i SKRIPSI
RENI HARPIANTI 130823010
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
ii
FAKTOR-FAKTOR YANG MEMPENGARUHI KEMISKINAN PROVINSI ACEH MENGGUNAKAN ANALISIS DISKRIMINAN
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
RENI HARPIANTI 130823010
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
i
Judul : FAKTOR-FAKTOR YANG MEMPENGARUHI
KEMISKINAN PROVINSI ACEH MENGGUNAKAN ANALISIS DISKRIMINAN
Kategori : SKRIPSI
Nama : RENI HARPIANTI
Nomor Induk Mahasiswa : 130823010
Program Studi : SARJANA (S1) MATEMATIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, Agustus 2015
Komisi Pembimbing:
Pembimbing 2 Pembimbing 1
Drs. Partano Siagian, M.Sc Drs. Pengarapen Bangun, M.Si NIP. 19511227 198003 1 001 NIP. 19560815198503 1 005
Diketahui/Disetujui oleh
Departemen Matematika FMIPA USU Ketua,
Prof. Dr. Tulus, M.Si
ii
FAKTOR-FAKTOR YANG MEMPENGARUHI KEMISKINAN PROVINSI ACEH MENGGUNAKAN ANALISIS DISKRIMINAN
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Agustus 2015
iii
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Pemurah dan Maha Penyayang, dengan limpah karunia-Nya penulis dapat menyelesaikan penyusunan Skripsi ini dengan judul Faktor-Faktor yang Mempengaruhi Kemiskinan Provinsi Aceh Menggunakan Analisis Diskriminan.
iv ABSTRAK
Di Indonesia khususnya Provinsi Aceh, masalah kemiskinan merupakan salah satu persoalan mendasar yang menjadi pusat perhatian pemerintah baik pemerintah pusat maupun pemerintah daerah. Walaupun angka kemiskinan menurun, tetapi faktanya masih banyak orang yang berada pada garis kemiskinan. Kemiskinan yang terjadi meliputi beberapa aspek antara lain pendidikan, kesehatan, demografi, dan juga struktural serta budaya. Penelitian ini akan membahas tentang beberapa faktor seperti Kepadatan Penduduk, Tingkat Pengangguran Terbuka (TPT), PDRB ADHK Perkapita, PDRB ADHB Per Kapita, Pertumbuhan Ekonomi dan Angka Harapan Hidup (AHH) yang mempengaruhi kemiskinan di Indonesia. Untuk mengetahui faktor yang paling mempengaruhi dan membedakan tingkat kemiskinan daerah Kabupaten/Kota Provinsi Aceh digunakan metode analisis diskriminan. Analisis diskriminan adalah salah satu teknik analisis multivariat yang digunakan untuk mengklasifikasikan data ke dalam suatu kelompok berdasarkan variabel terikat dan variabel bebas. Dengan menggunakan analisis diskriminan, terbukti bahwa faktor yang mempengaruhi kemiskinan adalah Angka Harapan Hidup.
v ABSTRACT
In Indonesia, especially Province Aceh, the problem of poverty is one of the fundamental problems that become the focus of government both central and local government. Although the poverty rate decreased but the fact is there are many people who are poor. Poverty happens covers several aspects such as education, health, demographics, and also structural and cultural. This research will discuss about several factors such as population density, Unemployment Rate, GDP per capita ADHK, ADHB GDP per capita, economic growth and life expectancy that affect poverty in Indonesia. To determine the factors that most influence and differentiate the level of poverty of the Regency/City Province Aceh used discriminant analysis method. Discriminant analysis is one multivariate analysis technique are used to classify the data into a group based on the dependent variable and independent variable. Using discriminant analysis, it is evident that the factor affecting poverty is Life Expectancy.
vi
Halaman
PERSETUJUAN i
PERNYATAAN ii
PENGHARGAAN iii
ABSTRAK iv
ABSTRACT v
DAFTAR ISI vi
DAFTAR TABEL viii
DAFTAR LAMPIRAN ix
BAB 1. PENDAHULUAN 1.1. Latar Belakang 1
1.2. Perumusan Masalah 4
1.3. Pembatasan Masalah 4
1.4. Tujuan Penelitian 4
1.5. Manfaat Penelitian 4
1.6. Metodologi Penelitian 5
BAB 2. LANDASAN TEORI 2.1 Kemiskinan 6
2.2. Kepadatan Penduduk 6
2.3. Tingkat Pengangguran Terbuka 7
2.4. PDRB ADHB Perkapita dan PDRB ADHK Perkapita 7
2.5. Pertumbuhan Ekonomi 8
2.6. Angka Harapan Hidup 8
2.7. Variabel 9
2.7.1. Variabel Penelitian 9
2.8. Data 10
2.9. Populasi 11
2.10. Matriks 11
2.11. Nilai Eigen (Eigen Value) 12
2.12. Analisis Diskriminan 12
2.12.1. Tujuan Analisis Diskriminan 12
2.12.2. Asumsi dalam Analisis Diskriminan 13
2.12.3. Proses Analisis Diskriminan 13
2.12.4. Model Analisis Diskriminan 14
2.12.5. Fungsi Diskriminan 14
2.12.6. Algoritma Pokok Analisis Diskriminan dan Model Matematis 18
BAB 3. HASIL DAN PEMBAHASAN 3.1. Populasi dan Data Penelitian 21
viii
3.2.1. Uji Kenormalan Data 22
3.2.2. Uji Kesamaan Rata-rata 23
3.3. Interpretasi Output SPSS 30
3.3.1. Variabel-variabel yang Dimasukkan 31
3.3.2. Nilai Korelasi Kanonikal Eigenvalue 33
3.3.3. Uji Signifikansi 33
3.3.4. Struktur Matriks 34
3.3.5. Koefisien Fungsi Diskriminan Kanonik 34
3.3.6. Fungsi Pada Kelompok Terpusat 35
3.3.7. Peluang Utama Untuk Kelompok 35
3.3.8. Uji Hasil Klasifikasi 36
BAB 4. KESIMPULAN DAN SARAN 4.1. Kesimpulan 38
viii
Nomor Judul Halaman
Tabel
2.1. Matriks Pengamatan 15
2.2. Matriks Data Pengamatan dari Kelompok I 16
2.3. Matriks Data Pengamatan dari Kelompok II 17
3.1. Data Kependudukan,Sosial, dan Ekonomi Provinsi Aceh 21
3.2. Uji Kolmogorv Smirnov 22
3.3. Uji Kesamaan Rata-rata 23
3.4. Group Statistik 30
3.5. Variabel-variabel yang Dimasukkan 31
3.6. Variabel yang Dianalisis 31
3.7. Variabel yang Tidak Dianalisis 32
3.8. Wilk’s Lambda 32
3.9. Korelasi Kanonikal Eigen Value 33
3.10. Wilk’s Lambda 33
3.11. Struktur Matriks 34
3.12. Koefisien Fungsi Diskriminan Kanonik 34
3.13. Fungsi Pada Kelompok Terpusat 35
3.14. Peluang Utama Untuk Kelompok 35
ix
Nomor Judul Halaman
Lamp
1. Perhitungan Rata-rata Untuk Setiap Variabel Kelompok II 40
2. Perhitungan Varians Kovarians Kelompok I 42
3. Perhitungan Varians Kovarians Kelompok II 48
4. Tabel Output SPSS 56
iv ABSTRAK
Di Indonesia khususnya Provinsi Aceh, masalah kemiskinan merupakan salah satu persoalan mendasar yang menjadi pusat perhatian pemerintah baik pemerintah pusat maupun pemerintah daerah. Walaupun angka kemiskinan menurun, tetapi faktanya masih banyak orang yang berada pada garis kemiskinan. Kemiskinan yang terjadi meliputi beberapa aspek antara lain pendidikan, kesehatan, demografi, dan juga struktural serta budaya. Penelitian ini akan membahas tentang beberapa faktor seperti Kepadatan Penduduk, Tingkat Pengangguran Terbuka (TPT), PDRB ADHK Perkapita, PDRB ADHB Per Kapita, Pertumbuhan Ekonomi dan Angka Harapan Hidup (AHH) yang mempengaruhi kemiskinan di Indonesia. Untuk mengetahui faktor yang paling mempengaruhi dan membedakan tingkat kemiskinan daerah Kabupaten/Kota Provinsi Aceh digunakan metode analisis diskriminan. Analisis diskriminan adalah salah satu teknik analisis multivariat yang digunakan untuk mengklasifikasikan data ke dalam suatu kelompok berdasarkan variabel terikat dan variabel bebas. Dengan menggunakan analisis diskriminan, terbukti bahwa faktor yang mempengaruhi kemiskinan adalah Angka Harapan Hidup.
v ABSTRACT
In Indonesia, especially Province Aceh, the problem of poverty is one of the fundamental problems that become the focus of government both central and local government. Although the poverty rate decreased but the fact is there are many people who are poor. Poverty happens covers several aspects such as education, health, demographics, and also structural and cultural. This research will discuss about several factors such as population density, Unemployment Rate, GDP per capita ADHK, ADHB GDP per capita, economic growth and life expectancy that affect poverty in Indonesia. To determine the factors that most influence and differentiate the level of poverty of the Regency/City Province Aceh used discriminant analysis method. Discriminant analysis is one multivariate analysis technique are used to classify the data into a group based on the dependent variable and independent variable. Using discriminant analysis, it is evident that the factor affecting poverty is Life Expectancy.
BAB 1
PENDAHULUAN
1.1Latar Belakang
Aceh adalah daerah provinsi yang merupakan kesatuan masyarakat hukum yang bersifat istimewa dan diberi kewenangan khusus untuk mengatur dan mengurus sendiri urusan pemerintahan dan kepentingan masyarakat setempat sesuai dengan peraturan perundang-undangan dalam sistem dan prinsip Negara Kesatuan Republik Indonesia berdasarkan Undang-Undang Dasar Negara Republik Indonesia Tahun 1945, yang dipimpin oleh seorang Gubernur. Di Provinsi Aceh masalah kemiskinan merupakan salah satu persoalan mendasar yang menjadi pusat perhatian pemerintah baik pemerintah pusat maupun pemerintah daerah. Kemiskinan adalah keadaan dimana terjadi ketidakmampuan untuk memenuhi kebutuhan dasar seperti makanan , pakaian , tempat berlindung, pendidikan, dan kesehatan. Kemiskinan dapat disebabkan oleh kelangkaan alat pemenuh kebutuhan dasar, ataupun sulitnya akses terhadap pendidikan dan pekerjaan. Besar kecilnya penduduk miskin sangat dipengaruhi oleh garis kemiskinan, karena penduduk miskin adalah penduduk yang memiliki rata-rata pengeluaran perkapita perbulan di bawah garis kemiskinan. Persoalan kemiskinan bukan hanya sekedar berapa jumlah dan persentase penduduk miskin. Dimensi lain yang perlu diperhatikan adalah tingkat kedalaman dan keparahan dari kemiskinan. Selain harus mampu memperkecil jumlah penduduk miskin, kebijakan kemiskinan juga harus bisa mengurangi tingkat kedalaman dan keparahan dari kemiskinan. Fenomena kemiskinan pada prinsipnya muncul karena sebagian penduduk tidak dapat mengakses terhadap peluang-peluang ekonomi yang tersedia. Apabila masalah kemiskinan tidak ditanggapi dengan serius, maka dapat menghambat proses pembangunan.
mengentaskan kemiskinan. Masalah pokok yang dihadapi oleh pedesaan di Indonesia salah satunya di daerah provinsi aceh adalah kemiskinan dan keterbelakangan. Keadaan ini ditandai oleh pendapatan yang rendah dari sebagian besar penduduk pedesaan dan terdapatnya kesenjangan antara golongan kaya dan miskin dalam usaha-usaha pembangunan sehingga kondisi-kondisi tersebut kurang menguntungkan dalam mempercepat laju pertumbuhan. Pembangunan nasional mempunyai beberapa tujuan salah satu diantaranya adalah meningkatkan taraf hidup masyarakat agar menjadi manusia seutuhnya yang berdasarkan Pancasila dan Undang-Undang Dasar 1945. Dalam Garis-Garis Besar Haluan Negara (GBHN), dinyatakan bahwa pembangunan ekonomi merupakan salah satu bagian penting dalam pembangunan nasional dengan tujuan akhir untuk meningkatkan kesejahteraan rakyat. Pembangunan yang dilakukan tidak hanya secara fisik tetapi juga pembangunan manusianya. Sehingga dengan terpenuhinya kebutuhan dasar masyarakat maka pembangunan baru dapat berhasil mencapai tujuan, dimana salah satu tujuan pembangunan adalah mencapai masyarakat sejahtera, adil dan makmur, yang artinya kemiskinan dapat dikurangi (Utari, 2013).
sebagai studi kasus di BPS adalah data kependudukan, sosial, dan ekonomi Provinsi Aceh Tahun 2013, yang diuraikan kedalam: 1) Kepadatan Penduduk; 2) Tingkat Pengangguran Terbuka; 3) PDRB Per Kapita Atas Dasar Harga Konstan; 4) PDRB Per Kapita Atas Dasar Harga Berlaku; 5) Pertumbuhan Ekonomi; dan 6) Angka Harapan Hidup. Metode yang digunakan adalah analisis diskriminan.
Analisis diskriminan merupakan salah satu metode yang digunakan dalam analisis multivariat dengan metode dependensi (dimana hubungan antar variabel sudah bisa dibedakan mana variabel terikat dan mana variabel bebas). Analisis diskriminan digunakan pada kasus dimana variabel bebas berupa data metrik (interval atau rasio) dan variabel terikat berupa data nonmetrik (nominal atau ordinal). Analisis diskriminan digunakan untuk mengklasifikasikan individu atau objek ke dalam suatu kelompok atau kelas berdasarkan sekumpulan variabel bebas (Dillon dan Goldstein,1984). Analisis diskriminan adalah salah satu metode yang dapat digunakan untuk mengetahui variabel mana yang membedakan suatu kelompok dengan kelompok lain dalam suatu populasi. Pada dasarnya analisis diskriminan dapat dipergunakan untuk mengetahui peubah-peubah penciri yang membedakan kelompok populasi yang ada, selain itu juga dapat dipergunakan sebagai kriteria pengelompokan yang terlebih dahulu diketahui secara jelas pengelompokkannya. Analisis diskriminan bertujuan untuk mengenali faktor – faktor yang dapat membedakan dua kelompok atau lebih. Faktor – faktor pembeda ini akan membentuk sebuah fungsi pembeda (disebut fungsi diskriminan).
Berdasarkan latar belakang di atas penulis memilih judul “Faktor-Faktor yang Mempengaruhi Kemiskinan Provinsi Aceh Menggunakan Analisis
1.2Perumusan Masalah
Dalam upaya mengurangi tingkat kemiskinan provinsi aceh yang masih tinggi, perlu diketahui sebenarnya faktor-faktor apa sajakah yang berhubungan atau mempengaruhi tinggi rendahnya tingkat kemiskinan provinsi aceh sehingga kedepannya dapat menghasilkan sebuah kebijakan yang efektif untuk mengurangi tingkat kemiskinan, merupakan permasalahan yang akan dibahas dalam penelitian ini.
1.3Pembatasan Masalah
Ruang lingkup dari pembahasan penelitian ini adalah data berupa data sekunder, yaitu data kependudukan, sosial, dan ekonomi Provinsi Aceh tahun 2013 yang telah dipublikasikan oleh Badan Pusat Statistik. Penelitian ini menggunakan analisis diskriminan untuk mengetahui faktor-faktor yang mempengaruhi kemiskinan provinsi aceh.
1.4Tujuan Penelitian
Tujuan yang ingin dicapai dari penelitian ini adalah untuk mengetahui faktor-faktor apa saja yang paling berpengaruh dan membedakan tinggi rendahnya tingkat kemiskinan Provinsi Aceh.
1.5Manfaat Penelitian
Kontribusi dari penelitian ini adalah :
1. Diharapkan semoga penelitian ini dapat menambah dan meningkatkan wawasan dalam penerapan ilmu statistika dengan metode analisis diskriminan sebagai faktor-faktor yang mempengaruhi kemiskinan Provinsi Aceh.
3. Hasil penelitian ini dapat dijadikan sebagai bahan referensi untuk peneliti –peneliti berikutnya dalam data yang akan dianalisis.
1.6Metodologi Penelitian
Penelitian ini dilakukan dengan beberapa tahap yaitu: 1. Pengumpulan Data
Data yang digunakan dalam penelitian ini adalah data sekunder yang di ambil dari kantor Badan Pusat Statistik (BPS) Provinsi Aceh.
2. Pengolahan Data
a. Menghitung nilai rata-rata, nilai varians, kovarians, matriks varians-kovarians dan matriks varians varians-kovarians dalam kelompok gabungan pada setiap kelompok.
b. Melakukan pengujian asumsi analisis diskriminan yaitu: menguji kenormalan data, menguji kesamaan rata-rata kelompok dan menguji kesamaan varians dengan bantuan SPSS.
c. Menguji signifikansi dari fungsi diskriminan dengan nilai uji F dan Wilks’ Lambda dengan bantuan SPSS.
d. Membuat suatu fungsi diskriminan dari variabel bebas yang bias mendiskriminasi atau membedakan kelompok variabel terikat dengan bantuan SPSS.
e. Menentukan klasifikasi terhadap objek, apakah suatu objek termasuk pada kelompok I atau kelompok II dengan bantuan SPSS.
BAB 2
LANDASAN TEORI
2.1 Kemiskinan
Definisi tentang kemiskinan telah mengalami perluasan, seiring dengan semakin kompleksnya faktor penyebab, indikator, maupun permasalahan lain yang melingkupinya. Kemiskinan tidak lagi hanya dianggap sebagai dimensi ekonomi melainkan telah meluas hingga kedimensi sosial, kesehatan, pendidikan dan politik. Menurut Badan Pusat Statistik, kemiskinan adalah ketidakmampuan memenuhi standar minimum kebutuhan dasar yang meliputi makanan maupun non makanan.
Untuk mengukur kemiskinan, Indonesia melalui BPS menggunakan pendekatan kebutuhan dasar (basic needs) yang dapat diukur dengan angka atau hitungan Indeks Perkepala (Head Count Index), yakni jumlah dan persentase penduduk miskin yang berada di bawah garis kemiskinan. Garis kemiskinan ditetapkan pada tingkat yang selalu konstan secara riil sehingga kita dapat mengurangi angka kemiskinan dengan menelusuri kemajuan yang diperoleh dalam mengentaskan kemiskinan disepanjang waktu. (BPS, 2009-2013)
2.2 Kepadatan Penduduk
Kepadatan penduduk adalah jumlah penduduk yang mendiami suatu daerah per satuan unit wilayah (kilometer persegi). Ciri-ciri kepadatan penduduk yang makin lama makin tinggi adalah tingginya pertumbuhan penduduk yang terus berjalan dan meningkatnya jumlah pemukiman di daerah tersebut. Adapun Kepadatan Penduduk dapat dirumuskan :
Penyebut dapat berupa luas wilayah, luas daerah pedesaan, atau luas pertanian (BPS, 2000).
2.3 Tingkat Pengangguran Terbuka (TPT)
Angka pengangguran menunjukkan ketidakmampuan suatu perekonomian dalam menyerap tenaga kerja yang ada di suatu daerah. Angka pengangguran dihitung dengan Tingkat Pengangguran Terbuka (TPT). TPT merupakan persentase jumlah pengangguran terhadap jumlah angkatan kerja. Tingkat pengangguran terbuka diukur sebagai persentase jumlah penganggur/pencari kerja terhadap jumlah angkatan kerja.
Pengangguran terbuka adalah mereka yang sedang mencari kerja atau sedang menyiapkan usaha, atau tidak mencari kerja karena merasa tidak mungkin memperoleh pekerjaan, atau sudah diterima kerja tetapi belum mulai bekerja. (BPS, 2009-2013)
2.4 PDRB ADHB Perkapita dan PDRB ADHK Perkapita
Produk Domestik Regional Bruto (PDRB) merupakan salah satu indikator penting untuk mengetahui kondisi ekonomi di suatu daerah dalam suatu periode tertentu, baik atas dasar harga berlaku maupun atas dasar harga konstan.
1. PDRB atas dasar harga berlaku menggambarkan nilai tambah barang dan jasa yang dihitung menggunakan harga pada tahun berjalan. PDRB menurut harga berlaku digunakan untuk mengetahui kemampuan sumber daya ekonomi, pergeseran, dan struktur ekonomi suatu daerah.
2.5 Pertumbuhan Ekonomi
Pertumbuhan ekonomi merupakan salah satu ukuran dari hasil pembangunan yang dilaksanakan khususnya dalam bidang ekonomi. Pertumbuhan tersebut merupakan rangkuman laju pertumbuhan dari berbagai sektor ekonomi yang menggambarkan tingkat perubahan ekonomi yang terjadi.
Pertumbuhan ekonomi merupakan salah satu indikator yang sangat penting untuk mengetahui dan mengevaluasi hasil pembangunan yang dilaksanakan, khususnya dalam bidang ekonomi. Pertumbuhan ekonomi akan menunjukkkan sejauh mana kinerja atau aktivitas dari berbagai sektor ekonomi dalam menghasilkan nilai tambah atau pendapatan masyarakat pada suatu priode tertentu. Untuk mengetahui fluktuasi pertumbuhan ekonomi tersebut secara riil dari tahun ke tahun, digunakan PDRB atas dasar harga konstan secara berkala. Pertumbuhan yang positif menunjukkan adanya peningkatan kinerja perekonomian, sebaliknya bila negatif menunjukkkan terjadinya penurunan kinerja perekonomian yang dilaksanakan dibanding periode sebelumnya (BPS, 1989 - 2008).
2.6 Angka Harapan Hidup
2.7 Variabel
Dalam melakukan observasi tentunya perlu ditentukan karakter yang akan diobservasi dari unit atau amatan yang disebut variabel (variable). Variabel dalam penelitian merupakan suatu atribut dari sekelompok objek yang diteliti yang memiliki variasi antara satu objek dengan objek yang lain dalam kelompok tersebut.
Berdasarkan bulat atau tidaknya nilai yang diperoleh, variabel dapat dibedakan menjadi variabel kontinu dan variabel diskrit. Variabel kontinu adalah variabel yang besarannya dapat menempati semua nilai yang ada diantara dua titik. Pada umumnya variabel kontinu diperoleh dari hasil pengukuran. Pada variabel kontinu dapat dijumpai nilai-nilai pecahan ataupun nilai-nilai yang bulat. Sedangkan variabel diskrit merupakan variabel yang besarannya tidak dapat menempati semua nilai. Nilai variabel diskrit selalu berupa bilangan bulat. Pada umumnya variabel diskrit diperoleh melalui pencacahan/penghitungan.
Dalam kaitan hubungan suatu variabel dengan variabel lainnya, variabel di bagi 2 yaitu :
1. Variabel independen (independent variable) atau variabel bebas, yaitu
variabel yang menjadi sebab terjadinya (terpengaruhnya) variabel dependen (variabel tak bebas).
2. Variabel dependen (dependent variable) atau variabel tak bebas, yaitu variabel
yang nilainya dipengaruhi oleh variabel independen. (Sugiarto, 2001). 2.7.1 Variabel Penelitian
1. Variabel terikat (Y) pada penelitian ini adalah Persentase Kemiskinan (%). Untuk dapat dianalisis dengan analisis diskriminan maka dikelompokkan menjadi dua, yaitu :
Y1 : Tingkat kemiskinan rendah adalah daerah dengan persentase penduduk miskin <18% diberi kode 0.
2. Variabel bebas (X) pada penelitian ini adalah: X1 : Kepadatan Penduduk (Jiwa/Km2)
X2 : Tingkat Pengangguran Terbuka (TPT) (%)
X3 : PDRB Per Kapita Atas Dasar Harga Konstan (PDRB ADHK) (Ribu Rupiah)
X4 : PDRB Per Kapita Atas Dasar Harga Berlaku (PDRB ADHB) (Ribu Rupiah)
X5 : Pertumbuhan Ekonomi (%)
X6 : Angka Harapan Hidup (AHH) (%)
2.8 Data
Dalam pengertian data adalah sesuatu yang bersifat numerik , hal ini berarti data statistik hanya bisa diproses jika berupa angka atau sesuatu yang bisa dikuantitatifkan (Santoso, 2010).
Data merupakan komponen utama dalam statistik. Sebagai komponen utama maka akurasi dan presisi suatu data akan sangat menentukan dalam menghasilkan ketepatan pengambilan suatu keputusan. Untuk itu data harus sesuai dengan kenyataan yang sebenarnya (akurasinya tinggi), harus bisa mewakili parameter yang diukur dengan variasi yang kecil (presisinya tinggi), harus relevan untuk menjawab suatu persoalan yang sedang menjadi pokok bahasan dan harus tepat waktu.
Metode pengumpulan data menunjukkan cara-cara yang dapat ditempuh untuk memperoleh data yang dibutuhkan. Dalam kenyataannya dikenal metode pengumpulan data primer dan metode pengumpulan data sekunder:
1. Metode pengumpulan data primer
Metode pengumpulan data primer merupakan data yang didapat dari sumber pertama, baik dari individu atau perorangan seperti hasil wawancara atau hasil pengisian kuisioner yang biasa dilakukan oleh peneliti.
2. Metode pengumpulan data sekunder
sendiri tetapi meneliti dan memanfaatkan data atau dokumen yang dihasilkan oleh pihak-pihak lain.
2.9 Populasi
Populasi ialah kumpulan yang lengkap dari seluruh elemen yang sejenis, tetapi dapat dibedakan karena karakteristiknya. (Supranto, 2010). Populasi berarti keseluruhan unit atau individu dalam ruang lingkup yang ingin diteliti. Populasi dibedakan menjadi populasi sasaran (target population) dan populasi sampel
(sampling population). Populasi sasaran adalah keseluruhan individu dalam
areal/wilayah/lokasi/kurun waktu yang sesuai dengan tujuan penelitian. Populasi sampel adalah keseluruhan individu yang akan menjadi satuan analisis dalam populasi yang layak dan sesuai untuk dijadikan atau ditarik sebagai sampel penelitian sesuai dengan kerangka sampelnya (sampling frame) (Sugiarto, 2001).
2.10 Matriks
Matriks adalah suatu kumpulan angka-angka yang juga sering disebut elemen-elemen yang disusun secara teratur menurut baris dan kolom sehingga berbentuk persegi panjang, dimana panjang dan lebarnya ditunjukkan oleh banyaknya kolom dan baris serta dibatasi tanda “[ ]” atau “( )” (Anton, 1987).
Matriks S yang berukuran dari n baris dan p kolom ( ) adalah:
(2.1)
Entri disebut elemen matriks pada baris ke-i dan kolom ke-j. Jika n =
2.11 Nilai Eigen (Eigen Value)
Misalkan A adalah matriks persegi berukuran dan I adalah matriks identitas berukuran . Skalar , , … , yang memenuhi persamaan: |A - I| = 0 disebut nilai eigen atau akar karakteristik. Dan suatu matriks A berukuran dan adalah nilai eigen dari matriks A jika terdapat suatu vektor x tak nol sedemikian sehingga Ax = x, maka x disebut vektor eigen atau vektor karakteristik dari matriks A yang bersesuaian dengan nilai eigen . Untuk mencari nilai eigen matriks A yang berukuran , dapat ditulis kembali sebagai suatu persamaan homogen |A - I| = 0. Dengan I adalah matriks identitas yang berordo sama dengan matriks A.
2.12 Analisis Diskriminan
Menurut Yasril & Heru Subaris Kasjono (2008), Analisis Diskriminan merupakan teknik menganalisis data, dimana variabel dependen merupakan variabel kategorik (nominal atau ordinal) sedangkan variabel independen merupakan variabel numerik (interval atau rasio).
Menurut Johnson dan Wichern (2007) Analisis Diskriminan digunakan untuk mengklasifikasikan individu ke dalam salah satu dari dua kelompok atau lebih. Suatu fungsi diskriminan layak untuk dibentuk, bila terdapat perbedaan nilai rataan di antara kelompok-kelompok yang ada.
2.12.1 Tujuan Analisis Diskriminan
Tujuan analisis diskriminan adalah (Yasril & Heru Subaris Kasjono,2008):
1. Membuat suatu fungsi diskriminan dari variabel independen yang bisa mendiskriminasi atau membedakan kelompok variabel dependen, artinya mampu membedakan suatu objek masuk kelompok yang mana 2. Menguji apakah ada perbedaan signifikan antara kelonpok, dikaitkan
dengan variabel independen
4. Mengelompokkan (mengklasifikasikan) variabel dependen ke dalam suatu kelompok didasarkan pada nilai variabel independen.
2.12.2 Asumsi dalam Analisis Diskriminan
Selain dasar dan tujuan diskriminan, ternyata ada asumsi-asumsi yang harus dipenuhi sebelum melakukan analisis diskriminan, yakni variabel bebas berdistribusi normal multivariate (multivariates normal distribution) dan varians dalam setiap kelompok adalah sama (equal variances).
2.12.3 Proses Analisis Diskriminan
Pada umumnya proses dasar dari analisis diskriminan adalah:
1. Memisah variabel-variabel menjadi variabel terikat dan variabel bebas.
2. Menentukan metode untuk membuat fungsi diskriminan. Dimana pada prinsipnya terdapat dua metode dasar untuk itu:
a. Simultaneous Estimation, metode dengan cara memasukkan semua
variabel secara bersama-sama kemudian dilakukan proses diskriminan.
b. Stepwise Estimation, metode dengan cara memasukkan satu per satu
variabel kedalam model diskriminan. Pada metode ini, tentu terdapat variabel yang tetap ada pada model, dan terdapat kemungkinan satu atau lebih variabel bebas yang dibuang dari model.
3. Melakukan pengujian signifikansi dari fungsi diskriminan yang telah terbentuk, dengan menggunakan Wilk’s Lambda, Nilai F test dan lainnya. 4. Melakukan interpretasi terhadap fungsi diskriminan yang telah terbentuk. 5. Melakukan pengujian ketepatan klasifikasi dari fungsi diskriminan, termasuk
mengetahui ketepatan klasifikasi secara individual dengan casewise diagnostics.
2.12.4 Model Analisis Diskriminan
Di = (2.2)
keterangan :
Di = nilai (skor) diskriminan dari responden (objek) ke-i ( i = 1, 2, . . ., n). D merupakan variabel tak bebas
bj = koefisien atau timbangan diskriminan dari variabel atau atribut ke-j (j= 0,1,2,...,k)
= variabel bebas (atribut) ke-j dari responden ke-i.
Yang diestimasi adalah koefisien “bj” sehingga nilai “D” setiap grup
sedapat mungkin berbeda. Ini terjadi pada saat jumlah kuadrat antar grup terhadap jumlah kuadrat dalam grup untuk skor diskriminan mencapai maksimum. Berdasarkan nilai D itulah keanggotaan seseorang diprediksi.
2.12.5 Fungsi Diskriminan
Suatu fungsi diskriminan layak untuk dibentuk bila terdapat perbedaan nilai rataan di antara kelompok-kelompok yang ada. Oleh karena itu sebelum fungsi diskriminan dibentuk perlu dilakukan pengujian terhadap perbedaan vektor nilai rataan dari kelompok-kelompok tersebut.
Tabel 2.1 Matriks Pengamatan
Variabel ... ...
Pengamatan
. . .
... ... . . . ...
.
... ... . . . ...
.
Untuk variabel (j = 1, 2, 3, ..., k) yang dihitung adalah variansinya, diberi lambang dengan rumus:
(2.3)
Semua ada buah varians, yaitu yang masing-masing adalah varians untuk variabel . Antara dan untuk i ≠ j terdapat kovarians, diberi lambang yang dapat dihitung dengan rumus sebagai berikut:
(2.4)
Semuanya ada ( buah kovarians, varians dan kovarians disusun dalam sebuah matriks yang disebut dengan matriks varians kovarians (S) dengan bentuk sebagai berikut:
(2.5)
Dengan i = j maka , varians untuk variabel dan . Matriks varians kovarians gabungannya dapat dihitung dengan menggunakan rumus sebagai berikut:
keterangan:
= Matriks varians-kovarians gabungan = Matriks varians-kovarians tiap kelompok
= Banyaknya responden tiap kelompok = Jumlah kelompok
Andaikan ada dua kelompok yang memiliki variabel masing-masing
buah yaitu dalam kelompok I dan dalam
kelompok II. Perhatikan bahwa menyatakan variabel ke-j dalam kelompok ke-l, dengan l = 1 atau 2 sedangkan j = 1, 2, ..., k. Variabel dalam setiap kelompok dapat dituliskan dalam bentuk vektor kolom sebagai berikut:
= dan = (2.7)
keterangan :
= menyatakan variabel X ke-j dalam kelompok ke-1, . menyatakan variabel X ke-j dalam kelompok ke-2,
Dari setiap kelompok diambil sebuah sampel acak berukuran dari kelompok ke-1 dan berukuran dari kelompok ke-2. Data pengamatan akan membentuk matriks yang bentuknya masing-masing seperti berikut ini:
Tabel 2.2 Matriks Data Pengamatan dari Kelompok I
Variabel ... ...
Pengamatan . . . . . . . . . ... ... ... . . . ... . . . ... ... ... . . . ... . . .
Tabel 2.3 Matriks Data Pengamatan dari Kelompok II
Variabel ... ...
Pengamatan . . . . . . . . . ... ... ... . . . ... . . . ... ... ... . . . ... . . .
Rata-rata ... ...
Hasil pengamatan ini akan menghasilkan rata-rata untuk tiap variabel yang dalam bentuk vektor dapat ditulis sebagai berikut:
= dan = (2.8)
keterangan:
= rata – rata variabel ke-j dalam kelompok ke-1, . = rata – rata variabel ke-j dalam kelompok ke-2, .
Setelah diperoleh rata-rata dari kelompok I dan rata-rata dari kelompok II, selanjutnya akan dihitung varians dan kovariansnya. Varians dan kovariansnya tersebut dalam matriks dan matriks , masing-masing dari sampel kelompok I dan kelompok II, yaitu :
(2.9)
keterangan:
Meskipun dalam dan digunakan yang sama namun jelas besarnya berlainan antara dalam dan dalam , kedua data sampelnya juga berlainan yaitu diambil dari kelompok I dan dari kelompok II. Untuk kedua buah matriks varians-kovarians ini bisa dihitung matriks varians-kovarians gabungan, diberi lambing S dengan rumus:
(2.10)
keterangan:
= Matriks varians-kovarians gabungan.
= Matriks varians-kovarians dari kelompok I dan kelompok II. = Jumlah data pengamatan kelompok I dan kelompok II.
2.12.6 Algoritma Pokok Analisis Diskriminan dan Model Matematis
Secara ringkas, langkah-langkah dari analisis diskriminan adalah:
1. Pengecekan adanya kemungkinan hubungan linier antara variabel bebas. Pengecekan dilakukan dengan bantuan matriks korelasi (pembentukan matriks korelasi sudah difasilitasi pada analisis diskriminan). Pada hasil output SPSS, matriks korelasi dapat dilihat pada Pooled Within-Groups Matrices.
2. Uji vektor rata-rata kedua kelompok
Pengujian terhadap vektor nilai rataan antar kelompok dilakukan dengan hipotesis:
H0 : µ1= µ2= µ3= ... = µl
H1 : sedikitnya ada dua kelompok yang berbeda Angka signifikan:
Jika angka Sig > 0,05, tidak ada perbedaan antar kelompok Jika angka Sig ≤ 0,05, ada perbedaan antar kelompok
Pada SPSS, uji ini dilakukan secara univariate (yang diuji bukan berupa vektor), dengan bantuan tabel Tests of Equality of Group Means.
3. Pembentukan Model Diskriminan a. Pembentukan Fungsi Linier
Pada output SPSS, koefisien untuk tiap variabel yang masuk dalam model dapat dilihat pada tabel Canonical Discriminant Function Coefficient. Tabel ini akan dihasilkan pada output apabila pilihan Function Coefficient
bagia Unstandardized diaktifkan. b. Menghitung Discriminant Score
Setelah fungsi liniernya dibentuk, maka dapat dihitung skor diskriminan untuk tiap observasi dengan cara memasukkan nilai-nilai variabel penjelasnya.
c. Menghitung Cutting Score
Untuk memprediksi responden yang mana masuk kedalam golongan yang mana, kita dapat menggunakan optimum cutting score. Memang dari komputer informasi ini sudah diperoleh. Untuk cara mengerjakan secara manual Cutting Score dapat dihitung dengan rumus sebagai berikut dengan ketentuan:
1. Untuk dua kelompok yang mempunyai ukuran yang sama cutting
score dinyatakan dengan rumus (Simamora, 2005):
(2.11)
keterangan:
= Cutting score untuk kelompok yang mempunyai ukuran yang sama
= Centroid kelompok A = Centroid kelompok B
2. Untuk dua kelompok yang mempunyai ukuran yang berbeda, rumus cutting score yang digunakan adalah:
keterangan:
= Cutting score untuk kelompok yang mempunyai ukuran yang berbeda
= Jumlah sampel kelompok A = Jumlah sampel kelompok B = Centroid kelompok A = Centroid kelompok B
Centroid adalah nilai rata-rata skor diskriminan untuk kelompok tertentu.
Kemudian nilai-nilai discriminant score tiap observasi akan dibandingkan dengan nilai cutting score, sehingga dapat diklasifikasikan suatu obsevasi akan termasuk kedalam kelompok yang mana. Dapat dihitung dengan bantuan tabel
BAB 3
PEMBAHASAN DAN HASIL
3.1 Populasi dan Data Penelitian
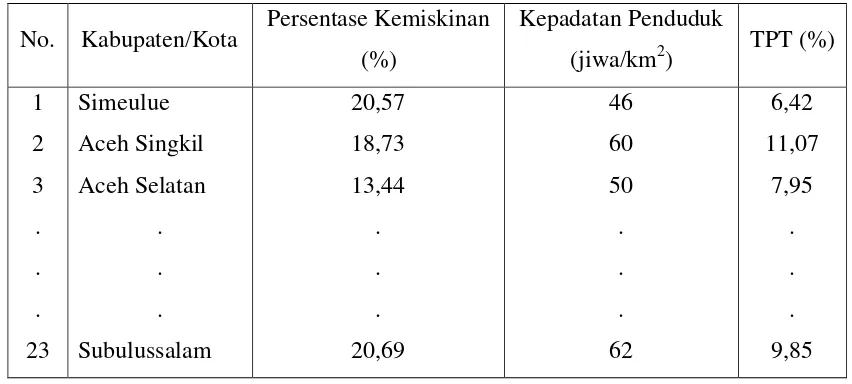
Populasi adalah keseluruhan unit atau individu dalam ruang lingkup yang ingin diteliti. Pada penelitian ini populasinya adalah seluruh Kabupaten/Kota di Provinsi Aceh yang berjumlah 23 Kabupaten/Kota yang dibagi kedalam dua kelompok, yaitu:
1. Kelompok I : daerah Kabupaten/Kota dengan Persentase Kemiskinan <18%, yaitu Kabupaten Aceh Selatan, Kabupaten Aceh Tenggara, Kabupaten Aceh Timur, Kabupaten Aceh Tengah, Kabupaten Aceh Besar, Kabupaten Bireuen, Kabupaten Aceh Tamiang, Kabupaten Aceh Jaya, Kota Banda Aceh, Kota Langsa, Kota Lhokseumawe.
[image:34.595.104.530.546.738.2]2. Kelompok II : daerah Kabupaten/Kota dengan Persentase Kemiskinan 18%, yaitu Kabupaten Simeulue, Kabupaten Aceh Singkil, Kabupaten Aceh Barat, Kabupaten Pidie, Kabupaten Aceh Utara, Kabupaten Aceh Barat Daya, Kabupaten Gayo Lues, Kabupaten Nagan Raya, Kabupaten Bener Meriah, Kabupaten Pidie Jaya, Kota Sabang, Kabupaten Subulussalam.
Tabel 3.1 Data Kependudukan,Sosial, Dan Ekonomi Provinsi Aceh Tahun 2013 No. Kabupaten/Kota Persentase Kemiskinan
(%)
Kepadatan Penduduk
Sambungan Tabel 3.1
No. Kabupaten/Kota
PDRB ADHK Perkapita (Rupiah) PDRB ADHB Perkapita (Rupiah) Laju Pertumbuhan Ekonomi ADHK (%) AHH (%) 1 2 3 . . . 23 Simeulue Aceh Singkil Aceh Selatan . . . Subulussalam 301.718,02 561.577,83 1.481.559,10 . . . 309.578,77 724.702,92 1.026.661,77 3.125.168,82 . . . 474.351,72 5,41 5,08 4,27 . . . 6,03 63,32 65,58 67,54 . . . 66,63 Keseluruhan Data Penelitian dapat dilihat pada lampiran.
3.2 Analisis Data
Dalam penelitian ini penulis menggunakan analisis diskriminan sebagai alat untuk menganalisis data yang diperoleh. Analisis diskriminan dimulai dengan hal-hal yang ringan yaitu pemilihan variabel terikat dan variabel bebas, dimana variabel terikat bersifat kategorik atau kualitatif sedangkan variable bebas harus bersifat metrik atau kuantitatif. Kemudian melakukan analisis univariat untuk mengetahui kenormalan data.
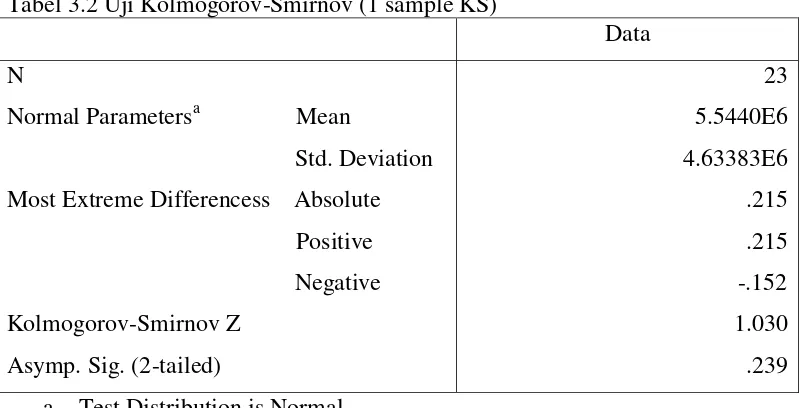
3.2.1 Uji Kenormalan Data
Tabel 3.2 Uji Kolmogorov-Smirnov (1 sample KS)
Data N
Normal Parametersa Mean
Std. Deviation Most Extreme Differencess Absolute
Positive Negative Kolmogorov-Smirnov Z
Asymp. Sig. (2-tailed)
23 5.5440E6 4.63383E6 .215 .215 -.152 1.030 .239 a. Test Distribution is Normal
Dari hasil test Kolmogorov Smirnov diatas terlihat bahwa nilai-p KS > 0,05 sehingga dapat disimpulkan bahwa data yang diuji berdistribusi normal. 3.2.2 Uji Kesamaan Rata-rata
Selanjutnya dilakukan uji kesamaan untuk memenuhi asumsi bahwa varians variabel bebas untuk tiap grup harus sama dan varians diantara variabel-variabel bebas harus sama (grup covariance matrices adalah relatif sama), hal ini dapat dilihat dari angka (tingkat) signifikan Wilk’s Lambda. Jika angka Sig > 0,05 menunjukkan variabel sama.
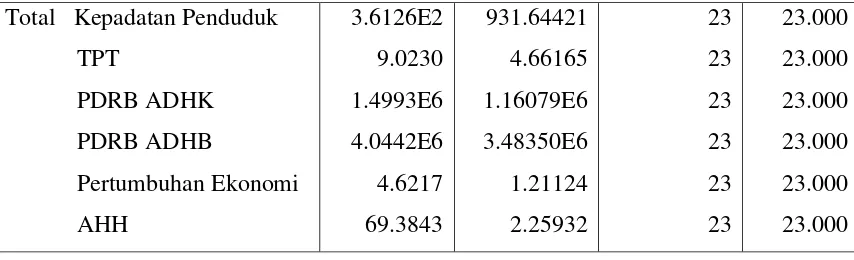
Tabel 3.3 Uji Kesamaan Rata-rata
Test of Equality of Group Means
Wilks’ Lambda F df1 df2 Sig.
[image:36.595.108.517.543.696.2]Pada tabel 3.3 terlihat bahwa angka Wilk’s Lambda berkisar antara 0,826 sampai 0,999 (mendekati 1), ini berarti data tiap grup cenderung sama. Dilihat dari kolom signifikan bahwa angka signifikan untuk variable AHH (0,048) yang berarti bahwa ada perbedaan antar grup, atau suatu daerah dikatakan memiliki tingkat kemiskinan rendah dan tinggi tergantung pada variabel AHH. Namun hal tersebut tidak menjamin apakah variabel tersebut akan dimasukkan pada fungsi diskriminan. Untuk itu dilakukan fungsi diskriminan dengan tetap menyertakan seluruh variabel yang ada. Sedangkan, angka signifikan untuk variabel Kepadatan Penduduk (0,162), TPT (0,900), PDRB ADHK (0,094), PDRB ADHB (0,136), Pertumbuhan Ekonomi (0,607) jauh diatas 0,05 yang berarti bahwa variabel Kepadatan Penduduk, TPT, PDRB ADHK, PDRB ADHB, dan Pertumbuhan Ekonomi tidak mempengaruhi rendah atau tingginya tingkat kemiskinan suatu daerah (Kabupaten/Kota) di Provinsi Aceh.
Sebelum melakukan analisis diskriminan. Variabel terikat diperoleh dari persentase penduduk miskin daerah Kabupaten/Kota Provinsi Aceh. Variabel terikat dibagi menjadi 2 (dua) kelompok, yaitu:
Y1 : Kelompok I, tingkat kemiskinan rendah adalah daerah dengan persentase penduduk miskin <18%.
Y2 : Kelompok II, tingkat kemiskinan tinggi adalah daerah dengan persentase penduduk miskin ≥18%.
Sedangkan variabel bebas dalam penelitian ini adalah: X1 : Kepadatan Penduduk (Jiwa/Km2)
X2 : Tingkat Pengangguran Terbuka (TPT) (%)
X3 : PDRB Per Kapita Atas Dasar Harga Konstan (PDRB ADHK) (Ribu Rupiah)
X4 : PDRB Per Kapita Atas Dasar Harga Berlaku (PDRB ADHB) (Ribu Rupiah)
X5 : Pertumbuhan Ekonomi (%)
Kelompok I berjumlah (n1) 11 kabupaten/kota yang memiliki persentase kemiskinan <18%, kelompok II berjumlah (n2) 12 kabupaten/kota yang memiliki persentase kemiskinan ≥18%. Kemudian dianggap memiliki n1 observasi dari faktor acak multivariat dari populasi (kelompok I) dan n2 pengukuran kuantitas dari dengan – .
Untuk mencari matriks varians-kovarians, data dari kelompok I dan kelompok II dibentuk matriks kelompok I dan kelompok II, yaitu :
Rata-rata untuk tiap variabel kelompok I adalah :
0
Untuk mencari rata-rata tiap variabel untuk kelompok II digunakan dengan rumus yang sama (lihat Lampiran 1).
Berdasarkan Persamaan 2.8 maka diperoleh hasil bentuk vektor untuk rata-rata tiap variabel kelompok I dan kelompok II:
Untuk mencari matriks varians-kovarians dari kelompok I, pertama kali yang dilakukan adalah menjumlahkan dan mengalikan nilai dari setiap variabel kelompok pertama. Dari matriks X kelompok I, diperoleh nilai-nilai untuk:
7.131 25.484,35
100,70 21.582.106.638
21.148.750,990 66.311.591.626
57.016.482,380 37.848,36
49,30 510.653,62
773,810 175.061.324,1
21.920.557 451251054,7
1.144,117 434,4581
5,173678 7.070,6237 4,057352 1,437070
233,6296 94.187.303,58
54.460,28 1.499.107.320
253.881.910,4 4.046.717.151
3.467,8717
Berdasarkan Persamaan 2.3 diperoleh hasil varians sebagai berikut:
Berdasarkan Persamaan 2.4 diperoleh hasil kovarians sebagai berikut:
Untuk mencari kovarians S13, S14, S15, S16, S23, S24, S25, S26, S34, S35, S36, S45, S46, dan S56 digunakan dengan rumus yang sama (lihat lampiran 2). Kemudian dibentuk matriks yang berisi nilai varians dan kovarians dari kelompok I, dan dengan cara yang sama diatas dibentuk matriks yang berisi nilai varians dan kovarians dari kelompok II (lihat Lampiran 3).
Berdasarkan persamaan (2.9) maka diperoleh Matriks varians-kovarians untuk setiap kelompok.
Matriks varians-kovarians untuk kelompok I:
S1 =
Matriks varians-kovarians untuk kelompok II :
S2 =
1.729.772,42
-3979,67
7,87 2.934.936,11 588,85
901,37
-3.979,67 22,23 -1.854.587,82 -7.070.892,49 -1,69 -1,33
7,87 -1.854587,82 1,11 3,41 -59.755,32 1.136.959,24 2.934.936,11 -7.070.892,49 3,41 1,10 -165.559,70 3.581.494,42
588,85 - 1,69 -59.755,32 -165.559,70 1,27 -0,02 901,37 -1,33 1.136.959,24 3.581.494,82 -0,02 2,56
5.514,52 249,34 3,42 101.086.193,6 -62,00 114,77
249,34 23,22 2.850.804,67 8.009.390,67 -3,36 3,85
3,42 2.850.804,67 1,34 3,96 -1.151.737,57 1.188.669,05
101.086.193,6 8.009.390,67 3,96 1,18 -3.290.840,40 3.656.167,40
-62,00 -3,36 -1.151.737,57 -3.290.840,40 1,74 -1,00
Nilai-nilai dari matriks varians-kovarians S1 dan S2 diatas dapat juga dilihat pada tabel hasil output SPSS (lihat Lampiran 4). Dari kedua matriks varians-kovarians tersebut dapat dihitung matriks varians-kovarians gabungan (S). Berdasarkan persamaan (2.10) maka diperoleh :
S =
Nilai-nilai matriks varians-kovarians diatas dapat juga dilihat pada tabel hasil output SPSS (lihat Lampiran 4).
Penyelesaian secara manual cukup panjang, penulis menggunakan bantuan SPSS dalam menyelesaikan fungsi diskriminan.
Langkah-langkah melakukan analisis diskriminan dengan SPSS: 1. Klik menu Analyze
2. Pilih Classify
3. Pilih Discriminant
4. Masukkan variabel terikat kebagian Grouping Variable. Kemudian buka ikon
Define Range, isi minimum dan maksimum variabel terikat.
5. Masukkan variabel bebas kebagian Independents.
6. Klik ikon Statistics, pada bagian Descriptives aktifkan pilihan Means; pada bagian Function Coeficient aktifkan pilihan Fisher’s dan Unstandardized; pada bagian Matrices aktifkan Within-grups Correlation dan Within-grups
Covariance, kemudian klik continue.
7. Pada bagian tengah kotak dialog utama, pilih Use Stepwise Method, maka secara otomatis ikon Method yang ada dibagian kanan dialog utama akan aktif. Memilih Stepwise Method berarti variabel akan dimasukkan satu per satu kedalam model.
8. Klik ikon Method, pada bagian Method pilih Mahalanobis distance
merupakan metode yang digunakan untuk menganalisis kasus pada analisa diskriminan, dimana metode ini juga dapat mengidentifikasi multivariate
826.589,71 -1.764,47
3,93 1,49 247,93 489,34
-1.764,47 22,75 610.141,58 828.303,45 -2,56 1,39
3,93 610.141,58 1,23 3,69 -631.746,02 1,16
1,45 828.303,45 3,69 1,14 -1.802.611,49 3,62
247,93 -2,56 -631.746,02 -1.802.611,49 1,52 -0,54
outlier. Mahalanobis distance adalah jarak antara kasus dengan centroid pada setiap kelompok variabel terikat. Setiap kasus mempunyai satu jarak
Mahalanobis untuk setiap kelompok dan akan diklasifikasikan ke dalam
kelompok dimana jarak tersebut paling kecil. Pada bagian Criteria, pilih Use
probability of F, tetapi jangan mengubah isi yang sudah ada. Disini lolos
tidaknya sebuah variabel akan diuji dengan uji F, dengan batasan signifikansi 5%. Kemudian klik continue.
9. Pada bagian kanan kotak dialog utama klik ikon Classify. Classify adalah pelengkap dari pembuatan model diskriminan terutama cara penyajian model diskriminan serta kelayakan model tersebut. Pada bagian Display aktifkan pilihan Casewise result dan Leave-one-out-classification. Kemudian klik
continue.
10.Klik Ok.
[image:43.595.109.542.436.730.2]3.3 Interpretasi Output SPSS
Tabel 3.4 Grup Statistik
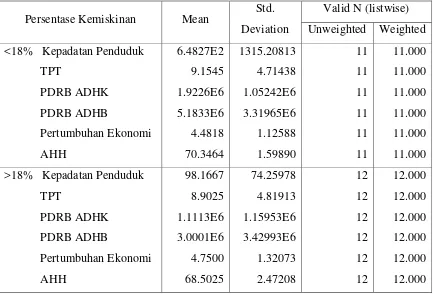
Persentase Kemiskinan Mean Std. Deviation
Valid N (listwise) Unweighted Weighted <18% Kepadatan Penduduk
TPT PDRB ADHK PDRB ADHB Pertumbuhan Ekonomi AHH 6.4827E2 9.1545 1.9226E6 5.1833E6 4.4818 70.3464 1315.20813 4.71438 1.05242E6 3.31965E6 1.12588 1.59890 11 11 11 11 11 11 11.000 11.000 11.000 11.000 11.000 11.000 >18% Kepadatan Penduduk
Total Kepadatan Penduduk TPT PDRB ADHK PDRB ADHB Pertumbuhan Ekonomi AHH 3.6126E2 9.0230 1.4993E6 4.0442E6 4.6217 69.3843 931.64421 4.66165 1.16079E6 3.48350E6 1.21124 2.25932 23 23 23 23 23 23 23.000 23.000 23.000 23.000 23.000 23.000
Tabel Grup Statistik pada dasarnya berisi data statistik (deskriptif) yang utama, yaitu rata-rata dan standar deviasi dari kedua kelompok. Sebagai contoh, daerah Kabupaten/Kota yang tingkat kemiskinan rendah mempunyai AHH rata-rata (70.3464). Sedangkan daerah Kabupaten/Kota yang tingkat kemiskinannya tinggi mempunyai AHH rata-rata (68.5025). Demikian pula untuk variabel lainnya, semua mempunyai rata-rata dan standar deviasi yang berbeda untuk kedua kelompok daerah Kabupaten/Kota. Pada tabel Grup Statistik terlihat perbedaan rata-rata variabel setiap kelompok dan rata–rata total. Apabila nilai rata-rata dari setiap kelompok berbeda mengindikasikan bahwa variabel-variabel di dalamnya berperan di dalam mengelompokkan responden yaitu daerah Kabupaten/Kota. Jika rata-rata sebuah variabel sama pada kedua kelompok maka kemungkinan variabel tersebut tidak berperan dalam mengelompokkan objek (responden).
[image:44.595.111.538.84.214.2]3.3.1 Variabel-variabel yang dimasukkan
Tabel 3.5 Variabel-variabel yang dimasukkan
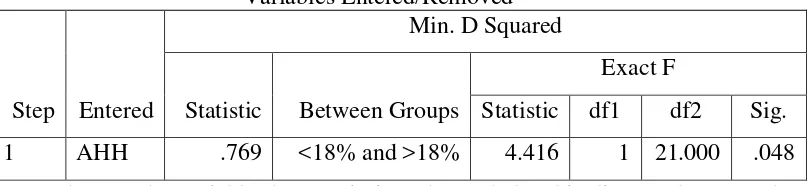
Variables Entered/Removeda,b,c,d
Step Entered
Min. D Squared
Statistic Between Groups
Exact F
Statistic df1 df2 Sig. 1 AHH .769 <18% and >18% 4.416 1 21.000 .048 At each step, the variable that maximizes the Mahalanobis distance between the two closest groups is entered
a. Maximum number of steps is 12.
b. Maximum significance of F to enter is .05. c. Minimum significance of F to remove is .10.
d. F level, tolerance, or VIN insufficient for further computation.
[image:45.595.109.516.522.565.2]Tabel Variables Entered/Removed ini menyajikan variabel mana saja dari enam variabel yang bisa dimasukkan (entered) kedalam persamaan diskriminan. Karena proses adalah stepwise maka akan dimulai dengan variabel yang mempunyai angka F hitung terbesar. Pada kasus ini hanya terjadi satu tahap, dimana variabel yang terpilih dan signifikan adalah AHH. Atau bisa dikatakan AHH mempengaruhi tinggi atau rendahnya tingkat kemiskinan daerah Kabupaten/Kota di Provinsi Aceh.
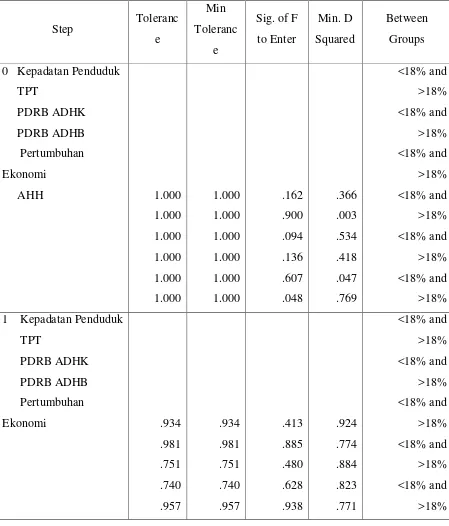
Tabel 3.6 Variabel yang dianalisis
Step Tolerance Sig. of F to Remove
1 AHH 1.000 .048
Tabel 3.7 Variabel yang tidak dianalisis
Step Toleranc
e
Min Toleranc
e
Sig. of F to Enter
Min. D Squared
Between Groups 0 Kepadatan Penduduk
TPT
PDRB ADHK PDRB ADHB Pertumbuhan Ekonomi
AHH 1.000
1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 .162 .900 .094 .136 .607 .048 .366 .003 .534 .418 .047 .769 <18% and >18% <18% and >18% <18% and >18% <18% and >18% <18% and >18% <18% and >18% 1 Kepadatan Penduduk
TPT
PDRB ADHK PDRB ADHB Pertumbuhan
Ekonomi .934
.981 .751 .740 .957 .934 .981 .751 .740 .957 .413 .885 .480 .628 .938 .924 .774 .884 .823 .771 <18% and >18% <18% and >18% <18% and >18% <18% and >18% <18% and >18% Tabel Variabel yang tidak dianalisis adalah kebalikan dari tabel
sebelumnya, dimana pada tabel ini justru yang ditayangkan adalah proses pengeluaran variabel secara bertahap:
1. Pada step 0, keenam variabel secara lengkap ditayangkan dengan angka Sig.
paling kecil adalah pada variabel AHH dengan angka 0,048. Maka variabel AHH dikeluarkan dari step 0, yang berarti variabel tersebut termasuk variabel yang dianalisis.
[image:47.595.111.516.341.407.2]2. Pada step 1, sekarang terlihat lima variabel dan terlihat kelima variabel tersebut mempunyai angka Sig. Of F to Enter diatas 0,05, yaitu Kepadatan Penduduk (0,413), TPT (0,885), PDRB ADHK (0,480), PDRB ADHB (0,628), dan Pertumbuhan Ekonomi (0,938). Karena sudah tidak ada variabel yang memenuhi syarat maka proses pengeluaran variabel terhenti, kelima variabel tersebut tidak dikeluarkan, yang berarti kelimanya termasuk pada Variabel yang tidak dianalisis, atau variabel yang tidak masuk dalam model.
Tabel 3.8 Wilks’ lambda
Step
Number of
Variables Lambda df1 df2 df3
Exact F
Statistic df1 df2 df3
1 1 .826 1 1 21 4.416 1 21.000 .048
Tabel Wilk’s Lambda pada prinsipnya adalah varians total dalam
discriminant scores yang tidak bisa dijelaskan oleh perbedaan diantara
kelompok-kelompok yang ada. Perhatikan pada tabel Wilk’s Lambda yang hanya terdiri atas satu step, yang terkait dengan variabel yang dimasukkan pada tahap analisis sebelumnya. Pada step 1, variabel yang dimasukkan AHH dengan angka Wilk’s
Lambda sebesar 0,826. Hal ini berarti 82,6% varians tidak dapat dijelaskan oleh
3.3.2 Nilai Korelasi Kanonikal Eigen value
Tabel 3.9 Korelasi Kanonikal Eigen value
Function Eigenvalue % of Variance Cumulative %
Canonical Correlation
1 .210a 100.0 100.0 .417
Tabel Korelasi Kanonikal Eigen value mengukur keeratan hubungan antara discriminant score dengan kelompok. Angka Canonical Correlation
sebesar 0,417 menunjukkan keeratan yang cukup, dengan ukuran skala asosiasi antara 0 sampai 1. Dari nilai eigenvalue terlihat bahwa fungsi diskriminan dengan
eigenvalue 0,210 dapat menjelaskan 100% varians.
[image:48.595.107.518.397.441.2]3.3.3 Uji Signifikansi
Tabel 3.10 Wilks’ Lambda
Test of Function(s) Wilks’ Lambda Chi-Square df Sig.
1 .826 3.913 1 .048
3.3.4 Struktur Matriks
Tabel 3.11 Struktur Matriks
Function
1
AHH
PDRB ADHBa
PDRB ADHKa
Kepadatan Penduduka
Pertumbuhan Ekonomia
TPTa
1.000
.510
.499
.256
-.207
.138
Tabel Struktur Matriks menjelaskan korelasi antara variabel bebas dengan fungsi diskriminan yang terbentuk. Pada tabel Struktur Matriks terlihat bahwa variabel AHH paling erat hubungannya dengan fungsi diskriminan, diikuti oleh variabel PDRB ADHB, PDRB ADHK, Kepadatan Penduduk, Pertumbuhan Ekonomi dan TPT. Hanya disini variabel PDRB ADHB, PDRB ADHK, Kepadatan Penduduk, Pertumbuhan Ekonomi dan TPT tidak dimasukkan pada model diskriminan, hal ini dapat dilihat dari tanda huruf a didekat variabel-variabel tersebut.
[image:49.595.105.517.544.628.2]3.3.5 Koefisien Fungsi Diskriminan Kanonik
Tabel 3.12 Koefisien fungsi diskriminan kanonik
Function 1 AHH
(Constant)
.476 -33.009 Unstandardized coefficients
sebagai Fungsi Diskriminan. Dengan menggunakan koefisien fungsi diskriminan kanonik maka dapat dibentuk fungsi diskriminan.
Melalui persamaan 2.2 dengan bantuan SPSS diperoleh persamaan akhir sebagai berikut:
Kegunaan fungsi ini untuk mengetahui sebuah kasus (dalam kasus ini adalah faktor yang mempengaruhi daerah Kabupaten/Kota Provinsi Aceh) masuk pada kelompok yang satu, ataukah tergolong pada kelompok yang lainnya.
[image:50.595.105.520.361.455.2]3.3.6 Fungsi Pada Kelompok Terpusat
Tabel 3.13 Fungsi pada kelompok terpusat
Functions at Group Centroids
Persentase Kemiskinan
Function 1 <18%
>18%
.458 -.420
Tabel Functions at Group Centroid memperlihatkan nilai rata-rata tiap kelompok. Oleh karena ada dua tipe daerah Kabupaten/Kota maka dikatakan Two
Grup Discriminant, kelompok yang memiliki centroid (grup means) positif adalah
3.3.7 Peluang Utama untuk Kelompok
Tabel 3.14 Peluang Utama untuk Kelompok
Prior Probabilities for Groups Persentase
Kemiskinan
Prior Cases Used in Analysis Unweighted Weighted <18%
>18% Total
.500 .500 1.000
11 12 23
11.000 12.000 23.000 Pada tabel Prior Probabilities for Groups yang ingin diperlihatkan adalah peluang utama untuk kelompok agar dapat memperlihatkan komposisi objek atau daerah Kabupaten/Kota pada fungsi diskriminan. Tabel diatas memperlihatkan komposisi ke 23 objek, yang dengan model diskriminan menghasilkan 11 objek dikelompok tingkat kemiskinan rendah dan 12 objek dikelompok tingkat kemiskinan tinggi. Untuk Cutting Score (nilai batas), dilakukan perhitungan :
3.3.8 Uji Hasil Klasifikasi
Tabel 3.15 Hasil Klasifikasi
Classification Resultsb,c
Persentase Kemiskinan
Predicted Group Membership
Total <18% >18%
Original Count <18% >18% % <18% >18% Cross-validateda Count <18% >18% % <18% >18% 8 6 3 6 11 12 72.7 50.0 27.3 50.0 100.0 100.0 8 6 3 6 11 12 72.7 50.0 27.3 50.0 100.0 100.0 a. Cross validation is done only for those cases in the analysis. In cross
validation, each case is classified by the functions derived from all cases other than that case.
b. 60,9% of original grouped cases correctly classified
c. 60,9% of cross-validated grouped cases correctly classified
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Berdasarkan hasil penelitian tentang “Faktor-faktor yang Mempengaruhi Kemiskinan Provinsi Aceh dengan Menggunakan Analisis Diskriminan”, maka diperoleh kesimpulan sebagai berikut :
1. Faktor yang paling mempengaruhi tingkat kemiskinan daerah Provinsi Aceh adalah Angka Harapan Hidup (AHH) dan fungsi diskriminannya yaitu :
2. Ketepatan model dianggap tinggi jika hasil klasifikasi di atas 50%, dimana fungsi diskriminan yang diperoleh mempunyai ketepatan mengklasifikasikan kasus sebesar 60,9%, sehingga dapat digunakan untuk mengklasifikasikan faktor-faktor yang mempengaruhi kemiskinan daerah Kabupaten/ Kota Provinsi Aceh.
4.2 Saran
DAFTAR PUSTAKA
Badan Pusat Statistik. (1989-2008). Aceh dalam Angka. Badan Pusat Statistik. Aceh.
Badan Pusat Statistik. 2004. Monitoring dan Kajian Terhadap Program
Kemiskinan di Indonesia. Jakarta.
Badan Pusat Statistik. (2009-2013). Tinjauan Perekonomian Menurut Lapangan
Usaha. Provinsi Aceh
Johnson & Wichern. 2007. Applied Multivariate Statistical Analysis. Uper Saddle River, New Jersey : Prentice-Hall
Santoso, Singgih. 2010. Statistik Multivariat: Konsep dan Aplikasi dengan SPSS. PT Elex Media Komputindo. Jakarta.
Sianipar, Pangeran. 2010. Aljabar Linier. Medan: Intan Dirja Lela.
Simamora, B. 2005. Analysis Multivariat Pemasaran. Jakarta: PT Gramedia Pustaka Utama
Sugiarto, dkk. 2001. Teknik Sampling. Gramedia Pustaka Utama. Jakarta.
Supranto, J. 2010. Analisis Multivariat Arti dan Interpretasi. PT Rineka Cipta. Jakarta.
Suyogyo, 1997, Garis Kemiskinan dan Kebutuhan Minimum Pangan dalam
Harian Kompas, 17 Nopember 1997.
Lampiran 1.
PERHITUNGAN RATA-RATA UNTUK SETIAP VARIABEL KELOMPOK II
98,167
8,903
1.111.293,332
3.000.093,308
Lampiran 2.
PERHITUNGAN VARIANS DAN KOVARIANS KELOMPOK 1
Varians :
Maka,
Kovarians:
Lampiran 3.
PERHITUNGAN VARIANS DAN KOVARIANS KELOMPOK II
Hasil Penjumlahan dan Perkalian Nilai Setiap Variabel:
1.178 13.229,92
106,83 1.685.069.675
13.335.519,98 4.646.058.046
36.001.119,69 4.913,47
57 81.958,44
822,03 150.078.317,9
176.300 408.603.265,3
1.206,5177 470,5259
2,960939 7.360,4745 2,374150 8,360034
289,9376 50.674.607
56.378,3331 926.591.817
134.806.074,1 2.506.384.543
3.893,5929
Varians :
Maka,
Kovarians :
Maka,
Lampiran 4.
[image:69.842.53.753.176.513.2]TABEL OUTPUT SPSS
Tabel Varians Kovarians
Covariance Matrices
Persentase Kemiskinan Kepadatan Penduduk TPT PDRB ADHK PDRB ADHB Pertumbuhan Ekonomi AHH
<18% Kepadatan Penduduk 1729772.42 -3979.671 7.872E8 2.935E9 588.851 901.370
TPT -3979.671 22.225 -1854587.82 -7070892.49 -1.686 -1.326
PDRB ADHK 7.872E8 -1854587.82 1.108E12 3.409E12 -59755.313 1.137E6
PDRB ADHB 2.935E9 -7070892.49 3.409E12 1.102E13 -1.656E5 3.581E6
Pertumbuhan Ekonomi 588.851 -1.686 -59755.313 -165559.700 1.268 -.020
AHH 901.370 -1.326 1136959.243 3581494.817 -.020 2.556
>18% Kepadatan Penduduk 5514.515 249.343 3.418E7 101086193.6 -62.003 114.772
TPT 249.343 23.224 2850804.661 8009390.663 -3.356 3.850
PDRB ADHK 3.418E7 2850804.661 1.345E12 3.963E12 -1151737.54 1188669.052
PDRB ADHB 101086193.6 8009390.663 3.963E12 1.176E13 -3290840.403 3656167.393
Pertumbuhan Ekonomi -62.003 -3.356 -1151737.54 -3290840.403 1.744 -1.005
AHH 114.772 3.850 1188669.052 3656167.393 -1.005 6.111
Tabel Varians Kovarians Gabungan
Pooled Within-Groups Matricesa
Kepadatan Penduduk TPT PDRB ADHK PDRB ADHB Pertumbuhan Ekonomi AHH
Covariance Kepadatan Penduduk 826589.707 -1764.473 3.928E8 1.451E9 247.928 489.343
TPT -1764.473 22.748 610141.577 828303.449 -2.561 1.386
PDRB ADHK 3.928E8 610141.577 1.232E12 3.699E12 -631746.004 1.164E6
PDRB ADHB 1.451E9 828303.449 3.699E12 1.141E13 -1.803E6 3.621E6
Pertumbuhan Ekonomi 247.928 -2.561 -631746.004 -1.803E6 1.517 -.536
AHH 489.343 1.386 1164045.333 3620609.023 -.536 4.418
a. The covariance matrix has 21 degrees of freedom.