KLASIFIKASI BIDANG KERJA LULUSAN MENGGUNAKAN
ALGORITMA K-NEAREST NEIGHBOR
Nursalim, Suprapedi, dan H. Himawan
Pascasarjana Teknik Informatika Universitas Dian Nuswantoro ABSTRACT
Field of graduate work is field work in accordance with the competency, so that graduates could improve job skills and develop in accordance with their expertise. Research on classification of graduate field work needs to be done as an anticipatory measure for educational institutions to improve academic skills so that graduates in the future can be predicted whether graduates can work in the field according to academic ability, by looking at the variables that influence it. classification of field work needs to be done to prepare graduate students to work in accordance with the competence to see some influential variables or attributes such as GPA, course grades, course of study, gender and so forth. In this case the role of data mining is needed to dig up the information. Classification algorithms used in this study are K -Nearest neigbor, as a comparison used Naïve Bayes, Decision Tree, Neural Network and Support Vector Manchine. Results of classification is evaluated using cross validation, confusion matrix and ROC Curve to determine the classification accuracy rate of graduate employment fields . The results showed the data mining algorithm of k- nearest neighbor has the best performance for classification of occupations that graduates with 83.33 % accuracy values and the value of Area Under the Curve ( AUC ) was 0.900 . Keywords : fields of employment, classification, data mining, K-Nearest neigbor, Naïve Bayes, Decision Tree, Neural Network, Support Vector Manchine, Cross validation, confusion matrix ROC Curve
1. PENDAHULUAN 1.1 Latar Belakang
Dunia kerja merupakan aspek penting yang harus diperhatikan oleh mahasiswa sebelum lulus dari perguruan tinggi. Pengetahuan yang memadai tentang dunia kerja akan membawa konsekuensi logis bagi mahasiswa untuk mempersiapkan diri sebaik-baiknya sebelum terjun kedalamnya. Beberapa hal yang perlu mendapat perhatian adalah pertama kemampuan soft skill yaitu keterampilan untuk berhubungan dengan orang (interpersonal skill) dan keterampilan untuk mengatur dirinya sendiri (intrapersonal skill), kedua adalah kemampuan hard skill yaitu pengusaan ilmu pengetahuan, teknologi dan kemampuan teknis yang memadai sesuai dengan bidang ilmunya. Hal lain yang juga perlu mendapat perhatian oleh perguruan tinggi adalah pengarahan dan pempersiapan lulusan untuk bekerja sesuai dengan kemampuan akademik (kompetensinya), karena dengan ini para lulusan dapat bekerja dengan optimal dan bisa mengembangkan dirinya.
Penelitian tentang klasifikasi bidang kerja lulusan perlu dilakukan sebagai langkah antisipatif bagi institusi pendidikan untuk meningkatkan kemampuan akademik lulusannya sehingga di masa depan bisa diprediksi apakah lulusan bisa bekerja di bidang yang sesuai dengan kemampuan akademik, dengan melihat variabel-variabel yang mempengaruhinya?
Database akademik perguruan tinggi yang besar menyimpan banyak pengetahuan baru dan informasi potensial jika digali dengan benar serta dapat dimanfaatkan oleh pihak manajemen perguruan tinggi untuk pengambilan keputusan. Sejak awal berdiri 2001 s/d 2012, Sekolah Tinggi Manajemen Informatika dan Komputer (STMIK) Adhi Guna sebagai salah satu perguruan tinggi komputer di kota Palu telah meluluskan 563 mahasiswa dari dua program studi yaitu teknik informatika dan sistem informasi. Walaupun perguruan tinggi tersebut telah memiliki database berkaitan dengan lulusan yang sudah bekerja
32 http://research.pps.dinus.ac.id namun belum dapat digali informasi mengenai klasifikasi bidang pekerjaannya. Padahal klasifikasi bidang kerja lulusan perlu dilakukan guna mempersiapkan mahasiswa untuk bekerja sesuai dengan kompetensinya dengan melihat beberapa variabel atau atribut yang berpengaruh misalnya IPK, nilai matakuliah, program studi, jenis kelamin dan lain sebagainya. Dalam kasus ini peranan data mining sangat diperlukan untuk menggali informasi tersebut.
1.2 Rumusan Masalah
a. Banyak lulusan yang bekerja tidak sesuai bidang dan kemampuan akademisnya.
b. Klasifikasi bidang kerja berdasarkan nilai atau prestasi belajar mahasiswa guna memprediksi kesesuaiannya dengan bidang kerja masih rendah.
1.3 Tujuan
Adapun tujuan yang ingin dicapai dari penelitian ini adalah:
a. Diperolehnya hubungan antara kemampuan akademis dan bidang kerja yang sesuai.
b. Meningkatkan akurasi dan AUC klasifikasi bidang kerja berdasarkan nilai atau prestasi belajar mahasiswa dengan algoritma K-Nearest Neighbor.
1.4 Manfaat
Dari hasil penelitian ini diharapkan dapat memberikan informasi mengenai:
a. Manfaat bagi masyarakat khususnya STMIK AG adalah untuk memberikan gambaran pekerjaan yang sesuai bagi alumni.
b. Manfaat bagi iptek adalah memberikan sumbangan kepada bidang kajian data mining tentang kemampuan algorithma k-nearest neighbor dalam melakukan klasifikasi pekerjaaan
2. TINJAUAN PUSTAKA 2.1 Penelitian Terkait
Penelitian terkait yang pernah dilakukan dengan metode klasifikasi dengan algoritma k-nearest neighbor adalah sebagai berikut:
1. Penelitian yang dilakukan oleh Iin Ernawati, pada tahun 2008 [3], penelitian mengkaji perbandingan algoritma C4.5 dan K-Nearest Neighbor untuk Prediksi Status Keaktifan Studi Mahasiswa. Penelitian menghasilkan kesimpulan Variabel IPK adalah variabel yang menentukan potensi seorang mahasiswa aktif atau tidak aktif pada waktu yang akan datang. Dalam studi kasus pada FIK-UPNVJ, diperoleh hasil bahwa sebagian besar mahasiswa yang tidak aktif adalah mahasiswa dengan IPK di bawah 1,77. Hal ini menunjukkan bahwa kualitas mahasiswa yang diterima sebagian besar masih berkualitas rendah. Rata-rata keberhasilan algoritma C5.0 dan KNN dalam melakukan klasifikasi data mencapai akurasi di atas 90%. Hal ini menunjukkan bahwa keduanya memiliki performa yang handal dalam melakukan klasifikasi. Algoritma C5.0 tetap dianggap sebagai algoritma yang sangat membantu dalam melakukan klasifikasi data karena karakteristik data yang diklasifikasi dapat diperoleh dengan jelas baik dalam bentuk struktur pohon keputusan maupun aturan if-then, sehingga memudahkan pengguna dalam melakukan penggalian informasi terhadap data yang bersangkutan.
2. Penelitian yang dilakukan oleh Zhou Yong et all tahun 2009 [4], penelitian ini membahas klasifikasi teks menggunakan algoritma KNN. Algoritma klasifikasi teks KNN tradisional yang digunakan semua sampel pelatihan untuk klasifikasi, sehingga memiliki sejumlah besar sampel pelatihan dan tingkat tinggi kompleksitas perhitungan, dan juga tidak mencerminkan kepentingan yang berbeda dari sampel yang berbeda. Dalam kiasan untuk masalah di atas, sebuah KNN teks algoritma klasifikasi ditingkatkan berdasarkan pusat clustering diusulkan dalam tulisan ini. Pertama, set pelatihan yang diberikan dikompresi dan sampel dekat dengan perbatasan dihapus, sehingga efek multipeak dari sampel set pelatihan dihilangkan. Kedua, sampel set pelatihan masing-masing kategori ini terkelompok oleh algoritma k-means, dan semua pusat klaster yang diambil sebagai sampel pelatihan
baru. Ketiga, nilai bobot diperkenalkan, yang menunjukkan pentingnya setiap sampel pelatihan sesuai dengan jumlah sampel dalam cluster yang berisi ini center cluster. Akhirnya, sampel dimodifikasi digunakan untuk mencapai klasifikasi teks KNN. Hasil simulasi menunjukkan bahwa algoritma yang diusulkan dalam makalah ini tidak hanya dapat secara efektif mengurangi jumlah sebenarnya sampel pelatihan dan menurunkan kompleksitas perhitungan, tetapi juga meningkatkan akurasi algoritma klasifikasi teks KNN.
3. Penelitian yang dilakukan oleh Tsung-Hsien Chiang, Hung-Yi Lo dan Shou-De Lin, pada tahun 2012 [5], penelitian ini membahas Perengkingan berbasis pendekatan KNN untuk klasifikasi multi label. Dalam penelitian ini, Dalam tulisan ini, masalah ditujukan untuk merancang lazy learning pendekatan dengan menggunakan pendekatan multi label, dimana metode berbasis tetangga k-terdekat untuk klasifikasi multi-label bernama ML-kNN diusulkan. Percobaan pada multi data yang bioinformatic label menunjukkan bahwa algoritma yang diusulkan sangat kompetitif untuk pelajar label multi-lain yang sudah ada. Namun demikian, hasil eksperimen yang dilaporkan dalam makalah ini agak awal. Dengan demikian, melakukan eksperimen lebih lanjut tentang data multi-label lainnya set untuk sepenuhnya mengevaluasi efektivitas ML-kNN akan menjadi isu penting yang harus dieksplorasi dalam waktu dekat. Di sisi lain, mengadaptasi pendekatan pembelajaran mesin tradisional lainnya seperti jaringan saraf untuk menangani data multilabel akan menjadi masalah lain yang menarik untuk diselidiki.
4. Penelitian yang dilakukan oleh Nobertus Krisandi, Helmi dan Bayu Prihandono, tahun 2013 [6]. Berdasarkan hasil penelitian, data diklasifikasikan ke dalam 6 cluster. Berdasarkan hasil penelitian dapat dilihat kemiripan hasil produksi dari 50 kelompok tani yang ada di KUD. HIMADO. Nilai k yang di gunakan sebagai hasil pengamatan adalah k=7, karena untuk jarak38 N. minimum pada C1 memiliki persentase yang lebih besar yaitu 34%. Pada penelitian ini hasil produksi yang dominan adalah produksi dari kelompok tani kelapa sawit yang terletak pada C1. Dengan keanggotaan kelompok tani yaitu kelompok 1, 2, 33, 34, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49,50. Dari penelitian ini diketahui hubungan kemiripan hasil produksi antar kelompok tani, Dengan demikian dapat diperkirakan hasil produksi kelapa sawit dimasa mendatang, berkisar pada hubungan kesamaan hasil produksi antar kelompok-kelompok tani berdasarkan cluster-clusternya masing-masing. Dengan demikian dapat diselidiki akibat-akibat dari perbedaan yang mencolok dari hasil produksi (tonase) kelompok-kelompok tani yang ada pada Cluster tersebut dengan melakukan perbandingan hasil produksi kelompok-kelompok tani berdasarkan keanggotan clusternya masing-masing. Hal ini tentunya berguna bagi peningkatan hasil produksi (tonase) kelompok-kelompok tani dimasa yang akan datang.
2.2 Landasan Teori 2.2.1 Data Mining
Data besar yang dimiliki dan disimpan bertahun-tahun oleh sebuah institusi pendidikan, merupakan sumber pengetahuan dan informasi yang potensial bagi kemajuan instutisi tersebut jika mampu menggali dan mengekplornya. Data mining adalah suatu konsep yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang tersimpan di dalam database besar [8]. Data mining adalah bagian dari proses KDD ( Knowledge Discovery in Databases) yang terdiri dari beberapa tahapan seperti pemilihan data, pra pengolahan, transformasi, data mining, dan evaluasi hasil [9]. Dalam pengertian yang lain data mining juga didefinisikan sebagai proses untuk mendapatkan informasi yang berguna dari gudang basis data yang besar. Data mining juga dapat diartikan proses pengekstrakan informasi baru yang diambil dari bongkahan data besar yang yang membantu dalam pengambilan keputusan [10].
34 http://research.pps.dinus.ac.id (2.1)
berupa pengetahuan yang selama ini tidak diketahui secara manual. Kata mining berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar [11]. Data mining merupakan proses pencarian pola dan relasi-relasi yang tersembunyi dalam sejumlah data yang besar dengan tujuan untuk melakukan klasifikasi, estimasi, prediksi, association rule, clustering, deskripsi dan visualisasi [ 13] .
Secara sederhana data mining bisa dikatakan sebagai proses menyaring atau “menambang” pengetahuan dari sejumlah data yang besar. Proses dan teknik penyaringan data menentukan mutu pengetahuan dan informasi yang akan diperoleh. Istilah lain untuk data mining adalah Knowledge
Discovery in Databases (KDD).
KDD merupakan sebuah proses yang terdiri dari serangkaian proses interasi yang terurut, dan data
mining merupakan salah satu langkah dalam proses KDD [12]. Urutan langkah dalam KDD diilustrasikan seperti gambar 2.2, adalah sebagai berikut:
1. Pembersihan Data
Pembersihan terhadap data dilakukan untuk menghilangkan noise dan data yang tidak konsisten 2. Integrasi Data
Proses integrasi data dilakukan untuk menggabungkan data dari berbagai sumber. 3. Seleksi Data
Seleksi data dilakukan untuk mengambil data yang relevan, yang akan digunakan untuk proses analisis dalam data mining.
4. Transformasi Data
Proses ini dilakukan untuk mentransformasikan data ke dalam bentuk yang tepat untuk di-mine. 5. Data Mining
Data mining merupakan proses untuk mengaplikasikan suatu metode untuk mengekstrak pola-pola dalam data.
6. Evaluasi pola
Evaluasi pola diperlukan untuk mengidentifikasi beberapa pola yang menarik yang merepresentasikan pengetahuan.
7. Presentasi pengetahuan
Merepresentasikan pengetahuan yang telah digali kepada pengguna dengan memvisualisasikan pengetahuan tersebut.
2.2.2 K-Nearest Neigbor
Algoritma k-NN adalah suatu metode yang menggunakan algoritma supervised [14], [15], [16], [17], [18]. Perbedaan antara supervised learning dengan unsupervised learning adalah pada supervised learning bertujuan untuk menemukan pola baru dalam data dengan menghubungkan pola data yang sudah ada dengan data yang baru. Sedangkan pada unsupervised learning, data belum memiliki pola apapun, dan tujuan unsupervised learning untuk menemukan pola dalam sebuah data[14], [15], [16], [17]. Tujuan dari algoritma k-NN adalah untuk mengklasifikasi objek baru berdasarkan atribut dan training samples [15], [16].
K-Nearest Neighbor sering digunakan dalam klasifikasi dengan tujuan dari algoritma ini adalah untuk mengklasifikasi objek baru berdasarkan atribut dan training samples [15].Algoritma K-Nearest Neighbor (K-NN atau KNN) adalah sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut.Teknik ini sangat sederhana dan mudah diimplementasikan.Data pembelajaran diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data.Ruang ini dibagi menjadi bagian-bagian berdasarkan klasifikasi data pembelajaran.Sebuah titik pada ruang ini ditandai kelas c jika kelas c merupakan klasifikasi yang paling banyak ditemui pada k buah tetangga terdekat titk tersebut.Dekat atau jauhnya tetangga biasanya dihitung berdasarkan jarak Euclidean.
(2.2)
Untuk mendefinisikan jarak antara dua titik yaitu titik pada data training (x) dan titik pada data
testing (y) maka digunakan rumus Euclidean sebagai berikut.
Keterangan:
⇔ x= data training ⇔ y = data testing ⇔ n = jumlah atribut
⇔ f = fungsi similarityantara titik x dan titik y ⇔ wi = bobot yang diberikan pada atribut i 2.2.3 Naive Bayes
Bayesian filteratau Naive Bayes Classifiermerupakan metode terbaru yang digunakan untuk mengklasifikasikan sekumpulan dokumen. Algoritma ini memanfaatkan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes yaitumemprediksiprobabilitasdimasa depanberdasarkan pengalamandimasa sebelumnya.
Naive bayes classifier mengestimasi peluang kelas bersyarat dengan mengasumsikan bahwa atribut adalah independen secara bersyarat yang diberikan dengan label kelas
y
. Asumsi independen bersyarat dapat dinyatakan dalam bentuk berikut :(
)
∏
(
)
= = = = d i iY y X P y Y X P 1dengan tiap set atribut X =
{
X1,X2,K,Xd}
terdiri dari d atribut.2.2.4 Decision Tree
Pembelajaran pohon keputusan adalah metode yang umum digunakan dalam data mining [27]. Tujuannya adalah untuk menciptakan sebuah model yang memprediksi nilai variabel target berdasarkan beberapa variabel masukan. Contoh ditunjukkan pada gambar 2.5. Setiap simpul interior sesuai dengan salah satu variabel masukan, ada tepi untuk anak-anak untuk setiap nilai yang mungkin dari variabel masukan. Setiap daun merupakan nilai dari variabel target yang diberikan nilai-nilai variabel input diwakili oleh jalan dari akar ke daun.
Dalam data mining , pohon keputusan dapat digambarkan juga sebagai kombinasi teknik matematika dan komputasi untuk membantu deskripsi, kategorisasi dan generalisasi dari himpunan data.
Data datang dalam catatan dalam bentuk:
2.2.5 Neural Network
Neural Network adalah processor yang terdistribusi paralel, terbuat dari unit-unityang sederhana, dan memiliki kemampuan untuk menyimpan pengetahuan yangdiperoleh secara eksperimental dan siap pakai untuk berbagai tujuan [25].
36 http://research.pps.dinus.ac.id
Neural network ini meniru otak manusia dari sudut:
1) Pengetahuan diperoleh oleh network dari lingkungan, melalui suatu prosespembelajaran.
2) Kekuatan koneksi antar unit yang disebut synaptic weights, berfungsi untukmenyimpan pengetahuan yang telah diperoleh oleh network tersebut.
Pada tahun 1943, Mc. Culloch dan Pitts memperkenalkan model matematika yangmerupakan penyederhanaan dari struktur sel saraf yang sebenarnya.
2.2.6 Support Vector Machine
SupportVectorMachine(SVM)adalahsistempembelajaran yangpengklasifikasiannya menggunakan ruang hipotesis berupa fungsi-fungsi linear dalam sebuah ruang fitur (feature space) berdimensi tinggi, dilatih dengan algoritma pembelajaran yang didasarkan pada teori optimasi dengan mengimplementasikan
learning bias yang berasal dari teori pembelajaran statistik [ 2 6 ] .
Dalam konsep SVM berusaha menemukan fungsi pemisah (hyperplane) terbaik diantara fungsi yang tidak terbatas jumlahnya. Hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin hyperplane tersebut dan mencari titik maksimalnya. Adapun datayang berada padabidang pembatas disebut support vector. Secara matematika, konsep dasar SVM yaitu:
Keterangan: untuk kelas 1, dan untuk kelas 2, adalah dataset, adalah output dari data , adalah parameter yang dicari nilainya. Formulasi optimasi untuk SVM untuk kasus klasifikasi dua kelas dibedakan menjadi kelas linear dan non-linear.
2.2.7 Cross Validation
Cross-Validation adalah metode statistik untuk mengevaluasi dan membandingkan algoritma pembelajaran dengan membagi data menjadi dua segmen: satu digunakan untuk belajar atau melatih model dan yang lainnya digunakan untuk memvalidasi model. Dalam cross-validation, pelatihan dan validasi set harus menyeberang dalam putaran berturut-turut sehingga setiap titik data memiliki kesempatan yang divalidasi. Bentuk dasar cross-validation adalah k-fold cross-validation. Bentuk lain dari cross-validation adalah kasus khusus dari k-fold cross-validation atau melibatkan putaran berulang k-fold
cross-validation [24]. 2.2.8 Confusion Matrix
Confusion Matrix digunakan untuk evaluasi kinerja model klasifikasi yang berdasarkan pada kemampuan akurasi prediktif suatu model [12]. Akurasi prediktif merupakan parameter untuk mengukur ketepatan aturan klasifikasi yang dihasilkan dalam mengklasifikasikan test set berdasarkan atribut yang ada ke dalam kelasnya.
Akurasi dinyatakan dalam persentase, sehingga aturan dengan akurasi 100% artinya semua kasus yang tercakup oleh aturan klasifikasi, diklasifikasikan dengan benar ke dalam kelas yang diprediksinya. Untuk mendapatkan nilai akurasi prediktif diperlukan perhitungan jumlah kasus yang diprediksikan dengan benar dan jumlah kasus yang diprediksikan dengan salah. Perhitungan tersebut ditabulasikan ke dalam tabel yang disebut confusion matrix (Tabel 1).
Tabel 1.Confusion Matrix Actual Class Predicted Class Kelas=Ya Kelas=Tidak Kelas = Ya a (TP) b (FN) Kelas = Tidak c (FP) d (TN)
2.3 Klasifikasi Bidang Kerja Lulusan Menggunakan Algoritma K-Nearest Neighbor
3. METODE PENELITIAN 3.1 Pengumpulan Data
Tahap pengumpulan data merupakan tahap yang penting dari suatu penelitian. Data yang digunakan untuk penelitian harus bena-benar angkurat dan jelas sumbernya. Data yang digunakan dalam penelitian adalah data yang bersumber dari Biro Administrasi Akademik dan Kemahasiswaan (BAAK) STMIK Adhi Guna. Data yang digunakan adalah dataset alumni angkatan I-VIII yang berjumlah 150 record (tuple).
38 http://research.pps.dinus.ac.id 3.2 Pengolahan Data Awal
Pengolahan data awal perlu diperlukan untuk menyiapkan data yang benar-benar valid sebelum di proses. Data alumni yang telah diperoleh kemudian dilakukan kegaiatan pre-processing data yaitu Seleksi Atribut dan Cleansing data, seleksi atribut dilakukan dengan mengambil sebagian variabel pada seluruh atribut yang ada untuk dijadikan atribut penentu dalam pengambilan keputusan. Jumlah atribut keseluruhan dalam dataset alumni adalah 58 atribut, kemudian dilakukan seleksi atribut menjadi 11 atribut. Penentuan atribut ini didasari oleh pemikiran bahwa 11 atribut memiliki peranan untuk menentukan kopetensi lulusan. Data cleansing dilakukan untuk membersihkan atribut-atribut yang tidak digunakan dan menghapus data yang dobel serta data yang atributnya masih kosong.
3.3 Eksperimen dan Pengujian Model
Metode pengujian yang dilakukan mengacu pada pengukuran yang dilakukan oleh Lan Yu et all [23] yaitu dengan mengukur tingkat akurasi dari masing-masing model atau algoritma berdasarkan dataset alumni yang dibagi ke dalam beberapa variabel atau atribut penentu keputusan.
Dari hasil pengumpulan dan pengolahan data awal terdapat 150 data alumni, dengan jumlah alumni yang bekerja sesuai dengan keahliannya sebanyak 116 data dan yang tidak sesuai sebanyak 34 data. Eksperimen dan pengujian model menggunakan algoritma k-nearest neighbor dan k-fold cros-validation dengan nilai k=10 serta metode sampling menggunakan stratified sampling.
4. HASIL PENELITIAN DAN PEMBAHASAN 4.1 Pengolahan Data Awal
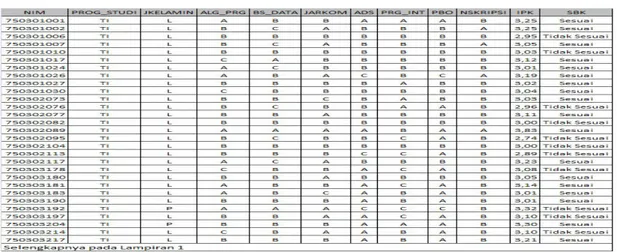
Hasil dari pengolahan data awal (pre-processing data) berupa atribut-atribut yang sudah dipilih untuk proses pengujian. Adapun fitur-fitur (atribut-atribut) dari dataset alumni seperti tabel 2.
Tabel 2 Fitur Dataset Alumni
Nama Atribut Keterangan
NIM Nomor Induk Mahasiswa
PRODI Program Studi
JKELAMIN Jenis Kelamin
ALG_PRG Nilai Matakuliah Algoritma Pemrograman
BS_DATA Nilai Matakuliah Basis Data
JARKOM Nilai Matakuliah Jaringan Komputer ADS Nilai Matakuliah Analisis dan Desain Sistem PRG_INT Nilai Matakuliah Pemrogram Internet
PBO Nilai Matakuliah Pemrograman Berorientasi Objek
NILAI_SKRIPSI Nilai Skripsi
IPK Indeks Prestasi Komulatif
SBK Status Bidang Kerja
Tabel 3. Dataset Alumni
4.2
Eksperimen dan Pengujian Model
Eksperimen dan pengujian model menggunakan algoritma k-nearest neighbor dan k-fold cros-validation dengan nilai k=10 serta metode sampling menggunakan stratified sampling.
Tahapan pengujian terhadap data baru dapat dilakukan dengan tahapan sebagai berikut : Atribut yang menjadi tujuan pada penelitian ini adalah Status Bidang Kerja (SBK).
Penentuan Bobot Atribut bukan tujuan. Bobot atribut bukan tujuan dapat didefinisikan dengan nilai berbeda, selengkapnya pada tabel 4. berikut.
Tabel 4. Definisi Bobot Atribut Atribut Bobot PROG_STUDI 0.5 JKELAMIN 0.5 ALG_PRG 0.75 BS_DATA 0.75 JARKOM 0.75 ADS 0.75 PRG_INT 0.75 PBO 0.75 NSKRIPSI 0.75 IPK 1
4.3
Evaluasi dan Validasi Hasil Penelitian
Tujuan dari penelitian ini adalah Membuat klasifikasi bidang kerja berdasarkan hasil prestasi belajar mahasiswa menggunakan algoritma K-Nearest Neighbor dan mengukur tingkat akurasi dan AUC algoritma K-Nearest Neighbor dalam melakukan klasifikasi bidang kerja berdasarkan nilai mata kuliah. Hasil analisis dengan algoritma K-Nearest Neighbor kemudian dikomparasi dengan algoritma klasifikasi lainnya yaitu Naïve Bayes, Decision Tree, Neural Network dan
Support Vector Machine. Metode pengujian dalam penelitian menggunakan 10-fold
40 http://research.pps.dinus.ac.id Setelah dilakukan pengujian dengan model k-nearest neighbor dengan k=1, k=3, k=5 dan k=7, maka perlu dilakukan rekapitulasi untuk melihat hasil pengujian terbaik berdasarkan nilai k tersebut, selengkapnya lihat tabel 5.
Tabel 5 Rekapitulasi hasil pengujian k-nearest neighbor Jenis Pengujian K=1 K=3 K=5 K=7 Accuracy 80% 83,33% 78,67% 80% Precision 0,8707 0,8640 0,8281 0,8258 Recall 0,8707 0,9310 0,9138 0,9397 AUC 0,941 0,900 0,872 0,889
Dari dari hasil rekapitulasi pengujian model k-nearest neighbor pada tabel 4.20 dapat ditarik kesimpulan hasil pengujian terbaik ada pada nilai k=3
Untuk memperkuat hasil pengujian klasifikasi bidang kerja lulusan dengan model K-Nearest
Neighbor, maka perlu dilakukan pengujian dengan model yang lain sebagai pembanding. Ada 4 model klasifikasi yang diuji sebagai pembanding yaitu Naive Bayes (NB), Decision Tree (DT), Neural Network (NN) dan Support Vector Machine (SVM). Adapun hasil pengujian dari 4 model klasifikasi tersebut adalah sebagai berikut.
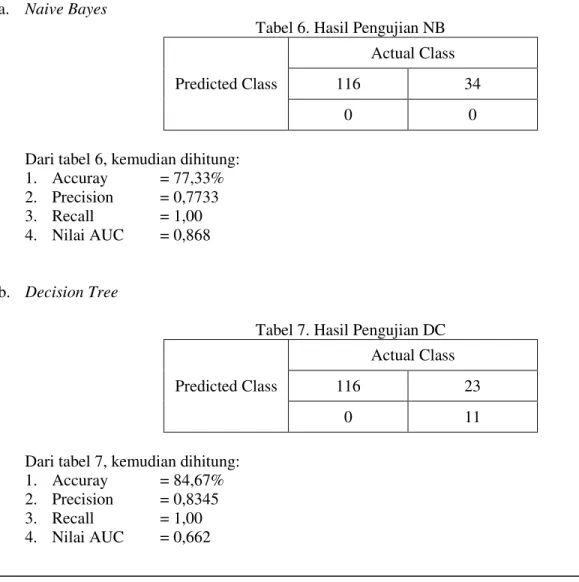
a. Naive Bayes
Tabel 6. Hasil Pengujian NB
Predicted Class
Actual Class
116 34
0 0
Dari tabel 6, kemudian dihitung: 1. Accuray = 77,33% 2. Precision = 0,7733 3. Recall = 1,00 4. Nilai AUC = 0,868
b. Decision Tree
Tabel 7. Hasil Pengujian DC
Predicted Class
Actual Class
116 23
0 11
Dari tabel 7, kemudian dihitung: 1. Accuray = 84,67% 2. Precision = 0,8345 3. Recall = 1,00 4. Nilai AUC = 0,662
c. Neural Network
Tabel 8. Hasil Pengujian NN
Predicted Class
Actual Class
76 8
40 26
Dari tabel 8, kemudian dihitung: 1. Accuray = 68% 2. Precision = 0,9048 3. Recall = 0,6552 4. Nilai AUC = 0,868 d. Support Vector Machine
Tabel 9. Hasil Pengujian SVM
Predicted Class
Actual Class
116 34
0 0
Dari tabel 9, kemudian dihitung: 1. Accuray = 77,33% 2. Precision = 0,7733 3. Recall = 1,00 4. Nilai AUC = 0,276
Berikut ini adalah hasil rekapitulasi pengujian model k-nearest neighbor, naive bayes, decision tree,
neural network dan support vector machine, selengkapnya pada tabel 10.
Tabel 10. Rekapitulasi Pengujian Model Jenis Pengujian KNN NB DC NN SVM Accuracy 83,33% 77,33% 84,67% 68% 77,33% Precision 0,8640 0,7733 0,8345 0,9048 0,7733 Recall 0,9310 1,00 1,00 0,6552 1,00 AUC 0,900 0,868 0,662 0,868 0,276
Dari data pada tabel 10, dapat ditarik kesimpulan bahwa algoritma K-Nearest Neighbor menghasilkan pengujian terbaik dengan accuracy 83,33% dan nilai Area Under the Curve (AUC) = 0.90.
42 http://research.pps.dinus.ac.id 5. KESIMPULAN DAN SARAN
5.1 Kesimpulan
Dari hasil analisis menggunakan confusion matrix dan ROC Curve dapat disimpulkan bahwa algoritma data mining k-nearest neighbor memiliki kinerja terbaik untuk klasifikasi bidang kerja lulusan dengan nilai accuracy yaitu 83,33% dan nilai Area Under The Curve (AUC) adalah 0,900.
5.2 Saran
Walapun pada hasil analisis Klasifikasi Bidang Kerja Lulusan menempatkan k-nearet neighbor sebagai algoritma terbaik, namun ada beberapa penambahan yang perlu dilakukan, antara lain:
a. Penambahan kuantitas dan kualitas dataset yang akan digunakan untuk klasifikasi data mining.
b. Menambahkan beberapa model klasifikasi yang baru misalnya linear regression, logistic regression untuk diuji coba untuk mengetahui tingkat accuracy dan AUC untuk klasifikasi bidang kerja lulusan. c. Melakukan modifikasi untuk KNN tradisional dengan Modified K-Nearest Neighbor (MKNN) untuk
meningkatkan nilai akurasi dari KNN
DAFTAR PUSTAKA
[1]. Peraturan Presiden Republik Indonesia Nomor : 8 Tahun 2012 tentang Kerangka Kualifikasi Nasional Indonesia
[2]. Florin Gorunescu, Data Mining: Concepts, Models and Techniques, Springer, 2011.
[3]. Ernawati, Iin. 2008. Prediksi Status Keaktifan Mahasiswa dengan Algoritma K-Nearest Neighbor. Bogor. Tesis.
[4]. Zhou Yong, Li Youwen and Xia Shixiong School of Computer Science & Technology, China University of Mining & Technology, Xuzhou, Jiangsu 221116, China, 2009
[5]. Tsung-Hsien Chiang, Hung-Yi Lo hungyi, Shou-De Lin Graduate Institute of Computer Science and Information Engineering National Taiwan University, 2012.
[6]. Nobertus Krisandi, Helmi, Bayu Prihandono, Buletin Ilmiah Math. Stat. dan Terapannya (Bimaster) Volume 02, No.1(2013), hal. 33-38. 33
[7]. http://irmar.staff.gunadarma.ac.id/download/files/11618/standarisasi+profesi.doc. Tanggal akses 10 Juni 2013.
[8]. Turban, R., Rainer, R. and Potter, R 2005. ‘Introduction to Information Technology’. USA: John Wiley&Sons, Inc.
[9]. Maimon, O. dan Last, M. 2000. Knowledge Discovery and Data Mining, The Info-Fuzzy Network
(IFN) Methodology. Dordrecht: Kluwer Academic.
[10]. Tan, P, et al. 2006. Introduction to Data Mining. Boston:Pearsion Education
[11]. Iko Pramudiono, (2003), Pengantar Data Mining, Ilmu Komputer, (Online), (http://ikc.depsos.go.id/umum/iko-datamining.php, diakses 20 April 2013).
[12]. Thomas E. 2004. Data Mining : Definition and Decision Tree Examples, e-book
[13]. Han J, Kamber M. 2001. Data Mining : Concepts and Techniques. Simon Fraser University, Morgan Kaufmann Publishers.
[14]. Wu X, Kumar V. The Top Ten Algorithms in Data Mining. New York:CRC Press;2009.
[15]. Larose, Daniel T. 2005. Discovering Knowledge in Data: An Introduction to Data Mining. John Willey & Sons, Inc
[16]. Han J and Kamber M. Data Mining:Concept and Techniques. New York:Morgan Kaufmann Publisher ;2006.
[18]. Nugroho A. k-Nearest Neighbor (k-NN). 2010 [Updated 2011 Mei 2; cited 2011 Okt 14]. Available from:Http://asnugroho.Wordpress.com/ 2007/01/26/k-nearest-neighbor-classifier/.
[19]. Santosa, B. 2007. Data Mining : Teknik Pemanfaatan Data untuk Keperluan Bisnis, Teori dan Aplikasi. Graha Ilmu Yogyakarta
[20]. Kusrini, & Luthfi, Emha. 2009. Algoritma Data Mining. Yogyakarta:Penerbit Andi [21]. Data Mining Tools Used Poll (May 2009). KDnuggets. Retrieved 4 July 2012
[22]. Data Mining / Analytic Tools Used Poll (May 2010). KDnuggets. Retrieved 4 July 2012
[23]. Lan Yu, Guoqing Chen, Andy Koronios, Shiwu Zhu, and Xunhua Guo (2008) Application and Comparison of Classification Techniques in Controlling Credit Risk. Recent Advances In Data Mining Of Enterprise Data: Algorithms And Applications: pp. 111-145.
[24]. http://www.cse.iitb.ac.in/~tarung/smt/papers_ppt/ency-cross-validation.pdf
[25]. S Haykin, Neural Networks: A Comprehensive Foundation.: Prentice Hall, 46 1999.
[26]. Christianini, Nello, dan Jhon S. Taylor. 2000. An Introduction to Support Vector Machines and
Other Kernel-based Learning Methods. Jurnal. Cambridge University Press. Australia.
[27]. Rokach, Lior; Maimon, O. (2008). Data mining with decision trees: theory and
applications . World Scientific Pub Co Inc. ISBN 978-9812771711.
[28]. Quinlan, JR, (1986). Induction of Decision Trees. Machine Learning 1: 81-106, Kluwer Academic Publishers
[29]. Barros RC, Cerri R., Jaskowiak PA, Carvalho, ACPLF, A bottom-up oblique decision tree induction algorithm . Proceedings of the 11th International Conference on Intelligent Systems Design and Applications (ISDA 2011).