTAKA
Metode Pencarian
Beberapa metode yang dapat diterapkan untuk pencarian data diantaranya pencarian berumtan (sequential searchi~tg). Cara kerja metode iiii adalah melakukan pembacaan data yang akan dicari dan dibandingkan satu per satu dengan data pertama sampai data terakhir secara bemmtan, sehingga data tersebut ditemukan atau tidak ditemukan. Pada saat data yang dicari telah ditemukan, maka proses pencarian dapat langsung dihentikan. Jika data yang dicari belum ditemukan maka pencarian tems dilakukan sampai selumh data dibandingkan. Dalam kasus terbumk, untuk vektor dengan N buah elemen hams dilakukan pencarian sebanyak N kali pula (Stinson, 1985).
Metode yang kedua adalah pencarian pada tabel yang sudah diumtkan (sorting table senrclting), yaitu mencari suatu unsur dari suatu tabel, setiap unsur dari tabel tersebut mempunyai seknmpulan nilai yang disebut atribut. Salah satu dari atribut ini disebut kata kunci atau nama yang digunakan untuk menentukan unsur tersebut (Slamet at a1.,1990).
Metode yang terakhir adalah pencarian bemmtan berindeks (indexed scquerrlirrl searcltirrg). Data yang akan diproses dalam suatu tabel sudah diumtkan menumt suatu urutan tertentu dari key. Metode ini melakukan pengindeksan terhadap teks dan dapat digunakan untuk meningkatkan kecepatan pencarian. Ukuran indeks biasanya proporsional dengan ukuran basisdata dan waktu pencarian sublinear terhadap ukuran teks, contohnya inverter1 jile (Frakes&Baeza-Yates, 1992).
meneeunakan o ~ c r a t o r boolcan. sistem ~eringkat, -
....
.,-
dan sumber Gata dalam Bahasa indoiisia, x"vcrtcdl'ile
sedangkan pada penelitian ini melakukan Inverledjile adalah daftar yang diuiutkan olch implenlentasi sistem temu-kembali ke dalam istilah, dimana setiap istilah mempunyai bentuk lrypertext dengan menggunakan metode Ilubungan ke atau
Iebih
dOkumen Yaiig...:....-...
mengandung istilah. Fungsi irtvertedfilc adalahuntuk ii~emperbaiki efisieusi pencarian dengan
Tujuau beberapa ukuran jarak yang biasanya diperlukan
Tujuan penelitian ini a ~ a l a h untuk bcrkas teks yang besar. Ada dua algoritmc mengimpleme?tasikan sistem temll-kembali pencarian untuk irtverte(1 file, yaitu pencarian
untuk mencari suatu dokumen yang istilah dan algoritme possible search. Algoritme
PENDAHULUAN
Latar Belakang
Pengembangan sistem informasi elektronik dimulai pada sekitar 1940. Sistem temu-kembali informasi (ir$ormation retrieval Syste~n) secara otomatis pada awalnya dikembangkan untuk membantu mengatur literatur ilmu pengetahuan yang jumlahnya banyak. Kantor-kantor, pemsahaan dan perpustakaan telah menggunakan sistem temu-kembali informasi untuk mengakses buku-buku, koran, majalah, jumal, dan dokumen lainnya. Sistem ini mengolah dokumen-dokumen yang terorganisasi dalam record pada berkas Vile) dan mengelola pemintaan (request) i~~fotmasi, kemudian mengembalikamya dalam berkas tertentu sebagai tanggapan terhadap permintaan tersebut (Frakes & Baeza-Yates, 1992).
Kebutuhan informasi bagi user dan jumlah dokumen yang banyak menuntut sistem temu- kembali informasi untuk bekerja secara efisien. Berdasarkan lokasi sumber data, Local Searclt Engine memanfaatkan internet sebagai penghubung sistem temu-kembali informasi yang ada di dalamnya dengan user.
Salah satu algoritme temu-kembali infomiasi nntuk membandingkan kesamaan string adalah rr-
grants yang membandingkan humf pada kata taopa memperhatikan bahasa yang digunakan. Semakin banyak n-gra~ris yang sama muncul pada kedua string, maka dikatakan semakin mirip. Ada dua parameter yang dapat dipilih ketika memakai metode ini, yaitu ( I ) panjang 11-graets dan (2) spasi tamballan. Untuk parameter panjang 11-grants, trigram dan digram memperoleh hasil yang paling baik dalam pangambilan kata-kata yang niirip pada setiap kata (Pfeifer el nl., 1996).
Sebena~nya penelitian mengeiiai sistem temu- kembali infomasi telah dilakukan oleh Fittiyanti (1997). Pada kalya ilmiah tersebut implementasi sistem temu-ken~bali infomlasi bertumt-tumt
dapat diakses melalui internet dalam bentuk Itypcrtext dengan menggunakan metode trigram.
TINJAUAN PUSTAKA
Metode Pencarian
Beberapa metode yang dapat diterapkan untuk pencarian data diantaranya pencarian berumtan (sequential searchi~tg). Cara kerja metode iiii adalah melakukan pembacaan data yang akan dicari dan dibandingkan satu per satu dengan data pertama sampai data terakhir secara bemmtan, sehingga data tersebut ditemukan atau tidak ditemukan. Pada saat data yang dicari telah ditemukan, maka proses pencarian dapat langsung dihentikan. Jika data yang dicari belum ditemukan maka pencarian tems dilakukan sampai selumh data dibandingkan. Dalam kasus terbumk, untuk vektor dengan N buah elemen hams dilakukan pencarian sebanyak N kali pula (Stinson, 1985).
Metode yang kedua adalah pencarian pada tabel yang sudah diumtkan (sorting table senrclting), yaitu mencari suatu unsur dari suatu tabel, setiap unsur dari tabel tersebut mempunyai seknmpulan nilai yang disebut atribut. Salah satu dari atribut ini disebut kata kunci atau nama yang digunakan untuk menentukan unsur tersebut (Slamet at a1.,1990).
Metode yang terakhir adalah pencarian bemmtan berindeks (indexed scquerrlirrl searcltirrg). Data yang akan diproses dalam suatu tabel sudah diumtkan menumt suatu urutan tertentu dari key. Metode ini melakukan pengindeksan terhadap teks dan dapat digunakan untuk meningkatkan kecepatan pencarian. Ukuran indeks biasanya proporsional dengan ukuran basisdata dan waktu pencarian sublinear terhadap ukuran teks, contohnya inverter1 jile (Frakes&Baeza-Yates, 1992).
meneeunakan o ~ c r a t o r boolcan. sistem ~eringkat, -
....
.,-
dan sumber Gata dalam Bahasa indoiisia, x"vcrtcdl'ile
sedangkan pada penelitian ini melakukan Inverledjile adalah daftar yang diuiutkan olch implenlentasi sistem temu-kembali ke dalam istilah, dimana setiap istilah mempunyai bentuk lrypertext dengan menggunakan metode Ilubungan ke atau
Iebih
dOkumen Yaiig...:....-...
mengandung istilah. Fungsi irtvertedfilc adalahuntuk ii~emperbaiki efisieusi pencarian dengan
Tujuau beberapa ukuran jarak yang biasanya diperlukan
Tujuan penelitian ini a ~ a l a h untuk bcrkas teks yang besar. Ada dua algoritmc mengimpleme?tasikan sistem temll-kembali pencarian untuk irtverte(1 file, yaitu pencarian
untuk mencari suatu dokumen yang istilah dan algoritme possible search. Algoritme
search mengembalika~i sekumpulan dokumen sebagai hasil pencariannya. Beberapa struktur yang dapat diimplementasikan pada irtvertedfile, misalnya larik yang diurutkan (sorted array), B- Tree dan tries. Pada metode ini inverted file diimplementasikan seperti Ga~nbar 1. Kerugian menggunakan struktur ini adalah rendahnya efisiensi ketika melakukan pe~neliharaan indeks, sedangkan keuntungannya adalah kemudahan dalam penyimpanan dan kecepatannya dalam pencarian.
Filc Indcks Filc I'cu~njuk File Dokunicn
IslilsL Junllvl! Link Doc.# Link Ooku1nen2
Jika c adalah banyaknya substring yalig sania antara ti dan mk, maka ukuran kesamaan antara T dan M dapat dihitung dengan menggunakan koefisien dice sebagai berikut :
[image:30.595.74.281.81.498.2]Jika I = 3, maka algoritme di atas dinamakan algoritme trigram. Sebagai contoh istilali COMBINING dalam dokumen dibandingkan dengan istilah COMBINE dala~n query, algoritme di atas dapat diterangkan sebagai berikut :
Gambar I. lmplementasi irzverted File dengall ~nenggunakan Sorted Array
Penemu-kembalian dokumen-dokumen yang tersimpan untuk menjawab permintaan harus berdasarkan penentuan ukuran kesamaan antara query dan iten? yang disimpan dan penga~nbilan itcal-item yang dapat dibuktikan cukup mirip dengan query. Padalial dokunien-dokumcn yang disimpan dan informasi yang diminta dapat tidak terstruktur dan keputusan penemu-kembaliannya tergantulig pada teks yang berliubungan.
Algoritme n-gram
Misalkan T adalah sebuah istilah dalam dokumen dengan panjang n karakter dan disimpan sebagai larik yang mengandung substring t, dengan panjang I, untuk i = 1,2
,...,
n+l-
1 (Angell, 1982 dalam Waliyudin). Misalkan M adalah istilah dalam q~rerj.\dengan panjang n' karakter dan disilnpan sebagai larik yang mengandung substring mk dengan panjang I, untuk k = 1,2,...,
n'+
I+
1.1. Kata COMBINING terdiri dari 11 substring, yaitu : $$C, $CO, COM, OMB, MBI, BIN, INI, NIN, ING, NG$. G$$.
2. Kata COMBINE terdiri atas 9 substring, yaitu : $$C, $CO, COM, OMB, MBI, BIN,
INE, NE$, E$$.
3. Jumlah substring yang sama
G yaitu
: $$C, $CO, COM, OMB, MBI, BIN.4. Memakai rumus koefisien dice maka didapatkan nilai koefisien dice 0.60
Jika nilai tersebut merupakan nilai terbesar dari koefisien dice untuk setiap pasangan istilali dala~n dokumen dan istilah dalam query, maka COMBINING adalah istilah dalam dokumen yang mirip dengan istilah COMBINE dalam qvmy. Ulturan Kinerja
Untuk mengukur kinerja sistem temu-kembali informasi dilakukan dcngan melihat perbandingan banyaknya dokumen yang terambil dari sekumpulan dokumen pada saat query diterapkan. Dokumen terambil merupakan kumpulan dokumen yang menjadi keluaran sistem, yang ~iierupakan subset dari koleksi dokumcn. Menurut Salton (1989) recall-precisior~ adalah metode yang digunakan untuk mcngukur ofektivitas temu-kembali.
Recall merupakan ukuran banyaknya dokumen-dokumen yang relevan yang terambil dari kumpulan dokumen pada saat qtrery diterapkan. RecaN didefinisikan sebagai berikut :
Jurnlah doku~iic~i rclcvan tcrambil
R=
Ju~iilali kcsclurulian dokumen rclcvan dalam basisdata
sangat menentukan dalam meniunculkan hasil query yang relevan. Jika nilai ambang terlalu besar, nlaka hasil query yang ditampilkan aka11 benar-benar dekat dengan query yang diterapkan dan ada kemungkinan istilah yang diharapkan tidak ditampilkan. Jika nilai ambang terlalu kecil, niaka hasil query yang ditampilkan selain istilah yang dekat juga akan mencakup istilah-istilali yang jauh dari query yang diterapkan. Nilai ambang dinyatakan dengan selang bilangan nyata antara 0 dan 1 ([O,l])sedangkan [0,0] diberikan untuk istilali yang tidak mirip atau tidak relevan.
Dalani penelitian ini, penentuan nilai ambang untuk masing-masing istilali dalam dokumen menggunakan interval. Tujuan penggunaan interval ini adalah untuk mengetahui tingkat recall dan precision yang optinium. Nilai ambang yang digunakan berada pada selang [0.2
-
0.51. Dari keempat nilai ambang ini akan diambil suatu nilai recall-precision yang kinerjanya optimum.Perangkat lunak d a n Perangkat keras
Pembuatan program pada saat mengembangkan sistem ini dilakukan dengan menggunakan sisteni operasi Windows 95. , Perangkat lunak yang
digunakan adalah Persortal Web Server (PWS), HTML, VB-Scripf untuk program aplikasi ASP, MS Access 97 untuk basisdata, pen~olahan gambar
Pengukuran Kinerja Recall-Precisio~~
Pengukuran kinerja recirll dan precisiorr didasarkan pada tingkat relevansi yang tcrdiri atas dua macam yaitu : Relevan (R) dan Tidak Relevan (TR). Sedangkan proses pengukuran kinerjanya dijelaskan sebagai berikut:
.
Anggap nilai recall telah diketaliui, yaitu terdiri dari 0.1 sampai 1.0..
Hasil keluaran program yaitu berupa dokunien-dokumen yang terambil diliitung jumlaluya. Nomor urut dokumen-dokunien menjadi acak sesuai dengan hasil keluaran program. Kemudian dicari dokumen- dokumen relevan dan dokumen-dokumen yang tidak rclevan..
Setelah selesai maka nilai precisio~r dapat diliitung, sesuai dengan rumus perliitungan precision pada lialaman 3.Pengukuran kinerja berdasarkan waktu proses dilakukan pada saat implementasi program temu- kenibali informasi. Waktu proses dimulai saat pengguna memasukan query dan berakhir ketika dokumen-dokumen telah terambil. Waktu proses diliitung dalam satuan detik. Pada penelitian ini waktu proses tidak diperhitungkan.
dengan Adobe Photoshop 5.0. ~ n 6 k hubuigan ke
server basisdata dilakukan nielalui ODBC (Operr
HASIL DAN PEMBAHASAN
Data Base Cortnectivity). Sedangkan perangkatkeras, yang digunakan Personcrl Cosrpurer (PC) dengan prosesor 486DX, RAM 16 MB dan kapasitas ltarddisk 540 MB.
Algoritrne Program Pencarian Qrrery
Secara unium algoritnie program pencarian qtrery dapat digambarkan seperi diagram alur pada Gambar 3.
Percobaan
Tujuan percobaan ini adalah untuk niengetnhui kinerja algorime frigrarrt, dengan memasukkan satu istilab dalam query dan nilai flrresholil yang berbeda-beda. Akan dilihat apakah metode tersebut niemberikan perkiraan istilah yang cukup baik untuk berbagai variasi qrrery. Junllah query yang diterapkan sebanyak 20 dengan nilai ambang berada pada selang [0.2
-
0.51. Lampiran 1 sampai 3 adalah tampilan awal, salah satu contoh query yang diujicoba seaa hasilnya.\.
Lampiran 4 sanlpai 7 menunjukkan hasil percobaan keefektifan algorihne frigru~r~ dengan irlverled file untuk masing-masing nilai fl~resl~olil. Pada Lampiran ini kolom pertama adalah nomor query, kolom kedua adalah qtrery, kolom ketiga adalah jumlah dokumen terambil dan kolom keempat adalah daftar varian istilah yang ditampilkan untuk masing-masing query. Perkiraan istilah dalam basisdata yang diniunculkan adalah istilah-istilah yang mempunyai koefisien dice yang melampaui atau sama dcngan nilai flrreshol~i yatig telah ditentukan.
sangat menentukan dalam meniunculkan hasil query yang relevan. Jika nilai ambang terlalu besar, nlaka hasil query yang ditampilkan aka11 benar-benar dekat dengan query yang diterapkan dan ada kemungkinan istilah yang diharapkan tidak ditampilkan. Jika nilai ambang terlalu kecil, niaka hasil query yang ditampilkan selain istilah yang dekat juga akan mencakup istilah-istilali yang jauh dari query yang diterapkan. Nilai ambang dinyatakan dengan selang bilangan nyata antara 0 dan 1 ([O,l])sedangkan [0,0] diberikan untuk istilali yang tidak mirip atau tidak relevan.
Dalani penelitian ini, penentuan nilai ambang untuk masing-masing istilali dalam dokumen menggunakan interval. Tujuan penggunaan interval ini adalah untuk mengetahui tingkat recall dan precision yang optinium. Nilai ambang yang digunakan berada pada selang [0.2
-
0.51. Dari keempat nilai ambang ini akan diambil suatu nilai recall-precision yang kinerjanya optimum.Perangkat lunak d a n Perangkat keras
Pembuatan program pada saat mengembangkan sistem ini dilakukan dengan menggunakan sisteni operasi Windows 95. , Perangkat lunak yang
digunakan adalah Persortal Web Server (PWS), HTML, VB-Scripf untuk program aplikasi ASP, MS Access 97 untuk basisdata, pen~olahan gambar
Pengukuran Kinerja Recall-Precisio~~
Pengukuran kinerja recirll dan precisiorr didasarkan pada tingkat relevansi yang tcrdiri atas dua macam yaitu : Relevan (R) dan Tidak Relevan (TR). Sedangkan proses pengukuran kinerjanya dijelaskan sebagai berikut:
.
Anggap nilai recall telah diketaliui, yaitu terdiri dari 0.1 sampai 1.0..
Hasil keluaran program yaitu berupa dokunien-dokumen yang terambil diliitung jumlaluya. Nomor urut dokumen-dokunien menjadi acak sesuai dengan hasil keluaran program. Kemudian dicari dokumen- dokumen relevan dan dokumen-dokumen yang tidak rclevan..
Setelah selesai maka nilai precisio~r dapat diliitung, sesuai dengan rumus perliitungan precision pada lialaman 3.Pengukuran kinerja berdasarkan waktu proses dilakukan pada saat implementasi program temu- kenibali informasi. Waktu proses dimulai saat pengguna memasukan query dan berakhir ketika dokumen-dokumen telah terambil. Waktu proses diliitung dalam satuan detik. Pada penelitian ini waktu proses tidak diperhitungkan.
dengan Adobe Photoshop 5.0. ~ n 6 k hubuigan ke
server basisdata dilakukan nielalui ODBC (Operr
HASIL DAN PEMBAHASAN
Data Base Cortnectivity). Sedangkan perangkatkeras, yang digunakan Personcrl Cosrpurer (PC) dengan prosesor 486DX, RAM 16 MB dan kapasitas ltarddisk 540 MB.
Algoritrne Program Pencarian Qrrery
Secara unium algoritnie program pencarian qtrery dapat digambarkan seperi diagram alur pada Gambar 3.
Percobaan
Tujuan percobaan ini adalah untuk niengetnhui kinerja algorime frigrarrt, dengan memasukkan satu istilab dalam query dan nilai flrresholil yang berbeda-beda. Akan dilihat apakah metode tersebut niemberikan perkiraan istilah yang cukup baik untuk berbagai variasi qrrery. Junllah query yang diterapkan sebanyak 20 dengan nilai ambang berada pada selang [0.2
-
0.51. Lampiran 1 sampai 3 adalah tampilan awal, salah satu contoh query yang diujicoba seaa hasilnya.\.
Lampiran 4 sanlpai 7 menunjukkan hasil percobaan keefektifan algorihne frigru~r~ dengan irlverled file untuk masing-masing nilai fl~resl~olil. Pada Lampiran ini kolom pertama adalah nomor query, kolom kedua adalah qtrery, kolom ketiga adalah jumlah dokumen terambil dan kolom keempat adalah daftar varian istilah yang ditampilkan untuk masing-masing query. Perkiraan istilah dalam basisdata yang diniunculkan adalah istilah-istilah yang mempunyai koefisien dice yang melampaui atau sama dcngan nilai flrreshol~i yatig telah ditentukan.
1
Query don Tl?resl~old]
diparsing
Cnri Substring
Dapatkan Kocfisico-Dicc
f
Istilah sesuai
qtcery
1
Urutkan Hasil
sesuai besarnya Kd
Tampilkan istilab le~igkap
dcngnn URL
[image:35.595.71.375.76.768.2]\.
Gambar 3. Diagram Alur Program Algoritme Pigroar
..---"r/ ..
nilai tersebut dapat memperluas proses pencarian istilah dalam basisdata. Meskipun hasil q u e ~ y yang ditampilkan selain istilah yang dekat juga akan mencakup istilah-istilah yang jauh dari qiroy yang diterapkan. Misalnya bila menerapkan nilai tltreshold 0.2 atau 0.3.
Keefektifan Algoritme Trigran]
Banyaknya istilah yang dimunculkan tergantung pada banyaknya istilah dalam basisdata yang mempunyai koefisien dice tinggi, atau dengan kata lain istilah tersebut dianggap semakin mirip. Besarnya nilai lltresltol(1 telah ditentukan untuk bisa memunculkan istilah dengan mengacu pada satu atau lebih doku~nen yang terambil.
Untuk nilai tltreshold 0.2 istilah dan jumlah dokumen yang terambil dari basisdata cukup banyak, berbeda pada saat nilai tltresl~old 0.3 diterapkan untuk q u a y yang sama. Terjadi perbedaan jumlah dokumen dan istilah yang terambil dari basisdata. Yaitu ketika query ke 7
sampai 20 diterapkan kecuali untuk query ke 13,15,16, dan 17 jumlah dokumen dan istilah yang terambil sama banyak. Penggunaan nilai tltresl~old 0.4 dan 0.5, istilah yang dimunculkan benar-benar dekat dengan yang diinginkan. Ketika istilah tersebut mengacu pada dokumen yang memuat istilah-istilab yang didapatkan, dokumen tersebut nlempakan dokumen yang relevan yang telah ditentukan sebelumnya. Pemilihan qtrery yang digunakan sangat berpengaruli terhadap banyak sedikitnya istilah yang ditemu-kembalikan.
Besarnya nilai tl~reshold yang digunakan memberikan pengamh pada nilai rata-rata precision sehingga menghasilkan nilai yang tinggi. Seperti yang diuraikan sebelumnya pemilihan nilai tl~reshold ini dianggap sebagai formula yang cocok dan dapat memperluas proses pencarian, dengan hasil percobaan yang didapatkan menunjukkan bahwa dari keempat nilai tltresltold tersebut menggambarkan penggunaan algoritme trigrartl mempunyai kinerja yang cukup baik.
Keefektifan didefinisikan sebagai presentase istilah yang terseleksi dari senlua istilah yang diperiksa. Berdasarkan jumlah varian istilah yang terambil maka algoritme wigram dengall inverted jile memperlihatkan kinerja terbaik pada nilai fhreshold 0.2. Untuk nilai tltresltold 0.5 juga memperlihatkan kinerja yang baik karena nilai rata-rata precisiort yang dillasilkan tinggi, dan varian yang terambil lebih mendekati istilah yang dicari.
\.
Secara umum algoritme lrigrarn mempunyai kinerja yang cukup baik dalam menyeleksi istilah dalam query dengan istilah dalam basisdata, sepanjang istilah yang diharapkan terdapat dalam basisdata.
Kinerja Sistem berdasarkan Recall-Prccisio~l Kinerja sistem temu-kenlbali informasi dianalisis berdasarkan nilai Recall-Precision untuk setiap pemilihan nilai lhresslrold. Nilai rata-rata recall-precision untuk masing-masing nilai llrresltold dicantumkan pada Tabel 1. Utituk memperjelas perbedaan nilai precision pada setiap tingkat recall untuk masing-masing nilai tl~reshold direpresentasikan dalam Gambar 4.
Grafik pada Gambar 4 secara jelas menampilkan perbedaan kinerja setiap nilai tl~reskold. Ada dua buah grafik pada Gambar 4 ini yang memiliki nilai precisiorl menurun bersan~aan dengan bertambahnya nilai recall, yaitu grafik untuk nilai tl~resshold 0.2 dan nilai thresl~old 0.3. Hal ini terjadi karena pada saat query-query diterapkan jumlah dokumen yang terambil dalam basisdata banyak. Sedangkan untuk grafik pada nilai ihreshold 0.5 memiliki tingkat persiciort yaug tinggi dari nilai tl~resltold yang laimya. Disebabkan pada saat query diterapkan jumlah dokumen yang terambil dalam basisdata lebih mendekati istilah yang dicari atau diinginkan. Meskipun jumlah istilah yang mempunyai nilai koefisien dice lebih besar atau sama dengan nilai tltreshold yang terdapat dalam basisdata junllahnya sedikit. Masalah lain adalah adanya istilah yang me'mpunyai dokumen yang sania dengan istilah lain.
Jumlah dokumen yang ditampilkan pada nilai ~Itreshold 0.4 relatif sama dengan nilai tltreshold 0.5, perbedaannya terjadi pada saat q u e ~ y 13 diterapkan. Pada nilai tltreshold 0.4 jumlah dokumen yang terambil 3 buah, sedangkan pada nilai ~ltresl~old 0.5 hanya 2 buah dokumen yang terambil.
Kelebil~arl Sisterr~ K c l e n ~ a l ~ a ~ l Sistcrn
Sistein dapat bekerja sesuai dengan harapan, Sistem ini inasih menggunakan PWS yang yakni sejauh i~ii dapat ditampilkao oleh browser, dan bekerja pada Windows 95/98 yang ~nerupakaii sistein telah dapat diakses oleli user nielalui intranet. operasi yang tidak didesain kliusus sebagai server, Penggunaan algorit~ne irigra~ir dapat ~iierilberikan sehingga belurn mampu menanggung beban berat. keuntungan bagi zrser yaitu qtle~y yang dituliskan Pernakaian Access sebagai basisdata ternyata tidak atau yang diterapkan tidak rnesti saina dengall yang dapat rnenampung data yang banyak. Maka altan
dicari. lebili baik untuk basisdatariya inenggunakan SQL
Server.
Tabel I. Nilai rata-rata recall-precision pada nilai rl?r.es/lold 0.2
-
0.5R e c a l l Precision pada Threshold
0.2
I
0.3I
0.4I
0.5
0 i 7.. , ..~~ ?--.
_
. /. -- .~. v- .' '.0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall
[image:37.595.74.519.121.793.2]ICESIMPULAN DAN SARAN
I(esi1npu1a11
Pada prinsipnya, penemu-kenibalian dokumen-dokunlen yang tersimpan untuk menjawab pernlintaan hams berdasarkan penentuan ukuran kesamaan antara query dan iterrr yang disimpan dan pengambilan itenr-iteirr yang dapat dibuktikan cukup mirip dengan query.
Berdasarkan jumlah varian istilali yang teranibil, algorit~ne trigram dengan irlverterl file memberikan kinerja yang baik pada penieriksaan istilali dalam basisdata. Keefektifan algoritme ini niernberikan kinerja terbaik pada nilai tlzreshold 0.2 selain itu pada nilai threslrold 0.5 juga nlemperliliatkan kinerja yang baik karena nilai rata- rata precisiort yang dihasilkan tinggi, dan varian yang tera~nbil lebih niendekati istilali yang dicari nielalui query atau benar-benar dekat de~igan yang diinginkan. Naniun untuk mengetahui tingkat recall yang opti~nuni tidak dapat disajikan, karena tingkat precision tidak pernah berada pada selang
Fitriyanti, M. 1997. Perigenibangan Temu- Kenibali Infol-niasi dengan Menginiplenientasikan Operasi Boolean, Sistem Peringkat, Perbaikan qrre,y dan
Pemanfaatan Tesaurus. Skripsi. Fakultas Ilmu Komputer, Universitas Indonesia, Depok.
Frakes, W. B. & R. Raeza-Yates. 1992. Iifor?nuliort Retrievnl : Data Strricf~tre &
Algoritlrnzs. Prentice IJall, New Jersey. Pfeifer, U., T. Poerscll & N. F u l ~ r . 1996.
Retrieval 8ffectiveness of Proper Nrrrrte Seurcl~ Melltods. Irfornrntiorz Pmcessir~g cE Marmgcrizeirt. 32: 667-679.
Salton, G . 1989. Arrtorrzafic Text Processirrg : Tlze
Trrn~sforrrrntior~. Aitalysis, roril Reaievttl of
Irfo,?r~ntiorr by Corripzrler. Addison Wesley Publishing Company, Canada.
nilai 0.5
-
O.G. ~ i n g k a t precisiorr~ pada 11asipenelitian ini berada diatas nilai 0.6. Slamet, S. I.S., FX. Nursalim., C. II. Makaliwe
& W. C. Wibolvo. 1990. Petlnantar
Saran St~uktur Data. PT Elex Media Kompu~indo,
Faktor yang sangat penting dalam ten~u-kemnbali Jakarta. informasi adalah ukuran kinerja sistem yaitu waktu
proses dall relevallsi yang diberikan sesuai dengan Stinson, D. R. 1985. An ltrf,url~rctiorr to fhe kebutuhan. Secara unium algoritn~e frigrarrr <lesigrr arrd Arralysis Algorifhazs. Winnipeg, nienlberikan kineria yang cukup baik untuk sisteln . . . Canada.
temu-kembali informasi.
perlu dilakukall pula percobaan dengall nlencari Wal~yudin, A. 1999. Algoritme Trigram untuk altelnatif algorihiie lain misalnya 4-gram untuk nlengoreksi Ejaan. Skripsi. Jurusan llmu niengetahui kineria yang lebili baik. Selain itu perlu . . - Komputer FMIPA IPB, Bogor.
dilakukan penyusunan suatu shxktur irrvertedfile, misalnya B-Tree dan fries untuk n~endapatkan tingkat recall yang optimum.
Sesuai dengan kelemahan yang masili ada sebaiknya dalam peniilihan basisdata menggunakan basisdata yaug dapat menampung data yang banyak misalnya SQL Swver.