IMPLEMENTASI SUPPORT VECTOR MACHINE (SVM)
UNTUK KLASIFIKASI DOKUMEN
DEALIS HENDRA PRATAMA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul implementasi support vector machine (SVM) untuk klasifikasi dokumen adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir disertasi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juni 2013
Dealis Hendra Pratama
ABSTRAK
DEALIS HENDRA PRATAMA. Implementasi Support Vector Machine
(SVM) Untuk Klasifikasi Dokumen. Dibimbing oleh Ir. Julio Adisantoso, M.Kom. Klasifikasi dokumen merupakan proses pengelompokan dokumen ke dalam kategori tertentu yang sudah ditentukan sebelumnya. Pada dunia nyata, umumnya sebaran data bersifat non-linear yang artinya sebaran data tidak terpisah secara sempurna. Oleh karena itu dibutuhkan sebuah metode yang dapat mengklasifikasikan dokumen yang bersifat non-linear. Support vector machine
bisa melakukan klasifikasi dokumen yang bersifat non-linear dengan meningkatkan dimensi sebaran dokumen menggunakan kernel trick. Penelitian ini akan menggunakan linear kernel untuk klasifikasi dokumen teks. Hasil akurasi terbesar pada penelitian ini adalah 76% dari 150 dokumen uji dengan nilai epsilon 0.01. Faktor yang mempengaruhi hasil klasifikasi diantaranya adalah nilai epsilon dan panjang dokumen uji.
Kata kunci: SVM, linear kernel, support vector machine, klasifikasi dokumen.
ABSTRACT
DEALIS HENDRA PRATAMA Support Vector Machine (SVM) implementation for document classification. Supervised by Ir. Julio Adisantoso, M.Kom.
Document classification is the process of grouping documents into specific categories that have been defined previously. In the real world, the distribution of the data is generally non-linear, which means the distribution of the data did not separate properly. Therefore we need a method that can classify documents that are non-linear. Support vector machine can classify documents that are non-linear with increasing dimension of the distribution of documents using kernel trick. This study will use a linear kernel for the classification of text documents. Results greatest accuracy in this study was 76% of 150 test documents with epsilon value 0.01. Factors affecting the results of the classification of which is the value of epsilon and length of test documents.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
IMPLEMENTASI SUPPORT VECTOR MACHINE (SVM)
UNTUK KLASIFIKASI DOKUMEN
DEALIS HENDRA PRATAMA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Implementasi Support Vector Machine (SVM) Untuk Klasifikasi Dokumen
Nama : Dealis Hendra Pratama
NIM : G64104001
Disetujui oleh
Ir. Julio Adisantoso, M.Kom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Agustus 2012 ini ialah klasifikasi dokumen, dengan judul implementasi support vector machine (SVM) untuk klasifikasi dokumen.
Penulis menyadari bahwa penelitian ini tidak akan selesai jika tidak ada bantuan dari berbagai pihak. Pada kesempatan ini penuli ingin mengucapkan terimakasih kepada :
1. Orang tua tersayang, Ayah (alm) Dalimin dan Ibu Sriwiji, serta adik Olga Dealis Saputri, dan juga keluarga yang selalu memberikan doa, nasihat, semangat, dukungan yang luar biasa kepada penulis.
2. Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing, dengan bantuan bimbingan disertai kesabaran dalam penyelesaian penelitian ini. 3. Bapak Mushtofa, S.Kom, M.Sc dan Sony Hartono Wijaya, S.Kom., M.Kom
selaku dosen penguji yang telah memberikan banyak saran dan pembelajaran dalam penyempurnaan penelitian ini.
4. Ina Ainul Ariefah yang selalu ada dan membantu, memberikan ketenangan, solusi, dan kesabaran dalam menyelesaikan penelitian ini.
5. Teman-teman satu bimbingan yang saling membantu dalam penyelesaian masalah yang ada selama penyelesaian penelitian ini.
6. Seluruh staf program Alih Jenis Ilmu Komputer yang telah banyak membantu selama perkuliahan dan selama penyelesaian penelitian ini. Dalam penelitian ini penuli menyadari masih banyak kekurangan dan kesalahan dalam penyelesaiannya karena keterbatasan kemampuan penulis. Untuk itu penulis menerima saran dan kritik yang bersifat membangun mengenai penelitian ini. Semoga penelitian ini bermanfaat baik sekarang atau di masa yang akan datang.
Bogor, Juni 2013
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN vii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Tahap Pengumpulan Dokumen 2
Tahap Pelatihan 3
Tahap Pengujian 9
Lingkungan Pengembangan 10
HASIL DAN PEMBAHASAN 10
Pengumpulan Dokumen 10
Tokenisasi 11
Seleksi Fitur 12
Pembobotan 12
Support Vector Machine 12
Evaluasi kinerja klasifikasi 13
SIMPULAN DAN SARAN 16
Simpulan 16
Saran 16
DAFTAR PUSTAKA 17
LAMPIRAN 18
DAFTAR TABEL
1. Tabel kontigensi antara kata terhadap kelas 4
2. Contoh kernel 7
3. Struktur tabel dokumen latih 10
4. Struktur tabel kelas dokumen latih 11
5. Jumlah kata dan rata-rata jumlah kata 11
6. Total kata yang diterima dan ditolak sebagai fitur 12
7. Bobot terbesar, terkecil, dan rata-rata bobot 12
8. Perbandingan kategori long document 13
9. Perbandingan kategori short document 13
DAFTAR GAMBAR
1. Diagram alur proses tahap pelatihan 3
2. Konsep dasar SVM 5
3. Fungsi Φ memetakan data ke ruang vektor berdimensi lebih tinggi 7
4. Diagram alur tahap pengujian 9
5. Contoh Dokumen Uji 11
6. Perbandingan akurasi untuk kategori dokumen 14
7. Perbandingan akurasi seluruh dokumen 15
8. Perbandingan akurasi SVM dan SS (short document) 15
PENDAHULUAN
Latar Belakang
Pada saat ini jumlah dokumen teks di jaringan global sudah berkembang sangat pesat. Jumlah dokumen yang semakin banyak akan membuat masyarakat umum mengalami kesulitan dalam menemukan dokumen teks yang dibutuhkan sesuai dengan keinginan. Hal ini memerlukan sebuah teknik pengolahan dokumen teks agar menjadi beberapa kelompok yang sudah terorganisir dengan baik. Salah satu teknik yang bisa digunakan adalah teknik klasifikasi dokumen, yaitu dengan membagi-bagi kelompok dokumen berdasarkan kelompok yang sudah ditentukan sebelumnya. Untuk itu dibutuhkan sistem klasifikasi dokumen teks yang mampu mengelompokkan dokumen teks ke dalam kelompok-kelompok yang sudah ditentukan sebelumnya. Dengan adanya sistem klasifikasi dokumen, maka pengguna tidak perlu mengelompokkan dokumen secara manual, sehingga dapat mengurangi waktu dan tenaga dalam melakukan penyimpanan dokumen kedalam kelompok yang sudah ditentukan. Selain itu, masyarakat juga sudah mudah untuk mencari dokumen yang diinginkan apabila dokumen sudah tersusun rapih berdasarkan kelompok masing-masing.
Pada saat ini sudah banyak metode yang digunakan untuk mengatasi permasalahan klasifikasi dokumen. Manning et al (2007) mengelompokkan metode klasifikasi dokumen atau teks menjadi tiga pendekatan, yaitu klasifikasi manual, klasifikasi berbasis aturan (hand-crafted rules), dan klasifikasi berbasis pembelajaran mesin (machine learning-based text classification). Pada klasifikasi berbasis pembelajaran, beberapa aturan keputusan dari pengklasifikasi teks dipelajari secara otomatis dengan menggunakan metode statistika dari dokumen latih. Ada beberapa metode yang dapat digunakan dalam proses pembelajaran (supervised learning) yaitu Naïve Bayes, Rocchio classsfication, K Nearst Neighbor
(KNN), dan Support Vector Machine (SVM).
Pada penelitian sebelumnya, klasifikasi dokumen dengan metode semantic smoothing telah dilakukan oleh Ramadhina (2011). Klasifikasi dengan metode
semantic smoothing sangat bergantung pada pasangan kata atau topic signature
(Ramadhina, 2011). Oleh karena itu metode ini tidak cocok untuk digunakan untuk berbagai dokumen karena dokumen yang berbeda akan menghasilkan topic signature yang berbeda.
Untuk itu dibutuhkan algoritme klasifikasi yang bisa lebih fleksibel sehingga bisa digunakan untuk berbagai macam dokumen. Algoritme klasifikasi
2
Perumusan Masalah
Pemasalahan klasifikasi pada dunia nyata lebih banyak yang bersifat non-linear artinya data tidak terpisah secara sempurna. Untuk melakukan klasifikasi dalam kasus non-linear dibutuhkan sebuah metode yang dapat meningkatkan dimensi data agar bisa memisahkan data secara sempurna. Support vector machine
(SVM) adalah metode yang dapat melakukan klasifikasi yang bersifat non-linear. Untuk menaikkan dimensi, SVM menggunakan kernel trick dalam penerapannya. Oleh karena itu pada penelitian ini, penulis mencoba menerapkan kernel linier pada SVM untuk klasifikasi dokumen teks.
Tujuan Penelitian
Tujuan dari penelitian ini adalah mengimplementasikan linear kernel pada SVM untuk klasifikasi dokumen.
Manfaat Penelitian
Manfaat penelitian ini adalah mengelompokkan dokumen secara otomatis, yang diharapkan dapat membantu seseorang dalam mengelompokkan dokumen berdasarkan kategori tertentu.
Ruang Lingkup Penelitian
Ruang lingkup pada penelitian ini adalah dokumen yang digunakan adalah dokumen teks berbahasa Indonesia mengenai tanaman holtikultura dari bidang pertanian.
METODE
Klasifikasi adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data dengan tujuan untuk memperkirakan kelas yang tidak diketahui dari suatu objek. Klasifikasi dokumen adalah pemberian kategori yang telah didefinisikan kepada dokumen yang belum memiliki kategori (Goller et al, 2000). Dokumen-dokumen yang sama akan dimasukkan ke dalam kelompok yang sama. Perkembangan jumlah dokumen yang sangat cepat, mendorong berkembangnya metode pengklasifikasian dokumen. Penelitian ini melakukan klasifikasi dokumen secara otomatis menggunakan metode support vector machine (SVM). Metode ini melakukan klasifikasi dengan cara belajar dari sekumpulan dokumen latih yang telah dikasifikasikan sebelumnya.
Tahap Pengumpulan Dokumen
3
document. Hal ini dilakukan untuk melihat pengaruh jumlah kata yang digunakan untuk perhitungan klasifikasi. Untuk masing-masing kelas mempunyai 25 dokumen uji untuk setiap kategori. Pada penelitian ini, kelas dari klasifikasi dibagi menjadi tiga, yaitu :
1. Ekofisiologi dan Agronomi 2. Pemuliaan dan Teknologi Benih 3. Proteksi (Hama dan Penyakit)
Tahap Pelatihan
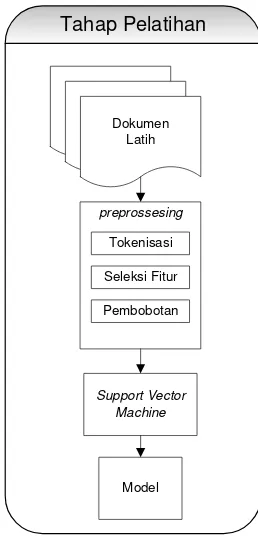
Tahap ini dilakukan untuk menghasilkan sebuah model klasifikasi yang akan digunakan untuk tahap pengujian. Tahap pelatihan dimulai dari preprossesing
dokumen hingga menghasilkan model klasifikasi. Diagram alur tahap pelatihan bias dilihat pada gambar 1.
Gambar 1 Diagram alur proses tahap pelatihan Tokenisasi
Tokenisasi adalah suatu tahap pemrosesan teks input yang dibagi menjadi unit-unit kecil yang disebut dengan token atau term, yang berupa satu kata atau angka (Herawan, 2011). Pada penelitian ini, token yang dimaksud adalah kata. Aturan dalam melakukan tokenisasi adalah sebagai berikut :
1. Teks dipotong menjadi token. Karakter yang dianggap sebagai pemisah
token didefinisikan dengan ekspresi reguler sebagai berikut : /[\s\-+\/*0-9%,.\"\];()\':=`?\[!@><]+/
2. Token yang berupa numerik tidak diikutsertakan. Seleksi Fitur
4
dalam klasifikasi dokumen (Maning et al, 2007). Dalam penelitian ini, metode yang digunakan untuk pemilihan fitur adalah chi-kuadrat . Chi-kuadrat adalah analisis untuk mengetahui apakah distribusi data seragam atau tidak. Persamaan untuk menghitung chi-kuadrat sebagai berikut :
� = ∑ − ℎℎ (1)
dengan adalah frekuensi yang didapat dari sampel, dan ℎ adalah frekuensi harapan. Pada penelitian ini, chi-kuadrat mengukur derajat kebebasan antara kata penciri t dengan kelas c agar dapat dibandingkan dengan persebaran nilai chi-kuadrat. Perhitungan nilai chi-kuadrat pada setiap kata t yang muncul pada setiap kelas c dapat dibantu dengan menggunakan tabel kontigensi. Tabel 1 menununjukan tabel kontigensi antara kata terhadap kelas. Nilai yang terdapat pada tabel kontingensi merupakan nilai frekuensi observasi dari suatu kata terhadap kelas.
Tabel 1 Tabel kontigensi antara kata terhadap kelas Kelas
Kelas c Kelas ¬c
Kata Kata t A B
Kata ¬t C D
Perhitungan nilai chi-kuadrat berdasarkan tabel kontigensi tersebut disederhanakan pada persamaan 2.
� , = + �+ − + + (2)
dengan t merupakan kata yang sedang diujikan terhadap suatu kelas c, N merupakan jumlah dokumen latih, A merupakan banyaknya dokumen pada kelas c yang memuat kata t, B merupakan banyaknya dokumen yang tidak berada pada kelas c yang memuat kata t, B merpakan banyaknya dokumen yang tidak berada pada kelas
c namun memuat kata t, C merupakan banyaknya dokumen yang berada pada kelas
c namun tidak mengandung kata t, dan D merupakan banyaknya dokumen yang bukan merupakan dokumen kelas c dan tidak memuat kata t.
Pengambilan keputusan dilakukan berdasarkan nilai � dari masing-masing kata. Kata yang memiliki nilai � diatas nilai kritis pada tingkat signifikansi α adalah kata yang akan dipili sebagai penciri dokumen. Tabel distribusi chi-kuadrat pada berbagai tingkat signifikansi dan derajat bebas tertentu ditunjukkan pada lampiran 1.
Pembobotan
Tiap dokumen diwujudkan sebagai vektor dengan elemen sebanyak term
yang didapatkan melalui proses pemilihan fitur. Vektor tersebut beranggotakan bobot dari setiap term. Salah satu metode untuk menghitung bobot term adalah tf-idf. Metode ini merupakan metode pembobotan yang merupakan hasil kali antara
term frequency (tf), dan inverse document frequency (idf). Formula dari tf-idf adalah sebagai berikut :
5
= log (� ) (4)
dengan ,�adalah bobot dari term t pada dokumen d, adalah frekuensi term t dalam dokumen,� adalah jumlah dokumen, dan adalah jumlah dokumen yang mengandung t.
Support Vector Machine
Konsep SVM dapat dijelaskan secara sederhana sebagai usaha mencari hyperplane terbaik yang berfungsi sebagai pemisah dua kelas yang berbeda pada ruang input (Cristianini & Shawe-Taylor, 2000). Gambar 2 menggambarkan beberapa pola yang merupakan anggota dari dua buah kelas +1 dan kelas -1.
Gambar 2 Konsep dasar SVM
Hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin hyperplane tersebut dan mencari titik maksimalnya, sedangkan margin adalah jarak antara hyperplane tersebut dengan pola yang terdekat dari masing-masing kelas. Vektor pola yang terdekat disebut dengan support vector.
Data yang tersedia dinotasikan ⃗⃗⃗ ∈ �� sedangkan label masing-masing dinotasikan ∈ {− , + } untuk i = 1,2,…,l , dimana l adalah banyaknya data. Diasumsikan kelas -1 dan +1 dapat terpisah secara sempurna oleh hyplerplane berdimensi d yang didefinisikan sebagai berikut :
⃗⃗ . + = (5)
Margin terbesar dapat ditemukan dengan memaksimalkan jarak antara hyperplane dan titik terdekatnya, yaitu ⁄‖⃗⃗ ‖. Hal ini dapat dirumuskan sebagai permasalahan Quadratic Programming (QP), yaitu mencari titik minimal persamaan (6) dengan memperhatikan constraint persamaan (7).
min⃗⃗ � = ‖⃗⃗ ‖ (6)
⃗⃗⃗ . ⃗⃗ + − ≥ , ∀ (7)
Masalah ini dapat dipecahkan dengan berbagai teknik komputasi, di antaranya Lagrange Multiplier.
⃗⃗ , , = ‖⃗⃗ ‖ − ∑ �
=
6
� adalah pengganda lagrange, yang bernilai nol atau positif. Nilai optimal dari persamaan (5) dapat dihitung dengan memaksimalkan nilai L terhadap ⃗⃗ dan
b, dan memaksimalkan L terhadap � . Dengan memperhatikan sifat bahwa titik optimal gradient L=0, persamaan (8) dapat dimodifikasi sebagai memaksimalisasi masalah yang hanya mengandung �, sebagaimana persamaan berikut ini.
Maksimasi :
Dari hasil perhitungan ini diperoleh � yang sebagian besar bernilai positif. Data yang berkorelasi dengan � yang positif inilah yang disebut sebagai support vector
tinggi (Nugroho et al, 2003). Soft Margin
Penjelasan pada sub bab support vector machine berdasarkan asumsi bahwa kedua kelas dapat dipisah secara sempurna oleh hyperplane. Akan tetapi pada umumnya dua kelas pada ruang vektor tidak dapat terpisah secara sempurna. Hal ini menyebabkan constraint pada persamaan 8 tidak dapat terpenuhi, sehingga optimasi tidak dapat dilakukan. Untuk mengatasi masalah ini, SVM dirumuskan ulang dengan memperkenalkan teknik softmargin. Pada softmargin, persamaan (7) dimodifikasi dengan memasukan slack variable� � > sebagai berikut :
⃗⃗⃗ . ⃗⃗ + ≥ − � , ∀ (11)
Dengan demikian persamaan (6) diubah menjadi :
min⃗⃗ � ⃗⃗ , � = ‖⃗⃗ ‖ + ∑ �
=
(12)
Parameter C dipilih untuk mengontrol tradeoff antara margin dan error klasifikasi
�. Nilai C yang besar berarti akan memberikan penalty yang lebih besar terhadap error klasifikasi tersebut.
Non-Linear Classification
7
Gambar 3 Fungsi Φ memetakan data ke ruang vektor berdimensi lebih tinggi Pada gambar 3a diperlihatkan data pada kelas kuning dan data pada kelas merah berada pada ruang vektor berdimensi dua tidak dapat dipisahkan secara linier. Selanjutnya gambar 3b menunjukan bahwa fungsi Φ memetakan tiap data pada ruang vektor tersebut ke ruang vektor baru yang berdimensi lebih tinggi (dimensi 3), dimana kedua kelas dapat dipisahkan oleh sebuah hyperplane. Notasi matematika pada mapping ini adalah sebagai berikut :
Φ ∶ ℜ� → ℜ� d<q (13)
Selanjutnya proses pembelajaran SVM dalam menemukan titik-titik support vector hanya bergantung pada dot product dari data yang sudah ditransformasikan pada ruang baru yang berdimensi lebih tinggi, yaitu Φ . Φ . Karena umumnya transformasi Φ ini tidak diketahui, dan sangat sulit untuk dipahami secara mudah, maka perhitungan dot product tersebut dapat digantikan dengan funsi kernel , yang mendefinisikan secara implisit transformasi Φ. Hal inilah disebut dengan kernel trick, yang dirumuskan sebagai berikut :
( , ) = Φ . Φ( ) (14)
Ada berbagai fungsi kernel yang biasa digunakan, diantaranya adalah yang terdapat pada Tabel 2.
Tabel 2 Contoh kernel
Jenis kernel Definisi
Linear , = +
Polynomial , = � + �
Gaussian
( , ) = exp (−‖ − ‖� )
Pada penelitian ini, kernel yang akan digunakan adalah linear kernel. Linear kernel
adalah kernel paling sederhana yang biasa digunakan.
8
Sequential Minimal Optimization (SMO) adalah algoritma untuk proses pelatihan pada SVM yang dapat memberikan solusi pada masalah optimisasi. Pada dasarnya penggunaan SVM hanya terbatas pada masalah yang kecil karena algoritma pelatihan SVM cenderung lambat, kompleks, dan sulit untuk diimplementasikan. Berdasarkan hasil penelitian, algoritma SMO lebih sederhana, lebih mudah diimplementasikan, dan lebih cepat waktu komputasinya daripada algoritma Chunking (platt 1998). Pada setiap tahap SMO memilih dua pengganda lagrange �, untuk dioptimasi bersama-sama, mencari nilai yang paling optimal dari pengganda lagrange tersebut, dan memperbaharui SVM dengan nilai optimal yang baru. SMO bekerja berdasarkan working set yang merupakan kumpulan variable yang sedang dioptimasi pada current iteration. SMO menggunakan working set
berelemen dua. Algoritma SMO seperti yang dijelaskan oleh Platt (1998) adalah sebagai berikut :
1. Masukkan data latih, nilai parameter SMO C dan epsilon (ε). Inisialisasi nilai α dan bias b.
2. Lakukan iterasi pada seluruh data latih, cari � yang melanggar sifat gradien. Jika � diperoleh maka ke tahap 3. Jika iterasi pada seluruh data latih selesai, maka lakukan iterasi pada data yang tidak terdapat pada batas. Lakukan iterasi pada seluruh data latih dan pada data yang tidak terdapat pada batas secara bergantian untuk mencari � yang melanggar sifat gradient sampai seluruh αmemenuhi sifat gradient.
9 Jika L=H, maka perkembangan optimasi tidak dapat dibuat, buang � dan ke tahap 4. Selainnya, hitung nilai η :
� = ⃗⃗⃗ , ⃗⃗⃗⃗ − ⃗⃗⃗ , ⃗⃗⃗ − ⃗⃗⃗⃗ , ⃗⃗⃗⃗ .
Jika nilai � negative, maka hitung nilai nilai � yang baru. Selainnya, hitung fungsi objektif pada titik L dan H dan gunakan nilai � yang memberikan fungsi objektif paling tinggi sebagai nilai � yang baru. Jika
|� � − � | lebih kecil dari nilai epsilon (ε), maka buang nilai � dan
ke tahap 4. Selainnya, ke tahap 5.
4. Lakukan iterasi pada data yang tidak terdapat pada batas sampai diperoleh
� yang dapat membuat perkembangan optimasi di tahap 3. Jika tidak diperoleh, maka lakukan iterasi pada seluruh data latih sampai diperoleh � yang dapat membuat perkembangan optimasi di tahap 3. Jika � tidak diperoleh setelah dua iterasi tersebut, maka lewati nilai � yang diperoleh dan kembali ke tahap 2 untuk mencari nilai � baru yang melanggar sifat gradien.
5. Hitung nilai � yang baru. Perbaharui nilai b dan error cache. Simpan nilai
� dan � yang baru. Kembali ke tahap 2. Tahap Pengujian
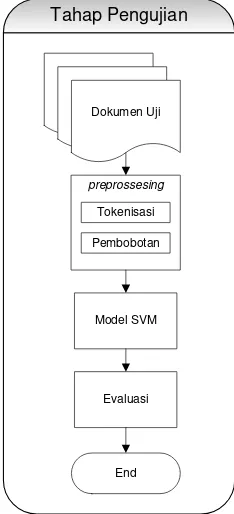
Pada tahap pengujian, tahapan yang dilakukan hampir sama dengan tahap pelatihan, hanya pada tahap ini tidak dilakukan seleksi fitur. Pada tahap ini, model yang dihasilkan dari tahap pelatihan akan digunakan untuk proses klasifikasi dokumen uji. Hasil dari proses klasifikasi akan di evaluasi menggunakan recall dan
precision Gambar 4 memperlihatkan diagram alur pada tahap pengujian.
Dokumen Uji
Tokenisasi
Pembobotan
preprossesing
Model SVM Tahap Pengujian
Evaluasi
End
10 Evaluasi
Evaluasi kinerja sistem dilakukan dengan menghitung nilai akurasi dari 150 dokumen uji untuk mendapatkan persentase ketepatan suatu dokumen masuk ke dalam kelas tertentu dalam sistem klasifikasi dokumen. Persamaan untuk menghitung akurasi adalah sebagai berikut :
= ℎ ℎ ℎ × %
Lingkungan Pengembangan
Lingkungan pengembangan merupakan kumpulan fasilitas yang diperlukan dalam pelaksanaan penelitian. Pada penelitian ini lingkungan pengembangan yang digunakan adalah :
Perangkat keras :
a. CPU Intel® Core™ i3-2330M CPU @2.20 GHz b. Memory 4 GB
Perangkat lunak :
a. Windows 8 Enterprise Edition b. Visual Studio 2012 Ultimate c. SQL Server 2012
Pada tahap ini, dokumen latih yang sudah terkumpul, akan disimpan ke dalam 2 tabel pada database. Tabel pertama akan menyimpan data detail dari setiap dokumen yang berisi id dokumen, judul, kata kunci, penulis, dan abstrak. Tabel yang kedua akan digunakan untuk menyimpan data dokumen latih beserta kelasnya. Pada tabel yang kedua, yang disimpan hanyalah id dokumen dan id kelasnya. Tabel 3 adalah struktur tabel penyimpanan dokumen latih pada database.
Tabel 3 Struktur tabel dokumen latih
Field Tipe data
11 Tabel 4 Struktur tabel kelas dokumen latih
Field Tipe data
IdDoc int
IdClass int
Gambar 5 Contoh Dokumen Uji Tokenisasi
Tahap tokenisasi adalah tahap memisahkan dokumen menjadi bagian-bagian kecil yang disebut dengan term. Pada dokumen latih, tokenisasi dilakukan pada abstrak. Pada penelitian ini tokenisasi dokumen latih dilakukan secara offline
dengan menggunakan stored procedure pada SQL Server. Langkah awal untuk memisahkan dokumen menjadi beberapa kata (term) adalah dengan mengganti seluruh tanda baca menjadi karakter spasi (white space). Setelah semua tanda baca menjadi spasi, kemudian dokumen dipecah menjadi beberapa bagian dengan karakter pemisah adalah karakter spasi. Setalah selesai melakukan proses pemisahan, kumpulan kata yang dihasilkan kembali diproses dengan membuang karakter berupa angka dan membuang kata yang berupa kata depan. Setelah semua proses pemecahan selesai, kumpulan kata tersebut disimpan di dalam tabel pada
database. Tabel 5 menggambarkan jumlah kata hasil tokenisasi, dan rata-rata jumlah kata tiap dokumen.
Tabel 5 Jumlah kata dan rata-rata jumlah kata Jumlah Kata Rata-rata jumlah kata
25318 146
12
Seleksi Fitur
Pada tahap ini, kumpulan kata yang sudah ada diproses kembali untuk menentukan apakah kata tersebut layak dijadikan fitur dalam pembentukan model klasifikasi. Untuk melakukan proses seleksi fitur, metode yang digunakan pada penelitian ini adalah kuadrat. Setalah dihitung menggunakan metode chi-kuadrat, setiap kata mempunyai nilai chi-kuadrat yang digunakan sebagai acuan dalam menentukan apakah kata tersebut layak digunakan sebagai fitur atau tidak. Batasan dari nilai chi-kuadrat ditentukan oleh derajat bebas dan tingkat signifikansi. Pada penelitian ini derajat bebas yang digunakan adalah 1 dengan tingkat signifikansi 0.10 yang berarti kata yang memiliki nilai chi-kuadrat diatas 2.71 yang diterima sebagai fitur. Tabel 6 memperlihatkan total kata yang diterima, dan total kata yang tidak diterima sebagai fitur.
Tabel 6 Total kata yang diterima dan ditolak sebagai fitur Total kata yang diterima Total kata yang ditolak
4890 10053
Berdasarkan tabel 6, proses seleksi fitur sangat bermanfaat untuk mengurangi kata-kata yang akan digunakan sebagai fitur. Karena dengan berkurangnya kata-kata yang digunakan, maka proses komputasi akan semakin ringan.
Pembobotan
Setelah dilakukan proses seleksi fitur, kata yang telah terpilih dihitung bobotnya menggunakan metode tf-idf. Langkah pertama yang dilakukan pada proses ini adalah menghitung jumlah masing-masing kata pada setiap dokumen. Setelah itu dihitung pula jumlah dokumen yang mengandung suatu kata tertentu. Kedua hasil perhitungan tersebut menjadi faktor utama dalam perhitungan bobot menggunakan metode tf-idf. Tabel 7 memperlihatkan bobot terbesar, bobot terkecil, dan rata-rata bobot yang diperoleh dari proses pembobotan ini.
Tabel 7 Bobot terbesar, terkecil, dan rata-rata bobot Bobot terbesar Bobot terkecil Rata-rata bobot
69.03 0 3.86
Support Vector Machine
Setelah melalui tahap-tahap sebelumnya, dokumen diproses untuk menghasilkan model klasifikasi support vector machine (SVM). Model SVM adalah model klasifikasi berbasis vektor. Vektor yang sudah dipetakan akan dihitung jaraknya. Jarak terjauh akan digunakan sebagai pemisah kelas dari vektor. Kemudian diberikan sebuah hyperplane untuk memisahkan dua kelas.
13 Proses selanjutnya setelah semua vektor dokumen terbentuk, vektor-vektor yang sudah terbentuk dibagi menjadi 3 bagian dengan menggunakan metode
support vector machine (SVM). Ada dua parameter penentu yang digunakan dalam pembuatan model SVM, yaitu C dan epsilon. C yang dimaksud adalah cost pinalti untuk data yang diklasifikasikan secara salah pada model. Pada penelitian ini, nilai yang C digunakan adalah 1.0. Sedangkan epsilon adalah nilai yang mengontrol lebar dari zona insensitive. Pada penelitian ini akan dicoba menggunakan empat variasi nilai epsilon yaitu 0.1, 0.01, 0.001, dan 0.0001. Variasi nilai ini digunakan untuk menemukan nilai untuk mencapai tingkat akurasi terbaik. Tahap selanjutnya ada memasukkan jenis kernel yang digunakan yaitu linear kernel ke dalam SVM. Setelah semua parameter dimasukkan, maka dilakukan proses pelatihan terhadap seluruh vektor agar menghasil model SVM yang disimpan dalam database. Penyimpanan model dalam database dilakukan untuk mempercepat proses klasifikasi, karena proses pembuatan model membutuhkan waktu yang cukup lama. Pada tahap pengujian, tahap yang dilakukan hampir sama pada tahap pelatihan. Tahap pertama yang dilakukan adalah dengan mangambil kembali model SVM yang tersimpan di database. Tahap selanjutnya dokumen uji dipecah menjadi beberapa kata. Kumpulan kata tersebut kemudian disimpan dalam tabel sementara pada database. Setelah semua kata tersimpan, kemudian proses dilanjutkan dengan perhitungan bobot untuk masing-masing kata. Proses ini diperlukan untuk mengkonversi dokumen uji menjadi vektor. Proses selanjutnya adalah dengan mengambil data kata dokumen uji yang biasa disebut vektor untuk kemudian dimasukkan ke dalam model SVM yang telah dibuat sebelumnya.
Evaluasi kinerja klasifikasi
Pada tahapan sebelumnya sudah dijelaskan tahap-tahap pembuatan model klasifikasi sampai dengan pengujian dokumen uji. Ada beberapa faktor yang menentukan hasil klasifikasi dokumen uji. Diantaranya adalah panjang dokumen dan nilai epsilon. Tahapan ini akan menjelaskan hasil kinerja klasifikasi berdasarkan beberapa parameter yang telah digunakan. Untuk melihat perbandingan hasil, maka dibuat percobaan klasifikasi dengan dokumen uji sebanyak 150 dokumen dengan masing-masing 75 dokumen pada kategori long document dan 75 dokumen pada kategori short dokumen. Evaluasi dilakukan dengan membandingkan akurasi dari masing-masing nilai epsilon. Tabel 8 adalah perbandingan untuk kategori long document dari akurasi masing-masing nilai
epsilon.
Tabel 8 Perbandingan kategori long document
0.1 0.01 0.001 0.0001
akurasi 33.33 84 86.67 85.33
Sedangkan untuk perbandingan untuk kategori short document dapat dilihat pada tabel 9.
Tabel 9 Perbandingan kategori short document
0.1 0.01 0.001 0.0001
14
Setelah melihat tabel 8 dan tabel 9, maka bisa disimpulkan bahwa nilai epsilon dan panjangnya data uji sangat mempengaruhi hasil dari klasifikasi. Nilai epsilon 0.01 adalah nilai maksimum untuk mencapai akurasi yang paling baik. Sedangkan untuk kategori dokumen, long document memiliki tingkat akurasi lebih baik dibandingkan dengan short document.
Bila dilihat dari nilai epsilon, seharusnya memang semakin kecil nilainya maka akan semakin baik hasilnya. Hal ini terjadi karena nilai epsilon itu adalah jarak antar vektor yang bisa dijadikan acuan untuk menentukan vektor tersebut berada dalam satu kelas atau tidak. Tetapi tidak selamanya nilai epsilon yang rendah akan menghasilkan hasil yang lebih baik. Terbukti pada nilai 0.001 hasil klasifikasi mulai menurun. Hal ini terjadi karena jarak yang terlalu dekat juga tidak baik, karena jangkauan vektor satu dengan vektor yang lain akan berkurang.
Sedangkan bila kita lihat dari kategori dokumen, dapat terlihat jelas bahwa panjang dokumen sangat mempengaruhi hasil klasifikasi. Semakin panjang dokumen maka akan semakin banyak kata yang bisa dihitung bobotnya dan kemudian dijadikan vektor. Vektor inilah yang menjadi masukkan kedalam model SVM. Gambar 6 adalah grafik perbandingan antar nilai epsilon untuk mempermudah dalam melihat progress peningkatan dan penurunan akurasi pada masing-masing kategori dokumen.
Gambar 6 Perbandingan akurasi untuk kategori dokumen
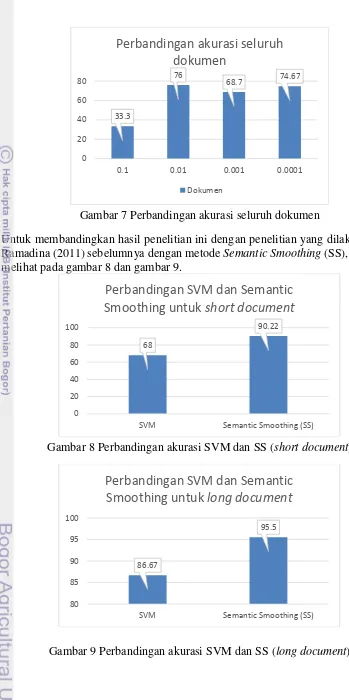
Sedangkan untuk akurasi keseluruhan tanpa memperhatikan panjang dokumen dapat dilihat pada gambar 7.
15
Gambar 7 Perbandingan akurasi seluruh dokumen
Untuk membandingkan hasil penelitian ini dengan penelitian yang dilakukan oleh Ramadina (2011) sebelumnya dengan metode Semantic Smoothing (SS), kita dapat melihat pada gambar 8 dan gambar 9.
Gambar 8 Perbandingan akurasi SVM dan SS (short document)
Gambar 9 Perbandingan akurasi SVM dan SS (long document)
16
Dari perbandingan yang dilihatkan pada gambar 8 dan gambar 9, dapat disimpulkan bahwa penelitian yang dilakukan oleh Ramadina (2011) memiliki akurasi lebih baik dibandingkan hasil pada penelitian ini. Hal ini disebabkan oleh proses semantic smoothing yang dilakukan pada penelitian Ramadina (2011). Sedangkan pada penelitian ini hanya mengandalkan hasil murni dari klasifikasi SVM. Selain itu, pemilihan parameter pada SVM juga sangat penting dalam mempengaruhi hasil klasifikasi dokumen.
SIMPULAN DAN SARAN
Simpulan
Setelah melakukan beberapa percobaan, penelitian ini menghasilkan beberapa simpulan, yaitu :
1. Metode support vector machine cukup baik digunakan untuk mengembangkan sistem klasifikasi dokumen teks.
2. Hasil akurasi terbaik adalah 76 % pada nilai epsilon 0.01.
3. Pemilihan fitur sangat mempengaruhi kinerja sistem klasifikasi dokumen karena sistem akan bekerja secara efisien.
4. Nilai epsilon dan panjang dokumen uji sangat mempengaruhi hasil klasifikasi dokumen.
5. Semakin kecil nilai epsilon belum tentu meningkatkan hasil klasifikasi dokumen.
Saran
1. Perlu dilakukan penelitian lebih lanjut mengenai pemilihan kernel yang akan digunakan.
2. Ada beberapa faktor yang perlu diteliti lebih lanjut untuk meningkatkan hasil klasifikasi seperti nilai C dan kernel yang digunakan.
3. Agar kata yang dihasilkan dari preprossesing lebih akurat dan efisien, maka perlu dilakukan tahap lain selain tahap yang sudah dijelaskan pada penelitian ini.
4. Untuk meningkatkan akurasi klasifikasi, gunakan semantic smoothing
17
DAFTAR PUSTAKA
Baeza-Yates R, Riberio-Neto B. 1999. Modern information retrieval. England: Addison Wesley.
Christianini, N and J. Shawe-Taylor. 2000. An introduction to support vector machines and other kernel-based learning methods. Cambridge University Press, Cambridge, U.K.
Goller C, et al. 2000. Automatic document classification : a thorough evaluation of various methods.SAIL-LABS, München, Germany.
Herawan Y. 2011. Ekstraksi ciri dokumen tumbuhan obat menggunakan chi-kuadrat dengan klasifikasi naive bayes [Skripsi]. Departemen Ilmu Komputer FMIPA-IPB.
Joachims, T. 1998. Text categorization with support vector machines : learning with many relevant features. Universitat Dortmund, Germany.
Manning, C.D, P. Raghavan, H.Schütze, 2007. An introduction to information retrieval. Cambridge University Press, Cambridge, England.
Nugroho AS, Witarto AB, Handoko D. 2003. Support vektor machine -teori dan aplikasinya dalam bioinformatika-. Kuliah Umum Ilmukomputer.com, Indonesia.
Platt JC. 1998. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machine.
18
Lampiran 1 Tabel distribusi nilai chi-kuadrat dengan nilai derajat bebas dan tingkat signifikansi tertentu
Sumber: Ronald J. Wonnacolt and Thomas H. Wonnacot.
19