Klasifikasi Kelompok Varietas Unggul Padi Menggunakan Modified
K-Nearest Neighbor
Aldion Cahya Imanda1), Nurul Hidayat2), M. Tanzil Furqon3)
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1)[email protected], 2)[email protected], 3)[email protected]
ABSTRAK
Varietas Unggul merupakan jenis varietas padi yang dihasilkan dari persilangan varietas unggul padi lokal. Tujuannya yaitu untuk menghasilkan varietas padi unggulan terbaik. Dalam perkembangannya, varietas unggul padi menjadi komponen penting dalam peningkatan produksi padi nasional. Setiap jenis varietas unggul padi memiliki ekosistem atau media tanam yang berbeda sehingga diperlukan pengklasifikasian varietas. Klasifikasi varietas direkayasa dengan mengadaptasi data mining. Pada penelitian ini digunakan metode Modified K-Nearest Neighbor (MKNN) untuk memprediksi kelas suatu data. Berdasarkan pengujian yang telah dilakukan didapatkan nilai rata-rata akurasi maksimum sebesar 79,96% dan nilai akurasi minimum sebesar 51,2%.
Kata Kunci: varietas unggul padi, prediksi, Modified K-Nearest Neighbor, data mining, akurasi. ABSTRACT
Supreme varieties is a kind of varieties that produced from the cross of local supreme varieties. The main idea is to produce the best rice varieties. Nowadays the supreme varieties becoming an national important production component which is each of varieties have their own ecosystem. That’s why the classification system is required. Classification engineered by adapting from data mining. The method that used is Modified K-Nearest Neighbor to predict a class from unclassified data. Based on the test that have been done the highest accuracy is 79,96% and the minimum accuracy is 51,2%.
Keywords: supreme varieties, prediction, Modified K-Nearest Neighbor, data mining, accuracy.
1. PENDAHULUAN
Padi merupakan tanaman pangan yang dikonsumsi secara umum oleh masyarakat Indonesia. Upaya peningkatan produksi pertanian umumnya padi masih dan akan tetap menjadi kebutuhan bangsa ini mengingat semakin meningkatnya kebutuhan pangan beras sejalan dengan meningkatnya penduduk dan kualitas hidup masyarakat.
Varietas unggul merupakan komponen pendukung yang berperan penting dalam peningkatan produksi padi nasional. Kontribusi nyata varietas unggul tercermin dari pencapaian swasembada beras pada tahun 1984 dan 2007. Dukungan terhadap swasembada beras tersebut tetap berlanjut hingga tahun 2016 ini dengan dilepasnya berbagai varietas unggul padi oleh Badan Penelitian dan Pengembangan Pertanian melalui Balai Besar Penelitian Tanaman Padi.
Kelompok VUB tersebut yaitu Inpa (Inbrida Padi) dan Hipa (Hibrida Padi). Khusus untuk Inbrida Padi, representasi ekosistem ditunjukkan dengan suku kata tambahan di ujung inpa, yaitu sebagai berikut: Inpari = Inbrida Padi Sawah Irigasi, Inpara = Inbrida. Padi Rawa (rawa pasang surut/lebak), dan Inpago = Inbrida Padi Gogo. (Balai Besar Penelitian Tanaman Padi, 2015).
Setiap jenis varietas unggul padi memiliki ekosistem atau media tanam yang berbeda. Petani perlu mengetahui tergolong dalam jenis apakah benih yang ditanam sehingga peningkatan produksi tetap terjaga. Oleh karena itu, diperlukan pengklasifikasian varietas padi. Klasifikasi benih padi direkayasa dengan mengadaptasi salah satu bidang ilmu dalam bidang informatika yaitu data mining. Data mining adalah proses menemukan hubungan atau keterkaitan yang memiliki arti ataupun
pola dengan cara memeriksa kumpulan data dalam jumlah besar dan tersimpan di dalam media penyimpanan dengan menggunakan teknik pengenalan pola, seperti teknik statistik dan matematika (Alfian, 2013).
Metode yang digunakan dalam penelitian ini yaitu metode Modified K-Nearest Neighbor (MKNN). Dalam penelitian yang dilakukan oleh Parvin, MKNN adalah modifikasi dari algoritma KNN yang diberi tambahan beberapa proses, yaitu validasi data latih dan weight voting. Perbandingan tingkat akurasi metode MKNN dengan KNN yang lama pada beberapa dataset didapatkan tingkat akurasi yang lebih baik dengan metode MKNN daripada KNN (Parvin, 2008).
Pada penelitian sebelumnya yang dilakukan oleh Yessivirna, metode KNN yang digunakan untuk mengklasifikasi suara berdasar gender memiliki persentase akurasi minimal sebesar 71,5% dan maksimal 76,2%. Metode yang sama digunakan pada penelitian oleh Arandika berjudul Implementasi Algoritma K-Nearest Neighbor untuk Klasifikasi Data Wine. Persentase akurasi yang didapat pada penelitian tersebut sebesar 66,48%. Sementara itu, metode berbeda digunakan oleh Hardono dalam penelitian berjudul Klasifikasi Kondisi Penderita Penyakit Hepatitis. Metode yang digunakan yaitu Support Vector Machine (SVM) dengan persentase akurasi sebesar 84,93% (Yessivirna, 2013).
Sedangkan metode MKNN digunakan pada penelitian oleh Kumalasari pada penentuan tingkat resiko penyakit lemak darah. Akurasi minimal yang didapat metode MKNN pada kasus tersebut sebesar 73,55% dan akurasi maksimal sebesar 85,81% (Kumalasari, 2014). Berdasarkan uraian tersebut maka dilakukanlah penelitian ini dengan judul Klasifikasi Kelompok Varietas Unggul Padi Menggunakan Modified K-Nearest Neighbor (MKNN), di mana parameter yang digunakan untuk pengklasifikasian ada delapan, yaitu umur tanaman, kerontokan, kerebahan, tekstur nasi, rata-rata hasil, potensi hasil, ketahanan terhadap hama, dan ketahanan terhadap penyakit.
2. DASAR TEORI 2.1 Kajian Pustaka
Penelitian pertama yang dikaji yaitu penelitian dari Noviana Ayu Kumalasari pada tahun 2014. Judul penelitiannya yaitu “Implementasi Algoritma Modified K-Nearest Neighbor (MKNN) untuk Menentukan Tingkat Resiko Penyakit Lemak Darah (Profil Lipid)”. Penelitian ini bertujuan untuk menentukan tingkat resiko penyakit lemak darah. Parameter yang digunakan ada empat, yaitu kolesterol total, kolesterol HDL, kolesterol LDL, dan trigliserida. Hasil dari sistem yaitu tingkat resiko penyakit berupa kelas yang terdiri dari tiga kelas, yaitu Normal, Tinggi, dan Waspada. Akurasi yang didapat dari metode MKNN pada penelitian ini yaitu 73,55% dan tertinggi 85,81% (Kumalasari, 2014).
Penelitian berikutnya yaitu penelitian dari Azhar Arandika pada tahun 2014. Penelitian tersebut berjudul “Implementasi Algoritma K-Nearest Neighbor (KNN) untuk Klasifikasi Data Wine”. Penelitian ini bertujuan untuk mengklasifikasikan minuman anggur agar dapat membantu peran pakar dalam proses pelabelan kelas. Jumlah data sebanyak 165 dan fitur yang digunakan ada 13, yaitu alkohol, malic acid, ash, alkalinity of ash, magnesium, total phenols, flavonoids, nonflavanoid phenols, proanthocyanins, color intensity, hue, OD280/OD315 of diluted wines, prolines. Hasil keluaran sistem nanti berupa kelas yang terdiri dari 3 kelas, yaitu Kelas 1, Kelas 2, dan Kelas 3. Hasil akurasi tertinggi yang diperoleh yaitu sebesar 66,48%.
Masih dengan metode yang sama yaitu KNN, penelitian yang dilakukan oleh Riska Yessivirna diberi judul “Klasifikasi Suara Berdasarkan Gender (Jenis Kelamin) dengan
Metode K-Nearest Neighbor (KNN)”.
Penelitian ini dibuat dengan tujuan agar komputer dapat membedakan suara laki-laki dan perempuan. Dengan kemampuan tersebut, komputer yang memiliki sistem keamanan berdasar suara akan mencapai tingkatan yang lebih tinggi yaitu dengan tidak hanya mengenali kata, tetapi juga ditambah dengan pencocokan karakteristik suara. Penelitian yang
memiliki akurasi tertinggi sebesar 76,2% ini hanya memerlukan satu input yaitu berkas suara berformat .wav. Sampel suara yang digunakan adalah suara orang dewasa yang melafalkan kata “Aku” secara normal.
Penelitian berkaitan dengan klasifikasi yang menggunakan metode selain KNN dan MKNN yaitu dilakukan oleh Jendi Hardono. Judul penelitian tersebut adalah “Klasifikasi Kondisi Penderita Penyakit Hepatitis Dengan Menggunakan Metode Support Vector Machine (SVM)”. Penelitian yang bertujuan untuk menggolongkan kondisi seseorang ini memiliki akurasi sebesar 84,93%. Parameter yang digunakan terdiri dari 19 fitur dengan 1 kelas, dan jumlah data sebanyak 155. Data fitur berupa age, sex, steroid, antiviral, fatigue, malaise, anorexia, liver, big, liver, firm, spleen, palpable, spiders, ascites, varices, bilirubin, alk, phosphate, SGOT, albumin, protime, hystologi, serta kelas berupa live atau die. 2.2 Data Mining
Data mining adalah proses menemukan hubungan atau keterkaitan yang memiliki arti ataupun pola dengan cara memeriksa kumpulan data dalam jumlah besar dan tersimpan di dalam media penyimpanan dengan menggunakan teknik pengenalan pola, seperti teknik statistik dan matematika (Ardhi, 2013). Saat suatu oraganisasi baik itu perusahaan atau suatu institusi mempunyai banyak data, tidak menutup kemungkinan banyak sekali informasi yang dapat diperoleh dari banyaknya data tersebut. Data mining akan menghasilkan suatu pengetahuan baru yang belum diketahui secara manual dari sekumpulan data.
Tujuan data mining yaitu untuk mengekstrak pengetahuan dan wawasan melalui analisis data dalam jumlah besar. Dengan memanfaatkan data mining, suatu perusahaan dapat memperoleh informasi penting dari gudang data (data warehouse). Sebagai contoh, yaitu memprediksi target pemasaran suatu produk, dengan melakukan klasifikasi terhadap tingkat penghasilan konsumen, kebiasaan pembeli, dan karakteristik lainnya. Data mining mengeksplorasi basis data untuk menemukan pola-pola yang belum pernah ditemui.
2.3 Klasifikasi
Klasifikasi adalah sebuah metode untuk mengelompokkan data. Klasifikasi juga dapat diartikan sebagai pengelompokan data atau objek baru ke dalam kelas atau kategori berdasarkan variabel-variabel tertentu (Septianto, 2015). Klasifikasi merupakan teknik data mining yang melihat atribut dari kelompok data yang sudah didefinisikan sebelumnya. Atribut-atribut tersebut digunakan sebagai variabel dalam penentuan kelas suatu objek baru. Tujuan klasifikasi yaitu untuk menentukan kelas dari suatu objek yang belum diketahui kelasnya dengan akurat.
Terdapat beberapa tahapan dalam klasifikasi yaitu pembangunan model, penerapan model, dan evaluasi. Pembangunan model dilakukan berdasarkan data latih yang telah memiliki atribut dan kelas data. Kemudian data-data tersebut diadaptasi untuk menentukan kelas dari data atau objek yang baru. Setelah menerapkan model, maka tahap berikutnya yaitu evaluasi. Tahap ini meliputi bagaimana tingkat akurasi yang didapat dari pembangunan dan penerapan model terhadap data baru. Jika tingkat akurasi sesuai dengan yang diinginkan, maka model yang telah dibangun tersebut dapat dilanjutkan untuk analisa data lebih lanjut (Kumalasari, 2014).
Proses klasifikasi terdiri dari dua fase, yaitu fase learning dan fase testing. Fase Learning yaitu fase di mana sebagian data yang kelas datanya telah diketahui dijadikan model untuk sistem yang akan dibangun. Sedangkan fase testing yaitu fase di mana model yang sudah terbentuk diuji dengan sebagian data lainnya untuk mengetahui akurasi dari model tersebut. Bila akurasinya mencukupi, maka model ini dapat digunakan untuk memprediksi kelas data yang belum diketahui.
2.4 Modified K-Nearest Neighbor
Hamid Parvin memperkenalkan algoritma pengembangan dari KNN yang dapat mengatasi rendahnya tingkat akurasi yang diperoleh dari metode KNN dalam papernya yang berjudul MKNN: Modified K-Nearest Neighbor (2008). Metode pengembangan tersebut dimulai dari melakukan pra-proses pada data latih,
kemudian menghitung validitas dari setiap sampel pada data latih. Kemudian klasifikasi pada objek baru dilakukan dengan melakukan weighted K-NN yang mana weight ini menggunakan validitas sebagai faktor perkalian (Parvin, 2008).
Dalam tahapannya, metode M-KNN ini menambahkan beberapa proses, yaitu validasi data latih dan weight voting. Tujuan utamanya yaitu menentukan referensi prediksi sistem terhadap kelas data yang akan diuji.
Sedikit memodifikasi metode KNN, jika KNN melakukan klasifikasi objek berdasarkan kelas mayoritas dari nilai k dan jarak terdekat objek, maka MKNN memvalidasi data latih terlebih dahulu setelah menghitung jarak, dan setelah itu melakukan weighting untuk setiap data uji sebelum mengklasifikasikan objek ke dalam kelas tertentu (Akbar, 2016). Validasi dalam hal ini digunakan untuk mencari jumlah titik yang memiliki kategori atau label yang sama pada semua data latih, kemudian hasilnya akan digunakan sebagai informasi tambahan mengenai data tersebut.
Karena adanya validasi pada data latih, metode MKNN dapat menghasilkan akurasi yang lebih tinggi dari KNN. Metode MKNN ini mengoptimalkan data latih yang memiliki validitas tinggi dan memiliki jarak terdekat dengan data uji, sehingga jika terdapat data yang tidak stabil, hal itu tidak banyak berpengaruh dalam pemberian label atau kelas pada objek. Secara garis besar terdapat dua proses utama dalam metode MKNN, yaitu validasi data latih dan weight voting (Parvin, 2010).
1. Validasi Data Latih
Pada metode M-KNN setiap data latih harus divalidasi. Validitas setiap data tergantung pada setiap tetangganya. Setelah dihitung validitas tiap data maka nilai validitas tersebut akan digunakan pada penghitungan weight voting. Validasi digunakan untuk menentukan referensi terbaik sebagai prediksi sistem terhadap kelas suatu data. Persamaan yang digunakan untuk menghitung validitas dari setiap data didefinisikan pada Persamaan (1). 𝑉𝑎𝑙𝑖𝑑𝑖𝑡𝑎𝑠(𝑥) 1 𝑘∑ 𝑆 (𝑙𝑎𝑏𝑒𝑙(𝑥), (𝑙𝑎𝑏𝑒𝑙(𝑁𝑖(𝑥)))) 𝑘 𝑖=1 (1) di mana:
k : jumlah titik terdekat label (x) : kelas data x
label Ni(x) : label kelas titik terdekat data x Fungsi S digunakan untuk menghitung kesamaan antara titik x dan data ke-I tetangga terdekat. Persamaan untuk mendefinisikan fungsi S terdapat dalam Persamaan (2).
𝑆(𝑎,𝑏)= {0 𝑎 ≠ 𝑏1 𝑎 = 𝑏 (2)
di mana:
a = kelas pada data latih
b = kelas selain a pada data latih Melalui Persamaan (2) ditunjukkan bahwa a dan b adalah label kelas kategori suatu data latih. S akan bernilai 1 jika label kategori a sama dengan label kategori b. S bernilai 0 jika label kategori a tidak sama dengan label kategori b.
2. Weight Voting
Weight Voting adalah salah satu variasi dari metode KNN yang menggunakan k tetangga terdekat dan hasil perhitungan dari jarak masing-masing data. Dalam persamaan (3).
𝑊(𝑖)=
1
𝑑+∝ (3)
di mana d adalah jarak Euclidean dan ∝ merupakan nilai regulator smoothing. Dalam penelitian ini, ∝ menggunakan ∝ = 0.5. Weight voting ini kemudian dijumlahkan setiap kelasnya dan kelas dengan jumlah terbesar yang akan dipilih menjadi sebuah keputusan.
Pada metode MKNN, masing-masing k tetangga terdekat dihitung menggunakan persamaan 2.2. Setelah itu, nilai validitas setiap data yang telah dihitung sebelumnya dikalikan dengan hasil weight voting berdasarkan jarak. Sehingga dalam metode MKNN didapatkan persamaan weight voting pada Persamaan (4).
𝑊(𝑖)= 𝑉𝑎𝑙𝑖𝑑𝑖𝑡𝑎𝑠(𝑖) × 1
𝑑+0.5 (4)
di mana:
W(i) : weighted voting ke-i Validitas(i) : nilai validitas
d : jarak Euclidean
Menurut penelitian Hamid Parvin yang berjudul A Modification on K-Nearest Neighbor Classifier, teknik weight voting ini berpengaruh terhadap data yang mempunyai nilai validitas lebih tinggi dan paling dekat dengan data. Selain itu, perkalian validitas dengan jarak data mengatasi dapat kelemahan antara jarak setiap data dengan weight yang memiliki banyak masalah dalam outlier. Oleh karena itu, metode M-KNN secara signifikan akan lebih kuat daripada metode KNN tradisional yang hanya didasarkan pada jarak (Parvin, 2010).
3. METODOLOGI PENELITIAN
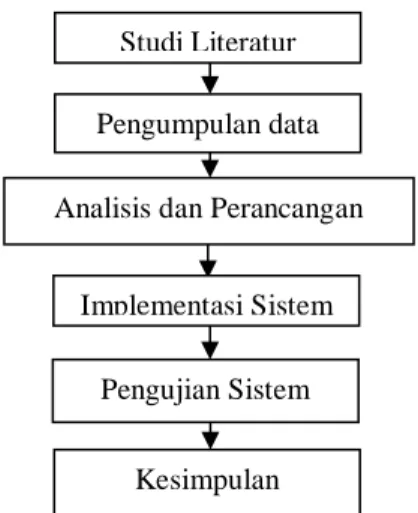
Metodologi pada penelitian ini dilakukan dalam beberapa tahap yang ditunjukkan pada Gambar 1.
4. PERANCANGAN
Pada penelitian ini perancangan dilakukan dalam lima tahap secara umum, yaitu terdiri dari: 1) analisis kebutuhan perangkat lunak, 2) perancangan sistem, 3) contoh perhitungan manual, 4) perancangan antarmuka, dan 5) perancangan pengujian.
4.1 Analisis Kebutuhan Perangkat Lunak Analisis kebutuhan perangkat lunak mencakup kegiatan yang diperlukan sistem, antara lain identifikasi pengguna, penjelasan kebutuhan masukan, proses, dan keluaran. 4.1.1 Identifikasi Pengguna
Pada tahap ini direpresentasikan user yang menggunakan sistem. Sistem diperuntukkan bagi semua user tanpa klasifikasi tingkatan. Semua user dapat melakukan proses klasifikasi kelompok varietas unggul padi.
4.1.2 Analisa Kebutuhan Masukan
Masukan yang dibutuhkan sistem adalah kriteria varietas yang akan diklasifikasi dan nilai k. Dari kedua masukan tersebut, sistem akan memproses perhitungan berdasar algoritma MKNN.
4.1.3 Analisa Kebutuhan Keluaran
Keluaran yang diharapkan dari sistem ini adalah hasil klasifikasi berdasarkan kriteria yang dimasukkan user. Hasil klasifikasi sistem kemudian dibandingkan dengan data asli. Perbandingan hasil dari sistem dengan data asli dihitung sehingga didapat tingkat akurasi. 4.2 Perancangan Sistem
Pada tahap ini akan digambarkan pembuatan sistem, yaitu dengan akuisisi pengetahuan, dan memodelkan sistem dengan diagram alir atau flowchart. Proses yang digambarkan pada perancangan ini yaitu proses sistem secara umum dan proses MKNN. 4.2.1 Akuisisi Pengetahuian
Akuisisi pengetahuan adalah akumulasi, transfer, dan transformasi keahlian dalam menyelesaikan masalah dari sumber pengetahuan ke dalam program komputer (Akbar, 2016). Dalam tahap ini knowledge engineer berusaha menyerap pengetahuan dari pakar untuk selanjutnya ditransfer ke dalam basis pengetahuan.
Berdasarkan pengetahuan dari pakar, didapatkan pembobotan dari beberapa kriteria Studi Literatur
Pengumpulan data Analisis dan Perancangan
Implementasi Sistem Pengujian Sistem
Kesimpulan
yang dibutuhkan sistem. Pembobotan tersebut ditunjukkan pada Tabel 1.
Tabel 1 - Tabel Bobot Kriteria
Kriteria Subkriteria Nilai
<=100 hari (cepat) 9 >100 & <125 (normal 7 >125 lama 5 Tahan, Toleran, Kuat 9 Sedang, Agak 7 Mudah, Rentan 4 Tahan, Toleran, Kuat 9 Sedang, Agak 7 Mudah, Rentan 4 Pulen 8 Agak pulen 7 Agak pera 6 Pera 5 >= 7 t/ha GKG 8 >= 6 t/ha & < 7 t/ha GKG 7 < 6 t/ha 4 >= 8 t/ha GKG 8 >= 7 t/ha GKG & <8 t/ha GKG 7 < 7 t/ha 6 Tahan 9 Agak tahan 7 Rentan 4 Tahan 9 Agak tahan 7 Rentan 4
5. PENGUJIAN DAN ANALISIS
Dalam pengujian ini terdapat 84 dataset yang dapat diolah menjadi data latih maupun data uji. Pengujian dilakukan untuk mengetahui hasil akurasi dari implementasi yang telah dilakukan.
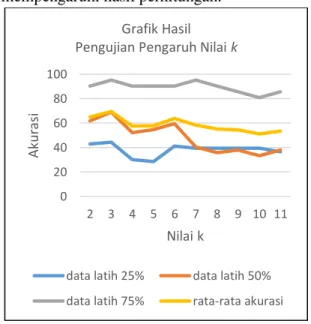
5.1 Pengujian Pengaruh Nilai k
Tabel 2 – Hasil Pengujian Pengaruh Nilai k
Nilai
k
Jumlah Data Latih Rata-rata Akurasi (%) 25% 50% 75% 2 42,8 61,9 90,4 65 3 44,4 69 95,2 69,5 4 30,1 52,3 90,4 57,6 5 28,5 54,7 90,4 57,8 6 41,2 59,5 90,4 63,7 7 39,6 40,4 95,2 58,4 8 39,6 35,7 90,4 55,2 9 39,6 38 85,7 54,4 10 39,6 33,3 80,9 51,2 11 36,5 38 85,7 53,4
Pada pengujian pengaruh nilai k ini, dihasilkan rata-rata nilai akurasi. Rata-rata akurasi tertinggi didapat pada waktu k = 3 yaitu sebesar 69,5%. Sementara rata-rata terendah didapat pada waktu k = 10 yaitu sebesar 51,2%. Hal ini disebabkan karena pada metode penghitungan jarak, ketika nilai k kecil maka jumlah ketetanggaan yang dihitung juga sedikit. Sebaliknya, jika nilai k besar maka jumlah ketetanggaan yang dihitung semakin banyak. Persebaran data juga sangat mempengaruhi hasil perhitungan.
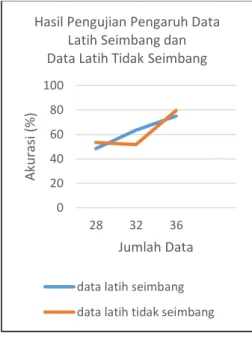
5.2 Pengujian Pengaruh Data Latih Seimbang dan Data Latih Tidak Seimbang terhadap Akurasi
Pada pengujian Pengaruh Data Latih Seimbang dan Data Latih Tidak Seimbang terhadap Akurasi ini, didapatkan rata-rata akurasi tertinggi pada kategori data tidak
0 20 40 60 80 100 2 3 4 5 6 7 8 9 10 11 Ak u ras i Nilai k Grafik Hasil Pengujian Pengaruh Nilai k
data latih 25% data latih 50%
data latih 75% rata-rata akurasi
Gambar 2 – Grafik Hasil Pengujian Pengaruh Nilai k
seimbang, yaitu sebesar 79,96%. Sedangkan rata-rata akurasi terendah didapatkan pada kategori data seimbang yaitu sebesar 48,32%. Hasil pengujian dimodelkan pada Tabel 3.
Jenis Data Jm l. D. La tih Jm l. D. Uji
Akurasi (%) Pengujian ke- Rat a Aku rasi (%) 1 2 3 4 5 28 12 50 50 41,6 50 50 48,3 2 32 12 50 75 66,6 66, 6 58, 3 63,3 36 12 58, 3 83, 3 83,3 75 75 74,9 8 28 12 50 50 41,6 75 50 53,3 2 32 12 58, 3 50 50 50 50 51,6 6 36 12 50 83, 3 91,6 83, 3 91, 6 79,9 6
Berdasarkan hasil pengujian data latih seimbang dan tidak seimbang, akurasi yang didapat secara umum meningkat pada kedua jenis data. Pada saat data latih seimbang, terjadi peningkatan nilai akurasi dari 48,32% dengan jumlah data latih sebanyak 28, menjadi 63,3% dengan penambahan jumlah data latih menjadi 32. Akurasi tertinggi didapat ketika jumlah data latih berjumlah 36, yaitu sebesar 74,98%.
Jika pada persebaran data latih seimbang nilai akurasi yang didapat cenderung mengalami peningkatan secara stabil, berbeda dengan pengujian yang dilakukan pada persebaran data latih tidak seimbang. Pada pengujian data latih tidak seimbang, terjadi penurunan nilai akurasi dari 53,32% dengan jumlah data latih 28, menjadi 51,66% dengan jumlah data latih 32. Namun pada saat data latih ditambah menjadi 36, nilai akurasi meningkat drastis yaitu sebesar 79,96%.
Gambar 3 – Hasil Pengujian Pengaruh Data Latih Seimbang dan Data Latih Tidak Seimbang 6. KESIMPULAN
Berdasarkan hasil perancangan, implementasi, dan pengujian yang dilakukan pada penelitian klasifikasi kelompok varietas unggul padi, terdapat beberapa kesimpulan, yaitu:
1. Metode Modified K-Nearest Neighbor dapat diimplementasikan untuk mengklasifikasi varietas unggul padi dengan menggunakan delapan parameter, yaitu umur, kerontokan, kerabahan, tekstur nasi, rata-rata hasil, potensi hasil, ketahanan terhadap hama, dan ketahanan terhadap penyakit.
2. Rata-rata akurasi tertinggi pada penelitian ini yaitu sebesar 79,96%, sedangkan rata-rata akurasi terendah sebesar 51,2%. Tingkat akurasi yang dihasilkan metode Modified K-Nearest Neighbor ini adalah dipengaruhi oleh beberapa faktor, yaitu: a. Penambahan atau pengurangan nilai
k.
b. Penambahan atau pengurangan jumlah data latih.
c. Pengelompokan data latih seimbang dan data latih tidak seimbang.
0 20 40 60 80 100 28 32 36 Ak u ras i (%) Jumlah Data Hasil Pengujian Pengaruh Data
Latih Seimbang dan Data Latih Tidak Seimbang
data latih seimbang data latih tidak seimbang Tabel 3 – Hasil Pengujian Pengaruh Data Latih
7. DAFTAR PUSTAKA
Alfian, Ardhi. 2013. Pencarian Asosiasi Topik dalam Ayat Al-Qur’an dengan Menerapkan Algoritma Multipass Direct Hashing and Prunning (M-DHP). Skripsi. Universitas Brawijaya, Malang.
Kumalasari, Noviana Ayu. 2014. Implementasi Algoritma Modified K-Nearest
Neighbor (MKNN) untuk
Menentukan Tingkat Resiko Penyakit Lemak Darah (Profil Lipid). Skripsi. Universitas Brawijaya, Malang.
Parvin, Hamid. 2008. MKNN: Modified K-Nearest Neighbor. Proceedings of the World Congress on Engineering and Computer Science. San Francisco, USA.
Yessivirna, Riska. 2013. Klasifikasi Suara
Berdasarkan Gender (Jenis
Kelamin) dengan Metode K-Nearest Neighbor (KNN). Skripsi. Program Teknologi Informasi dan Ilmu Komputer Universitas Brawijaya, Malang.
Septianto, Ryan Hendy. 2015. Diagnosa Penyakit Tanaman Kopi Arabika dengan Metode Modified K-Nearest Neighbor (MK-NN). Skripsi. Universitas Brawijaya, Malang. Akbar, Deby Faisol. 2016. Implementasi
Metode Modified K-Nearest
Neighbor (MK-NN) Pada Sistem Diagnosa Penyakit Paru-paru Anak. Skripsi. Universitas Brawijaya, Malang.