FAJAR MATIUS GINTING 101402055
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana
Teknologi Informasi
FAJAR MATIUS GINTING
101402055
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : PENGENALAN KATA MENGGUNAKAN
SELF-ORGANIZING MAP SEBAGAI INPUT KAMUS
BERBASIS ANDROID
Kategori : SKRIPSI
Nama : FAJAR MATIUS GINTING
Nomor Induk Mahasiswa : 101402055
Program Studi : S1 TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dani Gunawan, ST.,MT Dedy Arisandi, S.T., M.Kom
NIP. 19820915 201212 1 002 NIP 19790831 200912 1 002
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi
Ketua,
PERNYATAAN
PENGENALAN KATA MENGGUNAKAN SELF-ORGANIZING MAP SEBAGAI INPUT KAMUS BERBASIS ANDROID
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 29 Agustus 2015
Fajar Matius Ginting
UCAPAN TERIMA KASIH
Puji dan syukur penulis sampaikan kehadirat Tuhan Yang Maha Esa atas berkat dan rahmat yang telah diberikan sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Teknologi Informasi Universitas Sumatera Utara.
Penulis mengucapkan banyak terima kasih kepada Bapak Bapak Dedy Arisandi, S.T., M.Kom selaku dosen pembimbing pertama dan Bapak Dani Gunawan, ST.,MT selaku dosen pembimbing kedua yang telah membimbing, memberi kritik dan saran kepada penulis selama proses penelitian serta penulisan skripsi. Tanpa inspirasi serta motivasi dari kedua dosen pembimbing, tentunya penulis tidak akan mampu menyelesaikan skripsi ini. Penulis juga mengucapkan terima kasih kepada Bapak Prof. Dr. Opim Salim Sitompul, M.Sc selaku dosen pembanding pertama dan Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc sebagai dosen pembanding kedua yang telah membantu memberikan kritik dan saran yang membantu penulis dalam pengerjaan skripsi ini. Ucapan terima kasih juga penulis tujukan pada semua dosen, pegawai serta staff pada program studi S1 Teknologi Informasi yang telah membantu dan membimbing penulis selama proses perkuliahan.
Penulis juga berterima kasih terutama kepada kedua orang tua penulis, Bapak Laurentius Ginting Manik serta Ibu Rasmita Milala yang telah membesarkan penulis dengan sabar dan penuh kasih sayang. Penulis juga berterima kasih kepada adik dan kakak penulis Terbit Kornelius Ginting dan Maria Mentari Ginting serta seluruh anggota keluarga penulis yang namanya tidak dapat disebutkan satu per satu.
ABSTRAK
Salah satu kesulitan yang dialami turis ketika berkunjung ke Rusia adalah masalah bahasa. Penggunaan aplikasi kamus Bahasa Rusia dapat digunakan untuk mengatasi masalah tersebut. Akan tetapi, muncul masalah jika turis tidak familiar terhadap huruf yang dipakai Bahasa Rusia. Bahasa Rusia menggunakan huruf Cyrillic yang penggunaannya terbatas pada Rusia dan beberapa negara tetangganya. Huruf Cyrillic bentuknya berbeda dengan huruf latin. Hal ini sangat menyulitkan turis ketika ingin melakukan penerjemahan dengan mengetikkan kata dari Bahasa Rusia ke aplikasi kamus. Oleh karena itu dibutuhkan sebuah cara untuk menginputkan kata dalam Bahasa Rusia yang menggunakan huruf Cyrillic tersebut. Salah satunya adalah dengan mengambil gambar dari kata yang ingin diterjemahkan, lalu dikenali polanya. Pengenalan pola akan menggunakan jaringan saraf tiruan Self-organizing Map. Pengolahan citra untuk mendapatkan nilai masukan untuk pengenalan polanya akan menggunakan binarisasi, penapisan derau, segmentasi, thinning, dan kemudian fitur akan diekstrak menggunakan pemetaan piksel. Citra kata akan di potong-potong menjadi citra karakter, kemudian setiap citra karakter akan di ekstrak fiturnya, dan dikirim ke server untuk dikenali polanya. Hasil dari server akan dikirim ke klien untuk ditampilkan. Hasil yang didapat adalah, sistem mampu mengenali karakter Cyrillic dengan akurasi dari pengenalan yang didapatkan adalah 91,92% terhadap data uji yang berupa huruf dan 83,79% untuk data uji yang berupa kata.
ANDROID DICTIONARY APPLICATION WITH IMAGE RECOGNITION USING SELF ORGANIZING MAP
ABSTRACT
One of tourist problems when visiting Russia is language problem. The use of dictionary application for Russian language can overcome this language problem. But another problem arise when the tourist is not familiar with the alphabet used by Russian language. The Russian language using Cyrillic alphabet, which its use limited only to Russia and some of Russias neighboring states. The Cyrillic alphabet has different form than Latin alphabet. Because of this, tourist will encounter difficulties when trying to translate Russian word by typing it to the dictionary application. Therefore, other method of inputting is needed. One of them is by taking the picture of the word, and then recognize the pattern. Pattern recognizing will use one of neural network method, Self-organizing Map. Image processing will be used to get the input value for pattern recognition, such as binarisation, noise filtering, segmentation, thinning, and then the feature will be extracted using pixel mapping. The image containing the word is segmented into many image that containing one character each, and each of that isolated image will have its feature extracted, and then send to server for recognition. The recognition result will be send back to the android client, and shown to the user. The result is, system is able to recognize Cyrillic character pattern with accuracy of recognition is 91,92% for test data in the form of letters and 83,79% for test data in the form of words.
DAFTAR ISI
Persetujuan ii
Pernyataan iii
Ucapan Terima Kasih iv
Abstrak v
Abstract vi
Daftar Isi vii
Dafter Tabel ix
Daftar Gambar x
BAB 1 PENDAHULUAN 1
1.1Latar Belakang 1
1.2Rumusan Masalah 3
1.3Tujuan Penelitian 3
1.4Batasan Masalah 3
1.5Manfaat Penelitian 4
1.6Sistematika Penulisan 4
BAB 2 LANDASAN TEORI 5
2.1 Bahasa Rusia 5
2.2 Pengolahan Citra Digital 8
2.2.1 Pengertian Citra 8
2.2.2. Binerisasi 9
2.2.3 Penapisan Derau 11
2.2.4 Segmentasi 13
2.2.5 Thinning 14
2.3 Ekstraksi Fitur 16
2.4 Pengenalan Pola 17
2.5 Self-Organizing Map 18
3.1 Basis data yang digunakan 23
3.2 Arsitektur umum 24
3.2.1 Input Citra 26
3.2.2 Prapengolahan Citra 26
3.2.3 Ekstraksi Fitur 38
3.2.4 Menerima Data pada server 38
3.2.5 Klasifikasi 39
3.2.6 Pelatihan 40
3.2.7 Menerima Data pada klien 41
3.2.8 Penerjemahan 42
3.2.9 Menampilkan Hasil 42
3.3 Use case dan User case spesification 44
3.3.1 Use case 44
3.3.2 Use case spesification 44
BAB 4 IMPLEMENTASI DAN PENGUJIAN 48
4.1 Pengujian Server 48
4.1.1 Proses Pelatihan 48
4.1.2 Proses Pengujian 48
4.2 Pengujian Klien 50
BAB 5 KESIMPULAN DAN SARAN 57
5.1 Kesimpulan 57
5.2 Saran 57
Daftar Pustaka 59
Lampiran A : Hasil Pengujian terhadap huruf 62
DAFTAR TABEL
Tabel 2.1 Tabel huruf Cyrillic 7
Tabel 2.2 Tabel Penelitian Terdahulu 21
Tabel 3.1 Contoh rekord dari database 23
Tabel 3.2 Penggunaan Font 40
Tabel 3.3 HКЬТХ PОЧМШМШФКЧ НКЭКЛКЬО НОЧРКЧ ЦКЬЮФКЧ “ ” 42
Tabel 3.4 Use Case spesifikasi untuk user 45
Tabel 3.5 Use Case spesifikasi untuk pelatihan 45
Tabel 4.6 Use Case spesifikasi untuk pengujian 46
Tabel 4.1 Hasil pengujian data latih 49
Tabel 4.2 Hasil pengujian data uji 49
DAFTAR GAMBAR
Gambar 2.1 Piksel pada citra 8
Gambar 2.2 Hasil binerisasi dengn algoritma Otsu 11
Gambar 2.3 Piksel dan tetangganya 12
Gambar 2.4 Citra dengan Median Filter 13
Gambar 2.5 Ilustrasi pemotongan karakter dari sebuah citra 14
Gambar 2.6 Proses Thinning 16
Gambar 2.7 Ilustrasi pemetaan piksel, dari citra menjadi untaian nilai 17
Gambar 2.8 Struktur Sistem Pengenalan Pola 17
Gambar 2.9 Contoh jaringan kohonen dengan ukuran node 4x4 dan
2 unit masukan 19
Gambar 3.1 Diagram blok sistem secara keseluruhan 24
Gambar 3.2 Diagram blok prapengolahan citra pada klien 25
Gambar 3.3 Diagram blok pelatihan pada server 26
Gambar 3.4 Diagram blok prapengolahan citra pada server 26
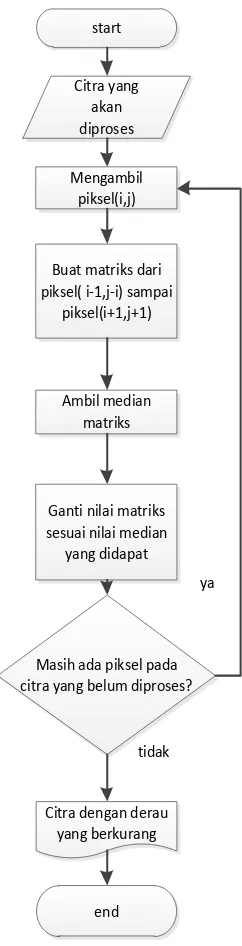
Gambar 3.5 Flowchart median filter 3x3 27
Gambar 3.6 Hasil penapisan derau 28
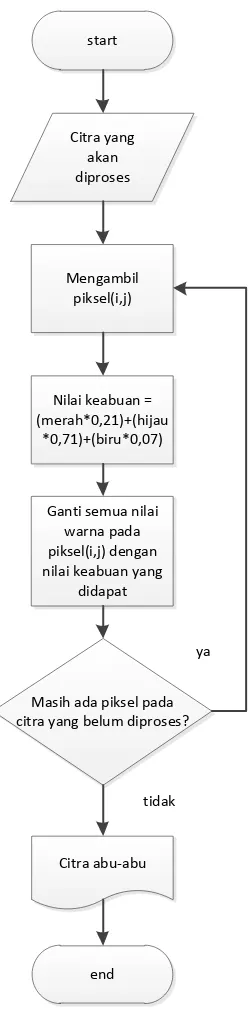
Gambar 3.7 Flowchart Grayscaling 29
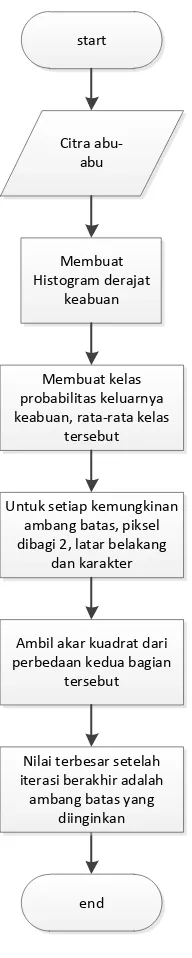
Gambar 3.8 Flowchart penentuan ambang batas menggunakan metode Otsu 30
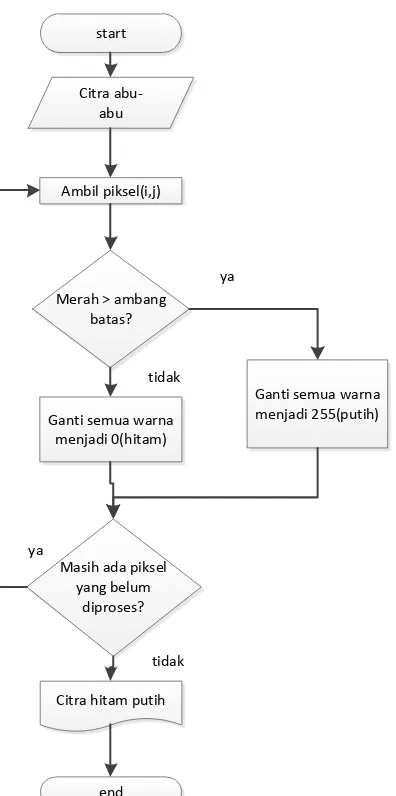
Gambar 3.9 Flowchart metode ambang batas 31
Gambar 3.10 Hasil Binerisasi 32
Gambar 3.11 Flowchart segmentasi kata menjadi kolom yang berisi satu huruf 34
Gambar 3.12 Hasil Segmentasi 35
Gambar 3.13 Flowchart proses penskalaan 35
Gambar 3.14 Hasil penskalaan dari sebuah karakter 36
Gambar 3.15 Flowchart proses thinning dengan metode Zhang-Suen 37
Gambar 3.17 Diagram alir klasifikasi data hasil ekstraksi fitur 39
Gambar 3.18 Diagram alir proses pelatihan 41
Gambar 3.19 Rancangan tampilan hasil 43
Gambar 3.20 Use Case 44
Gambar 4.1 Iklan dari potongan sebuah majalah berbahasa Rusia 50
Gambar 4.2 Menentukan bagian yang mengandung kata yang ingin
diterjemahkan 51
Gambar 4.3 Bagian yang dipilih oleh user 51
Gambar 4.4 Hasil penapisan derau 52
Gambar 4.5 Hasil binerisasi 52
Gambar 4.6 Hasil segmentasi 53
Gambar 4.7 Hasil penskalaan 53
Gambar 4.8 Hasil dari prapengolahan citra 53
Gambar 4.9 Hasil penerjemahan ditampilkan berserta bagian yang dijadikan
ABSTRAK
Salah satu kesulitan yang dialami turis ketika berkunjung ke Rusia adalah masalah bahasa. Penggunaan aplikasi kamus Bahasa Rusia dapat digunakan untuk mengatasi masalah tersebut. Akan tetapi, muncul masalah jika turis tidak familiar terhadap huruf yang dipakai Bahasa Rusia. Bahasa Rusia menggunakan huruf Cyrillic yang penggunaannya terbatas pada Rusia dan beberapa negara tetangganya. Huruf Cyrillic bentuknya berbeda dengan huruf latin. Hal ini sangat menyulitkan turis ketika ingin melakukan penerjemahan dengan mengetikkan kata dari Bahasa Rusia ke aplikasi kamus. Oleh karena itu dibutuhkan sebuah cara untuk menginputkan kata dalam Bahasa Rusia yang menggunakan huruf Cyrillic tersebut. Salah satunya adalah dengan mengambil gambar dari kata yang ingin diterjemahkan, lalu dikenali polanya. Pengenalan pola akan menggunakan jaringan saraf tiruan Self-organizing Map. Pengolahan citra untuk mendapatkan nilai masukan untuk pengenalan polanya akan menggunakan binarisasi, penapisan derau, segmentasi, thinning, dan kemudian fitur akan diekstrak menggunakan pemetaan piksel. Citra kata akan di potong-potong menjadi citra karakter, kemudian setiap citra karakter akan di ekstrak fiturnya, dan dikirim ke server untuk dikenali polanya. Hasil dari server akan dikirim ke klien untuk ditampilkan. Hasil yang didapat adalah, sistem mampu mengenali karakter Cyrillic dengan akurasi dari pengenalan yang didapatkan adalah 91,92% terhadap data uji yang berupa huruf dan 83,79% untuk data uji yang berupa kata.
ANDROID DICTIONARY APPLICATION WITH IMAGE RECOGNITION USING SELF ORGANIZING MAP
ABSTRACT
One of tourist problems when visiting Russia is language problem. The use of dictionary application for Russian language can overcome this language problem. But another problem arise when the tourist is not familiar with the alphabet used by Russian language. The Russian language using Cyrillic alphabet, which its use limited only to Russia and some of Russias neighboring states. The Cyrillic alphabet has different form than Latin alphabet. Because of this, tourist will encounter difficulties when trying to translate Russian word by typing it to the dictionary application. Therefore, other method of inputting is needed. One of them is by taking the picture of the word, and then recognize the pattern. Pattern recognizing will use one of neural network method, Self-organizing Map. Image processing will be used to get the input value for pattern recognition, such as binarisation, noise filtering, segmentation, thinning, and then the feature will be extracted using pixel mapping. The image containing the word is segmented into many image that containing one character each, and each of that isolated image will have its feature extracted, and then send to server for recognition. The recognition result will be send back to the android client, and shown to the user. The result is, system is able to recognize Cyrillic character pattern with accuracy of recognition is 91,92% for test data in the form of letters and 83,79% for test data in the form of words.
1.1Latar Belakang
Rusia adalah salah satu negara tujuan wisata. Menurut dari data laporan kunjungan wisatawan yang dikeluarkan oleh United Nations World Tourism Organization (UNWTO), kunjungan turis ke negara Rusia adalah urutan ke sembilan di dunia dengan 25 juta wisatawan pada 2012 dan 28 juta wisatawan pada 2013 (UNWTO, 2014). Data kunjungan turis mancanegara ke Rusia dari UNWTO tersebut membuktikan bahwa Rusia adalah salah satu negara yang sangat digemari oleh turis untuk dikunjungi. Masalah yang sering dihadapi turis mancanegara ketika berkunjung ke Rusia adalah masalah bahasa. Hal ini dikarenakan, turis mancanegara tidak diwajibkan untuk mengetahui bahasa dari daerah yang ingin dikunjunginya terlebih dahulu. Oleh karena itu, turis tidak diwajibkan untuk mempelajari Bahasa Rusia untuk dapat berkunjung ke Rusia. Turis mancanegara yang berkunjung ke Rusia tentunya sangat sulit untuk mengartikan kata-kata yang dilihatnya di jalanan, gedung atau pemberitahuan tertulis.
Kesulitan turis mancanegara dalam membaca tulisan Rusia terletak pada penggunaan huruf. Huruf yang digunakan oleh Bahasa Rusia adalah huruf Cyrillic. Penggunaan huruf Cyrillic hanya terbatas pada Rusia dan beberapa negara tetangganya. Selain keterbatasan penggunaan, huruf Cyrillic bentuknya juga berbeda dengan huruf Latin. Perbedaan bentuk huruf tersebut tentunya menyulitkan turis yang tidak familiar dengan huruf Cyrillic. Kesulitan tersebut berimbas pada kesulitan dalam menerjemahkan kata dari Bahasa Rusia.
telepon cerdas seperti android, dapat digunakan untuk menggunakan aplikasi tersebut. Turis yang berkunjung ke Rusia tinggal mengetikkan kata Rusia yang ingin dicari terjemahannya pada aplikasi tersebut. Turis dapat mengetik kata tersebut dengan papan ketik untuk huruf Cyrillic yang disediakan oleh android. Akan tetapi muncul masalah apabila turis tersebut tidak familiar terhadap bahasa Rusia dan huruf Cyrillic. Pengguna yang tidak mengerti bahasa tersebut berikut hurufnya akan kesulitan dalam mengetikkannya kedalam aplikasi kamus tersebut. Solusi alternatif untuk mengatasi masalah ini adalah dengan memperoleh kata yang ingin dialihbahasakan dengan mengambil citranya. Citra yang diambil tersebut kemudian diproses agar dapat diambil kata yang termuat di dalamnya.
Ada beberapa cara untuk mengenali kata yang termuat pada sebuah citra. Salah satunya ialah dengan menggunakan metode Jaringan Saraf Tiruan, contohnya dengan metode Propagasi Balik (Harjono, 2013). Dengan jaringan saraf tiruan, maka sebuah sistem akan mampu mengenali sebuah gambar atau pola tertentu. Jaringan saraf tiruan tidak hanya mampu mengenali gambar, tetapi semua hal yang memiliki pola tertentu yang unik. Gambar berupa huruf memiliki pola tertentu, sehingga jaringan saraf tiruan akan mampu untuk mengenali gambar tersebut. Hasil dari jaringan saraf tiruan tersebut adalah sebuah pengenalan pola yang diukur berdasarkan akurasi atau ketepatan pengenalan. Penggunaan algoritma dan metode jaringan saraf tiruan yang berbeda, akan memberikan nilai akurasi yang berbeda pula. Rentang dari akurasi pengenalan itu adalah sebesar 0-100%.
data dengan dimensi tinggi. Algoritma self-organizing map telah banyak digunakan untuk mengenali berbagai pola, seperti pengenalan wajah (Nagi, et al. 2007) dan pengenalan suara (Kohonen, et al. 1997).
Pada skripsi ini akan dibahas bagaimana cara mengenali tulisan Rusia dengan mengambil citranya, kemudian citra tersebut dikenali. Berdasarkan latar belakang tersebut, maka penulis mengajukan penelitian dengan УЮНЮХ “Pengenalan Kata Menggunakan Self-Organizing Map Sebagai Input Kamus Berbasis Android”.
1.2Rumusan Masalah
Turis yang berkunjung ke Rusia akan kesulitan menerjemahkan kata yang dilihatnya tanpa bantuan kamus. Penggunaan perangkat lunak kamus dapat menggantikan kamus konvensional yang tidak praktis. Tetapi ditemukan kesulitan mengetik kata tersebut ke aplikasi kamus, karena bahasa tersebut menggunakan huruf Cyrillic. Bagaimanakah solusi alternatif untuk menginputkan kata dengan huruf Cyrillic tersebut?
1.3Tujuan Penelitian
Tujuan penelitian ini adalah untuk membuat sebuah aplikasi yang mampu memberikan solusi alternatif dalam menginputkan kata, yaitu dengan mengambil citra melalui kamera dan kemudian menerjemahkannya.
1.4Batasan Masalah
Untuk menghindari penyimpangan dan perluasan yang tidak diperlukan, penulis membuat batasan:
1. Kata yang akan dikenali menggunakan huruf Cyrillic tak bersambung. 2. Kata yang akan dikenali memiliki ukuran huruf yang relatif sama 3. Pengambilan gambar tidak dalam posisi miring
5. Gambar diambil dalam kondisi penerangan yang baik.
1.5Manfaat Penelitian
Manfaat dari penelitian ini adalah:
1. Mengembangkan aplikasi android yang dapat digunakan untuk membantu penerjemahan kata bahasa Rusia
2. Membantu menerjemahkan kata bahasa asing dengan lebih mudah.
1.6 Sistematika Penulisan
Penulisan skripsi ini menggunakan sistematika penulisan berikut ini.
BAB 1 PENDAHULUAN
Pada bab ini dibahas perihal latar belakang, rumusan masalah, tujuan penilitian, batasan masalah, metodologi, dan sistematika penulisan skripsi.
BAB 2 LANDASAN TEORI
Pada bab ini dibahas perihal teori-teori yang mendukung dan berkaitan tentang proses pembangunan aplikasi ini, seperti teori pemrosesan citra dan pengenalan dengan jaringan saraf tiruan.
BAB 3 ANALISIS DAN PERANCANGAN
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Pada bab ini dibahas perihal pengimplementasian metode-metode yang sudah ditentukan dalam menyelesaikan permasalahan yang sudah dirumuskan sebelumnya, berikut pembangunan dan hasil dari aplikasi yang dibangun.
BAB 5 KESIMPULAN DAN SARAN
Bab ini membahas tentang teori landasan teori dalam penyelesaian masalah skripsi ini. Hal-hal yang akan dibahas ialah Bahasa Rusia, teori pengolahan citra digital, ektraksi fitur, pengenalan pola, Self-Organizing Map.
2.1. Bahasa Rusia
Bahasa Rusia adalah Bahasa Nasional dari Rusia, Belarus, Kazakhstan, dan Kyrgyzstan. Selain sebagai bahasa Nasional, Bahasa Rusia juga diakui sebagai bahasa kedua di Ukraina, Moldovia, Transnistria, Abkhazia, dan Ossetia Selatan. Bahasa Rusia termasuk rumpun bahasa Eropa Timur. Bahasa lain yang sangat dekat dengan Bahasa Rusia adalah Bahasa Ukraina, Bahasa Belarus dan Bahasa Rusyn. Selain bahasa-bahasa tersebut, Bahasa Rusia juga masih serumpun dengan bahasa lain seperti Bahasa Bulgaria, Bahasa Serbia, Bahasa Polandia, dan sebagainya.
Bahasa Rusia tidak menggunakan alfabet dari huruf latin, melainkan huruf Cyrillic. Huruf Cyrillic adalah huruf yang digunakan oleh sebagian besar bahasa-bahasa di Eropa Timur. Huruf Cyrillic yang digunakan oleh Bahasa Rusia mengandung 33 huruf, dan memiliki huruf besar. Huruf Cyrillic ditulis dari kiri ke kanan. Untuk daftar huruf Cyrillic yang digunakan oleh Bahasa Rusia dan pembacaannya dengan huruf latin yang setara, dapat dilihat pada tabel 2.1.
Hampir semua bahasa yang serumpun dengan Bahasa Rusia menggunakan huruf Cyrillic, seperti bahasa Belarus, Bahasa Ukraina, Bahasa Bulgaria, dan sebagainya. Bahasa yang serumpun dengan Bahasa Rusia tetapi tidak menggunakan huruf Cyrillic contohnya adalah Bahasa Polandia dan Bahasa Ceko. Keduanya menggunakan huruf Latin.
adalah pada huruf Cyrillic yang digunakan oleh Bahasa Serbia yang terdapat huruf yang tidak terdapat pada hurЮП CвЫТХХТМ ЩКНК BКСКЬК ЊЮЬТК, ЬОЩОЫЭТ СЮЫЮП “ ” НКЧ “ ”.
Tabel 2.1. Tabel huruf Cyrillic
No Huruf besar Huruf kecil Nama Bunyi Transkripsi
1 A a /a/ a
2 be /b/ b
3 B ve, we /v, w/ v
4 ge /g/ g
5 de /d/ d
6 E ye /ye/ gye, e
7 Ё yo /yo/ yo
8 zhe /zh/ zh
9 ze /z/ z
10 i /i/ i
11 i-kratkoye /y/ y, i
12 ka /k/ k
13 el /l/ l
14 M em /m/ m
15 H en /n/ n
16 O o /o/ o
17 pe /p/ p
18 P er /r/ r
19 C es /s/ s
20 T te /t/ t
21 u /u/ u
22 ef /f/ f
23 X ha, kha /kh/ j, kh
24 tse /ts/ ts
25 che /ch/ ch
26 sya /sy/ sy
27 scha /sch/ sycy
28 tvyordiy znak (tidak dibaca)
29 Ї /Ї/ y
30 myagkiy znak (tidak dibaca)
31 e /e/ e
32 yu /yu/ yu
33 ya /ya/ ya
“Р” ЩКНК BКСКЬК ЊЮЬТК, ЭОЭКЩТ ЩКНК BКСКЬК UФЫКТЧК, СЮЫЮП ЭОЫЬОЛЮЭ ЬОЭКЫК НОЧРКЧ СЮЫЮП “С”.
Perbedaan-perbedaan dalam penggunaan huruf Cyrillic dan perbedaan bahasa yang menggunakannya memnunjukkan bahwa tidak semua kata yang menggunakan huruf Cyrillic merupakan kata dari Bahasa Rusia. Oleh karena itu, tidak semua kata yang menggunakan huruf Cyrillic dapat diterjemahkan menggunakan kamus bahasa Rusia.
2.2. Pengolahan Citra Digital
Pengolahan citra adalah memanipulasi citra untuk meningkatkan kualitas citra sehingga lebih mudah diinterpretasi oleh mesin atau manusia (Munir, 2004). Pengolahan citra disebut juga pemrosesan citra atau image processing.
Proses pengolahan citra yang dilakukan untuk menyiapkan citra adalah seperti binerisasi, penghilangan derau, deteksi kemiringan, segmentasi karakter, normalisasi ukuran citra, thinning dan skeletonisation (Alginahi, 2010)
2.2.1. Pengertian Citra
Citra adalah gambar pada bidang dwimatra atau dua dimensi (Munir, 2004). Citra yang dapat diproses secara digital adalah citra digital. Citra digital dapat diperoleh dari alat penangkap citra digital serperti kamera digital atau scanner.
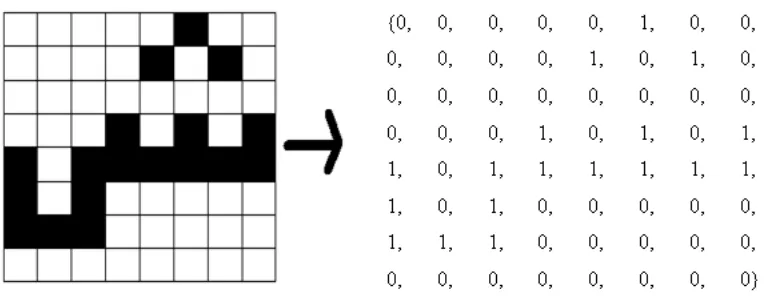
Citra digital disusun oleh banyak kotak kecil yang disebut piksel, seperti pada ditunjukkan pada persamaan 2.1. Piksel-piksel tersebut masing masing menyimpan informasi warna seperti merah, hijau dan biru. Nilai yang disimpan berjarak antara 0 sampai 255 dengan 0 artinya hitam dan 255 berarti putih. Citra digital dapat dinyatakan dalam bentuk matriks x*y, dengan panjang matriks M dan tinggi matriks N dengan anggota matriks adalah piksel-piksel dari citra digital tersebut. Matriksnya adalah sebagai berikut:
2.2.2. Binerisasi
Proses binerisasi adalah proses untuk menghasilkan citra biner atau citra hitam putih. Metode yang digunakan adalah metode pengambangan atau thresholding, yaitu mengganti nilai piksel menjadi 0 atau 255 sesuai dengan nilai ambang batas atau
threshold yang sudah ditentukan.
Citra harus dibinerkan terlebih dahulu karena citra tersebut akan diambil atau diekstrak fiturnya. Fitur yang diinginkan hanyalah bagian huruf yang ingin dikenali saja, tanpa memuat informasi lain yang tidak penting seperti warna. Oleh karena itu, citra harus dibinerkan terlebih dahulu.
Ada beberapa cara untuk menentukan nilai ambang batas pada proses pengambangan. Salah satu metode yang cukup terkenal untuk menentukan nilai ambang batas tersebut adalah metode Otsu (Singh et al, 2011). Metode Otsu adalah metode yang digunakan untuk menghasilkan citra biner atau citra hitam putih dari sebuah citra yang masih memiliki tingkat keabuan atau grayscale (Bhargava et al, 2014). Oleh karena itu, sebuah citra harus diubah menjadi citra grayscale terlebih dahulu.
Tahapan dalam memperoleh citra grayscale adalah sebagai berikut. 1. Mengambil piksel dari citra yang akan diproses
3. Mengalikan setiap nilai warna tersebut dengan koefisien warna masing masing. Kemudian nilai tersebut ditotalkan.
4. Mengganti nilai warna dari piksel yang sedang diproses dengan nilai warna yang didapat pada proses sebelumnya.
5. Proses kemudian diulangi ke piksel berikutnya sampai seluruh piksel pada citra diproses.
Koefisien warna untuk setiap nilai warna digunakan karena adanya perbedaan cara mata manusia membedakan warna.
Citra yang sudah menjadi abu-abu sudah boleh diproses menjadi citra hitam putih dengan menggunakan algoritma Otsu. Langkah-langkah binerisasi citra
grayscale menggunakan algoritma Otsu untuk mencari ambang batas adalah sebagai berikut (Otsu, 1979).
1. Membuat histogram dari tingkat kemunculan semua tingkat keabuan pada citra grayscale.
2. Menghitung kemungkinan (probabilitas) kelas dan rata-rata (mean) kelas pada kemungkinan ambang batas (threshold) pada 0.
3. Untuk setiap kemungkinan ambang batas yang mungkin ada (sesuai histogram), piksel dipisahkan menjadi 2 bagian, mewakili piksel later belakang dan piksel karakter. Kemudian dicarilah akar dari kuadrat perbedaan antara rata-rata dari kedua bagian tersebut.
4. Nilai dari ambang batas diperbaharui untuk setiap iterasi, dan nilainya sesuai pada hasil langkah sebelumnya
5. Nilai yang terbesar setelah iterasi berakhir adalah nilai ambang batas yang diinginkan
6. Setiap piksel kemudian diperbaharui pada citra grayscale dengan menggantinya menjadi putih jika lebih besar dari ambang batas, dan hitam jika lebih kecil atau sama dengan ambang batas.
Gambar 2.2. Hasil binerisasi dengan algoritma Otsu. Gambar asli (kiri) dan hasil binerisasi (kanan).
2.2.3.. Penapisan Derau
Penapisan derau adalah proses untuk menapis derau yang terdapat pada sebuah citra. Proses ini disebut juga penghilangan derau. Derau adalah piksel yang memiliki variasi intensitas yang tidak berkorelasi pada tetangganya (Munir, 2004).
Pengambilan gambar menggunakan kamera sering meninggalkan bercak atau titik-titik yang sebenarnya tidak ada pada objek aslinya. Titik-titik tersebut disebut juga dengan derau. Derau dihasilkan dari adanya lonjakan intensitas yang disebabkan oleh piksel yang tidak berhasil diisi, timbulnya galat pada konversi analog ke digital, galat pada transmisi data, atau kesalahan pada proses pendigitalan (Leavline, 2013). Derau akan menggangu proses pengambilan tulang pada karakter (Tarabek, 2008), sehingga harus diminimalisir agar tulang yang dihasilkan masih dapat mewakili citra karakter yang diproses dengan baik.
P9 P2 P3 P8 P1 P4 P7 P6 P5
Gambar 2.3. Piksel dan tetangganya (Alginahi, 2010)
Median filter mengambil median dari sebuah piksel dan tetangganya sesuai ukuran ketetanggaannya. Ukuran ketetanggaan 5x5 akan berukuran 5 piksel x 5 piksel, dan seterusnya. Median diapat dengan menyortir nilai nilai tersebut dari yang rendah ke yang tinggi, kemudian mengambil nilai tengahnya. Nilai dari piksel yang sedang diproses akan digantikan dengan nilai median tersebut.
Tahapan sederhana dari median filter adalah sebagai berikut:
1. Mengambil sebuah piksel dan tetangganya (sesuai ukuran ketetanggaan) sehingga membentuk sebuah matriks.
2. Median dari matriks tersebut diambil
3. Mengganti nilai piksel sedang diproses dengan median yang didapat pada tahap sebelumnya.
4. Proses diulangi ke piksel berikutnya sampai seluruh piksel pada citra diproses.
Gambar 2.4. Citra dengan Median Filter. Citra asli (kiri atas), citra hasil median filter 3x3 (kanan atas), x5 (kiri bawah) dan 9x9 (kanan bawah)
2.2.4. Segmentasi
Proses memotong citra yang mengandung satu buah kata menjadi banyak citra yang mengandung satu buah karakter per citra, secara bertahap adalah sebagai berikut: 1. Citra diubah menjadi citra hitem putih terlebih dahulu. Hitam akan menjadi piksel karakter, dan putih adalah piksel latar belakang. Citra akan dibagi menjadi kolom-kolom yang akan berisi satu karakter per kolom.
2. Selusuri piksel mulai dari kiri atas ke bawah untuk mencari piksel karakter. Jika ditemukan piksel latar belakang, maka cek terus apakah piksel tersebut terus menerus latar belakang (tak mengandung piksel karakter). Lakukan sampai ditemukan barisan piksel yang mengandung piksel karakter. Kemudian cek terus sampai ditemukan barisan yang hanya piksel latar belakang lagi.. 3. Dengan demikian, akan diperoleh koordinat dari piksel-piksel paling sudut dari
karakter tersebut.
4. Potong gambar dengan koordinat yang didapat dari proses sebelumnya. Simpan potongan gambar tersebut sebagai citra baru. Dengan demikian, kolom pertama sudah selesai.
5. Ulangi proses pencarian piksel karakter paling kiri atas untuk kolom berikutnya. Ulangi terus sampei piksel karakter paling kanan bawah untuk seluruh gambar.
Ilustrasi dari pengisolasian karakter dari sebuah citra berisi sebuah kata dapat dilihat pada gambar 2.5.
Gambar 2.5. Ilustrasi pemotongan karakter dari sebuah citra
2.2.5. Thinning
secara umum sehingga menyisakan bagian yang benar benar fitur utama dari citra karakter tersebut.
Salah satu metode cepat untuk mendapatkan tulang adalah metode Zhang-Suen (Widiarti, 2011). Algoritma Zhang-Suen adalah algoritma untuk menghasilkan citra tulang dari sebuah citra biner. Pada algoritma ini, terdapat istilah Contour Point , yaitu piksel yang memilki nilai 1 dan 8 tetangga yang bernilai 0. Adapun tahapan dari algoritma Zhang-Suen adalah sebagai berikut (Zhang & Suen, 1984):
1. Piksel hitam diasumsikan menjadi 1 dan piksel putih diasumsikan menjadi 0, serta citra masukan berukuran panjang dan lebar MxN.
2. Setiap piksel akan memiliki delapan tetangga, dengan ketetanggaan sesuai gambar 2.3.
3. Diasumsikan A(p1) adalah jumlah transisi dari putih ke hitam pada urutan piksel P2,P3,P4,P5,P6,P7,P8,P9,P2. P2 diakhir adalah untuk menunjukkan sirkulasi. Asumsikan B(p1) adalah jumlah tetangga yang hitam dari P1.
4. Semua piksel akan dites apakah memenuhi kondisi berikut: a. Piksel tersebut hitam dan punya 8 tetangga
b. 2 <= B(p1) <= 6 c. A(p1) = 1
d. Paling tidak salah satu dari P2,P4 dan P6 adalah putih e. Paling tidak salah satu dari P4, P6 dan P8 adalah putih
Piksel yang memenuhi kondisi ini akan diubah menjadi putih. 5. Semua piksel akan dites sekali lagi apakah memenuhi kondisi berikut:
a. Piksel tersebut hitam dan punya 8 tetangga b. 2 <= B(p1) <= 6
c. A(p1) = 1
d. Paling tidak salah satu dari P2, P4 dan P8 adalah putih e. Paling tidak salah satu dari P2, P6 dan P8 adalah putih
Piksel yang memenuhi kondisi ini akan diubah menjadi putih
6. Proses akan diulangi terus untuk semua piksel di citra sampai tidak ada lagi yang boleh diubah.
(a) (b)
Gambar 2.6. Proses Thinning. Citra sebelum thinning (a) dan citra hasil thinning (b)
2.3. Ekstraksi Fitur
Ekstraksi fitur atau feature extraction adalah proses mereduksi citra yang didapat dari proses pengolahan citra menjadi fitur yang mampu mewakili citra tersebut. Salah satu metode ekstraksi fitur adalah pixel mapping atau pemetaan piksel (Mulyo et al, 2004).
Pemetaan piksel dilakukan dengan cara membuat sebuah string yang akan panjangnya sama dengan panjang citra dikali dengan lebar citra. Hal ini dilakukan karena string haruslah mampu menampung semua piksel dari citra. Fitur yang diekstrak dari citra adalah keberadaan piksel dan pola piksel tersebut.
Gambar 2.7. Ilustrasi pemetaan piksel, dari citra menjadi untaian nilai
2.4. Pengenalan Pola
Pola adalah sebuah entitas yang dapat memiliki ciri. Ciri tersebut bisa pakai untuk membedakan satu pola dengan pola yang lain. Dengan demikian, pola yang satu memiliki keunikan dari pola yang lain. Oleh karena itu, setiap pola bisa dibedakan dengan melihat ciri-ciri yang dimiliki pola tersebut (Bishop, 2006).
[image:31.595.122.507.103.254.2]Pengenalan pola adalah suatu ilmu untuk mengklasifikasikan sebuah objek dengan objek lain berdasarkan ciri yang ada.
Gambar 2.8. Struktur Sistem Pengenalan Pola
Struktur dari pengenalan pola selalu dimulai dari sensor yang akan menangkap data. Prapengolahan dilakukan untuk menyiapkan data agar siap diklasifikasi. Setelah itu data akan diekstrak sehingga menjadi fitur yang siap untuk diklasifikasikan. Setelah itu digunakan algoritma klasifikasi untuk mengklasifikasikan pola tersebut. Ilustrasi dari strukturnya dapat dilihat pada gambar 2.8.
Sensor Prapengolahan Ekstraksi Ciri Algoritma Klasifikasi
Algoritma klasifikasi ialah algoritma yang digunakan untuk mengklasifikasikan data masukan. Contoh dari algoritma klasifikasi adalah jaringan saraf tiruan (JST) (Schalkoff, 1992). Dengan JST, masukan bisa diklasifikasikan berdasarkan hasil pencarian beberapa ciri yang signifikan dan memproses serta menganalisis ciri tersebut.
2.5. Self-Organizing Map
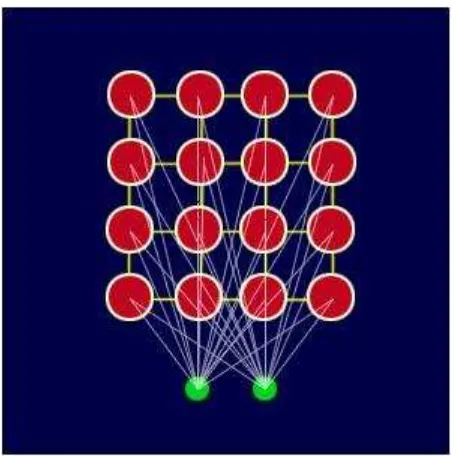
Teknik Self-OrganizingMap atau disebut juga Kohonen Map (sesuai dengan nama penemunya, Teuvo Kohonen) adalah salah satu algoritma pembelajaran dalam jaringan saraf tiruan (Heaton, 2005). Algoritma ini menganalogikan cara kerja otak manusia, dimana setiap sel otak manusia memiliki tugas yang berbeda-beda. Sel-sel saraf tersebut mengkelompokkan diri mereka sendiri sesuai dengan informasi yang diterima. Pengelompokan seperti ini disebut unsupervised learning (Kusumadewi, 2003).
Unsupervised learning adalah metode pembejalaran yang tidak terawasi, dimana tidak diperlukan adanya target output. Metode ini tidak menentukan hasil seperti apa yang diharapkan selagi proses pembelajaran. Tujuan dari metode ini yaitu agar dapat mengelompokkan semua unit dengan pola yang mirip atau sama ke dalam sebuah pengelompokan klasifikasi tertentu.
Gambar 2.9. Contoh jaringan kohonen dengan ukuran node 4x4 dan 2 unit masukan (Heaton, 2005)
Tahapan proses pembelajaran dari jaringan saraf tiruan self-organizing map
adalah sebagai berikut (Zamasari, 2005):
1. Diinisialisasikan seluruh bobot dengan nilai random Wij, radius tetangga dan ХКУЮ ЩОЦЛОХКУКЫКЧ α.
2. Mengerjakan tahap a-f sampai kondisi berhenti dipenuhi
a. mengevaluasi kesalahan untuk setiap vektor masukan x
b. menyimpan bobot dengan kesalahan paling minimal
c. mengecek neuron keluaran yang telah aktif, jika terdapat neuron keluaran yang tidak pernah firing, maka forcewin dan kembali ke (a). Jika tidak, lanjut ke langkah (e)
d. Forcewin :
ii. Setiap neuron keluaran dengan vektor masukan yang didapat pada (a) dan pilih indeks neuron keluaran dengan nilai terbesar yang tidak pernah aktif selama pelatihan
iii. Memodifikasi bobot dari neuron keluaran pada (b)
e. MenyesЮКТФКЧ ЛШЛШЭ НОЧРКЧ ЩОЫЬКЦККЧ а’ = а + К(б-w)
f. Memperbaiki learning rate
g. Mengecek kondisi berhenti
3. Mengambil bobot terbaik
4. Normalisasi bobot
2.6. Penelitian Terkait
Beberapa penelitian terdahulu terkait dengan penelitian pengolahan citra, Self-organizing Map, dan pengenalan pola serta karakter, dapat dilihat pada tabel 2.2.
Pada penelitian Limbing (2007), Self-organizing Map digunakan untuk mengenali citra huruf latin yang ada pada dokumen tertulis. Penelitian yang dilakukan oleh Limbing yaitu membuat sebuah perangkat lunak yang dapat melakukan pengenalan huruf cetak pada dokumen yang dipindai dan kemudian menjadi sebuah berkas teks. Huruf yang dikenali adalah berupa huruf cetak. Pengolahan citra yang terjadi adalah binerisasi, thinning dan segmentasi karakter. Dari penelitian ini, didapat kesimpulan bahwa metode Self-organizing Map bisa digunakan untuk mengenali huruf cetak, dengan akurasi 95,62% untuk pemindaian kalimat saja, 72,40% untuk pemindaian paragraf. Tetapi hasil tersebut didapat jika font yang dipindai sudah dilatihkan terlebih dahulu. Untuk font yang belum dilatihkan, didapat 70,43% pada pemindaian kalimat saja, dan 55,62% untuk pemindaian paragraf.
Lampung yang diambil adalah hasil huruf cetak yang dicetak dan kemudian dipindai. Penggunaan pengolahan citra pada penelitian ini masih sama dengan penelitian Limbing. Pengolahan citra yang dilakukan adalah pemotongan gambar, segmentasi huruf, perubahan ukuran, dan thinning. Hasil yang didapat adalah Self-organizing Map mampu mengenali huruf Lampung dengan akurasi 75%.
[image:35.595.99.530.501.755.2]Pada penelitian Fauziah (2013), Self-organizing Map digunakan untuk mengenali citra huruf Korea yang didapat dari print screen. Tujuan dari penelitian yang dilakukan oleh Fauziah adalah untuk membuat sebuah aplikasi yang dapat mengidenfitikasikan huruf Korea lalu menerjemahkannya ke huruf Latin dan Bahasa Indonesia. Metode ektraksi fitur yang digunakan adalah Principal Component Analysis, sedangkan pada pengenalannya digunakan Self-organizing Map. Huruf Korea yang diidentifikasikan adalah print screen dari huruf Korea di layar komputer. Hasilnya adalah, Self-organizing map mampu mengenali huruf Korea dengan akurasi 97,31%. Hasil pengenalan pada penelitian ini sangat tinggi, karena citra yang diproses adalah citra print screen yang tentunya tidak membutuhkan pengolahan citra yang kompleks, tidak seperti hasil pengambilan citra pada kamera yang ditemukan derau atau pengambilan kata yang miring. Hal ini tentunya sangat berpengaruh pada akurasi dari pengenalan pola.
Tabel 2.2. Tabel Penelitian Terdahulu
Penulis Judul Penelitian Keterangan
Stefanus Suriaatmadja Limbing (2007)
Pembuatan aplikasi perangkat lunak pengenalan huruf cetak pada file text hasil scanning dengan menggunakan metode kohonen neural network
Self-organizing Map digunakan untuk
mengenali citra dokumen hasil scan. Huruf yang dikenali adalah huruf Latin.
Cahyo Prarian (2010)
Desain dan Implementasi Sistem Penerjemah Aksara Lampung ke Huruf Latin Berbasis Pengolahan Citra Digital dan Jaringan Syaraf Tiruan Self-organizing Map
Lampung yang dipotong terlebih dahulu. Citra didapat dari webcam dan
print screen. Farah Fauziah
(2012)
Sistem Penerjemah Huruf Korea Ke Huruf Latin Dan Bahasa Indonesia Berbasis Pengolahan Citra Digital Dan Jaringan Syaraf Tiruan Self-Organizing Map (Som)
Self-organizing Map digunakan untuk mengenali citra huruf korea yang diambil dari
Bab ini membahas tentang implementasi penggunaan Jaringan Saraf Tiruan Self-organizing Map, prapengolahan citra, serta arsitektur sistem.
3.1. Basis Data yang digunakan
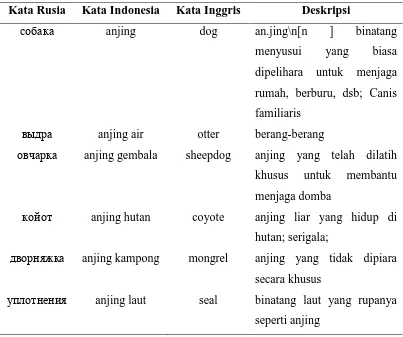
[image:37.595.115.518.416.753.2]Basis data yang digunakan adalah basis data Kamus Besar Bahasa Indonesia (KBBI) yang telah diterjemahkan menggunakan Google Translate (translate.google.com) ke Bahasa Rusia. Basis data yang digunakan terdiri dari satu tabel dan 4 kolom yang terdiri dari kolom kata rusia, indonesia, inggris, kolom deksripsi. Basis data memiliki 71406 rekord. Contoh dari rekord dapat dilihat pada tabel 3.1.
Tabel 3.1. Contoh rekord dari database
Kata Rusia Kata Indonesia Kata Inggris Deskripsi
anjing dog an.jing\n[n ] binatang
menyusui yang biasa dipelihara untuk menjaga rumah, berburu, dsb; Canis familiaris
anjing air otter berang-berang
anjing gembala sheepdog anjing yang telah dilatih khusus untuk membantu menjaga domba
anjing hutan coyote anjing liar yang hidup di hutan; serigala;
anjing kampong mongrel anjing yang tidak dipiara secara khusus
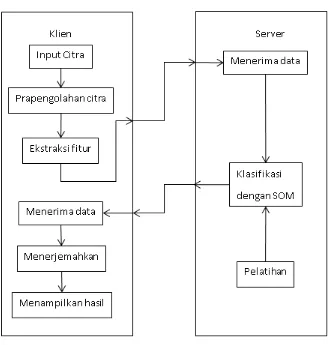
3.2. Arsitektur umum
[image:38.595.149.479.229.574.2]Sistem akan berbentuk klien dan server. Klien dari sistem adalah aplikasi yang ada pada Android, sedangkan servernya adalah yang aplikasi yang dilatih untuk mengenali pola huruf dengan algoritma Self-organizing Map. Diagram blok dari sistem yang akan dibangun dapat dilihat pada gambar 3.1.
Gambar 3.1. Diagram blok sistem secara keseluruhan
Citra akan diperoleh dari aplikasi yang ada pada klien/Android dari kamera atau galeri gambar. Citra tersebut akan masuk ke tahap prapengolahan citra. Pada tahap ini, citra akan mengalami pemrosesan citra. Pemrosesan citra yang terjadi dapat dilihat pada gambar 3.2.
Tugas server adalah menerima pesan dari klien dan mengklasifikasikan hasil ekstraksi fitur yang dikirmkan oleh klien. Oleh karena itu, proses pelatihan dan proses pengujian akan berada pada server.
Pada proses pelatihan yang sederhana, aplikasi server akan menerima sebuah МТЭЫК ФКЫКФЭОЫ, ЦТЬКХФКЧ МТЭЫК ФКЫКФЭОЫ “К” НКЫТ font arial. Kemudian akan diberitahu ЛКСаК МТЭЫК ЭОЫЬОЛЮЭ КНКХКС МТЭЫК “К”. CТЭЫК ЭОЫЬОЛЮЭ ФОЦЮНТКЧ КФКЧ ЦОЧРКХКЦТ ЩЫШЬОЬ pemrosesan citra, seperti pada klien. Bedanya adalah, pada server yang diproses adalah citra karakter, sedangkan pada klien yang diproses adalah citra kata. Hal ini berarti, pada server tidak ada proses segmentasi karakter, karena pada server yang diinputkan adalah citra yang hanya membuat sebuah huruf saja. Hasilnya juga mengalami ekstraksi fitur seperti pada klien. Proses berikutnya adalah mesin dilatih ЮЧЭЮФ ЦОЧРОЧКХ ФКЫКФЭОЫ “К” НКЫТ ПТЭЮЫ вКЧР НТОФЬЭЫКФ НКЫТ МТЭЫК ЭОЫЬОЛЮЭ. DТКРЫКЦ ЛХШФ dari proses pelatihan dapat dilihat pada gambar 3.3.
Penapisan derau Binerisasi Segmentasi Citra
Penskalaan
Thinning
Gambar 3.2. Diagram blok prapengolahan citra pada klien
Prapengolahan citra pada server tentunya berbeda pada prapengolahan pada klien. Hal ini, seperti yang sudah diutarakan sebelumnya, klien akan memproses citra bermuatan kata, sedangkan pada server hanya bermuatan sebuah karakter. Hal ini artinya tidak ada proses segmentasi karakter pada server. Diagram blok dari prapengolahan citra pada server dapat dilihat pada gambar 3.4.
3.2.1. Input Citra
Citra yang diambil adalah citra tulisan Cyrillic berbahasa Rusia yang didapat dari papan pemberitahuan, papan pengunguman, spanduk, iklan, majalah, koran, dan sumber-sumber yang memiliki tulisan lainnya. Input Citra pada klien dilakukan dengan menggunakan galeri atau kamera pada android. Citra yang didapat dari proses ini akan dipotong untuk diambil bagian yang ingin diterjemahkan. Pemotongan dilakukan oleh pengguna. Pengguna yang akan memilih bagian mana yang ingin dipakai dari citra yang diambil.
3.2.2. Prapengolahan Citra
Prapengolahan citra adalah bagian penting yang menyiapkan citra agar dapat Diberikan
nama
Prapengolahan citra
Citra
Ekstraksi fitur
Pelatihan
Gambar 3.3. Diagram blok pelatihan pada server
Ke Ekstraksi Fitur
Penapisan derau Binerisasi Penskalaan Citra
Thinning
pelatihan). Tahapan-tahapan dari prapengolahan citra adalah penapisan derau, binerisasi, penskalaan, thinning, dan segmentasi karakter.
3.2.2.1. Penapisan Derau
Penapisan derau akan menggunakan metode Median filter 3x3 untuk server dan klien. Flowchart dari penapisan derau dengan Median filter 3x3 dapat dilihat pada gambar 3.5.
start
Citra yang akan diproses
Buat matriks dari piksel( i-1,j-i) sampai
piksel(i+1,j+1) Mengambil
piksel(i,j)
Ambil median matriks
Ganti nilai matriks sesuai nilai median
yang didapat
Masih ada piksel pada citra yang belum diproses?
end
ya
tidak
[image:41.595.242.363.251.724.2]Citra dengan derau yang berkurang
Dapat dilihat pada gambar 3.5, citra hasil pengambilan gambar akan ditapis menggunakan Median Filter dengan ukuran ketetanggaan 3x3. Citra akan diproses mulai dari piksel pertama pada koordinat 0,0 sampai piksel terakhir. Piksel diproses dengan cara diambil tetangganya mulai dari koordinat i-1,j-1 sampai i+1,j+1 yang menandakan ukuran ketetanggaannya adalah 3x3. Hasilnya akan dihimpun dalam bentuk matriks. Matriks itu kemudian akan diambil median dari warna-warnanya, yaitu median dari warna hijau, warna biru dan warna merah yang ada pada matriks tersebut. Median didapat dengan mengurutkan nilai-nilai warna tersebut, dan kemudian diambil nilai tengahnya (median). Nilai tersebut kemudian akan mengganti nilai warna seluruh piksel yang ada pada matriks ketetanggaan tersebut. Setelah selesai, maka piksel akan diproses piksel lain hingga seluruh piksel pada citra terproses. Contoh hasil dari penapisan derau dapat dilihat pada gambar 3.6.
(a) (b)
Gambar 3.6. Hasil penapisan derau. Sebelum (a) dan sesudah (b)
3.2.2.2 Binerisasi
start
Citra yang akan diproses
Nilai keabuan = (merah*0,21)+(hijau
*0,71)+(biru*0,07) Mengambil
piksel(i,j)
Ganti semua nilai warna pada piksel(i,j) dengan nilai keabuan yang
didapat
Masih ada piksel pada citra yang belum diproses?
end
ya
tidak
[image:43.595.244.369.81.591.2]Citra abu-abu
Gambar 3.7. Flowchart Grayscaling
warna yang dimiliki sebuah piksel, kemudian hasilnya dijumlahkan. Nilai yang didapat akan menggantikan semua nilai warna dalam piksel tersebut, sehingga nilai merah, hijau dan birunya menjadi seragam. Nilai yang didapat itulah yang akan menjadi derajat keabuan. Kemudian akan diproses piksel lain hingga semua piksel pada citra selesai diproses.
Binerisasi citra akan menggunakan metode ambang batas dengan penentuan ambang batas menggunakan metode Otsu. Flowchart penentuan ambang batas dari metode Otsu dapat dilihat pada gambar 3.8.
start
Citra abu-abu
Membuat kelas probabilitas keluarnya keabuan, rata-rata kelas
tersebut Membuat Histogram derajat
keabuan
Untuk setiap kemungkinan ambang batas, piksel dibagi 2, latar belakang
dan karakter
end
Ambil akar kuadrat dari perbedaan kedua bagian
tersebut
Nilai terbesar setelah iterasi berakhir adalah ambang batas yang
[image:44.595.269.365.262.741.2]diinginkan
Dapat dilihat pada gambar 3.8, metode Otsu dimulai dengan membuat histogram kemunculan derajat keabuan pada citra abu-abu yang diproses. Histogram derajat keabuan adalah data berapa jumlah kemunculan sebuah derajat keabuan pada sebuah citra. Derajat keabuan yang dimaksud adalah mulai dari 0 atau hitam sampai dengan 255 atau putih. Kemudian dari histogram tersebut dibuat kelas probabilitas munculnya sebuah derajat keabuan dan diambil rata-rata dari kelas tersebut. Setelah itu, dibuat 2 kelas dari proses sebelumnya, yaitu kelas latar belakang dan kelas karakter. Kemudian diambil akar kuadrat dari kedua kelas tersebut, diulang terus menerus untuk semua derajat keabuan. Hasil yang terbesar yang didapat setelah pengulangan berakhir adalah ambang batas yang diinginkan.
start
Citra abu-abu
Ambil piksel(i,j)
end Merah > ambang
batas?
Ganti semua warna menjadi 0(hitam)
tidak ya
Ganti semua warna menjadi 255(putih)
Masih ada piksel yang belum
diproses?
[image:45.595.228.426.323.721.2]Citra hitam putih tidak ya
Metode Ambang Batas adalah metode yang mengganti semua nilai menjadi 1 atau 0, sesuai dengan derajat keabuan sebuah piksel dibandingkan dengan ambang batas yang sudah didapat. Flowchart dari metode ambang batas dengan menggunakan ambang batas yang diperoleh dari metode otsu dapat dilihat pada gambar 3.9.
Sesuai pada gambar 3.9, dapat dilihat bahwa proses ambang batas akan menerima citra abu-abu hasil proses greyscaling yang ada pada tahap sebelumnya. Kemudian akan dicek piksel yang ada pada citra tersebut. Setelah itu, akan dicek apakah warna merah pada piksel tersebut melebihi atau lebih kecil dari ambang batas yang didapat. Pemilihan warna lain selain merah, yaitu hijau atau biru, tidak memiliki perbedaan sama sekali. Hal ini karena pada citra abu abu, semua warna pada piksel sudah memiliki nilai yang sama, yaitu derajat keabuan. Jika warna merahnya lebih besar dari ambang batas, maka piksel akan diubah menjadi piksel putih, dan selain itu akan menjadi piksel hitam. Proses akan dilanjutkan sampai semua piksel pada citra sudah diubah. Hasil yang didapat setelah proses ini adalah, seluruh citra sudah menjadi citra hitam dan putih. Hasilnya dapat dilihat pada gambar 3.10.
(a)
[image:46.595.179.452.438.682.2](b)
3.2.2.3 Segmentasi
Proses segmentasi akan dilakukan setelah proses binerisasi. Hal ini karena proses segmentasi akan memeriksa seluruh piksel citra dengan mengandaikan hanya terdapat dua jenis piksel, yaitu piksel latar belakang dan piksel karakter. Penemuan piksel karakter akan dicatat, sedangkan piksel latar belakang akan dilewati. Pembagian piksel dari citra menjadi dua bagian tersebut hanya dapat dilakukan jika citra sudah menjadi citra biner, yaitu citra yang hanya memiliki dua warna, hitam dan putih. Jika citra sudah biner, maka dapat diandaikan piksel karakter adalah piksel hitam dan piksel latar belakang adalah piksel putih. Dengan demikian, piksel putih akan dilewati pada saat sistem sedang menelusiri semua piksel.
Pemotongan citra dengan cara ini akan menganggap piksel-piksel yang masih bersatu dan tidak putus sebagai satu buah karakter, sehingga tulisan sambung akan selalu dikenali sebagai satu karakter. Oleh karena itu, sistem tidak akan mengenali tulisan sambung.
start
Scan citra dari piksel paling atas ke
bawah
Ditemukan piksel karakter? Citra hitam
putih
Mulai dari (0,0)
Cek pada aksis x+1
Lanjutkan pengecekan
Sampai pada piksel paling bawah? Piksel yang ditemukan menjadi koordinat kolom paling kiri tidak ya Ditemukan piksel karakter? tidak Piksel yang ditemukan menjadi koordinat kolom paling kanan ya
Cek pada aksis x+1
ya
tidak
Didapat kolom berisi satu karakter.
Potong bagian tersebut dari citra.
Sampai pada piksel paling
akhir dari citra? end
tidak
[image:48.595.118.525.71.621.2]ya
Gambar 3.11. Flowchart segmentasi kata menjadi kolom yang berisi satu huruf
(a)
[image:49.595.275.355.479.720.2](b) (c) (d) (e) (f) (g) (h) (i) (j)
Gambar 3.12. Hasil Segmentasi. Sebelum(a) dan Sesudah(b – j)
3.2.2.4. Penskalaan
Tiap tiap karakter yang berhasil diisolasi akan mengalami proses pengskalaan. Proses ini akan menggunakan fungsi penskalaan yang ada pada Android
(createScaledBitmap) sedangkan pada bagian server akan menggunakan
java.awt.geom.AffineTransform. Ukuran yang ditentukan adalah 20 piksel x 25 piksel. Flowchart untuk proses penskalaan dapat dilihat pada gambar 3.13.
start
Citra berukuran 20 piksel x 25 piksel
Citra karakter
Proses penskalaan ke ukuran 20 piksel
x 25 piksel
end
Sesuai dengan gambar 3.13, dapat dilihat bahwa citra yang akan menjadi masukan pada proses penskalaan adalah citra karakter yang berhasil didapat pada proses segmentasi karakter. Citra tersebut kemudian akan diproses untuk diperkecil menjadi ukuran 20 piksel x 25 piksel dengan bantuan fungsi createScaledBitmap
untuk klien dan untuk server akan menggunakan fungsi java.awt.geom.AffineTransform. Fungsi tersebut telah disediakan oleh android dan java untuk digunakan, sehingga tidak diperlukan untuk membuat metode sendiri. Hasil dari proses penskalaan dapat dilihat pada gambar 3.14.
Gambar 3.14. Hasil Penskalaan dari sebuah karakter. Sebelum(kiri) dan sesudah(kanan)
3.2.2.5. Thinning
Tiap karakter terisolasi kemudian akan mengalami proses thinning. Metode yang digunakan adalah metode Zhang-Suen. Proses thinning akan menghasilkan tulang dari citra karakter. tulang yang dihasilkan akan memiliki ketebalan sebesar satu piksel.
start
Citra biner huruf Cyrillic
Piksel tersebut hitam dan punya 8 tetangga? Memproses piksel(i,j) dan
membuat matriks tetangganya sebesar 3x3
2 <= B(p1) <= 6
A(p1) = 1
P2 atau p4 atau p6 putih
P4 atau p6 atau p8 putih
ya
ya
ya
ya
Hapus piksel(i,j)
Masih ada piksel pada citra yang belum diproses?
end
tidak
tidak
tidak
tidak
tidak
ya
ya
[image:51.595.241.398.78.648.2]tidak
Gambar 3.15. Flowchart proses thinning dengan metode Zhang-Suen
tersebut hitam dan punya 8 tetangga. Kemudian dicek kembali apakah jumlah tetangga yang hitam dari piksel tersebut lebih besar atau sama dengan 2 dan lebih kecil atau sama dengan 6. Kemudian dicek lagi apakah jumlah transisi dari putih ke hitam dengan urutan P2, P3, P4, P5, P6, P7, P8, P9, P2 yang sesuai dengan gambar 2.3, adalah sama dengan 1. Kemudian dicek kembali apakah P2, P4 atau P6 putih. Setelah itu dicek lagi apakah P4, P6 dan P8 adalah putih. Jika semua kondisi yang dicek tersebut benar, maka piksel akan dihapus. Proses akan berakhir setelah semua piksel diproses. Hasil dari metode ini dapat dilihat pada gambar 3.16.
Gambar 3.16. Hasil proses thinning. Sebelum(kiri) dan sesudah(kanan)
3.2.3. Ekstraksi Fitur
Hasil dari prapengolahan citra adalah karakter-karakter yang berhasil diisolasi dari citra kata. Setiap karakter tersebut akan diekstrak fiturnya dengan metode pemetaan piksel. Piksel hitam akan bernilai 1, dan piksel putih akan bernilai 0. Nilai akan disimpan sebagai sebuah untaian string. Karena ukuran dari citra karakter terisolasi adalah 20 x 25 piksel, maka ukuran dari untaian tersebut adalah 20x25 = 500 satuan. Piksel pada koordinat f(0,0) akan berada pada indeks untaian 0, f(0,1) akan berada pada indeks 1, dan selanjutnya sampai seluruh indeks terisi. Hasil dari ekstraksi fitur ini akan dikirimkan ke mesin yang sudah dilatih untuk dikenali.
3.2.4. Menerima Data pada server
3.2.5. Klasifikasi
Metode klasifikasi yang digunakan untuk mengenali hasil dari ekstraksi fitur adalah metode jaringan saraf tiruan. Metode jaringan saraf tiruan yang digunakan adalah Self-Organizing Map atau Kohonen Map. Klasifikasi dilakukan setelah sistem telah dilatih untuk mengenali karakter Cyrillic. Mesin yang dilatih adalah mesin yang terdapat pada server, sehingga pelatihan dilakukan di server. Hasil dari proses klasifikasi ini adalah huruf-huruf yang berhasil dikenali dari pola yang dikirimkan oleh klien. Flowchart klasifikasi data ekstraksi fitur pada sistem yang sudah dilatih dapat dilihat pada gambar 3.17.
start
Data hasil ekstraksi
fitur
end Cek pada network
node mana yang kenal pada data
Cek huruf yang dikenal oleh node
tersebut
[image:53.595.271.356.284.599.2]Huruf yang dikenal
Gambar 3.17. Diagram alir klasifikasi data hasil ekstraksi fitur
huruf apakah yang dilatihkan ke node tersebut. Huruf yang diberikan oleh node tersebut akan menjadi huruf yang dikenal untuk hasil ektraksi fitur tersebut.
3.2.6. Pelatihan
[image:54.595.106.526.353.655.2]Pelatihan yang dilakukan adalah dengan metode tidak terbimbing (unsupervised). Sistem akan dilatih menggunakan data huruf Cyrillic dalam 11 font yang berbeda. Juga terdapat 3 font lainnya yang akan digunakan sebagai data uji. Setiap font memuat 33 huruf kecil dan 33 huruf besar, sehingga totalnya 66. Tabel data yang digunakan dapat dilihat pada tabel 3.2. Tahapan pelatihan pada server dalam bentuk flowchart dapat dilihat pada gambar 3.18.
Tabel 3.2. Penggunaan Font
Jenis Font Jumlah Karakter Status Data
Arial 66 Data Latih
Arial Black 66 Data Latih
Arial Narrow 66 Data Uji
Batang 66 Data Latih
Book Antiqua 66 Data Uji
Calibri 66 Data Latih
Cambria 66 Data Latih
Comic Sans 66 Data Latih
Courier New 66 Data Latih
Lucida Console 66 Data Uji
Lucida Sans 66 Data Latih
Tahoma 66 Data Latih
Times New Roman 66 Data Latih
Gambar 3.18. Diagram alir proses pelatihan
3.2.7. Menerima Data pada Klien
3.2.8. Penerjemahan
[image:56.595.98.525.210.569.2]Penerjemahan akan menggunakan pencocokan kata. Kata yang diterima pada tahap ЬОЛОХЮЦЧвК КФКЧ НТМШМШФФКЧ ФО ЛКЬТЬ НКЭК. CШЧЭШСЧвК, НТЭОЫТЦК ФКЭК “ ” НКЫТ server. Maka akan didapat hasil sesuai tabel 3.3 berikut.
Tabel 3.3. Hasil pencocokan database dengan masukan “вечный”
Kata Indonesia Kata Inggris Deskripsi
abadi timeless aba.di\n[a] kekal; tidak berkesudahan: di dunia ini tidak ada yg --
baka eternal ba.ka\n[a] tidak berubah selama-lamanya; abadi; kekal\n\n[Mk n] (1) keluarga yg menurunkan; (2) asal keturunan
berwaktu timeless ber.wak.tu\n[v] mempunyai waktu yg tertentu; dng waktu yg tertentu; memakai waktu
kekal everlasting ke.kal\n[a] tetap (tidak berubah, tidak bergeser, dsb) selama-lamanya; abadi; lestari: kematian adalah sekadar penutup babak kefanaan bagi suatu babak baru hidup --
kekal abadi eternal kekal untuk selama-lamanya
lestari everlasting les.ta.ri\n[a] tetap spt keadaannya semula; tidak berubah; bertahan; kekal
3.2.9 Menampilkan hasil
Gambar 3.19. Rancangan tampilan hasil
Penjelasan dari gambar adalah sebagai berikut :
1. Tombol kamera digunakan untuk mengambil citra menggunakan kamera android
2. Tombol galeri digunakan untuk mengambil citra dari galeri android
3. Tombol dengarkan digunakan untuk mendengarkan kata bahasa rusia yang didapat
5. Bagian tampilan terjemahan adalah menunjukkan kata rusia yang didapat, arti serta deskripsinya. Jika ada arti kedua, maka akan ditampilkan dibawahnya, dan seterusnya.
3.3. Use case dan User case spesification
Use case adalah pemodelan dari cara kerja sistem. Use case digunakan sebagai alat untuk mendokumentasikan cara kerja sistem.
3.2.1. Use Case
Use Case dari aplikasi ini dapat dilihat pada gambar 3.20..
Gambar 3.20. Use Case
3.5.2. Use case spesification
Tabel 3.4. Use Case spesifikasi untuk user
Nama use case Proses penerjemahan kata pada citra
Aktor User
Deskripsi Proses utama dari aplikasi. Pengguna menginputkan sebuah citra untuk mendapat arti dari kata yang terkandung dalam citra.
Pre-condition User sudah membuka aplikasi
Basic flow - User mengklik pilihan menginputkan gambar dari galeri android atau kamera
- User memilih/mengambil sebuah gambar - User memilih bagian yang mengandung kata
yang ingin diterjemahkan - User mengklik simpan
- User menunggu proses pengolahan citra pada android dan pengiriman pesan secara klien-server.
- Aplikasi menampilkan citra kata yang dipotong oleh user dan terjemahan dari kata tersebut
Post condition User dapat memilih citra lain untuk diproses
Limitation -
Tabel 3.5. Use case spesifikasi untuk pelatihan
Nama use case Proses pelatihan
Aktor Admin
Deskripsi Proses admin melatih mesin untuk mengenali pola Pre-condition Admin sudah membuka aplikasi server
Basic flow - Admin mengklik tombol cari gambar
adalah gambar dari karakter apa
- Admin dapat menambah gambar lain sampai sebanyak yang admin mau
- Jika seluruh data yang akan digunakan untuk melatih sudah diinputkan berikut informasi karakternya, maka admin mengklik tombol train(latih)
- Admin menunggu proses pelatihan
- Jika sudah selesai, admin dapat menyimpan network tersebut atau mengulang langkah dari awal jika ingin menambah gambar baru atau menghapus data latih yang salah.
- Jika admin melakukan perubahan pada data latih, maka admin akan mengulangi proses train
Post condition Mesin akan terlatih untuk mengenali pola yang dilatihkan oleh admin, terbukti dari jika admin menginputkan sebuah pola untuk dikenali, maka mesin akan memberikan sebuah output.
Limitation -
Tabel 3.6. Use case spesifikasi untuk pengujian Nama use case Proses pengujian
Aktor Admin
Deskripsi Admin menguji apakah mesin mampu mengenali beberapa pola setelah dilatih terlebih dahulu
Pre condition Mesin telah dilatih terlebih dahulu
Basic flow - Admin mengklik tombol cari gambar
- Admin mengklik tombol kenali gambar
- Aplikasi menampilkan karakter sesuai dengan apa yang diberikan mesin sebagai keluaran Post condition Admin dapat mengetahui berapa citra yang secara
tepat dikenali dan berapa citra yang dikenali secara salah.
Bab ini membahas hasil implementasi jaringan saraf tiruan Self-organizing map untuk mengenali pola huruf Cyrillic berikut akurasi dari pengenalan.
4.1. Pengujian Server
Bagian yang perlu diuji paling pertama adalah bagian server. Hal ini dikarenakan bagian klien tidak independen dari server. Pada bagian server, pengujian yang dilakukan adalah proses pelatihan dan proses pengujian.
4.1.1. Proses Pelatihan
Proses pelatihan dilakukan dengan mengajarkan kepada mesin pola-pola huruf Cyrillic agar mesin dapat mengenali pola huruf Cyrillic baru yang akan diujikan. Metode pembelajarannya adalah unsupervised dengan algoritma Self-organizing Map
serta dengan laju pembelajaran atau α (КХЩСК) ЬОЛОЬКЫ 0,1. UЧЭЮФ НКЭК ХКЭТС вКЧР digunakan pada pelatihan ini, dapat dilihat pada tabel 3.1.
4.1.2. Proses Pengujian
Tabel 4.1. Hasil pengujian data latih
Jenis Font Jumlah Karakter Dikenali Akurasi(%)
Arial 66 66 100
Arial Black 66 66 100
Batang 66 66 100
Calibri 66 66 100
Cambria 66 66 100
Comic Sans 66 66 100
Courier New 66 66 100
Lucida Sans 66 66 100
Tahoma 66 66 100
Times New Roman 66 66 100
Verdana 66 66 100
TOTAL 726 726 100
Sesuai dengan tabel 4.1, hasil memorisasi dari mesin yang sudah dilatih dihitung dengan menggunakan persamaan 4.1. adalah 100%.
Tabel 4.2. Hasil pengujian data uji
Jenis Font Jumlah Karakter Dikenali Akurasi(%)
Arial Narrow 66 65 98,48
Book Antiqua 66 54 81,81
Lucida Console 66 63 95,45
TOTAL 198 182 91,92
[image:63.595.103.533.519.624.2]4.2. Pengujian Klien
Bagian yang diuji dari klien adalah proses prapengolahan citra dan penerjemahan. Proses prapengolahan citra bersifat independen terhadap server, tetapi proses penerjemahan bergantung pada keberadaan server.
[image:64.595.108.526.325.538.2]Proses prapengolahan citra dimulai dengan user pada klien memilih atau mengambil sebuah gambar dan kemudian memilih bagian yang ingin diterjemahkan. Contoh citra yang dipilih dapat dilihat pada gambar 4.1. Gambar 4.1. berikut adalah gambar sebuah iklan komputer dari sebuah majalah berbahasa Rusia.
Gambar 4.1. Iklan dari potongan sebuah majalah berbahasa Rusia
Gambar 4.2. Menentukan bagian yang mengandung kata yang ingin diterjemahkan
Setelah menekan tombol simpan, bagian yang dipilih oleh pengguna akan diproses. Bagian yang dipilih oleh pengguna dapat dilihat pada gambar 4.3.
[image:65.595.129.505.589.692.2]Proses pertama dari prapengolahan citra adalah penapisan derau. Derau yang muncul akibat timbulnya galat pada pengambilan citra akan ditapis dengan memperhalus warnanya. Bagian yang telah dipilih oleh pengguna akan ditapis deraunya sehingga citra yang dihasilkan menjadi lebih halus. Hasil dari penapisan derau yang dilakukan oleh klien dapat dilihat pada gambar 4.4.
Gambar 4.4. Hasil penapisan derau
Tahap selanjutnya adalah binerisasi. Citra hasil penapisan derau akan diubah menjadi citra biner. Citra biner adalah citra yang setiap pikselnya hanya bernilai hitam atau putih. Proses ini akan menjadikan citra menjadi citra abu-abu terlebih dahulu, dan kemudian membuatnya menjadi citra biner. Citra hasil binersasi dapat dilihat pada gambar 4.5.
Gambar 4.5. Hasil binerisasi
(a) (b) (c) (d) (e) (f) (g) (h) (i)
Gambar 4.6. (a) sampai dengan (i) adalah hasil segmentasi
Tahap selanjutnya adalah penskalaan. Proses penskalaan adalah proses dimana setiap citra yang didapat dari proses segmentasi akan dilakukan standardisasi ukuran citra. Ukuran yang diinginkan adalah 20 piksel untuk panjang dan 25 piksel untuk lebar. Hasil dari proses penskalaan untuk setiap citra karakter dapat dilihat pada gambar 4.7(a) sampai 4.7(i).
(a) (b) (c) (d) (e) (f) (g) (h) (i)
Gambar 4.7. (a) sampai dengan (i) adalah hasil penskalaan
Tahap terakhir dari prapengolahan citra adalah pengambilan tulang citra. Setiap citra yang sudah melewati proses standardisasi ukuran akan diambil tulangnya. Tulang dari citra akan sebesar satu piksel dan akan mewakili citra tersebut. Hasil dari pengambilan tulang dapat dilihat pada gambar 4.8(a) sampai 4.8(i).
[image:67.595.111.504.622.677.2](a) (b) (c) (d) (e) (f) (g) (h) (i)
Sembilan citra yang didapat dari hasil prapengolahan akan diubah menjadi pesan dengan metode pemetaan piksel. Pesan tersebut akan diterima oleh server, dan kemudian dikenali polanya oleh mesin yang sudah dilatih. Hasil dari pengenalan pola akan dikirimkan server dalam bentuk pesan kepada klien.
[image:68.595.177.454.245.513.2]Pesan yang diterima klien akan diterjemahkan dengan mencocokkannya dengan database kamus. Hasil penerjemahan dapat dilihat gambar 4.9.
Gambar 4.9. Hasil penerjemahan ditampilkan berserta bagian yang dijadikan masukan oleh pengguna
Pada percobaan pengenalan untuk data uji yang sama yang digunakan pada server, didapat hasil yang berbeda dari yang didapat pada serve