DOI: 10.12928/TELKOMNIKA.v14i3.3550 824
Research on Optimization Strategy to Data Clustered
Storage of Consistent Hashing Algorithm
Ningjia Qiu1, Xiaojuan Hu2, Peng Wang1*, Huamin Yang1 1
School of Computer Science and Technology, Changchun University of Science and Technology, China 130022
2
College of Computer Science and Technology, Jilin University, China, 130022 *Corresponding author, e-mail: [email protected], 13504306257
Abstract
This paper presents a consistent hashing data optimize multiple copy distributed clustered storage placement strategy, using technology to create a virtual node and aliquots storage area to ensure the balanced distribution of data storage. With the speed of data processing accelerated, it is possible for clusters actual required to complete the expansion, and complete the development of adaptive optimization. Experiments show that the execution speed has effectively improved to ensure the load balance. With possible extensions and reducing problems treatment in actual situation, oscillation has little impact on the load balancing, and the execution time is consistent with the proportion of the load trends.
Keywords: cluster storage, HDFS, consistent hashing, copy optimization
Copyright © 2016 Universitas Ahmad Dahlan. All rights reserved.
1.Introduction
Distributed clustered storage is the key technology of large data storage management. Including because of the high transmission rate and high fault tolerance of HDFS, which has became effectively to solve big data storage applications [1-4]. However, the randomness data placement strategies could cause uneven data distribution, and affect the overall system performance issues, which has been proposed to solve this problem from several aspects research programs [5-8]. Wang proposed a Minimum service cost policies to achieve dynamic adjustment of the number and the location can save storage space and improve the reliability and stability of the system [9]. Zhai has proposed a tradeoff storage cost and bandwidth costs P2P cache capacity design method, optimal buffer capacity design problem as an integer programming problem [10]. Pamies-Juarez has concluded the optimal data placement strategy to reduce the use of redundancy [11, 12]. However, the data did not take the implementation of balanced performance problems and system issues into account.
To solve these problems, Li proposes a virtual disk layout scheduling method based on energy-efficient. The dynamic work area is divided into Workspace and ready region, which distribute resources to user and effectively alleviate the problem of prolonged response time [13], Jiang presents a problem to solve the bottleneck of name node performance in storage to reduce access latency and improve the access efficiency [14], Wang is intended to implement a process to read and write files in HDFS parallel transmission strategy, improved copy automatically copy strategy to improve the reading and writing efficiency, reduce latency, to provide efficient and reliable service for cloud storage users [15]. On this basis, store copies of data dispersed principles methods using consistent hashing algorithm are proposed. Combined with improved consistency hashing algorithm [16, 17], virtual data storage node and an aliquot area are introduced [18-20]. It is possible to consider the data evenly distributed simultaneously, adaptively completed quickly locate stored data and improve system performance.
2. Consistent Hashing Algorithm for Data Storage 2.1. Basic Principle
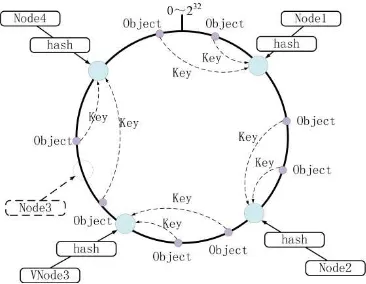
following. All of the storage clusters are abstracted into a closed loop Hash space. Using the hash algorithm, cluster machine are distributed to the ring with uniquely identify names. Usually, it uses the machine's IP or machine alias as the unique identification name. The data nodes are mapped into the annular space with uniquely identify, and ultimately finding the rack number through hash function mapped to determine the specific location of the data node, as shown in Figure 1.
Figure 1. Consistent Hashing Mapping Process
Figure 2. Virtual Node Mapping Process
2.2. Consistent Hashing Algorithm Description
In a distributed clustered storage, it can distribute well as evenly as possible to each data node based on the organizational form of a hash of the data. Racks and data are mapped directly to the hash ring. As dispersion and reduce the load, it would be unevenly distributed for the data storage. With the size of the system considered, the object could be assigned to each virtual node evenly through the consistent hashing mapping, and reducing data migration from the expansion node directly mapped, as shown in Figure 2.
It is possible that each rack and data nodes in the storage ring corresponds to the virtual nodes. Because of the virtual nodes can be mapped into the annular space in consistent hashing calculation process, the data queries could be made into racks and nodes with the task of inquiry to the virtual nodes completed. The number of virtual nodes can be divided according to device hardware performance, which guarantees a balanced distribution of the data stored and taking into the factors of each node to improve overall system performance.
3. Optimization Strategies
3.1. Optimal Adjustment for the Storage Space
The design schemes of HDFS are used to support large file data storage. The typical default block size is 64MB. There are three factors to affect the file access time of memory space: seek time, response time and transfer time. The access performance is usually measured by
η
eff , as the Formula (1).1
rep trans adr
eff
adr rep trans adr rep block
t t t
t t t t t s
η
ν
+
= = −
+ + + + (1)
Where,
t
adr is the addressing time?t
rep is the response time.t
trans is the data transmissionfile transfer efficiency is improved, and it would cause uneven load distribution. When the data storage space had been set too small, it can reduce the load needs better, and it would reduce the file transfer efficiency. Therefore, we need to adjust data storage space sensibly to consider between the file transfer efficiency and load balancing.
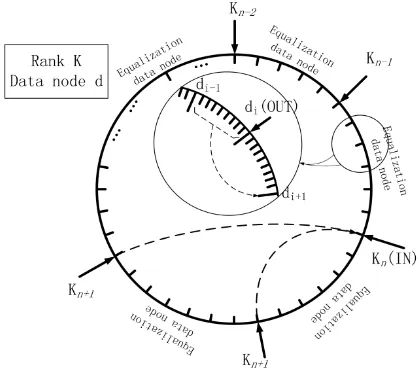
The annular area of storage space is divided equally in this paper, and then each virtual data comprises some sharing storage area. That is, each virtual node is a plurality of storage space and average area. When the data node was mapped, the location of the data node was addressed to find the first node region mapping position. If the position is occupied, it would be find in the next average area using a linear method to detect re-hash in the clockwise direction. Therefore, the data is divided into storage space completely. When the cluster is added or deleted in the ring, it will be reduced for the migration amount of data and the pressure of the server according to the consistent hashing algorithm, as shown in Figure 3.
Figure 3. Illustrate for an Aliquot Storage Space Mapping
3.2. Data Adjustment Strategy
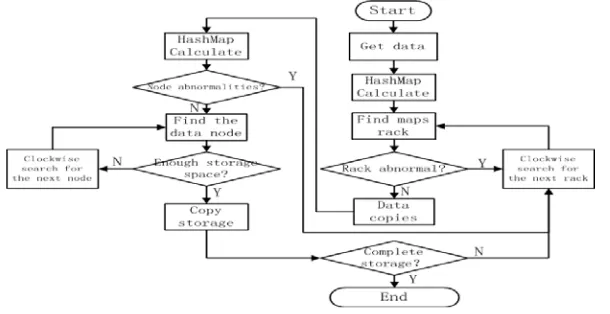
There are two aspects of replica placement strategy, which is copy account and placement. It has the more copies, the higher the data availability and system performance. Therefore, the cost of storage and communication systems consumption is great, which would affect user service quality. A copy of HDFS placement policy is introduced as follows. Two copies are placed in different nodes on the same rack, and the third copy in different rack is different from the data nodes. It could improve data writing performance and reduce network aggregate bandwidth read operations using this method. Setting data is stored in the n racks, it needs to select two different data nodes to store two copies in k racks and one copies in other racks(n-k). Calculated by two hashes mapping in the annular space to find data node storage rack, the specific process is shown in Figure 4.
Figure 5. Data Migration Examples
When the storage racks into the annular space, the backup data needs to be migrated, and migration condition is shown in Figure 5. When the rack changes, mapping data node can be determined according to the flow, which is shown in Figure 5. It can be seen that it can be inherited consistent hashing algorithm with maintaining monotonicity, and the large amounts of data migration is avoided to increase server pressures.
3.3. Performance Analysis
When the stored data optimization, data files are in the given region of space aliquot backup operations, and completed in accordance with consistent hashing distribution storage. According to the above-mentioned data alignment strategies in the process of analyzing the data, the data is used for the distribution of data in different nodes and different racks, so that it is the main issue to be considered by using the MapReduce framework to process data parallel computing node communication. Setting the copies account is m, the rack account is n and the aliquots storage area size is q. Then it can express as the probability of two copies distributed in k rack:
2 2 2( )
P
(
1)( - )
!
−
−
−
=
k n k
m m m n
i
C C
n
n k
P
m
(2)The process of performing data traffic computing tasks is:
1
=
=
∑
m ii
S
Pq
(3)When extracting data from different data nodes, it depends on the network bandwidth. Setting v1 is the network bandwidth (value measures) which is extracted data from the same rack, p1 is the probability of data block and task nodes in the same rack, v2 is the network bandwidth which is extracted data from the different rack, p2 is the probability of data block and task nodes in the different rack. The extracted data network bandwidth is as:
2 1
(
)
=
=
∑
i ij
V
p v
(4)1
Seen from Formula 5, factors affecting performance are storage cluster size, backup copies, the rack account, communications bandwidth. It is obtained for the probability of improved performance by increasing the data. Considering the coherence factor of data storage, the number of copies should be properly selected, so file transfer efficiency and load balancing should be combined to consider. Therefore, if the change of communication bandwidth is small, it can improve the data processing efficiency by using consistent hashing algorithm.
4. Experiment and Analysis
Built HDFS storage cluster in LAN, the OS was Ubuntu14.04, and cloud computing platforms is installed. Other devices contain Intel xeon quad-core CPU, 8G memory, 1TBSATA hard drive, gigabit ethernet configured to connect the storage node of the cluster data. 6 racks is simulated (each rack had 6, 8, 12, 9, 8, 10 data nodes).
Table 1. Testing Data
File Copies Size Space Records
User info 3 1MB 3MB 2130
Release info 3 16GB 48GB 512k
Environmental data 3 640MB 1900MB 9680
The experimental data was real data from the use of "research on intelligent inventory management of key technology and systems development", and the data set are shown in Table 1. The performance data was same, so the node needs to be configured based on the actual storage cluster. Joint the physical address of network card and the LAN IP as the sole identification, aliquots of storage space size had been set to 64MB, the data size uploaded is 50GB, and storage areas are about 1200.
Figure 6. Distribution Backup of Rack Figure 7. Data Connection Query Run-Time Comparative
of the running time in Figure 7 using consistent hashing algorithm and optimization reduction standard to query processing algorithm. The result shows that the local data connection time is shorter than the time from the map data transmission, and start-up cost of data transmission is reduced.
Figure 8. Distribution of Actual Running Time For The Backup
Figure 9. Distribution Node Adjustment
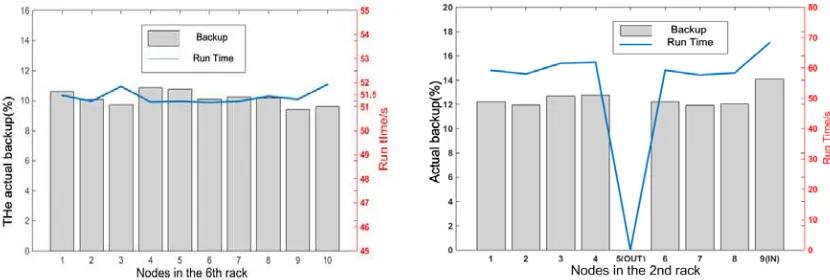
Data upload experiment is that the data setting of HDFS is uploaded from the local file system, the relationship between storage strategy and uploading speed is verified. In theory, the data nodes distribute evenly in the area, and then it would obtain equal opportunities to be assigned in racks. From Figure 8, with the growth of the data size, final data communication time is stable (about 51.5s and floating small amplitude), and the backup-got probability of data nodes are able to maintain in the theoretical value level. It indicates that load balancing is guaranteed when the data node was allocated backups.
Based on the experiment trends of data migration, the hash algorithm monotonic and load balancing features are verified. As shown in Figure 9, the added node had a higher probability to gain backup, and the probability of obtain data backup is required re-planning in the mapping process. However, amplitude oscillation is in a reasonable extent (about 1.8%), which does not affect the overall load balancing. With the increase of the data size, running time has a lesser extent, which illustrates that the algorithm design can meet large-scale data processing.
5. Conclusion
This article describes the big data stored optimization problems as a distributed clustered storage. Multiple copies of optimize storage location placement policy is put forward, which is based on the principle of consistency of consistent hashing. The use of virtual node technology and aliquots storage area ensured the balanced distribution of data storage, which accelerates the speed of data processing. It is possible to complete the expansion of the actual requirements of the cluster, and enables data storage to complete the adjustment with the development of adaptive optimization.
Experiments show that the execution speed has been effectively improved with storage optimization study. For the GB-scale data, the result ensures the load balancing. The time of multi-rack optimized connection experiment is significantly lower than conventional reduction processing algorithms. The amplitude oscillation could be in reasonable limits in the experiment of using optimized storage strategy to deal with extensions or deletion, which has little effect on the overall load balancing, and the execution time is consistent with the load share trends.
Acknowledgements
The authors would like to thank the editor and all the referees for their useful comments and contributions for the improvement of this paper. This research work is supported by the National Natural Science Foundation of China, the China Postdoctoral Science Foundation under Grant and the Key Program for Science and Technology Development of Jilin Province of China under Grant, Nos. 61100090, 20150101054JC and 20150204036GX.
References
[1] Kim K, Kim J, Min C, et al. Content-based chunk placement scheme for decentralized deduplication on distributed file systems. Computational Science and Its Applications–ICCSA 2013. Springer Berlin Heidelberg. 2013: 173-183.
[2] Spillner Josef, Muller Johannes, Schill Alexander. Creating optimal cloud storage systems. Future Generation Computer Systems. 2013; 29(4): 1062-1072.
[3] Londhe S, Mahajan S. Effective and Efficient Way of Reduce Dependency on Dataset with the Help of Mapreduce on Big Data. International Journal of Students' Research in Technology & Management. 2015; 3(6): 401-405.
[4] Liu Y, Wei W, Zhang Y. Checkpoint and Replication Oriented Fault Tolerant Mechanism for MapReduce Framework. TELKOMNIKA Indonesian Journal of Electrical Engineering. 2014; 12(2): 1029-1036.
[5] Liu ChenGuang. Research on optimizing energy efficiency for Hadoop storage system. Huazhong University of Science&Technology. 2012.
[6] Beilei S, Kun F, Keming W, et al. Research of Embedded GIS Data Management Strategies for Large Capacity. TELKOMNIKA Indonesian Journal of Electrical Engineering. 2014; 12(1): 275-279.
[7] Lei W, Yuwang Y, Wei Z, et al. NCStorage: A Prototype of Network Coding-based Distributed Storage System. TELKOMNIKA Indonesian Journal of Electrical Engineering. 2013; 11(12): 7689-7698.
[8] Bhuiyan MAS, Rosly HNB, bin Ibne Reaz M, et al. Advances on CMOS Shift Registers for Digital Data Storage. TELKOMNIKA Indonesian Journal of Electrical Engineering. 2014; 12(5): 3849-3862. [9] WANG Ning, YANG Yang, MENG Kun, et al. A Customer Experience-Based Cost Mini mization
Strategy of Storing Data i n Cloud Computing. ACTA Electronica Sinica. 2014; 42(1): 20-27.
[10] ZHAI Hai-bin, ZHANG Hong, LIU Xin-ran. A P2P Cache Capacity Design Method to Minimize the Total Traffic Cost of Access ISPs. ACTA Electronica Sinica. 2015; 43(5): 879-887.
[11] Pamies-Juarez L, García-López P, Sánchez-Artigas M. Towards the design of optimal data redundancy schemes for heterogeneous cloud storage infrastructures. Computer Networks the International Journal of Computer & Telecommunications Networking. 2011; 55(5): 1100-1113. [12] Sutikno T, Stiawan D, Subroto IMI. Fortifying Big Data infrastructures to Face Security and Privacy
Issues. TELKOMNIKA Telecommunication Computing Electronics and Control. 2014; 12(4): 751-752. [13] LI Jiandun, PENG Junjie, ZHANG Wu. A Layout-Based Energy-Aware Approach for Virtual Disk
Scheduling in Cloud Storage. ACTA Electronica Sinica. 2012; 40(11): 2247-2254.
[14] Jiangliu. The Research of Increase the IO Speed of Small Files in HDFS. Beijing University of Posts and Telecommunication. 2010.
[15] Wang YJ, Sun WD, Zhou S, et al. Key Technologies of Distributed Storage for Cloud Computing.
Journal of Software. 2012; 23(4): 962-986.
[16] Tena FL, Knauth T, Fetzer C. PowerCass: Energy Efficient, Consistent Hashing Based Storage for Micro Clouds Based Infrastructure. Cloud Computing (CLOUD), IEEE 7th International Conference on IEEE. 2014: 48-55.
[17] Jianwei L, Huijie C. A Dynamic Hashing Algorithm Suitable for Embedded System. TELKOMNIKA Indonesian Journal of Electrical Engineering. 2013; 11(6): 3220-3227.
[18] XI Ping, XUE Feng. Replica Placement Strategy Based on Multi-layer Consistent Hashing in HDFS.
Computer systems & applications. 2015; 24(2): 127-133.
[19] Bowers KD, Juels A, Oprea A. HAIL: a high-availability and integrity layer for cloud storage, Cryptology e-Print Archive. New York: ACM. 2009: 187-198.