ANALISIS KELOMPOK HIRARKI UNTUK
PERBANDINGAN MULTI SAMPEL
TESIS
Oleh ELFITRA
127021012/MT
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
MEDAN
ANALISIS KELOMPOK HIRARKI UNTUK
PERBANDINGAN MULTI SAMPEL
T E S I S
Diajukan Sebagai Salah Satu Syarat
Untuk Memperoleh Gelar Magister Sains dalam Program Studi Magister Matematika pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara
Oleh: ELFITRA 127021014/MT
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
Judul Tesis : ANALISIS KELOMPOK HIRARKI UNTUK PERBANDINGAN MULTI SAMPEL
Nama Mahasiswa : Elfitra Nomor Pokok : 127021014
Program Studi : Magister Matematika
Menyetujui, Komisi Pembimbing
(Dr. Sutarman, M.Sc) (Prof. Dr. Herman Mawengkang)
Ketua Anggota
Ketua Program Studi Dekan
(Prof. Dr. Herman Mawengkang) (Dr. Sutarman, MSc)
Telah diuji pada
5 Juni 2014
PANITIA PENGUJI TESIS
Ketua : Dr. Sutarman, M.Sc
PERNYATAAN
ANALISIS KELOMPOK HIRARKI UNTUK PERBANDINGAN MULTI SAMPEL
T E S I S
Saya mengakui bahwa tesis ini adalah hasil karya sendiri, kecuali beberapa kuti-pan dan ringkasan yang masing-masing dituliskan sumbernya.
Medan, 5 Juni 2014
ABSTRAK
Biasanya dalam usaha perbandingan sampel dari banyak observasi, banyak me-tode yang digunakan. Tujuan dari beberapa meme-tode ini adalah untuk menguji hipotesis kesamaan pasangan, akan tetapi sulit menyaring sifat-sifat khusus dari data yang disajikan. Sebuah pendekatan alternatif diperkenalkan dengan tidak melibatkan tes hipotesis untuk menguji kesamaan kelompok melainkan melihat perbedaan mean kemudian mengkategorikan mean dan sampel berbeda jika bera-da pabera-da kelompok yang berbebera-da yakni metode analisis kelompok. Metode Analisis kelompok yang dikenalkan disini tidak menggunakan jarak seperti analisis kelom-pok pada umumnya namun menggunakan algoritma secara hirarki dan menggu-nakan model informasi kriteria Akaike’s Information Criteria(AIC) untuk meli-hat pasangan kelompok yang memiliki kesamaan. Secara umum dalam analisis kelompok diasumsi berdistribusi normal. Analisis kelompok juga dapat dikerjakan dengan distribusi power normal. Hasil analisis kelompok dengan power normal juga memiliki kesamaan gambaran seperti yang ditampilkan dalam grafik statistik.
ABSTRACT
Usually in proccces of a comparison sample of many observations, many methods are used. The purpose of some of these methods is to test the similarity hypo-thesis pair, but difficult to filter the specific properties of the data presented. An alternative procedures introduced by not involving tests of hypotheses to test the similarity of group mean differences rather see then categorize different sample mean and if it is in a different group. Analysis cluster method introduced here not using distance like ussually in analysis cluster but using algorithm hirarchi and criteria information models Akaike’s Information Criteria (AIC) to see pairwise who have the same group. In general, the analysis assumed normal distribution group. analysis cluster can done by the normal power distribution. The results of the analysis of the group with normal power also have the same picture as shown in statistical graphs.
KATA PENGANTAR
Setinggi puji dan sedalam syukur penulis serahkan kehadirat Allah SWT yang telah memberikan berkat dan rahmadNya sehingga penulis dapat menyele-saikan tesis yang berjudul ANALISIS KELOMPOK HIRARKI UNTUK MULTI SAMPEL. Tesis ini merupakan salah satu syarat untuk menyelesaikan studi pada Program Studi Magister Matematika Fakultas Matematika dan Ilmu Pengetahuan Alam (FMIPA) Universitas Sumatera Utara.
Pada kesempatan ini, penulis menyampaikan terimakasih sebesar-besarnya kepada :
Prof. Dr. dr. Syahril Pasaribu, DTM&H, M.Sc(CTM), Sp.A(K) selaku Rektor Universitas Sumatera Utara
Dr. Sutarman, M.Sc selaku Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam (FMIPA) Universitas Sumatera Utara sekaligus pembimbing utama yang telah banyak memberikan bantuan dalam penulisan tesis.
Prof. Dr. Herman Mawengkang selaku Ketua Program Studi Magister Matemati-ka FMIPA USU dan pembimbing kedua yang telah banyak memberiMatemati-kan bantuan dalam penulisan tesis ini.
Prof. Dr. Saib Suwilo, M.Sc selaku Sekretaris Program Studi Magister Matema-tika FMIPA USU dan selaku penguji yang telah banyak memberikan bimbingan dan arahan serta motivasi kepada penulis dalam penulisan tesis ini.
Dr. Marwan Ramli, M.Sc selaku penguji yang juga telah banyak memberikan bimbingan kepada penulis dalam penulisan tesis ini.
Seluruh Staf Pengajar pada Program Studi Magister Matematika FMIPA USU yang telah banyak memberikan ilmu pengetahuan selama masa perkuliahan.
Seluruh rekan-rekan mahasiswa program studi magister matematika FMIPA USU tahun 2012 ganjil (Teh wilma, bang sulaiman, kak hana, romi, isna, dilla, hari, adi, ari, silvi, wenny, tiur, liza, rini, ugi, bang mail,well, susanto, ryandi, kak juli dan sari) yang telah memberikan bantuan moril dan dorongan kepada penulis dalam penulisan tesis ini.
Tak lupa penulis mengucapkan terimakasih sebesar-besarnya dan penghar-gaan setinggi-tingginya kepada ibunda tercinta Mariah binti Ismail dan ayahan-da Alm H. Hafas Bakri yang mencurahkan kasih sayang ayahan-dan dukungan kepaayahan-da penulis, terlebih yang dengan setia mendampingi dan membantu penulis selama mengikuti perkuliahan hingga sampai penulisan tesis ini. Tak lupa yang spesial kepada suami tercinta Juliandi yang telah memberikan semangat dan motivasi selama penulisan tesis ini dan putri kecilku Maghfirah Balqis yang menjadi moti-vasi terbesar dalam penulisan ini. Terima kasih kepada sahabat-sahabatku serta rekan-rekan kerja unimed lainnya yang tidak dapat disebutkan satu-persatu. Se-moga Allah SWT memberikan balasan atas jasa-jasa mereka yang telah diberikan kepada penulis.
Penulis menyadari bahwa tesis ini masih jauh dari sempurna, untuk itu penulis mengharapkan kritik saran untuk penyempurnaan tesis ini. Semoga tesis ini dapat bermanfaat bagi pembaca dan pihak-pihak lain yang memerlukannya. Terimakasih.
Medan, 5 Juni 2014 Penulis,
RIWAYAT HIDUP
Elfitra dilahirkan di Peureulak, Aceh Timur pada tanggal 26 Juni 1982 dari pasangan Bapak Alm H. Hafas Bakri & Ibu Mariah. Penulis menamatkan pen-didikan Sekolah Dasar 060796 Medan tahun 1994, Sekolah Menengah Pertama (SMP) Swasta Darussalam Medan tahun 1997, Sekolah Menengah Atas (SMA) Swasta Tunas Kartika I-1 Medan tahun 2000. Pada tahun 2000 memasuki Per-guruan Tinggi Universitas Negeri Medan fakultas MIPA jurusan Pendidikan Ma-tematika pada Strata Satu (S-I) dan lulus tahun 2006.
DAFTAR ISI
Halaman
PERNYATAAN i
ABSTRAK ii
ABSTRACT iii
KATA PENGANTAR iv
RIWAYAT HIDUP vi
DAFTAR ISI vii
DAFTAR TABEL ix
DAFTAR GAMBAR x
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 4
1.3 Tujuan Penelitian 4
1.4 Manfaat Penelitian 4
1.5 Metode Penelitian 4
BAB 2 TINJAUAN PUSTAKA 6
BAB 3 LANDASAN TEORI 9
3.1 ANOVA dan MANOVA 9
3.2 Analisis Kelompok 10
3.2.2 Analisis kelompok non hirarki 13
BAB 4 ANALISIS KELOMPOK MULTI SAMPEL 14
4.1 Permasalahan Pengelompokan Multi Sampel 14
4.2 Menghitung Alternatif Kelompok 15
4.3 Model Kriteria Informasi 17
4.3.1 Akaike Information Criterion (AIC) 17
4.3.2 Consistent Akaike Information Criterion (CAIC) 18
4.3.3 Schwarz Bayesian Criterion (SBC) 18
4.3.4 Information Complexiry Information Criterion (ICOMP) 18
4.4 Analisis Kelompok Multi Sampel Berdistribusi Normal 19
4.5 Analisis Kelompok Multi Sampel Berdistribusi Power Normal 23
4.6 Contoh Permasalahan 24
BAB 5 KESIMPULAN DAN SARAN 35
5.1 Kesimpulan 35
5.2 Saran 36
DAFTAR TABEL
Nomor Judul Halaman
4.1 Contoh alternatif pengelompokan 17
4.2 Analisis kelompok multi sampel untuk K = 4 22
4.3 Pengamatan awal bayi jalan (bulan) 25
4.4 Hasil perhitungan ANOVA 26
4.5 Multiple comparisons hasil uji LSD 26
DAFTAR GAMBAR
Nomor Judul Halaman
3.1 Klasifikasi metode analisis kelompok 11
3.2 Contoh pohon alur analisis kelompok hirarki 13
4.1 Tahapan pembagian kelompok 22
4.2 Diagram boxplot pengamatan bayi berjalan 25
4.3 Dendogram analisis kelompok berdistribusi normal 34
ABSTRAK
Biasanya dalam usaha perbandingan sampel dari banyak observasi, banyak me-tode yang digunakan. Tujuan dari beberapa meme-tode ini adalah untuk menguji hipotesis kesamaan pasangan, akan tetapi sulit menyaring sifat-sifat khusus dari data yang disajikan. Sebuah pendekatan alternatif diperkenalkan dengan tidak melibatkan tes hipotesis untuk menguji kesamaan kelompok melainkan melihat perbedaan mean kemudian mengkategorikan mean dan sampel berbeda jika bera-da pabera-da kelompok yang berbebera-da yakni metode analisis kelompok. Metode Analisis kelompok yang dikenalkan disini tidak menggunakan jarak seperti analisis kelom-pok pada umumnya namun menggunakan algoritma secara hirarki dan menggu-nakan model informasi kriteria Akaike’s Information Criteria(AIC) untuk meli-hat pasangan kelompok yang memiliki kesamaan. Secara umum dalam analisis kelompok diasumsi berdistribusi normal. Analisis kelompok juga dapat dikerjakan dengan distribusi power normal. Hasil analisis kelompok dengan power normal juga memiliki kesamaan gambaran seperti yang ditampilkan dalam grafik statistik.
ABSTRACT
Usually in proccces of a comparison sample of many observations, many methods are used. The purpose of some of these methods is to test the similarity hypo-thesis pair, but difficult to filter the specific properties of the data presented. An alternative procedures introduced by not involving tests of hypotheses to test the similarity of group mean differences rather see then categorize different sample mean and if it is in a different group. Analysis cluster method introduced here not using distance like ussually in analysis cluster but using algorithm hirarchi and criteria information models Akaike’s Information Criteria (AIC) to see pairwise who have the same group. In general, the analysis assumed normal distribution group. analysis cluster can done by the normal power distribution. The results of the analysis of the group with normal power also have the same picture as shown in statistical graphs.
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Manajemen informasi sangat penting dalam hal pengambilan keputusan baik dalam skala kecil ataupun besar. Keberagaman informasi sering dijumpai pada institusi, perusahaan besar, organisasi, medis dan bidang keilmuan lainnya. In-formasi tentang sesuatu yang diperoleh disebut juga data. Data yang diperoleh dalam suatu penelitian dapat menampilkan banyak karakter atau sifat. Menu-rut Trebuna dan Halcinova (2013), variasi data yang luas dapat menimbulkan masalah dalam pengambilan keputusan.
Data yang dikumpulkan berapapun banyaknya, bukan tujuan dari suatu penelitian. Akan tetapi merupakan sarana untuk memudahkan penafsiran dan memahami maknanya. Untuk itu dibutuhkan suatu teknik analisis data sebagai upaya mengolah data sehingga karakteristik atau sifat-sifat data tersebut dapat dengan mudah dipahami dan bermanfaat untuk menjawab masalah-masalah yang berkaitan denngan penelitian.
Ada beberapa teknik statistik yang dapat digunakan untuk menganalisis data. Tujuannya untuk mendapatkan informasi yang relevan. Teknik statistika yang paling sering digunakan adalah Analysis of variance (ANOVA) untuk da-ta univariat dan ada-tau Multivariat Analysis of variance (MANOVA) untuk data multivariat. Atau lebih dikenal uji statistik t atau uji statistik F.
Namun, menurut Bozdogan (1986) usaha analisis data dengan ANOVA atau-pun MANOVA tidak informatif. Penolakan hipotesis tidak mengindikasikan bah-wa kelompok sampel berbeda seperti yang seharusnya ditunjukkan. Almuitari (2011) juga mengemukakan salah satu aspek yang menjadi kontra dalam pene-litian adalah tidak adanya tolak ukur pemilihan penggunaan tingkat signifikan
2
Berangkat dari beberapa alasan diatas, beberapa peneliti mencoba melaku-kan analisis data dengan menggunamelaku-kan metode perbandingan tanpa menggunamelaku-kan hipotesis. Sebagai contoh penelitian yang dilakukan oleh Bozdogan (1986) yang mengenalkan alternatif pendekatan baru untuk melihat perbedaan sampel dengan melakukan perbandingan beberapa sampel yang dikenal dengan analisis kelom-pok sampel-sampel. Tukey dalam Shimokawa dan Goto (2011) juga merekomen-dasikan penjelasan data sampel-sampel dengan menggunakan analisis kelompok.
Metode analisis kelompok merupakan salah satu metode statistika multivari-at. Trebuna dan Halcinova (2013) menjelaskan banyak situasi praktis memerlukan penyajian data multivariat dari beberapa sampel tersturktur untuk inferensi kom-peratif dan pengelompokkan sampel hetrogen ke sampel homogen. Selanjutnya Ferreira dan Hitchcok (2003) menjelaskan pengelompokkan data berdasarkan ho-mogenitas sangat penting karena dapat mengungkapkan informasi data. Secara umum metode analisis kelompok dikerjakan dengan melakukan pendekatan jarak antar kelompok. Persamaan karakteristik dalam pengelompokan mengakibatkan sulit untuk melihat yang terbaik dari kelompok yang telah terbentuk. Penge-lompokkan tidak hanya berdasarkan ukuran homogenitas dan usaha membentuk kelompok dengan menggunakan algoritma. Algoritma pengelompokan harus da-pat memaksimalkan perbedaan relatif kelompok terhadap variasi dalam kelompok. Dua metode umum dalam algoritma pengelompokan adalah metode hirarki dan non hirarki.
3
Menurut Bozdogan (1986) model seleksi kriteria dikenalkan oleh Akaike’s pada tahun 1973 untuk mengidentifikasi data secara optimal dan hati-hati dengan perhitungan yang lebih kompleks. Pendekatan ini berdasarkan pada Kullback Liebler Information (KLIC) dan nilai rasio maksimum likelihood data statistik. Model seleksi kriteria yang pertama dikenal dengan Akaike’s Information Criterion (AIC).
Pada banyak kasus analisis kelompok untuk perbandingan multi sampel, di-asumsikan berdistribusi normal. Namun pada kenyataannya menurut Shimokawa dan Goto (2011) sulit memenuhi asumsi ini. Pada tahun 1977, Worsley dalam penelitiannya memperkenalkan versi non parametrik Scott dan Knott’s dengan menggunakan uji Kruskal-Wallis untuk mengukur homogenitas. Dengan menggu-nakan versi non parametrik, tidak perlu memenuhi distribusi normal dan memu-ngkinkan untuk memperoleh informasi yang merupakan bagian dalam data (seper-ti posisi, penyebaran dan bentuk)
Selain dari pendekatan diatas, Shimokawa dan Goto (2011) dalam melaku-kan analisis kelompok untuk multi sampel menggunamelaku-kan distribusi power normal yang didefenisikan sebagai distribusi spesifik sebelum transformasi power nor-mal. Dijelaskan Shimokawa dan Goto (2011) dan Ishogawa (2012) sebuah power-transformasi positif variabelX didefinisikan sebagai berikut:
xλ =
xλ−1
λ , λ 6= 0, logx, λ = 0.
Dari hasil penelitian, diasumsikan dalam analisis data menggunakan dis-tribusi power normal, dapat menggambarkan situasi keadaan data yang tergam-barkan dalam grafik statistik.
4
1.2 Rumusan Masalah
Dalam usaha mendapatkan sebuah kesimpulan dari sekumpulan informasi, dibutuhkan suatu teknik analisis data untuk mengolah data agar data mudah dipahami untuk menjawab masalah dalam penelitian. Teknik analisis data yang umum digunakan untuk melakukan perbandingan sampel adalah ANOVA atau MANOVA. Akan tetapi beberapa peneliti berpendapat dengan teknik diatas tidak informatif. Karenanya dikenalkan suatu metode perbandingan sampel tanpa harus melakukan hipotesis, yakni dengan pengelompokkan sampel berdasarkan homogenitas atau lebih dikenal metode analisis kelompok. Algoritma yang digu-nakan dalam pengelompokkan adalah secara hirarki.
1.3 Tujuan Penelitian
Penelitian ini bertujuan untuk melakukan perbandingan multi sampel de-ngan teknik analisis kelompok secara hirarki untuk dapat menemukan pasade-ngan kelompok terbaik berdasarkan kesamaan karakteristik dengan menggunkan model kriteria informasi AIC.
1.4 Manfaat Penelitian
Penelitian ini bermanfaat untuk memperkaya literatur tentang metode ana-lisis kelompok secara hirarki dan memberikan suatu gambaran dalam anaana-lisis data atau pengambilan kesimpulan dengan menggunakan metode analisis kelompok se-cara hirarki untuk perbandingan multi sampel.
1.5 Metode Penelitian
Metode penelitian ini bersifat studi literatur dan kepustakaan dengan me-ngumpulkan informasi terkait dari beberapa jurnal. Adapun langkah yang di-lakukan adalah sebagai berikut :
5
2. Menjelaskan analisis kelompok beserta pembagiannya.
3. Menjelaskan analisis kelompok dengan menggunakan model kriteria infor-masi.
4. Melakukan pengkajian contoh analisis kelompok untuk perbandingan multi sampel.
5. Menarik kesimpulan.
BAB 2
TINJAUAN PUSTAKA
Analisis data mempunyai peranan untuk memahami berbagai macam je-nis data. Dalam Moleong (2000) dijelaskan pendapat Bogdan dan Taylor pada tahunn 1975 bahwa analisa data adalah proses yang merinci usaha formal untuk menemukan tema dan merumuskan hipotesis (ide) seperti yang disarankan oleh data dan sebagai usaha untuk memberikan bantuan pada tema dan hipotesis itu.
Analisa data adalah proses mengorganisasikan dan mengurutkan data ke dalam pola, kategori, dan satuan uraian dasar sehingga dapat ditemukan tema dan dapat dirumuskan hipotesis kerja seperti yang disarankan oleh data. Analisis data diartikan sebagai upaya mengolah data menjadi informasi, sehingga karakte-ristik atau sifat-sifat data tersebut dapat dengan mudah dipahami dan bermanfaat untuk menjawab masalah-masalah yang berkaitan dengan kegiatan penelitian.
Salah satu cara dalam analisis data bentuk multivariat adalah analisis kelom-pok. Secara umum analisis kelompok adalah usaha membandingkan sampel de-ngan menggunakan jarak. Namun, analisis kelompok juga dapat dilakukan dede-ngan metode lain seperti yang pernah dilakukan Bozdogan (1986). Tahapan awal dalam analisis kelompok ini adalah penentuan algoritma pengelompokan yang akan digu-nakan. Pentingnya penentuan algoritma dalam pengelompokan data dikemukakan oleh Xu dan Wunsch (2005) yang melakukan survey algoritma pengelompokan untuk himpunan data dalam bidang statistik, ilmu komputer,travelling salesman problem, bioinformatik dan suatu bidang usaha baru yang menarik.
Algoritma pengelompokan secara umum adalah pengelompokan secara hi-rarki dan pengelompokan secara non hihi-rarki. Dalam tulisan Shimokawa dan Goto (2011) mengatakan bahwa Cox dan Spotvol tahun 1982 memperkenalkan analisis pengelompokan secara non hirarki untuk perbandingan multi sampel dimana nilai
7
Analisis kelompok multi sampel merupakan metode alternatif untuk per-bandingan sampel. Permasalahan dari berbagai proses perper-bandingan bisa dilihat dari pengelompokan rata-rata grup, sampel atau perlakuan. Analisis kelompok multi sampel pertama kali dikenalkan oleh Bozdogan (1986, 2000). Bozdogan menggunakan model seleksi kriteria untuk mengenalkan metode analisis kelompok multi sampel sebagai alternatif perbandingan sampel. Dalam analisis kelompok multi sampel, sekumpulan grup, sampel atau perlakuan dikelompokkan dalam himpunan yang memiliki kesamaan. Permasalahan ini lebih rumit dibandingkan pengelompokkan individu atau objek kedalam satu kasus sampel.
Metode analisis kelompok multi sampel merupakan suatu pendekatan baru dan berbeda. Pada pendekatan ini model seleksi kriteria digunakan untuk memi-lih alternatif kelompok terbaik. Tahapan dalam analisis kelompok multi sampel adalah mengelompokkan semua alternatif kelompok yang mungkin menggunakan algoritma kombinatorial. Kemudian informasi kriteria digunakan untuk meng-golongkan perbedaan tanpa membuat pilihan sendiri selama alternatif kelompok dibentuk. Alternatif kelompok dengan nilai informasi kriteria terkecil dipilih.
Almuitari (2011) dalam penelitiannya mengenalkan algoritma untuk analisis kelompok multi sampel. Didalam penelitian dipaparkan beberapa informasi kri-teria dan formula untuk perbandingan sampel. Formula yang digunakan dikenal dengan Clique Partioning Problem Formulation (CPP) dengan algoritma Branch and Bound
8
BAB 3
LANDASAN TEORI
Analisis data adalah proses penyederhanaan data agar lebih mudah dibaca atau di interprestasi. Berdasarkan variabel sampel, analisis data dapat dibedakan atas analisis data univariat, bivariat dan multivariat. Ada beberapa cara da-lam melihat perbedaan sampel yang terdapat didada-lam data, diantaranya sebagai berikut:
3.1 ANOVA dan MANOVA
ANOVA merupakan teknik analisis data univariat. ANOVA digunakan untuk menguji perbedaan mean dua sampel atau lebih. Prosedur analisis vari-ans (ANOVA) menggunakan variabel numerik tunggal yang diukur dari sejumlah sampel untuk menguji hipotesis nol dari populasi yang (diperkirakan) memiliki rata-rata hitung (mean) sama. Variabel dimaksud harus berupa variabel kuan-titatif. Variabel ini terkadang dinamakan sebagai variabel terikat (dependent variable).
Sedangkan MANOVA merupakan teknik analisis data tentang perbedaan pe-ngaruh beberapa variabel independen dalam skala nominal terhadap sekelompok variabel dependen dalam skala rasio. Skala nominal adalah tingkat mengkate-gorikan obyek yang diteliti dengan angka yang diberikan pada obyek mempunyai arti sebagai label saja, sedangkan skala rasio adalah ukuran nilai absolute pada objek yang akan diteliti dan mempunyai nilai nol (0).
10
ANOVA
Y1 =X1 +X2+X3+...+Xn
MANOVA
Y1+Y2+Y3+...+Yn =X1+X2+X3+...+Xn
Dan perbedaannya juga terletak pada hipotesis nol dan hipotesis alternat-ifnya. Dengan menggunakan teknik ANOVA atau MANOVA, ada atau tidaknya hubungan antara sampel dilihat dari uji hipotesis mean sampel data yang di ana-lisis.
3.2 Analisis Kelompok
Analisis kelompok mengarah pada metode statistik multivariat. Trebuna dan Halcinova (2013) menjelaskan analisis kelompok didefenisikan sebagai teknik logika umum, prosedur, yang kemudian diikuti pengelompokan variabel objek ke dalam grup kelompok yang berdasarkan pada persamaan atau perbedaan. Ana-lisis kelompok di desain untuk menditeksi grup atau kelompok tersembunyi pada sebuah himpunan yang di sajikan dengan data kuantitaif, data struktural atau
linguisticyang mana anggota setiap kelompok memiliki kesamaan satu sama lain (berkenaan dengan data yang diberi) dan kelompok yang terbaik yang dipisahkan.
Analisis kelompok mengklasifikasikan objek sehingga setiap objek yang pa-ling dekat kesamaannya akan berada dalam satu kelompok. Kelompok yang ter-bentuk memiliki homogenitas internal yang tingggi dan heterogenitas eksternal yang tinggi. Dilihat dari apa yang dikelompokkan, analisis kelompok dibagi atas pengelompokan observasi dan pengelompokan variabel.
Pengelompokan di sajikan dalam bentuk matrik x tipe n x p dimana n
menyatakan nomor objek dan p menyatakan nomor variabel.
11
Pada umumnya ketika objek dikelompokkan, perbedaan antara dua kelom-pok objek ditandai dengan jarak. Beberapa macam jarak yang biasa dipakai didalam analisis kelompok antara lain jarak euclidian, jarak manhattan, jarak pearson, korelasi dan jarak mutlak korelasi.
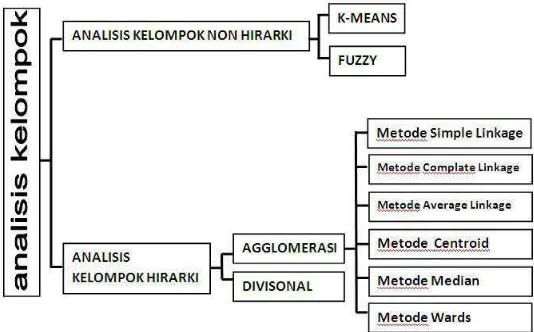
Metode dalam analisis kelompok diklasifikasikan dua bagian yakni metode hirarki dan non hirarki seperti yang dijelaskan pada gambar berikut:
Gambar 3.1 Klasifikasi metode analisis kelompok
3.2.1 Analisis kelompok hirarki
12
1. Metode simple linkage
Metode simple linkage bisa di defenisikan jika D adalah suatu koefisien perbedaan acak, C1, C2 adalah dua kelompok berbeda, Ai bagian dariC1 danAj bagian dariC2, maka untuk menentukan jarak metode simple linkage adalah:
dSL(C1, C2) =mini,j{d(Ai, Aj)}
2. Metode complete linkage
Metode complete linkage hampir sama dengan metode simple linkage, hanya untuk menetukan jarak metode complete linkage adalah:
dCL(C1, C2) =maxi,j{d(Ai, Aj)}
3. Metode average linkage
Jarak antara kelompok pada metode average linkage adalah:
dAL(C1, C2) =
penentuan jarak pada metode ini ketika nomor objekn1dann2 berada pada
C1danC2
4. Metode centroid
Jarak antara kelompok di tentukan dengan korelasi Lance William
13
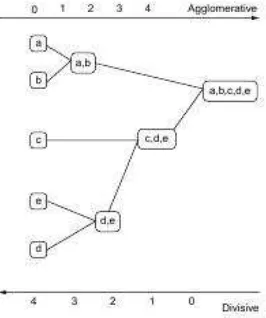
Alat yang membantu untuk memperjelas proses hirarki adalah diagram po-hon yang dikenal dengan dendogram. Berikut contoh alur metode analisis kelom-pok hirarki diambil dari everittet al., (2011).
Gambar 3.2 Contoh pohon alur analisis kelompok hirarki
3.2.2 Analisis kelompok non hirarki
BAB 4
ANALISIS KELOMPOK MULTI SAMPEL
Menurut Almuitari (2011) analisis kelompok multi sampel di perkenalkan pertama kali oleh Bozdogan sebagai salah satu alternatif dalam prosedur perban-dingan sampel untuk analisis data yang multi sampel. Analisis kelompok yang diperkenalkan tidak seperti analisis kelompok pada umumnya. Usaha perbandi-ngan multi sampel menggunakan algoritma membentuk alternatif kelompok yang mungkin terbentuk dan memasukkan nilai model kriteria informasi sebagai dasar acuan pemilihan pasangan kelompok yang memiliki homogenitas.
4.1 Permasalahan Pengelompokan Multi Sampel
Permasalahan dalam analisis kelompok untuk multi sampel muncul keti-ka didapat sekumpulan data, sampel atau tindaketi-kan dan lain-lain, apaketi-kah itu secara alami atau tidak, dan tujuannya adalah untuk mengelompkkan menjadi grup/kelompok yang memiliki kesamaan. Masalahnya disini adalah untuk mem-buat kelompok atau sampel bukannya individual atau objek seperti pada kasus single sample.
Dijelaskan dalam Bozdogan (1986), setiap objek ditandai dengan ukuran p
yang secara bersamaan berada dalam K kelompok.
X(n×p) =
MisalX adalah matriks dari K kelompok, dimana Xg(ng ×p) mewakilkan pengamatan dari grup ke-g, g = 1,2, ..., K dan n = PK
15
4.2 Menghitung Alternatif Kelompok
Jika menggunakan teknik enumerasi komplit, kemudian pengelompokan dari
K data kelompok kedalam k kelompok yang tak kosong, maka teorema adalah sebagai berikut (Bozdogan,1986):
Teorema 4.1. Banyaknya jalan untuk pengelompokkan K data sampel kedalam k
kelompok dimanak ≤K, dan tak satupun dari kelompokk yang kosong, diberikan sebagai berikut:
k
X
g=0
(−1)ghkgi(k−g)K (4.2)
dimana setiap kelompok k tidak saling relevan.
Bukti. Anggap kelompok sampel-k berbeda. Pengelompokkan K data sampel ke dalam himpunan bagian k, tak satu pun yang kosong dan isi dari himpunan bagian k tidak relevan. Dari fakta dan teorema 4.1, maka dapat didapat total jumlah pengelompokan K data sampel ke dalam kkelompok himpunan bagian di berikan sebagai berikut (Bozdogan,1986):
Lebih dikenal dengan Stirling Number of the Second Time yang akan mem-berikan jumlah alternatif pengelompokkan. Jika jumlah alternatif k tidak dike-tahui, maka jumlah alternatif pengelompokan diberikan sebagai berikut (Bozdo-gan,1986):
K
X
k=1
16
Dengan catatan k ≤ K. S(K, k) bisa dijelaskan dengan rumus sebagai berikut (Bozdogan,1986):
S(K, k) =kS(K−1, k) +S(K−1, k−1) (4.5)
dengan
S(1,1) = 1, S(1, k) = 0, k 6= 1
S(K,2) = 2K−1
−1
Contoh: Misal data suatu sampelK = 3. Banyaknya alternatif pengelompokkan
k adalah 1, 2 dan 3 kelompok yakni,
3 = {3} = {2}+{1} = {1}+{1}+{1}
17
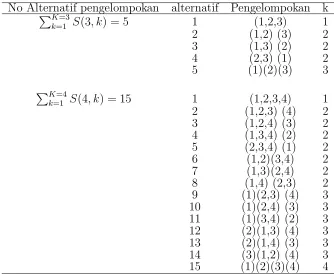
Tabel 4.1 Contoh alternatif pengelompokan
No Alternatif pengelompokan alternatif Pengelompokan k PK=3
Dalam Almuitari (2011) disampaikan bahwa kriteria informasi pertama kali diperkenakan oleh Akaike pada tahun 1973. Ini mempelopori penggabungan teori
kemungkinan dan teori informasi untuk menghasilkan pendekatan secara sig-nifikan dan langsung untuk model seleksi statistik. Almuitari (2011) juga menye-butkan, ada banyak kriteria informasi telah diperkenalkan diantaranya Akaike Information Criterion (AIC), Consistent Akaike Information Criterion (CAIC), Schwarz Bayesian Criterion (SBC), Information Complexiry Information Crite-rion (ICOMP).
4.3.1 Akaike Information Criterion (AIC)
Misal {Mk : k ∈ K} adalah sekumpulan himpunan model yang akan digunakan dimana k= 1,2, ...., K, maka:
18
dimana nilai terkecil adalah model terpilih dari himpunan model yang disebut AIC. L[ˆθ(k)] adalah kemungkinan fungsi dari observasi, ˆθ(k) adalah nilai perki-raan maksimum dari parameter vektor ˆθ pada model Mk, mk adalah parameter independen.
4.3.2 Consistent Akaike Information Criterion (CAIC)
ModelConsistent Akaike Information Criterion(CAIC) merupakan hasil pengem-bangan Akaike Information Criterion (AIC) oleh Bozdogan dengan memasukkan efek dari ukuran sampel dengan tujuan agar fungsi kriteria informasi lebih kon-sisten. Misal {Mk : k ∈ K} adalah sekumpulan himpunan model yang akan digunakan dimana k = 1,2, ...., K, maka:
AIC(k) =−2logeL[ˆθ(k)] +m(k)[logen+ 1] (4.7)
4.3.3 Schwarz Bayesian Criterion (SBC)
Model Schwarz Bayesian Criterion (SBC) mempunyai komponen yang hampir sama dengan CAIC. Sering disebut model kriteria Bayesian karena mengacu pada penerapan bayesian dalam analisis statistik. Misal{Mk:k ∈K}adalah sekumpu-lan himpunan model yang akan digunakan dimana k= 1,2, ...., K, maka:
AIC(k) =−2logeL[ˆθ(k)] +m(k)[loge] (4.8)
4.3.4 Information Complexiry Information Criterion (ICOMP)
Model kriteria ini dikembangkan untuk mengukur data multivariat berbentuk linier atau non linier. Secara umum ditulis sebagai berikut:
19
disebut juga suatu perkiraan kompleks yang merupakan invers dari matrik infor-masi Fisher ˆF1(IF IM). Sering juga disebut matriks batas bawah Cramer Rao (Almautari,2011). s adalah rangking IFIM,trF−1adalah mean dari IFIM, |F−1| determinan IFIM.
4.4 Analisis Kelompok Multi Sampel Berdistribusi Normal
Pada bagian ini akan dibahas mengenai proses analisis kelompok untuk per-bandingan multi sampel. Sebelumnya Bozdogan (1986,2000) telah melakukan penelitian analisis kelompok multi sampel untuk prosedur perbandingan sampel dengan menggunakan model kriteria informasi AIC, CAIC dan ICOMP. Peneli-tiannya dapat dikatakan hirarki karena metode pengelompokkan menggunakan al-goritma secara aglomiratif. Tahapan pertama yang harus dilakukan dalam analisis kelompok multi sampel adalah membuat algoritma sehingga K kelompok sampel dapat di optimalkan ke arah k himpunan bagian kelompok sampel (k≤ K). Ke-mudian pada masa algoritma berjalan model kriteria informasi di masukkan se-bagai acuan memilih pasangan kelompok yang memiliki sedikit perbedaan. Pasa-ngan terpilih adalah yang memiliki nilai minimum. Adapun algoritmanya adalah sebagai berikut:
1. Tahap 1 : mulai dari k = 1 alternatif himpunan bagian kelompok. Pada keadaan k = 1 semua kelompok sampel berada dalam satu kelompok. Se-lanjutnya hitung nilai AIC.
2. Tahap 2 : lanjut k = 2 alternatif himpunan bagian kelompok. Banyak kelompok dapat diperoleh melalui rumus 4.3. Kemudian hitung nilai AIC untuk semua alternatif himpunan bagian kelompok yangterbentuk. Kelom-pok yang terpilih adalah yang memiliki nilai AIC minimum.
20
Pada kejadian ini diasumsikan kasus populasi data multi sampel berdis-tribusi normal dengan nilai vektor mean berbeda (µg), g = 1,2, ..., K dan nilai varian (σ) yang sama. Untuk mendapatkan nilai AIC (4.6) dimana nilai parameter
m=kp+p(p+ 1)/2 sehingga diperoleh rumus AIC sebagai berikut :
AIC(k) =−2logeL[ˆθ(k)] + 2[kp+p(p+ 1) 2 ]
Nilai fungsi log likelihood diperoleh sebagai berikut:
l({µg}, σ2 :X) ≡ Log({µg}, σ2 :X)
Dengan memasukkan nilai fungsi maksimum likelihood, maka AIC dapat didefenisikan sebagai berikut (Bozdogan, 1986):
AIC =nploge(2π) +nlogekn(−1)
Wk+np+ 2[kp+p(p+ 1)
2 ] (4.11)
dimana
n = Ruang sampel
kWk = Determinan dari ”within groups” sum of square matriks k = J umlah alternatif grup
21
Sebagai contoh yang akan dibahas disini studi kasus terhadap jenis padi yang datanya sudah diberikan dalam Srivastava dan Carter (Bozdogan, 1986). Varians jenis padi terdiri dari empat yang dinotasikan a,b,cdanddengan setiap jenis terdiri dari 5 macam. Selama 6 minggu dilakukan pengukuran terhadapx1= pertumbuhan tinggi pohon dan x2= jumlah tangkai perpohon. Ini berarti data diatas memilikin =P
ng = 20, n = 5, g = 1,2,3,4.
Untuk jenis kelompok varian padi diatas terdiri dariK = 4 kelompok sampel yang akan dikelompokkan kedalam k = 1,2,3 dan 4 kelompok himpunan bagian. Dimana banyaknya anggota dalam k kelompok himpunan bagian dapat dilihat seperti dibawah. Jumlah alternatif kelompok yang mungkin terjadi adalah 15 dengan nilai.
4 = {4} = {3}+{1} = {2}+{2} = {2}+{1}+{1} = {1}+{1}+{1}+{1}
22
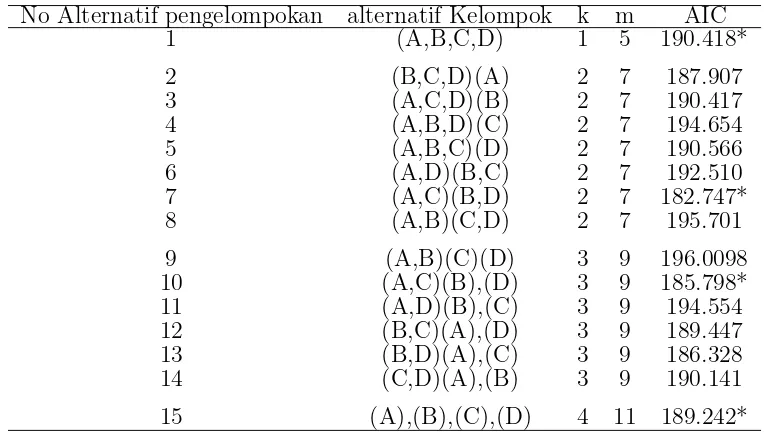
Tabel 4.2 Analisis kelompok multi sampel untuk K = 4 No Alternatif pengelompokan alternatif Kelompok k m AIC
1 (A,B,C,D) 1 5 190.418*
15 (A),(B),(C),(D) 4 11 189.242*
Catatan :
n=20 ; p=2 ; m=kp+p(p+1)/2 parameter
AIC =nploge(2π) +nlogekn(−1)Wk+np+ 2m * merupakan nilai minimum
Dari hasil pengamatan tabel diatas dapat dilihat pada saat alternatif kelom-pok k = 2, pasangan yang memiliki homogenitas terbaik adalah yang memiliki nilai AIC minimum yakni pada alternatif kelompok ke 7 untuk pasangan (A,C) (B,D). Berlanjut pada saat alternatif kelompok k = 3, pasangan yang memiliki nilai AIC minimum pada alternatif kelompok ke 10 untuk pasangan (A,C), (B), (D). Secara dendogram, tahapan pembagian kelompok disajikan pada gambar 4.1.
23
4.5 Analisis Kelompok Multi Sampel Berdistribusi Power Normal
Pada banyak kasus analisis kelompok untuk perbandingan multi sampel, observasi diasumsi harus memenuhi distribusi normal. Pada kenyataannya sulit untuk memenuhi asumsi tersebut. Karenanya dikenalkan suatu metode yang tidak memandang kebutuhan distribusi normal, namun menggunakan distribusi power normal yang merupakan distribusi yang ditetapkan sebelum perubahan bentuk normal oleh Box dan Cox tahun 1964 oleh Shimokawa dan Goto (2011).
Secara umum variabel randomxuntuk transformasi power normal menurut Shimokawa dan Goto (2011) dan Ishogawa(2012) adalah:
xλ =
xλ−1
λ , λ 6= 0,
logx, λ = 0. (4.12)
Fungsi densitas probabilitas untuk distribusi power normal dalam Shimokawa dan Goto (2011) adalah sebagai berikut:
f dpDP N(x;λ, µ, σ) = x
λ−1
A(λ)√2πσ2eksp{−
(x(λ)−µ)2
2σ2 } (4.13)
Nilaiµadalah lokasi parameter, σ2 adalah skala parameter dan A(Λ) pelu-ang proporsional dari distribusi power normal ypelu-ang didefenisikan sebagai berikut:
A(λ) =n φ[sign(λ)k ≡ k1, λ] λ 6= 0= 0,.
Dimana ≡ = (λµ)/λσ adalah titik pemotongan standar dari pemotongan distribusi normal dan φ adalah fungsi distribusi kumulatif dari distribusi nor-mal. Untuk memenuhi kebutuhan bahwa itu power normal dengan menganggap
A(λn)≈1 perubahan observasi adalah berdistribusi normal.
24 diasumsikan bahwa hasil dari analisis kelompok dengan distribusi normal akan sama dengan hasil dari analisis kelompok distribusi power normal. Algoritma yang akan digunakan juga sama dengan algoritma berdistribusi normal hanya letak perbedaanya pada parameter yang telah berubah bentuk power normal. Jika pada distribusi normal yang dihitung nilai mean dari kelompok, pada distribusi power normal yang dihitung lokasi parameter dan skala parameter. Selanjutnya menghitung nilai AICDP N dengan rumus (4.14).
4.6 Contoh Permasalahan
Dalam kasus ini akan dilakukan analisis kelompok hirarki berdasarkan dis-tribusi normal. Tapi sebelumnya akan ditampilkan perhitungan dengan meng-gunakan uji ANOVA, LSD, dan kemudian akan dibandingkan dengan hasil per-hitungan analisis kelompok hirarki berdasarkan distribusi normal dan distribusi power normal yang telah ada.
25
Tabel 4.3 Pengamatan awal bayi jalan (bulan) Kelompok Hasil Pengamatan (bulan) Mean
AK 9.00;9.50;9.75;10.00;13.00;9.50 10.125 PK 11.00;10.00;10.00;11.75;10.50;15.00 11.375 NK 11.50;12.00;9.00;11.50;13.25;13.00 11.708 EK 13.25;11.50;12.00;13.50;11.50 12.350
Dimana AK adalah kelompok bayi aktif latihan menerima stimulasi motorik empat kali sehari selama delapan minggu, PK adalah kelompok bayi pasif selama menerima stimulasi motorik yang sama empat kali sehari selama delapan minggu. NK adalah kelompok bayi yang tidak menerima latihan tetapi tetap diuji bersama bayi kelompok AK. Dan EK adalah kelompok bayi dalam kelas kontrol delapan minggu untuk mengendalikan kemungkinan pemeriksaan ulang.
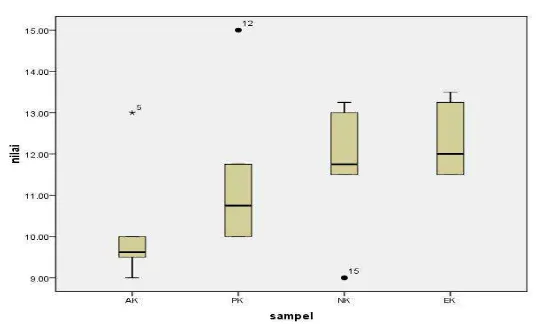
Menurut Shimokawa dan Goto (2011) seperti yang pernah dijelaskan se-belumnya bahwa perbedaan kelompok sampel dapat dilihat dari tampilan grafik. Tampilan grafik boxplot data dapat dilihat pada gambar 4.2
Gambar 4.2 Diagram boxplot pengamatan bayi berjalan
26
Tabel 4.4 Hasil perhitungan ANOVA
Sum Of Squares df Mean Square F Sig Between Groups 14.788 3 4.926 2.142 .129
Within Groups 43.690 19 2.299
Total 58.467 22
Dari tabel 4.4, menurut hitungan ANOVA didapat nilai Signifikan > 0,05, maka H0 diterima dan H1 ditolak. Ini berarti seluruh sampel memiliki rata-rata yang sama secara statistik pada tingkat signifikansi 0,05. Tidak tampak ada perbedaan seperti yang seharusnya ditunjukkan pada tabel boxplot.
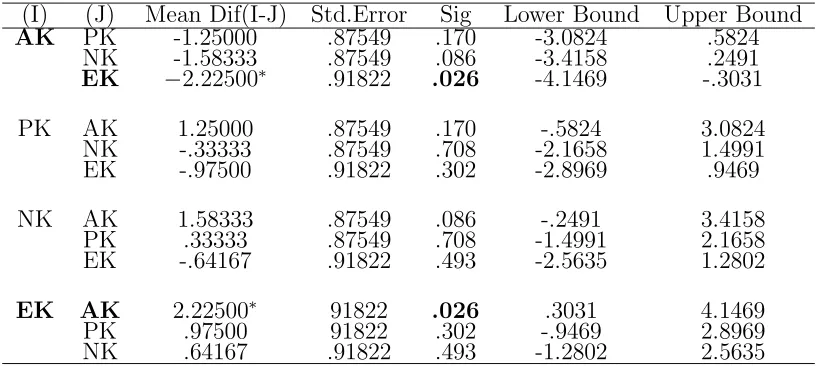
Namun apabila data diuji menggunakan uji LSD maka di peroleh bahwa kelompok sampel AK dan EK berbeda secara signifikan pada tingkat signifikansi 5%, karena nilai sig 0.026 < 0.05 (pada tabel 4.5). Terlihat hasil yang dipero-leh dengan perhitungan uji LSD berbeda dengan perodipero-lehan dari perhitungan uji ANOVA.
Tabel 4.5 Multiple comparisons hasil uji LSD
(I) (J) Mean Dif(I-J) Std.Error Sig Lower Bound Upper Bound
AK PK -1.25000 .87549 .170 -3.0824 .5824
NK -1.58333 .87549 .086 -3.4158 .2491
EK −2.22500∗
.91822 .026 -4.1469 -.3031
PK AK 1.25000 .87549 .170 -.5824 3.0824
NK -.33333 .87549 .708 -2.1658 1.4991
EK -.97500 .91822 .302 -2.8969 .9469
NK AK 1.58333 .87549 .086 -.2491 3.4158
PK .33333 .87549 .708 -1.4991 2.1658
EK -.64167 .91822 .493 -2.5635 1.2802
EK AK 2.22500∗
91822 .026 .3031 4.1469
PK .97500 91822 .302 -.9469 2.8969
NK .64167 .91822 .493 -1.2802 2.5635
* The mean differences is significant at the 0.05 level
da-27
yang mungkin terbentuk menggunakan teorema 4.1. Dari K = 4 kelompok men-jadi k bagian kelompok dengan syarat K < k, banyaknya alternatif himpunan bagian kelompok ditemukan sebagai berikut:
K
Dimana banyaknya alternatif kelompok untuk himpunan bagian kelompok dengan k = 1 adalah S(4,1) = 1, k = 2 adalah S(4,2) = 7, k = 3 adalah
S(4,3) = 6 dank= 4 adalahS(4,4) = 1, dengan jumlah total alternatif kelompok yang terbentuk keseluruhannya adalah 15.
28
1. Untuk k=1
No alternatif pengelompokan 1 (AK,PK,NK,EK)
AIC = nploge(2π) +nlogekn(−1)W
k+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗58.467k+ 23∗1 + 2∗2 = 23log(6.28) + 23log(2.542) + 23 + 4
= 18.353 + 9.319 + 23 + 4 = 54.672
2. Untuk k=2
(a) No alternatif pengelompokan 2 (AK)(PK,NK,EK)
AIC = nploge(2π) +nlogekn(−1)W
k+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗46.329k+ 23∗1 + 2∗3 = 23log(6.28) + 23log(2.014) + 23 + 6
= 18.353 + 6.995 + 23 + 6 = 54.348
(b) No alternatif pengelompokan 3 (PK)(AK,NK,EK)
AIC = nploge(2π) +nlogekn(−1)
Wk+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗58.461k+ 23∗1 + 2∗3 = 23log(6.28) + 23log(2.541) + 23 + 6
29
(c) No alternatif pengelompokan 4 (NK)(AK,PK,EK)
AIC = nploge(2π) +nlogekn(−1)W
k+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗57.412k+ 23∗1 + 2∗3 = 23log(6.28) + 23log(2.496) + 23 + 6
= 18.353 + 9.137 + 23 + 6 = 56.490
(d) No alternatif pengelompokan 5 (EK)(AK,PK,NK)
AIC = nploge(2π) +nlogekn(−1)W
k+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗52.051k+ 23∗1 + 2∗3 = 23log(6.28) + 23log(2.226) + 23 + 6
= 18.353 + 8.816 + 23 + 6 = 55.511
(e) No Alternatif pengelompokan 6 (AK,PK)(NK,EK)
AIC = nploge(2π) +nlogekn(−1)
Wk+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗49.500k+ 23∗1 + 2∗3 = 23log(6.28) + 23log(2.152) + 23 + 6
30
(f) No alternatif pengelompokan 7 (AK,NK)(PK,EK)
AIC = nploge(2π) +nlogekn(−1)W
k+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗53.803k+ 23∗1 + 2∗3 = 23log(6.28) + 23log(2.339) + 23 + 6
= 18.353 + 8.488 + 23 + 6 = 55.842
(g) No alternatif pengelompokan 8 (AK,EK)(PK,NK)
AIC = nploge(2π) +nlogekn(−1)W
k+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗57.525k+ 23∗1 + 2∗3 = 23log(6.28) + 23log(2.501) + 23 + 6
= 18.353 + 9.157 + 23 + 6 = 56.510
3. Untuk k=3
(a) No alternatif pengelompokan 9 (AK)(PK)(NK,EK)
AIC = nploge(2π) +nlogekn(−1)W
k+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1 ∗44.813k+ 23∗1 + 2∗4 = 23log(6.28) + 23log(1.948) + 23 + 8
31
(b) No alternatif pengelompokan 10 (AK)(NK)(PK,EK)
AIC = nploge(2π) +nlogekn(−1)W
k+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗46.282k+ 23∗1 + 2∗4 = 23log(6.28) + 23log(2.012) + 23 + 8
= 18.353 + 6.985 + 23 + 8 = 56.338
(c) No alternatif pengelompokan 11 (AK)(EK)(PK,NK)
AIC = nploge(2π) +nlogekn(−1)W
k+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗44.023k+ 23∗1 + 2∗4 = 23log(6.28) + 23log(1.914) + 23 + 8
= 18.353 + 6.485 + 23 + 8 = 55.838
(d) No alternatif pengelompokan 12 (PK)(NK)(AK,EK)
AIC = nploge(2π) +nlogekn(−1)
Wk+np+ 2m
= 23∗1log(2∗3.14) + 23logk23−1
∗57.191k+ 23∗1 + 2∗4 = 23log(6.28) + 23log(2.487) + 23 + 8
32
(e) No alternatif pengelompokan 13 (PK)(EK)(AK,NK)
AIC = nploge(2π) +nlogekn(−1)W
(f) No alternatif pengelompokan 14 (NK)(EK)(AK,PK)
AIC = nploge(2π) +nlogekn(−1)
No alternatif pengelompokan 15 (AK)(PK)(NK)(EK)
AIC = nploge(2π) +nlogekn(−1)W
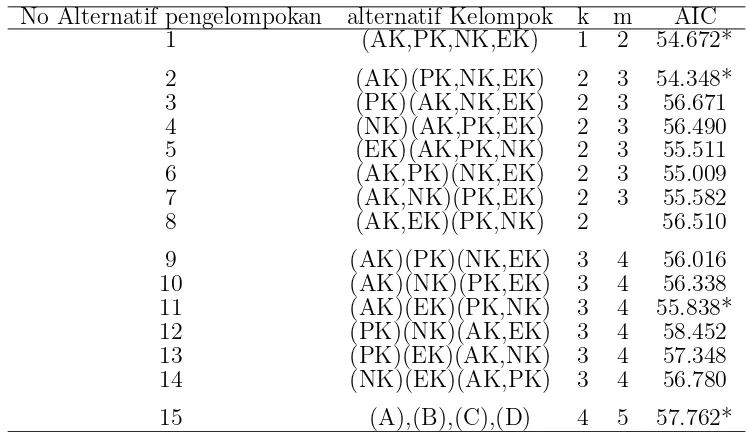
Untuk mempermudah pengamatan, nilai keseluruhan AIC pembagian alter-natif kelompok himpunan bagian kemudian disajikan pada tabel 4.6.
33
dan terakhir (AK). Itu dapat diartikan bahwa metode analisis kelompok hirarki menunjukkan bahwa dalam tahapan belajar berjalan tidak menyarankan adanya pelatihan karena pada awal pengelompokkan ada kelompok yang mendapat sti-mulus (PK) dan tidak mendapat stisti-mulus (NK).
Tabel 4.6 Analisis kelompok pengamatan bayi berjalan No Alternatif pengelompokan alternatif Kelompok k m AIC
1 (AK,PK,NK,EK) 1 2 54.672*
2 (AK)(PK,NK,EK) 2 3 54.348*
3 (PK)(AK,NK,EK) 2 3 56.671
4 (NK)(AK,PK,EK) 2 3 56.490
5 (EK)(AK,PK,NK) 2 3 55.511
6 (AK,PK)(NK,EK) 2 3 55.009
7 (AK,NK)(PK,EK) 2 3 55.582
8 (AK,EK)(PK,NK) 2 56.510
9 (AK)(PK)(NK,EK) 3 4 56.016
10 (AK)(NK)(PK,EK) 3 4 56.338
11 (AK)(EK)(PK,NK) 3 4 55.838*
12 (PK)(NK)(AK,EK) 3 4 58.452
13 (PK)(EK)(AK,NK) 3 4 57.348
14 (NK)(EK)(AK,PK) 3 4 56.780
15 (A),(B),(C),(D) 4 5 57.762*
Catatan :
n=23 ; p=1 ; m=kp+p(p+1)/2 parameter
AIC =nploge(2π) +nlogekn(−1)Wk+np+ 2m * merupakan nilai minimum
34
Gambar 4.3 Dendogram analisis kelompok berdistribusi normal
Gambar 4.4 Dendogram analisis kelompok berdistribusi power normal
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Dalam tesis ini, penulis menjelaskan mengenai analisis kelompok secara umum. Analisis kelompok merupakan suatu teknik analisis data multivariat dengan mengelompokkan sampel kedalam kelompok berdasarkan homogenitas. Pada umumnya metode analisis data yang digunakan untuk prosedur perban-dingan sampel adalah uji t, uji F, ANOVA atau MANOVA. Beberapa peneli-ti berpendapat metode diatas peneli-tidak informapeneli-tif dan memberikan gambaran yang jelas tentang karakteristik sampel. Maka dikenal suatu pendekatan baru dalam prosedur perbandingan sampel tanpa harus menguji hipotesis kesamaan pasangan kelompok yakni metode analisis kelompok.
Tahapan awal dalam metode kelompok adalah penentuan algoritma, dima-na algoritma yang dipilih disini adalah secara hirarki agglomiratif. Kemudian untuk memilih pasangan kelompok terbaik selama algoritma pengelompokkan model informasi kriteria AIC digunakan. Sebenarnya secara grafik statistik dapat memberikan gambaran perbedaan kelompok sampel, namun dengan uji F atau ANOVA tidak memberikan penjelasan tentang perbedaan sampel. Bahkan tidak menunjukkan perbedaan seperti yang ditampilkan grafik statistik. Begitu juga ketika metode analisis kelompok secara hirarki berdistribusi normal diterapkan, akan tetapi dengan analisis kelompok hirarki dengan asumsi berdistribusi nor-mal menggunakan model kriteria AIC, hasil yang diperoleh lebih mendekati pada gambaran tampilan box plot.
36
5.2 Saran
DAFTAR PUSTAKA
Almuitari,Fahad. (2011).Algorithms for Multi-SAmple Cluster Anlysis. A Disserta-tion presented for the doctoral of philosophy degree the university of Tenessee, Knoxville.
Bozdogan, H. (1986). Multi-sample cluster analysis as an alternative to multiple comparison procedures. Bulletin of Information and Cybernetics, Vol.22(1-2), pp.95-130.
Bozdogan, H.(2000). Akaike’s Information Criterion and Recent Developments in information Complexity. Journal of Mathematical and Psycology, Vol.44, pp.62–91.
Everitt,B.S. Landau,S. Leese,Morven. Stahl,Daniel. (2011).Cluster Analysis. Wil-ley, London.
Ferreira, Laura. dan Hitchcok,D.B. (2003). A Comparison of Hierarchical Methods for Clustering Functional Data. Depaertment of Statistic University of South Carolina
Ishogawa,Naoki. (2012).reditive Performance Bayesian Diagnoses. A Dissertation presented for the doctoral philosophy in engineering, Osaka Uninersity Konishi,Sadanori. dan Kitagawa,Gensiro. (1996).Generalised Information Criteria
In Model Selection. Bulletin of Information and Cybernetics, Vol.22(1-2), pp.95–130
Moleong,Lexy,J. (2000). Metode Penelitian Kuantitatif. Remaja Rusda Karya, Bandung.
Neath,Andrew. dan Casanaugh,Joseph. (2006).A Bayesiayn Approach to Multiple Comparisons Problem. Journal of data sains, Vol.4, pp.131–146.
Shimokawa,Thosio. dan Goto,Massashi.(2011). Hierarchical Cluster Analysis for Multi-Sample Comparison Based on the Power Normal Distribution. Behav-iormatrika, Vol.36(2), pp.125-138.
Trebuna, Peter. dan Halcinova, Jana. (2013). Mathematical Tools of Cluster Ana-lysis. Scientific Reasearsch, Vol.4, pp.814–816.