1
KLASIFIKASI STATUS GIZI MENGGUNAKAN
K-NEAREST NEIGHBOR
Sumarni Arifin Hasani¹, Sitti Suhada², Lillyan Hadjaratie³
¹Program Studi Sistem Informasi, Fakultas Teknik, Universitas Negeri Gorontalo Email: [email protected]
²Program Studi Sistem Informasi, Fakultas Teknik, Universitas Negeri Gorontalo Email: [email protected]
³ Program Studi Sistem Informasi, Fakultas Teknik, Universitas Negeri Gorontalo Email: [email protected]
INTISARI
Kesibukan mahasiswa yang pada umumnya selalu disibukkan dengan berbagai kegiatan sehari-hari menyebabkan mahasiswa tersebut kurang memperhatikan asupan gizi, sehingga menyebabkan masalah kekurangan ataupun kelebihan gizi yang berpengaruh pada kesehatan. Selain itu sering ditemui seorang mahasiswa tidak mengetahui berada dimana kelompok status gizinya. Tujuan dari penelitian ini yaitu menerapkan algoritma K-Nearest
Neighboar dalam mengklasifikasi status gizi. Penelitian ini menggunakan salah satu
metode klasifikasi dalam Data Mining, yaitu K-Nearest Neighbor (KNN) dengan menggunakan perhitungan jarak Euclidean. Hasil pengujian yang dilakukan terhadap 10 data sampel mahasiswa, diperoleh nilai keakuratan sistem sebesar 100%.
Kata Kunci : Data Mining, Klasifikasi, K-Nearest Neighbor, Eucledian, Status Gizi.
ABSTRACT
Students are often busy with their daily activities which often made them pay less attention to their nutrition intake, thus, causing the lack or over nutrition problem that influence their health. In addition, it is often found that students do not know their nutrition status group. The objective of this research was to implement the K-Nearest Neighbor algorithm in nutritional status classification. This research used one of the classification methods in data mining called K-Nearest Neighbor with the Euclidean space calculation. The test administered to 10 data sample of students obtained the accuracy of the system was 100%
Keywords : Data Mining, Classification, K-Nearest Neighbor, Euclidean, Nutritional
2 1. PENDAHULUAN
Menurut Wulandari (2011), masalah kekurangan dan kelebihan gizi pada orang dewasa (usia 18 tahun keatas) merupakan masalah penting, karena selain mempunyai resiko penyakit- penyakit tertentu, juga dapat mempengaruhi produktifitas kerja.
Kesibukan mahasiswa yang pada umumnya selalu disibukkan dengan berbagai kegiatan sehari-hari menyebabkan mahasiswa tersebut kurang memperhatikan asupan gizi, sehingga menyebabkan masalah kekurangan ataupun kelebihan gizi yang berpengaruh pada kesehatan. Selain itu sering ditemui seorang mahasiswa tidak mengetahui berada dimana kelompok status gizinya. Oleh Karena itu perlu dilakukan pengelompokan status gizi berdasarkan data yang ada dengan menggunakan metode klasifikasi.
Dalam dunia Teknologi Informasi (TI) ada beberapa teknik yang bisa digunakan untuk mengatasi hal tersebut, salah satunya adalah teknik Data Mining (Turban dkk dalam Kusrini, 2009). Salah satu metode Data Mining yang bisa digunakan adalah Mining Classification
Rule atau metode Klasifikasi Data Mining. Metode ini merupakan proses
menentukan klas (label) dari suatu objek yang tidak memiliki label. Pelabelan objek dilakukan berdasarkan kesamaan karakteristik antara sekumpulan objek (training set) dengan objek baru tersebut (Abidin dalam Hasan, 2012). Terdapat beberapa Algoritma yang dapat digunakan dalam Data Mining untuk metode klasifikasi salah satunya adalah
K-Nearest Neighbor. K-Nearest
Neighbor adalah pendekatan untuk
mencari kasus dengan menghitung kedekatan antara kasus baru dengan kasus lama, yaitu dengan berdasarkan pada pencocokan bobot dari sejumlah fitur yang ada. (Kusrini, 2009).
2. TINJAUAN PUSTAKA 2.1 Definisi Data Mining
Data mining adalah suatu istilah
yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan
machine learning untuk mengekstraksi
dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban, dkk. 2005).
2.2 Algoritma K-Nearest Neighbor
Metode K-Nearest Neighbor
merupakan salah satu metode yang digunakan dalam pengklasifikasian data. Prinsip kerja K-Nearest Neighbor (KNN) adalah mencari jarak terdekat antara data yang akan di evaluasi dengan K tetangga (neighbor) terdekatnya dalam data pelatihan (Rismawan, dkk. 2008)
Berikut rumus pencarian jarak menggunakan rumus Euclidean (Sutanto, 2009).
𝑑𝑖𝑗= √∑𝑝𝑖=1(𝑥𝑖𝑘 − 𝑥𝑗𝑘 )2… ….(1) Keterangan:
Xjk = Sample Data / Data Training Xik = Data Uji / Testing
ij = Variabel Data d = Jarak
p = Dimensi Data 2.3 Definisi Status Gizi
Mengenai definisi status gizi, berikut adalah beberapa pendapat dari berbagai sumber (Putra,2013), yakni : 1. Status gizi adalah keadaan tubuh
yang diakibatkan oleh konsumsi makanan dan penggunaan zat-zat gizi.
2. Status gizi adalah status kesehatan yang dihasilkan oleh keseimbangan antara kebutuhan dan masukan nutrisi.
3 2.4 Indeks Massa Tubuh (IMT)
Menurut Hartono (2006), Indeks Massa Tubuh (IMT) merupakan suatu pengukuran yang membandingkan berat badan dengan tinggi badan. IMT merupakan teknik untuk menghitung index berat badan, sehingga dapat diketahui kategori tubuh kita apakah tergolong kurus, normal atau gemuk. Dalam menghitung IMT diperlukan dua parameter, yaitu berat badan (kg) dan tinggi badan (m)2. IMT dapat dihitung dengan menggunakan persamaan berikut:
𝐼𝑀𝑇 = 𝐵𝑒𝑟𝑎𝑡 𝐵𝑎𝑑𝑎𝑛 (𝑘𝑔)
𝑇𝑖𝑛𝑔𝑔𝑖 𝐵𝑎𝑑𝑎𝑛 (𝑚)2 ….(2)
Nilai standar IMT untuk orang Asia adalah sebagai berikut:
IMT < 18,5 : Kurang IMT ≥ 18,5 - 22,9 : Normal
IMT ≥ 23 – 24,9 : Obesitas Ringan IMT ≥ 25 – 29,9 : Obesitas Sedang IMT ≥ 30 : Obesitas Berat 3. METODE PENELITIAN
Metode penelitian yang digunakan dalam peneliti ini lebih merujuk kepada penggunaan teori pengembangan System
Development Life Cycle (SDLC).
Menurut Sutabri (2004), Siklus hidup pengembangan sistem merupakan suatu bentuk yang digunakan untuk menggambarkan tahapan utama dan langkah-langkah pada tahapan tersebut dalam proses pengembangan sistem. Siklus hidup pembangunan atau pengembangan sistem informasi menyajikan metodologi atau proses yang diorganisasikan guna membangun suatu sistem informasi.
Ada 6 tahapan dalam penelitian ini yaitu perencanaan, analisis sistem, perancangan sistem, implementasi, pengujian sistem, pembuatan laporan. 4. HASIL DAN PEMBAHASAN A. Hasil Penelitian
1) Perancanaan (Pengumpulan Data) Sumber data yang digunakan dalam penelitian berasal dari data hasil kuisioner
yang sebelumnya telah dibagikan oleh peneliti kepada mahasiswa reguler jurusan Teknik Informatika UNG yang masih aktif sebanyak 254 sampel data mahasiswa. Data mahasiswa jurusan Informatika UNG sebanyak 254 sampel diperoleh dari perhitungan sampel dengan Rumus Slovin (Ellen, 2010), yang diperoleh dari jumlah mahasiswa reguler yang masih aktif sebanyak 698 mahasiswa. Adapun penjelasan dari pengambilan sampel dengan menggunakan rumus slovin, sebagai berikut :
………(3) Dimana :
Dari rumus tersebut diperoleh jumlah sampel dalam penelitian ini adalah: 𝑛 = 698 1 + 698 𝑥 (5%)2 = 698 1 + 698 𝑥 (0.0025) = 698 2.745 = 254.3 𝑛 = 254
Dengan demikian jumlah sampel yang akan digunakan dalam penelitian ini adalah 254 data mahasiswa yang dianggap mewakili sampel secara keseluruhan.
2) Analisis Sistem
Pada tahap analisis sistem yang dilakukan meliputi analisis permasalahan, analisis kebutuhan sistem baik fungsional maupun non fungsional, dan analisis pemecahan masalah dengan metode K-Nearest Neighbor menggunakan jarak eucledian untuk
2 1 Ne N n n = ukuran sampel N = ukuran populasi
e = persen kelonggaran ketidak telitian yang digunakan karena kesalahan pengambilan sampel yang masih
4 mengklasifikasi status gizi mahasiswa. Sebelum dilakukan perhitungan dengan menggunakan algoritma KNN, data sampel yang di dapatkan dari hasil kuisioner, di hitung dengan menggunakan perhitungan Indeks Massa tubuh (IMT) untuk memperoleh status gizi mahasiswa, data hasil perhitugan IMT tersebut akan dijadikan sebagai data training. Berikut hasil perhitungan IMT data mahasiswa dengan menggunakan persamaan 2 yang dapat dilihat pada tabel 1.
Tabel 1. Hasil perhitungan IMT Data mahasiswa (data training)
No Tinggi Badan Berat Badan Status Gizi 1 153 40 Kurang 2 157 48 Normal 3 163 56 Normal 4 160 50 Normal 5 161 49 Normal 6 158 39 Kurang 7 159 40 Kurang 8 158 47 Normal 9 154 40 Kurang 10 150 40 Kurang … …. ….. ….. 254 166 48 Kurang Keterangan: TB : Tinggi Badan BB : Berat Badan JK : Jenis Kelamin LPG : Lingkar Pergelangan LP : Lingkar Perut SG : Status Gizi
Cara perhitungan algoritma
K-Nearest Neighbor dengan menggunakan
formulasi perhitungan jarak eucledian dengan melibatkan 254 sampel data mahasiswa (data training) apabila diberikan inputan seorang yang memiliki tinggi badan 153 cm, berat badan 40 kg. Berikut perhitungan jarak yang dilakukan.
a. Jarak Eucledian 1. Tentukan parameter K
Nilai K yang digunakan adalah 5. 2. Hitung jarak antara data baru dengan
semua data training, gunakan persamaan (1). 𝑑𝑖𝑗 = √(153 − 157)2+ (40 − 48)2 = √(−4)2+ (−8)2 = √16 + 64 = √80 = 8.94
Untuk hasil perhitungan jarak
eucledian 254 data sampel mahasiswa,
dapat dilihat pada tabel 2.
Tabel 2. Hasil Perhitungan Jarak dengan melibatkan 254 data training
No Tinggi Badan Berat Badan Status Gizi Jarak 1 153 40 Kurang 0.00 2 157 48 Normal 8.94 3 163 56 Normal 18.87 4 160 50 Normal 12.21 5 161 49 Normal 12.04 6 158 39 Kurang 5.10 7 159 40 Kurang 6.00 8 158 47 Normal 8.60 9 154 40 Kurang 1.00 10 150 40 Kurang 3.00 … …. … ….. … 254 166 48 Kurang 15.26
3. Data di urutkan berdasarkan nilai jarak dari nilai yang terkecil sampai yang terbesar, seperti yang terlihat pada tabel 3.
Tabel 3. Hasil Pengurutan 254 data training berdasarkan nilai Jarak
No Tinggi Badan Berat Badan Status Gizi Jarak 1 153 40 Kurang 0.00 9 154 40 Kurang 1.00 45 152 40 Kurang 1.00
5 69 153 39 Kurang 1.00 215 153 39 Kurang 1.00 38 155 40 Kurang 2.00 60 155 40 Kurang 2.00 173 155 40 Kurang 2.00 62 154 42 Kurang 2.24 10 150 40 Kurang 3.00 … …. …. ….. ….. 207 165 110 Obesitas Berat 71.02
4. Tetapkan tetangga terdekat berdasarkan jarak minimum ke-k, apabila ditetapkan nilai k=5, maka diambil 5 jarak terdekat yang terlihat pada table 4.
Tabel 4. Pengambilan Data Sejumlah Nilai K No Tinggi Badan Berat Badan Status Gizi Jarak 1 153 40 Kurang 0.00 9 154 40 Kurang 1.00 45 152 40 Kurang 1.00 69 153 39 Kurang 1.00 215 153 39 Kurang 1.00
5. Periksa kelas dari tetangga terdekat. Berdasarkan hasil pada tabel 4 menunjukkan bahwa dari 5 tetangga terdekat, terdapat 5 status gizi kurang, maka dapat disimpulkan bahwa data baru termasuk kedalam kelas status gizi “KURANG”.
3) Perancangan Sistem
Pada tahap perancangan sistem ini, akan dirancang mengenai sistem yang akan dibuat mulai dari pemodelan proses sistemnya, rancangan database, dan rancangan antar muka sistem. Berikut ini adalah gambar rancangan dari sistem klasifikasi status gizi:
a. Pemodelan Proses Sistem
Sistem Klasifikasi Status Gizi
Admin User
Data Training Data Urut Eucledian Hasil Klasifikasi Laporan Hasil Klasifikasi Data User untuk Proses Klasifikasi Data Training
Hasil Klasifikasi Data Mahasiswa Data User untuk Proses Klasifikasi
Gambar 1. Diagram Konteks
b. Rancangan Antar Muka
Berikut ini adalah rancangan antar muka sistem yang akan dibuat:
K-Nearest Neighbor
Sistem Klasifikasi Status Gizi
Beranda KlasifikasiKlasifikasi Informasi Petunjuk
Header
Login Admin Beranda
Status Gizi Dalam Garafik
Grafik
Gambar 2. Rancangan Menu Utama (Pengunjung)
4) Implementasi
Tahapan ini merupakan tahapan untuk mengimplementasikan hasil pembuatan aplikasi
.
Gambar 3. Merupakan
Implementasi Website Sistem Klasifikasi Status Gizi yang menyajikan fasilitas yang ada.
Gambar 3. Tampilan Halaman Beranda (Pengunjung)
Menu pada gambar 4 dibawah ini digunakan admin untuk menginput, mengedit serta menghapus data training.
6 Gambar 4. Menu Data Training
5) Pengujian Sistem
Setelah melewati tahapan pengembangan sebelumnya, ditahapan ini akan dilakukan proses pengujian menggunakan sensitifitas, kekhususan, nilai terprediksi benar dan nilai terprediksi salah. Pengujian ini dilakukan untuk menilai kinerja sistem terhadap beberapa data. Data yang digunakan dalam pengujian ini berjumlah 10 sampel data mahasiswa, yang terlihat pada tabel 5.
Tabel 5. Data Sampel mahsiswa No. Tinggi Badan Berat Badan StatusGizi 1 167.5 55 Normal 2 172 72 Obesitas Ringan 3 175 55 Kurang 4 167 52 Normal 5 169 50 Kurang 6 167 52 Normal 7 170 63 Normal 8 169 51 Kurang 9 167 85 Obesitas Berat 10 167 67 Obesitas Ringan Dalam pengujian ini, nilai K yang digunakan adalah 5. Pengujian kinerja sistem untuk 10 data sampel mahasiswa dengan cara melakukan perhitungan setiap baris data pada tabel 5 dengan melibatkan data training yang ada pada tabel 1. Hasilnya dapat dilihat pada tabel 6.
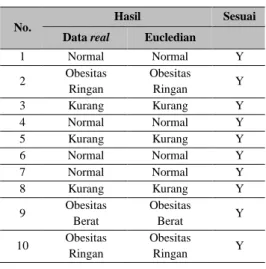
Tabel 6. Hasil Pengujian Data Sampel Mahasiswa
No.
Hasil Sesuai
Data real Eucledian
1 Normal Normal Y 2 Obesitas Ringan Obesitas Ringan Y 3 Kurang Kurang Y 4 Normal Normal Y 5 Kurang Kurang Y 6 Normal Normal Y 7 Normal Normal Y 8 Kurang Kurang Y 9 Obesitas Berat Obesitas Berat Y 10 Obesitas Ringan Obesitas Ringan Y Keterangan : Y = Ya T = Tidak
Dari hasil pengujian 10 data sampel mahasiswa pada tabel 6. terdapat Data Asli (hasil klasifikasi IMT), dan Hasil Sistem (hasil klasifikasi sistem). Dari data asli terdapat 4 kategori status gizi, yakni 4 data status gizi Normal, 3 data status gizi Kurang, 2 data status gizi Obesitas Ringan, dan 1 data status gizi Obesitas Berat. Berdasarkan hasil pengujian, diperoleh hasil bahwa dari ke 10 data tersebut semuanya sesuai dengan sistem
Dalam menilai kinerja sistem diperlukan proses penilaian kinerja yang dilakukan dengan konsep sensitivitas, kekhususan, nilai prediksi benar, dan nilai prediksi salah (Bemmel dalam Kusumadewi, 2009).
Sensitivitas (TPV) adalah rasio orang yang mengalami status gizi X dan model keputusan juga memutuskan orang tersebut mengalami status gizi X dibagi dengan orang yang mengalami status gizi X. Kekhususan (TNV) adalah rasio orang yanFg tidak mengalami status gizi X dan model keputusan, juga memutuskan orang tersebut tidak mengalami status gizi X dibagi dengan orang yang tidak mengalami status gizi X. Nilai terprediksi benar (FPV) adalah rasio orang yang mengalami status gizi X, namun model
7 keputusan memutuskan orang tersebut tidak mengalami status gizi X dibagi dengan jumlah keduanya. Nilai terprediksi salah (FNV) adalah rasio orang yang tidak mengalami status gizi X, namun model keputusan memutuskan orang-orang tersebut mengalami status gizi X dibagi dengan jumlah keduanya. Kinerja sistem dapat dihitung dengan formula berikut.
Kinerja = (TP + TN) / (TP + TN + FP + FN) …………(4) Tabel 7. Kinerja Sistem untuk Setiap Status Gizi Status Gizi TP (TPV) TN (TNV) FP (FPV) FN (FNV Kinerja Kurang 3 (3/3) 7 (7/7) 0 (0/3) 0 (0/7) 10/10 Normal 4 (4/4) 6 (6/6) 0 (0/4) 0 (0/6) 10/10 Obesitas Ringan 2 (2/2) 8 (8/8) 0 (0/2) 0 (0/8) 10/10 Obesitas Sedang 0 (0/0) 10 (10/10) 0 (0/0) 0 (0/10) 10/10 Obesitas Berat 1 (1/1) 9 (9/9) 0 (0/1) 0 (0/9) 10/10
Setelah melakukan pengujian dari 5 kategori status gizi pada tabel 7, maka didapatkan nilai TP, TN, FP, FN dari masing-masing kategori status gizi tersebut. Untuk menilai total kinerja sistem secara keseluruhan, maka diambil nilai total TP, TN, FP, FN dari semua kategori status gizi. Apabila diambil nilai total kinerja untuk semua status gizi, akan diperoleh nilai total kinerja sebesar 100% Berdasarkan hasil pengujian sistem terhadap 10 sampel data uji, didapatkan hasil kinerja sistem untuk jarak eucledian dengan nilai total kinerja sebesar 100%. sehingga dapat disimpulkan bahwa model sistem telah memiliki kinerja yang baik dalam pengklasifikasian status gizi.
B. Pembahasan
Berdasarkan penelitian yang peneliti lakukan, masih banyaknya mahasiswa yang tidak mengetahui berada dimana kelompok status gizinya, dan belum
adanya sebuah sistem informasi pengklasifikasian status gizi.
Setelah melakukan penelitian ini maka peneliti mengusulkan sebuah sistem kalsifikasi status gizi menggunakan metode K-Nearest Neighbor yang dapat memberikan informasi pengklasifikasian status gizi kepada masyarakat khususnya mahasiswa. Dalam mengklasifikasi status gizi terdapat beberapa kategori status gizi yang ditentukan berdasarkan pehitungan Indeks Massa Tubuh (IMT). Ada 5 kategori status gizi yang digunakan dalam penelitian ini berdasarkan pehitungan Indeks Massa Tubuh (IMT) yaitu, kurang, normal, obesitas ringan, obesitas sedang, dan obesitas berat.
Untuk data sampel yang digunakan yakni 254 data sampel mahasiswa yang dihitung berdasarkan rumus slovin dalam pengambilan sampel. 254 data sampel mahasiswa akan dihitung dengan menggunakan metode KNN. Sebelum dilakukan perhitungan dengan menggunakan metode KNN, data sampel yang didapatkan, di hitung dengan menggunakan perhitungan IMT untuk memperoleh status gizi mahasiswa. Setelah didapatkan status gizi dari masing-masing mahasiswa, data sampel mahasiswa tersebut dihitung dengan menggunakan metode KNN dengan menggunakan formulasi perhitungan jarak eucledian.
Untuk mengukur keakurat hasil klasifikasi, penulis melakukan pengujian dengan menggunakan pengujian sensitivitas, kekhususan, nilai prediksi benar, dan nilai prediksi salah, dimana akan mengambil 10 data sampel mahasiswa dari 254 data training untuk diklasifikasi. Tabel 7 menunjukan hasil kinerja sistem untuk setiap status gizi dengan menggunakan perhitungan jarak eucledian.
Dengan menerapkan metode
K-Nearest Neighbor dengan menggunakan
8 terhadap 10 sampel data uji dengan menggunakan nilai K=5, diperoleh hasil klasifikasi untuk jarak eucledian mencapai 100%.
Berdasarkan penelitian ini, maka peneliti menyimpulkan bahwa penerapan metode K-Nearest Neighbor dalam pengklasifikasian status gizi dengan menggunakan formulasi perhitungan jarak eucledian memiliki kinerja yang baik. Hal ini dapat dilihat dari hasil penguji kinerja sistem yang dihasilkan oleh jarak Eucledian dengan nilai akurasi sebesar 100 %.
KESIMPULAN
Berdasarkan hasil dan pembahasan yang peneliti lakukan mengenai klasifikasi status gizi menggunakan metode K-Nearest Neighbor dengan melibatkan variabel tinggi badan dan berat badan, dapat disimpulkan bahwa penerapan metode K-Nearest Neighbor dalam pengklasifikasian status gizi dengan menggunakan formulasi perhitungan jarak eucledian memiliki kinerja yang baik. Hal ini dapat dilihat dari hasil penguji kinerja sistem yang dihasilkan oleh jarak Eucledian dengan nilai akurasi sebesar 100%.
5.2. Saran
Beberapa saran untuk pengembangan sistem selanjutnya yaitu:
1. Disarankan pengembangan selanjutnya menggunakan perhitungan jarak yang berbeda sehingga diperoleh hasil yang lebih bervariasi
2. Disarankan dalam pengambilan data sampel bisa lebih besar jumlahnya sehingga memperoleh hasil klasifikasi yang lebih baik..
5. REFERENSI
Ellen, S. 2010. Principles and Methods
of Research, eHow Contributor.
Hartono, A. (2006). Terapi gizi dan diet rumah sakit, Jakarta: Kedokteran ECG.
Hasan, I. 2012. Penerapan Algoritma K-Nearest Neighbor Untuk Prediksi Potensi Calon Kreditur Di Xyz Finance. [Skripsi] tidak diterbitkan. Gorontalo : Universitas Negeri Gorontalo.
Hasani, S, Arifin. 2015. Klasifikasi Status Gizi Menggunakan K-Nearest Neighbor. [Skripsi] tidak
diterbitkan. Gorontalo: Universitas Negeri Gorontalo.
Kusrini dan Luthfi, M. 2009. Algoritma
Data Mining. Yogyakarta : Penerbit
Andi Offset.
Kusumadewi, S. 2009. Klasifikasi Status Gizi Menggunakan Naive Bayesian
Classification. Yogyakarta :
Universitas Islam Indonesia.
CommIT, Vol. 3, No. 1.
Rismawan, T., Irawan, A, Wiedha., Prabowo, W., Kusumadewi, S. 2008. Sistem Pendukung Keputusan Berbasis Pocket PC Sebagai Penentu Status Gizi Menggunakan Metode KNN (K-Nearest Neighbor). Yogyakarta : Universitas Islam Indonesia. Vol. 13, No. 2
Putra, S. 2013. Pengantar Ilmu Gizi
dan Diet. Jogjakarta : D-Medika.
Sutabri, T. 2004. Analisa Sistem Informasi. Yogyakarta : Penerbit Andi.Sutanto, H, Tri. 2009. Cluster Analysis. Prosiding Seminar Nasional Matematika dan Pendidikan Matematika Jurusan Pendidikan Matematika FMIPA UNY, ISBN: 978-979-16353-3-2. Jawa Timur : Universitas Negeri Surabaya. Turban, E., dkk. 2005. Decicion Support
Systems and Intelligent Systems.
Yogyakarta : Andi Offset.
Wulandari, Y. 2011. Aplikasi Metode Mamdani Dalam Penentuan Status Gizi Dengan Indeks Massa Tubuh (IMT) Menggunakan Logika Fuzzy. Yogyakarta : Universitas Negeri Yogyakarta.