SEGMENTASI PELANGGAN PLN UPJ BOGOR TIMUR DAERAH BOGOR
MENGGUNAKAN FUZZY C-MEANS
KAMAL AFIAT
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
KAMAL AFIAT. Customer Segmentation of PLN UPJ East Bogor Region Using Fuzzy C-Means. Under the direction of ANNISA.
Electricity is a very crucial source of energy nowadays. This is proven by the increase of PLN customers every month. The increasing number of customers and the use of electricity should be followed by increasing the quality of service. PLN can make a better decision to increase its service by knowing its customer’s segmentations. The data of electricity usage is periodically kept by PLN and can be used for customer segmentation analysis. Customer segmentation can be conducted using clustering method such as Fuzzy C-Means algorithm. After the segmentation has been done, the characteristics of electricity usage of each segment can be identified, and the distribution of each segment can be visualized on a map to make it easier to see the distribution of each segment from its spatial aspects. The clustering process in this research is used four clusters, which represent the usage level, which are low class, medium class, high class, and very high class. As the result of the research, we found out that the low class users are the majoring, whereas the high class has the least users. Areas that have users from all segments are Babakan, Bantarjati, Baranang Siang, and Kedung Halang.
SEGMENTASI PELANGGAN PLN UPJ BOGOR TIMUR DAERAH BOGOR
MENGGUNAKAN FUZZY C-MEANS
KAMAL AFIAT
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Segmentasi Pelanggan PLN UPJ Bogor Timur Daerah Bogor Menggunakan Fuzzy C-Means Nama : Kamal Afiat
NIM : G64076037
Menyetujui: Pembimbing,
Annisa, S.Kom, M.Kom NIP. 197907312005012002
Mengetahui: Ketua Departemen,
Dr. Ir. Sri Nurdiati, M.Sc NIP. 196011261986012001
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala rahmat dan hidayah-Nya sehingga skripsi dengan judul Segmentasi Pelanggan PLN UPJ Bogor Timur Daerah Bogor Menggunakan Fuzzy C-Means dapat terselesaikan. Penelitian ini dilaksanakan mulai Maret 2010 sampai dengan April 2011, bertempat di Departemen Ilmu Komputer.
Penulis ucapkan terima kasih kepada pihak-pihak yang telah membantu dalam penyelesaian tugas akhir ini, antara lain:
1 Kepada ayah dan ibu, serta seluruh keluarga atas doa, dukungan, dan kasih sayangnya.
2 Kepada ibu Annisa, S.Kom., M.Kom. selaku pembimbing yang telah banyak memberi arahan selama penulis menjalankan penelitian
3 Kepada bapak Tajudin dan bapak Yai dari pihak PLN yang telah membantu penulis dalam mendapatkan data penelitian
4 Kepada Anggi Haryo Saksono, M. Rafi Muttaqin, Mas Satrio, dan Mas Azrul atas bantuan dan dukungannya
5 Kepada teman-teman seperjuangan ekstensi Ilmu Komputer angkatan dua atas semangat dan dukungannya
6 Kepada Desi Purnama Sari, Nadia Kaulika, dan murid-murid tersayang yang telah memberikan semangat dan dukungannya
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2011
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 2 April 1987 dari ayah H. Sofyan Rahmat Hidayat dan ibu Metrawati Ramli. Penulis merupakan anak pertama dari tiga bersaudara.
iv
DAFTAR ISI
Halaman
DAFTAR TABEL ... v
DAFTAR GAMBAR ... v
DAFTAR LAMPIRAN ... v
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA Knowledge Discovery in Databases (KDD) ... 1
Normalisasi z-score... 2
Data Mining ... 2
Clustering ... 2
Himpunan Fuzzy ... 3
Fungsi Keanggotaan ... 3
Fungsi Keanggotaan pada Fuzzy Cluster ... 4
Operasi Himpunan Fuzzy ... 4
Fuzzy C-Means (FCM) ... 4
Algoritme FCM ... 5
METODE PENELITIAN Studi Pustaka ... 7
Proses Knowledge Discovery in Databases ... 7
Perancangan Sistem ... 8
Implementasi Sistem ... 9
HASIL DAN PEMBAHASAN Data Penelitian ... 9
Praproses Data ... 10
Pemilihan Atribut ... 10
Normalisasi Data ... 10
Segmentasi menggunakan Fuzzy C-Means ... 10
Evaluasi Cluster Berdasarkan Pelanggan ... 13
Evaluasi Cluster Berdasarkan Daerah... 15
Visualisasi Clustering ... 15
KESIMPULAN DAN SARAN Kesimpulan ... 16
Saran ... 16
v
DAFTAR TABEL
Halaman
1 Perbedaan matriks derajat keanggotaan HCM dengan FCM ... 5
2 Data contoh ... 6
3 Fungsi objektif dalam 22 iterasi pada data contoh ... 6
4 Tabel penggunaan daya ... 9
5 Persentase dan jumlah anggota cluster pada clustering berdasarkan pelanggan ... 13
6 Persentase dan jumlah anggota cluster pada clustering berdasarkan daerah ... 13
7 Karakteristik pengguna listrik kelas rendah (cluster 1) ... 13
8 Karakteristik pengguna listrik kelas sedang (cluster 2) ... 13
9 Karakteristik pengguna listrik kelas tinggi (cluster 3) ... 14
10 Karakteristik pengguna listrik kelas sangat tinggi (cluster 4) ... 14
11 Karakteristik penggunaan listrik berdasarkan segmentasi daerah ... 15
DAFTAR GAMBAR
Halaman 1 Kurva fungsi keanggotaan ... 42 Fungsi keanggotaan pada fuzzy cluster (Cox 2005) ... 4
3 Derajat keanggotaan pada Hard C-Means (K-Means) ... 5
4 Derajat Keanggotaan pada Fuzzy C-Means ... 5
5 Plot 2 dimensi pada program FCM untuk data contoh ... 7
6 Diagram alur penelitian ... 8
7 Pengaturan parameter pada program FCM ... 11
8 Ringkasan hasil clustering pada program FCM ... 11
9 Grafik hasil clustering pada segmentasi berdasarkan pelanggan ... 12
10 Grafik hasil clustering pada segmentasi berdasarkan daerah ... 12
11 Grafik nilai fungsi objektif untuk clustering berdasarkan pelanggan ... 12
12 Grafik nilai fungsi objektif untuk clustering berdasarkan daerah ... 12
13 Pesebaran spasial pengguna listrik kelas rendah ... 13
14 Pesebaran spasial pengguna listrik kelas sedang ... 13
15 Pesebaran spasial pengguna listrik kelas tinggi ... 14
16 Pesebaran spasial pengguna listrik kelas sangat tinggi ... 14
17 Pesebaran spasial pengguna listrik semua kelas ... 14
18 Plotclustering berdasarkan pelanggan ... 15
19 Plotclustering berdasarkan daerah ... 16
DAFTAR LAMPIRAN
Halaman 1 Contoh sebagian data penelitian ... 182 Histogram pengguna daya ... 19
3 Transformasi nilai atribut menggunakan normalisasi z-score ... 20
4 Tabel penggunaan listrik rata-rata berdasarkan daerah ... 21
5 Tabel hasil clustering dengan FCM terhadap pelanggan ... 22
6 Tabel jumlah anggota cluster terhadap seluruh daerah ... 23
1
PENDAHULUAN
Latar Belakang
Listrik merupakan sumber daya yang sangat dibutuhkan saat ini. Penggunaan listrik setiap tahun, bahkan setiap bulan terus meningkat. Hal ini dibuktikan dengan selalu bertambahnya jumlah pelanggan PLN pada setiap bulannya. Peningkatan jumlah pelanggan dan penggunaan listrik, tentunya harus didukung oleh pihak PLN dengan meningkatkan pelayanannya. Pihak PLN dapat melakukan pengambilan keputusan yang lebih baik untuk meningkatkan pelayanannya dengan mengetahui segmentasi pelanggannya.
PLN menyimpan data penggunaan listrik dari pelanggannya secara berkala. Data penggunaan listrik yang ada dapat dimanfaatkan untuk analisis segmentasi pelanggan. Segmentasi pelanggan, dapat dilakukan dengan teknik clustering. Setelah segmentasi dilakukan, pesebaran setiap segmen dapat divisualisasikan pada peta untuk mempermudah melihat persebaran setiap segmen dari aspek spasialnya.
Pada penelitan sebelumnya, Daulay (2006) telah melakukan segmentasi pasar mie instant dengan menggunakan algoritme clustering Fuzzy C-Means. Algoritme Fuzzy C-Means dapat memberikan hasil segmentasi yang lebih alami dibandingkan Hard C-Means (K-Means) karena hasil clustering dipengaruhi oleh kecenderungan masing-masing data terhadap cluster-nya. Suatu data tidak hanya tepat milik satu cluster, tetapi juga dapat memiliki nilai derajat keanggotaan pada cluster lainnya. Ukuran rendah, sedang, tinggi, dan sangat tinggi bersifat alami, sehingga metode Fuzzy C-Means lebih cocok digunakan untuk melakukan segmentasi dibandingkan dengan menggunakan Hard C-Means.
Perbedaan penelitian ini dengan penelitian yang dilakukan oleh Daulay (2006) adalah dari segi pemilihan jumlah cluster atau segmen yang dihasilkan. Penelitian Daulay (2006) ditujukan untuk mencari jumlah cluster yang tepat untuk digunakan dalam clustering (segmentasi), sedangkan pada penelitian ini jumlah cluster yang digunakan sudah ditentukan, yaitu sebanyak empat cluster, di mana keempat cluster tersebut akan menjadi empat kelas pengguna listrik, yaitu: kelas rendah, kelas sedang, kelas tinggi, dan kelas sangat tinggi.
Tujuan
Tujuan dari penelitian ini adalah:
1. Melakukan segmentasi penggunaan listrik dengan menerapkan metode clustering Fuzzy C-Means pada data pelanggan PLN UPJ Bogor Timur berdasarkan pelanggan dan daerah.
2. Mendapatkan karakteristik kelas penggunaan listrik setiap segmen yang terbentuk dari hasil clustering.
3. Menampilkan persebaran cluster yang terbentuk pada peta
Ruang Lingkup
Segmentasi pelanggan PLN yang dilakukan menggunakan data pelanggan PLN UPJ Bogor Timur pada bulan Desember tahun 2009 dengan algoritme clustering Fuzzy C-Means.
Manfaat Penelitian
Penerapan algoritme clustering Fuzzy C-Means pada data penggunaan listrik dapat memperlihatkan segmentasi dan karakteristik dari setiap segmen penggunaan listrik di daerah Bogor Timur berdasarkan pelanggan dan daerah. Penelitian ini diharapkan dapat membantu pihak PLN UPJ Bogor Timur dalam melakukan pengambilan keputusan yang lebih baik untuk meningkatkan pelayanan PLN UPJ Bogor Timur dengan mengevaluasi persebaran segmen penggunaan listrik.
TINJAUAN PUSTAKA
Knowledge Discovery in Databases (KDD)
Knowledge discovery in databases (KDD) adalah keseluruhan proses untuk mengubah data mentah menjadi informasi yang berguna (Tan et al. 2006). KDD merupakan sebuah proses iteratif yang terurut, dan data mining merupakan salah satu langkah dalam KDD (Han & Kamber 2006). Tahapan proses KDD menurut Han & Kamber (2006), yaitu: 1. Pembersihan data
Pembersihan terhadap data dilakukan untuk menghilangkan data yang tidak konsisten dan data yang mengandung noise.
2. Integrasi data
2 3. Seleksi data
Proses seleksi data mengambil data yang relevan digunakan untuk proses analisis. 4. Transformasi data
Proses menransformasikan atau menggabungkan data ke dalam bentuk yang sesuai dengan teknik data mining yang akan digunakan.
5. Data mining
Data mining merupakan proses yang penting dimana metode-metode cerdas diaplikasikan untuk mengekstrak pola-pola dalam data.
6. Evaluasi pola
Evaluasi pola diperlukan untuk mengidentifikasi beberapa pola yang menarik yang merepresentasikan pengetahuan.
7. Representasi pengetahuan
Penggunaan visualisasi dan teknik representasi untuk menunjukkan hasil penggalian pengetahuan dari data kepada pengguna.
Normalisasi z-score
Normalisasi merupakan bagian dari transformasi data, yaitu atribut diskalakan ke dalam rentang nilai tertentu yang lebih kecil seperti -1,0 – 1,0 atau 0,0 – 1,0. Salah satu teknik normalisasi yang dapat digunakan adalah z-score.
Normalisasi z-score (zero-mean normalization) merupakan normalisasi berdasarkan nilai rata-rata dan standar deviasi dari suatu atribut (Han & Kamber 2006). Misalkan nilai v merupakan elemen dari A, Ᾱ adalah rata-rata, dan A adalah nilai standar
deviasi dari atribut A, maka nilai v akan ditransformasikan menjadi v’ dengan fungsi
... (1) Normalisasi z-score berguna ketika nilai aktual dari maksimum dan minimum suatu atribut tidak diketahui atau ketika outlier mendominasi pada normalisasi min-max. Data Mining
Data mining merupakan proses ekstraksi informasi data berukuran besar (Han & Kamber 2006). Teknik data mining digunakan untuk memeriksa database berukuran besar sebagai cara untuk menemukan pola yang baru dan berguna, sehingga bisa didapatkan informasi berguna yang mungkin sebelumnya belum diketahui.
Tugas data mining dari sudut pandang analisis data dapat diklasifikasi menjadi dua kategori, yaitu descriptive data mining dan predictive data mining. Descriptive data mining menjelaskan sekumpulan data dalam cara yang lebih ringkas. Ringkasan tersebut menjelaskan sifat-sifat yang menarik dari data. Predictive data mining menganalisis data dengan tujuan mengonstruksi satu atau sekumpulan model dan melakukan prediksi perilaku dari kumpulan data baru.
Beberapa tugas dari data mining adalah:
Analisis asosiasi
Klasifikasi dan prediksi
Analisis cluster
Analisis outlier
Analisis trend dan evolusi Clustering
Analisis cluster atau yang biasa disebut clustering berbeda dengan classification dimana tidak terdapat variabel target untuk clustering. Algoritme clustering membagi-bagi dari keseluruhan himpunan data menjadi subkelompok atau cluster yang relatif homogen, dimana kesamaan record-record di dalam cluster diperbesar, dan kesamaan record-record di luar cluster diperkecil. Clustering seringkali diterapkan dalam langkah persiapan pada proses data mining dengan menghasilkan cluster-cluster yang digunakan sebagai input untuk berbagai teknik, seperti jaringan syaraf tiruan.
Struktur data yang digunakan dalam clustering adalah data matriks sedangkan tipe data yang digunakan adalah (Han & Kamber 2006):
Interval-scaled variable merupakan ukuran kontinu pada penskalaan linear. Contoh variabel yang termasuk pada tipe data ini yaitu tinggi, berat, temperatur cuaca, dan koordinat bujur-lintang.
Atribut biner hanya mempunyai dua nilai yaitu 0 dan 1.
Atribut nominal memiliki lebih dari dua nilai, misalkan merah, biru, kuning, hijau.
Atribut ordinal dapat berupa data diskret atau data kontinu. Tipe data ini dapat diperlakukan seperti tipe data interval-scaled variable yang sangat mempertimbangkan urutan.
3 Beberapa pengukuran jarak yang populer
digunakan antara lain: Jarak Euclidean biasa digunakan untuk mengevaluasi kedekatan objek dalam ruang dua atau tiga dimensi. (Abonyi & Feil 2007).
Jarak Minkowski, merupakan generalisasi dari jarak Euclidean dan jarak Manhattan, dimana p merupakan nilai integer positif. Jarak Minkowski akan merepresentasikan jarak Manhattan jika p = 1, dan akan merepresentasikan jarak Euclidean jika p = 2 (Han & Kamber 2006).
Menurut Han & Kamber (2006), beberapa pendekatan yang sering digunakan dalam clustering, yaitu:
1. Partitional method, yaitu membangun sebuah partisi dari sebuah database D dengan n objek ke dalam himpunan k cluster. Kemudian diberikan sebuah k, temukan partisi dari k cluster yang mengoptimisasi pilihan kriteria partisi, yaitu:
Global optimal: menyelesaikan dengan menjumlahkan semua partisi.
Heuristic methods:
2. Hierarchical method, yaitu membuat sebuah dekomposisi berhirarki dari himpunan data (atau objek) menggunakan beberapa kriteria. Metode ini memiliki dua jenis pendekatan yaitu:
Agglomerative, dimulai dengan titik-titik sebagai cluster individu. Pada setiap tahap dilakukan penggabungan setiap pasangan titik pada cluster sampai hanya satu titik (atau cluster) yang tertinggal.
Divisive, dimulai dengan satu cluster besar yang berisi semua titik data (all inclusive cluster). Pada setiap langkah, dilakukan pemecahan sebuah cluster sampai setiap cluster berisi sebuah titik (atau terdapat k cluster).
3. Density-based, merupakan pendekatan yang berdasarkan konektivitas dan fungsi kepadatan.
4. Grid-based, merupakan pendekatan yang berdasarkan pada struktur multiple-level granularity.
5. Model-based, sebuah model yang dihipotesis untuk tiap cluster dan ide dasarnya adalah untuk menemukan model yang pantas untuk tiap cluster.
Kualitas hasil clustering bergantung pada metode ukuran kesamaan yang digunakan dan implementasinya. Selain itu, kualitas dari metode clustering yang digunakan juga diukur dari kemampuannya untuk menemukan beberapa atau semua pola yang tersembunyi.
Himpunan Fuzzy
Teori himpunan fuzzy dan logika fuzzy adalah suatu cara yang dapat digunakan untuk mengatasi ketidaktepatan dan ketidakpastian. Secara singkat, teori himpunan fuzzy memungkinkan suatu objek adalah milik suatu himpunan dengan nilai derajat keanggotaan di antara 0 dan 1, sedangkan logika fuzzy memungkinkan pernyataan untuk membenarkan dengan tingkat kepastian antara 0 dan 1. Teori ini diperkenalkan oleh Lotfi Zadeh pada tahun 1965 (Tan et al. 2006).
Nilai derajat keanggotaan menunjukkan bahwa suatu objek tidak hanya memiliki kondisi benar (bernilai 1) atau salah (bernilai 0), tetapi juga ada kondisi yang terletak di antara keduanya. Kondisi tersebut direpresentasikan dengan nilai derajat keanggotaan yang berada pada selang nilai 0 dan 1.
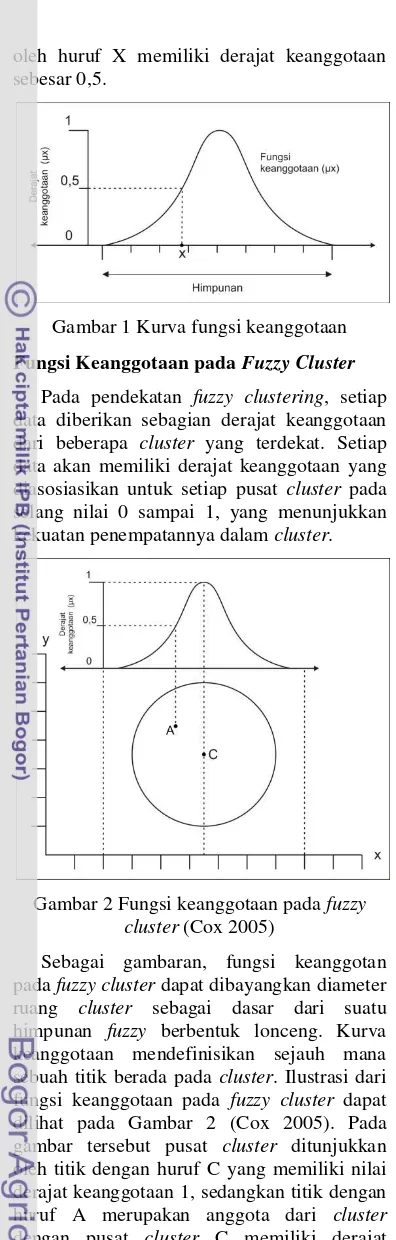
Fungsi Keanggotaan
4 oleh huruf X memiliki derajat keanggotaan
sebesar 0,5.
Gambar 1 Kurva fungsi keanggotaan
Fungsi Keanggotaan pada Fuzzy Cluster
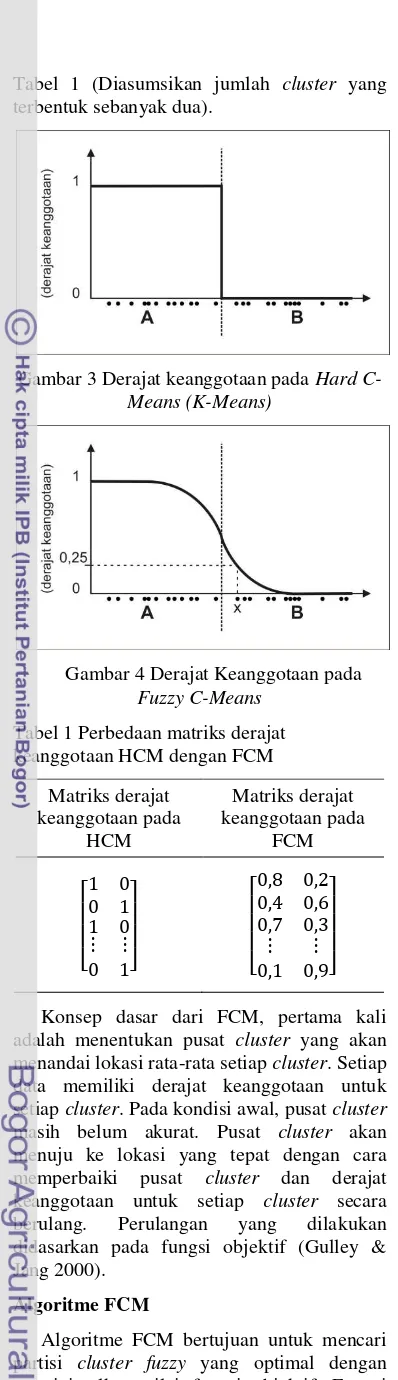
Pada pendekatan fuzzy clustering, setiap data diberikan sebagian derajat keanggotaan dari beberapa cluster yang terdekat. Setiap data akan memiliki derajat keanggotaan yang diasosiasikan untuk setiap pusat cluster pada selang nilai 0 sampai 1, yang menunjukkan kekuatan penempatannya dalam cluster.
Gambar 2 Fungsi keanggotaan pada fuzzy cluster (Cox 2005)
Sebagai gambaran, fungsi keanggotan pada fuzzy cluster dapat dibayangkan diameter ruang cluster sebagai dasar dari suatu himpunan fuzzy berbentuk lonceng. Kurva keanggotaan mendefinisikan sejauh mana sebuah titik berada pada cluster. Ilustrasi dari fungsi keanggotaan pada fuzzy cluster dapat dilihat pada Gambar 2 (Cox 2005). Pada gambar tersebut pusat cluster ditunjukkan oleh titik dengan huruf C yang memiliki nilai derajat keanggotaan 1, sedangkan titik dengan huruf A merupakan anggota dari cluster dengan pusat cluster C memiliki derajat keanggotaan sebesar 0,5 pada cluster tersebut.
Operasi Himpunan Fuzzy
Misalkan himpunan A dan B adalah dua nilai dari himpunan fuzzy pada semesta
pembicaraan U dengan fungsi keangotaan μ
A
dan μ
B, maka operasi-operasi dasar himpunan
fuzzy berikut dapat didefinisikan: a. Union (Penggabungan)
Gabungan dua himpunan samar A
b. Intersection (Irisan)
Irisan dua himpunan samar A dan B
c. Complement (Ingkaran)
Komplemen himpunan samar A diberi tanda Ā (NOT A) dan didefinisikan sebagai berikut:
μĀ (x) = 1 - μ
A(x)
Fuzzy C-Means (FCM)
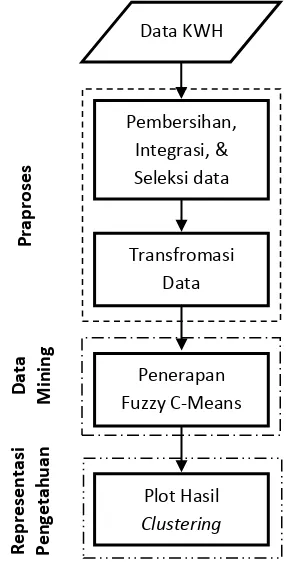
Fuzzy C-Means merupakan salah satu teknik clustering yang menggunakan model pengelompokan fuzzy, sehingga data dapat menjadi semua anggota kelas atau cluster yang terbentuk dengan derajat atau tingkat keanggotaan yang berbeda pada selang nilai 0 sampai 1. Keberadaan suatu data pada cluster ditentukan oleh derajat keanggotaannya. Teknik FCM ini pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981.
5 Tabel 1 (Diasumsikan jumlah cluster yang
terbentuk sebanyak dua).
Gambar 3 Derajat keanggotaan pada Hard C-Means (K-C-Means)
Gambar 4 Derajat Keanggotaan pada Fuzzy C-Means
Tabel 1 Perbedaan matriks derajat keanggotaan HCM dengan FCM
Matriks derajat menandai lokasi rata-rata setiap cluster. Setiap data memiliki derajat keanggotaan untuk setiap cluster. Pada kondisi awal, pusat cluster masih belum akurat. Pusat cluster akan menuju ke lokasi yang tepat dengan cara memperbaiki pusat cluster dan derajat keanggotaan untuk setiap cluster secara berulang. Perulangan yang dilakukan didasarkan pada fungsi objektif (Gulley & Jang 2000).
Algoritme FCM
Algoritme FCM bertujuan untuk mencari partisi cluster fuzzy yang optimal dengan meminimalkan nilai fungsi objektif. Fungsi
objektif yang digunakan pada algoritme FCM adalah sebagai berikut (Ross 2005):
keanggotaan cluster):
6 Algoritme FCM secara lengkap diberikan
sebagai berikut (Ross 2005): 1. Menentukan:
a. Matriks X berukuran n × m, dengan n = jumlah data yang akan di-cluster dan m = jumlah variabel (kriteria).
b. Jumlah cluster yang akan dibentuk (n > c≥ 2).
c. pembobot (w > 1) d. Maksimum iterasi (i)
e. Kriteria penghentian/treshold (ɛ = nilai positif yang sangat kecil).
2. Membentuk matriks partisi awal U (derajat keanggotaan dalam cluster) dengan ukuran nc; matriks partisi biasanya dibuat acak. 3. Menghitung pusat cluster V untuk setiap
cluster dengan menggunakan persamaan nomor 8.
4. Memperbaiki derajat keanggotaan setiap data pada setiap cluster (perbaiki matriks partisi) menggunakan persamaan nomor 6. 5. Menghentikan iterasi jika pusat cluster V tidak berubah. Alternatif kriteria penghentian adalah jika perubahan nilai error (selisih nilai fungsi objektif) < nilai treshold atau jika nilai absolut perubahan matriks U di bawah nilai treshold (Höppner et al. 1999). Nilai perubahan matriks partisi pada iterasi sekarang dengan iterasi sebelumnya menggunakan fungsi nomor 9.
... (9)
Apabila Δ ≤ ε maka iterasi dihentikan. Pencarian nilai Δ dilakukan dengan mengambil elemen terbesar dari nilai mutlak antara ik (t) dengan ik (t-1). Jika
tidak memenuhi kriteria penghentian, kembali ke langkah nomor 3.
Algoritme FCM diterapkan pada data contoh yang terdapat pada Tabel 2.
Tabel 2 Data contoh
X Y
Melalui proses FCM, clustering optimal terbentuk pada iterasi ke-22, dengan hasil:
i = 22 (iterasi terakhir)
Matriks pusat vektor (V):
V = dilihat pada Tabel 3.
Tabel 3 Fungsi objektif dalam 22 iterasi pada data contoh
7 Iterasi ke- Fungsi Objektif
11 233,635708 contoh dapat dilihat pada Gambar 5. Cluster 1 ditunjukkan oleh warna cyan, cluster 2 ditunjukkan oleh warna magenta, dan cluster 3 ditunjukkan oleh warna biru. Pusat cluster ditunjukkan oleh titik berbentuk kotak dengan warna yang sejenis dengan cluster-nya.
Gambar 5 Plot 2 dimensi pada program FCM untuk data contoh
METODE PENELITIAN
Langkah-langkah yang dilakukan pada penelitian ini adalah sebagai berikut:
Studi Pustaka
Pada tahap ini dilakukan pengumpulan informasi dan bahan pustaka yang berkaitan dengan data mining dan logika fuzzy khususnya Fuzzy C-Means.
Proses Knowledge Discovery in Databases
Pada penelitian ini, proses Knowledge Discovery in Databases (KDD) dilakukan sesuai dengan tahap KDD menurut Han & Kamber (2006). Tahap-tahap KDD yang dilakukan pada penelitian ini adalah:
1. Pembersihan data
Pembersihan data dilakukan dengan cara menghapus data yang tidak valid seperti data yang kurang lengkap nilai atributnya. Selain dari data yang kurang nilai atributnya, pembersihan data juga dilakukan dengan tidak mengikutsertakan data yang memiliki atribut daerah yang tidak terdapat pada peta. Daerah-daerah yang dianggap tidak valid karena tidak terdapat pada peta adalah: Babakan Fakultas, Bojong Enyod, Ceger, Desa Tengah, Graha Indah, Kalibata, Karang Asem, Komplek LPTI, Panggugah, Pulo Armin, dan Sampora.
2. Integrasi data
Proses integrasi data yang dilakukan adalah dengan menambahkan titik koordinat dummy (X dan Y) untuk setiap data, karena data sumber yang didapatkan tidak memiliki titik koordinat. Integrasi titik koordinat pada data diperlukan untuk visualisasi persebaran cluster penggunaan listrik pada peta.
Titik koordinat yang diberikan bersifat random pada satu daerah. Sebagai contoh, dalam satu daerah terdapat 100 data yang memiliki atribut lingkungan Babakan, maka disebar sebanyak 100 titik koordinat pada daerah Babakan. Kemudian 100 titik koordinat tersebut diintegrasikan pada 100 data yang memiliki atribut daerah Babakan.
3. Seleksi data
Tahap seleksi data pada penelitian ini terdapat dua tahap seleksi, yaitu seleksi berdasarkan daerah dan seleksi berdasarkan jam penggunaan listrik. Sebelum melakukan seleksi berdasarkan daerah, dilakukan pengelompokan daerah terlebih dahulu. Proses pengelompokan daerah dilakukan dengan menggabungkan beberapa daerah ke dalam satu kelurahan. Sebagai contoh, data yang memiliki atribut daerah Kedung Halang, Nanggrak Indah, Nanggrak Mekar, dan Pasir Jambu dijadikan satu daerah, yaitu daerah kelurahan Kedung Halang.
8 mendapat limpahan pelanggan dari daerah
lain seperti daerah Citeureup, Semplak, dan Bogor Kota. Selain itu, pembagian daerah Bogor menurut PLN berbeda dengan pembagian daerah Bogor menurut pemerintah, karena beberapa daerah di sekitar Bogor Timur menurut pemerintah dimasukkan sebagai daerah Bogor Timur oleh PLN UPJ Bogor Timur. Sebagai contoh, daerah Kedung Halang yang terdapat di Bogor Utara termasuk sebagai daerah Bogor Timur oleh PLN UPJ Bogor Timur. Data pelanggan yang tidak dianggap sebagai pelanggan PLN UPJ Bogor Timur tidak diikutsertakan dalam proses clustering. Untuk membedakan pelanggan tersebut, dapat dilihat dari lima digit pertama kode pelanggan. Lima digit pertama yang digunakan untuk pelanggan PLN UPJ Bogor Timur adalah 53821xxxxxxx.
Seleksi data dengan menggunakan kode pelanggan ternyata masih belum bersih dari daerah selain Bogor. Oleh karena itu, seleksi daerah juga dilakukan secara manual dengan tidak memasukkan data yang daerahnya tidak dianggap sebagai daerah Bogor seperti daerah Citeurep. Tahap seleksi data kedua adalah seleksi berdasarkan jam penggunaan listrik. Pada tahap ini, data pelanggan yang dipilih adalah data pengguna yang menggunakan KWH ≥ 150 jam. Alasannya adalah, penggunaan listrik dengan KWH < 150 jam dianggap sebagai rumah kosong atau tidak aktif menggunakan listrik. Data sumber yang didapat tidak terdapat keterangan jumlah jam penggunaan listrik. Cara mendapatkan jam penggunaan listrik dari data pelanggan adalah dengan menggunakan persamaan nomor 10.
... (10)
4. Transformasi data
Tahap transformasi data dilakukan untuk mengubah data agar dapat digunakan dalam proses data mining. Transformasi data yang dilakukan pada penelitian ini adalah melakukan normalisasi data dengan normalisasi z-score.
5. Data mining
Proses data mining yang dilakukan pada penelitian ini adalah menerapkan teknik clustering dengan algoritme Fuzzy C-Means untuk mendapatkan karakteristik
dari data. Cluster yang digunakan pada penelitian ini sebanyak empat cluster. Empat cluster tersebut akan dijadikan empat kelas penggunaan listrik, yaitu rendah, sedang, tinggi, dan sangat tinggi. 6. Evaluasi pola
Setelah melakukan data mining, dilakukan evaluasi pola yang dilakukan dengan cara melihat karakteristik dari setiap cluster yang sudah dibentuk.
7. Representasi pengetahuan
Representasi pengetahuan yang digunakan pada penelitian ini adalah dengan visualisasi persebaran titik pelanggan pada peta. Setiap anggota cluster akan ditampilkan dalam warna yang berbeda pada peta menurut cluster-nya.
Diagram alur penelitian yang digunakan dapat dilihat pada Gambar 6.
Gambar 6 Diagram alur penelitian Perancangan Sistem
9 Implementasi Sistem
Clustering FCM diimplementasikan pada program yang dikembangkan dengan perangkat lunak Matlab v.7.7. Tahap implementasi sistem mengikuti langkah-langkah melakukan clustering dengan FCM, yaitu:
1. Memilih data yang akan di-cluster 2. Menetapkan parameter-parameter untuk:
Jumlah cluster (n > c≥ 2)
Pangkat pembobot (w > 1)
Maksimum iterasi (i)
Kriteria penghentian (ɛ)
3. Menghitung pusat cluster, fungsi objektif, dan perubahan derajat keanggotaan pada matriks U.
Tahap representasi pengetahuan dengan peta diimplementasikan menggunakan perangkat lunak Quantum GIS v.1.6.0.
HASIL DAN PEMBAHASAN
Data Penelitian
Data sumber yang digunakan pada penelitian ini adalah data pelanggan UPJ Bogor Timur pada bulan Desember 2009 dengan jumlah record sebanyak 104.773 baris dan 5 atribut. Atribut-atribut tersebut adalah nomor pelanggan, golongan, daya, lingkungan, dan KWH. Contoh sebagian data penelitian yang digunakan dapat dilihat pada Lampiran 1.
Berikut penjelasan masing-masing atribut pada data sumber. Atribut nomor pelanggan adalah nomor unik yang dimiliki oleh setiap pelanggan. Setiap nomor pelanggan terdiri dari dua belas digit. Lima digit pertama merupakan inisialisasi daerah pelanggan. Dua digit pertama dari lima digit tersebut menunjukkan provinsi dan tiga digit selanjutnya menunjukkan pembagian daerah dari provinsi. Sebagai contoh, terdapat pelanggan yang memiliki lima digit pertama 53821. Dua digit pertama, yaitu 53 menunjukkan bahwa pelanggan berada di daerah Jawa Barat, sedangkan tiga digit selanjutnya 821 menunjukkan bahwa pelanggan berada di daerah Bogor Timur.
Atribut golongan merupakan representasi dari penggolongan pelanggan berdasarkan jenis pelanggan dan tarif penggunaan per KWH. Setiap golongan memiliki tarif yang berbeda-beda untuk pembayaran listrik. Sebagai contoh, tarif penggunaan listrik per KWH golongan rumah tangga lebih murah
dibandingkan dengan golongan bisnis. Golongan-golongan yang terdapat pada data pelanggan UPJ Bogor Timur adalah bisnis (B), industri (I), pemerintah (P), rumah tangga (R), dan sosial (S). Golongan pelanggan juga dibagi menjadi beberapa bagian tergantung dari daya yang digunakan. Sebagai contoh, daya pelangggan golongan bisnis ada dua, yaitu B1 dan B2, sedangkan untuk rumah tangga dibagi menjadi tiga golongan pengguna daya, yaitu R1, R2, dan R3. Penggunaan daya setiap golongan dapat dilihat pada Tabel 4.
Atribut daya adalah nilai daya tetap yang dipilih oleh pelanggan. Sebagai contoh, jika dalam suatu rumah memiliki barang elektronik yang membutuhkan daya 450 Watt, rumah tersebut harus memiliki daya sekitar 450 Watt atau lebih untuk menyalakan alat tersebut. Pada data sumber didapatkan sebanyak 49 jenis daya. Kisaran daya yang digunakan dimulai dari 160 – 197.000 Watt. Pada histrogram yang disajikan pada Lampiran 2 terlihat bahwa pengguna daya 450 Watt merupakan yang paling banyak jumlahnya, disusul dengan pengguna daya 770, 1.300, dan 2.200 Watt. Jumlah pengguna pada empat jenis daya tersebut memiliki lebih dari 2.000 pelanggan, sedangkan pengguna daya lainnya memiliki pelanggan di bawah 2.000 pelanggan.
Tabel 4 Tabel penggunaan daya Daya (Watt) Golongan Terendah Tertinggi
B1 450 2.200
Atribut lingkungan adalah atribut yang berisi nama-nama daerah tempat pelanggan berada. Daerah-daerah yang terdapat pada atribut ini biasanya berupa nama kelurahan, walaupun terdapat beberapa nama daerah yang bukan merupakan nama kelurahan.
10 Praproses Data
Hasil dari penelitian akan ditampilkan dalam bentuk peta, untuk itu dibutuhkan titik koordinat (X & Y). Namun data yang digunakan pada penelitian ini tidak memiliki data koordinat (X & Y) dari setiap pelanggan. Oleh karena itu, dilakukan integrasi data dengan menambahkan data koordinat (X dan Y) yang dibuat secara random dengan bantuan perangkat lunak Quantum GIS v.1.6.0.
Jumlah daerah (lingkungan) yang terdapat pada data sebanyak 45 daerah. Kemudian daerah-daerah tersebut dikelompokkan ke dalam kelurahan-kelurahan dengan total kelurahan yang didapat adalah sebanyak 39 kelurahan (dalam hal ini, daerah yang berada pada daerah Citeureup dijadikan satu kelurahan karena tidak dianggap sebagai daerah kota Bogor). Setelah data dikelompokkan ke dalam kelurahan, data disaring dengan memilih data pelanggan PLN UPJ Bogor Timur dengan memilih data pelanggan yang memiliki awalan 53821xxxxxxx pada kode pelanggan. Selain itu, penyaringan juga dilakukan berdasarkan kelurahan yang dimasukkan ke dalam kategori daerah kota Bogor. Sebanyak 23 kelurahan terpilih dari 39 kelurahan. Tahap penyaringan data selanjutnya adalah dengan memilih data pelanggan yang menggunakan KWH ≥ 150 jam.
Setelah melalui proses integrasi dan penyaringan data, data yang digunakan pada penelitian menjadi sebanyak 39.822 record dan delapan field. Field-field yang terdapat pada data penelitian adalah: Koordinat_X, Koordinat_Y, No_Pelanggan, Golongan, Daya, Lingkungan, KWH, dan Jam.
Pemilihan Atribut
Untuk melakukan segmentasi, dilakukan pemilihan atribut yang sesuai untuk digunakan pada proses clustering. Pemilihan atribut yang digunakan adalah atribut-atribut yang relevan dalam hal penggunaan listrik. Atribut yang terpilih dalam penelitian ini adalah sebanyak dua atribut dari delapan atribut yang ada, yaitu daya dan KWH. Kedua atribut ini dianggap sebagai atribut yang paling merepresentasikan penggunaan listrik pelanggan.
Normalisasi Data
Proses normalisasi terhadap data dilakukan terlebih dahulu sebelum masuk ke tahap proses clustering, karena data yang digunakan memiliki rentang nilai yang sangat besar.
Rentang nilai yang sangat besar cukup mempengaruhi pada metode clustering yang berbasis jarak seperti FCM. Normalisasi pada umumnya digunakan untuk menyetarakan atribut agar atribut satu dengan lainnya memiliki ukuran yang sama. Normalisasi juga membuat rentang nilai menjadi jauh lebih kecil sehingga membantu perhitungan jarak menjadi lebih cepat dan efisien.
Teknik normalisasi yang digunakan pada penelitian ini adalah z-score. Normalisasi z-score dipilih karena pada data penelitian outlier mendominasi pada daerah nilai minimum. Setelah data dinormalisasi dengan z-score, nilai rata-rata dari masing-masing atribut menjadi 0 dan standar deviasinya bernilai 1. Contoh sebagian data sebelum dan sesudah ditransformasi dengan normalisasi z-score dapat dilihat pada Lampiran 3.
Segmentasi menggunakan Fuzzy C-Means
Proses segmentasi yang dilakukan pada penelitian ini terdapat dua jenis, yaitu segmentasi berdasarkan pelanggan dan segmentasi berdasarkan daerah. Segmentasi berdasarkan pelanggan adalah segmentasi dengan menggunakan data pelanggan yang sebelumnya sudah mengalami tahap praproses, sedangkan untuk segmentasi berdasarkan daerah, menggunakan data yang sama namun data tersebut diperkecil dengan mengambil rata-rata daya, KWH per daerahnya. Nilai rata-rata yang diambil bukanlah nilai rata-rata data pelanggan yang sudah dinormalisasi. Karena itu data tersebut dinormalisasi setelah data rata-rata penggunaan listrik (daya dan KWH) dari setiap daerah didapatkan. Data yang digunakan untuk segmentasi berdasarkan daerah dapat dilihat pada Lampiran 4.
Untuk mendapatkan hasil segmentasi penggunaan listrik, dilakukan penerapan teknik clustering pada data menggunakan algoritme Fuzzy C-Means (FCM). Proses clustering dilakukan dengan menggunakan program yang dikembangkan dengan perangkat lunak Matlab v.7.7. Sebelum melakukan clustering dengan FCM, ditentukan terlebih dahulu parameter-parameter FCM yang dibutuhkan seperti yang telah dibahas pada implementasi sistem.
11 (c) yang digunakan pada penelitian ini adalah
sebanyak empat cluster. merupakan generalisasi dari algoritme pendahulunya, yaitu algoritme Hard C-Means. Nilai w = 1 akan menyebabkan pembagian dengan 0 pada persamaan nomor 8. Jadi, nilai pembobot (w) harus lebih besar dari 1 (Höppner et al. 1999). Jika w > 2, pembobot (w) akan mengurangi bobot yang ditetapkan untuk cluster yang dekat dengan titik. Terdapat beberapa pertimbangan untuk memlih w = 2, salah satunya adalah untuk menyederhanakan fungsi derajat keanggotaan (ik) pada persamaan nomor 6 (Tan et al.
2006). Jadi, nilai pembobot yang digunakan pada penelitian ini adalah 2.
Iterasi maksimum yang ditentukan pada penelitian ini adalah sebanyak 100 iterasi, agar proses perulangan tidak terlalu banyak. Walaupun demikian, iterasi akan dihentikan apabila nilai pada persamaan nomor 9 sudah lebih kecil dari nilai kriteria penghentian (ɛ) yang ditentukan.
Nilai kriteria penghentian (ɛ) yang ditentukan pada penelitian ini adalah 10-5. Nilai tersebut sudah dianggap sebagai nilai positif yang sangat kecil pada penelitian ini. Jadi, nilai-nilai parameter yang digunakan untuk melakukan clustering dengan menggunakan FCM pada penelitian ini adalah sebagai berikut:
Jumlah cluster (c) = 4
Pangkat pembobot (w) = 2
Maksimum iterasi (i) = 100
Kriteria penghentian/treshold (ɛ) = 10-5
Gambar 7 Pengaturan parameter pada program FCM
Gambar 7 merupakan window dari program yang telah dibuat untuk memilih data yang akan digunakan untuk proses clustering dengan FCM. Window tersebut juga merupakan tempat memasukkan parameter-parameter FCM yang akan digunakan. Tombol Cluster merupakan tombol untuk melakukan proses clustering, tentunya setelah data dipilih dan parameter-parameternya telah dimasukkan.
Setelah program melakukan proses clustering dengan teknik FCM, program akan memunculkan ringkasan statistik dari hasil proses clustering seperti yang dapat dilihat pada Gambar 8. Pada window tersebut menampilkan karakteristik dari data yang digunakan, parameter-paramater yang digunakan, jumlah anggota dari masing-masing cluster, dan log nilai fungsi objektif. Pada window tersebut juga terdapat beberapa tombol yang dapat digunakan untuk mendapatkan keterangan lebih lanjut dari hasil clustering seperti tombol untuk melihat tabel hasil clustering, tombol untuk melihat grafik cluster, tombol untuk melihat plot cluster dalam bentuk 2 dimensi, dan tombol untuk menyimpan hasil clustering.
Gambar 8 Ringkasan hasil clustering pada program FCM
12 Grafik hasil clustering dari segmentasi
berdasarkan pelanggan dapat dilihat pada Gambar 9 dan grafik hasil clustering dari segmentasi berdasarkan daerah dapat dilihat pada Gambar 10. Pada kedua grafik tersebut, cluster 1 merupakan pengguna listrik kelas rendah, cluster 2 merupakan pengguna listrik kelas sedang, cluster 3 merupakan penggunaan listrik kelas tinggi, dan cluster 4 merupakan pengguna listrik kelas sangat tinggi. Terlihat pada kedua grafik tersebut bahwa cluster 1 (kelas rendah) memiliki anggota paling banyak dibandingkan dengan cluster yang lain, dan yang paling sedikit adalah cluster 4 (kelas sangat tinggi).
Gambar 9 Grafik hasil clustering pada segmentasi berdasarkan pelanggan
Gambar 10 Grafik hasil clustering pada segmentasi berdasarkan daerah Pada clustering berdasarkan pelanggan, proses clustering dengan FCM berhenti pada iterasi maksimum (iterasi ke-100) dengan pusat vektor terakhir (matriks V) sebagai
Pada clustering berdasarkan daerah, iterasi berhenti pada iterasi ke-11 dengan pusat vektor terakhir (matriks V) sebagai berikut:
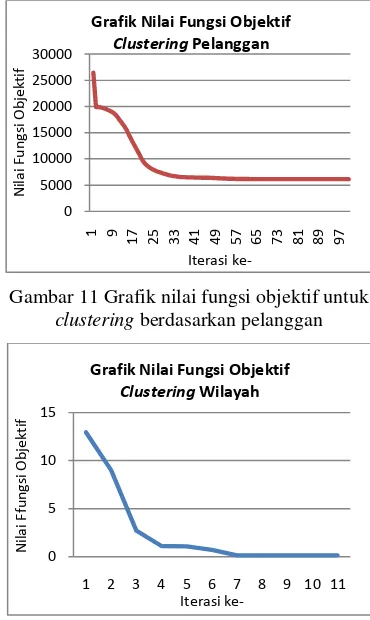
Grafik dari fungsi objektif yang dihasilkan dari clustering berdasarkan pelanggan dapat dilihat pada Gambar 11. Pada grafik tersebut terlihat nilai fungsi objektif sudah mulai stabil pada iterasi ke-56, artinya cluster yang terbentuk pada iterasi tersebut sudah mulai optimal walaupun belum mencapai nilai kriteria penghentian (treshold). Grafik nilai fungsi objektif dari clustering berdasarkan daerah, dapat dilihat pada Gambar 12. Pada grafik tersebut nilai fungsi objektif sudah mulai stabil pada iterasi ke-7 dan iterasi berhenti pada iterasi ke-11 karena nilai treshold sudah terpenuhi.
Gambar 11 Grafik nilai fungsi objektif untuk clustering berdasarkan pelanggan
Gambar 12 Grafik nilai fungsi objektif untuk clustering berdasarkan daerah Tabel hasil clustering berdasarkan pelanggan yang berisi data yang digunakan, nilai derajat keanggotaan dari setiap data, dan cluster yang ditentukan pada setiap data tidak ditampilkan seluruhnya karena ukuran dari tabel tersebut terlalu besar. Sebagian tabel
13 hasil clustering berdasarkan pelanggan dapat
dilihat pada Lampiran 5.
Hasil clustering berdasarkan pelanggan disajikan pada Lampiran 6. Persentase dan jumlah anggota masing-masing cluster disajikan pada Tabel 5.
Tabel 5 Persentase dan jumlah anggota cluster pada clustering berdasarkan pelanggan
Cluster Persentase Hasil clustering berdasarkan daerah secara lengkap disajikan pada Lampiran 7. Persentase dan jumlah anggota masing-masing cluster disajikan pada Tabel 6. Tabel 6 Persentase dan jumlah anggota cluster pada clustering berdasarkan daerah
Cluster Persentase
Evaluasi Cluster Berdasarkan Pelanggan
Hasil clustering terhadap pelanggan, menghasilkan karakteristik penggunaan listrik dari setiap segmen sebagai berikut:
1. Pengguna listrik kelas rendah
Pengguna listrik kelas rendah diwakili oleh cluster 1 dengan karakteristik pengguna yang disajikan pada Tabel 7. Tabel 7 Karakteristik pengguna listrik kelas rendah (cluster 1)
Terendah Tertinggi Rata-rata Daya 160 10.600 932,86
KWH 60 3.532 243,39
Jam 150 2.252 277,88
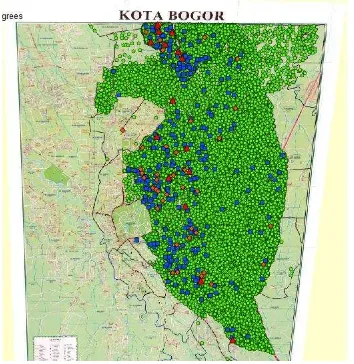
Golongan pelanggan yang terdapat pada pengguna listrik kelas rendah adalah bisnis (B1 dan B2), industri (I1), pemerintah (P1 dan P3), rumah tangga (R1, R2, dan R3), dan sosial (S2) dengan persebaran di seluruh daerah. Daerah yang memiliki persebaran tertinggi pada cluster ini adalah Kedung Halang dengan jumlah pelanggan sebanyak 11.440 pelanggan. Pesebaran spasial pengguna listrik kelas rendah dapat dilihat pada Gambar 13.
Gambar 13 Pesebaran spasial pengguna listrik kelas rendah
Gambar 14 Pesebaran spasial pengguna listrik kelas sedang
2. Pengguna listrik kelas sedang
Pengguna listrik kelas sedang diwakili oleh cluster 2 dengan karakteristik pengguna yang disajikan pada Tabel 8. Tabel 8 Karakteristik pengguna listrik kelas sedang (cluster 2)
Terendah Tertinggi Rata-rata Daya 2.200 53.000 19.197,65 KWH 1.702 13.568 4.308,88
Jam 150 2.012 253,11
14 Baru, dan Tegal Lega. Daerah yang
memiliki persebaran tertinggi pada cluster ini adalah Bantarjati dengan jumlah pelanggan sebanyak 59 pelanggan. Pesebaran spasial pengguna listrik kelas sedang dapat dilihat pada Gambar 14. 3. Pengguna listrik kelas tinggi
Pengguna listrik kelas tinggi diwakili oleh cluster 3 dengan karakteristik pengguna yang disajikan pada Tabel 9.
Tabel 9 Karakteristik pengguna listrik kelas tinggi (cluster 3)
Terendah Tertinggi Rata-rata Daya 53.000 147.000 84.930,23 KWH 10.020 32.320 18.462,65
Jam 150 448 222,07
Golongan pelanggan yang terdapat pada pengguna listrik kelas tinggi adalah bisnis (B2), industri (I2), pemerintah (P1), dan sosial (S2) dengan penyebaran di daerah Babakan, Bantarjati, Baranang Siang, Ciparigi, Kedung Halang, Sukaraja, Tanah Baru, dan Tanah Sareal. Daerah yang memiliki jumlah persebaran tertinggi pada cluster ini adalah Babakan dengan pelanggan sebanyak 13 pelanggan. Pesebaran spasial pengguna listrik kelas tinggi dapat dilihat pada Gambar 15. 4. Pengguna listrik kelas sangat tinggi
Pengguna listrik kelas sangat tinggi diwakili oleh cluster 4 dengan karakteristik pengguna yang disajikan pada Tabel 10.
Tabel 10 Karakteristik pengguna listrik kelas sangat tinggi (cluster 4)
Terendah Tertinggi Rata-rata Daya 105.000 197.000 175.466,67 KWH 36.004 67.373 49.990,63
Jam 194 446 291,34
Golongan pelanggan yang terdapat pada pengguna listrik kelas sangat tinggi adalah bisnis (B2), industri (I2), pemerintah (P3), dan sosial (S2) dengan persebaran di daerah Babakan, Bantarjati, Baranang Siang, Cibuluh, Katulampa, Kedung Halang, dan Tegal Lega. Daerah yang memiliki persebaran tertinggi pada cluster ini adalah daerah Kedung Halang dengan jumlah pelanggan sebanyak 7 pelanggan. Pesebaran spasial pengguna listrik kelas sangat tinggi dapat dilihat pada Gambar 16.
Gambar 15 Pesebaran spasial pengguna listrik kelas tinggi
Gambar 16 Pesebaran spasial pengguna listrik kelas sangat tinggi
Gambar 17 Pesebaran spasial pengguna listrik semua kelas
15 tersebut terlihat pengguna listrik kelas rendah
mendominasi di seluruh wilayah, bahkan ada beberapa daerah yang hanya terdapat pengguna listrik kelas rendah saja.
Evaluasi Cluster Berdasarkan Daerah
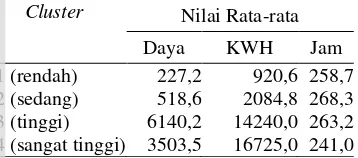
Segmentasi berdasarkan daerah, dilakukan berdasarkan rata-rata penggunaan listrik dari masing-masing daerah. Karakteristik penggunaan listrik dari setiap segmen pada clustering berdasarkan daerah dapat dilihat pada Tabel 11.
Tabel 11 Karakteristik penggunaan listrik berdasarkan segmentasi daerah
Cluster Nilai Rata-rata Daya KWH Jam C1 (rendah) 227,2 920,6 258,7 C2 (sedang) 518,6 2084,8 268,3 C3 (tinggi) 6140,2 14240,0 263,2 C4 (sangat tinggi) 3503,5 16725,0 241,0 1. Daerah penggunan listrik kelas rendah
Daerah penggunaan listrik kelas rendah diwakili oleh cluster 1. Daerah-daerah yang termasuk pada kelas ini sebanyak 17 daerah, yaitu: Cibuluh, Cilebut, Ciluar, Cimahpar, Ciparigi, Katulampa, Kebon Pedes, Kedung Badak, Kedung Halang, Pakuan, Pasir Laja, Sempur, Sukaraja, Sukaresmi, Sukasari, Sukatani, dan Tanah Baru.
2. Daerah penggunaan listrik kelas sedang Daerah penggunaan listrik kelas sedang diwakili oleh cluster 2. Daerah-daerah yang termasuk pada kelas ini sebanyak 4 daerah, yaitu: Babakan, Bantarjati, Baranang Siang, dan Tegal Lega.
3. Daerah penggunaan listrik kelas tinggi Daerah penggunaan listrik kelas tinggi diwakili oleh cluster 3. Daerah yang termasuk pada kelas ini hanya satu daerah, yaitu Babakan Pasar.
4. Daerah penggunaan listrik sangat tinggi Daerah penggunaan listrik kelas sangat tinggi diwakili oleh cluster 4. Daerah yang termasuk pada kelas ini hanya satu daerah, yaitu Tanah Sareal.
Visualisasi Clustering
Visualisasi hasil clustering disajikan dalam bentuk plot 2 dimensi dan juga penyebaran titik pada peta untuk mempermudah analisis. Pada program clustering FCM yang telah dibuat terdapat fasilitas untuk visualisasi dalam bentuk plot 2
dimensi dengan mengombinasikan dua variabel (x dan y) dari data yang digunakan. Setiap cluster dibedakan dengan warna yang berbeda dan pusat cluster ditampilkan berbentuk kotak dengan ukuran yang lebih besar dari anggota cluster.
Visualisasi hasil clustering berdasarkan pelanggan dengan plot 2 dimensi dapat dilihat pada Gambar 18. Inisalisasi warna yang digunakan sebagai pembeda cluster pada Gambar 18 adalah: padahal sebenarnya terjadi penumpukan titik anggota cluster yang mengumpul pada cluster tersebut. Begitu pula untuk cluster 2, terjadi penumpukan titik anggota cluster pada cluster tersebut.
Gambar 18 Plotclustering berdasarkan pelanggan
16 gambar tersebut juga terlihat dua titik yang
berbentuk kotak dengan warna yang berbeda. Kedua titik tersebut merupakan cluster 3 dan cluster 4 dimana masing-masing anggota cluster tersebut berjumlah satu, sehingga anggota dari cluster tersebut juga merupakan pusat cluster-nya.
Gambar 19 Plotclustering berdasarkan daerah
KESIMPULAN DAN SARAN
Kesimpulan
Proses segmentasi penggunaan listrik dapat dilakukan dengan menggunakan algoritme clustering Fuzzy C-Means. Setelah clustering dilakukan, didapatkan karakteristik dari setiap segmen penggunaan listrik.
Pada segmentasi berdasarkan pelanggan, segmen pengguna listrik kelas rendah merupakan segmen yang paling banyak anggotanya, sedangkan yang paling sedikit adalah segmen pengguna listrik kelas sangat tinggi. Daerah yang memiliki persebaran dari semua segmentasi adalah Babakan, Bantarjati, Baranang Siang, dan Kedung Halang. Pihak PLN dapat memberikan perhatian yang lebih terhadap pelayanan di daerah-daerah tersebut, karena pada daerah-daerah tersebut terdapat semua segmen dan juga memiliki pengguna listrik kelas tinggi dan sangat tinggi yang lebih banyak dibandingkan dengan daerah lain.
Saran
Program yang dikembangkan dan data yang digunakan untuk melakukan clustering pada penelitian ini masih memiliki kekurangan. Saran untuk penelitian ini adalah:
1. Mengintegrasikan hasil yang ditampilkan pada peta ke dalam program clustering 2. Selain menampilkan penyebaran pengguna
listrik, juga ditampilkan penyebaran instalasi dari alat listrik.
DAFTAR PUSTAKA
Abonyi J, Feil B. 2007. Cluster Analysis for Data Mining and System Identification. Berlin: Birkhauser Verlag AG.
Cox, Earl. 2005. Fuzzy Modeling and Genetic Algorithms for Data Mining and Exploration. San Francisco: Elsevier Inc.
Daulay A M. 2006. Segmentasi Pasar Produk Mie Cepat Saji Menggunakan Fuzzy C-Means [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Gulley N, Jang R. 2000. Fuzzy Logic Toolbox. USA: Mathwork, Inc.
Han J, Kamber M. 2006. Data Mining: Concept and Techniques. Ed ke-2. San Francisco: Morgan Kaufman Publisher. Höppner F, Klawonn F, Kruse R, Runkler T. 1999. Fuzzy Cluster Analysis Methods for Classification, Data Analysis and Image Recognition. Inggris: John Wiley & Sons Inc.
Ross, Timothy J. 2005. Fuzzy Logic with Engineering Applications. Ed ke-2. Inggris: John Wiley & Sons Inc. Tan P, Steinbach M, Kumar V. 2006.
18 Lampiran 1 Contoh sebagian data penelitian
No Koordinat_X Koordinat_Y No_Pelanggan Golongan Daya Lingkungan KWH Jam
1 701937.566 9271639.268 538210000034 R1 900 CIMAHPAR 348 387
2 700992.314 9274976.155 538210000075 R1 900 KEDUNG HALANG 141 157 3 699927.652 9275462.678 538210000105 R1 1300 KEDUNG HALANG 249 192 4 700397.165 9274406.737 538210000113 R1 1300 KEDUNG HALANG 336 258
5 700320.110 9273550.683 538210000154 R1 900 CIBULUH 244 271
6 700789.138 9273085.180 538210000290 R1 1300 BANTARJATI 500 385 7 700336.178 9274728.261 538210000312 R1 900 KEDUNG HALANG 157 174 8 700371.357 9272040.426 538210000416 R1 900 BANTARJATI 532 591 9 699830.507 9275900.955 538210000432 R1 900 KEDUNG HALANG 148 164 10 700012.067 9272219.479 538210000440 R1 900 BANTARJATI 179 199 11 699971.362 9268593.425 538210000465 R1 1300 BARANANG SIANG 305 235
12 699486.387 9270765.480 538210000511 B1 900 BABAKAN 632 702
13 702239.370 9268915.660 538210000586 B1 900 SUKARAJA 342 380
14 700516.346 9274751.798 538210000615 R1 2200 KEDUNG HALANG 1015 461 15 702689.191 9266759.437 538210000656 R1 900 KATULAMPA 401 446
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . . 39.818 700311.241 9274672.843 538215217868 R1 900 KEDUNG HALANG 146 162 39.819 700225.479 9275541.743 538215218255 B1 900 CIPARIGI 140 156 39.820 699956.836 9275862.257 538215218263 B2 16500 KEDUNG HALANG 6100 370
39.821 699601.665 9270883.986 538215218271 B1 900 BABAKAN 180 200
19 Lampiran 2 Histogram pengguna daya
0 2000 4000 6000 8000 10000 12000 14000 16000 18000 20000
160 640
1.000 1.500 2.200 3.500 4.400 6.115 6.585 7.000 7.860 9.560
13.200 33.000 66
.00
0
131.00
0
197.00
0
Histogram Pengguna Daya
20 Lampiran 3 Transformasi nilai atribut menggunakan normalisasi z-score
No. Sebelum Normalisasi Sesudah Normalisasi (z-score) Daya (Watt) Penggunaan KWH* Daya KWH
1 900 348.000 -0,06456 0,03045
2 900 141.000 -0,06456 -0,13489
3 1.300 249.000 0,01731 -0,04863
4 1.300 336.000 0,01731 0,02086
5 900 244.000 -0,06456 -0,05262
6 1.300 500.000 0,01731 0,15185
7 900 157.000 -0,06456 -0,12211
8 900 532.000 -0,06456 0,17741
9 900 148.000 -0,06456 -0,12930
10 900 179.000 -0,06456 -0,10454
11 1.300 305.000 0,01731 -0,00390
12 900 632.000 -0,06456 0,25729
13 900 342.000 -0,06456 0,02565
14 2.200 1.015.000 0,20152 0,56320
15 900 401.000 -0,06456 0,07278
. . .
. . .
. . .
. . .
. . .
39.818 900 146.000 -0,06456 -0,13090
39.819 900 140.000 -0,06456 -0,13569
39.820 16.500 6.100.000 3,12841 4,62476
39.821 900 180.000 -0,06456 -0,10374
39.822 3.500 1.177.000 0,46760 0,69260
21 Lampiran 4 Tabel penggunaan listrik rata-rata berdasarkan daerah
Daerah Sebelum Normalisasi Setelah Normalisasi
Daya KWH* Daya KWH
BABAKAN 2.970,53 701.283,29 0,13892 0,01732
BABAKAN PASAR 16.725,00 3.503.500,00 3,42670 2,05739 BANTARJATI 1.573,97 385.464,61 -0,19491 -0,21261 BARANANG SIANG 1.798,32 442.286,43 -0,14128 -0,17124
CIBULUH 1.346,90 398.071,86 -0,24918 -0,20343
CILEBUT 900,00 185.500,00 -0,35601 -0,35818
CILUAR 815,46 199.621,11 -0,37622 -0,34790
CIMAHPAR 723,31 189.963,08 -0,39824 -0,35494
CIPARIGI 1.085,99 274.569,59 -0,31155 -0,29334
KATULAMPA 824,12 218.606,91 -0,37415 -0,33408
KEBON PEDES 450,00 119.000,00 -0,46357 -0,40660 KEDUNG BADAK 1.106,23 268.808,93 -0,30671 -0,29753 KEDUNG HALANG 983,55 263.693,21 -0,33604 -0,30126
PAKUAN 1.033,33 182.000,00 -0,32414 -0,36073
PASIR LAJA 655,71 169.373,26 -0,41440 -0,36993
SEMPUR 841,13 196.161,29 -0,37008 -0,35042
SUKARAJA 877,60 241.134,79 -0,36136 -0,31768
SUKARESMI 841,07 197.928,57 -0,37009 -0,34914
SUKASARI 1.252,69 304.666,67 -0,27170 -0,27143
SUKATANI 662,50 146.250,00 -0,41278 -0,38676
22 Lampiran 5 Tabel hasil clustering dengan FCM terhadap pelanggan
No. Daya KWH C1 C2 C3 C4 C1 C2 C3 C4 Cluster
1 -0,06456 0,03045 0,9996 0,0004 0,0000 0,0000 1 0 0 0 '1' 2 -0,06456 -0,13489 0,9997 0,0003 0,0000 0,0000 1 0 0 0 '1' 3 0,01731 -0,04863 0,9997 0,0003 0,0000 0,0000 1 0 0 0 '1' 4 0,01731 0,02086 0,9993 0,0006 0,0000 0,0000 1 0 0 0 '1' 5 -0,06456 -0,05262 1,0000 0,0000 0,0000 0,0000 1 0 0 0 '1' 6 0,01731 0,15185 0,9972 0,0027 0,0001 0,0000 1 0 0 0 '1' 7 -0,06456 -0,12211 0,9998 0,0002 0,0000 0,0000 1 0 0 0 '1' 8 -0,06456 0,17741 0,9970 0,0029 0,0001 0,0000 1 0 0 0 '1' 9 -0,06456 -0,12930 0,9997 0,0002 0,0000 0,0000 1 0 0 0 '1' 10 -0,06456 -0,10454 0,9999 0,0001 0,0000 0,0000 1 0 0 0 '1' 11 0,01731 -0,00390 0,9995 0,0005 0,0000 0,0000 1 0 0 0 '1' 12 -0,06456 0,25729 0,9945 0,0053 0,0002 0,0000 1 0 0 0 '1' 13 -0,06456 0,02565 0,9996 0,0003 0,0000 0,0000 1 0 0 0 '1' 14 0,20152 0,56320 0,9702 0,0286 0,0010 0,0002 1 0 0 0 '1' 15 -0,06456 0,07278 0,9991 0,0009 0,0000 0,0000 1 0 0 0 '1'
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
23 Lampiran 6 Tabel jumlah anggota cluster terhadap seluruh daerah
Daerah Cluster Jumlah
1 2 3 4
Babakan 1129 36 13 1 1179
Babakan Pasar 1 1 0 0 2
Bantarjati 5738 59 7 3 5807
Baranang Siang 3847 56 10 1 3914
Cibuluh 559 5 0 1 565
Cilebut 2 0 0 0 2
Ciluar 1061 0 0 0 1061
Cimahpar 2296 6 0 0 2302
Ciparigi 2795 6 1 0 2802
Katulampa 3293 6 0 1 3300
Kebon Pedes 1 0 0 0 1
Kedung Badak 804 2 0 0 806
Kedung Halang 11440 56 6 7 11509
Pakuan 3 0 0 0 3
Pasir Laja 359 0 0 0 359
Sempur 62 0 0 0 62
Sukaraja 2325 10 2 0 2337
Sukaresmi 28 0 0 0 28
Sukasari 183 3 0 0 186
Sukatani 4 0 0 0 4
Tanah Baru 3218 21 3 0 3242
Tanah Sareal 4 0 1 0 5
Tegal Lega 337 8 0 1 346
24 Lampiran 7 Tabel hasil clustering terhadap daerah
No. Daya KWH C1 C2 C3 C4 C1 C2 C3 C4 Cluster