ABSTRACT
KARINA GUSRIANI. OLAP Operations and Addition of Aggregate Functions in The Food Crops Temporal Data Warehouse in Karo. Under direction of ANNISA.
Yearly data recorded in an organization would lead to accumulation of the data. Many organizations now already use data warehouse technology to obtain more structured information. Data warehouse could help them in making decisions by analyzing historical data, but changes in the process of recording object data such as split and merge, would complicate search in the data warehouse. Currently there's already a developed data warehouse with temporal approach to address issues such as split and merge.
This study improves food crop temporal data warehouse in Karo by adding OLAP operations. Implementation of OLAP in multidimensional data would make data analysis in the data warehouse easier for the user. OLAP operations which will be developed in this temporal data warehouse is slicing, dicing, drill down, and roll up process, and also aggregate functions.
PENAMBAHAN OPERASI OLAP DAN FUNGSI AGREGAT
PADA
TEMPORAL DATA WAREHOUSE
TANAMAN PANGAN
KABUPATEN KARO
KARINA GUSRIANI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
PENAMBAHAN OPERASI OLAP DAN FUNGSI AGREGAT
PADA
TEMPORAL DATA WAREHOUSE
TANAMAN PANGAN
KABUPATEN KARO
KARINA GUSRIANI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
PENAMBAHAN OPERASI OLAP DAN FUNGSI AGREGAT
PADA
TEMPORAL DATA WAREHOUSE
TANAMAN PANGAN
KABUPATEN KARO
KARINA GUSRIANI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
KARINA GUSRIANI. OLAP Operations and Addition of Aggregate Functions in The Food Crops Temporal Data Warehouse in Karo. Under direction of ANNISA.
Yearly data recorded in an organization would lead to accumulation of the data. Many organizations now already use data warehouse technology to obtain more structured information. Data warehouse could help them in making decisions by analyzing historical data, but changes in the process of recording object data such as split and merge, would complicate search in the data warehouse. Currently there's already a developed data warehouse with temporal approach to address issues such as split and merge.
This study improves food crop temporal data warehouse in Karo by adding OLAP operations. Implementation of OLAP in multidimensional data would make data analysis in the data warehouse easier for the user. OLAP operations which will be developed in this temporal data warehouse is slicing, dicing, drill down, and roll up process, and also aggregate functions.
Judul : Penambahan Operasi OLAP dan Fungsi Agregat pada Temporal Data Warehouse
Tanaman Pangan Kabupaten Karo Nama : Karina Gusriani
NIM : G64052349
Menyetujui:
Pembimbing
Annisa, S.Kom., M.Kom. NIP. 197907312005012
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Dr. Drh. Hasim, DEA NIP 196103281986011002
RIWAYAT HIDUP
Penulis dilahirkan di Bogor, Jawa Barat pada tanggal 14 Agustus 1987, sebagai anak kedua dari dua bersaudara pasangan Bapak Muchtar Thoyib dan Ibu Endang Yusmariah. Pada tahun 2005, penulis lulus dari SMA Negeri 3 Bogor dan pada tahun yang sama penulis diterima menjadi mahasiswa Institut Pertanian Bogor melalui jalur SPMB (Seleksi Penerimaan Mahasiswa Baru). Pada tahun 2006, berdasarkan hasil seleksi Mayor Minor, penulis diterima di Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam IPB (FMIPA IPB) yang merupakan departemen pilihan pertama penulis. Selain itu, untuk melengkapi kompetensi, penulis memilih minor Pengembangan Masyarakat pada Departemen Komunikasi dan Pengembangan Masyarakat Fakultas Ekologi Manusia IPB (FEMA IPB).
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur yang sedalam-dalamnya penulis panjatkan kepada Allah Subhanahu wa Ta’ala atas limpahan rahmat dan hidayah-Nya sehingga tugas akhir yang berjudul Penambahan Operasi OLAP dan Fungsi Agregat pada Temporal Data Warehouse
Tanaman Pangan Kabupaten Karo dapat diselesaikan. Penulis juga menyampaikan ucapan terima kasih kepada:
1. Kedua orang tua, Ibu dan Bapak, Kakak tercinta, Kartika Muchtar yang selalu memberikan do‟a, semangat, nasehat serta dukungan untuk penulis,
2. Ibu Annisa, S.Kom.,M.Kom. selaku dosen pembimbing yang telah memberikan arahan dan bimbingan, kesabaran, perhatian dan waktunya kepada penulis dalam menyelesaikan skripsi ini,
3. Dosen-dosen Departemen Ilmu Komputer IPB yang telah begitu mulia membagi ilmunya kepada penulis, terutama Pak Hari Agung dan Pak Firman sebagai penguji, dan Ibu Sri Nurdiati sebagai penasehat terbaik,
4. Mirna, Mega, Agnes, Tsamrul, dan Kurni sebagai teman-teman satu bimbingan yang selalu memberikan masukan, saran dan semangat kepada penulis,
5. Venerate Zone, Vera Yunita, Yuni Arti, Sri Danuriati, Zissalwa Hafsari, Ninon NF dan semua anak-anak kost Harmony, Wisma Cantik, RZ atas dukungan dan semangat yang telah diberikan,
6. Teman-teman seperjuangan di Ilkomerz 42 IPB. Annisa, Chika, Ida, Elen, Indah, Siti, Banio, Dika, Anindra, Akhyar, Dani dan semua teman-teman yang selalu memberi keceriaan,
7. Kakak-kakak angkatan yang telah bersedia berbagi ilmu, terutama Kak Jefry, Mba Ayu, Kak Iwan,
8. Teman-teman yang selalu dekat di hati, Adi Adrian, Erdiansyah, Bang Ragil, Deasy, Shintana, Ratna, Uti, Mena, Lili, Monik, Anggi, Cipie, Icha.
9. Para staf di Departemen Ilmu Komputer IPB.
Penulis menyadari bahwa masih terdapat kekurangan dalam penulisan skripsi ini. Semoga skripsi ini dapat memberikan manfaat bagi siapapun yang membaca.
Bogor, Agustus 2009
iv DAFTAR ISI
Halaman
DAFTAR TABEL ... v
DAFTAR GAMBAR ... v
DAFTAR LAMPIRAN ... v
PENDAHULUAN ... 1
Latar belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA ... 1
Temporal Data Warehouse ... 1
Versi Struktur ... 1
Transformation Function ... 2
OLAP (On-Line Analytical Processing) ... 2
Operasi-Operasi pada OLAP ... 3
Model Data Multidimensi ... 4
Data Level ... 4
Arsitektur Data Warehouse ... 5
METODE PENELITIAN ... 5
Analisis Data ... 5
Pembuatan Data warehouse ... 5
Penambahan Operasi OLAP ... 5
Penambahan Fungsi Agregat ... 5
Uji Query ... 6
Lingkup Pengembangan ... 6
HASIL DAN PEMBAHASAN ... 6
Analisis Data ... 6
Pemuatan Data ... 7
Penambahan Operasi OLAP ... 8
Penambahan Fungsi Agregat ... 10
Analisis Visual dari Cross-tabulation dan Grafik ... 10
KESIMPULAN DAN SARAN ... 11
Kesimpulan ... 11
Saran ... 11
v DAFTAR TABEL
Halaman
1 Jumlah bunga yang memiliki bagian kombinasi antara lebar daun bunga, panjang daun bunga,
dan tipe spesies ... 3
2 Cross-tabulation dari bunga yang berdasarkan panjang dan lebar daun bunga untuk tipe spesies Setosa. ... 3
3 Cross-tabulation dari bunga yang berdasarkan panjang dan lebar daun bunga untuk tipe spesies Versicolor ... 3
4 Cross-tabulation dari bunga yang berdasarkan panjang dan lebar daun bunga untuk tipe spesies Virginica ... 3
5 Cross-tabulation untuk operasi dicing pada spesies Virginica dengan panjang daun bunga „high‟ ... 4
6 Pembagian versi struktur berdasarkan perubahan yang terjadi. ... 7
7 Dimensi dan elemen dimensi pada setiap cube. ... 8
DAFTAR GAMBAR Halaman 1 Dimensi divisi sales ... 2
2 Empat level data ... 4
3 Arsitektur three-tier (Han and Kamber 2006) ... 5
4 Ilustrasi arsitektur penelitian ... 5
5 Diagram alir metode penelitian ... 6
6 Skema bintang untuk temporal data warehouse tanaman pangan ... 6
7 Hirarki pada versi struktur tahun 2003 (StructureVersion1) ... 7
8 Hirarki pada versi struktur tahun 2004-2005 (StructureVersion2) ... 7
9 Hirarki pada versi struktur tahun 2006-2007 (StructureVersion3) ... 7
10 Hasil query total produksi padi pada tahun 2003 hingga 2007 ... 9
11 Hasil operasi drill down pada penelitian Malau (2009) ... 9
12 Hasil operasi drill down setelah ditambah fungsi transformasi data atomik ... 9
13 Hasil operasi drill down pada dimensi waktu... 9
14 Contoh operasi slicing ... 10
15 Contoh operasi dicing ... 10
16 Hasil query untuk fungsi agregat min, max, dan average ... 10
17 Cross-tabulation dan grafik batang untuk perkembangan produksi padi dan jagung pada tahun 2003 hingga 2007 di Kabupaten Karo ... 10
DAFTAR LAMPIRAN Halaman 1 Visualisasi 2-D dari luas tanam padi untuk semua wilayah kecamatan berdasarkan pada dimensi waktu dan wilayah. Measure yang ditampilkan adalah luas tanam dalam satuan Ha ... 13
1
PENDAHULUAN
Latar Belakang
Analisis data historis dan pengolahan data multidimensi bukan merupakan hal yang baru untuk mendukung suatu pengambilan keputusan. Namun perubahan objek data yang dicatat, membuat analisis data historis dan penelusuran terhadap data menjadi sulit untuk dilakukan. Misalnya, pada tahun 2003, objek yang dicatat oleh perusahaan adalah produksi padi dan jagung, sementara itu pada tahun 2004, objek yang dicatat oleh perusahaan adalah produksi padi sawah, padi gogo, jagung komposit dan jagung hybrida. Oleh karena itu, jika pengguna ingin mengetahui total produksi padi dari tahun 2003 hingga 2004, maka akan sulit memperoleh informasi total produksi padi, karena perubahan atribut yang dicatat tersebut. Untuk itu, teknologi
data warehouse saat ini sudah dikembangkan dengan melakukan pendekatan secara
temporal atau data warehouse berorientasi waktu untuk menangani perubahan objek.
Penelitian mengenai temporal data warehouse sudah pernah dilakukan oleh Eder (2001). Penelitian tersebut memberi penjelasan mengenai model untuk temporal data warehouse bagi penelitian selanjutnya. Selanjutnya, penelitian Eder (2001) tersebut coba diterapkan oleh Malau (2009) untuk data tanaman pangan dan hortikultura di Kabupaten Karo. Penelitian lanjutan tersebut telah mampu menangani masalah split dan
merge serta fungsi agregat sum.
Namun ada beberapa kekurangan dari
temporal data warehouse yang dilakukan oleh Malau (2009) tersebut, yaitu belum dapat mendukung operasi OLAP seperti slicing, dicing, drill down, dan roll up. Oleh karena itu, sebagai pelengkap dari temporal data warehouse yang sudah dibuat, diperlukan penambahan operasi OLAP seperti slicing,
dicing, drill down, roll up serta fungsi agregat seperti min, max, dan average agar menjadi
temporal data warehouse yang lebih baik.
Tujuan
Merancang dan membangun suatu model
temporal data warehouse yang memiliki fitur operasi dasar data warehouse yaitu roll up,
drill down, slicing, dan dicing serta fungsi agregat seperti min, max, dan average. Ruang Lingkup
Penelitian ini difokuskan pada operasi dasar data warehouse yaitu slicing, dicing,
Temporal Data Warehouse
Temporal data warehouse merupakan suatu perbaikan dari teknologi data warehouse dengan melakukan pendekatan
temporal, sehingga mampu menangani operasi dasar data warehouse seperti roll up, drill down, slicing dan dicing serta operasi-operasi yang kompleks seperti split (pembagian) dan
merge (penggabungan). Temporal data
warehouse menitikberatkan pada fungsi transformasi yang berasal dari versi struktur (Eder et al 2001). Contoh permasalahan yang tidak dapat ditangani oleh data warehouse
biasa, misalnya diketahui sebuah divisi A mengalami pembagian divisi yaitu divisi A1 dan divisi A2 pada bulan Maret tahun 2000, jika ingin diketahui perkembangan divisi A, maka tanpa pendekatan temporal data warehouse tersebut tidak akan mampu memberikan informasi mengenai seluruh perkembangan divisi A. Informasi yang diperoleh oleh pengguna mengenai divisi A hanya sampai pada bulan Februari 2000, sebelum divisi A mengalami perubahan struktur. Namun demikian, apabila data warehouse tersebut telah menggunakan pendekatan temporal, maka akan diperlihatkan seluruh data melalui penelusuran structure version yang didukung fungsi transformasi. Dengan demikian, operasi split (pembagian) dan merge
(penggabungan) yang terjadi pada divisi A dapat diketahui dan query pengguna mengenai seluruh data divisi A dapat dipenuhi. Versi Struktur
Versi struktur merepresentasikan sudut pandang pada temporal data warehouse yang menangani struktur valid untuk interval waktu [Ts,Te]. Modifikasi anggota dimensi atau
relasi hirarki memastikan berada pada suatu versi struktur. Jika interval waktu tertentu tidak ada berada dalam suatu versi struktur maka diperlukan suatu versi struktur baru yang dapat memastikan interval waktu tersebut dapat tertangani (Eder et al 2001).
Secara umum structure version (SV) terdiri atas empat tuple dengan format <SVid,
T, {DMDi, SVid, …, DMDN, SVid, DMF,SVid}, HSVid>
dimana SVid adalah unique identifier, T
2
structure version dengan selang waktu [Ts,
Te], Ts adalah start time atau waktu awal, dan
Te adalah end time atau waktu akhir. DMDi, SV-id adalah himpunan dari semua
anggota-anggota dimensi, dimana merupakan bagian dari dimensi Di dan valid untuk waktu P
dengan Ts ≤ P ≤ Te. DMF,SVid adalah himpunan
dari seluruh fakta-fakta yang valid pada waktu P dengan Ts ≤ P ≤ Te, HSvid adalah himpunan
dari penambahan hirarki yang valid pada waktu P dengan Ts ≤ P ≤ Te.
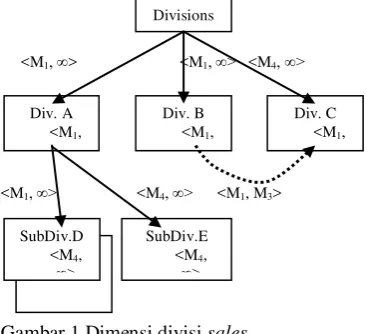
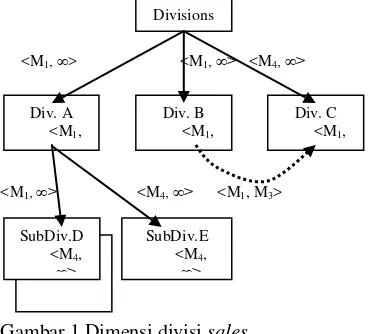
Ilustrasi untuk structure version (SV) seperti diperlihatkan pada Gambar 1, mengenai dimensi divisi untuk penjualan (sales) yang disertai interval (selang) waktu (Eder et al 2001):
<M1, ∞> <M1, ∞> <M4, ∞>
<M1, ∞> <M4, ∞> <M1, M3>
Gambar 1 Dimensi divisi sales.
Pada Gambar 1 terlihat bahwa SubDiv.D telah dimodifikasi pada waktu M4, SubDiv.
yang baru yaitu SubDiv.E dimasukkan pada saat waktu M4, Div.C merupakan subdivisi
dari Div.B pada waktu M1 sampai M3 (pada
gambar ditandai dengan garis putus-putus). Berdasarkan Gambar 1, diperoleh beberapa
structure version (SV), yaitu:
1. <SV1, [M1, M3], {{Divisions, Div.A,
Div.B, Div.C, SubDiv.D}, {Sales}},
{Div.A → Divisions, SubDIv.D→ Div.A, …}>
2. <SV2, [M4, ∞], {{Divisions, Div.A, Div.B,
Div.C, SubDiv.D, SubDiv.E}, {Sales}},
{Div.A → Divisions, SubDiv.D → Div.A, SubDiv.E → Div.A, …}>
Structure version yang diperoleh ada dua yaitu SV1 dan SV2. SV1 dan seluruh anggota-anggota dimensi (Divisions, Div.A, Div.B,…)
dan penambahan hirarki (Div.A →
Divisions,…) valid pada saat M1 ke M3,
sedangkan untuk SV2 valid pada saat M4
sampai dengan waktu yang belum ditentukan.
Transformation Function (TF)
Transformation function dalam temporal data warehouse dinamakan dengan MapF
(Mapping Function) dan menggunakan operasi dasar penjumlahan (sum). Misalnya suatu divisi A mengalami split pada bulan Maret tahun 2000 menjadi divisi A1 dan A2. Jika kita ingin menganalisis semua bulan pada tahun 2000 untuk divisi A, perusahaan hanya memiliki data untuk bulan Januari dan Februari, dimana untuk bulan Maret ke depan, perusahaan memiliki data untuk divisi A1 dan A2. Contoh jika ingin merepresentasikan omset dari divisi A1 untuk periode sebelum Maret tahun 2000 maka sebagai fungsi omset (A1, periode) = 30% dari omset (A, periode). Contoh lainnya, jika kita ingin mengetahui seluruh periode pada bulan Maret ke depan pada tahun 2000, maka jumlah dari karyawan M# dari divisi A terkait dengan fungsi M# (A, periode) = M# (A1, periode) + M# (A2, periode). Fungsi inilah yang disebut
transformation function (MapF) dan untuk operasi yang digunakan adalah operasi sum
(Eder et al 2001).
Pada data tanaman pangan, operasi MapF
akan digunakan untuk data jumlah produksi, luas tanam dan luas panen dari tanaman pangan, padi dan jagung. Misalnya, pada tahun 2003, padi yang ditanam berasal dari satu varietas saja (A), untuk itu pencatatan total padi untuk semua kecamatan dapat dikumulatifkan. Namun, pada tahun 2004, terdapat 2 varietas padi yaitu B dan C yang ditanam pada beberapa kecamatan. Dengan demikian, apabila pengguna ingin mengetahui hasil padi pada 2003 hingga 2004, sistem tidak akan mampu menjawab query tersebut. Pada kasus ini, jika struktur pencatatan padi tidak berubah, maka sistem tidak akan mampu menjawab query tentang berapa hasil produksi padi jenis A, B, atau C, karena pencatatan sebelumnya tidak membedakan jenis padi. Untuk itu diperlukan sebuah struktur baru dan bentuk MapF yang sesuai bagi struktur tersebut sehingga dapat menjawab query
mengenai berapa hasil produksi padi di tahun 2003 hingga 2004 di setiap kecamatan. OLAP ( On-Line Analytical Processing)
OLAP adalah sistem yang memfokuskan pada interaktif analisis data dan biasanya memiliki kemampuan luas mengenai visualisasi data dan membangkitkan ringkasan statistika. Karena alasan ini, pendekatan analisis multidimensional data didasarkan
3 pada terminologi dan konsep OLAP ( Tan et
al 2006).
Data yang biasanya ditampilkan oleh OLAP adalah fungsi agregasi seperti
summary, max, min, dan average. OLAP menyediakan proses kalkulasi dan perbandingan data serta dapat menampilkan hasil dalam bentuk tabel dan grafik.
Operasi-Operasi pada OLAP
Operasi-operasi OLAP adalah sebagai berikut (Han dan Kamber 2006):
- Slicing
Slicing adalah proses melakukan
pemilihan satu dimensi dari suatu kubus data sehingga menghasilkan subcube.
- Dicing
Dicing adalah proses melakukan pemilihan dua atau lebih dimensi dari suatu kubus data sehingga menghasilkan subcube.
- Roll up
Operasi roll up dilakukan pada kubus data dengan cara menaikkan tingkat suatu hirarki. Pada saat roll up dilakukan, maka jumlah dimensi akan berkurang. Contohnya, operasi
roll up yang dilakukan pada kubus data di tingkat kecamatan menjadi tingkat kabupaten. - Drill down
Drill down adalah operasi yang
berkebalikan dengan roll up. Operasi ini merepresentasikan kubus data dengan lebih terperinci.
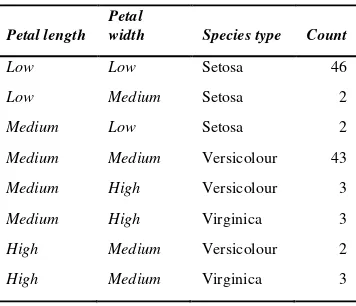
Ilustrasi mengenai operasi slicing dan dicing dapat dilihat pada Tabel 1 berikut ini (Tan et al 2006).
Tabel 1 Jumlah bunga yang memiliki bagian kombinasi antara lebar daun bunga, panjang daun bunga, dan tipe spesies.
Petal length Petal
width Species type Count
Low Low Setosa 46
Low Medium Setosa 2
Medium Low Setosa 2
Medium Medium Versicolour 43
Medium High Versicolour 3
width Species type Count
high high Versicolour 2
high high Virginica 44
Operasi slicing yang dilakukan pada data di Tabel 1 digambarkan pada Tabel 2, Tabel 3, dan Tabel 4 sebagai berikut.
Tabel 2 Cross-tabulation dari bunga yang berdasarkan panjang dan lebar daun bunga untuk tipe spesies Setosa.
Width
Tabel 3 Cross-tabulation dari bunga berdasarkan pada panjang dan lebar daun bunga untuk spesies Versicolour.
Width bunga untuk spesies Virginica.
Width Tabel 4 telah dihasilkan tiga slice dari operasi
slicing yang telah dilakukan pada data iris
yang diperoleh dari tiga nilai terpisah untuk dimensi spesies. Di sisi lain, hasil dari operasi
dicing merupakan suatu subset dari ketiga tabel tersebut dengan memilih ukuran panjang daun bunga atau lebar daun bunga. Misalnya
dicing yang dilakukan untuk spesies Virginica
4 Tabel 5 Cross-tabulation untuk operasi dicing
pada spesies Virginica dengan panjang
daun bunga „high‟.
Width
low medium high
Length high 0 3 44
- Pivoting
Pivoting merupakan suatu kemampuan OLAP yang dapat melihat data dari berbagai sudut pandang (view point). Kita dapat mengatur sumbu pada cube sehingga memperoleh data yang diinginkan sesuai dengan sudut pandang analisis yang diperlukan.
Model Data Multidimensi
Model data multidimensi adalah model data yang digunakan pada data warehouse. Model data multidimensi terdiri atas dua data yaitu (Mallach 2000 dalam Kusumaningtias 2007) :
- Data dimensi
Data dimensi adalah entitas yang ingin disimpan oleh perusahaan (organisasi). Data dimensi akan berubah jika analisis kebutuhan pengguna berubah. Data dimensi mendefinisikan label yang membentuk isi laporan. Setiap dimensi diulang untuk setiap kelompok. Atribut data dimensi diletakkan pada tabel dimensi. Tabel dimensi berukuran lebih kecil daripada tabel fakta, berisi data bukan numerik yang berasosiasi dengan atribut dimensi.
- Data fakta
Data fakta adalah data utama dari data multidimensi yang merupakan kuantitas yang ingin diketahui dengan menganalisis hubungan antar dimensi. Data fakta diekstrak dari berbagai sumber. Data fakta cenderung stabil dan tidak berubah seiring waktu. Atribut data fakta diletakkan pada tabel fakta.
Data Level
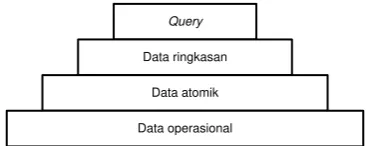
Lingkungan data warehouse terdiri atas 4 tingkatan data, dapat dilihat pada Gambar 2 (Mallach 2000) berikut ini.
Query
Data ringkasan
Data atomik
Data operasional
Gambar 2 Empat level data. 1. Data operasional
Data yang berada di data warehouse
berasal dari database operasional perusahaan.
Data warehouse tidak akan berjalan tanpa data operasional. Contoh, hari ini saya menabung Rp. 150.000.
2. Data atomik
Data atomik terdiri atas data barang itu sendiri. Data atomik merupakan tingkat data terendah dari data dalam data warehouse. Semua fungsi data warehouse dimulai dengan data atomik atau dengan data yang berasal dari data atomik. Data atomik sesuai untuk data transaksi dengan penambahan dimensi waktu. Tingkat ini merupakan data yang dimasukkan ke dalam database data
warehouse dari database operasional
perusahaan. Contoh, saldo tabungan pada bulan Agustus adalah Rp. 240.000.
3. Data ringkasan data warehouse
Para analis memerlukan pengetahuan yang cukup mengenai kegunaan data warehouse. Ringkasan suatu data akan diperlukan pada proses analisis sehingga ringkasan tersebut akan digunakan secara berulang. Contoh, pada akhir bulan Agustus perusahaan memiliki pelanggan sebanyak 1487 yang berada di kode pos 16610-16180.
4. Data yang dapat menjawab pertanyaan yang spesifik
Tingkat ini biasanya dibuat sebagai kebutuhan dan disimpan hanya sampai pengguna yang meminta itu selesai menggunakan data tersebut. Jika pengguna ingin menyimpan itu, microcomputer
5 Arsitektur Data Warehouse
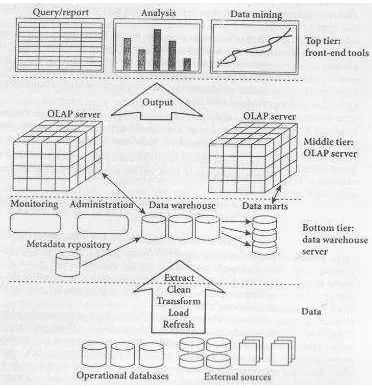
Arsitektur data warehouse yang umum digunakan adalah arsitektur three-tier.
Arsitektur ini memiliki tiga lapisan yaitu lapisan bawah, lapisan tengah, dan lapisan atas (Han & Kamber 2006). Ilustrasi arsitektur
three-tier dapat lihat pada Gambar 3.
Gambar 3 Arsitektur three-tier (Han and Kamber 2006).
Penelitian ini mengacu pada arsitektur
data warehouse three-tier, tiga lapisan tersebut adalah:
1. Lapisan bawah (bottom tier)
Lapisan bawah merupakan tempat pengolahan sumber data warehouse yang bertujuan agar data tersebut dapat digunakan dengan baik.
2. Lapisan tengah (middle tier)
Lapisan tengah merupakan OLAP server
yang berfungsi menyimpan struktur dari kubus data.
3. Lapisan atas (top tier)
Lapisan atas adalah lapisan untuk end-user
yang berisi query dan menampilkan informasi atau ringkasan. Query yang diuji pada penelitian ini dilakukan di Palo Add-in Win32 3.0 yang terintegrasi dengan Microsoft Office Excel.
Arsitektur data warehouse dalam penelitian ini dapat diilustrasikan pada Gambar 4 berikut.
Gambar 4 Ilustrasi arsitektur penelitian
Gambar 4 menjelaskan bahwa lapisan bawah dari arsitektur temporal data warehouse ini adalah data warehouse yang direpresentasikan dengan model dimensi, yaitu skema bintang. Lapisan tengah dari arsitektur temporal data warehouse adalah penyimpanan struktur kubus data yang dilakukan oleh tools Palo server. Lapisan atas dari arsitektur temporal data warehouse ini berupa aplikasi untuk end-user, aplikasi yang digunakan adalah Microsoft Office Excel.
METODE PENELITIAN
Data yang digunakan pada penelitian ini adalah data tanaman pangan yang berupa padi dan jagung di Kabupaten Karo dari tahun 2003 hingga tahun 2007 pada ruang lingkup jumlah produksi, luas tanam dan luas panen. Data diperoleh dari Dinas Pertanian, Peternakan, Perikanan dan Perkebunan Kabupaten Karo.Analisis Data
Data tanaman pangan yang telah diperoleh selanjutnya dianalisis untuk mendapatkan atribut-atribut yang tepat dalam pembuatan
temporal data warehouse. Hasil analisis ini digunakan untuk menentukan dimensi, fakta, dan skema yang tepat untuk model data multidimensi.
Pembuatan Data warehouse
Setelah dilakukan analisis data, dilakukan proses pembuatan data warehouse. Input data dilakukan berdasarkan skema yang telah dirancang. Data yang dimasukkan berdasarkan pada versi struktur yang terbentuk.
Penambahan Operasi OLAP
Pada tahap ini, dilakukan penambahan operasi dasar OLAP seperti slicing, dicing,
roll up, dan drill down. Proses ini dilakukan dengan menransformasikan lower level dari setiap dimensi.
Penambahan Fungsi Agregat
Fungsi agregat yang ditambahkan pada
6
Uji Query
Uji query adalah tahap untuk menguji
temporal data warehouse apakah telah sesuai dengan kebutuhan dan berfungsi dengan baik serta memeriksa apakah operasi dasar data warehouse dan fungsi agregat berhasil diterapkan tanpa mengubah versi struktur dan fungsi transformasi. Pengujian dilakukan dengan kubus data yang divisualisasikan dengan tools OLAP pada Palo.
Metode penelitian dapat digambarkan dengan visualisasi diagram alir pada Gambar 5.
Gambar 5 Diagram alir metode penelitian. Lingkup Pengembangan
Temporal data warehouse ini
menggunakan perangkat keras dan perangkat lunak dengan spesifikasi sebagai berikut : Perangkat keras :
- Processor Intel Core 2 Duo 1.83 GHz
- RAM 2GB DDR2
- HDD 160 GB
- Keyboard dan mouse
- Monitor LCD 14‟ dengan resolusi 1280
x 800 Perangkat lunak :
- Sistem operasi Windows 7 RC 1
- Microsoft Office 2007 SP 1
- Palo add-in Win32 3.0
HASIL DAN PEMBAHASAN
Analisis DataData yang digunakan pada penelitian ini adalah data tanaman pangan dan hortikultura pada tahun 2003 sampai tahun 2007. Atribut yang terdapat pada data sumber adalah data kecamatan, waktu, dan jenis tanaman pangan. Fakta yang terkait dengan tanaman pangan meliputi luas tanam, luas panen,dan produksi. Kabupaten Karo memiliki 13 kecamatan yaitu Barusjahe, Tigapanah, Kabanjahe, Simpang IV, Payung, Munte, Tigabinanga, Juhar, Kutabuluh, Mardingding, Berastagi, Merek, Lau Baleng. Elemen waktu yang dimiliki adalah tahun 2003, 2004, 2005, 2006, dan 2007. Jenis tanaman pangan yang dianalisis adalah tanaman padi dan jagung.
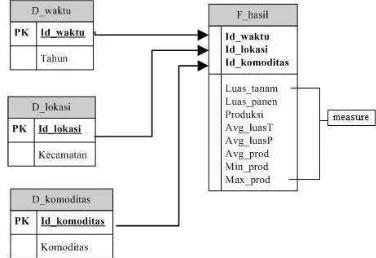
Pembuatan temporal data warehouse ini bertujuan untuk mengatasi permasalahan sulitnya menganalisis data apabila terjadi perubahan objek pada data tersebut. Berdasarkan atribut yang terdapat pada sumber data, dihasilkan tiga tabel dimensi yaitu dimensi waktu, dimensi lokasi, dan dimensi komoditas, serta satu tabel fakta. Ilustrasi data multidimensi dari atribut yang telah diketahui dapat dilihat pada Gambar 6.
Gambar 6 Skema bintang untuk temporal data warehouse tanaman pangan.
Atribut target yang akan dianalisis pada
7 minimum, maksimum dan rata-rata untuk nilai
luas tanam, luas panen, serta jumlah produksi. Konseptual model data multidimensional merupakan bagian inti dari proses perancangan dan pemeliharaan yang berisi gabungan dari semua kebutuhan pengguna tapi belum tentu bagian dari kelengkapan implementasi. Semua model data yang terjadi selanjutnya dalam proses perancangan merupakan perbaikan dari model konseptual (Blaschka 1999).
Perubahan struktur yang terjadi pada data yang digunakan dalam penelitian ini diantaranya adalah pada tahun 2003 diketahui jumlah produksi, luas tanam, dan luas panen dari komoditas padi dan jagung. Lalu pada tahun 2004 hingga 2005, data jagung dan data padi mengalami split (pemecahan) yaitu data padi terdiri dari data padi gogo dan padi sawah serta data jagung terdiri dari data jagung hybrida dan jagung komposit. Selanjutnya pada tahun 2006 hingga 2007 data padi dan jagung yang telah mengalami
split tersebut mengalami merge
(penggabungan) sehingga data padi dan jagung mengalami versi struktur yang sama pada tahun 2003. Ilustrasi dari versi struktur yang terjadi pada data tersebut dapat dilihat pada Gambar 7, Gambar 8, dan Gambar 9.
padi jagung
Tanaman pangan
2003 2003
Gambar 7 Hirarki pada versi struktur tahun 2003 (StructureVersion1).
padi
Padi sawah Padi gogo Jagung hybrid kompositJagung
2004,2005 2004, 2005 2004, 2005 2004, 2005
jagung Tanaman pangan
2003 2003
Gambar 8 Hirarki pada versi struktur tahun 2004-2005 (StructureVersion2).
padi jagung
Tanaman pangan
2006, 2007 2006, 2007
Gambar 9 Hirarki pada versi struktur tahun 2006-2007 (StructureVersion3).
Berdasarkan Gambar 5, Gambar 6, dan Gambar 7 diperoleh tiga versi struktur yaitu versi struktur 1 dengan interval waktu 2003, data dimensi komoditas yang valid pada versi struktur 1 adalah padi dan jagung. Versi struktur 2 dengan interval waktu 2004 hingga 2005, data dimensi komoditas yang valid
adalah padi sawah, padi gogo, jagung hybrida, dan jagung komposit. Versi struktur 3 dengan interval waktu 2006 hingga 2007, data dimensi komoditas yang valid adalah padi dan jagung. Penjelasan lebih jelas dapat dilihat pada Tabel 6 berikut ini.
Tabel 6 Pembagian versi struktur berdasarkan perubahan yang terjadi.
Versi Struktur Jenis Perubahan
Versi Struktur 1 Padi dan Jagung tidak mengalami perubahan. Versi Struktur 2 Padi dibagi menjadi 2 bagian
yaitu padi sawah dan padi gogo.
Jagung juga mengalami perubahan yaitu dibagi menjadi 2 bagian yaitu jagung hybrida dan jagung komposit.
Versi Stuktur 3 Padi dan Jagung digabung kembali.
Pemuatan Data
Versi struktur adalah sudut pandang dalam
temporal data warehouse valid untuk mengetahui periode waktu [Ts, Te]. Semua
anggota dimensi dan semua hubungan hirarki serta struktur multidimensional harus valid
pada setiap waktu interval. Dengan kata lain, dalam satu versi struktur tidak boleh ada versi berbeda dari anggota dimensi dan hubungan hirarki. Dan setiap modifikasi dari anggota dimensi atau hubungan hirarki pasti akan menjadi versi struktur yang baru, jika struktur versi untuk waktu interval yang ada belum terpenuhi (Eder et al 2001).
Berdasarkan pada penjelasan di atas, maka untuk versi struktur 1, versi struktur 2, dan versi struktur 3 dibuat cube yang berbeda, secara berurutan diberi nama
StructureVersion1, StructureVersion2, dan
StructureVersion3. Setiap cube tersusun atas tiga tabel dimensi dan satu tabel fakta. Dalam implementasi, Palo tidak membedakan antara
8 produksi dibuat dalam dimensi yang bernama
measure. Dimensi dan elemen dimensi dari setiap cube dapat dilihat pada Tabel 7. Tabel 7 Dimensi dan elemen dimensi pada setiap cube
Versi struktur Dimensi Elemen dimensi
StructureVersion1 Waktu 2003 Lokasi All StructureVersion3 Waktu 2006
2007
Setelah dilakukan pembuatan cube dari setiap versi struktur, selanjutnya dilakukan pemuatan data. Pemuatan data merupakan proses pemindahan data dari spreadsheet excel ke cube yang dibuat di tools Palo.
Untuk menjawab query pada data warehouse, pengguna harus menentukan versi struktur mana yang harus digunakan. Oleh karena itu, apabila pengguna ingin melihat data yang berasal dari dua versi struktur yang berbeda, pengguna harus melihat data dengan menggunakan dua cube. Untuk memudahkan pengguna agar mendapatkan data yang
diinginkan yang berasal dari cube atau versi struktur yang berbeda, diperlukan fungsi transformasi yang dapat memetakan data dari satu versi struktur ke versi struktur yang lain. Palo mendukung terbentuknya suatu fungsi transformasi dengan membentuk serangkaian
rule. Rule tersebut disimpan didalam suatu
cube. Cube tersebut diberi nama cubequery. Cube query merupakan cube yang dapat menangani beberapa query yang berkaitan dengan penggunaan versi struktur dan fungsi transformasi. Cube query memiliki dimensi yang sama dengan dimensi versi struktur yang lain yaitu dimensi lokasi, dimensi waktu, dimensi komoditas, dan dimensi measure. Data dimensi komoditas yang berada dalam
cube query adalah tanaman padi dan jagung tanpa dibedakan berdasarkan jenis.
Konsep hirarki yang ada pada cube query
misalnya, untuk dimensi waktu terdapat elemen dimensi 20032007 yang merupakan
upper level dari tahun 2003, 2004, 2005, 2006, 2007. Konsep hirarki pada dimensi lokasi adalah All sebagai upper level untuk
lower level kecamatan. Konsep hirarki pada dimensi komoditas adalah All sebagai upper level untuk padi dan jagung.
TOLAP (Temporal On-Line Analytical
Processing) merupakan bahasa yang
berdasarkan rule (rule-based) (Vaisman 2002). Palo mendukung pendekatan temporal
pada data warehouse karena Palo menyediakan fitur untuk membuat suatu rule. Syntax dari rule dalam PALO secara umum yaitu : [target] = f[source], dimana target adalah area di dalam cube yang dihitung atau didefinisikan dengan rule. Target area didefinisikan dengan elemen dimensi.
Contoh query agregat yang membutuhkan
MapF adalah, “ total produksi tanaman padi sebagai berikut : Produksi[2003-2007, wilayah: All, padi] = Padi (2003, wilayah: All) + Padi Gogo (2004-2005, wilayah: All) + Padi Sawah (2004-2005, wilayah: All) + Padi (2006-2007, wilayah: All).
Penambahan Operasi Dasar OLAP
Operasi dasar OLAP yang ditambahkan dalam temporal data warehouse ini adalah
9 mengimplementasikan operasi dasar OLAP
tersebut.
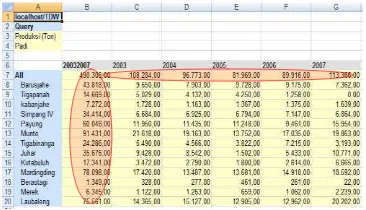
Contoh, untuk query, total produksi padi tahun 2003 hingga 2007 pada seluruh wilayah Kabupaten Karo, hasil yang ditampilkan dapat dilihat pada Gambar 10.
Gambar 10 Hasil query total produksi padi pada tahun 2003 hingga 2007.
Query tersebut merupakan query yang melibatkan data yang berada pada upper level.
All pada dimensi wilayah merupakan upper level untuk kecamatan. Data yang bersifat
upper level merupakan hasil agregat dari elemen dimensi yang berada di level bawah. Artinya elemen All untuk dimensi wilayah merupakan hasil agregat dari level kecamatan. Nilai konsolidasi yang dimiliki oleh All
dapat menghasilkan suatu tampilan yang lebih
detail berupa data produksi dari setiap kecamatan. Proses tersebut belum dapat ditangani oleh penelitian Malau (2009). Hal yang dilakukan agar proses tersebut dapat ditangani adalah dengan menransformasikan data atomik sebagai penyusun data summary.
Hasil yang dilakukan pada penelitian Malau (2009) apabila pada Gambar 10 dikenakan operasi drill down, akan terlihat seperti pada Gambar 11.
Gambar 11 Hasil operasi drill down pada penelitian Malau (2009).
Hasil yang diperoleh dari query tersebut adalah 490.308,00 Ton padi pada tahun 2003 hingga 2007. Pada Gambar 11, terlihat hasil produksi padi pada setiap kecamatan bernilai nol. Hal ini terjadi karena fungsi transformasi pada data atomik belum ada. Setelah
dilakukan penambahan fungsi transformasi untuk data atomik dari setiap kecamatan, hasil yang diperoleh apabila Gambar 8 dikenakan operasi drill down, dapat terlihat pada Gambar 12.
Gambar 12 Hasil operasi drill down setelah ditambah fungsi transformasi data atomik.
Hasil perbaikan dari Gambar 11 dapat dilihat dari ilustrasi Gambar 12, dimana hasil produksi padi pada tahun 2003 hingga 2007 dapat diperoleh beserta informasi detail
mengenai total produksi padi pada setiap kecamatan. Operasi drill down tidak hanya dapat dilakukan pada dimensi wilayah saja, dimensi waktu pun dapat dikenakan operasi
drill down. Hasil dari drill down pada dimensi waktu dapat dilihat pada Gambar 13.
Gambar 13 Hasil operasi drill down pada dimensi waktu.
Operasi drill down seperti pada Gambar 13 dibutuhkan rule untuk memetakan data atomik dari 13 kecamatan yang ada di Kabupaten Karo untuk jangka waktu 5 tahun. Cell value
dari anggota dimensi yang berada dalam
upper level dihitung dari subordinat lower level–nya. Sebelum melakukan transformasi data, kita memilih cube dari anggota dimensi yang berada di lower level dan menransformasikan setiap cell value untuk menghitung upper level- nya. Oleh karena itu, kolom dan baris yang diberi tanda pada Gambar 13, tidak memerlukan rule untuk mendeskripsikan nilai di setiap cell value-nya,
10
upper level dari level yang berada di bawahnya.
Contoh operasi slicing pada temporal data warehouse ini diilustrasikan pada Gambar 14.
Gambar 14 Contoh operasi slicing.
Contoh operasi dicing pada temporal data warehouse dapat dilihat pada Gambar 15.
Gambar 15 Contoh operasi dicing.
Penambahan Fungsi Agregat
Fungsi agregat yang ditambahkan pada
temporal data warehouse ini adalah min, max,
dan average. Min adalah fungsi agregat untuk mencari nilai minimum dari suatu subset. Max
adalah fungsi agregat untuk mencari nilai maksimum dari suatu subset. Average adalah fungsi agregat untuk mencari nilai rata-rata dari suatu subset. Fungsi agregat tersebut ditambahkan dalam dimensi measure.
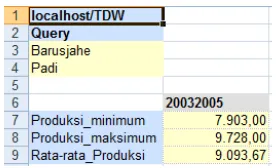
Contoh query untuk mengetahui fungsi agregat misalnya, produksi minimum, produksi maksimum dan nilai rata-rata padi pada tahun 2003 hingga 2005 untuk kota Barusjahe. Hasil yang akan diperoleh dari
query tersebut dapat dilihat pada Gambar 16.
Gambar 16 Hasil query untuk fungsi agregat
min, max, dan average.
Berdasarkan hasil query di atas, diperoleh hasil rata-rata produksi tahun 2003 hingga 2005 adalah 9.093,67, produksi minimum adalah 7.903,00, dan produksi maksimum adalah 9.728,00.
Analisis Visual dari Cross-tabulation dan Grafik
Informasi yang dapat diperoleh dari
temporal data warehouse ini misalnya, perkembangan produksi tanaman jagung yang terjadi di Kabupaten Karo dari tahun 2003 hingga tahun 2007. Crosstab dan grafik dari informasi di atas dapat dilihat pada Gambar 17.
Gambar 17 Cross-tabulation dan grafik batang untuk perkembangan produksi padi dan jagung pada tahun 2003 hingga 2007 di Kabupaten Karo.
11 dilakukan dengan menggunakan PALO 3.0 telah berhasil menangani beberapa query yang mengalami perubahan struktur. Perubahan struktur yang terjadi pada tahun 2003 hingga 2007 adalah split dan merge. Semakin banyak perubahan struktur yang terjadi maka semakin banyak kubus data yang terbentuk.
Operasi OLAP (drill down, roll up, slicing, dicing) dapat diimplementasikan dengan baik dalam temporal data warehouse. Fungsi agregat seperti min, max dan average
telah berhasil diimplementasikan pada
temporal data warehouse. Perkembangan produksi, luas tanam, dan luas panen pada setiap kecamatan dapat dilihat lebih jelas dengan analisis visual terhadap crosstab dan grafik.
Keunggulan dari pendekatan temporal
pada data warehouse tanaman pangan adalah ketika terjadi suatu perubahan pencatatan objek antara tahun 2003-2007, analisis data historis masih dapat berjalan dengan baik. Hal ini terjadi karena perubahan yang ada dalam suatu interval waktu yaitu pada tahun 2003, 2004-2005, dan 2006-2007 dibentuk ke dalam tiga versi struktur dan dipetakan oleh fungsi transformasi berupa MapF (Mapping Function) sehingga perubahan dimensi yang terjadi karena operasi split dan merge dapat ditangani.
Saran
Perubahan pencatatan data yang dilakukan setiap tahun akan banyak membutuhkan kubus data karena perubahan versi struktur yang terjadi. Oleh karena itu, diperlukan suatu mekanisme penyimpanan kubus data yang lebih baik. Pembuatan modul input dan modul
update untuk penelitian selanjutnya diharapkan dapat mempermudah pengguna dalam pembuatan temporal data warehouse.
DAFTAR PUSTAKA
Blaschka M. 1998. On Evolution in Multidimensional Databases. In Proc. of
the DaWak‟99 Conference.
Eder J, Christian K. 2001. Evolution of Dimension Data in Temporal Data
Warehouses. University of Klagenfurt; Dep. of Informatics-Systems.
Eder J, Christian K, Tadeuz M. 2001. A Model for Temporal Data Warehouse. In Proc. of the Int. OESSEO 2001 Conference.
Han J, Kamber M. 2006. Data Mining: Concepts and Techniques. San Fransisco: MorganKaufman Publisher.
Hayardisi. 2008. Data Warehouse dan OLAP Berbasis Web Untuk Persebaran Hotspot
di Wilayah Indonesia Menggunakan Palo 2.0 [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor. Kusumaningtias, DW. 2007.Pembuatan Data
Warehouse Potensi Desa di Wilayah Bogor Menggunakan Oracle Data Warehouse [skripsi]. Bogor : Departemen Ilmu Komputer, Institut Pertanian Bogor. Malau, TJ. 2009. Pembuatan Temporal Data
Warehouse pada Komoditi Tanaman Pangan dan Hortikultura Kabupaten Karo, Sumatera Utara [skripsi]. Bogor : Departemen Ilmu Komputer, Institut Pertanian Bogor.
Mallach, EG. 2000. Decision Support and Data warehouse System. USA : Mc. Graw-Hill, Inc.
Tan et al. 2006. Introduction to Data Mining.
USA : Pearson Education, Inc.
1
PENDAHULUAN
Latar Belakang
Analisis data historis dan pengolahan data multidimensi bukan merupakan hal yang baru untuk mendukung suatu pengambilan keputusan. Namun perubahan objek data yang dicatat, membuat analisis data historis dan penelusuran terhadap data menjadi sulit untuk dilakukan. Misalnya, pada tahun 2003, objek yang dicatat oleh perusahaan adalah produksi padi dan jagung, sementara itu pada tahun 2004, objek yang dicatat oleh perusahaan adalah produksi padi sawah, padi gogo, jagung komposit dan jagung hybrida. Oleh karena itu, jika pengguna ingin mengetahui total produksi padi dari tahun 2003 hingga 2004, maka akan sulit memperoleh informasi total produksi padi, karena perubahan atribut yang dicatat tersebut. Untuk itu, teknologi
data warehouse saat ini sudah dikembangkan dengan melakukan pendekatan secara
temporal atau data warehouse berorientasi waktu untuk menangani perubahan objek.
Penelitian mengenai temporal data warehouse sudah pernah dilakukan oleh Eder (2001). Penelitian tersebut memberi penjelasan mengenai model untuk temporal data warehouse bagi penelitian selanjutnya. Selanjutnya, penelitian Eder (2001) tersebut coba diterapkan oleh Malau (2009) untuk data tanaman pangan dan hortikultura di Kabupaten Karo. Penelitian lanjutan tersebut telah mampu menangani masalah split dan
merge serta fungsi agregat sum.
Namun ada beberapa kekurangan dari
temporal data warehouse yang dilakukan oleh Malau (2009) tersebut, yaitu belum dapat mendukung operasi OLAP seperti slicing, dicing, drill down, dan roll up. Oleh karena itu, sebagai pelengkap dari temporal data warehouse yang sudah dibuat, diperlukan penambahan operasi OLAP seperti slicing,
dicing, drill down, roll up serta fungsi agregat seperti min, max, dan average agar menjadi
temporal data warehouse yang lebih baik.
Tujuan
Merancang dan membangun suatu model
temporal data warehouse yang memiliki fitur operasi dasar data warehouse yaitu roll up,
drill down, slicing, dan dicing serta fungsi agregat seperti min, max, dan average. Ruang Lingkup
Penelitian ini difokuskan pada operasi dasar data warehouse yaitu slicing, dicing,
Temporal Data Warehouse
Temporal data warehouse merupakan suatu perbaikan dari teknologi data warehouse dengan melakukan pendekatan
temporal, sehingga mampu menangani operasi dasar data warehouse seperti roll up, drill down, slicing dan dicing serta operasi-operasi yang kompleks seperti split (pembagian) dan
merge (penggabungan). Temporal data
warehouse menitikberatkan pada fungsi transformasi yang berasal dari versi struktur (Eder et al 2001). Contoh permasalahan yang tidak dapat ditangani oleh data warehouse
biasa, misalnya diketahui sebuah divisi A mengalami pembagian divisi yaitu divisi A1 dan divisi A2 pada bulan Maret tahun 2000, jika ingin diketahui perkembangan divisi A, maka tanpa pendekatan temporal data warehouse tersebut tidak akan mampu memberikan informasi mengenai seluruh perkembangan divisi A. Informasi yang diperoleh oleh pengguna mengenai divisi A hanya sampai pada bulan Februari 2000, sebelum divisi A mengalami perubahan struktur. Namun demikian, apabila data warehouse tersebut telah menggunakan pendekatan temporal, maka akan diperlihatkan seluruh data melalui penelusuran structure version yang didukung fungsi transformasi. Dengan demikian, operasi split (pembagian) dan merge
(penggabungan) yang terjadi pada divisi A dapat diketahui dan query pengguna mengenai seluruh data divisi A dapat dipenuhi. Versi Struktur
Versi struktur merepresentasikan sudut pandang pada temporal data warehouse yang menangani struktur valid untuk interval waktu [Ts,Te]. Modifikasi anggota dimensi atau
relasi hirarki memastikan berada pada suatu versi struktur. Jika interval waktu tertentu tidak ada berada dalam suatu versi struktur maka diperlukan suatu versi struktur baru yang dapat memastikan interval waktu tersebut dapat tertangani (Eder et al 2001).
Secara umum structure version (SV) terdiri atas empat tuple dengan format <SVid,
T, {DMDi, SVid, …, DMDN, SVid, DMF,SVid}, HSVid>
dimana SVid adalah unique identifier, T
1
PENDAHULUAN
Latar Belakang
Analisis data historis dan pengolahan data multidimensi bukan merupakan hal yang baru untuk mendukung suatu pengambilan keputusan. Namun perubahan objek data yang dicatat, membuat analisis data historis dan penelusuran terhadap data menjadi sulit untuk dilakukan. Misalnya, pada tahun 2003, objek yang dicatat oleh perusahaan adalah produksi padi dan jagung, sementara itu pada tahun 2004, objek yang dicatat oleh perusahaan adalah produksi padi sawah, padi gogo, jagung komposit dan jagung hybrida. Oleh karena itu, jika pengguna ingin mengetahui total produksi padi dari tahun 2003 hingga 2004, maka akan sulit memperoleh informasi total produksi padi, karena perubahan atribut yang dicatat tersebut. Untuk itu, teknologi
data warehouse saat ini sudah dikembangkan dengan melakukan pendekatan secara
temporal atau data warehouse berorientasi waktu untuk menangani perubahan objek.
Penelitian mengenai temporal data warehouse sudah pernah dilakukan oleh Eder (2001). Penelitian tersebut memberi penjelasan mengenai model untuk temporal data warehouse bagi penelitian selanjutnya. Selanjutnya, penelitian Eder (2001) tersebut coba diterapkan oleh Malau (2009) untuk data tanaman pangan dan hortikultura di Kabupaten Karo. Penelitian lanjutan tersebut telah mampu menangani masalah split dan
merge serta fungsi agregat sum.
Namun ada beberapa kekurangan dari
temporal data warehouse yang dilakukan oleh Malau (2009) tersebut, yaitu belum dapat mendukung operasi OLAP seperti slicing, dicing, drill down, dan roll up. Oleh karena itu, sebagai pelengkap dari temporal data warehouse yang sudah dibuat, diperlukan penambahan operasi OLAP seperti slicing,
dicing, drill down, roll up serta fungsi agregat seperti min, max, dan average agar menjadi
temporal data warehouse yang lebih baik.
Tujuan
Merancang dan membangun suatu model
temporal data warehouse yang memiliki fitur operasi dasar data warehouse yaitu roll up,
drill down, slicing, dan dicing serta fungsi agregat seperti min, max, dan average. Ruang Lingkup
Penelitian ini difokuskan pada operasi dasar data warehouse yaitu slicing, dicing,
Temporal Data Warehouse
Temporal data warehouse merupakan suatu perbaikan dari teknologi data warehouse dengan melakukan pendekatan
temporal, sehingga mampu menangani operasi dasar data warehouse seperti roll up, drill down, slicing dan dicing serta operasi-operasi yang kompleks seperti split (pembagian) dan
merge (penggabungan). Temporal data
warehouse menitikberatkan pada fungsi transformasi yang berasal dari versi struktur (Eder et al 2001). Contoh permasalahan yang tidak dapat ditangani oleh data warehouse
biasa, misalnya diketahui sebuah divisi A mengalami pembagian divisi yaitu divisi A1 dan divisi A2 pada bulan Maret tahun 2000, jika ingin diketahui perkembangan divisi A, maka tanpa pendekatan temporal data warehouse tersebut tidak akan mampu memberikan informasi mengenai seluruh perkembangan divisi A. Informasi yang diperoleh oleh pengguna mengenai divisi A hanya sampai pada bulan Februari 2000, sebelum divisi A mengalami perubahan struktur. Namun demikian, apabila data warehouse tersebut telah menggunakan pendekatan temporal, maka akan diperlihatkan seluruh data melalui penelusuran structure version yang didukung fungsi transformasi. Dengan demikian, operasi split (pembagian) dan merge
(penggabungan) yang terjadi pada divisi A dapat diketahui dan query pengguna mengenai seluruh data divisi A dapat dipenuhi. Versi Struktur
Versi struktur merepresentasikan sudut pandang pada temporal data warehouse yang menangani struktur valid untuk interval waktu [Ts,Te]. Modifikasi anggota dimensi atau
relasi hirarki memastikan berada pada suatu versi struktur. Jika interval waktu tertentu tidak ada berada dalam suatu versi struktur maka diperlukan suatu versi struktur baru yang dapat memastikan interval waktu tersebut dapat tertangani (Eder et al 2001).
Secara umum structure version (SV) terdiri atas empat tuple dengan format <SVid,
T, {DMDi, SVid, …, DMDN, SVid, DMF,SVid}, HSVid>
dimana SVid adalah unique identifier, T
2
structure version dengan selang waktu [Ts,
Te], Ts adalah start time atau waktu awal, dan
Te adalah end time atau waktu akhir. DMDi, SV-id adalah himpunan dari semua
anggota-anggota dimensi, dimana merupakan bagian dari dimensi Di dan valid untuk waktu P
dengan Ts ≤ P ≤ Te. DMF,SVid adalah himpunan
dari seluruh fakta-fakta yang valid pada waktu P dengan Ts ≤ P ≤ Te, HSvid adalah himpunan
dari penambahan hirarki yang valid pada waktu P dengan Ts ≤ P ≤ Te.
Ilustrasi untuk structure version (SV) seperti diperlihatkan pada Gambar 1, mengenai dimensi divisi untuk penjualan (sales) yang disertai interval (selang) waktu (Eder et al 2001):
<M1, ∞> <M1, ∞> <M4, ∞>
<M1, ∞> <M4, ∞> <M1, M3>
Gambar 1 Dimensi divisi sales.
Pada Gambar 1 terlihat bahwa SubDiv.D telah dimodifikasi pada waktu M4, SubDiv.
yang baru yaitu SubDiv.E dimasukkan pada saat waktu M4, Div.C merupakan subdivisi
dari Div.B pada waktu M1 sampai M3 (pada
gambar ditandai dengan garis putus-putus). Berdasarkan Gambar 1, diperoleh beberapa
structure version (SV), yaitu:
1. <SV1, [M1, M3], {{Divisions, Div.A,
Div.B, Div.C, SubDiv.D}, {Sales}},
{Div.A → Divisions, SubDIv.D→ Div.A, …}>
2. <SV2, [M4, ∞], {{Divisions, Div.A, Div.B,
Div.C, SubDiv.D, SubDiv.E}, {Sales}},
{Div.A → Divisions, SubDiv.D → Div.A, SubDiv.E → Div.A, …}>
Structure version yang diperoleh ada dua yaitu SV1 dan SV2. SV1 dan seluruh anggota-anggota dimensi (Divisions, Div.A, Div.B,…)
dan penambahan hirarki (Div.A →
Divisions,…) valid pada saat M1 ke M3,
sedangkan untuk SV2 valid pada saat M4
sampai dengan waktu yang belum ditentukan.
Transformation Function (TF)
Transformation function dalam temporal data warehouse dinamakan dengan MapF
(Mapping Function) dan menggunakan operasi dasar penjumlahan (sum). Misalnya suatu divisi A mengalami split pada bulan Maret tahun 2000 menjadi divisi A1 dan A2. Jika kita ingin menganalisis semua bulan pada tahun 2000 untuk divisi A, perusahaan hanya memiliki data untuk bulan Januari dan Februari, dimana untuk bulan Maret ke depan, perusahaan memiliki data untuk divisi A1 dan A2. Contoh jika ingin merepresentasikan omset dari divisi A1 untuk periode sebelum Maret tahun 2000 maka sebagai fungsi omset (A1, periode) = 30% dari omset (A, periode). Contoh lainnya, jika kita ingin mengetahui seluruh periode pada bulan Maret ke depan pada tahun 2000, maka jumlah dari karyawan M# dari divisi A terkait dengan fungsi M# (A, periode) = M# (A1, periode) + M# (A2, periode). Fungsi inilah yang disebut
transformation function (MapF) dan untuk operasi yang digunakan adalah operasi sum
(Eder et al 2001).
Pada data tanaman pangan, operasi MapF
akan digunakan untuk data jumlah produksi, luas tanam dan luas panen dari tanaman pangan, padi dan jagung. Misalnya, pada tahun 2003, padi yang ditanam berasal dari satu varietas saja (A), untuk itu pencatatan total padi untuk semua kecamatan dapat dikumulatifkan. Namun, pada tahun 2004, terdapat 2 varietas padi yaitu B dan C yang ditanam pada beberapa kecamatan. Dengan demikian, apabila pengguna ingin mengetahui hasil padi pada 2003 hingga 2004, sistem tidak akan mampu menjawab query tersebut. Pada kasus ini, jika struktur pencatatan padi tidak berubah, maka sistem tidak akan mampu menjawab query tentang berapa hasil produksi padi jenis A, B, atau C, karena pencatatan sebelumnya tidak membedakan jenis padi. Untuk itu diperlukan sebuah struktur baru dan bentuk MapF yang sesuai bagi struktur tersebut sehingga dapat menjawab query
mengenai berapa hasil produksi padi di tahun 2003 hingga 2004 di setiap kecamatan. OLAP ( On-Line Analytical Processing)
OLAP adalah sistem yang memfokuskan pada interaktif analisis data dan biasanya memiliki kemampuan luas mengenai visualisasi data dan membangkitkan ringkasan statistika. Karena alasan ini, pendekatan analisis multidimensional data didasarkan
3 pada terminologi dan konsep OLAP ( Tan et
al 2006).
Data yang biasanya ditampilkan oleh OLAP adalah fungsi agregasi seperti
summary, max, min, dan average. OLAP menyediakan proses kalkulasi dan perbandingan data serta dapat menampilkan hasil dalam bentuk tabel dan grafik.
Operasi-Operasi pada OLAP
Operasi-operasi OLAP adalah sebagai berikut (Han dan Kamber 2006):
- Slicing
Slicing adalah proses melakukan
pemilihan satu dimensi dari suatu kubus data sehingga menghasilkan subcube.
- Dicing
Dicing adalah proses melakukan pemilihan dua atau lebih dimensi dari suatu kubus data sehingga menghasilkan subcube.
- Roll up
Operasi roll up dilakukan pada kubus data dengan cara menaikkan tingkat suatu hirarki. Pada saat roll up dilakukan, maka jumlah dimensi akan berkurang. Contohnya, operasi
roll up yang dilakukan pada kubus data di tingkat kecamatan menjadi tingkat kabupaten. - Drill down
Drill down adalah operasi yang
berkebalikan dengan roll up. Operasi ini merepresentasikan kubus data dengan lebih terperinci.
Ilustrasi mengenai operasi slicing dan dicing dapat dilihat pada Tabel 1 berikut ini (Tan et al 2006).
Tabel 1 Jumlah bunga yang memiliki bagian kombinasi antara lebar daun bunga, panjang daun bunga, dan tipe spesies.
Petal length Petal
width Species type Count
Low Low Setosa 46
Low Medium Setosa 2
Medium Low Setosa 2
Medium Medium Versicolour 43
Medium High Versicolour 3
width Species type Count
high high Versicolour 2
high high Virginica 44
Operasi slicing yang dilakukan pada data di Tabel 1 digambarkan pada Tabel 2, Tabel 3, dan Tabel 4 sebagai berikut.
Tabel 2 Cross-tabulation dari bunga yang berdasarkan panjang dan lebar daun bunga untuk tipe spesies Setosa.
Width
Tabel 3 Cross-tabulation dari bunga berdasarkan pada panjang dan lebar daun bunga untuk spesies Versicolour.
Width bunga untuk spesies Virginica.
Width Tabel 4 telah dihasilkan tiga slice dari operasi
slicing yang telah dilakukan pada data iris
yang diperoleh dari tiga nilai terpisah untuk dimensi spesies. Di sisi lain, hasil dari operasi
dicing merupakan suatu subset dari ketiga tabel tersebut dengan memilih ukuran panjang daun bunga atau lebar daun bunga. Misalnya
dicing yang dilakukan untuk spesies Virginica
4 Tabel 5 Cross-tabulation untuk operasi dicing
pada spesies Virginica dengan panjang
daun bunga „high‟.
Width
low medium high
Length high 0 3 44
- Pivoting
Pivoting merupakan suatu kemampuan OLAP yang dapat melihat data dari berbagai sudut pandang (view point). Kita dapat mengatur sumbu pada cube sehingga memperoleh data yang diinginkan sesuai dengan sudut pandang analisis yang diperlukan.
Model Data Multidimensi
Model data multidimensi adalah model data yang digunakan pada data warehouse. Model data multidimensi terdiri atas dua data yaitu (Mallach 2000 dalam Kusumaningtias 2007) :
- Data dimensi
Data dimensi adalah entitas yang ingin disimpan oleh perusahaan (organisasi). Data dimensi akan berubah jika analisis kebutuhan pengguna berubah. Data dimensi mendefinisikan label yang membentuk isi laporan. Setiap dimensi diulang untuk setiap kelompok. Atribut data dimensi diletakkan pada tabel dimensi. Tabel dimensi berukuran lebih kecil daripada tabel fakta, berisi data bukan numerik yang berasosiasi dengan atribut dimensi.
- Data fakta
Data fakta adalah data utama dari data multidimensi yang merupakan kuantitas yang ingin diketahui dengan menganalisis hubungan antar dimensi. Data fakta diekstrak dari berbagai sumber. Data fakta cenderung stabil dan tidak berubah seiring waktu. Atribut data fakta diletakkan pada tabel fakta.
Data Level
Lingkungan data warehouse terdiri atas 4 tingkatan data, dapat dilihat pada Gambar 2 (Mallach 2000) berikut ini.
Query
Data ringkasan
Data atomik
Data operasional
Gambar 2 Empat level data. 1. Data operasional
Data yang berada di data warehouse
berasal dari database operasional perusahaan.
Data warehouse tidak akan berjalan tanpa data operasional. Contoh, hari ini saya menabung Rp. 150.000.
2. Data atomik
Data atomik terdiri atas data barang itu sendiri. Data atomik merupakan tingkat data terendah dari data dalam data warehouse. Semua fungsi data warehouse dimulai dengan data atomik atau dengan data yang berasal dari data atomik. Data atomik sesuai untuk data transaksi dengan penambahan dimensi waktu. Tingkat ini merupakan data yang dimasukkan ke dalam database data
warehouse dari database operasional
perusahaan. Contoh, saldo tabungan pada bulan Agustus adalah Rp. 240.000.
3. Data ringkasan data warehouse
Para analis memerlukan pengetahuan yang cukup mengenai kegunaan data warehouse. Ringkasan suatu data akan diperlukan pada proses analisis sehingga ringkasan tersebut akan digunakan secara berulang. Contoh, pada akhir bulan Agustus perusahaan memiliki pelanggan sebanyak 1487 yang berada di kode pos 16610-16180.
4. Data yang dapat menjawab pertanyaan yang spesifik
Tingkat ini biasanya dibuat sebagai kebutuhan dan disimpan hanya sampai pengguna yang meminta itu selesai menggunakan data tersebut. Jika pengguna ingin menyimpan itu, microcomputer
5 Arsitektur Data Warehouse
Arsitektur data warehouse yang umum digunakan adalah arsitektur three-tier.
Arsitektur ini memiliki tiga lapisan yaitu lapisan bawah, lapisan tengah, dan lapisan atas (Han & Kamber 2006). Ilustrasi arsitektur
three-tier dapat lihat pada Gambar 3.
Gambar 3 Arsitektur three-tier (Han and Kamber 2006).
Penelitian ini mengacu pada arsitektur
data warehouse three-tier, tiga lapisan tersebut adalah:
1. Lapisan bawah (bottom tier)
Lapisan bawah merupakan tempat pengolahan sumber data warehouse yang bertujuan agar data tersebut dapat digunakan dengan baik.
2. Lapisan tengah (middle tier)
Lapisan tengah merupakan OLAP server
yang berfungsi menyimpan struktur dari kubus data.
3. Lapisan atas (top tier)
Lapisan atas adalah lapisan untuk end-user
yang berisi query dan menampilkan informasi atau ringkasan. Query yang diuji pada penelitian ini dilakukan di Palo Add-in Win32 3.0 yang terintegrasi dengan Microsoft Office Excel.
Arsitektur data warehouse dalam penelitian ini dapat diilustrasikan pada Gambar 4 berikut.
Gambar 4 Ilustrasi arsitektur penelitian
Gambar 4 menjelaskan bahwa lapisan bawah dari arsitektur temporal data warehouse ini adalah data warehouse yang direpresentasikan dengan model dimensi, yaitu skema bintang. Lapisan tengah dari arsitektur temporal data warehouse adalah penyimpanan struktur kubus data yang dilakukan oleh tools Palo server. Lapisan atas dari arsitektur temporal data warehouse ini berupa aplikasi untuk end-user, aplikasi yang digunakan adalah Microsoft Office Excel.
METODE PENELITIAN
Data yang digunakan pada penelitian ini adalah data tanaman pangan yang berupa padi dan jagung di Kabupaten Karo dari tahun 2003 hingga tahun 2007 pada ruang lingkup jumlah produksi, luas tanam dan luas panen. Data diperoleh dari Dinas Pertanian, Peternakan, Perikanan dan Perkebunan Kabupaten Karo.Analisis Data
Data tanaman pangan yang telah diperoleh selanjutnya dianalisis untuk mendapatkan atribut-atribut yang tepat dalam pembuatan
temporal data warehouse. Hasil analisis ini digunakan untuk menentukan dimensi, fakta, dan skema yang tepat untuk model data multidimensi.
Pembuatan Data warehouse
Setelah dilakukan analisis data, dilakukan proses pembuatan data warehouse. Input data dilakukan berdasarkan skema yang telah dirancang. Data yang dimasukkan berdasarkan pada versi struktur yang terbentuk.
Penambahan Operasi OLAP
Pada tahap ini, dilakukan penambahan operasi dasar OLAP seperti slicing, dicing,
roll up, dan drill down. Proses ini dilakukan dengan menransformasikan lower level dari setiap dimensi.
Penambahan Fungsi Agregat
Fungsi agregat yang ditambahkan pada