MODEL
STEMMING
BERBASIS KAMUS UNTUK
DOKUMEN BERBAHASA SUNDA
ANDHY PURWOKO
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis Model Stemming Berbasis Kamus untuk Dokumen Berbahasa Sunda adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Agustus 2011
Andhy Purwoko
ABSTRACT
ANDHY PURWOKO. Dictionary-Based Stemming Model for Documents in Sundanese Language. Under the direction of AGUS BUONO and AHMAD RIDHA.
The use of local languanges tends to vanish, and one of the reasons is the reluctance of local people to practice their own language. Research on the local language, particulary Sundanesse, is also not considered to be interesting topic. More documents in Sundanesse have been digitized, but research on the documents is still limited. Information Retrieval (IR) has been used to explore information from tested documents. In IR, the documents will be parsed to obtain their tokens. The tokens will be saved in index files. In order to make the IR optimal, the index files should be created as small as possible. Therefore, discarding unimportant words should be done. Prefixes, infixes, sufixes, confixes, ambifixes, and repeated patterns in the tokens will be eliminated. This elimination proccess is called stemming. The stemming algorithm is based on dictionary, i.e., the stemmed words will be compared with dictionary. This algorithm has produced the expected words with 91.38% accuracy. In the future researches, this algorithm can be deployed on seacrh engine, Natural Language Processing (NLP) or machine translation for Sundanese.
RINGKASAN
ANDHY PURWOKO. Model Stemming Berbasis Kamus untuk Dokumen Berbahasa Sunda. Di bawah bimbingan AGUS BUONO dan AHMAD RIDHA.
Penggunaan bahasa daerah cenderung menuju ke arah kepunahan. Hal ini disebabkan karena makin enggannya orang daerah menggunakan Bahasa daerahnya sendiri. Penelitian terhadap bahasa daerah khususnya Bahasa Sunda juga bukan merupakan bahasan yang menarik. Telah ada dokumen berbahasa Sunda yang sudah berbentuk file digital, namun belum banyak penelitian terhadap dokumen berbahasa Sunda tersebut. Salah satu metode untuk mengeksplorasi informasi dari dokumen-dokumen Bahasa Sunda adalah sistem temu kembali informasi. Dalam Sistem Temu Kembali Informasi dokumen-dokumen tersebut akan di-parse untuk mendapatkan token. Token-token tersebut akan disimpan dalam sebuah file indeks. Agar sistem temu kembali optimal maka file indeks dibuat sekecil mungkin. Agar file indeks kecil, proses parsing selanjutnya adalah penghilangan kata yang tidak penting. Selanjutnya token-token tersebut akan dihilangkan awalan, sisipan, akhiran, imbuhan terbelah dan imbuhan gabungannya. Proses tersebut diberi nama stemming.
Algoritme stemming yang dirancang adalah algoritme berdasarkan kamus. Algoritme akan menghilangkan awalan, sisipan, akhiran imbuhan terbelah dan imbuhan gabungan serta kata ulang, dan pada setiap hasil proses akan dibandingkan dengan kamus. Dalam penelitian ini disiapkan data kamus dan dokumen uji sebanyak 130 dokumen dalam bahasa Sunda.
Pada proses tokenizer, dari 130 dokumen uji didapat 100 824 kata. Kata- kata tersebut belum unik, sehingga perlu diproses lebih lanjut untuk mendapatkan satu kata unik dari sejumlah kata yang memiliki bentuk yang sama. Setelah kata yang sama dihilangkan didapat kata unik sebesar 16 949 kata. Dari jumlah kata tersebut setelah di-stem hasilnya adalah 11 515 kata. Dari 16 949 kata tersebut setelah dipelajari ternyata banyak kata yang bukan berasal dari bahasa Sunda. Terdapat kata-kata dalam bahasa Arab, bahasa Jawa, bahasa Indonesia dan bahasa Inggris. Ada juga bahasa Indonesia yang di’sunda’kan, misalnya dimanfaatkeun
(seharusnya dimangpaatkeun); panolong, ngarakit, usulanana, mertahankeun
(bahasa Indonesia yang diberi imbuhan bahasa Sunda); juga nama-nama, baik nama orang, nama tempat, nama sungai dan lain-lain. Selain itu, banyak juga singkatan-singkatan serta penulisan-penulisan yang salah ketik. Tentu saja kata- kata di atas jika di-stem dengan algoritme stemming bahasa Sunda hasilnya tidak akan pernah sesuai dengan yang diharapkan. Untuk melihat apakah stemming
bekerja sesuai dengan yang diharapkan, kata-kata tersebut di atas dihilangkan dan hasilnya didapat 10 416 kata.
stemming hasil kata yang diharapkan adalah sebesar: (4 693/5 136) x 100% = 91.38%
Dalam proses stemming ternyata didapat kata-kata yang overstemming dan tidak ada kata hasil yang yang dikatagorikan dalam understemming. Algoritme yang dirancang dapat dikatagorikan ke dalam algoritme heavy stemming karena tidak ditemukan hasil kata yang understemming. Algoritme yang dirancang sebagian besar memberikan hasil yang cukup baik, meskipun masih dapat terjadi beberapa kata tidak menghasilkan kata seperti yang diharapkan. Potensi kegagalan masih dapat terjadi jika kata yang akan di-stem memiliki pola yang sama dengan kata yang gagal distemming. Dari hasil stemming didapat 8,62% kata yang tidak sesuai dengan harapan. Hal tersebut disebabkan karena masih ada kekurangsempurnaan dari algoritme yang dirancang. Untuk penelitian selanjutnya ini, algoritme ini diterapkan untuk mesin pencari dokumen berbahasa Sunda, NLP (Natural Language Processing) atau mesin translator dokumen bahasa Sunda. Kata Kunci: stemming, awalan, sisipan, akhiran, imbuhan terbelah, imbuhan
© Hak Cipta milik IPB, tahun 2011 Hak Cipta dilindungi Undang-undang
1. Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumber
a. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik atau tinjauan suatu masalah
b. Pengutipan tidak merugikan kepentingan yang wajar IPB
MODEL
STEMMING
BERBASIS KAMUS UNTUK
DOKUMEN BERBAHASA SUNDA
ANDHY PURWOKO
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Departemen Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
LEMBAR PENGESAHAN
Judul Tesis : Model Stemming Berbasis Kamus untuk Dokumen Berbahasa Sunda
Nama : Andhy Purwoko
NRP : G 651060014
Program Studi : Ilmu Komputer
Disetujui Komisi Pembimbing
Dr. Ir. Agus Buono, M. Si, M. Kom Ahmad Ridha, S.Kom, M.S
Ketua Anggota
Diketahui
Ketua Program Studi Dekan Sekolah Pascasarjana Ilmu Komputer
Dr. Ir. Agus Buono, M. Si, M. Kom Dr. Ir. Dahrul Syah, MSc.Agr
PRAKATA
Dengan memanjatkan puji dan syukur ke hadirat Allah Subhanahu Wa
Ta’ala atas segala petunjuk dan karunia-Nya sehingga karya ilmiah ini berhasil
diselesaikan. Pada penelitian ini judul yang dipilih adalah Model Stemming
Berbasis Kamus untuk Dokumen Berbahasa Sunda. Karya ilmiah ini disusun sebagai salah satu persyaratan untuk memperoleh gelar Magister Sains pada Departemen Ilmu Komputer Intitut Pertanian Bogor.
Pada penulisan karya ilmiah ini penulis banyak menerima bantuan dari berbagai pihak. Untuk itu ucapan terima kasih penulis tujukan kepada Bapak Dr. Ir. Agus Buono, M.Si, M.Kom dan Bapak Ahmad Ridha, S. Kom, M.S sebagai komisi pembimbing yang telah banyak memberi bimbingan dan arahan selama proses penelitian hingga terselesaikannya tesis ini. Ucapan terima kasih juga penulis sampaikan kepada Bapak Sony Hartono Wijaya, S.Kom selaku penguji pada sidang tesis. Selain itu ucapan terima kasih juga kami ucapkan kepada seluruh staf Departemen Ilmu Komputer yang telah banyak membantu selama ini. Dorongan moril juga banyak diberikan kepada penulis oleh istri tercinta, putra- putri penulis dan juga semua anggota keluarga, yang dengan gigih terus mendorong agar segera menyelesaikan tesis ini. Pemahaman tentang tata bahasa Sunda banyak diberikan oleh Bapak Yayat Sudaryat, untuk itu penulis mengucapkan terimakasih atas ilmu yang diberikan oleh beliau.
Penulis menyadari bahwa penelitian ini masih banyak yang perlu disempurnakan. Mudah-mudahan penelitian lebih lanjut terhadap stemming
bahasa Sunda dapat dikembangkan lebih lanjut. Semoga penelitian ini dapat bermanfaat bagi kita semua demi kemajuan ilmu pengetahuan dan teknologi.
Bogor, Agustus 2011
RIWAYAT HIDUP
Penulis dilahirkan di Blora, pada tanggal 05 September 1969 dari pasangan M. Sutijono, BE dan Sumarsih. Penulis merupakan putera pertama dari empat bersaudara. Menikah dengan Puspita Sari Dewi dan dikarunai 2 putra dan 1 putri.
Tahun 1988 penulis lulus dari SMA Negeri 4 Bandung. Tahun 1990 melanjutkan pendidikan di jurusan Teknik Informatika ST INTEN Bandung, dan lulus pada tahun 1995.
Penulis pernah bekerja pada PT Kwarsa Hexagon (1995) dan PT Wiraguna Tani (1996-1997). Pada kedua perusahaan tersebut penulis bekerja sebagai
programmer. Tahun 1998 penulis bekerja pada Kantor Pengolahan Data
DAFTAR ISI
2.1.1.4 Rarangken Barung (Imbuhan Terbelah) ... 11
2.1.1.5 Rarangken Bareng (Imbuhan Gabungan) ... 12
Halaman
3.2.3 Tahap Proses Perancangan Tokenizer ... 22
3.2.4 Tahap Pembuatan Kata Uji dari Dokumen ... 23
3.2.5 Tahap Pembuatan Stoplist ... 23
3.2.6 Tahap Perancangan Stemming ... 24
3.2.6.1 Modul/Fungsi Hilangkan_Awalan() ... 25
3.2.6.2 Modul/Fungsi Hilangkan_Akhiran() ... 27
3.2.6.3 Modul/Fungsi Hilangkan_Sisipan() ... 28
3.2.6.4 Modul/Fungsi Hilangkan_Barung() ... 33
3.2.6.5 Modul/Fungsi Hilangkan_Bareng() ... 34
3.2.6.6 Modul/Fungsi Cek_Kata_Ulang() ... 35
3.2.7 Tahap Evaluasi Stemming ... 35
3.2.8 Tahap Penulisan Tesis ... 36
3.2.9 Tahap Pembuatan Kesimpulan ... 36
4. HASIL PENELITIAN DAN PEMBAHASAN ... 37
4.1 Hasil Penelitian ... 37
4.1.1 Hasil Kata yang Overstemming ... 38
4.1.2 Hasil Kata yang Tidak Sesuai Harapan ... 39
4.2 Analisis Terhadap Pengujian Stemming ... 39
4.2.1 Analisis Terhadap Kata yang Overstemming ... 40
4.2.2 Analisis Terhadap Kata yang Tidak Sesuai Harapan ... 43
5. KESIMPULAN DAN SARAN 47 5.1 Kesimpulan ... 47
5.2 Saran ... 47
DAFTAR PUSTAKA ... 49
DAFTAR GAMBAR
Halaman
1 Diagram pembetukan kata yang berimbuhan ... 5
2 Diagram pembetukan kata ulang ... 14
3 Ilustrasi proses stemming ... 17
4 Langkah-langkah penelitian ... 21
5 Diagram proses stemming ... 24
6 Fungsi Cek_Prefiks() ... 25
7 Fungsi Hilangkan_Awalan() ... 26
8 Fungsi Cek_Sufiks() ... 27
9 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang 10 diawali dengan huruf “l” ... Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang 28 11 diawali dengan huruf “r” ... Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang 29 mengandung suku kata "tr”, “br”, “ cr”, “kr”, “ pr”, “ jr”, “dr” ... 29
12 Fungsi in_str_ar() ... 30
13 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata “ar” ... 30
14 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata “ra” ... 31
15 Fungsi infiks_in() ... 31
16 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata “in” ... 31
17 Fungsi in_str_um() ... 32
18 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata “um” ... 32
19 Bagian algoritme Hilangkan_Barung() ... 33
20 Bagian algoritme Hilangkan_Bareng() ... 34
Halaman
22 Bagian algoritme Hilangkan_Sisipan() yang menghasilkan kata
DAFTAR LAMPIRAN
1. PENDAHULUAN
1.1 Latar Belakang
Indonesia adalah negara yang memiliki banyak pulau yang terbentuk dengan karakteristik unik dan spesifik. Berbeda dengan bangsa lain yang menjadi suatu negara atau bangsa karena kesamaan bahasa, Indonesia adalah negara yang terbentuk karena latar belakang historis, kondisi sosiologis, antropologis dan geografis yang unik dan spesifik. Akibat keragaman dan keunikan ini terdapat ratusan bahasa daerah dalam Negara Kesatuan Republik Indonesia ini.
Menurut hasil survey Litbang Media Group, bahasa daerah cenderung menuju ke arah kepunahan (Media Indonesia 2009). Kepunahan tersebut disebabkan oleh makin berkurangnya pengguna bahasa daerah. Hal ini disebabkan oleh ketertarikan orang daerah itu sendiri untuk menggunakan bahasa daerahnya. Selain itu penelitian-penelitian terhadap bahasa daerah bukan merupakan sesuatu bahasan yang dianggap menarik untuk diteliti.
Penelitian di bidang teknologi informasi terhadap bahasa daerah pun sangat kurang. Dokumen-dokumen dalam bahasa daerah sudah banyak yang berbentuk digital, namun belum banyak penelitian terhadap dokumen-dokumen bahasa daerah tersebut.
Salah satu metode untuk mengeksplorasi informasi dari dokumen- dokumen bahasa daerah adalah sistem temu kembali informasi. Dalam sistem temu kembali informasi dokumen-dokumen tersebut di-parse untuk mendapatkan
token. Hasil dari proses parsing ini nantinya adalah sebuah tabel indeks yang
merupakan kumpulan token-token.
Token adalah unsur terkecil dari suatu dokumen yang mempunyai arti.
Untuk meningkatkan kinerja dari sistem temu kembali informasi, token-token
tersebut dipilah-pilah kembali dan kata-kata yang tidak perlu dibuang. Selain itu untuk memperkecil ukuran indeks token yang disimpan dalam indeks harus berupa kata dasar saja. Proses untuk mencari kata dasar dengan cara membuang awalan, sisipan dan akhiran dari suatu kata disebut stemming. Dengan proses
yang kecil diharapkan kinerja dari sistem temu kembali informasi meningkat. Dengan stemming kata dahar (makan), dahareun (makanan), didahar (dimakan) akan disimpan dalam indeks sebagai kata dahar saja. Hal ini tentu saja sangat menghemat ukuran indeks.
Pada penelitian ini akan dicoba untuk mengeksplorasi stemming untuk bahasa Sunda. Dengan penelitian ini diharapkan lahir aplikasi-aplikasi sistem temu kembali informasi yang berkaitan dengan bahasa daerah khususnya bahasa Sunda.
1.2 Perumusan Masalah
Tata bahasa Sunda hampir mirip dengan tata bahasa Indonesia. Beberapa algoritme yang pernah diteliti oleh beberapa peneliti terhadap stemming bahasa Indonesia dapat diterapkan dalam proses mencari kata dasar terhadap bahasa Sunda dengan beberapa modifikasi. Dari sekian banyak algoritme stemming
bahasa Indonesia yang dihasilkan oleh para peneliti, beberapa peneliti sudah membandingkan bagaimana kinerja dari masing-masing algoritme stemming
bahasa Indonesia yang ada. Asian et al (2005) membandingkan algoritme
stemming Nazief dan Adriani dengan algoritme Arifin dan Setiono. Dari
penelitan tersebut diperoleh kesimpulan bahwa algoritme stemming Nazief dan Adriani menghasilkan kata-kata yang diharapkan sekitar 93% dari dokumen- dokumen ujinya. Jadi sampai sejauh ini penelitian yang memberikan hasil terbaik terhadap stemming bahasa Indonesia adalah penelitian yang dilakukan oleh Nasief dan Adriani.
Dalam algoritme stemming bahasa Indonesia, sebagian besar algoritme-
algoritme tersebut belum banyak mengeksplorasi tentang stemming terhadap sisipan dan kata ulang. Sisipan dan kata ulang dalam bahasa Indonesia tidak banyak mengubah bentuk kata. Selain itu tidak banyak kata dalam bahasa Indonesia yang dapat diberi sisipan.
Hal ini berbeda dengan sisipan dan kata ulang dalam bahasa daerah khususnya bahasa Sunda. Sisipan dan kata ulang dalam bahasa Sunda sangat produktif dan banyak kata dalam bahasa Sunda yang dapat diberi sisipan.
tata bahasa Sunda memiliki kerumitan tersendiri. Ada beberapa aturan dalam tata bahasa Sunda yang tidak ada dalam tata bahasa Indonesia, sehingga algoritme
stemmingnya pun akan mempuyai kerumitan tersendiri.
Jenis huruf dalam pembacaan dokumen juga berpengaruh terhadap proses
parsing dan pastinya berpengaruh juga pada proses stemmingnya. Pada penelitian
ini, dokumen bahasa Sunda yang diteliti adalah dokumen yang ditulis dalam huruf latin.
1.3 Ruang Lingkup
Dalam penelitian ini pembahasan difokuskan pada:
1. Algoritme stemming bahasa Sunda yang dibangun adalah algoritme yang didasarkan atas perbandingan dengan kamus.
2. Stemming bahasa Sunda yang diteliti adalah terhadap imbuhan (awalan,
akhiran, sisipan), imbuhan terbelah, imbuhan gabungan dan kata ulang.
1.4 Tujuan Penelitian
Penelitian ini bertujuan mengembangkan algoritme stemming berbasis kamus untuk dokumen-dokumen berbahasa Sunda.
1.5 Manfaat Penelitian
Penelitian terhadap algoritme stemming bahasa Sunda ini diharapkan dapat diaplikasikan untuk mencari kata dasar dalam dokumen-dokumen berbahasa Sunda dengan hasil yang paling optimal. Hasil dari pencarian kata dasar tersebut nantinya dapat digunakan untuk pengindeksan dokumen yang siap untuk digunakan oleh aplikasi-aplikasi dalam sistem temu kembali informasi khususnya untuk dokumen-dokumen berbahasa Sunda.
2. TINJAUAN PUSTAKA
2.1 Morfologi bahasa Sunda
Morfem adalah satuan bahasa terkecil yang mengandung makna (Zaenal & Junaiyah 2007). Terdapat dua macam morfem, yaitu morfem bebas dan morfem terikat. Morfem bebas adalah morfem yang berdiri sendiri misalnya: jual dan beuli. Sedangkan morfem terikat adalah morfem yang digabungkan dengan morfem lain. Contoh morfem terikat adalah: dijualbeulikeun. Kata tersebut dapat dipecah menjadi: jual beuli dan di- + … -keun}. Kata jual dan beuli adalah dua morfem bebas yang merupakan satuan terkecil yang tidak dapat dipecah lagi dan yang mempunyai arti. Bentuk di-, dan -keun juga tergolong morfem karena merupakan satuan terkecil yang mengandung makna.
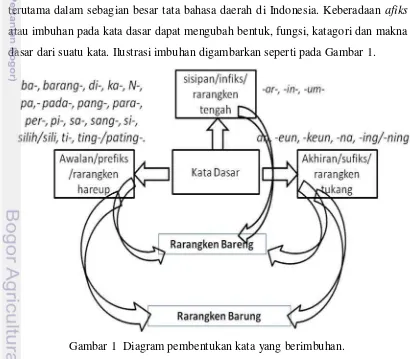
Imbuhan atau afiks mempunyai arti penting dalam suatu tata bahasa terutama dalam sebagian besar tata bahasa daerah di Indonesia. Keberadaan afiks
atau imbuhan pada kata dasar dapat mengubah bentuk, fungsi, katagori dan makna dasar dari suatu kata. Ilustrasi imbuhan digambarkan seperti pada Gambar 1.
2.1.1 Imbuhan (Afiks)
Bahasa Sunda memiliki imbuhan sama halnya seperti bahasa Indonesia. Ada lima macam imbuhan, yaitu rarangken hareup (awalan/prefiks), rarangken
tengah/seselan (sisipan//infiks), rarangken tukang/ahiran (akhiran/sufiks),
Rarangken barung (imbuhan terbelah/konfiks), dan rarangken bareng (imbuhan
gabungan/ambifiks) (Sudaryat et al. 2007).
2.1.1.1 Rarangken Hareup (Awalan)
Rarangken hareup adalah imbuhan yang terletak di awal kata. Rarangken
hareup pada bahasa Sunda yaitu: ba-, barang-, di-, ka-, N-, pa,- pada-, pang-,
para-, per-, pi-, sa-, sang-, si-, silih/sili, ti-, ting-/pating-.
1. Rarangken hareup ba- (contoh: balayar = berlayar, badarat = berjalan,
barempug=berdiskusi).
2. Rarangken hareup barang- (contoh: barangbeuli = sesuatu untuk dibeli,
baranginjeum = sesuatu yang dipinjam, barangdahar = sesuatu untuk
dimakan).
3. Rarangken hareup di- (contoh: digawe = bekerja, dibaju = memakai baju,
disada = berbunyi).
4. Rarangken hareup ka- (contoh: karasa = terasa, kabawa = terbawa, kageleng
= tergilas).
5. Rarangken hareup
N-Pada rarangken hareup N- (nasal) terdapat alomorf m-, n-, ng-, nga-, nge-,
dan ny-. Aturan rarangken hareup N- adalah sebagai berikut:
- Rarangken N- berubah menjadi m- apabila digunakan pada kata dasar yang
diawali konsonan b atau p (contoh: baca menjadi maca = membaca, pacul
- Rarangken N- berubah menjadi n- apabila digunakan pada kata dasar yang diawali konsonan t (contoh: tulis menjadi nulis = menulis, tanya menjadi
nanya = bertanya).
- Rarangken N- berubah menjadi ng- apabila digunakan pada kata dasar
yang diawali konsonan k atau huruf vokal (contoh: karang menjadi
ngarang = mengarang, aku menjadi ngaku = mengaku).
- Rarangken N- berubah menjadi nga- apabila digunakan pada kata dasar
yang diawali konsonan b, d, g, h, j, l, m, n, w, dan y (contoh: badug
menjadi ngabadug = terbentur, dulag menjadi ngadulag = menabuh bedug,
goler menjadi ngagoler = berbaring, hampas menjadi ngahampas =
meremehkan/membuat ampas), juru menjadi ngajuru = melahirkan, liang
menjadi ngaliang = membuat lubang, ma’lum menjadi ngama’lum = memaklumi, riung menjadi ngariung = berkumpul, wadul menjadi
ngawadul = berbohong).
- Rarangken N- berubah menjadi nge- apabila digunakan pada kata dasar
yang diawali konsonan dan hanya terdiri dari satu suku kata (contoh: cet
menjadi ngecet = mengecat, bor menjadi ngebor = mengebor).
- Rarangken N- berubah menjadi ny- apabila digunakan pada kata dasar
yang diawali konsonan c dan s (contoh: colok menjadi nyolok = menusuk,
sapih menjadi nyapih = menyapih).
6. Rarangken hareup pa- (contoh: tani menjadi patani (petani), tugas menjadi
patugas = petugas, takol menjadi panakol = pemukul).
7. Rarangken hareup pada- (contoh: kepung menjadi padangepung (sedang
mengepung), dagang menjadi padadagang (sedang dagang), kuat menjadi
padakuat (sama-sama kuat)).
8. Rarangken hareup para- (contoh: guru menjadi paraguru (guru-guru), siswa
9. Rarangken hareup per- (contoh: lambang menjadi perlambang (tanda-tanda),
watak menjadi perwatak)
10. Rarangken hareup pi- (contoh: tuduh menjadi pituduh (petunjuk), ruhak
menjadi piruhak (arang yang masih membara), tapak menjadi pitapak (jejak),
damel menjadi pidamel (mengerjakan))
11. Rarangken hareup sa- (contoh: rupa menjadi sarupa (serupa), kilo menjadi
sakilo=sekilo)
12. Rarangken hareup sang- (contoh: hulu menjadi sanghulu (kepala mengarah ke suatu arah), hareup menjadi sanghareup (mengarah ke depan).
13. Rarangken hareup si- (contoh: dakep menjadi sidakep (posisi tangan dilipat didepan perut (seperti posisi shalat)), deang menjadi sideang (memanaskan badan di perapian)).
14. Rarangken hareup silih- (contoh: teunggeul menjadi silihteunggeul (saling pukul), tajong menjadi silihtajong (saling tendang).
15. Rarangken hareup ti- (contoh: tajong menjadi titajong (tertendang), teuleum
menjadi titeuleum (tenggelam)).
16. Rarangken hareup ting-/pating- (contoh: gerendeng menjadi tinggerendeng
(beberapa orang saling berbicara tapi tidak terlalu keras), burinyay menjadi
tingburinyay (berkilatan)).
2.1.1.2 Rarangken Tengah (Sisipan)
Rarangken tengah adalah imbuhan yang disisipkan di tengah kata dasar,
Rarangken tengah pada bahasa Sunda yaitu: -ar-, -in-, -um-. Berikut adalah
penjelasan rincinya.
1. Rarangken tengah
-ar-Pada rarangken tengah -ar- terdapat alomorf -al-, -ar-, dan
1) Digunakan pada kata dasar yang diawali konsonan l (contoh: lieur
menjadi lalieur (pusing-pusing), leuleus menjadi laleuleus (lemas- lemas)).
2) Digunakan pada kata dasar yang diakhiri konsonan r (contoh: bageur
menjadi balageur (banyak yang baik hati), pinter menjadi palinter
(banyak yang pintar).
3) Digunakan pada kata dasar yang mengandung konsonan gabung br, tr,
cr, kr, pr, jr, dan dr (contoh: kempreng menjadi kalempreng (tangan-
tangan yang kaku), gombrang menjadi galombrang (pakaian yang kedodoran)).
- Rarangken tengah -ar- berubah menjadi ar- apabila digunakan pada kata
dasar yang diawali huruf vokal (contoh: asup menjadi arasup (banyak yang masuk), ulin menjadi arulin (banyak yang main)).
- Rarangken tengah -ar- berubah menjadi ra- apabila digunakan pada kata
dasar yang hanya terdiri dari satu suku kata dan diawali huruf konsonan (contoh: cleng menjadi racleng (berloncatan), beng menjadi rabeng
(berterbangan)).
2. Rarangken tengah -in- (contoh: tulis menjadi tinulis (tertulis/ditulis), panggih
menjadi pinanggih (bertemu), sareng menjadi sinareng (bersama)).
3. Rarangken tengah -um- (contoh: sujud menjadi sumujud (bersujud), gantung
menjadi gumantung (tergantung), lengis menjadi lumengis (memelas-melas)).
Pada rarangken tengah -um- terdapat alomorf um-, yang terjadi apabila digunakan pada kata dasar yang diawali huruf vokal (contoh: amis menjadi
umamis (macam-macam manis), aing menjadi umaing (egois)).
2.1.1.3 Rarangken Tukang (Akhiran)
Rarangken tukang adalah imbuhan yang diletakkan pada akhir kata dasar.
Rarangken tukang pada bahasa Sunda yaitu: -an, -eun, -keun, -na, -ing/-ning.
1. Rarangken tukang -an (contoh: sakola menjadi sakolaan (sekolahan), tulis
menjadi tulisan (tulisan), omong menjadi omongan (omongan), meter
menjadi meteran (meteran).
2. Rarangken tukang -eun (contoh: dahar menjadi dahareun (untuk dimakan),
rujak menjadi rujakeun (untuk dirujak)).
3. Rarangken tukang -keun (contoh: kawih menjadi kawihkeun (nyanyikan),
gambar menjadi gambarkeun (gambarkan), tiung menjadi tiungkeun
(kerudungkan)).
4. Rarangken tukang -na
Pada Rarangken tukang -na terdapat alomorf -ana dan -nana
- Rarangken -na berubah menjadi -ana apabila:
1) Digunakan pada kata dasar yang sudah ditambahkan akhiran -eun
(contoh: bawa menjadi bawaeunana (hal yang harus dibawanya),
dahar menjadi dahareunana (makan yang harus dimakanannya)).
2) Digunakan pada kata dasar yang sudah ditambahkan akhiran -an
(contoh: tilu menjadi tiluanana = ketiga-tiganya, kabeh menjadi
kabehanana (semuanya)).
3) Digunakan pada kata dasar yang sudah ditambahkan akhiran -keun
(contoh: catet menjadi nyatetkeunana (mencatatkannya), bawa
menjadi mawakeunana (membawakan untuk orang lain)).
- Rarangken -na berubah menjadi -nana apabila digunakan pada kata dua
dan eta (contoh: dua menjadi duanana (kedua-duanya), eta menjadi
etanana (menunjukkan itu)).
5. Rarangken tukang -ing/-ning (contoh: bakat menjadi bakating (karena
terlalu),kersaning menjadi kersaning (keinginan, kehendak), awah menjadi
Rarangken -ing digunakan pada kata yang diakhiri konsonan (contoh:
mungguh menjadi munguhing (sesungguhnya), bakat menjadi bakating
(karena terlalu) sedangkan rarangken tengah -ning digunakan pada kata yang diakhiri vokal (contoh: estu menjadi estuning (sebenarnya), kersa menjadi
kersaning (ketentuan = kehendak)).
2.1.1.4 Rarangken Barung (Imbuhan Terbelah)
Rarangken barung adalah imbuhan yang dipakai di awal dan atau di akhir
kata dasar secara bersamaan. Ciri utama rarangken barung adalah apabila salah satu imbuhan (awalan atau akhiran) dihilangkan, kata tersebut tidak dapat berdiri sendiri. Rarangken barung pada bahasa Sunda yaitu: ka- -an, kapi-, pa- -an,
pang--na pang- -keun, pi- -eun, pika-, pika- -eun, sa- pang--na, dan sa- -eun.
1. Rarangken barung ka- -an (contoh: kaamanan = keamanan, kaolahan =
masakan, kaperluan = keperluan)
2. Rarangken barung kapi- (contoh: kapimilik = milik, kapiraray = selalu
terkenang-kenang)
3. Rarangken barung pa- -an (contoh: paguyuban = perkumpulan, pamandian =
kolam renang, pausahaan = perusahaan)
4. Rarangken barung pang- -na (contoh: panggeulisna = tercantik, pangagulna
= paling sombong, pangpinterna = paling pintar)
5. Rarangken barung pang- -keun (contoh: pangmawakeun = tolong bawakan,
pangdongengkeun = tolong ceritakan)
6. Rarangken barung pi- -eun (contoh: pibajueun = bahan baju, pigeuliseun =
akan cantik, pigedeeun = akan besar)
7. Rarangken barung pika- (contoh: pikareueus = membuat bangga,
pikameumeut = selalu rindu)
8. Rarangken barung pika- -eun (contoh: pikabungaheun = membuat gembira,
9. Rarangken barung sa- -na (contoh: salilana = selamanya, sakabehna = semuanya, sawaregna = sekenyangnya)
10. Rarangken barung sa- -eun (contoh: satujueun = setuju, sahadapeun = lebih
bawah, samobileun = untuk satu mobil)
2.1.1.5 Rarangken Bareng (Imbuhan Gabungan)
Rarangken bareng adalah imbuhan gabungan dari dua atau lebih imbuhan
sebelumnya. Rarangken bareng pada bahasa Sunda yaitu: + -ar-, + -an, di-+ -ar- di-+ -an, di- di-+ -keun, di- di-+-ar- di-+ -keun, di- di-+ -pi, di- di-+ -pika, di- di-+ pang- di-+ -
keun, di- + pang- + N- + -keun, di- + pang- + N- + -ar- + -keun, di- + pang- +
N- + -ar- +-an +-keun, N- + -ar-, N- + -an, N- + -ar- + -keun, N- + -pi-, N- + -
, N- + pang- + -keun-, pa- + N-, pang- + di + -na, pang- + N- +
pika-+ -na, ting- pika-+ -ar-.
1. Rarangken bareng di- + -ar, contoh: diparacul = dicangkul oleh banyak
orang, ditarajong = ditendang oleh banyak orang.
2. Rarangken bareng di- + -an, contoh: dimandian = dimandikan, dibajuan =
dipakaikan baju.
3. Rarangken bareng di- + -ar- + -an, contoh: diparaculan = dicangkul
(jamak), ditarajongan = ditendang-tendang.
4. Rarangken bareng di- + -keun, contoh: dihurungkeun = dinyalakan,
dimakamkeun = dikuburkan.
5. Rarangken bareng di- +-ar- + -keun, contoh: dilalieurkeun = dibuat pusing.
6. Rarangken bareng di- + -pi, contoh dipiwarang =disuruh, dipidamel =
dikerjakan, dipirojong = didorong, dipireueus = dikasihani.
7. Rarangken bareng di- + -pika, contoh: dipikaresep = disenangi, dipikasieun =
ditakuti, dipikanyaah = disayangi, dipikatineung = teringat selalu.
8. Rarangken bareng di- + pang- + -keun, dipangdamelkeun = dikerjakan oleh
9. Rarangken bareng di- + pang- + N- + -keun, contoh: dipangmeulikeun = dibelikan oleh orang lain, dipangnuliskeun = dituliskan oleh orang lain.
10. Rarangken bareng di- + pang- + N- + -ar- + -keun, contoh:
dipangmaraculkeun = dicangkulkan oleh orang lain.
11. Rarangken bareng di- + pang- + N- + -ar- +-an +-keun, contoh:
dipangnaruliskeun = dituliskan oleh orang lain.
12. Rarangken bareng N- + -ar-, contoh: nyarapu = menyapu, narulis = menulis.
13. Rarangken bareng N- + -an, contoh: nyapuan = menyapui, nulisan =
menulisi.
14. Rarangken bareng N- + -ar- + -keun, contoh: maraculkeun = dicangkulkan,
naruliskeun = dituliskan.
15. Rarangken bareng N- + -pi-, contoh: mieling = diingatkan, miindung =
dijadikan ibu.
16. Rarangken bareng N- + -pika-, contoh: mikaeling = saling diingatkan,
mikahayang = saling ingin, mikatineung = saling rindu.
17. Rarangken bareng N- + pang- + -keun-, contoh: manghanjakalkeun =
menyayangkan.
18. Rarangken bareng pa- + N-, contoh: panumbak = sesuatu buat menombak,
panakol = sesuatu untuk memukul.
19. Rarangken bareng pang- + dipika- + -na, contoh: pangdipikanyaahna = yang
paling disayang.
20. Rarangken bareng pang- + N- + pika- + -na, contoh: pangmikameumeutna =
paling dirindukan.
2.1.2 Kata Ulang
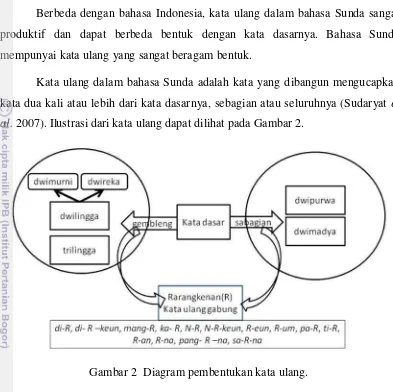
Berbeda dengan bahasa Indonesia, kata ulang dalam bahasa Sunda sangat produktif dan dapat berbeda bentuk dengan kata dasarnya. Bahasa Sunda mempunyai kata ulang yang sangat beragam bentuk.
Kata ulang dalam bahasa Sunda adalah kata yang dibangun mengucapkan kata dua kali atau lebih dari kata dasarnya, sebagian atau seluruhnya (Sudaryat et al. 2007). Ilustrasi dari kata ulang dapat dilihat pada Gambar 2.
Gambar 2 Diagram pembentukan kata ulang.
Kata ulang dalam bahasa Sunda dapat dibagi menjadi dua yaitu gembleng dan
sabagian. Kata ulang juga dapat diberi imbuhan yang dalam bahasa Sunda diberi
nama rarangkenan.
2.1.2.1 Gembleng (seluruhnya)
Kata ulang gembleng (seluruhnya) dibagi lagi menjadi dua yaitu:
1. Dwilingga: Kata ulang dwilingga dibangun dengan cara mengucapkan dua
kali dari kata dasarnya. Terdapat dua dwilingga yaitu:
a. Dwimurni: kata dasar yang diulang tidak berubah, contohnya: bapa
b. Dwireka: kata dasar yang diulang berubah bunyi, contohnya: tajong
(tendang) menjadi tujang-tajong (tendang-tendang).
2. Trilingga: kata dasar diulang tiga kali, dan selalu berubah bunyi, contohnya:
plak-plik-pluk.
2.1.2.2 Sabagian (sebagian)
Kata ulang sabagian (sebagian) dibangun dengan cara mengulang kembali salah satu suku kata dasarnya. Ada dua bentuk kata ulang sabagian, yaitu:
1. dwipurwa, yaitu jika suku kata yang diulang adalah suku kata pertama,
contohnya: tajong (tendang) menjadi tatajong,
2. dwimadya, yaitu jika suku kata yang diulang ada di tengah kata, contohnya:
sabaraha (berapa) menjadi sababaraha.
2.1.2.3 Rarangkenan (kata ulang gabungan)
Kata ulang gembleng atau sabagian dapat digabung dengan imbuhan. Gabungan kata ulang dengan imbuhan dapat mempunyai bentuk sebagai berikut:
1. Rarangkenan di-R, suatu kata ulang dalam bentuk dwimurni atau dwireka
dan dwipurwa dapat diberi awalan di-. Contoh untuk bentuk ini adalah:
rasa menjadi dirasa-rasa, pikir manjadi dipikir-pikir, riung menjadi
diriung-riung (dikelilingi oleh banyak orang), dirarasa, dipipikir,
diririung.
2. Rarangkenan di-R-keun. Kata ulang dalam bentuk dwimurni, dwireka dan
dwipurwa dapat diberi awalan di- dan akhiran -keun, contohnya adalah:
asup menjadi diasup-asupkeun (dimasuk-masukkan), tawar menjadi
ditatawarkeun (ditawar-tawarkan).
3. Rarangkenan mang-R. Kata ulang dwilingga dapat diberi awalan mang-,
dengan contohnya adalah sebagai berikut: kata taun menjadi mangtaun-
4. Rarangkenan ka-R. Kata ulang dalam bentuk dwilingga (dwireka dan
dwimurni) dan dwipurwa dapat diberi awalan ka- dengan contoh sebagai
berikut: kata ombak menjadi kaombak-ombak (kena ombak), kata seuit
menjadi kaseuit-seuit, kata candak menjadi kacacandak.
5. Rarangkenan N-R. Kata ulang dalam bentuk dwilingga (dwireka dan
dwimurni) dapat diberi nasal (N-). Contohnya adalah sebagai berikut: kata
tunggu menjadi nunggu-nunggu (menunggu-nunggu), kata beda menjadi
ngabeda-beda (membeda-bedakan).
6. Rarangkenan N-R-keun. Kata ulang dwimurni dapat diberi nasal (N-) dan
akhiran -keun, contohnya adalah sebagai berikut: kata asup menjadi
ngasup-ngasupkeun (memasuk-masukan), kata sorot menjadi nyorot-
nyorotkeun (menyorot-nyorotkan).
7. Rarangkenan R-eun. Kata ulang dwipurwa dapat mendapat akhiran -eun.
Contohnya adalah sebagai berikut: kata lini (gempa) menjadi lilinieun
(terasa sepeti gempa), kata jauh menjadi jajauheun (terasa jauh)
8. Rarangkenan R-um. Kata ulang dwilingga juga bisa diberi sisipan -um-,
contohnya adalah sebagai berikut: kata tuluy (terus) menjadi tuluy-tumuluy
(keterus-terusan)
9. Rarangkenan pa-R. Kata ulang dwilingga dapat diberi awalan pa-,
contohnya adalah sebagai berikut: kata tarik menjadi patarik-tarik (saling menarik), palaun-laun (saling lambat-lambat).
10. Rarangkenan ti-R. Kata ulang dengan bentuk dwipurwa dapat diberi
awalan ti-, contohnya adalah sebagai berikut: tipoporose, tipaparetot.
11. Rarangkenan R-an. Kata ulang dengan bentuk dwilinga dan dwipurwa
dapat diberi akhiran -an, contohnya adalah: kata layar menjadi lalayaran
12. Rarangkenan R-na. Kata ulang dwilingga dan dwipurwa dapat diberi akhiran -na, contohnya adalah sebagai berikut: kata gede (besar) menjadi
gegedena (yang besarnya), dalit (sahabat) menjadi dalit-dalitna (sahabat-
sahabatnya).
13. Rarangkenan pang-R-na. Kata ulang dwilingga dapat diberi awalan pang-
dan akhiran -na. Contohnya adalah sebagai berikut: alus (bagus) menjadi
pangalus-alusna (yang terbagus), bageur (baik hati ) menjadi pangbageur-
bageurna (yang terbaik hati).
14. Rarangkenan sa-R-na. Kata ulang dwilingga dapat diberi awalan sa- dan
akhiran -na. Contohnya adalah sebagai berikut: hade (bagus) menjadi
sahade-hadena (sebagus-bagusnya), bisa menjadi sabisa-bisana (sebisa-
bisanya).
2.2 Stemming
Stemming adalah proses penghilangan prefiks, infiks dan sufiks dari suatu
kata. Stemming dilakukan atas dasar asumsi bahwa kata-kata yang memiliki stem
yang sama memiliki makna yang serupa sehingga pengguna tidak keberatan untuk memperoleh dokumen-dokumen yang di dalamnya terdapat kata-kata dengan stem
yang sama dengan query-nya. Proses stemming tersebut dapat diilustrasikan dengan Gambar 3.
Gambar 3 Ilustrasi proses stemming. Teknik-teknik stemming dapat dikategorikan menjadi:
- berdasarkan kamus,
- berdasarkan kemunculan bersama.
Stemming dalam sistem temu kembali informasi tergantung pada bahasa
yang digunakan dalam dokumen yang akan dicari. Algoritme stemming untuk bahasa Inggris kurang optimal untuk menangani dokumen dalam bahasa Indonesia. Selain itu bahasa Indonesia pastinya juga memiliki daftar kata buang
(stoplist) serta sistem pembentukan kata yang sangat berbeda dengan bahasa
Inggris, sehingga diperlukan algoritme stemming yang khusus untuk bahasa Indonesia. Demikian juga untuk bahasa Sunda, juga diperlukan algoritme
stemming khusus untuk mencari kata dasar dari suatu kata dalam bahasa Sunda.
Terdapat bermacam-macam jenis stemmer, di antaranya adalah: stemmer
infleksional yaitu stemmer yang membuang imbuhan (inflection) dari kata dengan
menggunakan aturan tata bahasanya. Contoh dari stemmer ini adalah stemmer
yang menggunakan algoritme Potter. Algoritme stemmer infleksional dalam bahasa Indonesia salah satunya diteliti oleh Adriani et al. (2007). Jenis stemmer
yang lain adalah stemmer corpus-based, yaitu stemmer yang menggunakan koleksi dokumen untuk mendapatkan kata dasar dari sebuah kata.
Siregar (1995) dalam penelitiannya menyatakan, untuk mendapatkan kata dasar dari suatu kata berimbuhan, dilakukan proses stemming dan untuk menguji apakah kata hasil stemming tersebut valid maka kata tersebut dibandingkan dengan Kamus Besar bahasa Indonesia. Adriani et al. (2007), meneliti stemmer
morfologi untuk bahasa Indonesia dengan mengemukakan algoritme stemming
yang juga membandingkan kata yang akan di-stem dengan Kamus Besar bahasa Indonesia. Pada penelitian lainnya, Ichsan (1996) mengemukakan teknik stemmer
corpus-based dengan menggunakan statistic co-occurace dari variasi kata untuk
2.3 Kesalahan Stemming
Menurut Paice (1996), terdapat dua jenis kesalahan dalam stemming, yaitu:
1. Understemming, adalah proses stemming yang menghasilkan kata yang tidak
terkelompok dalam satu kelompok atau kelas. Hal ini menyebabkan konsep tunggal yang tersebar di beberapa hasil stem yang berbeda. Misalnya terdapat kata-kata sebagai berikut: disanghareupeunana, sanghareupeun, hareup,
hareupeun, nyanghareup. Kata yang diharapkan setelah proses stemming
adalah hareup, akan tetapi ternyata setelah proses stemming hasilnya adalah
sanghareup, hareup dan nyanghareup.
2. Overstemming, adalah proses stemming yang menghasilkan kata namun kata
tersebut seharusnya tidak diletakan dalam kelompok atau kelas tertentu. Pada proses stemming ternyata kata tersebut dimasukan dalam kelompok lainnya. Contoh overstemming adalah: kata cina menghasilkan ci, kata tini
menghasilkan ti, dan lain-lain.
Algoritme stemming yang lebih banyak menghasilkan understemming
dibandingkan overstemming dikatagorikan dalam algoritme light stemming, Sedangkan algoritme stemming yang lebih banyak menghasilkan overstemming
3. METODOLOGI PENELITIAN
3.1 Kerangka Penelitian
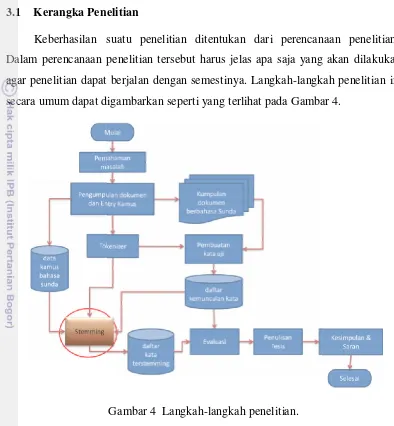
Keberhasilan suatu penelitian ditentukan dari perencanaan penelitian. Dalam perencanaan penelitian tersebut harus jelas apa saja yang akan dilakukan agar penelitian dapat berjalan dengan semestinya. Langkah-langkah penelitian ini secara umum dapat digambarkan seperti yang terlihat pada Gambar 4.
Gambar 4 Langkah-langkah penelitian. 3.2 Prosedur Penelitian
Berdasarkan langkah-langkah penelitian pada Gambar 4, tahapan penelitian yang dilakukan pada tiap langkah diuraikan pada pembahasan selanjutnya.
3.2.1 Tahap Pemahaman Masalah
wawancara dengan nara sumber yang kompeten yaitu Bapak Dr. Yayat Sudaryat, M.Hum. (dosen Sastra Sunda Universitas Pendidikan Indonesia)
3.2.2 Tahap Pengumpulan Dokumen dan Pemasukan Data Kamus
Dokumen-dokumen dalam bahasa Sunda digunakan untuk pengujian pada tahap evaluasi stemming. Dokumen uji yang terkumpul adalah sebanyak 130 dokumen berbahasa Sunda dengan topik yang beragam. Topik dokumen berisi tentang sejarah, budaya, agama, berita dan lain-lain. Seluruh dokumen yang terkumpul, format penulisan dokumen kemudian diubah menjadi bentuk teks. Hal ini untuk memudahkan pembacaan dokumen oleh tokenizer.
Data kamus diperlukan untuk pembandingan kata pada proses stemming. Untuk memasukan data kamus, sumber data didapat dari Kamus Lengkep Sunda- Indonesia Indonesia Sunda Sunda-Sunda (Tamsyah 1996) dan dilengkapi dengan kamus Sunda – Indonesia (Satjadibrata 2011). Dari hasil pemasukan data kamus tersebut didapat 8 234 kata.
3.2.3 Tahap Perancangan Tokenizer
Tokenizer akan membaca kata per kata dari dokumen. Modul tokenizer
akan menerima masukan berupa dokumen dan keluarannya adalah kumpulan kata atau token. Tokenizer akan mengabaikan tanda baca, dan tanda-tanda lainnya yang tidak diperlukan. Tokenizer akan membaca dokumen dalam bentuk teks atau HTML. Program selengkapnya tokenizer dapat dilihat pada Lampiran 1.
3.2.4 Tahap Pembuatan Kata Uji dari Dokumen
Pada tahap ini, dokumen yang terkumpul akan dicari token atau kata yang ada dalam dokumen tersebut. Pembuatan kata uji ini akan menggunakan tokenizer
Kata uji ini akan digunakan untuk pengujian algoritme stemming yang dirancang. Selanjutnya kata hasil stemming akan dievaluasi apakah hasil stemming
sesuai dengan kata yang diharapkan.
3.2.5 Tahap Pembuatan Stoplist
Pada tahapan ini akan dibuang semua kata-kata dalam bahasa Sunda yang kurang memiliki arti. Pembuatan daftar stoplist dibuat secara manual. Kata-kata yang kurang berarti yang ditemukan, akan dimasukan dalam database stoplist. Daftar stoplist ini dikelompokan dalam kelompok sepeti terlihat pada Tabel 1.
Tabel 1 Daftar stoplist
Jenis Kata Contoh
Kata Tanya saha, naon, mana, naha, iraha, kumaha, sabaraha
Kata Penunjuk ieu, eta, dieu, kieu
Kata Sambung jeung, sareng, nepi, jaba, lian, nu, lamun, tapi, atawa, atanapi, tuluy, terus, teras, yen, majar, nu, anu, matak, majar
teh, mah, seug, heug, mun, boa, ketah, ketang, pisan,
Kata Lainnya sok, nu, anu
Kata Pangwates bae, be, wae, we, weh, mung, ngan, ukur, keur, nuju, masih, keneh, pikeun, kanggo
Kata Sabab/Slesan da, kapan, kapanan, apan, pan, apanan
Kata Wengkuan deui, deuih, ge, oge,ongkoh
Kata Matotoskeun nya, nyah, enya, lain, sanes
3.2.6 Tahap Perancangan Stemming
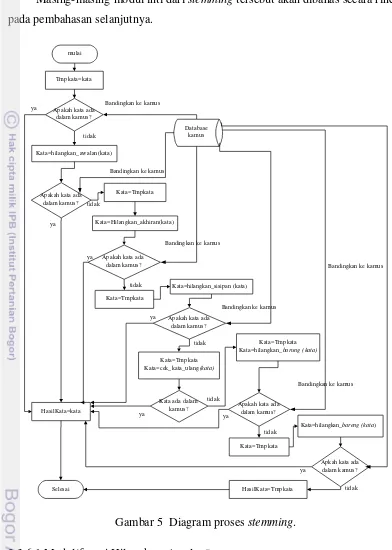
Proses stemming akan menghilangkan awalan (rarangken hareup), sisipan
(rarangken tengah), akhiran (rarangken tukang), kata imbuhan terbelah
(rarangken barung), dan kata gabungan (rarangken bareng). Selain itu algoritme
stemming juga akan menguji apakah kata adalah kata ulang. Algoritme stemming
yang dirancang berbentuk flowchart, seperti yang ada pada Gambar 5. Pada
flowchart tersebut terlihat inti dari algoritme tersebut adalah pada proses
Masing-masing modul inti dari stemming tersebut akan dibahas secara rinci
dalam kamus? Bandingkan ke kamus
tidak
Selesai HasilKata=Tmpkata tidak
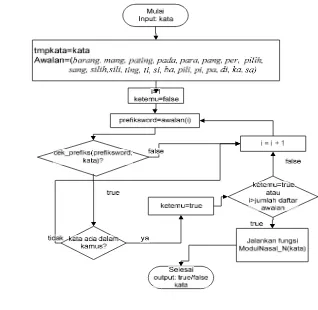
Gambar 5 Diagram proses stemming. 3.2.6.1 Modul/fungsi Hilangkan_Awalan()
si-, silih/sili, ti-, ting-/pating-. Modul/fungsi pengujian ini diberi nama
Cek_Prefiks().
Fungsi Cek_Prefiks() ini akan mendapat masukan berupa kata awalan dan kata yang akan diuji. Keluarannya adalah berupa tipe data boolean true/benar atau
false/salah. Jika kata yang akan di-stem mengandung awalan yang disebut di atas,
maka fungsi Cek_Prefiks() akan bernilai true/benar dan keluaran lainnya adalah, variabel kata akan berisi kata yang sudah dihilangkan awalannya. Sebagai contoh diberikan kata barangbeuli (sesuatu untuk dibeli). Fungsi Cek_Prefiks() akan berbentuk Cek_Prefiks(“barang”,kata). Parameter pada fungsi Cek_prefiks() yaitu prefiksword akan berisi “barang” dan kata akan berisi “barangbeuli”. Selanjutnya fungsi Cek_Prefiks(“barang”, kata) akan menguji apakah awalan dari kata tersebut adalah “barang”, jika ya maka akan dihilangkan awalan tersebut sehingga sekarang variabel kata berisi “beuli”. Bentuk modul/fungsi Cek_Prefiks() ini seperti terlihat pada Gambar 6.
Fungsi Cek_Prefiks(prefiksword As String, kata As String) : Boolean n = Length(kata)
i = Length(prefiksword)
kt = Left(kata, i) //kt = Awalan dari kata
If (kt = prfiksword) Then //Dibandingkan antara kt dengan awalan
kata= Right(kata, n - i) //Jika benar kata=kata yang sdh
// dihilangkan akhirannya
Gambar 6 Fungsi Cek_Prefiks().
Algoritme dari modul/fungsi Hilangkan_ Awalan() ini dapat dilihat pada Gambar 7. Pada algoritme tersebut terlihat ada modul/fungsi yang berguna untuk menguji apakah kata mengandung nasal (N-), yaitu ModulNasal_N(). Algoritme untuk ModulNasal_N adalah sebagai berikut:
Gambar 7 Fungsi Hilangkan_Awalan().
- Jika tidak mengandung prefiks “nga”, uji lagi apakah mengandung prefiks “nge”, bandingkan lagi dengan kamus.
- Jika tidak mengandung “nge” uji apakah huruf awalnya adalah “m”, jika ya maka ganti huruf awal dengan huruf “b” atau “p” masing-masing penggantian huruf hasilnya dibandingkan dengan kamus.
- Jika tidak mengandung huruf awal “m”, maka uji lagi apakah dua huruf awal = “ny”, jika ya maka ganti huruf awal dengan huruf “c” atau “s” masing- masing penggantian huruf hasilnya dibandingkan dengan kamus.
- Jika tidak mengandung dua huruf “ny” maka uji apakah huruf awal = “n” jika ya ganti huruf awal dengan “t” dan bandingkan dengan kamus.
3.2.6.2 Modul/fungsi Hilangkan_Akhiran()
Sama seperti modul/fungsi Hilangkan_Awalan(), modul/fungsi Hilangkan_Akhiran() juga memerlukan fungsi pembantu lain untuk menguji apakah suatu kata mengandung akhiran. Akhiran yang akan diuji adalah: -an, -
eun, -keun, -na, -ing/-ning.
Modul/fungsi pengujian akhiran ini diberi nama Cek_Sufiks(). Modul ini menerima masukan berupa kata akhiran seperti yang disebut di atas dan kata yang akan dihilangkan akhirannya. Sebagai contoh akan diuji kata acukna (bajunya), yang mempunyai kata dasar acuk (baju) dan diberi akhiran -na. Fungsi Cek_Sufiks() akan berbentuk: Cek_Sufiks(“na”,”acukna”). Tugasnya membandingkan apakah ada akhiran -na pada kata “acukna”. Fungsi Cek_Sudiks akan menghasilkan true (benar) jika ada akhiran -na, serta menghilangkan akhiran -na pada kata acukna sehingga didapat kata dasar acuk. Bentuk algoritme Cek_Sufiks() ini adalah seperti terlihat pada Gambar 8.
Fungsi Cek_Sufiks(sufiksword As String, kata As String) : Boolean n = Length(kata)
i = Length(sufiksword)
kt = Right(kata, i) //kt = akhiran dari kata
If (kt = sufiksword)Then //Dibandingkan antara kt dengan akhiran kata= Left(kata, n - i) //Jika benar kata=kata yang sdh
// dihilangkanakhirannya
Gambar 8 Fungsi Cek_Sufiks().
2)
Pada modul/fungsi Hilangkan_Sisipan() ini terdapat aturan-aturan seperti yang dibahas pada Bab 2. Aturan-aturan tersebut diterapkan dalam algoritme seperti pembahasan di bawah ini:
1) Digunakan pada kata dasar yang diawali konsonan “l”, contoh: kata lieur
menjadi lalieur (pusing-pusing), leuleus menjadi laleuleus (lemas-lemas). Algoritme untuk aturan tersebut terlihat pada Gambar 9.
If Cek_Prefiks("l", kata) Then //Jika huruf pertama adalah huruf //“l” maka
If Cek_Prefiks("al",kata) Then //diuji lagi apakah huruf //berikutnya=al
gab = "l" + kata //jika ya ganti al dengan huruf “l”
If ReadKamus(gab)Then //bandingkan dengan kamus kata = gab
Gambar 9 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang diawali dengan huruf “l”.
Untuk lebih jelasnya diberi contoh sebagai berikut. Misalnya akan diuji untuk kata lalieur. Pengujian Cek_Prefiks("l", kata) akan memberikan hasil
true dan kata berubah menjadi “alieur”. Pengujian berikutnya yaitu
Cek_Prefiks("al", kata) maka akan memberikan nilai true juga dan kata akan menjadi “ieur”. Perintah gab = "l" + kata akan menambahkan huruf “l” pada kata “ieur” sehingga didapat kata “lieur” yang selanjutnya akan dibandingkan dengan kamus.
2) Digunakan pada kata dasar yang diakhiri konsonan “r” contoh: bageur
4) 5)
If Cek_Sufiks("r", kata)Then //Apakah huruf terkahir adalah “r”
kata = dummy //kata dikembalikan ke bentuk semula
If InStr(kata, "al") Then //uji apakah kata mengandung “al” kata = Replace(kata, "al", "") //hilangkan “al” dalam kata
If ReadKamus(kata) Then //Bandingkan dengan kamus
infiks = True
Gambar 10 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang diawali dengan huruf “r”.
Pada modul ini terdapat sebuah variabel yang disebut dummy, yang fungsinya untuk mencatat kata sebelum diubah bentuknya. Variebel dummy ini berfungsi untuk mengembali kata menjadi bentuk semula jika diperlukan. Kata yang diberikan akan diuji apakah mempunyai huruf akhir “r” jika ya maka kata=dummy dan diuji lagi apakah kata mengandung suku kata “al”. Jika ya maka hilangkan suku kata “al” dan cari kata dalam kamus. Jika kata tidak ditemukan dalam kamus maka variabel infiks akan bernilai false dan variabel kata dikembalikan menjadi bentuk semula.
3) Digunakan pada kata dasar yang mengandung konsonan gabung br, tr, cr, kr,
pr, jr, dan dr, contoh: kempreng menjadi kalempreng (tangan-tangan yang
kaku), gombrang menjadi galombrang (pakaian yang kedodoran). Algoritme untuk aturan ini terlihat seperti pada Gambar 11.
If infiks_ar("tr br cr kr pr jr dr", kata) Then gab = Replace(kata, "al", "")
kata = gab infiks = True ....
End if
Kata yang diberikan, akan diuji apakah mengandung gabungan huruf "tr”,
barudak (anak-anak), diperlukan fungsi pembantu untuk menguji apakah
suatu kata mengandung suku kata “ar”. Fungsi tersebut memiliki bentuk seperti yang ditunjukkan pada Gambar 12.
Fungsi in_str_ar(kata) : Boolean
Sedangkan penggalan algoritme untuk mengatasi rarangken tengah “ar” ini adalah seperti yang terlihat pada Gambar 13.
If in_str_ar(kata) Then kata = dummy
kata = Replace(kata, "ar", "") If ReadKamus(kata) Then
Gambar 13 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata “ar”.
5) Rarangken tengah -ar- berubah menjadi ra- apabila digunakan pada kata
(berterbangan). Algoritme untuk aturan tersebut terlihat seperti pada Gambar 14.
If Cek_Prefiks("ra", kata) Then kata = Replace(kata, "ra", "") If ReadKamus(kata) Then
Gambar 14 Bagian algoritme Hilangkan_Sisipan() untuk aturan kata yang mengandung suku kata “ra”.
6) Rarangken tengah -in-, contoh: tulis menjadi tinulis (tertulis/ditulis), panggih
menjadi pinanggih (bertemu), sareng menjadi sinareng (bersama).
Rarangken tengah -in- ini juga memerika fungsi pembantu yang berfungsi
untuk menguji apakah sutu kata mengandung suku kata “in”. Fungsi tersebut memiliki bentuk seperti terlihat pada Gambar 15.
Fungsi infiks_in(kata As String) : Boolean
in1 = Mid(kata, 2, 2) //ambil huruf kedua kata sebanyak 2 //huruf
Penggalan algoritme untuk mencari apakah kata mengandung suku kata “in”
adalah seperti terlihat pada Gambar 16.
If infiks_in(kata) Then
kata = Replace(kata, "in", "") If ReadKamus(kata) Then
Rarangken tengah -um-, contoh: sujud menjadi sumujud (bersujud), gantung
menjadi gumantung (tergantung), lengis menjadi lumengis (memelas-melas) Pada
Rarangken tengah -um- terdapat alomorf um-, yang terjadi apabila digunakan
pada kata dasar yang diawali huruf vokal, contoh: amis menjadi umamis (macam- macam manis), aing menjadi umaing (egois). Untuk mengatasi rarangken tengah
“-um-“ ini juga diperlukan fungsi pembantu yang bertugas untuk menguji apakah kata mengandung suku kata “um” baik di awal kata maupun di tengah kata. Bentuk dari fungsi tersebut seperti terlihat pada Gambar 17. Sedangkan penggalan algoritme untuk rarangken tengah “-um-” seperti yang ditunjukkan pada Gambar 18. Algoritme selengkapnya untuk modul/fungsi Hilangkan_Sisipan() dapat dilihat pada Lampiran 2.
Fungsi In_Str_Um(kata As String) As Boolean um1 = Left(kata, 2)
If In_Str_Um(kata) <> 0 Then kata = Replace(kata, "um", "") If ReadKamus(kata) Then
3.2.6.4 Modul/fungsi Hilangkan_Barung()
Pada modul/fungsi Hilangkan_Barung() ini juga harus memenuhi aturan- aturan seperti yang dibahas pada Bab 2. Misalnya untuk aturan yang berakhiran “eun”, ternyata akhiran “-eun” ini mempunyai banyak aturan pada awalannya, contohnya: Rarangken barung sa- -eun (contoh: satujueun = setuju, sahandapeun
= lebih bawah, samobileun = untuk satu mobil), Rarangken barung pika- -eun
(contoh: pikabungaheun = membuat gembira, pikasebeleun = menyebalkan, pikanyaaheun = membuat jadi sayang), Rarangken barung pi- -eun (contoh:
pibajueun = bahan baju, pigeuliseun = akan cantik, pigedeeun = akan besar)
Algoritme untuk rarangken barung yang memiliki pola seperti di atas, mula-mula akan diuji apakah akhiran dari kata yang diberikan adalah “eun”. Jika ya, maka selanjutnya diuji satu per satu apakah kata memiliki awalan pi-, pika- atau sa-. Sehingga algoritme dengan pola seperti ini adalah penggalan algoritme yang terlihat seperti pada Gambar 19. Algoritme selengkapnya untuk modul/fungsi Hilangkan_Barung() ini dapat dilihat pada Lampiran 2.
If (Cek_Sufiks("eun", kata)) Then
If Cek_Prefiks("pika", kata) Then 'jika barung = pika- -eun Hilangkan_Barung = True
Else
If Cek_Prefiks("pi", kata) Then 'jika barung = pi- -eun Hilangkan_Barung = True
Else
If Cek_Prefiks("sa", kata) Then 'jika barung = sa- -eun Hilangkan_Barung = True
3.2.6.5 Modul/fungsi Hilangkan_Bareng()
Pembuatan algoritme untuk modul/fungsi Hilangkan_Bareng() ini mengikuti pola seperti yang sudah di bahas pada Sub Bab 3.2.6.4.
Salah satu contoh adalah untuk kata yang mempunyai pola, awalan “pang”, bisa mendapatkan gabungan pang- + kata + -na, pangdipika + kata, pang- + kata,
pang- N- pika- + kata + -na. Penggalan algoritme untuk pola seperti itu terlihat
pada Gambar 20. Algoritme selengkapnya untuk modul/fungsi Hilangkan_Bareng() dapat dilihat pada Lampiran 2.
If Cek_Prefiks("pang", kata) Then
3.2.6.5 Modul/fungsi Cek_Kata_Ulang()
Pada modul/fungsi kata ulang, akan memisahkan dua hal, yaitu kata ulang yang berbentuk gembleng (seluruhnya) dan kata ulang yang berbentuk sabagian
(sebagian). Kata ulang gembleng (seluruhnya) memiliki ciri setiap kata yang diulang dipisahkan dengan tanda “-“. Jika kata berbentuk gembleng (seluruhnya) maka kata yang diambil adalah kata terakhir setelah tanda “-“, setelah itu dicoba untuk menghilangkan imbuhan dari kata tersebut. Untuk kata ulang yang berbentuk sabagian (sebagian), kata ulang yang diberikan akan dihilangkan dahulu imbuhannya baru setelah itu dihilangkan unsur kata ulangnya. Bentuk dari algoritme untuk kata ulang ini dapat dilihat pada Lampiran 2.
3.2.7 Tahap Evaluasi Stemming
Pada proses evaluasi stemming ini akan coba dibandingkan antara daftar kata yang muncul dalam dokumen dan daftar kata yang sudah dilakukan proses
stemming. Pada tahap ini akan dilihat apakah kata yang ada dalam daftar kata
yang muncul dalam dokumen sudah terstemming seperti yang diharapkan. Proses evaluasi dilakukan dengan mengamati secara manual.
3.2.8 Tahap Penulisan Tesis
Setelah semua tahapan di atas selesai dilakukan, tahapan berikutnya adalah penulisan dokumen tesis. Penulisan dokumen tesis ini ditulis berdasarkan hasil yang sudah diuji coba dan penulisannya mengikuti standar yang sudah diberikan oleh Institut Pertanian Bogor.
3.2.9 Tahap Pembuatan Kesimpulan
4.
HASIL PENELITIAN DAN PEMBAHASAN
4.1. Hasil Penelitian
Algoritme stemming yang dirancang akan diuji dengan kumpulan token/kata yang berasal dari daftar kemunculan kata dalam dokumen. Selanjutnya kumpulan
token/kata tersebut di-stem, dan hasilnya akan dilihat apakah menghasilkan kata
sesuai dengan harapan.
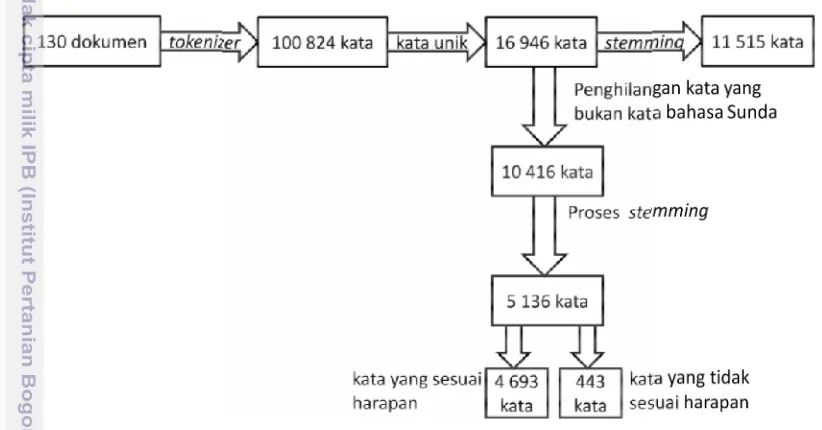
Dari 130 dokumen uji, didapat 100 824 kata. Kata-kata tersebut belum unik, sehingga perlu diproses lebih lanjut untuk mendapatkan satu kata unik dari sejumlah kata yang memiliki bentuk yang sama. Setelah kata yang sama dihilangkan didapat kata unik sebesar 16 949 kata. Dari jumlah kata tersebut setelah dilakukan proses stemming dihasilkan 11 515 kata.
Dari 16 949 kata, setelah dipelajari ternyata banyak kata yang bukan berasal dari bahasa Sunda. Terdapat kata-kata dalam bahasa Arab, bahasa Jawa, bahasa Indonesia dan bahasa Inggris. Ada juga bahasa Indonesia yang disundakan, misalnya dimanfaatkeun (seharusnya dimangpaatkeun); panolong, ngarakit,
usulanana, mertahankeun (bahasa Indonesia yang diberi imbuhan bahasa Sunda);
juga nama-nama, baik nama orang, nama tempat, nama sungai dan lain-lain. Selain itu, banyak juga singkatan-singkatan serta penulisan-penulisan yang salah ketik.
Tentu saja kata-kata di atas jika dilakukan proses stemming dengan algoritme stemming bahasa Sunda hasilnya tidak akan pernah sesuai dengan yang diharapkan. Untuk melihat apakah stemming bekerja sesuai dengan yang diharapkan, kata-kata tersebut dihilangkan dan hasilnya didapat 10 416 kata. Dari jumlah kata tersebut setelah di-stem didapat hasil 5 136 kata.
berjumlah 4 693 kata dan sisanya 443 adalah kata-kata yang tidak sesuai dengan harapan. Dari data ini dapat dihitung bahwa akurasi stemming
diharapkan adalah sebesar:
(4 693/5 136) x 100% = 91.38%
hasil kata yang
Proses pengujian algorime stemming dan hasilnya, diilustrasikan seperti yang terlihat pada Gambar 21.
Gambar 21 Proses percobaan stemming terhadap dokumen uji.
Evaluasi terhadap pengujian ini dilakukan secara manual, dengan melihat satu per satu kata hasil stemming. Dari hasil pengujian stemming sebelum penghilangan kata-kata yang bukan dalam bahasa Sunda (16 946 kata), ditemukan kata-kata yang overstemming namun tidak ada satupun kata-kata yang
understemming. Selain itu, didapat juga hasil stemming yang tidak sesuai dengan
harapan. Berikut ini adalah pembahasan hasil pengujian yang overstemming, dan kata-kata hasil stemming yang tidak sesuai dengan harapan.
4.1.1. Hasil Kata yang Overstemming