Fakultas Ilmu Komputer
Universitas Brawijaya 1215
Implementasi Metode Support Vector Machine Untuk Klasifikasi Jenis Penyakit Malaria
Tryse Rezza Biantong1, Muhammad Tanzil Furqon2, Arief Andy Soebroto3 Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya
Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Malaria merupakan suatu penyakit yang ditularkan oleh nyamuk Anopheles betina yang terinfeksi oleh suatu parasit (protozoa) yang berasal dari genus Plasmodium. Terdapat empat spesies parasit protozoa yang umumnya menyerang manusia, diantaranya: Plasmodium vivax yang menyebabkan malaria tertiana, Plasmodium falciparum menyebabkan malaria tropika, Plasmodium malariae menyebabkan malaria kuartana, dan Plasmodium ovale menyebabkan malaria ovale. Dari keempat penyakit malaria ini memiliki gejala yang hampir sama sehingga tidak mudah untuk membedakan antara jenis malaria yang satu dengan yang lain. Maka dari itu, dibutuhkan suatu sistem yang dapat mengklasifikasan jenis penyakit malaria berdasarkan gejala yang ditimbulkan. Klasifikasi merupakan pembuatan suatu model yang digunakan untuk mengelompokkan suatu objek yang memiliki ciri-ciri yang sama ke dalam suatu kelas yang telah ditentukan. Salah satu metode klasifikasi adalah Support Vector Machine (SVM). Oleh karena itu dalam penelitian ini digunakan algoritma klasifikasi SVM dengan menggunakan kernel RBF.
Data yang digunakan sebanyak 200 data yang diambil dari Dinas Kesehatan Kabupaten Nabire, Papua.
Pada pengujian ini digunakan K-fold Cross Validation dengan nilai K-fold=10. Hasil akurasi terbaik yang dihasilkan oleh sistem ini adalah 72% dengan nilai parameter λ=0.1, σ=1, γ=0.001, C=0.1, ε=1.10- 5, itermax = 50 pada data rasio 80% data training : 20% data testing.
Kata kunci: Malaria, Klasifikasi, Support Vector Machine, One Against All Abstract
Malaria is a disease transmitted by female Anopheles mosquitoes infected by a parasite (protozoa) originating from the genus Plasmodium. There are four species of protozoa parasites that commonly attack humans, including: Plasmodium vivax which causes malaria tertiana, Plasmodium falciparum causes malaria tropica, Plasmodium malariae causes malaria quartana, and Plasmodium ovale causes malaria ovale. These four malaria cases almost have the same symptoms, so it is not easy to distinguish between one to another. Therefore, a system that can classify these types of malaria based on the symptoms is needed. Classification is the creation of a model that is used to classify an object into a predetermined class based on the same characteristics. One of the classification method is Support Vector Machine (SVM). Therefore the SVMs classification algorithm using the RBF kernel is being used in this study. The data used were 200 data taken from Dinas Kesehatan Kabupaten Nabire, Papua. In this test used K-fold Cross Validation with the K-fold values = 10. The best accuracy results generated by this system is 72.5% with the value of the parameter λ=0.1, σ=1, γ=0.001, C=0.1, ε=1.10-5, itermax=50 data on the ratio of 80% training data : 20% testing data.
Keywords: Malaria, Classification, Support Vector Machine, One Against All
1. PENDAHULUAN
Malaria merupakan suatu penyakit yang ditularkan oleh nyamuk Anopheles betina yang terinfeksi oleh suatu parasit (protozoa) yang berasal dari genus Plasmodium. Terdapat empat spesies parasit protozoa yang menyerang
manusia, diantaranya : Plasmodium vivax yang menyebabkan malaria tertiana, Plasmodium falciparum menyebabkan malaria tropika, Plasmodium malariae menyebabkan malaria kuartana, Plasmodium ovale menyebabkan malaria ovale (Hiswani, 2004).
Penyakit malaria tergolong ke dalam salah satu penyakit dengan resiko dan angka kematian
yang cukup tinggi. World Health Organization (WHO) mencatat bahwa tahun 2015 ditemukan 214 juta orang terinfeksi penyakit malaria dan 438.000 orang diantaranya meninggal dunia. Di Indonesia sendiri, angka kesakitan malaria pada tahun 2016 menurut data Kementerian Kesehatan Republik Indonesia adalah 0,84 per 1000 penduduk yang beresiko terserang penyakit malaria dengan daerah endemis tertinggi adalah Papua, Papua Barat, Ambon, NTT dan NTB (KEMENKESRI, 2017). Terlihat dari data tersebut bahwa daerah yang banyak terserang penyakit malaria adalah yang tergolong daerah terpencil.
Jika ditinjau lebih dalam sebenarnya angka kesembuhan penyakit ini cukup tinggi jika dapat dideteksi sejak dini (Anon., 2016). Namun, banyaknya jenis penyakit malaria dengan gejala yang hampir sama membuat orang awam atau para medis sekalipun pun seringkali salah dalam mendiagnosis ataupun mengklasifikasikan jenis penyakit malaria ini, sehingga mengakibatkan pasien tidak langsung mendapat penanganan medis dan harus menunggu hasil laboratorium.
Masalah ini semakin dipersulit dengan kurangnya alat atau laboratorium dalam mendiagnosis penyakit malaria dan hal ini umumnya terjadi di daerah terpencil. Oleh karena itu, sangatlah penting membuat sebuah sistem klasifikasi untuk membantu pengguna dalam mendiagnosa awal penyakit malaria yang diderita. Karena setiap jenis penyakit malaria memiliki tingkat penanganan yang berbeda. Ada yang harus ditangani dengan cepat dan ada pula yang tidak. Dengan adanya sistem klasifikasi penyakit malaria ini diharapkan dapat memudahkan masyarakat terlebih khusus para medis dalam menangani tiap pasien dengan lebih cepat dan mengurangi human error yang dilakukan masyarat.
Sudah banyak yang menggunakan metode dalam machine learning di bidang kesehatan untuk menganalisis dataset medis. Salah satunya Support Vector Machine (SVM) yang merupakan suatu metode atau teknik dalam melakukan suatu prediksi, baik dalam kasus klasifikasi maupun regresi (Santoso, 2007).
Beberapa peneliti telah membuktikan bahwa metode SVM lebih unggul dalam melakukan klasifikasi. Seperti pada penelitian yang dilakukan oleh Aegarut Pinkaew dalam mengklasifikasikan jenis parasite Plasmodium falciparum dan parasite Plasmodium vivax berdasarkan data citra parasit penyebab malaria yang diambil dari Biodemical Signal Processing
Laboratory, NECTED, Thailand. Jumlah data yang digunakan adalah 103 yang terdiri dari 56 dataset kelas p.falciparum dan 47 dataset untuk kelas p.vivax. Penelitian ini menggunakan 5 jenis fitur yang didapat dari ekstraksi 4 komponen warna citra parasit. Nilai akurasi yang dihasilkan dari penelitian ini adalah 85,71%
untuk kelas P.falciparum dan 78,72% untuk kelas P.vivax (Pankaew, et al., 2015) .
Berdasarkan uraian tersebut maka penelitian ini juga akan mencoba mengklasifikasikan jenis penyakit malaria menggunakan SVM berdasarkan gejala yang dialami oleh pasien-pasien sebelumnya, sehingga dengan sistem ini kedepannya dapat mempermudah pengguna dan para medis untuk mengetahui jenis penyakit malaria mana yang dialami pasien, sehingga penanganannya akan lebih cepat diatasi.
2. TINJAUAN PUSTAKA 2.1 Data Mining
Data mining adalah suatu metode statistik, kecerdasan buatan, dan machine learning yang dapat menganalisa secara otomatis data dalam jumlah yang besar serta kompleks untuk mendapatkan suatu pola yang tidak disadari keberadaannya. Dalam suatu jurnal ilmiah, data mining juga dikenal dengan nama Knowledge Discovery in Databases (KDD). Kehadiran data mining dilatarbelakangi oleh problematika yang dialami saat ini yaitu adanya data explosion di banyak bidang dan organisasi karena data yang terkumpul setiap hari, bulan, bahkan setiap tahunnya (Sucahyo, 2003).
Prosedur yang digunakan pada proses data mining adalah melalui tahapan seperti yang diungkapkan oleh Kantardsic (2003) yaitu sebagai berikut:
1. Menentukan masalah dan rumusan hipotesis.
Pada tahap ini yang harus dilakukan adalah menentukan variabel-variabel terkait dan membuat rumusan hipotesis.
2. Pengumpulan Data
Di tahap ini dilakukan pengumpulan data- data yang terkait dan bagaimana data dihasilkan.
3. Preprocessing data
Tahap ini dilakukan sebagai fungsi cleaning dimana dilakukan pembersihan terhadap outlier, penanganan missing value, dan transformasi data. Sehingga data training memiliki rentang yang baik, dan lebih mudah
dalam proses pengukuran dan perhitungan.
Salah satu contoh preprocessing data adalah normalisasi.
4. Perkiraan Model
Di tahap ini, akan dilakukan pemilihan teknik data mining sesuai tugas yang dilakukan.
5. Menafsirkan model dan menarik kesimpulan Tahap ini berfungsi untuk menafsirkan model sebagai pendukung kesimpulan yang didapat.
2.2 Support Vector Machine (SVM)
Support Vector Machine (SVM) dikembangkan oleh Boser, Guyon, dan Vapnik.
SVM pertama kali direpresentasikan pada tahun 1992 di Annual Workshop on Computational Learning Theory. Konsep dasar SVM sebenarnya dapat dijelaskan secara sederhana yaitu sebagai usaha untuk mencari hyperplane terbaik yang berfungsi sebagai pemisah dua buah class pada input space. Hyperplane merupakan sebuah garis lurus atau bidang mendatar yang memisahkan kelas-kelas (Munawarah, et al., 2016).
Menurut Burges proses klasifikasi data menggunakan Support Vector Machine dapat dibedakan atas 2 berdasarkan kernel yang digunakan yaitu :
1. SVM Linear
Support Vector Machine dengan menggunakan kernel Linear digunakan pada saat data yang akan diklasifikasi dapat dipisahkan dengan sebuah garis/hyperplane dengan mudah dengan pembagian yang jelas (Honakan, et al., 2018). Perhitungan kernel Linear dapat didefinisikan pada Persamaan (1).
𝐾(𝑥, 𝑦) = 𝑥. 𝑦 (1)
Keterangan :
𝐾(𝑥, 𝑦): Hasil perhitungan kernel 𝑥 ∶ data ke -𝑥
𝑦 ∶ data ke -𝑦 2. SVM Nonlinear
Support Vector Machine Non-Linear merupakan cara untuk memisahkan data-data dari yang sifatnya non-linear menjadi linear dengan menggunakan fungsi kernel. Fungsi kernel dalam metode ini juga disebut kernel trick. Kernel trick merupakan fungsi yang mengelompokkan data dari dimensi rendah menjadi data dimensi tinggi (Nugroho, et al., 2003). Terdapat beberapa macam fungsi kernel Non-Linear yang dapat digunakan
pada sebuah aplikasi untuk mengatasi masalah, seperti :
1. Kernel Polynomial
𝐾(𝑥, 𝑦) = (𝑥. 𝑦 + 1)𝑝 (2) 2. Kernel Gaussian RBF
𝐾(𝑥, 𝑦) = 𝑒−||𝑥−𝑦||2/2𝜎2 (3) 3. Kernel Sigmoid
𝐾(𝑥, 𝑦) = tanh(𝜅𝑥. 𝑦 − 𝛿) (4) Keterangan :
𝑝 ∶pangkat (degree of ) 𝜎 ∶nilai sigma
𝛿 ∶nilai delta
Berikut merupakan langkah-langkah proses klasifikasi menggunakan algoritma Support Vector Machine (Munawarah, et al., 2016).
1. Menghitung kernel SVM
Proses pertama yaitu menentukan dot product setiap data dengan memasukkan fungsi kernel baik kernel Linear maupun kernel Non-Linear.
2. Menghitung nilai matriks Hessian
Fungsi dari matriks Hessian adalah untuk mengidentifikasi optimum relatif suatu nilai fungsi. Untuk menghitung matriks Hessian, dapat ditunjukkan pada persamaan (5).
[𝐷]𝑖𝑗= 𝑦𝑖𝑦𝑗(𝐾(𝑥, 𝑦) + 𝜆2 (5) Keterangan :
[𝐷]𝑖𝑗∶ nilai matriks Hessian ke- 𝑖, 𝑗 𝑦𝑖 ∶ kelas data ke-𝑖
𝑦𝑗∶ kelas data ke-𝑗
𝜆 ∶ nilai lambda yang diinisialisasi 3. Menghitung nilai gamma
Nilai gamma (γ) berfungsi untuk mempercepat fungsi pada kernel SVM untuk mendapatkan akurasi classifier model klasifikasi yang optimal (Karima, 2014).
Perhitungan nilai gamma dapat ditunjukkan pada Persamaan (6).
𝛾 = 𝑐𝐿𝑅
max(𝐻𝑒𝑠𝑠𝑖𝑎𝑛) (6)
Keterangan :
𝑐𝐿𝑅 ∶ nilai constanta Learning Rate 4. Proses perhitungan Sequential Training
SVM
Dalam proses perhitungan Sequential Training SVM, terdapat beberapa tahapan yaitu :
a. Hitung nilai error (𝐸𝑖)
𝐸𝑖 = ∑𝑛
𝑗 = 1 𝛼𝑖𝐷𝑖𝑗 (7) b. Hitung nilai 𝛿𝛼𝑖
𝛿𝛼𝑖= min{max[𝛾(1 − 𝐸1), −𝛼𝑖],
𝐶 − 𝛼𝑖} (8)
c. Hitung nilai 𝛼𝑖
𝛼𝑖= 𝛼𝑖+ 𝛿𝛼𝑖 (9)
Keterangan :
𝛼𝑖∶ nilai parameter alpha data ke- 𝑖 𝐶 ∶ nilai parameter complexity 𝛿𝛼𝑖:nilai delta alpha data ke-𝑖 5. Menghitung nilai bobot/weight (𝑤)
Sebelum menghitung nilai 𝑤, terlebih dahulu harus menentukan nilai 𝛼𝑖𝑚𝑎𝑥 kelas positif dan nilai 𝛼𝑖𝑚𝑎𝑥 kelas negatif.
Pada proses perhitungan nilai 𝑤 dapat ditunjukkan pada persamaan berikut.
w. x+= K(x. y+) ∗ max(αi+) ∗ yi (10) w. x−= K(x. y−) ∗ max(αi−) ∗ yi (11) Keterangan :
w. x+∶ nilai bobot kelas positif w. x−∶ nilai bobot kelas negatif K(x. y+): kernel kelas 𝛼𝑖𝑚𝑎𝑥 positif K(x. y+): kernel kelas 𝛼𝑖𝑚𝑎𝑥 negatif 6. Menghitung nilai bias (𝑏)
Proses perhitungan nilai bias dapat ditunjukkan pada Persamaan (12).
𝑏 = −1
2(∑ w. x++ ∑ w. x−) (12) 7. Proses Perhitungan Pengujian SVM
Pada proses perhitungan pengujian SVM terdapat beberapa tahapan yaitu:
a. Perhitungan kernel data testing
Setelah mendapat nilai α, w, dan b dari proses training SVM maka langkah pertama dalam proses pengujian adalah menghitung semua dot product kernel antara data testing dan data training berdasarkan perhitungan kernel yang digunakan sebelumnya pada proses training SVM. Selanjutnya dilakukan perhitungan ∑𝛼𝑦𝑖(𝐾(𝑥, 𝑦) terhadap keseluruhan data testing menggunakan perhitungan pada Persamaan (13).
∑ 𝛼𝑖∗ 𝑦𝑖∗ (𝐾(𝑥, 𝑦) (13) b. Melakukan perhitungan 𝑓(𝑥)
Perhitungan nilai 𝑓(𝑥) bertujuan untuk mencari nilai klasifikasi dari setiap data
testing dengan menggunakan fungsi sign. Perhitungan fungsi klasifikasi dapat ditunjukkan pada Persamaan (14).
𝑓(𝑥) = 𝑠𝑖𝑔𝑛(∑𝑚𝑖=1𝛼𝑖𝑦𝑖𝐾(𝑥, 𝑦) + 𝑏)(14) 2.3 Studi Literatur
Pada tahapan ini dilakukan pembelajaran literatur atau pustaka dari bidang-bidang ilmu yang berhubungan dengan penelitian, diantaranya :
1. Penyakit Malaria 2. Data Mining
3. Metode Support Vector Machine
Literatur diperoleh dari e-book, jurnal, buku, penelitia sebelumnya, serta artikel-artikel dari internet yang dipandang dengan tema penelitian.
2.4 Pengumpulan Data
Pada penelitian ini, data yang digunakan merupakan data sekunder yang didapatkan dari data rekam medis Dinas Kesehatan Kabupaten Nabire, Papua selama rentang waktu tahun 2015- 2017. Terdiri dari 200 data pasien pengidap penyakit malaria dengan data gejala sebanyak 32 data. Data gejala yang didapatkan dapat dijabarkan pada Tabel 1 berikut.
Tabel 1. Data Gejala Malaria
ID Gejala Jenis Penyakit
K1 K2 K3 K4
F1 Sakit kepala 1 0 0 1
F2
Demam tinggi (40 derajat) atau lebih
0 1 0 1
F3 Menggigil 15
menit-1 jam 0 1 1 0
F4 Merasa
capek/lemah 1 1 1 1
F5 Kulit menjadi
merah 1 0 0 0
F6
Menggigil selama periode dingin
0 0 1 1
F7 Kulit dingin 0 1 1 0
F8 Kulit Kering 0 0 1 0
F9
Wajah terlihat kurang darah (pucat)
1 0 0 0
F10
Suhu meningkat(1 jam pertama)
0 1 0 1
F11 Wajah
memerah 1 0 0 1
F12 Kulit panas dan 0 0 1 0
keringat (40 derajat)
F13 Nadi cepat 0 1 1 1
F14 Nafas cepat 0 0 1 0
F15
Nyeri kepala dan persendian
0 1 1 1
F16
Muntah- muntah/ Rasa Mual
0 1 1 1
F17
Syok (periode ini selama 2 jam setelah periode dingin)
0 0 1 0
F18 Seluruh badan
tubuh basah 0 0 0 1
F19 Suhu turun 0 1 0 0
F20 Lelah 0 1 0 0
F21 Nyeri otot 1 0 1 1
F22 Diare 1 0 0 0
F23 DDR Plasmodium malariae positif
0 1 0 0
F24 DDR Plasmodium vivax positif
1 0 0 0
F25 DDR Plasmodium falciparum positif
0 0 1 0
F26 Batuk/Pilek 1 0 1 0
F27
Malas makan/tidak nafsu makan
0 1 1 0
F28
Gatal-gatal dilipatan buah dada
0 0 1 1
F29 Panas 1 1 1 0
F30 Sakit di ulu
hati 0 1 0 0
F31 Tidak sadarkan
diri 0 0 0 1
F32 Nafas sesak 0 0 0 1
Keterangan : K1: Tertiana K2: Kuartana K3:Tropika K4: Ovale 1 : terdapat gejala 0 : tidak terdapat gejala
2.5 Perancangan Sistem
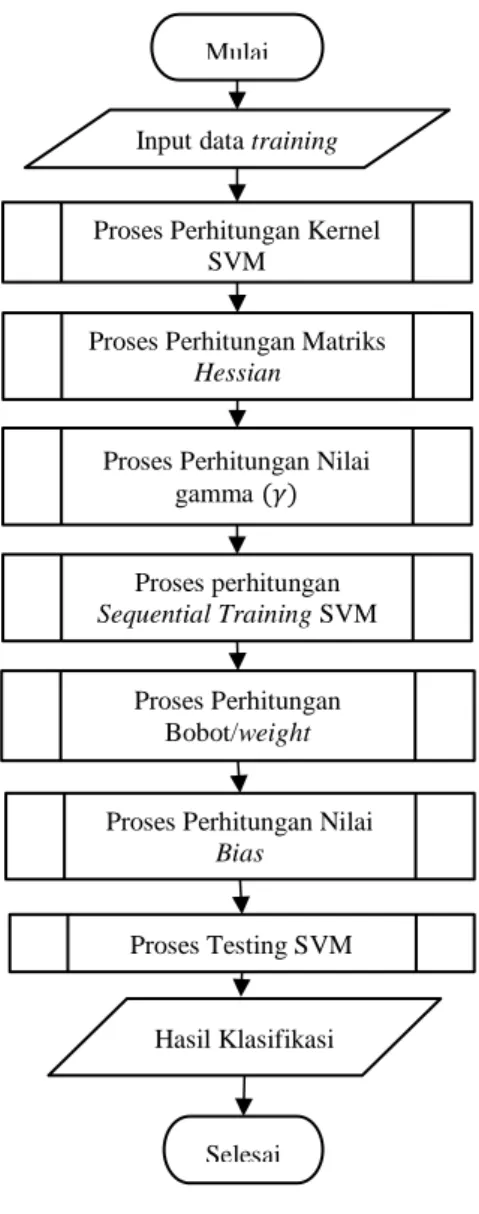
Perancangan sistem merupakan tahapan yang dilakukan dalam merancang sistem baik dari segi model maupun arsitekturnya, hal apa saja yang dibutuhkan serta bagaimana langkah kerja sistem. Berikut ini adalah langkah-langkah kerja sistem klasifikasi menggunakan metode SVM dan untuk diagram alirnya dapat dilihat pada Gambar 1.
1. Input
Masukan dari sistem ini berupa data pasien
berpenyakit malaria beserta gejala yang dialami tiap pasien.
2. Proses
Proses perhitungan klasifikasi penyakit malaria menggunakan metode SVM adalah sebagai berikut :
a. Menginputkan data training dan data testing, inisialisasi parameter, jumlah fitur, dan jumlah maksimal iterasi.
b. Melakukan perhitungan training SVM, berdasarkan jumlah level kelas.
Langkah-langkah training SVM adalah:
i. Menghitung kernel SVM menggunakan kernel RBF ii. Menghitung nilai matriks
Hessian.
iii. Menghitung nilai gamma untuk digunakan pada proses Sequential Training SVM.
iv. Melakukan perhitungan Sequential Training SVM yang diantaranya menghitung nilai error (𝐸𝑖), nilai 𝛿𝛼𝑖,nilai 𝛼𝑖. Proses ini dilakukan sebanyak iterasi yang ditentukan.
v. Menghitung nilai bobot/weight (w)
vi. Menghitung nilai bias
c. Melakukan perhitungan proses testing SVM. Yang terdiri dari :
i. Memilih data testing SVM ii. Menghitung kernel data testing
terhadap data training.
iii. Menghitung jumlah kernel data testing dikali nilai alpha dan kelas sistem.
iv. Menghitung nilai fungsi klasifikasi 𝑓(𝑥) dengan fungsi sign dan menggunakan metode One-Against-All.
3. Output
Keluaran sistem berupa hasil klasifikasi dari suatu data malaria.
Gambar 1. Diagram Alir Algoritma SVM 2.6 Implementasi
Penerapan sistem sesuai dengan perancangan yang telah dibuat yaitu menggunakan pemrograman Java sebagai platform-nya. Adapun fase dari implementasi sistem adalah :
1. Implementasi antarmuka sistem dan menggunakan bahasa pemrograman Java.
2. Implementasi metode Support Vector Machine (SVM) untuk sistem klasifikasi.
Keluaran dari sistem berupa hasil klasifikasi penyakit malaria dan nilai akurasi dari sistem.
2.7 Pengujian
Perancangan pengujian bertujuan untuk menguji validasi dari sistem yang telah dibuat.
Sistem dikatakan baik jika hanya menghasilkan nilai error yang kecil. Oleh karena itu sangat perlu melakukan pengujian pada suatu sistem.
Beberapa proses atau skenario pengujian yang akan dilakukan terhadap sistem dengan menggunakan metode K-Fold Cross Validation yaitu:
1. Pengujian terhadap jenis kernel
2. Pengujian terhadap setiap parameter λ (lambda)
3. Pengujian terhadap setiap parameter C (complexity)
4. Pengujian terhadap setiap parameter γ (gamma)
5. Pengujian terhadap setiap parameter 𝜎 (sigma)
6. Pengujian terhadap jumlah iterasi pada Support Vector Machine.
Pada setiap skenario pengujian terdapat 10 fold atau segmen dimana 1 fold terdiri atas 20 data. Dari 20 data tersebut akan dibagi lagi ke dalam data training dan data testing dengan pembagian 80% data training dan 20% data testing. Setiap fold terdiri atas 16 data training yang masing-masing terbagi atas 4 data tertiana, 4 data kuartana, 5 data tropika, 3 data ovale.
Serta 4 data testing yang terdiri atas masing- masing 1 data perwakilan tiap kelas. Pembagian data yang tidak seimbang antar kelas disebabkan karena jumlah data yang diperoleh setiap kelasnya berbeda.
3. HASIL DAN PEMBAHASAN
Hasil dan pembahasan merupakan tahap pengujian hasil dari perancangan dan implementasi.
3.1 Pengujian Terhadap Jenis Kernel Pengujian jenis kernel berguna untuk menunjukkan jenis kernel mana yang memiliki akurasi tertinggi. Jenis kernel yang akan diuji adalah kernel linear, kernel polynomial degree 2, dan kernel RBF. Pada pengujian jenis kernel nilai parameter yang digunakan meliputi λ=0.5, σ=1, γ=0.01, C=1, ε=1.10-5, iterasi=50, k- fold=10, serta menggunakan perbandingan data rasio 80% data training:20% data testing.
Sebagai hasil pengujian jenis kernel tersebut dapat ditunjukkan pada Gambar 2.
Mulai
Input data training
Proses Perhitungan Kernel SVM
Proses Perhitungan Matriks Hessian
Proses Perhitungan Nilai gamma (𝛾)
Proses perhitungan Sequential Training SVM
Proses Perhitungan Bobot/weight
Proses Perhitungan Nilai Bias
Proses Testing SVM
Hasil Klasifikasi
Selesai
Gambar 2. Hasil Pengujian Jenis Kernel Berdasarkan Gambar 2 menunjukkan bahwa tingkat akurasi tertinggi yaitu dengan menggunakan kernel RBF dengan akurasi 62.5%. Untuk akurasi terendah terdapat pada pengujian dengan menggunakan kernel Linear yaitu sebesar 47.5% dan untuk kernel Polynomial menghasilkan akurasi sebesar 50%.
Sehingga untuk klasifikasi penyakit malaria digunakan kernel RBF. Hal ini sesuai dengan pernyataan bahwa kernel RBF dapat digunakan sebagai pilihan pertama dalam klasifikasi SVM yang memiliki data dengan sifat Non-Linear.
Karena kernel RBF ini memiliki jumlah hiperparameter yang mempengaruhi kompleksitas pemilihan model lebih sedikit dibanding kernel lainnya. Namun, kernel RBF juga memiliki kelemahan yaitu tidak cocok dengan sistem klasifikasi yang memiliki fitur yang banyak (Hsu, et al., 2016).
3.2 Pengujian Nilai Parameter Lambda (𝝀) Pengujian terhadap nilai parameter λ ini berguna untuk menjelaskan hasil dari nilai lambda yang digunakan. Pengujian nilai parameter 𝜆 dilakukan berdasarkan nilai parameter yang dimasukkan meliputi, σ=1, γ=0.01, C=1, ε=1.10-5, k-fold=10, menggunakan kernel RBF, iterasi=50 serta menggunakan perbandingan data rasio 80% data training: 20%
data testing. Sebagai hasil pengujian nilai lambda tersebut dapat ditunjukkan pada Gambar 3.
Gambar 3. Hasil Pengujian Nilai Lambda
Berdasarkan Gambar 3. dapat diketahui bahwa nilai rata-rata tingkat akurasi lambda tertinggi ada pada nilai 𝜆=0.1 yaitu sebesar 55%
dan nilai terendah terdapat pada 𝜆=1, 5, 10 dan 100 dengan nilai 40%. Dari grafik tersebut bisa disimpulkan bahwa semakin besar nilai lambda bukan berarti dapat membuat akurasi menjadi lebih baik. Hal ini disebabkan karena jika nilai lambda semakin tinggi maka dapat membuat proses komputasi pada tahap perhitungan matriks hessian akan semakin lama. Hal tersebut dapat menyebabkan terjadinya augmented factor (lambda) yang menjadikan sistem lebih lambat saat akan mencapai nilai konvergen sehingga mengakibatkan ketidakstabilan proses pembelajaran yang dilakukan. Oleh karena itu maka pada pengujian selanjutnya akan menggunakan lambda 0.1.
3.3 Pengujian Nilai Parameter Complexity (𝑪)
Pengujian tehadap nilai parameter complexity (C) bermanfaat untuk mengetahui hasil akurasi dari setiap parameter 𝐶 yang digunakan. Pengujian nilai parameter 𝐶 dilakukan berdasarkan nilai parameter yang dimasukkan meliputi, λ=0.1, σ=1, γ=0.01, ε=1.10-5, k-fold=10 iterasi=50, menggunakan kernel RBF serta menggunakan perbandingan data rasio 80% data training : 20% data testing.
Sebagai hasil pengujian nilai parameter 𝐶 tersebut dapat ditunjukkan pada Gambar 4.
Gambar 4. Hasil Pengujian Nilai Complexity Berdasarkan Gambar 4. didapatkan nilai akurasi tertinggi sebesar 70% pada parameter Complexity yaitu 0.1 dan akurasi terendah pada nilai C=30 dan 50 dengan nilai akurasi sebesar 27.5%. Hasil akurasi mulai menurun pada C=1.
Nilai Complexity digunakan untuk memperkecil nilai error pada proses training saat menghitung nilai 𝑤 (weight) serta meminimalkan nilai slock variabel. Hal ini penting untuk memaksimalkan
47,5 50 62,5
0 20 40 60 80
Kernel Linier Kernel Polynomial
Kernel RBF
Hasil Rata-Rata Akurasi Jenis Kernel
52,5 55
42,5 40 40 40 40 40
0 20 40 60
0,01 0,1 0,5 1 5 10 50 100 Hasil Rata-Rata Akurasi Nilai Lambda
60 70 52,5
35 32,5 27,5 27,5
0 20 40 60 80
0,01 0,1 1 10 20 30 50
Hasil Rata-Rata Akurasi Nilai Complexity
margin dan meminimalkan jumlah slock (Puspitasari, et al., 2018).
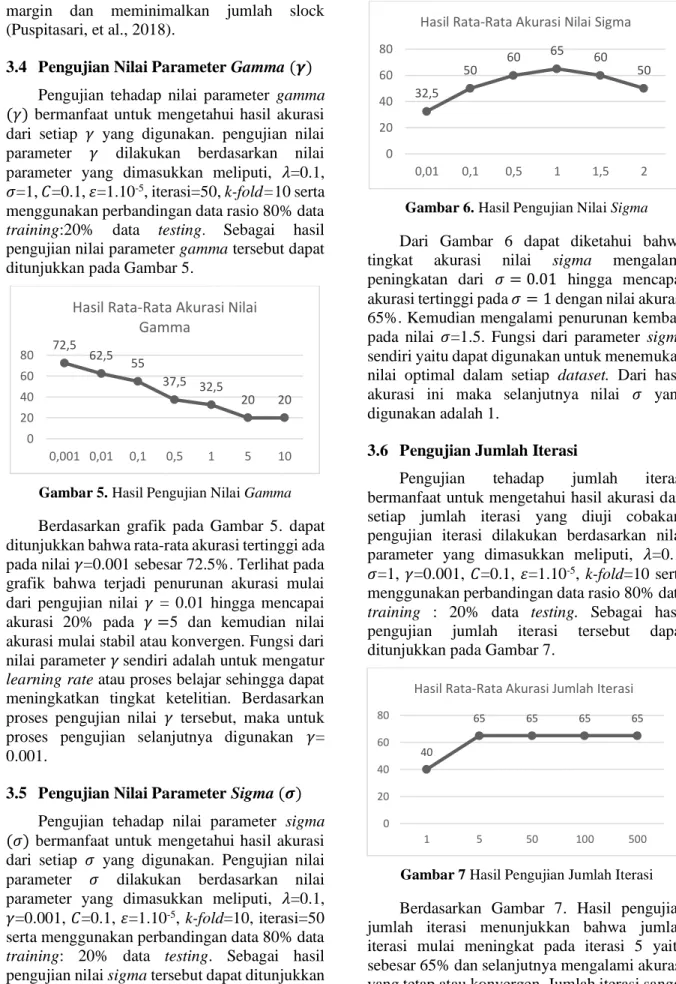
3.4 Pengujian Nilai Parameter Gamma (𝜸) Pengujian tehadap nilai parameter gamma (𝛾) bermanfaat untuk mengetahui hasil akurasi dari setiap 𝛾 yang digunakan. pengujian nilai parameter 𝛾 dilakukan berdasarkan nilai parameter yang dimasukkan meliputi, 𝜆=0.1, 𝜎=1, 𝐶=0.1, 𝜀=1.10-5, iterasi=50, k-fold=10 serta menggunakan perbandingan data rasio 80% data training:20% data testing. Sebagai hasil pengujian nilai parameter gamma tersebut dapat ditunjukkan pada Gambar 5.
Gambar 5. Hasil Pengujian Nilai Gamma Berdasarkan grafik pada Gambar 5. dapat ditunjukkan bahwa rata-rata akurasi tertinggi ada pada nilai 𝛾=0.001 sebesar 72.5%. Terlihat pada grafik bahwa terjadi penurunan akurasi mulai dari pengujian nilai 𝛾 = 0.01 hingga mencapai akurasi 20% pada 𝛾 =5 dan kemudian nilai akurasi mulai stabil atau konvergen. Fungsi dari nilai parameter 𝛾sendiri adalah untuk mengatur learning rate atau proses belajar sehingga dapat meningkatkan tingkat ketelitian. Berdasarkan proses pengujian nilai 𝛾 tersebut, maka untuk proses pengujian selanjutnya digunakan 𝛾=
0.001.
3.5 Pengujian Nilai Parameter Sigma (𝝈) Pengujian tehadap nilai parameter sigma (𝜎) bermanfaat untuk mengetahui hasil akurasi dari setiap 𝜎 yang digunakan. Pengujian nilai parameter 𝜎 dilakukan berdasarkan nilai parameter yang dimasukkan meliputi, 𝜆=0.1, 𝛾=0.001, 𝐶=0.1, 𝜀=1.10-5, k-fold=10, iterasi=50 serta menggunakan perbandingan data 80% data training: 20% data testing. Sebagai hasil pengujian nilai sigma tersebut dapat ditunjukkan pada Gambar 6.
Gambar 6. Hasil Pengujian Nilai Sigma Dari Gambar 6 dapat diketahui bahwa tingkat akurasi nilai sigma mengalami peningkatan dari 𝜎 = 0.01 hingga mencapai akurasi tertinggi pada 𝜎 = 1 dengan nilai akurasi 65%. Kemudian mengalami penurunan kembali pada nilai 𝜎=1.5. Fungsi dari parameter sigma sendiri yaitu dapat digunakan untuk menemukan nilai optimal dalam setiap dataset. Dari hasil akurasi ini maka selanjutnya nilai 𝜎 yang digunakan adalah 1.
3.6 Pengujian Jumlah Iterasi
Pengujian tehadap jumlah iterasi bermanfaat untuk mengetahui hasil akurasi dari setiap jumlah iterasi yang diuji cobakan.
pengujian iterasi dilakukan berdasarkan nilai parameter yang dimasukkan meliputi, 𝜆=0.1, 𝜎=1, 𝛾=0.001, 𝐶=0.1, 𝜀=1.10-5, k-fold=10 serta menggunakan perbandingan data rasio 80% data training : 20% data testing. Sebagai hasil pengujian jumlah iterasi tersebut dapat ditunjukkan pada Gambar 7.
Gambar 7 Hasil Pengujian Jumlah Iterasi Berdasarkan Gambar 7. Hasil pengujian jumlah iterasi menunjukkan bahwa jumlah iterasi mulai meningkat pada iterasi 5 yaitu sebesar 65% dan selanjutnya mengalami akurasi yang tetap atau konvergen. Jumlah iterasi sangat berpengaruh terhadap kinerja nilai 𝛼 (alpha).
Nilai iterasi akan berhenti pada saat telah memenuhi syarat konvergen dimana nilai Max
72,5 62,5 55
37,5 32,5
20 20
0 20 40 60 80
0,001 0,01 0,1 0,5 1 5 10
Hasil Rata-Rata Akurasi Nilai Gamma
32,5
50 60 65 60
50
0 20 40 60 80
0,01 0,1 0,5 1 1,5 2
Hasil Rata-Rata Akurasi Nilai Sigma
40
65 65 65 65
0 20 40 60 80
1 5 50 100 500
Hasil Rata-Rata Akurasi Jumlah Iterasi
(|𝛿𝛼𝑖|) memiliki nilai kurang dari nilai epsilon(𝜀). Terjadinya nilai konvergen mulai pada iterasi 5 karena mulai bertambahnya jumlah iterasi sehingga membuat Support Vector dapat berjalan secara seimbang dan juga dapat dipastikan bahwa tiap fitur data memiliki posisi yang tidak jauh dari hyperplane atau bidang pemisah (Puspitasari, et al., 2018).
4. KESIMPULAN
Berdasarkan hasil penelitian dari sistem klasifikasi penyakit malaria menggunakan metode Support Vector Machine maka dapat disimpulkan bahwa:
1. Metode Support Vector Machine dapat diterapkan pada permasalahan klasifikasi penyakit malaria dengan hasil rata-rata akurasi terbaik sebesar 72.5 % berdasarkan rasio data 80% data training : 20% data testing, dengan nilai parameter terbaik 𝜆=0.1, 𝜎=1, 𝛾=0.001, 𝐶 = 0.1, 𝜀=1.10-5 dengan itermax=50. Selain itu, terdapat beberapa kali menghasilkan akurasi terbaik sebesar 100%. Sehingga hasil yang didapatkan adalah sistem mampu mengklasifikasikan jenis penyakit malaria ke dalam 4 kelas yaitu kelas Tertiana, Kuartana, Tropika, dan Ovale dengan baik.
2. Proses klasifikasi penyakit malaria ini masih menggunakan dataset yang terbatas yaitu 200 data. Dataset ini terbagi atas 50 data kelas Tertiana, 50 kelas Kuartana, 60 kelas Tropika, dan 40 kelas Ovale.
3. Pada pengujian kernel hasil yang paling optimal dihasilkan oleh kernel RBF dengan nilai akurasi 62.5%. Dapat disimpulkan bahwa dibanding kernel lainnya kernel RBF lebih cocok digunakan pada data jenis penelitian ini karena kernel RBF mampu memprediksi kelas pada data itu sendiri.
Sehingga mampu menghasilkan klasifikasi yang tepat sesuai kelas aslinya.
5. DAFTAR PUSTAKA
Anon., 2016. Dinas Kesehatan Kabupaten
Indragiri Hulu.
[Online] Available at:
http://www.dnkes.inkuhab.go.id/?p=40 28
[Accessed 3 Juli 2018].
Burges, C. J., 1998. A tutorial on Support Vector Machine for Pattern Recognition.
Kluwer Academic Publisher,Boston., Issue 2, pp. 121-167.
DEPKES RI, 2011. Departemen Kesehatan Republik Indonesia. Jakarta: DEPKES RI.
Hiswani, 2004. Gambaran Penyakit dan Vector Malaria di Indonesia. USU digital library.
Honakan, Adiwijaya & Faraby, S. A., 2018.
Analisis dan Implementasi Support Vector Machine dngan String Kernel dalam Melakukan Klasifikasi Berita Berbahasa Indonesia. e-Proceeding of Engineering, V(1), pp. 1701-17010.
Hsu, C.-W., Chang, C.-C. & Lin, C.-J., 2016. A Practical Guide to Support Vector Classification. Department of Computer Science National Taiwan University.
Kantardzic, M., 2003. Data Mining : Concepts, Models, Methods and Algorithm. New York: John Wiley and Sons.
Karima, I. S., 2014. Optimasi Parameter pada Support Vector Machine Untuk Klasifikasi Fragmen Metagenome Menggunakan Algoritme Genetika..
KEMENKESRI, 2017. Profil Kesehatan Indonesia Tahun 2016. Jakarta:
Kementrian Kesehatan RI.
Munawarah, R., Soesanto, O. & Faizal, M. R., 2016. Penerapan Metode Support Vector Machine pada Diagnosa Hepatitis.
Nugroho, A. S., Witarto, A. B. & Handoko, D., 2003. Support Vector Machine ,Teori dan Aplikasinya dalam Bioinformatika.
Pankaew, A., Limpiti, T. & Tritat, A., 2015.
Automated classification of malaria parasite species on thick blood film using support vector machine. IEEE Xplore.
Puspitasari, A. M., Ratnawati, D. E. & Widodo, A. W., 2018. Klasifikasi Penyakit Gigi Dan Mulut Menggunakan Metode Support Vector Machine.
Pengembangan Teknologi Informasi dan Ilmu Komputer, Volume II.
Roser, M. & Ritchie, H., 2017. Malaria.
Santoso, 2007. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta: Graha Ilmu.
Sucahyo, Y. G., 2003. Data Mining? Menggali Informasi yang Terpendam. Artikel Populer IlmuKomputer.Com.
UNITED NATIONS, 2015. The Millenium Development Goals Report 2015. New York: s.n.