SIMULASI PEMANTAUAN SUMBERDAYA KOMPUTER
KLASTER PADA MODEL ANTRIAN M/M/S DAN
ANTRIAN FCFS
MUHAMMAD AL-MABRURI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Simulasi Pemantauan Sumberdaya Komputer Klaster pada Model Antrian M/M/S dan Antrian FCFS adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Februari 2016
Muhammad al-Mabruri
ABSTRAK
MUHAMMAD AL-MABRURI. Simulasi Pemantauan Sumberdaya Komputer Klaster pada Model Antrian M/M/S dan Antrian FCFS. Dibimbing oleh HERU SUKOCO.
Pertumbuhan teknologi yang cepat membuat kebutuhan terhadap pemrosesan data semakin besar dan banyak. Hal ini membuat beban kerja dari komputasi meningkat pesat. Pemroses dituntut untuk dapat melayani permintaan pengguna dalam memproses suatu komputasi besar dengan cepat. Komputer klaster dapat menjadi alternatif dalam memproses beban komputasi yang besar. Penelitian ini melakukan pemantauan sumberdaya sebuah komputer klaster dalam melakukan pemrosesan, sehingga dapat menginformasikan besar dari beban kerja dan ketersediaan CPU sebuah komputer kluster. Model antrian yang digunakan dalam penelitian ini adalah M/M/S dan FCFS. Berdasarkan simulasi yang dilakukan sebanyak 100 kali pengulangan dapat diketahui bahwa model yang digunakan pada penelitian ini berhasil menginformasikan jumlah job yang telah diselesaikan, ketersediaan CPU, dan beban kerja.
Kata kunci: beban kerja, ketersediaan CPU, komputer klaster
ABSTRACT
MUHAMMAD AL-MABRURI. Cluster Computing Resource Monitoring Simulation on Queuing Model M/M/S and FCFS Queue. Supervised by HERU SUKOCO.
The rapid growth of technology makes the increasing need for data processing. It makes the workload of computing is increasing rapidly. Processors must serve user request to process a large computing quickly. Computer cluster can be an alternative for processing large computational load. This research aim was to monitor the resources of a computer cluster to do the processing, so as to inform of the workload and the CPU availability of a computer cluster. The queuing model that is used in this study is a M/M/S and FCFS. Based on the simulation 100 times of repetition can be seen that the model used in this study successfully inform the number of jobs that have been completed, CPU availability, and workload.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
SIMULASI PEMANTAUAN SUMBERDAYA KOMPUTER
KLASTER PADA MODEL ANTRIAN M/M/S DAN
ANTRIAN FCFS
MUHAMMAD AL-MABRURI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Penguji:
1 Dr Ir Sri Wahjuni, MT
Judul Skripsi : Simulasi Pemantauan Sumberdaya Komputer Klaster pada Model Antrian M/M/S dan Antrian FCFS
Nama : Muhammad al-Mabruri
NIM : G64110091
Disetujui oleh
DrEng Heru Sukoco, SSi MT Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Alhamdulillah, puji dan syukur penulis panjatkan kepada Allah subhanahu
wa ta’ala atas limpahan rahmat dan segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan.
Penyusunan dan penyelesaian tugas akhir ini tidak terlepas dari bantuan berbagai pihak. Oleh karena itu, penulis ingin menyampaikan terima kasih kepada: 1 Bapak (Sumarno), Ibu (Ruli Yantine Dali), Syifa Fauzia dan Akmal lizal yang selalu mendoakan penulis, memberikan dukungan, dan kasih sayang yang tak terbalas.
2 Bapak DrEng Heru Sukoco, SSi MT selaku dosen pembimbing yang telah dengan sabar, tulus dan ikhlas meluangkan waktu, tenaga dan pikiran dalam memberikan bimbingan serta nasehat selama pengerjaan tugas akhir.
3 Ibu Dr Ir Sri Wahjuni, MT dan Bapak Auriza Rahmad Akbar, SKomp MKom selaku dosen penguji, terima kasih atas arahan, masukan, dan saran dalam pengujian tugas akhir.
4 Herdi Agusthio PD, Dwi Agung Prastya, Hanif Bagus Guritno dan Tri Ardini terima kasih untuk selalu mendukung, memotivasi, serta mendoakan dan setia menemani proses, dan selalu memberikan masukan kepada penulis.
5 Agisha Mutiara Yoga A.S yang membantu dalam pembuatan abstrak, dan selalu mengingatkan dan memotivasi penulis agar menyelesaikan tugas akhir ini. 6 Riko Ahmad M, Ahmad Fauzi dan rekan-rekan mahasiswa Lab NCC yang
bersama-sama dalam menyelesaikan tugas akhir.
7 Keluarga Ilmu Komputer 48 terima kasih untuk persaudaraan yang terjalin selama ini.
Semoga segala bimbingan, motivasi, masukan dan kebaikan-kebaikan yang telah diberikan kepada penulis akan dilipat gandakan oleh Allah subhanahu wa
ta’ala.
Akhirnya, semoga penulisan karya ilmiah ini dapat bermanfaat bagi kita semua.
Bogor, Februari 2016
DAFTAR ISI
DAFTAR TABEL vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 1
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 2
Komputer Klaster dan Pemrograman Paralel 2
First Come First Served (FCFS) 3
Notasi Kendall 3
Distribusi Eksponensial 4
METODE PENELITIAN 4
Tahapan Penelitian 4
Analisis Masalah 4
Membuat Model 4
Membuat Simulasi 5
Analisis Hasil Simulasi 5
Lingkungan Pengembangan 5
HASIL DAN PEMBAHASAN 5
Analisis Masalah 5
Pembuatan Model 5
Simulasi 8
Analisis Hasil Simulasi 10
Job Selesai 10
CPU Available 13
Beban Kerja 15
SIMPULAN DAN SARAN 18
Simpulan 18
DAFTAR PUSTAKA 19
DAFTAR GAMBAR
1 Model Sistem Antrian M/M/S 3
2 Tahapan penelitian 4
3 model antrian M/M/S (Bloomers 1996) 6
4 Alur simulasi 9
5 Ilustrasi model tahap ke-1 9
6 Ilustrasi model tahap ke-2 9
7 Ilustrasi model tahap ke-3 10
8 Ilustrasi model tahap ke-4 10
9 Hasil rata-rata simulasi jumlah job 1000 11
10 Hasil rata-rata simulasi dengan jumlah job 2000 11
11 Hasil rata-rata simulasi jumlah job 5000 12
12 Hasil rata-rata simulasi jumlah job 7000 12
PENDAHULUAN
Latar Belakang
Pesatnya pertumbuhan teknologi informasi di dunia saat ini menuntut semua proses agar dapat dikerjakan dengan cepat. Menurut Kemkominfo (2014) menyebutkan bahwa pada tahun 2014 kemkoninfo melakukan survey penggunaan TIK. Pada penggunaan komputer terjadi perbedaan persentase pada setiap sektor. Pada sektor rumah tangga sebesar 25.20% dengan 22.20% memiliki akses internet, pada sektor perusahaan yang menggunakan komputer sebesar 61.76% dengan 85.35% memiliki akses internet. Bersamaan dengan pertumbuhan teknologi yang cepat, kebutuhan terhadap pemrosesan data yang besar dan cepat sangat banyak. Berbagai teknologi alternatif hadir untuk memenuhi kebutuhan tersebut. Salah satu cara untuk mempercepat proses tersebut adalah membuat komputer klaster.
Komputer klaster merupakan penggabungan beberapa komputer yang di dalamnya terdapat beberapa prosesor dan diprogram menjadi satu kesatuan komputasi (Kunkel 2013). Berbagai perbedaan spesifikasi dari prosesor yang terdapat pada suatu komputer klaster memungkinkan adanya perbedaan alokasi beban pemrosesan job yang diterima pada setiap prosesor. Adanya keterbatasan kemampuan dari masing-masing prosesor akan menyebabkan terjadinya suatu antrian.
Teori antrian pertama kali diperkenalkan oleh Erlang pada awal abad ke 20, di dalam suatu antrian terjadi proses waiting and response time (Sztrik 2012). Sistem antrian terdiri atas dua jenis, yaitu single server dan multiserver. Single server adalah sistem antrian dengan satu server, sedangkan multiserver adalah sistem antrian dengan lebih dari satu server. Adanya perbedaan kapasitas dari setiap prosesor dalam mengerjakan job, sangat memungkinkan untuk dilakukan pemantauan aktivitas yang dilakukan komputer klaster tersebut, sehingga dapat diketahui informasi mengenai banyaknya job yang dikerjakan oleh masing-masing prosesor.
Ahadi (2013) telah membuat penelitian mengenai pengembangan sistem pengukur indeks beban pada komputer klaster paralel. Dalam penelitian tersebut dilakukan pengindeksan beban pada sumberdaya untuk digunakan pada algoritme
load balancing yang dapat meningkatkan kinerja sebuah sistem paralel. Pada penelitian ini algoritme yang digunakan dalam manajemen proses adalah first come first server (FCFS).
Perumusan Masalah
Berdasarkan latar belakang di atas, perumusan masalah dalam penelitian ini adalah berapa banyak job yang dapat dikerjakan oleh setiap prosesor dan ketersediaan sumberdaya komputer klaster dalam waktu pemantauan.
Tujuan Penelitian
2
menginformasikan ketersediaan sumberdaya komputer klaster yang dapat digunakan kepada seluruh pengguna.
Manfaat Penelitian
Manfaat penelitian ini adalah administrator dan pengguna komputer klaster dapat mengetahui kinerja dari prosesor dalam mengerjakan beban kerja suatu job
dan menginformasikan ketersediaan sumberdaya klaster kepada pengguna. Ruang Lingkup Penelitian
Ruang lingkup penelitian ini, yaitu:
1 Penelitian menggunakan pemodelan antrian pada klaster dengan notasi Kendall M/M/S.
2 Penelitian melakukan model simulasi percobaan menggunakan bahasa pemrograman R.
3 Algoritme manajemen proses yang digunakan pada komputer klaster adalah FCFS.
TINJAUAN PUSTAKA
Komputer Klaster dan Pemrograman Paralel
Pemrograman paralel adalah program yang dibuat untuk menggunakan sumber daya perangkat keras dan diharapkan dapat mengefisiensi penggunaan prosesor multicore. Pemrograman paralel dapat digunakan baik pada komputer
multicore dan komputer klaster, perhitungan yang akan dilkakukan harus dipartisi menjadi beberapa bagian terlebih dahulu. Sebuah model sederhana diberikan oleh Flynn taksonomi. Taksonomi ini mencirikan komputer paralel sesuai dengan kontrol global dan aliran arus data yang dihasilkan (Rauber dan Ringer 2010).
Kategori komputer paralel dibedakan menjadi empat (Rauber dan Ringer 2010):
1 Single-instruction, single-data (SISD)
Kategori ini hanya terjadi satu proses dan merupakan komputer sekuensial tradisional menurut Von Neumann.
2 Multiple-instruction, single-data (MISD)
Kategori ini memiliki banyak proses tetapi hanya ada satu akses data global. Membuat model kategori ini sangat terbatas dan tidak ada komputer paralel komersial jenis ini yang pernah dibangun.
3 Single-instruction, multiple-data (SIMD)
Kategori ini memiliki beberapa pengolahan data yang bisa diakses tetapi hanya memiliki satu proses yang dapat dilakukan, untuk aplikasi tertentu SIMD bisa sangat efisien. Contohnya aplikasi multimedia atau komputer algoritme grafis. 4 Multiple-instruction, multiple-data (MIMD)
3 dengan yang lain. Prosesor multicore atau sistem komputer klasteradalah contoh untuk model MIMD.
Komputer klaster merupakan kumpulan dari komputer dengan jaringan interkoneksi yang berdedikasi. Komputer klaster biasanya terdiri dari komputer standar bahkan topologi jaringan standar dan diprogram menjadi satu kesatuan komputasi.
First Come First Served (FCFS)
Sejauh ini FCFS merupakan algoritme CPU scheduling yang paling sederhana dan mudah di pahami. Dengan skema, proses yang meminta untuk dilayani oleh CPU pertama kali akan dilayani pertama. Implementasi FCFS mudah dikelola dengan antrian first in fisrt out (FIFO). Sisi negatif dari FCFS yaitu waktu tunggu yang cukup panjang (Silberschatz et al. 2012).
Notasi Kendall
Kendall memperkenalkan notasi singkat untuk mengkarakterisasi berbagai model-model antrian. Yaitu dengan kode a/b/c. Huruf pertama menentukan distribusi antar waktu kedatangan. Huruf kedua untuk distribusi waktu pelayanan. Contohnya untuk notasi umum menggunakan huruf G, M untuk distribusi eksponensial dan D untuk deterministik, dan huruf ketiga adalah untuk menentukan jumlah server (Adan dan Resing 2015).
Pada penelitian ini menggunakan notasi kendall M/M/S karena menggunakan rata-rata laju kedatangan dan rata-rata laju pelayanan secara eksponensial dan jumlah server yang dapat ditentukan sejumlah S. Gambar 1 merupakan model sistem antrian M/M/S secara umum.
Gambar 1 Model sistem antrian M/M/S Keterangan:
4
Distribusi Eksponensial
Distribusi eksponensial merupakan distribusi yang banyak digunakan secara luas dan sudah banyak dikenal. Distribusi eksponensial dapat menggambarkan jumlah percobaan diskrit pada setiap perubahan statusnya, distribusi eksponensial menggambarkan waktu untuk proses yang berkesinambungan (Walck 2007).
Berikut fungsi distribusi eksponensial
� = − �−�� (1)
METODE PENELITIAN
Tahapan Penelitian
Tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 2.
Gambar 2 Tahapan penelitian Analisis Masalah
Pada tahap ini dilakukan analisis masalah yang ada pada sistem komputer klaster. Analisis masalah tersebut, yaitu jumlah kinerja dari setiap sumber daya yang ada pada suatu komputer klaster dapat dilihat baik dari sisi pengguna komputer klaster maupun dari sisi pengembang komputer klaster.
Membuat Model
Model merupakan abstraksi dari sistem, artinya hanya mewakili fitur dan karakteristik yang dipilih sementara dari sistem. Oleh karena itu model yang diperoleh merupakan representasi yang lebih kecil dari sistem yang dipertimbangkan berdasarkan penyederhanaan dan asumsi.(Wehrle et al. 2010). Model antrian yang digunakan pada penelitian ini adalah model antrian dengan notasi Kendall M/M/S.
Mulai Membuat model
Membuat simulasi Selesai
Analisis masalah
5 Membuat Simulasi
Pada tahap ini dilakukan penerapan model pada tahap sebelumnya dalam bentuk simulasi. Untuk mendapatkan hasil yang valid dan benar dalam memprediksi perilaku sistem yang nyata, semua efek yang relevan harus digunakan dalam model simulasi (Wehrle etal. 2010). Pada penelitian ini digunakan simulasi yang dilakukan dengan bahasa pemrograman R dan perangkat lunak Rstudio untuk implementasi simulasi.
Analisis Hasil Simulasi
Pada tahap terakhir ini dilakukan analisis hasil simulasi dari model yang digunakan dengan membuat sebuah skenario simulasi untuk mendapatkan hasil beserta gambaran dari kinerja model yang dipakai.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
Perangkat lunak:
1 Sistem operasi Windows 10
2 Bahasa pemrograman R versi 3.1.1 3 RStudio versi 0.98.1062
4 Notepad++ digunakan untuk catatan program Perangkat keras:
1 Processor Intel Core i7-3632QM 2.20 GHz 2 RAM 8 GB
3 Harddisk berkapasitas 500 GB
HASIL DAN PEMBAHASAN
Analisis Masalah
Komputer klaster memiliki S jumlah komputer yang saling terhubung dan pengguna yang dapat mengakses suatu komputer klaster, akan ada Njob yang akan diproses pada setiap komputer klaster. Dengan jumlah job yang sejumlah N serta keterbatasan kapasitas suatu komputer klaster maka dapat dilakukan prediksi lamanya waktu pemrosesan yang terjadi dalam suatu komputer klaster.
Pembuatan Model
6
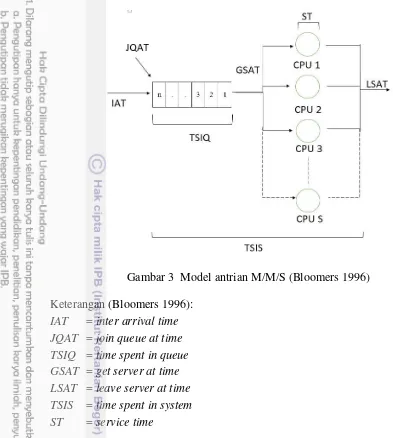
Gambar 3 Model antrian M/M/S (Bloomers 1996) Keterangan (Bloomers 1996):
IAT = inter arrival time JQAT = join queue at time TSIQ = time spent in queue GSAT = get server at time LSAT = leave server at time TSIS = time spent in system ST = service time
IAT merupakan perbedaan waktu kedatangan antarjob yang datang kedalam sistem, ST merupakan waktu proses yang dibutuhkan oleh suatu job, IAT dan ST
dibangkitkan secara eksponensial. Nilai IAT dan ST diinvers dari fungsi eksponensial sehingga digunakan logaritma natural dan dibagi oleh rata-rata laju kedatangan job dan rata-rata laju pelayanan prosesor, untuk lebih jelas dapat dilihat pada Persamaan 2 dan 3.
7
(2)
(3)
JQAT merupakan waktu awal job masuk ke dalam antrian, JQAT diperoleh dengan mengakumulasikan nilai IAT, untuk lebih jelas dapat dilihat pada Persamaan 4.
�� = �� + � (4)
GSAT merupakan waktu pada saat job mendapatkan service, LSAT
merupakan waktu pada saat job sudah selesai diproses dan meninggalkan server, berikut pseudocode untuk mendapatkan nilai GSAT dan LSAT.
If jumlah job <= jumlah server
Looping sebanyak jumlah job; GSAT = JQAT;
LSAT = GSAT+ST; Else
Looping sebanyak jumlah job;
GSAT(jumlah job sesuai server) = JQAT; LSAT(jumlah job sesuai server) = GSAT+ST;
GSAT job selanjutnya = current, JQAT(current) dibandingkan dengan waktu LSAT dari job sebelumnya;
Looping sebanyak server;
If JQAT(current)>= LSAT(job sebelumnya) Counter <- server available; Terpilih = acak counter;
= − �−�.�
�−�. = −
= ln −−�
� =−ln random . −λ
= − �−µ.�
�−µ. = −
=ln −−µ
8
GSAT(terpilih) <- JQAT(current); Else
Counter <- server not available; Terpilih = acak counter;
GSAT(terpilih) <- LSAT(job server sebelumnya);
TSIQ merupakan waktu selama job berada di antrian, TSIQ dapat diperoleh dengan mengurangi nilai GSAT dengan JQAT, untuk lebih jelas dapat dilihat pada Persamaan 5.
�� = GSAT – JQAT (5)
TSIS merupakan waktu selama job berada di sistem, TSIS dapat diperoleh dengan mengurangi nilai LSAT dengan JQAT, untuk lebih jelas dapat dilihat pada Persamaan 6.
= � � − �� (6)
Simulasi
Pada penelitian ini algoritme FCFS digunakan untuk mengalokasikan sumber daya pada komputer klaster kepada pengguna. Adanya perbedaan dari setiap sumber daya pada komputer klaster membuat adanya perbedaan waktu dalam proses eksekusi yang dapat menyebabkan antrian dapat terjadi. Pengaturan manajemen antrian menggunakan teori antrian dengan notasi Kendall M/M/S yang nilai arrival rate dan service rate akan dibangkitkan secara acak dengan sebaran
uniform. Jumlah pengguna dan jumlah job yang akan dikerjakan pada simulasi ini akan dibangkitkan terlebih dahulu secara bersamaan pada awal simulasi, semua prosesor diasumsikan memiliki kemampuan yang sama yaitu
� = 6 ���/detik µ = ���/detik
Hal ini dilakukan agar terjadi rekayasa antrian yang terjadi karena nilai laju pelayanan yang lebih kecil dibandingkan dengan nilai laju kedatangan. Kode simulasi dapat dilihat pada Lampiran 1
Pada proses pemantauan yang dilakukan pengguna pada sistem, pengguna dapat melihat informasi berapa jumlah job yang sudah selesai dikerjakan dan berapa jumlah job yang belum dikerjakan, informasi ketersediaan sumberdaya, serta berapa lama waktu perkiraan proses akan selesai. Proses pemantauan dilakukan setiap detik selama 60 detik.
9
Gambar 5 Alur simulasi
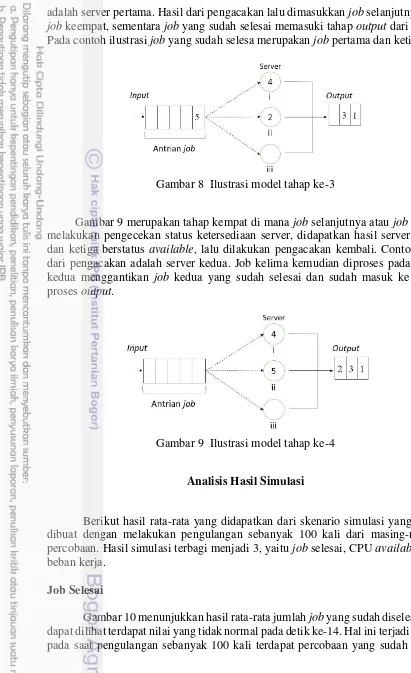
Contoh ilustrasi pada model ini dengan 3 server dan jumlah job 5 dapat dilihat pada gambar 6 , 7, 8, dan 9.
Gambar 6 merupakan tahap awal dengan terdapat 5 job yang sudah pada antrian dan 3 server yang masih available.
Gambar 6 Ilustrasi model tahap ke-1
Gambar 7 merupakan tahap kedua, karena jumlah server tiga jadi hanya tiga
job yang dapat langsung diproses oleh server sementara job keempat dan kelima masih menunggu pada proses antrian.
Gambar 7 Ilustrasi model tahap ke-2
10
adalah server pertama. Hasil dari pengacakan lalu dimasukkan job selanjutnya atau
job keempat, sementara job yang sudah selesai memasuki tahap output dari server. Pada contoh ilustrasi job yang sudah selesa merupakan job pertama dan ketiga.
Gambar 8 Ilustrasi model tahap ke-3
Gambar 9 merupakan tahap kempat di mana job selanjutnya atau job kelima melakukan pengecekan status ketersediaan server, didapatkan hasil server kedua dan ketiga berstatus available, lalu dilakukan pengacakan kembali. Contoh hasil dari pengacakan adalah server kedua. Job kelima kemudian diproses pada server kedua menggantikan job kedua yang sudah selesai dan sudah masuk ke dalam proses output.
Gambar 9 Ilustrasi model tahap ke-4
Analisis Hasil Simulasi
Berikut hasil rata-rata yang didapatkan dari skenario simulasi yang sudah dibuat dengan melakukan pengulangan sebanyak 100 kali dari masing-masing percobaan. Hasil simulasi terbagi menjadi 3, yaitu job selesai, CPU available, dan beban kerja.
Job Selesai
11 pada detik 14 dan ada yang belum selesai, sehingga membuat perbedaan nilai rataan terlihat signifikan.
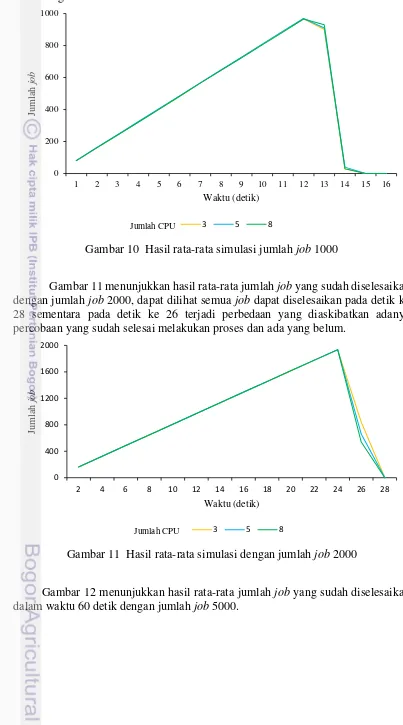
Gambar 10 Hasil rata-rata simulasi jumlah job 1000
Gambar 11 menunjukkan hasil rata-rata jumlah job yang sudah diselesaikan dengan jumlah job 2000, dapat dilihat semua job dapat diselesaikan pada detik ke 28 sementara pada detik ke 26 terjadi perbedaan yang diaskibatkan adanya percobaan yang sudah selesai melakukan proses dan ada yang belum.
Gambar 11 Hasil rata-rata simulasi dengan jumlah job 2000
Gambar 12 menunjukkan hasil rata-rata jumlah job yang sudah diselesaikan dalam waktu 60 detik dengan jumlah job 5000.
12
Gambar 12 Hasil rata-rata simulasi jumlah job 5000
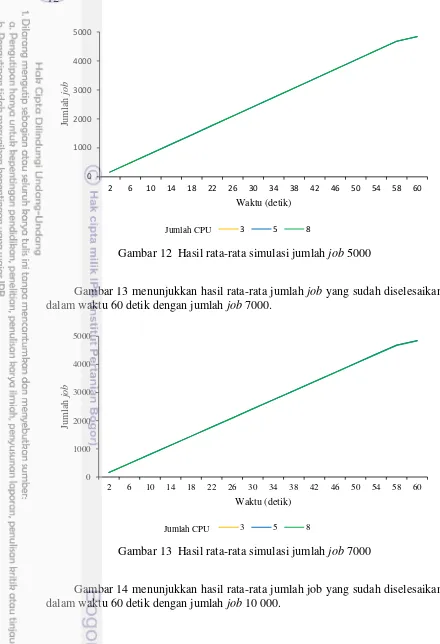
Gambar 13 menunjukkan hasil rata-rata jumlah job yang sudah diselesaikan dalam waktu 60 detik dengan jumlah job 7000.
Gambar 13 Hasil rata-rata simulasi jumlah job 7000
Gambar 14 menunjukkan hasil rata-rata jumlah job yang sudah diselesaikan dalam waktu 60 detik dengan jumlah job 10 000.
13
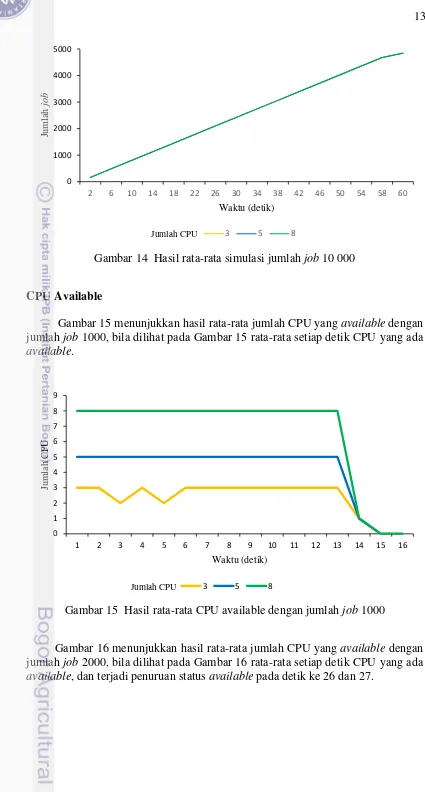
Gambar 14 Hasil rata-rata simulasi jumlah job 10 000
CPU Available
Gambar 15 menunjukkan hasil rata-rata jumlah CPU yang available dengan jumlah job 1000, bila dilihat pada Gambar 15 rata-rata setiap detik CPU yang ada
available.
Gambar 15 Hasil rata-rata CPU available dengan jumlah job 1000
Gambar 16 menunjukkan hasil rata-rata jumlah CPU yang available dengan jumlah job 2000, bila dilihat pada Gambar 16 rata-rata setiap detik CPU yang ada
14
Gambar 16 Hasil rata-rata CPU available dengan jumlah job 2000
Gambar 17 menunjukkan hasil rata-rata jumlah CPU yang available dengan jumlah job 5000, bila dilihat pada Gambar 17 dapat dilihat setiap detik rata-rata CPU yang ada available.
Gambar 17 Hasil rata-rata CPU available dengan jumlah job 5000
Gambar 18 menunjukkan hasil rata-rata jumlah CPU yang available dengan jumlah job 7000, bila dilihat pada Gambar 18 rata-rata jumlah CPU available
dengan jumlah CPU 3 terjadi penurunan dan peningkatan hal ini dapat terjadi karena jumlah CPU yang sedikit dan jumlah job yang banyak.
15
Gambar 18 Hasil rata-rata CPU available dengan jumlah job 7000
Gambar 19 menunjukkan hasil rata-rata jumlah CPU yang available dengan jumlah job 10 000, bila dilihat pada Gambar 19 rata-rata jumlah CPU available
dengan jumlah CPU 3 terjadi penurunan dan peningkatan hal ini dapat terjadi karena jumlah CPU yang sedikit dan jumlah job yang banyak.
Gambar 19 Hasil rata-rata CPU available dengan jumlah job 10 000
Beban Kerja
Gambar 20-24 menunjukkan hasil rata-rata beban kerja, bila dilihat pada setiap gambar tidak terjadi perbedaan yang signifikan hal ini terjadi karena dilakukan random pada saat pemilihan CPU available yang akan digunakan sehingga semua CPU dapat dioptimalkan dan jumlah job yang dikerjakan merata.
16
Gambar 20 Hasil rata-rata beban kerja dengan jumlah job 1000
Gambar 21 Hasil rata-rata beban kerja dengan jumlah job 2000
331 335 335
201 201 200 201 200
126 126 125 124 126 127 125 126
1 2 3 4 5 6 7 8
Jum
la
h
job
Jumlah CPU
3
5
8
667 668 666
399 404 400 401 398
252 252 252 248 252 249 250 248
1 2 3 4 5 6 7 8
Jum
la
h
job
Jumlah CPU
3
5
8
Jumlah CPU
17
Gambar 22 Hasil rata-rata beban kerja dengan jumlah job 5000
Gambar 23 Hasil rata-rata beban kerja dengan jumlah job 7000
1667 1667 1668
996 1008 1001 998 1000
626 629 626 623 624 626 627 623
1 2 3 4 5 6 7 8
Jum
la
h
job
Jumlah CPU
3
5
8
2335 2334 2332
1402 1402 1396 1404 1398
876 875 873 877 877 870 878 878
1 2 3 4 5 6 7 8
Jum
la
h
job
Jumlah CPU
3
5
8
Jumlah CPU
18
Gambar 24 Hasil rata-rata beban kerja dengan jumlah job 10 000
SIMPULAN DAN SARAN
Simpulan
Kesimpulan dari hasil penelitian ini, yaitu model yang dibuat dari hasil simulasi mampu menginformasikan jumlah job yang dapat diselesaikan, beban kerja sebuah komputer klaster dan juga dapat menginformasikan ketersediaan sumberdaya. Berdasarkan simulasi yang dilakukan dengan 100 kali pengulangan nilai dari ketersediaan CPU dalam setiap percobaan pada jumlah CPU 5 dan 8 mendapati rata-rata nilai yang sama dengan CPU yang digunakan. Hal ini dapat terjadi karena saat pemantauan dilakukan nilai waktu pada setiap server adalah sama dan berdekatan, sehingga nilai hasil dari setiap pemantauan tidak jauh berbeda dengan total CPU yang digunakan, artinya selama waktu pemantauan yang dilakukan, sumberdaya CPU yang ada dapat digunakan.
Saran
Saran yang dapat dilakukan untuk penelitian selanjutnya:
1 Membuat uji coba pemantauan pada komputer klasterreal, sehingga dapat lebih realtime dalam pengambilan data.
2 Membuat aplikasi berbasis website sehingga dapat mempermudah user dalam melakukan pemantauan komputer klaster.
3328 3330 3344
2006 1999 2000 2004 1994
1246 1254 1246 1256 1253 1252 1248 1250
1 2 3 4 5 6 7 8
Jum
la
h
job
Jumlah CPU
3
5
8
19
DAFTAR PUSTAKA
Adan I, Resing J. 2015. Queueing System. Eindhoven (NL): Eindhoven University of Technology.
Ahadi I. 2013. Pengembangan sistem pengukur indeks beban pada komputer paralel
cluster [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Bloomers J. 1996. Practical Planing for Network Growth. Upper Saddle River (US): Prentice Hall.
[Kemkominfo] Kementrian Komunikasi dan Informatika. 2014. Buku Saku Data dan Tren TIK 2014. Jakarta (ID): Kemkominfo.
Kunkel JM. 2013. Simulation of parallel programs on application and system level [disertasi]. Hamburg (DE): University of Hamburg.
Rauber T, Rünger G. 2010. Parallel Programming For Multicore and Cluster Systems. New York (US): Springer.
Silberschatz A, Galvin PB, Gagne G. 2012. Operating System Concepts. Ed ke-7. Hoboken: J Wiley
Sztrik J. 2012. Basic Queueing Theory. Debrecen (HU): University Debrecen. Walck C. 2007. Statistical Distributions for Experimentalist. Stockholm (SE):
University of Stockholm.
Wehrle K, Gunes M, Gross J. 2010. Modeling and Tools for Network Simulation.
20
Lampiran 1 Kode simulasi M/M/S
MMS<-function(L,M,S,N)
matrixL[i,]<-round((runif(1,0.1,1)),digits= 3) }
for(i in 1:N) {
matrixM[i,]<-round((runif(1,0.1,1)),digits= 3) }
for(i in 1:N) {
21 Lampiran 1 Lanjutan
{
ST[i,]<-round((-log(matrixM[i,])/M), digits=3) }
LSAT_server[i,1]<-JQAT[i,1]+ST[i,1] Posisi_job[i,1]<-i
Server_terpilih<-i
monitor_server[i,]<-Server_terpilih }
if(LSAT_server[counter_cek,1]<=JQAT[i,1]) {
Posisi_server_penuh[counter_pos,1]<-counter_cek counter_pos<-counter_pos+1
22
Lampiran 1 Lanjutan
jumlah_available_counter<-tabulate(Posisi_server) jumlah_available<-sum(jumlah_available_counter) monitor_server[i,]<-Server_terpilih
}
jumlah_not_available_counter<-tabulate(Posisi_server_penuh) jumlah_not_available<-sum(jumlah_available_counter)
}
if(jumlah_available!=0)#artinya ada yang available {
GSAT[i,]<-JQAT[i,]
GSAT_server[Server_terpilih,]<-JQAT[i,] LSAT[i,]<-JQAT[i]+ST[i,]
LSAT_server[Server_terpilih,]<-JQAT[i]+ST[i,] Posisi_job[i]<-Server_terpilih
} else {
Posisi_job[i]<-Server_terpilih_penuh
GSAT[i,]<-LSAT_server[Server_terpilih_penuh,] GSAT_server[Server_terpilih_penuh,]<-
LSAT_server[Server_terpilih_penuh,] LSAT[i,]<-GSAT[i,]+ST[i,]
LSAT_server[Server_terpilih_penuh,]<-GSAT[i,]+ST[i,]
}
23 Lampiran 1 Lanjutan
}
avg_iat=mean(IAT) avg_lamda=(1/avg_iat) avg_ST=mean(ST) avg_miu=(1/avg_ST) miu<-matrixM lamda<-matrixL
hasil<-data.frame(lamda,IAT,JQAT,miu,ST,GSAT,LSAT,GSAT_server,LSAT_serve r,TSIS,TSIQ,Posisi_job)
rataan<-data.frame(avg_iat,avg_lamda,avg_ST,avg_miu )
Penggunaan_server<-Posisi_job
jumlah_memproses<-table(Penggunaan_server)
24
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 11 September 1993 yang merupakan anak kedua dari dua bersaudara dengan ayah bernama Muhammad Sumarno dan ibu bernama Ruli Yantine Dali.