LAMPIRAN B
LAMPIRAN C
Sintaks Program MATLAB rekaman suara
% Record your voice for 2 second.
rec0bj = audiorecorder; disp('Start speaking.') recordblocking(rec0bj, 5); disp('End of Recording.');
% Play back the recording.
play(rec0bj);
% store data in double-precision array.
myRecording = getaudiodata(rec0bj);
wavwrite(myRecording,'suaraujipertama.wav');
% plot the wavefrom.
LAMPIRAN D
Sintaks Program MATLAB pengambilan data %Data Awal Speech Continuous
[data, Fs, nbits, opts] = wavread('suaraujipertama.wav'); siz = wavread('suaraujipertama.wav','size');
%xlswrite('zero2.xlsx',data);
nbFrames = ceil((length(data)-N)/M); Frames = zeros(nbFrames+1,N);
for i = 0:nbFrames-1
lastLength = length(data)- nbFrames*M;
temp(1:lastLength) = data(nbFrames*M+1:(nbFrames*M +1 + lastLength-1));
Windows = zeros(nbFrames,nbSamples); for i = 1:nbFrames
%% Fourier Transform..
%% Mel-frequency Wrapping.. % (a) Calculate Power spectrum..
PowSpecs = abs(fourir).^2; PowSpecs = PowSpecs(1:NN-1,:);
% (b) Mel filter generation
nof_c = 20; % Number of channels..
df = Fs/N; Nmax = N/2; fmax = Fs/2;
% Convert to mel scale..
melmax = 2595*log10(1+fmax/700); melinc = melmax/(nof_c+1);
melcenters = (1:nof_c).*melinc;
% Convert to frequency scale..
fcenters = 700*((10.^(melcenters./2595))-1); centerf = round(fcenters./df);
startf = [1,centerf(1:nof_c-1)]; stopf = [centerf(2:nof_c),Nmax]; W = zeros(nof_c,Nmax);
% (c) Apply mel filters to Power spectrum coeffs..
melPowSpecs = W*PowSpecs;
% (d) MFCC calculations..
plot(cepstrum);
title('After Cepstrum');
%Display
if y == 66971
%fprintf('Nilai Koefisien Sinyal Suara\n');
fprintf('SINYAL SUARA MILIK SAUDARA WINDY\n');
msgbox('SINYAL SUARA MILIK SAUDARA WINDY','Success'); elseif y == 59399
fprintf('SINYAL SUARA MILIK SAUDARA A\n');
msgbox('SINYAL SUARA MILIK SAUDARA A','Success'); elseif y == 344028
fprintf('SINYAL SUARA MILIK SAUDARA B\n');
msgbox('SINYAL SUARA MILIK SAUDARA B','Success'); elseif y == 58991
fprintf('SINYAL SUARA MILIK SAUDARA C\n');
msgbox('SINYAL SUARA MILIK SAUDARA C','Success'); elseif y == 60540
fprintf('SINYAL SUARA MILIK SAUDARA D\n');
msgbox('SINYAL SUARA MILIK SAUDARA D','Success'); elseif y == 76828
fprintf('SINYAL SUARA MILIK SAUDARA E\n');
DAFTAR PUSTAKA
[1]
Ananda A. Ardha “Penggunaan pengenal pengucap tidak berdasarkan Teks (Speaker Recognition Text-Independent) sebagai Otorasi Pengaksesan Pintu” Teknik Elektro, Fakultas Teknik, Universitas Diponegoro, 2010.[2] DSP Mini-Project: An Automatic Speaker Recognition System
[3] Setiawan Angga, Achmad Hidayanto, R. Rizal Isnanto “Aplikasi pengenalan ucapan dengan ekstraksi Mel Frequency Cepstrum Coefficients (MFCC) melalui jaringan syaraf tiruan (JST) Learning Vektor Quantization (LVQ) untuk mengoperasikan kursor komputer”, ejournal.undip.ac.id, 2011.
[4] Mandalia Darshan, Pravin Gareta “ Speaker Recognition Using Mel Frequency Cepstrum Coefficient (MFCC) and Vector Quantization
Model” Teknik Elektro, Fakultas Teknik, Universitas Nirma, 17 Mei 2011.
[5] Putra Darma, Adi Resmawan “Verifikasi Biometri suara menggunakan Metode Mel Frequency Cepstrum Coefficient (MFCC) dan Dynamic Time Warping (DTW)” Teknik Informasi, Fakultas Teknik, Universitas
Udayana, 1 Juni 2011.
BAB III
PERANCANGAN SISTEM PENGENALAN PEMBICARA
3.1 Pendahuluan
Pengolahan suara adalah mempelajari sinyal suara dan cara mengolah sinyal tersebut. Sinyal biasanya diproses dalam tampilan digital yang mana nantinya pengolahan suara dapat terlihat pada interaksi pengolahan sinyal digital dan bahasa alami pemrosesan. Bahasa alami pemrosesan mencakup tentang kecerdasan buatan dan linguistik. Sinyal suara diperoleh melalui sebuah alat yang mengubah energi gelombang suara menjadi besaran - besaran listrik yang akan diteruskan dan diolah kembali menggunakan metode tertentu. Pada sistem ini sinyal suara diambil dari hasil pengumpulan data yang telah diekstrak kedalam format Extanstion xlsx. Secara keseluruhan data inilah yang akan dibangkitkan ulang untuk menghasilkan file suara dalam bentuk format dot wave. Hasil akhirnya sistem yang akan dibuat menggunakan software berbahasa MATLAB ini akan mampu membedakan setiap file suara yang telah diambil datanya.
3.2 Blok Diagram Perancangan Sistem
mempengaruhi setiap bagian komponen utama maupun pendukung dalam saat dijalankan selama proses berlangsung.
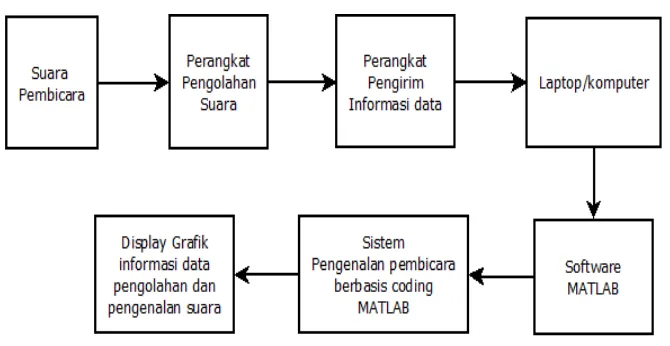
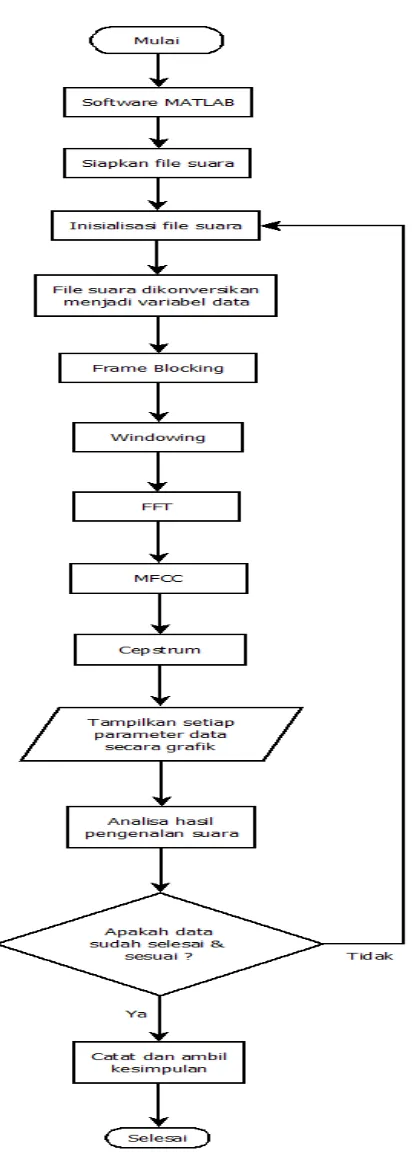
Untuk itu diperlukan sebuah blok diagram yang akan membantu penulis dan pembaca dalam memahami sistem perancangan pengenalan pembicara secara keseluruhan. Pada Gambar 3.1 terdapat blok diagram sistem secara keseluruhan yang menjadi garis besar tentang cara kerja sistem perancangan pengenalan pembicara.
Gambar 3.1Blok diagram Perancangan sistem pengenalan pembicara
Blok diagram yang dijelaskan pada penelitian ini mencakup blok diagram mengenai perancangan sistem pengenalan pembicara. Berdasarkan gambar blok diagram diatas, fungsi kerja dari masing – masing blok, adalah sebagai berikut :
1. Suara
gelombang sinus murni dimulai pada 20 Hz (20 siklus per detik atau suara terendah telinga manusia sehat dapat menerima) dan naik secara bertahap sampai 20 kHz (20.000 siklus per detik dan merupakan suara tertinggi yang bisa kita dengar). Dalam perancangan sistem ini telah ditentukan bahwa frekuensi sampling 8000 kHz berasal dari kelipatan teorema nyquist yang mengharuskan frekuensi sampling 2 kali lipat dari frekuensi sinyal suara. Pada penelitian ini besar sinyal suara sebesar 4 kHz dengan ketentuan percakapan manusia sebesar 340-3400 Hz.
2. Perangkat Pengolahan suara
Untuk perangkat perancangan sistem ini menggunakan Filter Anti Aliasing yang dapat meminimalisir munculnya sinyal baru yang berbeda dengan frekuensi sinyal aslinya. Filter yang akan digunakan adalah filter low pass chebyshev dengan rentang frekuensi yang dilewatkan dibawah 5 kHz.
Dalam perancangan sistem pengenalan pembicara ini terdiri dari penguat mikrofon dan anti aliasing filter. Tahap pertama dalam proses perekaman adalah mengubah gelombang akustik suara menjadi sinyal analog menggunakan mikrofon. Sinyal analog yang masih lemah ini perlu dikuatkan. Sebagai penguat dibutuhkan IC LM567.
3. Perangkat pengirim informasi data
transmitter). Perangkat ini terdapat pada fungsi khusus mikro kontroler
Arduino UNO.
4. Laptop atau Komputer
Perancangan sistem pengenalan pembicara ini menggunakan laptop atau komputer. Secara umum komputer adalah sistem elektronik yang memiliki kemampuan memanipulasi data dengan cepat dan tepat serta dirancang dan diorganisasikan agar secara otomatis menerima dan menyimpan data input, memprosesnya, dan menghasilkan output dibawah pengawasan suatu langkah–langkah instruksi program yang tersimpan didalam penyimpanannya.
5. Matlab
6. Sistem pengenalan pembicara berbasis coding Matlab
Merupakan sistem yang dibuat menggunakan software Matlab berbentuk program pengkodingan, yang dirancang pada format m-file. Program ini berisi algoritma dan urutan struktur program yang dibuat sedemikian rupa berdasarkan algoritma pengenalan pembicara.
7. Display grafik informasi data pengolahan dan pengenalan suara
Merupakan tampilan yang dihasilkan oleh sistem setelah program dijalankan.
3.3 Algoritma sistem pengenalan pembicara
Gambar 3.2 Bagan alir algoritma program perancangan sistem pengenalan
Untuk menjelaskan secara ringkas algoritma diatas, maka dapat kita kategorikan dalam beberapa bagian sebagai berikut :
1. Matlab
Matlab (Matrix Laboratory) merupakan salah satu bahasa pemrograman yang dikembangkan oleh MathWorks. Matlab adalah sebuah bahasa pemrograman dengan unjuk kerja tinggi (high performance) untuk komputasi teknis, yang mengintegrasikan komputasi,
visualisasi, dan pemrograman didalam lingkungan yang mudah penggunaannya dalam memecahkan persoalan dengan solusinya yang dinyatakan dengan notasi matematik.
Gambar 3.3 Tampilan program Matlab
Sistem Matlab terdiri dari 5 bagian utama, yaitu :
a. Bahasa (pemrograman) Matlab
Bagian ini adalah bahasa (pemrograman) tingkat tinggi yang menggunakan matriks/array dengan pernyataan aliran kendali program, struktur data, masukan/keluaran, dan fitur-fitur pemrograman berorientasi objek.
b. Lingkungan kerja Matlab
Bagian ini adalah sekumpulan tools dan fasilitas Matlab yang digunakan oleh pengguna atau pemrograman. Fasilitas yang dimaksudkan misalkan untuk mengelola variable didalam ruang kerja (workspace) dan melakukan impor dan ekspor data.
c. Penanganan Grafik
d. Pustaka (Library) fungsi matematis MATLAB
Bagian ini adalah koleksi algoritma komputasi mulai dari fungsi dasar seperti menjumlahkan (sum), menentukan nilai sinus (sine), kosinus (cosine), dan aritmatik bilangan kompleks.
e. API (Application Program Interface)
Bagian ini adalah pustaka (Library) untuk menuliskan program dalam bahasa C dan Fortran yang berinteraksi dengan MATLAB, termasuk fasilitas untuk memanggil rutin program dari MATLAB (dynamic linking), memanggil MATLAB sebagai mesin komputasi (computation engine) dan untuk pembacaan serta penulisan MAT – files.
2. File Suara
File suara yang dijadikan inputan pada sistem ini berasal dari data yang dikirim kan oleh alat pengolahan suara analog yang disimpan dalam bentuk format file dokumen dan akan diubah kembali menjadi file suara dalam format dot wav. Wav merupakan standar format container file yang digunakan oleh Windows. Wav umumnya digunakan untuk menyimpan audio tak termampatkan, file suara yang memiliki kualitas CD, yang berukuran besar (sekitar 10 MB per menit). File wav juga dapat berisi data terkodekan dengan beraneka ragam codec untuk mengurangi ukuran file. File audio WAV dengan PCM, namun bisa terkompresi maupun tidak
Kualitas produksi waveform audio bergantung pada sampling rate (banyaknya sampel per detik). Waveformaudio disebut juga pulse code modulator (pcm) audio. WAV merupakan standar untuk komputer
berbasis Windows, namum dapat digunakan dikomputer berbasis Machitosh. Adapun file suara yang akan dijadikan sampel memiliki
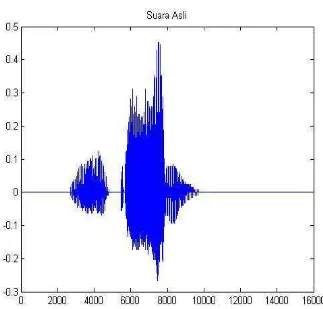
rentang atau pita suara sebesar 2 detik dengan satu buah pengucapan kata tertentu dengan perbedaan setiap sampel kata terdiri dari satu suara manusia. Adapun contoh file suara yang telah diambil ditunjukkan pada Gambar 3.4
Adapun file suara yang akan diinisialisasi berdasarkan file name suara yang akan diproses menjadi 4 buah variable data. Untuk lebih jelasnya sintaks program Matlab adalah sebagai berikut :
%Data Awal Speech Continuous
[data, Fs, nbits, opts] = wavread('s1.wav'); siz = wavread('s1.wav','size');
subplot(2, 1, 1); plot(data);
title('Suara Asli');
3. Frame Blocking
Pada perancangan sistem ini nilai N ditentukan atau ditetapkan berdasarkan nilai yang ditulis dalam program yang panjang nya antara 10-30 ms atau 256-1024 data.Panjang frame yang digunakan sangat mempengaruhi keberhasilan dalam analisa spectral. Di satu sisi ukuran dalam frame harus sepanjang mungkin untuk dapat menunjukkan resolusi frekuensi yang baik. Akan tetapi, di lain sisi ukuran frame juga harus cukup pendek untuk dapat menunjukkan resolusi waktu yang baik.
Dalam perancangan sistem ini sinyal suara yang kontinyu akan diblock menjadi frame sampel N, dengan frame yang berdekatan dipisahkan oleh M (M<N). Frame pertama terdiri dari N sampel, Frame kedua dimulai sampel M setelah frame yang pertama, dan melawati dari sampel N-M dan seterusnya. Proses ini berlanjut sampai semua suara dicatat dalam satu frame atau lebih. Dengan cara yang sama, frame ketiga dimulai 2M sampel
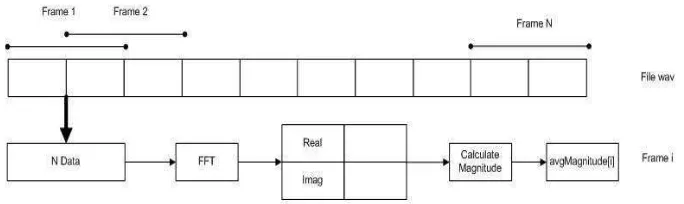
256 dan M =100. Berikut ini adalah diagram blok untuk proses penentuan frame yang ditunjukkan pada Gambar 3.5 [6].
Gambar 3.5 Diagram block proses penentuan frame blocking
Jadi, proses frame tersebut dilakukan secara terus-menerus hingga semua sinyal dapat terproses. Selain itu, proses ini umumnya dilakukan secara overlapping untuk setiap frame-nya. Panjang daerah overlap yang umum digunakan adalah kurang lebih 30% sampai 50% dari panjang frame. Untuk lebih jelasnya sintaks program Frame Blocking pada Matlab adalah sebagai berikut :
%% (1) Frame Blocking..
N = 256; % N point FFT M = 100; % Overlapping NN = floor(N/2+1); %N/2
nbFrames = ceil((length(data)-N)/M); Frames = zeros(nbFrames+1,N);
lastLength = length(data)- nbFrames*M;
4. Windowing
Pada perancangan sistem pengenalan pembicara proses windowing ini bertujuan untuk mengurangi terjadinya kebocoran spectral atau aliasing yang mana merupakan suatu efek dari timbulnya sinyal baru yang memiliki frekuensi yang berbeda dengan sinyal aslinya. Efek tersebut dapat terjadi karena rendahnya jumlah sampling rate atau karena proses frame blocking yang menyebabkan sinyal menjadi discontinue.
Hamming windows digunakan pada perancangan sistem ini dikarenakan
tujuan penulis untuk mengetahui seberapa besar pengaruh windowing ini terhadap sinyal analog yang akan diproses. Secara umum Fungsi ini menghasilkan sidelobe level yang tidak terlalu tinggi (kurang lebih -43 dB). Selain itu, noise yang dihasilkan pun tidak terlalu besar (kurang lebih 1.36 BINS). Untuk lebih jelas memahami mengenai sistem kerja atau pengaruh sinyal yang diakibatkan oleh Hamming window ditunjukan pada Gambar 3.6 [6].
Untuk lebih jelas, adapun script sintaks program Windowing pada Matlab adalah sebagai berikut :
% Windowing
Windows = zeros(nbFrames,nbSamples);
for i = 1:nbFrames
5. FFT (fast fourier transform)
Pada perancangan sistem ini untuk mendapatkan sinyal dalam domain frekuensi dari sebuah sinyal discrete, maka digunakan salah satu metode transformasi discrete fourier transform.DFT dilakukan terhadap masing-masing frame dari sinyal yang telah di windowing. Namun, yang menjadi persoalan adalah bahwa DFT tersebut memerlukan waktu komputasi yang sangat panjang untuk data yang besar. Oleh karena itu, diperlukan suatu teknik komputasi yang efisien, baik dari sisi waktu maupun dari sisi penggunaan memori.
FFT adalah algoritma cepat untuk mengimplementasikan discrete fourier transform (DFT).FFT ini mengubah masing-masing frame N sampel dari
domain waktu menjadi domain frekuensi.
analog yang diambil secara digital dengan satuan Hertz (Hz). Sample rate sinyal suara berpengaruh pada besarnya jangkauan frekuensi dari koefisien hasil FFT. Jangkauan frekuensi hasil FFT adalah setengah dari sample rate sinyal suara yang ditransformasi. Artinya, apabila terdapat sinyal suara dengan sample rate 44100 Hz, maka koefisien-koefisien hasil transformasi dari sinyal suara tersebut berkisar dari 0 Hz sampai 22050 Hz. Jadi, semakin besar sample rate , maka akan semakin detail pula sampel analog yang diambil secara digital.
Sedangkan FFT size adalah panjang dari FFT yang digunakan. FFT size berpengaruh terhadap ketelitian tiap koefisien FFT. Semakin besar FFT size, maka tiap koefisien hasil FFT akan mewakili rentang frekuensi yang semakin kecil, sehingga ketelitiannya semakin tinggi. Sebaliknya apabila ukuran sampel FFT semakin kecil, maka tiap koefisien hasil FFT akan mewakili rentang frekuensi yang semakin besar, sehingga ketelitiannya semakin rendah. Adapun script program Matlab tentang FFT (fast fourier transform) adalah sebagai berikut :
%% Fourier Transform..
ffts = fft (Windows'); subplot(6, 1, 4); plot(ffts);
title('After Fourier Transform');
6. MFCC (mel frequency cepstrum coefficients)
spectrum yag berasal dari spectrum yang lain. Perbedaan antara ceptrum dan mel frequency cepsturm adalah terletak pada MFC nya, Band frekuensi diposiskan secara algoritma pada skala mel yang mendekati respon sistem pendengaran manusia, lebih dekat dari band frekuensi ruang yang diperoleh secara langsung dari FFT dan DCT. Cara ini mampu memberikan peluang yang lebih baik dalam memproses data, sebagai contonya adalah audio compression.
MFCC secara umum diperoleh sebagai berikut :
a. Mengambil perubahan Fourier dari windowing sebuah sinyal b. Pemetaan logaritma amplitude dari perolehan spectrum diatas
menuju ke skala mel, menggunakan jendela overlap berbentuk segitiga
c. Memerlukan discrete cosine transform (DCT) dari logaritma amplitude mel, hanya jika itu merupakan sebuah sinyal
d. MFCC adalah aplitudo dalam menghasilkan spectrum
Dalam metode MFCC ini dapat dijelaskan script pemrograman dalam Matlab adalah sebagai berikut :
%% Mel-frequency Wrapping.. % (a) Calculate Power spectrum.. PowSpecs = abs(ffts).^2;
PowSpecs = PowSpecs(1:NN-1,:); % (b) Mel filter generation
nof_c = 20; % Number of channels.. df = Fs/N;
% Convert to mel scale..
melmax = 2595*log10(1+fmax/700); melinc = melmax/(nof_c+1);
melcenters = (1:nof_c).*melinc; % Convert to frequency scale..
fcenters = 700*((10.^(melcenters./2595))-1); centerf = round(fcenters./df);
for j = startf(i):centerf(i)
W(i,j) = (j-startf(i))*increment;
end
decrement = 1.0/(stopf(i)-centerf(i));
for j = centerf(i):stopf(i)
W(i,j) = (j-centerf(i))*decrement;
% (c) Apply mel filters to Power spectrum coeffs.. melPowSpecs = W*PowSpecs;
% (d) MFCC calculations..
melCeps = dct(log(melPowSpecs)); melCeps(1,:) = [];
subplot(6, 1, 5); plot(melCeps);
title('After MFCC');
7. Cepstrum
dikurangi, amplitudonya dibawa kedalam suatu skala yang dapat dipakai, dan menghasilkan suatu bentuk gelombang periodik dalam daerah frekuensi, periode berhubungan dengan frekuensi fundamental sinyal asli. Cepstrum merupakan suatu analisis spectral dengan keluaran berupa
alihragam Fourier dari fungsi logaritma magnitudo spectrum gelombang masukan. Prosedur ini dikembangkan dalam percobaan untuk membuat suatu sistem tidak linier agar lebih linier. Cepstrum atau koefisien cepstral, didefenisikan sebagai balikan alihragam Fourier dari spectrum amplitude logaritmik waktu pendek. Maksud dari cepstrum sesungguhnya adalah menyederhanakan koefisien yang diperoleh dari MFCC. Hasil dari penyederhanaan inilah yang menjadi data Matriks yang digunakan untuk mengidentifikasi kepemilikan sinyal suara masukan.
Adapun script pemrograman Matlab tentang cepstrum ini adalah sebagai berikut :
%Cepstrum
cepstrum = rceps(melCeps);
[long,coefficient] = size(cepstrum); x = iccpes(long,coefficient);
z = max(sum(abs(cepstrum))); y = round(10000*z);
figure(6);
BAB IV
HASIL DAN PENGUJIAN SISTEM
4.1 Gambaran Umum pengujian Sistem Pengenalan Pembicara
Tahapan pengujian sistem perancangan ini dilakukan dengan tujuan adalah untuk mengetahui hasil dari perancangan sistem yang telah dibuat. Pada pengujian sistem ini terdiri dari beberapa tahapan, dimulai dari gambaran umum pengujian sistem pengenalan pembicara, kemudian persiapan perangkat pendukung pengujian sistem dan pengujian terhadap file suara yang akan dianalisa. Sistem yang digunakan pada aplikasi ini menitikberatkan pada pengguna. Pengguna harus melakukan pengujian terhadap file suara yang mana akan diproses untuk dapat dikenali kepilikan suara tersebut. File suara yang merupakan hasil dari kontruksi ulang yang berasal dari pengiriman data oleh sistem filter anti aliasing. Rekontruksi ulang file suara yang berasal dari data tersebut akan diubat menjadi file suara dalam format dot wave menggunakan software pemrograman Matlab.
Program Matlab yang digunakan hanya berbentuk data dalam lingkungan kerja coding m-file. Adapun langkah – langkah untuk melakukan pengujian sistem ini
adalah sebagai berikut :
1. Jalankan program Matlab
2. Pilih program m-file yang telah dibuat sebelumnya 3. Atur parameter N dan M pada frame blocking 4. Tentukan file suara yang akan dianalisa
6. Analisa setiap output yang ditampilkan secara grafik
7. Simpulkan apakah file suara yang dianalisa sesuai dengan file suara yang diinputkan
4.2 Persiapan Perangkat Pendukung Pengujian Sistem
Untuk melakukan pengujian sistem ini diperlukan beberapa perangkat pendukung yang digunakan untuk mempermudah pengujian sistem yang baik untuk data referensi maupun mempermudah pengujian sistem untuk proses yang diharapkan penulis. Perangkat yang dimaksud penulis dalam pengujian sistem ini tidak hanya beralat yang berupa barang tetapi berhubungan juga terhadap tempat dan waktu serta orang – orang yang membantu dalam pengujian sistem ini. Adapun beberapa perangkat yang digunakan antara lain :
1. Tempat dan Waktu
Pengujian sistem dan pengambilan data ini dilakukan pada tanggal 20 Agustus 2015 dan bertempat di Komplek Puri, Pasar 1 Tanjung Sari No. 30 Ringroad Medan.
2. Partisipasi
3. Laptop
Dalam pengujian sistem ini digunakan Laptop bermerk HP ProBook 4421s dengan Spesifikasi Intel® Core™ i3 CPU sebagai unit pengolahan data yang dikirim oleh sistem dan sekaligus untuk menampilkan data dalam bentuk grafik.
4. Software Matlab
Matlab merupakan salah satu bahasa pemrograman dengan unjuk kerja tinggi (high performance) untuk komputasi Teknis yang mengintegrasikan komputasi visualisasi dan pemrograman didalam lingkungan yang mudah penggunaannya dalam memecahkan persoalan dengan solusi yang dinyatakan dengan notasi matematik. Pada pengujian sistem ini digunakan Matlab R2012a dengan batasan lingkungan kerja hanya pada pemrograman koding pada lingkungan ,m-file.
4.3 Pengujian Sistem terhadap file Suara
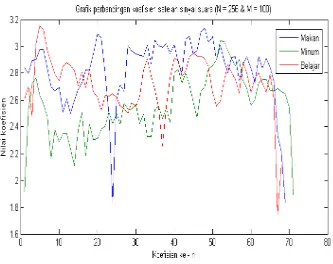
Gambar 4.1Grafik perbandingan koefisien untuk N = 256 dan M = 100
Pada Grafik yang ditunjukkan pada Gambar 4.1, data 1 merupakan pengucapan kata “MAKAN”, data 2 merupakan pengucapan kata “MINUM”, data 3 merupakan pengucapan kata “BELAJAR”.
Pengucapan kata “MAKAN” memiliki selisih jumlah koefisien terhadap pengucapan kata “MINUM” sebesar 2 koefisien, pengucapan kata “MAKAN” terhadap koefisien pengucapan kata “BELAJAR” memiliki selisih 3 koefisien.
Pengucapan kata “MINUM” terhadap koefisien pengucapan kata “BELAJAR” memiliki selisih 3 koefisien. Sedangkan untuk perbedaan koefisien sinyal suara untuk N = 512 dan M = 100 ditunjukkan pada Gambar 4.2
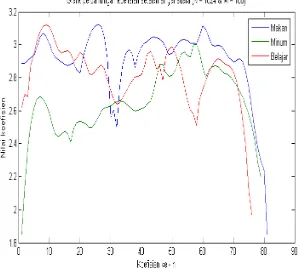
Gambar 4.2 Grafik perbandingan koefisien untuk N = 512 dan M = 100
koefisien pengucapan kata “BELAJAR” bernilai mulai dari 2.0437 mv sampai 3.1589 mv dan rata – rata 2.775177 mv dengan jumlah total koefisien 71 buah.
Pengucapan kata “MAKAN” memiliki selisih jumlah koefisien terhadap pengucapan kata “MINUM” sebesar 1 koefisien, pengucapan kata “MAKAN” terhadap koefisien pengucapan kata “BELAJAR” memiliki selisih 4 koefisien.
Pengucapan kata “MINUM” terhadap koefisien pengucapan kata “BELAJAR” memiliki selisih 3 koefisien.. Sedangkan untuk perbedaan koefisien sinyal suara untuk N = 1024 dan M = 100 ditunjukkan pada Gambar 4.3
Gambar 4.3 Grafik perbandingan koefisien untuk N = 1024 dan M = 100
kata “MINUM” bernilai mulai dari 1.8532 mv sampai 2.9992 mv dan nilai rata – rata 2.652034 mv dengan jumlah total koefisien 79 buah. Kemudian untuk koefisien pengucapan kata “BELAJAR” bernilai mulai dari 1.9730 mv sampai 3.1204 mv dan rata – rata 2.665712 mv dengan jumlah total koefisien 76 buah.
Pengucapan kata “MAKAN” memiliki selisih jumlah koefisien terhadap pengucapan kata “MINUM” sebesar 2 koefisien, pengucapan kata “MAKAN” terhadap koefisien pengucapan kata “BELAJAR” memiliki selisih 5 koefisien. Pengucapan kata “MINUM” terhadap koefisien pengucapan kata “BELAJAR” memiliki selisih 3 koefisien.
BAB V
PENUTUP
5.1 Kesimpulan
1. Sinyal suara dapat diidentifikasi berdasarkan jumlah koefisien yang dihasilkan.
2. Rentang koefisien berbanding lurus dengan frekuensi sinyal suara walaupun berbeda sumber suara tersebut.
3. Penggunaan frame blocking yang berbeda mempengaruhi rentang dan jumlah koefisien setiap sinyal suara.
4. Pengucapan jumlah suku kata sangat mempengaruhi jumlah koefisien setiap sinyal suara.
5. Pada penelitian ini Frame Blocking dengan nilai N = 256 adalah yang terbaik untuk menganalisa karakteristik sinyal suara manusia.
5.2 Saran
1. Lebih banyak melakukan sampel sinyal suara untuk mengahasilkan nilai koefisien yang lebih baik.
2. Diharapkan Tugas Akhir ini dapat menjadi acuan untuk melakukan penelitian pada sistem pengenalan suara.
BAB II
DASAR TEORI
2.1 Suara (Speaker)
Suara adalah sinyal atau gelombang yang merambat dengan frekuensi dan amplitudo tertentu melalui media perantara yang dihantarkannya seperti media air, udara maupun benda padat. Manusia dapat berkomunikasi dengan manusia lainnya dengan suara. Pembangkitan ucapan manusia dimulai dengan awal konsep dari gagasan yang ingin disampaikan pada pendengar. Pengucap mengubah gagasan tadi dalam struktur linguistic dengan memilih kata atau frasa yang secara tepat dapat mewakili dan membawakannya dengan tata bahasa yang dimengerti antara pengucap dan pendengar. Ucapan yang diucapkan memiliki tujuan tertentu dengan asumsi bahwa ucapan tersebut diucapkan secara benar, dapat diterima, dan dipahami oleh pendengar yang dituju.
Gambar 2.1 Lingkaran komunikasi Suara
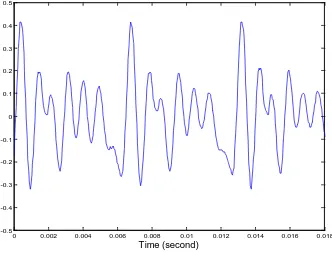
Sinyal suara terjadi secara perlahan waktu variasi sinyal (disebut sebagai kuasi stasioner). Contoh dari sinyal suara yang ditunjukkan pada Gambar 2.2 dibawah. Ketika diperiksa selama periode yang cukup singkat (5 sampai 100 msec), karakteristiknya cukup stasioner. Namun, selama jangka waktu yang lama (diurutan 1/5 detik atau lebih) sinyal karakteristik dapat mengubah pantulan berbicara berbeda dengan suara yang diucapkan. Oleh karena itu, waktu singkat spectral analisis adalah cara yang paling umum untuk mengkarakteristik sinyal suara.
Gambar 2.2 Contoh sinyal suara
0 0.002 0.004 0.006 0.008 0.01 0.012 0.014 0.016 0.018 -0.5
-0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.5
Pada dasarnya banyak macam kemungkinan parameter yang mewakili sinyal suara untuk melakukan pengenalan pembicara, seperti Linear Prediksi Coding (LPC), Mel Frequency Cepstrum Coefficients (MFCC), dan lain –lain. MFCC mungkin yang paling dikenal dan paling popular, dan akan dijelaskan dalam tulisan ini.
MFCC (mel frequency cepstrum coefficients) yang didasarkan pada variasi Bandwidth yang dikenali telinga manusia dengan frekuensi, filter spasi linear pada frekuensi rendah dan logaritmik pada frekuensi tinggi telah digunakan untuk menangkap karakteristik penting dari pembicara. Hal ini dinyatakan dalam skala mel frequency, yang merupakan frekuensi linier berada dibawah 1000 Hz dan
logaritmik diatas 1000 Hz [2].
2.2 Pengolahan suara
2.2.1 Produksi Pengolahan Ucapan
Untuk dapat memahami bagaimana produksi ucapan dilakukan, maka kita perlu mengetahui bagaimana Mekanisme vocal manusia dibangun. Pada Gambar 2.3 bagian yang paling penting dari mekanisme vocal manusia adalah saluran vocal bersama dan rongga nasal, yang dimulai pada velum. Velum merupakan sebuah mekanisme seperti pintu jebakan yang digunakan untuk merumuskan bunyi nasal saat diperlukan. Ketika velum diturunkan, rongga nasal digabungkan bersama-sama dengan saluran vocal untuk merumuskan sinyal ucapan yang diinginkan. Daerah crossectional dari saluran vocal dibatasi oleh lidah, bibir, rahang dan velum dan bervariasi 0-20 cm2 [4].
2.2.2 Sifat ucapan manusia
Salah satu tolak ukur yang paling penting dari ucapan adalah frekuensi ucapan itu sendiri. Ucapan dapat dibedakan satu sama lain dengan bantuan frekuensi. Ketika frekuensi ucapan meningkat, nada ucapan menjadi tinggi dan menyakitkan. Ketika frekuensi ucapan berkurang, ucapan akan lebih dalam. Gelombang ucapan adalah gelombang yang terjadi dari getaran materi ucapan. Nilai tertinggi dari frekuensi yang manusia dapat hasilkan sekitar 10 kHz. Dan nilai terendah adalah sekitar 70 Hz.
Ini adalah nilai – nilai maksimum dan minimum. Interval frekuensi ini berubah untuk setiap orang. Dan besarnya ucapan dinyatakan dalam decibel (dB). Ucapan manusia normal memiliki Interval frekuensi 100 Hz – 3200 Hz dan besarmya antara 16 Hz dan 20 kHz. Dan 0,5 % perubahan frekuensi adalah kepekaan telinga manusia [4].
Karakteristik Pembicara :
a) Berdasarkan perbedaan panjang saluran vocal, laki-laki, perempuan, dan ucapan anak-anak yang berbeda.
b) Aksen daerah adalah perbedaan frekuensi resonansi, jangka waktu, dan nada.
2.3 Mel Frequency Cepstrum Coefficients (MFCC)
Mel Frequency Cepstrum Coefficients (MFCC) merupakan satu metode
yang banyak dipakai dalam bidang speech recognition. Metode ini digunakan untuk melakukan feature extraction, sebuah proses yang mengkonversikan sinyal suara menjadi beberapa parameter. Masukan suara biasanya direkam pada sampling rate diatas 10000 Hz. Frekuensi sampling ini dipilih untuk meminimalkan atau mengkonversi efek aliasing dari analog ke digital. Sinyal-sinyal ini dapat menangkap semua frekuensi sampai dengan 5 Hz, yang meliputi sebagian besar energi suara yang dihasilkan oleh manusia. Seperti yang telah dibahas sebelumnya, tujuan utama dari proses MFCC adalah untuk mengikuti perilaku telinga manusia. Lihat Gambar 2.4 [2].
Gambar 2.4 Block diagram proses MFCC
Keunggulan dari metode MFCC ini adalah :
a. Mampu menangkap karakteristik suara yang sangat penting bagi pengenalan suara atau dengan kata lain mampu menangkap informasi-informasi yang terkandung dalam sinyal suara.
b. Menghasilkan data seminimal mungkin tanpa menghilangkan informasi-informasi penting yang ada.
c. Mereplikasi organ pendengaran manusia dalam melakukan persepsi sinyal suara.
2.4 Frame Blocking
Frame Blocking adalah pembagian sinyal audio menjadi beberapa frame
yang nantinya dapat memudahkan dalam perhitungan dan analisa sinyal, suatu frame terdiri dari beberapa sampel tergantung tiap berapa detik suara akan
disampel dan berapa frekuensi samplingnya. Pada proses ini dilakukan pemotongan sinyal dalam slot-slot tertentu agar memenuhi syarat yaitu linear dan timeinvariant.
Dalam langkah ini sinyal suara yang kontinyu diblock menjadi frame sampel N, dengan frame yang berdekatan dipisahkan oleh M (M<N). Frame
pertama terdiri dari N sampel, Frame kedua dimulai sampel M setelah frame yang pertama, dan melawati dari sampel N-M dan seterusnya. Proses ini berlanjut sampai semua suara dicatat dalam satu frame atau lebih. Nilai-nilai untuk N dan M akan berubah-rubah sesuai dengan pengujian yang akan dilakukan [5].
2.5 Windowing
yang kurang akurat. Untuk itu perlu diaplikasikan suatu window penghalus pada setiap frame dengan melakukan overlapping antara satu frame dengan frame yang lain, sehingga dapat dibangkitkan suatu feature yang lebih halus sepanjang durasi waktu tersebut. Dalam proyek ini akan digunakan metode Hamming. Digunakan Hamming window karena Hamming window memiliki side lobe yang paling kecil
dan Main lobe yang paling besar sehingga hasil windowing akan lebih dalam menghasilkan efek diskontinuitas. Konsep disini adalah untuk meminimalkan distorsi spectral dengan menggunakan window untuk sinyal ke nol pada awal dan akhir disetiap frame. Jika kita mendefenisikan window seperti ini, dimana N adalah jumlah sampel disetiap frame, maka hasil windowing adalah sinyal [2].
Sebuah fungsi window yang baik harus menyempit pada bagian main lobe dan melebar pada bagian side lobe-nya.
Berikut ini adalah representasi dari fungsi window terhadap signal suara yang diinputkan :
y1(n) = x1(n)w(n), 0 ≤ n ≤ N – 1 (2.1)
Dimana :
x(n) = x1(n)w(n) n = 0,1,….,N-1
x(n) = nilai sampel signal hasil windowing
x1(n) = nilai sampel dari frame signal ke i
w(n) = fungsi window
Windowing Hamming biasa digunakan sebagai berikut :
2.6 Fast Fourier Transform (FFT)
Langkah pengolahan selanjutnya adalah Fast Fourier Transform (FFT), yang mengubah setiap frame sampel N dari domain waktu ke domain frekuensi. FFT adalah algoritma cepat untuk mengimplementasikan Discrete Fourier Transform (DFT), yang didefenisikan pada himpunan N sampel {xn} sebagai
berikut :
Dalam Xk’s adalah bilangan kompleks dan hanya mempertimbang kan
nilai tersebut (besaran frekuensi). Urutan yang dihasilkan {Xk} ditafsirkan sebagai
berikut : frekuensi positif 0 ≤ f < Fs / 2 sesuai dengan nilai-nilai 0 ≤ n ≤ N / 2 – 1,
sedangkan frekuensi negative – Fs / 2 < 0 sesuai dengan N/2+1≤n≤N−1.
2.7 Mel Frequency Wrapping
Studi psikofisik telah menunjukkan bahwa persepsi manusia tentang frekuensi suara untuk sinyal ucapan tidak mengikuti skala linear. Jadi, untuk setiap suara dengan frekuensi seseungguhnya f, dalam Hz, sebuah pola diukur dalam sebuah skala yang disebut “mel”. Skala “mel frequency” adalah skala frekuensi linear dibawah 1000 Hz dan skala logaritmik diatas 1000 Hz. Salah satu pendekatan untuk simulasi spectrum subjektif adalah dengan menggunakan filterbank, jarak pada mel skala (lihat Gambar 2.5). Artinya Filter bank memiliki respon frekuensi Bandpass segitiga, dan jarak bandwidth ditentukan oleh interval frekuensi mel konstan. Jumlah koefisien spectrum mel, K, biasanya dipilih sebagai 20.
Gambar 2.5 Contoh Mel - spasi filterbank
0 1000 2000 3000 4000 5000 6000 7000
Filterbank ini dapat diterapkan dalam domain frekuensi, sehingga hanya sebesar yang diterapkan dijendela segitiga, bentuk seperti pada gambar diatas sampai spectrum. Sebuah cara yang digunakan tentang Filter bank mel frequency ini adalah untuk melihat setiap filter sebagai histogram bin (dimana bins memiliki kemampuan) dalam domain frekuensi [2].
Skala ini didefenisikan oleh Stanley Smith, John Volkman dan Edwin Newman sebagai :
���(�) = 2595∗log10 (1 + �
700) (2.4)
Dalam mel frequency wrapping, sinyal hasil FFT dikelompokkan kedalam berkas filter triangular ini. Maksud pengelompokan disini adalah setiap nilai FFT dikalikan terhadap gain filter yang bersesuaian dan hasilnya dijumlahkan.
2.8 Cepsturm
Cepstrum adalah sebutan kabalikan untuk spectrum. Cepstrum biasa digunakan untuk mendapatkan informasi dari suatu sinyal suara yang diucapkan oleh manusia. Pada langkah terakhir ini, spectrum log mel dikonversikan menjadi cepstrum menggunakan Discrete Cosine Transform (DCT). Oleh karena itu jika
1.1 Latar Belakang
Perkembangan teknologi pengolahan sinyal suara manusia pada akhir-akhir ini banyak digemari dan dikembangkan. Salah satu contoh pengolahan sinyal suara manusia yang sedang dikembangkan adalah sistem pengenalan pembicara (speaker recognitionsystem). Manusia mampu membedakan identitas dari orang yang mereka kenal hanya melalui suara saja. Hal ini dikarenakan setiap orang memiliki karakteristik suara tersendiri. Proses pengidentifikasian seseorang melalui karakteristik suaranya disebut speaker recognition.
Pengenalan pembicara (Speaker recognition) memungkinkan untuk menggunakan suara untuk mengontrol atau memverifikasi identitas sumber suara, Sistem tersebut mampu mengontrol keamanan untuk daerah informasi rahasia, dan remote akses layanan informasi. Sinyal suara memiliki banyak parameter yang sangat rumit. Hal ini menjadi alasan penulis menggunakan teknik ekstraksi sinyal suara yang sangat kompleks. Metode ekstraksi suara MFCC (Mel Frequency Cepstrurm Coefficient) dapat menjadi alternatif untuk menyelesaikan
masalah yang diakibatkan karena terjadinya kebocoran spektral atau aliasing pada sinyal suara.
Untuk memfokuskan pembahasan tugas akhir ini, maka pembahasan masalah dirumuskan pada hal - hal sebagai berikut:
1. Bagaimana MFCC (Mel Frequency Cepstrum Coefficients) mampu mengolah data suara dengan baik.
2. Bagaimana MFCC ditujukan untuk meminimalkan kebocoran yang terjadi pada sinyal suara yang diakibatkan oleh frame blocking.
3. Bagaimana menggunakan MFCC dapat mengurangi noise pada pengolahan sinyal suara.
4. Bagaimana menentukan N frame blocking pada algoritma MFCC untuk memaksimalkan kinerja algoritma tersebut.
5. Bagaimana MFCC untuk pengolahan data suara yang efektif pada rentang frekuensi pendengaran manusia.
1.3 Tujuan Penelitian
Adapun tujuan dari penulisan Tugas Akhir ini adalah :
Untuk menganalisa algoritma MFCC (mel frequency cepstrum coefficients) dalam mengekstraksi ciri dari suara masukan sehingga suara dapat
diidentifikasikan.
Agar isi dan pembahasan Tugas Akhir ini menjadi terarah, maka penulis perlu membuat batasan masalah yang akan dibahas. Adapun batasan masalah pada penulisan Tugas Akhir ini adalah sebagai berikut :
1. Data suara yang akan dianalisa berasal dari file audio atau hasil tangkapan menggunakan mikrofon yang telah difilter menggunakan filter anti aliasing.
2. Metode Ekstraksi yang digunakan adalah metode MFCC (mel frequency cepstrum coefficients).
3. Program dikembangkan dengan menggunakan bahasa pemograman MATLAB sebagai alat bantu untuk pemrosesan data suara.
1.5 Metode Penelitian
Dalam penulisan Tugas Akhir ini digunakan beberapa metode untuk mendapatkan data-data yang diperlukan dalam menulis laporan Tugas Akhir ini.
Metode-metode tersebut adalah :
1. Studi Pustaka menggunakan beberapa literatur berupa buku-buku teks dan jurnal nasional maupun internasional.
2. Perancangan Sistem yang terdiri dari dua bagian utama, yaitu bagian perangkat keras dan perangkat lunak.
4. Analisa Sistem diperlukan untuk memastikan apakah sudah sesuai dengan ketentuan yang telat dipelajari selama Studi Pustaka.
5. Kesimpulan dan Saran digunakan untuk menyampaikan informasi yang diperoleh selama melakukan penelitian.
1.6 Sistematika Penelitian
Penulisan Tugas Akhir ini ditulis dan disusun dalam urutan sebagai berikut:
BAB I PENDAHULUAN
Bab ini menjelaskan secara singkat tentang latar belakang, tujuan penelitian, pembatasan masalah dan metodologi.
BAB II LANDASAN TEORI
Membuat model sistem untuk penyelesaian proyek akhir ini sesuai dengan teori dasar yang diberikan meliputi : Pembuatan algoritma MFCC (mel frequency cepstrum coefficient), Pemrosesan data suara dari analog kedigital.
BAB III PERANCANGAN DAN PENGUJIAN SISTEM
BAB IV HASIL PENGUJIAN DAN ANALISA DATA
Bab ini membahas hasil dan analisa sistem yang dilakukan untuk menguji apakah hasil yang diperoleh sesuai dengan studi literature yang telah dipelajari.
BAB V PENUTUP
ABSTRAK
Perkembangan teknologi pengolahan sinyal suara manusia pada akhir-akhir ini banyak digemari dan dikembangkan. Salah satu contoh pengolahan sinyal suara manusia yang sedang dikembangkan adalah sistem pengenalan pembicara (speaker recognitionsystem). Pengenalan pembicara (Speaker recognition) memungkinkan untuk menggunakan suara untuk mengontrol atau
memverifikasi identitas sumber suara. Pada sistem penelitian ini digunakan metode MFCC (mel frequency cepstrum coefficients) dimana MFCC ini mampu menangkap karakteristik pengenalan suara manusia atau dengan kata lain mampu menangkap informasi yang terkandung dalam sinyal suara.
Pada sistem yang akan dibuat menggunakan software MATLAB memiliki kemampuan membedakan setiap file suara yang telah diambil datanya. Pada penerapannya nilai jumlah koefisien (N) ditentukan atau ditetapkan berdasarkan nilai yang ditulis dalam program yang panjangnya antara 10-30 ms atau 256-1024 data. Sinyal suara yang kontinyu akan diblock menjadi frame sampel N, dengan frame yang berdekatan dipisahkan oleh nilai koefisien (M) dengan ketentuan
dimana M<N.
Berdasarkan hasil pengujian sistem yang telah dilakukan terdapat beberapa jumlah sinyal suara yang telah dianalisa dan memiliki perbedaan jumlah koefisien pada pengujian pertama pada pengucapan kata “MAKAN” memiliki selisih jumlah koefisien terhadap pengucapan kata “MINUM” sebesar 2 koefisien, pengucapan kata “MAKAN” terhadap koefisien pengucapan kata “BELAJAR” memiliki selisih 3 koefisien.
TUGAS AKHIR
PENGENALAN KARAKTERISTIK SUARA MENGGUNAKAN MEL
FREQUENCY CEPSTRUM COEFFICIENTS (MFCC) PADA SISTEM
PENGENALAN PEMBICARA (SPEAKER RECOGNITION SISTEM)
Diajukan untuk memenuhi persyaratan
menyelesaikan Pendidikan Sarjana (S-1) pada
Departemen Teknik Elektro Sub konsentrasi Teknik Telekomunikasi
Oleh
NIM : 100402004 WINDY PRATAMA RIZKIA
DEPARTEMEN TEKNIK ELEKTRO
FAKULTAS TEKNIK
UNIVERSITAS SUMATERA UTARA
MEDAN
ABSTRAK
Perkembangan teknologi pengolahan sinyal suara manusia pada akhir-akhir ini banyak digemari dan dikembangkan. Salah satu contoh pengolahan sinyal suara manusia yang sedang dikembangkan adalah sistem pengenalan pembicara (speaker recognitionsystem). Pengenalan pembicara (Speaker recognition) memungkinkan untuk menggunakan suara untuk mengontrol atau
memverifikasi identitas sumber suara. Pada sistem penelitian ini digunakan metode MFCC (mel frequency cepstrum coefficients) dimana MFCC ini mampu menangkap karakteristik pengenalan suara manusia atau dengan kata lain mampu menangkap informasi yang terkandung dalam sinyal suara.
Pada sistem yang akan dibuat menggunakan software MATLAB memiliki kemampuan membedakan setiap file suara yang telah diambil datanya. Pada penerapannya nilai jumlah koefisien (N) ditentukan atau ditetapkan berdasarkan nilai yang ditulis dalam program yang panjangnya antara 10-30 ms atau 256-1024 data. Sinyal suara yang kontinyu akan diblock menjadi frame sampel N, dengan frame yang berdekatan dipisahkan oleh nilai koefisien (M) dengan ketentuan
dimana M<N.
Berdasarkan hasil pengujian sistem yang telah dilakukan terdapat beberapa jumlah sinyal suara yang telah dianalisa dan memiliki perbedaan jumlah koefisien pada pengujian pertama pada pengucapan kata “MAKAN” memiliki selisih jumlah koefisien terhadap pengucapan kata “MINUM” sebesar 2 koefisien, pengucapan kata “MAKAN” terhadap koefisien pengucapan kata “BELAJAR” memiliki selisih 3 koefisien.
KATA PENGANTAR
Segala Puji dan syukur penulis ucapkan kepada Allah SWT atas Berkah dan Rahmat-Nya sehingga penulis dapat menyelesaikan Tugas Akhir yang berjudul:
“PENGENALAN KARAKTERISTIK SUARA MENGGUNAKAN MEL
FREQUENCY CEPSTRUM COEFFICIENTS (MFCC) PADA SISTEM
PENGENALAN PEMBICARA (SPEAKER RECOGNITION SISTEM)”
Tugas akhir ini merupakan bagian dari kurikulum yang harus diselesaikan untuk memenuhi persyaratan menyelesaikan pendidikan Sarjana Strata Satu (S-1) di Departemen Teknik Elektro Fakultas Teknik Universitas Sumatera Utara.
Selama penulis menjalani pendidikan di kampus hingga diselesaikannya Tugas Akhir ini, penulis banyak menerima bantuan, bimbingan serta dukungan dari berbagai pihak. Pada kesempatan ini penulis ingin menyampaikan terimakasih yang tulus dan sebesar-besarnya kepada:
1. Bapak Ir. Arman Sani, MT sebagai Dosen Pembimbing Tugas Akhir penulis yang selalu bersedia memberikan bantuan yang sangat dibutuhkan oleh penulis dalam menyelesaikan Tugas Akhir ini.
2. Bapak Ir. Surya Tarmizi Kasim,M.Si sebagai Ketua Departemen Teknik Elektro Fakultas Teknik Universitas Sumatera Utara.
3. Bapak Rahmad Fauzi, ST, MT sebagai Sekretaris Departemen Teknik Elektro dan Bapak Yulianta Siregar, ST, MT sebagai Dosen Wali penulis yang membantu penulis selama menyelesaikan pendidikan di kampus USU.
4. Seluruh Staf Pengajar dan Pegawai Departemen Teknik Elektro FT-USU. 5. Orang tua khususnya Ayahanda Nukman Hasfa dan Ibunda Hanizar yang
senantiasa memberikan semangat dan do’anya kepada penulis dengan segala pengorbanan dan kasih sayang yang tidak ternilai harganya.
7. Kepada Mitra Gustinur Rahma AP, S.KG sebagai orang yang selalu memberikan motivasi, dukungan dan do’a bagi penulis.
8. Kepada sahabat penulis Ranzyskhar, Ricky Mahyuddin, Rhobby Maulana, Oki Januri, Arifin, Irsyad, Agustinus Ginting, Acmerian, Aweluddin. 9. Teman – teman di Teknik Elektro FT-USU, terkhusus angkatan 2010
Zulfahmi dhuha, Deny Destian H, Jaka Cindy Djamin, Hamdan Siregar, Fatih, Rio Gultum, Fontes Marpaung, Puti Mayang sari, Muhammad mulia, atas dukungan, do’a bagi penulis.
10. Seluruh senior dan junior angkatan 2011 dan 2012 di Departemen Teknik Elektro, atas dukungan dan bantuan yang diberikan kepada penulis.
11. Keluarga Besar MME-GS yang telah memberikan banyak sekali pembelajaran.
12. Semua orang yang pernah mengisi setiap detik waktu yang telah dilalui bersama penulis yang tidak dapat disebutkan satu per satu. Tanpa mereka, pengalaman penulis tidaklah lengkap.
Penulis menyadari bahwa Tugas Akhir ini masih banyak kekurangannya. Kritik dan saran dari pembaca untuk menyempurnakan Tugas Akhir ini sangat penulis harapkan.
Kiranya Tugas Akhir ini dapat bermanfaat bagi kita semua.Terimakasih.
Medan, 9September 2015 Penulis
DAFTAR ISI
ABSTRAK ... i
KATA PENGANTAR ... ii
DAFTAR ISI ... iv
DAFTAR GAMBAR ... vii
DAFTAR TABEL ... viii
I. PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Perumusan Masalah ... 2
1.3 Tujuan Penelitian ... 2
1.4 Batasan Masalah... 3
1.5 Metode Penelitian... 3
1.6 Sistematika Penulisan... 4
II. DASAR TEORI ... 6
2.1 Suara (speaker) ... 6
2.2 Pengolahan Suara ... 8
2.2.1 Produksi Pengolahan Ucapan... 9
2.2.2 Sifat ucapan manusia... . 10
2.3 Mel frequency Cepstrum Coefficients (MFCC) ... 11
2.4 Frame Blocking... ... 12
2.5 Windowing... ... 12
2.6 Fast Fourier Transform (FFT) ... 14
2.7 Mel Frequency Wrapping... 15
III. PERANCANGAN SISTEM PENGENALAN PEMBICARA ... 18
3.1 Pendahuluan ... 18
3.2 Block diagram Perancangan sistem... 18
3.3 Algoritma Sistem Pengenalan pembicara ... 22
IV. HASIL DAN PENGUJIAN SISTEM ... 36
4.1 Gambaran umum pengujian sistem pengenalan pembicara ... 36
4.2 Persiapan perangkat pendukung pengujian sistem ... 37
4.3 Pengujian sistem terhadap file suara ... 38
V. PENUTUP ... 43
5.1 Kesimpulan ... 43
5.2 Saran ... 43
DAFTAR PUSTAKA ... 44
DAFTAR GAMBAR
Gambar 2.1Lingkaran komunikasi suara ... 7
Gambar 2.2Contoh sinyal suara... 7
Gambar 2.3Mekanisme vocal manusia ... 9
Gambar2.4 Blok diagram proses MFCC ... 11
Gambar 2.5 Contoh Mel spasi filterbank ... 15
Gambar 3.1 Blok diagram perancangan sistem pengenalan pembicara ... 19
Gambar 3.2 Bagan alir algoritma program perancangan sistem pengenalan pengenalan pembicara ... 23
Gambar 3.3 Tampilan program Matlab ... 25
Gambar 3.4 Contoh sampel suara “MAKAN” ... 27
Gambar 3.5 Diagram blok proses penentuan frame blocking ... 29
Gambar 3.6 Pengaruh sinyal yang diakibatkan Hamming window ... 30
Gambar 4.1 Grafik perbandingan koefisien untuk N = 256 & M = 100 ... 39
Gambar 4.2 Grafik perbandingan koefisien untuk N = 512 & M = 100 ... 40
Gambar 4.3 Grafik perbandingan koefisien untuk N = 1024 & M = 100 ... 41
BAB I
![Gambar 3.6 [6].](https://thumb-ap.123doks.com/thumbv2/123dok/916865.599080/26.595.208.442.496.703/gambar.webp)