SISTEM IDENTIFIKASI FAMILI SECARA OTOMATIS
BERBASIS TEKS MENGGUNAKAN DOKUMEN
ETNOFITOMEDIKA
RYANTIE OCTAVIANI SUGANDA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
SISTEM IDENTIFIKASI FAMILI SECARA OTOMATIS
BERBASIS TEKS MENGGUNAKAN DOKUMEN
ETNOFITOMEDIKA
RYANTIE OCTAVIANI SUGANDA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
RYANTIE OCTAVIANI SUGANDA. Text Based Automatic Family Identification System Using Etnofitomedika Document. Supervised by YENI HERDIYENI and ELLYN K. DAMAYANTI.
This research represents a text-based system that can be used for automatic identification of plant families according to the taxonomy of plants. The identification was done by utilizing information from etnofitomedika documents on plant characteristics that can represent the family of each plant including morphology, habitats, habitus, and biochemical compounds. The method used in this research is Chi-Square method to select important words in each document and Naïve Bayes method to classify the words. The experimental results showed that the critical value using significance level of 0,001 had better accuracy than the critical value using significance level of 0,01. The accuracy of classification systems based on family category using K-fold cross validation with significance value of 0,001 was 85,5%. It was found this system is useful in helping users especially researchers and taxonomists for plant family identification. Furthermore, it can help strengthening the knowledge on biodiversity and the use of medical plants.
Judul Skripsi : Sistem Identifikasi Famili Secara Otomatis Berbasis Teks Menggunakan Dokumen Etnofitomedika
Nama : Ryantie Octaviani Suganda
NIM : G64080030
Menyetujui:
Pembimbing Pembimbing
Dr. Yeni Herdiyeni, S.Si., M.Kom. Ellyn K. Damayanti,Ph.D.Agr.
NIP. 19750923 200012 2 001
Mengetahui:
Ketua Departemen Ilmu Komputer
Dr. Ir. Agus Buono, M.Si, M.Kom NIP.196607021993021001
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah subhanahu wa-ta'ala atas segala rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan tugas akhir dengan judul Sistem Identifikasi Famili secara Otomatis Berbasis Teks Terhadap Dokumen Etnofitomedika. Penelitian ini dilaksanakan mulai Desember 2011 sampai dengan Januari 2013 dan bertempat di Departemen Ilmu Komputer Institut Pertanian Bogor.
Penulis juga menyampaikan terima kasih kepada pihak-pihak yang telah membantu dalam penyelesaian tugas akhir ini,yaitu:
1 Ayahanda Suganda, Ibunda Dharma Astuti, adikku Ferdimas, dan MUSA big family yang
selalu memberikan kasih sayang, semangat, dan doa.
2 Ibu Dr. Yeni Herdiyeni, S.Si., M.Kom. dan Ibu Ellyn K. Damayanti, Ph.D.Agr. selaku dosen pembimbing yang telah memberikan arahan dan bimbingan dengan sabar kepada penulis dalam menyelesaikan skripsi ini.
3 Bapak Endang Purnama Giri,S.Kom, M.Kom selaku dosen penguji.
4 Mayanda Mega Santoni, Ni Kadek Sri Wahyuni, Oki Maulana, Siska Susanti, Kak Pauzi,
Pak Rico, Mbak Gibtha, Kak Rahmat, Kak Muchlis dan teman-teman satu bimbingan
yang selalu memberikan masukan, saran, dan semangat kepada penulis, specially for Ka
Desta yang telah banyak membantu dan memberi semangat dalam melakukan penelitian ini.
5 Para sahabat seperjuangan Hafizhia Dhikrul A, Ilman Dwi S, Putrantio J, Anita Dly, Tiara
Mitra Lia, Niken Eka, Meri Marliana, Cut Malisa Irwan, Annisa A, Ardini yang selalu mendukung dan selalu bersama penulis dikala senang maupun sedih.
6 Para sahabat Hutomo Triasmoro, M. Rifkiansyah, Rahmat Hafid, M.Wahyu, Jaka Ahmad,
Tenri T. Talkanda, dan Irvan Raditya Putra yang selalu member semangat dan motivasi.
7 Rekan-rekan di Departemen Ilmu Komputer IPB angkatan 45 atas segala kebersamaan,
canda tawa, dan kenangan indah yang telah mengisi kehidupan penulis selama di kampus.
8 Teman-teman Genggong, kostan putri Asy-Syifa, DBM F.L.C, DBM Depok, DBM
Timur, Transformatika, dan AGRIC IPB.
Penulis menyadari bahwa masih banyak kekurangan yang ditemukan dalam tugas akhir ini. Penulis berharap adanya saran dan kritik yang membangun dari semua pihak yang membaca tulisan ini. Semoga tulisan ini bermanfaat dan dapat menambah wawasan ilmu pengetahuan bagi penulis khususnya dan pembaca umumnya.
Bogor, Januari 2013
RIWAYAT HIDUP
Penulis dilahirkan di Tengerang pada tanggal 17 Oktober 1990 dari ayah Suganda dan ibu Dharma Astuti. Penulis merupakan putri pertama dari dua bersaudara. Penulis merupakan lulusan dari SMAN 101Jakarta (2005-2008), SMPN 142Jakarta (2002-2005), SDNSudimara 7 Ciledug (1996-2002) dan TK Islam Al-Azhar (1994-1996).
Saat ini penulis sedang menempuh studi S1 di Departemen Ilmu Komputer, Fakultas MIPA, Institut Pertanian Bogor, sejak tahun 2008 sampai dengan sekarang. Selama mengikuti perkuliahan, penulis aktif dalam kegiatan kampus seperti kepanitiaan dalam suatu acara di IPB maupun acara yang diselenggarakan oleh Departemen Ilmu Komputer. Penulis berkedudukan
sebagai staff Marketing and Relationship (MR) di HIMALKOM, dan anggota UKM Basket IPB.
v
DAFTAR ISI
Halaman
DAFTAR TABEL ...vi
DAFTAR GAMBAR ...vi
DAFTAR LAMPIRAN ...vi
PENDAHULUAN ...1
Latar Belakang ...1
Tujuan Penelitian ...1
Ruang Lingkup ...1
TINJAUAN PUSTAKA ...2
Etnofitomedika ...2
Taksonomi ...2
Pemilihan Fitur Dokumen ...2
Klasifikasi ...2
Chi-Kuadrat (χ2)...2
Naïve Bayes Classifier ...3
Confusion Matrix ...4
K-Fold Cross Validation ...4
METODE PENELITIAN ...4
Wawancara...5
Dokumen Etnofitomedika ...5
Praproses Data ...6
Pembagian Data...6
Pemilihan Fitur ...6
KlasifikasiNaive Bayes ...6
Evaluasi ...7
Lingkungan Pengembangan Sistem ...7
HASIL DAN PEMBAHASAN ...7
Dokumen Etnofitomedika ...7
Praproses Data ...7
Pemilihan Fitur ...7
Evaluasi Kinerja Sistem Klasifikasi ...7
Analisis Dokumen ... 7
Analisis waktu eksekusi... 9
Evaluasi K-fold cross validation... 10
KESIMPULAN DAN SARAN ... 10
Kesimpulan ... 10
Saran ... 10
DAFTAR PUSTAKA ... 10
vi
DAFTAR TABEL
Halaman
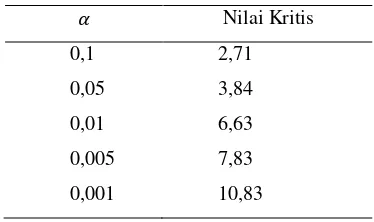
1 Kategori dan golongan tumbuhan ... 2
2 Tabel kontingensi ... 3
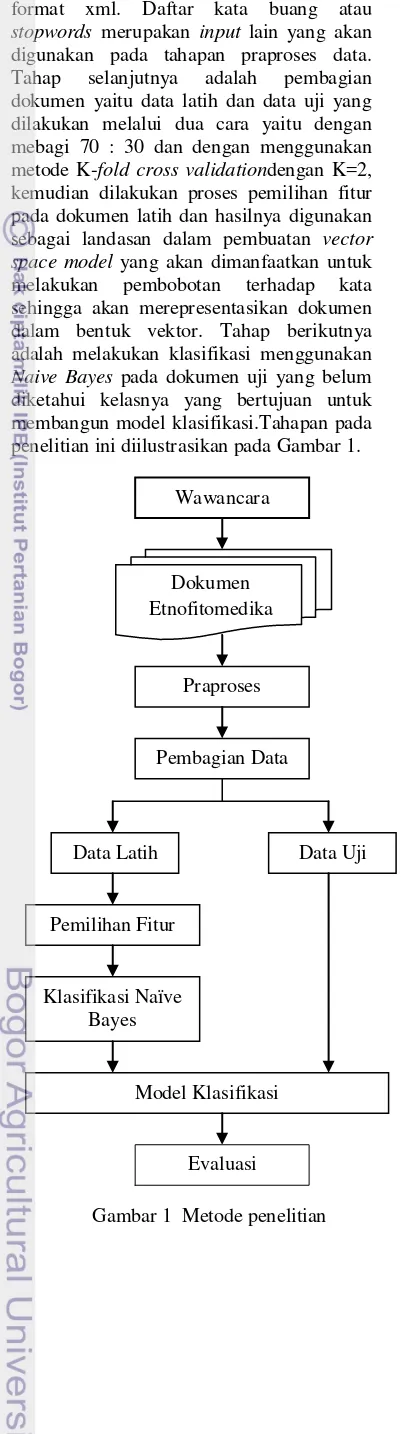
3 Nilai kritis χ2 dengan derajat bebas satu dan taraf nyata α ... 3
4 Confusion matrix untuk klasifikasi biner ... 4
5 Distribusi dokumen famili ... 7
6 Persamaan ciri pada famili Rutaceae dan Myrtacea ... 8
7 Ciri atau karakteristik ordo Rutales dan Myrtales (Tjitrosoepomo 1994)... 9
8 Hasil akurasi menggunakan k-fold ... 10
DAFTAR GAMBAR
Halaman 1 Metode penelitian ... 52 Format koleksi dokumen ... 5
3 Grafik hasil klasifikasi dokumen etnofitomedika ... 8
4 Grafik kinerja rataan pemilihan fitur ... 9
5 Alur taksonomi famili Rutacea dan famili Myrtaceae ... 10
DAFTAR LAMPIRAN
Halaman 1 Daftar jenis tumbuhan obat Indonesia yang digunakan dalam penelitian ... 132 Tabel distribusi chi-kuadrat pada berbagai tingkat signifikansi dan derajat bebas tertentu ... 16
3 Confusionmatrix untuk kelas family pada nilai signifikansi 0.001 ... 17
1
PENDAHULUAN
Latar Belakang
Indonesia sebagai negara tropis
memiliki keanekaragaman hayati yang tinggibaik secara kualitas maupun kuantitas, salah satunya yaitu tumbuhan obat. Terdapat 38.000 spesies tumbuhan di Indonesia dengan jumlah spesies endemik sebanyak
55% (Damayanti et al. 2011). Sampai tahun
2001, Laboratorium Konservasi Tumbuhan, Fakultas Kehutanan IPB hanya dapat mengidentifikasikan 2.039 spesies tumbuhan obat yang berasal dari ekosistem hutan Indonesia (Zuhud 2009). Keanekaragaman tumbuhan obat dapat dikategorikan kedalam
kelompok famili, habitat, habitus,
pemanfaatan, dan bagian tanaman yang
digunakan sebagai obat. Penggunaan
tumbuhan sebagai obat-obatan selalu dengan cara tradisional yaitu dengan resep yang diwariskan oleh nenek moyang bangsa Indonesia. Potensi tumbuhan obat di Indonesia sebagian besar disimpan dalam bentuk pengetahuan masyarakat tradisional atau etnis suatu daerah. Pengetahuan ini memunculkan bidang kajian baru dalam
dunia ilmu pengetahuan, yaitu
etnofitomedika yang merupakan
pengetahuan pemanfaatan potensi tumbuhan untuk obat tradisional yang erat kaitannya
dengan kebiasaan atau tradisi serta
kebudayaan setempat (Sangat
2000).Indonesia memiliki lebih dari 550 etnis yang menyebar dari bagian barat Pulau
Sumatera ke bagian timur Indonesia
(Damayanti et al. 2011). Antar etnis dapat menggunakan spesies dan bagian tumbuhan yang sama atau berbeda. Hal ini tergantung pada pengalaman mereka dan mewariskan resep dari nenek moyang mereka. Adapun
masalah yang ditemukan dalam
keanekaragaman tersebut yaitu dalam
pengidentifikasian spesies.
Keterbatasan pengetahuan penduduk
setempat akan keanekaragaman dan
penggunaan tumbuhan obat menjadi salah satu masalah dalam pengidentifikasian. Selain itu ada beberapa masalah lainnya, seperti terbatasnya jumlah buku identifikasi dan banyaknya halaman di setiap buku identifikasi atau buku panduan yang menyulitkan untuk dibawa kelapangan, terbatasnya jumlah instansi yang berwenang dan fasilitas untuk identifikasi tumbuhan, terbatasnya jumlah taksonom di setiap
instansi yang dapat mengidentifikasi
tumbuhan secara ilmiah, dan banyaknya tenaga, waktu, dan uang yang diperlukan untuk melakukan identifikasi tersebut. Saat ini sudah banyak riset yang meneliti tentang etnofitomedika. Banyak informasi yang terkandung dalam tiap dokumen, misalnya informasi mengenai deskripsi tumbuhan seperti ciri-ciri atau karakteristik dan famili
tumbuhan, manfaat tumbuhan, etnis,
kandungan kimia yang terkandung dalam tumbuhan dan masih banyak informasi lainnya. Saat ini klasifikasi dilakukan secara manual, yaitu dengan cara mengamati lingkungan sekitar dan menganalisa ciri atau karakteristik dari tumbuhan obat secara langsung atau mencocokkan pada tiap dokumen. Cara tersebut membutuhkan waktu lama dan merepotkan sehingga perlu adanya sistem pengidentifikasian otomatis pada dokumen etnofitomedika.
Pada penelitian sebelumnya telah
dilakukan perbandingan mengenai ekstraksi ciri dokumen tumbuhan obat menggunakan
Chi-Kuadratdan menggunakan teknik
document thresholding frequency (df)
dengan klasifikasi Naïve Bayes (Herawan
2011) dan ekstraksi ciri dokumen tumbuhan obat menggunakan Chi-Kuadrat dengan klasifikasi algoritma KNN Fuzzy (Paskianti 2011). Pengelompokan atau klasifikasi tumbuhan obat perlu dilakukan dengan cara mengembangkan teknologi untuk mengatasi masalah dalam identifikasi tumbuhan. Hal tersebut menjadi tantangan bagi ilmuwan di bidang komputer dan teknologi informasi untuk memahami bagaimana taksonomis mengidentifikasi tumbuhan. Oleh sebab itu, pada penelitian ini akan dikembangkan sistem identifikasi otomatis berdasarkan kelompok famili berbasis teks dengan menggunakan dokumen etnofitomedika. Tujuan Penelitian
Tujuan penelitian ini adalah
1 Mengembangkan sistem berbasis teks
yang dapat digunakan untuk
pengidentifikasian famili secara
otomatis sesuai dengan taksonomi.
2 Mengetahui akurasi kinerja sistem.
Ruang Lingkup
2
pengklasifikasian etnofitmedika hanya
berdasarkan kategori famili.
TINJAUAN PUSTAKA
Etnofitomedika
Menurut Damayanti (2010),
etnofitomedika adalah keterkaitan
pengetahuan lokal etnis tertentu yang
menghuni kawasan hutan dengan
keanekaragaman spesies tumbuhan yang dapat dijadikan bahan pengobatan yang berkaitan dengan tumbuhan obat. Sangat (2000) menyatakan bahwa etnofitomedika
merupakan pengetahuan pemanfaatan
potensi tumbuhan untuk obat tradisional yang erat kaitannya dengan kebiasaan atau tradisi serta kebudayaan setempat (local knowledge).
Taksonomi
Taksonomi tumbuhan merupakan ilmu
yang mempelajari tentang berbagai
penelusuran jenis tumbuhan, penyimpanan
herbarium tumbuhan, pengenalan atau
identifikasi tumbuhan, pengelompokan atau klasifikasi tumbuhan, dan pemberian nama tumbuhan (Tjitrosoepomo 1994). Taksonomi tumbuhan lebih banyak mempelajari aspek
penanganan sampel-sampel (spesimen)
tumbuhan dan pengelompokan (klasifikasi).
Ilmu taksonomi tumbuhan mengalami
banyak perubahan cepat semenjak
digunakannya berbagai teknik biologi
molekular dalam berbagai kajiannya. Contoh kategori dan golongan tumbuhan dapat dilihat pada Tabel 1.
Tabel 1 Kategori dan golongan tumbuhan
Kategori Golongan
Species Shorea pinanga
Pemilihan Fitur Dokumen
Pemilihan fitur dokumen merupakan suatu proses memilih kata terbaik pada tiap
dokumen. Kata tersebut merupakan
himpunan dari semua kata yang ada pada data latih. Pemilihan fitur dokumen memiliki dua tujuan utama, yaitu membuat data latih yang diterapkan oleh sistem klasifikasi
menjadi lebih sederhana serta untuk
meningkatkan akurasi sistem klasifikasi.
Peningkatan akurasi sistem klasifikasi
disebabkan oleh dihilangkannya kata-kata yang bukan merupakan penciri dokumen yang dilakukan pada proses penghilangan fitur (Manning et al.2008). Dalam penelitian ini, data yang digunakan adalah dokumen etnofitomedika yang berasal dari beberapa dokumen hasil riset dan buku tumbuhan obat. Dokumen yang digunakan dibuat dalam format xml. Data dari himpunan tersebut akan digunakan sebagai penciri dokumen yang akan diklasifikasikan. Klasifikasi
Klasifikasi adalah proses untuk
menentukan kelas dari suatu objek tertentu. Proses klasifikasi dibagi menjadi dua tahap, yaitu tahapan pembelajaran dan pengujian. Pada tahap pembelajaran, sebagian data yang telah diketahui kelasnya yang disebut sebagai data latih digunakan untuk membuat model klasifikasi. Tahap pengujian adalah tahap menguji data uji dengan model klasifikasi untuk mengetahui akurasi model klasifikasi tersebut. Jika akurasi cukup maka model tersebut dapat digunakan untuk
memprediksi kelas data yang belum
diketahui (Han dan Kamber 2006).
Pada klasifikasi dokumen,
permasalahan yang muncul adalah sebagai berikut: diberikan sebuah deskripsi d ∈ X
dari sebuah dokumen dimana X merupakan
ruang dokumen. Sebuah himpunan
tetapkelas C = c1, c2, c3, …,cj, dengan
menggunakan algoritma pembelajaran,
dilakukan proses pembelajaran terhadap
fungsi klasifikasi γ sehingga dapat
memetakan dokumen � pada kelas C.
γ: X→C Chi-Kuadrat (χ2)
3
sampel dihitung nilai χ2 sehingga diperoleh distribusi sampling untuk χ2yang disebut distribusi Chi-Kuadrat.
Distribusi Chi-Kuadrat tergantung pada satu parameter, yaitu derajat kebebasan (df). Berikut adalah rumus untuk menghitung besarnya jumlah derajat bebas dari suatu
menguji pengaruh antara frekuensi observasi dengan frekuensi harapan. Hipotesis nol berarti tidak ada perbedaan yang signifikan antara frekuensi observasi dengan frekuensi harapan. Hipotesis nol dapat diterima apabila nilai �2
< nilai kritis pada derajat bebas dan tingkat nilai signifikan tertentu, sedangkan hipotesis nol ditolak ketika nilai �2
> nilai kritis pada derajat bebas dan tingkat nilai signifikan tertentu.
Perhitungan nilai Chi-Kuadratdapat
dibantu dengan tabel kontingensi. Nilai pada tabel kontingensi merupakan nilai frekuensi
observasi dari suatu kata terhadap
kelas.Tabel kontingensi dapat dilihat pada Tabel 2.
Tabel 2 Tabel kontingensi Kelas
Kata Kelas = 1 Kelas = 0
Kata = 1 A B
Kata = 0 C D
Perhitungan nilai Chi-Kuadrat berdasarkan tabel kontingensi disederhanakan sebagai berikut:
X(t, c)2 = N(AD-CB)
2
A+C B+D A+B(C+D) (1)
Dari rumus diatas, t merupakan kata yang sedang diujikan terhadap suatu kelas c. Jumlah dokumen latih dilambangkan dengan N. Banyaknya dokumen pada kelas c yang
memuat kata t dilambangkan dengan A,
banyaknya dokumen yang tidak berada di kelas c namun memuat kata t dilambangkan dengan huruf B, banyaknya dokumen yang
berada di kelas c namun tidak memiliki kata
t dilambangkan dengan huruf C,
danbanyaknya dokumen yang bukan
merupakan dokumen kelas c dan tidak
memuat kata t dilambangkan dengan huruf D.
Pengambilan keputusan berdasarkan nilai χ2 dari masing-masing kata. Kata yang memiliki nilai χ2di atas nilai kritis pada tingkat signifikasi α adalah kata yang dipilih sebagai penciri dokumen, sehingga kata yang dipilih sebagai penciri dokumen merupakan kata yang memiliki pengaruh terhadap kelas c. Nilai kritis �2
dengan
derajat bebas satu dan taraf nyata �
ditunjukkan oleh Tabel 3. Tabel distribusi
chi-kuadrat pada berbagai tingkat
signifikansi dan derajat bebas tertentu dapat dilihat pada Lampiran 2.
Tabel 3 Nilai kritis χ2 dengan derajat bebas
Metode klasifikasi yang
mengasumsikan seluruh atribut yang bersifat independent satu sama lain pada konteks
kelas yaitu metode Naïve Bayes (McCallum
dan Nigam 1998). Peluang Bayes dapat
digunakan untuk menghitung peluang
bersyarat, yaitu peluang kejadian apabila suatu kejadian diketahui. Metode ini dapat memprediksi kemungkinan anggota suatu kelas berdasarkan sampel yang berasal dari anggota kelas tersebut (Manning 2008).
4 c, dan P(d) adalah peluang awal kemunculan
dokumen d. Peluang awal kemunculan
dokumen d dapat diabaikan karena memiliki
nilai yang sama untuk seluruh kelas c, sehingga Persamaan 2 dapat disederhanakan dalam Persamaan 3:
P cd = P dc P c (3)
Rumus untuk menghitung nilai peluang
dokumen masuk ke dalam kelas c dan
peluang kemunculan dokumen d berada
pada kelas c adalah tinggi yaitu seperti ditunjukkan pada Persamaan 4:
max
c ∈C P dc P(c) (4)
Nilai peluang awal P(c) dapat diestimasi dengan melihat jumlah dokumen yang dimiliki oleh kelas c relatif terhadap jumlah seluruh dokumen yang ada.
Confusion Matrix
Confusion matrix merupakan sebuah tabel yang terdiri atas banyaknya baris data uji yang diprediksi benar dan salah oleh model klasifikasi, yang digunakan untuk menentukan kinerja suatu model klasifikasi. Data uji diujikan untuk mendapatkan tingkat akurasi hasil prediksi yang berupa jumlah true positive, true negative, false positive, dan false negative seperti yang dilihat pada Tabel 4 (Herawan 2011).
Tabel 4 Confusion matrix untuk klasifikasi biner
Keterangan untuk Tabel 4 dinyatakan sebagai berikut:
F11, yaitu jumlah dokumen dari kelas 1
yang benar diklasifikasikan sebagai kelas 1.
F00, yaitu jumlah dokumen dari kelas 0
yang benar diklasifikasikan sebagai kelas 0.
F01, yaitu jumlah dokumen dari kelas 0
yang salah diklasifikasikan sebagai kelas 1.
F10, yaitu jumlah dokumen dari kelas 1 yang salah diklasifikasikan sebagai kelas 0.
Perhitungan akurasi dinyatakan dalam
Persamaan 5.
Akurasi = F11+F10+F01+F00F11+F00 (5)
K-Fold Cross Validation
Dalam K-fold cross validation data akan dibagi ke dalam k buah partisi dengan
ukuran yang sama
D1, D2, D3,…, Dk. Pelatihan dan pengujian dilakukan sebanyak k kali. Dalam iterasi ke-i, partisi ��akan menjadi data uji, selainnya menjadi data latih. Pada iterasi pertama, D1 akan menjadi data uji, D2, D3, …, Dk akan menjadi data latih. Selanjutnya iterasi ke-2,
D2 akan menjadi data uji,
D1, D3, …, Dk menjadi data latih, dan seterusnya (Han dan Kamber 2006).
METODE PENELITIAN
Penelitian ini dilaksanakan dalam
beberapa tahapan. Tahap awal pada
penelitian ini yaitu peneliti melakukan tahap
wawancara kepada para pakar
etnofitomedika. Data yang diproses dalam
sistem ini adalah koleksi dokumen
etnofitomedika, seperti dokumen hasil riset
5
Dokumen tersebut diubah menjadi bentuk format xml. Daftar kata buang atau stopwords merupakan input lain yang akan digunakan pada tahapan praproses data.
Tahap selanjutnya adalah pembagian
dokumen yaitu data latih dan data uji yang dilakukan melalui dua cara yaitu dengan mebagi 70 : 30 dan dengan menggunakan metode K-fold cross validationdengan K=2, kemudian dilakukan proses pemilihan fitur pada dokumen latih dan hasilnya digunakan
sebagai landasan dalam pembuatan vector
space model yang akan dimanfaatkan untuk
melakukan pembobotan terhadap kata
sehingga akan merepresentasikan dokumen dalam bentuk vektor. Tahap berikutnya adalah melakukan klasifikasi menggunakan Naive Bayes pada dokumen uji yang belum diketahui kelasnya yang bertujuan untuk membangun model klasifikasi.Tahapan pada penelitian ini diilustrasikan pada Gambar 1.
Gambar 1 Metode penelitian
Wawancara
Pada penelitian ini dilakukan
wawancara terhadap salah satu pakar tumbuhan obat. (Hikmat Agus 3 Januari 2012, komunikasi pribadi) menyatakan bahwa etnofitomedika merupakan interaksi antara manusia dengan tumbuhan obat yang berhubungan dengan suatu etnis tertentu. Tiap entis memiliki tumbuhan obat yang beraneka ragam. Tidak semua penduduk setempat mengetahui jenis dan manfaat dari tumbuhan tersebut. Saat ini sudah banyak riset yang meneliti tentang etnofitomedika tetapi masih dalam bentuk laporan atau makalah dan tidak terstruktur. Masyarakat pada umumnya membutuhkan informasi mengenai tumbuhan obat di tiap etnis yang berbeda. Adapun informasi yang dibutuhkan untuk mengidentifikasikan etnofitomedika, yaitu berupa etnis, penyakit, nama lokal, nama ilmiah, famili, penggunaan, bagian, dan deskripsi.
Dokumen Etnofitomedika
Dokumen yang digunakan pada
penelitian ini adalah suatu data yang memuat informasi mengenai satu jenis tumbuhan obat. Informasi tersebut didapatkan dari beberapa laporan atau makalah hasil riset dan buku tumbuhan obat. Dokumen tersebut dibentuk dalam format xml. Koleksi dokumen dijadikan sebagai korpus. Tiap
dokumen merepresentasikan informasi
mengenai jenistumbuhan obat berdasarkan etnisyang berada di Indonesia yang meliputi etnis, penyakit, nama lokal, nama ilmiah, famili, penggunaan, bagian, dan deskripsi. Koleksi dokumen bertipe file.xml dengan contoh format dokumen yang terdapat pada Gambar 2.
6
Dokumen dikelompokkan ke dalam tag
sebagai berikut:
<dok></dok>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag lain yang lebih spesifik.
<id></id>, tag ini menunjukkan id dari dokumen.
<etnis></etnis>, tag ini menunjukkan etnis dari tiap tumbuhan obat.
<penyakit></penyakit>, tag ini menunjukkan penyakit yang dapat disembuhkan dari jenis tumbuhan obat.
<namalokal></namalokal>, tag ini menunjukkan nama dari suatu jenis tanaman obat.
<namailmiah></namailmiah>, tag ini
menunjukkan nama ilmiah dari
tumbuhan obat.
<fam></fam>, tag ini menunjukkan nama famili dari tanaman obat.
<penggunaan></penggunaan>, tag ini menunjukkan cara penggunaan dari tanaman obat.
<bagian></bagian>, tag ini
menunjukkan bagian yang digunakan dari tanaman obat.
<deskripsi></deskripsi>, tag ini mewakili isi dari dokumen meliputi deskripsi tumbuhan obat.
Praproses Data
Ada tiga tahap awal praproses data yaitu lowercasing, tokenisasi, dan pembuangan stopwords. Lowercasing adalah proses untuk
mengubah semua huruf menjadi
non-capital-agar menjadi case-insensitive pada saat
dilakukan pemrosesan teks dokumen,
sedangkan tahap pemrosesan teks masukan (input) yang dibagi menjadi unit-unit kecil (token atau term) dapat berupa suatu kata
atau angka disebut sebagai tokenisasi.
Stopwords adalah daftar kata yang dianggap tidak memiliki makna yaitu kata yang sering muncul di setiap dokumen dan tidak bisa dijadikan sebagai penciri suatu dokumen, lalu daftar kata tersebut dibuang dan tidak diikut sertakan pada tahap selanjutnya. Pembagian Data
Dokumen etnofitomedika yang telah melewati tahap praproses dibagi menjadi dua, yaitu data latih dan data uji. Pembagian
data tersebut menggunakan metode K-fold cross validation dengan K=2. Data latih digunakan sebagai input pelatihan dalam pengklasifikasian Naive Bayes dan data uji digunakan untuk menguji model hasil pelatihan Naive Bayes.
Pemilihan Fitur
Menurut Manning (2008), pemilihan fitur memilik dua tujuan, yaitu mengurangi jumlah kata yang digunakan dan meningkatkan akurasi hasil klasifikasi. Pemilihan fitur dilakukan pada vector term hasil dari tahap praproses dengan menggunakan metode uji chi-kuadrat, lalu fitur tersebut digunakan pada tahap klasifikasi dokumen. Teknik chi-kuadrat memilih fitur berpengaruh dengan menghitung nilai antara kata dengan kelas yang dinyatakan dalam Persamaan 1.
Pemilihan fitur dilakukan pada dua tingkat signifikansi, yaitu 0,01 dan 0,001. Kata yang terpilih pada tingkat signifikansi α=0,01 adalah kata yang memiliki nilai diatas nilai kritis 6,63, sedangkan kata yang terpilih pada tingkat signifikansi α=0,001 adalah kata yang memiliki nilai di atas nilai kritis 10,83. Fitur yang dihasilkan pada tahap ini akan
digunakan untuk membuat vector space
model. Model terdiri atas beberapa dokumen yang direpresentasikan sebagai vektor dari frekuensi kemunculan fitur.
KlasifikasiNaive Bayes
Ada 11 famili hasil klasifikasi
dokumen, yaitu:
1: Menispremaeceae 7: Apiaceae
2: Lamiaceae 8: Crassulaceae
3: Euphorbiaceae 9: Myrtaceae
4: Rutaceae 10: Araliaceae
5: Dioscoreaceae 11: Acanthaceae
6: Malvaceae
Pada Tabel 5 dijelaskan tentang distribusi dokumen pada kategori kelas famili. Hasil matriks kata pada vector space model yang dihasilkan pada pemilihan fitur digunakan untuk menglasifikasikan dokumen baru. Tahap awal yang dilakukan yaitu dengan menghitung peluang kata terhadap dokumen latih yang dicerminkan oleh suatu kelas. Nilai peluang kata yang diperoleh digunakan untuk
melakukan perhitungan Naive Bayes pada
7
dokumen uji. Dokumen yang ditampilkan diurutkan berdasarkan ranking dari tiap dokumen.
Tabel 5 Distribusi dokumen famili
No Kelas Jumlah
Dokumen
1 Menispremaeceae 12
2 Lamiaceae 26
Evaluasi dilakukan pada model
klasifikasi. Evaluasi terhadap kinerja model
penglasifikasi Naive Bayes dilakukan
dengan menghitung persentase ketepatan suatu dokumen etnofitomedika masuk ke dalam kelas tertentu. Evaluasi untuk model
penglasifikasi Naive Bayes dinyatakan
dalam bentuk confusion matrix. Perhitungan nilai akurasi terhadap model klasifikasi diperoleh melalui Persamaan 5.
Lingkungan Pengembangan Sistem
Penelitian ini menggunakan perangkat
lunak dan perangkat keras dengan
spesifikasi adalah sebagai berikut:
a. Perangkat lunak yang digunakan pada
penelitian ini adalah Sistem operasi Microsoft Windows 7, Notepad++
sebagai code editor, Server XAMPP,
Perangkat lunak MySQL untuk
database, Web Browser (melalui Local Area Connection): Mozilla Firefox dan Google Chrome
b. Perangkat keras yang digunakan pada
penelitian ini adalah Intel Core i3 @2.2
Ghz ,Memory 2GB RAM, harddisk
dengan kapasitas sisa 500GB, mouse
dan keyboard.
HASIL DAN PEMBAHASAN
Dokumen Etnofitomedika
Penelitian ini menggunakan 170
dokumen etnofitomedika yang mencangkup 18 jenis tumbuhan obat, dapat dilihat pada Lampiran 1. Dokumen tersebut terbagi menjadi dua jenis data yaitu data latih dan
data uji. Pembagian data dengan
menggunakan perbandingan 70 : 30
menghasilkan 117 data latih dan 53 data uji. Praproses Data
Praproses data menghasilkan daftar term yang sudah melewati tahap tokenisasi
dan pembuangan stopwords. Jumlah
stopwords sebanyak adalah 662 kata.Kata atau term akhir yang dihasilkan dari tahap praproses berjumlah 12.137 untuk data latih famili.
Pemilihan Fitur
Vektor kata unik yang telah dihasilkan dari tahap praproses kemudian diproses pada tahap pemilihan fitur dengan menggunakan
metode Chi-Kuadrat. Pemilihan fitur
dilakukan pada dua nilai signifikansi (Tabel 2), yaitu nilai signifikansi 0,01 dan 0,001. Berdasarkan teori terpenuhinya hipotesis, nilai signifikansi 0,01 diartikan sebagai kriteria kata yang dipilih adalah kata yang memiliki nilai χ2 diatas 6,63 dan nilai signifikansi 0,001 dapat diartikan bahwa kriteria kata yang dipilih adalah kata yang
memiliki nilai χ2 diatas 10,83. Tahap
pemilihan fitur menghasilkan 1.143 kata penciri untuk signifikansi 0,01dan 865 kata peciri untuk signifikansi 0,001. Kumpulan kata yang dihasilkan pada tahapan pemilihan fitur inilah yang kemudian akan diolah pada sistem klasifikasi.
Evaluasi Kinerja Sistem Klasifikasi
Pengelompokkan atau pengklasifikasian dokumen dilakukan pada kelas famili.Kelas tersebut dapat diidentifikasikan melalui
informasi yang memuat ciri atau
karakteristik dari suatu tumbuhan obat pada tiap dokumen. Akurasi yang dihasilkan pada klasifikasi dokumen dengan menggunakan nilai signifikansi 0,001 adalah 77,35%. Analisis Dokumen
8
baik, sehingga hasil klasifikasi dokumen tersebut bernilai 100%. Hal itu disebabkan oleh informasi yang terdapat pada tiap dokumen mengandung ciri atau karakteristik
famili Apiacae. Perbandingan antara
informasi ciri atau karakteristik yang
terkandung dalam dokumen dengan
informasi pada buku panduan mengenai ciri atau karakteristik famili tersebut disajikan pada Lampiran 4.
Jumlah dokumen yang benar dalam pengklasifikasian kelas famili dapat dilihat pada Gambar 3.
Gambar 3 Grafik hasil klasifikasi dokumen etnofitomedika
Pada kelas Acanthaceae, Araliaceae, dan Menispermaceae jumlah dokumen yang benar dalam pengklasifikasian kelas tersebut adalah 0. Kelas Acanthaceae bernilai 0 disebabkan oleh informasi yang terdapat pada dokumen tersebut memiliki beberapa kesamaan ciri pada dokumen yang memuat kelas Lamiaceae dan Myrtaceae, kelas Araliaceae bernilai 0 disebabkan oleh sedikitnya jumlah dokumen latih dan dokumen uji sehingga kurangnya fitur yang merepresentasikan kelas Araliacea, dan kelas Menispermaceae bernilai 0 disebabkan oleh informasi yang terdapat pada tumbuhan Arcangelisia flava L. memiliki beberapa kesamaan ciri dengan tumbuhan yang berada di kelas Apiaceae dan Euphorbiaceae.
Kesalahan pelabelan pada kelas famili disebabkan oleh informasi yang terdapat pada dokumen etnofitomedika tersebut, salah satunya adalah tumbuhan Jambu Biji yang memiliki kelas famili Myrtaceae.Pada sistem identifikasi, tumbuhan Jambu Biji masuk kedalam kelas Rutaceae. Hal tersebut
disebabkan oleh kemiripan ciri atau
karakteristik yang yang dimiliki oleh kelas famili Myrtaceae dan kelas famili Rutaceae. Persamaan ciri dari kedua famili tersebut dapat dilihat pada Tabel 6.
Tabel 6 Persamaan ciri pada famili Rutaceae dan Myrtacea
Kemiripan yang terdapat pada dokumen tersebut menyebabkan kesalahan dalam pelabelan pada kategori kelas family. Pada Tabel 1 telah dipaparkan contoh kategori
dan golongan tumbuhan. Pada buku
taksonomi tumbuhan obat-obatan (Gembong 1994), ada lima divisi pada tumbuhan obat yaitu divisi Schizophyta (tumbuhan belah), divisi Thallophyta (tumbuhan talus) yang mempunyai tiga anak divisi yaitu Algae (ganggang), Fungi (jamur, cendawan), dan Lichenes (lumut kulit), divisi Bryophyta (lumut), divisi Pteridophyta, dan divisi
Spematophyta yang mempunyai tiga
anakdivisi yaitu Coniferospermae,
Chlamydospermae, dan Angiospermae.
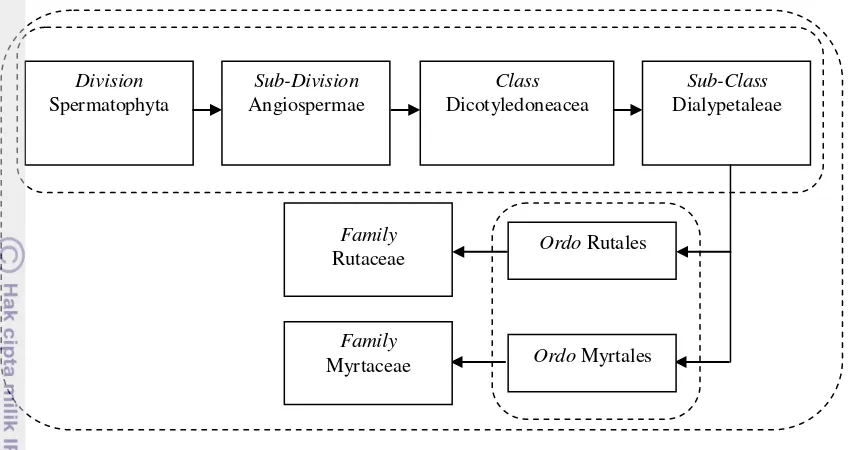
Ordo dari famili Rutaceae adalah Rutales dan ordo dari Myrtaceae adalah Myrtales.
Kedua ordo tersebut termasuk kedalam Dialypetaleae yang merupakan anak kelas
dari Dicotyledoneacea (tumbuhan biji
belah). Dicotyledoneacea adalah salah satu 1 2 3 4 5 6 7 8 9 10 11
Kategori Famili
1 Acanthaceae 2 Apiaceae
9
kelas dari Angiospermae yang merupakan anak divisi dari Spematophyta. Ciri dari Dialypetaleae yaitu adanya hiasan bunga yang ganda. Hiasan bunga tersebut terdiri atas kelopak dan mahkota, yang daun-daunnya saling bebas.Kedua ordo memiliki ciri atau karakteristik umum yang hampir sama yang disajikan pada Tabel 7.
Tabel 7 Ciri atau karakteristik ordo Rutales dan Myrtales (Tjitrosoepomo 1994)
Rutales Myrtales
2 Daun tunggal 2 Daun majemuk
3 Mempunyai
Begitu pula dengan ciri atau karakteristik dari famili Rutaceae dan Myrtaceae, kedua
famili tersebut memiliki beberapa
kemiripan. Kemiripan ciri atau karakteristik yang dimiliki menyebabkan kedua famili tersebut berada dalam satu jenjang takson yang sama. Kedua ordo masuk kedalam
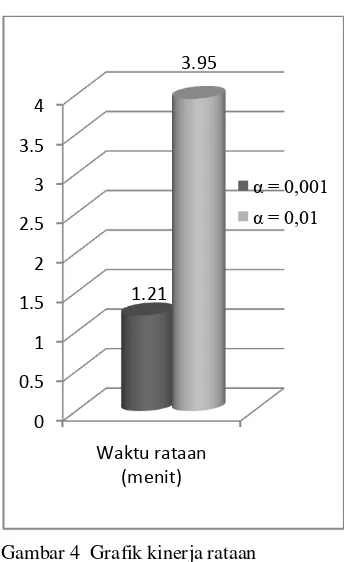
Waktu eksekusi pada proses klasifikasi dipengaruhi oleh pemilihan nilai signifikansi taraf nyata (α). Perbandingan waktu rataan kinerja dalam pemilihan fitur disajikan pada Gambar 4.
Gambar 4 Grafik kinerja rataan pemilihan fitur
Pada grafik tersebut dapat disimpulkan bahwa semakin besar nilai taraf nyata (α) yang dipilih, maka semakin banyak kata atau
term penciri yang dihasilkan sehingga
semakin informatif tetapi waktu eksekusi yang dibutuhkan dalam proses klasifikasi atau pelabelan dokumen semakin banyak. Pada penelitian ini, proses klasifikasi untuk fitur dengan nilai signifikansi α=0,01 membutuhkan waktu yang lebih lama
dibandingkan dengan fitur yang
menggunakan nilai signifikansi α=0,001. Hal tersebut disebabkan karena jumlah kata atau term penciri yang dihasilkan oleh α=0,01 lebih banyak yaitu 1.1432 kata penciri dibandingkan dengan jumlah kata penciri yang dihasilkan oleh α=0,001 yang berjumlah 865 kata peciri. Jumlah kata atau term penciri akan sangat berpengaruh pada saat penghitungan nilai similaritas antara
dokumen uji dengan dokumen latih.
10
Gambar 5 Alur taksonomi famili Rutacea dan famili Myrtaceae
Evaluasi K-fold cross validation
Pada penelitian ini peneliti mencoba menggunakan model evaluasi menggunakan cross validation dengan metode K-fold atau disebut K-fold cross validation. K-fold cross validation bertujuan untuk menentukan sample yang terbaik.Nilai K yang digunakan yaitu dua (K=2). Hasil akurasi yang dihasilkan dapat dilihat pada Tabel 8.
Tabel 8 Hasil akurasi menggunakan k-fold
Nilai K Nilai Akurasi
K = 1 75,9%
K = 2 85,5%
Iterasi 1menghasilkan nilai akurasi
sebesar 75,9% dan iterasi dua menghasilkan nilai akurasi sebesar 85,5%. Oleh sebab itu, jika dilihat dari kedua nilai akurasi pada tiap iterasi maka sample dokumen yang dipilih adalah sample dokumen pada iterasi dua.
Nilai akurasi menggunakan K-fold cross
validation lebih tinggi dibandingkan dengan
nilai akurasi sebelum menggunkan
K-foldcross validation, hal ini disebabkan karena pada K-fold setiap data berperan sebagai data latih. Dari hasil yang sudah ada, maka akurasi sistem klasifikasi pada penelitian ini bernilai 85,5% dan pembagian data yang dipilih digunakan untuk mengidentifikasi famili secara otomatis sesuai dengan ilmu taksonomi tumbuhan.
Akurasi kinerja sistem klasifikasi
pada kategori famili adalah sebesar 85,5% dengan menggunakan metode K-fold cross validation dalam pembagian datanya.
Saran
Hal yang perlu dikembangkan dalam penelitian ini adalah menambah jumlah korpus etnofitomedika.
DAFTAR PUSTAKA
Damayanti EK. 2010. Etnofitomedika. Bogor
(ID): Fakultas Kehutanan, Institut
Pertanian Bogor.
Damayanti EK, Hikmat A, Zuhud EAM. 2011. Indonesian tropical medicinal plants diversity: problems and challenges in
identification. Di dalam: 2011
11
Technology to Enhance Sustainable Utilization of Indonesian Tropical Medicinal Plants; Bogor, 11 Agu 2011. Bogor (ID): Institut Pertanian Bogor.
Han J, Kamber M. 2006. Data Mining:
Concepts and Techniques. San Francisco (US-CA): Morgan Kaufmann.
Herawan Y. 2011. Ekstraksi ciri dokumen tumbuhan obat menggunakan chi-kuadrat dengan klasifikasi naive Bayes [skripsi]. Bogor (ID): Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Manning CD, Raghavan P, Schütze H. 2009. An Introduction to Information Retrieval. Cambridge (UK): Cambridge University Press.
McCalum A, Nigam K. 1998. A comparison of event models for naïve Bayes text
classification. Di dalam: AAAI-98
Workshop on Learning for Text Categorization; Madison (US-WI), 27 Jul 1998. hlm 41-48.
Paskianti K. 2011. Klasifikasi dokumen tumbuhan obat menggunakan algoritme fuzzy KNN [skripsi]. Bogor (ID): Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor
Sangat HM, Zuhud EAM, Damayanti EK.
2000. Kamus Penyakit dan Tumbuhan
Obat Indonesia (Etnofitomedika). Jakarta (ID): Pustaka Populer Obor.
Tjitrosoepomo G. 1994. Taksonomi
Tumbuhan Obat-Obatan. Yogyakarta (ID): Gadjah Mada University Press. Zuhud EAM. 2009. Potensi hutan tropika
Indonesia sebagai penyangga bahan obat
alam untuk kesehatan bangsa. Jurnal
13
Lampiran 1 Daftar jenis tumbuhan obat Indonesia yang digunakan dalam penelitian
No NamaLatin Nama Etnis
1 Arcangelisia flava L.
Akar Kuning , Akar Kunyit
Talang Mamak, Ambon, Atoni, Anak Dalam (Orang Rimbo) AkarTigaTali,
Sokondo Urat Melayu Tradisional
Peron Sunda
MongkoLawak Saluan
Merkunyit Kutai
2 Ocimum basilicum Selasih Kutai, Samawa, Sunda
Sorawung Sunda
Telasih DayakTunjung
3 Coleusscutellarioides Linn, Benth
Serikati Rejang
Jawer Kotok Sunda
4 Orthosiphon aristatus (B1) Miq.
Kumis Kucing
Sakai, Melayu Tradisional, Ambon, Bolaangmongondow, Dayak, Bali, Jawa
Remujung Jawa
5 Jatropha curcas L.
Nawah Aceh
Jarak kandang Rejang
Jarak kosta Sunda
Jarak pagar Sunda
Kaliki Sunda
Damar Putih Atoni, Sumba
Belacai Saluan
Jarak Samawa,Bali, Madura
6 Citrus aurantifolia Swingle
Kuyun Padi Aceh
Lemon Nipis Ambon, Madura, Jawa
LimoAsam Atoni
Jeruk Lawar Samawa
Jeruk Nipis Jawa, Sunda, Melayu
Tradisional 7 Dioscorea hispida Dennst. Gadung Bali, Sunda
8 Urenalobata L
Pulut-pulut Melayu Tradisional
Pupuli Sakai
Pulutan Jawa
Apupuliut Mentawai
Celopai DayakTunjung
14
Pungpurutan Sunda
9 Centellaasiatica (Linn) Urban.
Pegagan Ambon, Melayu,
Madura, Jawa
Daun kaki kuda Ambon,
Bolaangmongondow
Antanan Rambat Sunda
Antanan Sunda
Ki Antanan Sunda
Kuku Kuda Menado
Pinduk, TapalKuda Bali
10 Kalanchoepinnata (Lam.)Pers
Sedingin Anak Dalam (Orang
Rimbo),TalangMamak
Bangun Muku Menado
Buntiris Sunda
CocorBebek Bolaangmongondow,
Punan Lisum, Bali
Buntianak Atoni
Dan Surga Kutai
Sedingin Anak Dalam(Orang
Rimbo)
Tumbuh Daun DayakKedayan
11 Psidium guajavaL.
Gelimah Aceh
JambuBatu Sunda, Sakai
JambuBiji Bali, Rejang,Menado,
Bolaangmongondow
Jambu Sunda
Jambu Klutuk Madura, Kutai
Kujawas Antoni
Kuncek DayakTunjung
12 Nothopanax scutellarium Merr
Mangkok Bali
Dadap Dayak Nganjuk
13 Clinacanthus nutans Lindau Kitajam Sunda
14 Acanthus ilicifoliusL Jaruju Sunda
15 Graptophyllumpictum Griffith
Puding Aceh
Susok Fatima Talang Mamak
Puding Hitam Melayu Tradisional
Hembalang Rejang
15
Handeuleum Sunda
Temen Bali
Wungu Jawa
16 Odiaeumveriegatum L. Kereta Emas Kutai
17 Coleusatropurpureus Benth
DaunMayana Ambon
Miana Bali
Jawer Kotok Sunda
18 Murraya paniculata [L.] Jack
Kemuning Bali
Kamuning Suda
16
Lampiran 2 Tabel distribusi chi-kuadrat pada berbagai tingkat signifikansi dan derajat bebas tertentu
d.f
1 1.32 2.71 3.84 5.02 6.63 7.88 10.8
2 2.77 4.61 5.99 7.38 9.21 10.6 13.8
3 4.11 6.25 7.81 9.35 11.3 12.8 16.3
4 5.39 7.78 9.49 11.1 13.3 14.9 18.5
5 6.63 9.24 11.1 12.8 15.1 16.7 20.5
6 7.84 10.6 12.6 14.5 16.8 18.5 22.5
7 9.04 12 14.1 16 18.5 20.3 24.3
8 10.2 13.4 15.5 17.5 20.1 22 26.1
9 11.4 14.7 16.9 19 21.7 23.6 27.9
10 12.5 16 18.3 20.5 23.2 25.2 29.6
11 13.7 17.3 19.7 21.9 24.7 26.8 31.3
12 14.8 18.5 21 23.3 26.2 28.3 32.9
13 16 19.8 22.4 24.7 27.7 29.8 34.5
14 17.1 21.1 23.7 26.1 29.1 31.3 36.1
15 18.2 22.3 25 27.5 30.6 32.8 37.7
16 19.4 23.5 26.3 28.8 32 34.3 39.3
17 20.5 24.8 27.6 30.2 33.4 35.7 40.8
18 21.6 26 28.9 31.5 34.8 37.2 42.3
19 22.7 27.2 30.1 32.9 36.2 38.6 32.8
20 23.8 28.4 31.4 34.2 37.6 40 45.3
21 24.9 29.6 32.7 35.5 38.9 41.4 46.8
22 26 30.8 33.9 36.8 40.3 42.8 48.3
23 27.1 32 35.2 38.1 41.6 44.2 49.7
24 28.2 33.2 36.4 39.4 32 45.6 51.2
25 29.3 34.4 37.7 40.6 44.3 46.9 52.6
26 30.4 35.6 38.9 42.9 45.6 48.3 54.1
27 31.5 36.7 40.1 43.2 47 49.6 55.5
28 32.6 37.9 41.3 44.5 48.3 51 56.9
29 33.7 39.1 42.6 45.7 49.6 52.3 58.3
30 34.8 40.3 43.8 47 50.9 53.7 59.7
40 45.6 51.8 55.8 59.3 63.7 66.8 73.4
50 56.3 63.2 67.5 71.4 76.2 79.5 86.7
60 67 74.4 79.1 83.3 88.4 92 99.6
70 77.6 85.5 90.5 95 100 104 112
80 88.1 96.6 102 107 112 116 125
80 98.6 108 113 118 124 128 137
100 109 118 124 130 136 140 149
Sumber: RonaldJ.Wonnacoltand Thomas H. Wonnacot.
17
Lampiran 3 Confusionmatrix untuk kelas family pada nilai signifikansi 0.001
Nama Famili
A B C D E F G H I J K
A 7
B 3 1
C 5 3
D 7
E 3
F 5
G 8
H 5
I
J 1
K 1
: Famili yang tidak terindentifikasi.
Keterangan :
A =Euphorbiaceae B = Menispermaceae C = Rutaceae D =Apiaceae E =malvaceae F =Crassulaceae G = Lamiaceae H = Myrtaceae I = Acanthaceae
J =Dioscoreaceae
18
Lampiran 4 Perbandingan antara dokumen dengan buku panduan
No Dokumen Buku Panduan (Tjitrosoepomo 1994)
1 Terna liar Terna berumur pendek atau panjang.
2
Akar keluar dari setiap bonggol, banyak bercabang yang membentuk tumbuhan baru
Bunya majemuk berupa bunga paying atau bunga paying bersusun (kapitulum).
3
Berada di Asia Tropis. terna menahun tanpa batang, tetapi dengan rimpang pendek dan stolon-stolon yang merayap dengan panjang 1-80 cm
Berada di daerah tropic, di Jawa terutama di bagian barat dari dataran rendah sampai 2500 m antara lai, tempat-tempat yang basah dan
mendapatkan cukup sinar atau sedikit
keteduhan.
4
Kadang-kadang ditanam sebagai penutup tanah di perkebunan atau sebagai tanaman sayuran (sebagai lalap), terdapat sampai ketinggian 2.500 meter di atas permukaan laut.
Daun tersebar, berseling atau berhadapan, majemuk ganda atau banyak berbagi. Tanpa daun penumpu. Mempunyai pelepah yang besar dan pipih yang disebut perikladium dan tidak membalut batang.
5
Menyukai tanah yang agak lembap dan cukup mendapat sinar matahari atau teduh, seperti di padang rumput, pinggir selokan, sawah, dan sebagainya.
Batang berongga sebelah dalam dan beralur atau bergerigi membujur pada permukaannya.
6
Helai daun tunggal, berbentuk ginjal. Tepinya bergerigi atau beringgit, dengan penampang 1 -7 cm tersusun dalam roset yang terdiri atas 2-10 helai daun, kadang-kadang agak berambut.
Bunga kecil, kebanyakan banci, aktinomorf atau sedikit zigomorf, berbilang 5. Kelopak seringkali amat kecil, daun mahkota 5 dengan ujungnya yang melengkung kedalam berwarna kuning atau keputih-putihan, jarang merah jambu atau lembayung.
7
Bunga berwarna putih atau merah muda, tersusun dalam karangan berupa payung, tunggal atau 3-5 bersama-sama keluar dari ketiak daun.