KLASIFIKASI BAHAN PANGAN BERDASARKAN KANDUNGAN
ZAT GIZI BAHAN PANGAN MENGGUNAKAN
FUZZY
K-NEAREST NEIGHBOR
ANISAUL MUAWWANAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Bahan Pangan berdasarkan Kandungan Zat Gizi Bahan Pangan Menggunakan Fuzzy K-Nearest Neighbor adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir disertasi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
ANISAUL MUAWWANAH. Klasifikasi Bahan Pangan berdasarkan Kandungan Zat Gizi Bahan Pangan Menggunakan Fuzzy K-Nearest Neighbor. Dibimbing oleh SRI NURDIATI.
Indeks glikemik merupakan salah satu parameter yang tepat untuk memilih pangan yang sesuai bagi penderita diabetes. Salah satu kendala dalam penerapan konsep ini adalah terbatasnya data indeks glikemik pangan yang telah diketahui. Dengan berbekal pengetahuan mengenai kandungan zat gizi dan proses pemasakan sebagai faktor yang memengaruhi indeks glikemik, penelitian ini mengusulkan model klasifikasi bahan pangan berdasarkan kandungan zat gizi bahan pangan menggunakan algoritme fuzzy k-nearest neighbor. Dari hasil penelitian diketahui bahwa kondisi data yang tidak seimbang membuat hasil klasifikasi menjadi kurang optimal. Model hanya mampu mencapai nilai akurasi sebesar 53.69%. Untuk mengatasi kondisi tersebut maka pada penelitian ini diterapkan 4 teknik resampling. Penerapan keempat teknik tersebut berhasil mengatasi kondisi data tidak seimbang. Secara umum teknik random over -sampling memiliki kinerja terbaik dengan hasil akurasi sebesar 84.39% pada 1-NN. Teknik selanjutnya yang menghasilkan kinerja terbaik adalah SMOTE dengan nilai akurasi sebesar 73.37% pada 1-NN dan 2-NN.
Kata kunci: data tidak seimbang, fuzzy k-nearest neighbor, indeks glikemik, resampling
ABSTRACT
ANISAUL MUAWWANAH. Classification of Food Based on Food Nutrients Using Fuzzy K-Nearest Neighbor. Supervised by SRI NURDIATI.
The concept of glycemic index is an approach to select the right food for diabetics. One obstacle to implement this concept is the limited amount of known glycemic index data. With this knowledge about food nutrient and cooking process as factors that influence the glycemic index, we proposed a model to classify food based on its nutrients using fuzzy k-nearest neighbor algorithm. The results revealed that the classifier performance was not optimal because of the imbalanced data. The best accuracy for this model was only 53.69%. To overcome imbalanced data condition, we applied 4 different resampling techiques. The results showed that resampling techniques successfully solved the imbalanced data problem. In general, random over-sampling technique had the best performance with an accuracy of 84.39% in 1-NN. The next technique that had the best performance was synthetic minority over-sampling technique (SMOTE) with an accuracy of 73.37% in 1-NN and 2-NN.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI BAHAN PANGAN BERDASARKAN KANDUNGAN
ZAT GIZI BAHAN PANGAN MENGGUNAKAN
FUZZY
K-NEAREST NEIGHBOR
ANISAUL MUAWWANAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul Skripsi : Klasifikasi Bahan Pangan berdasarkan Kandungan Zat Gizi Bahan Pangan Menggunakan Fuzzy K-Nearest Neighbor
Nama : Anisaul Muawwanah NIM : G64090088
Disetujui oleh
Dr Ir Sri Nurdiati, MSc Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga skripsi ini berhasil diselesaikan. Penulis menyampaikan terima kasih kepada kedua orang tua, yaitu Bapak Teguh Gunadi dan Ibu Bois Asnawati atas dukungan dan doa yang diberikan kepada penulis. Selain itu, penulis juga mengucapkan terima kasih kepada:
1 Ibu Dr Ir Sri Nurdiati, MSc selaku dosen pembimbing skripsi
2 Bapak Dr Ir Agus Buono, MSi MKom dan Ibu Karlina Khiyarin Nisa SKom, MT selaku penguji
3 Para dosen dan seluruh civitas akademik Departemen Ilmu Komputer Institut Pertanian Bogor
4 Teman-teman yang telah membantu pengerjaan skripsi ini
5 Semua pihak yang telah membantu penulis menyelesaikan skripsi ini. Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 3
METODE 3
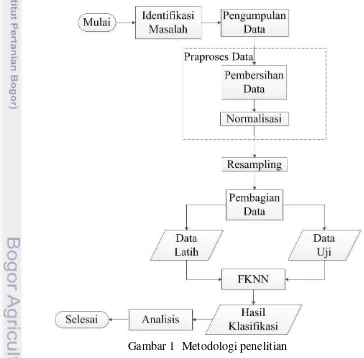
Identifikasi Masalah 4
Pengumpulan Data 4
Praproses Data 5
Resampling 5
Pembagian Data 6
Klasifikasi Menggunakan FKNN 6
Analisis 9
Spesifikasi Perangkat Lunak 9
HASIL DAN PEMBAHASAN 9
Pengumpulan Data 9
Praproses Data 10
Resampling 10
Pembagian Data 11
Klasifikasi Menggunakan FKNN 11
Analisis 12
SIMPULAN DAN SARAN 16
Simpulan 16
Saran 17
DAFTAR PUSTAKA 17
LAMPIRAN 19
DAFTAR TABEL
1 Contoh data komposisi bahan pangan (USDA 2012) 4
2 Contoh data indeks glikemik pangan (Mendosa 2008) 4 3 Confusion matrix dengan dua kelas 8 4 Pengkodean data kategorik menjadi data nominal 10 5 Perbandingan banyak data asli dan data hasil resampling 10
6 Hasil akurasi rata-rata dalam satuan persen 11
DAFTAR GAMBAR
1 Metodologi penelitian 3
2 Grafik hasil akurasi 12
3 Grafik hasil precision (kiri) dan recall (kanan) 13
4 Grafik f-measure 13
5 Grafik distribusi normal kandungan protein pada kelas GI berbeda 15 6 Grafik distribusi normal kandungan serat pada kelas GI berbeda 16 7 Grafik distribusi normal kandungan lemak pada kelas GI berbeda 16
DAFTAR LAMPIRAN
1 Nilai rata-rata precision, recall, dan f-measure setiap kelas pada nilai k
1 sampai 5 19
2 Contoh data hasil tahap praproses data (data asli) 20
3 Data hasil proses random under-sampling 21
4 Data hasil proses k-means based under-sampling 24
5 Contoh data hasil proses random over-sampling 27
PENDAHULUAN
Latar Belakang
Diabetes merupakan salah satu penyakit yang memiliki tingkat kematian tertinggi di dunia. Setiap tahun terjadi sekitar 3.2 juta kematian di seluruh dunia akibat penyakit ini. Dengan kata lain setiap hari terjadi sekitar 8700 kematian akibat diabetes. Jumlah tersebut diperkirakan akan terus meningkat sejalan dengan pertambahan penderita diabetes setiap tahun. Pada tahun 2000 tercatat sekitar 171 juta penderita diabetes di seluruh dunia dan WHO memperkirakan jumlah tersebut akan meningkat menjadi lebih dari dua kali lipatnya pada tahun 2030 (WHO 2004). Indonesia menempati peringkat keempat dalam daftar negara dengan tingkat penderita diabetes terbanyak di dunia pada tahun 2000. Saat itu Indonesia memiliki 8.4 juta penderita dan diperkirakan akan memiliki 21.3 juta penderita pada tahun 2030 (Wild et al. 2004).
Salah satu penyebab penyakit diabetes adalah konsumsi zat gizi yang tidak seimbang, khususnya kelebihan asupan karbohidrat. Kelebihan asupan karbohidrat berkaitan dengan kemampuan tubuh dalam mengolah karbohidrat. Pada kasus ini tubuh akan meningkatkan sekresi (pengeluaran) insulin untuk mengimbangi banyaknya karbohidrat. Insulin akan berupaya menjaga kadar glukosa darah pada batas normal. Namun bila kondisi kelebihan karbohidrat tersebut berlangsung lama, insulin tidak mampu lagi melaksanakan fungsinya sehingga kadar glukosa darah tinggi. Kondisi kadar gula darah tinggi inilah yang menjadi masalah utama bagi penderita diabetes. Selain kondisi kadar gula darah tinggi, peningkatan kadar gula darah secara drastis merupakan masalah lain yang kerap dihadapi penderita diabetes. Kondisi ketika kadar gula darah meningkat secara drastis (hiperglikemik) sedapat mungkin harus dihindari karena dapat berakibat fatal pada kondisi kesehatannya.
2
Indeks glikemik bahan pangan dipengaruhi beberapa faktor seperti kandungan zat gizi dan proses pemasakan bahan pangan. Dari hasil uji laboratorium diketahui bahwa kandungan protein dan serat memiliki pengaruh yang berbanding terbalik dengan indeks glikemik bahan pangan (Trout et al. 1993). Hal yang sama juga berlaku pada pengaruh kandungan lemak pada indeks glikemik. Semakin rendah kandungan lemak suatu bahan pangan cenderung membuat indeks glikemiknya semakin tinggi (Wolever 1990). Sebaliknya, proses pemasakan yang terjadi pada bahan pangan justru memiliki efek positif terhadap indeks glikemik. Semakin rumit proses yang dilakukan, semakin tinggi pula indeks glikemik yang akan dihasilkan (Brand et al. 1985).
Salah satu kendala penerapan konsep indeks glikemik adalah belum lengkapnya data indeks glikemik bahan pangan, khususnya bahan pangan Indonesia. Upaya untuk melengkapi data indeks glikemik bahan pangan hingga saat ini masih terus dilakukan. Akan tetapi penelitian di bidang ini membutuhkan waktu yang cukup lama dan biaya yang cukup besar. Oleh sebab itu, berbekal pengetahuan yang ada mengenai indeks glikemik dan faktor-faktor yang memengaruhinya, pada penelitian ini akan dibuat suatu model untuk mengklasifikasikan bahan pangan berdasarkan kandungan zat gizi bahan pangan menggunakan algoritme fuzzy k-nearest neighbor (FKNN). Algoritme ini dipilih karena mampu menghasilkan akurasi yang baik dengan proses perhitungan yang sederhana. Nilai akurasi yang dihasilkan pun lebih baik dari nilai akurasi algoritme KNN biasa. Selain itu, kesalahan klasifikasi pada kelas yang memiliki nilai membershipfunction besar sangat jarang terjadi (Keller et al. 1985).
Perumusan Masalah
Perumusan masalah pada penelitian ini adalah bagaimana membuat model yang mampu mengklasifikasikan bahan pangan menurut kandungan zat gizi bahan pangan menggunakan algoritme FKNN.
Tujuan Penelitian
Tujuan dari penelitian ini adalah membangun sebuah model yang mampu mengklasifikasikan bahan pangan menurut kandungan zat gizi bahan pangan menggunakan algoritme FKNN.
Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut: 1 Memudahkan prediksi status indeks glikemik pangan.
2 Membantu pemilihan sumber karbohidrat yang cocok bagi penderita diabetes. 3 Membantu penyusunan menu makanan sesuai konsep indeks glikemik untuk
3 Ruang Lingkup Penelitian
Ruang lingkup pada penelitian ini adalah sebagai berikut:
1 Penelitian ini difokuskan pada proses pembuatan model untuk klasifikasi bahan pangan menurut kandungan zat gizi bahan pangan.
2 Data yang digunakan meliputi data komposisi bahan pangan dan status indeks glikemik bahan pangan.
3 Zat gizi yang dilibatkan dalam penelitian ini adalah karbohidrat, protein, lemak, dan serat. Selain itu, proses pemasakan bahan pangan juga dilibatkan dalam penelitian ini.
4 Teknik yang digunakan adalah teknik FKNN.
METODE
Penelitian ini dilakukan dalam beberapa tahap seperti yang terlihat pada Gambar 1. Secara umum metodologi penelitian ini terdiri atas identifikasi masalah,
4
pengumpulan data, praproses data, resampling, pembagian data, klasifikasi menggunakan FKNN, dan analisis hasil klasifikasi.
Identifikasi Masalah
Tahap ini meliputi tahap pemilihan dan identifikasi masalah dan tujuan. Masalah dalam penelitian ini ialah belum tersedianya data yang lengkap terkait indeks glikemik bahan pangan sehingga tidak semua bahan pangan dapat diketahui nilai indeks glikemiknya. Salah satu solusi dari masalah tersebut adalah pembuatan model klasifikasi terhadap status indeks glikemik bahan pangan berdasarkan kandungan zat gizi bahan pangan. Model yang dihasilkan diharapkan dapat membantu proses prediksi status bahan pangan untuk bahan pangan yang belum diketahui nilai indeks glikemiknya.
Pengumpulan Data
Data yang digunakan dalam penelitian ini meliputi daftar komposisi pangan dan tabel indeks glikemik bahan pangan. Daftar komposisi pangan yang digunakan merupakan data sekunder yang diadopsi dari USDA National Nutrient Database for Standard Reference (USDA 2012). Daftar ini memuat kandungan energi dan beberapa zat gizi, seperi karbohidrat, protein, lemak, kalsium, fosfor, besi, vitamin A, vitamin B1, vitamin C, serat, serta kandungan air dari beberapa pangan. Adapun contoh komposisi pangan dapat dilihat pada Tabel 1.
Tabel indeks glikemik bahan pangan memuat kandungan indeks glikemik dan nilai beban glikemik dari berbagai jenis pangan yang banyak dijumpai di beberapa negara. Daftar ini diadopsi dari RevisedInternational Table of Glycemic Index and Glycemic Load Values: 2008 (Mendosa 2008). Tabel tersebut berisi nilai indeks glikemik (GI) dan beban glikemik (GL) pangan, seperti yang terdapat pada Tabel 2. Indeks glikemik dalam daftar tersebut dinyatakan dalam ukuran 50
Tabel 1 Contoh data komposisi bahan pangan (USDA 2012)
Pangan Karbohidrat
Tabel 2 Contoh data indeks glikemik pangan (Mendosa 2008)
Food Glycemic Index Glycemic Load
Pea, froze, boiled 39 2.7
Pea, green 51 3.6
Pumpkin 75 3.0
5 gram karbohidrat. Pangan yang terdaftar meliputi bahan pangan dan olahan bahan pangan dengan berbagai varietas dan proses pemasakan. Indeks glikemik adalah nilai yang menyatakan seberapa cepat peningkatan kadar gula darah setelah mengonsumsi suatu bahan pangan. Semakin besar nilai GI dari suatu bahan pangan menandakan semakin cepat kenaikan gula darah dapat terjadi. Adapun beban glikemik menyatakan kandungan glukosa dalam penyajian suatu bahan pangan. Semakin besar nilai GL menandakan semakin banyak glukosa yang terkandung dalam suatu bahan pangan (Mendosa 2008).
Praproses Data
Pada penelitian ini, data yang tersedia memiliki dua jenis atribut, yaitu atribut numerik dan kategorik. Untuk memudahkan proses klasifikasi, atribut dengan tipe kategorik diubah menjadi atribut nominal dengan cara kodifikasi. Tahap selanjutnya adalah konversi kandungan lemak, protein, dan serat agar sebanding dengan indeks glikemik. Konversi kandungan lemak, protein, dan serat dilakukan dalam ukuran 50 gram karbohidrat. Tahap berikutnya dari praproses data meliputi proses pembersihan data dan normalisasi. Proses pembersihan data terdiri dari proses penghapusan missing value. Selanjutnya, data yang sudah bersih dinormalisasi untuk menyamakan range dari data. Normalisasi dilakukan untuk mencegah dominasi salah satu atribut ketika proses klasifikasi. Pada penelitian ini diterapkan min-max normalization dengan formulasi sebagai berikut (Larose 2005):
Proses resampling dilakukan sebagai upaya mengatasi kondisi data yang tidak seimbang. Data yang tidak seimbang ditandai dengan tidak samanya sebaran data setiap kelas. Resampling merupakan teknik menyelesaikan masalah data tidak seimbang dengan pendekatan data. Metode resampling yang digunakan terdiri atas under-sampling dan over-sampling. Pada penelitian ini digunakan 2 jenis metode under-sampling, yaitu random under-sampling dan k-means based under-sampling, dan 2 jenis metode over-sampling, yaitu random over-sampling dan synthetic minority over-sampling technique (SMOTE).
6
under-sampling diterapkan algoritme k-means clustering pada data. Selanjutnya, dipilih beberapa data dari setiap cluster yang dihasilkan. Data pilihan tersebut kemudian digunakan untuk menggantikan kelas mayoritas (Cohen et al. 2006). Adapun untuk menentukan banyak data yang harus diambil dari setiap cluster dapat menggunakan rumus berikut:
n
a
dengan
Ci : banyak data yang harus diambil dari cluster ke-i Nmin : banyak data pada kelas minoritas
Nmax : banyak data pada kelas mayoritas Ni : banyak data pada cluster ke-i n : banyak cluster
Metode over-sampling menambahkan beberapa data pada kelas minoritas sampai banyak anggota kelas minoritas sama dengan kelas mayoritas. Serupa dengan random under-sampling, metode random over-sampling secara acak memilih beberapa anggota kelas minoritas untuk ditambahkan pada kelas itu sendiri (Liao 2008). Berbeda dengan random over-sampling yang menduplikasi anggota kelas minoritas secara acak, SMOTE membangkitkan data buatan berdasarkan konsep tetangga terdekat. Langkah pertama yang harus dilakukan pada metode ini ialah mencari 5 tetangga terdekat dari setiap anggota kelas minoritas. Selanjutnya dari data tetangga tersebut akan dibangkitkan data buatan. Proses membangkitkan data buatan dimulai dengan memilih secara acak beberapa tetangga terdekat dari suatu anggota kelas minoritas. Selanjutnya, perbedaan antara anggota kelas minoritas dengan tetangganya dihitung dan dikalikan dengan suatu bilangan acak dari 0 sampai 1. Hasil perkalian tersebut kemudian dijumlahkan dengan anggota kelas minoritas. Hasil penjumlahan tersebut merupakan data buatan yang akan digabungkan pada kelas minoritas (Chawla et subset selanjutnya akan dilaksanakan bergantian sehingga setiap subset pernah berperan sebagai data uji.
Klasifikasi Menggunakan FKNN
7 kelas yang berbeda berdasarkan jarak yang didapatkan dari hasil perhitungan KNN. Inti dari algoritme FKNN adalah memberikan derajat keanggotaan sebagai fungsi dari jarak data uji ke tetangga terdekatnya dan kelas yang mungkin (Keller et al. 1985).
Langkah pertama yang harus dilakukan dalam proses FKNN adalah menghitung jarak dari objek yang akan diuji ke setiap objek yang ada pada data latih. Pada penelitian ini digunakan dua jenis atribut, yaitu atribut numerik dan atribut nominal. Oleh sebab itu, jarak yang digunakan pada proses FKNN merupakan hasil penjumlahan antara jarak numerik diboboti dan jarak nominal diboboti. Perhitungan jarak numerik dari objek yang akan diuji terhadap suatu objek pada data latih dicerminkan pada persamaan berikut:
nu
Adapun perhitungan jarak nominalnya dapat dicerminkan pada persamaan berikut:
n n n
dengan
x : objek yang akan diuji y : objek pada data latih
xnom : nilai atribut nominal pada objek x ynom : nilai atribut nominal pada objek y
8
akan diberi bobot 0.5 dan jarak numerik diberi bobot 1 (Nurjayanti 2011). Hal ini dilakukan agar atribut nominal tidak terlalu mendominasi hasil perhitungan.
Setelah didapatkan nilai total jarak, perhitungan menurut konsep FKNN mulai dilakukan. Untuk mendapatkan derajat keanggotaan dari suatu objek yang akan diuji digunakan fungsi berikut (Keller et al. 1985):
u u K : banyak tetangga terdekat yang akan diperhitungkan
: jarak dari objek x terhadap objek yk
m : bobot untuk pengaruh jarak pada derajat keanggotaan
Setelah didapatkan nilai derajat keanggotaan dari setiap kelas, nilai-nilai tersebut dibandingkan dan diambil nilai terbesar sebagai acuan pemilihan kelas. Pada akhirnya data uji akan dimasukkan ke kelas dengan nilai derajat keanggotaan terbesar.
Model yang telah dibangun selanjutnya diuji menggunakan data uji yang hasil dari tahap pembagian data. Pengujian ini dilakukan untuk mengetahui akurasi dan efektifitas model yang telah dibangun. Pengujian dilakukan pada k = 1 (1-NN) sampai k = 5 (5-NN). Pengukuran kinerja algoritme akan dilakukan menggunakan confusionmatrix yang ditampilkan pada Tabel 3.
Confusion matrix selanjutnya digunakan untuk menghitung nilai beberapa kriteria evaluasi berikut:
Akurasi merupakan proporsi jumlah prediksi yang tepat. Akurasi dinyatakan dalam persamaan berikut (Maning et al. 2008):
Precision merupakan proporsi dari data kelas positif yang berhasil diprediksi dengan benar dari keseluruhan hasil prediksi kelas positif. Precision
Tabel 3 Confusion matrix dengan dua kelas
Aktual Prediksi
Positif Negatif
Positif TP FN
9 dinyatakan sebagai berikut (Maning et al. 2008):
s n
Recall merupakan proporsi dari hasil prediksi kelas positif yang benar dari seluruh data kelas positif. Recall dinyatakan dalam persamaan berikut (Maning et al. 2008):
all
F-measure merupakan kriteria evaluasi yang menggabungkan nilai precision dan recall ke dalam satu nilai. Nilai f-measure dapat dihitung menggunakan rumus berikut (Maning et al. 2008):
asu all all s n s n
Analisis
Hasil dari proses klasifikasi akan dianalisis di tahap ini. Beberapa hal yang akan dianalisis antara lain kinerja algoritme FKNN secara umum, pengaruh data tidak seimbang pada hasil klasifikasi, dan pengaruh teknik resampling terhadap hasil klasifikasi. Selain itu, pada tahap ini juga akan diajukan model terbaik untuk klasifikasi data baru.
Spesifikasi Perangkat Lunak
Perangkat lunak yang digunakan dalam penelitian ini adalah Matlab 7.7.0 (R2008b) dan Microsoft Office Excel 2007. Kedua perangkat lunak tersebut digunakan dalam proses praproses data sampai klasifikasi FKNN.
HASIL DAN PEMBAHASAN
Pengumpulan Data
10
Praproses Data
Pengkodean data kategorik menjadi data nominal dapat dilihat pada Tabel 4. Selanjutnya dilakukan normalisasi pada data bertipe numerik menggunakan min-max normalization. Setelah melalui seluruh tahapan praproses data, didapatkan 196 data pangan, meliputi 111 data GI rendah, 50 data GI sedang, dan 35 data GI tinggi. Data ini selanjutnya akan disebut sebagai data 1.
Resampling
Pada penelitian ini ditemukan bahwa data yang digunakan (data 1) merupakan data tidak seimbang dengan sebuah kelas mayoritas (kelas GI rendah) dan dua buah kelas minoritas (kelas GI sedang dan tinggi). Oleh sebab itu, untuk mengatasi kondisi data yang tidak seimbang dilakukan proses resampling. Proses under-sampling dilakukan sampai banyak data setiap kelas sama dengan banyak data pada kelas GI tinggi. Sebaliknya, over-sampling dilakukan sampai banyak data setiap kelas sama dengan banyak data pada kelas GI rendah. Adapun perbandingan banyak data pada data asli dan data hasil resampling dapat dilihat pada Tabel 5.
Tabel 4 Pengkodean data kategorik menjadi data nominal
11 Pembagian Data
Pembagian data dilakukan menggunakan teknik 10-fold cross validation agar data latih untuk setiap k mendekati data aslinya. Setiap set data akan dibagi menjadi 10 subset dengan 9 subset berperan sebagai data latih dan 1 subset berperan sebagai data uji. Data uji akan diperankan secara bergantian oleh setiap subset. Oleh sebab itu, untuk setiap set data akan memiliki 10 paket data latih dan data uji.
Klasifikasi Menggunakan FKNN
Model klasifikasi dibuat dengan nilai m = 2. Selanjutnya, pengujian dilakukan menggunakan data latih dan data uji hasil proses pembagian data. Untuk setiap set data dilakukan pengujian sebanyak 3 kali ulangan. Dengan kata lain, proses pembagian data perlu dilakukan sebanyak 3 kali. Hasil uji dari ketiga ulangan tersebut selanjutnya dihitung rataannya untuk mendapatkan hasil uji keseluruhan. Pada Tabel 6 disajikan akurasi rata-rata yang didapatkan untuk masing-masing set data dan k tetangga terdekat.
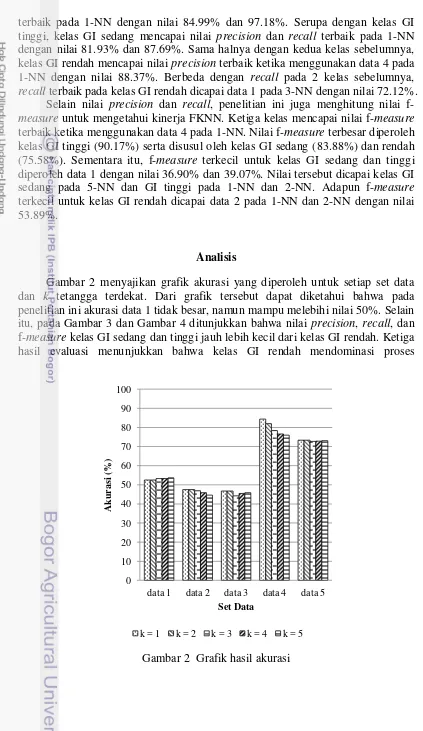
Dari Tabel 6 diketahui bahwa nilai akurasi untuk data 1 hanya mampu mencapai akurasi tertinggi sebesar 53.69% pada 5-NN. Penerapan teknik random under-sampling pada data menyebabkan terjadinya penurunan akurasi. Penggunaan data 2 hanya mampu menghasilkan nilai akurasi antara 45-47%, dengan nilai akurasi tertinggi dicapai pada 1-NN dan 2-NN sebesar 47.48%. Teknik resampling berikutnya yang diterapkan adalah teknik k-means based under-sampling yang menghasilkan data 3. Penggunaan data 3 juga menyebabkan terjadinya penurunan nilai akurasi. Data tersebut menghasilkan nilai akurasi tertinggi sebesar 46.82% pada 1-NN dan 2-NN. Selain teknik under-sampling, penelitian ini menerapkan teknik over-sampling yang menghasilkan data 4 dan data 5. Data 4 mampu mencapai nilai akurasi 84.39% pada 1-NN. Data 5 menghasilkan nilai akurasi terbaik sebesar 73.37%. Dari hasil tersebut dapat diketahui bahwa secara umum nilai akurasi terbesar dihasilkan oleh data 4 untuk 1-NN, yaitu sebesar 84.39%. Sementara itu, nilai akurasi terkecil dihasilkan oleh data 3 untuk 3-NN, yaitu sebesar 44.30%.
Dari hasil perhitungan menggunakan confusion matrix diketahui bahwa secara umum nilai precision dan recall terbaik untuk setiap kelas didapatkan ketika menggunakan data 4. Kelas GI tinggi mencapai nilai precision dan recall
Tabel 6 Hasil akurasi rata-rata dalam satuan persen
12
terbaik pada 1-NN dengan nilai 84.99% dan 97.18%. Serupa dengan kelas GI tinggi, kelas GI sedang mencapai nilai precision dan recall terbaik pada 1-NN dengan nilai 81.93% dan 87.69%. Sama halnya dengan kedua kelas sebelumnya, kelas GI rendah mencapai nilai precision terbaik ketika menggunakan data 4 pada 1-NN dengan nilai 88.37%. Berbeda dengan recall pada 2 kelas sebelumnya, recall terbaik pada kelas GI rendah dicapai data 1 pada 3-NN dengan nilai 72.12%.
Selain nilai precision dan recall, penelitian ini juga menghitung nilai f-measure untuk mengetahui kinerja FKNN. Ketiga kelas mencapai nilai f-measure terbaik ketika menggunakan data 4 pada 1-NN. Nilai f-measure terbesar diperoleh kelas GI tinggi (90.17%) serta disusul oleh kelas GI sedang (83.88%) dan rendah (75.58%). Sementara itu, f-measure terkecil untuk kelas GI sedang dan tinggi diperoleh data 1 dengan nilai 36.90% dan 39.07%. Nilai tersebut dicapai kelas GI sedang pada 5-NN dan GI tinggi pada 1-NN dan 2-NN. Adapun f-measure terkecil untuk kelas GI rendah dicapai data 2 pada 1-NN dan 2-NN dengan nilai 53.89%.
Analisis
Gambar 2 menyajikan grafik akurasi yang diperoleh untuk setiap set data dan k tetangga terdekat. Dari grafik tersebut dapat diketahui bahwa pada penelitian ini akurasi data 1 tidak besar, namun mampu melebihi nilai 50%. Selain itu, pada Gambar 3 dan Gambar 4 ditunjukkan bahwa nilai precision, recall, dan f-measure kelas GI sedang dan tinggi jauh lebih kecil dari kelas GI rendah. Ketiga hasil evaluasi menunjukkan bahwa kelas GI rendah mendominasi proses
13 klasifikasi. Dengan kata lain, sebuah data akan cenderung diklasifikasi ke kelas GI rendah daripada ke 2 kelas lainnya. Kondisi ini dicurigai terjadi karena jumlah data yang tidak seimbang. Oleh sebab itu, penelitian ini menerapkan beberapa teknik resampling untuk mengatasi masalah data tidak seimbang dan meningkatkan akurasi hasil klasifikasi.
Dari grafik pada Gambar 2 terlihat bahwa nilai akurasi pada data 2 dan 3 lebih rendah bila dibandingkan dengan akurasi data 1. Kedua data tersebut menunjukkan bahwa data hasil teknik under-sampling tidak berhasil meningkatkan nilai akurasi. Di sisi lain, nilai akurasi meningkat pada data yang menerapkan teknik over-sampling, yaitu data 4 dan 5. Nilai akurasi terbesar dicapai oleh data 4 yang menerapkan teknik randomover-sampling.
Meskipun terjadi penurunan akurasi pada data 2 dan 3, kedua data tersebut meningkatkan nilai f-measure dari kelas GI sedang dan tinggi. Di sisi lain, kelas
Gambar 3 Grafik hasil precision (kiri) dan recall (kanan)
14
GI rendah pada kedua data tersebut mengalami penurunan nilai precision, recall, dan f-measure. Kondisi ini terjadi akibat penerapan teknik under-sampling. Teknik ini menghapus beberapa anggota kelas mayoritas sehingga beberapa informasi dari kelas tersebut hilang.
Secara keseluruhan, hasil terbaik untuk seluruh kriteria evaluasi diperoleh ketika menggunakan data 4. Hal ini dipengaruhi teknik resampling yang digunakan, yaitu teknik random over-sampling. Pada teknik ini, data asli akan diduplikasi secara acak sehingga menghasilkan data baru. Oleh sebab itu, terdapat kemungkinan bahwa FKNN membandingkan data uji yang digunakan dengan duplikat dari data tersebut. Kondisi ini dikhawatirkan dapat mengakibatkan hasil yang kurang akurat jika data 4 digunakan untuk klasifikasi data baru.
Data berikutnya yang juga memiliki hasil evaluasi cukup besar adalah data 5. Meskipun peningkatan hasil evaluasi yang dihasilkan tidak sebesar pada data 4, secara umum data 5 memberikan hasil yang baik. Pada Gambar 3 dan Gambar 4 ditunjukkan bahwa nilai precision, recall, dan f-measure yang dihasilkan data 5 meningkat sekitar 2 kali lipat kecuali pada kelas GI rendah. Pada kelas GI rendah, data 5 mengalami kenaikan nilai precision sekitar 7% dan penurunan nilai recall sekitar 8%. Hal ini disebabkan teknik resampling yang diterapkan, yaitu SMOTE. SMOTE menambahkan anggota kelas minoritas dengan membangkitkan data buatan dari tetangga yang saling berdekatan. Dengan cara tersebut, wilayah dari kelas minoritas menjadi lebih luas sehingga meningkatkan kemungkinan klasifikasi suatu data ke dalam kelas minoritas. Penurunan nilai precision, recall, dan f-measure kelas GI rendah juga dapat disebabkan oleh meluasnya wilayah dari kelas GI sedang dan tinggi. Penggunaan SMOTE juga menurunkan kemungkinan terjadinya duplikasi data seperti yang terjadi pada teknik random over-sampling. Dengan teknik ini diharapkan hasil klasifikasi data baru lebih akurat bila dibandingkan dengan teknik randomover-sampling.
Meskipun secara umum teknik resampling berhasil meningkatkan kinerja FKNN dan memperbaiki dominasi kelas mayoritas, hasil klasifikasi masih belum optimal. Hal ini diduga disebabkan oleh banyak data yang belum memenuhi kebutuhan. Pada kasus klasifikasi data tidak seimbang, banyak data yang digunakan menjadi salah satu faktor penentu keberhasilan klasifikasi. Semakin banyak data yang digunakan maka tingkat error yang dihasilkan akan semakin menurun. Bahkan jika ukuran data yang digunakan besar, kondisi data yang tidak seimbang tidak akan berpengaruh besar pada hasil klasifikasi (Sun et al. 2006).
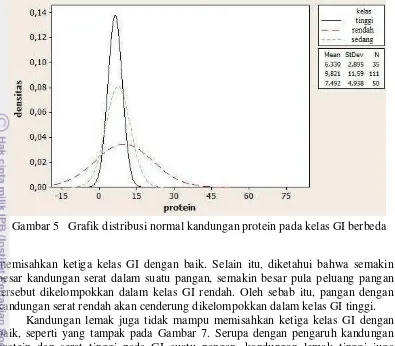
Gambar 5, Gambar 6, dan Gambar 7 menyajikan grafik distribusi normal untuk kandungan protein, serat, dan lemak dari data 1 pada kelas GI berbeda. Dari Gambar 5 dapat diketahui bahwa kandungan protein tidak memisahkan ketiga kelas dengan baik. Ketiga grafik tersebut berhimpit antara satu dengan yang lain. Kelas GI tinggi dan sedang terpusat pada kadar protein rendah. Sementara itu, kelas GI rendah memiliki jangkauan yang lebih luas dari kedua kelas lainnya, yaitu meliputi kadar protein rendah hingga kadar protein tinggi. Dari grafik tersebut terlihat bahwa semakin besar kadar protein suatu pangan maka semakin besar pula peluang pangan tersebut memasuki kelas GI rendah. Sebaliknya, semakin rendah kandungan protein dalam suatu pangan maka semakin besar pula kemungkinan bahwa pangan tersebut memiliki GI tinggi.
15
memisahkan ketiga kelas GI dengan baik. Selain itu, diketahui bahwa semakin besar kandungan serat dalam suatu pangan, semakin besar pula peluang pangan tersebut dikelompokkan dalam kelas GI rendah. Oleh sebab itu, pangan dengan kandungan serat rendah akan cenderung dikelompokkan dalam kelas GI tinggi.
Kandungan lemak juga tidak mampu memisahkan ketiga kelas GI dengan baik, seperti yang tampak pada Gambar 7. Serupa dengan pengaruh kandungan protein dan serat tinggi pada GI suatu pangan, kandungan lemak tinggi juga membuat suatu pangan berpotensi lebih besar untuk memiliki GI rendah. Akan tetapi, hal serupa tidak terjadi pada pangan dengan kandungan lemak rendah. Berbeda dengan kandungan protein dan serat rendah yang berpotensi besar menyebabkan pangan memiliki GI tinggi, kandungan lemak rendah justru berpotensi besar menyebabkan pangan memiliki GI sedang. Hal ini bertentangan dengan teori yang menyatakan bahwa semakin rendah kandungan lemak suatu pangan maka semakin besar nilai GI dari pangan tersebut. Kondisi ini diduga terjadi karena pengaruh kandungan zat gizi lainnya dan proses pemasakan yang dilakukan pada pangan.
Kandungan protein, lemak, dan serat ternyata belum mampu memisahkan ketiga kelas dengan sempurna. Grafik yang dihasilkan masing-masing zat gizi berhimpit antara satu kelas dengan kelas lainnya. Ketiga grafik berhimpit pada kandungan zat gizi sedang dan rendah. Kondisi ini mengakibatkan rentan terjadinya kesalahan klasifikasi pada kandungan protein, serat, dan lemak rendah dan sedang. Hal ini diduga merupakan penyebab rendahnya nilai akurasi pada hasil klasifikasi menggunakan data 1.
16
SIMPULAN DAN SARAN
Simpulan
Penelitian ini telah berhasil menerapkan algoritme FKNN dalam proses klasifikasi bahan pangan berdasarkan kandungan zat gizi bahan pangan. Model klasifikasi yang menggunakan data asli ternyata belum mampu memberikan hasil klasifikasi yang optimal karena kondisi data yang tidak seimbang. Selain itu, hasil klasifikasi cenderung didominasi oleh kelas GI rendah sebagai kelas minoritas.
Gambar 6 Grafik distribusi normal kandungan serat pada kelas GI berbeda
17 Kondisi ini berhasil diperbaiki dengan menerapkan beberapa teknik resampling, yaitu random under-sampling, k-means based under-sampling, random over -sampling, dan SMOTE. Dari keempat teknik resampling yang digunakan, model yang menggunakan data hasil proses random over-sampling memberikan hasil terbaik untuk seluruh kriteria evaluasi.
Saran
Meskipun kinerja FKNN berhasil ditingkatkan dengan menggunakan beberapa teknik resampling, hasil klasifikasi yang diberikan dalam penelitian ini belum optimal. Oleh sebab itu, pada penelitian selanjutnya dapat dilakukan beberapa hal berikut untuk membuat hasil klasifikasi lebih optimal:
1 Menambah banyaknya data yang digunakan.
2 Menerapkan teknik penyelesaian masalah data tidak seimbang berdasarkan pendekatan algoritme.
3 Mencari fungsi distribusi peluang terbaik untuk setiap atribut data dan memanipulasi data berdasarkan parameter fungsi tersebut untuk mengatasi kondisi data tidak seimbang.
DAFTAR PUSTAKA
Brand JC, Nicholson PL, Thorburn AW, Truswell AS. 1985. Food processing and the glycemic index. The American Journal of Clinical Nutrition. 42(6): 1192-1196.
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. 2002. SMOTE: synthetic minority over-sampling technique. Journal of Artificial Intelligence Research. 16: 321-357. doi: 10.1613/jair.953.
Cohen G, Hilario M, Sax H, Hogonnet S, Geissbuhler A. 2006. Learning from imbalanced data in surveillance of nosocomial infection. Artificial Intelligence in Medicine. 37(1): 7-18. doi: 10.1016/j.artmed.2005.03.002.
Keller JM, Gray MR, Givens JA. 1985. A fuzzy k-nearest neigbor algorithm. IEEE Trans System Man Cybernet, 15(4): 580-585. doi: 10.1109/TSMC.1985.65313426.
Larose DT. 2005. Discovering Knowledge in Data: An introduction to Data Mining. Canada (US): John Wiley & Sons, Inc.
Liao TW. 2008. Classification of weld flaws with imbalanced class data. Expert System with Application. 35(3): 580-585. doi: 10.1016/j.eswa.207.08.044. Maning CD, Raghavan P, Schütze H. 2008. An Introduction to Information
Retrieval. Cambridge (GB): Cambridge University Press.
Mendosa D. 2008. Revised International Table of Glycemic Index (GI) and Glycemic Load (GL) Values-2008 [internet]. [diunduh 2013 Mar 18]. Tersedia dari: http://www.mendosa.com/gilists.htm.
18
Rimbawan, Siagian A. 2005. Kontroversi konsep glycemic index pada penatalaksanaan diet penderita diabetes melitus. Media Gizi dan Keluarga. 29(1): 99-105.
Sun Y, Kamel MS, Wong AKC, Wang Y. 2006. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognition. 40: 3358-3378. doi: 10.1016/j.patcog.2007.04.009.
Teknomo K. 2006. Similarity Measurement [internet]. [diunduh 11 April 2013]. Tersedia dari http://people.revoledu.com/kardi/tutorial/Similarity/
Trout DL, Behall KM, Osilesi O. 1993. Prediction of glycemic index for starchy foods. The American Journal of Clinical Nutrition. 58(6): 873-878.
[USDA] United Stated Department of Agriculture. 2012. USDA National Nutrient Database for Standard Reference, Release 25 [internet]. [diunduh 2013 Apr 23]. Tersedia dari: http://www.ars.usda.gov/ba/bhnrc/ndl.
[WHO] World Health Organization. 2004. Diabetes Action Now Boolet [internet]. [diunduh 2013 Mar 12]. Tersedia dari: http://whqlibdoc.who.int/publications/-2004/924159151X.pdf.
Wild S, Roglic G, Green A, Sicree R, King H. 2004. Global prevalence of diabetes: estimates for the year 2000 and projections for 2030. Diabetes Care. 27(5):1047-1053.
19 Lampiran 1 Nilai rata-rata precision, recall, dan f-measure setiap kelas pada nilai
20
Lampiran 2 Contoh data hasil tahap praproses data (data asli)
21 Lampiran 3 Data hasil proses random under-sampling
23 Lampiran 3 Lanjutan
Protein (gr) Lemak (gr) Serat (gr) Pemasakan Kelas GI
2.54 0.72 6.03 1 3
3.91 0.29 0.64 1 3
3.22 1.24 2.82 1 3
3.97 1.21 0.24 1 3
5.80 2.26 5.98 1 3
7.02 0.93 2.19 1 3
5.97 0.56 14.24 5 3
5.12 22.54 1.48 5 3
7.39 22.65 2.58 5 3
9.71 2.23 5.13 5 3
7.41 2.11 2.75 3 3
7.99 28.55 9.28 5 3
4.55 0.23 3.48 5 3
8.31 0.29 9.59 3 3
4.51 0.21 3.44 5 3
7.41 0.17 9.28 5 3
5.44 1.62 4.27 3 3
6.48 1.65 1.88 5 3
5.77 2.18 1.20 5 3
3.87 0.40 7.05 3 3
24
Lampiran 4 Data hasil proses k-means based under-sampling
26
Lampiran 4 Lanjutan
Protein (gr) Lemak (gr) Serat (gr) Pemasakan Kelas GI
10.92 4.92 6.68 1 3
4.34 0.17 0.62 1 3
8.25 4.60 6.42 1 3
3.11 1.88 3.29 1 3
3.64 1.04 5.92 1 3
6.05 2.41 5.21 1 3
4.42 1.10 4.42 1 3
4.46 0.24 1.96 1 3
2.54 0.72 6.03 1 3
3.91 0.29 0.64 1 3
3.22 1.24 2.82 1 3
3.97 1.21 0.24 1 3
5.80 2.26 5.98 1 3
7.02 0.93 2.19 1 3
7.41 2.11 2.75 3 3
5.43 1.62 4.27 3 3
3.87 0.40 7.05 3 3
4.04 1.00 2.65 1 3
5.12 22.54 1.48 5 3
7.39 22.65 2.58 5 3
27 Lampiran 5 Contoh data hasil proses random over-sampling
28
Lampiran 6 Contoh data hasil proses SMOTE
29
RIWAYAT HIDUP
Penulis adalah anak pertama dari pasangan Bapak Teguh Gunadi dan Ibu Bois Asnawati. Penulis merupakan lulusan SMP Negeri 1 Cirebon (2006) dan SMA Negeri 1 Cirebon (2009). Pada tahun 2009, penulis diterima sebagai mahasiswa Departemen Ilmu Komputer, Institut Pertanian Bogor melalui jalur Beasiswa Utusan Daerah (BUD).