MASHUP INFORMASI PADA SITUS BLOG INSTITUT
PERTANIAN BOGOR BERBASIS WORDPRESS
MENGGUNAKAN WEB SERVICE
NATAN PURNAWAN PARDOMUAN MANULLANG
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Mashup Informasi pada Situs Blog Institut Pertanian Bogor Berbasis Wordpress Menggunakan Web Service adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
NATAN PURNAWAN PARDOMUAN MANULLANG. Mashup Informasi pada Situs Blog Institut Pertanian Bogor Berbasis Wordpress Menggunakan Web Service. Dibimbing oleh FIRMAN ARDIANSYAH.
Wordpress merupakan salah satu content management system (CMS) untuk pengembangan aplikasi web. Situs web Institut Pertanian Bogor (IPB) memiliki subdomain bagi mahasiswa, dosen, atau lembaga kemahasiswaan untuk memiliki sebuah blog berbasiskan Wordpress. Isi dari Wordpress biasanya memiliki struktur yang sama dan isinya dapat dipanggil dalam format tertentu melalui web service yang sudah tersedia di dalamnya. Pada penelitian ini akan diintegrasikan isi dari total 20 blog Wordpress di situs IPB, yang terdiri dari lima blog mahasiswa dan lima blog lembaga kemahasiswaan, serta sepuluh blog dosen. Web service yang digunakan yaitu JSON API, sebuah API yang tersedia untuk Wordpress. JSON API mengijinkan sisi klien mendapatkan dan memanipulasi isi wordpress menggunakan HTTP request. Isi dikembalikan dalam data berstruktur JSON yang akan mengalami praproses sehingga dapat diindeks oleh Sphinx Search, sebuah library tambahan untuk membangun sebuah sistem pencari. Hasil evaluasi sistem pencari yang didapatkan yaitu nilai mean average precision dari 9 query yang diuji sebesar 0.48, yang berarti sekitar 48% dokumen yang didapatkan oleh sistem berdasarkan query, relevan terhadap query.
Kata kunci: JSON RESTful API, mashup, web service, wordpress
ABSTRACT
NATAN PURNAWAN PARDOMUAN MANULLANG. Information Mashup on Bogor Agricultural University‟s Wordpress-Based Blog using Web Service. Supervised by FIRMAN ARDIANSYAH.
Wordpress is one type of Content Management System (CMS) in web application development. Bogor Agricultural University (IPB) website has subdomains for every student, faculty, or student organization to have a blog using Wordpress. Wordpress contents usually have standardized structure and the contents can be called in a particular format via a web service plugin that is installed in it. This research will integrate the contents of total 20 blogs of IPB, 5 blog each belong to students and student organizations, and the remaining 10 belong to lecturers. Web service that is used is JSON API, an API available for Wordpress. JSON API allows the client to obtain and manipulate Wordpress content using HTTP requests. The content is returned in JSON structured data which will be pre-processed so that it can be indexed by Sphinx Search, an additional library to develop a search engine. The result of the search engine evaluation is the mean average precision of 9 queries tested to the system, which is 0.48. That means approximately 48% of the documents retrieved by the system based on the query, are relevant to the query.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
MASHUP INFORMASI PADA SITUS BLOG INSTITUT
PERTANIAN BOGOR BERBASIS WORDPRESS
MENGGUNAKAN WEB SERVICE
NATAN PURNAWAN PARDOMUAN MANULLANG
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Mashup Informasi pada Situs Blog Institut Pertanian Bogor Berbasis Wordpress Menggunakan Web Service
Nama : Natan Purnawan Pardomuan Manullang NIM : G64090099
Disetujui oleh
Firman Ardiansyah, SKom MSi Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa atas kasih karunia-Nya sehingga karya ilmiah yang berjudul Mashup Informasi pada Situs Blog Institut Pertanian Bogor Berbasis Wordpress Menggunakan Web Service ini berhasil diselesaikan. Penelitian ini dilaksanakan mulai April 2013 sampai dengan September 2013 dan bertempat di Departemen Ilmu Komputer Institut Pertanian Bogor.
Terima kasih penulis ucapkan kepada Bapak Firman Ardiansyah, SKom, MSi selaku pembimbing. Ucapan terima kasih tak lupa penulis ucapkan kepada semua pihak yang telah membantu penulisan skripsi ini, terutama rekan-rekan satu departemen yang mendukung secara moral maupun ide-ide dalam menyelesaikan skripsi ini, dan juga kepada Bapak Hanif Affandi Hartanto dan Bapak Priyo Puji Nugroho dari Direktorat Komunikasi dan Sistem Informasi Institut Pertanian Bogor. Ungkapan terima kasih juga disampaikan kepada ayah, ibu, serta seluruh keluarga, atas segala doa dan dukungannya.
Semoga penelitian ini dapat bermanfaat.
Bogor, November 2013
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 1
Ruang Lingkup Penelitian 2
METODE 2
Analisis 2
Pemilihan dan Pemasangan Web Service 2
Akuisisi dan Transformasi Data 2
Implementasi 3
Evaluasi 4
HASIL DAN PEMBAHASAN 5
Analisis Kebutuhan 5
Pemasangan Web Service 6
Akuisisi dan Transformasi Data 6
Implementasi 8
Evaluasi 9
SIMPULAN DAN SARAN 10
Simpulan 10
Saran 11
LAMPIRAN 12
DAFTAR TABEL
1 Struktur data dari JSON API 7
2 Struktur data XML 8
3 Perhitungan AVP dan MAP dari kesembilan query 10
DAFTAR GAMBAR
1 Diagram metode penelitian hasil analisis 3
2 Ilustrasi dan rumus perhitungan precision dan 4
3 Arsitektur sistem mashup blog IPB 5
4 Contoh potongan data artikel berstruktur JSON 7
5 Contoh dokumen hasil konversi dari JSON ke XML 8
6 Tampilan pencarian sistem 9
DAFTAR LAMPIRAN
1 Daftar blog yang digunakan sebagai sumber data penelitian 12
2 Lima teratas hasil pencarian API 13
3 Potongan dokumen akhir siap untuk diindeks oleh Sphinx 14
4 Daftar stopwords 15
PENDAHULUAN
Latar Belakang
Institut Pertanian Bogor (IPB) adalah salah satu perguruan tinggi terbesar dan terkemuka di Indonesia. IPB memiliki 36 departemen yang tersebar ke dalam sembilan fakultas. Setiap departemen memiliki 80 sampai 130 mahasiswa dan puluhan dosen. Selain itu IPB memiliki berbagai macam Lembaga Kemahasiswaan (LK) resmi seperti Badan Eksekutif Mahasiswa (BEM) di setiap fakultas, Unit Kegiatan Mahasiswa (UKM), Himpunan Kemahasiswaan, dan LK lainnya.
Pada situs utama IPB (http://ipb.ac.id), sudah disediakan subdomain berupa situs blog berbasis Wordpress untuk setiap mahasiswa, dosen, dan LK. Apabila setiap mahasiswa, dosen, dan LK memiliki sebuah blog, tentu betapa banyaknya informasi (isi) yang tersebar oleh setiap pengguna blog tersebut. Berdasarkan observasi pada penelitian ini, diketahui terdapat 13 330 blog mahasiswa, 114 blog lembaga kemahasiswaan, dan 1 458 blog staff/dosen di situs IPB. Oleh sebab itu sangat dibutuhkan suatu sistem yang dapat membantu pengguna mendapatkan informasi yang dibutuhkan secara cepat dari blog-blog tersebut.
Mashup menggabungkan berbagai produk dari suatu aplikasi menggunakan layanan yang tersedia pada aplikasi, menjadi produk yang baru (Griffin 2008). Produk dari suatu aplikasi mashup harapannya dapat menghasilkan informasi yang lebih bermanfaat. Pada penelitian ini, produk yang digunakan yaitu isi dari blog-blog pada situs IPB. Oleh karena itu dalam penelitian ini akan dikembangkan aplikasi mashup informasi atau isi dari blog-blog yang ada di situs Institut Pertanian Bogor. Diharapkan dengan aplikasi ini, pengguna mendapatkan informasi yang relevan dengan kebutuhan informasi yang diinginkan pengguna.
Perumusan Masalah
Rumusan masalah pada penelitian ini yakni bagaimana cara mengintegrasikan isi dari situs-situs blog IPB berbasis Wordpress yang berjumlah banyak. Setelah isi berhasil diintegrasikan, masalah lainnya yakni bagaimana mengatasi kesulitan pengguna dalam mencari suatu informasi dikarenakan jumlah blog sebagai sumber informasi yang sangat banyak.
Tujuan Penelitian
2
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini terfokus kepada pengembangan sistem yang mampu mengintegrasikan isi/informasi yang tersebar di blog-blog pada situs IPB sebagai sumber data. Penelitian ini menggunakan total 20 blog sebagai sampel data penelitian, yang terdiri dari 5 blog mahasiswa, 5 blog lembaga kemahasiswaan, dan 10 blog dosen/staff.
METODE
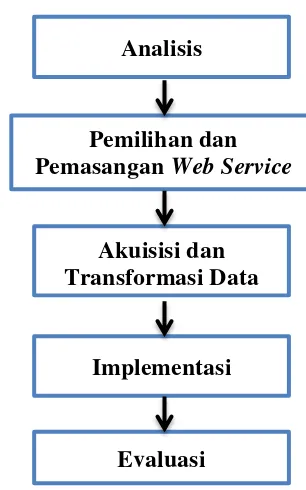
Metode yang digunakan dalam penelitian ini dapat dilihat pada Gambar 1. Metode yang digunakan terdiri atas analisis, pemilihan dan pemasangan web service, akuisisi dan transformasi data, implementasi, dan evaluasi.
Analisis
Pada tahap ini, dilakukan analisis kebutuhan pengembangan sistem. Berdasarkan kebutuhan tersebut, diperoleh tahapan proses pembuatan sistem ini (Gambar 1), spesifikasi kebutuhan sumber data dan arsitektur sistem mashup yang akan dikembangkan. Sumber-sumber yang didapatkan berupa jurnal, buku, dan informasi–informasi lain yang relevan dengan penelitian.
Pemilihan dan Pemasangan Web Service
Pada tahap ini dilakukan pemilihan dan pemasangan web service yang merupakan plugin tambahan bagi blog-blog berbasis Wordpress. Pemilihan dilakukan melalui observasi apakah web service tersebut dapat mengembalikan data (isi) dari blog atau tidak. Pemasangan suatu plugin ke suatu blog hanya dapat dilakukan oleh pemilik blog tersebut (administrator), yakni melalui sistem admin blog yang akan ditambahkan plugin.
Akuisisi dan Transformasi Data
Pada tahap ini dilakukan proses akuisisi data yang dibutuhkan sesuai dengan hasil analisis kebutuhan sistem. Data mentah berformat plain text dengan struktur JavaScript object notation (JSON) diperoleh dengan melakukan pemanggilan data melalui web service ke setiap blog (Wordpress) yang dituju, dengan kondisi di mana plugin web service pada setiap blog sudah terpasang.
3
Implementasi
Survey di internet (Fallows 2004) menemukan bahwa 92% pengguna internet mengatakan bahwa internet adalah tempat yang baik untuk mencari informasi setiap hari. Fakta tersebut menunjukkan bahwa perkembangan teknologi information retrieval (IR) semakin dibutuhkan untuk mempermudah pencarian informasi oleh pengguna.
IR adalah kegiatan mencari materi (biasanya dokumen) dari suatu teks yang memberi jawaban terhadap suatu kebutuhan informasi dari koleksi data yang besar (biasanya terdapat pada komputer) (Manning et al. 2008). Sistem IR tidak melakukan perubahan pada dokumen. Sistem IR hanya melakukan pemanggilan informasi yang berkaitan dengan informasi yang diinginkan. Representasi dari informasi yang diinginkan berupa kata atau frasa yang biasanya disebut query. Query dimasukkan ke dalam sistem sebagai input, kemudian sistem menampilkan dokumen–dokumen yang relevan dengan query.
Pada tahap ini dilakukan implementasi pembangunan sistem pencari. Implementasi meliputi pembangunan antarmuka sistem untuk pengguna, penentuan variabel penyimpanan data, dan mengindeks (indexing) data menggunakan Sphinx Search.
Indexing adalah sebuah proses di mana dilakukan pengindeksan terhadap suatu kumpulan dokumen maupun query. Indexing dapat dilakukan otomatis oleh sistem maupun manual. Berikut ini tahapan mengindeks di antaranya,
1 Tokenisasi
Tokenisasi adalah proses memotong teks input menjadi unit-unit terkecil yang disebut token dan pada saat yang sama dimungkinkan untuk membuang karakter tertentu, seperti tanda baca (Manning et al. 2008). Tokenisasi melakukan pemisahan terhadap isi dokumen menjadi unit yang paling kecil atau biasa disebut juga kata. Tokenisasi dapat menangani pengolahan linguistik tambahan seperti normalisasi tanggal, stemming, dan lain-lain. Tokenisasi
Analisis
Pemilihan dan Pemasangan Web Service
Akuisisi dan Transformasi Data
Implementasi
Evaluasi
4
dapat diperluas untuk menangani sumber data baru, jenis file baru dan bahasa baru (Dumais S et al. 2003).
2 Pembuangan Stopwords
Stopwords merupakan kata umum yang biasanya sering muncul dalam jumlah besar pada suatu dokumen, tetapi tidak memiliki makna. Kata-kata seperti “ke”,
“yang”, “untuk” dan kata-kata umum lainnya hanya akan membuat sistem tidak efektif dalam mencari karena kata-kata tersebut biasanya selalu ada dan berfrekuensi besar dalam dokumen. Stopwords lebih baik tidak digunakan agar meningkatkan akurasi dan efektivitas pencarian sebuah sistem pencari.
3 Pembobotan
Pembobotan adalah proses pemberian bobot pada suatu term yang ada pada suatu dokumen. Pembobotan dilakukan untuk memberi nilai pada suatu term di mana nilai tersebut digunakan sebagai penciri term tersebut. Nilai bobot tersebut akan membentuk peringkat, yang akan mengurutkan term terhadap dokumen dengan query yang diberikan pengguna.
Evaluasi
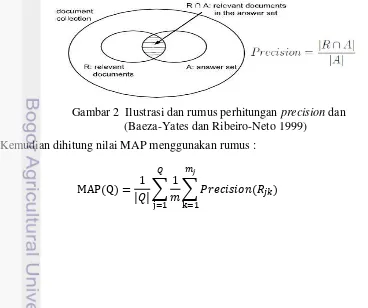
Pada tahap ini dilakukan evaluasi terhadap sistem mashup. Di evaluasi seberapa baik hasil pencarian sistem dengan melihat hubungan antara query dan informasi yang diperoleh. Pada sistem mashup ini hasil akhirnya akan berbentuk sistem pencari, dan sebuah sistem pencari sangat berkaitan dengan ilmu information retrieval (IR). Dalam IR, salah satu teknik evaluasi paling umum yang digunakan adalah mean average precision (MAP). Nilai MAP merupakan rataan aritmatik dari average precision (AVP) atau rata-rata precision suatu pencarian query (Manning et al. 2008). Precision adalah pembagian dari dokumen relevan terhadap query yang ditemukan dengan dokumen yang ditemukan oleh sistem pencari (Gambar 2).
Kemudian dihitung nilai MAP menggunakan rumus :
∑
∑
(1) Gambar 2 Ilustrasi dan rumus perhitungan precision dan
5 MAP(Q) adalah hasil evaluasi MAP dari kumpulan query sebanyak Q.
adalah nilai precision pada hasil dokumen yang ditampilkan
mulai dari dokumenj sampai dokumenk. Nilai dibagi dengan jumlah dokumen relevan yang ditampilkan ( ) untuk mendapatkan nilai AVP.
HASIL DAN PEMBAHASAN
Analisis Kebutuhan
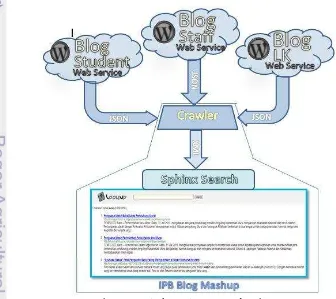
Data yang digunakan dalam penelitian ini berupa isi dari beberapa blog-blog berbasis Wordpress yang merupakan subdomain dari situs Institut Pertanian Bogor (IPB). Blog-blog IPB tersebut diantaranya http://lk.ipb.ac.id, http://student.ipb.ac.id, http://staff.ipb.ac.id. Dari setiap subdomain blog tersebut diambil masing-masing sampel lima blog mahasiswa, lima blog lembaga kemahasiswaan, dan sepuluh blog dosen/staff, sehingga terdapat 20 blog sebagai sumber data yang isinya akan diintegrasikan (daftar ke-20 blog terdapat pada Lampiran 1). Blog-blog yang dipilih sebagai sampel penelitian adalah blog-blog yang isinya minimal memiliki tiga artikel sehingga memiliki data untuk diintegrasikan.
Pada tahap analisis didapatkan arsitektur sistem mashup yang dikembangkan pada penelitian ini. Arsitektur sistem dapat dilihat pada Gambar 3. Sistem mashup blog-blog di situs IPB menggabungkan isi dari blog-blog di situs IPB, kemudian menampilkan informasi yang dibutuhkan sesuai informasi yang dibutuhkan pengguna. Informasi yang dibutuhkan pengguna direpresentasikan sebagai suatu query, yang dapat berupa kata atau frasa.
6
Pemilihan Pemasangan Web Service
Web service pada Wordpress menggunakan plugin yang dipasang ke setiap blog-blog subdomain dari situs IPB. Plugin yang digunakan yaitu JSON application programming interface (API) yang dikembangkan oleh Dan Phiffer (Phiffer 2009). JSON API dipilih berdasarkan observasi pada penelitian ini. Observasi yang dilakukan dalam pemilihan web service yakni mencari menggunakan keyword “JSON API” pada pencarian plugin di situs http://wordpress.org/plugins/. Dari lima teratas hasil pencarian plugin API yang didapatkan, dipasang dan diuji satu-persatu ke blog Wordpress di server lokal, apakah plugin API tersebut menghasilkan data yang merepresentasikan isi dari blog. Lima teratas hasil pencarian plugin API beserta alasan penggunaannya, dapat dilihat pada Lampiran 2.
JSON API mengijinkan penggunanya untuk mendapatkan dan memanipulasi isi dari Wordpress melalui hypertext transfer protocol (HTTP) request. HTTP request adalah protokol antara komputer klien dan server, di mana komputer klien melakukan permintaan suatu file atau halaman web ke server, dan komputer server merespon terhadap apa yang diminta oleh komputer klien.
Pada tahap ini, pemasangan plugin hanya dapat dilakukan oleh administrator pada blog yang akan diambil datanya. Dalam penelitian ini administrator adalah pihak Direktorat Komunikasi dan Sistem Informasi (DKSI) IPB, sehingga pemasangan web service harus dilakukan bersama pihak DKSI IPB. Pemasangan yang dilakukan yaitu memasang plugin JSON API ke subdomain blog http://lk.ipb.ac.id, http://student.ipb.ac.id, dan http://staff.ipb.ac.id.
Akuisisi dan Transformasi Data
Data yang digunakan pada penelitian ini diperoleh dari blog-blog yang akan diambil isinya. Isi didapatkan dan ditransformasi dengan menggunakan program crawler yang dibuat pada penelitian ini. Crawler atau dikenal dengan nama web spider adalah sebuah program yang melakukan crawling atau proses mengumpulkan halaman-halaman dari internet (Castillo 2004). Crawler tersebutlah yang melakukan parsing dari data JSON, hingga data akhir berupa XML. Pada pengembangan sistem mashup ini, crawler hanya melakukan akuisisi dan transformasi terhadap data yang akan digunakan. Berikut tahap-tahap dalam membuat crawler untuk mengakuisisi hingga mentransformasi data:
1 Input query ke web service (API) blog
Pertama diberikan query ke web service melalui Uniform Resource Locator (URL) blog yang dituju, misalnya untuk situs blog http://bemfkh.lk.ipb.ac.id/, URL-nya menjadi:
http://bemfkh.lk.ipb.ac.id/?json=get_posts
7
Query yang akan digunakan pada web service JSON API sudah disediakan oleh JSON API, tergantung kebutuhan informasi seperti apa yang dibutuhkan pengguna. Query „get_posts‟ yang digunakan pada URL merupakan query yang sudah ditentukan oleh API jika ingin mendapatkan seluruh artikel dari halaman situs blog yang dituju.
Tabel 1 Struktur data dari JSON API
Nama parameter Tipe Nama parameter Tipe
id type slug url title title_plain content excerpt date modified
Integer Varchar Varchar Varchar Varchar Varchar Text Text Varchar Varchar
Categories tags author comments attachments comment_count comment_status thumbnail custom_fields taxonomy_
Varchar Varchar Varchar Varchar Varchar Integer Varchar Varchar Varchar Varchar 2 Konversi data JSON menjadi XML
Dari data berstruktur JSON pada Tabel 1, kemudian dilakukan pembersihan data terhadap atribut-atribut yang tidak diperlukan sistem, lalu dikonversi menjadi struktur XML. Pembersihan data yang dilakukan yaitu melakukan pembuangan atribut-atribut selain atribut url, title, dan content. Hasil konversi data JSON menjadi XML dapat dilihat pada Gambar 5.
8
Hasil konversi data JSON menjadi XML dari satu blog kemudian disimpan menjadi satu file XML. Akuisisi dan konversi data JSON diterapkan bagi setiap blog yang akan dijadikan sumber data.
3 Menggabungkan setiap file XML
Setiap file XML dari setiap blog kemudian digabung menjadi satu file XML dengan atribut-atribut yang sesuai agar bisa diindeks menggunakan Sphinx Search. Tabel 2 menunjukkan struktur data XML hasil praproses dan contoh potongan dokumen dapat dilihat pada Lampiran 3.
Tabel 2 Struktur data XML Nama Parameter Tipe Document id
title link content
Integer Varchar Varchar Text
Implementasi
Data akhir pada penelitian ini merupakan kumpulan dokumen yang akan digunakan sistem pencari bagi pengguna. Data atau kumpulan dokumen disimpan menjadi satu file untuk mempermudah proses indexing oleh Sphinx. Crawler dijalankan pada 8 September 2013, dan dari sumber data berupa 20 blog didapatkan 144 dokumen-dokumen yang menjadi kumpulan dokumen.
Pada tahap ini tampilan antarmuka bagi pengguna dibuat setelah service dari Sphinx sudah aktif. Tampilan antarmuka bagi pengguna dibuat dalam bentuk sistem pencari. Berikut langkah-langkah dalam mengindeks dokumen yang dilakukan oleh Sphinx Search:
1 Tokenisasi
Tokenisasi merupakan proses untuk mendapatkan unit terkecil dari suatu teks. Hasil tokenisasi berupa token-token yang dapat berupa suatu suatu kata atau angka. Sphinx Search dapat melakukan tokenisasi terhadap data XML. Pada penelitian ini, tokenisasi dilakukan oleh Sphinx Search juga karena tokenisasi oleh Sphinx Search tergolong mudah dan cepat prosesnya. Kata yang diindeks adalah kata yang memiliki jumlah minimal 3 huruf, sehingga untuk kata yang kurang dari 3 huruf tidak akan diindeks. Pada akhir tokenisasi didapatkan 9895 kata atau angka sebagai kumpulan token yang berasal dari 144 dokumen.
9 2 Pembuangan Stopwords
Stopwords adalah kata-kata umum yang biasanya sering dipakai sehingga muncul dalam jumlah besar pada dokumen. Pada penelitian kali ini, daftar stopwords yang akan dihilangkan didapat dari laboratorium Temu Kembali Informasi Ilmu Komputer IPB. File stopwords tersebut memiliki sekitar 732 kata. Daftar stopwords yang digunakan dapat dilihat pada Lampiran 4.
3 Pembobotan
Pada penelitian ini, pembobotan dilakukan dengan menggunakan model peluang BM25 (Best Match 25) dengan bantuan Sphinx. BM25 pada Sphinx mencari peluang relevansi terbesar suatu dokumen dapat relevan dengan query yang diberikan pengguna. Tahapannya, kepada setiap komponen kata pada query diberikan nilai peluang, kemudian nilai-nilai tersebut disatukan untuk menghitung nilai peluang akhir yang akan menunjukkan besar atau kecilnya relevansi query dan dokumen.
Evaluasi
Tahap evaluasi dilakukan dengan melakukan pencarian sembilan query terpilih yang hasil pencariannya akan digunakan untuk mengevaluasi sistem. Query yang dipilih berdasarkan jumlah minimal dokumen hasil pencarian yang relevan terhadap query. Pada penelitian ini, setiap query ditentukan memiliki minimal dua dokumen relevan yang ditampilkan dari pencarian oleh sistem. Daftar query beserta dokumen yang relevan terhadap query dapat dilihat pada Lampiran 5. Hasil pencarian query ditampilkan pada Gambar 6, berupa:
1 Pilihan judul dokumen yang memiliki tautan ke blog sumber, 2 String URL tautan ke blog sumber,
3 Kutipan isi dari dokumen terkait, namun hanya ditampilkan 50 kata pertama saja.
Proses evaluasi dilakukan dengan menghitung nilai MAP dari sembilan query yang dievaluasi terhadap hasil pencarian oleh sistem. Nilai MAP merupakan rataan dari AVP kesembilan query yang diujikan terhadap sistem.
Perhitungan MAP yaitu misalnya pada query 1, dokumen-dokumen relevan yang ditampilkan sistem terdapat pada urutan pertama, kelima, dan kedelapan. Dengan demikian nilai precision dari query tersebut adalah 1/1, 2/5, dan 3/8. Nilai tersebut dihitung rataannya agar mendapatkan nilai AVP bagi query 1. Proses
10
perhitungan tersebut dilakukan terhadap kedelapan query lainnya. Kemudian kesembilan nilai AVP tersebut dijumlahkan dan dihitung rataannya sehingga mendapatkan nilai MAP. Dari perhitungan didapatkan nilai MAP sebesar 0.48. Nilai AVP dari setiap query dapat dilihat pada Tabel 3.
Tabel 3 Perhitungan AVP dan MAP dari kesembilan query
Query AVP
1 0.59
2 0.21
3 0.34
4 0.74
5 0.83
6 0.21
7 0.57
8 0.19
9 0.66
MAP 0.48
Dari pengujian yang diakukan terhadap sembilan query didapatkan nilai MAP sebesar 0.48. Dapat dikatakan 48% dokumen dari keseluruhan dokumen yang ditampilkan oleh sistem relevan terhadap query yang diuji.
Nilai AVP tersebut dapat dipengaruhi kumpulan dokumen yang digunakan sistem. Kumpulan dokumen didapatkan dari blog-blog yang isi/artikel-artikelnya tidak memiliki topik yang sama, tidak semua bahasa yang digunakan baku, dan terdapat artikel-artikel berbahasa inggris, sehingga kumpulan term yang diindeks sangat bervariasi. Term merupakan kata-kata penciri dari suatu dokumen dari proses mengindeks. Kata term yang sangat bervariasi akan membuat sistem kesulitan mencari kata-kata pada query yang sama dengan kata term yang mewakili dokumen yang relevan dengan query. Sebagai contoh terdapat kata
“social” dan “sosial” yang keduanya memiliki makna yang sama, namun karena perbedaan bahasa, sistem menganggap kedua kata tersebut berbeda. Hal tersebut dapat mengakibatkan saat dilakukan pencarian query “dunia sosial”, sistem tidak mengembalikan dokumen yang memiliki kata “social”.
SIMPULAN DAN SARAN
Simpulan
11 blog karena web service yang tidak menyediakan fitur mengambil keseluruhan isi, melainkan hanya dari satu halaman web saja.
Saran
Terdapat beberapa hal yang dapat ditambahkan ataupun diperbaiki untuk penelitian selanjutnya, di antaranya menggunakan stopwords untuk bahasa Inggris pada sistem mashup blog IPB berbasis Wordpress ini, karena terdapat artikel-artikel pada blog yang menggunakan bahasa Inggris sehingga kata-kata yang terlalu umum tidak perlu menjadi term bagi dokumen.
DAFTAR PUSTAKA
Baeza-Yates R, Ribeiro-Neto B. 1999. Modern Information Retrieval. New York (US): Addison Wesley.
Castillo C. 2004. Effective web crawling [tesis]. Santiago (CL): University of Chile.
Dumais S, Cutrell E, Cadiz JJ, Jancke G, Sarin R, Robbins DC. 2003. Stuff I've seen: a system for personal information retrieval and re-use. Di dalam: 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval; 2003 Jul; Redmond, USA. hlm 72-79.
Fallows D. 2004. The internet and daily life [Internet]. [diunduh 2013 Okt 3]. Tersedia pada: http://www.pewinternet.org/pdfs/PIP_Internet_and_Daily _Life.pdf.
Griffin E. 2008. Foundations of Popfly Rapid Mashup Development. New York (US): Apress.
Manning CD, Raghavan P, Schütze H. 2008. Introduction to Information Retrieval. Cambridge (GB): Cambridge University Press.
12
LAMPIRAN
Lampiran 1 Daftar blog yang digunakan sebagai sumber data penelitian
No URL
1 http://forces.lk.ipb.ac.id 2 http://bemfkh.lk.ipb.ac.id 3 http://ruminansia.lk.ipb.ac.id 4 http://himagizi.lk.ipb.ac.id 5 http://hmit.lk.ipb.ac.id
6 http://lenis11s.student.ipb.ac.id 7 http://habiba09.student.ipb.ac.id 8 http://wahyuni_sri12u.student.ipb.ac.id 9 http://cynthia_rizki12u.student.ipb.ac.id 10 http://dietrich_gerry12u.student.ipb.ac.id 11 http://anuragaja.staff.ipb.ac.id
13 Lampiran 2 Lima teratas hasil pencarian API
Rank pencarian
Nama web service (API)
Digunakan Alasan digunakan / tidak digunakan
1 JSON API Ya JSON API menghasilkan output yang merupakan isi
dari suatu blog Wordpress. JSON API menampilkan isi dari blog Wordpress dengan struktur JSON. JSON API memiliki 16 query yang dapat digunakan untuk memanggil isi dari blog, tergantung isi seperti apa yang dibutuhkan pengembang. Misalnya query 'get_recent_posts' digunakan untuk memanggil isi dari blog yang terakhir diperbaharui, kemudian 'get_posts' untuk memanggil keseluruhan isi dari halaman suatu blog. Query-query lainnya dapat dilihat pada http://wordpress.org/plugins/json-api/other_notes/.
2 IdeaPress
JSON API
Tidak IdeaPress merupakan plugin JSON API yang dimodifikasi. Hasil yang ditampilkan sama seperti pada JSON API, hanya memiliki query tambahan yaitu 'get_recent_posts_on_hub'.
3
JSON-API-
for-BuddyPress
Tidak JSON-API-for-BuddyPress merupakan plugin JSON
API yang dimodifikasi. BuddyPress menambahkan fitur agar isi dari blog Wordpress dapat diintegrasikan dengan isi dari BuddyPress
4 WPML
JSON API
Tidak WPML JSON API melakukan modifikasi terhadap
hasil dari plugin JSON API. WPML JSON API dapat menerjemahkan hasil yang ditampilkan dari plugin JSON API.
5 Foliodock
API
Tidak Foliodock digunakan untuk membuat online portfolio dari isi suatu blog Wordpress. Hasil dari API
14
<sphinx:docset xmlns:sphinx="mynamespaceURI"> <sphinx:schema>
<sphinx:field xmlns:sphinx="mynamespaceURI" name="title" attr="string"/> <sphinx:field xmlns:sphinx="mynamespaceURI" name="link" attr="string"/> <sphinx:field xmlns:sphinx="mynamespaceURI" name="content" attr="string"/> <sphinx:attr name="id" type="int" bits="16" default="1"/>
</sphinx:schema>
<sphinx:document id="1">
<title>“Syuhada Rabaa” Foto Pengantin Baru Paling Menyedihkan di Mesir Menurut Reuters
</title> <link>
http://anuragaja.staff.ipb.ac.id/2013/08/21/syuhada-rabaa-foto-pengantin-baru-paling-menyedihkan-di-mesir-menurut-reuters/
</link> <content>
Foto diatas adalah salah satu syuhada diantara ribuan yang gugur pada pembantaian junta militer Mesir saat pembumihangusan Medan Rabi’ah Al-Adawiyah (14/8/2013). Dengan membawa mushaf, sang istri memeluknya untuk yang terakhir kali. Foto ini oleh Reuters disebut foto pengantin baru yang paling menyedihkan di Mesir. Para syuhada telah menunaikan dan membuktikan janjinya dihadapan Allah, mereka hidup disisiNya dengan penuh kebahagiaan. Yang ditinggal pun tetap tegar dengan keyakinan bahwa kelak mereka akan dipertemukan kembali di jannahNYa. Berikut, salah satu ungkapan istri syuhada, Asmaa Hussein, yang suaminya Amr Mohammed Kassem diantara ribuan syuhada Mesir. Gambarannya mirip dengan foto diatas… Suamiku, Amr Mohamed Kassem kembali ke pangkuan Tuhannya pada usia 26 tahun.
</content>
</sphinx:document> <sphinx:document id="2"> <title>
Analisa Sosok Dzulqarnain, Ya’juj Ma’juj dan Negeri Zionis | Tafsir </title>
<link>
http://anuragaja.staff.ipb.ac.id/2013/08/14/analisa-sosok-dzulqarnain-yajuj-majuj-dan-negeri-zionis-tafsir/
</link> <content>
Oleh Nur Ihsan Jundulloh
Mahasiswa Ummul Quro, Mekah
*** Siapakah sosok Dzulqarnain yang disebut dalam surat Al-Kahfi? Syarat sosok Dzulqarnain : 1. Penguasa (innaa makkannaa lahuu fil ardhi)
2. Daerah kekuasaannya membentang dari barat (balagha maghribasy syamsi) sampai timur (balagha mathli’asy syamsi)
3. Penganut monotheis/tauhid (haadzaa rahmatun min rabbii)
“The ram that you saw, the one with the horns, represents the king of Media and Persia”
-ed). Muncul beberapa kemungkinan jawaban: 1. Perintah Allah untuk tidak menyerang Yajuj dan Majuj
</content>
</sphinx:document>
15 Lampiran 4 Daftar stopwords
16
17 Lampiran 4 Lanjutan
terkait terkecuali terlalu terlebih termasuk ternyata tersebut tertentu
terus tetap tetapi tiap tiba tidak tidaklah tidaknya
tiga tinggi tutur tuturnya ucap ucapan ucapannya ucapkan
ucapnya ujar ujarnya umpamanya umum umumnya ungkap ungkapan
ungkapkan ungkapnya untuk usah usahlah usai usianya waktu
18
Lampiran 5 Relevance set dari kueri yang diuji coba terhadap sistem
No Kueri Gugus Jawaban (id document)
1 pangan indonesia 122, 44, 110
2 lomba pertanian 49, 48
3 gizi indonesia 60, 59
4 seminar pertanian 48, 98, 102, 68, 101, 49, 100
5 departemen kelautan 23, 25
6 inovasi dalam penelitian 15, 100, 22, 126, 20, 11, 45, 46, 97, 122,
7 teknologi pertanian 44, 93, 79, 97, 98, 99, 100, 102, 111
8 wisata laut indonesia 26, 94, 21, 27
19
RIWAYAT HIDUP
Penulis dilahirkan di Bogor. Penulis merupakan anak pertama dari tiga bersaudara. Tahun 2006 penulis lulus dari SMP BPK Penabur Bogor, lalu pada tahun 2009 penulis lulus dari SMA Negeri 3 Bogor dan pada tahun yang sama penulis diterima di Institut Pertanian Bogor (IPB) melalui jalur Ujian Talenta Mandiri (UTM) program studi Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.