PERBANDINGAN KINERJA PEMILIHAN FITUR
CHI-SQUARE DAN SINGULAR VALUE DECOMPOSITION
SISTEM TEMU KEMBALI DOKUMEN TUMBUHAN OBAT
RICO ANDRIAN
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Perbandingan Kinerja Pemilihan Fitur Chi-square Dan Singular Value Decomposition Sistem Temu Kembali Dokumen Tumbuhan Obat adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juni 2013
Rico Andrian
RINGKASAN
RICO ANDRIAN. Perbandingan Kinerja Pemilihan Fitur Chi-square Dan
Singular Value Decomposition Sistem Temu Kembali Dokumen Tumbuhan Obat. Dibimbing oleh YENI HERDIYENI dan HARI AGUNG ADRIANTO.
Penelitian ini menganalisis kinerja pemilihan fitur chi-square dan Singular Value Decomposition (SVD) sistem temu kembali dokumen tumbuhan obat. Metode ini untuk mencari sistem pencarian dokumen yang efektif berdasarkan kueri sehingga menghasilkan dokumen yang relevan bagi pengguna. Teknik pemilihan chi-square melakukan pemilihan fitur kata berdasarkan kata-kata yang penting yang digunakan untuk membuat vector space model. Model terdiri atas beberapa dokumen yang direpresentasikan sebagai vektor dari frekuensi kemunculan fitur. Teknik pemilihan fitur SVD menggunakan kata-kata penting yang ditemui di setiap dokumen. Kata-kata penting menjadi term dari matriks
term-dokumen. Dokumen tumbuhan obat berbahasa Indonesia berjumlah 132 dokumen digunakan pada temu kembali chi-square dan SVD. Temu kembali chi-square dan SVD diuji dengan 29 kueri non semantik dan semantik. Hasilnya adalah perbandingan kinerja dari temu kembali kedua metode tersebut pada kueri non semantik dan semantik.
SUMMARY
RICO Andrian. Comparison of Chi-square Feature Selection and Singular Value Decomposition for Medicinal Plant Document Retrieval System. Advised
by YENI HERDIYENI and HARI AGUNG ADRIANTO.
This study analyzes the performance of the chi-square feature selection and Singular Value Decomposition (SVD) document retrieval system medicinal plants. The method is to find an effective document retrieval system based on queries to produce documents relevant to the user. Chi-square selection techniques make the selection based on the features that are important words that are used to create a vector space models. The model consists of several documents represented as vectors of the frequency of occurrence of features. SVD feature selection technique using key words found in each document. Important words become terms of the term-document matrix. Indonesian language document medicinal plants totaling 132 documents used in the chi-square retrieval and SVD. Retrieval and SVD chi-square test with 29 non-semantic and semantic query. The result is a comparison of the performance of the retrieval of both methods on non-semantic and semantic query.
© Hak Cipta Milik IPB, Tahun 2013
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
PERBANDINGAN KINERJA PEMILIHAN FITUR
CHI-SQUARE DAN SINGULAR VALUE DECOMPOSITION
SISTEM TEMU KEMBALI DOKUMEN TUMBUHAN OBAT
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2013
Judul Tesis : Perbandingan Kinerja Pemilihan Fitur Chi-square Dan Singular Value Decomposition Sistem Temu Kembali Dokumen Tumbuhan Obat
Nama : Rico Andrian NIM : G651090121
Disetujui oleh Komisi Pembimbing
Dr Yeni Herdiyeni, SSi MKom Ketua
Hari Agung Adrianto, SKom MSi Anggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
Dr Yani Nurhadriyani, SSi MT
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Oktober 2010 ini ialah temu kembali informasi, dengan judul Perbandingan Kinerja Pemilihan Fitur Chi-Square Dan Singular Value Decomposition Sistem Temu Kembali Dokumen Tumbuhan Obat.
Terima kasih penulis ucapkan kepada Ibu Dr Yeni Herdiyeni, SSi MKom dan Bapak Hari Agung Adrianto, SKom MSi selaku pembimbing, serta Sony Hartono Wijaya, SKom MKom dan Ibu Dr Yani Nurhadriyani, SSi MT yang telah banyak memberi saran. Di samping itu, penghargaan penulis sampaikan kepada Bapak Prof. Dr. Ervizal AM Zuhud, MS, peneliti Laboratorium Konservasi Tumbuhan, Fakultas Kehutanan IPB, yang telah membantu selama pengumpulan data.
Ungkapan terima kasih juga disampaikan kepada istri Erna Erawati, Zaif, Zati dan Ziyad serta Nie, Kherry, Vie, atas segala doa dan kasih sayangnya. Disamping itu, semoga Allah Ta’ala memberikan pahala atas kebaikan : Bapak Gunawan IP, Warsito, Komarudin, Tjipto, Dwi, Abe, Ari Wibowo, Suharso, Warsono, Irman, Ibu Dian, Ardiansyah, Rossy, Didi, tim riset Lab CI (Yoga, Oki, Gibtha, Mega, Ryantie, Kadek, Desta, Fauzi, Ardiansyah, Rizky, Ngakan, Indra, Franki, Yunda, Dedi, A. Muchlis, Kholis, Altro Trio) dan dukungan Bapak Ucup, Teguh, Samsul, Dedi, Aristoteles, Mucle, Amanto, Agustiansyah, Jekvy, Rangga, Heri, Muamar, Muhar, Irjal, Ibu Wamiliana, Ibu Astria, Dewi dan Zuriati.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juni 2013
DAFTAR ISI
DAFTAR TABEL xi
DAFTAR GAMBAR xi
DAFTAR LAMPIRAN xi
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
Ruang Lingkup Penelitian 2
2 TINJAUAN PUSTAKA 2
Temu Kembali Informasi 2
Praproses Dokumen 3
Chi-square (χ2) 3
Latent Semantic Indexing 4
Singular Value Decomposition 4
Recall Precision 6
Mean Average Precision 6
3 METODE 7
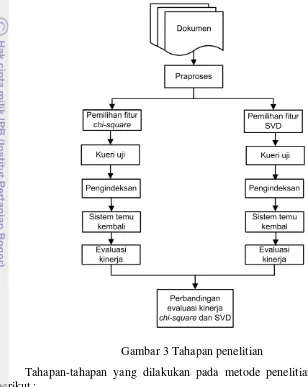
Tahapan Penelitian 7
4 HASIL DAN PEMBAHASAN 11
Kinerja sistem temu kembali SVD untuk menemukan dokumen 11 Perbandingan kinerja sistem temu kembali dokumen chi-square dan SVD
pada kueri uji non semantik 12
Perbandingan kinerja sistem temu kembali dokumen chi-square dan SVD
pada 29 kueri uji semantik 14
5 SIMPULAN DAN SARAN 16
Simpulan 16
Saran 16
DAFTAR PUSTAKA 17
LAMPIRAN 18
DAFTAR TABEL
1 Tabel kontingensi antara kata terhadap kelas 3
2 Nilai kritis χ2 untuk tingkat signifikansi α 4
3 Kumpulan kueri uji 9
4 Kumpulan kata yang memiliki makna semantik 10
5 Dokumen hasil pencarian sistem temu kembali SVD dengan kueri
‘kencing manis’ 11
6 Kata-kata yang berhubungan dengan kueri ‘kencing manis’ 11 7 Recall precision temu kembali chi-square dan SVD k=4% kueri non
semantik 13
8 Recallprecision temu kembali chi-square dan SVD k=4% kueri semantik 15
DAFTAR GAMBAR
1 Skema singular value decomposition untuk matriks term-dokumen 5 2 Matriks term-dokumen X yang sudah dikurangi dimensinya dengan nilai
k 5
3 Tahapan penelitian 7
4 Contoh format file koleksi dokumen 8
5 Recall precision sistem temu kembaliSVD pada k=2% dan k=4% 12 6 Recall precision temu kembali chi-square dan SVD k=4% kueri non
semantik 14
7 Recall precision temu kembali chi-square dan SVD k=4% kueri semantik 16
DAFTAR LAMPIRAN
Daftar dokumen jenis tumbuhan obat Indonesia yang digunakan dalam
1
PENDAHULUAN
Latar Belakang
Indonesia merupakan negara mega biodiversity yang mempunyai kekayaan flora berlimpah termasuk tumbuhan obat. Sampai tahun 2001, Laboratorium Konservasi Tumbuhan, Fakultas Kehutanan IPB telah mendata dari berbagai hasil riset bahwa tidak kurang dari 2.039 spesies tumbuhan obat berasal dari hutan Indonesia (Zuhud 2009). Penelitian terhadap tumbuhan obat terus dilakukan karena manfaat suatu tumbuhan obat yang dapat menyembuhkan penyakit tertentu. Dokumen hasil penelitian tumbuhan obat sudah di publikasikan melalui media cetak dan elektronik, namun dokumen tersebut belum memberikan manfaat yang optimal karena pengguna belum tentu mendapatkan dokumen yang relevan pada pencarian dokumen yang dilakukan. Hal ini membutuhkan metode pencarian yang efektif sehingga sistem temu kembali dokumen akan dapat menemukembalikan dokumen yang relevan.
Pemilihan fitur adalah tahap yang penting dalam suatu sistem pencarian. Pemilihan fitur bertujuan mengurangi dimensi fitur pada dataset agar pembuatan sistem pencarian dapat dilakukan dengan lebih mudah. Sistem pencarian dengan kategorisasi pada dokumen teks yang melibatkan ribuan bahkan sampai ratusan ribu fitur mutlak membutuhkan pemilihan fitur supaya sistem pencarian dapat berjalan dengan efisien. Kinerja pemilihan fitur dokumen dengan teknik chi-square lebih baik dibanding dengan document thresholding frequency (Herawan 2011). Chi-square merupakan teknik pemilihan fitur dokumen yang sangat efektif untuk memilih kata penciri suatu dokumen namun tidak menurunkan akurasi sistem (Yang 1997). Latent Semantic Indexing (LSI) adalah suatu teknik yang memetakan kueri dan dokumen ke dalam suatu ruang yang disebut Latent Semantic Space. Dalam Latent Semantic Space, suatu kueri dan dokumen dapat memiliki nilai kemiripan yang tinggi walaupun kueri dan dokumen tersebut tidak memiliki kata (term) yang sama. Selama kata tersebut mirip secara semantik, nilai kemiripan yang dihasilkan akan tinggi. Latent Semantic adalah suatu hubungan makna tersembunyi antara dua term yang berbeda, meliputi hubungan sinonim dan polisemi yang maknanya menyertakan dua term tersebut, kemiripan konsep, dan konsep yang berhubungan. Sistem temu kembali informasi yang mampu mengatasi latent semantic akan mengembalikan dokumen-dokumen yang memiliki hubungan tersembunyi dengan kata yang diberikan pada kueri, tanpa harus memberikan kata yang sama dengan kata yang terdapat dalam dokumen tersebut sehingga dapat menambah efektifitas sistem temu kembali informasi sebesar 30% dibandingkan penggunaan metode biasa (Deerwester et al. 1990).
LSI menggunakan teknik Singular Value Decomposition (SVD) untuk mendekomposisikan matriks term-dokumen. Dengan mengurangi ruang term dan dokumen menjadi dimensi yang lebih kecil, SVD menampakkan hubungan yang mendasari kata dan dokumen dalam semua kombinasi yang memungkinkan dan membuang noise yang ada pada ruang vektor (Deerwester et al. 1990). Teknik lain juga diterapkan untuk mengembangkan Latent Semantic Indexing
2
sebagai salah satu cara untuk mengestimasi struktur penggunaan kata dalam dokumen. Pencarian dokumen berdasarkan kueri kemudian dilakukan pada nilai
singular yang dihasilkan oleh SVD yang tersimpan dalam basis data (Berry et al. 1995). Matriks hasil aproksimasi SVD cukup dekat dengan matriks asalnya, pengembalian dokumen menggunakan matriks tersebut diharapkan sama baiknya seperti matriks asalnya. SVD selain lebih baik dalam pengembalian dokumen juga
lebih banyak pengembalian dokumennya (Kolda dan O’Leary 1998).
Penelitian ini menggunakan SVD sebagai teknik pemilihan fitur dokumen yang digunakan untuk membangun sistem mesin pencari dokumen. Kinerja SVD akan dibandingkan dengan kinerja chi-square untuk pemilihan kata penciri pada dokumen tumbuhan obat.
Tujuan Penelitian
Penelitian ini bertujuan menganalisis kinerja pemilihan fitur chi-square dan
singular value decomposition untuk kueri yang mengandung unsur semantik dan non semantik dalam mesin pencari.
Ruang Lingkup Penelitian
Pengembangan sistem temu kembali dokumen tumbuhan obat ini diterapkan pada 132 dokumen berbahasa Indonesia yang berisi tentang tumbuhan obat yang ada di Indonesia.
2
TINJAUAN PUSTAKA
Temu Kembali Informasi
Sistem temu kembali informasi (Information retrieval system) merupakan sistem pencari pada sekumpulan dokumen elektronik yang memenuhi kebutuhan informasi tertentu (Manning et al. 2009). Sistem temu kembali informasi bertujuan menjembatani kebutuhan informasi pengguna dengan sumber informasi.
3
Praproses Dokumen
Pada tahap praproses ini teks-teks dalam dokumen yang sudah di tagging, diberikan 3 perlakuan yaitu lowercasing, tokenisasi dan pembuangan stop word.
Lowercasing adalah proses untuk mengubah semua huruf menjadi huruf non-capital agar menjadi case-sensitive pada saat dilakukan pemrosesan teks dokumen (Manning et al. 2009).
Tokenisasi adalah proses memotong dokumen menjadi bagian-bagian kecil (token) dengan cara membuang imbuhan dan kata sambung yang ada. Token yang dihasilkan merupakan kata dasar sehingga token yang dihasilkan lebih sedikit (Manning et al. 2009). Proses tokenisasi teks adalah sebagai berikut.
1. Teks dipotong menjadi token selanjutnya karakter yang dianggap sebagai karakter pemisah token didefinisikan dengan ekspresi reguler berikut : /[\s\-+\/*0-9%,.\”\];()\’:=’?\[!@><]+/.
2. Token yang terdiri atas karakter numerik saja tidak diikutsertakan.
3. Besar kecilnya karakter dari token dipertahankan atau tidak dilakukan penyeragaman.
Tahap terakhir dari praproses adalah pembuangan stop word yang terdiri dari kata-kata yang tidak mencirikan topik tumbuhan obat dari koleksi dokumen.
Stopwords adalah daftar kata - kata yang dianggap tidak memiliki makna. Kata yang tercantum dalam daftar ini dibuang dan tidak ikut diproses pada tahap selanjutnya. Pada umumnya kata- kata yang masuk ke dalam stopwords memiliki tingkat kemunculan yang tinggi di dokumen sehingga kata tersebut tidak dapat digunakan sebagai penciri suatu dokumen (Ridha 2002). Kata-kata yang akan dibuang (stopwords) tersebut akan disimpan dalam sebuah daftar kata yang disebut stoplist. Stoplist sangat tergantung dengan bahasa yang digunakan sehingga stoplist suatu bahasa akan berbeda dengan stoplist bahasa yang lain. Dalam bahasa Indonesia, beberapa kata yang termasuk dalam stoplist diantaranya
adalah ‘yang’, ‘hingga’, dan ‘dengan’ (Ridha 2002).
Chi-square (χ2)
Chi-square mengukur derajat kebebasan antara kata penciri t dengan kelas c
agar dapat dibandingkan dengan distribusi nilai chi-square (Mesleh 2007). Chi-square mengevaluasi korelasi antara dua variabel dan kemudian menentukan apakah saling bebas atau berhubungan sesuai dengan tabel chi.
Penghitungan nilai chi-square pada setiap kata t yang muncul pada setiap kelas c dapat dibantu dengan tabel kontingensi. Nilai yang terdapat pada tabel kontingensi merupakan nilai frekuensi observasi dari suatu kata terhadap kelas. Tabel 1 menunjukkan tabel kontingensi antara kata terhadap kelas.
Tabel 1 Tabel kontingensi antara kata terhadap kelas
Kelas
Kelas = 1 Kelas = 0 Kata
Kata =1 A B
4
Penghitungan nilai chi-square berdasarkan tabel kontingensi tersebut disederhanakan dalam rumus :
(1)
dengan t merupakan kata yang sedang diujikan terhadap suatu kelas c, N
merupakan jumlah dokumen latih, A merupakan banyaknya dokumen pada kelas c
yang memuat kata t, B merupakan banyaknya dokumen yang tidak berada di c
namun memuat kata t, C merupakan banyaknya dokumen yang berada di kelas c
namun tidak memiliki kata t didalamnya, serta D merupakan banyaknya dokumen yang bukan merupakan dokumen kelas c dan tidak memuat kata t.
Pengambilan keputusan dilakukan berdasarkan nilai χ2 dari masing-masing kata. Kata yang memiliki nilai χ2 diatas nilai kritis pada tingkat signifikansi α adalah kata yang akan dipilih sebagai penciri dokumen. Kata yang dipilih sebagai penciri merupakan kata yang memiliki pengaruh terhadap kelas c. Nilai kritis χ2 untuk tingkat signifikansi α ditunjukkan oleh Tabel 2.
Latent Semantic Indexing
Latent Semantic Analysis (LSA) merupakan teknik matematika atau statistika untuk mengekstraksi dan menyimpulkan hubungan kontekstual arti kata yang diaplikasikan pada bagian teks yang dibutuhkan (Landauer et al. 1998). Pada LSA, dilakukan preprocessing yang salah satunya berfungsi sebagai penentu kumpulan term untuk direpresentasikan dalam sebuah matriks semantik dan kemudian diolah secara matematis menggunakan teknik aljabar linier Singular Value Decomposition (SVD), sehingga dalam hal ini, query dapat dibandingkan dengan hasil SVD untuk menghitung kemiripan (similarity) antara query-document (Deerwester et al.1990)
Singular Value Decomposition
Pada Gambar 1 ditunjukkan matriks X dengan t x d untuk t adalah term dan
d adalah dokumen. Matriks X melakukan proses perkalian ketiga matriks T0, S0
dan D0 sehingga X= T0S0D0. T0 dan D0 memiliki kolom orthonormal dan
merupakan matriks left dan right singular vectors. S0 adalah matriks diagonal dari singular value, t adalah jumlah baris X, d adalah jumlah kolom X, m adalah rankX (≤ min(t,d)). Umumnya, untuk X=T0S0D0’ , maka matriks T0, S0, dan D0 harus full
Tabel 2 Nilai kritis χ2 untuk tingkat signifikansi α
5
rank. Namun SVD membuat strategi sederhana untuk mendapatkan aproksimasi yang optimal dengan menggunakan matriks yang lebih kecil. Jika nilai singular pada S0 terurut sesuai ukuran, maka k pertama yang terbesar dapat disimpan dan yang lebih kecil dibuat menjadi nol. Matriks hasilnya adalah matriks Xhihat yang diperkirakan sama dengan X, dan sesuai dengan nilai k. Matriks baru Xhihat
adalah matriks peringkat k yang paling dekat matriks X (Deerwester et al.1990).
Gambar 1 Skema singular value decomposition untuk matriks term-dokumen Representasinya dapat disederhanakan dengan menghapus baris dan kolom nol dari S0 untuk memperoleh matriks S diagonal baru, kemudian menghapus kolom yang terkait T0 dan Do untuk memperoleh T dan S. Hasilnya adalah
pengurangan dimensi matriks sesuai dengan nilai k, yaitu : X≈Xhihat =TSD’
(Deerwester et al. 1990).
Model pengurangan dimensi matriks ditunjukkan pada Gambar 2, dan digunakan untuk aproksimasi data.
Jumlah pengurangan dimensi nilai k sangat penting pada penelitian. Cara terbaik untuk menentukan pilihan merupakan masalah yang banyak ditemukan pada literatur tentang analisis faktor. Pada prakteknya, digunakan kriteria operasional, yaitu nilai k yang menghasilkan kinerja temu kembali informasi yang baik (Deerwester et al.1990).
6
Recall Precision
Recall Precision adalah kriteria yang digunakan untuk mengevaluasi tingkat efektifitas kinerja sistem temu kembali informasi. Recall adalah rasio jumlah dokumen relevan yang ditemukembalikan (retrieve) terhadap jumlah seluruh dokumen yang relevan. Precision adalah rasio jumlah dokumen relevan yang ditampilkan terhadap jumlah seluruh dokumen yang ditampilkan (Manning et al. 2009). Perhitungan recall precision sebagai berikut :
(2)
� � � (3)
Menurut Baeza-Yates dan Ribeiro-Neto (1999), algoritme temu kembali yang dievaluasi menggunakan beberapa kueri berbeda, akan menghasilkan nilai R-P yang berbeda untuk masing-masing kueri. Average Precision (AVP) diperlukan untuk menghitung rata-rata tingkat precision pada 11 tingkat recall, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Formula untuk menghitung AVP adalah sebagai berikut:
�( ) ∑ (4)
Asumsi, P (rj) adalah AVP pada level recallr, Nq adalah jumlah kueri yang digunakan, dan � adalah precision pada level recall r untuk kueri ke-i.
Mean Average Precision
MAP adalah salah satu metode evaluasi temu kembali informasi yang sering digunakan. Nilai MAP diambil dari rata-rata nilai Average Precision. Jika tidak ada dokumen relevan yang ditemukembalikan, maka nilai MAP adalah 0. MAP untuk koleksi kueri adalah rata-ratanya. Jika diketahui kumpulan dokumen relevan untuk kueri tertentu adalah dan Rjk adalah
urutan hasil temu kembali dari dari hasil teratas pencarian sampai dokumen dk
didapatkan (Manning et al. 2009), maka perhitungan MAP adalah sebagai berikut :
7
3
METODE
Tahapan Penelitian Tahapan penelitian dapat dilihat pada Gambar 3.
Tahapan-tahapan yang dilakukan pada metode penelitian adalah sebagai berikut :
a. Dokumen
Pengelompokkan dokumen dikategorikan ke dalam kategori kelas family
dan kategori penyakit. Pemilihan kategori tersebut karena kedua informasi mengenai family tumbuhan obat dan penyakit yang dapat disembuhkan oleh suatu jenis tumbuhan obat adalah informasi yang sering dicari. Dokumen direpresentasikan ke dalam bentuk corpus dan berjumlah 132 dokumen. Jumlah dokumen tumbuhan obat yang digunakan dibagi dua, yaitu data latih 70% dan data uji 30% sehingga 93 dokumen sebagai dokumen latih dan 39 dokumen sebagai dokumen uji. Dokumen yang digunakan sebagai sampel adalah dokumen berbahasa Indonesia mengenai tumbuhan obat yang dimiliki oleh Bagian Konservasi Keanekaragaman Tumbuhan, Departemen Konservasi Sumber Daya Hutan dan Ekowisata, Fakultas Kehutanan IPB (Herawan 2011).
8
Dokumen tumbuhan obat diformat berdasarkan tag-tag yang mewakili unit-unit informasinya yang ada dalam dokumen, sebagai berikut:
1. <DOK></DOK>, tag ini mewakili keseluruhan dokumen dan meliputi tag-tag lain yang lebih spesifik;
2. <ID></ID>, tag ini menunjukkan identitas dari dokumen;
3. <NAMA></NAMA>, tag ini menunjukkan nama dari tumbuhan obat;
4. <NAMAL></NAMAL>, tag ini menunjukkan nama latin dari tumbuhan obat; 5. <DESKRIPSI></DESKRIPSI>, tag ini mewakili isi dari dokumen meliputi
deskripsi tanaman dan kegunaannya;
6. <FAM></FAM>, tag ini menunjukkan nama family dari tanaman obat;
7. <PENYAKIT></PENYAKIT>, tag ini menunjukkan penyakit yang dapat disembuhkan oleh tumbuhan obat.
Selanjutnya koleksi dokumen diubah ke dalam bentuk file.txt dengan contoh format file seperti pada Gambar 4.
b. Praproses
Pada tahap praproses ini teks-teks dalam dokumen yang sudah di tagging, diberikan 3 perlakuan yaitu lowercasing, tokenisasi dan pembuangan stop word. Misalnya sebagian dari dokumen tumbuhan obat yang menjelaskan deskripsi dari sebuah tumbuhan obat :
Setelah melalui ketiga tahap diatas maka hasil praproses sebagai berikut :
c. Pemilihan fitur dengan teknik chi-square
Hasil dari tahap praproses adalah vector term yang terdiri dari kata-kata penting yang akan diseleksi melalui pemilihan fitur dengan chi-square. Pemilihan fitur dilakukan pada dua tingkat signifikansi α, yaitu 0,01 dan 0,001. Kata yang terpilih pada tingkat signifikansi α=0,01 adalah kata yang memiliki nilai χ2 diatas nilai kritis 6,63, sedangkan kata yang terpilih pada tingkat signifikansi α=0,001 adalah kata yang memiliki nilai di atas nilai kritis 10,83. Fitur yang dihasilkan pada tahapan pemilihan fitur akan digunakan untuk membuat vector space model. Model terdiri atas beberapa dokumen yang direpresentasikan sebagai vektor dari frekuensi kemunculan fitur (Herawan 2011).
<dok>
<id>17</id>
<nama>Sosor Bebek</nama>
<namal>Kalanchoe pinnata Lamk.</namal>
<deskripsi>Famili : Crassulaceae. Nama Lokal : Cakar itek (Sunda); dan sosor bebek, cakar bebek (Jawa). Deskripsi : Terna
tegak dengan tinggi 0.3m-1.25m …… </deskripsi>
<fam>Crassulaceae</fam> <penyakit>Kulit</penyakit> </dok>
Gambar 4 Contoh format file koleksi dokumen
Deskripsi : Batang bulat, membelit, kasar, berwarna cokelat kehitaman dan kayunya berwarna kuning cerah.
deskripsi batang bulat membelit kasar berwarna cokelat
9 d. Pemilihan Fitur SVD
Teknik pemilihan fitur SVD menggunakan hasil praproses yaitu kata-kata unik yang ditemui di setiap dokumen dalam keseluruhan dokumen latih. Kata-kata unik menjadi term dari sebagai matriks term-dokumen X =TSD’. Vektor T adalah vektor term yang ada pada suatu dokumen tumbuhan obat. Vektor D
merepresentasikan dokumen tumbuhan obat dan Vektor S merupakan tingkat penciri fitur dari matriks X.
e. Kueri uji
Kata-kata yang menjadi kueri uji merupakan kata non semantik yang sudah diuji pada sistem chi-square (Herawan 2011) dan kata yang mengandung makna semantik.
f. Pengindeksan
Sistem temu kembali informasi pada dasarnya dibagi dalam dua komponen utama yaitu sistem pengindeksan (indexing) yang menghasilkan basis data sistem dan temu kembali yang merupakan gabungan dari user interface dan look-up-table. Indexing merupakan sebuah proses untuk melakukan pengindeksan terhadap kumpulan dokumen yang akan disediakan sebagai informasi kepada pemakai. Proses pengindeksan bisa secara manual ataupun secara otomatis. Pengindeksan memiliki peranan penting dalam sistem temu kembali informasi untuk menyediakan pemrosesan kueri yang lebih cepat dan daftar terurut dokumen hasil temu kembali.
g. Sistem temu kembali
Sistem temu kembali dokumen merupakan hasil implementasi dari metode pemilihan fitur chi-square dan SVD. Sistem temu kembali dokumen tersebut akan menguji kueri-kueri untuk pemilihan fitur chi-square dan SVD. Kemampuan temu kembali chi-square dan SVD dalam menghasilkan dokumen yang relevan bagi pengguna menjadi penilaian kinerja pada tahap metode penelitian berikutnya.
h. Evaluasi kinerja
10
Pengukuran kinerja sistem juga dilakukan dengan menggunakan 29 kueri uji yang memiliki makna semantik. Tabel 4 menunjukkan kata-kata yang memiliki makna semantik. Kueri uji semantik ditentukan dengan memilih kata-kata yang memiliki makna semantik yaitu sinonim dan polisemi. Sinonim adalah dua kata atau lebih yang memiliki makna yang sama sedangkan polisemi adalah sebuah kata yang memiliki makna ganda.
Tabel 4 Kumpulan kata yang memiliki makna semantik No. Sinonim
1 Kencing manis, Gula darah 2 Diare, Mencret
14 Bronkitis, Radang Saluran Napas Polisemi
1 Mangkok
11 i. Perbandingan evaluasi kinerja chi-square dan SVD
Tahap ini dilakukan untuk membandingkan Mean Average Precision
(MAP) pada teknik chi-square dan SVD pada kueri semantik dan non semantik sehingga akan didapatkan teknik temu kembali yang paling baik diantara kedua teknik tersebut.
4
HASIL DAN PEMBAHASAN
Kinerja sistem temu kembali SVD untuk menemukan dokumen Pencarian dokumen dengan sebuah kueri dilakukan pada sistem temu kembali SVD. Misalnya kueri yang digunakan adalah ‘kencing manis’. Sistem temu kembali SVD menghasilkan 7 dokumen. Tabel 5 menunjukkan dokumen hasil pencarian sistem temu kembali SVD dengan kueri ‘kencing manis’.
Tabel 5 Dokumen hasil pencarian sistem temu kembali SVD dengan kueri
‘kencing manis’
No. Id Dokumen Nama Dokumen Tumbuhan Obat
1 62 Sambang Darah
darah’. Dokumen-dokumen yang dihasilkan sistem temu kambali SVD dengan
kueri ‘kencing manis’ mengandung sinonim dari kueri ‘kencing manis’. Misalnya
pada dokumen Tapak Dara (Id 8), dokumen ini mengandung kata ‘diabetes’ dan
dokumen Tapak Dara (Id57), dokumen ini mengandung kata ‘diabetes’ dan ‘gula
darah’. Sistem temu kembali SVD menghasilkan dokumen yang mengandung kata
yang sesuai dengan kueri yaitu ‘kencing manis’ dan sebagian kata dari kueri dan
sinonimnya yaitu ‘kencing’, ‘manis’, ‘gula’ dan ‘darah’. Tabel 6 menunjukkan
kata-kata yang berhubungan dengan kueri ‘kencing manis’.
12
Latent Semantic Space ditunjukkan oleh sistem SVD dengan kueri dan dokumen memiliki nilai kemiripan yang tinggi walaupun kueri dan dokumen tersebut tidak memiliki kata (term) yang sama. Selama kata tersebut mirip secara semantik, nilai kemiripan yang dihasilkan akan tinggi. Sistem temu kembali informasi yang mampu mengatasi latent semantic akan mengembalikan dokumen-dokumen yang memiliki hubungan tersembunyi dengan kata yang diberikan pada kueri, tanpa harus memberikan kata yang sama dengan kata yang terdapat dalam dokumen.
Perbandingan kinerja sistem temu kembali dokumen chi-square dan SVD pada kueri uji non semantik
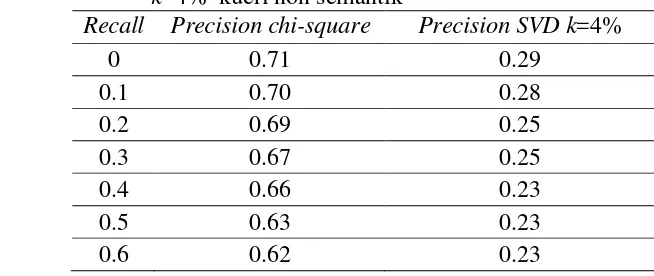
Evaluasi sistem temu kembali dokumen dilakukan menggunakan 29 kueri uji yang merepresentasikan isi dokumen. Pada SVD, matriks kata-dokumen yang sudah diproses akan dilihat hasil pengujiannya dengan 29 kueri dan beberapa nilai reduksi ukuran matriks atau k dalam bentuk persen (%). Pada percobaan yang dilakukan nilai k yang digunakan adalah 2%, 4%, 5%, 6%, 7%, 8%, dan 10%. Hasil percobaan pada 29 kueri menunjukkan bahwa nilai k yang memberikan hasil yang terbaik adalah pada nilai k=2% dan k=4%. Hasil recall precison sistem temu kembali dokumen SVD pada k=2% dan k=4%dapat dilihat pada Gambar 5.
Gambar 5 Recall precision sistem temu kembaliSVD pada k=2% dan k=4%
Recall precision sistem temu kembali pada k=4% lebih tinggi dibandingkan dengan nilai k=2%. Hal ini menunjukkan dokumen yang relevan untuk pengguna lebih banyak dihasilkan pada nilai k=4% dibandingkan pada nilai k=2%. Kata-kata penting yang hilang akibat reduksi dimensi matriks pada k=2% lebih banyak dibandingkan pada k=4% sehingga mempengaruhi hasil pencarian dokumen yang relevan.
13 dihasilkan oleh kueri ‘buah buni’. Hal ini ditunjukkan dengan nilai precision pada sebelas titik recallnya yaitu 1. Dokumen yang dihasilkan oleh kueri selain ‘buah
buni’ memiliki nilai precision 0,5 pada sebelas titik recallnya yaitu pada kueri
‘protein’ dan ‘sesak nafas’. Kueri yang lain pada k=2% memiliki nilai precision
yang kecil sehingga mempengaruhi nilai MAP.
Nilai MAP sistem temu kembali SVD pada k=4% adalah 24,38%. Dokumen yang berhasil ditemukembalikan oleh sistem berdasarkan nilai recall precision
dihasilkan oleh 12 kueri. Dokumen relevan yang akurasinya baik dihasilkan oleh
kueri ‘kanker’ dan ‘kalsium’. Hal ini ditunjukkan dengan nilai precision kedua
kueri tersebut di sebelas titik recallnya bernilai 1. Dokumen relevan yang memiliki nilai precision 1 pada titik awal recallnya adalah ‘flu’, ‘diabetes’,
‘menjari’ dan ‘bergerigi’. Dokumen yang ditemukembalikan pada k=4% memiliki
nilai precision yang lebih tinggi dibandingkan pada k=2% sehingga MAP pada
k=4% lebih tinggi daripada k=2%.
Sistem temu kembali dokumen SVD pada k=4% kueri non semantik memiliki recall precision yang lebih baik sehingga dipilih untuk dibandingkan dengan sistem temu kembali chi-square. Dokumen relevan yang berhasil ditemukembalikan oleh sistem temu kembali chi-square dan memiliki akurasi yang baik ada pada 8 kueri. Kueri-kueri tersebut adalah yaitu ‘kanker’, ‘flu’,
‘pusing’,’menjari’, ‘menyirip’, ‘antioksidan’, ‘datang bulan’ dan ‘merambat’. Hal
ini ditunjukkan dengan precision yang bernilai 1 pada sebelas titik recallnya. Sistem temu kembali SVD pada k=4% berhasil menemukembalikan dokumen
relevan yang memiliki tingkat akurasi tinggi hanya ada 2 kueri yaitu ‘kanker’ dan ‘kalsium’.
Kesalahan sistem temu kembali dokumen juga karena kueri tersebut memiliki banyak arti penerjemahan antar setiap dokumen tumbuhan obat sehingga kueri tersebut tidak mampu mewakili informasi yang sebenarnya diinginkan oleh pengguna. Misalnya informasi yang diinginkan pengguna adalah informasi mengenai penyakit kencing batu yang disembuhkan oleh tumbuhan obat misalnya kueri ‘kencing batu’ namun sistem menemukembalikan dokumen pada peringkat
pertama tidak mengandung kata ‘kencing batu’ tetapi mengandung kata ‘batuk’
atau ‘gula batu’. Jumlah dokumen relevan dan dokumen tersebut memiliki akurasi
tinggi yang dihasilkan oleh sistem temu kembali mempengaruhi Mean Average Precision (MAP).
Perbandingan kinerja sistem temu kembali dokumen chi-square dan SVD dapat dilihat pada Tabel 7 dan grafiknya pada Gambar 6.
Tabel 7 Recall precision temu kembali chi-square dan SVD
k=4% kueri non semantik
Recall Precision chi-square Precision SVD k=4%
14
Recall Precision chi-square Precision SVD k=4%
0.7 0.61 0.23 ditemukembalikan. Sistem temu kembali dokumen melakukan pencarian dokumen untuk masing-masing kata kueri secara terpisah sehingga dokumen yang tidak relevan ikut terambil lebih banyak. Misalnya untuk kueri ‘kencing batu’, sistem akan melakukan pembobotan terhadap kata ‘kencing’ dan kata ‘batu’. Dokumen yang dihasilkan pada nilai k=4% ada 9 dokumen, peringkat dokumen
yang mengandung ‘kencing batu’ ada pada peringkat ke 5, sedangkan dokumen yang lain yang hanya mengandung kata ‘kencing’ dan ‘batu’ serta dokumen yang
tidak mengandung dari dua kata tersebut.
Perbandingan kinerja sistem temu kembali dokumen chi-square dan SVD pada 29 kueri uji semantik
Kinerja sistem SVD pada kata yang mengandung sinonim menghasilkan dokumen relevan dan memiliki akurasi yang baik, misalnya pada kueri ‘mencret’. Sistem temu kembali menghasilkan dokumen yang relevan yaitu 4 dokumen.
Dokumen peringkat 1 dan 2 mengandung kata ‘mencret’ dan ‘sakit perut’ dan dokumen peringkat 3 mengandung kata ‘mencret’ dan ‘diare’ serta dokumen peringkat ke 4 tidak mengandung kata ‘mencret’ tetapi mengandung kata ‘diare’
dan ‘disentri’. Sistem temu kembali SVD juga menguji kueri yang mengandung
15
dokumen dan hanya 1 dokumen yang mengandung kata ‘mangkok’ dalam arti
bentuk seperti mangkok tetapi tidak menemukembalikan tumbuhan obat yang bernama mangkokan. Sistem temu kembali dokumen SVD, dokumen relevan dan
memiliki akurasi yang baik dihasilkan oleh 3 kueri yaitu ‘mencret’, ‘penawar sakit’ dan ‘penawar racun’.
Kinerja sistem chi-square pada kata yang mengandung sinonim menghasilkan dokumen relevan dan memiliki akurasi yang baik. Sistem temu kembali dokumen chi-square dokumen relevan dan memiliki akurasi yang baik
dihasilkan oleh 5 kueri yaitu ‘toksik’, ‘sayur’, ‘lalap’, ‘pereda demam’ dan ‘sakit
kuning’. Sistem temu kembali chi-square juga menguji kueri yang mengandung
polisemi yaitu kueri ‘mangkok’. Dokumen yang dihasilkan oleh kueri ini 7
dokumen. Sistem berhasil menemukembalikan dokumen tumbuhan obat
‘mangkokan’ dan dokumen yang mengandung kata ‘mangkok’ dalam arti bentuk
seperti mangkok.
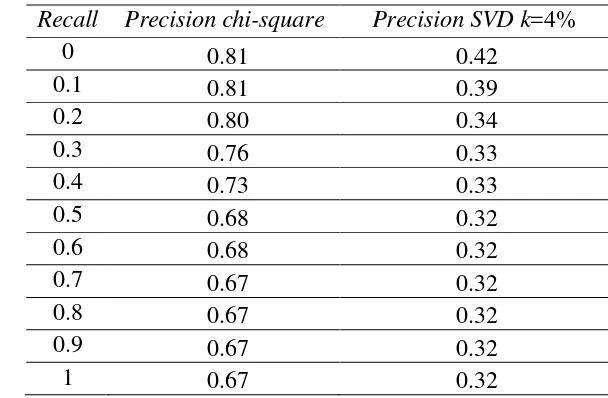
Evaluasi sistem temu kembali dokumen dilakukan menggunakan 29 kueri semantik untuk melihat kinerja chi-square dan SVD dengan nilai k=4%. Dokumen relevan dan memiliki akurasi yang baik sebagai hasil pencarian kedua sistem temu kembali dengan kueri semantik ditunjukkan oleh recall precision
pada Tabel 8 dan grafiknya pada Gambar 7. Hasil percobaan menunjukkan MAP sistem temu kembali dokumen chi-square pada kueri semantik adalah 72,12% dan SVD k=4% adalah 33,93%. Sistem temu kembali chi-square menghasilkan berhasil menemukembalikan dokumen pada 29 kueri uji semantik sedangkan sistem SVD hanya 19 kueri. Hal ini ditunjukkan dengan nilai precision pada sebelas titik recallnya. Sistem chi-square pada semua kueri memiliki nilai
precision sedangkan sistem SVD 10 kueri nilai precisionnya bernilai 0. Tabel 8 Recallprecision temu kembali chi-square dan SVD k=4%
kueri semantik
Recall Precision chi-square Precision SVD k=4%
16
Gambar 7 Recall precision temu kembali chi-square dan SVD k=4% kueri semantik
5
SIMPULAN DAN SARAN
Simpulan
Penelitian ini menganalisis kinerja sistem temu kembali dokumen menggunakan chi-square dan SVD pada kueri non semantik serta menganalisis kinerja SVD pada kueri semantik. Dari hasil yang diperoleh dapat disimpulkan bahwa:
1. MAP sistem temu kembali dokumen chi-square pada kueri non semantik adalah 64,71% sedangkan SVD adalah 24,38%.
2. MAP sistem temu kembali dokumen chi-square pada kueri semantik adalah 72,12% dan sedangkan SVD adalah 33,93%.
3. Penggunaan kueri semantik meningkatkan MAP pada sistem chi-square dan SVD.
Saran
Beberapa hal yang perlu dikembangkan dalam penelitian ini:
1. Menggunakan dokumen corpus yang lebih beragam dan dalam jumlah yang lebih banyak.
17
DAFTAR PUSTAKA
Baeza-Yates R, Riberio-Neto B. 1999. Modern Information Retrieval. England: Addison Wesley.
Berry MW, Dumais ST, O’Brien GW. 1995. Using linear algebra for intelligent information retrieval. SIAM Rewiew 37:573-595.
Deerwester S, Dumas S, Furnas G, Landauer T, Harsman R. 1990. Indexing by Latent Semantic Analysis. Journal of the American Society for Information Science 41:391–407.
Herawan Y. 2011. Ekstraksi Ciri Dokumen Tumbuhan Obat Menggunakan Chi-kuadrat dengan Klasifikasi Naive Bayes [Skripsi]. Bogor : Institut Pertanian Bogor.
Herdiyeni Y, Hasibuan ZA. 2003. Information Retrieval System in Bahasa Indonesia Using Latent Semantic Indexing and Semi-Discrete Matrix Decomposition. iiWAS'2003 - The Fifth International Conference on Information Integrationand Web-based Applications Services. (September) Kolda T, O’Leary D. 1998. A semi-discrete matrix decomposition for latent
semantic indexing in information retrieval. ACM Trans. Inform. Systems (322-346).
Launder TK, Foltz PW, Laham D. 1998. Introduction to Latent Semantic Analysis.
Manning CD, Raghavan P, Schutze H. 2009. An Introduction to Information Retrieval. Cambridge, Cambridge University Press.
Mesleh AA. 2007. Chi-square Feature Extraction Based Svms Arabic Language Text Categorization Systems, Journal of Computer Science (3:6:430-435). Ridha A. 2002. Pengindeksan Otomatis dengan istilah Tunggal untuk Dokumen
Berbahasa indonesia [skripsi]. Bogor : Institut Pertanian Bogor.
Yang Y, Pedersen J. 1997. A Comparative Study on Feature Selection in Text Categorization. International Conference on Machine Learning.
18
Lampiran Daftar dokumen jenis tumbuhan obat Indonesia yang digunakan dalam penelitian
No Nama Nama Latin
1 Pandan wangi Pandanus amaryllifolius Roxb.
2 Jarak pagar Jatropha curcas Linn.
3 Dandang gendis Clinacanthus nutans Lindau
4 Akar kuning Arcangelisiaflava L.
11 Iler Coleus scutellarioides, Linn,Benth
12 Jeruk nipis Citrus aurantifolia, Swingle.
13 Sambang darah Excoecaria cochinchinensis Lour.
14 Nanas kerang Rhoeo discolor (L.Her.) Hance
15 Sambang colok Aerva sanguinolenta Bl.
16 Remek daging Excecaria bicolor Hassk
17 Kumis kucing Orthosiphon aristatus (B1) Miq.
18 Sosor bebek Kalanchoe pinnata (Lam.) Per.
19 Landik Barleria lupulina Lindl.
20 Jambu biji Psidium guajava L.
21 Tapak dara Catharantus roseus (L.) G. Don.
22 Som jawa Talinum paniculatum (jacq.) Gaertn.
23 Jarong Achyranthes aspera Linn.
24 Mangkokan Nothopanax scutellarium Merr.
25 Andong Cordyline fruticosa (L) A. Cheval.
26 Kemangi Ocimum basilicum
27 Patah tulang Eupharbia tirucalli L.
28 Cincau hitam Cyclea peltata Miq.
29 Awar – awar Ficus septica Burm f.
30 Semanggi gunung Hydrocotyle sibthorpioides Lam.
31 Salam Syzygium polyanthum (Wight.) Walp.
19